
Abstract
Recent studies indicate that examiners make a number of intentional and unintentional errors when administering reading assessments to students. Because these errors introduce construct-irrelevant variance in scores, the fidelity of test administrations could influence the results of evaluation studies. To determine how assessment fidelity is being addressed in reading intervention research, we systematically reviewed 46 studies conducted with students in Grades K–8 identified as having a reading disability or at-risk for reading failure. Articles were coded for features such as the number and type of tests administered, experience and role of examiners, tester to student ratio, initial and follow-up training provided, monitoring procedures, testing environment, and scoring procedures. Findings suggest assessment integrity data are rarely reported. We discuss the results in a framework of potential threats to assessment fidelity and the implications of these threats for interpreting intervention study results.
In intervention studies, the importance of monitoring treatment integrity (operationalized here as the extent to which the intervention was implemented as intended) is well known, albeit often lacking from reports of the methods employed (Gearing et al., 2011; Swanson, Wanzek, Haring, Ciullo, & McCulley, 2011). Researchers are admonished to monitor treatment integrity, or implementation fidelity, to increase confidence in concluding that the outcomes are attributable to the independent variable (Century, Freeman, & Rudnick, 2008; Gersten et al., 2005). Examinations of data from individual studies suggest treatment integrity influences the effectiveness of early reading interventions (Foorman & Moats, 2004; Stein et al., 2008) as well as reading interventions for middle school students (e.g., Benner, Nelson, Stage, & Ralston, 2011; Vaughn et al., 2013). Moreover, simulated comparisons of effect sizes at different levels of fidelity indicate poor treatment integrity likely produces systematically biased results that minimize the true impact of the intervention (Stockard, 2010).
Recent work suggests assessment fidelity (operationalized here as the extent to which performance-based reading assessments are administered and scored as intended) also might play an important role in interpreting student outcomes. For example, significant differences in oral reading fluency and retell scores can result from delivering different directions and prompts (Reed & Petscher, 2012), as well as having a different assessor or using a different testing environment (Derr & Shapiro, 1989). Furthermore, estimates of student growth over time during progress monitoring have been demonstrated to vary appreciably as the data set quality is compromised—some of which is likely due to examiner variability (Christ, Zopluoglu, Long, & Monaghen, 2012).
There is reason to believe unintended alterations of testing protocols might be occurring with regularity both in research and authentic school settings. A study utilizing hired data collectors in Grades 6 to 8 found as much as 8% of closely monitored test administrations demonstrated extreme lack of fidelity, and 91% of accurate administrations still had correctable errors identified in double scoring (Reed & Sturges, 2012). In research conducted with Head Start and kindergarten children, almost 40% of the variance in end of year scores was attributable to the assessor when the test was administered by the students’ own classroom teacher (Waterman, McDermott, Fantuzzo, & Gadsden, 2011). However, variance associated with examiners in the study who were outside of and independent from the classroom was only 5.3% or less. A separate study of archival data gathered from typical school administrations found that 16% of the variance in oral reading fluency scores of students in Grade 3 was attributable to examiners (Cummings, Biancarosa, Schaper, & Reed, 2013). This error effect was observed after accounting for student- and school-level variance and correcting computation errors on scoring forms. Hence, assessment fidelity can introduce systematic error, or construct irrelevant variance, that compromises the measurement of the intended reading constructs.
Construct Irrelevant Variance in Standardized Testing
Systematic error has been identified as an issue not only for individually administered reading tests, such as oral reading fluency and retell, but also for group administered, standardized tests. Chief among these concerns has been the presence of irregularities suggestive of cheating (U.S. Department of Education, 2013). Haladyna and Downing (2005) outlined a taxonomy of construct-irrelevant variance sources that threaten the interpretation of high-stakes tests in which cheating is only one category. The others are uniformity in and types of test preparation; test development, administration, and scoring; and students. In the sections that follow, we describe the particular sources of examiner error within these categories that might apply to reading tests used for intervention research purposes.
Unethical Test Preparation
Critics of practices associated with high-stakes tests have noted that educators are inclined to teach to the test (Pedulla et al., 2003; Tanner, 2013). This type of unethical preparation might include narrowing the curriculum to the specific content on which students will be assessed or having students practice items from current or older versions, depending on the accessibility of these forms. Although these behaviors have been exhibited by school personnel subject to accountability systems, archival data from state-mandated assessments are often used to screen participants for reading intervention studies (e.g., Faggella-Luby & Wardwell, 2011; Thompson & Davis, 2002) or determining student improvements (e.g., Ritter & Saxon, 2011; Vaughn et al., 2010). In addition, the potential exists for classroom teachers or research staff to bias outcomes on study measures should recommendations for test security not be enacted (Wollack & Fremer, 2013).
Test Administration
During testing, student performance might be influenced by changing the wording of the directions (Colón & Kranzler, 2006; Reed & Petscher, 2012), timing (Derr-Minneci & Shapiro, 1992), or a number of environmental distractions (Christ, Zopluoglu, Long, & Monaghen, 2012). The impact of these factors has been more closely studied with individually administered reading tests, but such alterations have also been documented during group administered assessments (e.g., Nolen, Haladyna, & Haas, 1992; Sackes, 2000). The location of the test administration may be more problematic during research studies than during state- or district-mandated assessments. That is, space restrictions at school sites may limit researchers’ abilities to control aspects of the testing environment such as the number of students per room or the ambient noise present (Reed & Sturges, 2012).
Test Scoring
When tests are individually administered, pressure is placed on the examiner to record student responses accurately. In the case of some assessments, such as spelling and intelligence tests, there are basal or ceiling rules examiners must apply in real time. Other assessments may require transferring, converting, or calculating a score. All these scenarios introduce the possibility of mistakes being made (Charter, Walden, & Padilla, 2000; Loe, Kadlubek, & Marks, 2007; Ramos, Alfonso, & Schermerhorn, 2009). Many group administered tests are machine scored, which in theory should limit the kinds of examiner errors reportedly found when double scoring test documents by hand (Cummings et al., 2013; Reed & Sturges, 2012). Still, there have been a number of high-profile machine scoring errors that highlight the importance of verifying the accuracy of all test data (e.g., Baker, 2013; Metz, 2007; Romano, 2006).
Individual Cheating
Among the egregious errors observed by Reed and Sturges (2012) was an instance of coaching in which the examiner used hand motions to encourage a student to continue providing more information until he delivered the correct response. Although this was committed during an individually administered assessment, it is equally likely that students could be coached during standardized group testing. Providing answers, cueing students to incorrect answers, and leaving tested information or “cheat sheets” visible in the room have all been documented as irregularities on high-stakes assessments (Amrein-Beardsley, Berliner, & Rideau, 2010). As noted for unethical test preparation, data from these measures might be used in reading intervention studies for participant selection or estimating treatment effects. Moreover, the potential for examiner bias in intervention research has prompted recommendations for ensuring data collectors are blind to study condition (Gearing et al., 2011; Gersten et al., 2005).
Purpose
Given the variety of systematic errors that are possible when testing student participants in a reading intervention study, an accounting of assessment fidelity might be just as important as documentation of treatment integrity in establishing the quality of research results. Whereas the extant literature yields a rich history of reviewing implementation fidelity (Dane & Schneider, 1998; Gresham, MacMillan, Beebe-Frankenberger, & Bocian, 2000; McIntyre, Gresham, DiGennaro, & Reed, 2007; O’Donnell, 2008; Swanson et al., 2011), we could locate no synthesis of assessment fidelity. Therefore, we conducted a systematic review of studies to address the question: To what extent is assessment fidelity reported in reading intervention research conducted in elementary and middle schools?
Method
Search Procedures
We searched for relevant articles to include in this review in two ways. First, the ERIC, Academic Search Complete, and PsycINFO electronic databases were searched for peer-reviewed publications using combinations of the following terms: read*, learning disabilit*, reading disabilit*, literacy, dyslex*, and intervention. Second, we examined the references of recent reading intervention syntheses and meta-analyses (e.g., Flynn, Zheng, & Swanson, 2012; Tran, Sanchez, Arellano, & Swanson, 2011) to determine if any studies were missed in the electronic search. Over 9,000 articles published in the last decade (2001-July 2012), a time during which increased attention has been placed on implementation fidelity in educational research (National Research Council, 2002), were identified and evaluated against the following criteria for inclusion in this review:
Participating students were in Grades K–8 (ages 5–14). Studies including younger or older students were accepted if the majority of the participants were in Grades K–8.
At least some of the students were identified with a learning disability (LD), reading disability (RD), dyslexia, or at-risk for reading failure. If all students were identified on the basis of intellectual disability alone, the study was excluded (e.g., Allor, Mathes, Roberts, Cheatham, & Champlin, 2010).
The instructional intervention was focused on reading skills: word identification, fluency, vocabulary, or comprehension. Studies were excluded if a major focus of the intervention was oral or auditory language, attention therapy, math skills, or behavioral or affective factors (e.g., Nelson & Manset-Williamson, 2006).
The studies had an experimental or quasi-experimental design with a defined comparison group. These designs were chosen because they often use larger groups of students and, therefore, are more likely to exhibit factors with the potential for affecting assessment fidelity. Specifically, they are more likely to utilize multiple testers, have testers assessing multiple students, incorporate more than one instrument, and include treatment conditions from which the testers may or may not be blinded (Gersten et al., 2005).
Assessments used were standardized measures of reading with publicly available technical manuals in keeping with quality indicators for intervention research (Gersten et al., 2005; Towne, Wise, & Winters, 2005). Studies that employed only tests of listening comprehension or content learning were excluded (e.g., DiCecco & Gleason, 2002; Wilder & Williams, 2001). Studies that included informal measures of reading, such as researcher-developed measures without established technical adequacy or that are not publicly available, were included only if they also administered and reported standardized measures. Standardized measures have clearly delineated and disseminated protocols for their use, thus providing a known standard against which the fidelity of their use could be compared objectively.
The intervention had to target development of English reading skills. The students’ native language could have been used in some instruction or assessment as long as the goal was to teach students to read in English. For example, bilingual and transitional English instruction were accepted (e.g., Kamps et al., 2007) but two-way immersion was rejected (e.g., Calhoon, Otaiba, Cihak, King, & Avalos, 2007).
Consistent with recent syntheses of intervention fidelity (Gearing et al., 2011; Swanson et al., 2011), the study was reported in a peer-reviewed journal.
Of the more than 9,000 abstracts evaluated, 46 met all seven criteria and were included in the analysis. These were drawn from 13 different journals, with two journals (Journal of Learning Disabilities and Learning Disabilities Research and Practice) accounting for more than half (n = 24) of the studies. All journals were representative of special education publications, which we believe was an artifact of the search terms employed. Although we acknowledge other journals dedicated to reading research (e.g., Reading Research Quarterly, Scientific Studies of Reading, Reading and Writing: An Interdisciplinary Journal) would likely contribute additional articles, we decided to maintain the special education focus of the corpus and not manually search other journals for two reasons. First, students in special education or those receiving other types of supplementary education (e.g., dyslexia services) arguably are the most affected by instructional, placement, and outcome decisions made based on reading assessment data. Second, assessment fidelity has not received as much attention as treatment integrity (Reed & Sturges, 2012), yet previous syntheses of the latter have found that little information on implementation fidelity is reported (Gearing et al., 2011; Swanson et al., 2011). Hence, we approached this review of assessment fidelity as exploratory and not exhaustive.
Data Analysis
Coding the 46 studies proceeded via a three-stage iterative process of revision and refinement. In the first stage, three of the four investigators refined the codes used to review the studies. In the second, two investigators preliminarily coded all articles in the corpus. And in the third stage, the four investigators double coded all articles and resolved coding discrepancies.
Stage 1 Coding Procedures
Given that no previous review of assessment fidelity was identified in the extant literature, an original coding scheme had to be devised. Using suggested threats to assessment fidelity (see introduction; Haladyna & Downing, 2005; Reed & Sturges, 2012) and assessment administration requirements described in the manuals of commonly used measures (e.g., Good & Kaminski, 2002; Torgesen, Wagner, & Rashotte, 1999; Woodcock, 1998), three investigators decided on preliminary codes: number of students tested, measures administered, training of testers, testing procedures, monitoring of test administrations, follow-up training, and verification of scoring. We then employed an iterative refinement process. That is, the investigators independently coded an article chosen at random, discussed their work, and made adjustments to the coding instrument before proceeding to a second and third study in succession.
Refinements of the coding scheme took into account complexities in the articles and characteristics not previously considered such as variability of testing purposes, functions, and procedures within each study; differing counts of treatment and control subjects; and the use of extant data. Our final code sheet consisted of 28 separate codes. Discrepancies in this phase were considered resolved when all three raters were in agreement with (a) the classification of the information in the articles and (b) the sufficiency and accuracy with which the coding scheme captured that information.
Stage 2 Coding Procedures
During the preliminary coding stage, the other 43 articles in the corpus of 46 studies were independently coded by two investigators. A list of the studies was ordered alphabetically by first author and divided. One investigator coded the first 22 articles, and another coded the second 21 articles in the list. The raters discussed their work with the other investigators in a weekly conference call and made further refinements to the coding schemes to address errors (e.g., the classification of testing procedures vs. scoring procedures), allow for hypothesized sources of administration errors not captured by current codes (e.g., increasing the complexity of testing by administering researcher-developed measures in addition to standardized assessments), or address unique issues of the studies (e.g., using extant data as the solitary pre- and posttest).
Stage 3 Coding Procedures
The initial double coding involved a third investigator independently coding a random sample of 10 articles, five from each of those assigned to the first two raters. A fourth investigator then highlighted all discrepancies among the raters. In the discussion among all investigators, it became apparent that double coding all studies in the corpus was necessary to ensure accuracy. The discrepancies between two coders exceeded acceptable standards (Krippendorff, 2004) for several reasons. First, there was no precedent for coding assessment fidelity information, so essentially the instrument had to be developed while it was being used. There also was not a standard for reporting assessment fidelity, as exists for treatment integrity (Gersten et al., 2005), so relevant information was more widely distributed across sections of the articles. This increased the likelihood that some things were missed by a single coder. Finally, there were many inconsistencies in the way information was reported within and between studies, including but not limited to (a) narrative descriptions of measures not matching what was included in data tables, (b) lack of clarity regarding whether the researchers administered a particular test or gathered scores from administration by school personnel, and (c) screening measures described in a different section of the article than where pre- and posttests were reported.
To overcome these challenges, all four investigators were assigned a random sample of the corpus such that the original raters’ sets of articles were distributed among three other investigators for double coding. The two raters of each article (i.e., the original and double coder) then conferred and resolved discrepancies until they achieved 100% agreement. Coded information was checked against the source article a final time when being organized into tables.
Results
Study Features
This study sought to determine the extent to which assessment fidelity is reported in reading intervention research conducted with students in Grades K–8 identified with LD, RD, or reading difficulties. We first present descriptive information (i.e., student characteristics, eligibility criteria related to screening measures administered, sample size, number and names of standardized measures, and number of informal measures) on the 46 studies meeting inclusion criteria in Table 1 and in the sections that follow.
Description of studies included in the assessment fidelity literature synthesis

Note. N/A = not applicable. NR = not reported. CELF-3 = Clinical Evaluation of Language Fundamentals–3; CMERS = Comprehensive Monitoring of Early Reading Skills; CRMT = Connecticut Reading Mastery Test; CTOPP = Comprehensive Test of Phonological Processing; DIBELS = Dynamic Indicators of Basic Early Literacy Skills; DRA = Developmental Reading Assessment; EFL = English as a foreign language; ELL = English language learner; GMRT = Gates-MacGinitie Reading Comprehension Test; GORT-III = Gray Oral Reading Test 3rd Edition; GSRT = Gray Silent Reading Test; IDEL = Indicadores Dinamicos del Exito en la Lectura; KBIT = Kaufman Brief Intelligence Test; KBIT-2 = Kaufman Brief Intelligence Test 2nd Edition; KTEA = Kaufman Test of Educational Achievement; KTEA-II = Kaufman Test of Educational Achievement 2nd Edition; LAC = Lindamood Auditory Conceptualization Test; MAT = Metropolitan Achievement Test; MBSPR = Monitoring Basic Skills Progress Reading; PAT = Phonological Awareness Test; PPVT = Peabody Picture Vocabulary Test; PPVT-R = Peabody Picture Vocabulary Test Revised; PPVT-III = Peabody Picture Vocabulary Test 3rd Edition; RAN-RAS = Test of Rapid Automatic Naming and Rapid Altering Stimulus; RIST = Reynold’s Intellectual Screening Test; SBIT-4 = Stanford Binet Intelligence Test 4th Edition; SDRT = Stanford Diagnostic Reading Test; TAKS = Texas Assessment of Knowledge and Skills; TAALD = Test of Adolescent and Adult Language Development; TOLD-P:3 = Test of Language Development Primary 3rd Edition; TOLD-I:2 = Test of Language Development Intermediate 2nd Edition; TOPA = Test of Phonemic Awareness; TOPP-S = Test of Phonological Processing in Spanish; TORF = Test of Oral Reading Fluency; TOSS = Test of Semantic Skills-Primary; TOSRE = Test of Sentence Reading Efficiency; TOWRE = Test of Word Reading Efficiency; TOWS-3 = Test of Written Spelling 3rd Edition; TPRI = Texas Primary Reading Inventory; WISC-3 = Wechsler Intelligence Scale for Children 3rd Edition; WISC-4 = Wechsler Intelligence Scale for Children 4th Edition; WJ = Woodcock Johnson Tests of Cognitive Abilities; WJ-R = Woodcock Johnson Tests of Cognitive Abilities Revised; WJ-III = Woodcock Johnson Test of Cognitive Abilities 3rd Edition; WLPB = Woodcock Language Proficiency Battery; WLPB-R = Woodcock Language Proficiency Battery Revised; WLPB-R Spanish = Woodcock Language Proficiency Battery Revised Spanish Edition; WLS = Woodcock Language Survey; WRAT-3 = Wide Range Achievement Test 3rd Edition; WRMT = Woodcock Reading Mastery Test; WRMT-R = Woodcock Reading Mastery Test Revised; WRMT-R/NU = Woodcock Reading Mastery Test Revised/Normative Update; YSTPS = Yopp-Singer Test of Phoneme Segmentation.
Measures include screeners, pretests, posttests, interim/PM tests, and informal measures. Among the screeners, pre, post, interim/PM, there could be extant data. Informal measures refer to researcher-developed measures or those without reliability and validity data.
Study 2 coded here.
Lagged treatment design (control group received treatment after serving as control for first treatment group).
Longitudinal design.
Group administered measure.
Used growth curve modeling, and subsequently subjects served as their own control.
Student Characteristics
The search criteria allowed for studies conducted in Grades K–8, and within the final corpus, all-inclusive grades and grade equivalents (e.g., ages 5–13) were represented. Grades K–2 and 6–8 were included slightly more often than Grades 3 to 5 as shown in Figure 1. Note that studies may have had participants from multiple grade levels.
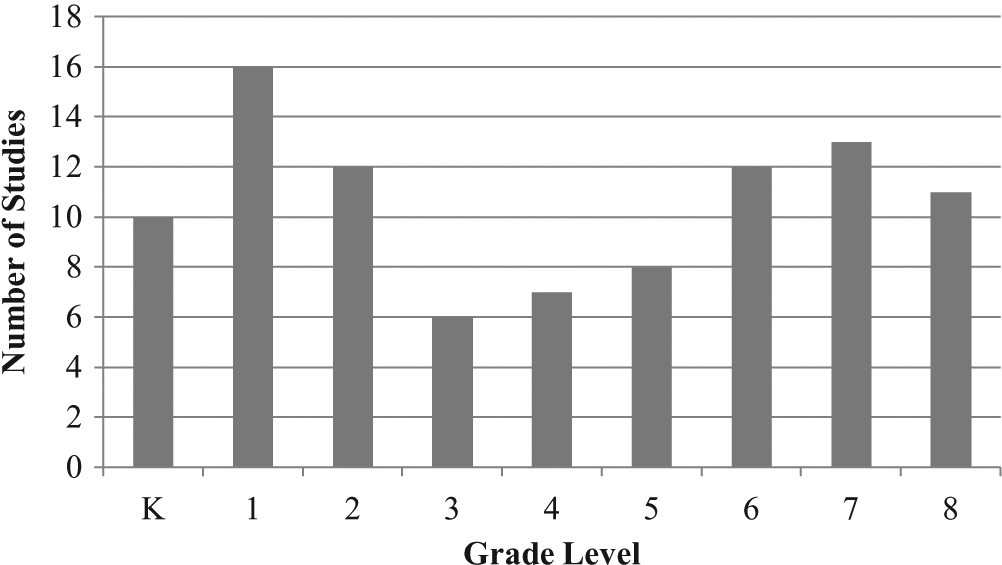
Number of studies in which each grade level was included.
To better define the students with reading difficulties participating in the studies, we coded for participants’ first language. Eight studies did not include students who were English language learners (ELLs; Aaron, Joshi, Gooden, & Bentum, 2008; Calhoon, Sandow, & Hunter, 2010; Manset-Williamson & Nelson, 2005; Morris et al., 2012; Ritter & Saxon, 2011; Santoro, Coyne, & Simmons, 2006; Simmons et al., 2007; Torgesen et al., 2001), and three studies had only ELL participants. In two of those studies, students’ first language was Spanish (Gerber et al., 2004; Vaughn et al., 2006). In the third study, the students had a variety of first languages (Lovett et al., 2008). Another 17 studies included some ELLs. In one study, students’ first language was Spanish (Thompson & Davis, 2002), four studies had multiple first languages (Berninger, Abbott, Vermeulen, & Fulton, 2006; Cartledge, Yurick, Singh, Keyes, & Kourea, 2011; Kamps et al., 2007; Leafstedt, Richards, & Gerber, 2004), and 12 studies did not report the first languages of the ELLs. The remaining 18 studies did not provide any information on the language backgrounds of their participants.
Eligibility Criteria Related to Screening Measures
Individual subtests were counted separately when tabulating screening measures administered to determine student eligibility for participation in the study or placement into treatment/comparison groups. Nine studies did not include this use of screening measures for participant eligibility (Aaron et al., 2008; Allinder, Dunse, Brunken, & Obermiller-Krolikowski, 2001; Guthrie et al., 2009; Joshi, Dahlgren, & Boulware-Gooden, 2002; Kamps et al., 2007; Leafstedt et al., 2004; O’Connor, Fulmer, Harty, & Bell, 2005; Osborn et al., 2007; Ritter & Saxon, 2011). Among the remaining 37 studies, the number of screening measures described ranged from one (Berninger et al., 2006; Bhat, Griffin, & Sindelar, 2003; Denton, Wexler, Vaughn, & Bryan, 2008; Fagella-Luby & Wardwell, 2011; Gerber et al., 2004; Helf, Cooke, & Flowers, 2009; Oudeans, 2003; Vadasy, Sanders, Peyton, & Jenkins, 2002; Vaughn et al., 2011; Wanzek, Vaughn, Roberts, & Fletcher, 2011; Wanzek & Roberts, 2012) to eight (Manset-Williamson & Nelson, 2005). However, six studies did not clearly identify all tests or subtests administered, so their total number of screening measures is anticipated to be larger than the number listed in Table 1 (Therrien, Wickstrom, & Jones, 2006; Thompson & Davis, 2002; Torgesen, Wagner, Rashotte, Herron, & Lindamood, 2010; Vadasy, Sanders, & Peyton, 2005; Vaughn et al., 2010). Six studies relied on extant state assessment data obtained from the schools for eligibility determination (Berninger et al., 2006; Denton et al., 2010; Thompson & Davis, 2002; Vaughn et al., 2010; Wanzek et al., 2011).
Sample Size
The total number of student participants as well as the number of students assigned to the treatment and comparison conditions were determined by the final sample sizes reported for the end of the study. The total number ranged from a low of 20 (Mansett-Williams & Nelson, 2005) to a high of 576 (Vaughn et al., 2010), with a median of 86 students. Those assigned to the treatment condition often were administered more tests, such as additional pretests (e.g., Hook, Macaruso, & Jones, 2001) or progress monitoring (e.g., Leafstedt et al., 2004), that students in the comparison condition did not take. The number of treatment students ranged from 11 (Mansett-Williams & Nelson, 2005) to 279 (Morris et al., 2012), with a median of 47. Two studies did not clearly report the treatment and comparison sample sizes (Santoro et al., 2006; Thompson & Davis, 2002). One study employed growth curve modeling with an unreported number of students serving as their own controls (Morris et al., 2012).
Standardized Measures
Standardized measures were defined as publicly or commercially available instruments with norming data and an established technical adequacy. Each subtest of an assessment was counted separately when determining the total number of standardized measures administered as a screener, pretest, progress monitor, interim assessment, or posttest. Even if a measure was administered at more than one point during the study, it was only counted once in the tabulation of the overall total. The number of standardized measures administered ranged from one (Ritter & Saxon, 2011) to 29 (Vaughn et al., 2006), with a median of seven. Two studies did not clearly identify all subtests of a given measure (Thompson & Davis, 2002) or the particular verbal intelligence test administered (Torgesen et al., 2010), so the total number of standardized measures for these studies could be greater than that reported in Table 1.
One or more subtests of approximately 40 different standardized measures were administered across the 46 studies in the corpus. Assessments that were used most frequently (i.e., in 10 or more studies) included Comprehensive Test of Phonological Processing, Dynamic Indicators of Basic Early Literacy Skills, Peabody Picture Vocabulary Test, Test of Word Reading Efficiency, Woodcock Johnson Test of Achievement, and Woodcock Reading Mastery Test.
Informal Measures
Informal measures were defined as those that were researcher-developed, did not have established reliability and validity, or were not publicly available. Although studies were excluded if they only administered informal measures, 30 studies in the corpus administered one or more informal measures in addition to standardized measures. Therefore, we tabulated these measures to better define the breadth of testing conducted in studies, but we did not include the informal measures in the other analyses. The number of informal measures ranged from one (Allor & McCathren, 2004; Denton et al., 2010; Faggella-Luby & Wardwell, 2011; Hudson, Isakson, Richman, Lane, & Arriaza-Allen, 2011; Mathes & Babyak, 2001; Nelson, Benner, & Gonzalez, 2005; Ritter & Saxon, 2011; Ukrainetz, Ross, & Harm, 2009) to six (Gerber et al., 2004), with a median of two. Whenever a test was not clearly identified, it was counted as an informal measure. For example, Ritter and Saxon (2011) obtained an unspecified “reading fluency score” (p. 6) at posttest only. Although this could have been one of the 10 subtests of the Texas Primary Reading Inventory (TPRI) administered, the task was not clearly identified and was described as being used in addition to TPRI at posttest. Hence, it was counted as an informal measure.
Features of Assessment Fidelity
Based on previous work (Cummings et al., 2013; Reed & Sturges, 2012), we analyzed the 46 studies for features hypothesized to influence the fidelity with which assessments might be administered (e.g., tester expertise, training of testers, monitoring of administrations, whether the testers were blind to condition, alternating test forms, number of testing days, distractions in the environment, and verification of scoring). Table 2 presents the coding results using symbols to represent the completeness of the information provided. A solid circle (●) was used to indicate the study provided all (i.e., 100%) of the details indicated in the parentheses of the column label. A partially completed circle (◉) was used for studies that provided some but not all of the details for that feature, and an open circle (○) was used when none of the information on that feature of assessment fidelity was reported. In the sections below, we describe the results for each feature.
Completeness in reporting assessment fidelity factors
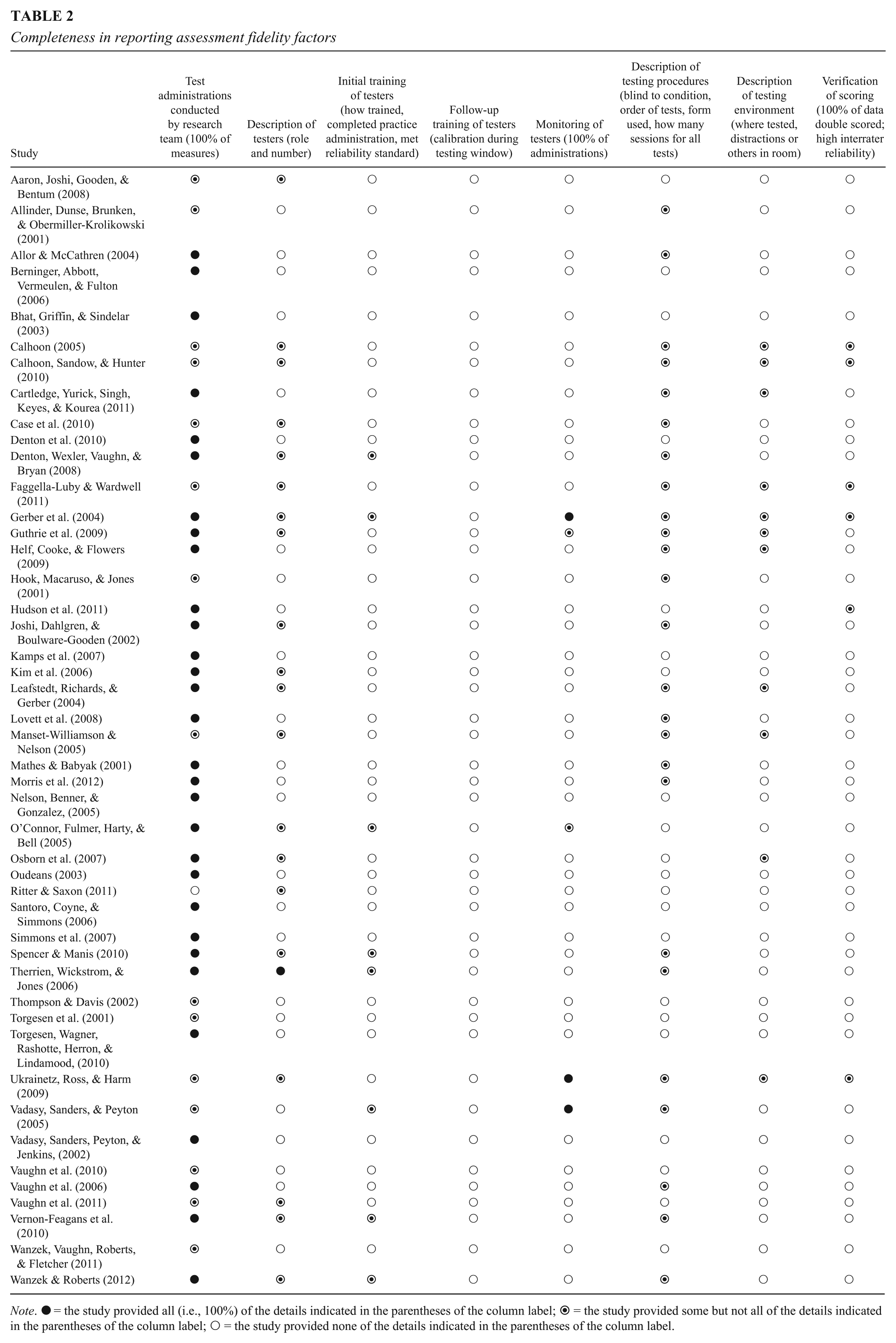
Note. ●= the study provided all (i.e., 100%) of the details indicated in the parentheses of the column label; ◉ = the study provided some but not all of the details indicated in the parentheses of the column label; ○ = the study provided none of the details indicated in the parentheses of the column label.
Test Administrations Conducted by Research Team
Study authors were more likely to report whether the research team administered the tests than any other aspect of assessment fidelity coded. Of the 46 studies, 30 specified collecting all data. Another 15 indicated some of the data were archival from state assessments (Allinder et al., 2001; Faggella-Luby & Wardwell, 2011; Thompson & Davis, 2002; Vaughn et al., 2010; Vaughn et al., 2011; Wanzek et al., 2011), locally mandated tests (Case et al., 2010), special education records (Aaron et al., 2008), intelligence tests (Calhoon, 2005; Calhoon et al., 2010; Hook et al., 2001; Torgesen et al., 2001), or an unspecified testing requirement resulting in accessible records (Manset-Williamson & Nelson, 2005; Vadasy et al., 2005; Ukrainetz et al., 2009). In one study, the only data reportedly collected from a standardized measure was a state required assessment administered by classroom teachers under typical conditions (Ritter & Saxon, 2011).
Description of Testers
The majority of studies (n = 26) did not provide any information on the individuals who administered the assessments to study participants. Only one study reported all coded details of this assessment fidelity feature. Therrien et al. (2006) described having two graduate assistants administer all pre- and posttests, yielding a tester–student ratio of approximately 1:15. The information derived from the 28 studies with a partial description of the testers is provided by the type of detail coded.
Role of testers
When clearly reported for all measures administered (excluding the gathering of extant data), testers were described as playing various roles in the study. In six studies, the testers were all graduate students or graduate research assistants (Calhoon, 2005; Calhoon et al., 2010; Case et al., 2010; Denton et al., 2008; Osborn et al., 2007; Vernon-Feagans et al., 2010). Testers also were identified as being exclusively bilingual undergraduates (Gerber et al., 2004), the study authors (O’Connor et al., 2005), or classroom teachers (Guthrie et al., 2009; Ritter & Saxon, 2011). Unspecified research assistants or research team members were employed in three studies (Faggella-Luby & Wardwell, 2011; Spencer & Manis, 2010; Wanzek & Roberts, 2012). Another five studies had testers who served in a combination of roles: bilingual researcher or bilingual undergraduate assistant (Leafstedt et al., 2004); tutors, graduate students, or the principal investigators (Manset-Williamson & Nelson, 2005); study authors and research assistants (Kim et al., 2006; Ukrainetz et al., 2009); and graduate students or school psychologists (Aaron et al., 2008).
The remaining six studies in the corpus providing some information about this detail inconsistently described the role of the testers they employed. This included what may have only been a semantic change from researchers to educators on an individual posttest (Vaughn et al., 2011). Other differences seemed more substantive such as having the authors administer all pretests and one interim assessment, but not describing the testers for another interim measure and employing “two education majors and a field supervisor in teacher preparation at the university” for posttests (O’Connor et al., 2005, p. 445). In three studies, the testers were not reported for a particular screening measure (Denton et al., 2008), or for the pre- and posttests (Denton et al., 2010; Lovett et al., 2008). The testers that were identified in these studies included “research psychometrists” from a clinic (Lovett et al., 2008, p. 336) administering the screening measures or graduate students administering the pre- and posttests (Denton et al., 2008) and research assistants (Denton et al., 2010).
Number of testers
Rarely within the corpus was the number of testers employed clearly identified such that a calculation of the tester–student ratio could be made. With the exception of the extant data gathered, Case et al. (2010) maintained a very low tester–student ratio of approximately 1:8 by consistently using four testers. Another article described having the four teachers administer all assessments to about 15 students in each of their classes (Ritter & Saxon, 2011). Finally, one study employed different testers for different instruments and testing points, resulting in a variable tester–student ratio (O’Connor et al., 2005). For the pretests and one interim measure in this study, there were four testers or about 1 tester per 102 students. Information was not provided about the testers of the other interim measure. At posttest, there were three different testers, yielding a tester–student ratio of approximately 1:136.
In two studies providing some information about the examiners, the number administering tests could not be determined definitively. For example, different sections of one article seemed to indicate there were six, eight, or nine teachers who might have been involved in testing their students (Guthrie et al., 2009). Another article noted, “Testing was carried out by the three authors and three research assistants” (p. 90), but did not specify whether or not each person administered all tests (Ukrainetz et al., 2009). Therefore, the tester–student ratio for individually administered assessments is unknown, but the authors did indicate the group administered measures were delivered to three to nine students at time. When the group size exceeded three children, two testers were present in the room. Based on these figures, each tester would have monitored no more than five students at a time. Similarly, a final study providing partial information on the testers did not identify the total number of examiners for the individually administered measures, but the authors described conducting the group administered tests with five to seven of the 56 student participants at a time (Joshi et al., 2002).
Initial Training of Testers
Most studies (n = 38) did not report whether the testers were trained, completed practice administrations, or met a reliability standard. However, eight studies provided at least some information about the coded details. Half of these stated the testers were trained (Denton et al., 2008), “trained by the lead researcher” (Spencer & Manis, 2010, p. 78), trained “by graduate research assistants” (Gerber et al., 2004, p. 243), or trained “as part of their graduate training” (Therrien et al., 2006, p. 93). However, no other information about the training was provided. Somewhat more description was given in the other four studies, which all reported holding practice administrations. The practice might have been supervised (Vadasy et al., 2005), conducted with a partner following a script (Wanzek & Roberts, 2012), enacted in totality with nonparticipating students (Vernon-Feagans et al., 2010), or conducted on researchers role playing student behaviors that trigger basal and ceiling rules (O’Connor et al., 2005). Only Wanzek and Roberts (2012) reported the reliability standard (90%) the testers had to meet in their practice session.
Two studies provided an indication of the amount of time spent training examiners. Although the exact number of hours was not stated, the testers participated in two sessions (O’Connor et al., 2005) or 2 days of training (Vernon-Feagans et al., 2010). In the latter, the authors also described the examiners as having previous experience administering assessments. This was noted for the researchers in the O’Connor et al. (2005) study who conducted the midyear testing, but the posttesting was done by college students who were trained by the researchers. Other than offering practice scenarios, little other information was provided about the content of the training. Testers in one study were provided stopwatches and sample passages to practice scoring (O’Connor et al., 2005), and in another the trainers reportedly followed “the instructions in the user’s manual” and included a combination of explanation and modeling (Vadasy et al., 2005, p. 372).
Follow-Up Training of Testers
In none of the 46 studies identified for inclusion in this narrative synthesis was there an indication that testers received follow-up training during a given testing period. This would have included efforts to recheck reliability and calibrate testers as needed.
Monitoring of Testers
After follow-up training, this feature of assessment fidelity was least often reported. One study monitored testers’ first two administrations but not the remaining testing, which involved more than 400 students (O’Connor et al., 2005). Three studies with smaller sample sizes (n = 41–57) reported monitoring all administrations. This was done through the supervision of graduate research assistants (Gerber et al., 2004) or research staff (Vadasy et al., 2005), or the observations of other testers (Ukrainetz et al., 2009). In one study, teachers who were testing their students were assisted by researchers, but monitoring for fidelity was not reported (Guthrie et al., 2009). Although O’Connor et al. (2005) noted that no feedback was needed on the two administrations that were observed, no authors offered information on whether or not any anomalies occurred during an entire assessment window.
Description of Testing Procedures
No studies in the corpus provided information on all coded details about the testing procedures: whether testers were blind to participants’ conditions, the form used, or how many minutes or sessions were needed to administer all tests. However, 25 studies reported some of the details. Of these, nine studies described the procedures for all tests administered (Cartledge et al., 2011; Gerber et al., 2004; Guthrie et al., 2009; Helf et al., 2009; Joshi et al., 2002; Leafstedt et al., 2004; Lovett et al., 2008; Spencer & Manis, 2010; Vernon-Feagans et al., 2010). The remaining 13 studies described the procedures for some but not all of the administrations resulting in data used to identify participants, establish baseline performance, monitor students’ progress, or determine treatment effectiveness. Information reported is described in the sections below.
Blind to condition
Rarely did authors directly state whether or not the assessors were aware of the students’ assignment to treatment or comparison conditions. In two studies, it was noted that research assistants did not test students to whom they were delivering the intervention (Case et al., 2010) or were otherwise blind to students’ conditions (Vernon-Feagans et al., 2010). Another author identified all testers as being blind to condition at pretest, but not at mid- or posttest (Ukrainetz et al., 2009). However, researchers described precautions taken to detect bias such as having observers in situ and reviewing audiotaped administrations. Manset-Williamson and Nelson (2005) referred to blinding the condition when scoring students’ retell responses, but the tutors and principal investigators administered measures. Those individuals would have been aware of the instruction delivered to each student. Similarly, students in four studies were assessed by their classroom teachers (Guthrie et al., 2009; Ritter & Saxon, 2011), the study authors and research assistants (Kim et al., 2006), or study authors (O’Connor et al., 2005).
Testing forms
A variety of information was provided about the testing documents used in 12 studies. Most often, authors reported counterbalancing alternate forms, passages, or the English and Spanish versions of tests (Allinder et al., 2004; Allor & McCathren, 2004; Calhoon, 2005; Faggella-Luby & Wardwell, 2011; Gerber et al., 2004; Mathes & Babyak, 2001; Wanzek & Roberts, 2012). In three studies, different forms were used at different testing points (Allor & MacCathern, 2004; Cartledge et al., 2011; Hook et al., 2001), and one study reported using a set order in which one measure was always administered first and the other second in pre- and posttesting (Guthrie et al., 2009). When progress monitoring, Helf et al. (2009) described administering parallel forms of the subtests. The particular form used (e.g., Blue, A/B, G, short) was identified in five studies (Faggella-Luby & Wardwell, 2011; Lovett et al., 2008; Manset-Williamson & Nelson, 2005; Morris et al., 2012; Vaughn et al., 2006).
Students who were bilingual or limited English proficient might have been tested in both languages (Gerber et al., 2004; Vaughn et al., 2006) or only in English for standardized measures but in both English and Spanish with informal measures (Leafstedt et al., 2004). Gerber et al. (2004) also described delivering instruction in the students’ dominant language or in both English and Spanish if a dominant language could not be determined.
Other information provided by authors concerned the difficulty level of the form or passages administered. This was determined by teacher judgment in two studies (Allinder et al., 2004; Guthrie et al., 2009) and by the current grade placement of the student in two other studies (Calhoon et al., 2010; Faggella-Luby & Wardwell, 2011). Therrien et al. (2006) used passages at a slightly lower grade level than the students’ current placement. Occasionally discontinue or branching rules were used such that student performance on one or more measures determined whether they received additional tests or test items (Leafstedt et al., 2004; Vadasy et al., 2005; Vaughn et al., 2006)
Testing time
Seven studies clearly identified the number of minutes or days it took to administer all measures. The time was described as mostly completed in three 20-minute sessions (Gerber et al., 2004), occurring over a 2-day period (Guthrie et al., 2009), separated by 1-day intervals in between each of three assessments (Joshi at al., 2002), and completed in one 90-minute session (Faggella-Luby & Wardwell, 2011). Sometimes the testing time varied for different points or conditions. For example, Faggella-Luby and Wardwell (2011) noted that a schedule issue resulted in the second treatment group being tested on “consecutive days within five days of post-testing” the first treatment and comparison groups (p. 41). This description suggests the 90 minutes might have been distributed for this treatment group. Other variations included a 3-hour total administration time for the full test battery but about 45 minutes for the partial battery used with different treatment conditions (Hook et al., 2001); pretesting for 95 to 120 minutes spread over 2 to 3 days per student, and posttesting for 60 minutes in one sitting per student (Spencer & Manis, 2010); or giving individually administered tests in the same sitting, but holding separate sessions for the group administered tests lasting about 30 minutes each (Ukrainetz et al., 2009).
Although the amount of testing time in other studies might be estimated from the standard administration prescribed in the technical manuals of the standardized measures, some researchers employed a large enough battery of assessments that it is reasonable to expect the administrations would have taken more than one session (e.g., Aaron et al., 2008; Denton et al., 2010; Hook et al., 2001; Lovett et al., 2008; Morris et al., 2012; Torgesen et al., 2001; Torgesen et al., 2010; Vaughn et al., 2006; Vaughn et al., 2011). In addition, some authors described making adaptations of published testing procedures or materials, which would render independent calculations of time imprecise (e.g., Denton et al., 2010; Guthrie et al., 2009; Ukrainetz et al., 2009).
Description of Testing Environment
Details coded for this feature of assessment fidelity included the location of testing and the potential for distractions during the administrations. Of the 11 studies providing at least some information, most indicated in general terms where the testing occurred: at the students’ school (Gerber et al., 2004; Leafstedt et al., 2004; Osborn et al., 2007), in the regular classroom (Guthrie et al., 2009), in the school library (Faggella-Luby & Wardwell, 2011), in a separate room or hallway (Cartledge et al., 2011), or in partitioned classrooms or the school library (Manset-Williamson & Nelson, 2005). In one study, the location of the progress monitoring was identified, a small tutoring classroom at the school, but not the setting for pre- and posttesting (Helf et al., 2009). These general descriptions do not allow for inferring the potential distractions in the environment, such as might be caused by having other students present who were not being tested or other activities occurring in the vicinity. Two studies attempted to account for distractions by utilizing the quietest available space (Gerber et al., 2004) or a secluded area somewhere in the school (Ukrainetz et al., 2009). An additional two studies described the testing environment as a quiet or secluded, distraction-free room (Calhoon, 2005; Calhoon et al., 2010).
Verification of Scoring
Four of the 46 studies in the corpus provided information on double scoring or inter-rater reliability of assessment scoring. All protocols or answer documents were checked and rechecked by different individuals during both the scoring and data entry stages of two studies (Gerber et al., 2004; Hudson et al., 2011). However, interrater agreement was not reported in either article. Randomly selected samples of testing documents (11% to 20%) were double scored in two other studies with interrater reliabilities reported as 99.7% (Faggella-Luby & Wardwell, 2011) and 99.6% (Ukrainetz et al., 2009). Ukrainetz et al. were the only authors of the 45 studies utilizing individually administered, standardized measures to report interrater agreement determined in double scoring assessment packets from those measures (as opposed to training protocols as done in the Wanzek et al., 2012, study). This rating does not include studies reporting interrater agreement of informal measures, which were not the primary focus of this narrative synthesis (e.g., Kim et al., 2006; Mansett-Williams & Nelson, 2005).
Despite the paucity of information on score verification, a number of studies described scoring procedures that might be prone to error such as generating composite scores from a number of tests or subtests (e.g., Bhat et al., 2003; Morris et al., 2012; Osborn et al., 2007; Vaughn et al., 2006). In addition, Spencer and Manis (2010) described removing an outlier from their analysis because “due to a scoring anomaly, his pretest data was [sic] found to grossly underestimate his reading ability, causing inflated gain scores at posttesting” (p. 80). Two studies reported using a computer program to sum raw scores and convert the scores from individual subtests to age-based standard scores (Calhoon, 2005; Calhoon et al., 2010).
Discussion
In examining the extent to which assessment fidelity is reported in K–8 reading intervention research, we iteratively coded 46 studies meeting inclusion criteria and employed a systematic process for extracting and categorizing relevant information. Unfortunately, none of the studies we reviewed reported sufficient information for determining whether all screening, pre-, interim, and postmeasures were administered and scored as intended. We wish to emphasize this does not mean that insufficient training, monitoring, blinding, calibrating, or double scoring occurred. Rather, our coding revealed little assessment fidelity data were described by the study authors, thus precluding us from drawing conclusions about whether tests were administered as intended consistently. As has been previously suggested, the absence of integrity data may be related to journals placing a lower priority on such information or having limited space to publish it (Moncher & Prinz, 1991; Perepletchikova, Treat, & Kazdin, 2007).
It is interesting to note that only 11 of the 46 studies (24%) included in this review did not overtly state whether implementation fidelity was monitored (Aaron et al., 2008; Allinder et al., 2001; Berninger et al., 2006; Bhat et al., 2003; Hook et al., 2001; Leafstedt et al., 2004; O’Connor et al., 2005; Osborn et al., 2007; Ritter & Saxon, 2011; Santoro et al., 2006; Torgesen et al., 2001). In the decade since the passing of the No Child Left Behind Act of 2001, the field seems to have acknowledged the importance of accounting for the delivery of treatments as intended; however, that concern has not extended to the tests administered to evaluate the effects of those treatments. Rather, there appears to be an assumption that the measures are always used in an error-free fashion. Unfortunately, several characteristics of the studies reviewed would suggest this might not be a safe supposition. Because our findings indicate there is a potential for construct irrelevant variance in the measurement of study participants, we discuss the results within a framework derived from Haladyna and Downing’s (2005) taxonomy of construct irrelevant sources of variance.
Unethical Test Preparation
Fifteen studies in our corpus utilized at least some extant data from state assessments, and one study (Ritter & Saxon, 2011) only used state required assessments for determining treatment effects. This practice is likely efficient for both the school sites and researchers in that it leverages available data from valid and reliable instruments and reduces the amount of lost instructional time for student participants. But this practice has the unfortunate side effect of rendering the researchers unable to account for the conditions under which those data were collected. If the business-as-usual condition in the schools involved teaching to the test (Pedulla et al., 2003; Tanner, 2013) or practices that otherwise compromised test security (Wollack & Fremer, 2013), the researchers would unknowingly be making flawed decisions about participant eligibility or outcomes.
Test Administration
Little data were reported about the individuals who were administering the measures to students, their training and expertise, how many were involved in testing, how they may have been monitored, the duration of all test administrations, or whether examiners’ training was refreshed in an extended testing timeframe. Only five studies did not use measures (e.g., Kaufman Brief Intelligence Test; Wechsler Intelligence Scale for Children; Woodcock Johnson Reading Mastery Test; Woodcock Johnson Tests of Achievement) that require documentation of professional preparation (Fagella-Luby & Wardwell, 2011; Helf et al., 2009; Nelson et al., 2005; Ritter & Saxon, 2011; Ukrainetz et al., 2009). That is not to suggest the study authors were not capable of adequately preparing their examiners, but that more onus might be placed on the rigor of training provided. After all, previous research has found students in graduate psychology, diagnostician, and counseling programs have difficulty achieving precision in administering these measures (Loe et al., 2007; Ramos et al., 2009).
Moreover, most studies reviewed here administered a large number of standardized tests and subtests (range = 1–29; median = 7) and may have also included informal measures (range = 1–6; median = 2). Nine studies used alternate forms, passages, or language versions in some sequence or with some students (Allinder et al., 2004; Allor & McCathren, 2004; Calhoon, 2005; Cartledge et al., 2011; Faggella-Luby & Wardwell, 2011; Gerber et al., 2004; Hook et al., 2001; Mathes & Babyak, 2001; Wanzek & Roberts, 2012), and three studies included discontinue or branching rules that would have altered the testing battery from student to student (Leafstedt et al., 2004; Vadasy et al., 2005; Vaughn et al., 2006). These procedures would have added to the complexity of learning and accurately administering the measures employed.
Despite how many rules and procedures testers would have needed to learn, only four studies specifically stated that practice sessions were held (O’Connor et al., 2005; Vadasy et al., 2005; Vernon-Feagans et al., 2010; Wanzek & Roberts, 2012), and only Wanzek and Roberts (2012) offered the reliability standard (90%) that testers had to meet in their preparation. In no studies was there an indication that the reliability of testers was checked during testing to ensure they had not deviated from protocol. O’Connor verified examiners’ first two administrations, but not again during the testing of more than 400 students. Three studies acknowledged supervising or observing the test administrations (Gerber et al., 2004; Ukrainetz et al., 2009; Vadasy et al., 2005) but not for the purposes of documenting integrity as might be done with implementation of interventions (Gersten et al., 2005). The potential for deviations to occur over the duration of implementation has been noted for intervention research, even when having demonstrated initial proficiency in the treatment (O’Donnell, 2008; Perepletchikova & Kazdin, 2005); thus, it is also reasonable to assume deviations might happen when administering assessments to many students over hours, days, and weeks. In fact, Waterman et al. (2011) found an increase in assessor variance over successive administrations of the same tests.
The total number of students in a given study was as high as 576 (Vaughn et al., 2010), with a median of 89 students. Rarely was it possible to determine how many students each examiner tested over what duration. From what was reported, the lowest tester–student ratio was 1:8 for five individually administered standardized measures (Case et al., 2010). The highest calculable ratio was 1:102 at pretest and 1:136 at posttest with three individually administered standardized measures, three individually administered informal measures, and one group administered standardized measure (O’Connor et al., 2005). Hence, an examiner who was reliable at the start of the testing might have made small lapses or in-the-moment decisions that gradually and cumulatively affected the way the measures were used. Significant variance in scores has been found with even small changes to how directions and prompts are delivered (Colón & Kranzler, 2006; Reed & Petscher, 2012) or how much time is provided to students (Derr-Minneci & Shapiro, 1992), so ongoing fidelity monitoring and training refreshers might help to reduce systematic error.
Recommendations for ensuring the quality of a data set have not only included adherence to standardized procedures, but also the elimination of environmental distractions (Christ et al., 2012). Three of the 46 studies referred to using a secluded or distraction-free location (Calhoon, 2005; Calhoon et al., 2010; Ukrainetz et al., 2009), and one described the environment as the quietest space available (Gerber et al., 2004). This choice of words reflects the reality of conducting research in natural school settings where testing has to occur in the best of what might be less than ideal location options. All but one study reviewed here utilized individually administered assessments that would necessitate hearing the student clearly in order to score responses (Fagella-Luby & Wardwell, 2011). Having a quiet space would be particularly important but may not be within the researchers’ ability to control. As an issue affecting the quality of the data to be analyzed, it warrants more attention when preparing for a study and negotiating the logistics with the school personnel.
Test Scoring
The nearly universal employment of individually administered assessments across the corpus also has implications for scoring errors, which have reportedly affected as much as 91% of a data set (Reed & Sturges, 2012). Although four studies explicitly described double scoring all (Gerber et al., 2004; Hudson et al., 2011) or a subset of testing documents (Fagella-Luby & Wardwell, 2011; Ukrainetz et al., 2009), none stated that raters were calibrated within the timeframe they were completing their work. Scoring in situ has been problematic for the types of measures commonly used in the studies reviewed due, in part, to the complexity of the scoring rules to be followed (Charter et al., 2000; Loe et al., 2007; Ramos et al., 2009). Similarly, significant within-rater variability has been found when scoring essays over time (Lamprianou, 2006; Myford & Wolf, 2009) and for raters with different levels of experience (Eckes, 2008; Leckie & Baird, 2011). Periodic calibration of scorers and double scoring 100% of testing documents would better protect the quality of the data used to determine participant eligibility and evaluate treatment effects.
Individual Cheating
A quality indicator for intervention research that is directly related to assessment fidelity is utilizing testers who are blind to the study participants’ conditions (Gearing et al., 2011; Gersten et al., 2005). This practice is to safeguard against bias, particularly when individually administering measures and hand scoring documents. Based on the role of testers in the studies, it was apparent they were often aware which students were in which treatment groups. This does not necessarily mean the testers were biased, but it would place greater importance on monitoring assessment fidelity.
Implications
The low reporting of assessment fidelity in the extant literature was not unexpected given the general lack of integrity data in social science research (Gearing et al., 2011; O’Donnell, 2008). Additionally, assessment fidelity has not been emphasized in efforts since 2001 to improve the rigor of educational research (e.g., National Research Council, 2002), in spite of awareness that reliability of tests in the social sciences is situational rather than an invariant property. Within our corpus, testing integrity (or testing variability) might offer explanation or possible insights into the scoring anomaly found by Spencer and Manis (2010) on one of the eight individually administered subtests of a student’s oral reading.
Variability in measure administration also might present an alternative explanation for why Vaughn et al. (2010) detected only small effects that were more apparent in particular subgroups (e.g., implementation site, participant age, or participant pretest levels) after their year-long, comprehensive intervention. This study included the largest number of participants (n = 576) and administered 11 standardized and two informal measures. The authors attributed the small effects to issues such as the provision of a primary intervention or the time it takes for adolescents to improve their reading abilities. However, the complexity of using so many outcome measures, with the potential for deviations to testing procedures over time, multiplied across the sheer number of students each examiner assessed could have threatened the reliability of the assessments.
Stockard (2010) argued that lower and higher levels of fidelity do not average out in the aggregate but, rather, “produce results that are systematically biased” (p. 9). Thus, a lack of assessment fidelity obscures the true value of the effect size such that “with poor implementation, the good programs would be less good and bad programs would be less bad” (Stockard, 2010, p. 10). Although it is possible that tester variance merely affected findings for the studies in this corpus, results from a recent study indicate observed variability around students’ true scores (i.e., 16%) is attributable to examiners (Cummings, Biancarosa, Schaper, & Reed, 2013). Hence, it is our position that data on assessment fidelity should be reported and considered when interpreting results of research. Doing so would document evidence of experimental control and add to the credibility of findings.
Limitations and Directions for Future Research
To conduct our review, we had to develop a coding system based on features that reasonably could be expected to influence the accurate administration and scoring of measures. As the first instance of doing this type of synthesis, there was not an existing standard for assessment fidelity we could apply. Moreover, information in which we were interested was not well contained in one section of the articles or well labeled when present. These realities made coding difficult, so we proceeded iteratively and systematically. That noted, developing clear standards for reporting testing integrity will improve the reliability of future attempts to examine the presence, quality, and impact of the information.
This synthesis relied on what was reported in published findings from K–8 reading intervention research, which does not necessarily capture the universe of assessment fidelity safeguards actually used. Because implementation fidelity is often not considered when determining treatment effectiveness (Stockard, 2010; Swanson et al., 2011), there likely is little impetus for consuming limited space in an article with the minutiae of testing procedures. Future research might directly query researchers to determine what kinds of training, monitoring, calibrating, and data checking or double scoring were enacted as well as what kinds of problems, if any, were experienced. Studies might also explore whether aspects of training and administration can be manipulated to improve assessment fidelity in both highly controlled research studies as well as more naturalistic environments where teachers test their own students for instructional purposes. Ultimately, protecting testing integrity should help us better understand student reading performance and make more accurate and precise decisions about their responsiveness to reading intervention.
Footnotes
Authors
DEBORAH K. REED, PhD, holds a joint appointment with the School of Teacher Education and the Florida Center for Reading Research at Florida State University, 2010 Levy Ave., Ste 100, Tallahassee, FL 32308; e-mail:
KELLI D. CUMMINGS, PhD, NCSP, is a faculty research associate at the University of Oregon, Center on Teaching and Learning,
ANDREW SCHAPER began his career in education as a middle and high school English teacher in San Francisco, which influences his applied research interests in school improvement. His methodological research interests center on multilevel statistical modeling techniques and incorporating Bayesian estimation into the modeling of school predictors on student outcomes. He is a graduate research fellow at the Center on Teaching and Learning, 5292 University of Oregon, Eugene, OR 97403; e-mail:
GINA BIANCAROSA, EdD, is an assistant professor in the Department of Educational Methodology, Policy, and Leadership at the University of Oregon’s College of Education, Lokey Education Building, Room 102R, Eugene, OR 97403; e-mail: