
Abstract
In this meta-analysis, we investigated the effects of methods for providing item-based feedback in a computer-based environment on students’ learning outcomes. From 40 studies, 70 effect sizes were computed, which ranged from −0.78 to 2.29. A mixed model was used for the data analysis. The results show that elaborated feedback (EF; e.g., providing an explanation) produced larger effect sizes (0.49) than feedback regarding the correctness of the answer (KR; 0.05) or providing the correct answer (KCR; 0.32). EF was particularly more effective than KR and KCR for higher order learning outcomes. Effect sizes were positively affected by EF feedback, and larger effect sizes were found for mathematics compared with social sciences, science, and languages. Effect sizes were negatively affected by delayed feedback timing and by primary and high school. Although the results suggested that immediate feedback was more effective for lower order learning than delayed feedback and vice versa, no significant interaction was found.
The importance of assessment in the learning process is widely acknowledged, especially with the growing popularity of the assessment for learning approach (Assessment Reform Group [ARG], 1999; Stobart, 2008). The role of assessment in the learning process is crucial. “It is only through assessment that we can find out whether a particular sequence of instructional activities has resulted in the intended learning outcomes” (Wiliam, 2011, p. 3). Many researchers currently claim that formative assessment can have a positive effect on the learning outcomes of students. However, these claims are not very well grounded, an issue that was recently addressed in detail by Bennett (2011), who argued that “the magnitude of commonly made quantitative claims for effectiveness is suspect, deriving from untraceable, flawed, dated, or unpublished resources” (p. 5). For example, the source that is most widely cited with regard to the effects of formative assessment is Black and Wiliam’s (1998a, 1998b, 1998c) collection of articles.
Often, effect sizes of between 0.4 and 0.7 were cited from these studies, suggesting that formative assessment had large, positive effects on student achievement. Bennett (2011) argued, however, that the studies involved in Black and Wiliam’s meta-analysis (1998b, 1998c) are too diverse to support a meaningful overall result. Consequently, the overall effect size for formative assessment is not very informative. Moreover, the meta-analysis itself has never been published and, therefore, cannot be criticized. Bennett (2011) called the effect sizes in Black and Wiliam’s studies (1998b, 1998c) “a mischaracterization that has essentially become the educational equivalent of urban legend” (p. 12). Additionally, Bennett (2011) argued that other meta-analyses on formative assessment (e.g., Bloom, 1984; Nyquist, 2003; Rodriguez, 2004) have limitations and do not provide strong evidence. The most recently published meta-analysis on formative assessment (Kingston & Nash, 2011) has already been criticized for its methodological aspects (Briggs, Ruiz-Primo, Furtak, Shepard, & Yin, 2012; McMillan, Venable, & Varier, 2013).
For meta-analyses to produce meaningful results, they have to focus on a specific topic in order to include studies that are sufficiently comparable. A key element of the assessment for learning approach is the feedback provided to students (ARG, 1999; Stobart, 2008). Various meta-analyses and systematic review studies have focused on the effects of feedback on learning outcomes (e.g., Bangert-Drowns, Kulik, Kulik, & Morgan, 1991; Kluger & DeNisi, 1996; Shute, 2008). The outcomes of these studies have not been univocal and are sometimes even contradictory. Many researchers have noted that the literature on the effects of feedback on learning provides conflicting results (e.g., Kluger & DeNisi, 1996; Shute, 2008). Given the current state of research, there is a need for an updated meta-analysis focusing on specific aspects of formative assessment. The present meta-analysis concentrates on the effects of feedback provided to students in a computer-based environment.
Methods for Providing Feedback
Feedback is viewed as one of the most powerful means to increase student learning (Hattie & Gan, 2011; Hattie & Timperley, 2007). Hattie and Timperley (2007) defined feedback as “information provided by an agent (e.g., teacher, peer, book, parent, self, experience) regarding aspects of one’s performance or understanding” (p. 81). Feedback provided to students can help reduce the distance between the current and the intended learning outcomes (Hattie & Timperley, 2007). Although there is no generally accepted model of how feedback leads to learning, most research that has investigated the effects of feedback rests on the notion that when students are provided with feedback on their response to an item, this can confirm or alter their knowledge and skills (Mory, 2004). Winne and Butler (1994) suggested “feedback is information with which a learner can confirm, add to, overwrite, tune, or restructure information in memory, whether that information is domain knowledge, meta-cognitive knowledge, beliefs about self and tasks, or cognitive tactics and strategies” (p. 5740).
A popular model of learning from feedback was proposed by Bangert-Drowns et al. (1991). This model presents a five-stage cyclic process of learning, starting with the learner being in some kind of initial state in terms of, for example, prior knowledge and motivation (Stage 1). When a test item is presented to a student, this activates cognitive processes to retrieve information and search for the answer (Stage 2), and the student responds to the item (Stage 3). When feedback is provided, the student uses this feedback to evaluate the response provided (Stage 4). In the last stage of the model, the student makes adjustments to, for example, knowledge, beliefs, or strategies (Stage 5), and the cycle starts over with a new adjusted initial state. The model further emphasizes that feedback has to be processed mindfully in order to have an effect on learning outcomes, that is, change the initial state (Bangert-Drowns et al., 1991). Specifically, feedback can help students identify and correct errors and misconceptions, develop more effective and efficient problem-solving strategies, and improve their self-regulation. Research has highlighted that there are many methods for providing feedback, not all of which are equally effective in terms of contributing to student learning (Hattie & Timperley, 2007; Shute, 2008).
Various categorizations of methods for providing feedback are reported in the literature. In this meta-analysis, we employ the classifications used in two important review studies that are also well known in the educational literature (Hattie & Timperley, 2007; Shute, 2008). A distinction is made between feedback levels (Hattie & Timperley, 2007) and types and timing (Shute, 2008), as proposed by Van der Kleij, Timmers, and Eggen (2011). The focus of this study was item-based feedback, which relates to a student’s response to an item on a test, rather than the total score achieved on the test, for example.
Hattie and Timperley (2007) used a model based on a study by Kluger and DeNisi (1996) to distinguish four levels of feedback. Feedback can be aimed at the self, task, process, and regulation levels. Feedback that is aimed at the level of self does not relate to the task performed but instead relates to characteristics of the learner. An obvious example of feedback at the level of self is praise, for example, “You are a fantastic student!” Feedback at the task level performs a corrective function. Feedback at the process level addresses the process that was followed to complete the task. Regulation level feedback is related to students’ self-regulation; aspects that play a role here include self-assessment and willingness to receive feedback.
Shute (2008) distinguished various types of feedback, which can be classified as knowledge of results (KR), knowledge of correct response (KCR), and elaborated feedback (EF). KR indicates whether the answer is correct or incorrect but does not provide the correct answer or any additional information. One type of feedback, error flagging, which shows the student the location of the error but does not provide the correct answer or any additional information, can be classified as KR. Its main purpose is to reinforce the correct recall of facts, which is consistent with a behaviorist view of learning (Hattie & Gan, 2011; Narciss, 2008). KR was often used as a synonym for feedback in the early years of feedback research, indicating that its sole purpose is to inform the learner about the quality of the response (Sadler, 1989). Over time research has recognized that a trial-and-error procedure was not very effective in student learning because it does not inform the learner about how to improve.
KCR is similar to KR, but its main purpose is to revise the student’s incorrect responses (Kulhavy & Stock, 1989) by providing the correct answer. This type of feedback originated in cognitivism. Thus, both KR and KCR merely have a corrective function. With EF, however, the distinction between feedback (in terms of corrections) and instruction fades (Hattie & Timperley, 2007) because “the process itself takes on the forms of new instruction, rather than informing the student solely about correctness” (Kulhavy, 1977, p. 212). According to Shute (2008), EF can take many forms, such as hints, additional information, extra study material, and an explanation of the correct answer. Since the term, EF, has a wide range of possible meanings, the degree to which EF is effective for learning purposes varies widely. EF is often accompanied by KCR or KR, either implicitly or explicitly. For example, a student might be told the answer is incorrect (KR), followed by the correct answer (KCR) and a worked out solution (EF). Shute (2008) classified try again as a feedback type. We, however, found it more useful to define this response as an additional feedback characteristic that can be combined with multiple types of feedback. It could, for example, be combined with KR or with KR and EF in the form of hints.
The feedback types distinguished by Shute (2008) are all task-related feedback types, which in this context means the feedback is item-specific, as opposed to, for example, summary feedback covering the entire assessment. Shute calls this task level feedback, but the task level outlined by Shute should not be confused with the task level feedback described by Hattie and Timperley (2007). In the present study, whenever the word task level is used, it refers to Hattie and Timperley’s definition.
Shute (2008) pointed out that, with regard to timing, the results in the literature are conflicting even though the topic has been widely studied. With respect to feedback timing, a distinction can be made between immediate and delayed feedback. The definitions of immediate and delayed feedback seem to differ widely. This difference might be one of the reasons for the varying effects reported for immediate and delayed feedback (Mory, 2004). In formative assessment situations, immediate feedback is usually delivered right after a student has responded to an item. It is, however, hard to clearly define delayed feedback because of the wide variations in the possible degrees of delay (Shute, 2008). For example, delayed feedback could mean after the student completed the entire test, a couple of hours, a day, or even a week later. An important difference between immediate and delayed feedback is that immediate feedback is provided while a student is taking a test, whereas this is not the case with delayed feedback. In computer-based environments, it is possible to provide students with feedback very quickly since the feedback is automatically given based on the students’ response. Therefore, when it comes to feedback in a computer-based environment, delayed feedback can be defined unambiguously as “all feedback that is not delivered immediately after completing each item” (Van der Kleij et al., 2011, p. 23). Recent research suggests that students prefer immediate to delayed feedback (Miller, 2009). An experiment performed by Van der Kleij, Eggen, Timmers, and Veldkamp (2012) showed that students spent significantly more time reading immediate feedback than delayed feedback. These results indicate that feedback timing is a relevant aspect to take into account when investigating the effects of feedback on learning.
Evidence of the Effects of Feedback in Computer-Based Environments
According to Bloom (1984), one-to-one tutoring is the most effective form of instruction. One-to-one tutoring is effective because the teacher can immediately intervene—provide feedback—when there is a misunderstanding. Thus, instruction can be adapted continuously to the needs of the learner. Unfortunately, this type of instruction is unimaginable in today’s educational systems. Current technology, however, offers promising solutions to this problem. Specifically, if an assessment is administered in a computerized environment, it is possible to provide the student with standardized feedback based on his or her response to an item. Computer-based assessments (CBAs) have various advantages, such as the possibility of providing more timely feedback, automated scoring, and higher test efficiency (Van der Kleij et al., 2011). As in one-to-one tutoring situations, feedback in CBA can serve to immediately resolve the gap between students’ current status in the learning process and the intended learning outcomes (Hattie & Timperley, 2007). In this way, CBA could assist teachers in providing students with individualized feedback. Similarly, most computer-based instruction environments include practice questions with feedback.
To the best of our knowledge, only three studies that provide an overview of the effects of feedback in computer-based environments on students’ learning outcomes have been published to date: Azevedo and Bernard (1995), Jaehnig and Miller (2007), and Van der Kleij et al. (2011). An overview of the characteristics and main results of these studies follows in chronological order.
Azevedo and Bernard (1995) conducted a meta-analysis to determine the effects of feedback on learning from computer-based instruction. In total, this meta-analysis included 22 studies (published between 1969 and 1992), which were mostly aimed at lower order learning outcomes. This level of learning demands that students recall, recognize, and understand concepts without the need to apply this knowledge. For higher order learning outcomes, though, students are required to apply their acquired knowledge in new situations, which is called transfer (see Smith & Ragan, 2005). An example of a test that is aimed at lower order learning outcomes in the subject of English as a foreign language is a test that measures student’s vocabulary. An example of a higher order learning test in the same subject is one that requires students to use, among other things, their vocabulary to write a letter to a pen pal.
The effect sizes from the studies included in Azevedo and Bernard’s (1995) meta-analysis ranged from 0.03 to 2.12. Azevedo and Bernard made a distinction between studies with an immediate posttest and studies with a delayed posttest. In total, the researchers extracted 34 effect sizes from 22 studies that used an immediate posttest. The unweighted mean effect size was estimated at 0.80. A mean effect size of 0.35 was found for a delayed posttest. In analyzing the data, the authors did not take any feedback characteristics (such as type) into consideration. It was only in the discussion section that the authors provided information on the characteristics of the feedback in the studies, which seemed to differ between studies with an immediate posttest and those with a delayed posttest. This section of the meta-analysis was, however, not very clarifying, because the differences found between effect sizes were not related to specific feedback characteristics. Based on the small sample, the datedness of the studies included and the lack of identifying moderator variables, one can question the value of this meta-analysis for providing insight into what works in current educational practice.
Jaehnig and Miller (2007) conducted a systematic review of the effects of different feedback types in programmed instruction. As can be expected from the topic of this review study, many outdated studies were included. The publication years of the reviewed studies ranged from 1964 to 2004 (N = 33). In these studies, only the effects of feedback on lower order learning outcomes, mostly recall, were investigated. Jaehnig and Miller concluded that KR is not effective for learning, that KCR is effective sometimes, and that EF seems to be the most effective. EF in this study included any feedback that contained additional information regarding the correctness of the response, such as an explanation. Furthermore, EF in this study also included answer until correct (AUC), a form of KR in which the student has to try again until the answer is correct. With regard to feedback timing, Jaehnig and Miller concluded that there were no differences between the effects of immediate and delayed feedback. However, in their study, no clear definitions of feedback immediacy and delay were provided. Sometimes delayed feedback was provided a certain number of seconds after the stimulus was presented to the student (e.g., 15 or 30 seconds after responding to the item), whereas at other times, it was delayed until after all items were completed. Furthermore, it is questionable to what degree the results of the studies included in this systematic review can be generalized to current educational practices because of the large number of outdated studies and the different approach to learning.
Recently, a systematic review study was conducted by Van der Kleij et al. (2011). In their study, the results found in various experiments on the effects of written feedback in a CBA were compared. Of the 18 studies selected for the review (published between 1989 and 2010), only nine reported a statistically significant positive effect of one feedback condition favoring another. One possible explanation for this result is that the sample sizes, and therefore the statistical power, in these studies were generally small. Van der Kleij et al. (2011) concluded that KR seems to be ineffective, KCR moderately beneficial for obtaining lower order learning outcomes and EF beneficial for obtaining both lower order and higher order learning outcomes. The outcomes of this review study suggest that it is necessary to take the level of learning outcomes (Smith & Ragan, 2005) into account when examining the effects of feedback.
Gaps in the Literature
The evidence in the available literature on the effects of feedback in computer-based environments supports some general conclusions (Azevedo & Bernard, 1995; Jaehnig & Miller, 2007; Van der Kleij et al., 2011). For example, the results suggest that feedback can positively affect learning, but not all methods for providing feedback are equally effective. Additionally, the results indicate that EF is generally more effective. However, these three review studies do not provide a complete picture of the effects of feedback in computer-based learning environments on students’ learning outcomes. Azevedo and Bernard (1995) found a mean effect size of 0.80. Since the magnitude of the effect size is not explicitly related to feedback characteristics and levels of learning outcomes, however, this study does not offer insight into how to effectively provide feedback in a computer-based environment in any given situation.
The studies by Jaehnig and Miller (2007) and Van der Kleij et al. (2011) do provide some useful insights in this respect. The studies have consistent results regarding feedback types, although the feedback classifications used in the two studies differ somewhat. KR seems to be ineffective, KCR somewhat effective (especially for lower order learning outcomes; Van der Kleij et al., 2011), and EF the most effective. However, the results of Jaehnig and Miller (2007) apply only to lower order learning outcomes. As well, the systematic review by Van der Kleij et al. (2011) focused only on the effects of written feedback and used strict inclusion requirements for the quality of studies, resulting in a limited sample size of 18 studies.
The results of the three overview studies can be helpful for informing theory and practice to a certain extent. However, together they do not shed sufficient light on the complex interplay of feedback type, feedback timing, and the level of learning outcomes and do not give usable insights into the magnitude of the effects. These lacks reveal certain gaps in the literature on the effects of feedback in computer-based learning environments. Therefore, there is a need for an updated meta-analysis that takes into account variables that seem relevant based on the literature and that builds on some conclusions drawn in existing review studies.
Objectives of the Present Study
The objective of this meta-analysis is to gain insight into the effectiveness of various methods for providing item-based feedback in a computer-based environment on students’ learning outcomes. Conducting a meta-analysis makes it possible to detect patterns and effects that are not visible at the level of individual experiments. It also provides us with insights into the magnitude of the feedback effects. In addition, this meta-analysis attempts to extend and update the results of previous review studies on this topic by taking into account variables that seem relevant according to the literature. The primary question that this meta-analysis seeks to answer is as follows: To what extent do various methods for providing item-based feedback in a computer-based learning environment affect students’ learning outcomes? It is not the aim of this meta-analysis to obtain an overall effect size expressing the effect of feedback in computer-based environments in general. In order to produce meaningful results, this meta-analysis has to provide multiple effect sizes, one for each type of feedback. Also taken into account is the level of learning outcomes, which has been shown to be a relevant variable when examining feedback effects in a computer-based environment (Van der Kleij et al., 2011). It is unlikely that there is one ideal situation that has a positive influence on the learning outcomes of all students in all subjects. However, a meta-analysis offers the opportunity to reveal some particularly relevant effects, which were not present in the primary studies because the sample sizes in the primary studies were often small.
Although the scope of this meta-analysis is narrower than those that have focused on feedback effects in classroom settings, the findings from the literature on feedback in classroom situations were also considered. It is not the aim of this study to review the review studies on feedback effects. There are, however, some interesting findings available in the literature that can be used as a starting point for investigating the effects of feedback in computer-based environments. General findings for feedback in classroom situations include the following:
Feedback at the level of self (praise) has not been shown to be effective in improving learning outcomes (Hattie & Gan, 2011; Hattie & Timperley, 2007; Kluger & DeNisi, 1996) but may positively influence student motivation and persistence.
Simple feedback (that is only related to the correctness of the response; KR and KCR) seems to be mainly effective for lower order learning outcomes (Kluger & DeNisi, 1996; Smith & Ragan, 2005; Van der Kleij et al., 2011).
EF (which can take many forms) seems to be the most effective feedback type (Mory, 2004; Shute, 2008; Van der Kleij et al., 2011), especially for higher order learning outcomes (Smith & Ragan, 2005; Van der Kleij et al., 2011). However, because of variations in the nature of EF, there is also wide variation in its effects (Narciss, 2008; Shute, 2008).
How the feedback is received differs from student to student (Hattie & Gan, 2011; Kluger & DeNisi, 1996; Stobart, 2008; Timmers & Veldkamp, 2011), and feedback has to be processed mindfully in order to have an effect on learning outcomes (Bangert-Drowns et al., 1991). Especially in a computer-based environment, students can easily ignore written feedback (e.g., Timmers & Veldkamp, 2011; Van der Kleij et al., 2012).
The effectiveness of immediate versus delayed feedback seems to differ depending on the level of the intended learning outcomes (Shute, 2008). Shute suggested that, when the feedback is intended to facilitate lower order learning outcomes, immediate feedback works best, and when higher order learning outcomes are at stake, it is best to provide feedback with a delay. However, the literature shows highly conflicting results when it comes to the timing of feedback.
The available evidence from the literature on feedback in classroom situations and the insights from literature on the effects of feedback in computer-based environments (Azevedo & Bernard, 1995; Jaehnig & Miller, 2007; Van der Kleij et al., 2011) were used to construct the hypotheses for this meta-analysis. In summary, the literature suggests that (1) KR and KCR have a small to moderate positive effect on lower order learning outcomes, (2) KR and KCR have virtually no effect on higher order learning outcomes, (3) EF has a moderate to large positive effect on lower order learning outcomes, (4) EF has a moderate to large positive effect on higher order learning outcomes, and (5) there is an interaction effect between feedback timing and the level of learning outcomes. Immediate feedback is more effective for lower order learning outcomes than delayed feedback and vice versa.
The commonly used benchmarks for interpretation of effect sizes were introduced by Cohen (1988). However, McMillan et al. (2013) noted that, although it is commonly assumed that these guidelines are suitable for interpreting the effects of interventions in the context of education, Cohen’s (1988) benchmarks for effect sizes have not been validated for use in educational contexts. Therefore, as benchmarks for the value of effect sizes, we used Hattie’s (2009) interpretations for the magnitude of effect sizes because they have been derived from the context of education. According to Hattie, an effect size of 0.2 can be considered small, an effect size of 0.4 can be considered moderate, and effect sizes of 0.6 are classified as large. Hypothesis 1 will be rejected if the effects of KR or KCR on lower order learning outcomes are significantly lower than 0.2 or higher than 0.6. We will reject Hypothesis 2 if the effects of KR or KCR on higher order learning outcomes are significantly larger than 0.2. Hypothesis 3 will be rejected if the effects of EF on lower order learning outcomes are significantly less than 0.4. If the effects of EF on higher order learning outcomes are significantly lower than 0.4, Hypothesis 4 will be rejected. Hypothesis 5 will be discarded if there is no interaction effect between feedback timing and the level of learning outcomes or if the expected direction of the effects is found to be reversed.
Finally, the relationships of various variables that seem relevant given the literature were explored in this meta-analysis, such as subject (e.g., Kingston & Nash, 2011), education level, level of learning outcomes (Van der Kleij et al., 2011), and the level at which the feedback is aimed (Hattie & Gan, 2011; Hattie & Timperley, 2007; Van der Kleij et al., 2011).
Method
Data Collection
For data collection, a thorough and systematic search was conducted, which consisted of three phases. The primary search included the online databases ERIC, PsycInfo, ScienceDirect, Scopus, and Web of Science. The search sought for terms related to feedback, formative assessment, and assessment for learning used in titles. In addition, the word “computer” or variants of had to appear in the abstract. In Web of Science, the search was restricted to titles with terms related to “computer” in the title. In Scopus, the search was limited to the social sciences. No restrictions were imposed regarding the publication year and publication type during the search.
The references retrieved were exported to Endnote version X4 (Thomson Reuters, 2010) and assessed based on their relevance using the inclusion criteria (which are specified in the inclusion criteria section). The full texts of studies that met the inclusion criteria were retrieved. Subsequently, the ancestry approach (White, 1994) was used as a secondary method for searching studies; the reference section of each selected study was scanned for potentially relevant references for inclusion. Studies that met the inclusion criteria were also included. Third, the reference sections of existing meta-analyses and review studies on this topic (Azevedo & Bernard, 1995; Jaehnig & Miller, 2007; Van der Kleij et al., 2011) were scanned for potentially relevant references for inclusion. Studies that were not yet included in the study and that met the inclusion criteria were also selected. This was done to satisfy the cumulative character of meta-analytic studies on the same topic, which meta-analyses often lack (Bennett, 2011).
Inclusion Criteria
In order for studies to be included in the current meta-analysis, they had to meet the following criteria: (a) the study was published in a journal article, scientific book, book section or dissertation; (b) the study was published in English language; and (c) the study compared the effects of different types of (standardized, response based) feedback in a computer-based assessment or computer-based learning environment on the learning outcomes of individual students in terms of achievement measured in a quantitative way.
Criterion (a) was used to include all the high-quality publications. Conference proceedings, (technical) reports, and meeting abstracts were excluded in this selection step. These types of documents were omitted because it was unclear whether they had been subjected to peer review, which is a generally accepted criterion for ensuring scientific quality. Unpublished documents, such as master theses, were also not included in this meta-analysis. Criterion (b) was set to obtain studies that have a high degree of accessibility. Criterion (c) was used to select only studies relevant for the purpose of this meta-analysis. In this selection step, studies that did not examine the effects of feedback in a computer environment were excluded. In addition, studies were excluded that did not use a comparison group (that received another type of feedback or no feedback) or did not measure students’ learning outcomes in a quantitative way.
The conditions in terms of test content and mode had to be identical for the experimental and control groups. Also, the constructs measured by the posttest had to be identical to the constructs in the formative test. The posttest could be computer based or paper based, as long as the conditions were identical for both groups to ensure that test mode did not interfere with feedback effects. In addition, the feedback had to be response based, meaning that the computer provided students with feedback based on their response to an item. Thus, the feedback had to be item specific and identical for all students in the experimental group based on the input response. Studies that used feedback that was generated by a human being and that therefore differed for students within one feedback condition were excluded. The requirement that the feedback had to be automatically generated and response based somewhat narrowed down the types of tests included in the studies, with the majority of them using some kind of selected response format, most often multiple choice. However, this requirement was necessary for holding the nature of the feedback within experimental groups constant.
An example of eligible experimental and control conditions is shown in Figure 1. In this example, the experimental group and control group took an identical formative test, which was composed of individual items. The experimental group received immediate EF on each item, and the control group received immediate KR on each item in the formative test. Subsequently, both groups took the same posttest on the same content as the formative test, with means (M = x) and standard deviations (SD = y) for test scores used to compute the effect size. Thus, the effects of various methods for providing feedback on learning were examined by comparing the posttest scores of students in groups with different feedback conditions, while all other conditions were held equal.
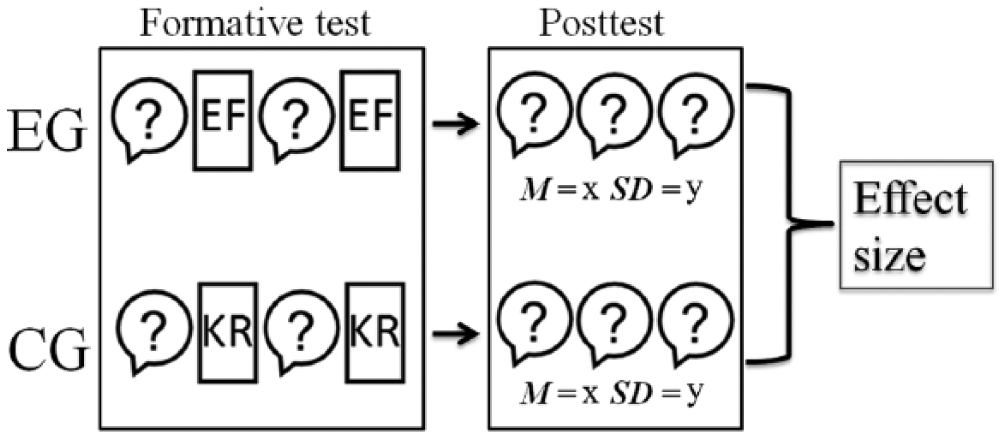
Example of eligible experimental and control conditions.
In this meta-analysis, students received item-based feedback, which meant they received feedback on every item in the formative test, be it immediately or with a delay. The intervention could consist of one or multiple formative tests in which feedback was provided, as long as the conditions were identical in the experimental and control groups except for the feedback intervention. No restrictions were placed on the subject matter, level of education, type of computer-based environment, the way in which feedback was provided (e.g., text, audio), and the nature of the tests used in the experiments—although most tests were constructed by school personnel and had a closed answer format. In the majority of the studies the posttest was administered shortly after students took the formative test and received feedback, that is, immediately, a couple of hours later, or a day later.
To be included in this meta-analysis, the study had to report sufficient quantitative information to estimate the effect size statistic. Whenever a small amount of essential information was missing, the authors were contacted through email. Furthermore, experimental and control groups had to contain at least 10 participants each. We did not make very strict restrictions with regard to the nature of the control groups. Students in the control condition could receive either no feedback, KR, or KCR. Although in traditional meta-analyses the control groups are held constant, the current meta-analysis deliberately included multiple control groups for various reasons. The first, and most prominent reason, was to come to a more complete picture with respect to how to effectively provide feedback in a computer-based environment. In recent years, the focus of research on the effectiveness of feedback has shifted away from investigating if feedback is effective to how feedback can be provided effectively (e.g., Hattie & Timperley, 2007; Mory, 2004; Shute, 2008).
Taking into account the effects of different types of feedback contrasted with no feedback, KR, or KCR allowed for richer comparisons across methods for providing feedback. As a consequence, the results of this meta-analysis will be more informative for both theory and practice. The second reason was related to methodological objectivity; when multiple experimental groups were used in the primary studies, there was no objective way to choose which treatment group to include or exclude. An example of an eligible study is one by Pridemore and Klein (1995). The study investigated the effects of immediate KCR, immediate EF (including KCR), and no feedback on items integrated into lesson material. In this meta-analysis, we computed three effect sizes from the Pridemore and Klein study, expressing the effects of KCR versus no feedback, EF versus no feedback, and EF versus KCR.
Two researchers independently conducted the selection steps for Criterion (a) and Criterion (b). After each selection step, the authors compared their judgments and discussed and resolved any differences. Interrater agreement was .93 for selection on Criterion (a) and .99 for selection on Criterion (b). In selecting studies on Criterion (c), two researchers judged the relevance, based on the selection criteria, of 58% of the studies; the other 42% were judged by one researcher. The interrater agreement rate on Criterion (c) was .92.
The full-text versions of studies that met the inclusion criteria were retrieved. Studies that were not available in their full-text versions through the library facilities at hand, including interlibrary loans, were requested from the authors. Studies whose full-text version could not be retrieved were not included in the meta-analysis.
Coding Procedures
The coding form was based on a method proposed by Lipsey and Wilson (2001). The literature was extensively consulted and their method was adapted to suit the requirements of this meta-analysis. The form was evaluated multiple times in repetitive cycles in consultation with the coders and specialists on this topic. The form contains multiple selections, such as study descriptors, sample descriptors, methods and procedures (including study quality), and effect size information.
Coding was conducted independently by four researchers. The first author coded all studies, while 40% of the studies and 31% of all effect sizes were double-coded by a different coder. The agreement rate between the coders was .81 for all studies and .81 for all effect sizes. In some studies with multiple experimental conditions, participants received the same type of feedback under different conditions. For example, a study compared the effects of KCR under program and learner control conditions (Corbalan, Kester, & Van Merriënboer, 2009). In this study, the mean scores of groups that received the same type of feedback under different conditions that were not relevant to the present meta-analysis were combined, using their weighted means and pooled SDs.
Statistical Methods
Meta-analysis is a method that enables the combination and summary of quantitative information from different studies focused on the same research question. Using information from several studies creates the opportunity to provide a structured summary of a specific research topic and to find relationships between variables that otherwise would not be detected. A central step in meta-analysis is to make the data from each separate study comparable. This can be done by using an effect size measure. Effect sizes in this meta-analysis express the effectiveness of each study’s variable of interest between a treatment and control group in terms of SD units (Lipsey & Wilson, 2001). The experimental and control groups in each study always took the same posttest. Usually, estimates of effect sizes obtain a plus sign if the treatment group is better than the control group and vice versa (Rosenthal, 1994). We used the standardized mean differences (see Equation 1) effect size statistic.

This statistic uses the contrast between the treatment and control groups divided by the pooled SD (see Equation 2).

Hedges (1981) showed that effect sizes calculated for studies with small samples might be biased. An unbiased alternative estimator developed by Hedges (1981; see Equation 3) was used to correct for this bias.
This estimator has the following standard error:
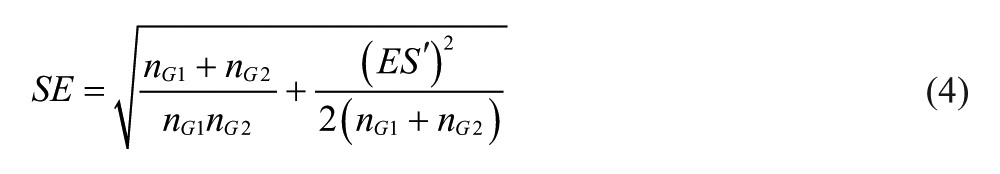
The adjusted effect sizes have been checked for potential outliers by evaluating whether certain effect sizes differed by more than three SDs from several group mean effect sizes, as they might have too large an impact on the summary statistics or even create a bias.
In a meta-analysis, one might assume that all the included studies estimate the same population mean. Models under this assumption are called fixed effects models. In this case, differences between effect size estimates and the true population mean can only be attributed to sampling error (Shadish & Haddock, 1994). The homogeneity test assesses if the observed variability in the results is more heterogeneous than expected from sampling variance alone. This test is based on the Q-statistic (Lipsey & Wilson, 2001), which is distributed as a chi-square distribution with the number of effects sizes minus one degree of freedom (Hedges & Olkin, 1985). If the homogeneity of the study results is rejected, random and mixed effects models are alternatives to the fixed effects model. In the former, studies are assumed to estimate a distribution of effect sizes, while in the latter, variance in effect sizes can be seen as having both a random and a systematic component. Study characteristics can be used to account for the systematic part of the differences between effects sizes estimates.
One of the factors that influences the precision of effect size estimates is the sample size. A common strategy in a meta-analysis is therefore to attach different weights to studies depending on their level of precision. Optimal weights are constructed using the standard error of the effect size (Hedges, 1982; Hedges & Olkin, 1985; see Equation 5).

These weights are used in the fixed effects models. In random effects models, these weights are supplemented by a constant that represents the variability across population effects (see Equation 6).

It might be that studies containing nonsignificant results about feedback are less easily published than studies with significant results. If that were the case, this meta-analysis would not cover the complete population of studies and would be potentially biased. This issue was addressed with the fail-safe N method (Orwin, 1983), which estimates how many studies reporting nonsignificant effects sizes would be need to be combined with the studies in the meta-analysis in order to arrive at a specific result.
In order to assess whether studies with different characteristics also have different mean effect sizes, we conducted an analysis of variance for effect sizes. To establish simultaneously the relationships between effect sizes and several study characteristics, we performed a weighted regression analysis. All analyses were carried out using adjusted SPSS macros written by Wilson (Version 2005.05.23).
Results
Results of the Selection Process
In the primary literature search conducted in May 2011, 2,318 publications were retrieved. After removing duplicate publications, 1,609 unique publications remained. These publications were subsequently subjected to the selection criteria. The results of the selection process can be found in Table 1. In total, 125 studies retrieved in the primary search appeared to match the selection criteria based on their titles and abstracts. However, some of the selected studies (n = 86) were excluded after retrieving their full-text versions because they did not report sufficient information, contain a sufficient sample size, or compare different types of (standardized, response based) feedback. Other studies were excluded because their full-text versions could not be obtained (n = 3). For two studies, both a dissertation and journal article were included in the search. In these cases, the dissertations were excluded from the selection. The primary search resulted in 36 relevant studies for this meta-analysis.
Results of the selection process in the primary search

Using the ancestry approach (White, 1994), another 18 studies were retrieved, and four met the inclusion criteria. Six studies that were not retrieved in the primary or secondary search but were included in an existing review study appeared to be relevant. However, none of these studies were eligible for inclusion. Thus, the secondary and tertiary searches resulted in another four eligible studies, which produced a total of 40 studies for this meta-analysis. From these 40 studies, 70 effect sizes were obtained. The number of effect sizes is indicated by k in the remainder of this article.
Characteristics of the Selected Studies
The studies in this meta-analysis were published between 1968 and 2012. Of the 40 studies, 30 appeared as journal articles, and 10 were published in the form of a doctoral dissertation. The majority of studies were conducted at a university, college, or adult education setting (n = 32, k = 56). Six studies were carried out in secondary education settings (k = 12), and two in primary education settings (k = 2). The studies were categorized based on their subject or content area. Four categories were distinguished: (a) social sciences (n = 5, k = 9; e.g., psychology and education); (b) mathematics (n = 6, k = 8; e.g., introductory statistics and algebra); (c) science, biology, and geography (n = 18, k = 29; e.g., chemistry, climate change, and medical education); and (d) languages (n = 13, k = 24; e.g., vocabulary and Spanish as a second language). The majority of the effect sizes were derived from studies that randomly assigned the subjects to the experimental or control condition (k = 52). The other effect sizes come from studies that randomly assigned their subjects by class (k = 4) or matching (k = 12), that used a nonrandom assignment procedure (k = 1), or that employed another assignment procedure (k = 1).
Effect Sizes
The sample size in the primary studies ranged from 24 to 463, with an average sample size of 106.66 (SD = 102.83). Given the relatively small sample size of some studies, a correction for an upwards bias was applied, which resulted in a corrected effect size noted as ES′ (Lipsey & Wilson, 2001). The correction for sample size bias made a very small difference on the effect sizes in this meta-analysis. This meta-analysis contained 70 effect sizes obtained from 40 unique studies. The effect sizes ranged from −0.78 to 2.29. Table 2 shows the unweighted effect sizes ordered from smallest to largest by feedback type in the experimental group. When interpreting these effect sizes, one has to take into account the nature of the control group the experimental group was contrasted with.
Authors, publication year, feedback type and timing, sample size, level of learning outcomes, and unweighted effect sizes
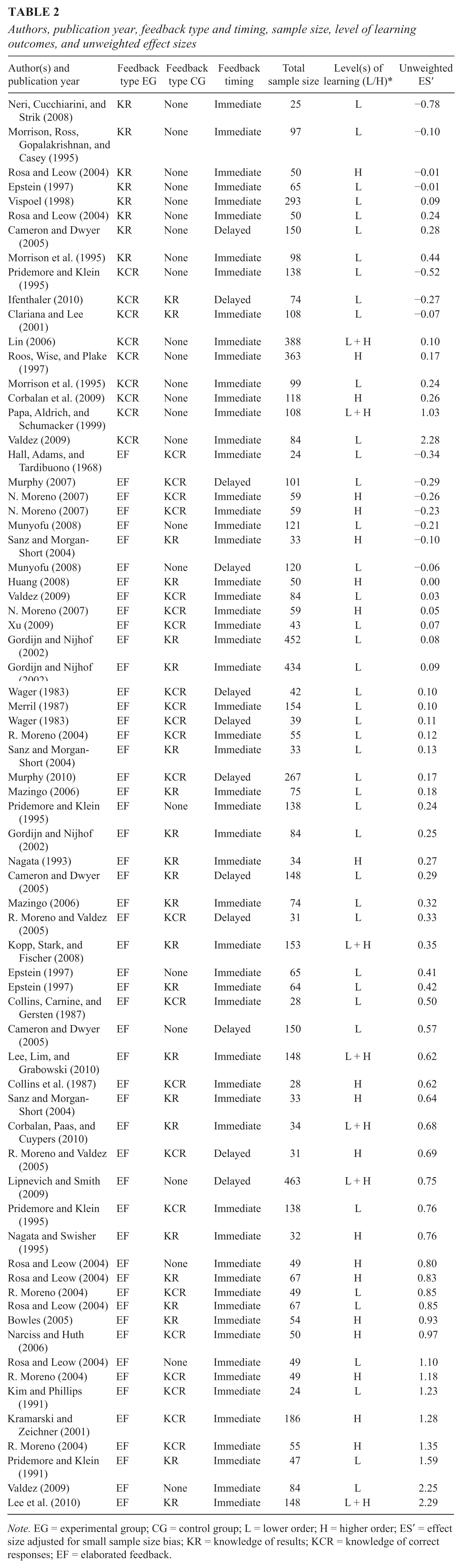
Note. EG = experimental group; CG = control group; L = lower order; H = higher order; ES′ = effect size adjusted for small sample size bias; KR = knowledge of results; KCR = knowledge of correct responses; EF = elaborated feedback.
It can be concluded from Table 2 that the majority of the effect sizes were concerned with the effects on lower order learning outcomes (k = 43). Other effect sizes (k = 27) described the effects on higher order learning outcomes or a combination of lower and higher order learning outcomes. In addition, the results showed that the majority of the effect sizes concerned immediate feedback (k = 58), and only a small number of the effect sizes were associated with feedback that was delivered with a delay (k = 12). In the majority of cases (k = 61), students received feedback at only one assessment occasion. In two cases, students twice received feedback on their assessment results. In the remainder of the cases (k = 7), students were given feedback three or more times. Table 2 shows that there are 12 negative effect sizes, and each feedback type had both negative and positive effect sizes. The distribution of the effect sizes and their 90% confidence interval (CI) is shown in Figure 2. No cases that deviated more than three standard deviations from several group averages were found. Therefore, we decided not to exclude or adjust any effect size.

Distribution of the unweighted overall effect sizes and their 90% confidence intervals.
The analyses for homogeneity showed that the observed variation in the effect sizes was more heterogeneous than what might be expected from sampling variance alone, χ2(69) = 446, p < .001. This result suggested that a fixed model might not be suitable. Therefore, we chose to supplement weights by a random component (see Equation 6). No indication was found for publication bias. In the case of this meta-analysis, one would need 76 extra studies with an overall effect size of 0 to obtain a small mean weighted effect size of 0.2 (Hattie, 2009). Furthermore, the ratio of the included effect sizes and studies (70/40) was considered too small to perform multilevel analyses in order to account for the non-independence of effect sizes within studies. Therefore, the analyses were performed using regular linear regression.
We computed the mean weighted effect sizes for various relevant variables. The results are shown in Table 3. The mean weighted effect size in Table 3 is the associated mean effect size for each category, followed by the corresponding 90% CI and p value. Table 3 shows that of the three feedback types, KR had the smallest effect size and EF the largest. Please note that the effects of KCR were contrasted with the effects of KR and no feedback, and the effects of EF were contrasted with KCR, KR, or no feedback. As a consequence, the overall mean weighted ES′ presented in Table 3 might be an underestimation when considering the meaning of the effect sizes from a traditional point of view, compared with no feedback. The effect sizes by feedback type for each control group are shown in Table 4. With regard to feedback timing, the effects for immediate feedback were larger than for delayed feedback. Additionally, the effect sizes appeared to be larger for higher order learning outcomes than lower order learning outcomes. The effects found in university or college settings were somewhat larger than those found in primary and high school settings. The effects also seemed to differ by the subject area from which they were derived. The effects in mathematics were very large, those in the social sciences and sciences were medium, and those in languages small. Table 5 shows the distribution of the feedback types investigated in each subject area.
Analysis of variance results

Note. CI = confidence interval; ES′ = effect size adjusted for small sample size bias; KR = knowledge of results; KCR = knowledge of correct response; EF = elaborated feedback.
These effect sizes may be underestimates because of the combination of different control conditions.
Effect sizes per feedback type per control condition

Note. CG = control group; EG = experimental group; CI = confidence interval; ES′ = effect size adjusted for small sample size bias; KR = knowledge of results; KCR = knowledge of correct response; EF = elaborated feedback.
Feedback types investigated in the different subject areas
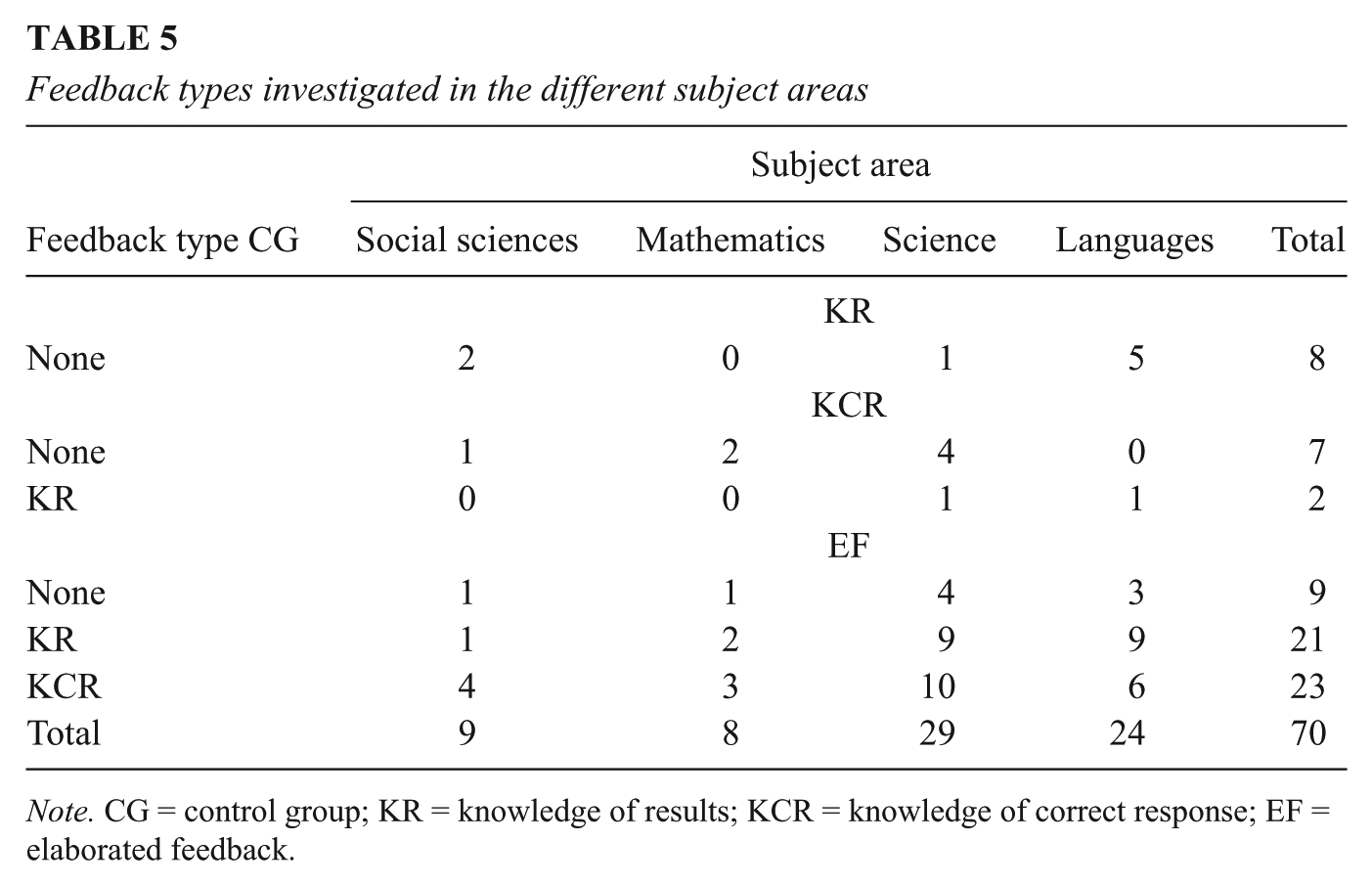
Note. CG = control group; KR = knowledge of results; KCR = knowledge of correct response; EF = elaborated feedback.
Next, the effect sizes by feedback type were computed for each of the control groups (see Table 4). In this study, we chose to contrast feedback types to other possible, dissimilar feedback conditions, as described in the Inclusion Criteria section. However, Table 4 shows that there was considerable variation in the magnitude of the effect sizes among the different control groups. However, given the small sample size in this meta-analysis, it was deemed that running separate analyses for each possible control group would not produce meaningful results in some cases. Instead, in the overall analyses, readers should take into account the potential underestimation of the KCR and EF effects. Whenever this is the case, it is brought to the attention of the reader by explicitly referring to overall results.
It was expected that KR and KCR would have a small to moderate positive effect (between 0.2 and 0.6) on lower order learning outcomes (Hypothesis 1). We also predicted that KR and KCR would have virtually no effect (less than 0.2) on higher order learning outcomes (Hypothesis 2). EF was expected to have a moderate to large positive effect (at least 0.4) on lower order learning outcomes (Hypothesis 3) and a moderate to large positive effect on higher order learning outcomes (Hypothesis 4).
The mean weighted effect sizes for KR on lower order learning outcomes was 0.12, 90% CI [0.00, 0.24], k = 7, which is lower than the expected effect of at least 0.2. The overall effects of KCR on lower order learning outcomes are in line with the expectations, namely ES′ = 0.31, 90% CI [−0.25, 0.87], k = 5. The number of effect sizes for KCR in relation to lower order learning outcomes was too small to provide meaningful results with respect to the different control conditions (k = 3 for no feedback and k = 2 for KR). The 90% CIs of both KR and KCR fall within the range of 0.2 to 0.6. However, the intervals were large because of the small number of observations, which indicate that we cannot meaningfully test Hypothesis 1. The effects on higher order learning outcomes of KR were as predicted, ES′ = −0.01, 90% CI [−0.51, 0.49], k = 1; however, the overall effects of KCR were larger than expected, ES′ = 0.38, 90% CI [−0.23, 0.99], k = 4. Again, the 90% CIs were large and the number of effect sizes was small, and we could not meaningfully test Hypothesis 2.
Table 6 shows the mean weighted effect sizes and their 90% CI for EF by level of learning outcomes, split out for each of the control groups. Hypothesis 3 (EF has a moderate to large positive effect on lower order learning outcomes) was not rejected because the overall effect of EF on lower order learning outcomes was 0.37, 90% CI [0.21, 0.53], k = 31, and the upper limit of the CI was higher than 0.4. The effects of EF on lower order learning outcomes are moderate to large in the different control conditions, and for none of the control groups the upper limit of the 90% CI was below .40. EF’s overall effects on higher order learning outcomes were somewhat larger than 0.4, ES′ = 0.67; therefore, Hypothesis 4 (EF has a moderate to large positive effect on higher order learning outcomes) was not rejected. The effects of EF on higher order learning outcomes are consistently large across the different control conditions, and for none of the control groups the upper limit of the 90% CI was less than 0.40. The results suggest that the additional value of EF over KR or KCR is much more substantial for higher order learning outcomes than for lower order learning outcomes.
Mean weighted effect sizes of EF by level of learning outcomes
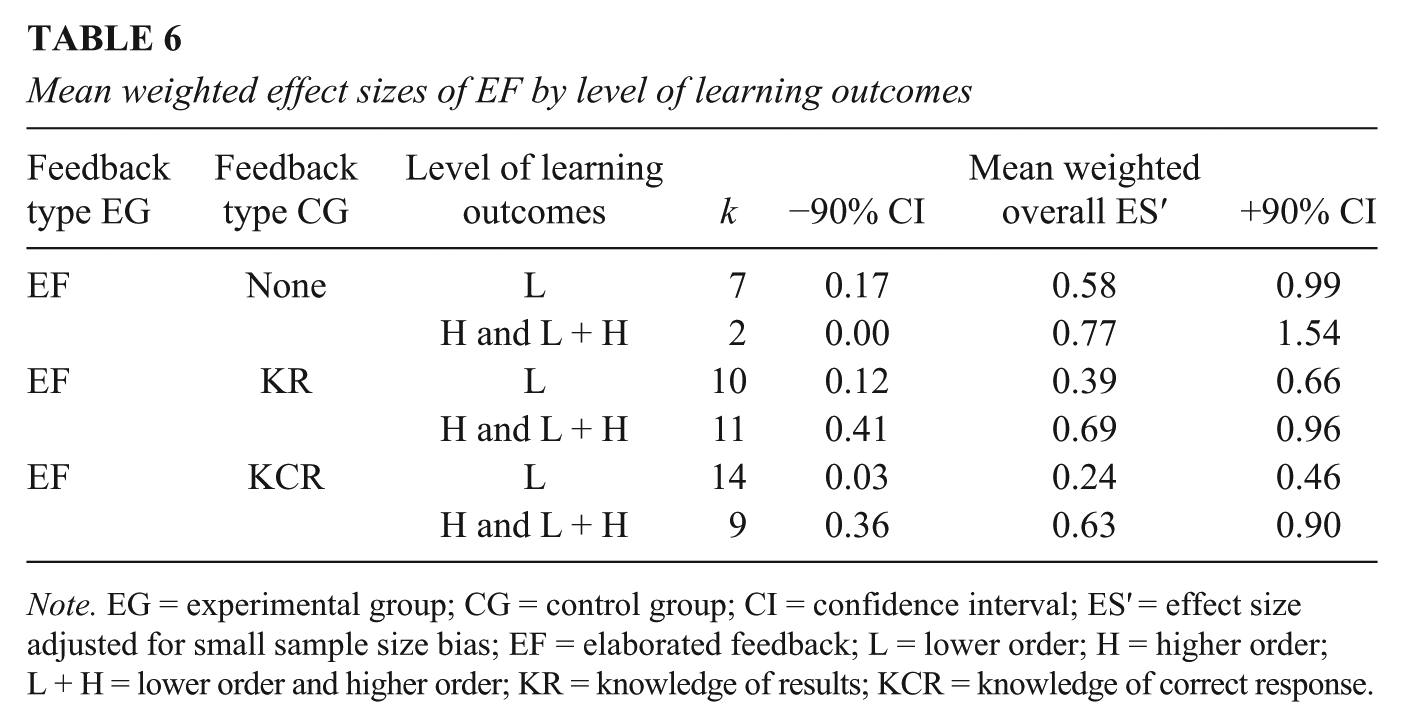
Note. EG = experimental group; CG = control group; CI = confidence interval; ES′ = effect size adjusted for small sample size bias; EF = elaborated feedback; L = lower order; H = higher order; L + H = lower order and higher order; KR = knowledge of results; KCR = knowledge of correct response.
The effects of EF seemed promising, but the nature of EF varies widely. Therefore, we categorized overall EF effects by the level (self, task, process, regulation; Hattie & Timperley, 2007), which they were intended to affect in order to gain insight into which EF method was most effective (see Table 7). The results showed that the majority of the effect sizes (k = 41) involved the task and process levels and produced moderately large effects (ES′ = 0.50). The largest effects were found for EF at the task and regulation levels (ES′ = 1.05, k = 4) and at the task, process, and regulation levels (ES′ = 1.29, k = 1), although the number of effects was small.
The mean weighted effect sizes of EF for each feedback level
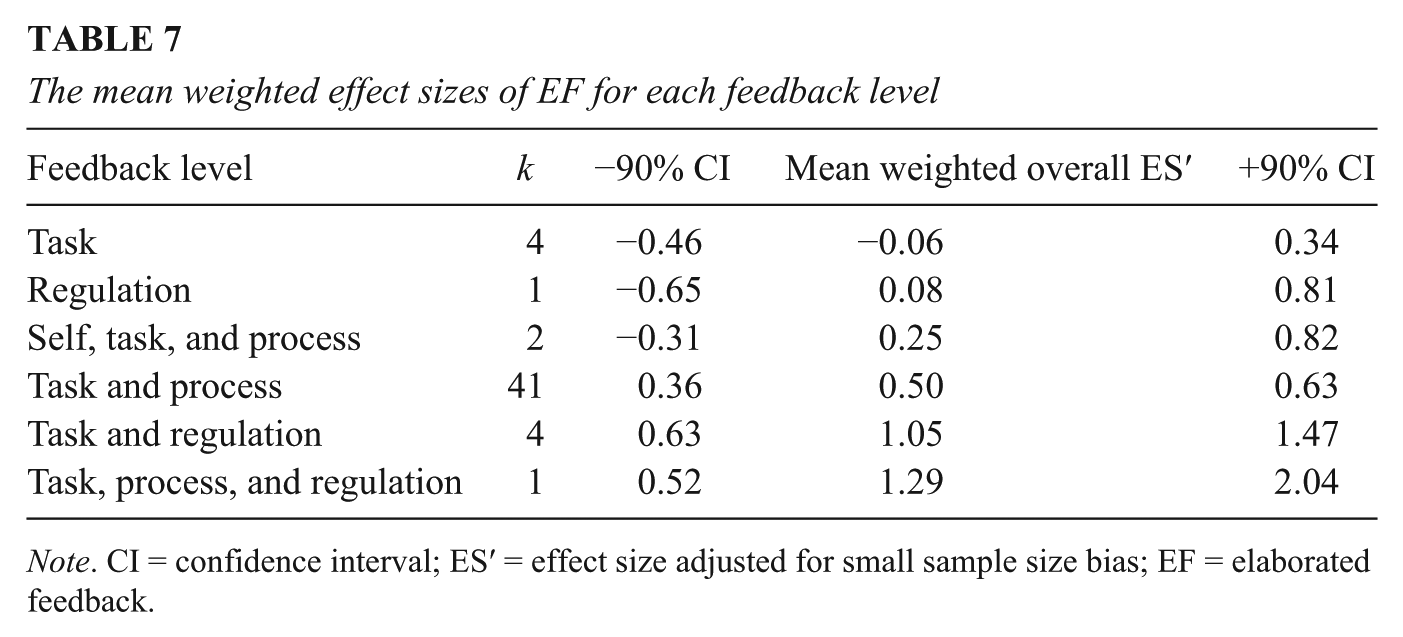
Note. CI = confidence interval; ES′ = effect size adjusted for small sample size bias; EF = elaborated feedback.
Table 7 shows the results of analyzing EF methods using an existing classification method, which research suggests affects the effectiveness of feedback (Hattie & Timperley, 2007). The results show an uneven distribution of EF across the feedback levels, which indicates a lack of research on certain levels at which EF seems to be highly effective (e.g., a combination of feedback at the process and regulation levels). To distinguish among various methods for providing EF by effect sizes, we developed a new EF typology (loosely based on Resing, 1990) and report the overall results of the EF interventions in this meta-analysis based on this typology (Table 8). In this typology, EF is viewed as consisting of various building blocks that can be added, for example, to KR or KCR. The various methods for providing EF exist on a continuum ranging from very subtle to highly specific guidance. For example, feedback that consists of metacognitive information or hints provides subtle guidance, whereas specific guidance can be provided through detailed explanations and demonstrations of the correct solution.
The mean weighted effect sizes of various methods for providing EF
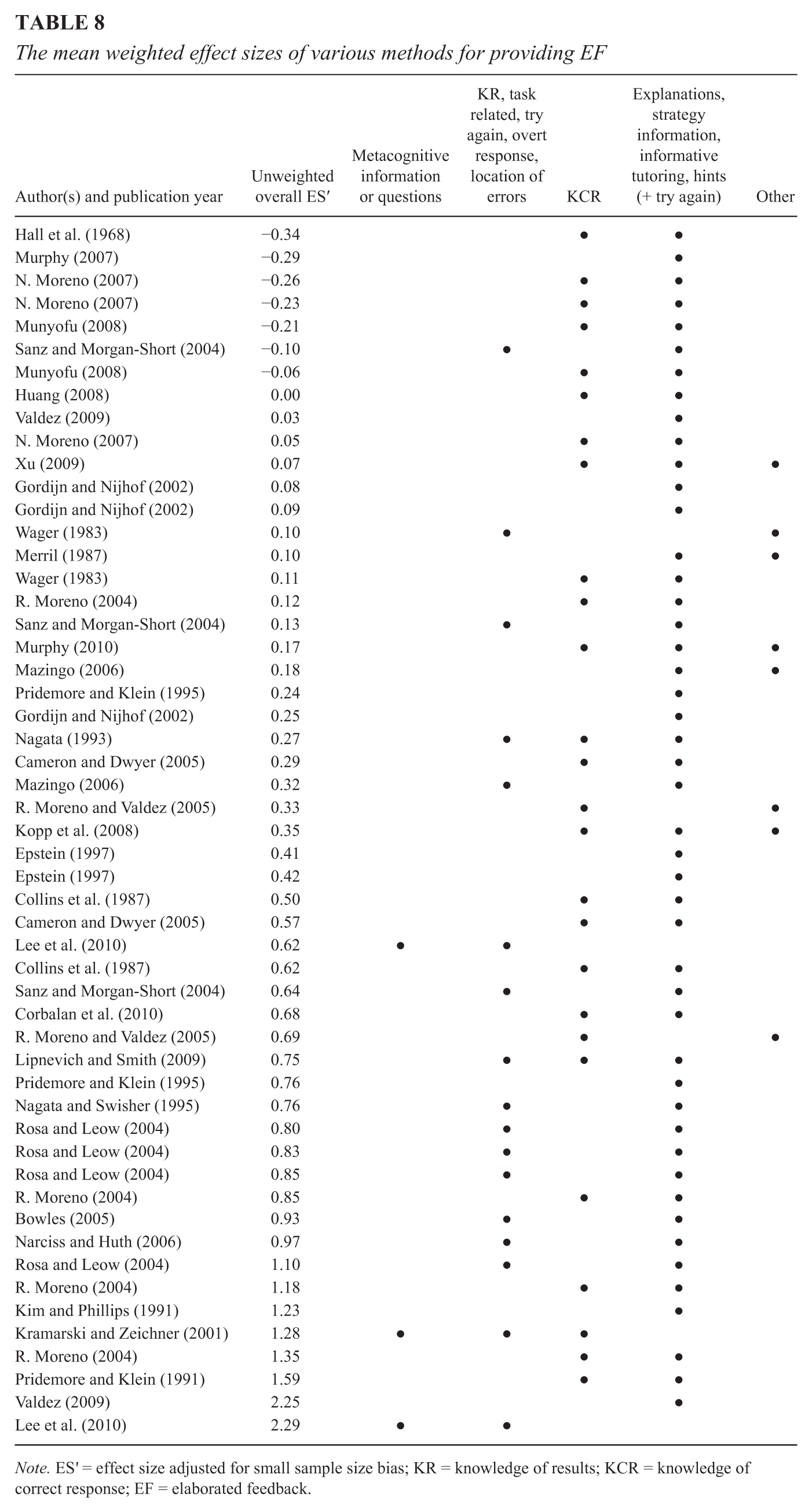
Note. ES′ = effect size adjusted for small sample size bias; KR = knowledge of results; KCR = knowledge of correct response; EF = elaborated feedback.
Table 8 shows that the majority of EF was delivered as KR or KCR combined with explanations, strategy information, informative tutoring, or hints. In Table 8, the density of KR combined with explanatory information increases as the magnitude of the overall effect sizes increases. Weighted linear regression analysis suggests that the effects of KCR + EF in the form of explanations (k = 23, ES′ = 0.35, 90% CI [0.18, 0.53]) are smaller than those of EF in the form of explanations not combined with KCR (k = 24, ES′ = 0.50, 90% CI [0.33, 0.67]), but the difference is not significant (p = .248). In addition, despite the small number of effect sizes (k = 3), the effects of metacognitive information and of questions combined with KR and/or KCR seem promising, as they are all larger than 0.60.
We expected that there would be an interaction effect between feedback timing and the level of learning outcomes (Hypothesis 5). Figure 3 shows that the directionality of the overall effects was consistent with Hypothesis 5, with immediate feedback being more effective for lower order learning outcomes and vice versa. However, there appeared to be no significant interaction effect between the level of learning outcomes and feedback timing (z = 0.82, p = .41). Therefore, Hypothesis 5 was rejected. The lack of power in the analysis might be a reason for the lack of statistical significance. For example, the combination of higher order learning outcomes and delayed feedback contained only two observations.

Effects of immediate and delayed feedback by level of learning outcomes.
To evaluate simultaneously the relationships between study attributes and overall effect sizes, a weighted regression analysis was conducted. Table 9 summarizes the results of this analysis. The regression model explained 25% of the total variance across overall effect size estimates. Table 9 shows that the feedback type EF and the subject areas of the social sciences, mathematics, and sciences had a particularly strong positive impact on the effect size estimates. The effects of mathematics on the effect size estimates were strikingly large. Delayed feedback and primary and high school had a negative effect on the estimates.
Weighted regression results, random intercept, fixed slopes model
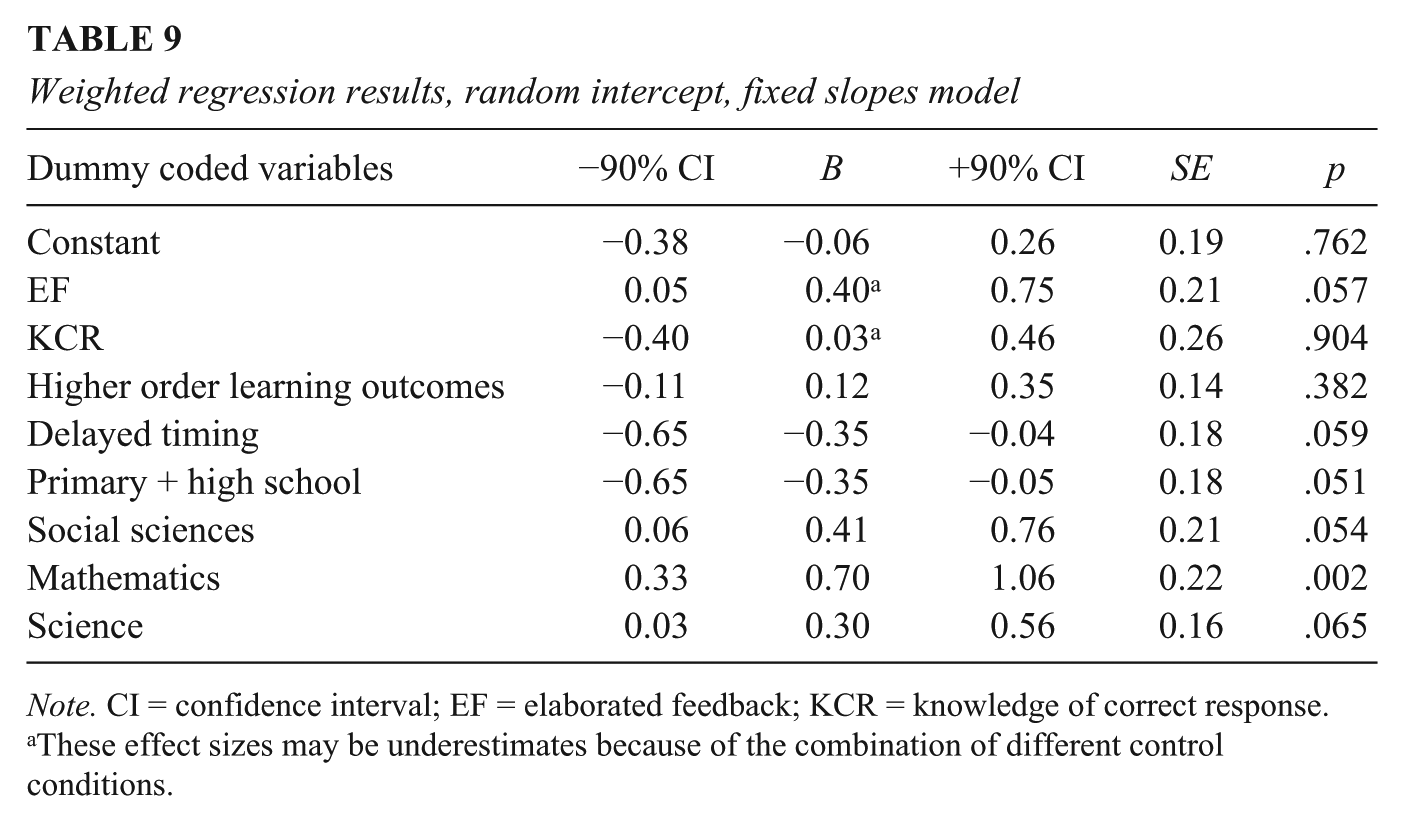
Note. CI = confidence interval; EF = elaborated feedback; KCR = knowledge of correct response.
These effect sizes may be underestimates because of the combination of different control conditions.
Discussion
The question central to this meta-analysis asked to what extent do various methods for providing item-based feedback in a computer-based learning environment affect students’ learning outcomes? The major independent variable in this meta-analysis was feedback type (Shute, 2008). Furthermore, the effects of various moderator variables that seemed relevant based on the literature on feedback effects, such as timing (Shute, 2008) and level of learning outcomes (Van der Kleij et al., 2011), were investigated. The 70 effect sizes in this meta-analysis were derived from 40 studies and expressed the difference in the effects of one feedback type compared with those of another feedback type or no feedback at all in terms of a test score. The effect sizes ranged from −0.78 to 2.29. A mixed model was used in the analyses because of the heterogeneous nature of the collection of effect sizes. The majority of the effect sizes (k = 53) concerned the investigation effects of EF in contrast to KCR, KR, and no feedback. The results suggested that EF was more effective than KR and KCR. The mean weighted overall effect size for EF was 0.49, which can be considered a moderately large effect. This effect size is likely to be an underestimate of the impact of EF, because EF was frequently compared with other forms of feedback. The weighted overall mean effect size of EF contrasted with no feedback was much larger, namely, 0.61. The mean weighted overall effect size for KCR (k = 9) was 0.32, which is considered small to moderate. The mean weighted effect size for KR (k = 8) was extremely small, at 0.05.
KR and KCR were expected to have a small to moderate positive effect (between 0.2 and 0.6) on lower order learning outcomes (Hypothesis 1). Due to the small number of observations, we could not meaningfully test Hypothesis 1, but the limited information available did not contradict our expectations. In addition, we expected that KR and KCR would have virtually no effect (less than 0.2) on higher order learning outcomes (Hypothesis 2). The overall effects of KCR were slightly larger than expected at 0.38. However, we had insufficient power to reject Hypothesis 2. EF was expected to have a moderate to large positive effect (at least 0.4) on both lower order learning outcomes (Hypothesis 3) and higher order learning outcomes (Hypothesis 4). Hypothesis 3 and Hypothesis 4 were not rejected, and the overall effects of EF on higher order learning outcomes (ES′ = 0.67) appeared to be larger than on lower order learning outcomes (ES′ = 0.37). This result was consistent across all control conditions. Furthermore, the results suggest that the additional value of EF over KR or KCR is much more substantial for higher order learning outcomes than for lower order learning outcomes.
The effects of EF seemed promising, although the nature of EF varies widely. By categorizing feedback effects based on the level at which they were aimed, we attempted to gain insight into which method for providing EF was most effective. However, the majority of the EF was aimed at the task and process levels (k = 41), which made it difficult to draw any generalizable conclusions about the effects of the different feedback levels. The mean weighted effect size of EF at the task and process levels was 0.50. In this meta-analysis, the overall effect sizes from EF at the task level (k = 4) were lowest (ES′ = −0.06). The overall effects of EF at the task and regulation levels (k = 4, ES′ = 1.05) and at the task, process, and regulation levels (k = 1, ES′ = 1.29) were highest. These effects can be regarded as extremely large, which suggests that more research on the effects of feedback at the task and/or process level in combination with the regulation level is warranted. The results of this meta-analysis are in line with the results of the systematic review by Van der Kleij et al. (2011), which found that the effects of EF at the regulation level are promising but have not been researched to a great extent. Consistent with the literature on feedback effects (e.g., Hattie & Timperley, 2007), adding feedback that was not task related but, instead, aimed at the characteristics of the learner seemed to impede the positive effects of EF (k = 2, ES′ = 0.25). It must be mentioned, however, that the number of studies examining feedback aimed at the level of self in a computer-based environment is fortunately low.
To gain more insight into the effectiveness of various methods for providing EF, descriptive analyses were conducted to create a more fine-grained classification of EF. This typology exists on a continuum that ranges from extremely subtle to highly specific guidance. The results showed promising effects for metacognitive information or questions in combination with KR and/or KCR. As well, the density of KR combined with explanatory information increased as the magnitude of the effect sizes increased. The results of a weighted linear regression analysis suggest that KCR + EF in the form of explanations leads to smaller effects than EF in the form of explanations not combined with KCR, but the difference was not significant. This finding suggests that EF in the form of subtle guidance might be generally more effective than highly specific guidance. These results are in line with claims by Narciss and Huth (2004) that not providing KCR leads to deep processing and subsequently better learning. More research is needed to investigate how to provide EF effectively.
Furthermore, it was hypothesized that there would be an interaction effect between feedback timing and the level of learning outcomes (Hypothesis 5). Hypothesis 5 was rejected because there appeared to be no significant interaction effect between the level of learning outcomes and feedback timing. The directionality of the effects was, however, consistent with Hypothesis 5. Specifically, it was expected that immediate feedback would be more effective for lower order learning outcomes and vice versa (Shute, 2008). However, possibly because of a lack of power, statistical significance was not reached. More research is needed to shed light on the possible interaction between feedback timing and the level of learning outcomes.
In addition, to evaluate simultaneously the relationships between study attributes and overall effect sizes, a weighted regression analysis was conducted. This analysis found that delayed feedback and primary and high school negatively affected the ES′ estimates. Furthermore, EF and the subject areas of social sciences, sciences, and mathematics, in particular, strongly positively affected the ES′ estimates. However, these effects must be interpreted with caution because the number of effect sizes and the feedback types investigated were distributed unevenly across the various subject areas (see Table 5). In addition, the effect of mathematics was strikingly high. However, this effect was based on only eight studies. Of these studies, only two did not include EF, which makes it likely that the high effects are undeservedly attributed to the subject of mathematics. Furthermore, it must be mentioned that the literature does not report any consistent positive effects of feedback in mathematics (e.g., Bangert-Drowns et al., 1991; Kingston & Nash, 2011). Therefore, the positive results from studies conducted in the field of mathematics must be interpreted with caution.
Limitations and Future Research
A limitation of this meta-analysis—and of review studies in general—is the impossibility of retrieving all the relevant studies. In addition, this meta-analysis included only published work with the exception of unpublished doctoral dissertations. The authors deliberately chose to exclude other unpublished sources because there is no way of objectively retrieving these works. It was also unclear whether they had been subjected to peer review, which is a generally accepted criterion to ensure scientific quality. With that exception, no strict requirements were established with regard to the quality of the included studies. Many studies considered low quality because of limited sample size had a relatively low weight compared with studies of higher quality. Additionally, many studies had to be excluded because they did not provide sufficient information to compute an effect size.
For some studies, multiple effect sizes were coded because the studies included multiple experimental groups. Therefore, the effect sizes within the data set were not completely independent. Multilevel analysis can appropriately address this nested data structure, but in our case, the ratio of effect sizes within studies (70/40) was too small to conduct a multilevel analysis. An additional analysis on the magnitude of the mean effect sizes across variables was conducted to examine the potential effects of dependency. For this purpose we used a random subset of the effect sizes allowing for only one effect size per study, thus including only 40 effect sizes in total. The results of this additional analysis were highly similar to the results of the original analyses, which provided substantial evidence that the results in this meta-analysis are not biased as a result of dependency between effect sizes. Also, the issue of nonindependence was partly addressed by running separate analyses for the different control conditions.
Another limitation of this meta-analysis was that it included insufficient data to meaningfully compare feedback effects across school types. The majority of the studies were conducted at universities, colleges, or other places of adult education. Given the low number of studies in secondary education settings (n = 6) and the even lower number of studies in primary education settings (n = 2), the degree to which the conclusions of this meta-analysis apply to young learners is questionable. The results of this meta-analysis, therefore, have to be interpreted with caution, because they might not apply to all schools settings. The results show somewhat lower effect sizes in school settings than in higher education settings, which suggests that feedback mechanisms might function differently within these various school types.
No clear reasons for these differences could be identified in this meta-analysis. However, the mean weighted effect size in primary and secondary education settings was still significantly larger than zero, as shown in Table 3 (ES′ = 0.34, p = .03). Moreover, providing feedback in the form of text might not be appropriate for younger learners since their reading abilities might not be sufficiently developed to fully understand and use the feedback and subsequently use it. However, current technology makes it possible to provide feedback in many ways (Narciss & Huth, 2006). For example, feedback could be directed to students through audio, graphical representations, video, or a game. Unfortunately, only a limited number of studies included in this meta-analysis used multimedia feedback (n = 7, e.g., Narciss & Huth, 2006; Xu, 2009), which means that no meaningful comparison of feedback mode could be made. Furthermore, no effects from the age of studies, used as a proxy for advances in computer-based environments, were found. The results do suggest, however, that the area of multimedia feedback needs further exploration.
It is striking that, in most of the studies in this meta-analysis, the researchers assumed that the learners paid attention to the feedback provided. The results of recent research, however, suggest that, in a computer-based environment, some students tend to ignore written feedback (e.g., Timmers & Veldkamp, 2011; Van der Kleij et al., 2012). Variables such as motivation and learners’ perceived need to receive feedback play an important role in how feedback is received and processed (Stobart, 2008). These variables thus intervene with other variables that contribute to feedback effectiveness, such as type and timing. Nevertheless, based on the available research, it is not possible to examine thoroughly the interplay of these variables. In the experiments by Timmers and Veldkamp (2011) and Van der Kleij et al. (2012), the time students chose to display feedback for each item was logged as an operationalization of time spent examining the feedback. Using eye-tracking technologies could reveal more detailed data about student behavior in examining feedback in computer-based environments.
Furthermore, the effects reported in this meta-analysis were all short term, measured using a posttest that was administered either immediately or shortly after the feedback intervention. For feedback to realize its full formative potential, however, continuous feedback loops are needed throughout the entire learning process.
The literature on the effectiveness of feedback suggests that the complex relationships between the feedback intervention, task, learning context, and characteristics of the learner affect the magnitude of feedback effects (Shute, 2008). However, the primary studies published to date have reported insufficient data to meaningfully examine these complex relationships. For example, research suggests that the learner’s initial ability level affects feedback effectiveness (e.g., Hattie & Gan, 2011; Smits, Boon, Sluijsmans, & Van Gog, 2008) but only a small number of studies in this meta-analysis reported information about the initial ability of the learners. Hattie and Gan (2011) suggested that feedback needs to be appropriate for the level at which the learner is functioning.
In a computer-based environment, the mechanisms of computerized adaptive testing (CAT; Wainer, 2000) are very promising in this respect. If not only the item selection but also the selection of the specific feedback to the item response were based on the learner’s current ability, feedback could perhaps fulfil its formative potential to a greater extent (Veldkamp, Matteucci, & Eggen, 2011). In addition, providing feedback that gradually becomes more elaborate in an interactive manner could be used to adapt the feedback to the needs of learners. This kind of feedback is called “intelligent tutoring feedback” (ITF; Narciss, 2008). Digital learning environments could become even more powerful if the feedback included a diagnostic component, meaning that it has been designed to address, prevent, and correct misconceptions and frequently made errors. However, research is needed to explore the potential of computer-based adaptive learning environments and adaptive feedback mechanisms.
Moreover, the degree to which the primary studies have described the psychometric properties of the instruments’ scores is strikingly low. For example, only a few studies reported the reliability (α) of posttest scores. As well, the number of items used in the posttest was also not reported in all studies, and the studies that did report the number of items used a notably low number. These assessments are not sufficiently reliable to make well-grounded claims about the differences in the effects of various feedback types. Additionally, only a few studies reported the difficulty level of the items in the assessments. In future research, it is recommended that these psychometrical properties be reported because they can be used to more accurately weight the effect sizes. Such data could also be used to examine the relationships between learners’ initial ability and optimal item difficulty in formative computer-based assessments because difficult items present more opportunity to learn from feedback than easier items (Van der Kleij et al., 2011). Ultimately, these insights could be used to optimize computer adaptive learning environments (e.g., Wauters, Desmet, & Van den Noortgate, 2010). Finally, in future research, it is recommended that larger groups of participants be used.
Conclusion
The results of this meta-analysis consistently showed that more elaborate feedback led to higher learning outcomes than simple feedback, in particular in regard to higher order learning outcomes. This finding has important implications for designers of educational software and computer-based learning environments. In addition, the insights gained from this meta-analysis could help educational practitioners to make well-informed choices with respect to digital learning tools.
This study aids in identifying various areas that need further attention in the literature on feedback in computer-based environments. This meta-analysis made an initial attempt to gain insight into the effectiveness of various methods for providing EF. More research that takes into account the specific characteristics of EF interventions is needed. In future experiments, it is advised that larger sample sizes be used and that the psychometric properties of the instruments be reported. Future investigations should account for and describe characteristics of the feedback, the task, the learning context, and the learners in order to advance the research field. Using eye-tracking technologies could also provide useful insight into how students react to the feedback provided, which might differ based on the correctness of their answer to the item. The results of this meta-analysis clearly show that there is a need for research on this topic in primary education settings. This type of research is particularly needed to gain insights into the effects across school settings and might inform practice as more and more computer-based learning environments that include feedback are being developed and used in various education settings. In addition, the authors recommend that the value of multimedia feedback be investigated in future research.
Footnotes
Notes
Authors
FABIENNE M. VAN DER KLEIJ completed her PhD at the Research Center for Examinations and Certification, a collaboration between Cito and the University of Twente in the Netherlands. She conducted her research at Cito’s Psychometric Research Center. Her specializations are feedback effectiveness, computer-based assessments, assessment for learning, data-based decision making, and diagnostic testing. She is currently employed as a research fellow at Australian Catholic University (Brisbane), P.O. Box 456, Virginia Queensland 4014, Australia; e-mail:
REMCO C. W. FESKENS is a senior research scientist at Cito’s Psychometric Research Centre, P.O. Box 1034, 6801 MG Arnhem, the Netherlands; e-mail:
THEO J. H. M. EGGEN is a member of Cito’s Psychometric Research Center, P.O. Box 1034, 6801 MG Arnhem, the Netherlands; e-mail: