
Abstract
Many teacher education researchers have expressed concerns about the lack of rigorous impact evaluations of teacher preparation practices. I summarize these various concerns as they relate to issues of internal validity, measurement, and external validity. I then assess the prevalence of these issues by reviewing 166 impact evaluations of teacher preparation practices published in peer-reviewed journals between 2002–2019. Although I find that very few studies address issues of internal validity, measurement, and external validity, I highlight some innovative approaches and present a checklist of considerations to assist future researchers in designing more rigorous impact evaluations.
Keywords
Researchers and policymakers have long sought to identify the most effective teacher preparation practices (i.e., “the approaches, activities and processes that can be undertaken by teacher educators to develop preservice teachers’ knowledge, skill, and dispositions”; Hill et al., 2021, p. 1). A wide variety of teacher preparation practices have been studied, including general education, content area, and methods courses; modules or workshops that run within or in parallel to coursework (e.g., Floden & Meniketti, 2005); teacher educator pedagogies such as clinically based teacher supervision or practice-based approaches within coursework (e.g., Burns et al., 2020; Forzani, 2014); and ways of structuring elements of teacher education programs like paired placements during practicum (e.g., Birrell & Bullough, 2005; Bullough et al., 2003).
Much has been learned from studying these teacher preparation practices through the most prevalent research approaches in the field, including interpretive research, practitioner research, and design research (Borko et al., 2007). Some teacher educator researchers, however, have noted the lack of rigorously designed impact evaluations—that is, studies able to identify the effects of specific teacher preparation practices on preservice teachers and their (future) students 1 (Cochran-Smith & Villegas, 2015; Cochran-Smith & Zeichner, 2005; Grossman, 2008; Grossman & McDonald, 2008; Sleeter, 2014; Wilson et al., 2002; Zientek et al., 2008). This lack of impact evaluations is a problem because it means researchers cannot provide teacher educators and policymakers with clear guidance on which teacher preparation practices work for whom and in what contexts.
This article aims to support teacher education researchers in designing more rigorous impact evaluations of teacher preparation practices. First, I define impact evaluations and justify the need to improve their quantity and quality in the field of teacher education. Second, I discuss the key issues of internal validity, measurement, and external validity that teacher education researchers over the past two decades have identified as hampering impact evaluations of teacher preparation practices. Third, I review the research designs and measurement approaches of 166 impact evaluations published in peer-reviewed journals between 2002–2019. I assess the extent to which they address issues of internal validity, measurement, and external validity, and provide examples and guidance for future researchers on how to overcome these issues. Finally, I share a checklist of considerations for designing and reporting on impact evaluations of teacher preparation practices. This checklist aims to support teacher education researchers to move closer toward developing a shared evaluation paradigm (Grossman & McDonald, 2008) by meeting calls for more “clearly articulated criteria for high quality studies” (Grossman, 2008, p. 17) and for more explicit guidance for peer reviewers “about the kinds of things that should be present in empirical research for it to be published” (Zeichner, 2005, p. 752).
The Need for Impact Evaluations
This article focuses on impact evaluations of teacher preparation practices—also known as “effects of teacher education” research (Borko et al., 2007) and “effectiveness research” (Hill et al., 2021). Impact evaluations investigate the effects of specific teacher preparation practices on preservice teachers’ knowledge, skills, and/or dispositions, and/or on their (future) students’ learning and development. They are different from process evaluations (also known as program monitoring or implementation analysis), which generally investigate how teacher preparation practices are implemented, and/or the extent to which they are implemented as designed (Humphrey et al., 2016).
According to modern standards for making causal claims in social science research (King et al., 1994; Mackie, 1974; Shadish et al., 2002), rigorous impact evaluations need to: (1) clearly identify a relationship between a teacher preparation practice and specific outcomes (i.e., when X changes, Y also changes); (2) ensure that the practice precedes the expected changes in the outcomes (i.e., X happens before Y); and (3) reject any other reasonable explanations for changes in the outcome (i.e., nothing else can explain the changes in Y except X). From the perspective of the potential outcomes framework (Angrist & Pischke, 2009; Holland, 1986), rigorous impact evaluations need to appropriately identify the counterfactual and then compare outcomes. That is, teacher education researchers need to identify what happened when preservice teachers experienced a particular teacher preparation practice and then compare this with what would have happened if they experienced a different practice (i.e., the counterfactual). 2 Unfortunately, reviews of teacher preparation research over the past two decades have consistently lamented the lack of research that meets these standards, with most research in the field not designed to isolate the effects of specific teacher preparation practices from the many varied influences on preservice teacher development (e.g., Wilson et al., 2002; Grossman, 2008; Cochran-Smith et al., 2016).
This is problematic for both political and practical reasons. From a political standpoint, teacher preparation programs are increasingly challenged to demonstrate their impact on their graduates’ outcomes using causal methods (Cochran-Smith et al. 2017; Wineburg, 2006). 3 As many “insider” critics of the field have expressed (Grossman, 2008; Zeichner, 2005), if teacher education researchers continue to provide few compelling responses to these challenges, we as a field will continue to lose “professional jurisdiction” over our work. This is because lack of causal evidence may continue to be interpreted as a lack of impact on teacher education (rather than a lack of investment in generating causal evidence); and/or because policymakers will continue to pay greater attention to (and we as a field will continue to be at the mercy of) research conducted by those outside our field (e.g., psychologists and economists). 4 As Wilson et al. (2002) warn: “unless we—as teacher educators and researchers—produce sound, robust measures of impact, others—policy makers and critics—will produce other, less appropriate measures” (p. 201).
There is also a practical imperative for increasing the number and improving the quality of impact evaluations. Impact evaluations of specific pedagogical practices can help guide teacher educators’ day-to-day course planning, particularly when they are trying to prioritize within limited instructional hours (e.g., “To develop pre-service teachers’ skills in eliciting and responding to student thinking, is it more effective to have them read and reflect on research on effective questioning, analyse videos of expert teachers, and/or practice questioning in a simulated environment?”). This is similar to evaluations causally identifying effective instructional strategies guiding K–12 teachers’ practice (e.g., the use of explicit phonics instruction for the teaching of reading). Rigorous impact evaluations are also practically useful to investigate emerging teacher preparation practices with strong anecdotal support, but the key mechanisms that drive its effectiveness remain unclear (e.g., are peer learning and low-stakes immediate feedback critical ingredients of rehearsals of practice, or can preservice teachers improve by simply rehearsing instructional practices to a wall?).
At a higher level, policymakers need impact evaluations of program-level interventions such as specific content requirements (e.g., what content should be covered in teacher preparation, and what can be covered once teachers are in-service?) and/or certain ways of organizing teacher preparation (e.g., is it better to have two to three preservice teachers undertaking their practicum with a highly effective mentor teacher or to have single placements but with more average mentor teachers?). Impact evaluations that answer these sorts of larger questions can help policymakers make better decisions about accreditation requirements, accountability regimes, and grant programs (Goldhaber, 2019).
Recently, some researchers have used longitudinal data to compare whether graduates of certain teacher preparation programs are more or less effective than other graduates. These studies generally find greater variation in workforce outcomes within programs rather than between programs (Koedel et al., 2015; von Hippel & Bellows, 2018), suggesting teacher education researchers should prioritize investigating the relative effectiveness of different teacher preparation practices within programs. Some program-level comparisons have identified at a high-level certain program characteristics that may drive effectiveness (e.g., Boyd et al., 2009), however, as Del Schalock et al. (2006) note, these studies “carry little explanatory power as to why, how, or what within teaching or teacher preparation account for relationships found and, thus, have limited utility in guiding or refining policy, practice, or research” (p. 110).
In arguing for more and more rigorous impact evaluations, I am not implying that the design-based and interpretive methodological approaches that are currently prevalent in the field are not practically useful for teacher educators and policymakers. These approaches enable individual teacher educators and teacher educator teams to design, implement, and share continuous program improvement initiatives that meet the highly localized needs of their preservice teachers and the communities they serve. I am also not implying that impact evaluations do not have limitations. For example, given that rigorous impact evaluations need to control variation to isolate causal effects, they can obscure and be insensitive to the diverse contexts of teacher education, teaching practices, and student outcomes. Rather, I argue that impact evaluations generate complimentary evidence not currently prevalent within the field and that this complimentary evidence can help teacher educators and policymakers better discern what teacher preparation practices may be effective for whom in specific contexts.
The Challenges of Undertaking Impact Evaluations
Despite the political and practical imperatives, the challenge of undertaking impact evaluations is well acknowledged. Reasons include lack of funding and allocated research time for scholars of teacher education (Cochran-Smith, 2004; Cochran-Smith et al., 2012); heavy teaching loads and mostly part-time or adjunct status of practicing teacher educators (Borko et al., 2007; Nuttall et al., 2006; Zeichner, 2005); historical separation between research and practice among education school faculty (Labaree, 2004); limited doctoral training on evaluative methods given the dominance of interpretive and design-based research over the past few decades (Borko et al., 2007; Grossman, 2008; Wilson, 2006; Zientek et al., 2008); the lack of teacher education research published in top-ranked, peer-reviewed journals (Grossman, 2008; Wilson et al., 2002; Zeichner, 2005); lack of capacity to engage in multisite and/or multidisciplinary partnerships so as to undertake large-scale evaluations (Borko et al., 2007; Del Schalock et al. 2006); difficulty in teacher preparation programs accessing and using data about their graduates’ teaching practice and/or the performance of K–12 students (Goldhaber, 2019); lack of consensus on common measures of teacher effectiveness in teacher preparation programs (Goldhaber, 2019; Grossman, 2008); the politicization of teacher education that leads much research and practice to be reactive to political imperatives and the local teaching market (Cochran-Smith & Villegas, 2015; Grossman & McDonald, 2008).
Although these challenges are significant, I share Nuttall et al.’s (2006) concern that:
these explanations have become something of a “default setting,” and do not go far enough in explicating the complex set of circumstances with which teacher education researchers must engage in order to attain the research quality and credibility necessary to influence initial teacher education policy, as well as teacher education practice. (p. 326)
As such, in this article, I investigate—with the aim of supporting teacher education researchers to address—one such circumstance that hampers the “research quality and credibility” of impact evaluations in the field: the lack of research design and measurement approaches that meet modern standards for making causal claims.
Issues of Research Design and Measurement
Reviews of teacher education research stretching over the past two decades have raised concerns about the research design and measurement approaches of impact evaluations of teacher preparation practices. In the first comprehensive review of research on effective teacher preparation, Wilson et al. (2002) noted the limited empirical evidence base for many common teacher preparation practices and made the first major call for more rigorous impact evaluations in the field. Similarly, in her summary of the findings and recommendations of the AERA Panel on Research and Teacher Education, Cochran-Smith (2005) writes: “we need more and better research on the outcomes of teacher education. . . . This requires better data collection and analysis tools for studying outcomes and consistent use of these tools across individual studies” (p. 302). More recently, Sleeter (2014) reviewed the 196 articles published in four top-ranked teacher education journals in 2012, finding “Only about 1% of the articles reported large-scale mixed-methods studies, only 6% examined the impact of teacher education on teaching practice and/or student learning, and only one did both” (p. 6).
Although many have raised concerns about research design and measurement, no single review has summarized them. In this section, I bring together themes from teacher education researchers 5 to identify key issues of internal validity, measurement, and external validity that have hampered impact evaluations of teacher preparation practices over the past two decades.
Internal Validity
Most studies of teacher preparation practices use small-scale, single-group study designs to investigate how a group of preservice teachers attending a single-teacher preparation program experience a specific teacher preparation practice unique to their context (Cochran-Smith & Zeichner, 2005; Cochran-Smith et al., 2016; Grossman, 2008; Menter et al., 2010; Wilson et al., 2002). This single-group approach allows researchers to develop a deep and nuanced understanding of the dynamic interplay between a teacher preparation practice and preservice teacher experiences (i.e., how are particular practices in this context enacted, received, perceived, and therefore, learned from?). However, it does not allow researchers to identify the causal effects of teacher preparation practices. This is because single-group designs leave open many possible alternative explanations for observed changes in participant outcomes (i.e., threats to internal validity) (Murnane & Willett, 2010; Shadish et al., 2002).
Four issues of internal validity, in particular, have been flagged by prior reviews as often unaccounted for (1) preservice teachers’ natural learning over time (maturation effects); (2) preservice teachers opting into (or out of) receiving a teacher preparation practice that is particularly suited to them (or not) (selection effects); (3) improvements caused by other teacher preparation practices that occur at the same time (history effects); and (4) preservice teachers leaving the study (attrition). 6
Without research designs that account for these threats to internal validity, impact evaluations cannot make rigorous causal claims about the effects of teacher preparation practices. As Zeichner (2005) describes in his summary of the findings and recommendations of the AERA Panel, what is needed are research designs that allow for “systematic analyses of distinct alternatives” (p. 745), such as those that compare the relative effectiveness of two different teacher preparation practices, or those that compare a novel teacher preparation practice with “business as usual” (“control”). Stated differently, impact evaluations need to clearly identify the counterfactual by constructing comparison groups that are baseline equivalent and then ensuring that throughout the study there is an ongoing balance of time-invariant characteristics across groups. Doing this allows researchers to better “disentangle the influence of teacher characteristics from those of their preparation programs” (Zeichner & Conklin, 2005, p. 663). Although practically challenging to implement, this includes using research designs that account for natural learning over time, such as by comparing the outcomes of a group of study participants who received the preparation practice with a group who did not. It also means using research designs that ensure participants are not able to choose to be part of (or not part of) the treatment group, that the only difference in the experiences of participants during the study is that one group receives the teacher preparation practice, and that any attrition is reported and discussed. Consideration of attrition is particularly important, as the practice being evaluated may cause attrition, and/or differential attrition may lead to study authors falsely detecting effects.
Measurement
One issue commonly raised by prior reviews is that impact evaluations of teacher preparation practices often do not use replicable measurement approaches, such as clearly defined and consistent rubric or rating schemes when measuring participant outcomes (Cochran-Smith et al., 2015; Floden & Meniketti, 2005; Grossman, 2008). Instead, teacher education researchers have primarily used idiosyncratic measures often developed through subjective inductive analysis. These measurement procedures are also not often reported in detail. As Zeichner (2005) remarks: “many studies reviewed [by the AERA Panel] provide no information about how instruments used for data collection were developed and validated, or how their reliability was assessed” (p. 741). This makes it difficult to assess the validity of researchers’ inferences during the peer review process and/or design replication studies.
A related issue raised by prior reviews is the lack of commonly used measures across impact evaluations. This limits the accumulation of knowledge across the field, as without common measures, it is more difficult to undertake meta-analyses that compare the relative effectiveness of different teacher preparation practices, and/or test whether differences in study findings across contexts are due to different measurement approaches (Zeichner, 2005). One contributing factor to this issue is that not enough researchers in the field produce and openly provide quality measures for use by others (Grossman, 2008; Grossman & McDonald, 2008). As Zientek et al. (2008) note in their review, “surveys were the dominant mode for collecting data, but only about half (52%) of the researcher-developed surveys were made available” (p. 212).
Another issue raised by prior reviews is that impact evaluations of teacher preparation practices rarely investigate effects on preservice teachers’ practice and student learning, preferring more proximal outcomes like preservice teacher perceptions and understanding. 7 For example, in their review of research on science teacher preparation, Cochran-Smith et al. (2016) note most studies “focused on relatively short-term changes in teacher candidates’ understandings and beliefs in the context of science methods courses” (p. 476). Similarly, Menter et al. (2010) find in their review of teacher education research in the United Kingdom that 60.1% of the 446 studies reviewed use “reflection” as their primary method of data collection. However, as Wilson et al. (2002) state: “Although it is important to know how teachers feel about the benefits of field experiences, attitude surveys do not answer questions about what prospective teachers actually learn” (p. 196). In other words, just because preservice teachers learn it in teacher preparation, doesn’t mean that they will put it into practice, or that K–12 students will learn from how it is implemented (Diez, 2010). For researchers to identify these longitudinal effects they need to track preservice teachers over time, potentially even once they are in their own classrooms with their own students (e.g., using teacher licensure processes and/or future teacher evaluations).
Outcome measures may also be too tightly aligned and narrowly focused on the target skills or knowledge of the teacher preparation practice (i.e., treatment-inherent; Slavin & Madden, 2011) to allow for generalizable findings that contribute to the broader evidence base (Zeichner, 2005). For example, say a study uses an outcome measure of how well preservice teachers complete a highly technical lesson planning template that they were trained on but is not used in schools. In this case, without a broader outcome measure, study authors can conclude that participants are better at lesson planning using the template, but they cannot conclude whether preservice teachers are generally better lesson planners or have improved instruction.
Prior reviews have also raised concerns about the extent to which measurement approaches mitigate participant and researcher bias (i.e., reactivity bias)—participants changing their behavior to meet their or others’ expectations about the effectiveness of the teacher preparation practice. Not accounting for reactivity bias (e.g., by blinding participants to their treatment condition) can lead to potential placebo effects, and/or findings that may primarily be due to participants changing their behavior as a result of being studied or their “desires to please the instructor” (Clift & Brady, 2005, p. 303).
Finally, for evaluations using quantitative measures, prior reviews have raised concerns about appropriate analysis and reporting. This includes concerns with whether studies undertake power calculations to ensure they are sufficiently powered (Hill et al., 2021). It also includes concerns with whether studies appropriately test and report reliability estimates for their data, as unreliable measures cannot detect statistically significant effects regardless of sample size. As Zientek et al. (2008) conclude in their review: “reliability coefficients also were not reported for the data in hand, and almost half of the studies that did report reliability estimates for their data or from previous studies [did so] incorrectly” (p. 212).
External Validity
The third set of issues raised by prior reviews relate to external validity—that is, the extent to which study findings may generalize to other teacher preparation programs and/or other preservice teachers. This is a particular challenge for the field given research is often conducted within the specific context of a single teacher preparation program (Cochran-Smith et al., 2016; Sleeter, 2014). That said, designing and reporting on external validity is important given the thousands of diverse and dynamic teacher preparation programs across the United States, and policymakers and teacher educators need to know whether and how study findings can scale to their/other contexts (Zeichner, 2005). Researchers also need to understand what works for whom and in what contexts to build a shared evidence base (Wilson et al., 2002).
When it comes to external validity, prior reviews of the field have primarily raised concerns about the lack of reporting for generalizability (Cochran-Smith et al., 2012; Grossman, 2008; Zeichner, 2005; Zientek et al., 2008). Two issues are particularly salient: (a) the lack of comparisons of study participants to the broader population of preservice teachers in the United States (participant generalizability) and (b) the lack of reporting on study site(s) to help determine the relevance of findings to other teacher preparation programs (site generalizability)—for example, by naming study site(s) and/or describing their location, size, program type, and certification level. What is needed is more standardized rather than idiosyncratic reporting. As Floden and Meniketti (2005) note in their review of evaluations of coursework:
when courses were described, the descriptions were idiosyncratic. Authors would mention particular texts or describe the academic tasks they posed to students, in ways that offered detail, but gave scant opportunity for linking to other studies. (p. 286)
Prior reviews have also raised concerns regarding whether studies are designed for scalability. Impact evaluations of teacher preparation practices are often conducted by their developers, who are often highly enthusiastic about, skilled in, and/or suited to the practice. This can limit external validity, as study findings may not replicate when teacher preparation practices are undertaken by other teacher educators. Unless study authors mitigate these potential instructor effects in their research design (e.g., by training instructors to deliver the teacher preparation practice), others cannot assess whether the practice can be scaled to other contexts. A related issue raised by prior reviews is the potential bias of researchers who study their own practices as teacher educators (researcher bias). Researchers may unknowingly make and/or overlook reporting on various research design and measurement choices that limit the generalizability of study findings to other contexts. As Wilson et al. (2002) note: “Although local teacher educator researchers have valuable knowledge of the phenomenon under investigation, critics have the right to raise questions about the conflict of interest” (p. 194).
The Present Study
To aid future researchers in addressing these issues of internal validity, measurement, and external validity, I systematically reviewed the research designs and measurement approaches of impact evaluations of teacher preparation practices conducted over the past two decades. I conducted an online and hand search of studies of teacher preparation practices to identify impact evaluations published in peer-reviewed journals between 2002–2019. I then coded studies based on whether they addressed issues of internal validity, measurement, and external validity raised by prior reviews. I did this to empirically assess prevalence, identify priorities and opportunities for the field, and highlight innovative and promising approaches that can be emulated by future researchers. My research questions were:
To what extent do impact evaluations of teacher preparation practices address issues of internal validity? For those that do, how do they do it?
To what extent do impact evaluations of teacher preparation practices address issues of measurement? For those that do, how do they do it?
To what extent do impact evaluations of teacher preparation practices address issues of external validity? For those that do, how do they do it?
Although no other study has focused exclusively on the research design and measurement approaches of impact evaluations of teacher preparation practices, three studies have undertaken a similar methodology of assessing the state of the field to guide future researchers. First, Zientek et al. (2008) reviewed the reporting practices of all quantitative research studies cited in Studying Teacher Education: The Report of the AERA Panel on Research and Teacher Education (Cochran-Smith & Zeichner, 2005). The authors coded studies based on their statistical methods and the extent to which they report various tests or statistics as recommended by the AERA Standards. Second, Sleeter (2014) investigated the extent to which teacher education research is “designed to influence policy” by reviewing 196 articles published in four top-ranked journals in the field in 2012. Sleeter (2014) categorized studies based on research design and the extent to which they connected teacher preparation policies and practices to impacts on teachers. Finally, Crawford and Tan (2019) investigated the extent to which teacher education research uses mixed methods by reviewing articles published in Journal of Teacher Education and Teaching and Teacher Education between 2010–2016. The authors coded empirical studies based on whether they used qualitative, quantitative, or mixed methods. In all three studies, the aim in assessing the state of the field was to highlight specific opportunities to advance research—whether that be more standardized reporting practices in quantitative studies (Zientek et al., 2008), more research designed to influence policy (Sleeter, 2014), or more mixed-methods studies (Crawford & Tan, 2019). In this paper, I seek to do the same but with a focus on supporting teacher education researchers to conduct more rigorous impact evaluations of teacher preparation practices.
Researcher Positionality
Before describing my methodological approach, it is important to acknowledge my positionality to be transparent about how my worldview has framed my approach. I began this study with the hope of identifying the teacher preparation practices with the strongest research evidence supporting their effectiveness. My motivation was both professional and personal. Professionally, I am a researcher interested in understanding whether the field of teacher preparation has heeded two decades’ worth of calls for more rigorous causal research. Personally, I am a teacher educator interested in learning from the field to improve my own practice. Together these motivations are why my approach was primarily focused on issues of internal validity, measurement, and external validity raised by prior reviews (rather than more general concerns had I approached the study from the standpoint of evaluation theory). It is also why my review was focused on identifying practical and implementable opportunities for the field (rather than a more critical treatment had I approached the study from an outsider’s perspective).
Method
Guided by general principles for undertaking systematic literature reviews (Kennedy, 2007; Polanin et al., 2017; Slavin, 1986), I first defined my inclusion criteria and then undertook a four-step process for identifying and assessing studies. This process is summarized in Figure 1 and detailed throughout.

Review procedure.
Inclusion Criteria
I defined the scope of my review as impact evaluations of teacher education practices focused on improving K–12 preservice teachers’ instructional quality that was published in peer-reviewed journals between January 2002 and April 2019. I chose to begin in 2002 because this was the year of the first major call for more rigorous evaluative research in the field (Wilson et al., 2002) and because it was the beginning of increased support for more rigorous impact evaluations in education through the establishment of the Institute of Education Sciences (Whitehurst, 2003). Given the diversity of teacher preparation contexts across the world, I only included studies conducted within the United States to ensure comparability across studies, particularly when it came to reporting information on external validity. I only included studies that had been published in peer-reviewed journals to ensure that studies had been quality assured by others within the field and to ensure that future reviews can more easily replicate my approach.
Impact Evaluations
I defined impact evaluations as studies intending to investigate the causal effects of a specific teacher preparation practice on one or more outcomes. I included studies where authors used causal language like “evaluate,” “impact,” “effective[ness],” “change,” “influence,” or “develop” when describing the purpose of the study in their introduction, rationale, research questions, or methods sections. I excluded studies that simply described the implementation of a teacher preparation practice and/or studies that only sought to understand how preservice teachers experienced a teacher preparation practice. There was no minimum sample size necessary for inclusion, and both quantitative and qualitative studies were included.
Teacher Preparation Practices
I defined teacher preparation practices as either: (1) a course or set of courses organized around a particular theme within a teacher preparation program (e.g., a redesigned science methods course focused on inquiry; a new course for elementary teachers on sustainability); (2) an activity, pedagogy, or process implemented within a course in a teacher preparation program (e.g., the use of peer feedback on assignments; a short module on assessment within a math methods course); (3) a way of organizing a program component like the practicum (e.g., being assigned a certain type of mentor during practicum; paired practicum placements); or (4) an experience organized by teacher educators to develop preservice teachers’ skills, knowledge, or dispositions (e.g., undertaking a workshop on behavior management; a penpal arrangement between preservice teachers and grade 4 students). Based on this definition, I excluded studies that evaluated the effects of a whole teacher preparation program and studies that compared the relative effectiveness of different programs. I also excluded studies that did not specify a particular teacher preparation practice but rather evaluated a bundle of practices related to a single philosophical approach (e.g., evaluating the impact of a whole program’s shift toward encouraging more reflective teaching). I did this because the way these studies were reported did not allow for clear identification of a treatment to which effects could be attributed.
Instructional Quality
Given my limited resources and the wide range of teacher preparation practices studied in the field, I follow Wilson et al. (2002) and focused only on teacher preparation practices directly aimed at improving preservice teachers’ subject matter knowledge and pedagogical skills, as well as teacher preparation practices conducted during or to improve the clinical experience. I included studies of practices that develop preservice teachers’ disciplinary content or pedagogical knowledge or skills, as well as their knowledge and skills in using certain instructional moves (e.g., for classroom management); assessing and providing feedback to students; developing unit plans and instructional materials; and/or addressing diverse academic and behavioral needs (e.g., supporting English language learners and students with Individualized Education Plans). 8 Studies did not need to directly measure instructional quality to be included (e.g., they could use changes in preservice teacher knowledge or teacher self-efficacy as the primary outcome).
Steps 1 and 2: Online Search and Inclusion
I conducted an online search in May 2019 of the primary US education research database (ERIC) using the limiters and search terms described in Figure 1. This returned an initial pool of 2228 studies. The abstract, introduction, research questions, and methods sections of each study were reviewed for inclusion using the criteria described previously. To ensure reproducibility, three research assistants were trained on and suggested clarifications to the criteria until independent percent agreement reached above 80%. Six hundred studies were double-coded in this manner. The remaining studies were coded for inclusion by me. To safeguard against accidental exclusion, two research assistants double-coded 100 randomly selected studies that had been coded only by me. No studies were found to be accidentally excluded. Based on this process, 2065 of these studies were excluded and 163 were marked for inclusion. 9
Step 3: Hand Search
Despite the wide online search parameters, I was concerned that key studies may have been missed. As such, two research assistants undertook hand searches of the Journal of Teacher Education, Teachers and Teaching, Teaching and Teacher Education, Educational Researcher, American Educational Research Journal, and Educational Evaluation and Policy Analysis to identify any studies missed. 10 Studies flagged for potential inclusion were discussed with me and a consensus decision was made. An additional three studies were identified through this process.
Characteristics of Included Studies
A total of 166 studies were included in this review. A reference list is presented in online appendix A, and a summary of study characteristics is presented in Table 1. Briefly, most studies evaluated a pedagogy or assessment within a course (54.22%; n = 90) or a particular course or set of courses (29.52% n = 49). The average number of study participants was 56.5, with 65.4% of studies having 50 or fewer participants, and 85.19% of studies having 100 or fewer participants. The modal study was of preservice teachers at the undergraduate level (65.05%; n = 108), attending traditional preparation programs (57.83%; n = 96) and seeking certification at the elementary level (66.27%; n = 110). The most common form of data collected was surveys (65.66%; n = 109), followed by teacher educators’ observations or reflections of preservice teachers’ participation in the teacher preparation practice (41.57%; n = 69), preservice teachers’ written reflections or journals (34.94%; n = 58), and interviews (34.94%; n = 58). Finally, 39.76% (n = 66) of studies used statistical analyses on at least one outcome measure.
Characteristics of Included Studies.

Step 4: Coding
Coding Scheme
I developed my coding scheme in partnership with another researcher with experience conducting systematic literature reviews of impact evaluations of teacher professional development. As no prior review had already identified a set of issues with research design and measurement that could be used as a coding scheme, we began by considering using existing standards such as the APA Journal Article Reporting Standards (JARS) and IES What Works Clearinghouse (WWC) Standards. However, we quickly realized that neither coding scheme was an appropriate grain size to meet our review goals. APA JARS was too comprehensive and detailed, and IES WWC was too simple and narrowly focused on internal validity. For our review to be useful for the field, we needed a coding scheme that both prioritized issues of research design and measurement raised by teacher education researchers and made them tractable.
We developed codes by first synthesizing issues raised by prior reviews of the field (as presented previously). We then used this synthesis to curate and simplify the taxonomy of issues related to internal validity, measurement, and external validity described in Campbell and Stanley (1963) and elaborated by Shadish et al. (2002). We then added to these codes based on our broad reading of research in program evaluation, causal inference, and research design (e.g., Institute of Education Sciences, 2020; King et al., 1994; Murnane & Willett, 2010) as well as our understanding of the contexts of teacher education as researchers and practitioners. We then iteratively refined and clarified this coding scheme using a random sample of included studies. The full coding scheme is presented in online appendix B. Key codes relevant to the study are described in online Appendix B and summarized with results in Table 2. The coding scheme aligns with APA JARS (but prioritizes certain issues) and elaborates on IES WWC.
Percent of Impact Evaluations Addressing Issues of Internal Validity, External Validity, and Measurement.

It is important to note that the coding scheme does not reify a single research design, such as randomized controlled trials (RCTs), nor does it reify quantitative over qualitative research methods. Like many others, I believe that RCTs are not the only way to generate causal evidence and that causal questions can be answered with both quantitative and qualitative data (King et al., 1994). This is why I began this review by discussing issues with impact evaluations raised by prior reviews rather than discussing the prevalence of any one particular design or research method. I wanted to approach my review from the problems we seek to address (i.e., the issues of internal validity, measurement, and external validity that teacher education researchers need to overcome), rather than from some preconceived belief that any one particular research design or measurement approach—qualitative or quantitative—is the best.
Coding Process
All included studies were independently coded by me and at least one other trained research assistant. 11 Any discrepant codes were discussed and a consensus was reached. The full dataset is available in online appendix C. Following all coding, I calculated summary statistics to describe study characteristics, research designs, and measurement approaches. I ran correlational analyses and trend analyses to determine any relationships between codes, and whether any types of studies or methods had become more or less prevalent over time. I found nothing meaningful and so do not present these results below; however, they are available upon request. I reviewed codes to identify research designs and measurement approaches that addressed particular issues in innovative ways and could be used as guidance for future studies. Although research assistants and I had already flagged some noteworthy studies as part of the initial coding process, I read every study coded as addressing each issue to ensure I did not miss any innovative approaches. Finally, I synthesized the coding framework, the summary statistics, and the findings from noteworthy studies to develop a common checklist of considerations for designing and reporting on impact evaluations of teacher preparation practices.
Results
In this section, I present my findings on the extent to which the impact evaluations reviewed addressed issues of internal validity, measurement, and external validity. I structure this section according to my three research questions. My general finding is that all issues raised by prior reviews remain prevalent in the field, but that there are bright spots in the literature. I highlight these studies as guidance for future researchers and then present a checklist of considerations for those seeking to undertake more rigorous impact evaluations in the future.
Internal Validity
Systematic Analyses of Distinct Alternatives/Identifying the Counterfactual
Of the 166 studies reviewed, only 26.67% (n = 43) addressed maturation effects by using a comparison group design. Though not initially accounted for in my coding scheme, an additional three studies addressed maturation effects by using within-person comparisons of intended vs. unrelated outcomes (1.81%; n = 3; design described later). Given that only comparison group designs can account for selection or history effects, I restricted analysis of those issues to only the 43 studies that used a comparison group design (Table 3). Most studies addressed selection effects by not allowing participants to choose whether they received the treatment, either through randomization (46.51%; n = 20) or by comparing cohorts of preservice teachers over multiple semesters or years (18.60%; n = 8). The remaining studies either allowed preservice teachers to select which group to be in (11.63%; n = 5), or did not report how preservice teachers were assigned to groups (23.26%; n = 10). Of the 43 studies that used comparison groups, only 55.81% (n = 24) addressed history effects by ensuring that the only difference between comparison groups during the study period was that one group received the teacher preparation practice. These results empirically affirm concerns raised by prior reviews that very few studies are designed to rigorously evaluate the causal effects of teacher preparation practices.
Types of Research Designs Used.

Many teacher education researchers have acknowledged the practical challenges of systematically analyzing distinct alternatives; that is, teacher preparation programs are and operate within highly institutionalized organizations and so researchers often have little control over what, when, and how preservice teachers learn (Labaree, 2004). Despite this, some studies reviewed still managed to address issues of maturation effects, selection bias, and history effects by leveraging program structures. For example, Kopcha and Alger (2011) note that preservice teachers in their program were “placed randomly into one of four cohorts at the beginning of the year” (p. 59) and so assigned treatment at the cohort level. Similarly, Mahalingappa et al. (2018) randomly assigned the teacher preparation practice being evaluated to one of two sections of a course. The authors reported minimal likely impact of selection bias given: (a) students had no foreknowledge of which section would be assigned the teacher preparation practice; (b) students enroll in sections primarily based on their schedule; and (c) researchers picked the section treated without knowledge of who was enrolled (see also Hanuscin & Zangori, 2016).
Some studies identified the counterfactual by comparing groups of preservice teachers across years or semesters, leveraging state-initiated reform or program-wide changes outside the control of study participants. For example, Matthews and Seaman (2007) evaluated the effects of a required specialized math content course by comparing cohorts the year before and after the course was introduced (see also Mizell & Cates, 2004; Smith et al., 2012). Similarly, Yadav et al. (2014) evaluated the effects of a one-week computational thinking module implemented in a required educational psychology course by comparing outcomes with students who took the same course (sans module) in the previous semester.
Some argue that given the high-stakes nature of teacher preparation, comparison group designs may be unethical as some preservice teachers do not receive a potentially beneficial teacher preparation practice (Sikes, 2006). One way some studies dealt with this issue was to use a counterbalanced design, where one group receives one teacher preparation practice while another group receives a different one; then after a period of time, they switch. For example, Bulunuz and Jarrett (2009) randomly assigned one group of students to one teacher preparation practice (learning stations) for three topics (A, B, C) and a different practice (scaffolded reading) for three different topics (D, E, F); the other group of students was assigned the opposite (i.e., learning stations for topics D, E, F and scaffolded reading for topics A, B, C). Participant outcomes were measured after each set of topics.
Another way studies dealt with ethical concerns while still addressing issues of internal validity was by using within-person comparisons of intended vs. unrelated outcomes. Pioneered by Morris and Hiebert (2017) and then replicated by Suppa et al. (2018) and Hiebert et al. (2019), these studies evaluated the effects of teacher preparation mathematics courses years after graduation. They did this by comparing graduate teachers’ skills and knowledge across multiple mathematical content areas, some of which were explicitly taught during teacher preparation courses and some of which were not. For example, Hiebert et al. (2019) test graduates on their conceptual understanding and ability to assess students’ work in the topics of multiplying whole numbers, subtracting fractions, and dividing fractions (topics taught during their first-year mathematics courses) as well as finding the mean (a topic not taught throughout the teacher preparation program). To mitigate history effects (i.e., the effects of any other experience during the study period that could lead to differences in knowledge and skills across different mathematics topics), Hiebert et al. (2019) collect data from graduates about other educational experiences and then systematically test whether those experiences are driving effects (e.g., other experiences during the preparation program; in-school professional development; the foci of school curricula).
Some research designs that allow for systematic comparison of distinct alternatives identifying the counterfactual were coded for but no study reviewed used them. These designs include noncompliance and encouragement designs, lab experiments, and extra treatment designs. Later I discuss the need for further research into designs that achieve rigorous standards for internal validity while being fit-for-purpose for teacher education contexts.
Finally, only 15.66% (n = 26) of all studies reviewed reported whether participants left for any reason at any time during the study period. Some studies provided the reasons for attrition, including incomplete data, participant preference, or scheduling issues unrelated to the study. Some studies explicitly noted that no participants left during the study period. Some studies compared participants with those who attrit to test for any systematic differences (e.g., Hiebert et al., 2019). However, no study explicitly discussed the possibility of the teacher preparation practice causing attrition, nor how any detected effects may have been influenced by differential attrition between comparison groups or any choices to exclude incomplete participant data. It may be that many studies experienced no attrition but study authors did not explicitly report it.
Measurement
Replicable Measures
Of the 166 studies reviewed, only 45.18% (n = 75) measured participant outcomes, whether qualitatively or quantitatively, using a clearly defined and consistent rubric or rating scheme. For example, Isabelle and de Groot (2008) developed a rubric to analyze the depth of students’ open-ended written responses to questions requiring scientific explanations. Bartell et al. (2013) developed a rubric for measuring preservice teachers’ conceptual understanding of mathematical content and their evaluations of children’s mathematical understanding. Foley et al. (2017) and Soh et al. (2007) coded the complexity of preservice teachers’ concept maps of their disciplinary content knowledge. The remaining studies reviewed (54.82%; n = 91) used idiosyncratic measures developed through subjective inductive analysis of collected data.
Of the studies reviewed, only 18.67% (n = 31) used measures developed by other researchers. Some study authors used whole measures (e.g., Mathematics Teaching Efficacy Beliefs Instrument [MTEBI], Science Teaching Efficacy Beliefs Instrument [STEBI]) whereas others adapted or augmented existing measures. Using already developed measures allowed some researchers to build on previous findings and develop a shared evidence base. For example, Wilkins and Brand (2004) used the Mathematics Belief Instrument (MBI), noting how their findings “provide additional support for the reliability of the initial quantitative findings related to the MBI presented by Hart (2002)” and that this replication was important given their study “was conducted with a larger sample of preservice teachers” (p. 231). Similarly, Lambert and Bleicher (2013) used an established measure of perspectives on climate change and then compared their participants’ data with the broader US adult population to discuss the relative magnitude of their findings. Two studies noted that although they used an already-established measure, it had not yet been used in the context of teacher preparation, so comparisons to other studies could not be made (Kopcha & Alger, 2011; McGee & Colby, 2014). In most cases, however, study authors did not use shared measures to compare the magnitude of findings and/or shed light on similarities and differences across study populations.
One challenge in using established measures is that there may be resistance within teacher preparation programs against using common measures, often due to issues of autonomy, agency, and a commitment to preserving the local context of the teacher preparation program. Although these are valid concerns, I believe that they can be appropriately mitigated through careful attention to how they are implemented and how scores are used. I also believe that the consequences are outweighed by the benefits of using common measures to generate shared knowledge and develop more durable lines of research.
Teacher Practice and/or Student Learning
Of the studies reviewed, only 24.7% (n = 41) evaluated the effect of a teacher preparation practice on preservice teachers’ practice and/or their students’ outcomes. Of these 41 studies, 36.59% (n = 15) used preservice teachers’ self-reports, 43.9% (n = 18) used direct observations of participants’ instruction, and 19.51% (n = 8) used both. Studies generally collected data on teacher practice through preservice teachers’ school placements, whether concurrent with or soon after the teacher preparation practice. For example, Girod and Girod (2006) timed their Web-based simulation experience in between already-scheduled mentor lesson evaluations. This allowed them to evaluate the effects of the simulation using data on preservice teachers’ practice. Some study authors triangulated practice data with other artifacts, such as lesson plans and instructional materials. These artifacts allowed researchers to track the impact of teacher preparation practice on preservice teacher learning and preservice teacher enactment. For example, Bangel et al. (2010) analyzed both lesson plans and lesson observations to observe whether what was taught ended up first in preservice teachers’ plans and then in their practice (see also Welsh and Schaffer, 2017).
Collecting data on teaching practice is resource intensive, and teacher education researchers often do not have funding to hire raters to conduct classroom observations or time to do it themselves. Some studies overcame this challenge by drawing on data already collected through state licensure requirements such as edTPA (e.g., Santagata & Yeh, 2014). Other studies tasked preservice teachers to collect data themselves, such as through assignments or online discussion boards. For example, Welsh and Schaffer (2017) used data from four course assignments spread across a semester; each assignment required students to provide a written lesson plan, a 10–15 minute video segment of their teaching the lesson, and a two- or three-page written reflection. Similarly, Caughlan et al. (2013) used data from a course discussion board where preservice teachers were required to post and reflect on multiple 5-minute videos of their teaching. However, Caughlan et al. (2013) admitted that because videos were chosen by preservice teachers, “any measured change over time is partly an artifact of why each candidate chose each video” (p. 225).
Another challenge with collecting teacher practice data from practicum is that the quality of mentor teachers and placement schools may significantly influence preservice teachers’ practice. This means that any findings could actually reflect mentor teacher or placement school quality rather than the effects of the teacher preparation practice. One study, Kopcha and Alger (2011), addressed this issue by collecting two survey measures of practicum support (Learning to Teach Scale; Learning Climate Questionnaire) and then using the data as a control variable.
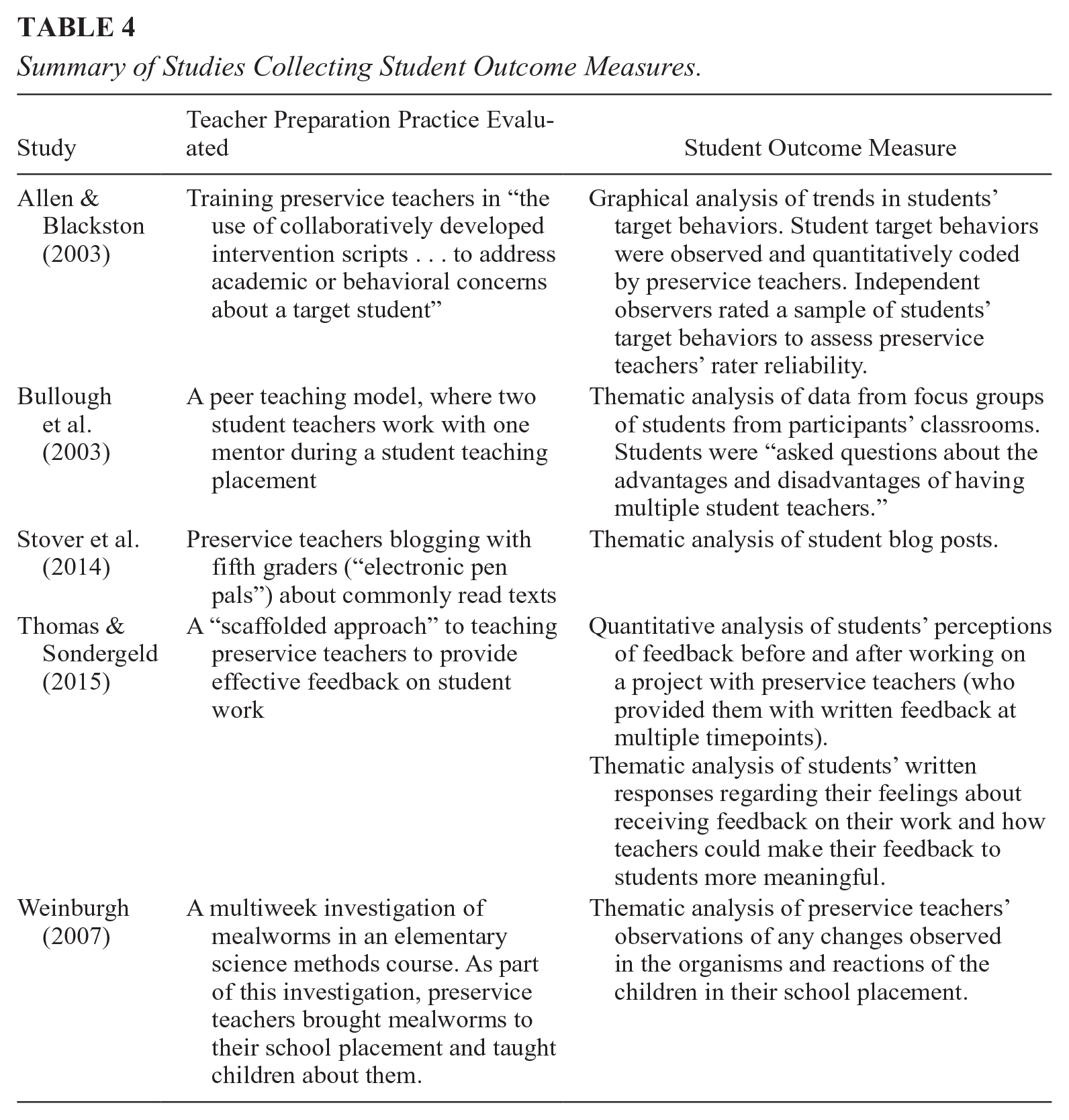
Only five studies reviewed (3%) collected data on student outcomes. A summary of these studies is presented in Table 4; they all leveraged distinct course structures that allowed for the collection and analysis of student outcomes during practicum placements. Three studies collected perception data (i.e., preservice teachers’ observations, or students’ self-reports); two studies collected student learning or behavioral data. Stover et al. (2014) collected and analyzed blog posts that students wrote as part of an electronic pen pal arrangement with preservice teachers (which was the teacher preparation practice being evaluated). Allen and Blackston (2003) collected multiple direct observations of students’ target behaviors. Although preservice teachers collected this data, the study authors sent independent observers to each student on three occasions to test for rater reliability.
Summary of Studies Collecting Student Outcome Measures.
Of the studies reviewed, 6.63% (n = 11) use a broader outcome measure to assess impacts on general instructional quality. For example, Chizhik et al. (2017) compare the edTPA scores of preservice teachers who completed practicum placements using a lesson-study approach with those who undertook a more traditional approach. Birrell & Bullough (2005) supplement interviews and observations with preservice teachers about the focal teacher preparation practice, with additional interviews with mentors and principals inquiring about general instructional quality. Using broader measures of general instructional quality allows study authors to make more generalizable claims about the impacts of teacher preparation practices and guards against concerns that any detected effects may be simply due to a treatment-inherent outcome measure.
Finally, of the studies reviewed, only 6.02% (n = 10) collected outcome measures over multiple time points to assess the persistence of effects (longitudinal measures). Three of these ten studies followed preservice teachers across multiple semesters to assess the impact of content or methods courses on preservice teaching practice during their practicum. For example, in addition to the data they collected during and directly after the science methods course being evaluated, Windschitl et al. (2008) also conducted multiple lesson observations and debriefs with study participants in their practicum placements a year later (see also Cartwright et al., 2014; Ragland, 2016). The remaining seven studies ran the same posttest outcome measure (or a parallel form) multiple times (Hiebert et al., 2019; Isabelle & de Groot, 2008; Morris & Hiebert, 2017; Rodriguez-Valls & Ponce, 2013; Sayeski et al., 2015; Sayeski et al., 2017; Suppa et al., 2018). This allowed researchers to assess whether preservice teachers retained the knowledge and skills learned from the teacher preparation practice.
Longitudinal studies are challenged by the significant barriers teacher preparation programs face in accessing school administrative data related to their program graduates and/or the achievement of K–12 students taught. Access is also complicated by the fact that program graduates often scatter across districts, each with their own administrative data, evaluation systems, and student testing regimes. Three studies reviewed managed to address this issue, using alumni databases to reach out to program graduates and collect data 2–4 years following graduation (Hiebert et al., 2019; Morris & Hiebert, 2017; Suppa et al., 2018). Although only ~20% of program graduates eventually participated in the study, researchers tested the representativeness of the sample with the broader cohort using program data.
Additional Issues
Of the 166 studies reviewed, only 4.22% (n = 7) mitigated reactivity bias by blinding participants to their treatment condition and/or discussing potential biases from participants changing their behavior based on their or others’ expectations. Studies did this differently depending on the practice being evaluated. For example, Fives and Barnes (2017) evaluated the impact of providing preservice teachers with additional guidance when developing assessments. As participants entered the room where the study was being conducted, they randomly received a package of papers; some included additional guidance, and some did not. As participants completed the task individually and were not told the purpose of the study, they were blind to the fact that some participants were receiving additional guidance. Some studies blinded participation by seeking retrospective consent. For example, both Crespo and Sinclair (2008) and Olson et al. (2016) evaluated the impact of various within-course activities but only advised preservice teachers they were part of a study and asked them for consent after the course.
Finally, no study reviewed reported undertaking a power analysis to ensure it was sufficiently powered to detect statistically significant results. One study calculated sampling error based on study size (Foley et al., 2017); however, no study that used quantitative measures and a comparison group design calculated the minimum detectable effect size given their sample size (or vice versa). Power calculations are critical to ensure that study authors recruit enough participants to feasibly detect statistically significant results, and so that lack of power can be excluded as an explanation for any null findings.
Further, of the 66 studies that used quantitative measures, 37.88% (n = 25) reported reliability estimates for their data. Admittedly, as also noted in Zientek et al.’s (2008) review, many study authors reported reliability estimates incorrectly, whether by attributing reliability to their measures rather than their data and/or by reporting reliability estimates from previous studies without comparing sample compositions and discussing how this may influence reliability estimates. Consideration and reporting of the reliability of scores are important to ensure studies can detect statistically significant effects. Zientek et al. (2008) and the Standards for Reporting on Empirical Social Science Research in AERA Publications (AERA, 2006) remain helpful ways forward for future researchers in the field.
External Validity
Representativeness
Nearly all studies reviewed described participant demographics; however, only one study compared sample demographics with preservice teachers across the United States. After describing the racial diversity of their 21 participants, Dass (2005) notes they are “not representative of the university’s general student population. This reflects the national trend of underrepresentation of minority groups entering the science teaching profession” (p. 98). That said, some studies used participant demographics (usually age, race, or academics) to assess the representativeness of their sample with the broader teacher preparation program(s) from which participants were sampled (e.g., Crespo & Nicol, 2006; Foley et al., 2017; Hiebert et al., 2019; Morris & Hiebert, 2017). Other studies described sampling procedures that ensured participants’ representativeness with the teacher preparation program(s) from which they were sampled. For example, Foley et al. (2017) evaluated a science methods course by randomly selecting 234 of the 687 preservice teachers who took the required course sometime between 2012–2014 (see also Santagata & Yeh, 2014).
Of the studies reviewed, 21.69% (n = 36) either named the study site(s) and/or described their location, size, type, and certification level to help others determine the relevance of study findings to other teacher preparation contexts. Addressing this issue is challenging given ethical concerns and institutional policies can limit the disclosure of contextual information lest participants become identifiable (Sikes, 2006). This is perhaps why studies with larger samples and/or conducted across multiple different institutions were more likely to report teacher preparation program characteristics or to identify the programs in which the study was conducted.
Regardless of the challenges, study authors need to define the broader population they believe their findings generalize to (e.g., US preservice teachers; preservice teachers attending a particular type of teacher preparation program; preservice teachers enrolled in the teacher preparation program in which the study is conducted) and present evidence that justifies the representativeness of their participant sample and/or study sites to this broader population. This allows readers to better assess the relevance of study findings across contexts, as well as link study findings to build the evidence base. Future researchers seeking to draw comparisons between their study sample and a broader population may wish to use publicly accessible national-, state-, and program-level gender and race/ethnicity data collected as part of Title II reporting (http://title2.ed.gov/).
Scalability
Of the 158 studies evaluating teacher preparation practices administered by instructors (e.g., courses, pedagogies, or experiences), only 10.13% (n = 16) addressed instructor effects by either training multiple instructors to deliver the teacher preparation practice and/or discussing issues of using instructors that were highly enthusiastic about, skilled in, or suited to it. These studies were mostly multisite evaluations where multiple instructors implemented the same practice across different course sections and/or teacher preparation programs. For example, Olson et al. (2016) evaluated how three instructors used video cases across nine course sections of elementary science methods courses over four semesters. To reduce instructor effects, study authors ensured all instructors taught at least one section across all study conditions and that sections “used the same course syllabi, objectives, goals, and reading materials to ensure continuity in course content and sequence” (p. 1508). Some studies with multiple instructors collected additional implementation data to ensure fidelity (e.g., Bell et al., 2011). Additionally, some studies ensured at least one study author did not have any interactions with participants to ensure an “outsider” perspective for data collection and analysis (e.g., Hart & Bennett, 2013; Hoppey & Mickelson, 2017).
Of the 139 studies that were undertaken within courses, 61.15% (n = 85) reported that at least one study author was also an instructor. Evaluating one’s own practices is often fraught as study authors may unknowingly bias data collection and analysis toward identifying positive findings. That said, evaluating one’s own practices is often necessary given the limited funding and research time available to teacher education researchers. In these cases, some studies mitigated researcher bias by separating course instructors from data collection and analysis. For example, Hanuscin and Zangori (2016) note that “the consent process was conducted by another individual and the instructor did not know whether or not students consented until the conclusion of the semester” (p. 807). Similarly, Duncan et al. (2010) collaborated with graduate students for data collection and ensured they did not share data or preliminary findings with the first author/course instructor until after the course concluded.
Checklist of Considerations
To aid future researchers in developing and reporting on impact evaluations of teacher preparation practices, I present a checklist of considerations in online appendix D. I aim to simplify the wide range of issues of research design and measurement described previously in a concise and consolidated way. For each consideration on the checklist, researchers are provided with a simple yes/no question to assess whether they are addressing the issue in their impact evaluation. If the answer is no, then researchers are presented with a follow-up, open-ended question to assist them in mitigating the underlying problem. Teacher education researchers can use this checklist at any point during the development, implementation, and write-up of their impact evaluations. In particular, if studies cannot be designed for rigorous internal validity through traditional means (i.e., individual-level random assignment), researchers can use this checklist of considerations to mitigate as many threats to internal validity as possible (see also Hill et al., 2021). Peer reviewers, research funders, and policymakers can use this checklist to demand greater transparency and accountability for more rigorous causal research methods in the field (Zeichner, 2005; Zientek et al., 2008).
Discussion and Conclusion
If we want high-quality instruction for all students, we need well-prepared teachers. To have well-prepared teachers, we need to identify the most effective teacher preparation practices and get teacher educators and policymakers to implement them at scale. To identify the most effective teacher preparation practices and support teacher educators and policymakers to implement them, we need to increase the quantity and rigor of our impact evaluations. To increase the quantity and rigor of our impact evaluations, we need to make tractable key issues of research design and measurement that have hampered impact evaluations over the past two decades and then identify ways to address them. This has been the aim of this review.
Like prior reviews, I find that we still have a lot of work to do in this field. Of the 166 studies reviewed, few used research designs that addressed issues of internal validity like maturation effects (27.71%; n = 46), selection effects (12.04%; n = 20), history effects (14.46%; n = 24), and attrition (15.66%; n = 26). Few studies measured the impact of teacher preparation practices on preservice teachers’ instruction, whether observed or self-reported (24.7%; n = 41), and even fewer measured the impact on student outcomes (3.01%; n = 5). Less than half of the studies (45.18%; n = 75) used replicable measures, and only 18.67% (n = 31) used established measures to facilitate the comparison of results across the field. And finally, few studies discussed the representativeness of their study participants (13.25%; n = 25) or study site(s) (21.69%; n = 36) to identify for whom and in what contexts study findings may generalize.
These findings may be skewed by my narrow inclusion criteria (i.e., impact evaluations of teacher preparation practices focused on improving instructional quality; published in peer-reviewed journal articles) or search procedure (e.g., online search only through ERIC; hand search of only six top-rated journals). For example, I excluded studies that made causal claims in their discussion or conclusion sections (e.g., “these findings show that this practice improves preservice teachers’ teaching skills”) but did not explicitly use causal language in their framing (e.g., “the aim of this study is to understand how preservice teachers experience this practice”). I did this to not mischaracterize studies. I also excluded studies not published in peer-reviewed academic journals. I did this to ensure that studies had already been reviewed and accepted by members of the field. However, these choices mean that the number of studies reviewed underrepresents how many impact evaluations have actually been undertaken. It also means that my findings may be inflated as studies may be more likely to exhibit issues of internal validity, measurement, and external validity when they do not characterize themselves as impact evaluations but then make causal claims and/or when they have not been through peer review.
Improving the rigor of impact evaluations is challenging but not impossible. One thing I found striking from undertaking this review is that while few studies consistently addressed issues of internal validity, measurement, and external validity, most studies addressed some various assortment of issues. This gives me hope as a researcher: each individual issue identified previously is addressable; we just need to find ways to learn from each other so that all the good things that studies are doing can be combined. In service of this, I have highlighted several studies that have demonstrated innovative and promising approaches for addressing various issues of research design and measurement. I have also presented a checklist of considerations in online appendix D to provide teacher education researchers with more specific guidance on conducting impact evaluations of teacher education. This paper alone, however, is unlikely to change research practice without accompanying whole-of-field efforts, and so in the following sections, I make more general recommendations about how we can improve as a field.
Focus on Causal Research
Despite the wide-ranging search terms and thousands of studies screened, I remain struck that only 166 studies were identified for inclusion in this review. As others have noted, this dearth of studies can be partly attributed to teacher education researchers’ lack of dedicated funding and time (Cochran-Smith, 2004; Sleeter, 2014; Zeichner, 2005). However, calls for more impact evaluations of teacher preparation practices have been ongoing since 2002, and since then there has been a proliferation of causal research across education particularly in cognate subfields (e.g., teacher professional development). There has also been a significant increase in professional support to undertake this work (e.g., funding through the IES and NSF; establishment of the Society for Research on Educational Effectiveness). Given these advancements elsewhere yet limited development within teacher education, I believe we must own up to our deprivileging of causal work. We must acknowledge that over and above the many challenges of undertaking impact evaluations, many teacher education researchers have chosen not to do them. Again, this is not to say that the dominant research traditions of the field over the past two decades have not provided useful insights (Borko et al., 2007; Cochran-Smith et al., 2016). Rather, it is simply to acknowledge that there remain answerable yet unanswered questions regarding the most effective teacher preparation practices and that policymakers, teacher educators, and researchers will benefit if we shift our collective focus toward them.
Teacher educators are interested in improving their practice. We want evidence that gives us confidence that the practices we choose to implement have a greater impact on our preservice teachers than if implementing something else (Cochran-Smith et al., 2016; Grossman, 2008; Wilson et al., 2002). However, current prevalent research methodologies in teacher education (i.e., localized descriptive investigations of one’s own practices) cannot alone give us this confidence. These localized descriptive investigations may allow for a deeper understanding of a particular teacher preparation practice as implemented; however, teacher educators reading these studies may necessarily wonder whether the practice itself is effective or if any outcomes observed are due to the particular teacher educator conducting the study, or a concurrent learning experience, or cohort effects, or some other contextual factor. Only systematic and reproducible impact evaluations of distinct alternatives can allay these teacher educators’ concerns. Only impact evaluations can extend what we know from localized descriptive investigations about how to implement a particular teacher preparation practice by providing rigorous evidence that can help teacher educators decide whether to implement it in the first place.
From a policymaking perspective, localized descriptive investigations of teacher preparation practices can help describe common and emergent practices, but they cannot be used for decision-making at scale because they do not give insights into what practices are effective for whom and in what contexts. Only impact evaluations can help policymakers decide whether mandating certain program structures through accreditation requirements or investing in grant programs that incentivize implementation will improve preservice teacher learning at scale.
Of course, impact evaluations have limitations as well. Impact evaluations can only answer narrow questions about whether a particular teacher preparation practice implemented in a particular way within a particular context was effective relative to some alternative also implemented in a particular way. This can raise concerns about the value of impact evaluations. For example, some teacher educators may find impact evaluations challenging to learn from given their context, preferring more contextualized process evaluations that give them more information to decide what is similar, what is different, and what can be learned across contexts. Personal preferences aside, 12 one way to think about the broader contribution of impact evaluations given the challenges of generalizability is to consider the alternative. Without rigorous impact evaluations, teacher educators have no way to discern whether a particular practice is having a causal effect and whether the context of the study is similar enough to their own to make the findings generalizable. With rigorous impact evaluations, teacher educators do not have to worry about whether the practice was effective within the context of the study; they only have to worry about whether the study findings are generalizable to their own context.
On a practical level, then, one way to increase the quantity and rigor of impact evaluations is to focus on ensuring that doctoral students and early career teacher education researchers have adequate training and support in not just qualitative and quantitative research methods but also in research design and measurement (Grossman, 2008; Wilson, 2006). As Borko et al. (2007) note, “That many teacher educators have specialized in research methods most attuned for interpretive and practitioner studies means that as a field, teacher education has less ability to design studies that speak to policymakers’ concerns and reflect teacher educators’ deep knowledge about learning to teach” (p. 9). Addressing this gap in training involves going beyond the standard prescription that “research methods should be tailored to specific research questions” and offering dedicated courses that help researchers-in-training identify causal questions and design studies that effectively answer them. One way this could happen collaboratively is if teacher education researchers developed proposals to conduct multiyear IES or NSF training programs specifically focused on impact evaluations in teacher preparation. It is important here to reiterate that this does not suggest the field should privilege more quantitative research training over more contextualized, qualitative methods. As noted previously, causal questions can be answered through both quantitative and qualitative methods—the challenge is supporting teacher education researchers to develop the skills and nous to deploy these methods in causal studies.
Another way forward is for future researchers to develop and socialize rigorous research designs that are easily implementable within the context of teacher preparation programs—in particular, designs that address issues of internal validity when individual-level random assignment is not possible (see Hill et al., 2021, for a preliminary discussion). Established teacher education researchers could also advocate for funding rounds (e.g., NSF, IES, and other major funding bodies) exclusively dedicated to rigorous impact evaluations of teacher preparation practices. Given the prevalence of ethical concerns related to randomized designs in teacher preparation, future research should investigate ethical considerations and potential risk mitigation strategies. This will help institutional review boards in making judgments about the relative risks and rewards of research that includes incomplete disclosure and deception.
Research funders, university systems, and/or departments of education could also support greater collaboration between teacher education researchers to conduct multisite studies such as cluster randomized trials like those increasingly used in K–12 education (Spybrook et al., 2020). Researchers could randomly assign certain teacher preparation programs to implement a certain teacher preparation practice, comparing preservice teacher outcomes from a different set of programs on a common set of measures (e.g., a common observation rubric used during practicum, or a common licensure performance assessment). Given the diverse range of teacher preparation programs across the United States, identifying sites interested in this sort of shared implementation may likely be challenging. However, across the United States, there are networks of teacher preparation programs collaborating on shared approaches, which may be prime opportunities for these sorts of research collaborations. Further research into the affordances and challenges of this clustered collaborative approach is needed.
Finally, calls for more rigorous impact evaluations have remained relatively unheeded for the past two decades, and so if we as a field truly want to change, we need to do something different. One way forward is for future researchers to apply theories of planned behavior to the field, such as considering teacher education researchers’ capability, motivation, and opportunity to undertake rigorous impact evaluations (Michie et al., 2011). This can help identify the specific actors and actions needed to advance the field’s focus on and uptake of more causal research.
Measure Teacher Practice and Student Outcomes
Future researchers need to develop more measures of teaching practice and student outcomes that can be used in the context of teacher education. This includes developing measures that go beyond general assessments of instructional quality and that can detect improvements in the specific domains or parts of instruction targeted by teacher preparation practices. Many researchers are already working on this, including through developing teaching simulations that require observational measures of discrete elements of instruction (Cohen et al., 2020; Shaughnessy & Boerst, 2018) or developing rubrics and rating schemes for assessing teaching artifacts, such as science teaching portfolios (Kloser et al., 2017; Martínez et al., 2012). Importantly, many of these measures are also starting to be publicly shared through repositories like EdInstruments (http://edinstruments.com/) to make it easier for researchers to find and use. Despite these developments, more needs to be done. More measures need to be developed, particularly in non-STEM teaching areas, and teacher education researchers need more encouragement to adopt and use established measures.
When selecting outcome measures, teacher education researchers need to consider the appropriate grain size. Outcome measures that are tightly aligned and narrowly focused are more likely to detect effects, but if they are too narrow then they can limit study authors from making broader conclusions about effective teacher preparation practice. This in turn can reduce the relevance of study findings in guiding broader teacher educator practice and policy. Teacher education researchers also need to consider potential biases caused by how measures are administered and used. For example, course grades may be appealing outcome measures as they do not require preservice teachers to undertake additional work outside class, and they are less “noisy” as researchers know students generally exert full effort for grades. However, course grades may be gameable or based on activities that are not generalizable to day-to-day teaching practice, and/or teacher educators doubling as researchers may unknowingly bias grades in favor of finding effects. There is no perfect measurement instrument, but study authors should consider and make explicit the tradeoffs involved in their choices.
Even if we had better measures of teacher practice and student outcomes, as well as clearer ways to discuss their tradeoffs, teacher education researchers must still find ways to actually administer them. Researchers could provide teachers with recording equipment and task them to collect videos of themselves teaching; alternatively, when teachers are asked to provide samples of instructional materials, they could also provide copies of strong, average, and weak student responses collected through their practicum. Doing this across multiple time points could enable researchers to assess improvements in teachers’ practice and the associated impact on student learning. Work like this has already gained some traction in the literature: Waggoner et al. (2015) discuss how all preservice teachers in their program collect student-level pre- and post-test data during practicum, and Brady et al. (2018) describe how student data from practica can be used to develop “value-added” measures that generate evidence of program effectiveness.
Another possibility is developing domain-general standardized instruments and procedures. For example, though not included in this review, to get around the challenge of study participants being prepared for different subject areas and grade levels, Metcalf and Cruickshank (1991) developed thirty 15-minute “Reflective Teaching” lesson plans that could be prepared for and implemented by participants and then scored by trained raters using a common rubric. Similarly, Jacoby-Senghor et al. (2016) provided trained participants on an unfamiliar subject (Byzantine history) and gave them 20 minutes to prepare a 7-minute lesson. Participants taught their lesson to someone who then took a content test. This enabled the authors to measure both instructional quality and student learning. Studies like this offer the prospect of evaluating teacher preparation practices across the whole causal pathway from what teacher educators do to what preservice teachers’ learn, to how these teachers teach, to what their students learn.
Of course, even if we can measure teacher practice and student outcomes, there also remains the problem of statistical power. Meta-analyses of professional development generally find much larger impacts at the teacher level than at the student level (Kraft, 2020). This suggests that if we want to detect the effects of teacher preparation practices at the student level, then future impact evaluations will either need extremely large samples (logistically challenging given the size of programs) or very large effects (possible but dependent on the teacher preparation practice being evaluated, as some are quite narrowly focused). Although there are some ways to mitigate the problem (e.g., increasing statistical power by collecting baseline data that explains variation in the outcome; running very large cluster randomized trials; only evaluating the effect on student outcomes of large practice changes; only using outcome measures that are overaligned with treatment), I look to future research to help us develop tools for statistical analysis that help us achieve our overall goal (i.e., assessing whether any changes in outcomes are due to chance) within the logistical constraints of teacher education.
Clear Guidance for Reporting on Studies
Like prior reviews (Cochran-Smith et al., 2012; Zeichner, 2005; Zientek et al., 2008), I find that studies generally underreport information about study participants, study site(s), and other contextual factors that influence how teacher preparation practices are implemented. This makes it difficult to determine for whom and in what contexts study findings generalize. I recommend, like others have before, that the field invests in developing shared vocabulary and norms for reporting (Borko et al., 2007; Grossman & McDonald, 2008; Zeichner, 2005). This must go beyond the general prescriptions from the AERA Standards (e.g., “The social, historical, or cultural context of the phenomena studied should also be described,” 2006, p. 35), and provide clarity to future researchers about what exactly to report and how. One way forward is for future researchers to preregister studies against existing standards like APA JARS or use the SREE Registry of Efficacy and Effectiveness Studies. This will facilitate deeper consideration of issues of internal validity, measurement, and external validity and ensure studies can be included in future meta-analyses, something critical for consolidating findings across studies and building more durable lines of research.
Developing field-specific guidelines for reporting will be challenging given the diversity of teacher education contexts and the myriad influences that contribute to preservice teacher development. However, without them, teacher education researchers will continue to provide either too little (or in some cases, too much) detail, making it difficult for policymakers, teacher educators, and other researchers to compare findings across studies, and determine the relevance of findings across contexts. For example, over a decade ago, Zientek et al. (2008) reviewed the quantitative reporting practices of studies in the field and found much of them misaligned with AERA Standards. Future research should investigate whether much has changed since this call to action and propose adaptations to already established standards to ensure they are fit for purpose given the contextual specifics of conducting research in the field. As the field develops toward more rigorous impact evaluations, I also look forward to future studies replicating my current approach to observe how the field has changed and celebrate novel developments in research design and measurement approaches.
Developing shared vocabulary and norms is a significant task but can be aided by adapting already-established standards for impact evaluations (e.g., What Works Clearinghouse standards and reporting procedures, or the APA Journal Article Reporting Standards) and encouraging more preregistration of studies for research transparency and replicability (e.g., via the Open Science Framework or the SREE Registry of Efficacy and Effectiveness Studies). It can also be aided through deeper collaborations between established teacher education researchers and education policy researchers (see Boyd et al., 2009, for an example). The former can identify practical and policy-relevant research questions and study sites; the latter can contribute methodological expertise for designing and reporting on studies that meet rigorous standards for impact evaluations. These sorts of collaborations can also help address issues of positionality in teacher education (i.e., outsiders with little understanding of teacher preparation contexts having outsized influence) by ensuring insiders and outsiders work together to improve the rigor of teacher education research.
Teacher education researchers could also begin to undertake more linked small-scale studies (Grossman, 2008). As Sleeter (2014) describes, “researchers in different geographic locations . . . with careful planning and coordinating, could carry out linked small-scale studies that ask the same questions and use the same methodology” (p. 7). This sort of collaboration will require developing a shared vocabulary and norms for describing the teacher preparation practice (so it can be implemented with fidelity) and reporting on site-specific contextual factors (so that researchers across institutions can identify and/or control for potential influences). From these efforts, other researchers could then conduct replication studies, adding more or less context depending on what they consider important for understanding the generalizability of findings across contexts. These sorts of “chains of inquiry around particular questions and consistently defined outcomes” (Zeichner, 2005, p. 742) will enable teacher education researchers to achieve our collective goal of developing a shared evidence base.
Supplemental Material
sj-docx-1-rer-10.3102_00346543231174413 – Supplemental material for Impact Evaluations of Teacher Preparation Practices: Challenges and Opportunities for More Rigorous Research
Supplemental material, sj-docx-1-rer-10.3102_00346543231174413 for Impact Evaluations of Teacher Preparation Practices: Challenges and Opportunities for More Rigorous Research by Zid Mancenido in Review of Educational Research
Supplemental Material
sj-xlsx-1-rer-10.3102_00346543231174413 – Supplemental material for Impact Evaluations of Teacher Preparation Practices: Challenges and Opportunities for More Rigorous Research
Supplemental material, sj-xlsx-1-rer-10.3102_00346543231174413 for Impact Evaluations of Teacher Preparation Practices: Challenges and Opportunities for More Rigorous Research by Zid Mancenido in Review of Educational Research
Footnotes
Acknowledgements
I thank Heather Hill, Susan Moore Johnson, and Eric Taylor for their helpful comments on earlier versions of this paper. I thank attendees at the Research Designs and Measurement for Teacher Education Conference in both 2019 and 2021 for the conversations that informed this paper. I thank Justin Hancock, Karen Andres, Aman Panjwani, and Rita Pello for their research support.
This material is based upon work supported by the National Science Foundation under Grant No.1920616.
Notes
Author
DR. ZID MANCENIDO is a lecturer at Harvard Graduate School of Education, 13 Appian Way, Cambridge MA 02138; e-mail:
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.