
Abstract
Numerous studies investigate high-stakes personnel evaluation systems in education, but nearly all focus on evaluation of teachers. We instead examine the evaluation of school principals at scale using data from the first 4 years of implementation of Tennessee’s multiple-measure administrator evaluation system. We focus specifically on the rubric-based practice ratings given by principals’ supervisors that constitute one half of principals’ overall evaluation scores. We find that supervisors’ ratings are internally consistent, relatively stable over time, and predictive of other performance measures, such as student achievement growth and teachers’ ratings of school leadership quality. However, raters fail to differentiate dimensions of principal practice, and ratings may be biased by factors, such as school poverty, outside the principal’s control.
A defining characteristic of this body of work, however, is that it has been focused almost exclusively on teachers. Inattention to related issues for principals persists even as, according to the National Conference of State Legislatures, at least 36 states have adopted laws requiring regular assessments of principals since 2010 (Superville, 2014).
In this study, we contribute to the nascent literature on principal evaluation in the context of new “multiple measures” systems, that is, evaluation systems that pull together evidence of principal performance from multiple sources. In particular, we make use of data from the first 4 years of implementation of the Tennessee Educator Acceleration Model (TEAM), a comprehensive evaluation system initiated as part of Tennessee’s Race to the Top reforms. In the TEAM system, half of school leaders’ evaluations are based on practice ratings in specific performance areas provided by the superintendent or other leaders. Evaluators score principals using a rubric aligned with statewide leadership standards, and these scores are combined with student achievement and other quantitative measures to assign overall effectiveness ratings to principals.
Although such supervisor ratings are a common feature of principal evaluation systems, little is known about the distributional properties of the ratings, the characteristics of principals they identify as effective, or how well they predict other policy-relevant outcomes. Understanding these ratings as measures of principal effectiveness has increased in importance as research has called into question the validity of value-added measures as a component of principal evaluation (Chiang, Lipscomb, & Gill, 2016; Fuller & Hollingworth, 2014; Grissom, Kalogrides, & Loeb, 2015). In addition, findings from examinations of teacher evaluation systems support the need to more carefully explore the properties of these subjective ratings for principals. High-stakes evaluations of teachers are often very left-skewed, with raters unwilling to utilize low rating categories even when they have concerns about teacher performance (Grissom & Loeb, 2017). Even when stakes are not attached, raters may only be able to reliably differentiate performance in the tails of the performance distribution (Jacob & Lefgren, 2008). Principals may be unable to differentiate teacher performance on some job dimensions from performance on other dimensions, limiting the value of the scores for feedback and performance improvement (Grissom & Loeb, 2017; Halverson, Kelley, & Kimball, 2004). Teacher evaluation research also has raised concerns that subjective rating scores implicitly penalize teachers with specific race or gender characteristics or who teach in classrooms with larger numbers of disadvantaged students (Jacob & Walsh, 2011; Whitehurst, Chingos, & Lindquist, 2014). The degree to which similar issues manifest for evaluations of principal performance has yet to receive research attention.
To address this gap, we focus on the end-of-year evaluations Tennessee principals received during the first 4 years of the statewide implementation of TEAM, 2011–2012 through 2014–2015. Tennessee was a first-round Race to the Top winner and one of the first states to roll out a new mandatory principal evaluation system, providing us with a unique opportunity to examine high-stakes principal evaluation at scale over a sustained period of implementation. We link principals’ scores on the various TEAM domains (e.g., “Culture of Teaching and Learning”) to administrative data on the principals and their schools and to other potential measures of their performance, including measures of student achievement growth and teachers’ assessments of their principals from a statewide survey. Using these data, we ask the following research questions. First, what are the distributional properties of the summative TEAM administrator practice ratings? How do they vary, and how do the different domain scores correlate with one another? Second, what principal characteristics (e.g., race, gender, years of experience) and school characteristics (e.g., level, proportion of students from low-income backgrounds) are associated with higher TEAM principal practice ratings? Third, does the TEAM administrator practice rating predict measures of student achievement? Finally, do TEAM ratings predict other indicators of principal effectiveness, such as teacher and assistant principal subjective assessments of leadership in the school? Answers to the latter two questions aim to provide evidence for concurrent and predictive validity of the ratings rather than to establish the causal impact of having a high-performing principal. Providing these answers is important because few studies have examined principal evaluation systems, and existing studies have largely focused on local district evaluation systems and policies (e.g., Catano & Stronge, 2007; Glasman & Martens, 1993; Goldring et al., 2009) or smaller scale state pilot programs with no stakes for principals (McCullough, Lipscomb, Chiang, Gill, & Cheban, 2016). Full-scale statewide evaluation systems, which are not designed by local actors, may not have local buy-in, and are coordinated among a larger set of stakeholders and evaluators, are likely to be implemented differently.
We begin by reviewing the literature on principal evaluation. We then give an overview of the history and structure of Tennessee’s TEAM system, followed by a description of the data, measures, and methods used in our analysis. The next section presents the results of our analyses. We end by discussing the implications, conclusions, and future directions for this research.
The Challenges of Evaluating Principals
Designers of principal evaluation systems face two broad considerations: What to assess and how to assess it (Goldring et al., 2009). The “what to assess” question generally consists of identifying the markers of or standards for effective leadership behaviors. The “how to assess” question focuses on developing instruments and processes for accurately and reliably measuring what principals do against the standards. Historically, neither of those questions was given close consideration in the design of most principal evaluation systems, with districts employing simplistic checklists of behaviors or narrative descriptions completed during short annual visits, falling far short of accepted measurement standards for assessing leaders’ performance (Lashway, 2003; Portin, Feldman, & Knapp, 2006). The content, form, and purpose of these evaluations often varied—and varies—widely from system to system, with indicators not aligned with existing professional standards (Clifford & Ross, 2012; Condon & Clifford, 2010; Davis, Kearney, Sanders, Thomas, & Leon, 2011).
The lack of rigor in many principal evaluation systems undercuts their value for providing feedback to principals for performance improvement. For example, Davis et al. (2011) documented a case of a system in the western United States, where “the evaluators’ erratic levels of fidelity to the implementation procedures and criteria significantly compromised the degree to which the standards-based approach was perceived as being helpful to principals” (p. 8). Similarly, Lashway (2003) summed up the general state of traditional evaluation systems as “Little is learned and not much happens” (p. 4). Although principals in a nationwide survey reported general satisfaction with the extent to which their evaluations were consistent with job expectations, fewer felt that the evaluation provided anything useful in terms of helping them improve their performance. Others complained of unknowledgeable supervisors or noted that they had not been evaluated at all (Reeves, 2005).
A robust system of principal evaluation requires taking both the what to assess and how to assess it questions seriously. Establishing standards for what is assessed or evaluated is challenging because the job of the school principal is highly complex. Job tasks associated with the principalship are diverse, ranging from managing staff personnel, to handling student behavior, to coordinating professional development, to connecting with the community, to overseeing instruction (e.g., Ginsberg & Thompson, 1992; Hallinger & Heck, 1996). Moreover, contextual differences from school to school affect what the principal’s job entails (Clifford & Ross, 2012; Glasman & Martens, 1993). Due to this complexity, there is not a universal set of agreed-upon definitions of what school leadership is meant to include, or even whether the foundation should be responsibilities, skills, processes, or outcomes (Goldring et al., 2009; Murphy, Elliott, Goldring, & Porter, 2006; Portin et al., 2006). Numerous attempts have been made to define broad standards for principal performance, including, most prominently, the Professional Standards for Educational Leaders (previously the Interstate School Leaders Licensure Consortium standards). Developed by the National Policy Board for Educational Administration and released in October 2015, these standards define essential qualities of school leadership among 10 broad dimensions, including mission, vision, and core values; curriculum, instruction, and assessment; and professional community for teachers and staff (National Policy Board for Educational Administration, 2015). Individual states have attempted to define their own standards for principal performance as well.
The broad challenge to designing approaches to assessing principals against whatever standards are chosen is establishing processes for measurement that have good reliability and validity properties so that policymakers and principals can be confident that evaluation scores accurately reflect principal performance. Typically, this process begins with writing a performance rubric that operationalizes the standards, usually to be completed by a supervisor, though beyond this commonality, research has shown little consistency in systems’ approaches to performance assessment, with instruments varying widely in the number of items measured, the content covered, and the weight given to subcomponents (Goldring et al., 2009; Goldring & Jones, 2014). Moreover, almost no attention is given to the reliability and validity properties of evaluation instruments. In a review of 65 principal evaluation tools employed by districts and states, Goldring et al. (2009) found that only two stated or described the psychometric properties of the evaluation instrument in the accompanying documentation.
Growing national attention to the importance of school leadership, coupled with a new focus on increasing the rigor of teacher evaluation as a means of improving teacher effectiveness, has led to widespread reform of principal evaluation in recent years. For example, several Race to the Top–winning states designed and fully implemented multiple measures-based principal evaluation systems as part of their awards that they used as the foundation for other processes, including rewarding effective principals, supporting principal development, determining compensation, and factoring into retention decisions (Scott, 2013).
Despite their increasingly widespread implementation, however, little research has examined the properties of these new principal evaluation systems. Researchers’ inattention to principal evaluation is long-standing. In reviewing the literature, Davis et al. (2011) concluded that “the field lacks a strong theoretical base or an empirically sound rationale for principal evaluation as a mechanism for advancing individual or organizational effectiveness” (p. 36), echoing a complaint that has persisted for decades (Ginsberg & Thompson, 1992). Studies of principal evaluation often have been unsystematic, lacking in methodological rigor, and focused on the particulars of the evaluation systems of individual districts (Condon & Clifford, 2010; Davis et al., 2011; Goldring et al., 2009).
For state systems, research thus far has been limited to studies of a pilot in Pennsylvania and pilot and first-year implementation in New Jersey. Studies of pilot data from Pennsylvania’s principal evaluation system rollout found generally good internal consistency in supervisors’ ratings of principals but relatively limited variation in ratings and mixed evidence on the correlation between ratings and student achievement growth (McCullough et al., 2016; Teh, Chiang, Lipscomb, & Gill, 2014). Analysis of data from the New Jersey system, piloted in 2012–2013 and rolled out statewide in 2013–2014, found that principal practice ratings were both moderately stable between years and overwhelmingly positive, with virtually all principals receiving scores of “effective” or “highly effective” (Herrmann & Ross, 2016). The authors also found small positive correlations between ratings and student achievement growth, and that principals of schools with larger numbers of economically disadvantaged students received systematically lower ratings.
The TEAM Evaluation Model for Principals in Tennessee
Our analysis focuses on principal evaluation in Tennessee. Tennessee became one of the first states to implement an annual statewide educator evaluation system during the 2011–2012 school year. 1 This evaluation system, called the TEAM, was mandated as part of the state’s First to the Top (FTTT) Act, passed by the Tennessee General Assembly in January 2010 in pursuance of the state’s successful Race to the Top application, which secured the state US$501 million to support school reform efforts.
Under the TEAM system, a school leader’s total annual evaluation score is comprised of two parts: 50% comes from measures of achievement, and 50% comes from subjective scores given to school leaders by the superintendent or his or her designee—often the principal’s supervisor—using the TEAM rubric. Of the 50% devoted to student achievement, 35% is based on school-wide student growth as measured by the Tennessee Value-Added Assessment System (referred to as “TVAAS”), and 15% is based on additional measures of achievement determined by mutual agreement of the administrator and their evaluator. The 50% based on subjective performance ratings comes from scores on a rubric based on the Tennessee Instructional Leadership Standards (TILS), first created in 2008 and revised in 2013. 2 The TILS “identify core performance indicators of ethical and effective instructional leaders” in Tennessee (Tennessee State Board of Education, 2015, p. 26).
Between 2011–2012 and 2014–2015, TEAM employed four different rubrics for capturing these indicators. An initial version used in 2011–2012 was shortened and reorganized by the Tennessee Department of Education (TDOE) for 2012–2013. In 2013–2014, most districts continued to use this second version, but 10 districts were selected to pilot a new rubric based on the revised TILS. A fourth version—very slightly updated from the 2013–2014 pilot—was employed in all TEAM districts in 2014–2015.
A list of domains and indicators for each version of the rubric is summarized in Appendix Table 1 (in the online version of the journal; see also Table 2 below). This list shows that constructs typically associated with instructional leadership (e.g., creating a culture for teaching and learning) appear across years, but there are important differences in content and organization from year to year as well. The changes between the 2012–2013 version and the pilot/2014–2015 versions are especially pronounced; the 2014–2015 version was streamlined from seven to four domains, albeit with approximately the same number of indicators. This update included, for example, making ethical behavior a theme that cut across rubric categories rather than its own explicit scored domain and moving the quality of the teacher evaluation process the principal conducted from being its own domain to being an indicator of the quality of professional learning and growth processes in the school.
All TEAM indicators are scored on a Likert-type scale that ranges from 1 (significantly below expectations) to 5 (significantly above expectations). Except in the first year, accompanying rubrics indicate what types of observed practices would qualify a score of 1, 3, or 5 on the instrument. For example, for “Evaluation Data and Use” in 2012–2013, a Level 1 (lowest) principal is described as one who “uses educator evaluation data with limited or no evidence of determining accurate trends,” while “regularly engaging leadership team to use educator evaluation data trends and patterns” would indicate that a principal was operating at a Level 5. Some indicators in some years are designated as optional if the evaluator determines the indicator does not fall within the scope of an administrator’s job responsibilities. 3 As an additional wrinkle, in 2012–2013, scores on the sole indicator in the “Ethics” domain were mandated to be either 3 or 5. The mean across items is used to calculate the rubric-based portion of the overall evaluation score.
Implementation of the Tennessee administrator evaluation process has evolved over time beyond changes to the rubric itself. For example, in the first year of implementation, TDOE required that administrators be evaluated only once, but at least twice (in the first and second halves of the school year) in subsequent years, with both scheduled and unscheduled school visits. TDOE also changed its expectations around training to conduct evaluations, moving from optional formal training on the TEAM administrator evaluation process in 2011–2012 and 2012–2013 to required training and certification to conduct evaluations.
Data, Measures, and Methods
Our analysis makes use of TEAM evaluation data for Tennessee principals from the first 4 years of TEAM implementation, 2011–2012 through 2014–2015, which we refer to henceforth by the spring year (i.e., 2014 for the 2013–2014 school year). We merge the evaluation data with a number of other administrative and survey data sources, all provided to us by TDOE through the Tennessee Education Research Alliance at Vanderbilt University.
TEAM Evaluation Data
TEAM evaluation data include ratings from the rubric-based professional practice portion of the evaluation for each principal each year. Ratings on a 5-point scale are provided at the individual item level—that is, for each of the indicators that make up a given domain.
According to TDOE guidelines, rubric ratings are supposed to come from observations conducted by principal supervisors or other designated staff. The data show that 89% of summative observations (in 2015) were conducted by district administrators, with about 40% conducted by the superintendent. The remaining 11% were conducted by school principals; some Tennessee districts utilize hybrid models in which school-level leaders serve dual leadership roles. 4 In about half the districts, there is one observer who conducts all principal evaluations, and statewide the overwhelming majority of principals (96%) are observed by only one observer throughout the year.
We focus on the end-of-year summative ratings recorded for each principal. 5 In 2014, we were provided data for practice ratings assigned using with the normal 2014 rubric as well as those conducted using the 2014 pilot rubric. We initially examine the two parts of the 2014 data separately but pool them in later models. Summary statistics and observation counts for all years of evaluation data are included in Table 1; means and standard deviations for all ratings and summative ratings only are very similar for each year. 6
Summary Statistics for TEAM Supervisor Ratings by Year/Rubric
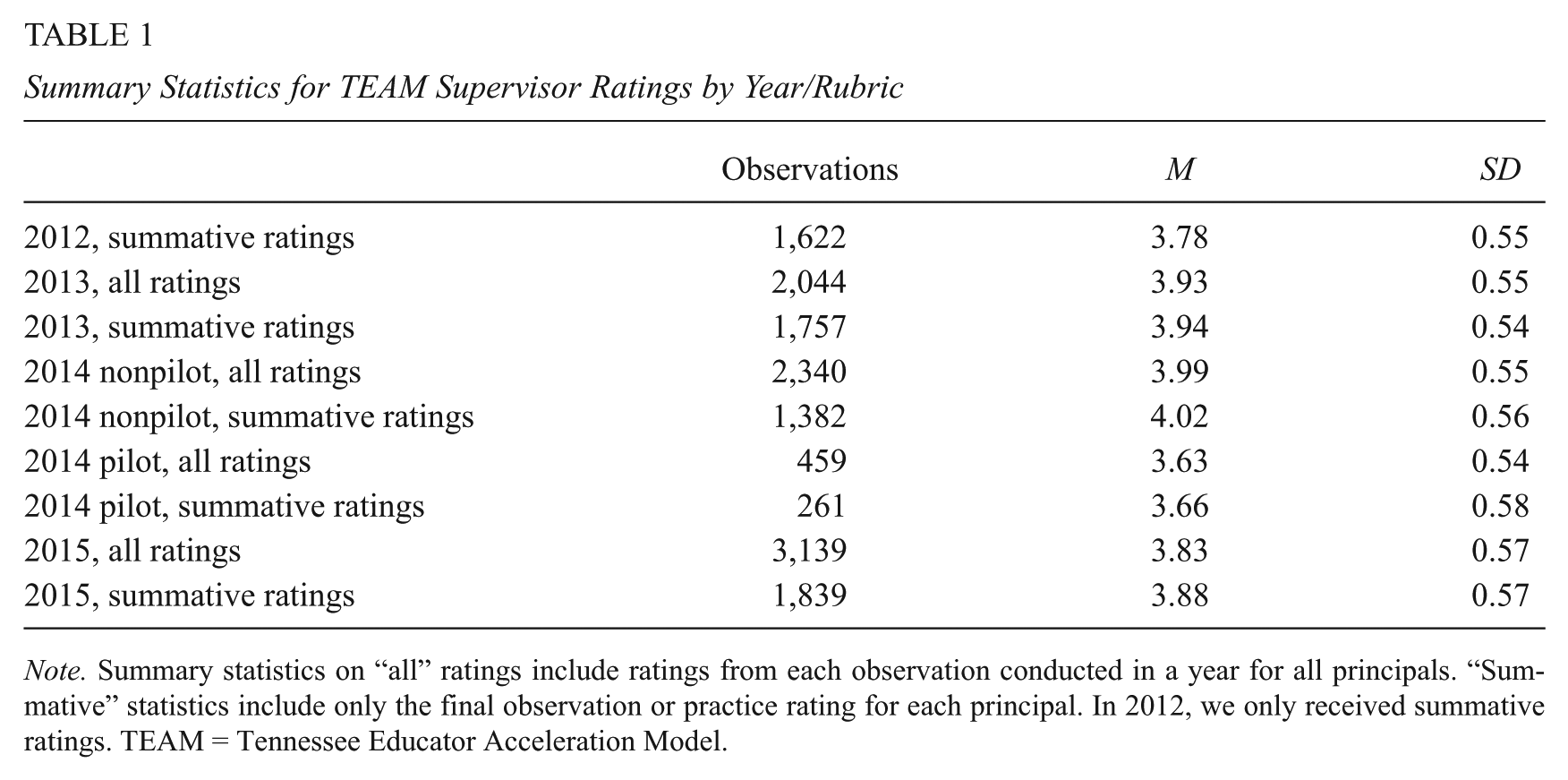
Note. Summary statistics on “all” ratings include ratings from each observation conducted in a year for all principals. “Summative” statistics include only the final observation or practice rating for each principal. In 2012, we only received summative ratings. TEAM = Tennessee Educator Acceleration Model.
Administrative Data on Principals, Schools, and Students
We matched TEAM evaluation information to longitudinal administrative data on principals, schools, and students from four school years spanning 2012 to 2015. Principal information includes the employee’s race/ethnicity, gender, age, years of experience as an educator, and education level. 7 The data do not include a measure of years of experience in the principal position, so we used job history data from 2004 forward to construct such a measure, top-coding principals already serving as principals in 2004.
We also made use of longitudinal student-level information on all students enrolled in Tennessee public schools since 2006. These data include student demographic and background characteristics such as gender, race, ethnicity, age, free and reduced price lunch (FRPL) eligibility, disability status, and gifted status. We used the student-level files to create parallel school-level measures (by aggregating student-level information) and to calculate total school enrollment. This information was supplemented with information on school locale type (e.g., urban, rural) from the school universe files in the Common Core of Data. Summary statistics for principal and school characteristics are provided in Appendix Table 2 (in the online version of the journal).
School and Student Achievement Measures
Our analysis of the relationships between TEAM principal practice ratings and other outcome measures includes TEAM ratings’ association with student achievement growth. Importantly, research has called into question the validity of school test score growth-based measures for capturing principal job performance, given the indirect nature of principal effects on students and uncertainty about the time horizon over which we would expect principal performance to translate into school performance (e.g., Grissom et al., 2015), so even accurate practice ratings may not be associated with these measures. Nonetheless, Tennessee’s principal evaluation system includes achievement growth metrics, suggesting policymakers’ interest in whether practice ratings and achievement growth metrics correlate, regardless of whether a contemporaneous correlation between practice ratings and achievement growth is interpreted as evidence for concurrent validity of the ratings. We utilize two sets of student achievement growth-based measures.
The first set is measures of school value-added from the TVAAS. TVAAS scores, which are estimated by the SAS Institute under contract with TDOE, are the official student growth measures used for evaluation and state accountability purposes, calculated from student scores on the state’s standardized end-of-grade tests in Grades 3 to 8 (Tennessee Comprehensive Assessment Program, or TCAP) and end-of-course tests in high school. 8 For each test, each school is scored according to how much more (or less) achievement growth is realized by its students, on average, compared with predictions from schools across the state whose students have similar prior achievement histories, unadjusted for student background and other characteristics. The school TVAAS composite measure then aggregates across these growth indexes for each test, weighting by the number of students contributing to each school’s score for each test. In addition to the single-year growth composite, the TVAAS system also provides 2- and 3-year growth composites that calculate growth over multiple years, weighting recent gains more heavily. 9 Summary statistics for each of these measures are shown in Appendix Table 3 (in the online version of the journal).
The second set of measures comes from student-level achievement scores on TCAP assessments in reading and math. We use these measures to estimate our own student growth models that, in contrast to TVAAS, control for student background characteristics and other factors that may bias the estimated association between principal ratings and changes in student tests scores. End-of-grade TCAP is administered only in Grades 3 to 8, so high schools are necessarily excluded from these analyses. 10 We utilize TCAP data from 2011 (which we use to lag achievement for 2012) to 2015.
Survey-Based Measures
We draw on two different statewide survey programs for additional measures of school leadership effectiveness. First, in 2013, Tennessee conducted the Teaching, Empowering, Leading, and Learning (TELL) survey to collect perceptions from school personnel about working conditions, instructional practice, and other topics. Versions of the survey were administered to all teachers, assistant principals, and principals. The total response rate for teachers was 71%, though we have at least one teacher response for 97% of schools. Approximately 57% and 46% of schools had responses from principals and assistant principals, respectively. One module of the TELL survey that appeared on all versions focuses on perceptions of different aspects of school leadership and impacts of leadership on school climate. A complete list of items in this module is shown in Appendix Table 4 (in the online version of the journal). High intercorrelations among items suggested responses could be reduced to a single summative school leadership effectiveness score via multilevel factor analysis within each respondent type (e.g., teacher). Examinations of scree plots confirmed the presence of a single latent factor. 11 We calculated scores using the standard linear factor scoring method, and then averaged by respondent type by school. Thus, for each school, we have up to three TELL assessments of leadership in the school—one each from teachers, assistant principals, and the principal himself or herself. All models predicting TELL scores use standardized factor scores so that results can be interpreted in standard deviation units.
The second set of survey data comes from the FTTT Survey, conducted by researchers at Vanderbilt University in cooperation with TDOE as part of evaluation efforts associated with the state’s award under Race to the Top. We make use of teacher respondents to the FTTT Survey from the springs of 2012, 2013, and 2014. In each year, a randomly chosen sample of teachers were asked to respond to a module of items about the quality of their school’s leadership (see Appendix Table 4, in the online version of the journal). As with TELL, an investigation of the factor structure of these items suggested they measured a single underlying construct, which we again scored using the standard linear factor scoring method and aggregated to the school level in each year. These measures provide a nice complement to the TELL measures because they repeat over time; however, response rates to the FTTT Survey were much lower (ranging from 25% to 40% over the years of the survey), both reducing power and raising concerns about sample selection in analysis of the FTTT data.
Given the importance of school climate for teachers and students and recent research suggesting that principals exercise important influence on a school’s climate (Burkhauser, 2017), we use a similar method to construct a school climate factor from teachers’ FTTT Survey responses. Items used to construct the school climate measure can be found in Appendix Table 4 (in the online version of the journal). If teachers’ ratings of leadership and climate capture elements of principal effectiveness that overlap with those rated by TEAM, we expect positive associations between teachers’ and supervisors’ ratings.
Method
Our analysis of TEAM practice ratings proceeds in three steps. First, we investigate the properties and structures of the ratings, including overall and domain reliability and factor structure. Second, we explore the extent to which principal and school characteristics predict higher TEAM ratings. For this analysis, we show bivariate correlations and estimate simple ordinary least squares (OLS) regression models of TEAM average ratings as a function of principal and school characteristics. Given differences in the TEAM rubrics employed over time, we conduct this analysis separately for each year. These models include district fixed effects to account for district-level differences in school leader performance expectations or how the evaluation process is implemented. Standard errors are clustered by district.
Third, we examine whether TEAM principal practice ratings predict other policy-relevant outcomes, controlling for other potentially confounding factors. We estimate a series of OLS models of these outcomes as a function of average TEAM ratings, plus control variables. For some outcomes (TVAAS, TCAP, and the leadership and climate outcomes from the FTTT Survey), we pool all years of available data to maximize power, treating the TEAM average ratings as capturing the same construct each year, despite differences in the rubric (analysis shown later finds support for this choice). 12 For example, for school-level TVAAS scores, we estimate a model of the form:
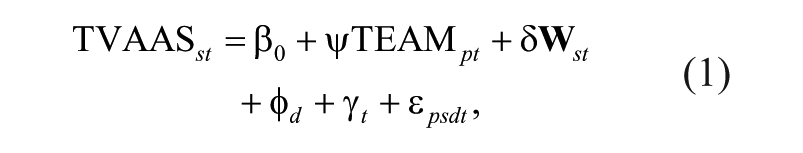
where TVAAS is the standardized TVAAS reading and math composite index score for school s in year t, TEAM is the mean TEAM practice rating for principal p in year t,
Models for the school leadership and climate measures from the FTTT Survey are similar to the model illustrated in Equation 1, substituting those measures as the dependent variable. We cluster standard errors by school. For the TELL teacher, assistant principal, and principal survey assessments of leadership, the models are cross-sectional, with each of those measures regressed individually; vector
We also estimate student-level growth models for TCAP scores in math and reading (separately) for students in Grades 3 to 8. Scores are standardized within grades and years. The main model is
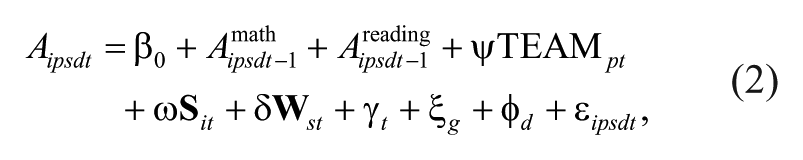
where A is student i’s achievement score in reading or math at time t; Amath is his or her achievement score in the previous year in math; Areading is the achievement score in the previous year in reading;
Including school fixed effects in the TVAAS and TCAP models helps address concerns about differentiating potential impacts of higher or lower rated principals on student test score growth from impacts of the school itself that are outside the principal’s control (Chiang et al., 2016; Grissom et al., 2015). As an alternative, we also estimate “principal value-added” by including principal fixed effects (υ) alongside school fixed effects in a version of Equation 2 that omits TEAM, then capturing the coefficients on υ as principals’ value-added to student achievement, adjusted for the long-run effects of the school (for a discussion, see Grissom et al., 2015). These principal value-added measures come closer to isolating principals’ average effects on student achievement growth but are necessarily calculated over multiple years, not just the year that a given TEAM rating is assigned, making the correlation between the two measures not directly comparable with the correlations between ratings and TVAAS or contemporaneous student-level growth. Principal value-added measures are estimated as an (adjusted) average value over the full TCAP sample (i.e., not just the years for which TEAM ratings are available). In supplementary validity analysis, we then regress these principal value-added measures on TEAM ratings and year fixed effects for the sample of principals with TEAM ratings. 15
Properties of the TEAM Ratings of Principal Practice
We begin by exploring characteristics of the TEAM practice ratings supplied by principals’ raters. The goal is to assess the variability, reliability, and stability of the ratings and explore their structure.
Distribution of Principal Ratings
Figure 1 shows the distribution of average TEAM ratings for principals for each year of the data. The figure shows that principal ratings are high, on average, though there is robust variation. Table 1 shows that mean summative ratings range from 3.7 in the 2014 pilot to 4.0 in the 2014 nonpilot districts, with other years falling in-between. Standard deviations across years are very similar, ranging from 0.54 to 0.58.
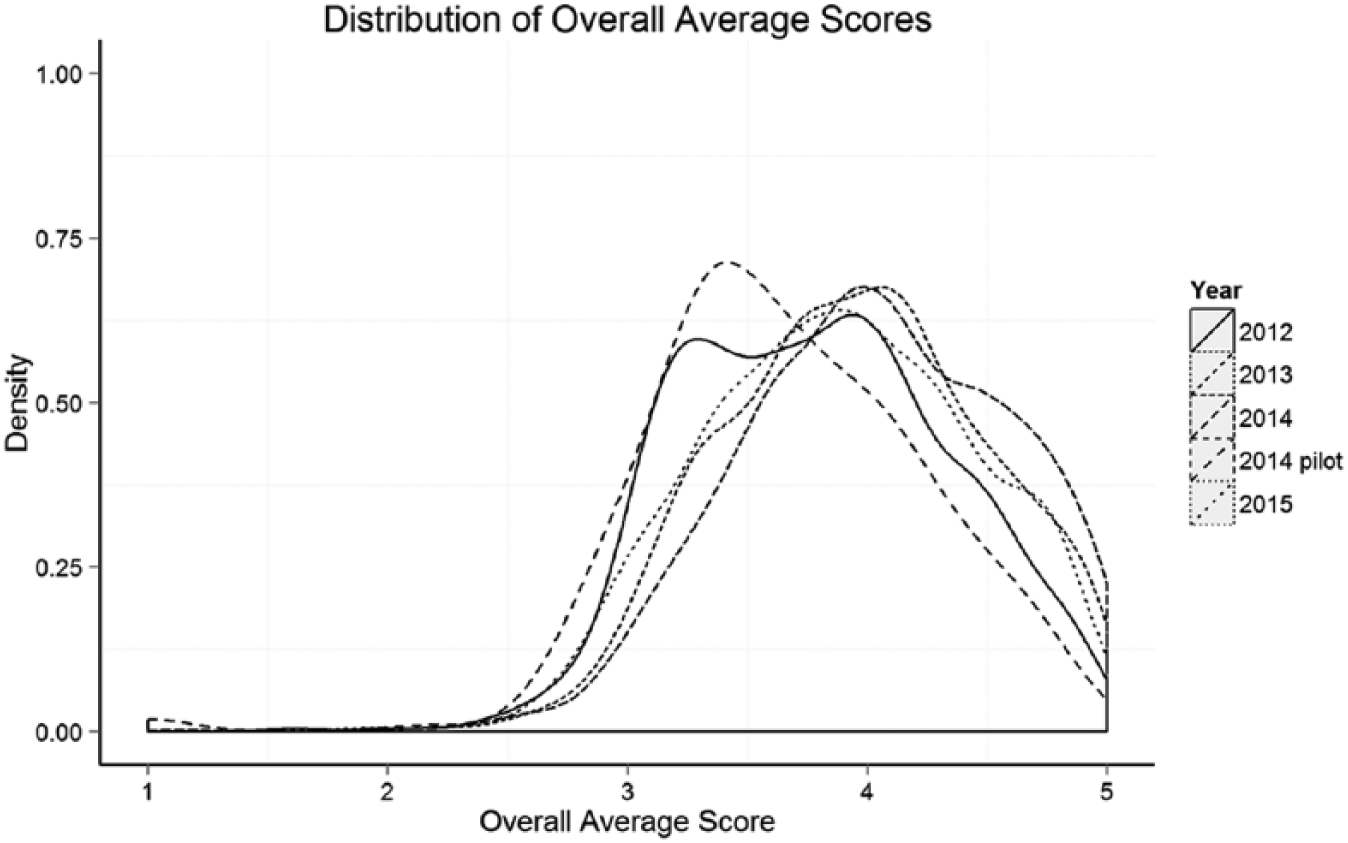
Distribution of TEAM principal practice ratings by year/rubric.
Figure 2 displays the distribution of average ratings by domain for each year; Table 2 shows means and standard deviations by domain by year. We make four observations. First, observers make little use of the lower range of the Likert-type ratings, with most principals receiving scores between 3 and 5, on average, in each domain across years. Second, despite rare use of ratings of 1 and 2, variation in the 3 to 5 range is substantial, and standard deviations typically are in the 0.6 to 0.7 range across domains and years. Third, within years, there is some variation in mean scores across domains. For example, in the first 3 years, principals are more likely to receive ratings of 5 in Ethics than in other domains. Finally, despite changes in the domain labels and organization across years, means and standard deviations of the domains are surprisingly similar from year to year. For instance, the range of means in 2012 (the first year of data) is 3.7 to 4.0, compared with a range of 3.8 to 4.0 in 2015 (the last year of data), and standard deviations in both years range between 0.56 and 0.70.
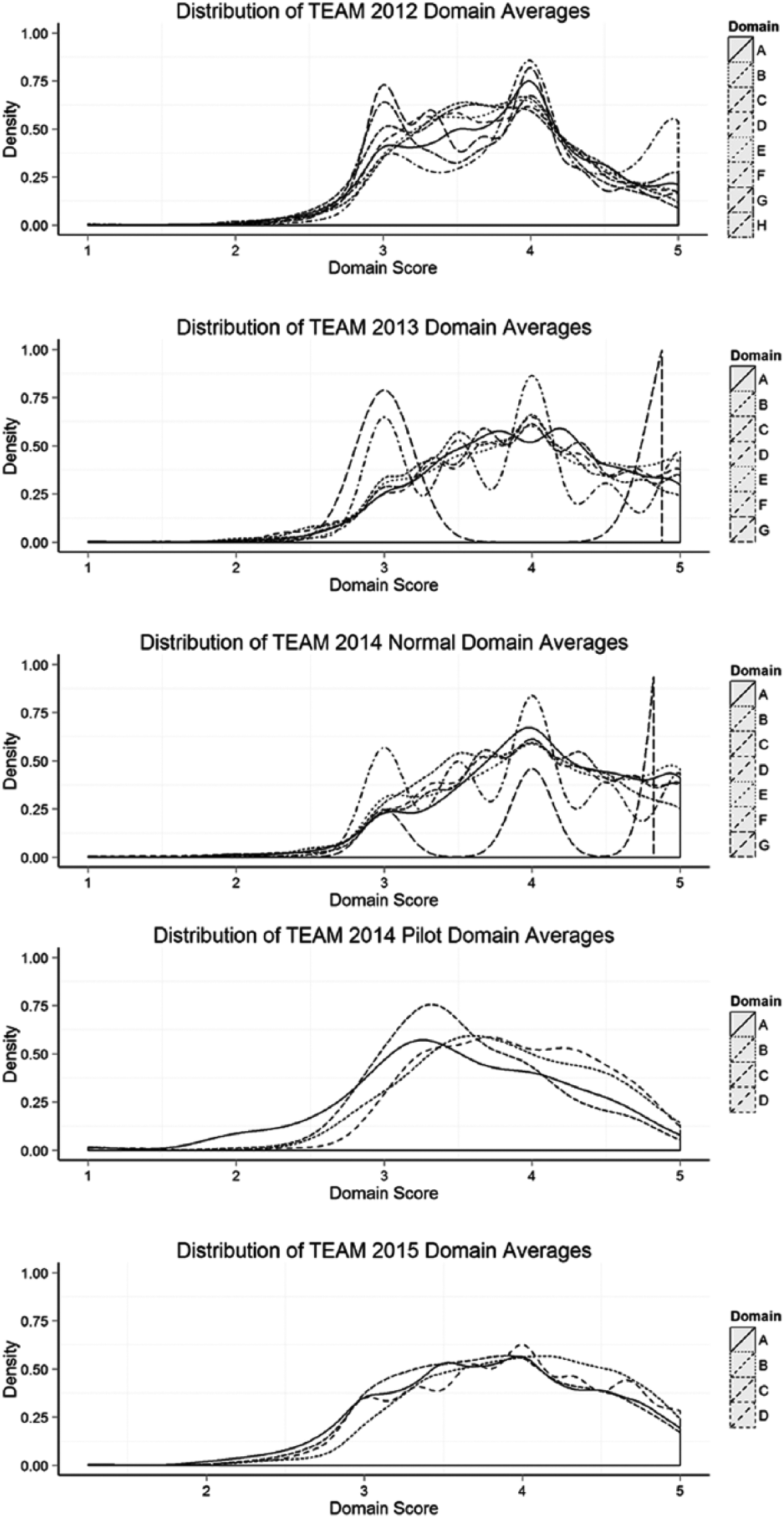
Distributions of TEAM principal practice ratings, by domain.
Summary Statistics for TEAM Average Practice Ratings by Domain
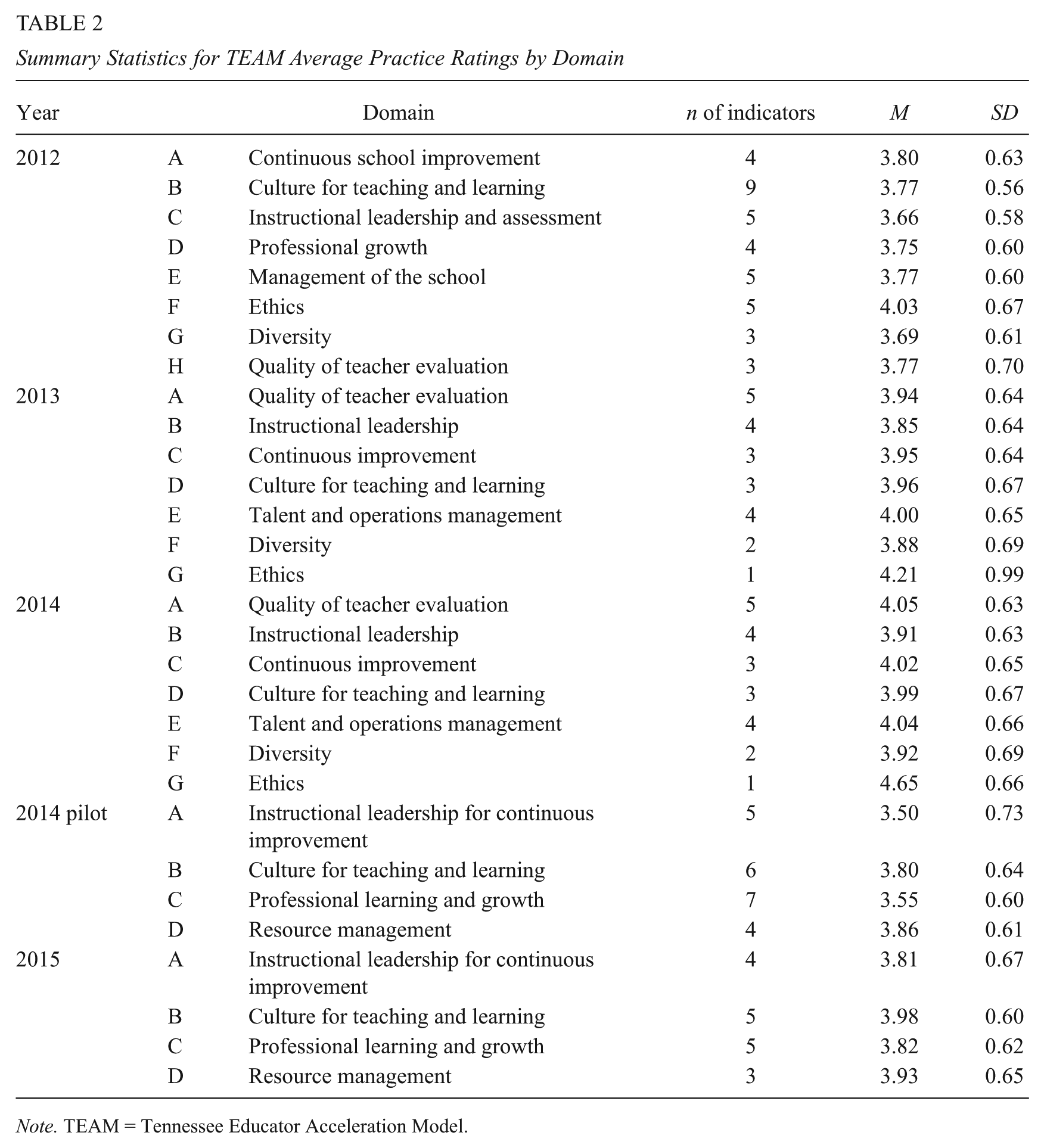
Note. TEAM = Tennessee Educator Acceleration Model.
Internal Consistency
We estimate the internal consistency reliability of each domain each year, as well as the overall rating, by computing Cronbach’s alpha for each set. These values are shown in Table 3. The table shows that for all domains in all years, internal consistency reliabilities are high (ranging from 0.73 to 0.91), suggesting that indicators within each domain are closely related to one another. Alpha values for the rubric as a whole, shown at the top of each year set, are very high, ranging from .94 to .97.
Internal Consistency and Item-Rest Correlations
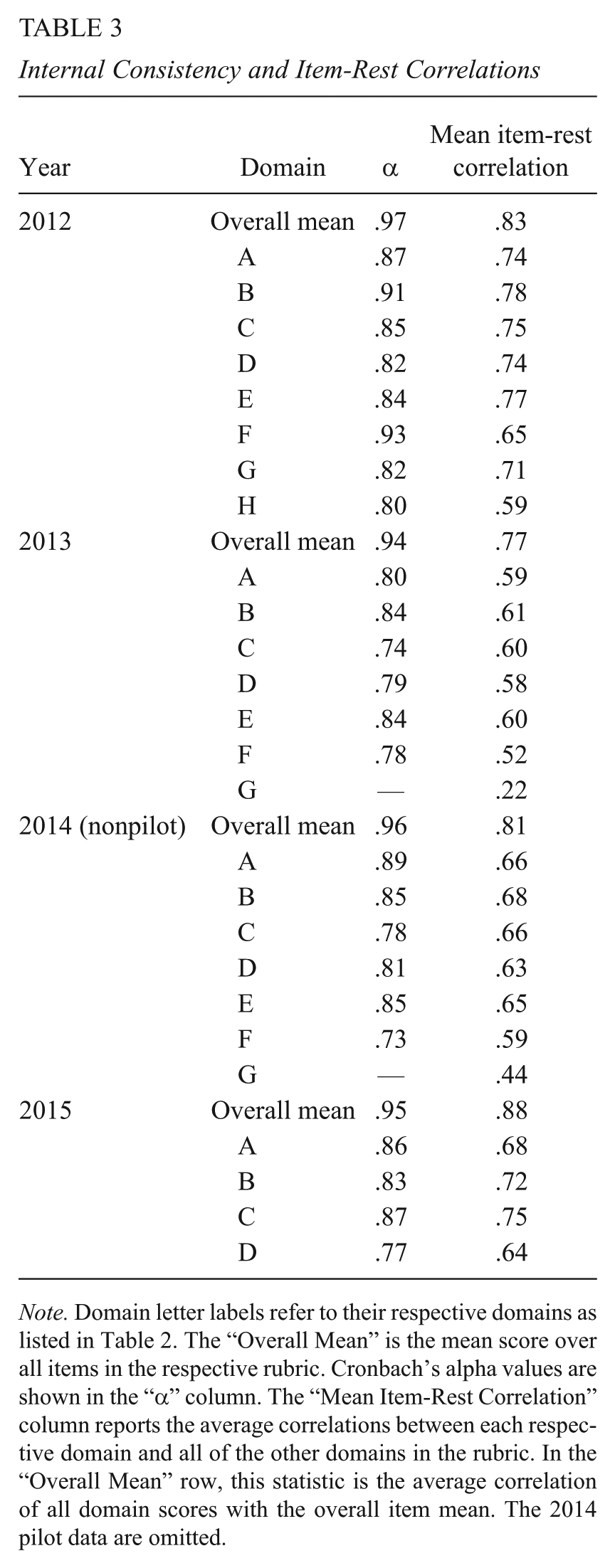
Note. Domain letter labels refer to their respective domains as listed in Table 2. The “Overall Mean” is the mean score over all items in the respective rubric. Cronbach’s alpha values are shown in the “α” column. The “Mean Item-Rest Correlation” column reports the average correlations between each respective domain and all of the other domains in the rubric. In the “Overall Mean” row, this statistic is the average correlation of all domain scores with the overall item mean. The 2014 pilot data are omitted.
Stability
Next, we investigate the stability in principal ratings in consecutive years. Because principal practice likely changes only gradually, we expect relatively high positive correlations in year-to-year ratings for the same principal (Herrmann & Ross, 2016). Because of changes in the rubrics across years, however, we may suspect that correlations will be lower between years in which the rubric was adjusted.
We calculated correlations in average domain ratings for each set of adjacent years. For brevity, these correlations are not shown, though as an illustration, Appendix Table 5 (in the online version of the journal) shows the correlations between the 2014 nonpilot districts and the preceding year (2013) and following year (2015). These comparisons are useful because the rubric did not change between 2013 and 2014 for the nonpilot districts but did change between 2014 and 2015. The general findings from this analysis is that principals’ overall average ratings are highly correlated between years, even when the rubric changes. For example, as Appendix Table 5 (in the online version of the journal) shows, the correlation for the same principals’ overall ratings for 2013 and 2014 (same rubric) is .77, and falls to only .72 for 2014 and 2015, when the rubrics were substantially different. Moreover, when the rubric is the same, correlations for the same domains (e.g., instructional leadership) from year-to-year are high (ranging from .61 to .70), though in fact cross-domain interyear correlations typically are moderate-to-high as well, 16 a pattern that persists even the following year when the domains are quite different and many of the indicators have changed. In other words, changes to the rubric do not appear to have substantially lowered stability in the ratings across years.
Dimensionality of Ratings
One hypothesis for why ratings are similarly correlated across years, even across domains and even when the rubrics ostensibly measure different domains, is that the rubric and rating process tend to identify a single underlying construct rather than multiple distinct constructs. Support for this hypothesis can be found in the rightmost column in Table 3, which shows mean item-rest correlations—that is, the average of all correlations between a given domain and all of the others—for each year. These correlations provide a measure of how the domain ratings move together. These correlations generally are high, and would be higher if not depressed by the low correlations with the single-indicator Ethics domain in the first 3 years.
To explore the dimensionality of the ratings in more depth, we conducted exploratory factor analyses (EFAs) on principals’ ratings each year. Given the ordinal nature of the rating scales, the maximum likelihood EFA was based on polychoric correlation matrices. To begin, we examined scree plots of the eigenvalues obtained from EFA (see Appendix Figure 1, in the online version of the journal), which showed strong evidence of a single underlying factor in each year. 17 This underlying factor produces relatively high correlations with the domain averages. We take the EFA results as evidence that TEAM ratings generally result from an underlying perceived effectiveness construct that drives raters’ ratings of principal practice. In each year, this factor explains 57% to 59% of variance in scores. 18
Although firmer conclusions regarding the degree to which TEAM ratings differentiate competencies defined in the TEAM rubrics would require additional analysis that is beyond the scope of what we aim to accomplish here, our initial investigation finds relatively strong evidence that TEAM ratings can be reduced to a single dimension. For this reason, in subsequent analyses, we use mean TEAM ratings, averaged over all indicators, as a single rating measure, which we pool across years under the assumption that the ratings capture the same construct each year. We use mean ratings rather than factor scores for ease of interpretability.
Are Principal and School Characteristics Associated With Principals’ Practice Ratings?
The next set of analyses turn to the question of whether TEAM practice ratings vary by the characteristics of principals and the schools in which they work. These analyses are exploratory. We begin by calculating conditional means of TEAM ratings by such principal characteristics as race/ethnicity, gender, education level, and categories of years of experience as a principal (0, 1–2, 3–4, 5+), pooling across years, and conducting t tests of differences in ratings. TEAM ratings were not statistically different for any of these categories (omitted for brevity). School characteristic variables mostly are continuous, so we calculate correlations between these variables and mean TEAM ratings, shown in Table 4. 19 Here, we do find some differences in ratings by school characteristics. The largest is with the proportion of students in a school eligible for subsidized lunches, which is correlated with average TEAM rating at –.20. In addition, the table shows that larger schools, schools with fewer Hispanic students, schools with larger gifted populations, and schools with larger numbers of students falling into the “other non-White” category tend to be led by higher rated principals.
Correlations Between TEAM Mean Rating and School Characteristics
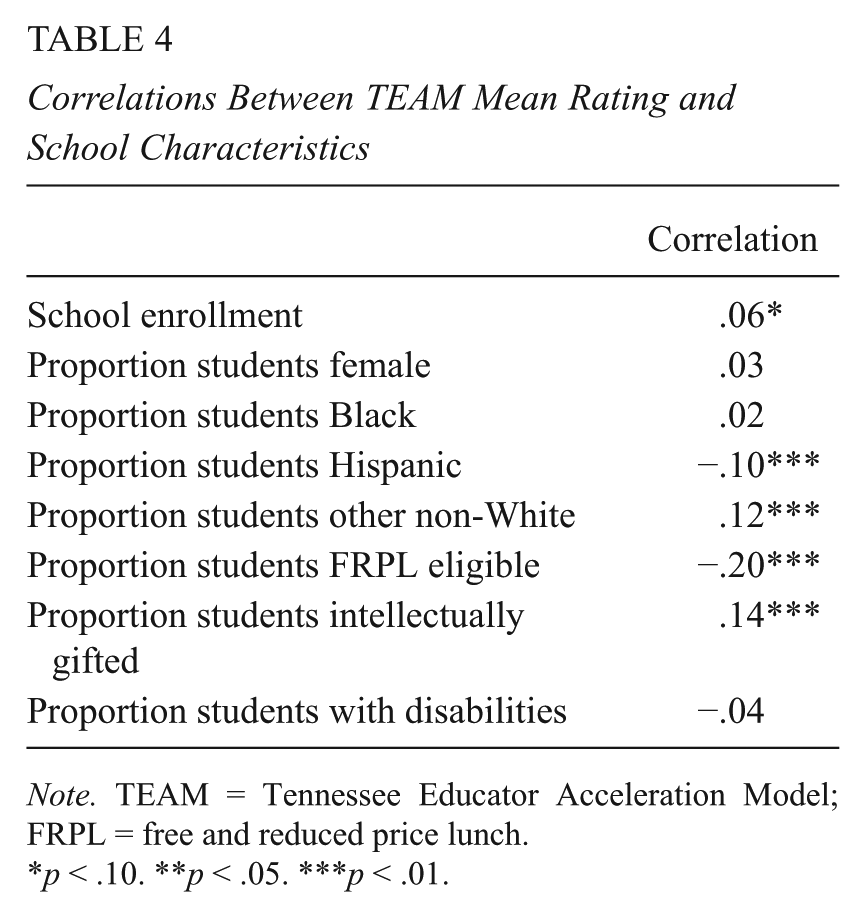
Note. TEAM = Tennessee Educator Acceleration Model; FRPL = free and reduced price lunch.
p < .10. **p < .05. ***p < .01.
Table 5 shows results from regression analysis of mean TEAM ratings on principal and school characteristics and district fixed effects. 20 Across years, we find two particularly notable patterns. First, conditional on other factors, principals’ TEAM ratings increase as they gain experience in the job. The difference in the rating between beginning principals and the most experienced principals is consistently above 0.25 points, and in both the 2014 and the 2014 pilot data, the differences are much larger, at 0.53 and 0.61 points, respectively (the difference is 0.34 points in the pooled model). Higher ratings for more experienced principals may reflect increases in performance with on-the-job learning, or may have other explanations, such as selection effects due to greater attrition of lower performing principals (Grissom & Bartanen, in press). To provide further evidence on this point, we estimate a simple model in which TEAM ratings are regressed on experience-group indicators, a year indicator, and a principal fixed effect (not shown). This model estimates the association between TEAM ratings and experience within principal (see also Gill, Shoji, Coen, & Place, 2016; Steinberg & Garrett, 2016). We find somewhat smaller coefficients than those shown in Table 5 (0.12, 0.12, and 0.17, respectively), though each is statistically distinguishable from zero, suggesting that differential attrition does not fully explain the association between ratings and experience.
Predicting TEAM Principal Practice Ratings
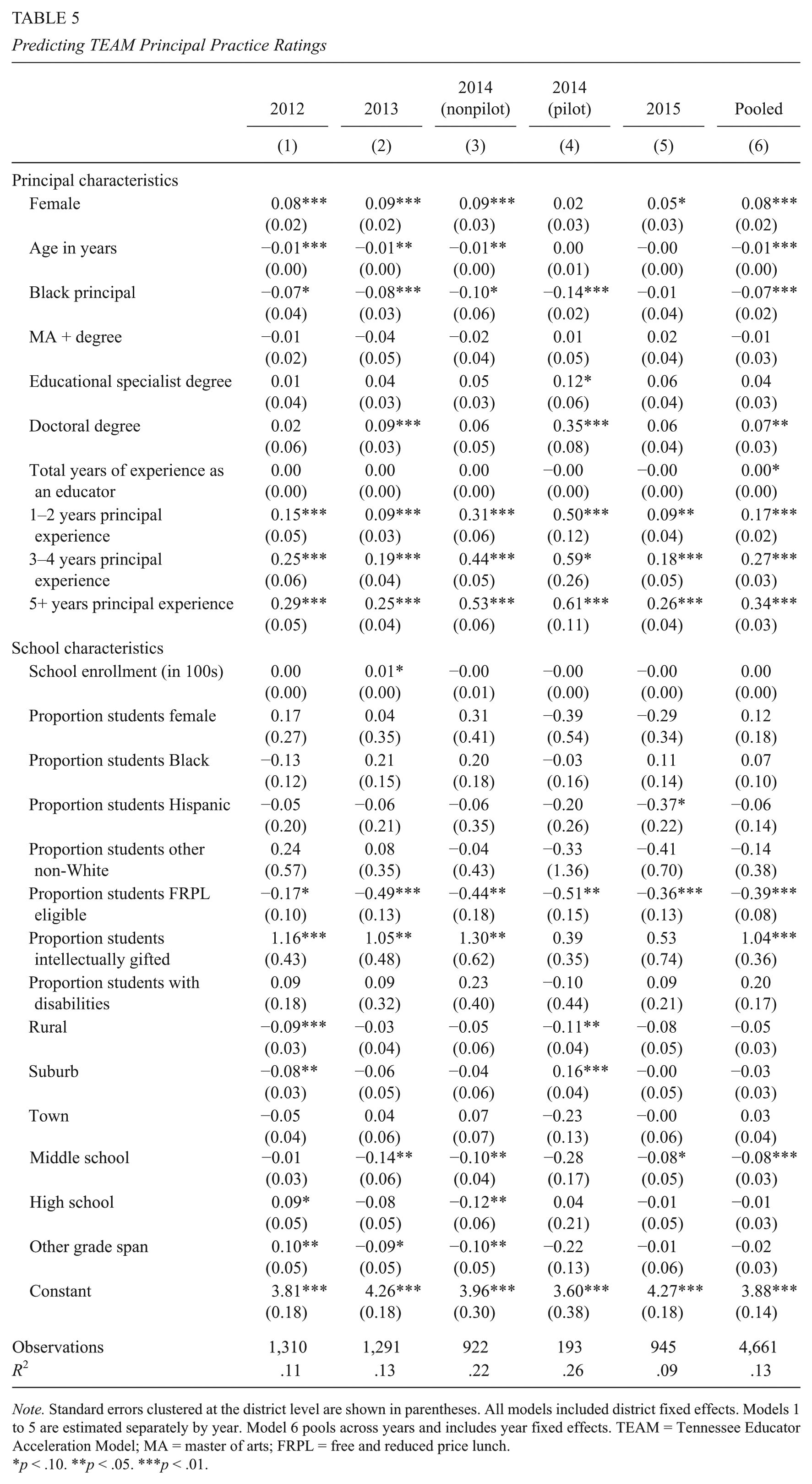
Note. Standard errors clustered at the district level are shown in parentheses. All models included district fixed effects. Models 1 to 5 are estimated separately by year. Model 6 pools across years and includes year fixed effects. TEAM = Tennessee Educator Acceleration Model; MA = master of arts; FRPL = free and reduced price lunch.
p < .10. **p < .05. ***p < .01.
Second, principals serving a large number of students eligible for the FRPL program tend to receive lower TEAM ratings. On average across years, each 10 percentage point increase in the percent of FRPL students is associated with a decrease of 0.04 points in the average TEAM rating. An association between TEAM rating and student poverty could arise because less effective principals tend to sort toward less advantaged schools, or because of bias in the rating process toward principals in those schools (Herrmann & Ross, 2016); raters might, for example, inadvertently attribute challenges in the school environment resulting from student poverty to poor principal performance. As with experience, we estimate a simple supplementary model of TEAM ratings as a function of the fraction of FRPL students, a year indicator, and a principal fixed effect, which limits the association to be within principal, either in the same or different schools (not shown). The coefficient on FRPL is −0.16 (p < .05). This coefficient indicates that the same principal indeed receives lower ratings, on average, in years when he or she works in a school with higher student poverty, which may suggest bias in the rating process toward principals in higher poverty schools.
Other patterns in Table 5 are evident as well. Across years, excluding the 2014 pilot districts, female principals tend to score higher than their male colleagues by 0.05 to 0.09 points, on average, conditional on other factors. Black principals tend to receive lower scores than White principals (range is 0.07 to 0.14 points), though this pattern is not evident in 2015. Although less consistent, we also see that older principals score slightly lower (by a small magnitude), while principals tend to receive higher ratings in schools with larger gifted populations. Other principal and school characteristics, including student race and ethnicity, are not consistent predictors of TEAM practice ratings. The generally low R2 values in the models suggest that factors beyond easily observable individual, school, and district characteristics are important contributors to the practice ratings assigned to principals by their supervisors.
Do TEAM Principal Practice Ratings Predict Other Measures of School or Principal Performance?
In this section, we investigate the extent to which average TEAM ratings predict other policy-relevant indicators of principal effectiveness, including measures based on student achievement and teacher assessments. For brevity, we only report coefficients on TEAM ratings in the tables, though all other relevant controls are included in the models.
School Value-Added Measures
We first take a descriptive look at the association between mean TEAM practice ratings and TVAAS index scores. Figure 3 shows scatterplots of TEAM ratings (on the x-axis) and TVAAS 1-year index scores (on the y-axis) with a line of best fit for all available years. In each year, there is a positive correlation between the two measures. This visual conclusion is confirmed by correlations reported in Appendix Table 7 (in the online version of the journal). For 2013, 2014, and 2015, the correlations with the 1-year TVAAS index are 0.23, 0.16, and 0.15, and are even higher for the 2014 pilot (0.32). Correlations with the 2- and 3-year index measures are similar.
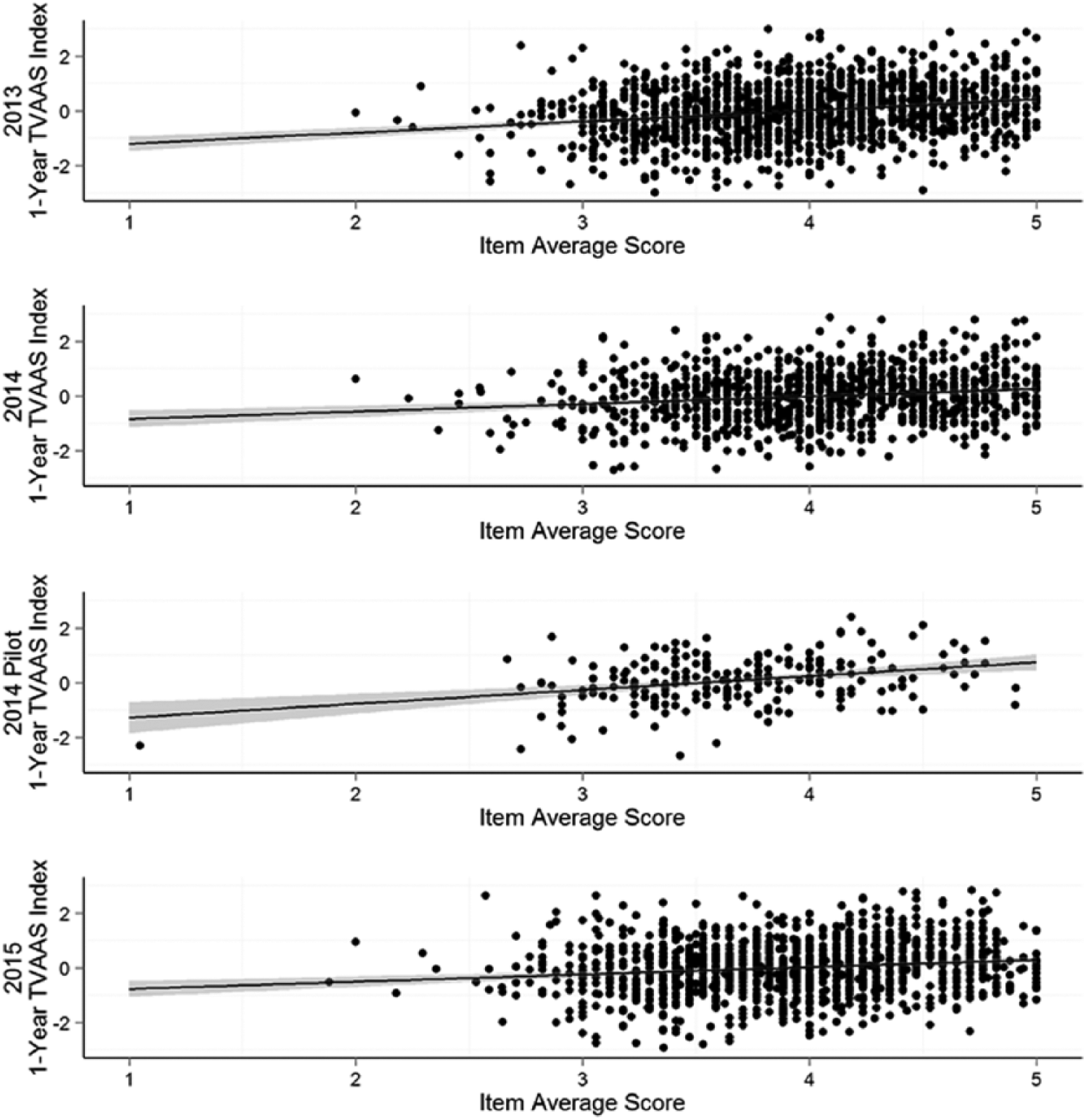
TEAM principal practice ratings and TVAAS.
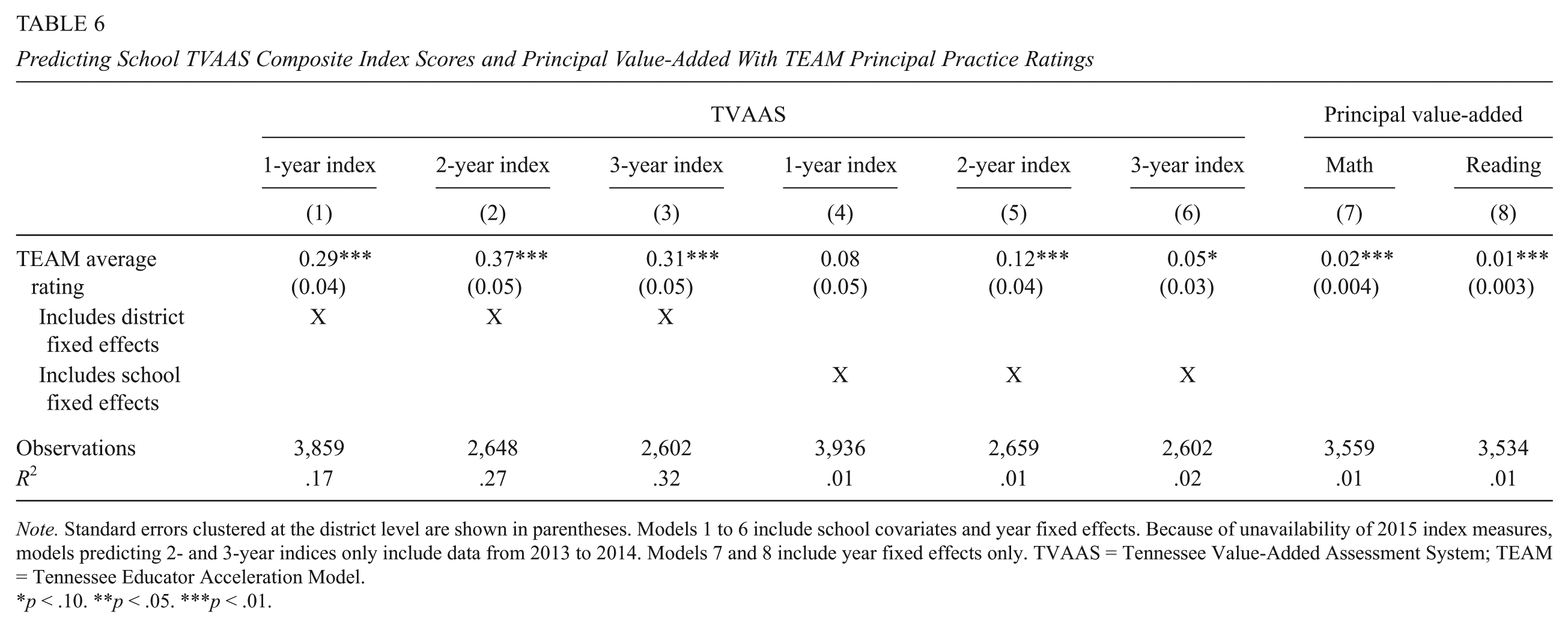
Results for regression models of standardized TVAAS (school-level value-added) index scores as a function of TEAM ratings are shown in the first six columns of Table 6. Models pool 2013, 2014, and 2015 (2012 TVAAS composites are not available). In addition, because only 1-year indices are available for 2015, all 2- and 3-year index models use data from only 2013 to 2014.
Predicting School TVAAS Composite Index Scores and Principal Value-Added With TEAM Principal Practice Ratings
Note. Standard errors clustered at the district level are shown in parentheses. Models 1 to 6 include school covariates and year fixed effects. Because of unavailability of 2015 index measures, models predicting 2- and 3-year indices only include data from 2013 to 2014. Models 7 and 8 include year fixed effects only. TVAAS = Tennessee Value-Added Assessment System; TEAM = Tennessee Educator Acceleration Model.
p < .10. **p < .05. ***p < .01.
Models 1 through 3 include district fixed effects. Column 1 shows that an increase of 1 point in the average TEAM rating is associated with a 0.29 SD increase in the 1-year TVAAS index, as compared with other schools in the same district. A similar increase in the TEAM rating is associated with a 0.37 SD and 0.31 SD increase in the 2- and 3-year index scores, respectively (columns 2 and 3).
Models 4 through 6 include school fixed effects, thus making the comparison for each school itself in another year. Including school fixed effects provides more rigorous validity evidence because it removes time-invariant school-level factors that may lead some schools to systematically perform at high or low levels. Column 4 shows that the correlation between TEAM rating and the 1-year TVAAS index, while positive, cannot be distinguished statistically from zero at conventional levels. In columns 5 and 6, however, we see that TEAM practice ratings remain statistically positively associated with the 2- and 3-year TVAAS index values, with a 1-point increase in the average TEAM rating corresponding to an increase of 0.12 SD and 0.05 SD, respectively, in TVAAS. In other words, these TVAAS index scores are substantially higher in schools in years in which the principal receives higher practice ratings. 21
If TVAAS scores are stable from year-to-year, then the fact that raters presumably know the school’s prior-year TVAAS score, which they may take into account in assigning this year’s TEAM rating, may drive the correlations shown in Table 6. 22 To assess this possibility, we regressed TVAAS index measures on TEAM ratings, controlling for 1-year-lagged TVAAS index measures, plus other covariates and district fixed effects. 23 Results are shown in Appendix Table 8 (in the online version of the journal). In all three cases, lagged TVAAS positively predicts this year’s TVAAS index. Inclusion of the lagged values also attenuates the coefficients on the TEAM ratings, though in all three cases, the TEAM rating continues to be a meaningful predictor of TVAAS, with a range of 0.14 to 0.24 for the different index values.
Student-Level Achievement
In Table 7, we present results from student-level achievement models for reading (columns 1 and 2) and math (columns 3 and 4). For both subjects, we find that TEAM ratings are positively associated with student gains in models with district fixed effects. However, when we substitute school fixed effects in columns 2 and 4, which provides more rigorous concurrent validity evidence, the reading coefficient goes to a precisely estimated zero, suggesting no within-school correlation between TEAM average ratings and student achievement gains in reading. In contrast, the math coefficient remains positive and statistically significant. A 1-point increase in the TEAM rating is associated with a 0.04 SD increase in standardized math scores, which, for reference, is about half of the magnitude of the coefficient for FRPL eligibility in the full model. 24 At least in math, achievement gains are larger in years that the principal receives higher TEAM ratings than they are in the same school in years that the principal’s TEAM ratings are lower.
Predicting Student TCAP Scores With TEAM Principal Practice Ratings
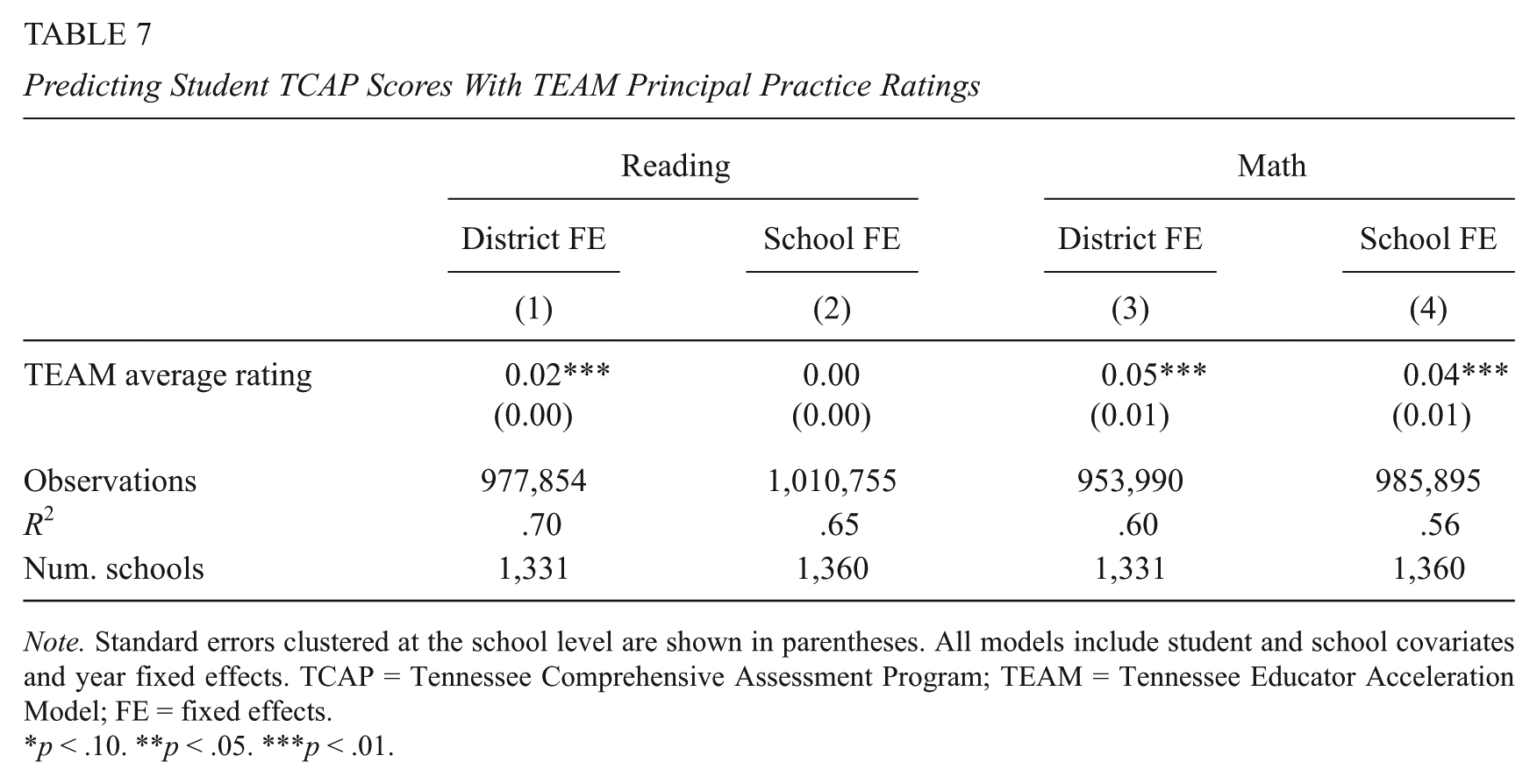
Note. Standard errors clustered at the school level are shown in parentheses. All models include student and school covariates and year fixed effects. TCAP = Tennessee Comprehensive Assessment Program; TEAM = Tennessee Educator Acceleration Model; FE = fixed effects.
p < .10. **p < .05. ***p < .01.
Principal Value-Added
In addition to school value-added composites and student-level achievement models, we also estimate models of principal value-added, calculated from TCAP scores, as a function of TEAM ratings and year fixed effects. Results for math and reading are shown in columns 7 and 8 of Table 6. In both cases, we find evidence that TEAM ratings are positively and statistically significantly correlated with principal value-added (β = .02 for math and .01 for reading). These results show that principals whose schools see higher achievement gains over their careers, adjusted for selection into which schools they lead, are rated more positively by their supervisors, on average, and provide further evidence of the association between TEAM ratings and student achievement growth. 25 We note, however, very low R2 values for these models, which suggests the ratings explain minimal variation in value-added.
Survey-Based Assessments of School Leadership and School Climate
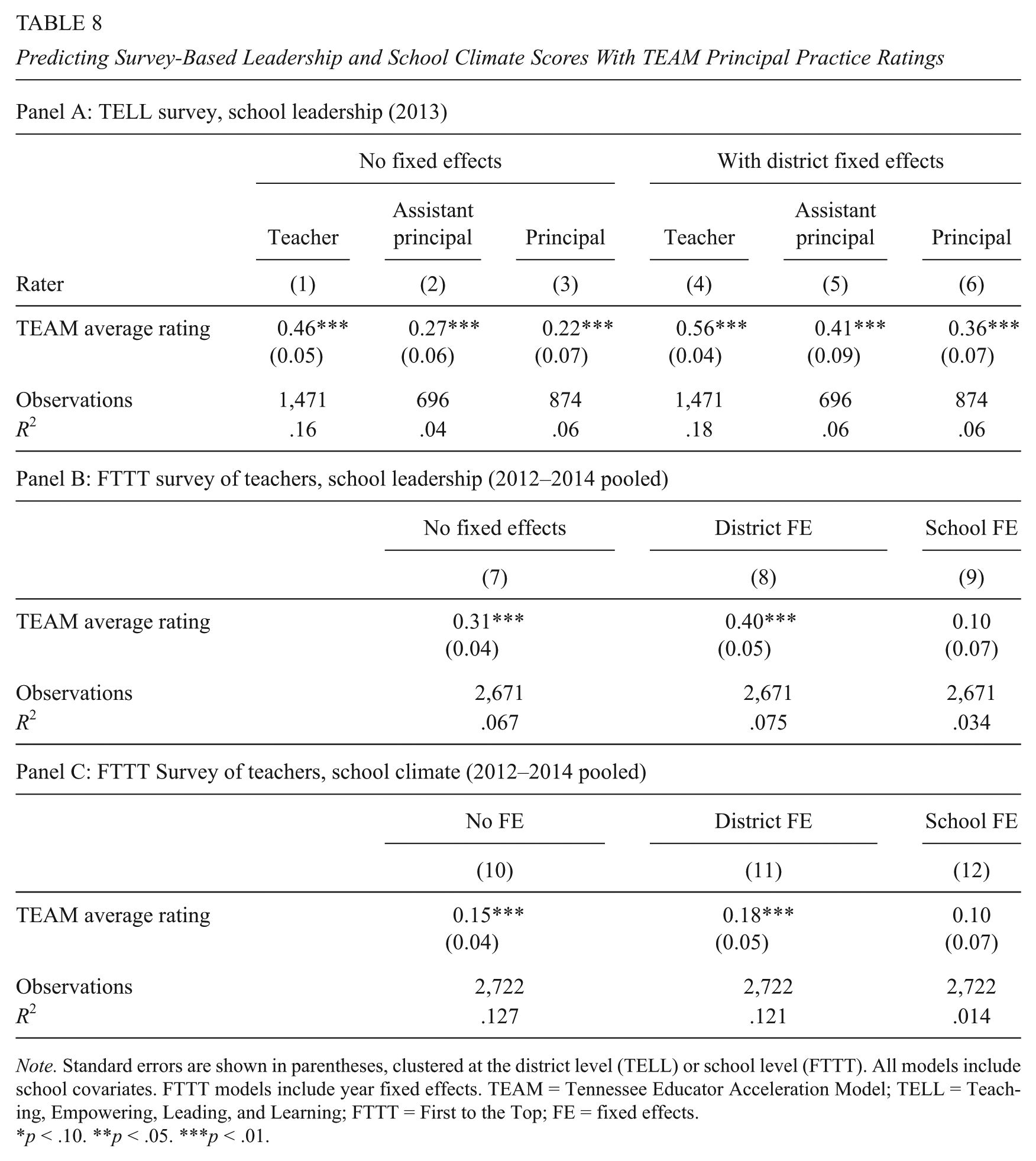
Next, we assess the degree to which supervisors’ ratings of principal practice correlate with teachers’, assistant principals’, and principals’ own assessments of leadership quality in the school. As shown in Appendix Table 7 (in the online version of the journal), TEAM ratings generally are positively correlated with the survey-based assessments. Regression results are shown in Table 8. Panel A shows results from the 2013 TELL survey, first from models with no fixed effects (columns 1–3), then with district fixed effects (columns 4–6). In both sets of models, and across raters, we find a consistent positive association between TEAM ratings and leadership assessments. 26 The association is largest for teachers, and larger when district fixed effects are included. The latter models suggest that a 1-point increase in the TEAM rating is associated with a 0.56 SD increase in teachers’ mean subjective evaluations of school leadership quality. The parallel increases in subjective evaluations provided by assistant principals and principals are 0.41 and 0.36 standard deviations, respectively. 27
Predicting Survey-Based Leadership and School Climate Scores With TEAM Principal Practice Ratings
Note. Standard errors are shown in parentheses, clustered at the district level (TELL) or school level (FTTT). All models include school covariates. FTTT models include year fixed effects. TEAM = Tennessee Educator Acceleration Model; TELL = Teaching, Empowering, Leading, and Learning; FTTT = First to the Top; FE = fixed effects.
p < .10. **p < .05. ***p < .01.
Panel B turns to the FTTT Survey teacher assessments. These models pool data from 2012 to 2014. Columns 7 and 8 show the results with no fixed effects and with district fixed effects. Once again, the coefficient increases with the addition of the fixed effects. The magnitude of the coefficient in column 8 suggests that a 1-point increase in TEAM rating is associated with a 0.40 SD increase in teachers’ assessments of school leadership on this instrument, which is similar to the comparable result in Panel A. However, when we add school fixed effects in column 9, which can provide the most rigorous evidence for concurrent validity, the coefficient is drastically reduced and becomes statistically indistinguishable from zero.
In Panel C, we again use responses to the FTTT Survey, this time to test the association between average TEAM ratings and teachers’ ratings of the school’s climate. Patterns are similar to the FTTT Survey leadership results in Panel B. In the district fixed effects model (column 11), we find evidence of a positive and statistically meaningful correlation between TEAM ratings and climate assessments, with a 1-point increase in TEAM rating corresponding to a 0.18 SD increase in teachers’ rating of the school’s climate. However, this correlation shrinks and becomes indistinguishable from zero in the presence of a school fixed effect. For both teachers’ ratings of leadership and climate, there may be too little within-school variation in TEAM ratings or with the dependent variables over just 3 years to identify meaningful covariation.
Predicting Future Measures of Performance
Up to this point, we have focused on whether TEAM ratings correlate with principal and school performance measures collected in the same school year as the rating. A policymaker may also be interested in whether a principal’s rating in year t predicts performance in year t + 1. In Table 9, we reestimate models for selected outcomes shown in prior tables, substituting the 1-year lagged TEAM rating in for the same-year TEAM rating. For the 1-year TVAAS index, TCAP measures, and TELL ratings by teachers and assistant principals, a principal’s TEAM rating at time t positively predicts outcomes at t + 1 when models include district fixed effects, though in all cases except TCAP reading, the correlations are smaller with the lagged rating than with the same-year rating. When school fixed effects are included, the positive correlation between concurrent TEAM ratings and TCAP math achievement growth is no longer present for the lagged TEAM rating.
Predicting Performance Outcomes With Lagged TEAM Principal Practice Ratings
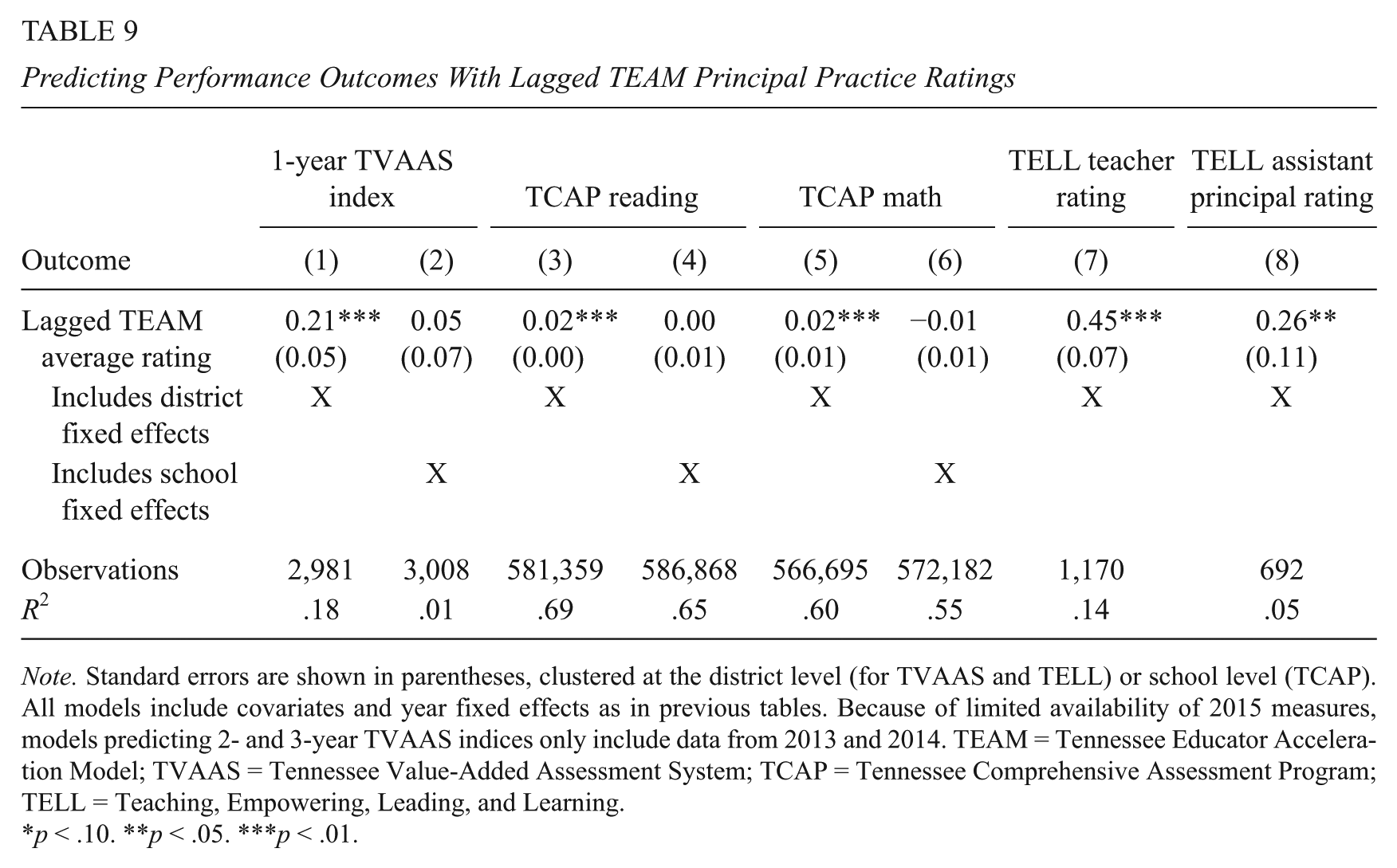
Note. Standard errors are shown in parentheses, clustered at the district level (for TVAAS and TELL) or school level (TCAP). All models include covariates and year fixed effects as in previous tables. Because of limited availability of 2015 measures, models predicting 2- and 3-year TVAAS indices only include data from 2013 and 2014. TEAM = Tennessee Educator Acceleration Model; TVAAS = Tennessee Value-Added Assessment System; TCAP = Tennessee Comprehensive Assessment Program; TELL = Teaching, Empowering, Leading, and Learning.
p < .10. **p < .05. ***p < .01.
Discussion and Conclusions
The use of both formative and summative evaluations for principals is increasing (Davis et al., 2011), but we do not yet have much evidence about the capacity for principal evaluation systems to identify principal competencies or accurately measure principal job performance. This evidence is particularly important when evaluation data are used to make personnel decisions, such as those about compensation or continued employment.
Our analysis of principal practice ratings from the TEAM evaluation system in Tennessee arrives at a number of important conclusions. Ratings appear internally consistent and relatively stable over time, despite changes to the TEAM rubric. The ratings also appear to derive from one underlying factor—the rater’s perception of the principal’s job performance—that drives the ratings; exploratory analysis does not suggest that raters differentiate among the different leadership domains the rubric measures in any year. Stated differently, principals who score well on one domain, such as instructional leadership, tend also to score well on other domains, such as promoting diversity and talent and operations management. Although principals who excel in one area may well excel in the others, it is also possible that the rubric—or the process of assigning ratings using the rubric—does not lend itself to differentiating among constructs that actually are distinct, which may limit the value of TEAM ratings for identifying areas for individual principal improvement.
Next, we find associations between TEAM ratings and principal and school characteristics. Some of these correlations, such as the positive association with principal experience, are consistent with a conclusion that on-the-job experience can improve principal performance, though selection effects (e.g., only relatively high-performing principals attain more experience) or rater bias (e.g., raters may be influenced to give higher ratings to principals they have known longer) may also be at play. Potentially more concerning, however, is that some immutable principal characteristics, such as sex and race, show significant associations with principals’ ratings, once we control for other characteristics of the principals and their schools. We cannot be sure whether these differences are a result of actual differences in principal performance or biases in the rubric or raters (Gill et al., 2016). This issue deserves further research attention.
We also find a troubling association between the proportion of low-income students a school serves, as proxied by FRPL eligibility, and principal TEAM ratings. More specifically, schools with larger numbers of low-income students tend to be led by principals who receive lower evaluation ratings. This correlation could arise if such schools are systematically more likely to be led by less effective principals, or if principals are rated differently on the basis of the characteristics of the student body they serve, a factor beyond their control. These issues are not mutually exclusive. Investigating the first explanation directly is beyond the scope of this article. As to the second explanation, our supplemental analysis comparing ratings for the same principal in schools with varying levels of poverty suggests that ratings may indeed contain some bias against principals of high-poverty schools. This finding highlights the need for further investigation of school context effects on principal evaluation.
The evidence on whether TEAM ratings predict other performance measures is mixed. Measures of student achievement growth and subjective assessments of leadership quality and school climate are all positively associated with TEAM ratings before any covariates are taken into account, which means that highly rated principals tend to work in schools with positive outcomes. When we introduce a large number of covariates and isolate estimates to be within district, we still conclude that TEAM ratings and outcomes are positively correlated. This news is positive from a concurrent validity perspective, as it suggests that ratings and other performance outcomes tend to move together, even after controlling for many potentially confounding influences. Using similar within-district models, we also find that TEAM ratings predict TVAAS scores, TCAP math and reading growth, and TELL leadership ratings the following year, evidence that ratings may be useful in making decisions about how to allocate leaders across schools in the future.
Nonetheless, we stop short of concluding that having a principal with a higher rating drives more positive outcomes. These positive correlations could be driven by selection; if high-performing schools in a district are more likely to attract or be assigned high-performing principals, we would expect outcomes and TEAM ratings to be correlated, even if principal effectiveness (as measured by TEAM) has little impact on outcomes. School fixed effects aim to at least partially account for this selection, and in these models, the results become murkier. We still find positive correlations between TEAM ratings and some of TVAAS index measures, and with standardized achievement growth in math, but the correlations with the subjective survey assessments become generally small and statistically insignificant. We may also be concerned about a kind of reverse causality that may occur if raters see high school performance and then credit the principal with that performance, even if that higher school performance results from factors not under the principal’s direct control (Grissom et al., 2015). Further analysis is necessary to establish any possible causal linkages between principal performance (as captured by practice ratings) and other outcomes.
There are several potential policy implications of our findings. The fact that TEAM ratings tend to move in the same direction as other ostensible performance measures is evidence for concurrent validity of the rating process. Furthermore, these positive associations are not driven purely by sorting on the basis of school or principal characteristics we can observe. Yet, the evidence here also suggests the possibility of biases in the TEAM rating process that TDOE might address through rater training or further rubric development. For example, principals in high-poverty schools systematically receive lower ratings. If this pattern derives from raters mistaking the additional challenges of leading such schools with ineffective leadership, principals engaging in high-quality leadership practice may be unfairly disadvantaged in the evaluation process, which could in turn contribute to higher leadership turnover rates in high-poverty schools (Loeb, Kalogrides, & Horng, 2010). On the contrary, if this pattern derives from systematic sorting of less effective leaders into high-needs schools, the state may not have an evaluation bias problem but instead a potentially larger, systemic problem that disadvantages low-income students. Which of these scenarios dominates is a worthy topic for research.
Our results may also speak to the need for further training of principal raters to better differentiate the competencies or behaviors the TEAM rubric describes. Our analysis on this point is not definitive, but it does not appear that raters reliably score the domains as distinct areas of principal job performance and are instead rating on the basis of a more global perception of the quality of the job the principal is doing (which itself explains only about 60% of the variation in principal ratings). If the goal of the evaluation process is to provide specific information to principals about their areas of strength and weakness, it is not apparent that the current process provides this kind of guidance, and there may be opportunities to better calibrate ratings within districts to provide reliable feedback.
Our results provide some initial evidence regarding principal outcomes under the kind of rigorous, high-stakes, multiple measures-based principal evaluation systems at scale that are becoming common nationwide. Of course, we cannot assume that our results generalize to other state systems, which may have different goals and processes, and it is important that researchers replicate these results in other contexts. Future research might also examine the consequences of these evaluation systems for such important processes as principal hiring, placement, and turnover, and investigate whether and how principal evaluation systems might drive principal performance improvement.
Supplemental Material
DS_10.3102_0162373718783883 – Supplemental material for Evaluating School Principals: Supervisor Ratings of Principal Practice and Principal Job Performance
Supplemental material, DS_10.3102_0162373718783883 for Prices for Evaluating School Principals: Supervisor Ratings of Principal Practice and Principal Job Performance by Jason A. Grissom, Richard S. L. Blissett and Hajime Mitani in Educational Evaluation and Policy Analysis
Footnotes
Acknowledgements
The authors appreciate support for this study from the Tennessee Education Research Alliance, a partnership between the Tennessee Department of Education (TDOE) and Vanderbilt University. Nate Schwartz and Paul Fleming at TDOE provided helpful insights and feedback on earlier drafts. Brendan Bartanen provided valuable research assistance. This research benefited from feedback on earlier drafts from presentations at Michigan State University and the 2015 meetings of the Association for Education Finance and Policy and the University Council for Educational Administration, and the 2016 meetings of the American Educational Research Association and the Association for Public Policy Analysis and Management.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Authors
JASON A. GRISSOM is an associate professor of public policy and education at Vanderbilt University’s Peabody College and faculty director of the Tennessee Education Research Alliance. His research interests include school leadership, educator labor markets, and K–12 politics and governance.
RICHARD S. L. BLISSETT is an assistant professor of education leadership, management, and policy at Seton Hall University. His research primarily focuses on the attitudinal and behavioral dimensions of the politics of education policymaking.
HAJIME MITANI is an assistant professor of educational leadership at Rowan University. His research interests include accountability, educational leadership, educator labor markets, and international and comparative education.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.