
Abstract
We provide a non-parametric method for stochastic volatility modelling. Our method allows the implied volatility to be governed by a general Lévy-driven Ornstein–Uhlenbeck process, the density function of which is hidden to market participants. Using discrete-time observation we estimate the density function of the stochastic volatility process via developing a cumulant M-estimator for the Lévy measure. In contrast to other non-parametric estimators (such as kernel estimators), our estimator is guaranteed to be of the correct type. We implement this method with the aid of a support-reduction algorithm, which is an efficient iterative unconstrained optimisation method. For the empirical analysis, we use discretely observed data from two implied volatility indices, VIX and VDAX. We also present an out-of-sample test to compare the performance of our method with other parametric models.
Keywords
Introduction
The surface of implied volatility inferred from options provides a rich source of information about risks in the economy and their pricing. In particular, implied volatility is considered as a forward looking indicator of tail events which are hard to measure from asset return data alone. Nevertheless, to accurately extract information, one may have to determine various sources of risk, such as jumps as well as shocks to stochastic volatility and jump intensity. While the literature is mostly focused on finding an accurate parametric specification for the aforementioned mentioned determinants of risk, we argue that parametric models are subject to significant misspecification risk, the effects of which are rather unclear due to the highly nonlinear dependence of the option prices on the various sources of risk. Thus, we propose a non-parametric method to estimate the density function of a time-series of implied volatility data.
We consider the implied volatility to be governed Lévy measure of a hidden Lévy process driving a stationary Ornstein–Uhlenbeck process which is observed at discrete time points. This Lévy measure can be expressed in terms of the canonical function of the stationary distribution of the Ornstein–Uhlenbeck process, which is known to be self-decomposable. Therefore, based on the seminal paper of Jongbloed et al. (2005), we provide a robust non-parametric estimation technique for estimating the Lévy density of the invariant law of a stationary OU process that is driven by a subordinator. In contrast to other non-parametric estimators (such as kernel estimators), our estimator is guaranteed to be of the correct type. We implement this method with the aid of a support-reduction algorithm, which is an efficient iterative unconstrained optimisation method.
Despite the elegance of the method, it has never been implemented in any financial applications.
Background
Understanding volatility is of fundamental importance for effective portfolio choice, derivative pricing, and risk management, among other issues. The unobservable nature of volatility leads us to two substantive aspects of the non-parametric identification procedure which we propose: 1) We assume that the stochastic implied volatility follows an OU process driven by a hidden Lévy process, which is observed at discrete time points. 2) We provide a non-parametric estimation of the Lévy measure based on a preliminary estimator of the characteristic function of the stationary distribution. These claims are supported by a conclusive body of empirical studies on the behaviour of implied volatilities of exchange traded options. In particular, using a Karhunen-Loéve decomposition of time series of volatility surfaces, Cont and da Fonseca (2002) performed a joint study of dynamics of implied volatilities for all strikes and maturities of index options. They concluded, among many other interesting findings, that Relative movements of implied volatilities have little correlation with the underlying asset; The projections of the surface on its principal components exhibit high positive autocorrelation and mean reversion over a time-scale close to a month; and The autocorrelation structure of principal component processes is well approximated by AR(1)/OU process.
The use of OU processes in volatility modelling to capture the mean reverting behaviour of data is so firmly established in the literature that it hardly requires further motivations (Hull and White (1987), Heston (1993) and Barndorff-Nielsen and Shephard (2001)). Much of the recent research has stemmed from the latter work where the volatility follows a non-Gaussian OU process. Notable references include, among others:
Roberts et al. (2004) who fit SV models with the changes in the log price modelled via a drift-less diffusion and volatilities through a superposition of OU processes with Gamma marginals; Griffin and Steel (2006) who, in addition, investigate models with jumps in the returns, an incorporation of a leverage effect and different risk premium coefficients for different component volatilities; Gander and Stephens (2007) look at such OU models when the marginal of the OU process is generalised inverse Gaussian or inverse gamma and introduce an approximation to fractional Brownian motion in the returns equation. The finance literature is slightly more varied, Li et al. (2008) consider the impact of models which include, in the jumps on the returns, infinite activity Lévy processes (e.g. Applebaum (2009)). In more recent papers, Zhang and Xu (2014) introduce stochastic state variables into volatility dynamics and analyse the influence of state-variable volatile characters on investment stopping boundaries; and Ma et al. (2015) use a discretised version of mean-reverting square root model for valuation of volatility options.
The Lévy density of the asset return process summarises the information about the jumps and has been the main object of study of a large body of statistical work (cf. Todorov (2011)). Todorov and Qin (2017) reasons that the Lévy density in the finite activity jump case can be viewed as the conditional probability of jump arrival of given size. Therefore, the Lévy density of time series of implied volatility data, would contain information both for future expected jump risk as well as for the so-called risk-neutral probability measure, which is of interest both from a theoretical and applied point of view. All of the aforementioned research (except for Todorov and Qin (2017)) exploit distinct parametric specifications for the Lévy measure in the information set. In contrast, the non-parametric volatility models are void of any specific functional form assumptions about the stochastic processes governing the dynamics. Additionally, they differ from the parametric models in their focus on providing measures of the notional volatility, rather than the expected volatility.
In contrast to the existing literature on non-parametric models of stochastic processes in financial mathematics, instead of estimating the drift function and the coefficient function of the Lévy measure (e.g. Soulier (1998), Ait-Sahalia (1996) and Bandi and Renò (2011)), we directly estimate the hidden Lévy measure of the OU process governing the stochastic volatility. For example, Bandi and Renò (2011) assume that the stochastic volatility is governed by a SDE consisting of a Brownian motion correlated with the underlying asset and a jump competent independent of the Brownian motion. Then they identify the relevant coefficient functions (through estimates of the system’s infinitesimal moments) using non-parametric kernel methods for jump-diffusion processes. Despite its efficiency, their method is still limiting because of the assumption of normality in the Brownian motion, as well as the Poisson (or Gaussian) jump distribution. We take one step further and make no distributional assumptions for the finite variation terms.
It is important to realise that traditional estimation techniques such as maximum-likelihood and Bayesian estimation are cumbersome. This is caused by the intractability of the likelihood. By the Lévy-Khintchine theorem, a Lévy process has its natural parametrisation in the Fourier domain and, in general, there exists no closed form for the marginal distribution of a Lévy process. For discrete time observations from a stationary OU-process, the estimation is further complicated by the fact that the observations are dependent, so that the transition density of the process is needed. The latter is even harder to get hold of than the marginal density. For this reason an alternative estimation method is proposed, which we will now explain briefly. As a starting point, we take a sequence of preliminary estimators such that for each point in time, we have an unbiased estimator of the characteristic functions, either almost surely or in probability. The canonical example of such an estimator is the empirical characteristic function, though other estimators are possible. To prove that the empirical characteristic function is an appropriate preliminary estimator, we can use the β-mixing result of Davydov (1973). Our estimator for the canonical function of the Lévy process is a Cumulant M-estimator (CME) that minimises the random criterion function. Our approach is closely related to the seminal work of Jongbloed et al. (2005), where the robust statistical properties of the M-estimator is developed. Since a stationary OU-process is β–mixing, the convergence is guaranteed by an application of Birkhoff’s ergodic theorem (Krengel and Brunel (1985)).
The CME is calculated by a high dimensional maximisation problem, for which there is no known analytical solutions. Apart from the classic expectation maximisation of Dempster et al. (1977) maximum, there are a number of recent innovations in optimisation in the field of statistics which can be used. Here, we employ the support reduction algorithm introduced in Groeneboom and Wellner (1992) and further developed in Groeneboom and Wellner (1992), Groeneboom et al. (2001) and Groeneboom et al. (2008).
After obtaining the non-parametric estimation of the distribution, we will examine the model’s explanatory power using Kolmogorov-Smirnov and Anderson-Darling goodness-of-fit tests. A fundamental issue in statistical analysis is testing the fit of a particular probability model to a set of observed data. A simulation approximation to the null distribution of the test provides a convenient and powerful means of testing model fit. In this paper we consider the acceptance-rejection method for the simulation part. Finally, we compare the forecasting performance of the estimation procedure, using out-of-sample observations, with two very well known stochastic volatility models; namely the Heston (1993) model and the Barndorff-Nielsen and Shephard (2001) (BNS) model.
The remainder of this paper is structured as follows. Section 2 explains the theoretical framework of our model and method for estimating the Lévy measure. Section 3 provides the details of the estimation via the support reduction algorithm, as well as the out-of-sample test to analyse the forecasting power of our method. Section 4 presents our conclusion.
Theoretical framwork
Let 𝒯 denote the time index set [0, T] of the economy, where T< ∞. To model uncertainty, we consider a complete probability space
A solution X (t) to this equation is called a Lévy-driven OU process. The process (2.1) is generated by the subordinator Z, which is an increasing Lévy process, by definition. To ensure the existence of a unique stationary solution for (2.1), suppose the Lévy measure ν of Z satisfies the bounding condition
It is easy to verify that a (strong) solution X = (X (t) , t ≥ 0) to the equation (2.1) is given by
Up to indistinguishability, this solution is unique (Sato (1999), Section 17). Furthermore, since X is given as a stochastic integral with respect to a cadlag semi-martingale, the OU-process (X (t) , t ≥ 0) can be assumed cadlag itself. The stochastic integral in (2.2) can be interpreted as a pathwise Lebesgue-Stieltjes integral, since the paths of Z are almost surely of finite variation on each interval (0, t] , t ∈ (0, ∞).
Denote by
This relation is easily proved for piecewise constant functions, the general form follows from approximation, which enables us to extend the result to (at least) continuous functions h. As a second step, we plug h (u) = e-λ(t-u) into the above equation to obtain (2.3).
Let bℰ denote the space of bounded ℰ-measurable functions. The transition kernel induces an operator P
t
: bℰ → bℰ by
Let C0 (E) denote the space of continuous functions on E vanishing at infinity.
Then P
t
(y, .) converges weakly to a limit distribution π as t→ ∞ for each y ∈ E and each λ > 0. Moreover, π is self-decomposable with canonical function
A self-decomposable distribution is a subclass of infinitely divisible distributions, which can be characterised by its generating triplet through the Lévy-Khintchine theorem. In general, all degenerate random variables are self-decomposable (cf. Sato (1999), Corollary 15.11), therefore, when a Lévy driven OU process, such as the X (t), is self decomposable, the Lévy measure of it can be expressed with a canonical function, k (y), similar to (2.5). In addition, Sato (1999) also shows that a self-decomposable distribution encompasses the parametric class of stable distribution.
Here, it is important to highlight that the close form expression of the density function in terms of k (.) is not known. As a result, the maximum likelihood techniques of estimating a self decomposable density functions are not possible. This has, also, been pointed out by Barndorff-Nielsen and Shephard (2001), where they showed it is impossible to obtain direct maximum likelihood estimators for their parameters indexing the stochastic volatility model.
However, similar to Jongbloed et al. (2005), we show that it is possible to calculate a non-parametric estimator for the characteristic function. Then, using the method of Schorr (1975), we will numerically invert this function to obtain a non-parametric estimator for the density function.
The β-mixing property of general (multidimensional) OU processes is also treated in Masuda (2004). There it is assumed that the OU process is strictly stationary and ∫|y| a π (dy)< ∞, for some a > 0. The β-mixing condition guarantees the consistency of the Cumulant M-Estimator, discussed below.
In practice, observations from the financial market are recorded at discrete time intervals, though we will allow for the sampling interval to tend to zero by collecting more observations. Doing so allows us to develop our model under the continuous-time framework, which might be more complicated mathematically, but facilitates a unified investigation of the processes at different time scales. Discrete time models (time-series), typically, have to be adjusted for irregularly spaced data.
The process (2.1) is a general form of OU-type models, conventional to the stochastic volatility literature. For example, the BNS model for volatility takes advantage of a superposition of such processes (see Barndorff-Nielsen and Shephard (2001)). Further, Barndorff-Nielsen et al., (2002) studied two special cases of this model, namely BNS Model with Gamma stochastic volatility (BNSGSV) and BNS Model with inverse Gaussian stochastic volatility (BNSIGSV). They derived the risk–neutral characteristic function of the log stock price under under both model assumptions, employing the self-decomposability of Gamma processes.
Another well-known example for (2.1) in the mathematical finance literature is the integrated CIR time-change, introduced in Carr et al. (2003), as an extension to the Cox-Ingersoll-Ross model. This kind of time change gives rise to jumps in the rate of time change processes. It captures the empirically tested phenomena that volatility jumps up when new information is released; after the up-jump, it tends to gradually decrease.
We purpose to derive a nonparametric estimator of the process X (t), which is observed at equal time intervals between [0, T]. Each observation time is defined by
Here, k (.) is a right-continuous, decreasing canonical function that describes the process Z by the relationship k (x) = ν (x, ∞) (x > 0). The special scaling in the defining equation for X, (2.1), allows for a separate estimation of λ and k. The former estimation problem is deferred to Section 2.2.
In this section we outline a new estimation method for the canonical function k. As pointed out in the introductory section, maximum likelihood techniques are hampered by the lack of a closed form expression for the density of π in terms of the “natural” parameter k (the density of a nondegenerate self-decomposable distribution always exists, see Sato (1999), Theorem 27.13). Even if such an expression would exist, we would in fact need more, namely, the transition densities of X, in terms of k. This motivates our choice for another type ofM-estimator.
This estimator is constructed by firstly defining a preliminary estimator
Jongbloed et al. (2005) discuss that the convergence and consistency of such estimator relies on three important properties of the OU process, namely, the Markov property, self-decomposability and β - mixing. We have proved these properties of (2.1), at the beginning of this section.
Let ℒ1 (η) be the space of integrable functions on ℛ+, for the measure η defined by
The definition of the measure η precisely suits the integrability condition on k, which can now be formulated by ||k|| η < ∞. Then, let K : = {k ∈ ℒ1 (η) : k (y) ≥0} for the measure η. Thus, we suppose K ⊆ ℒ1 (η) is a convex cone, containing the functions of non-degenerate self-decomposable distributions.
Suppose
Note that in (2.6) we are using the cumulant function (i.e. the distinguished logarithm of a characteristic function), instead of the characteristic function, directly. This is because, apart from the issue whether this estimator is well defined, one disadvantage of using characteristic function is that the objective function is non-convex in k (convexity being desirable from a computational point of view).
Now let G denote the set of cumulants corresponding to K. Then the cumulant corresponding to a particular canonical function k1, or characteristic function ψ1 is denoted by g1. Define L : K → G by
Jongbloed et al. (2005) proved that k is determined by the values of g = L (k) restricted to the compact support, S, under the assumption w is symmetric and strictly positive around the origin. Now let L2 (w) denote the space of square integrable functions with respect to w (t) dt, such that for f, a measurable function of time, ∫|f (t) |2w (t) dt< ∞. Since elements of G are continuous and w is compactly supported, G ⊆ L2 (w). Additionally, the mapping L : K → G is continuous, onto and one-to-one.
Next, define the mapping Γ
n
: G → [0, ∞) by
Then the cumulant M-estimator, Use the fact from Hilbert-space theory that every non-empty, closed, convex set in L2 (w) contains a unique element of smallest norm. Since Γ
n
is a squared norm, it suffices to specify a closed, convex subset G′ of G to obtain a unique minimiser of γ
n
over G′. Show that L admits an inverse on G′ so that
Let R > 0, and (i) K
R
is a compact, convex subset of ℒ1 (η), as well as (ii) G
R
is a compact, convex subset of L2 (w). Since Γ
n
has a unique minimiser over G
R
and to each G
R
belongs a unique member of K
R
, there exists a unique minimiser of Γ
n
L over K
R
. More precisely, Let
For numerical purposes we will approximate the convex cone K by a finite-dimensional subset. For 1 ≤ j ≤ N, set Θ = {θ1, . . . , θ
N
} such that θ
j
= jh corresponds to grid points of the mesh h. Then, set 𝒰
Θ
: = {u
θ
, θ ∈ Θ} and define a basis function by
Now define a convex cone K
Θ
by
Then define a unique sieved estimator by
The consistency of
Suppose X1Δ, X2Δ, …, X nΔ are discrete-time observations from the stationary OU process, where Δ is a constant. The latter condition is very important, otherwise, nΔ→ ∞ should be a necessary condition to identify the drift, since for a fixed time horizon even with continuous observations Girsanov’s theorem shows that the corresponding laws are equivalent and thus their distance is fixed as long as nΔ is bounded.
With a slight abuse of notations set X
i
: = X
iΔ
. The chain X
n
satisfies the first order auto-regressive relation
Let θ = e-λΔ and denote the true parameter by θ0. As in Jongbloed et al. (2005), define the estimator
Then,
Define
By dominated convergence,
Then
This approach is critically interesting, from the application point of view, compared to the parametric cases. The advantage is the flexibility and the ability to ‘let the data speak for themselves’. In other words, our data adaptive approach allows us to estimate the density function of the process for stochastic volatility, which is closer to the ‘true’ distribution. However, problems that can usually be solved using standard techniques in the parametric case, can be much more difficult in the non-parametric situation. For example, a M-estimator is defined as the minimiser of a random criterion function over an appropriate parameter set. In parametric models, estimates can be computed explicitly or approximated using some numerical technique; whereas, in non-parametric models, the computational issues often boil down to high dimensional constrained optimisation problems. From the practical point of view, this means higher computational expense, which may be a major deterrent to adopt to implementation. To overcome this problem, we use the support-reduction algorithm based on Groeneboom et al. (2008) for the computation of the estimator. See Section 3.1 further details.
Estimation and empirical results
We undertake an empirical examination of implied volatility over the period from January 1997 to December 2014. Our study used daily implied volatility indices of S&P500 (VIX) and DAX100 (VDAX). The VIX is derived from S&P500 index call and put options of a wide range of strike prices that are further weighted to represent a hypothetical at-the-money option with a constant maturity of 22 trading days (30 calendar days) to expiry. The VDAX is constructed by call and put DAX index options of eight different strike prices that are further linearly interpolated to a remaining life of 45 calendar days.
We opted to use 4250 data points, where
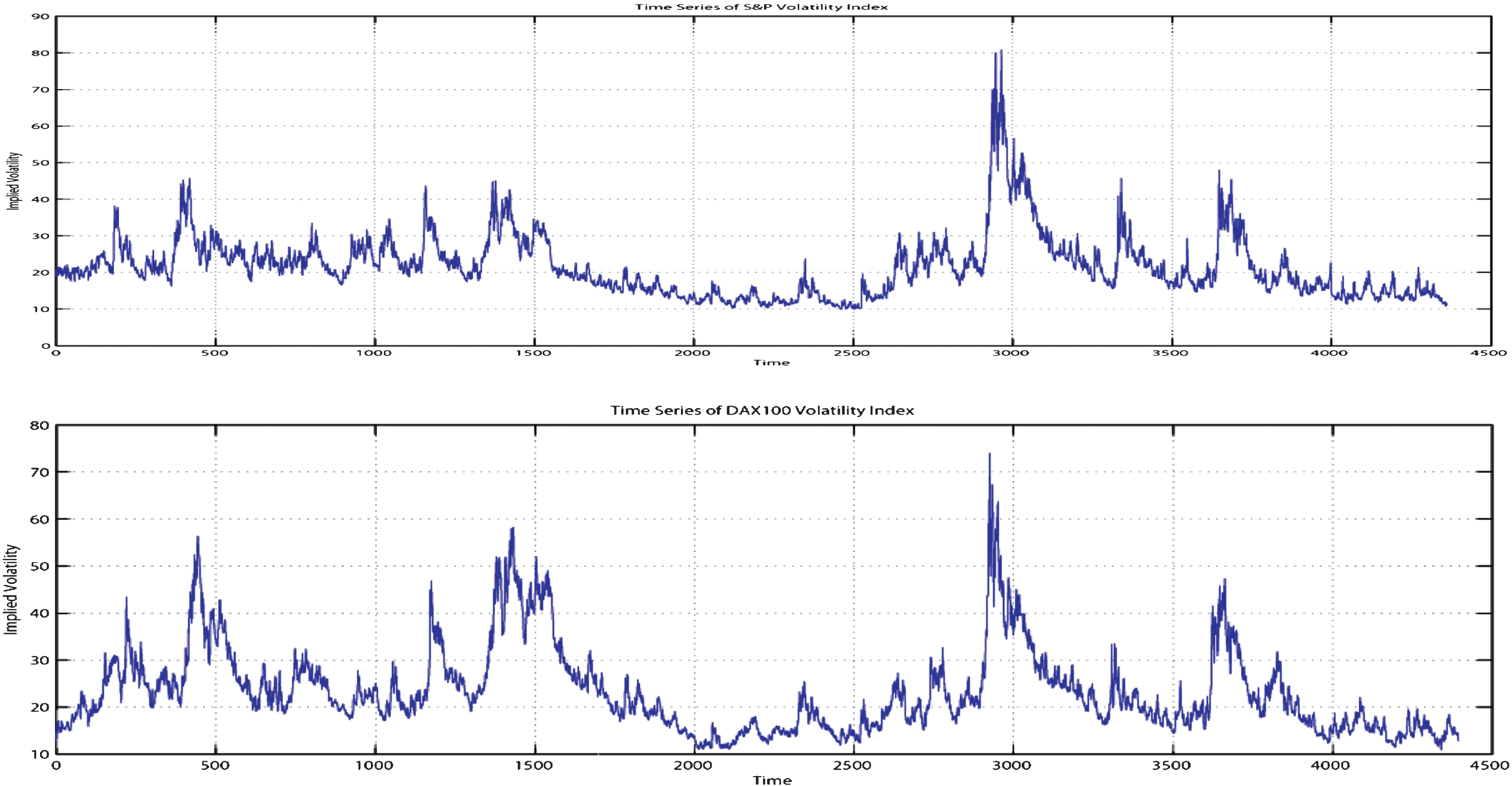
These figures present the time series of daily implied volatility for VIX (the top panel) and VDAX (the bottom panel) indices during the period 1997– 2014. The data sets show roughly the same behaviour during the time frame.This can be due to the effect of the global economic situation on the big markets. For instance, it can be observed that during the period of Subprime Lending Crisis, followed by the Global Financial Crisis (2007– 2009), the two markets exhibit a high level of volatility with a very similar pattern.
The M-estimator is defined as the minimiser of a random criterion function over the parameter set. In parametric models, estimates can often be computed explicitly or approximated using some numerical technique for solving (low dimensional) convex unconstrained optimisation problems. Nevertheless, in our non-parametric case, we face a high dimensional constrained optimisation problem. Apart from the classic expectation maximisation of Dempster et al. (1977), there are a number of recent innovations in optimisation in the field of statistics. Here, we use the support-reduction (SR) algorithm, introduced in Groeneboom and Wellner (1992) and further developed in Groeneboom and Wellner (1992), Groeneboom et al. (2001) and Groeneboom et al. (2008). A version of this algorithm, known as the iterative convex minorant algorithm, was also used in Jongbloed et al. (2005) for the numerical approximation of the CME introduced in Section 2.1. However, the method of Groeneboom et al. (2008) (which is used in this paper) provides faster convergence, when computing non-parametric M-estimators in mixture models. Within the optimisation theory, the SR algorithm can be classified as a specific instance of an active set method. Within the field of statistical computing, the algorithm fits in the class of vertex direction algorithms. An algorithm, related to our support reduction algorithm, can be found in Meyer (1997), which led to the idea of the iterative spline algorithm for convex regression, as described in Groeneboom et al. (2001).
The algorithm discussed here is based on isotonic regression techniques as can be found in Härdle (1989). It is mostly used to compute shape-restricted estimators of distribution functions in semiparametric models. We apply the algorithm to compute M-estimators in mixture models, using unconstrained optimisations iteratively. It is to be noted that in each step the algorithm adds one support knot among several possible support knots to the existing iterate, resulting in a sparse next iteration. These reduced knots causes a low-dimensional unlimited optimisation problem during the next iteration. A fundamental advantage of this method is that in problems where the solution is a sparse mixture, the model can be handled well, due to the speed at which the low-dimensional optimisations are performed.
We seek to find an approximate solution for
Note that whenever (Φ) (b)< ∞, convexity of Φ guarantees the existence of [D
a
(Φ)] (b). Using straight forward, but tedious, calculations we can show
With a slight abuse of notations, let k J from the cone K Θ be the current iterate from each iteration. Then suppose k J = ∑j∈Jα j u θ j .
The optimisation algorithm in Groeneboom et al. (2008) prescribes to evaluate the optimality of k J (3.8). If k J is not optimal, then there exist an i ∈ {1, . . . , N} ∖ J with a negative directional derivative, which means u θ i provides a direction of descent for the objective function. Therefore, our initial aim is to determine the set of grids with negative directional derivatives, all of which are non-optimal and provide a direction of descent. Then using a search algorithm, we pick a direction of descent and find a new iterate. In this stage, we must recalculate the optimal weights, using the standard least square technique. For doing so, we differentiate the objective functions with respect to α j (j ∈ {1, . . . , m}) and set them to zero. This gives the following system
Equation (3.9) is easily proved by showing that the left-hand-side is symmetric and non-singular. This is briefly as follows.
Let A : = 〈z
θ
i
, z
θ
j
〉
w
and
Then also,
Rewriting this in a linear system we find that
Since the matrix in this display is a generalised Vandermonde matrix, its determinant is unequal to zero. Thus, h1 = h2 = ⋯ = h m = 0.
Finally, we evaluate the new iterate by (3.8) for optimality, and repeat the process until the optimal solution is found.
Theorem 1 in Groeneboom et al. (2008) gives conditions to guarantee that the sequence of iterates {k(i)}
n
(generated by the support-reduction algorithm) indeed converges to the solution of our minimisation problem. Since these conditions are met in our case, we have
The support-reduction algorithm is summarised as follows
where
We implement the Divide and Conquer (D&C) algorithm to search for the solution. In this algorithm, a successful join of points is determined when the new solution decreases the objective function and is not outside of K Θ . Throughout the optimisation process, we may find solutions that contain support points in too close vicinity of each other. This is because the grids are not continuous. To prevent such situation we locally optimise the support by scanning for closely located points. If we found such support points, we determine a convex combination of them that minimises Γ n ∘ L (k). This may have a smoothing effect that does not interfere with the convergence condition specified in Groeneboom et al. (2008). Additionally, the extra step can reduce the convergence speed dramatically; therefore, we will only implement the replacement when we find two points with two new directions of descend, that cause the algorithm zigzag between them.
Another issue that might arise is that the solution α i may generate a measure ∑α i u θ i , not necessarily belonging to ℛ+ as α i might be negative for some i. If this function happens to belong to ℛ+, it is a new iterate. Otherwise, one travels as far as possible along the line segment connecting the current iterate with this infeasible measure. A remedy for this problem is offered in Groeneboom et al. (2008), which we implement in our algorithm as part of Step 2. For this purpose, we use a sequence of unrestricted minimisations and support-reduction, to obtain a new subset of support-points that minimises Γ n ∘ L (k).
Finally, in relation to the computational efficiency the support-reduction estimation has a very low run time. Even though the calculation of matrix c2 (θ) needs a long time (in fact it depends on the total number of mesh grids), the algorithm works highly efficiently, once it is initialised, the determination of the vector is fast.
In this section, we approximate the canonical functions for VDAX and VIX, using the cumulant M-estimator. Further, we approximate the intensity parameter λ for the implied volatility of both indices. Table 1 presents the results for the support-reduction algorithm applied to the volatility data set. Additionally, Fig. 2 plot
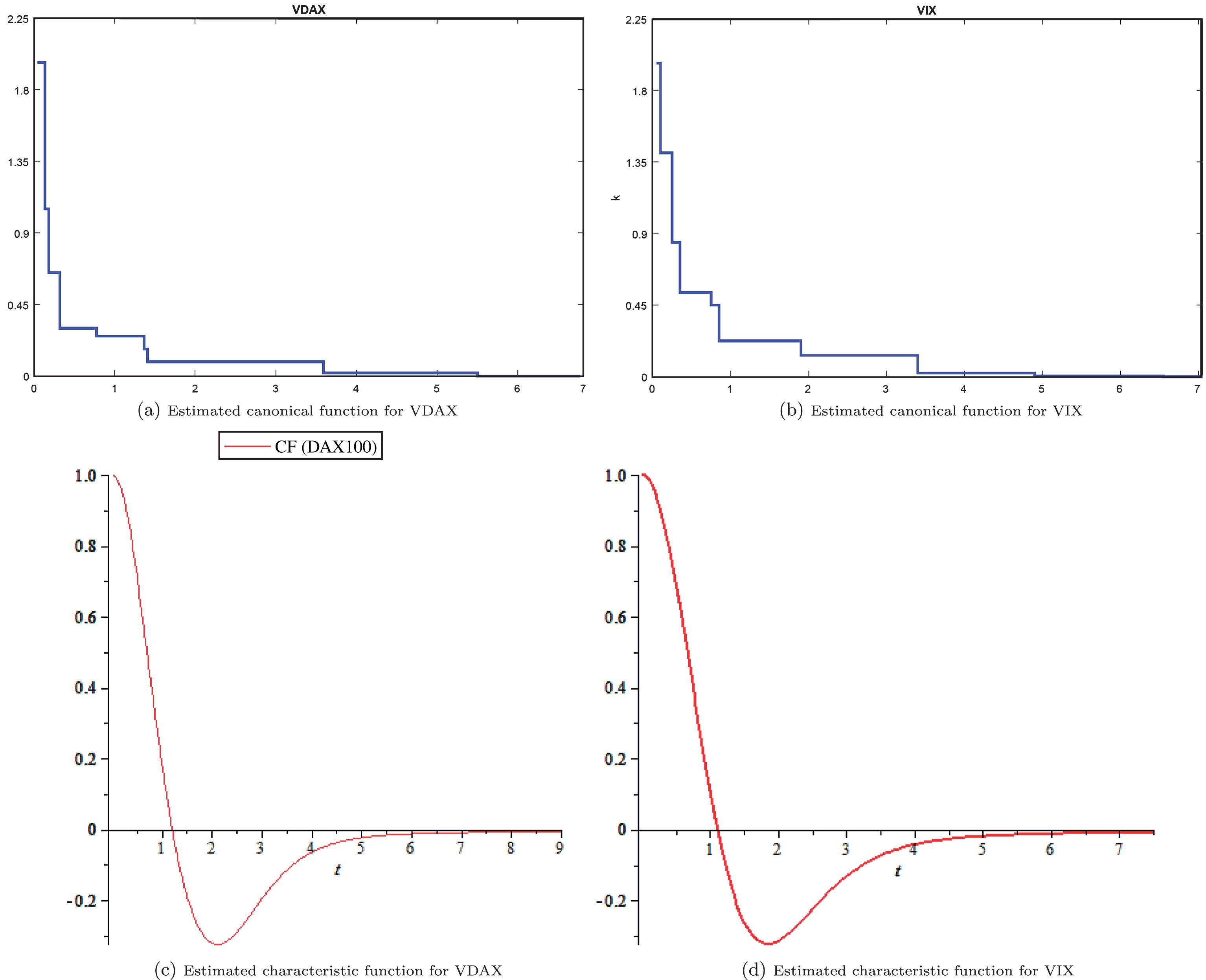
These figures exhibit the plots for the estimated canonical functions and characteristic functions for both VIX and VDAX. The shape of the characteristic functions remind us of log-normal distribution, therefore, we test the hypothesis that whether the data sets were drawn from log-normal distributions. The results are provided in Table 1.
This table reports M-estimators estimates and corresponding weights and lambda estimation for the two different data sets. The algorithm ran until the directional derivative on all grid points was above 10-15
Next, we want to obtain the stationary distribution function f
n
using fast Fourier transform. Note that
The characteristic function of a self-decomposable distribution does not need to be integrable. Such condition means that there is no guarantee that we can calculate the Fourier transform analytically. Here, we use an alternative method based on Schorr (1975), where we numerically approximate the Fourier transform. We only present the results for the numerical approximation, without the proof. Interested readers may refer to Schorr (1975) for the detailed calculations of similar examples.
We consider 60 grid points for the numerical approximation with lags of 0.05; therefore, we will have 60 basis functions. Moreover, for estimation of density functions based on the Fourier transform, T is considered to be 12 and κ takes values from -150 to 150. This interval is sufficiently large enough to obtain a reasonably accurate approximation.
Next, using the MLE method discussed in the previous section, we estimated the intensity parameters, λ, which are also reported in Table 1, then, in Fig. 3 we plot the non-parametrically estimated distributions for both indices, overlaying the histogram of the datasets.
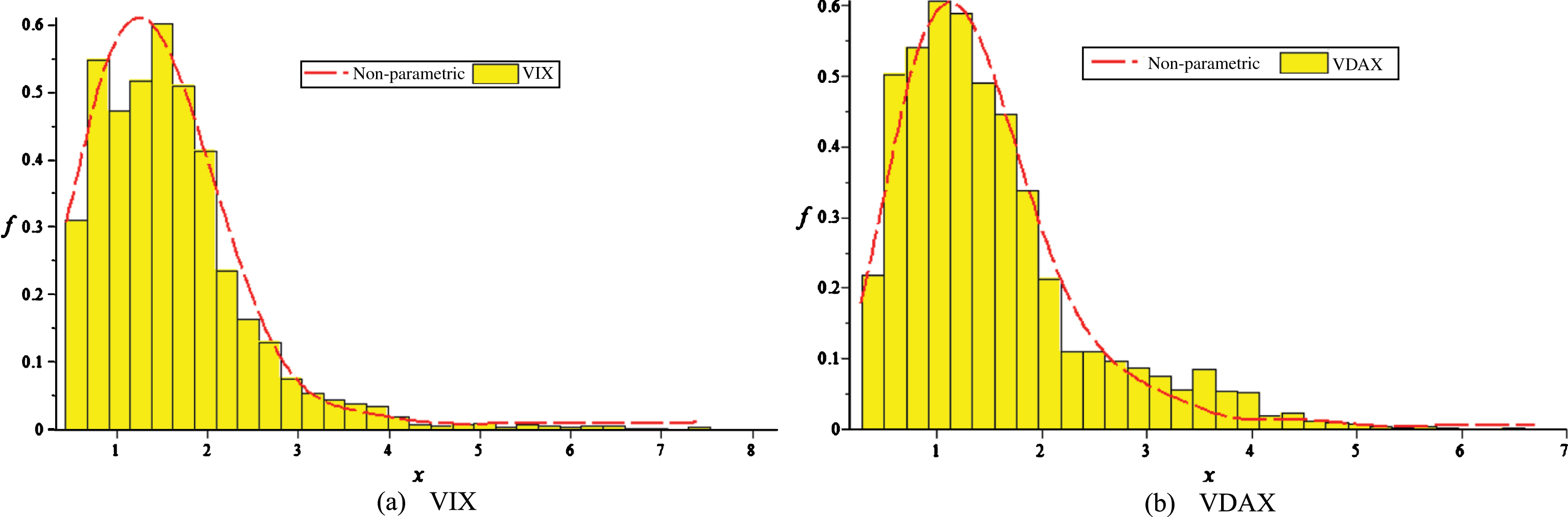
These figures exhibit the plots for the non-parametrically estimated density functions for VIX and VDAX, overlaying the histogram of the datasets.
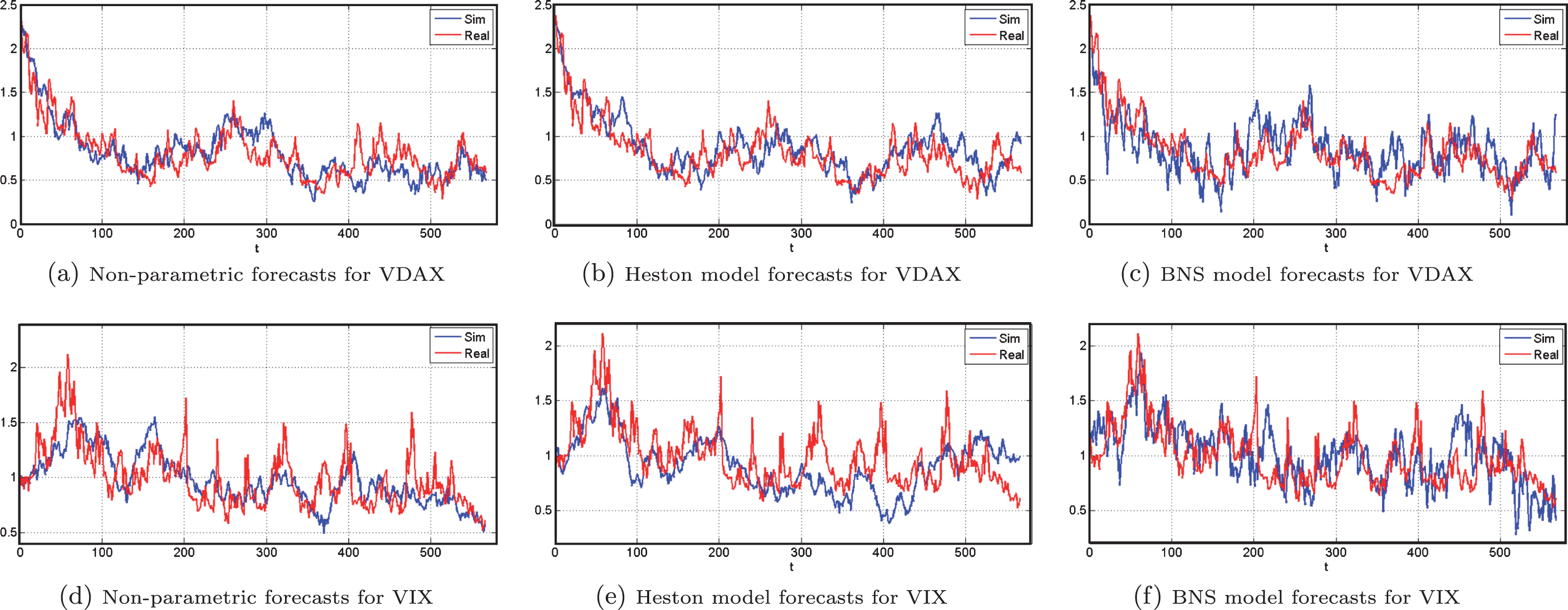
These figures present a comparison between different stochastic volatility models (i.e. non-parametric, Heston and BNS models) and their forecasting abilities. Out-of-sample simulated paths are indicated by blue lines and the times series (real) of daily implied volatility for the same time periods are indicated by red lines.
In order to compare the performance of our non-parametric model with some conventional parametric cases; namely, log-normal, Inverse Gaussian, Burr, and Gamma. At the beginning of the paper we argued that the flexibility of the non-parametric framework is a considerable advantage of our approach to model implied volatility, compared to the parametric cases. Here, we are interested to compare the statistical power of our model with the above mentioned parametric models. A fundamental issue in statistical analysis is testing the fit of a particular probability model to a set of observed data. A simulation approximation to the null distribution of the test provides a convenient and powerful means of testing model fit. Tu (2006) proposed a new Monte Carlo-based methodology to construct this type of approximation when the model is semi-structured. They showed that when there are no nuisance parameters to be estimated, the non-parametric Monte Carlo test can exactly maintain the significance level and when nuisance parameters exist, this method can allow the test to asymptotically maintain the level.
Generating random values from the estimated density function (3.12) requires some effort, since the quantile function is not available in closed form and the inversion method is, therefore, not possible. As an alternative, since
The basic idea is to search for a density function g, from which we already have an efficient algorithm to generate from, but also such that the function g is “close” to
As in Devroye (1986), the algorithm for generating random variables distributed as
For the density functions of both of the datasets, we consider a wide range of candidates for g and their parameters specifications, such that the dominance condition is met. Choosing the most appropriate g is a heuristic process, for which our best guide is the constant c. It can be mathematically presented that the acceptance rate is 1/c, then the expected number of iterations of the algorithm required must be c (cf. Sigman (2007)). If this is not met, we must try a different g.
We found that for simulating (3.12), log-normal distribution is a suitable choice for g. Simulating from this distribution is relatively simple and fast, which is especially important since, in order for the
This table reports the parametric specifications of the log-normal distributions used as g for each dataset, as well as the acceptance rate and the boundary constant, c. On the right-hand side, the table reports the Kolmogorov-Smirnov and Anderson-Darling statistics and p-values from the respective goodness-of-fit tests
Next, we compare if our non-parametric estimation of the density better fits the data better than some conventional parametric cases. Table 3 reports this comparison using log-normal, Inverse Gaussian, Burr, and Gamma distributions. At a significant level of 0.05, we can clearly reject the null hypothesis that our samples (both VIX and VDAX) are from Inverse Gaussian, Burr or Gamma distributions. Nevertheless, the log-normal appears to be a contester for our model. For both VIX and VDAX we can accept the null hypothesis that our sample is from a log-normal distribution. In terms of the KS-test, the log-normal distribution has even slightly out performed our model, evident from their p-values. However, the p-values of the AD tests suggests that our non-parametric model might out perform the log-normal distribution in modelling the tail behaviours. The results are too close to conclusively identify the better model, however, due to the general advantageous of non-parametric approaches (discussed in Section 1), our method is still preferred.
This table reports the Kolmogorov-Smirnov and Anderson-Darling statistics and p-values from the goodness-of-fit tests of different distributions; namely, log-normal, Inverse Gaussian, Burr, and Gamma, as well as our non-parametrically estimated density function
Model selection depends not only on the goodness-of-fit of a model to the data, but also on the objective of the analysis. For forecasting, a model that is best in the in-sample fitting does not necessarily provide more accurate forecasts. Thus, many people use the performance of out-of-sample forecasts to aid the selection of a statistical model.
Statistical tests of a model’s forecast performance are commonly conducted by splitting a given data set into an in-sample period, used for initial parameter estimation and model selection, and an out-of-sample period, used to evaluate forecast performance. Empirical evidence based on out-of-sample forecast performance is generally considered more trustworthy than evidence based on in-sample performance which can be more sensitive to outliers and data mining (White (2000)). Out-of-sample forecasts also better reflect the information available to the forecaster in “real time”. This has led many researchers to regard out-of-sample performance as the “ultimate test of a forecasting model” (Stock and Watson (2007)).
We divide the data for both VIX and VDAX into two sub-periods, namely, the estimation sub-sample which is the first period, and the forecasting sub-sample which is the remainder of the data set. Given T data points, say x1, …, x T , we divide the data as {x1, …, x n } and {xn+1, …, x T }, where n is the initial forecast origin.
Suppose, three competing models: A) the non-parametric model in the current work B) the Heston’s stochastic volatility model (Heston (1993)) and C) the BNS pure jump stochastic volatility model (Barndorff-Nielsen et al., (2002))) with Gamma marginal distribution as in Griffin and Steel (2006).
Let h be the forecast horizon, i.e. we are interested in 1-step to h-step ahead forecasts. The out-of-sample forecasting evaluation works as follows: Let m = n be the initial forecast origin. Fit models A, B and C. Note that for the non-parametric case, we need to repeat the support-reduction algorithm for the new window. For brevity, we do not discuss the calibration of models B and C. Interested readers may refer to Schorr (1975) and Griffin and Steel (2006). For each model, conduct a simulation experiment and calculate the 1-step to h-step ahead forecasts, denoted by Advance the forecast origin by 1, i.e. m = m + 1, and go to Step 1. The iteration stops when the forecast origin is m = T.
In this way, we will have (T - n - 1) 1-step ahead forecast errors for each model, and (T - n - 2) 2-step ahead forecast errors for each model, and so on. For l-step ahead forecasts of the model, we then compute the following three functions in the models out-of-sample forecast performance evaluation.
For all the three loss functions a smaller value is preferred. Table 4 reports the average MSE, R2LOG, and PSE for the two compared parametric implied volatility models, as well as the proposed non-parametric model. The results, unequivocally, suggest that our non-parametric model provides a better out-of-sample fit (in terms of MSE, R2LOG, and PSE) in all cases for both VIX and VDAX.
Average MSE, R2LOG, and PSE for the compared parametric implied volatility models (i.e. Heston model and BNS model with Gamma marginal distribution) and the proposed non parametric model
Average MSE, R2LOG, and PSE for the compared parametric implied volatility models (i.e. Heston model and BNS model with Gamma marginal distribution) and the proposed non parametric model
We developed an intuitive non-parametric framework to estimate stochastic implied volatility. We proposed that implied volatility can be modelled by a Lévy driven OU process, the Lévy measure of which is hidden to the market. Using discrete-time observation, we provide a robust non-parametric estimation technique for estimating the Lévy density of the invariant law of a stationary OU process that is driven by a subordinator. In contrast to other non-parametric estimators (such as kernel estimators), our estimator is guaranteed to be of the correct type. We implement this method with the aid of a support-reduction algorithm, which is an efficient iterative unconstrained optimisation method.
We present a comprehensive empirical analysis, using discretely observed data from two implied volatility indices, VIX and VDAX. Further, we analyse the goodness-of-fit of our estimated distribution by simulating it with the acceptance-rejection method. We have conducted the KS test and the AD test for the non-parametrically estimated density functions of VIX and VDAX data, as well as some conventional parametric cases for the purpose of comparison. We concluded that except for the case of log-normal distribution, our method clearly outperformed other methods. We also present an out-of-sample test to compare the forecasting power of our method with other parametric models; namely, Heston and BNS models. Our non-parametric method outperformed in every case, using different metrics.
This paper has extended an efficient and accurate statistical model for implied stochastic volatilities. Further research may investigate the application of this model in pricing derivatives, using the analytically tractable structure of (2.1).