
Abstract
This article uses Principal Component Analysis to compute and extract the main factors for the financial risk of a portfolio, to determine the most dominating stock for each risk factor and for each portfolio and finally to compute the total risk of the portfolio. Firstly, each dataset is standardized and yields a new datasets. For each obtained dataset a covariance matrix is constructed from which the eigenvalues and eigenvectors are computed. The eigenvectors are linearly independent one to another and span a real vector space where the dimension is equal to the number of the original variables. They are also orthogonal and yield the principal risk components (pcs) also called principal risk axis, principal risk directions or main risk factors for the risk of the portfolios. They capture the maximum variance (risk) of the original dataset. Their number may even be reduced with minimum (negligible) loss of information and they constitute the new system of coordinates. Every principal component is a linear combination of the original variables (stock rate of returns). For each dataset, each financial transaction can be written as a linear combination of the eigenvectors. Since they are mutually orthogonal and linearly independent and that they capture the maximum variance of the original data, the risk of the portfolio is calculated by using the principal components, then they have been used to calculate the total risk of the portfolio which is a weighted sum of the variance explained by the principal components.
Keywords
Introduction
Principal Component Analysis is an Unsupervised Machine Learning technique which is fundamentally a Mathematical Statistics and Data Analysis method. Very often Research in Engineering, in Economics and Finances, in Social, Political and Administrative sciences, in Psychology and Educational sciences, etc. involve hundreds of variables to represent the answer to a survey question. It is difficult even sometimes impossible to handle a big number of variables in a regression model, classification model and it poses a problem of dimensionality and redundancy preventing to analyse data easily and clearly and to visualize the results in a clear and understandable manner. Some of the variables are positively correlated in a such a way that they describe almost the same things so that using them together creates a problem of dimensionality and redundancy. Sometimes performing database queries for some selections in order to make relevant and reliable decisions becomes a tedious task. Principal Component Analysis is a technique of Mathematical Multivariate Statistics and Machine Learning to reduce dimensionality and remove redundancy while capturing maximum of data variation (minimizing loss of information). It enables to extract important information which can lead to the computation of relevant parameters in a simpler way. In this technique, the original variables can be combined in a particular manner so that they produce new variables where each of the new variables is a linear combination of the original variables. The new variables are linearly independent and called Principal Components. They generate a new axis coordinate system, a new reference system of coordinates. They indicate “latent” features that are not directly observable from the study subjects. The Principal Components are uncorrelated, linearly independent. The minimum number of principal components is one and the maximum number of Principal Components is the same as the number of the original variables. Depending on the researcher’s own judgement, the number of Principal Components can be reduced to a certain number while capturing information as much as possible.
In this article, a set of financial transactions of the original reference system of axis coordinate (where some of the underlying variables are linearly dependent vectors) will be orthogonally transformed into a set of financial transactions of the new reference system (where the underlying variables are linearly independent vectors), where each of these vectors is a linear combination of the original variables. Such vectors are called Principal Components, they produce Principal Axis, they are Principal variables, Principal Directions or principal factors. For each principal component, the order in which the coordinates (coefficients) in the matrix of eigenvectors are displayed is the same as the order in which the original variable values are listed at the starting table. Each principal component is a linear combination of the original variables. The components of the eigenvectors are the loadings, the weights of the principal components with respect to the original coordinate system variables. After having computed the eigenvalues and the associated eigenvectors of the covariance /correlation matrix of the rates of return, we have initially that the number of principal components is equal to the number of the original variables. It is important for the researcher to check rapidly after computation that the principal components are linearly independent. To check that the principal components are linearly independent it suffices to compute their covariance matrix and notice that it is a diagonal matrix with no zero element.
The theory of Principal Component Analysis can be intensively and popularly applied in Sciences, Humanities, Medicine (healthcare), Economics and Finances, Engineering, etc. and it has attracted a considerable research attention the last two decades. It can be used for crime signal detection, determination of the cities dominated by crime, disease signal detection, any feature detection, in crime intelligence, in crime detection, in security intelligence and analytics, in financial fraud detection, in principal disease sign detection, in face recognition, in earthquake signal detection, in tsunami detection, in remote sensing, in performance analysis, in disease diagnostic, in cancer detection, in drug effect estimation, in financial risk estimation, in data Filtering, data denoising, in data Compression for optimal storing and transfer, in noise detection and management, etc. It is used in Geology and Geo-Physics to solve the problem of Earth Quake Detection, Petrol and Mining Exploration, etc. It is used in Cellular and Molecular Biology and also in Medecine to analyze and solve heath problems related to Cardiology, Epidemiology, Cancer detection, the effect of different types of drugs in the human body, etc., in Biology to compare species, in Finances to detect inflation or growth, to detect fraud, to classify financial assets, to select a portfolio of financial instruments contributing the most to the life of the portfolio while minimizing the ones whose actions are negligible. There exist some works carried out on Principal Component Analysis. In Perlibakas (2004) the author proposed PCA or Karhunen-Loeve transform (KLT)-based face recognition method. It was studied by computer scientists and Psychologists and used as a baseline method for comparison of face recognition methods and implemented in commercial applications. Using PCA we find a subset of principal directions (principal components) in a set of training faces. Then we project faces into this principal components space and get feature vectors. Perlibakas (2004) compared 14 distance measures and their modifications between feature vectors with respect to the recognition performance of the pca-based face recognition method and propose modified sum square error (SSE)-based distance. Zong, Marcel and Galvasas (2014) proposed a different reconstruction method to perform compressed sensing by using pca. Such the experiment, demonstrate that this method can reduce analysis. They showed through the experiments, demonstrate that this method can reduce analysis. They showed through the experiments that this method can reduce a liasing artefacts and achieve a high peak signal to noise. Murali (2015) used a simple and efficient method to extract feature vector from images and to reduce the dimension of data. PCA is used for face recognition technique for feature...Khan and Farooq (2011) uses pca and LDA to design a system. It presents the realization of such technologies which demands reliable and error-free high dimensional patterns are not permitted due to eigen-decomposition in high dimensional image space ad degeneration of scattering matrices. Wang, Quanxue, Xinbo and Nie (2017) proposed a novel formulation of PCA, namely angle PCA. Such a formulation was developed to handle the fact that the development of many l1-norm based pca methods do not explicitly consider the reconstruction error and variance of projected data.
In this paper, the theory of Principal Component Analysis is applied to compute and extract the main financial risk factors for each of the portfolios, to determine (for each risk factor) the most dominating stock, to determine the total risk (for each portfolio) and to determine (for each portfolio risk) the stock contributing the most. Risk Estimation is an important issue for financial market operators. There exist many ways of estimating portfolio financial risk. In this paper financial risk is going to be analysed and estimated by using Principal Component Analysis. Such a risk is going to be estimated from a given dataset which is constituted by historical data of stock rates of return. This paper is related to Quantitative Finances, Algorithmic Finance, Data Science and Optimization. The aim is to use an unsupervised machine learning technique called PCA to compute the main financial risk factors for each portfolio and then the portfolio risks. It proposes a way of computing and measuring the financial risk of a stock portfolio.
It is generally known that the PCA technique allows the user to determine the axis which capture the maximum variance of a given dataset. Since financial risk is strongly related to variation of the data, this article aims to see if the PCA can also constitute a way of calculating the risk for a portfolio. Firstly, each multivariate time series for rate of return for stocks was normalized to prepare all the time series to have the same scale to ease the interpretation of the results. Secondly, for each multivariate time series, a covariance matrix was designed and diagonalized. Thirdly, the eigenvalues and the associated eigenvectors were computed. From the eigenvectors, the principal components scores are computed. Such principal components constitute the main factors of risk. From each factor, the dominating stock is extracted. From the eigenvalues, the total risk of the portfolio was computed.
It is stated that to each multivariate time series is associated a portfolio. For each of the portfolios the substantive contributions of this article are the main factors of risk, the proportions of risk explained by the principal components, the dominating stock for each factor, the total portfolio risk and the dominating stock for each portfolio. The main factors of risk are obtained from the eigenvectors of the covariance matrices. The proportions of variances (risks) explained by the principal components are obtained from the eigenvalues of the covariance matrices. Each of the covariance matrices is obtained from a standardized multivariate time series.
The research associated to this paper provides rigorous ways for collecting, cleaning, processing and analyzing financial data, for computing, predicting and managing the associated risk factors which are major issues for the financial market operators and which are very interesting to financial engineers, financial economists, financial mathematicians and financial computer scientists. Such ways can also be adapted in other areas. Since the technique used shows how much variation is captured by the obtain principal components, the PCA technique can also be used to solve Capital Budgeting Design, Financial Portfolio Construction, Portfolio Immunization, Financial Data Compression, Financial Noise Management, Financial Noise Removal, Drug effect on human body, Financial Data Encryption in Cryptography, Image Analysis for Heathcare, Financial Signal Processing and Analysis, Financial Anomaly Detection. It can also be used to predict the feasibility of a Telecommunication system configuration, to predict the feasibility of a Power network system configuration, to predict the performance of a computer network system, to assess the feasibility of a short term or a long term project.
The contributions of this paper are the computation of the main financial risk factors, the determination of the dominating stock for each risk factor, the determination of the dominating stock for the whole portfolio and the computation of the portfolio risk based on the principal components algebraic and statistical properties.
The paper is subdivided into the following sections: Section 2 states precisely the problem. Section 3 describes some linear algebra and algebraic geometry notions associated to the notion of principal component analysis. Section 4 presents briefly the approach to solve the problem. Section 5 solves the problem by applying PCA on each of the three multivariate time series and discusses on the results. Section 5 concludes the article.
Problem Formulation
Given three historical datasets D1,D2andD3. They are associated respectively to the multivariate time series R1,R2andR3where each of them presents as a matrix with M periods of time representing the rows and Nfinancial variables representing the columns. For each multivariate time series, the variables are the rates of return for stocks and constitute respectively the three portfolios π1,π2andπ3. By normalizing (standardizing) each of the above multivariate timeseries and by computing the covariance matrix of each of them we obtain the covariance matrices respectively denoted as Σ1,Σ2andΣ3. Notice that R1, R2andR3are obtained respectively from D1,D2andD3by excluding the first column listing the period of time labels and the first row listing the stock labels. The dataset D1,D2andD3correspond to the portfolios π1,π2andπ3. This paper addresses for each of the portfolios the following problems: Computation and extraction of the main factors of financial risk. Determination of the dominating stock for each of the computed factors. Computation of the resultant of the main factors. Determination of the dominating stock for each resultant. Computation of the total risk.
Linear Algebra, Algebraic Geometry and Multivariate Statistics Background
The questions of this paper take us to the application of some notions of Linear Algebra and Multivariate Statistics. The original reference system of coordinates as well as the new reference system of coordinates spanned a real vector space where the dimension is equal to the number of the original variables. So, the theory of vector space is relevant. The orthogonal transformation of the original reference system of coordinates into the new reference system of coordinates is performed through a linear map. Each eigenvalue of the covariance matrix of the multivariate time series is associated to an eigen subspace which is also a vector space from which a basis of eigenvector(s) can be extracted. The eigenvectors all together form a linearly independent family of vectors. Such vectors lead to the computation of the principal components which shows how relevant is the theory of linear dependence in the principal component analysis as an unsupervised machine learning technique. The principal component analysis as an unsupervised machine learning technique in data analysis is based on the fact that the number of variables is big and that some of the variables in the multivariate time series under study are correlated so that they create redundancy and confusion. One of the aim of the computation of principal components is to remove redundancies in the given multivariate time series by performing orthogonal projection of each of the given financial transactions from the original vector space into the new vector space, the vector space spanned by the set of principal components and by keeping the most relevant principal components, the ones capturing the maximum of variation of the data. This technique consists of linearly grouping the original variables and generate others which must be uncorrelated and thus linearly independent. In the orthogonal projection, the rotation matrix (the matrix storing the eigenvectors as columns) is multiplied by each of the financial transactions to generate new dataset where the underlying variables are linearly independent and from which we can select the most relevant, the ones capturing the maximum of variability of the information. If the new variables undergo the same operations as the original ones the covariance matrix will give a diagonal matrix. When the dataset is very big, one may perform matrix factorization to decompose the underlying matrix and process data in a very judicious way. The computation of eigenvalues and eigenvectors is performed through the solving linear system of algebraic equations. The question aiming to compute the principal components involves the applications of function spaces, projection of a function in a function space without excluding the notion of variance of a random variable which corresponds to the notion of a norm of a vector, norm of a random vector, correlation and covariance between random variables which correspond to the notion of projection of a vector in the direction of another vector also similar to scalar (dot) product between two vectors. The notion of risk(variance) and factors corresponds to that of eigenvalue and eigenvectors.
In tackling the problem using PCA, one must assume that some of the variables which are the rate of return stock time series are linearly correlated. The aim may also be to reduce the number of variables / columns of the associated matrix storing them so that data can be displayed and described in a understandable and efficient manner. We need also to investigate on the variability of the multivariate time series under study and see how each of the stocks contributes to this variability. Indeed, to normalize or standardize a multivariate time series, for each stock time series, the mean must be subtracted from each element of that time series and divided by the standard deviation. Such an operation is performed to normalise the data and change them into the same scale to avoid ambiguous interpretation of results. From the normalized data, compute the covariance / correlation matrix Σ. The covariance matrix Σ, as a symmetric matrix, is subject to a certain number of properties which involve and constrain the range for the eigenvaluesλ1, . . . , λ N and eigenvectors s v1, . . . , v N .
Since the covariance / correlation matrix is symmetric positive definite, then all its eigenvalues are real and positive. It is obviously known that the eigenvalues are the roots of a characteristic polynomial and that the characteristic polynomial of a matrix is obtained by computing the determinant of the matrix obtained by subtracting a diagonal matrix where having the same diagonal on the diagonal from the original matrix.
From the covariance / correlation matrix denoted Σ, construct the characteristic polynomial and the associated characteristic equation to compute the eigenvalues and the associated eigenvectors. Notice that every eigenvector is extracted from the basis of the associated eigensubspace. The transformation is performed such that the first principal component has the highest possible variance and each succeeding principal component has the largest variance and is orthogonal to the preceding.
The first eigenvector (first principal component) is the eigenvector associated with the largest eigenvalue. The second eigenvector is the eigenvector associated with the second largest eigenvalue and is orthogonal to the first principal component. Every following eigenvector is associated to a following eigenvalue and is orthogonal to each of the previous eigenvector. Once all the results of the principal component analysis are obtained, the interpretations and recommendations are based on the size and sign of eigenvalues, the components of the eigenvectors, the proportion of variance that each component explains.
Solution approach to the problem
Three datasets D1,D2andD3are considered. To tackle the problem in a precise way, ∀k = 1, 2, 3do the following: To each dataset D k is associated a multivariate time series R k = R ij . To each multivariate time seriesR k = R ij is associated a portfolio π k . ∀k = 1, 2, 3 R k = R ij can then be displayed as a matrix storing the rates of return during M periods of time and which concern N financial stocks. Thus the matrix R k = R ij has M rows and N columns. We have that ∀i = 1, . . . , M j = 1, . . . , NR k = R ij is the rate of return at period i and for the stock number j, the rate of return in month i and for stock number j.
Indeed, notice that for each of the portfolios we are given N stocks and each stock is concerned with a time series of size M. By picturing, displaying and storing vertically all the time series in a matrix we then have the above-mentioned matrix R k where the rows are the observation periods also called transaction periods and the columns are the variables concerning the stocks. each variable is a rate of return for a certain stock. In this paper every period of time is a month. 30 months are considered for each of the three multivariate time series, and each multivariate time series is associated to a portfolio. In total, for each portfolio we have 30 financial transactions and each transaction involves seven stocks.
Based on the matrix R k , computer programs are written in Matlab and Scilab to compute the covariance matrices, from each covariance matrix the eigenvalues and the associated eigenvectors are computed. Each eigenvalue indicates the proportion of variance explained by its corresponding principal component. From each of the eigenvector components and the original variables we obtain the principal component scores. For each multivariate time series / portfolio the principal components we determine the main factors for the risk. From the expression of each principal component as a linear combination of the original variables, the original variables (rates of return) with the maximum absolute value coefficient is the most dominating. After running the computer programs, we obtain the eigenvalues and for each eigenvalue the associated eigensubspace was obtained from which a basis of the eigenvector was extracted. The eigenvectors give the coefficients of each of the principal components with respect to the original variables. From the eigenvectors, the principal component scores are determined. the Hotelling as well as the means of the original variables are computed.
Application of the PCA to the given dataset (multivariate time series)
Application of the PCA to the first dataset
Introduction
The first given dataset D1 is constituted by the stock time series. D1 is the collection of the time series of stocks. In this case we have 7 stocks. Statistically speaking, D1 is a multivariate time series and store it into Table 1. The rows of D1 in Table 1 are the stock observations (the instantaneous stock rate of return vectors) and the columns are the data variables called stocks. By letting D1 = [X1, X2, X3, X4, X5, X6, X7], we have that Xi = Stock i ∀i = 1, . . . , 7. The columns of Table 1 are represented by the variables X1, X2, X3, X4, X5, X6 and X7. Each of them is a stock rate of return time series of length 30. By letting D1 = (R ij ) we have that R ij is the rate of return at period i of stock j. Let Σ be the covariance matrix of D1. It means that we have Σ = (cov (X i , X j )) , i, j = 1, . . . , 7. The eigenvectors of Σ are linearly independent and spanned a vector space of dimension equal to the number of the original variables which is 7. Their components represent the coefficients of the principal components (new variables) with respect to the original variables (the stocks). They are the columns and are stored in matrix cfA. The matrix cfA can be rewritten and stored explicitly in Table 2. We have that X i , i = 1, …, 7are the original variables and the pc i , i = 1, …, 7are the new variables called principal components, principal axis, principal factors.
Stock Returns during 30 months
Stock Returns during 30 months
Eigenvectors
Table 2 below displays the eigenvectors of the covariance matrix of the dataset defined by Table 1. It displays every eigenvector coefficients with respect to the original variables from whichthe results displayed in Table 2, one can notice the following:
0.6202 is the first column’s maximum value in absolute value. It is the coefficient of the first principal component with respect to variable 5 which is the stock number 5. Thus, the first principal component has the largest positive association with the stock number 5. In other words, stock number 5 is the most dominating variable to the construction of the first factor.
0.7649is the second column’s maximum value in absolute value. It is the coefficient of the second principal component with respect to variable 2 which is the stock number 2. Thus, the second principal component has the largest positive association with the stock number 2. In other words, stock number 2 is the most dominating variable for the construction of the second factor.
0.8079is the third column’s maximum value in absolute value. It is the coefficient of the third principal component with respect to variable 7 which is the stock number 7. Thus, the third principal component has the largest positive association with the stock number 7. In other words, stock number 7 is the most dominating variable for the construction of the third factor.
0.8576is the fourth column’s maximum value in absolute value. It is the coefficient of the fourth principal component with respect to variable 1 which is the stock number 1. Thus, the fourth principal component has the largest positive association with the stock number 1. In other words, stock number 1 is the most dominating variable in the construction of the fourth factor.
0.7062is the fifth column maximum’s value in absolute value. It is the coefficient of the fifth principal component with respect to variable 6 which is the stock number 6. The fifth principal component has the largest positive association with the stock number 6. In other words, stock number 6 is the most dominating variable in the construction of the the fifth factor.
0.6037is the sixth column maximum’s value in absolute value. It is the coefficient of the sixth principal component with respect to variable 6 which is the stock number 6. The sixth principal component has the largest positive association with the stock number 6. In other words, stock number 6 is the most dominating variable in the construction of the sixth factor.
0.8547is the seventh column maximum value in absolute value. It is the coefficient of the seventh principal component with respect to variable 3 which is the stock number 3. The seventh principal component has the largest positive association with the stock number 3. In other words, stock number 3 is the most dominating variable in the construction of the seventh factor.
Derivation of the principal components
It is known that each principal component pcA i , as a new variable, is a linear combination of the original variables X i . The linear combination coefficients are obtained from the orthogonal matrix whose columns are the eigenvectors. Define cfA1, cfA2, cfA3, cfA4, cfA5, cfA6 and cfA7 to be the columns of cfA.
Then we may write cfA = [cfA1, cfA2, cfA3, cfA4, cfA5, cfA6, cfA7] which is the orthogonal matrix of the problem. cfA i is the column number i of matrix cfA.
Define pcA
i
i = 1, . . . , 7 to be the columns of the matrix pcA containing the detailed principal components also called principal component analysis scores. Every pcA
i
is a column vector of length equal to that of every original variable. We obtain the principal component analysis scores by using the following rules:
The principal components pcA i , i = 1, . . . , 7of the given dataset, are columns of pcA.
Each principal component is a linear combination of the original variables. The principal component scores are stored in the matrix pcA. One can notice that the principal components are linearly independent and orthogonal. each row of pcA is obtained by performing orthogonal projection of the corresponding row of D1.
The eigenvalues of Σ are as follows:
The percentage of total variance explained by each principal component are stored in the vector
From the above matrix one can see that the first principal component explains 26.4% of the variance of the data, the second explains 21.1%, the third explains 16.9%, the fourth explains 12.4%, the fifth explains 10.5%, the sixth explains8.2%, and the seventh explains 4.3%. The component number i gives the variance of the principal component number i.
The Hottelings T-squares statistic for each observation are: 8.5422, 3.6803, 10.5643, 2.1607, 6.6421, 3.8776, 8.7216, 6.1998, 15.2258, 11.1648, 6.1408, 6.6841, 7.3681, 2.9614, 4.6807, 7.3765, 8.7605, 1.1035, 6.5842, 5.4048, 7.5054, 5.6638, 4.5312, 4.8147, 7.2122, 7.4761, 5.2448, 7.1830, 7.9925, 11.5326.
The Hotelling T-Squared Statistic, which is the sum of squares of the standardized scores for each observation, is returned as column vector. It is a statistical measure of the multivariate distance of each observation from the center of data. Estimated means of each variable in the original dataset is stored in the matrix MeansA.
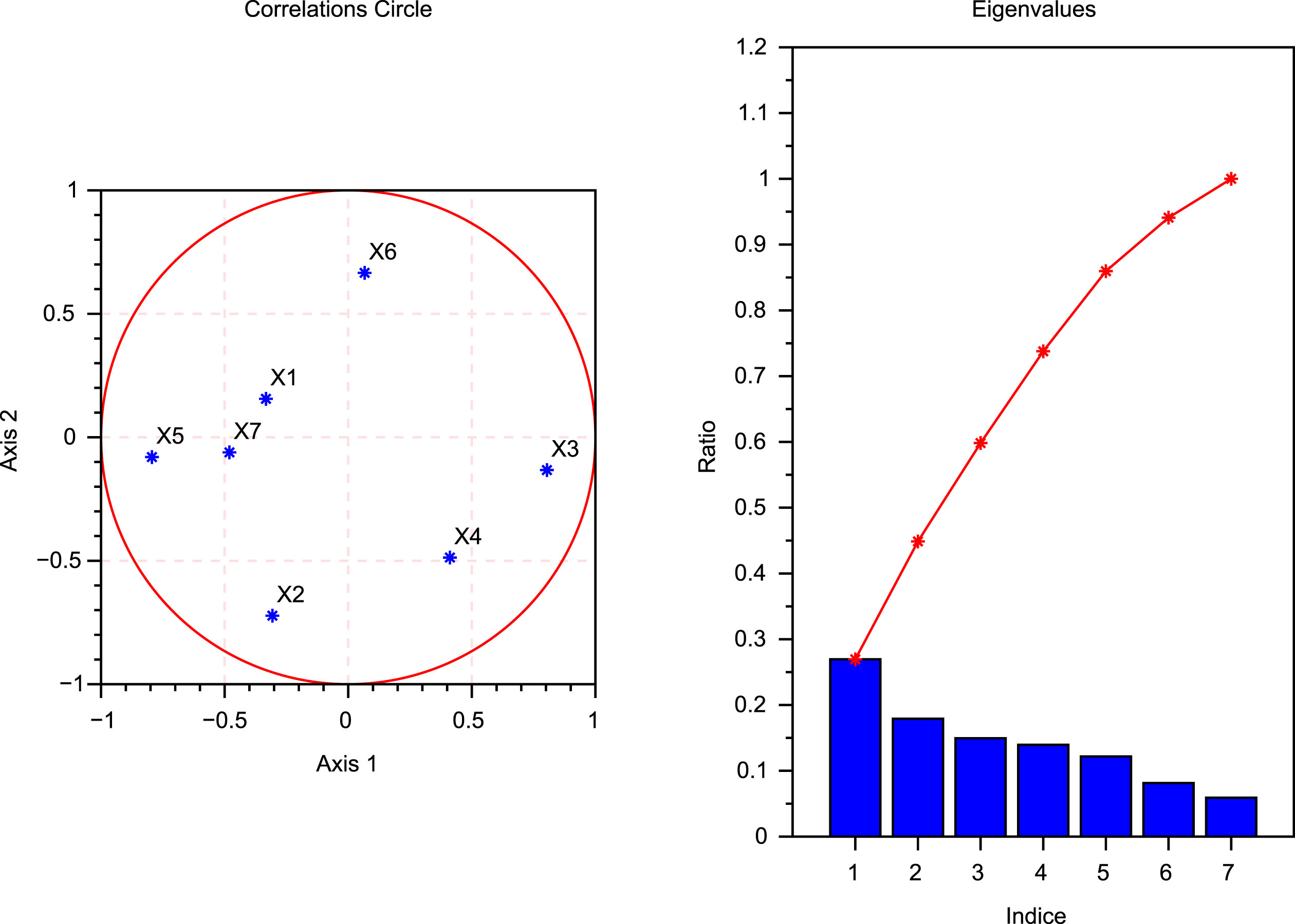
Computational Simulations of Table 1.
Consider the first diagram of the computational simulations of Table 1: Axis 1 is for the first principal component while Axis 2 is for the second principal component. Each of the points x1, x2, x3, x4, x5, x6 and x7 in that coordinate system axis are situated inside the correlation circle. ∀i = 1, 2, 3, 4, 5, 6, 7 we have x
i
= (corr (pcA1, stock
i
) , corr (pcA2, stock
i
)) equivalent to x
i
= (corr (pcA1, X
i
) , corr (pcA2, X
i
)) which can be expanded as follows:
By reconsidering the results in Table 2, notice the resultant of all the principal components is also a linear combination of the original variables and is given by
1.0457X1 + 1.0313X2 + 0.1152X3 + 0.9824X4+0.8281X5 + 1.2478X6 + 1.2734X7. Notice that before tackling the problem, the data of all the original variables are standardised, converted to a same scale and from this obtained resultant we see that the variable number 7 is the one having the maximum coefficient then we conclude that the stock number 7 is the dominating one in the portfolio.
It is known that the portfolio is represented by a multivariate time series of stocks. Such a multivariate time series has undergone a transformation to yield a new multivariate time series. The variables in the original multivariate time series are the stocks and the new variables in the new multivariate time series are the principal components. Such a transformation has consisted on performing orthogonal projection on each financial transactions to give new ones. Notice that this transformation enables to describe the variation of data in an efficient manner. Since the new variables, principal components involve the original ones, they enable to describe the variation of the original data. With the orthogonal transformation of the original data the total risk of the portfolio is conserve. Since the principal component analysis of the data have been applied, we do not need to use the original variables to calculate the portfolio risk. We can use the new variables since they involve the original ones and that the fact for them to be linearly independent ease and simplifies our task. It is known that the financial risk of the portfolio defined by the original dataset is the same as the one defined by the projections of the same data in the new coordinate system. it is also known that the principal components are linearly independent so that there is no correlation between them. Let Ω = (ω i ), i = 1, …, N be the proportion of stock i to be held in the portfolio π1. Then the total risk of the portfolio is
Introduction
The second given dataset D2 is stored in Table 3. The rows of D2 in Table 3 are the stock observations (the instantaneous stock rate of return vectors) and the columns are the data variables called stocks. By letting D2 = [Y1, Y2, Y3, Y4, Y5, Y6, Y7], we have that Yi = Stock i ∀i = 1, . . . , 7. The columns of Table 3 are represented by the variables Y1, Y2, Y3, Y4, Y5, Y6 and Y7. Each of them is a stock rate of return time series of length 30.
Stock Returns during 30 months
Stock Returns during 30 months
By letting D2 = (R ij ) we have that R ij is the rate of return at period i of stock j. Let Σ be the covariance matrix of D2. It means that we have Σ = (cov (Y i , Y j )) , i, j = 1, . . . , 7. The eigenvectors of Σ are linearly independent and spanned a vector space of dimension equal to the number of the original variables which is 7. Their components represent the coefficients of the principal components (new variables) with respect to the original variables (the stocks). They are the columns and are stored in the matrix cfB.
The above matrix can be rewritten and stored explicitly in Table 4.
Eigenvectors
In Table 4 Y1, Y2, Y3, Y4, Y5, Y6 and Y7 represent the original variables of the input dataset and pcB1, pcB2, pcB3, pcB4, pcB5, pcB6 and pcB7 are the new variables, the principal components.
From the results displayed in Table 4, one can notice the following:
0.5233is the first column’s maximum value in absolute value. It is the coefficient of the first principal component with respect to variable number 6 which is the stock number 6. Thus, the first principal component has the largest positive association with the stock number 6. In other words, stock number 6 is the most dominating variable to the construction of the first factor.
0.6350is the second column’s maximum value in absolute value. It is the coefficient of the second principal component with respect to variable number 1 which is the stock number 1. Thus, the second principal component has the largest positive association with the stock number 1. In other words, stock number 1 is the most dominating variable for the construction of the second factor.
0.6250is the third column’s maximum value in absolute value. It is the coefficient of the third principal component with respect to variable number 5 which is the stock number 5. Thus, the third principal component has the largest positive association with the stock number 5. In other words, stock number 5 is the most dominating variable for the construction of the third factor.
0.5540is the fourth column’s maximum value in absolute value. It is the coefficient of the fourth principal component with respect to variable number 6 which is the stock number 6. Thus, the fourth principal component has the largest positive association with the stock number 6. In other words, stock number 6 is the most dominating variable in the construction of the fourth factor.
0.6942is the fifth column maximum’s value in absolute value. It is the coefficient of the fifth principal component with respect to variable number 3 which is the stock number 3. The fifth principal component has the largest positive association with the stock number 3. In other words, stock number 3 is the most dominating variable in the construction of the the fifth factor.
0.6478is the sixth column maximum’s value in absolute value. It is the coefficient of the sixth principal component with respect to variable 7 which is the stock number 7. The sixth principal component has the largest positive association with the stock number 7. In other words, stock number 7 is the most dominating variable in the construction of the sixth factor.
0.6543is the seventh column maximum value in absolute value. It is the coefficient of the seventh principal component with respect to variable 4 which is the stock number 4. The seventh principal component has the largest positive association with the stock number 4. In other words, stock number 4 is the most dominating variable in the construction of the seventh factor.
Derivation of the principal components
Define cfB1, cfB2, cfB3, cfB4, cfB5, cfB6 and cfB7 to be the columns of cfB.
Then we have cfB = [cfB1, cfB2, cfB3, cfB4, cfB5, cfB6, cfB7] which is the orthogonal matrix of the problem. cfB i is the column number i of matrix cfB. In other words, cfB is a matrix containing all the elements of Table 4 except the first row and the first column of that table.
Define pcB
i
i = 1, . . . , 7 to be the columns of the matrix pc containing the detailed principal components also called principal component analysis scores. Every pcB
i
is vector of length equal to that of every original variable. we obtain the principal component analysis scores as follows:
The principal components pcB k , j = 1, . . . , 7of the given dataset, are columns of pcB and stored in Table 3.
Each column of cfBcontains the coefficients for one principal component. Such columns are written in descending order of the variances that the components explain. Each principal component is a linear combination of the original variables. The principal component scores are stored in the matrix pcB.
One can obviously notice that they are linearly independent, orthogonal and generator of the vector space of dimension 7 on the real line. The variances that the principal components explain are stored in the vector λ B .
The Hottelings T-squares statistic for each observation are as follows:
5.3224, 5.0771, 9.0640, 7.1351, 3.5359, 5.1076, 8.7438, 3.9244, 6.6498, 7.4036, 4.6746, 4.7577, 6.2109, 5.3660, 6.0453, 4.5116, 7.4065, 9.5139, 8.2515, 8.4744, 5.3549, 6.6486, 7.8785, 5.7396, 3.1049, 13.2194, 7.3085, 10.5162, 11.8674, 4.1862.
The percentage of total variance explained by each principal component are as follows:
From the above matrix one can see that the first principal component explains 25.9% of the variance of the data, the second explains 20.9%, the third explains 16.1%, the fourth explains11.7%, the fifth explains 10.4%, the sixth explains 9.4%, and the seventh explains5.7%. In general, the i t hprincipal component number explains percentage p of the total variance equal to ratio of the i t h(of the vector storing the eigenvalues) to the sum of all the eigenvalues.
The Hotelling T-Squared Statistic, which is the sum of squares of the standardized scores for each observation, returned as column vector. Hotellings T-Squared Statistic is a statistical measure of the multivariate distance of each observation from the center of data. Estimated means of each variable in D2 is as follows.
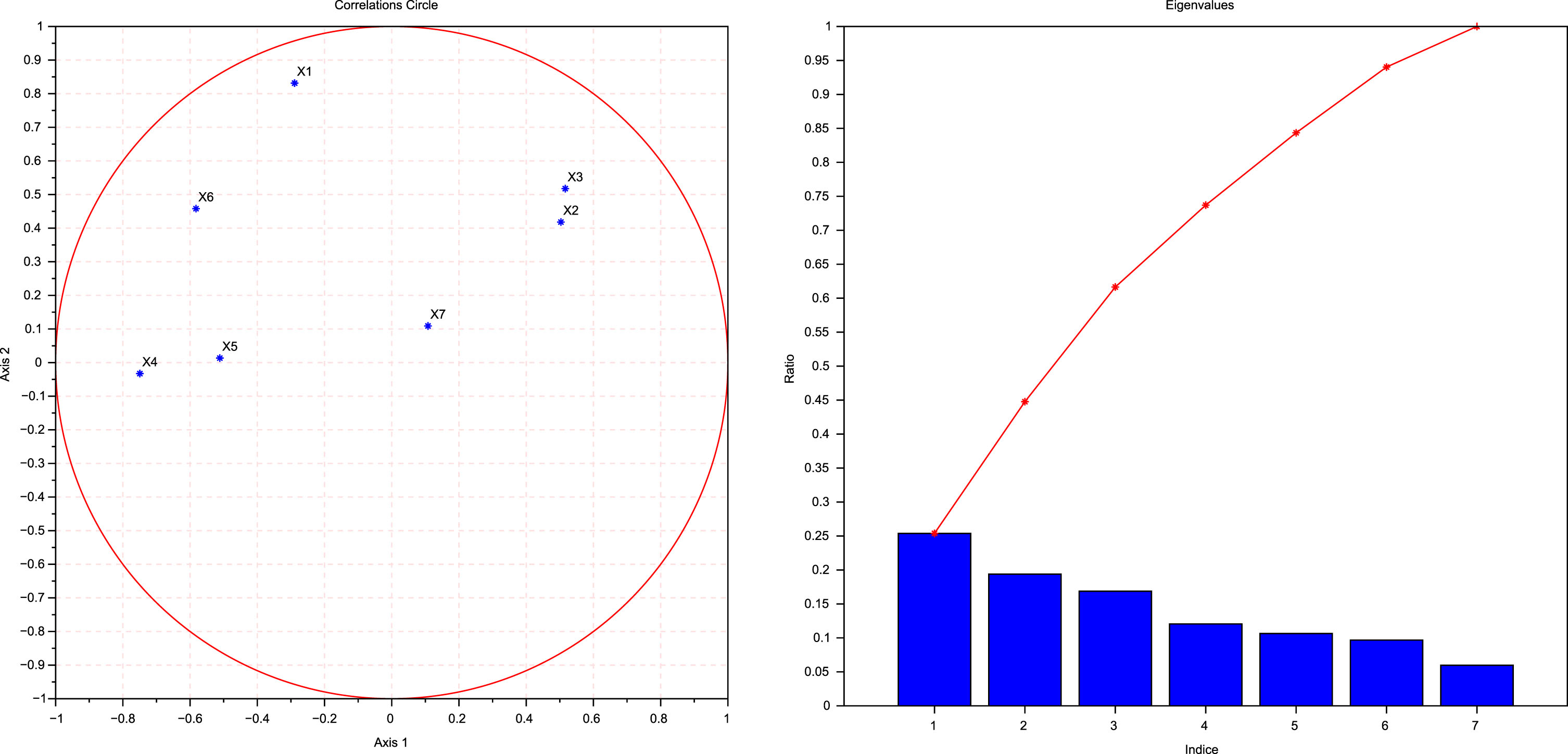
Computational simulations of Table 3.
Consider the first diagram of the computational simulations of Table 3: Axis 1 is for the first principal component while Axis 2 is for the second principal component. Each of the points x1, x2, x3, x4, x5, x6 and x7 in that coordinate system axis are situated inside the correlation circle. ∀i = 1, 2, 3, 4, 5, 6, 7 we have x
i
= (corr (pcB1, stock
i
) , corr (pcB2, stock
i
)) which can be expanded as follows:
By reconsidering the results in Table 4, notice the resultant of all the principal components is also a linear combination of the original variables and is given by
-0.4294Y1+ 0.245Y2 + 0.9171Y3 - 0.1318Y4 +1.2578Y5 + 1.9241Y6 - 0.7801Y7. Notice that before tackling this problem, the data of all the original variables were standardised, converted to a same scale and from this obtained resultant we see that the variable number 6 is the one having the maximum coefficient then we conclude that the stock number 6 is the dominating one in the portfolio.
Like the portfolio of the first dataset, this portfolio is represented by a multivariate time series of stocks. Every transaction of this portfolio is projected onto the space spanned by the principal components to give new transactions. The principal components are sufficient at this stage to compute the portfolio risk since they capture all the informations in an efficient manner. We do not need original variables to compute risk. New variables are sufficient to compute risk. Let Ω = (ω i ), i = 1, …, N be the proportion of stock i to be held in the portfolio π2
Introduction
The third given dataset D3 is stored in Table 5. The rows of D3 in Table 5 are the stock observations (the instantaneous stock rate of return vectors) and the columns are the data variables called stocks. By letting D3 = [Z1, Z2, Z3, Z4, Z5, Z6, Z7], we have that Zi = Stock i ∀i = 1, . . . , 7. The columns of Table 5 are represented by the variables Z1, Z2, Z3, Z4, Z5, Z6 and Z7. Each of them is a stock rate of return time series of length 30.
By letting D3 = (R ij ) we have that R ij is the rate of return at period i of stock j. Let Σ be the covariance matrix of D3. It means that we have Σ = (cov (Z i , Z j )) , i, j = 1, . . . , 7. The eigenvectors of Σ are linearly independent and spanned a vector space of dimension equal to the number of the original variables which is 7. Their components represent the coefficients of the principal components (new variables) with respect to the original variables (the stocks). They are the columns and are stored in the matrix cfC.
The given dataset D3 is stored in Table 5.
Stock Returns during 30 months
Stock Returns during 30 months
The rows of D3 are the observations and the columns are the variables called stocks. The principal component coefficients for the given dataset X3 are as stored in the matrix.
The above matrix can be rewritten as follows:
Each column of cfC contains the coefficients for one principal component. Such columns are in descending order of the component variances. Each principal component is a linear combination of the original variables. The principal component scores are stored in the matrix In Table 6 Z1, Z2, Z3, Z4, Z5, Z6 and Z7 represent the original variables of the third input dataset and pcC1, pcC2, pcC3, pcC4, pcC5, pcC6 and pcC7 are the new variables, the principal components.
Eigenvectors
From the results displayed in Table 6, one can notice the following:
0.5590is the first column’s maximum value in absolute value. It is the coefficient of the first principal component with respect to variable number 5 which is the stock number 5. Thus, the first principal component has the largest positive association with the stock number 5. In other words, stock number 5 is the most dominating variable to the construction of the first factor.
0.5907is the second column’s maximum value in absolute value. It is the coefficient of the second principal component with respect to variable number 1 which is the stock number 1. Thus, the second principal component has the largest positive association with the stock number 1. In other words, stock number 1 is the most dominating variable for the construction of the second factor.
0.7661is the third column’s maximum value in absolute value. It is the coefficient of the third principal component with respect to variable number 6 which is the stock number 6. Thus, the third principal component has the largest positive association with the stock number 6. In other words, stock number 6 is the most dominating variable for the construction of the third factor.
0.6342is the fourth column’s maximum value in absolute value. It is the coefficient of the fourth principal component with respect to variable number 6 which is the stock number 4. Thus, the fourth principal component has the largest positive association with the stock number 4. In other words, stock number 4 is the most dominating variable in the construction of the fourth factor.
0.8389is the fifth column maximum’s value in absolute value. It is the coefficient of the fifth principal component with respect to variable number 3 which is the stock number 3. The fifth principal component has the largest positive association with the stock number 3. In other words, stock number 3 is the most dominating variable in the construction of the the fifth factor.
0.6726is the sixth column maximum’s value in absolute value. It is the coefficient of the sixth principal component with respect to variable 2 which is the stock number 2. The sixth principal component has the largest positive association with the stock number 2. In other words, stock number 2 is the most dominating variable in the construction of the sixth factor.
0.8551is the seventh column maximum value in absolute value. It is the coefficient of the seventh principal component with respect to variable 7 which is the stock number 7. The seventh principal component has the largest positive association with the stock number 7. In other words, stock number 7 is the most dominating variable in the construction of the seventh factor.
Derivation of the principal components
Define cfC1, cfC2, cfC3, cfC4, cfC5, cfC6 and cfC7 to be the columns of cfC.
Then we have cfC = [cfC1, cfC2, cfC3, cfC4, cfC5, cfC6, cfC7] which is the orthogonal matrix of the problem. cfC i is the column number i of matrix cfC. In other words, cfC is a matrix containing all the elements of Table 4 except the first row and the first column of that table.
Define pcC
i
i = 1, . . . , 7 to be the columns of the matrix pc containing the detailed principal components also called principal component analysis scores. Every pcC
i
is vector of length equal to that of every original variable. we obtain the principal component analysis scores as follows:
The principal components pcC k , j = 1, . . . , 7of the third given dataset, are columns of the matrix pcC.
Each column of cfCcontains the coefficients for one principal component. Such columns are written in descending order of the variances that the components explain. Each principal component is a linear combination of the original variables. The principal component scores are stored in the matrix pcC.
One can notice that they are linearly independent, orthogonal and generator of a vector space of dimension 7 on the real line. The principal component variances are store in the vector
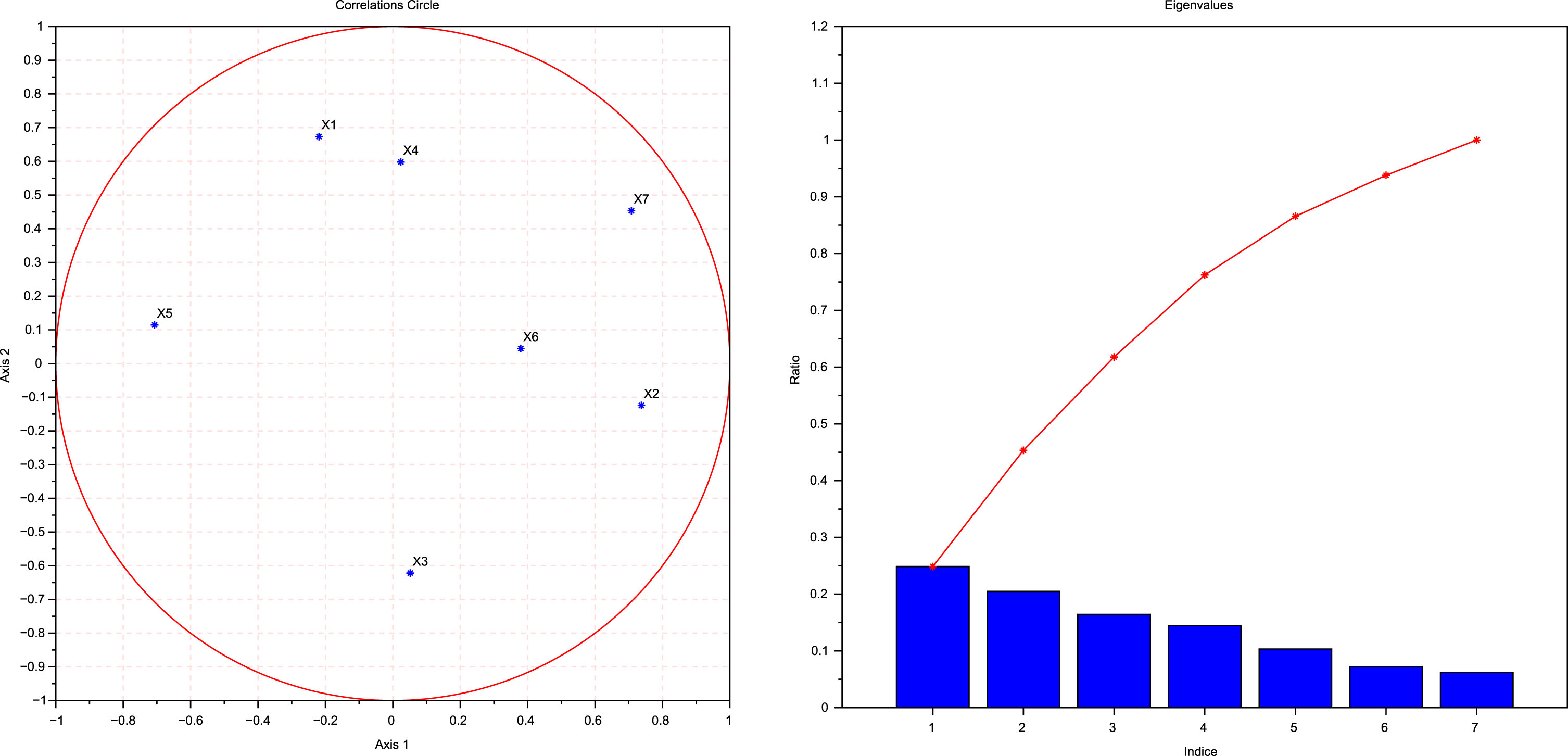
Computational simulations of Table 5.
The Hottelings T-squares statistic for each observation are
4.6474, 8.7695, 8.2686, 12.7156, 8.3218, 13.1801, 5.0752, 5.1374, 8.1940, 7.8769, 9.6110, 6.7539, 5.3577, 4.7498, 7.7517, 8.5354, 6.6269, 6.8349, 3.7165, 5.8610, 4.5746, 7.4329, 4.4709, 5.3213, 6.3937, 6.8974, 5.3588, 6.7165, 3.7167, 4.1318.
The percentage of total variance explained by each principal component are stored in the vector
From the above matrix one can see that the first principal component explains 24.7% of the total variance of the data, the second explains 19.7%, the third explains 18.6%the fourth explains 14.8%the fifth explains9.7%the sixth, explains 7.2%, and the seventh explains 5.2%. The principal component number i explains an amount of percentage (of the total variance of the data) equal to the component number i of the vector storing the eigenvalues.
The Hotelling T-Squared Statistic, which is the sum of squares of the standardized scores for each observation, returned as column vector. Hotellings T-Squared Statistic is a statistical measure of the multivariate distance of each observation from the center of data. Estimated means of each variable in D3 is as follows.
Consider the first diagram of the computational simulations of Table 5: Axis 1 is for the first principal component while Axis 2 is for the second principal component. Each of the points x1, x2, x3, x4, x5, x6 and x7 in that coordinate system axis are situated inside the correlation circle. ∀i = 1, 2, 3, 4, 5, 6, 7 we have x
i
= (corr (pcB1, Z
i
) , corr (pcB2, Z
i
)) which can be expanded as follows:
By reconsidering the results in Table 6, notice the resultant of all the principal components is also a linear combination of the original variables and is given by
0.4820Z10.2603Z2 + 0.5794Z3 + 1.8800Z4+1.1719Z5 - 0.2710Z6 + 1.1762Z7. Notice that before tackling this problem, the data of all the original variables were standardised, converted to a same scale and from this obtained resultant we see that the variable number 4 is the one having the maximum coefficient then we conclude that the stock number 4 is the dominating one in the portfolio.
Like the portfolio of the first and the second datasets, this portfolio is represented by a multivariate time series of stocks. Every transaction of this portfolio is projected onto the space spanned by the principal components to give new transactions. The principal components are sufficient at this stage to compute the portfolio risk since they capture all the informations in an efficient manner. We do not need necessarily the original variables to compute risk. New variables are sufficient to compute risk. Let Ω = (ω i ), i = 1, …, N be the proportion of stock i to be held in the portfolio π3. Then the risk is as follows:
The aim of this article was to apply principal component analysis to compute the main factors of the financial risk for each of the three considered portfolios, to extract the dominating stock for each computed factor of risk and for each portfolio and finally to compute the total risk for each portfolio. For each portfolio, the obtained eigenvalues of the covariance matrix determine the risks of the principal components which give the proportion of variance explained by the principal components. The associated eigenvector components determine how strong the principal components are connected to the original variables and determine the dominating variable for each main factor of risk. For each portfolio the dominating stock is determined. The Unsupervised Machine Learning technique used in this article involves notions of Linear Algebra, Multivariate Calculus, Probabilities, Mathematical Statistics and Algorithm development.
Footnotes
Acknowledgment
This work was supported by the University of Johannesburg.