
Abstract
We present an algorithmic trading strategy based upon a graph version of the dynamic mode decomposition (DMD) model. Unlike the traditional DMD model which tries to characterize a stock’s dynamics based on all other stocks in a universe, the proposed model characterizes a stock’s dynamics based only on stocks that are deemed relevant to the stock in question. The relevance between each pair of stocks in a universe is represented as a directed graph and is updated dynamically. The incorporation of a graph model into DMD effects a model reduction that avoids overfitting of data and improves the quality of the trend predictions. We show that, in a practical setting, the precision and recall rate of the proposed model are significantly better than the traditional DMD and the benchmarks. The proposed model yields portfolios that have more stable returns in most of the universes we backtested.
Introduction
Stock price prediction is a very challenging problem in finance. Stock price series are non-linear, non-stationary, and dependant on a multitude of factors. To exploit market inefficiencies, we adopt a technical analysis approach, which tries to identify trading opportunities by analyzing statistical trends gathered from historical traded prices and volumes. Algorithms based on technical analysis are typically rooted in sophisticated statistical or mathematical models. Signal decomposition is an advanced data analysis technique, which identifies oscillating patterns at different time scales existed in time series. Commonly used decomposition methods include Fourier transform, dynamic mode decomposition (Rowley et al., 2009; Schmid & Sesterhenn 2008; Schmid, 2010; Kutz et al., 2000), empirical mode decomposition (Huang et al. 1971) and super empirical mode decomposition (Chui & Mhaskar, 2016). In this work, we adopt the dynamic mode decomposition (DMD) for its ability to extract the growth, decay, and oscillating rates of time series, which is very useful to the modeling of stock prices. Moreover, DMD is a spatial-temporal analysis tool that can be applied to multiple time series to identify the collective behaviours of multiple stocks.
Research on DMD is prolific; a lot of theories and extensions have been studied. We refer the readers to Kutz et al. (2000) and Schmid (2022) for thorough overviews of the subject. Originally proposed for the analysis of fluid mechanics, DMD is an effective method to extract low-dimensional non-linear dynamics of complex systems. It is an equation-free method which does not require the specification of a physical model. It adopts a data-driven approach to learn the dynamics of the system by extracting various modes and their growth and oscillation rates. It is proven to yield promising results in areas such as sociology, epidemiology, neuroscience, and physics (Centola & Macy 2007; Bullmore & Sporns 2009). In applications such as fluid mechanics, dynamics are governed by physical laws and some governing equations have been devised in many settings. But DMD can help when the existing models fail to capture the dynamics accurately in some situations.
The application of DMD in finance was pioneered by Mann & Kutz (2016) and Hua et al. (2016). As there are no governing equations for stock prices, data-driven approach becomes especially viable. In Mann & Kutz (2016), DMD is applied to predict prices of stocks in specific industry sectors, where some good results are found in the transportation, home construction, and retail sectors. The interesting notion of hotspots is introduced to guide the choice of the forecast horizon and the lookback period that lead to robust predictions. The results are obtained using several selected industry sectors with some small numbers of stocks (about 10). We, however, aim to develop a method that generates larger and more diversified portfolios from some generic pools of stocks. In Hua et al. (2016), DMD is used to extract cycles exhibited in the historical stock price time series that are robust to the sampling rate. DMD has also been used in Cui & Long (2016) and Kuttichira et al. (2017) to develop trading strategies and tested on different stock markets. They use the same method as in Mann & Kutz (2016) to produce predicted prices, but they differ in the generation of the trading signals (buy/sell/hold) from the predicted prices.
In this paper, we aim to further develop the DMD model in Mann & Kutz (2016), so that it can extract the trends of price series better and obtain portfolios that are more favourable. As stock markets are very dynamic, the good results obtained in backtests on small sectors are often non-reproducible in live trading. To this end, it is desirable to develop a model that can select stocks from some larger pools of stocks effectively. For example, stocks in a market index or smart beta Exchange-Traded Fund (ETF) are good candidates. Moreover, such stocks usually have large market capitalizations which make them less likely to be influenced a few major investors and are usually more liquid so that they are less likely to suffer from trading problems and large slippage. We find that if we directly apply the traditional DMD to universes of dozens of stocks, the recall rates (for upward trend predictions) are often low albeit their high precision rates. As a result, the number of selected stocks will be small and the portfolios constructed often exhibit high volatility and large drawdowns even in bull markets. This can be attributed to the problem of overfitting for the number of model parameters of DMD scales quadratically with the number of stocks. We therefore propose to embed a graph model into DMD to achieve a model reduction. We name the proposed model Graph Embedded Dynamic Model Decomposition (GEDMD). The method dynamically determines, for each stock, its most relevant stocks for predictions. Then the DMD technology is used to estimate the dynamics of the stock prices and make predictions. We find that the model can find stocks that are missed by the traditional DMD and construct portfolios that are more diversified and have more stable returns.
In Section 2, we present the DMD method for estimating the dynamics of multiple stocks. In Section 3, we present the proposed GEDMD method. The method consists of a graph construction procedure and a DMD-like optimization model. In Section 4, we present the experimental results to evaluate performance of the model in trading and the quality of the signals.
The dynamic mode decomposition
In this section, we describe the dynamic mode decomposition (DMD) method in a way convenient to the development of the proposed model presented in the next section. For other formulations and their deeper relations to the Koopman theory and system of differential equations, we refer the reader to Kutz et al. (2000).
Consider a universe comprising N stocks. Let t1 < t2 < ⋯ < t
M
be the time points in a time window, in which the stock prices have been observed. Suppose that we would like to predict the price (or trend) at a future time, say tM+τ. Denote by
which maps from the feature space of the j-th stock to the feature space of the i-th stock. The above model resembles the multivariate Markov chain model in Ching et al. (2002) and Ching et al. (2003), but the feature vectors in these work are probability distributions of states and the operator
We remark that in Mann & Kutz (2016), Cui & Long (2016), Kuttichira et al. (2017), the feature vectors
We also remark that in Mann & Kutz (2016), Cui & Long (2016), Kuttichira et al. (2017), the horizon is set to τ = 1. To make a prediction of τ periods, the operator
To obtain the operator
In computational fluid dynamics, each Compute a reduced singular value decomposition (SVD) of Compute a similarity transform of Compute an eigenvalue decomposition of Obtain the eigenvectors and eigenvalues of
The idea here is that the matrix size of
In the original DMD, the model (1) produces a prediction for a stock by combining the feature vectors of all stocks. For each stock, there are L2N unknown parameters in
The idea of the proposed method is very natural. In stock modeling, we expect the price of one stock to be more related to a small number of stocks from related industries than others. We first construct a directed graph that depicts the relevance of a stock in the prediction of the price of another stock. The construction method will be presented in the next subsection. Once a graph, represented with an adjacency matrix
We note that the model in Salova et al. (2019) considers a block diagonal structure of
Graph Construction
The graphs that we use are unweighted, directed graphs with self-loops. We shall use the terms “graph” and “adjacency matrix” interchangeably. When selecting variables in regression algorithms, one often looks into the correlations between variables. Predictor variables that have little correlations to the response variable may be dropped, whereas predictor variables that are highly correlated may be compressed via dimension reduction techniques. It is therefore intuitive to rank the variables based on absolute correlations. In the analysis of time series of stock prices, it is common to calculate correlations based on the time series of daily simple return r i (t j ) = s i (t j )/s i (tj-1) -1 or daily log-return r i (t j ) = ln(s i (t j )/s i (tj-1)) Tsay (2010). Both kinds of return yield similar correlations, we use the daily simple return for its intuitive interpretation. In the prediction of a stock’s price, we use only its top k correlated stocks (including the stock itself) whose absolute correlations pass a test of statistical significance. Specifically, we determine the 99% confidence interval for each absolute correlation and require that the lower bound of the interval lies above a threshold c > 0, so that the interval is well above zero. For each stock, the number of selected stocks varies between 1 and k inclusively.
Mathematical Formulation
We present a formulation to embed a graph into DMD. For a given graph
In the rest of this subsection, we describe the main ideas of our method to solve the above minimization problem efficiently. In the next subsection, we will describe a regularized version to enhance the stability of the method. The regularized version is the ultimate method to propose, whose performance will be evaluated in the Section 4.
Consider Stock i and its neighbors
The stability of the minimization problem
We remark that a few other regularized DMD methods have been studied. They include Dicle et al. (2016), Takeishi et al. (2017), and Schmid (2022).
We test the proposed GEDMD model in two different aspects: 1) signal quality (precision and recall rates), and 2) trading performance. We compare the performance of GEDMD with DMD and some benchmarks. We also demonstrate the effectiveness of the regularization used.
Investment Objectives
While making profits is the ultimate investment goal, we view the GEDMD model as a basic tool used to form a part of a larger portfolio, and therefore, we evaluate the model on various aspects besides the return. Fund managers need different tools in different market conditions and to cater the risk appetite of different investors. Tools that can generate small but steady excess incomes are valuable. Specifically, if a model can generate an excess return over an off-the-shelf liquid traded instrument consistently over time, then the two instruments can form a hedged pair to generate positive incomes. It is also comfortable to leverage it to boost the return. On the other hand, models that show very high returns in backtests often bet on a small number of stocks and thus may suffer from concentration risks. Such models can be attractive at times, but the capital allocation should be exercised with caution, not to mention leveraging.
Datasets
In view of the aforementioned investment objectives, we test the performance of GEDMD with the eleven GICS industrial sectors of the S&P 500 index. Their underlying stocks make up the S&P 500 index and thus they represent the US market well. These sectors can be traded via exchange-traded funds (ETFs) which are summarized in Table 1. For each of these eleven universes, we compare the ETF (the benchmark) with DMD and GEDMD applied to the underlying stocks of the ETF. These ETFs have large capitalizations and are liquid, making them good candidates for comparison. For evaluation purposes, all the eleven universes are used. But the energy sector is volatile and consists of only a small number of stocks. So, trading on this universe exhibits high uncertainty. In fact, the ETF, which tracks the sector index, has only a 1% return in 2019–2021, see Table 1. We also do not filter the stocks, which may introduce biases.
Universes used in the experiments. The underlying stocks are as of 11/16/2021. The returns are for the period from 1/1/2019 to 11/15/2021
Universes used in the experiments. The underlying stocks are as of 11/16/2021. The returns are for the period from 1/1/2019 to 11/15/2021
The backtests are done for the period of 1/1/2019 to 11/15/2021. Time series of adjusted daily close prices are used. To examine the effects of introducing a graph structure into DMD, we compare GEDMD with the traditional DMD using a fixed set of parameters of τ = 20, L = 30, and M = 120. The parameters are set for practical reasons. In trading, a holding period of 1 month (approximately 20 trading days) allows for a predicted trend to develop. A shorter period may only reflect the volatility of the stocks. It is also desirable to rebalance portfolios monthly. In our experience, predictions with longer horizons using DMD-type methods often lead to poorer results as the dynamics are heterogenous.
To understand the behaviour of the models, we study the quality of the predictions in terms of precision and recall rates. The recall and precision rates are defined by
The average recall rates for the universes and the respective standard deviations are reported in Table 2. The GEDMD yields higher recall rates than the DMD across all thresholds. This indicates that GEDMD captures a larger number of stocks with an uptrend. This helps in the diversification of the portfolios. Notice that even if a prediction is deemed “wrong”, it may still generate a positive return. Readers are referred to Table 4 for the actual returns.
Performance statistics: Average recall for the universes (%). The respective standard deviations are shown in the brackets
Performance statistics: Average recall for the universes (%). The respective standard deviations are shown in the brackets
The average precision for the universes and the respective standard deviations are reported in Table 3. The baseline gives the prior distribution of the uptrend stocks. We see that the GEDMD yields higher precisions than the DMD and the baseline when the threshold is 5% or larger. However, when the threshold is lower than 5%, the precisions of the different methods are close. This is reasonable because a small predicted return is comparable to the intrinsic volatility of the stock. The standard deviations of GEDMD agree with that of the basline, showing the inherent variability among the universes. Note that the precisions give the probability of making a correct prediction. We will see in the trading experiments that the improved precision of GEDMD leads to an attractive excess return over the baseline when the portfolio involves hundreds of trades (predicted positives) over three years.
Performance statistics: Average precision for the universes (%). The respective standard deviations are shown in the brackets
In this subsection, portfolios of stocks from a universe are formed and are rebalanced monthly. On each rebalancing day, the models select stocks that are predicted to have an upward trend for the next period of time. A stock is classified as “UP” if the predicted return is higher than a threshold, which we will vary from 1% to 10%. The selected stocks will take long positions and will be held until the next rebalancing day. We trade only the long positions because in practice short positions are sometimes difficult to fully fill timely. All available capital will be invested/reinvested. The capital will be equally divided among the selected stocks. No stop-loss or take-profit rules are used.
In production, additional measures such as setting entry price limits, stop-loss, take-profit, capital allocation, and portfolio weights optimization should be taken. The choice of these rules can significantly affect the performance. To investigate the performance due to the GEDMD and DMD predictions, we isolate factors due to trading rules.
To avoid overwhelming with many statistics and to provide more reliable statistics, the average returns for the universes and the respective standard deviations are reported in Table 4. The GEDMD yields higher returns than the DMD and the benchmark across all thresholds. The return of GEDMD also shows in increasing trend with the threshold. This indicates that stocks that have a high predicted return (e.g. 10%) exhibit a stronger upward trend and are more likely to yield a positive return than stocks that have a low predicted return (e.g. 1%). When the threshold is 10%, the excess return of GEDMD is about 26.0%, annualized to 8.6%, which is quite good for such a diversified portfolio. The return of DMD does not show an increasing trend. This is related to the number of selected stocks and the low recall rate. The standard deviations reflect the diversity of the performance of the universes. GEDMD exhibits a slight increasing trend of the standard deviation with the return, which is the usual trade-off between return and risk. But we will see in Table 5 that the Sharpe ratios remain steady.
Performance statistics: Average return (standard deviation) for the universes (%). The respective standard deviations are shown in the brackets
Performance statistics: Average return (standard deviation) for the universes (%). The respective standard deviations are shown in the brackets
Performance statistics: Average Sharpe ratio (standard deviation) for the universes. The respective standard deviations are shown in the brackets
The average Sharpe ratios for the universes and the respective standard deviations are reported in Table 5. The GEDMD yields higher Sharpe ratios than the DMD across all thresholds and the baseline in 9 of the 10 thresholds. Thus, GEDMD is able to select stocks in a universe dynamically to improve the Sharpe ratio of the universe. The Sharpe ratio of GEDMD is quite robust to the threshold. The DMD shows a higher variability in the statistic.
To see the performance on the individual universes, the average returns for the thresholds are depicted in Table 6 universe. The GEDMD outperforms the DMD in 8 of the 11 universes and outperforms the baseline in 7 of the 11 universes. The DMD gives outstanding returns in XLE (energy) and XLY (consumer discretionary).
Performance statistics: Average return for the thresholds (%). The respective standard deviations are shown in the brackets. GEDMD has the highest excess return in XLV. DMD has the highest excess return in XLY
To compare the portfolios on a daily basis, we choose XLV and XLY to illustrate. The GEDMD and DMD have the highest excess returns over the benchmark in XLV and XLY, respectively. The portfolio values (per dollar initial investment) are shown in Fig. 1 and Fig. 2.
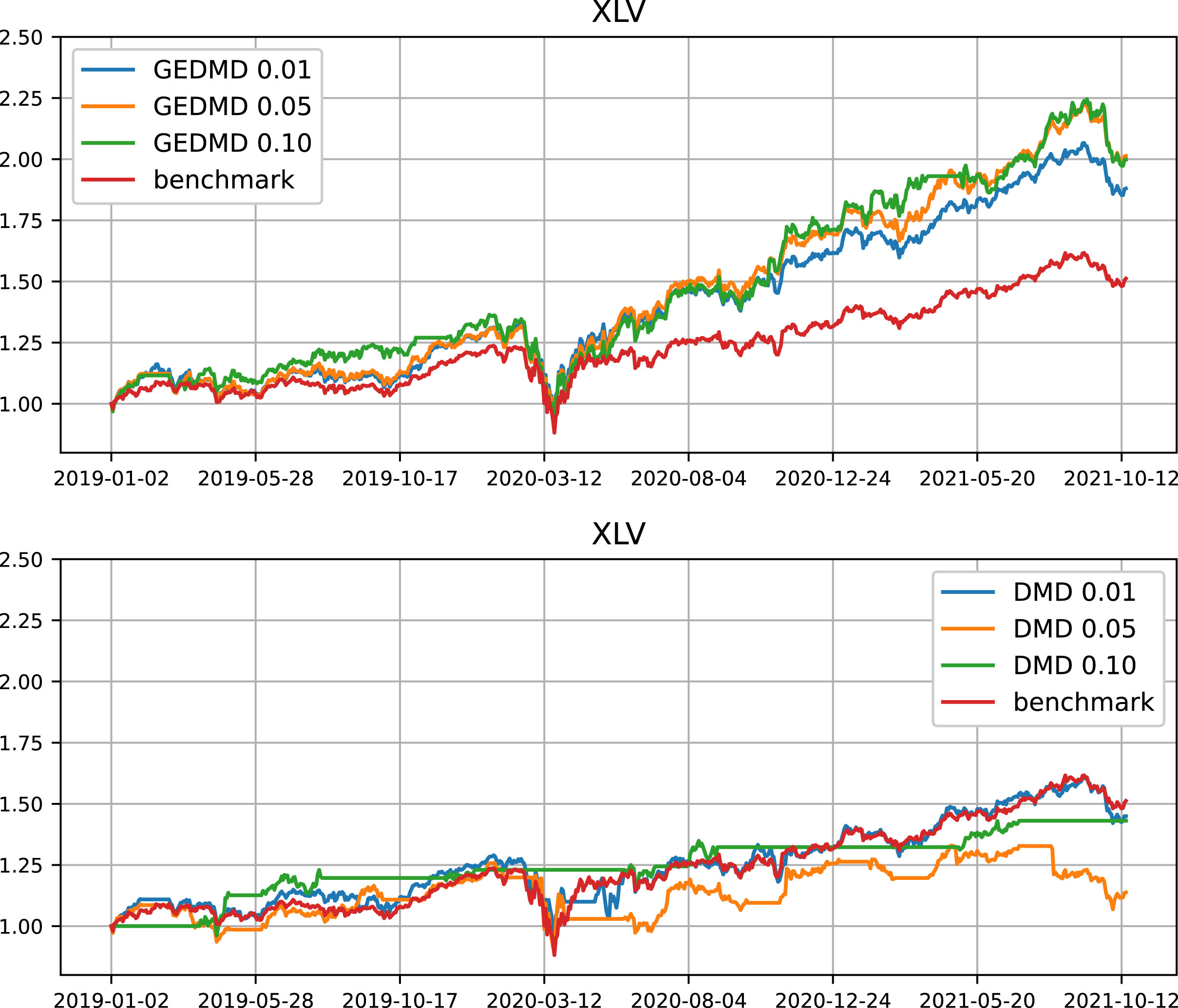
Trading performance in the XLV universe. Portfolio value per unit initial investment. This universe is chosen in favour of GEDMD. Note that GEDMD outperforms DMD in 8 of the 11 universes.
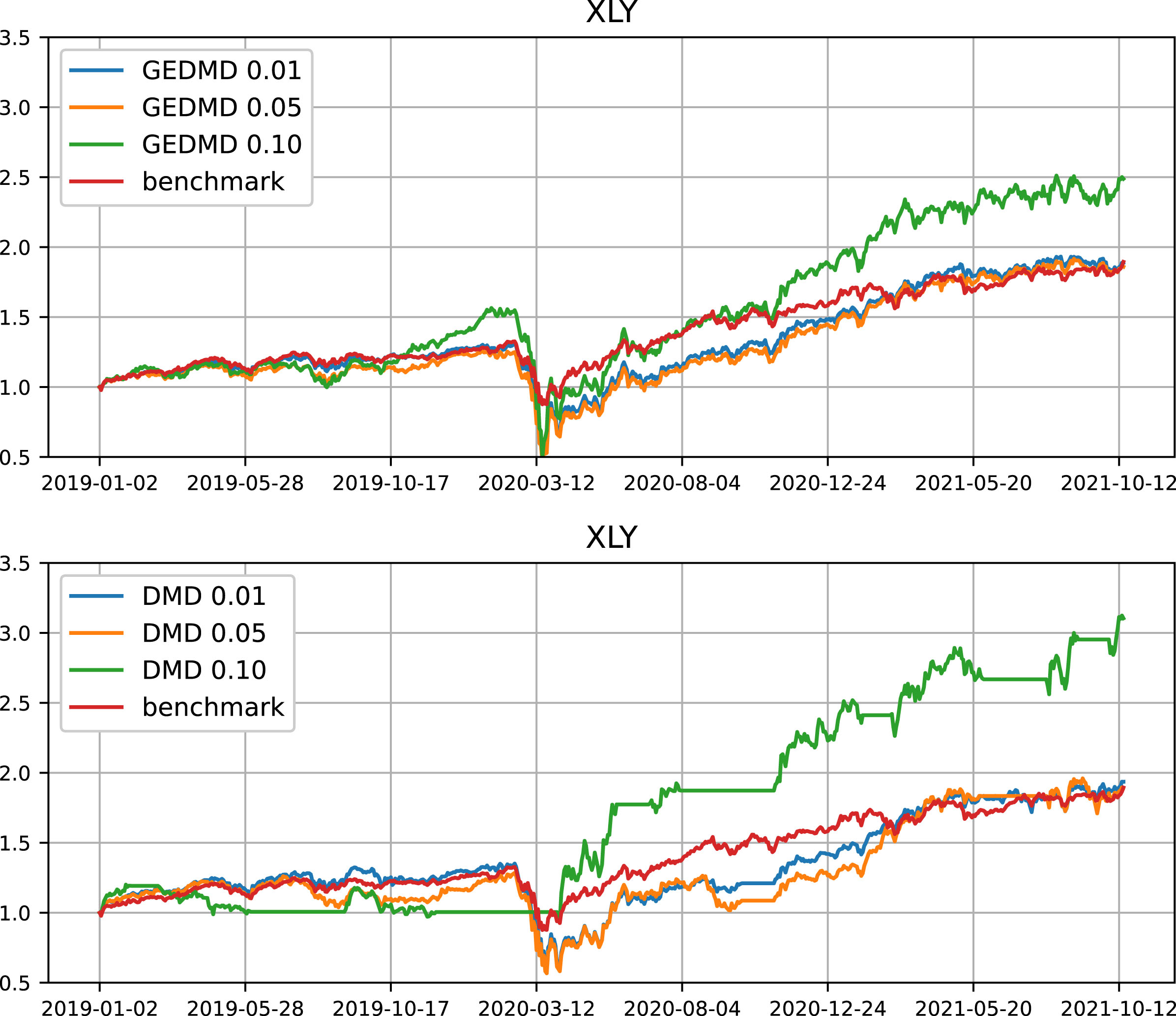
Trading performance in the XLY universe. Portfolio value per unit initial investment. This universe is chosen in favour of DMD. Note that GEDMD outperforms DMD in 8 of the 11 universes.
In Fig. 1, the GEDMD yields very consistent excess returns over time. The results are also robust to the choice of the threshold. The portfolios generally dropped during the market crash in 2020Q1 due to covid-19. Such infrequent black-swan events cannot be predicted with the models. Trading rules such as stop-loss should be imposed to limit the loss, but as mentioned above, it is not our purpose to study trading rules in this paper. The performance of DMD in the XLV universe is poor. With a threshold of 1%, it follows closely with the benchmark, meaning that most of the stocks in the universe are selected. With a threshold of 10%, there are many flat regions, indicating that no stocks are selected even though XLV has 64 stocks. The investment is halted for excessive long periods and has avoided the down markets. It reaches the same final return as the benchmark at the end. But it puts the capital into a very small number of stocks. There are only trades 33 times during the 3-year period.
Fig 2 shows a good case of DMD. For DMD, with a threshold of 1% and 5%, the performance is similar to the GEDMD and the benchmark. However, with a threshold of 10%, the return increases significantly. This is again due to the concentration on a small number of stocks. For example, in April 2019, DMD selects only one stock, namely, Align. This stock has a prolonged uptrend prior to April 2019 and is detected by DMD. We also see that the portfolio value is doubled in 2020Q2. But this kind of behaviour does not occur in all 11 universes. It is important to consider the average behaviour too. For GEDMD, it has a large drawdown in 2020Q1 and a pronounced rebound afterwards. The capital is indeed quintupled from $0.5 to $2.5.
To demonstrate the effectiveness of the regularization in Equation (3), we show the daily condition number of the least-squares problem for the XLV and the XLY universes in Fig. 3. For comparison purposes, we also include the condition number of the truncated SVD regularization, which is another commonly used regularization method. In truncated SVD, singular values of
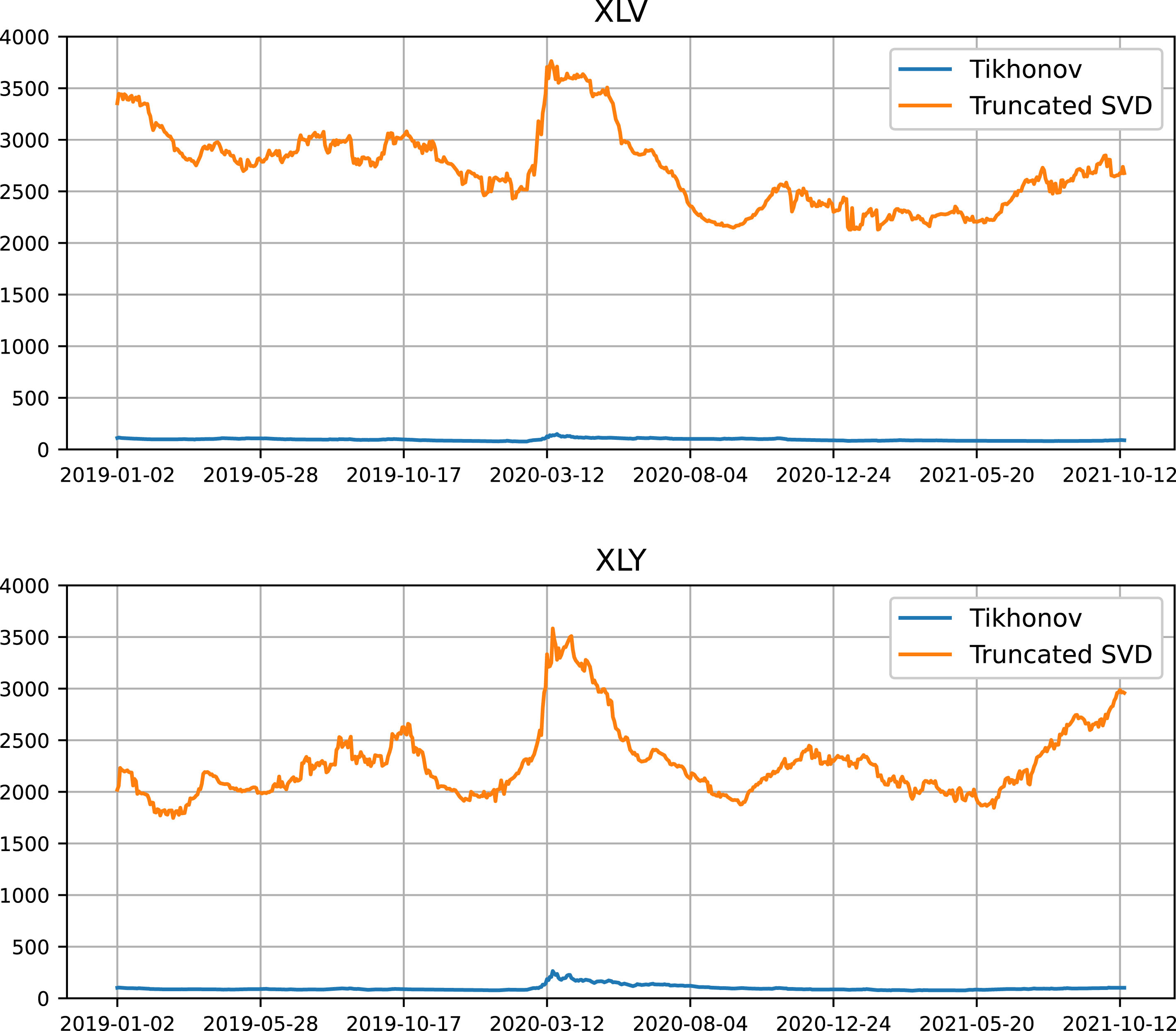
Daily condition number of minimization problems in GEDMD in the XLV and XLY universes.
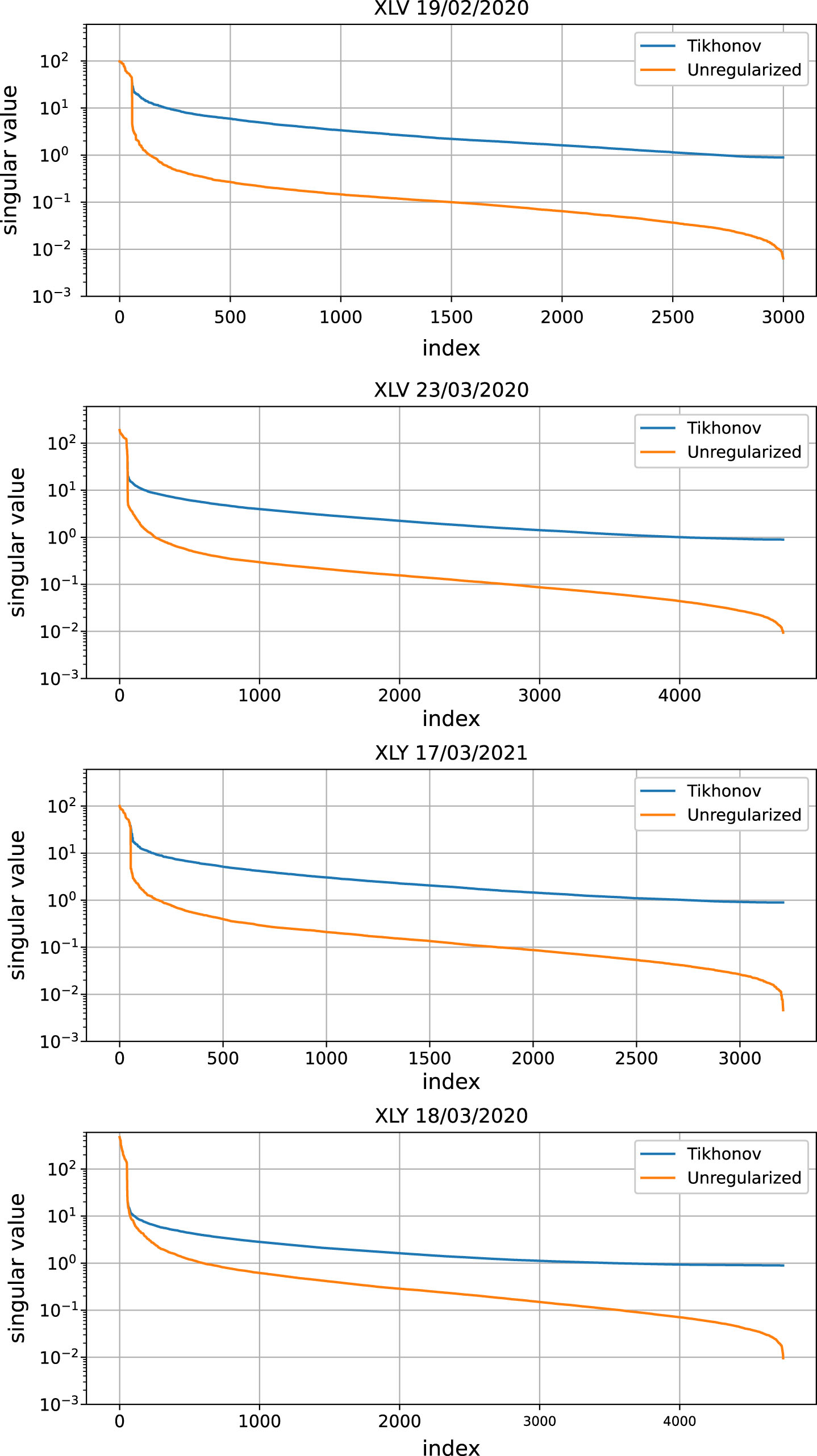
Singular values of
To show how the distribution of the singular values is improved by the regularization, we pick the day on which the condition number of the Tikhonov method depicted in Fig. 3 is the highest, as well as the day on which the condition number is the lowest. Then, we show in Fig. 4 all the singular values of
In this paper, we introduced the graph embedded dynamic mode decomposition (GEDMD) model to alleviate the potential overfitting of data in the original DMD. We proposed methods to construct graphs and to formulate the GEDMD problem. The method yields portfolios that are more diversified producing reasonable, attractive, and realistic returns. Consistent superior results are observed in different universes. To focus on the quality of the signals, we leave trading rules and portfolio optimization alone in our tests.
Footnotes
Acknowledgements
The authors would like to thank Mr. Kenny Cheung, Mr. Thomas Kwong, Mr. Ani Li, Ms. Elaine Liu, Mr. Raymond Wu, Dr. Chin-Ko Yau for their support and help in the preparation of the manuscript. Ng is supported by HKRGC GRF 12300519, 17201020 and 17300021, HKRGC CRF C1013-21GF and C7004-21GF, and Joint NSFC and RGC N-HKU769/21.