
Abstract
In many dynamic open systems, agents have to interact with one another to achieve their goals. These interactions pose challenges in relation to the trust modeling of agents which aim to facilitate an agent’s decision making regarding the uncertainty of the behaviour of its peers. A lot of literature has focused on describing trust models, but less on evaluating and comparing them. The most extensive way to evaluate trust models is executing simulations with different conditions and a given combination of different types of agents (honest, altruist, etc.). Trust models are then compared according to efficiency, speed of convergence, adaptability to sudden changes, etc. Our opinion is that such evaluation measures do not represent a complete way to determine the best trust model, since they do not include testing which one is evolutionarily stable.
Our contribution is the definition of a new way to compare trust models observing their ability to become dominant. It consists of finding out the right equilibrium of trust models in a multiagent system that is evolutionarily stable, and then observing which agent became dominant. We propose a sequence of simulations where evolution is implemented assuming that the worst agent in a simulation would replace its trust model with the best one in such simulation. Therefore the ability to become dominant couldbe an interesting feature for any trust model. Testing this ability through this evolutionary-inspired approach is then useful to compare and evaluate trust models in agent systems.
Specifically we have applied our evaluation method to the Agent Reputation and Trust competitions held at 2006, 2007 and 2008 AAMAS conferences. We observe then that the resulting ranking of comparing the agents ability of becoming dominant is different from the official one where the winner was decided running a game with a representative of all participants several times. Since it is a new evaluation method that, as our application to the ART competition showed, gives additional information on the quality of trust models, it would improve the way they are compared. The application of our proposal is not restricted to the ART domain, we suggest that this kind of evolutionary approach has to be taken into account in any evaluation of trust models in agent systems.
Introduction
In recent years, the relevance of trust and reputation research has been recognized a lot. The main reason is because they are a key factor to automate electronic commerce. Automation would come from the generalized use of software agents intelligent enough to search and select potential partners without prior interaction or experience [18]. With such intention, the reputation of an agent represents a statistical value about the trust probability computed from previous interactions and recommendations. In this way, reputation-based trust systems provide an incentive mechanism that mitigates the risks of interacting with malicious agents [6]. Many reputation-based trust systems have been proposed [25,28], the most popular ones such as eBay use very simple approaches (average) [27] but many of the academic systems use Bayesian/GameTheoretic [14,34] or belief/cognitive models [8,33] to quantify trust. Performance of these models is often evaluated with ad-hoc implementations and metrics. They consist of simulations of societies with several combinations of agent models (honest, malicious), with potential collusions of providers and recommenders, with different dynamicity (frequency and intensity of change of agent behaviors). Since it was very difficult to effectively compare the evaluation results of these ad-hoc implementations and metrics, a testbed platform for evaluating agent trust and reputation models was developed: the Agent Reputation and Trust (ART) testbed [12].1
From the extensive use of this testbed, a line of research arose on the ways trust and reputation models should be compared. Authors of [16] suggested distinguishing the way trust is acquired, modeled and updated (trust model) from the way trust is used or applied in decisions (trust strategy). On the other hand, authors of [2] suggested an extension of ART testbed to deal with heterogeneous and different domains and protocols. Finally authors of [19] suggested some predefined scenarios to overcome the limitations of the ART testbed comparing trust models. Although all these publications are related to ART evaluations, defining evaluation metrics for trust and reputation models is a general problem. It is a problem also shared by recommendation algorithms in mobile environments [17] and in e-commerce [29].
This paper belongs to this effort of proposing new ways to compare trust models that provide additional information on determining the quality of trust models. Our desired evaluation method does not intend to replace the classic way to compare reputation models, it just provides a new evaluation criteria to be additionally considered. Instead of defining complex controlled situations to evaluate agents’ trust models as [19] did, we aim to define an evaluation metric of trust models different from the usual ones: accuracy, efficiency, adaptability, etc. We pursue a new feature of trust models that will be able to be used to evaluate trust models in any agent simulations including ART testbed. It does not have an exclusive application into ART competition, we just use this testbed to show the utility of our approach to produce new knowledge on the different abilities or quality of trust models.
In Section 2 we explain how an evolutionary-inspired evaluation method can be applied to compare trust and reputation models. Afterwards, in Section 3, we show an application of this evaluation method on the ART 2006, 2007 and 2008 international competitions. Finally, in Section 4, we outlined some conclusions.
Evolutionarily stable strategies
Classic Game Theory [11] considers games with discrete actions and time-steps for decision making. In these games as tic-tac-toe and the prisoner’s dilemma [26] a particular situation (so called Nash equilibrium) [23] is defined when each player (agent) chooses a strategy that may not be improved for both players (agents) by any other alternative strategy. A Nash equilibrium can be achieved by agents through a process of Darwinian selection of strategies. In this case, the strategies involved in the Nash equilibrium are named evolutionary stable strategies (ESS) [21]. These concepts have shown useful for modeling many problems of social behaviour in animals and humans.
According to [10], in order to be solved by this evolutionary way to find an equilibrium of strategies, problems have to accomplished three strong assumptions: First, the evolving population of agents is assumed to be infinitely large, second, the payoffs that agents receive are assumed to be without noise, third, each agent is assumed to play against every other agent to determine its fitness. However, other authors demonstrate the dynamics and equilibria of evolutionary stable strategies apply also to finite populations [9].
From the point of view of research in autonomous agents, there is much interest in representing with agents the way how cooperation and reciprocity evolves in human society. Of our particular interest are the typical real-world situations where one agent can help another agent by sharing work/tasks such that the helping cost of the helper is less than the expense of the helped agent [30].
In this situation, the society of agents contains initially representatives of different cooperation strategies in similar proportions. Each of the agents are assigned some tasks. The cost of executing a task can be reduced or eliminated if help is obtained from another agent. Agents then interact repeatedly over a sustained period of time and their effectiveness is calculated as function of the total cost incurred to complete all assigned tasks. The resultant performance reflects the cost incurred for local tasks, the cost incurred to help other agents with their tasks, and the savings obtained from others when help was received.
Although in classical MAS settings, a trust model used by an agent is not open and available to other agents, an interesting alternative scenario (which could be also realistic) would be to give an agent the freedom of choosing from one to several of these cooperative strategies and to change its strategy as and when it seems to be appropriate [1,31]. An agent may be prompted to adopt a strategy if agents using that strategy are seen to be performing better than others. Such a strategy adoption method leads to an evolutionary process with a dynamic system composed of changing agent strategies by allowing propagation of more successful strategies and elimination of the unsuccessful ones. In this way, an evolutionary selection method identifies which cooperative strategies can perform dominantly.
In spite of its very different approach and motivation, we have also to mention that evolutionary game theory has also been applied in agent competitions in another way: Authors of [32] compute a Bayes–Nash equilibria in agent
In order to apply an evolutionary approach to trust games, we first have to recognize that trust games do not satisfy completely the three strong assumptions of game theoretic problems:
the evolving population is assumed to be infinitely large: the population of trust games has to be large enough to allow reputation making sense, since small populations work fine just with direct interactions. In spite of this, the number of participant agents in ART competitions is not very large (less than 20) and therefore its small size does not justify this assumption;
the payoffs that agents receive are assumed to be without noise: Noise is inherent to trust problems [24], since trust is used because it is applied in domains where there is no objective, universal and specific ways to evaluate products or services, such as the domain of appraising paintings in ART testbed. In fact, ART designers modeled noise as the variance of a normal distribution. But we can state at least that the payoffs that agents receive are assumed to be fair (directly proportional to the quality of the behaviour shown);
each agent is assumed to play against every other agent to determine its fitness: this assumption may be mostly accepted in trust games since in them it is not often to include groups or coalitions of agents representing the same interests, they represent individuals with different tasks, abilities and goals and act exclusively on behalf of the individuals.
Obviously trust is involved in decisions of classic game theoretic problems of cooperation, but only in an implicit way. The main difference between them and trust problems is the explicit exchange of reputation opinions between agents, but while decisions in classic and evolutionary game theory problems such as tic-tac-toe and prisoners’ dilemma are quite simple (choosing a position, cooperate/defect) that can be implemented as a single rule/function, decisions in trust games are rather more complex (choosing several real numbers in a continuous range of possible values) that have to be implemented by a sophisticated set of rules/functions. Trust problems in the agent community involve the next steps for a cooperative game:
deciding who and how (costs) to request help in the own assigned tasks;
deciding who and how (costs) to answer to requests of help in others assigned tasks;
deciding how (weights) to aggregate help from different agents in each task.
Furthermore trust games include decisions related to the explicit exchange of opinions about the reputation of third parties:
deciding who and how (according to potential costs involved) to request reputation on the ability of third parties in performing own assigned tasks; deciding who and how (according to potential costs involved) to answer to requests of reputation on the ability of third parties in performing others assigned tasks; deciding how (assigning weights) to aggregate reputation from different agents about each ability of a third party in a task.
Additionally, some trust simulations include the possibility of agents promoting (advertising) their own ability performing tasks.
Furthermore, decision making in all these steps is highly interdependent, where these dependencies are an open discussion in psychology and sociology, and therefore implemented in very different ways, particularly the way reputation is updated and aggregated depending on the source of information [4,5].
This complexity avoids the inclusion of mutations (crossing operators) in evolutionary trust games, since trust models are seen as an integrated module that encapsulates all trust decisions represented, addressed and computed in very interdependent way. Combining parts of trust models into an aggregated new trust model (mutation) is then not possible with the current most extended view of trust models. But since the ART testbed unified information exchanged and communication protocols in a particular trust game to compare heterogeneous trust models, it at least allows reproduction (propagation of most successful trust models) and death (elimination of unsuccessful ones). It means that agents may decide proactively to change their trust model. This approach of adopting trust models dynamically conceptually makes sense since the global goal of using trust in agent societies is to establish some kind of social control over malicious or distrustful agents (through the exchange of local and subjective evaluations between partners). So the idea of agents changing trust models is coherent with the final intention of trust decisions to filter out the agents who do not behave properly in such society. Following this line, it seems to be realistic that agents with a failing trust model would replace it and they would adopt a successful trust model in the future.
The absence of mutation, the limited definition of reproduction (just a complete change of trust model is allowed) and the insatisfaction of the three assumptions of game theoretic problems avoid considering our proposal as a ‘pure’ evolutionary approach, instead of it, our proposal is noted as an evolutionary-inspired approach.
Particularly we suggest implementing these evolutionary-inspired ideas in trust games following the next rule: the loser of a direct confrontation (several turns of a particular game) among single or multiple instances of trust models (not uniform population) would be removed from such society of agents. While the winner trust model of that game would be reproduced and included as an additional instance of the winning trust model.
While the first game would be run over a system with single instances of all trust models (uniform population), through this analogy we can run several games where trust models are being adopted and dropped by agents, defining a repeated game set that would allow us to evaluate the ability of trust models to be dominant or an evolutionarily stable trust model in case we would reach an equilibrium.
Additionally, we can by analogy then define as an evolutionarily stable strategy a trust model which, if applying this reproduction schema in as many games as needed it becomes dominant (adopted by a majority of agents) and it cannot be defeated by any alternative strategy. We can even determine the level of dominance by the percentage of agents implementing such strategy in the equilibrium reached, and by the number of games needed to reach such equilibrium. Equilibrium would be reached when no more changes of trust models take place.
This evolutionary-inspired approach to evaluate trust models implies the next assumptions that could be seen as limitations since not always can be satisfied in real-world trust problems:
The payoffs of all the agents have to be publicly known. Games have to be run in an independent way. Information acquired in a game is not used for the next games. Trust models have to be available to be reproduced. Each game has to be long-enough to decide and differences between agents are large enough to change trust model.
Application of an evaluation of trust models based on an evolutionary-inspired approach into ART competitions
Agent Reputation and Trust (ART) testbed, players and competitions
Agent Reputation and Trust (ART) testbed
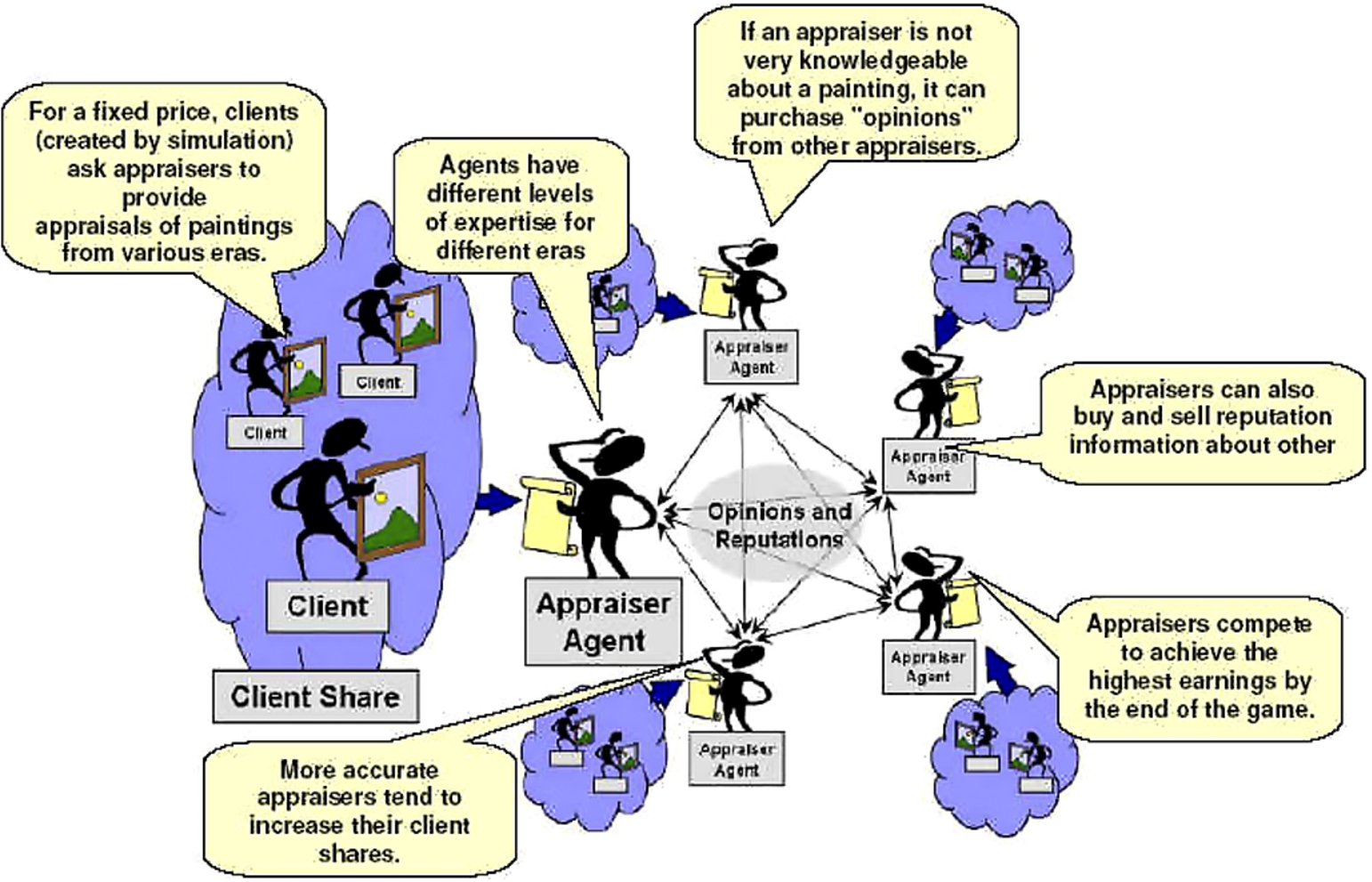
ART domain outline. Source: [12]. (Colors are visible in the online version of the article;
At each timestep, the simulator engine presents each appraiser agent with paintings (generated by the simulation engine) to be appraised, paying a fixed fee for each appraisal request. Very close valuations of paintings to the real value would lead to more future clients, and therefore to more earnings to win the competition. The corresponding steps of a turn in ART games is shown in Fig. 2.
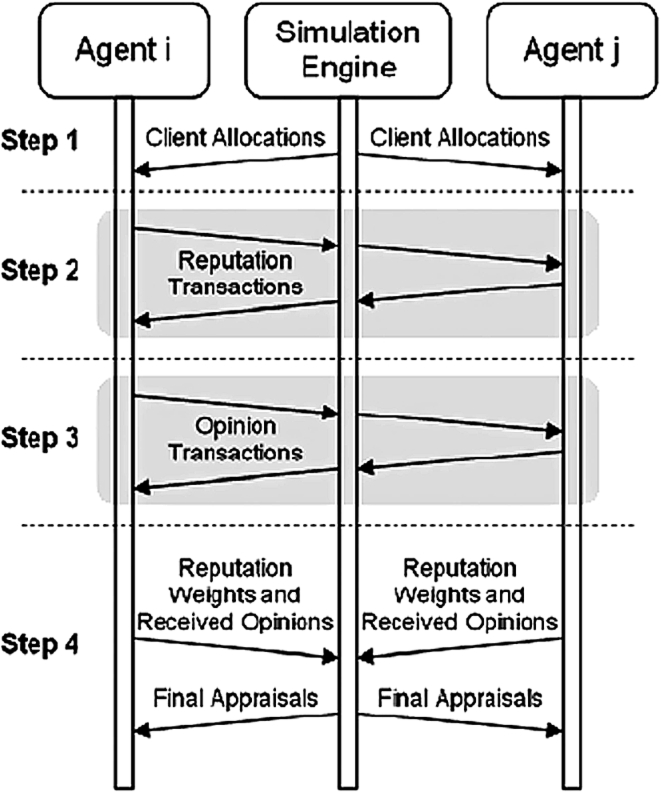
Steps of a gameturn in ART domain. Source: [13].
Each painting belongs to an era from among a set of artistic eras, while agents have different levels of expertise (ability to appraise) in each era. An agent can appraise its own paintings and may request opinions (at a fixed cost) from other appraisers to get its valuation of the painting close to the real value (specially useful in the eras where the agent has low expertise). An agent can act also as provider of appraisals in response to opinion (about paintings) requests from other agents. Additionally, an agent can similarly request reputation information about other appraisers (at a fixed and much lower cost than opinions). The winner of an ART game is the agent who earned more money over the number of iterations that were run in the game. Such earnings come from different sources: paintings appraised to the own clients (Client Fee), paintings appraised to other appraiser agents (Opinion Cost) and reputations shared with other appraiser agents (Reputation Cost), where Client Fees are the main source of income since: Client Fee ≫ Opinion Cost ≫ Reputation Cost. Trust models implemented in agents have to implement decisions involved in these protocols (aggregating opinion and reputation values, considering who to ask and answer, weighting opinions, etc.).
In 2008, a new version of the testbed included the possibility of expertise of agents about eras changing over time (expertise dynamicity). Every time step, a number of eras was randomly selected for each agent to change the corresponding expertise agents have about these eras. For every positive change in expertise of agent about an era, a negative change in expertise of the same amount was applied to another era, so that the average total expertise of the agent was not modified.
For instance, Uno2008 agent [22] classifies agents into four categories according to the level of knowledge about them regarding its role (opinion and reputation provider). These categories are used to decide between applying exploration or exploitation strategies with them. In this way authors of Uno2008 define the amount of effort dedicated to exploitation given a quality threshold QT, so that agents with a higher trust value will be used as appraisers, with an adaptive maximum number of requests to perform for each painting, T. This maximum is computed from:
Another example of an ART trust model is IAM [20]. It computes the estimated benefit of having an opinion from a particular agent to justify the decision of requesting an opinion from it (it calculates the expected variance of the final appraisal). Then the IAM agent selects the most profitable providers to ask for opinions. Furthermore, IAM agent assumes a general strategy of being honest with its partners although it looks for a minimum level of reciprocity. It classifies some agents as cheaters based on their previous interactions, and it then generates random responses for cheating agents. An additional important issue is how much effort IAM uses to generate opinions, it computes an empirical study to decide the compromise value (of
Agent Reputation and Trust (ART) competitions
Using the ART testbed, three international competitions were successfully carried out jointly with the last AAMAS international Conferences. The corresponding way to define the winner of competitions was slightly different each year.
In 2006, for scalability reasons, games could involve at most 5 agents, so the 13 participants were grouped in 14 different preliminary rounds. The 5 agents with better average score in such preliminary rounds played the final round. Each round was played 10 times with games of 60 minutes length whatever timesteps they took.5
In 2007, games involved all the participants (16) plus some dummy agents (9) of 60 minutes length whatever timesteps they took. Games were run 10 times to avoid noise due to initial conditions.6
In 2008, 9 games were played with all the participants (11). Three of them with low, medium and high expertise dynamicity respectively and with 90 timesteps per game.7
Evolution simulation 2006 results
Once the type of game to be run has been defined in Section 2.2, we have applied it to the participant agents of 2006 ART competition (the parameter setup and the code of 2006 participants are public and therefore these experiments are repeatable8
Comparison of rankings of 2006 agents
Specifically with this experiment we have shown that although the strategy of the winner of the 2006 international competitions spreads in the first game (with 2 agents implementing IAM trust model out of 5 participant agents), it never becomes dominant (there is never a majority of iam agents). In fact it is defeated by other trust model, joey, which becomes totally dominant (5 joey agents out of 5). Therefore IAM is not an evolutionarily stable trust model, so its superiority to the other agents is, at least, arguable. We also found out that the right equilibrium of trust models that forms an evolutionarily stable society is composed by 5 joey agents. Finally, from the order in which agents are excluded from the society, we can propose an alternative ranking of trust models in Table 2 which is slightly different from the competition ranking.
Since games in the 2006 version of ART testbed just involved 5 agents, we assume that conclusions of our evolutionary approach to trust comparisons would be more significant in the 2007 and 2008 games, since 5 agents is a small population. 2007 and 2008 competitions had more diversity of agents in the games. But even with 5 agents we can see how the apparent best quality of IAM agent strongly depends on the opponents. On the other hand, the evolutionarily stable trust model, joey, is not able to win the initial game, but it wins and it avoids to be excluded in all the next games becoming totally dominant of the game.
Next, we have applied the same type of game to the participant agents of 2007 ART competition with the parameter setup and code of 2007 competition participants.10
Evolution simulation 2007 results
Comparison of rankings of 2007 agents
Finally we have applied this type of game to the participant agents of the 2008 ART competition.11
Evolution simulation 2008 results
As it was expected, since there are no dummies, the value of the earnings of the winning agent in the first game is lower than that of the competition, but they are in general very similar. We can also observe that the differences between winners and losers become closer in the last games. From game 6, the differences are halved, so we can conclude that there is a significant gap between the agents excluded before such game number (IAM, artgente2, peles, olpagent and hailstorm) and the rest of them (uno2008, connected, fordprefect, simplet, nextagent and mrroboto). This division into two groups is different according to the greatest difference in the earnings of agents in the competition results. There uno2008, connected, fordprefect and nextagent had much score than the rest of agents.
Comparison of rankings of 2008 agents
Specifically with this experiment we have shown that although the strategy of the winner of the 2008 international competition, uno2008, spreads in the society of agents (until 7 agents implementing uno2008 trust models out of 11 participant agents), even becoming dominant (there is a majority of uno2008 agents), it is finally defeated by other trust model (connected), which becomes dominant (8 connected agents out of 11) in the final equilibrium (evolutionarily stable society) form by 7–8 connected agents and 3–4 uno2008 agents. Therefore uno2008 is not an evolutionarily stable trust model, so its superiority as winner of 2008 competition is, at least, relative. It seems that uno2008 agent performs rather well when there is enough diversity in the society, but, when it has to play against clone agents implementing the same trust model, its performance becomes heavily affected. On the other hand, connected agent shows no ability to win initial games, but it avoids to be excluded in all the games and when diversity of society is reduced it becomes a unbeatable opponent of uno2008 agent. Finally, from the order in which agents are excluded from the society, we can generate an alternative ranking of trust models in Table 6 which is slightly different from the competition ranking. Jointly with the alternative ranking we can see the game number in which the corresponding agents were excluded.
We can also comment that other abilities of agents different from dominance can be observed using our evolutionary-inspired approach. For instance, fordprefect agent lasts until game number 11, which it is an excellent result. This shows that it is clearly better than the other agents not present in the equilibrium society. Fordprefect agent avoids exclusion 2 games (number 9 and 10) competing with a society of uno2008 and connected agents. So we could also realize that fordprefect agent has more relevance than just the 3rd place in both (official and alternative) rankings.
Evolution simulation 2006 results with accumulative earnings
Evolution simulation 2006 results with accumulative earnings
Evolution simulation 2007 results with accumulative earnings
Evolution simulation 2008 results with accumulative earnings
Due to the relative success of the trust and reputation research, a good design foundation of fair comparisons among trust models will spread the inclusion of reputation and trust communications into more general service-oriented systems that would be truly distributed. According to this intention, we have defined what an evolutionarily stable strategy would be in trust domain, and how it can be shown through a repeated game with a simulation of evolution.
We have applied such game definition to the participant agents of 2006, 2007 and 2008 ART competitions and we found out relevant differences with the official ranking. For instance the winners of 2007 and 2008 competition were not implementing an evolutionarily stable strategy. It seems that both IAM2 and uno2008 agents perform rather well when there is enough diversity in the society, but when they have to face clone agents implementing the same trust model their performance becomes heavily affected. Additionally some other minor conclusions were outlined such as: the remarkably long life of fordprefect agent in 2008 and JAM agent in 2007, the very different ranking of 2007 and the unexpected relevant gap between two groups of agents in 2008. Therefore, the application of evolutionary game theory in ART competitions shows that this evaluation method for trust models is not redundant, it provides new information valuable to compare the quality of trust models. In this way, we have shown that quality of trust models cannot be determined completely with games based on direct competitions of an instance of each agent per game. More information could be obtained to determine the best trust model with other different types of games. Therefore, performance of agents depends on the opponents they face in games and on the particular game setup. In this way, new game setups have to be defined to evaluate performance of agents facing very different situations.
In our simulation we decided to apply a low frequency of changes of trust model (just the agent who lost the game may change of trust model) since there was a low number of participants in ART competitions. Therefore we reach an equilibrium in a small number of games. Other higher frequencies could be applied (particularly in simulations with very large populations of agents). Furthermore other different game conditions could fire the change of trust model, for instance, a very big difference between the loser and the winner after a given number of game iterations (avoiding changes in the case of even games). But if the possibility of changing trust model was unlimited (a very high frequency of changes), then the agents’ ability of becoming dominant would lose part of its desirability.
Regarding the results, the only big differences appear in the 2007 competition, while in 2006 and 2008 there are minimal differences. So it would be interesting (but not easy to do) to implement a deeper analysis on the differences between 2006, 2007 and 2008 competitions, since the competitors cannot be run in the testbed of another year. So we have to consider the possibility that the differences between official ART ranking and the evolutionary ranking might also be in the 2007 testbed design.
As a conclusion we stated that this kind of repeated game has to be taken into account in the evaluation of trust models, since new knowledge on the quality and abilities of trust models can be concluded from them. We do not claim that our evaluation method would be fairer or more efficient. Our approach is just another way to compare them. It is not better or worst than others, it is complementary. Any additional way to compare them provides more or less weight to the decision of adopting one instead the others. Specifically, our method is focused on how much advantage an agent loses when its trust model is replicated by other agents.
The application of our proposal would increase the information about the quality of trust models, and then it is a valuable contribution to Trust in Agent Societies literature. It is still open the problem of integrating this new information about the ability of becoming dominant with the classic direct comparison of games composed by one instance of each trust model. None of them is better than the other, and considering an average or weighted sum of rankings seems to have not enough justification. Since they measure the ability of trust models facing two different type of games, weights would depend on the type of games we expect these trust models to face in real world.
However, our approach is very focused on ART testbed, and therefore our approach accepts its assumptions (decided after an open discussion in AAMAS conferences) and our conclusions inherit its limitations, overall two of them: the low number of trust models involved in the games, which affects to trust and evolutionary justifications of use; and the use of shared utility functions, which generally had to be, in a more realistic approach, different for each agent. These are the ART-derived problems to generalize our conclusions. In spite of this ART-dependence of our work, we have to remark that although the ART competitors implemented their trust models in an ad hoc way to win ART competition with the previously established winning conditions, our evolutionary competition is run with ART rules, and each run was executed as ART competition did. So the only change included by us, is what the other competitors are, which was unknown for everyone before the games, also in ART competition. So, they had to be designed to beat any other trust model, including those which were very similar to them (or even equal to them as we do in our evolutionary computation).
We state that future work in the trust community would be not just thinking about the testbed design improvements, but also about the games definition and evaluation metrics. This consideration is not specific to ART testbed issues. Evolutionarily-inspired games have to be considered in any comparison of trust models. It is a metric that provides additional knowledge about the different abilities/quality of trust models and it can be applied in any of the simulations of agent societies that have been proposed until now for comparing trust models.
Footnotes
Acknowledgements
This work was supported in part by projects MINECO TEC2012-37832-C02-01, CICYT TEC2011-28626-C02-02, CAM CONTEXTS (S2009/TIC-1485).