
Abstract
Pattern Databases are among the most capable means for solving hard combinatorial problems. Since their conception, they have been enhanced along different directions. Recently, it has been shown that Pattern Databases can induce non-consistent heuristic functions and it has been conjectured that this sort of heuristic functions can be better informed than others. As a matter of fact, non-consistent heuristic functions allow specific rules to take place in order to propagate these inconsistencies with the hope of improving the heuristic estimates at some nodes. Also, it has been studied how to recognize infeasible values in Pattern Databases with the hope of being able to introduce corrections that would allow for more prunes.
In this work, a new approach is suggested that fulfills both ideas simultaneously: inducing naturally non-consistent heuristic functions just by recognizing feasible, yet admissible, heuristic values which serve to improve even further the bidirectional pathmax propagation rules. Appealing as it might seem, this idea has various pros and cons which are examined. Experiments on different benchmarks show a noticeable improvement in the number of generated nodes over classical Pattern Databases when applicable, though the difference does not necessarily payoff in running time.
Introduction
Since they were introduced in the literature for the first time [1,2], Pattern Databases (or PDBs for short) have received a lot of attention. After being widely used mainly for solving hard combinatorial problems, they were generalized by Stefan Edelkamp to be applied in domain-independent problem solvers [4,5]. Later on, Malte Helmert et al. showed that PDBs are just a special case of a more general mechanism for deriving automatically admissible heuristics known as merge-and-shrink [7,8]. In this paper, however, attention is restricted to the first case, using Pattern Databases for solving hard combinatorial problems with domain-dependent solvers.
In this particular case, the advantages of their use is twofold: first, they are effective means to compute admissible heuristic functions automatically in contraposition to other approaches which automatically derive inadmissible estimates such as the delete relaxation [9]; secondly, in practice the resulting heuristic functions save various orders of magnitude of generated nodes when being compared to other approaches which usually consist of computing heuristics by hand using the constraint relaxation procedure [16].
Pattern Databases are defined as abstractions of the original state space where each constant appearing in the original state space gets replaced by either a dedicated symbol or a special “don’t care” symbol. Thus, Pattern Databases are simply hash tables which store, for every pattern (or arrangement of symbols in the abstracted state), the minimum number of moves required to place the symbols considered in the abstraction for the very first time in their goal location while ignoring the others. This value can be easily computed with a backwards brute-force breadth-first search from the goal pattern, applying at each step the inverse of the available operators. So far, Pattern Databases are admissible heuristic functions.
Originally, all moves were counted in so that when comparing the values retrieved from different Pattern Databases (for a collection of different patterns), the only way to get an admissible heuristic is just to take the maximum of all of them – and thus these PDBs are usually denoted as
In practice, disjoint Pattern Databases are usually more efficient than
After setting up an abstraction for a given state space, the resulting PDB is usually a consistent heuristic function. Moreover, even if an ensemble of heuristic functions is simultaneously considered, and then the maximum of them picked up, the resulting value preserves consistency provided that the original heuristic functions are consistent as well [10]. In turn, it has been suggested that inconsistent heuristic functions can behave better in practice than consistent heuristic functions, because it is possible to propagate these inconsistencies throughout the search tree with the pathmax propagation rules [6]. For example, when a collection of heuristic functions are available and none strictly dominates the others, randomly selecting a heuristic leads very easily to inconsistent heuristic values which usually improve the overall performance. Also, when traversing a permutation state space, it is possible to return the maximum of a regular and a dual lookup [21]. The resulting heuristic function, known as the dual heuristic, is admissible, yet inconsistent, and usually far better informed. A third interesting approach to generate inconsistent heuristic functions consists of compressing PDBs [22]. Clearly, when reducing their size, consistency cannot be enforced and thus, inconsistencies are created. However, as opposed to the previous methods, inconsistent estimates computed this way do not improve over the original heuristic values by definition.
In this work, a new idea is considered for enhancing
The paper is arranged as follows: first, previous work related to the idea of identifying feasible heuristic values is examined; immediately after, the idea of
Related work
The idea of checking for infeasible values was introduced for the first time by Fan Yang et al. [19,20]. This was achieved by splitting the cost of every operator in two different costs: the primary cost, C and the residual cost, R which, obviously, demands more memory to store the resulting PDB. However, their approach applied only to additive Pattern Databases. An attempt was made later to generalize the idea and to detect infeasibility in
Recently, it has been suggested to store a predefined number of feasible values [14]. As a result, infeasible values are easily recognized as those not been recorded in the same interval examined by every PDB. The idea, as appealing as it is, has some drawbacks to be addressed but, as it will be shown, they can lead to a significant reduction in the number of generated nodes by pruning large subtrees under some circumstances.
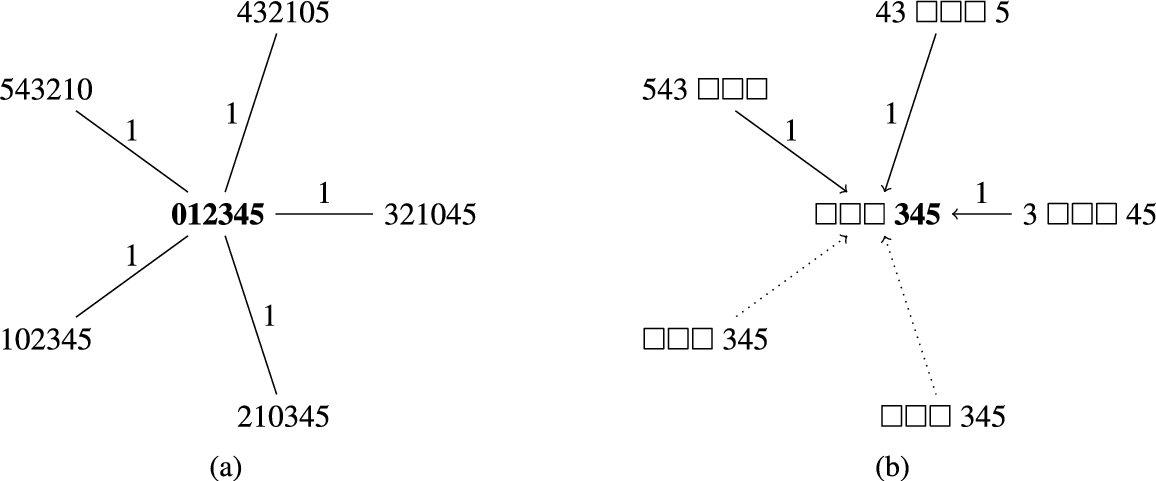
A partial view of the 6-Pancake and one particular abstraction of it. (a) A partial view of the original state space of the 6-Pancake. (b) A particular abstraction of the state space shown on the left.
Compared to the conference publication, the present paper includes the following novel content:
This section adheres to the nomenclature and definitions suggested by Fan Yang et al. [20] to introduce
A state space is a weighted directed graph
Consider, for example, the Pancake puzzle. The problem was originally posted by Jacob E. Goodman under the pseudonym of “Harry Dweighter” in 1975 [3]. In this domain, a particular instance is characterized by a permutation over K integers
From a particular state space it is possible to compute a Pattern Database by mapping some constants appearing in the original state space into distinguished constants while mapping the rest to “don’t care” symbols. The same mapping, when being applied to the goal state results in the goal pattern. Thus, the resulting state space is different. In the following, let
Figure 1(b) shows a particular abstraction of the states considered in the previous example. In this case, constants 3, 4 and 5 are preserved in the abstract state space whereas the constants 0, 1 and 2 are mapped to the “don’t care” symbol, represented as □. The goal pattern has been distinguished in boldface.
Now, it is possible to compute the minimum distance of every pattern in the abstract state space to the goal pattern with a backwards breadth-first search which is initialized with an OPEN list which only contains the goal pattern with a cost equal to 0. As shown in Fig. 1(b) all the descendants of the goal pattern are generated by applying the inverse of all the available operators. Doing so, new patterns are discovered and the cost to reach them is stored in the Pattern Database which is usually implemented as a hash table whose entries contain pairs of the form (pattern, cost), where the cost consists of a single scalar value. For example, patterns
Since the exploration of the abstract state space is conducted with a breadth-first search, the cost for reaching each pattern is known to be optimal. So far, Pattern Databases are admissible heuristic functions.
An abstraction mapping
The way these abstractions are defined guarantees that the mapping is a homomorphism or, in other words, that all edges in the original state space are preserved in the abstract state space:
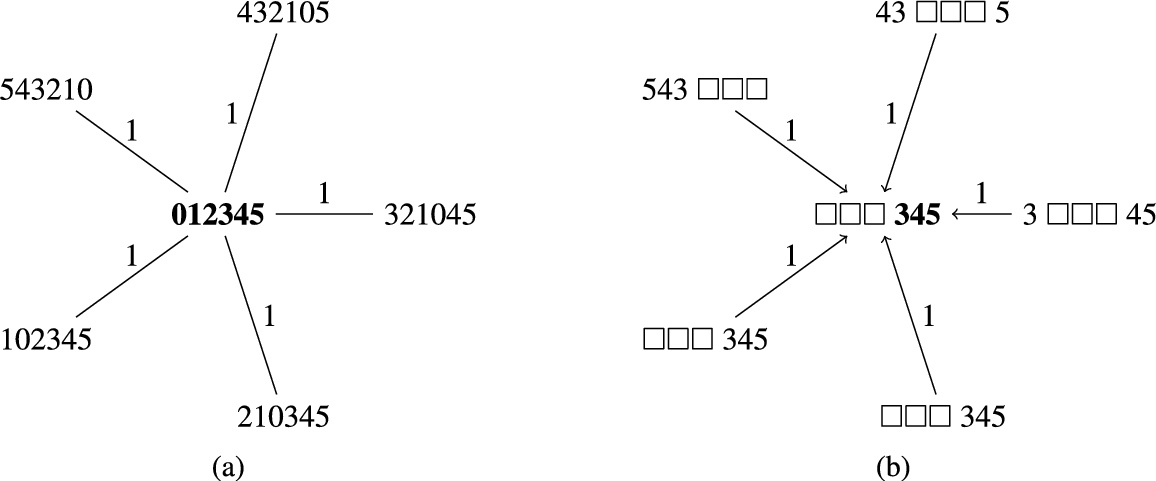
A partial view of the 6-Pancake and one abstraction of it as traversed by a vectorial Pattern Database. (a) A partial view of the original state space of the 6-Pancake. (b) A particular abstraction of the state space shown on the left as traversed by a vectorial Pattern Database with pattern generation depth
Of course, different mappings can be considered, each resulting in a different Pattern Database. For example, an abstraction which preserves constants 0, 1 and 2 while mapping 3, 4 and 5 to “don’t care” in the running example, would yield a heuristic value equal to 1 to the pattern
Now, given a collection of N abstractions
An interesting property of the heuristic function shown in Eq. (1) is that it preserves consistency. In other words, it is a consistent heuristic function if
This technique is able to solve hard combinatorial problems saving orders of magnitude on the number of generated nodes. Among other important achievements, one of their main contributions was to solve optimally the first instances of the
Instead of storing just the minimum distance to the first occurrence of each pattern in a given abstract state space
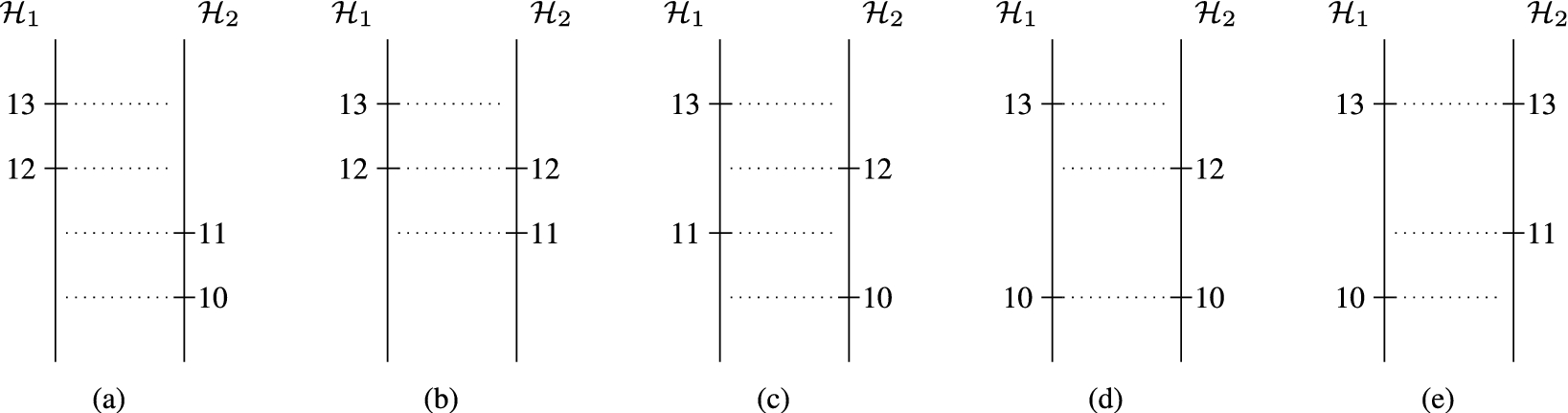
Two vectorial Pattern Databases generated with pattern generation depth
Figure 2 illustrates the main idea. The figure shows the same partial view of the 6-Pancake discussed in the previous section. As shown in Fig. 2(b), the abstracted state space differs from the state space shown in Fig. 1(b) in how duplicated nodes are treated. Instead of discarding them, they are accepted up to a given threshold (i.e., the pattern generation depth), d. Thus, the resulting Pattern Database consists of a hash table whose entries contain pairs of the form (pattern,
Recall from the previous section that abstractions are homomorphisms. Hence, a path
If two (or more) vectorial Pattern Databases return vectors
On the other hand, if two (or more) vectorial Pattern Databases return different values for the first component, it is clear that both Pattern Databases have traversed different paths from the target goal – in other words, different paths to different nodes with the same pattern have been found. In the classical case, the best one can do is to pick up the maximum of all of them, as in Eq. (1). However, in the vectorial case, if there are still more components in each vector to examine, one can scale up through each vector looking for an agreement among all of them. If any is found, this would be the heuristic estimate to return; otherwise, the maximum of all components is returned.
Figure 3 shows different cases that can arise in the comparison of two vectors,
Much the same happens in Fig. 3(b). In this case, after noticing that the first component of
However, in Fig. 3(c) there is never an agreement between both components. After scaling up through both vectors, the last comparison ends with 12 and 13. Since there are no more values to examine, the best one can do is to return 13 and the resulting value is still admissible. Much the same happens in Fig. 3(e), the only difference being that in this case an agreement has been found at the last position. In both cases, the values returned, 13, are larger than the values that would have been returned by two classical Pattern Databases, 11.
Since every
The same value has been repeatedly observed in all the other vectors,
it exceeds the maximum value observed in all the other vectors.
The first case serves to identify all the agreements among the vectors

Computation of H
Algorithm 1 shows how to compute H for a particular node n. It receives N vectors
It can be easily proven that in order to improve over the heuristic values returned by classical Pattern Databases, there should be at least one vectorial Pattern Database with a difference between two successive observations equal to 2 or larger. In other words,
If in the confrontation of different
The proof is trivial and proceeds by enumeration of a few cases.
Let us first consider two different vectors
If
If
If
Other arrangements of
If more vectors are considered, recall that H stores all values which appear in all abstractions and the values in the ith abstraction which are larger than the maximum values in all the other abstractions. Thus, after comparing two vectors
In any case, in the comparison of two vectors (one that results from
As a matter of fact, it might happen in practice that many nodes in the original state space are mapped to the same abstract state in one abstraction
On the opposite side, there are at least two different ways for exploiting the heuristic values computed with vectorial Pattern Databases: on one hand vectorial Pattern Databases naturally induce inconsistent heuristic functions; on the other hand, since the components of
As it was already noted in the Introduction, it has been suggested that inconsistency (while preserving admissibility) might be seen as a desired property. An example is provided to prove that vectorial Pattern Databases lead to inconsistent heuristic functions very easily.
Consider a node n and two abstractions
On the other hand, assume that the values returned by two vectorial Pattern Databases generated with a pattern generation depth equal to 2 (which actually explore the same abstract space than their classical counterparts and would extend it a little bit further until all patterns are found again) for the same node n are
When using inconsistent, yet admissible, heuristic functions it is possible to save the expansion of a (usually large) number of nodes by using the pathmax propagation rules [15]. Furthermore, if the original state space is an undirected graph, then these propagation rules can be extended with an additional rule [6].
In a nutshell, the pathmax propagation rules propagate the heuristic values between a node n and its descendant
where
which enables the effective propagation of heuristic values from children to parent. Bidirectional pathmax (or BPMX for short) uses rules 1 and 3 to propagate (inconsistent) heuristic values in any direction. As it will be shown in the following subsection, these updates can be further improved.
Feasibility analysis
A closer inspection to the preceding rules reveal that subtracting the cost of the edge is just a conservative assumption that is necessary to guarantee admissibility. Clearly, these updates can be improved if the feasible values of each node are known. The key observation is that the values not recorded by a given abstraction,
Credit shall be given to Fan Yang who also mentioned the possibility of storing more than one cost in each Pattern Database in the concluding remarks of one of her works [18] for this particular purpose.
Incidentally, the vector H contains feasible values as explained above: It computes all values which appear in all abstractions (so that they are likely to be feasible in the original state space) and the values in the ith abstraction which are larger than the maximum values in all the other abstractions (for which nothing can be said about its unfeasibility) with the purpose of performing the following feasibility analysis.
Since the heuristic function induced by vectorial Pattern Databases is known to be inconsistent (see Section 4.1), the first pathmax propagation rule can be applied after expanding node n and generating one of its children,
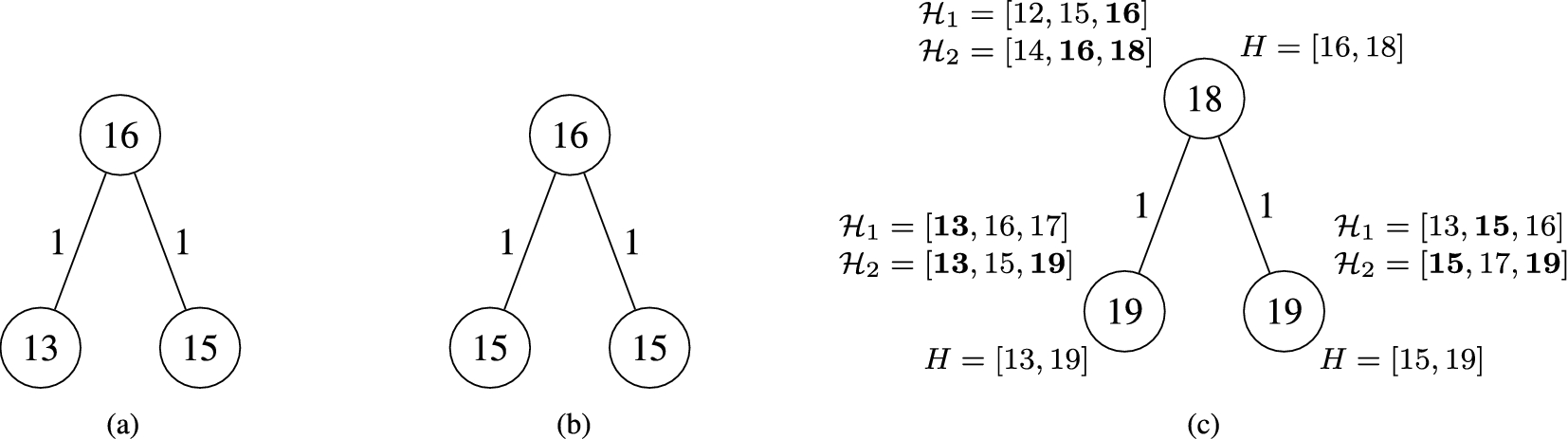
Example of BPMX without and with a feasibility analysis. (a) Original heuristic values. (b) Result of BPMX without a feasibility analysis. (c) Result of BPMX with a feasibility analysis.
However, using the feasible values reported in the vector H it is possible to improve the heuristic values of all nodes. Instead of correcting the heuristic values by subtracting one unit to either the heuristic value of the parent or the child (as suggested by BPMX and done also in preliminary work, see Section 2), it is possible now to pick up the next feasible value – which is greater or equal than the value returned by BPMX. The reason is that all values in between are known to be unfeasible.
Consider again the example shown in Fig. 4. Let us assume that two vectorial Pattern Databases with pattern generation depth
To summarize, while adhering to the conservative schema implemented in BPMX is a must to guarantee admissibility, the values returned by it are accepted if and only if they appear in the vector of feasible values H. Otherwise, it is possible to pick up the smallest value in H that exceeds the value returned by BPMX without violating admissibility. This is true since H records only values that appear in all the looked up vectors
In order to show that it is possible a significant reduction in the number of nodes generated with vectorial Pattern Databases, the puzzles M12 and M24 have been selected [13]. Other typical puzzles in this sort of experiments such as the sliding-tile puzzle, TopSpin or the Rubik’s Cube have the same difficulties than the Pancake already discussed in Section 4: namely, the fact that there are operators in the abstract space that will leave many patterns unaffected. In turn, M12 and M24 have operators that affect all locations at the same time. Besides, they do add some interesting properties such as the fact that the underlying state space is directed, in comparison with the aforementioned puzzles which do always engender undirected graphs. On the other hand, no optimal results have ever been reported.
These puzzles are motivated by the fact that they induce group structures different than those created by other problems. In fact, their underlying structure follows two of the five different Mathieu groups, which were the first sporadic simple groups found. Published at the end of the nineteenth century by Émile Léonard Mathieu, M12 is the second smaller group and M24 is the biggest of all. Nevertheless, these groups can be regarded as permutation groups (and hence as permutation puzzles) on sets of 12 and 24 objects, respectively. First, the results on every benchmark are reported and then a discussion of the results is offered.
All experiments have been run on an iMac 2.8 GHz Intel Core 2 Duo with 4 Gb of RAM.
M12
M12 consists of a permutation of 12 constants and two operators: invert and merge. While the former just inverts the whole permutation (e.g., from
Results in the M12 puzzle (number of generated nodes)
Results in the M12 puzzle (number of generated nodes)
Table 1 shows the number of nodes generated when solving 800 instances randomly generated in the M12 with either classical Pattern Databases (
From the preceding table it is clear that using vectorial PDBs leads to a reduction in the number of nodes generated of the 25,9% in the 4-4 setting, from 96,829 to 71,767. When the heuristic function is better informed, as in the case of the 4-4-4 arrangement, the reduction is smaller and only a little bit larger than 10%. The values for
M24 consists of a permutation of 24 positions, out of which
Results in the 12-M24 puzzle (number of generated nodes)
Results in the 12-M24 puzzle (number of generated nodes)
Results in the 24-M24 puzzle (number of generated nodes)
The second set of experiments consisted of running the original M24 puzzle with a 6-6-6 arrangement denoted as 24-M24. Table 3 shows the number of nodes generated when solving 1000 random instances. The savings in this case are very moderate mainly because the classical Pattern Database results in a very informed heuristic function (as witnessed by the low number of generated nodes) so there is no much room for improvement. Indeed, all instances are solved in less than 0.01 s on average in all configurations.
Although the numbers might seem modest in some cases, truth is that vectorial Pattern Databases prune large subtrees both in M12 and M24. To prove it, let us consider that in both cases there is one operator
Therefore, even if a new heuristic prunes a tree of height 10 (which would be quite remarkable), the number of saved nodes is bounded by the tenth number of the Fibonacci series, 144. To save thousands of nodes (see Table 3), tens of thousands (Table 1) or even millions (as in Table 2) it is necessary to prune many very deep subtrees.
Conclusions
It has been discussed to extend the abstract state space to visit all patterns a predefined number of times, instead of only once. The technique results in an inconsistent heuristic function that can be used also for jumping between feasible heuristic values. When considering the pros and cons, it became clear that this technique is useless in those cases where there are operators that leave several patterns unaffected, while it can contribute to a significant reduction in the number of generated nodes in other cases, such as the puzzles M12 and M24. Nevertheless, experiments in these domains show that this reduction does not necessarily payoff in running time due to the extra computation effort analyzed in Section 4.
On the other hand, the technique is clearly compatible with other ideas such as using symmetries, duality or maximizing over various multiple pattern databases and it only augments the size of the original Pattern Database by a constant factor.
Footnotes
Acknowledgements
This work has been partially supported by the Spanish MINECO project PlanInteraction: TIN2011-27652-C03-02.