
Abstract
Clustering is a process to discover unseen patterns in a given set of objects. Objects belonging to the same pattern are homogenous in nature while they are heterogeneous in other patterns. In this paper, a hybrid data clustering algorithm comprising of improved cat swarm optimization (CSO) and K-harmonic means (KHM) is proposed to solve the clustering problem. The proposed algorithm exhibits strengths of both the mentioned algorithms, it is named as improved CSOKHM (ICSOKHM). The performance of the proposed algorithm is evaluated using seven datasets and is compared with existing algorithms like KHM, PSO, PSOKHM, ACA, ACAKHM, GSAKHM and CSO. The experimental results demonstrate that the proposed algorithm not only improves the convergence speed of CSO algorithm but also prevents KHM algorithm from running into local optima.
Keywords
Introduction
Clustering is a powerful technique in pattern recognition, data mining and machine learning paradigm. It is an NP complete problem. It is used to discover hidden patterns, knowledge and information from a dataset using a criterion function which were previously unknown [4]. In clustering, a dataset is divided into K disjoint groups and data belongs to a group having more similar characteristics when compared to data resides in other groups. K-means is one of the oldest and most widely accepted clustering algorithm which is applied for obtaining the optimal cluster centers [15]. It is simple, fast and efficient algorithm, but suffers with initialization and local optima problems [20]. To overcome these problems and also to improve its efficacy, many hybrid versions of K-means algorithm have also been reported in the literature [7]. Zhang et al. [35] developed K-harmonic means (KHM) algorithm for data clustering using average harmonic mean to obtain the new cluster centers. KHM algorithm showed good results in comparison to the K-means algorithm, but the local optima problem remained unsolved. In recent years, a number of algorithms based on swarms, insects and natural phenomena have been developed to solve clustering problem. For example, an artificial bee colony (ABC) [10], ant colony optimization (ACO) [28], genetic algorithm (GA) [17], particle swarm optimization (PSO) [1], cat swarm optimization (CSO) [25], teacher learning based optimization (TLBO) [24,27], black hole optimization (BH) [6], gravitational search algorithm (GSA) [36] and charge system search algorithm (CSS) [11,12]. The above algorithms can be classified into swarm based algorithms, biological algorithms and basic science algorithms. Although, these algorithms have shown good potential over traditional algorithms, but they also suffer with several problems. For instance, GA suffers from population diversity problem and the quality of solutions in GA depends on the mutation and cross-over probability [23]. In ACO algorithm, convergence time is uncertain and the probability distribution function is also changed in each iteration [16]. PSO algorithm possesses weak exploitation properties and sometimes gets stuck in local optima [22]. In case of ABC algorithm, the performance of the algorithm depends on the dimension of the problem; increase in the dimension of the problem results in a decrease of the convergence speed [9]. In GSA algorithm, premature convergence can occur due to its memory-less nature [26].
Cat swarm optimization (CSO) is a latest and state of art algorithm developed by Chu et al. [2], by observing the behavior of cats. CSO is the first algorithm which reports on the behavior of cats in the literature. It has been applied in many domains, and giving remarkable results [13,14,19,21,30,31]. The advantage of the CSO algorithm is its good exploration property.
In this paper, a hybrid data clustering algorithm is proposed based on the Improved CSO and KHM algorithms, to prevent the KHM from running into local optima, and also to enhance the convergence speed of the CSO. To hybridize the CSO with KHM, few modifications need to be made to improve the original CSO. The performance of the proposed Improved CSOKHM (ICSOKHM) algorithm is tested on several benchmark datasets from the UCI repository. The experimental results prove that the proposed algorithm is more efficient, accurate and precise than others.
The rest of the paper is organized as follows. Sections 2 and 3 cover the discussion on KHM and CSO algorithms. Section 4 first presents the improvement of the CSO algorithm, followed by the improved CSOKHM algorithm for clustering. Investigational results of the proposed algorithm are discussed in Section 5 and the paper is concluded in Section 6.
K-harmonic algorithm
KHM is one of the popular techniques that has been applied in the clustering domain. It is insensitive to initialization issues due to inbuilt boosting function [35]. KHM is a partition based iterative algorithm which is applied to split the data into groups of pre-specified clusters. Data in the same group have similar characteristics when compared to data in other groups. KHM provides faster convergence than the K-means. But, it is also faced the same local optima problem [34]. In KHM, harmonic mean serves as the distance measure which can be described in Eq. (1),
The main steps of the KHM algorithm for clustering is listed as below.
Define the initial cluster centers ( Compute the value of objective function using Eq. (1). For each data instance Calculate its membership function Calculate the weight For each cluster center, recompute the cluster centers from all data vectors Repeat the steps 2–4, until the cluster centers do not change further. Assign the data vector
Chu and Tasi developed CSO algorithm in 2007, inspired from the behavior of cats [2]. The behavior of cats is measured in two states – in acting state and in resting state. These states are expressed in CSO algorithm as seeking mode and tracing mode. In CSO algorithm, the positions of the cats represent the possible solution sets. The detailed description of the CSO algorithm is given below.
Seeking mode
Seeking mode of the CSO algorithm describes the resting state of cats. In this mode, cats are always in alert position. In seeking mode, a cat continuously changes its position to achieve better position. The position of a cat changes according to its fitness function. The fitness function of CSO algorithm is determined using Eq. (5). Seeking mode of the CSO algorithm acts as global search for the solution. The following terms are involved in the seeking mode of the CSO algorithm.
Seeking Memory Pool (SMP): It indicates the number of copies of a cat produced in seeking mode.
Seeking Range of selected Dimension (SRD): It is the maximum difference between new and old values of the dimensions selected for mutation.
Counts of Dimension to Change (CDC): It represents the number of dimensions to be mutated,
The steps involved in this mode are given as:
Make “i” copies of Determine the shifting value for each of “i” copies using SRD ∗ position of Determine the number of copies undergo for mutation (randomly add or subtract the shifting value to “i” copies). Evaluate the fitness of all copies. Pick the best candidate from “i” copies and place it on the position of the jth cat.
The tracing mode of CSO algorithm describes the acting state of cats. This mode describes the movement of cats towards the targets i.e. ability of the cats to trace the targets. The movement of cats are directly proportional to their velocities in each dimension and these velocities are in turn used to update their positions. The position
The variable mixture ratio (MR) is used to combine the seeking and tracing mode of the CSO algorithm and it also determines the number of cats in seeking mode and tracing mode.
The steps of the CSO algorithm are as follows.
Initialize the population of Cats. Define the parameters and specify the numbers of cats for seeking mode as well as tracing mode according to MR. Evaluate the fitness function for each cat to determine the position and memorize the best position. According to the flag: If Cat is in seeking mode, apply the seeking mode process. Otherwise, apply tracing mode process. Again set the number of cats in tracing and seeking mode according the value of MR. Repeat steps 3–5 until the termination condition is satisfied.
Proposed improved CSOKHM algorithm
From the literature, it has been observed that the efficiency of optimization algorithms mainly depends on the balance between the local and global search. These searches can be perceived as exploitation and exploration of solutions in solution space. Therefore, all the swarm based algorithms follow some mechanism to ensure the balance between the exploration and exploitation. CSO algorithm has good exploration ability, but sometimes suffers with poor exploitation ability. Therefore, there is a need to enhance the exploitation ability or local search of the CSO algorithm by using some other strategy to obtain the best results. In order to improve the searching ability and the convergence rate of CSO algorithm, few modifications are made in the original CSO algorithm. These modifications are:
A selection mechanism is adopted in tracing mode of the CSO algorithm to improve the exploitation ability. Adaptive inertia weight concept is used to enhance the diversity of CSO algorithm. Boundary level constraints are handled in a more efficient way to overcome the premature convergence.
Proposed modifications in CSO algorithm
This subsection illustrates the proposed modifications in the CSO algorithm.
Selection mechanism
To enhance the exploitation ability, a selection mechanism is introduced in the tracing mode of the CSO algorithm. The purpose of the selection mechanism is to find more promising position of cats in the solution space. This mechanism not only improves the local search of CSO (as the small region of solution space is searched carefully for solution component) but also increases the population diversity. The steps of selection mechanism are described in Algorithm 1.

Selection mechanism for tracing mode of CSO
The aim of the selection mechanism is to pick a cat with better probability value (
Second modification in CSO algorithm is the idea of inertia weight. Shy et al. [29] proposed the concept of inertia weight to overcome the diversity problem in optimization techniques and also claimed that the large value of inertia weight initiates the global search, while the small value initiates the local search. Inertia weight techniques are classified into three classes i.e. constant or random inertia weight, time varying inertia weight and adaptive inertia weight [18]. In this paper, an adaptive inertia weight technique is used to compute weight “w”. It analyzes the search space direction of an optimization algorithm and calculates the weight based on one or more feedback parameters. The inertia weight “w” is introduced into Eq. (9), resulting in the improvement in diversity of CSO algorithm. Now the Eq. (9) can be rewritten as
Third issue related to CSO is the boundary level constraints. To handle this, two modifications are proposed in existing CSO algorithm: firstly, for seeking mode and secondly, in tracing mode.
Seeking mode modification. Tracing mode modification.
In seeking mode, cats are continuously changing their positions without tracing any target and find an appropriate position. This behavior of cats is implemented using SMP parameter. SMP parameter represents the number of possible position (movement) of a cat in the search space. The movement (position) of cats in seeking mode is obtained by randomly adding or subtracting the shifting values from the present cluster centers, which in turn results in (SMP ∗ K) positions. Addition or subtraction of shifting values from the cluster centers may lead the data vectors to cross the boundary of the dataset. Thus, a mechanism is adopted to deal with such data vectors. The proposed mechanism can be described as follows. If the position of cat
Tracing mode of the CSO algorithm is considered as local search for obtaining the solution set. In tracing mode, a cat traces its target with high speed. Mathematically, it can be achieved by defining the position and velocity of cat in D-dimensional search space. The position of a cat is obtained by Eq. (9). Hence, there is also a possibility that data vectors may go beyond the boundary limits. To deal with such data vectors, the following mechanism is outlined as follows.
When the position of cat
When the position of cat
An example dataset with
CDC parameter is used to determine the dimensions of a cat’s position to be mutated [25] and the shifting value is computed only for mutated dimensions. The updated position of a cat is obtained using the mutated dimensions. As a result, only mutated dimensions are updated and rest of dimensions remain unchanged. Thus, the position of cat is partially updated. To update the position of cat in each dimension, CDC parameter either should be equal to the SMP, or it can be removed. To illustrate this, consider an example dataset given in Table 1. Present position of the cat is assumed to be
Mixture ratio (MR) is a control parameter that can limit the number of cats to be moved into seeking mode and tracing mode [25]. The number of possible clusters in a dataset are described in terms of the number of cats and the final position of cats are used to obtain the optimal cluster centers. However, to determine the clusters accurately, the number of cats to be moved in seeking mode and tracing mode should be equal. If the number of cats in seeking mode are different from the number of cats in tracing mode, then it is not possible to compute the correct number of cluster centers. For example, Table 1 consists of three clusters. So, three cats are used to initialize the possible clusters in random order and the positions of cats correspond to the cluster centers. The objective function is computed using the position of cats, and the data is arranged into three clusters using objective function values. MR parameter is used to determine the number of cats to move into tracing mode according to its value. But the number of cats in the tracing mode should be equal to number of cats initialized, otherwise it will be conceptually wrong. In the above discussion, three cats are initialized to cluster the data. If the number of cats in tracing mode is 2 as per MR parameter then data is clustered in two clusters rather than three in tracing mode which is hypothetically wrong. Therefore, in this paper, the MR parameter is removed so that the number of cats in seeking mode and tracing mode remains same.
This section summarizes the pseudo-code of the seeking and tracing modes of the Improved CSO (ICSO) algorithm. Algorithms 2 and 3 provide the pseudo-code of seeking and tracing modes of the ICSO algorithm.

Seeking mode pseudo-code of ICSO algorithm

Tracing mode pseudo-code of ICSO algorithm
This section describes the proposed ICSOKHM algorithm. The proposed algorithm is the combination of Improved CSO (discussed above) and KHM algorithms. KHM is a fast and efficient algorithm which requires less number of function evaluations but suffers from local optima problem. The proposed hybrid algorithm includes the qualities of both the algorithms and it is given the name Improved CSOKHM (ICSOKHM). The objective of the proposed algorithm is to prevent the trapping of KHM algorithm in the local optima and also to improve the convergence speed of the CSO algorithm. In short, we start with Improved CSO algorithm and feed the output of Improved CSO algorithm to KHM algorithm to obtain final cluster centers. The main steps of the proposed ICSOKHM algorithm are summarized in Algorithm 4 and corresponding flowchart is mentioned in Fig. 1.

Pseudo-code of ICSOKHM algorithm
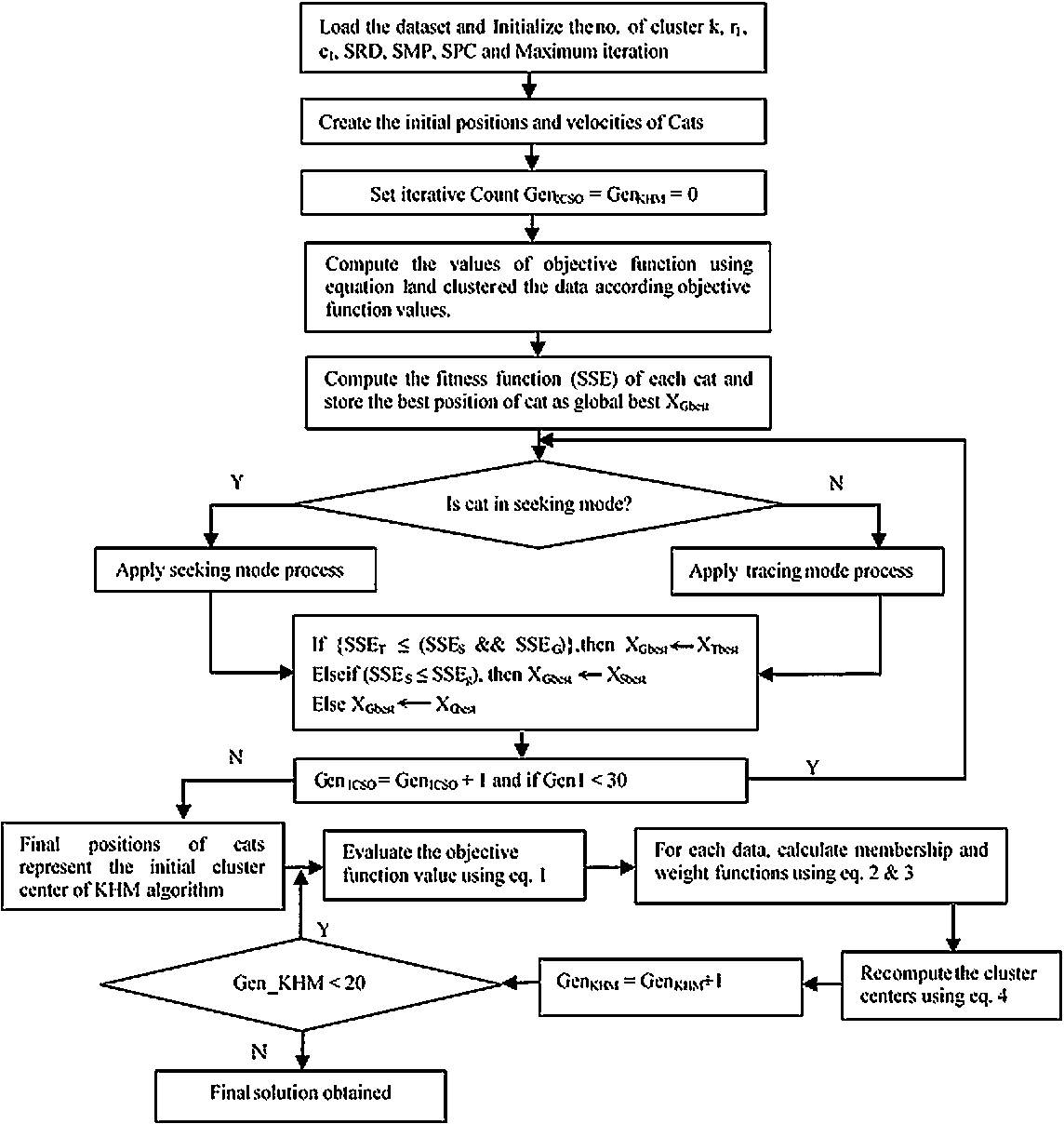
Flowchart of proposed CSOKHM.
Characteristics of datasets
Characteristics of datasets
Characteristics of datasets
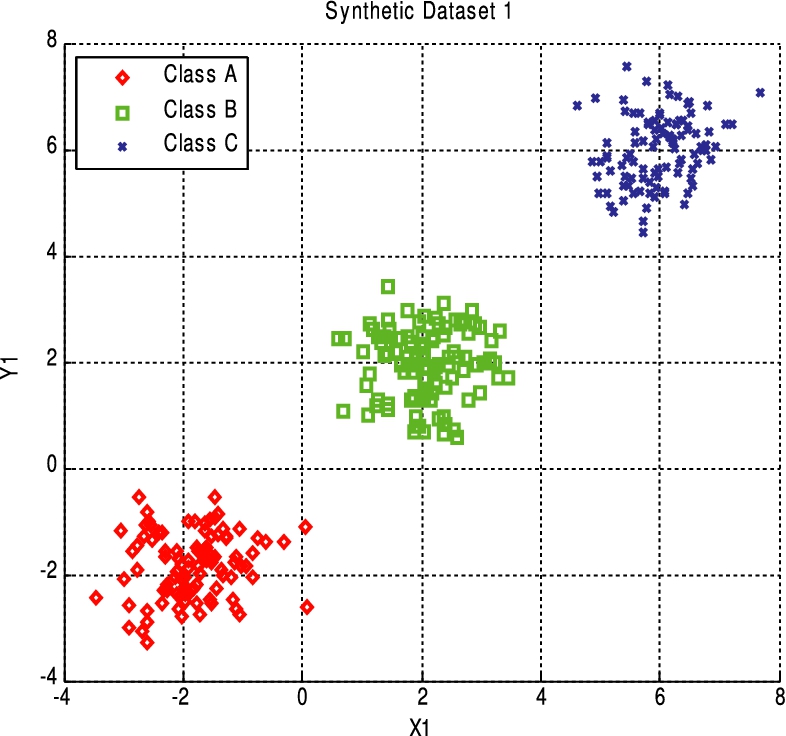
Represents the cluster centers in Synthetic2 dataset. (Colors are visible in the online version of the article;
1. Synthetic1 (
2. Synthetic2 (
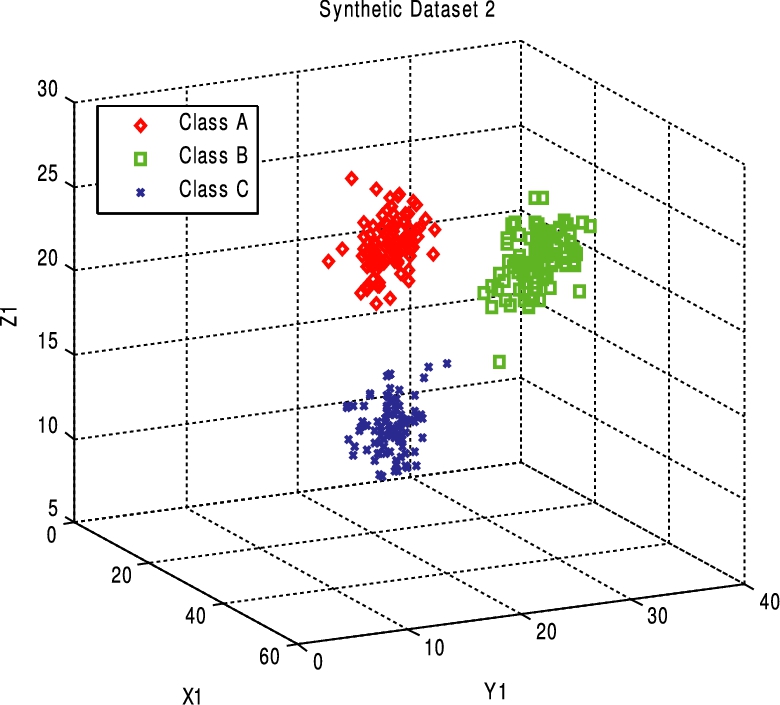
Represents the cluster centers in Synthetic2 dataset. (Colors are visible in the online version of the article;
3. Iris dataset (
4. Wine dataset (
5. Glass (
6. Cancer (
7. Contraceptive algorithm choice (CMC) (
1. K-harmonic mean (
2. F-measure: It is weighted harmonic mean of recall and precision from an information retrieval system [3,5]. The value of F-measure (
Comparison of results obtained using KHM, PSO, ACA, GSA, CSO, PSOKHM, ACAKHM, GSAKHM, CSOKHM and ICSOKHM for Synthetic1 and Synthetic2 datasets
Comparison of results obtained using KHM, PSO, ACA, GSA, CSO, PSOKHM, ACAKHM, GSAKHM, CSOKHM and ICSOKHM for Synthetic1 and Synthetic2 datasets
Comparison of results obtained using KHM, PSO, ACA, GSA, CSO, PSOKHM, ACAKHM, GSAKHM, CSOKHM and ICSOKHM for iris and glass datasets
Comparison of results obtained using KHM, PSO, ACA, GSA, CSO, PSOKHM, ACAKHM, GSAKHM, CSOKHM and ICSOKHM for cancer and CMC datasets
Comparison of results obtained using KHM, PSO, ACA, GSA, CSO, PSOKHM, ACAKHM, GSAKHM, CSOKHM and ICSOKHM for Synthetic1 and Synthetic2 datasets
Comparison of results obtained using KHM, PSO, ACA, GSA, CSO, PSOKHM, ACAKHM, GSAKHM, CSOKHM and ICSOKHM for iris and glass datasets
Comparison of results obtained using KHM, PSO, ACA, GSA, CSO, PSOKHM, ACAKHM, GSAKHM, CSOKHM and ICSOKHM for cancer and CMC datasets
Comparison of results obtained using KHM, PSO, ACA, GSA, CSO, PSOKHM, ACAKHM, GSAKHM, CSOKHM and ICSOKHM for wine dataset
Table 4 demonstrates the results of all the nine algorithms using Synthetic1 and 2 datasets when “p” is equal to 3. From results, it can be observed that performance of all the algorithms is almost equal (in terms of
Results of the iris and glass datasets for all algorithms is described in Table 5 when “p” value is 3. Table 5 indicates that proposed ICSOKHM algorithm provides better results (in terms of
Table 6 depicts the results of all algorithms for cancer and CMC datasets when “p” value is 3. From results, it can be concluded that GSAKHM algorithm gives better results in terms of
Table 7 shows the experimental results of all the nine algorithms for Synthetic1 and Synthetic2 datasets when “p” value is 3.5. From results, it can be stated that there is a slight variation between the performance (in terms of
Results of all the nine algorithms for iris and glass datasets are summarized in Table 8 when “p” is equal to 3.5. Results indicate that the proposed ICSOKHM algorithm gives better results (in terms of
Table 9 illustrates the results for cancer and CMC datasets when “p” value is 3.5. It is noticed that proposed ICSOKHM provides better results (in terms of
Finally, from Tables 4–10, it can be concluded that average
Proposed algorithm gives better results for most datasets with large “p” values (3.5) except wine dataset.
Proposed ICSOKHM algorithm also provides better runtime results when “p” value is large (3.5).
Proposed algorithm gives significant results with linearly non-separable datasets such as iris and glass datasets.
In this paper, a new improved CSOKHM (ICSOKHM) algorithm is proposed by combining the Improved cat swarm optimization (CSO) and K-harmonic means (KHM) algorithms. The proposed algorithm contains the qualities of both the algorithms. In addition to it, a selection algorithm is also introduced in tracing mode of the CSO algorithm. Along this, some heuristic approaches are also used to make the CSO algorithm more robust and efficient. Finally, the performance of the proposed algorithm is evaluated on two synthetic and five benchmark datasets and compared with existing algorithms like KHM, PSO, PSOKHM, ACA, ACAKHM, GSA, GSAKHM CSO and CSOKHM. The experimental results prove that ICSOKHM is an effective and more competent algorithm than other existing algorithms being compared. In this paper, harmonic average is taken as objective function for proposed algorithm instead of Euclidean distance. With the same objective function, the CSO algorithm requires more time and higher convergence rate while KHM gets stuck in local optima. But, the proposed ICSOKHM algorithm not only improves the convergence speed of the CSO but also prevents the KHM from running into local optima.