
Abstract
Immunization strategies are significant in many real scale-free networks, e.g. Internet or communication systems, to prevent virus infections. Several centralized and distributed strategies have been proposed in the last few years. They are efficient but they share the same major limitation: they need to know in advance the network topology and the size of the network or the number of nodes that must be immunized. These requirements make those strategies unsuitable for application to real and dynamic networks. In this paper, we propose an immunization strategy based on distributed autonomous entities that self-regulate their diffusion in the network where they are deployed. Experiments show that the proposed approach produces a population that is able to self regulate in many widely accepted benchmarks while achieving different target coverage rates.
Introduction
Many natural and technological networks that represent underlying human relationships and social activities have a scale-free topology, including World Wide Web links, Internet, social networks, email networks [1,7,8,18].
The scale-free property is strongly related with the network’s robustness to failure. If failures occur at random and the vast majority of nodes are those with small degree, the likelihood that a hub would be affected is almost negligible. On the other hand, if a hub-node is infected by a virus the spreading of the infection is very fast and this can have catastrophic effects. Thus, hubs are both the strength and the weakness of scale-free networks. These properties have been studied analytically using percolation theory by Cohen et al. [3,4] and by Callaway et al. [2].
In order to address this vulnerability, finding an optimal immunization strategy to minimize the risk of epidemic outbreaks on scale-free networks has become a major task with important practical and economical implications.
Effective and efficient immunization strategies have been proposed to counter virus propagation and to prevent a virus from becoming a rapid epidemic in the network, both in the case of random and scale-free networks [5,6,9–12,14,15]. Moreover a particular attention has been devoted to propose robust systems with the least use of resources, i.e. systems that minimize the number of immunized nodes [6,12].
These approaches are very efficient in most cases but they suffer from several limitations making them difficult to be applied in real networks. The approaches proposed in [6] and [15] assume to know the global topology of the network, that is impossible to know in most cases of real networks. The strategies proposed in [5,9,11,12,14], despite applying distributed approaches, rely and strongly depend on initial settings and parameters that are difficult to set in a proper way without any prior knowledge about the network. Moreover, it remains a challenge for [5,9,12,14] to deal with some real-world networks containing cliques or communities, since they can only vaccinate neighbors with the maximum degree within a certain range from the initial seeds.
The limit of these strategies lead to the definition of three properties that an efficient immunization strategy should have: (i) to maintain its efficiency, i.e. to scale up, also in large scale-free networks, (ii) to use a distributed approach, (iii) to work without knowing the global topology or the size of the network and (iv) to use as little resources as possible.
Starting from the above motivations, we propose a self-regulating immunization strategy based on [11]. The approach follows the Autonomy Oriented Computing (AOC) paradigm [13] that proposes to dispatch in the network a set of autonomous entities able to find the nodes with the highest degree.
In this paper a self-regulating immunization mechanism is introduced, some evaluation criteria are proposed and a wide experimentation is described. The strategy has been tested on widely accepted and publicly available datasets [17] in order to evaluate its effectiveness also in real cases. The focus of this work is on the ability of the entities to self-regulate their own population while they are reaching the highest degree nodes.
Three different evaluation criteria are proposed: the ability to regulate the population (the reproduction should stop after the first steps), the ability to find the nodes with the highest degree and the ability to reach a given immunization rate.
The rest of the paper is organized as follows. In Section 2 some related works for network immunization following both centralized and distributed approaches are described and discussed; Section 3 describes the AOC approach to network immunization providing the preliminaries needed to understand the proposed reproduction strategy and the self-regulating mechanism that are introduced in the core Section 4. In Section 5 the experimental results obtained by applying the proposed approach on a widely accepted benchmark are presented and discussed. Conclusions are drawn and future works are depicted in Section 6.
Related works
Scale-free networks exhibit a power-law degree distribution of the number of links k connecting to a node
Pastor-Satorras and Vespignani [15] and Dezső and Barabási [6] showed that traditional strategies based on random immunization, while effective in the case of random networks, are useless in scale-free networks. They introduced a very efficient method, called Targeted Immunization. This strategy proposes to vaccinate the highly connected nodes in order to cut the path through which most of the susceptible nodes catch the epidemics.
The problem has been mapped to the well-known percolation problem where nodes are immunized up to a concentration
An epidemic occurs in homogeneous networks only if the rate of infection of “healthy” individuals connected to infected ones exceeds the so-called epidemic threshold
Pastor-Satorras and Vespignani [15] and Dezső and Barabási [6] prove that in the case of random immunization the epidemic threshold vanishes, i.e
However, since this strategy assumes to know the global topology of the network and the nodes with the highest degree, the targeted immunization is unfeasible and impossible to be applied in largest majority of real networks.
Recently some efforts have been devoted to developing distributed immunization strategies, mainly applying the idea of targeted immunization in a decentralized and/or dynamic network. These works include acquaintance immunization [5,9], d-steps immunization (or covering immunization) [12,14] and immunization with distributed autonomy-oriented entities [11] based on the AOC approach introduced by Liu and Tsui [13]. Their aim is to vaccinate the highly-connected important nodes and thus cut the epidemic path without the global topological knowledge.
These strategies are very efficient in most cases but they are sensitive to their initial settings, i.e. initial number and position of seed nodes and length of steps. Moreover, it remains a challenge for [5,9,12,14] to deal with some real-world networks containing cliques or communities, since they can only vaccinate neighbors with the maximum degree within a certain range from the initial seeds. Gallos et al. show in [9] that the critical immunized fraction
Although the AOC approach [11] seems to address this limitation offering random jumps to escape cliques and communities, its effectiveness depends strongly on the number of initial entities dispatched in the network.
In the original AOC strategy a set of autonomous entities is dispatched in the network. These entities can explore the network moving between nodes and try to place themselves on the nodes with the highest degree. When the algorithm stops, the nodes resided by entities will be immunized.
Since the prior estimation of the proper number of initial entities is difficult, we propose a self regulating method able to autonomously decide how many entities are necessary to reach a given immunization rate. In the proposed approach the entities have the ability to reproduce and distributively self-regulate their population while optimizing the number of occupied high degree nodes. Each distributed autonomous entity estimates the percentage of occupation of the graph, based on its past observations and information found in its own local environment.
Each entity, during its exploration, can leave information about its past observations on the nodes in its local environment. These “traces” on nodes represent a form of shared memory that allows to realize an entity-to-entity communication. These information is then used to estimate the network immunization rate and decide whether or not, and how much, to reproduce itself.
A correspondence with the Ant Colony Optimization (ACO) metaheuristic can be drawn. In fact, the concept of pheromone used in ACO can be seen as a form of indirect communication between the ants and it plays a role similar to traces left by the entities on the nodes in the proposed model. The analogy is represented by the fact that pheromone/traces implement a form of distributed and sharable memory that can guide the ants/autonomous entities and can be reinforced/updated. On the other hand the decisions of the autonomous entities are deterministic while the ants’ behavior deterministically depends on the pheromone.
Given an immunization target as a percentage of the nodes to be immunized, the distributed strategy presented here (i) estimates the number of entities to dispatch in order to reach the immunization target and (ii) selects the nodes that is convenient to immunize without any information about the topology and the size of the network.
AOC approach to network immunization
In the AOC approach to network immunization, a group of computational autonomous entities is dispatched into a decentralized network [10,11]. These entities work together, to achieve a common goal, by communicating through their local environment: they decide autonomously to perform one of the available actions based on the information in their local environment.
In the immunization network perspective, the entities explore the network moving from a node to another node. The aim is to find the highest degree nodes and place themselves there. The final position of the entities represents the set of nodes which will be immunized. The performance of the strategy is measured considering the entities’ ability to find and recognize the best nodes. In this sense, the AOC immunization can be considered as a form of distributed targeted immunization [6,15].
The network is traditionally represented as a graph
The problem is NP-hard since it can be seen as a Maximum Coverage Problem (MCP) where each input set
(Entity).
An entity e is a tuple id: entity’s identifier, node: the node where the entity resides at a given time step t and its degree. The node is denoted by lifecycle: maximum time steps for an entity to reside on a node, rules: is the set of possible behaviour/action each entity can perform.
Before giving the definitions of the entity’s action rules the concept of local environment has to be introduced. The entities can communicate each other through their local environment. The local environment of an entity is the set of direct and indirect neighbor nodes as specified in the following definition.
(Local environment).
Let e be an entity and v the node in which it resides. The local environment of e at the time t is defined as it is the second-highest degree node, not being occupied by any other entities, and it is known to the entity, i.e. it is in
(Entity’s rules).
The set of possible actions used by an entity to explore the network are:
RationalMove: the entity moves to a highest-degree position in its local environment. If there exists more than one highest-degree position, the entity chooses the first one from its friend list. RandomJump: the entity moves randomly to a distant or long-range node in order to avoid getting stuck in local optima. Wait: the entity stays in its position because it does not know a better position where to move. The entity cannot stay on the same node for ever. The maximum number of steps it can stay is stored in lifecycle.
The RandomJump action is the discriminating factor that allows the AOC-approach to outperform the d-step strategy. This action is crucial in the case of networks containing community: without it, it is difficult for entities to move out of them. At the same time, the RandomJump is necessary for realizing the diversity and emergence of computable configurations in the AOC system.
Figure 1 represents a network where two entities E1 and E2 are dispatched. In particular the image shows how local environments are computed and the entities decide which action is better to choose. Initially the entities are placed respectively on the nodes

An example of a network with two autonomous entities E1 and E2. It shows how the entity E1 enlarges its local environment through its interaction with E2. The interaction starts when the two entities share the common direct neighbor
Local environment of an entity is not a static set of nodes because it can be modified by other entities. Due to this possibility the information of the important nodes on the network quickly reaches every entities. When a local environment is updated, it is possible for the entity to know a node with a greater degree that was previously unknown. In this sense the entity profits from its local environment.
The best local degree for the entity e at the time t is the highest degree of the nodes in the entity’s local environment
Based on the information received from its local environment, each entity takes one of the three possible actions: RationaleMove, RandomJump and Wait.
The algorithm is presented in Fig. 2.
The choice is based on the comparison between the entity’s utility
Otherwise, if its
When the algorithm stops, the final positions of the entities represent the set of nodes which will be immunized. The performance of the strategy is measured considering the entities’ ability to find and recognize the best nodes.

AOC decision phase.
The criterion used to evaluate the efficiency of the AOC strategy is the value
The approach is mathematically equivalent to a distributed combinatorial optimization problem (DCOP) [16] with the objective of finding the largest sum of vaccinated degrees when given a fixed number of vaccinated nodes.
Gao et al. [11] show how the AOC-based immunization is more efficient than other methods, in particular with respect to the d-steps strategy [12]. In particular they show that in most of the tested cases:
the coverage rates reached by the AOC-based strategy are much higher than the ones reached by the d-steps strategy,
the average of the moving steps applied by the AOC-based strategy are fewer than the ones applyed by the d-steps strategy.
Moreover they show that the AOC-based strategy adapts well to networks with community structures, whereas the d-steps strategy often fall into local optima. This is possible trough the RandomJump action. When entities cannot find a better node where to move in their local environment, they can randomly explore other positions and, eventually, move to them.
Nevertheless, a major assumption of the AOC-based strategy is that it has to take as input the (fixed) number of nodes to immunize, i.e. the number of entities to be deployed on the network in order to obtain a suitable coverage rate.
Since immunization is a costly task [6,12], overestimating the number of necessary entities can result in a waste of resources, which could be saved or, for instance, deployed in other networks. On the other hand, underestimating the number of nodes to immunize can lead to inefficient immunization and can make the network vulnerable and prone to virus attack. The problem of under/over estimation is particularly relevant to dynamic networks where the size grows or shrinks over time, and in the case of large online networks of unknown size where no central entity is available to provide the necessary data.
Our goal is to overcome the limitations stated in the previous section by proposing an approach which extends the AOC-based algorithm [11]. We do not want to decide a priori which is the exact number of entities to deploy, but we want simply give the percentage of network we want to immunize in order to immunize the whole network. In practice our proposal is to allow entities to self-regulate their population in order to reach a given immunization rate (percentage of nodes to immunize). In this case the immunization problem can be stated as: given a percentage of network nodes to be immunized (called immunization target), the goal is to regulate the entities population and positions in order to maximize the SID and reach the immunization target.
The basic idea is to extend the entity’s behaviors by a new action, called reproduction, that allows an existing entity to generate one or more new entities that will be deployed on the network. This behavior, driven by a suitable reproduction strategy, makes the algorithm independent from the parameter
(Entity with reproduction).
An entity with reproduction id, node, lifecycle are the same as in Definition 1, target: immunization target to reach; it represents the target percentage of nodes in the network we want to immunize, i.e. the percentage of nodes that must be resided by an entity at the end of the algorithm, observations: it is composed by two values rules: is the set of possible behavior/action each entity can perform. It is composed by the three AOC actions introduced in Definition 3 (RationalMove, RandomJump, Wait) plus the new action Reproduce used by the entities to generate other entities.
(Entity’s observations).
Entity’s observations at a time t are two values able to summarize the information about the entities met and the nodes seen by the entity itself collected by an entity e during its exploration until time t.
The entities can communicate each other through their local environment as in the classical AOC approach. Moreover they can share their observations about the network immunization rate in order to learn from the other entities’ experience. The local environment of an entity is defined in the same way as in Definition 2, as well as Best Local Degree has the same of Definition 4.
Given the information received from its local environment, each entity takes one of the following four possible actions: RationaleMove, RandomJump, Wait and Reproduce.
At first, the choice is based on the estimation of the graph immunization rate made by the entity: if the estimated immunization rate
The estimation of the immunization rate given by

AOC-reproduction decision phase.
Due to the decentralized nature of the algorithm, entities do not know the exact value of immunization rate at a given time step, so they have to estimate it in order to regulate the reproduction. The more the immunization rate is approaching the target the less the entities will reproduce themselves. The estimating ability is one of the most critical issue of the self-regulating mechanism because it has a direct effect on the whole immunization process. If the estimate is too high, the immunization target will never be reached or it will be reached too slowly after too many steps; on the other hand, if the estimate is too low a waste of resources is possible.
The estimation of the immunization rate is the core issue of the self regulating mechanism and it plays a key role in the success of the strategy. A too low estimate will depict a network with too few entities and will cause an over-reproduction of entities; the result is a possible waste of resources. On the other hand, a too high estimate leads the entities to believe that there are too much entities on the network and will cause a too early stop of the reproduction; it could prevent the target achievement.
Several techniques that compute this estimation have been developed and tested. It has been noted, as expected, that too rough estimates, like the simple estimate by means the percentage of resided neighbors, do not work. This is because scale-free networks are just characterized by a high standard deviation of the connectivity degree distribution.
The technique proposed in this work considers and combines three factors: the local coverage that an entity can observe in its neighbourhood, the entity’s exploration history and the traces left on the nodes by the other entities. To do that, the entities’ observations in (1) and (2) are used. A node’s component, called local memory, has been defined to make available to entities also the observations of other entities.
Each node n has a local memory where entities can store their observations about the network they have explored. This memory stores two values that are called entity’s traces and are represented by
These traces are useful to leave in the nodes information available to other entities and implement a form of entity-to-entity communication. The rationale behind this strategy is that more experienced entities i.e., entities with a greater An entity e estimates the immunization rate of the network at the time t by computing
The components local coverage and the entity’s exploration history are taken by the terms
In order to decide whether reproduce themselves or not, the entities compare their estimates of the immunization rate with the immunization target; if this is lower, then the entities decide to reproduce themselves according to the rules in the following section.
When an entity decides to reproduce itself, it has to determine:
branching factor: the number of entities to be generated, initial location: the location where a new entity will be placed, and initial state: the new entity’s initial state.
About the number of new generated entities, different strategies have been implemented and tested.
During preliminary experiments we have tested a strategy that fixes the branching factor as an input parameter of the program. However, besides the fact that a new external parameter does not embrace the concept of self-regulating mechanism, the experimental results did not seem to be promising in order to control the entities offspring. Even with low branching factors the network was immediately, after 3–4 steps, invaded by the entities. The immunization target was reached, but the number of entities was too high: if we consider the case in which a cost is associated to each entity, it is clear that a more refined technique was necessary.
Hence, it was necessary to design a self regulating mechanism that dynamically determines a local branching factor distributively by each entity. The number of new entities to be generated, called
This means that in the first steps the number of entities will increase quickly; then, after some steps, this increasing will grow more slowly, until it stops to grow because entities detect a more populated network. The reproduction strategy is one of the most studied and tested aspects of the proposed system.
Overview of the networks used in the experiments
Overview of the networks used in the experiments
Moreover, several strategies for determining initial location and initial state of a new entity have been implemented and tested.
For initial location, two strategies have been considered: Neighborhood locating strategy (Nls) and Random Jump locating strategy (RJls). In the Nls case, the offspring location is chosen in the neighborhood of the generating entity, while in the RJls case the offspring location is chosen performing a RandomJump action.
For the initial state, the strategies Empty Initial state strategy (EIss) and Inherited state strategy (Iss) have been defined and tested. In the EIss case each entity is born without any knowledge about the parent, i.e. with empty utility field; while, in the Iss case, some of the knowledge i.e., the utility value, is passed down to a new entity from its parent.
We have defined three evaluation measures for the AOC strategy with reproduction:
Coverage Rate: it is defined as the ratio between the SID reached by the entities at a given time step t, i.e. Immunization Rate: it is defined as the ratio between the number Reproduction Rate: it is introduced to evaluate the reproduction behavior and it is defined as the percentage of entities that are reproducing themselves at a given time step t. In formula (8),
Experiments
In this section we present and discuss the results obtained by experimenting the Self Regulating SR-AOC immunization strategy.
Datasets
Widely known and publicly available data sets from the Stanford Network Analysis Platform (SNAP) [17] were used for the experiments. We chose ten networks covering different classes of scale free graphs derived from technological social networks:
communication network: Enron Mail,
autonomous system network: NET6,
coauthorship network: NET7,
community-based network: NET9,
Internet peer-to-peer networks: p2p-Gnutella, p2p-Gnutella08,
social networks: Facebook, Wiki-vote,
collaboration networks: ca-CondMat, ca-HepPh.
Table 1 shows relevant properties of each experimented network where:
#Nodes and #Edges are respectively the number of nodes and edges of the network;
diameter is the greatest distance between any pair of vertices;
ACC (Average Cluster Coefficient) is the average of the local clustering coefficients of all the network nodes that is defined by the proportion of links between the vertices within its neighbourhood divided by the number of links that could possibly exist between them; it measures the degree to which nodes in a graph tend to cluster together;
#Triangles is the number of triangles in the network; a triangle exists when a vertex has two adjacent vertexes that are also adjacent to each other.
In order to avoid biases due to the randomized aspects of the proposed algorithm, all experimental results are computed as average values over 40 runs; an initial tuning phase has shown that over this limit the values remain quite stable.
Evaluation metrics
In order to identify suitable evaluation criteria, different metrics and dimensions have been considered in order to assess the experiments:
Coverage Rate: defined in (6). It measures the SID coverage, i.e. the ability of the algorithm to place the entities in the nodes with the highest degree thus maximizing the immunization effect. In the following we consider satisfactory results with a SID rate over 90%. It is important to note that the coverage rate should increase and maintained high through the exploration. However, we expect that some inflections can appear in the first steps when large groups of new generated entities are deployed in the network. Immunization Rate: defined in (7). The immunization rate is directly measuring one of the main objectives of our immunization strategy i.e., the convergence of the imm_rate to the given immunization target. This measure strongly depends on the capacity of the system to give a good estimate of the global immunization using the information collected by the entities during their exploration. In the case of under-estimation (or over-estimation) of the immunization, the algorithm will stop the reproduction too late (or too early) and it is possible to observe a convergence to a value that is higher (or less) than the goal. Reproduction Rate: defined in (8). It measures the ability of the SR-AOC strategy of progressively stopping the reproduction. While the convergence to a zero reproduction rate is the ideal situation, in practical cases a few entities can continue to reproduce themselves because they reside in quite isolated nodes and they locally observe an empty network. The use of a threshold
The problem is fundamentally a multi-objective optimization problem: we want to reach the target immunization rate in the shortest time with no waste of immunization resources. This can be translated in: as the number of reproducing entities converges to zero, the immunization rate should get closer to the given immunization target, while the coverage rate should be maximized. Moroever, all this should take place in the shortest number of time steps.
Experiment settings
Some tests have been designed to determine suitable values for the global parameters represented by (i) the initial number of entities and (ii) the parameters α and β in the formulas (1) and (2) defining the entity’s observations
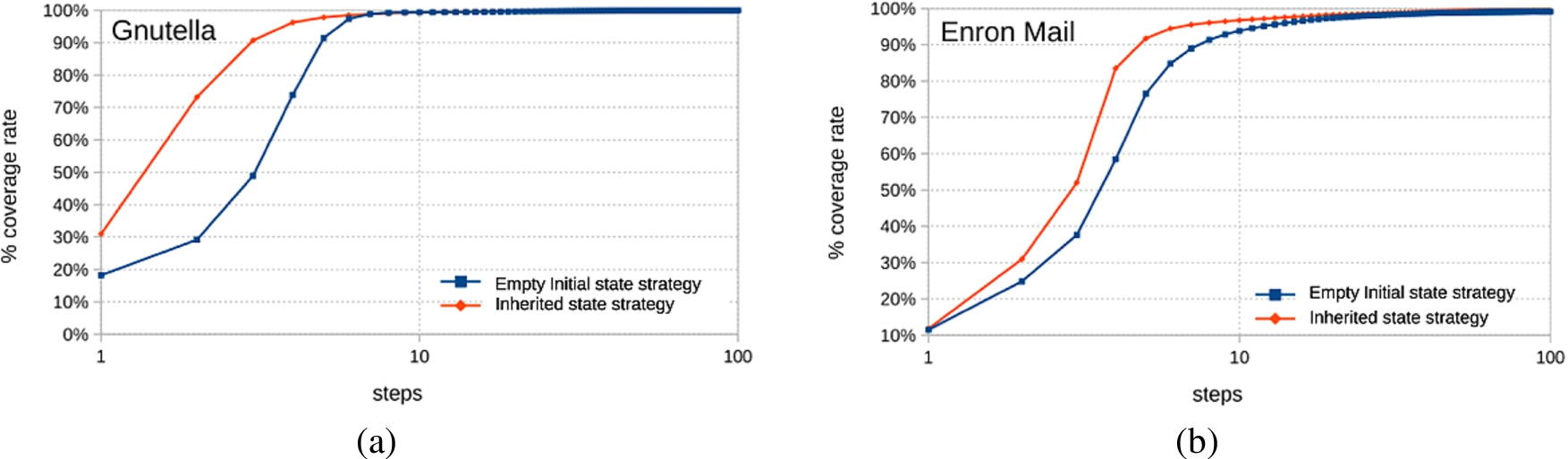
Comparisons between two versions of the algorithm differing in the strategy applied (EIss, Empty Initial state strategy and Iss, Inherited state strategy) to decide the initial state of the new entities. (a) Gnutella network. (b) Enron network. (Colors are visible in the online version of the article;
First of all we decided to define suitable values for α and β, then the program has been run with different values α and β and finally the results have been compared with respect to the three metrics defined in the previous section. As expected the metric most influenced by those parameters was the Immunization Rate. While the fluctuations of Coverage Rate and Reproduction Rate were uniformly distributed with respect to both different networks and different values, the differences noted over the Immunization Rate allowed to discriminate quite well which values were better to choose. Preliminary tests highlighted that values near to 0 or near to 1 produced worse results than values near to 0.5. More systematic tests have focused in the interval
Then, further tests have been run to determine a suitable value for the initial number of entities to deploy on the network. For these tests α and β remained fixed to the value
After the parameter setting phase a series of experiments were conducted in order to:
compare EIss and Iss strategies for determining the initial state and the initial location of new generated entities (Section 5.4),
show that the SR-AOC approach for network immunization performs as well as the original AOC approach with respect to the SID optimization; adding the self regulating mechanism does not make the AOC performance worsen (Section 5.5),
analyze the behaviour of Reproduction Rate and Coverage Rate with respect to increasing steps (Section 5.6),
analyze the behaviour of Immunization Rate with respect to increasing steps (Section 5.7).
Several strategies for determining initial location and initial state of a new entity have been implemented and tested. The strategies Neighborhood locating strategy (Nls) and Random Jump locating strategy (RJls) setting the initial position of a new entity has been tested. While the Empty Initial state strategy (EIss) and the Inherited state strategy (Iss) have been tested for the initial state.
RJls combined with Iss showed the best performances allowing to speed up the immunization target and coverage rate reachability.
Figure 4(a) and (b) show the comparison between two versions of the algorithm where Random Jump locating strategy (RJls) is fixed as locating strategy and both the two strategies EIss and Iss are used to determine the initial state of the new entities. The figures show that the approach with Inherited state strategy gives better results as it reaches a higher threshold for coverage rate in less time both for Gnutella and Enron cases. The results on the other tested network are very similar.

Comparisons between the original AOC and the Self Regulating AOC (SR-AOC) strategies with respect to the SID optimization. (a) CondMat network. (b) Gnutella network. (c) NET6 network. (d) NET7 network. (Colors are visible in the online version of the article;
The difference between the two strategies is due to the information received by the entities from their parents before start to search a node where move. This mechanism is used to speed up the process of finding important nodes.
These strategies have been used for the whole experimental phase whose results are presented in the next sections.
Gao et al. [11] show how the AOC-based immunization is more efficient than other distributed methods, in particular with respect to the d-steps strategy [12]. In this section a comparison between the SR-AOC and AOC approaches to network immunization is presented. The objective of this comparison is to show that the performance of the SR-AOC approach is comparable with the performance of the original AOC approach with respect to the SID optimization. The self regulating mechanism adds flexibility while it maintains the SID optimization capability of the AOC approach.

Experiment results for entity reproduction rate compared with the coverage rate. Each graph shows results obtained for different immunization targets (5%, 10%, 15% and 30%). The same color is used for the coverage rate and the reproduction rate in the same experiment. (a) Facebook network. (b) Enron Email network. (c) Gnutella network. (d) NET6 network. (Colors are visible in the online version of the article;

Experiment results for entity reproduction rate compared with the coverage rate. Each graph shows results obtained for different immunization targets (5%, 10%, 15% and 30%). The same color is used for the coverage rate and the reproduction rate in the same experiment. (a) NET7 network. (b) Wiki-vote network. (c) NET9 network. (d) Gnutella08 network. (Colors are visible in the online version of the article;
In Fig. 5 the SID values obtained with the SR-AOC and AOC strategies are plotted. The comparison is made considering the number of entities reached by the SR-AOC strategy at the time step when the number of entities is stable. We consider that the population is stable when less than 1% of entities are reproducing. In the graphics also the value reached by the Targeted Immunization is plotted because it represents the optimum. It is important to note that the Targeted Immunization is optimal because it assumes a global knowledge of the network topology.
As the graphics show in all the four cases, the SID obtained by the SR-AOC approach reaches the one computed by the original AOC strategy in a very few steps. Obviously the SR-AOC strategy needs some more steps to reach the value obtained by the original AOC because it starts with a completely different value for the number of initial entities. It also happen that in the case of NET7 network the SID value reached by the SR-AOC strategy is higher than the one obtained by the original AOC strategy.
The plots show the behaviour in different cases with different networks. The results with the other network are very similar.
It is important to analyze the algorithm behaviour over the time and evaluate the criteria on different data sets as well as on different immunization targets. The convergence of reproduction and coverage rates, as well as the precision with respect to the target immunization, has been then analyzed by means of three measures respectively reflecting the self-regulating mechanism, the optimal resource placement, and the immunization goal.
Convergence results for coverage rate and reproduction rate are presented and compared in Figs. 6 and 7. Each plot corresponds to one of the eight tested networks. It is possible to compare the behaviour over the time of reproduction and coverage rates, where in each case the results for four different immunization targets are shown by different colors. First, it can be noted that, for all the tests, the reproduction rate quickly decrease below the one percent threshold i.e. all the entities reproduction eventually stops. The coverage rate is plotted together with the reproduction rate in order to show how, after the convergence to zero of the reproduction rate, in a very few steps the coverage rate reach and exceed the 90% threshold.
Macroanalisys on the immunization rate
Macroanalisys on the immunization rate

Analysis of Immunization Rate with respect to the Immunization Target. (a) Gnutella network. (b) Gnutella08 network. (c) NET9 network. (d) Wiki-vote network. (Colors are visible in the online version of the article;
The results show that the main goal of building a mechanism in which the entities autonomously regulate their population, while moving on the network and maximizing the coverage rate, has been reached. Moreover it is worth noting that the results are obtained in all the experiments, regardless of the network types and the number of nodes, thus confirming the scalability of the SR-AOC strategy proposed in this work.
Further analysis has been conducted in order to evaluate the precision of the proposed method. The precision of the immunization strategy can be regarded as the ability to reach the immunization target when reproduction converges, i.e. the relative error between target and actual immunization rate. Experiments have been systematically held with different immunization targets on different network domains.
Figure 8 focuses on the results of immunization rate for some networks with three different targets (5%, 10% and 15%). In these plots different behaviours of the Self Regulating strategy can be observed.
Convergence and high stability has been generally obtained while, in some cases, see for instance Fig. 8(c) and (d), the immunization target has not been reached: in the case of NET9 network the actual reached coverage is respectively 3.5%, 8% and 13.7% for the targets 5%, 10% and 15% while in the case of Wiki-vote network the gap between the reached and target coverage is higher with reached coverages of respectively 2.3%, 6% and 11.2%. The main reason of this behaviour has been attributed to an over-estimation of the coverage
The best results have been obtained for the Gnutella network (Fig. 8(a)) where the target is reached in very few steps and the proposed strategy shows a high stability.
In some cases (e.g. Fig. 8(b)), the target is quickly reached but the immunization rate, on the long run, does not converge and continues to grow, although coverage and reproduction rate are both convergent. The reason is a cumulative effect of “noise” due to some isolated entities which continue to view an under-populated network and continue to reproduce themselves. The number is very low (less than 0.5%) but the effect is accumulated during the execution. Moreover, the effect on the plot of Fig. 8(b) is furtherly emphasized by the log scale in the “Steps” axis, where a lot of steps are represented in the last part of the axis. On the other hand, we have to note that, since this behaviour is observed after the convergence threshold, it could not be consider an inefficiency at all. Future studies and possible strategies to address this problem are depicted in the next section.
A comprehensive macro-analysis on the immunization rate has been made for all the tested networks and it is shown in Table 2. For each network the minimum, the maximum and the mean relative errors among the four relative errors computed for each different target (5%, 10%, 15% and 30%) have been reported respectively in the e_min, e_max and e_avg columns. Moreover, for each network, the minimum, the maximum and the mean ratio between the reached immunization rate and the immunization target among the four ratio computed for each different target (5%, 10%, 15% and 30%) have been reported respectively in the r_min, r_max and r_avg columns. These values are computed considering a snapshot of the program execution at the time-step when reproduction is practically stopped according to the threshold
The results of the macroanalysis on the relative imm_rate error confirm more generally the detailed results shown in Fig. 8. It can be noted that the minimal relative errors are obtained, with the Gnutella, NET9 and Wiki-vote networks, while the Enron and Facebook networks show a much lower precision.
Results for convergence of reproduction and coverage rate appear to be sound and to scale over different domains and immunization rate. Further experiments with immunization targets will be necessary to understand which network features (e.g. Table 1) affect the precision to reach the immunization target for certain domains in order to incorporate these factors in the distributed estimate (4).
Conclusions and future work
A Self Regulating Autonomy Oriented (SR-AOC) immunization algorithm has been presented in this work. The entities self regulate their population while exploring the graph and maximizing the immunization rate. Distributed immunization strategies, previously proposed in the literature, rely on knowing the total number of network nodes for obtaining a target immunization rate, since they initially deploy on the network a fixed static number of entities. Differently from those proposals, our method allows to immunize networks of unknown size.
Experiments on widely accepted datasets show that, when the entities population stabilizes, the coverage rate converges to the optimum. Tests on different networks confirm the scalability of the Self Regulating approach regardless of the type and the size of the network.
Further work is needed to improve the precision of the method with respect the reachability of the immunization target. Ongoing work is investigating tuning methods for the reproduction phase in order to avoid the sharp gap observed on the population growth among two consecutive steps of the algorithm. In some cases even a single reproductive step of a large number of entities can negatively affect the precision by largely exceeding the target. A smoother growth of the population could be obtained by randomizing the reproduction phase which is currently deterministically activated by a strict threshold. In order to improve the convergence to zero of the reproduction rate, it will be also worth considering the introduction of entity elimination action. This is to avoid the phenomenon of continuous, although slow, population growth because of the reproduction of few entities.