
Abstract
Online judges are online systems that test solutions in programming contests and practice sessions. They tend to become large live repositories of problems, with hundreds, or even thousands, of problems. This wide problem statement availability becomes a challenge for new users who want to choose the next problem to solve depending on their knowledge. This is due to the fact that online judges usually lack meta information about the problems and the users do not express their own preferences either. Nevertheless, online judges collect a rich information about which problems have been attempted, and solved, by which users. In this paper, we consider all this information as a social network, and use social network analysis techniques for creating similarity metrics between problems that can be then used for recommendation.
Introduction
Online judges are online systems that test programs in programming contests and practice sessions [12]. They are able to compile and execute the code sent by users and deliver a verdict regarding its correctness according to the problem statement. Usually, execution time and memory consumption are restricted in order to force the users to look for efficient solutions. Examples of such systems are the UVa Online Judge (
These systems are usually used for training on-site programming contests such as ACM-ICPC International Collegiate Programming Contest. Some of them are not mere problem repositories with automatic judges, but they also hold on-line contests that coincide with the publication of new problems. This way, users may practice with fresh problems and their final standing is reflected in different rankings managed by the system.
Moreover, most of them can even emulate past online and on-site contests for those users that could not participate in them. The user just manifests his intention of joining a past contest and the system starts a virtual contest for him. System displays problem statements and a ranking where the real submissions sent by the user are merged with submissions that were made by participants in the original contest.
For that reason, online judges are valuable resources for expert users who want to increase their performance on competitive programming. Unfortunately, these systems pay little or no attention to the newbies who are not biased by programming contests but just want to practice algorithms or data structures. Usually they are overwhelmed by the great amount of problems in the archive and they have no idea about which one they should try to solve next. The main reason is that online judges do not usually have any recommendation mechanism that guides those users. At most, they use the Global Ranking Method, which recommends the problem with more correct solutions in the system that the user has not resolved yet.
Having a recommender system on online judges is not easy, though. The users hardly ever rate problems, they do not express their preferences on their profiles and the information about the problem set is nonexistent or, at most, the problems are just tagged with the programming concepts that should be used in their solutions.
This paper introduces a technique to incorporate recommendation methods into these online judges. In order to do that, we characterize the user–problem interaction (which users have solved which problems) as an implicit social network. Then, we apply Social Network Analysis (SNA) techniques to extract information about the problems that will be used for a recommendation. In particular, we suggest the use of similarity-based link prediction techniques over the implicit user–problem interaction network to predict new links, which can be interpreted as a way to recommend problems to the users.
The experimental evaluation uses datasets from two different online judges with very different sizes and target audiences. The first one comes from Acepta el reto1
The remainder of this work runs as follows. Next section describes online judges in general and Acepta el reto and UVa online judge, in particular. It is followed by the description of how to characterize the user interaction of online judges as a social network. Section 4 describes the link prediction problem and enumerates the similarity metrics that we have used in our recommendation algorithms. Section 5 describes the experimental setup and the evaluation results. Then the related work is presented (Section 6) and, finally, a section with conclusions and future work closes this work.
Online judges are software platforms designed to evaluate programming exercises. They were born due to the necessity of managing programming contests, but they soon became repositories of problems used in previous contests, providing competitive learning platforms to practice or, more recently, to help in curricular learning.
Online judge users choose the next problem to confront and then try to solve it submitting code solutions in one of the accepted languages. The system compiles the source code and runs it against a set of test cases, whose solutions are known by the judge. The output generated by the submitted solution is compared with the official solution and a verdict is provided.
From the system point of view, a submission can be seen as a tuple
The solution submitted was correct because it produced the right answer and it did not exceed the time and memory usage thresholds.
The solution was almost correct, though it failed to write the output in the exact required format (having an excess of blanks or line endings, for example).
The solution did not compile.
The program failed to write the correct answer for one or more test cases.
The program crashed during the execution (because of segmentation fault, floating point exception…).
The execution took too long and was canceled.
The solution consumed too much memory and was aborted.
The program tried to write too much information. This usually occurs if the program enters an infinite loop.
All these verdicts are available in both online judges used in this paper, Acepta el reto and UVa online judges, although both of them have also some other less important verdicts not considered here.
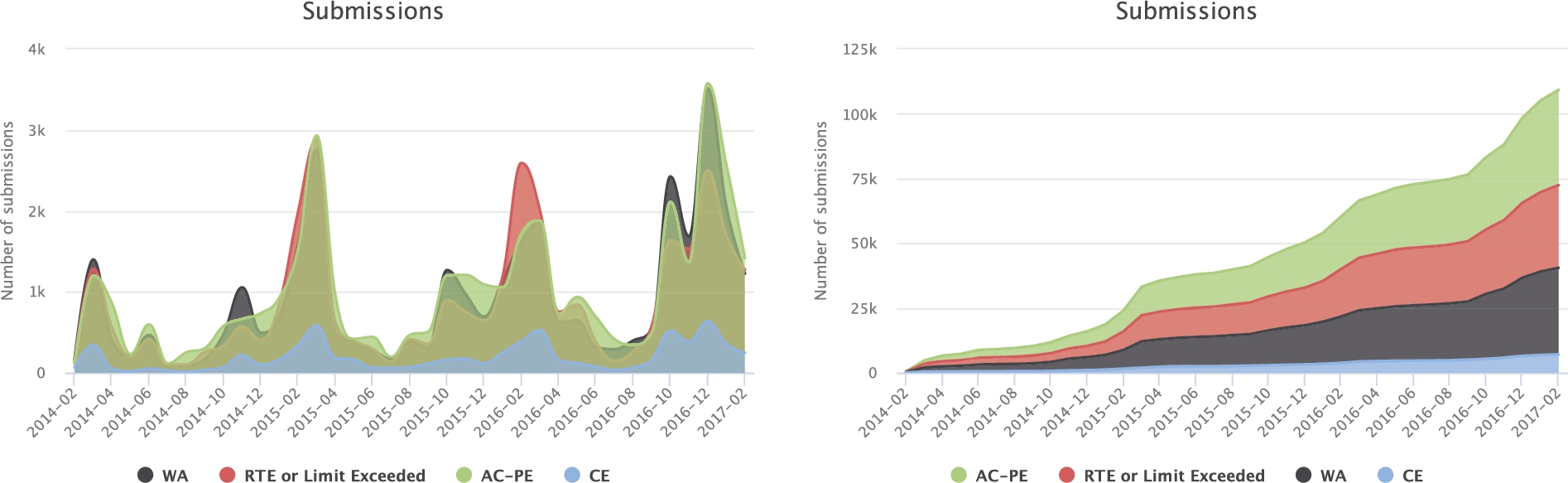
Submissions (left) and cumulative submissions (right) in ACR online judge between 2014-02 and 2017-02, categorized by verdict.
Acepta el reto (ACR) is an online judge created by two of the authors in 2014. It focuses on Spanish students, who find it hard to use other judges (with English statements) because of the language barrier. Problems are tagged according to the programming concepts needed to solve them, the kind of data structures required and some other aspects. It accepts solutions programmed using C,
At the time of this writing (March 2017), ACR has nearly 5,000 registered users, 288 problems and more than 110,000 submissions. Figure 1 shows the number of submissions and its cumulative count per month, categorized by verdicts. The high number of submissions around March and December is due to a local contest organized by the authors. The online judge contains the problems of past editions and contestants use it for training purposes. Runtime errors (RTE) and all the verdicts related to limits exceeded (TLE, MLE and OLE) are grouped for clarity. Presentation Error and Accepted verdicts have been also joined together. After all, solutions evaluated as Presentation Error are close to being correct, usually just deleting extra blanks at the end of the lines. Although a bad token separator can ruin, for example, a network protocol, this is not the case for the kind of problems that online judges focus on.
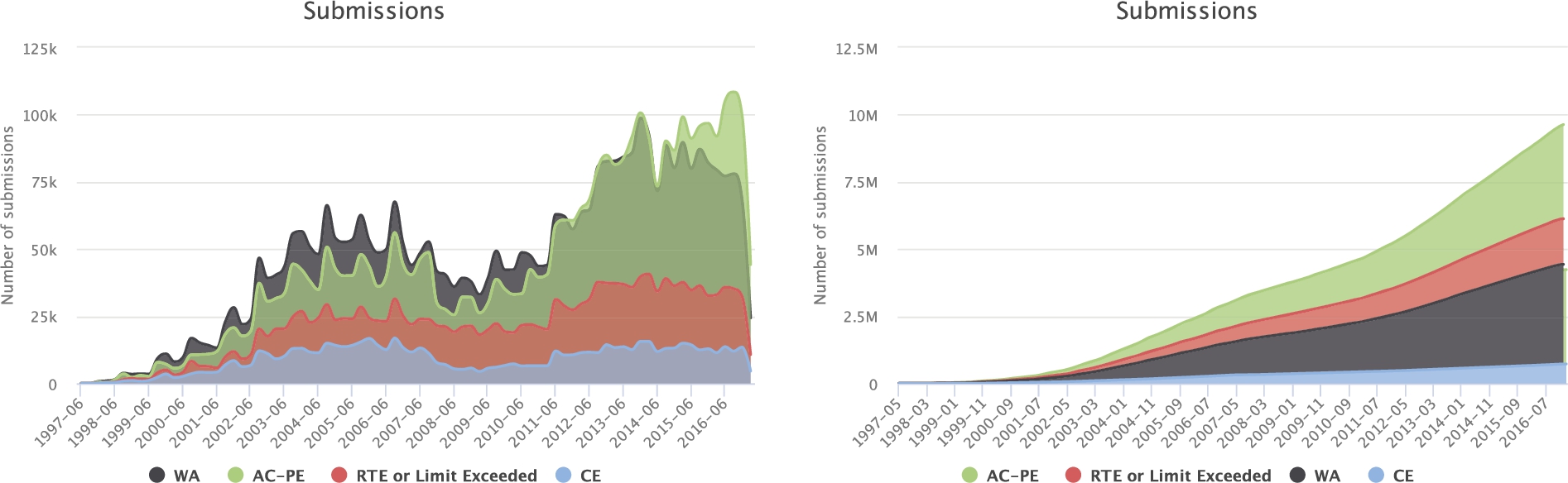
Submissions (left) and cumulative submissions (right) in UVa online judge between 1997 and 2016, categorized by verdict.
Concerning UVa online judge, it has nearly 900,000 users, more than 4,700 problems and about 19 millions of submissions in C,
We carried out an exploratory analysis of both datasets in order to familiarize with the data contained in them and find relevant information for our recommendation purposes. We confirmed that it is common in both online judges that users who get a negative verdict try to fix their code and then resubmit it. We also discovered that it is quite usual to receive resubmissions of users who already solved the problem. In this case, users perform optimizations in their solutions in order to make them faster and climb positions in the system ranking. Sometimes, those optimizations are not correct and the new solutions are evaluated with a negative verdict. Nevertheless, from the point of view of the system, users solve a problem when they obtain their first Accepted verdict, and the problem remains solved despite the non-AC verdicts in subsequent submissions.
Descriptive analysis of the submissions in ACR and UVa online judges: the original datasets (raw) and the filtered dataset (Accepted), where only the first AC–PE verdict for each user–problem submission is considered
For our recommendation purposes, all these resubmissions contribute to add noise to the dataset. Our recommendation is based on the relationship between users and problems and, from the point of view of a user, a problem can be:
Unattempted: the user did not submit any solution to that problem yet.
Attempted: the user submitted one or more solutions to the problem, but all of them were invalid.
Solved: the user submitted one or more solutions to the problem, and at least one of them was judged as Accepted.
The recommendation approach described in this paper works with the implicit social network created using the relationship between users and problems. In that sense, the key point is whether a user has solved a problem, not just attempted it. For this reason, we filter the datasets so only Accepted submissions are considered. Nevertheless, due to the proximity between AC and PE verdicts, they are considered synonymous. Table 1 provides a catalogue of descriptive statistics, as proposed in [4], about both versions of the datasets: the original (Raw) submission dataset and the filtered (Accepted) dataset.
A social network is a group of individuals or entities that are related to each other, traditionally represented as a graph. In an online judge system, user–problem interactions can be abstracted and represented into a user–problem non-weighted bipartite network G, where nodes belong exclusively to one of two disjoint sets, the problem-set
The network representation allows us to analyse the user–problem interactions that occurred in the online judge system using the methods and metrics defined by the Social Network Analysis field [8]. Link prediction is a technique used in social network analysis that aims to predict new links that might be formed between nodes in a future time or to predict missed links in the current network [15]. Then, problem recommendation in an online judge system can be viewed as a link prediction problem: given a graph that explicitly represents the interactions between users and problems, how can we predict new links between one user and other problems?
Instead of using a bipartite graph we will define a non-bipartite graph where the user–problem interactions will be transformed into implicit relationships among problems. To do that, we employ a mechanism called network projection, a process that aims to transform a bipartite graph into a non-bipartite one. This transformation is depicted in Fig. 3.
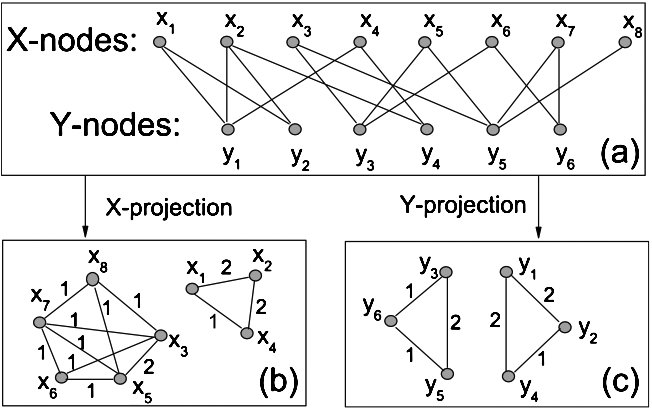
Illustration (from Wikipedia) of a bipartite network (a), as well as its X projection (b) and Y projection (c).
We employ a network projection in order to create the Problem-projection graph, a network containing only Problem nodes where two nodes are connected if they have at least one common user that solved both problems. To avoid losing information from the original network about user interactions we use a simple weighting method, where an edge
Link prediction algorithms are a family of graph-based algorithms that aims to predict new links that might be formed between nodes in a future time or to predict missed links in the current network [15]. The alternative approaches to predict these links are the following [24]:
Similarity-based methods, which compute the proximity or similarity between pairs of unconnected nodes in order to predict new links.
Learning-based methods, which use machine learning algorithms to classify non-connected pairs of nodes as positive or negative potential links.
Similarity metrics employed in the former approach can be also classified into:
Node-based metrics, which compute the similarity using node attributes.
Neighbour-based metrics, which compute the similarity using each node neighbourhood.
Path-based metrics, which do not only use node neighbours but also the paths between two nodes.
Random walk-based metrics, which use transition probabilities from a node to its neighbours and to non-connected nodes in order to simulate social interactions.
We will focus on similarity-based methods and we will employ a variation of these metrics in order to calculate a similarity score that expresses how similar two problems are in the graph according to the solutions submitted for these problems. These scores will be employed in the recommendation process for suggesting similar problems to the ones that a user successfully solved.
Before we describe the specific similarity metrics used in our study, first we need to introduce some notation:
Most of these metrics are detailed in [13,24] and some of them are defined in two different flavours: unweighted and weighted metrics [16]. Note that most of these metrics are not normalized and produce similarity scores that are not between 0 and 1. This is not a problem in our approach, however, because we only use the similarity scores to create a similarity ranking between problems.
Next, we describe the similarity metrics used in our study.
Edge weight
This simple metric measures the similarity between two nodes as the weight of the edge that links them. Two problems are more similar if there are more users that solved both. No connection between two nodes is represented by
Common neighbours
This metric measures the similarity between two nodes as the number of neighbours they have in common. The rationale behind this metric is that the greater the intersection of the neighbour sets of any two nodes, the greater the chance of future association between them. This metric has a weighted version (WCN).
Jaccard neighbours
This is an improvement of
Adar/Adamic
This metric considers evaluating the likelihood that a node x is linked to a node y as the sum of the number of neighbours they have in common. This metric also measures the intersection of neighbour-sets of two nodes in the graph, but emphasizing in the smaller overlap. This metric also defines a weighted version (WAA).
Preferential attachment
This metric is based on the consideration that nodes create links, with higher probability, with those nodes that already have a larger number of links. The similarity between nodes x and y is calculated as the product of the degree of the nodes x and y, so the higher the degree of both nodes, the higher is the similarity between them. This metric has the drawback of leading to high similarity values for highly connected nodes to the detriment of the less connected ones in the network. The weighted version (WPA) is an improvement of the previous one, where the edge weights are considered when computing the degree of nodes x and y.
Experimental setup and evaluation results
The absence of user ratings and the very shallow description of the problems make very difficult and ineffective the use of classical approaches based on collaborative filtering or content-based techniques. For this reason, in this section we evaluate the performance of previous similarity-based link prediction metrics to recommend new problems to the online judge users based on the problems that those users solved before.
For this evaluation, we developed a recommender system that performs recommendations based on the problem-projection graph described in Section 3. In particular, given a problem already solved by a user, the system recommends the k most similar problems according to the problem-projection graph and the similarity metric chosen.
We used two different datasets in this evaluation: ACR and UVa. As detailed before, both datasets differ in their size: number of users, submissions and problems. Since the UVa dataset contains several times more problems and users than ACR, we expect that the UVa domain will be a harder challenge that will test the scalability of our approach.
For both datasets we follow the next steps:
We select a particular timestamp t to split the submission dataset into two sets for training and evaluation. The training set contains the submissions made before time t and we use it to create the problem–problem graph and compute the similarity matrix between problems. The evaluation set contains the submissions made after time t and it is used to validate the recommendations. Using the training set, we build the projection graph, where nodes represent problems and edges between nodes represent that at least one user solved both problems – a user submission achieved an accepted (AC) or a presentation error (PE) verdict in both problems. Edge weights correspond to the number of users who solved both problems. Due to the high density of the projection graph, we filter the edges whose weight is below a defined threshold. Using the problem–problem graph we compute the problem similarity matrix for each similarity metric involved in the evaluation. We select the users to whom we are going to recommend new problems. In order to evaluate the recommendations provided to those users at time t, we require that those users have solved a minimum number of problems before t and have attempted a minimum number of problems after time t. The problems solved before t will be the input for the recommender system and the set of problems attempted after t will be used to validate the recommendations. Finally, the recommendations are evaluated using the following standard evaluation metrics for recommender systems [9,17,22]: Precision, Recall and F-Score in top k recommendations. At least one hit (1-hit): ratio of recommendations in which at least one recommended problem was attempted by the user. It corresponds to the metric Success@k with a success condition of guessing right at least one problem. Mean Reciprocal Rank (MRR): it evaluates the quality of a ranked list of recommendations based on the position of the first correct item. Since we only provide one list of recommendations per user, the MRR can be computed as follows:
ACR evaluation
Evaluation results by similarity metrics with
for ACR dataset
Evaluation results by similarity metrics with
We used the date 2015-08-16 to split the ACR dataset into two different subsets for training and evaluation. This date was chosen because it was in the middle of the submission period analysed (2014-02-17 to 2017-02-13). It is worth noting that this division does not imply that the training and evaluation dataset have the same size, due to the evolution of the number of submissions along the online judge lifetime. In fact, in order to split the submissions into two sets with approximately the same size, we should have chosen a date around 2016-03-14.
Next we created a problem-projection graph with 157 nodes and 7,899 edges, and a density of 32.05% after filtering the edges with
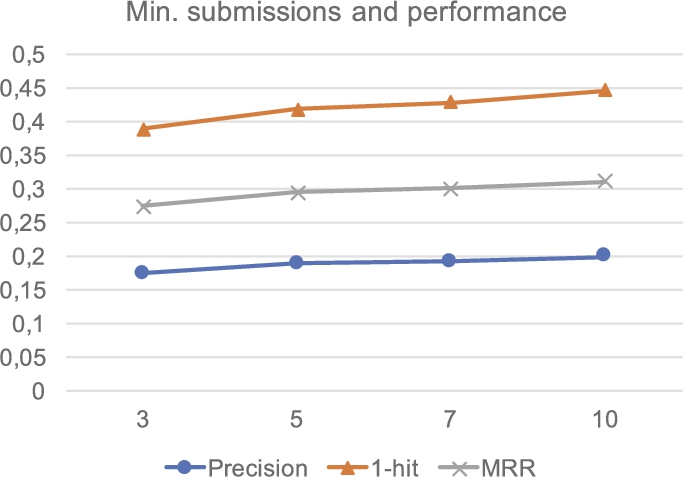
Evolution of the precision, 1-hit and MRR metrics for Edge Weights similarity according to the minimum number of submissions required from a user in order to perform a recommendation.
We can extract some interesting conclusions from these results. First, the Precision, 1-hit and MRR values of the Edge Weights performs the best results and dominates all the other similarities in every evaluation metric. Edge Weights obtains a precision value of 18.9%, 1-hit of 41.8% and MRR of 29.6% recommending only 3 problems to the user, far from the next best similarity metric. The weighted versions of the similarity metrics seem to work better that the ones without weights.
Recall (and therefore F-Score) values are really small, but this fact can be explained because we compare a list of 3 recommendations with all the problems the user attempted to solve after the split time. For example, if we increase the number of recommendations to

Precision, 1-HIT and MRR evolution when increasing the number of recommended problems for ACR dataset.
The number of problems that a user has solved affects the quality of the recommendations. This problem is known as the cold start problem [20] and it is related to recommendations for novel users or new items. Figure 4 shows the precision, 1-hit and MRR values for the Edge Weights similarity metric when we recommend problems to users with a minimum number of problems solved. The results improve as long as more information is available about the user (in this case in terms of the problems already solved), and we can provided better recommendations. The same effect occurs with the other similarity metrics.
Figure 5 shows the evolution of the precision, 1-hit and MRR metrics when we increase the number of recommendations (parameter k) from 1 to 10. For the sake of simplicity, we have removed the non-weighted similarity metrics CN, AA and PA from the figure because they always achieve worse results than the weighted versions WCN, WAA and WPA. As we expected, the precision decreases slowly because the last recommended problems are usually not as good as the first ones (their similarity is smaller). The trade off between the quality of recommendations and the number of choices available to the users is not easy to decide, and we will have to perform some tests with real users to adjust it. On the other hand, the probability of guessing right at least one problem increases as we make more recommendations. The same effect occurs with MRR, which takes into account the position of the relevant problem in the recommendation list. However, the growth slows down for lists with more than 5 elements. For every value of k, Edge Weights dominates all the other similarities.
The evaluation with the UVa dataset imposes a harder computation process due to the size of the dataset. For this reason, the training and evaluation sets have been reduced, including only submissions during the six months previous and after the split timestamp, which, in this case, was 2007-03-23. Despite this shrinkage, the graph created for the recommender system contains 1,433 nodes (different problems) and 232,163 edges, after the edge weight filtering process with a weight threshold value of 10. Additionally, the selection of users to whom perform recommendations was made increasing the minimum number of problems solved before the split timestamp and problems attempted after the split date. This way, 666 users fulfilled these requirements and the evaluation was executed with a total of 35,816 recommendations. Table 3 summarizes the results of the evaluation using
Evaluation results by similarity metrics with
for UVa dataset
Evaluation results by similarity metrics with

Precision, 1-HIT and MRR evolution when increasing the number of recommended problems for UVa dataset.
The evaluation with the UVa dataset confirms that the Edge Weights metric achieves the best results in Precision, 1-hit and MRR values. However, the values are significantly lower than the ones obtained in the ACR dataset recommending only 3 problems. Even when the number of recommended problems grows, the results remain below the ACR dataset figures. Additionally, the differences between the weighted and the non-weighted versions flip and in most of cases the non-weighted metrics outperform the weighted versions. We suppose that the density in the UVa graph undermines the evaluation results with the weighted metrics. To prove that, we revisited the ACR experiment creating the graph without filtering the edges and filtering the edges with
The analysis of the minimum number of submissions required and the cold start problem was omitted for this dataset. Finally, Fig. 6 shows the evolution of the precision, 1-hit and MRR metrics when we increase the number of recommendations (parameter k) from 1 to 10 in UVa dataset. For the sake of simplicity, we plot the evolution for Edge Weights and the unweighted metrics. As occurred with ACR dataset, 1-hit and MRR metrics increase as long as the number of recommended problems grows. This growth decreases in MRR for recommendations with more than 5 elements. However, the precision remains nearly constant for values of
Online judges are online repositories that store large amounts of programming exercises. These repositories traditionally suffer the problem of how to find resources that best match the user’s knowledge or his/her preferences. Recommendation systems help users in this task recommending items similar to those a user has liked in the past [19]. Similarity is therefore one of the most important metrics in these systems.
Some recommendation approaches that aim to suggest resources apply collaborative filtering, a technique that imposes that the user must rate the resources in order to find similar preferences [7]. Systems like CoFind [6], CYCLADES [2] or ISIS [5] are examples of online repositories that use collaborative technique engines. Commonly, online judges like ACR hardly ever provide mechanisms to rate problems so these techniques cannot be applied. Our approach does not need explicit ratings but it uses the implicit results (attempted-accepted) in user submissions, which represent the interactions among users and problems in the online judge.
On the other hand, content-based techniques require descriptions of the item characteristics and user profiles that describe the interests of that user [11]. These techniques can be enhanced with deeper knowledge about the resources. The work in [21] describes a knowledge-intensive approach for recommending learning objects in the computer programming domain. The educational resources are tagged and indexed using an ontology that provides knowledge about the similarity between the concepts that represent the domain topics. Most of online judges only tag their resources with some metadata about the type of the previous knowledge needed to solve it, so we think that these techniques are not suitable in the online judge system context.
Other authors consider that the process of recommending items to users can be considered as a link prediction problem in the user–item bipartite networks [3]. For this reason, we have reviewed some literature in the use of link prediction applied in recommender systems, concentrating our work on the similarity-based methods, which employ different similarity metrics in order to predict new links. Liben-Nowell and Kleinberg [13] systematically compared some neighbour, path and random walk based node similarity indices for link prediction problem in co-authorship networks. These algorithms have been also applied in the user–product bipartite graphs in recommender systems and its performance has been evaluated with a Flickr dataset, outperforming collaborative filtering methods in some cases [3]. The work in [10] also proposes bipartite graph-based algorithms to analyse user–item interactions in order to alleviate the data sparsity problem in collaborative filtering recommenders. They compare CN, JN, AA, PA and two path-based similarity metrics using a book sales dataset and the results show that both path-based and neighbour-based approaches can significantly outperform the standard user-based and item-based algorithms.
Most of the studies on link prediction focus on unweighted networks but ignore the naturally existed link weights. Proximity between nodes can be estimated better by using both graph proximity measures and the weights of existing links. The work in [16] proposed a simple way to extend similarity metrics for binary networks to weighted metrics. However, the latter performed even worse in several real networks. For this reason they introduced a free parameter to control the relative contributions of weak ties to the similarity measure. The experimental study highlighted that the contributions of weak ties can enhance the prediction accuracy in some networks, suggesting that weak ties are not as weak as their weights show.
Other research works transform bipartite graphs into non-bipartite graphs using projections. Our work projects the graph and weigh the edges in a straightforward way using the number of users that resolved a pair of problems. However, this is not the only way to weigh the edges. The work in [25] details a two-step weighting method and a recommendation algorithm that outperforms classical collaborative filtering algorithms in Movielens dataset.
Finally, several works aggregate similarity based methods with another approaches in order to enhance the recommendation. [1] proposes a hybrid similarity measure that combines network similarity with node profile similarity. Profile similarity compares personal data stored in the profile items associated with the users from two different social network. Other works describe alternative link prediction methods based on social theory-based metrics, which enhance well-known neighbour-based metrics with node centrality measures like betweenness, closeness or node degree [14].
Conclusions and future work
Online judges are online repositories with hundreds or even thousands of programming exercises. This wide problem availability becomes a challenge for new users who want to choose the next problem to solve depending on their programming knowledge. In some online judges, such as ACR, problems are categorized with semantic labels regarding the programming concepts involved in their solutions. Unfortunately, these labels only describe very general concepts and they are usually not enough for novel users who wants to choose a problem. Besides, most online judges do not even provide these tags.
This problem could be mitigated with the presence of some type of recommendation mechanism to guide those users. Unfortunately, recommender systems are quite uncommon in online judges because users hardly ever rate the problems, they do not express their preferences on their profiles and the meta-information about the problems is nonexistent or very superficial. For these reasons, it is very difficult and ineffective to use classical approaches based on collaborative filtering or content-based techniques to recommend new problems to specific users.
Online judges, however, collect rich records describing which users have solved or tried to solve which problems. In fact, when the submitted solution is not correct, the judge produces different verdicts describing different types of errors. In this work, we consider those user–problem interactions as a social network and we use social network analysis techniques, such as the similarity-based link prediction, for creating similarity metrics between problems. This way, the information regarding which problems are related or similar to each other emerges automatically from the daily use of the system. Our recommendation system takes advantage of this information to recommend similar problems to the ones the user has already solved in the past.
We have represented the user interactions as a problem–problem graph in which two problems are connected by a stronger tie as long as more users solve both problems. Next, we have evaluated the performance of different similarity metrics based on the graph structure to recommend interesting problems to users from two different online judges: ACR and UVa. The analysis has shown that the Edge Weights metric provides the best results consistently in both datasets. However, we must take into account that this similarity metric relies on the existence of an edge between two problem nodes and, therefore, it is not useful to find new relationships between currently unrelated nodes. Note that this situation occurs every time a new problem is added to the judge. We should investigate on feasible solutions to this problem. Additionally, we have found that the problem–problem graph density reduces the quality of the recommendations. For this reason, as part of the future work we would like to include new edge filtering methods to reduce the graph density but preserving the valuable information provided by the edge weights.
The research trend in the link prediction problem is growing and the number of measures and methods employed in this field increases quickly. We are confident that the use of these new similarity measures and approaches to recommend problems in online judges will achieve better results in the short term.
In this work, we have proposed a problem-based approach which recommends the most similar problems to the ones that a user solved before. However, as collaborative filtering proposes, the recommendation process can be reformulated as finding users similar to the current one, in order to recommended the problems solved by these users but not already attempted by the current user. We want to define this new approach and compare the results obtained by both alternatives.
Finally, this work only describes some theoretical recommendation results based on what the user did in two online judges that do not provide any type of recommendation mechanism. That is, maybe some of our recommendations are good but in the evaluations we consider them wrong because the users did not try to solve those problems. In the future, we plan to incorporate our recommendation approach in the ACR judge and carry out some A/B evaluations with users in order to test if these results are aligned with reality
Footnotes
Acknowledgements
This work was supported by Universidad Complutense de Madrid (Group 910494) and Spanish Committee of Economy and Competitiveness (TIN2014-55006-R).