
Abstract
Multidisciplinary Design Optimization (MDO) is a computational approach for optimizing design of a complex system of systems that require knowledge from multiple disciplines. In a former study, we explored and found that the individual discipline feasible (IDF), a type of MDO design technique, performed well in several benchmark test cases of decentralized Reinforcement Learning (RL) problems, in particular, stabilizing an unknown system. However, the earlier study was not able to resolve as to why the overall system of systems, even with strongly coupled systems, could be stabilized when each agent just focused on stabilizing itself. In this work, we make significant extension in resolving this behavior by conducting a theoretical analysis of the MDO solution of RL problems. Through the analysis, we show that with the proper control law, each MDO agent should be able to bring its state closer to the 0-stable point regardless of how the other agents’ states impact the state of the whole system. This is the main reason why the ‘selfish’ MDO-IDF agents are successful in learning to stabilize the overall system. The simulation results, including benchmark test cases, verify our analysis. Therefore, we propose that the MDO would be a promising solution in many other decentralized RL problems.
Keywords
Introduction
Decentralization learning, also referred to as distributed or multi-agent learning, has generated multiple promising computational techniques to solve large-scale reinforcement learning (RL) problems. The significant advantages of decentralized RL are extensively discussed in [8,9,18,41,54], in which decentralized RL not only reduces the dimensionality of the problem but also increases the robustness of the learning. However, to achieve high-quality decentralized RL solution, we need to tackle four major challenges. First, for each learning agent, when and how should it interact, and with whom [1]. Second, how should the agents define a learning goal: should the agent only focus on its own or should it incorporate the other agents’ goals in its learning goal [8]? Third, similar to other RL problems, the decentralized learning has an additional difficulty due to the multi-disciplinary and partially-defined nature of the problem [15]. This challenge could be tackled by system identification [30,45,55]. For example, in a mass-spring problem, the agent could use linear model to approximate how the position and velocity of the masses would change when applying an external (control) force given that the springs constants are unknown [35]. Fourth, even when the environment and feedback on learning performance could be closely approximated, finding the closed-form solution for the learning problem is unknown in general cases. Therefore, researchers have been focusing on approximation methods to tackle nonlinear Hamilton-Jacobi-Bellman (HJB) equation problem, which is the mathematical foundation of RL, such as [1,7,17,39].
Multidisciplinary Design Optimization (MDO) [2,3,6,12,28], which has been intensively researched and applied in aerospace and mechanical engineering, is potentially a promising approach to tackle the challenges in decentralized RL. In MDO, the computational agents are well-defined and decomposed according to the domain-knowledge of each discipline in a coupled optimization problem. For example, in aero-elastic optimization, there are two decentralized computational units: the aero dynamic units applies fluid dynamics law to manage the air-pressure on the aircraft wing and the structure unit applies the material law to manage the deflection and shape of the wing [10]. Other examples, especially on automatic vehicles, could be found in [13].
State of the art techniques
Most of the recent state-of-the-art techniques in decentralized reinforcement learning could be categorized into model-based and model-free techniques. Examples of model-free techniques, such as in [4,24,32,43], mostly cover Q-learning. Fundamentally, Q-learning stores the expected outcome of executing action u at scenario (also called state) × for each agent [46]. In these examples, each learning agent applies Q-learning algorithm to make its own action in a cooperative learning problem. The disadvantage of Q-learning and other model-free techniques is slow-convergence. For example, for a small tic-tac-toe problem, it takes millions of iterations for the Q-learning agent to learn the optimal action-plan [44]. In the other hand, the model-free techniques learn the underlying mechanisms regulating the changes of scenarios and environments in order to decide the action. For example, in [11,31,40], the learning problems are in MDP format and each agent makes the decision by using policy iteration scheme. In another example, [26] shows how each learning agent can apply its own policy computed by adaptive dynamic programming in a system-stabilizing problem. Overall, in these techniques, each learning agent still makes its own decisions independently. The model-based techniques often converge faster than the model-free techniques. However, the model-based techniques are often more complexed, expects more assumptions and require sustainably amount of domain-knowledge to construct. These may not be available in learning and performing in mostly unknown problems.
In related former work [36], we explored and found that the individual discipline feasible (IDF) design approach in MDO performed well for several toy-example RL problems, compared to the commonly used centralized and recent decentralized techniques, including using Markov Decision Process and Q-learning [37]. In the IDF design, which could be called ‘selfish’ design, each computational agent only aims to optimize its own optimization function and uses the other agents’ information as constrains. In this option, the agents tend to seek for local optimization of their objective functions; while, constraints and information from other agents ensure that the local solutions would eventually allow all agent to reach the objective. The exchanged constrains and information would add more computational complexity for each agent, for example: if one agent discretizes these constrains and information as extra parameters, which are subjected to changes in other agents, in the objective functions, then its solution would need more subcases. The exchanged information among the agents could then be preprocessed or transformed into simpler forms to reduce the complexity of the optimization in each agent. For a brief technical description, we used system identification to approximate the unknown environment (or system) in the RL problem. In the system identification step, each learning agent also identified the impact of other agent’s information on its learning performance, which was the central theme in MDO. From the identified model, each learning agent sets up Markov decision process (MDP) to compute the action/control solution [33]. Although [36] demonstrates that the IDF-MDO is successful in solving the problem of stabilizing unknown systems, it was not clear as to why the whole system, even with the strongly coupled sub-systems, could be stabilized when each agent focused only on stabilizing itself.
In this work, from the prior work [36], we make significant extension in several aspects, especially for the theoretical analysis of the MDO solution of RL problems. The major contributions of this work are:
We extend the scope of the learning problem toward linear systems and nonlinear system with noise. In both the linear and nonlinear cases, the MDO approach succeeds in learning how to stabilize an unknown dynamic system. The MDO also shows better learning performance, compared to the centralized approach, when the system contains noise. In our best knowledge, MDO has not been widely applied in decentralized RL.
We derive the control laws for each agent differently between the linear and the nonlinear. These reflex two different strategies to derive the control laws for a MDO agent, given the inter-communication among the agents. The first strategy is to ‘counter’ the impact of other agents’ state. The second strategy is to discretize the other agents’ state for setting up multi-model controls.
We provide the theoretical analysis showing that with the control laws derived in the second contribution, each MDO agent should be able to bring its state closer to the 0-stable point regardless of how the other agents’ state could impact its state. This is the main reason why the ‘selfish’ MDO-IDF agents are successful in learning to stabilize the entire system.
The structure of this work is as follow. First, we demonstrate the formation of the decentralized RL problem to be solved by MDO. Second, we show how to derive the control law for each agent assuming that the learning problem is completely known. Third, moving closer to RL, we review system identification techniques in approximating unknown system. Forth, combining system identification and the control law, we show how the MDO agents learn to stabilize the entire systems in several experimental and real-world examples with noise.
MDO in linear system of learning and control
Similar to many former system control and RL approaches [4,11,24,31,32,40,43], we start our theoretical analysis from the linear system due to its simplicity. In addition, recognizing the interconnection patterns among the learning agents is simple in linear cases because we can present these patterns by the system matrix entries. In this section, we emphasize the fundamental difference between MDO RL agents and the classical (engineering) MDO agent. The classical MDO agent optimizes the intermediate and well-defined criteria, which can be written in closed-form; meanwhile, the MDO RL agents optimize the aggregated long-term criteria, which is generally unknown and difficult to write in closed-form.
Formulation of the linear system in MDO
In general, a linear system is written as
The objective is to find the series of
The admissible (sub-optimal) control for the MDO problem in linear system
In this section, to simplify the notation, for every agent k, we rewrite
Let matrix
The proof is as follow. Rewriting (3) in this section for any agent k
While most of the control-engineering systems, built upon physical law, are linear, many real-world complex system are nonlinear by nature [5]. Nonlinear systems are generally much more complex. In addition, we have not been able to find the control solution universal for all nonlinear system. In this section, suppose that the nonlinear system satisfies the necessary conditions so that a control solution exists [37], we extend the MDO theory to nonlinear control problems in general form.
Formulation of nonlinear-system MDO
In this section, we reuse the MDO-IDF technique presented in [36] for the nonlinear and continuous systems. Briefly, suppose that we have a nonlinear, bounded system that could be decoupled for K agents to corporately control
Multiple MDP to control the nonlinear system by MDO-IDF
The key point in [36] is that each agent k has L MDP models from which to apply the policy-iteration algorithm [38] for learning and control. Here, L is the discretization resolution, or the number of discrete instances, into which agent k uniformly discretizes the other agents’ states
Theoretical analysis of the multiple MDP solutions in MDO-IDF
Similar to the linear system analysis, for any agent k, we rewrite
Given the condition above, we can prove that the multi-MDP solution is guarantee to stabilize (17) as follow. As in [35], we know that the MDP would stabilize the separated system eventually. However, it is unclear whether or not agent k’s state moving closer to 0 always helps the other agents to move their states closer to 0. Therefore, in the analysis, we focus on showing that for any agent k, has the ability to move closer to 0 regardless of other agents’ states. Therefore, the entire system would eventually converge. To achieve this, we prove the following theorems.
For any agent k, for any
The proof for this theorem relies on the following assumption in equation (17): for any agent k and any
For any agent k, there exist a function
To prove this theorem, we briefly the discretization process in [34] as follow. Suppose that each dimension of
The discretization in (25) and (26) allows partitioning the state space into different layers as follow: – The 0th layer contains only the hypercube with the
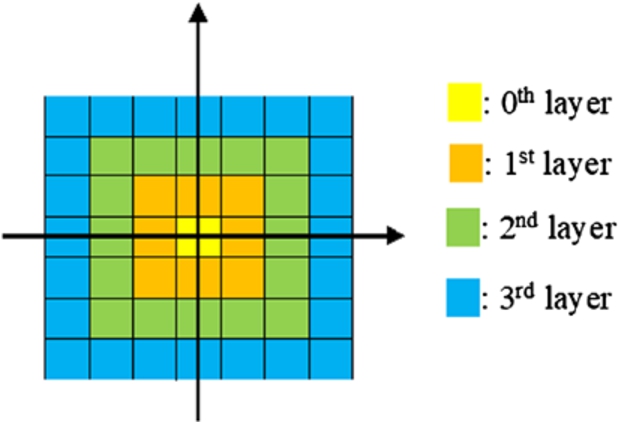
Demonstration of state-layers for discretization in two dimensions.
From the discretization in (25) and (26) and the layer definition above, we setup the penalty function as follow
It is easy to see that
Theorems 2 and 3 guarantee that every MDO-IDF agent k could drive its own system toward the equilibrium point
The multiple-MDP approach, in which the MDPs are setup as in [
11
,
35
], would stabilize every MDO-IDF agent to the 0-stable point
The proof for
In RL, the MDO faces another problem of unknown environment. In this work, without changing the characteristics of the RL problem, we assume that
Related to system identification, we reuse the ‘window size’ Ω concept in [35]. Briefly, window size Ω decides how frequently we call the identification while applying control techniques. Here, the choice of Ω and system identification algorithm should minimize the identification error
Simulation
In this section, we test the MDO performance in many existing problems in adaptive control and compare the MDO performance with other state-of-the-art approaches. Our simulative experiments include several benchmark problems helping explanation of how the MDO agents interacts and cooperates and real-world problems for comparison.
MDO agents stabilize the linear system
Toy example: When the MDO agents would ‘work together’ or ‘work separately’
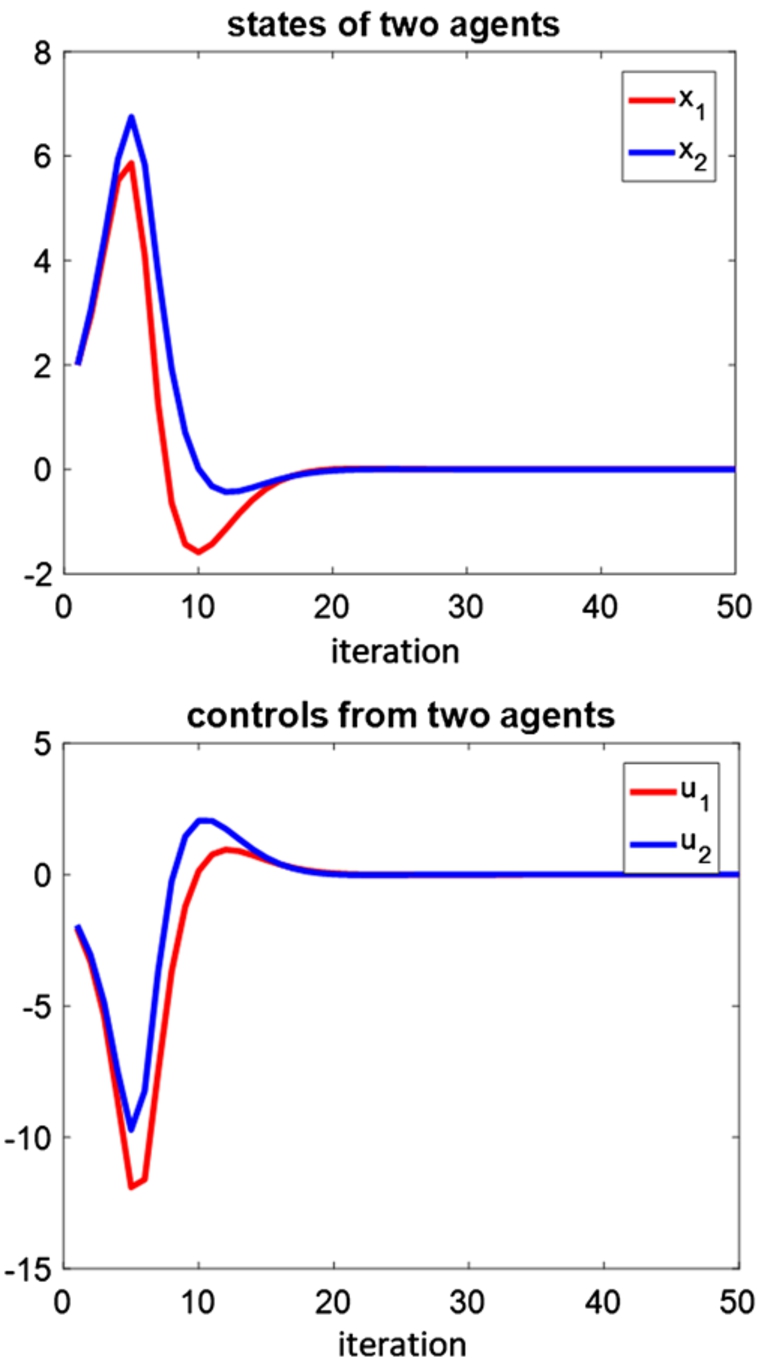
Two agents reach the stable point together in linear system.
The first simulation result explores one interesting characteristic of the linear system: agent k would behave more similar to a separated system as the other agents are closer to their stable points. To be more precise, in (12) and (13),
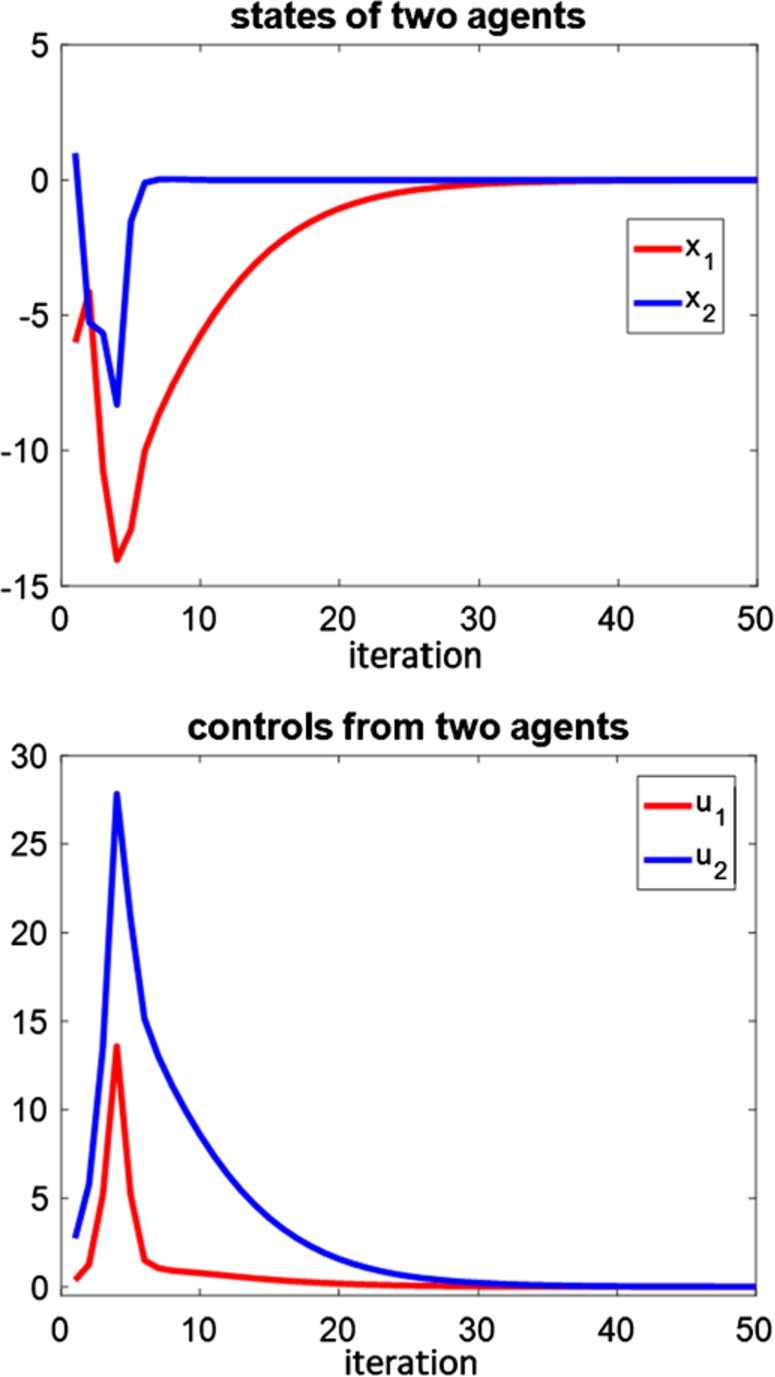
One agent reaches the stable point earlier and leave the other agent behaving as in a separated system.
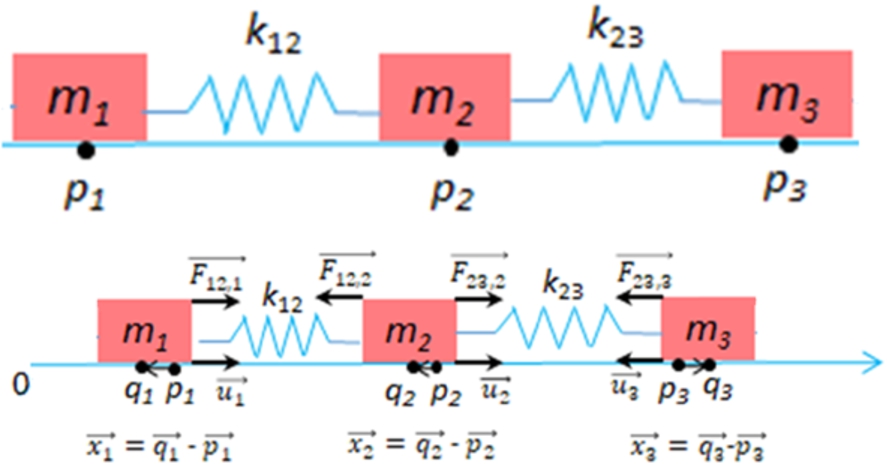
The automated vehicle mass-spring systems. Upper: at the default positions; lower: not at the default position.

Learning and control performance in mass-spring system. (a) MDO agents; (b) comparison among MDO, selective decentralization (SD) and adaptive dynamic programing (ADP). 100 iteration = 1 second.
In Figs 4 and 5, we show the performance of the MDO-IDF agents in learning to control the mass-spring system, which is a real-world and more complex than the simulation above. Here, we assume three automated vehicles travelling together (i.e. a large truck needs to carry several cars). They are connected to each other by springs to avoid collision in rare scenarios (i.e. one vehicle control unit suddenly loses power). The vehicles do not know the other vehicles’ parameters and the spring parameters. By default, three vehicles travel with the same velocity and the distances among them should be kept constantly. However, there are numerous reasons driving the vehicles from the default positions (i.e. unexpected road friction) on travel. Therefore, each vehicle (annotated as a mass m) has a specific control unit u to help itself returning to the default position.
From Fig. 4 example, when the automated vehicles are off from the default position, the following acting force on each vehicle are: – Vehicle
Where
Where
Here, the dimensionalities of
In Fig. 5, we see that these agents would eventually stabilize the system, after some periods of oscillation due to learning. We also implement the adaptive dynamic programming (ADP) [19], which is among the most well-developed techniques in RL and adaptive control recently and the selective decentralization (SD) technique [35], which was showed to outperform ADP in several examples. Here, the SD stabilizes the system state slightly faster than the MDO, but at the cost of scarifying the control cost. The ADP [19] is not able to stabilize the system. Investigating the issue with ADP, we found that the system (40), (41) is not Hurwitz; therefore, it is difficult for the ADP to initialize the suitable parameters for system identification [19,20].
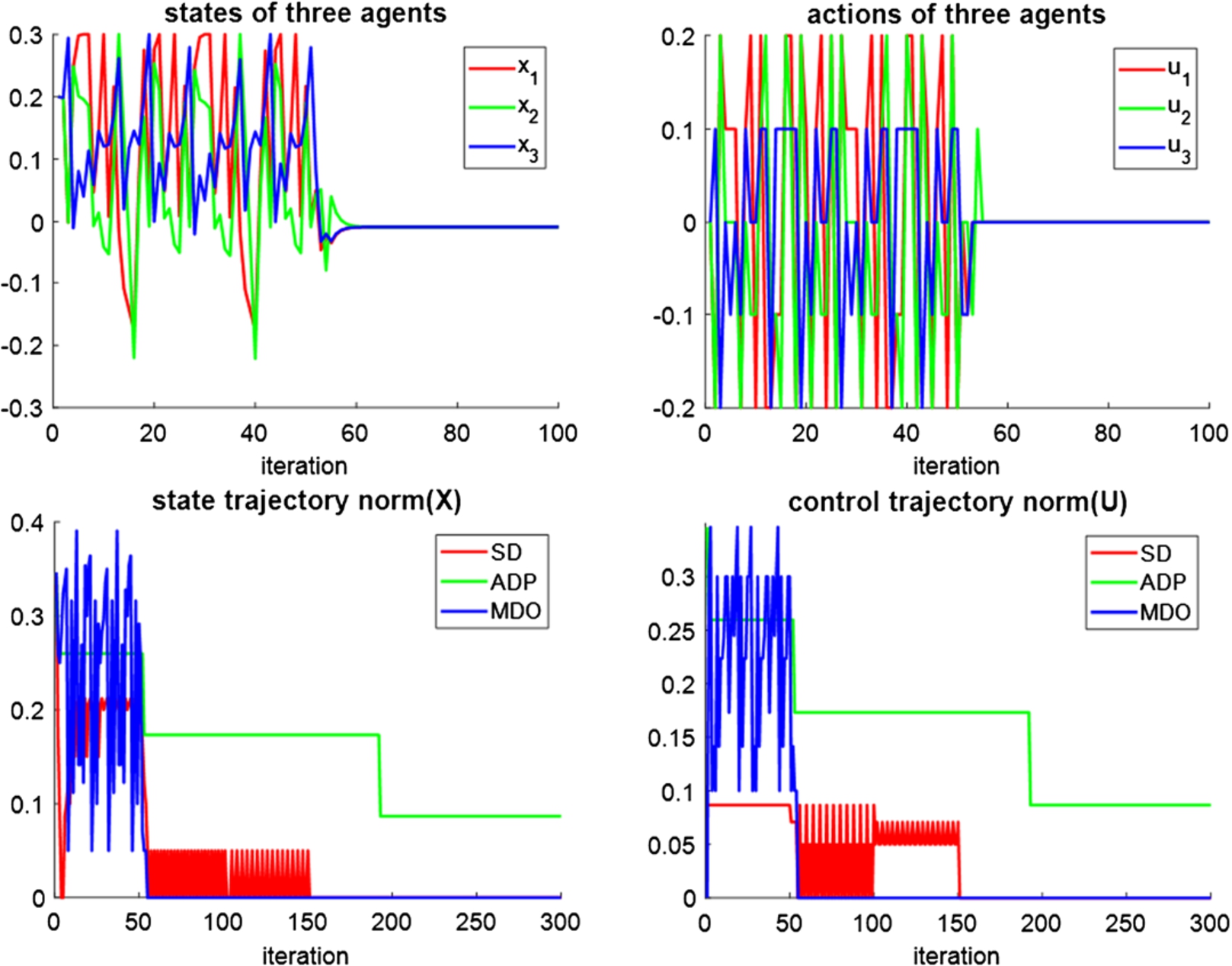
Upper: state and the control of the agents in system (42). Lower: comparison among MDP, Selective Decentralization (SD) and ADP.

Upper: state and the control of the agents in system (43). Lower: comparison among MDP, Selective Decentralization (SD) and ADP.
Unlike the linear system, in the nonlinear system, one agent does not necessary behave similar to a separated system when the other agents reach the stable points. Therefore, in this section, we demonstrate how the MDO agents stabilize the entire systems in two toy examples. In the first example (Fig. 6), we have
This example, three MDO agents, who are responsible for
Here, we also have three MDO agents as in (39). It is easy to see that the third agent, whose ‘separated’ system is
For both (40) and (41), we setup the MDO-IDF agents and discrete-MDP solution as showed in [4]. Briefly, each agent uniformly divides its state
Overall, in both examples, the selectively decentralized (SD), the MDO and the ADP agents could stabilize the systems. The SD and MDO drive the systems toward the zero-equilibrium point faster than the ADP techniques. Both the MDO and the SD behave similarly at the first few tens of iterations. Here, the oscillation implies that the ‘learning’ period, when the agents need to identify the system and make error frequently. The ADP has smoother learning curve; which implies ‘less aggressive’ learning but slower converging speed.
MDO in stabilizing noisy system
In this simulation section, we want to answer the following questions. First, to what extend the MDO could improve the system identification, compared to the centralized approach, given increasing level of noise? Second, to what extend the selective decentralization could stabilize the system faster than the centralized approach could, given increasing level of noise? To simplify the analysis, this section reuse (39) with added noise element
In which
Compared to the centralized approach, the MDO shows less learning performance when the noise level is low. However, when the noise level increases, MDO performance starts approaching and eventually outperforms the centralized performance, as showed in Fig. 9 and Fig. 10. Figures 7 and 8 show typical examples of the MDO performance in low-noise and high-noise scenarios. By low-noise, the standard deviation of
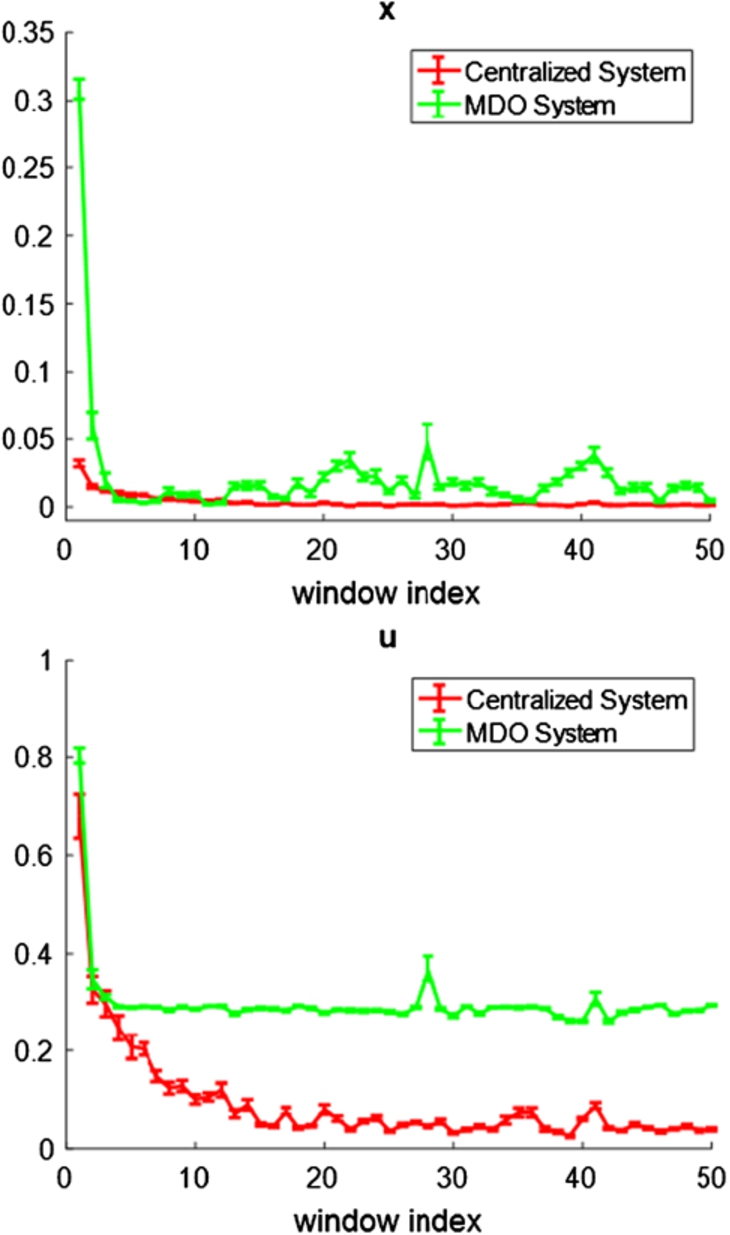
State and control trajectory of the MDO and centralized system in small-noise scenarios.
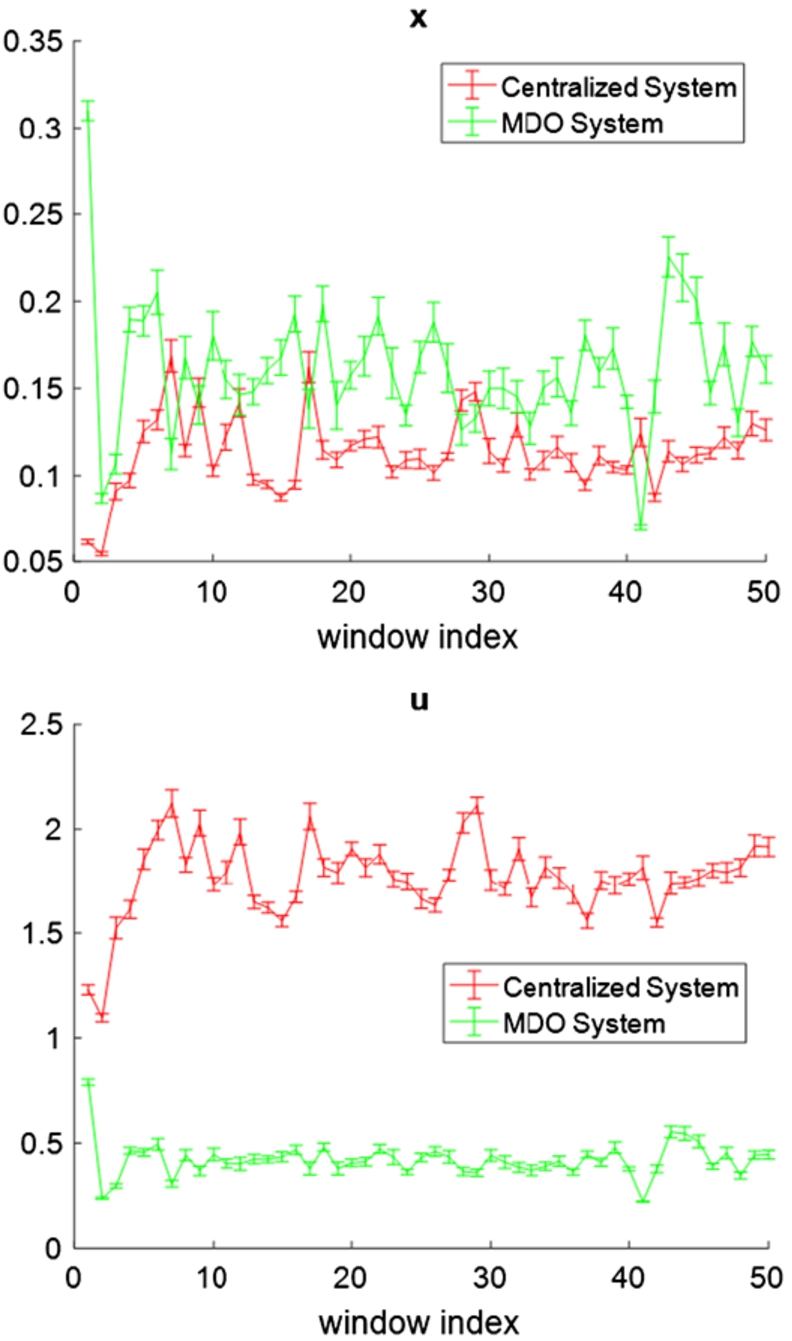
State and control trajectory of the MDO and centralized system in large-noise scenarios.
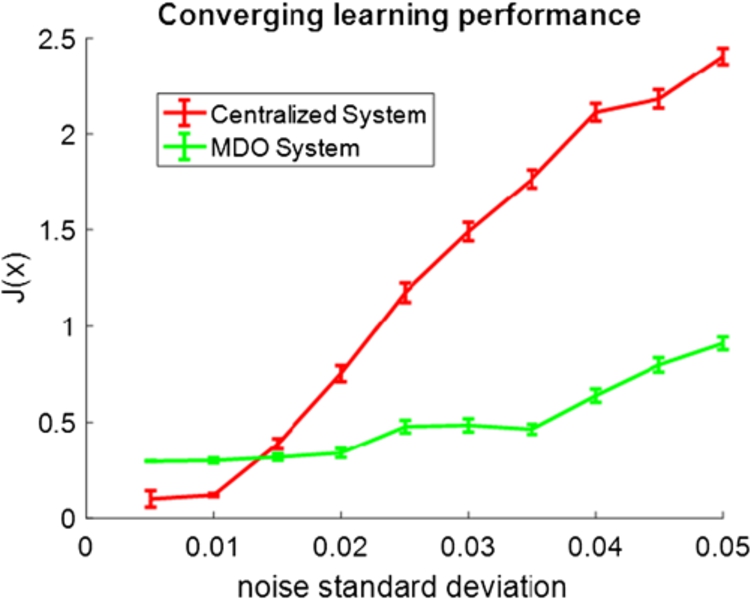
The converging learning performance of the MDO and the centralized system when the noise standard deviation increases.
In this work, we show that the MDO agents have two strategies to handle how the other agents’ state could impact their own state. The first strategy is to ‘cancel out’ the impact, especially when the agents could setup its own system in format
This work shows that choosing the right objective function for optimization is critical to ensure that the MDO solution would stabilize the system. As in (28)–(31), once we can choose the objective function such that ‘moving toward the stable and equilibrium point is better than moving away from it’, we show that the local MDO agents would eventually bring their sub-state toward the local equilibrium points. In addition, in (9) and (20), the global optimal value is equal to the sum of the local optimal value because we choose the objective functions as the quadratic. The sufficient condition is that the global optimal value is better if the local optimal value of one MDO agent is better, supposing that the other agents’ optimal values remain the same. Here, it is easy to see that the quadratic function is just a narrower condition.
Our experimental results show that there is a trade-off between the learning smoothness and converging speed among these techniques. Here, both SD and MDO are ‘aggressive’ learner. These techniques have oscillating learning curves and the agents’ state/action trajectories do not strictly decrease at the first few tens of iterations. In contrast adaptive dynamic programming shows smooth learning curves, and the state/action trajectories almost strictly decrease. However, MDO and SD stabilize the system significantly faster than ADP.
Given that the learning agents substantially learn the system such that we can skip the system identification phase, the ADP technique would require less computational resources since the ADP requires neural networks with size (mostly determined by input and output layer) growing linearly to the system size. However, SD and MDO require storing the Markov transitional matrices, whose size grow exponentially with the system size. Therefore, in practice, we may use MDO and SD for off-line training to take the advantage of less-sample requirements. The MDO and SD results could be reused in ADP training to improve performance.
Because we have no restriction on the format of the nonlinear system, it is difficult to find a closed-form solution, even for sub-optimal control. Therefore, we applied the discretized MDP approach as the control algorithm for nonlinear systems. There are three disadvantages of applying MDP. First, this method requires several ad-hoc parameters in order to discretize the state and action space. Second, this method is memory consuming: the memory needed for storing the MDP grows exponentially with the system dimensionality. Third, the MDP solution assume several tight conditions to ensure the convergence. Therefore, in narrower system formats, such as systems in feedback linearization form, other control techniques such as Adaptive Dynamic Programming [5,23,25,33,36–38] would be more suitable.
Another limitation in this work is that the theoretical analysis assumes that system identification would help the MDO agent precisely estimate its state dynamic. However, this assumption is not always true, given that the performance of system identification depends significantly on several other parameters, such as the learning rate [42] and initialization of the estimators [34]. Also, it is possible that the combination of these parameters may completely misidentify the system, leading to uncontrollable cases. Therefore, in order to apply MDO, the implementer needs to carefully examine the performance of system identification prior to learning and control.
Conclusions
Compared to our prior work in applying MDO in decentralized RL [36], this work provides more comprehensive analysis on setting up the MDO and the convergence of the MDO agents in learning and control problems. In this work, suppose that each MDO agent precisely learns its own system, the agent guarantees to bring its state closer toward the stable point regardless of other agents’ states. Therefore, the entire system would move closer toward and eventually reach the stable point
Our simulative examples show that the MDO may have the similar, if not better, performance in unknown system stabilization and learning than several state-of-the-art approaches, including selective decentralization (SD) [33] and adaptive dynamic programming (ADP) [19,47–53]. However, due to the lack of theoretical analysis on converging speed in SD and ADP, we are not able to address the performance gained by MDO. In linear system, which is easier for setting up real-world problems, we found that the Hurwitz-dependency is one reason explaining the MDO superior performance to ADP. When the system is non-Hurwitz, ADP will face much more difficulties in initialization, which further leads to poor performance. For nonlinear systems, since they are significantly more complexed, we are unable to incorporate more real-world nonlinear problem in this work. This would be done in some other future works, with intensive support from domain-experts, such as in hydroengineering.
Footnotes
Acknowledgements
This work was funded by the INFEWS program (award ID 2017-67003-26057), which is supported via an interagency collaboration between United States Department of Agriculture and National Science Foundation. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the funding agencies.