
Abstract
State-of-the-art automated theorem provers (ATPs) such as E and Vampire use a large number of different strategies to traverse the search space. Inventing targeted proof search strategies for specific problem sets is a difficult task. Several machine learning methods that invent strategies automatically for ATPs have been proposed previously. One of them is the Blind Strategymaker (BliStr) system for inventing strategies of the E prover.
In this paper we describe BliStrTune – a hierarchical extension of BliStr. BliStrTune explores much larger space of E strategies than BliStr by interleaving search for high-level parameters with their fine-tuning. We use BliStrTune to invent new strategies based also on new clause weight functions targeted at problems from large ITP libraries. We show that the new strategies significantly improve E’s performance.
Introduction: ATP strategy invention
State-of-the-art automated theorem provers (ATPs) such as E [22,23] and Vampire [14] achieve their performance by using sophisticated proof search strategies and their combinations. Constructing good ATP search strategies is a hard task that is potentially very rewarding. Until recently, there has been, however, little research in this direction in the ATP community.
With the arrival of large ATP problem sets and benchmarks extracted from the libraries of today’s interactive theorem prover (ITP) systems [2–4,10,11], automated generation of targeted ATP strategies became an attractive topic. It seems unlikely that manual (“theory-driven”) construction of targeted strategies can scale to large numbers of ATP problems spanning many different areas of mathematics and computer science. Starting with the Blind Strategymaker (BliStr) [28] that was used to invent E’s strategies for MaLARea [13,29] on the 2012 Mizar@Turing competition problems [24], several systems have been recently developed to invent targeted ATP strategies [15,21]. The underlying methods used so far include genetic algorithms and iterated local search, as popularized by the ParamILS [7] system.
A particular problem of the methods based on iterated local search is that their performance degrades as the number of possible strategy parameters gets high. This is the case for E, where a domain specific language allows construction of astronomic numbers of strategies. This gets worse as more and more sophisticated templates for strategies are added to E, such as our recent family of conjecture-oriented weight functions implementing various notions of term-based similarity [8]. The pragmatic solution used in the original BliStr consisted of re-using manually pre-designed high-level strategy components, rather than allowing the system to explore the space of all possible strategies. This is obviously unsatisfactory.
In this article we describe BliStrTune – a hierarchical extension of BliStr. BliStrTune allows exploring much larger space of E strategies by factoring the search into invention of good high-level strategy components and their low-level fine-tuning. The high-level invention and the low-level invention communicate to each other their best solutions, iteratively improving all parts of the strategy space. Together with our new conjecture-oriented weight functions, the hierarchical invention produces so far the strongest schedule of strategies on the small (bushy) versions of the Mizar@Turing problems. The improvement over Vampire 4.0 on the training set is nearly 10%, while the improvement on the testing (competition) set is over 5%.
The rest of the paper is organized as follows. Section 2 introduces the notion of proof search strategies, focusing on resolution/superposition ATPs and E prover. We also summarize our recent conjecture-oriented strategies that motivated the work on BliStrTune. Section 3 describes the ideas behind the original Blind Strategymaker based on the ParamILS system (see Section 3.2 for more details on ParamILS). Section 4 introduces the hierarchical invention algorithm and its implementation. The system is evaluated in several ways in Sections 5 and 6, showing significant improvements over the original BliStr and producing significantly improved ATP strategies.
This article is an extended version of our work presented at the CPP conference [9]. Several parts have been updated. The main Section 4 describing BliStrTune now explains the hierarchical invention in greater detail, Section 5 contains further analysis of the results, and Section 7 describing the practical use of the system has been added. The system has been streamlined and its distribution made publicly available.1
In this section we briefly describe the proof search of saturation-based automated theorem provers (ATPs). Section 2.1 describes the proof search control possibilities of E prover [22,23]. Section 6.1 describes our previous development of similarity based clause selection strategies [8] which we make use of and evaluate here.
Many state-of-the-art ATPs are based on the given clause algorithm introduced by Otter [18–20]. The input problem
Proof search strategies in E prover
E [22 ,23] is a state-of-the-art theorem prover which we use as a basis for implementation. The selection of a given clause in E is implemented by a combination of priority and weight functions. A priority function assigns an integer to a clause and is used to pre-order clauses for weight evaluation. A weight function takes additional specific arguments and assigns to each clause a real number called weight. A clause evaluation function (
One of the well-performing weight functions in E, which we also use as a reference for evaluation of our weight functions, is the conjecture symbol weight. This weight function counts symbol occurrences with different weights based on their appearance in the conjecture as follows. Different weights

An outline of the BliStr strategy invention loop.
Apart from clause selection, E prover introduces other parameters which influence the choice of the inference rules, term orderings, literal selection, etc. The selected values of the parameters which control the proof search are called a strategy.2
Also called a protocol in the literature.
Let us consider the following simplified E strategy written in the E prover command line syntax as follows.
This strategy selects term ordering
In this section we describe Blind Strategymaker (BliStr) [28] which we further extend in the following section to BliStrTune system. Both BliStr and BliStrTune are based on the BliStr strategy invention loop [28] which improves a given ATP system with given initial strategies (
BliStr strategy invention loop
Figure 1 provides an outline of the BliStr strategy invention loop which is common both for BliStr and BliStrTune presented in this work. The loop consists of four basic steps. Because no strategy can be improved more than once on the same set of problems (see Step 3) and the set of all possible strategies is typically finite, the loop must eventually terminate.3
Note however that the set of all possible strategies is usually astronomically large, and relatively fast termination is due to more complicated factors influenced by the BliStr settings.
Step 1: Generation evaluation. In the first phase, all strategies (
For each strategy S, we compute its set of best-performing problems
Step 2: Generation reduction. In the next step, we reduce the strategies invented so far (
Step 3: Strategy selection. The next step is to select a strategy to be improved on its best-performing problems. As a rule, no strategy can be improved on the same problems more than once within one execution of the
In more detail, for each problem p, we keep a counter
Step 4: Strategy improvement. The strategy improvement is done by the ParamILS [7] automated algorithm configuration framework. Given a strategy S and a set of problems P (
We always launch ParamILS to improve a strategy S on its currently best-performing problems
The guiding idea for strategy improvement in the BliStr loop is to use a data-driven approach. Problems in a given mathematical field often share a lot of structure and solution methods. Mathematicians become better and better by solving the problems, they become capable of doing larger and larger steps with confidence, and as a result they can gradually attack problems that were previously too hard for them. By this analogy, it is plausible to think that if the solvable problems become much easier for an ATP system, the system will be able to solve some more (harder, but related) problems. For this to work, a method that can improve an ATP on a set of solvable problems is needed. As already mentioned, the established ParamILS system can be used for this.
Let A be an algorithm whose parameters come from a configuration space (product of possible values) Θ. A parameter configuration is an element
To fully determine how to use ParamILS in a particular case, A, Θ,
Since it is unlikely that there is one best E strategy for all of the given benchmark problems, it would be counterproductive to use all problems as the set D for ParamILS runs. Hence we use only best-performing problems (
BliStrTune: Hierarchical invention
BliStr uses a fixed set of CEFs for inventing new strategies. The arguments of these fixed CEFs (the priority function, weight function arguments) cannot be modified during the iterative strategy improvement done by ParamILS. A straightforward way to achieve invention (fine-tuning) of CEF arguments would be to extend the ParamILS configuration space Θ. This, however, makes the configuration space grow from ca.
In this section we describe our new extension of BliStr – BliStrTune – where the invention of good high-level strategy parameters (Section 4.1) is interleaved with the invention of good CEF arguments (Section 4.3). The basic idea behind BliStrTune is iterated hierarchical invention: The large space of the optimized parameters is naturally factored into two (in general several) layers, and at any time only one layer is subjected to invention, while the other layer(s) remain fixed. The results then propagate between the layers, and the layer-tuning and propagation are iterated. BliStrTune is experimentally evaluated in Section 5.
Global parameter invention
The ParamILS runs used in the BliStrTune’s global-tuning phase are essentially the same as in the case of BliStr, with the following minor exceptions. BliStr uses a fixed configuration space Θ for all ParamILS runs. This is possible because a small set (currently 12) of CEFs is hard coded in Blistr’s Θ. BliStrTune uses in the global-tuning phase a parametrized configuration space
BliStrTune’s global-tuning usage of ParamILS is otherwise the same as in BliStr, that is, given Let us consider the E strategy from Example 1. In the global-tuning phase we instruct ParamILS to modify top level arguments, that is, term ordering (“
This section describes in details the parameter space
is one of the most significant proof search settings. We instruct ParamILS to select from 2 to
significantly influences the proof search by restricting applications of the inference rules. We instruct ParamILS to try various kinds of orderings and various methods for the generation of a precedence. We support 12 possible term ordering settings.
selects the literals on which superpositions can be applied. Four settings are supported.
can be used to implement superposition. Three settings are supported.
are simplification inference rules implemented in E Prover. We support two possible settings.
is used to split a clause into shorter clauses by introducing a fresh predicate symbol. We support 6 settings.
is a method for axiom filtering [6] which can be optionally turned on in E Prover. We support 561 possible SInE settings.
For the two values of
Invention of the CEF arguments
Given the result of the global-tuning phase
The CEF arguments (see Section 2.1) consist of the priority function and the weight function specific arguments. Because of the different number and semantics of the weight function arguments, we do not allow to change the CEF’s weight functions during the fine-tuning. They are fixed to the values provided in
Given the configuration space
The global invention (global tuning) and the local invention (fine-tuning) phases can be iterated. To do that, we need to transform the result of the fine-tuning
Recall the strategy from Example 1 and Example 2. In the fine-tuning phase we would fix all the top level arguments modified in the global-tuning phase (“
might be changed to different values while the rest of the strategy stays untouched.
The size of the configuration space
In order to simplify the construction of the configuration space
For example, a typical weight function ConjectureRelativeSymbolWeight
has 8 weight function arguments with approximately
Maintaining collections of CEFs
The global-tuning phase of BliStrTune requires the collection C of CEFs as an input. It is desirable that this collection C is limited in size (currently we use max. 50 CEFs) and that it contains the best performing CEFs.
Initially, for each weight function w defined in E, we have extracted the CEF that is most often used in the E auto-schedule mode. We have added a CEF for each of our new weight functions. This gave us the initial collection of 21 CEFs. Then we use a global database (shared by different BliStrTune runs) in which we store all CEFs together with a usage counter. This counter remembers how often was each CEF used in a strategy invented by BliStrTune. Recall that in one BliStrTune iteration, ParamILS is ran four times (two phases of global-tuning and two phases of fine-tuning). Whenever a CEF is contained in a strategy invented by any BliStrTune iteration (i.e., after the four ParamILS runs), we increase the CEF usage counter, perhaps adding a new CEF to the database when used for the first time.
To select the 50 best performing CEFs we start with
Experimental evaluation
This section provides an experimental evaluation5
All the experiments were run on
For the evaluation we use problems from division Mizar@Turing of the CASC 2012 (Turing100) competition mentioned in Section 1. These problems come from the MPTP translation [1,26,27] of the Mizar Mathematical Library [5]. The problems are divided into 1000 training and 400 testing problems. The training problems were published before the competition, while the testing problems were used in the competition. This fits our evaluation setting: we can use BliStrTune to invent targeted strategies for the training problems and then evaluate them on the testing problems.
To evaluate the hierarchical invention we ran BliStr and BliStrTune with equivalent arguments. Furthermore, we ran two instances of BliStrTune to evaluate the performance added by the new weight functions from Section 6.1. The first instance was allowed to use only the original E 1.9 weight functions, while the second additionally used our new weight functions.
BliStr and BliStrTune used the same input arguments. The first argument is the set of the training problems. We use the 1000 training problems from the Mizar@Turing competition in all experiments. Other arguments are:
the time limit (seconds) for one ParamILS run, the time limit for E prover runs within ParamILS, the time limit for the strategy evaluation in BliStr/Tune.
So that the times used to improve a strategy are equal.
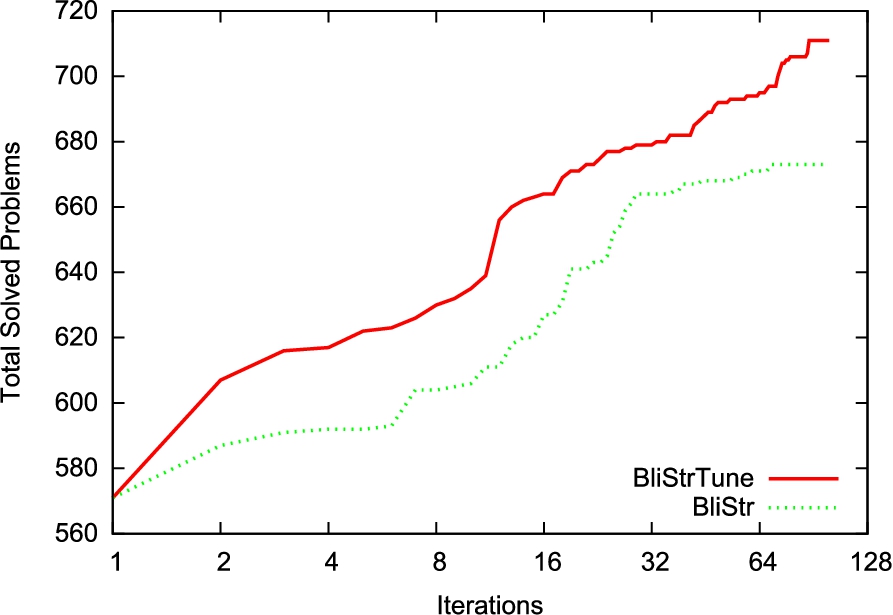
Value added by parameter fine-tuning and by new weight functions (Section 5.1).
The results are shown in Fig. 2. In each iteration (x-axis, logarithmic scale) we count the total number of the training problems solved (y-axis) by all the strategies invented so far, provided each strategy is given the time limit
The original BliStr solved 673 problems. BliStrTune without the new weights solved 702 problems, while BliStrTune with the new weights solved 711 problems. From this and from the figure we can see that the greatest improvement is thanks to the hierarchical parameter invention. However, the new weight functions still provide 9 more solved problems which is a useful additional improvement.
Evaluation of different BliStrTune training runs on Mizar@Turing problems (Section 5.2)
Evaluation of different BliStrTune training runs on Mizar@Turing problems (Section 5.2)
In this section we evaluate several BliStrTune runs with different input arguments. We run all the combinations of
The results are summarized in Table 1. Column iters contains the number of iterations executed by the appropriate BliStrTune run, proto is the total number of strategies generated, run time is the total run time of the given BliStrTune run, best proto is the number of training problems solved by the best strategy within
We can see that the most useful runs are the basic runs with smaller
The 6 runs of BliStrTune described above in Section 5.2 generated more than 900 different strategies. In this section we try to select the best subset of the strategies and construct a strategy scheduler which sequentially tries several strategies to solve a problem. We only experiment with the simplest schedulers where the time limit for solving a problem is equally distributed among all the strategies within a scheduler.7
We only use integer time limits for running the strategies, because E currently only supports integer time limits. If there are n seconds remaining after the integer division of the global time limit, they are equally distributed among the first n strategies in the scheduler.
We use three different ways to select the scheduler strategies. Firstly we use a greedy approach as follows. We evaluate all the strategies on all the training problems with a fixed time limit t. Then we construct a greedy covering sequence which starts with the best strategy, and each next strategy in the sequence is the strategy that adds most solutions to the union of the problems solved by all the previous strategies in the sequence. The resulting scheduler is denoted
The second way to construct a scheduler is based on the state-of-the-art contribution (SOTAC) used by CASC. The SOTAC for a problem is the inverse of the number of strategies that solved the problem. A strategy SOTAC is the average SOTAC over the problems solved by the strategy. We can sort the strategies by their SOTAC and select the first n strategies from this sequence. The resulting scheduler is denoted
The SOTAC of a strategy will be high even if the strategy solves only one problem which no other strategy can solve. That is why also the
Evaluation of the BliStrTune schedulers (Section 5.3)
The evaluation of 12 different schedulers with 60 seconds time limit on the training problems is provided in Table 2. The protos column specifies the count of the strategies within the scheduler. We shall use this evaluation to select the best scheduler, hence the results on the 400 testing problems are provided for reference only. The solved column is the number of the problems solved in 60s. The V+ column is the percentage gain/lost compared to the state-of-the-art theorem prover Vampire 4.0 which solves 667 of the 1000 training problems and 266 of the 400 testing problems.
We can see that the best results are achieved by the scheduler
Evaluation of the best BliStrTune scheduler on the 400 Mizar@Turing testing problems with 60 seconds time limit
Evaluation of the best BliStrTune scheduler on the 400 Mizar@Turing testing problems with 60 seconds time limit
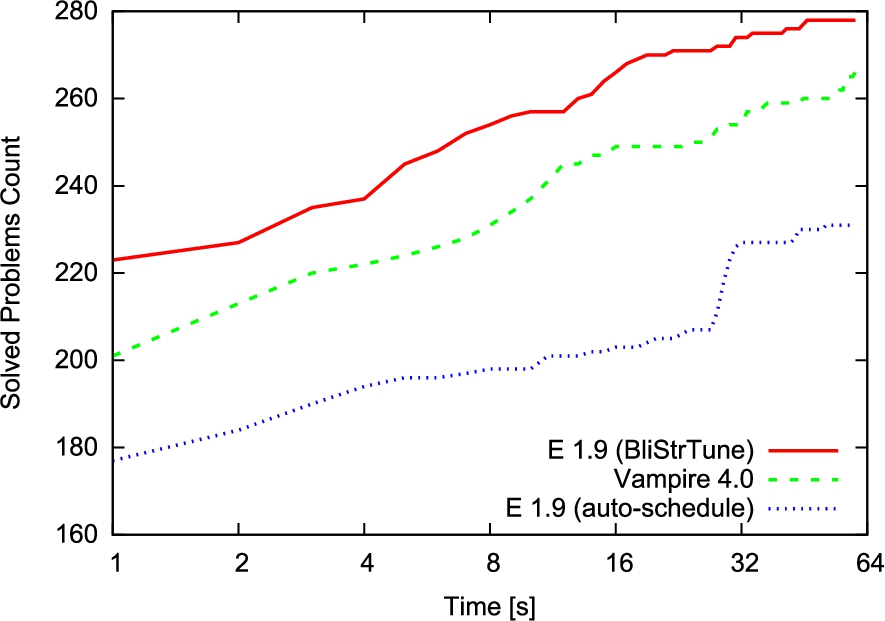
Progress of ATPs on the 400 Mizar@Turing testing problems with 60 seconds time limit.
In this section we evaluate the best strategy scheduler
The results are summarized in Table 3. We can see that E with scheduler
We can use the BliStrTune architecture to evaluate usefulness of various clause weight functions implemented in E. This evaluation can be done by (1) an analysis of the final best schedulers constructed previously in Section 5.4, and by (2) an analysis of all the invented strategies. Previously we proposed [8] several new E weight functions based on conjecture-similarity. Section 6.1 briefly summarizes the new weight functions, while Section 6.2 proceeds with the evaluation.
Similarity based clause selection functions
Many of the best-performing weight functions in E are based on a similarity of a clause with the conjecture, for example, the conjecture symbol weight from the previous section. A natural question arises whether or not it makes sense to extend the symbol-based similarity to more complex term-based similarities. Previously we proposed [8], implemented, and evaluated several weight functions which utilize conjecture similarity in different ways. Typically they extend the symbol-based similarity by similarity on terms. Using finer formula features improves the high-level premise selection task [12], which motivated us on steering also the internal selection in E. The following sections summarizes the new weight functions which we further evaluate later in Section 5.1 and Section 5.3.
Conjecture subterm weight (
Conjecture frequency weight (
Conjecture term prefix weight (
Conjecture Levenshtein distance weight (
Conjecture tree distance weight (
Conjecture structural distance weight (
Usefulness of weight functions
We can use our experiments to evaluate the usefulness of different E Prover weight functions, in particular of our new weight functions (Section 6.1). The first evaluation method is to inspect the best schedulers constructed in Section 5.3 and check which weight functions are used. The second method is to extract the weight function frequencies from the CEF database described in Section 4.5. Information about the usefulness of the different weight functions could be used in the future to restrict the configuration space of the ParamILS runs.
Usage of the weight functions in the best schedulers
Usage of the weight functions in the best schedulers
First, we use the schedulers from Section 5.3 to evaluate the contribution of our new weight functions. The more a weight function is represented in the final best schedulers, the more the weight function contributes to the achieved results and hence can be considered more useful. Table 4 summarizes the usage of the different weight functions in the final schedulers. Our weight functions are referred to by their names from Section 6.1 while the original weights are called by their E prover names. The count column states how many times the corresponding weight function was used in some selected scheduler strategy, while the freq column sums the frequencies of the occurrences of CEFs which use the given weight function. We can see that our new weight function
Weight functions in the invented strategies
In Section 4.5, we have described a global database which stores all the CEFs invented by different BliStrTune iterations. This database stores for each CEF the usage counter, describing how often the CEF was used in a strategy invented by BliStrTune. For each weight function, we can count how many times it was used in an invented CEF. This gives us a slightly different notion of weight function usefulness than the previous approach, because not every invented CEF needs to be used in the best schedulers. However, when a CEF is invented in some particular BliStrTune iteration, we can conclude that there is a set of problems for which the invented CEF is useful.
The results are provided in Table 5. The use column describes how often the given weight function was used in a CEF generated in a BliStrTune iteration. This gives us a slightly different results, however, two of our weight functions (
Another approach to evaluate the usefulness of some weight function w would be to run BliStrTune with and without a possibility to use function w. We could then construct best schedulers as in Section 5.3 and compare their performance. This could be done for every weight function w but it would be very time consuming. Instead, we resorted to a simplified evaluation and launched two instances of BliStrTune, with and without our new weight functions (Section 6.1). The result is that our new weight functions provided a valuable improvement of 9 newly solved (training) problems. Our new weight functions were used in the experiments from Section 5.
Similarly to BliStr, BliStrTune is an open-source software and its implementation is publicly available.8
Given the performance improvement obtained here over E’s auto mode, the strategy invention field might see more development in near future.
The software package consists of
the BliStrTune system proper, a database for the E Prover results, and utilities to create and execute schedulers.
The package assumes a standard Linux machine, no installation is required.10
Common software packages like Perl, Python, and Ruby need to be installed. Other software, namely ParamILS, E Prover, and GNU Parallel [25], is provided in our distribution.
To start the strategy invention, the user has to provide (1) the training problems in the TPTP format, and (2) an initial set of E’s strategies. The initial strategies might be collected from previous BliStrTune runs, or selected from the example strategies. We provide the scripts that import the benchmark problems and register the initial strategies.11
Before running BliStrTune, the following options can be adjusted by editing the main BliStrTune script:12
sets the number of cores used for the ParamILS runs and for the evaluation phase. More cores should result in better ParamILS results and faster evaluation. We recommend at least 8 cores.
sets the time limit in seconds for one global tuning phase. This corresponds to
sets the time limit for one fine tuning phase (again
sets the E Prover time limit
sets the E Prover evaluation time limit
sets the lower bound on the count of CEFs within a strategy. Use at least 2.
sets the upper bound on the count of CEFs in a strategy, that is, the value
sets a lower bound on the number of processed clauses in a proof. Problems with less processed clauses are considered “too easy” and never used for the ParamILS runs. The default is 500. This parameter should be decreased if BliStrTune terminates too fast without producing enough new strategies.
sets the upper bound on the number of processed clauses. Problems with more processed clauses are considered “too hard” and never used for the ParamILS runs. The default is 50000. This parameter should be increase if there is enough CPU time or if all the problems are hard.
sets versatility, the minimal number of problems on which a strategy must be best performing (better than all other strategies) in order to be considered by BliStrTune for improvement. Protocols which are not best performing at some problems are forgotten and never improved. The default is 10. Decrease this value if BliStrTune terminates too fast without generating satisfactory results.
sets the number of top strategies that are kept for improving. The default is 20. Decrease the number to make BliStrTune finish faster.
Our distribution additionally includes utilities to process the BliStrTune results. There are scripts which can import generated strategies into the result database and evaluate strategies on the provided evaluation problems. Other tools are provided to process the result database and to construct the strategy schedulers as described in Section 5.3. Finally, schedulers can be evaluated on the provided testing problems.
Conclusions and future work
In this paper we have described BliStrTune, an extension of the Blind Strategymaker (BliStr) system. BliStrTune can be used for hierarchical invention of strategies that are targeting a given set of ATP problems. The system is publicly available and can be used by interested users on any problem set.
The main contribution of BliStrTune is that it considers a much bigger space of strategies by interleaving the global-tuning phase with the argument fine-tuning. We have evaluated the original BliStr and BliStrTune on the same input data and showed that BliStrTune significantly outperforms BliStr on them. We have evaluated several ways of creating strategy schedulers and showed that E 1.9 with the best strategy scheduler constructed from the BliStrTune strategies invented for the training problems outperforms the state-of-the-art Vampire 4.0 ATP on the independent testing problems by more than 5%.
Furthermore, we have used BliStrTune to evaluate the contribution of our previously designed conjecture-oriented weight functions for E prover. We have shown that these new weight functions allow us to solve more problems and that (at least two of them) were often used in the best scheduler strategies. Interestingly, more complex structural weights (like
Several topics are suggested for future work. We have shown that new weight functions can enhance E’s performance, hence more weight functions which consider the term structure could be implemented. It seems that it might be better to design weight functions with lower time complexity, perhaps even providing approximate results. For example, we could use fast approximations of the Levenshtein distance.
Another direction for future research is to design more complex strategy schedulers. We have achieved good results with the simplest strategy schedulers where each strategy is given an equal amount of time when solving a problem. It would be interesting to design “smarter” schedulers and to see how many more problems can be solved.
And another direction for future research are enhancements of the BliStr/Tune main loop. We could experiment with addition of further layers to handle even more parameters in an efficient way, and with automated factoring of the parameters into the layers based on their joint behavior. There are also many settings of the various BliStrTune parameters to be experimented with, as well as selection of the training problems, etc. We could also try other underlying parameter improvement methods than ParamILS [30].
Footnotes
Acknowledgements
We thanks the CPP and AICOMM reviewers for their useful comments to the first version of this paper. This work was supported by the AI4REASON ERC Consolidator grant 649043, and by the Czech project AI & Reasoning CZ.02.1.01/0.0/0.0/15_003/0000466 and the European Regional Development Fund.