
Abstract
This paper proposes a new architecture for supervised incremental learning using neural networks. The key feature of this architecture is a special perceptron, called monitor perceptron, which decides whether a new sample belongs to a new class or to one of the known (already learnt) classes. In case if the decision by the monitor perceptron is that the sample belongs to a new class then the network is extended such that the new class is learnt by the network. The final network is a set of parallel neural networks (one for each class) whose output is fed into the monitor perceptron. A series of experiments are performed using benchmark data sets. The results obtained in these experiments are comparable with or better than those obtained using other, state of art, techniques. The growth in number of neurons is linear with respect to the growth of number of classes.
Introduction
Conventional supervised machine learning approaches work on data where the number of classes are known a priori. However, this condition may not be true in many real world scenarios where new samples may arrive and the machine may not know whether these samples belong to one of the known (already learnt) classes or whether the new sample belongs to a class that has not been learnt yet. In these situations we need an approach which can perform the following:
realize that the newly arrived sample belongs to a new, previously unseen class and
adapt the model so as to learn the new class.
Lazy classifiers like the Nearest Neighbor Classifier (NNC) [16,19] can easily perform the second task but it cannot perform the first task. Most of the other conventional classifiers would classify the new sample into one of the known classes on the basis of the models that it has learnt at the time of training. Thus, they can perform neither of the above tasks.
In case the newly arrived sample has a class label that is new, then the conventional classifiers will re-learn the models. Quite often, this re-learning starts from the beginning i.e. it has to forget the already learnt model in order to learn the new model. This is known as catastrophic forgetting [3,21]. Ideally, we would like to have systems that can perform the two tasks as given earlier and the adaptation of the system should be with minimal changes to the existing system. The dilemma here, known as the stability-plasticity dilemma, is that we want the system to be plastic such that it can learn the new class but also remain stable with respect to the already learnt classes [21].
Several techniques have been proposed earlier which can adapt to changes [3,10,12,20] and are able to solve the problem of stability-plasticity dilemma to a certain extent. However, most of these approaches are unable to decide whether a newly arrived sample belongs to a new class or whether it belongs to one of the known classes.
This statement can be understood if we consider a simple example. Let us consider a Multi-Layer Perceptron (MLP) that needs to be trained to classify samples from five classes (say C1, C2, …, C5). Now, if we assume that instead of training the MLP with training samples from all the five classes, we train the system with samples from only four of the classes, say C1, C2, C3 and C5. If we now present this MLP with samples from C3 then the trained system does not have any mechanism by which it can determine that the samples belong to a class that it has not encountered yet. It will simply declare the samples as belonging to any one of the classes that it has been trained for. Further, even if we want to retrain the system for the samples from the new class (C3 in the present example) then we shall have to retrain the entire system. This happens because the classes C1, C2, C4 and C5 will occupy the entire feature space and there is no room left to accommodate the samples from C3. We shall elaborate on this example in more detail in the third section where we will describe our architecture.
In this paper we present an architecture for supervised incremental learning, using neural networks, which can differentiate between samples that belong to known and previously unseen class. In case the sample belongs to a known class then the system simply classifies the data. On the other hand, if the sample belongs to a previously unseen class, then the network is expanded and adapted so that the new class is learnt by the system. Moreover, the extensions to the network are performed in a controlled manner so that the stability-plasticity dilemma is resolved satisfactorily [21]. As will be shown in the fourth section, the nature of adaptation is such that only small changes are required for some of the classes and most of the classes remain unaffected due to the arrival of samples of the new class. Thus, the major advantages of the proposed architecture are:
The system is able to recognize the fact that a newly arrived test sample is from a class that the system has not learnt yet.
The system is able to expand and adapt so that it can learn to recognize the samples from the new class i.e. add the new class to its knowledge base without changing its existing knowledge base significantly.
The expansion of the system is very controlled and is, in fact, linear with respect to the number of classes.
There are no free parameters that need to be adjusted for different data sets.
The proposed architecture consists of four layers. The first layer is the input layer that simply fans the input to all the neurons of the second layer. The second layer has a set of MLPs [39,42] operating in parallel. The number of MLPs is equal to the number of known (already learnt) classes i.e. each MLP is dedicated to one particular class. Each MLP has one output neuron. The purpose of each MLP is to decide whether a newly arrived sample belongs to the class to which that MLP is dedicated.
The novel aspect of the proposed architecture is the third layer that consists of a single perceptron, called the monitor perceptron. The monitor perceptron accepts the outputs of the MLPs in the second layer and decides whether the newly arrived sample belongs to one of the existing classes or to a new class. Basically, the monitor perceptron has the responsibility of saying “I don’t know” when a new sample belongs to a previously unseen class. In case the sample belongs to one of the known classes, then the outputs of the second layer and the monitor perceptron are sent to the fourth layer which performs the classification and outputs the class label. In case the monitor perceptron says “I don’t know” then the system is expanded by adding one more MLP in the second layer because “for incremental learning, model complexity must be variable” [19].
A series of experiments have been performed on different benchmark data sets taken from the UCI machine learning repository [25]. The results obtained in these experiments are very promising and, in most of the cases, they are more accurate than the existing, state of art, methods while in other cases our results are comparable to those obtained with other methods. We also compare our results with existing incremental techniques and simple multilayer perceptron network and observe similar findings.
This article is organized in the following format. A brief review of existing techniques for incremental learning using neural networks has been presented on Section 2. Section 3 contains details of the proposed architecture along with the motivation behind the architecture. Results of the experiments are presented in Section 4. Finally, conclusions are presented in Section 5.
Related work
There have been several approaches to incremental neural networks [7,10,11,20,28,34,36] in the past to satisfy the stability-plasticity dilemma. Different authors have used different methods for achieving the same.
Grossberg presented an unsupervised method called Adaptive Resonance Theory (ART) [21] which was extended for supervised learning and renamed as ARTMAP [10]. There are two ART structures at the base of ARTMAP. Extensive experiments by various researchers have shown that this architecture is sensitive to statistical overlapping between the classes. This sensitivity could also lead to uninhibited growth, which is sometimes referred to as category proliferation. This proliferation results in high computational complexity as well as high memory consumption. It also degrades the classification performance. Several modifications to the original ARTMAP have been proposed like Ellipsoid ART [4] and fuzzy ARTMAP [2,9] which reduces the above problem to some extent. A second issue observed with ARTMAP is deciding the value of the vigilance parameter which governs the decision as to when we should add a new cluster. Model prediction process is like a black box in ART based systems [40].
Some techniques have been proposed which use addition of new neurons for learning new data [5,20,22]. However, it has been observed that adding new neurons to acquire new knowledge leads to huge networks which lead to huge amount of memory requirements and computational cost. Some authors prune unused neurons (neurons that are not making substantial change to network response) from the network along with adding new neurons to the network if necessary so that network size may stay under control [15] and the size of the network remains optimal.
Another method uses incremental singular value decomposition to learn new data [1] for fixed number of output classes. Evolution based schemes for learning in neural nets have also been examined [32]. These techniques use mutation, crossover on fittest network to produce off springs. Huang and Chen presented an incremental neural network based on extreme learning machine [23]. Wang and Wang proposed an interesting technique where they used a combination of small networks for classification [37]. J.L. Calvo-Rolle et al. presented an online learning algorithm for automatic control system using two layer feedforward networks [8].
Probabilistic Neural Network (PNN) [35] has also been used for incremental probabilistic neural network [6,12]. However, the size of the network increases with time. Therefore, it needs huge amount of space for storage and high computational cost. A modified version of PNN was also introduced [11] that has a reduced architecture and provides some savings in terms of memory requirements.
Apart from uncontrolled growth of the network, a problem plaguing most of the existing systems is that they are sensitive to the order in which training data are processed by the network [10]. Adding new data to the network decreases the learning capacity of the network in some cases.
There are some Learning Vector Quantization (LVQ) [24] and k-Nearest Neighbor classifier (KNN) [16] based approaches which can learn within class incremental learning along with between class learning during training [14,33,38].
Incremental Class Learning (ICL) is a technique where we break the problem into sub-problems and train our network for one sub-problem at a time. We then freeze the weights of structure/structures which play a critical role in recognition and add another class [26]. Another sub-problem (new data) based approach has also been proposed by Murphey et al. [27]. In this approach the new data is first passed through the existing network. If the error is below a threshold then no changes are done to the network. However, in case the error is above the threshold then we need to train a new committee of networks and add them to the existing system. The error is then recalculated. If performance improves then we accept the new network otherwise reject them.
Fuzzy neural networks are also used for incremental learning [13,29,41]. These networks are used in a wide variety like with ARTMAP [2,13], MLP [31] or some other neural combinations [29,41].
Our method can be viewed as a member of constructive algorithms [17,18]. It is somewhat similar to the Cascade-Correlation algorithm where the machine learns by adding new hidden neurons to the network one by one. In the Cascade-Correlation method, when we add a new hidden neuron then we freeze all other weights of previously added neurons so that it cannot affect previously learnt data [17].
The discussions in this section show that there is a requirement of experimenting with new architectures in order to overcome the short comings of the existing techniques. We shall now proceed to describe our architecture in the next section.
Incremental artificial neural network with monitor perceptron
In previous section we see various approaches of incremental neural network and observe that there is scope for some improvement. In this section we first describe the motivation behind the INNAMP architecture followed by the INNAMP architecture.
Motivation for INNAMP
Let us consider the following example in order to understand why conventional neural network architectures like Multi-Layer Perceptrons (MLP) cannot handle the new classes, once it has been trained for a set of classes. In this example we have five classes (C1–C5) as shown in Fig. 1 above with two features ‘Feature 1’ and ‘Feature 2’. We generate this data using Gaussian distribution as given in Eqn. (1) where
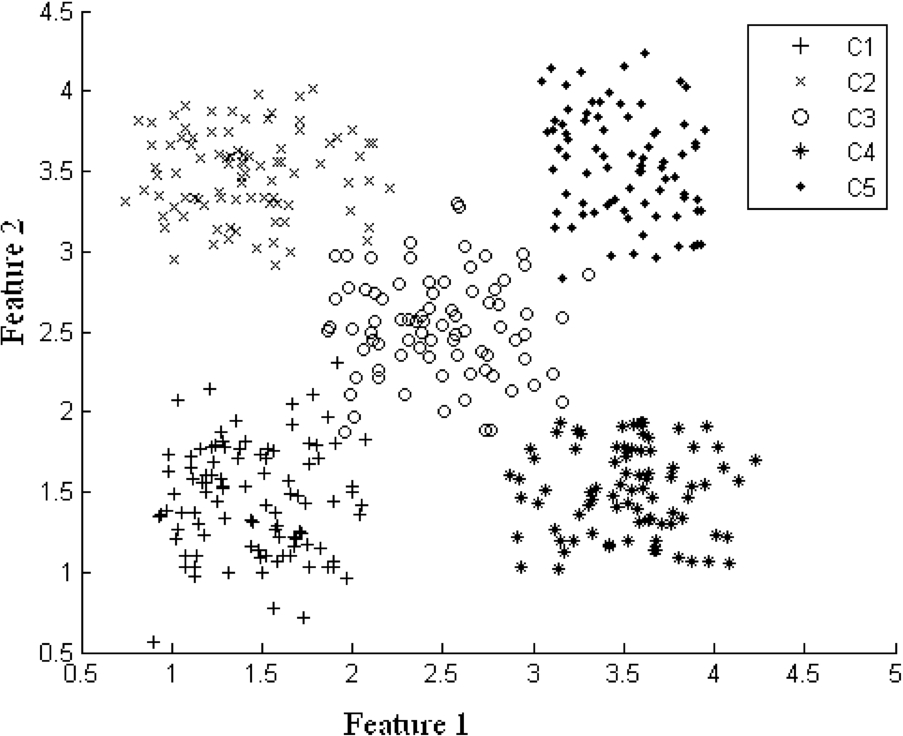
Initial class distribution.
When we train a standard MLP for the above data we get decision boundaries as shown in Fig. 2. It is clear from the figure that if any class is surrounded by other classes then we get a bounded region for that class as can be seen for class C3; otherwise the decision regions are unbounded as is the case with C1, C2, C4 and C5.
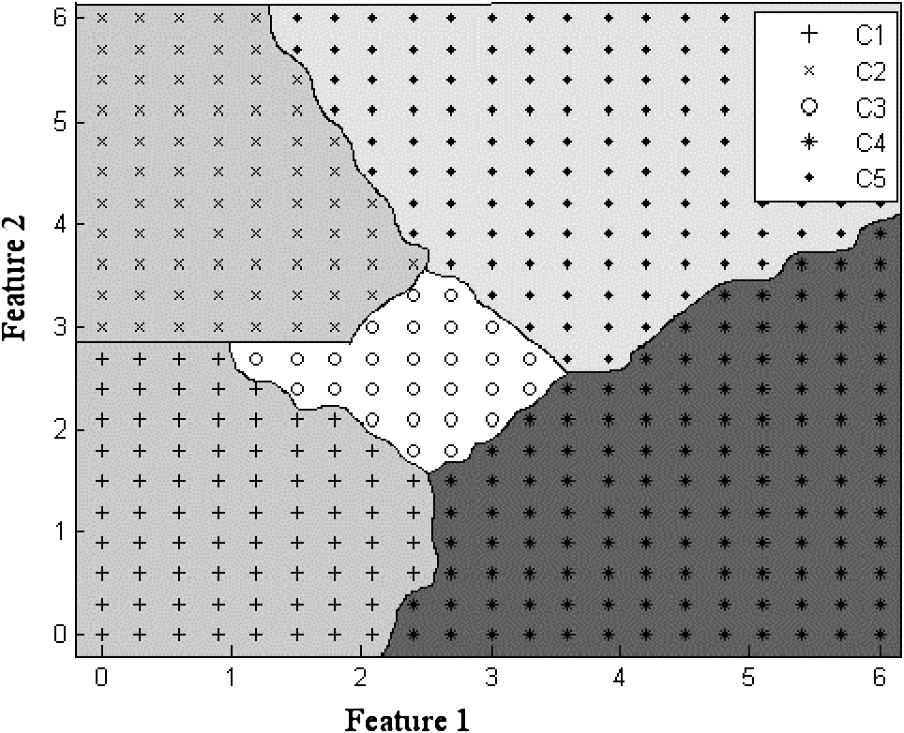
Class boundary using standard MLP.
These bounded and unbounded regions classify all other data (unseen data or new class data) into one of the existing classes. There is no mechanism by which such systems can identify whether a new data belongs to one of the existing classes or whether it belongs to a new class. Moreover, even if we have the information that the newly arrived samples belong to a new class, then we have to retrain the entire system because the decision regions will change quite drastically.
The above statement can be understood by performing an experiment that consists of training an MLP with samples from only four of the five classes namely C1, C2, C4 and C5. The resultant class boundaries are shown in Fig. 3. Now it is clear from the figure that if we present samples of C3 to this MLP then it classifies these samples into one of the existing classes and classification error rate is
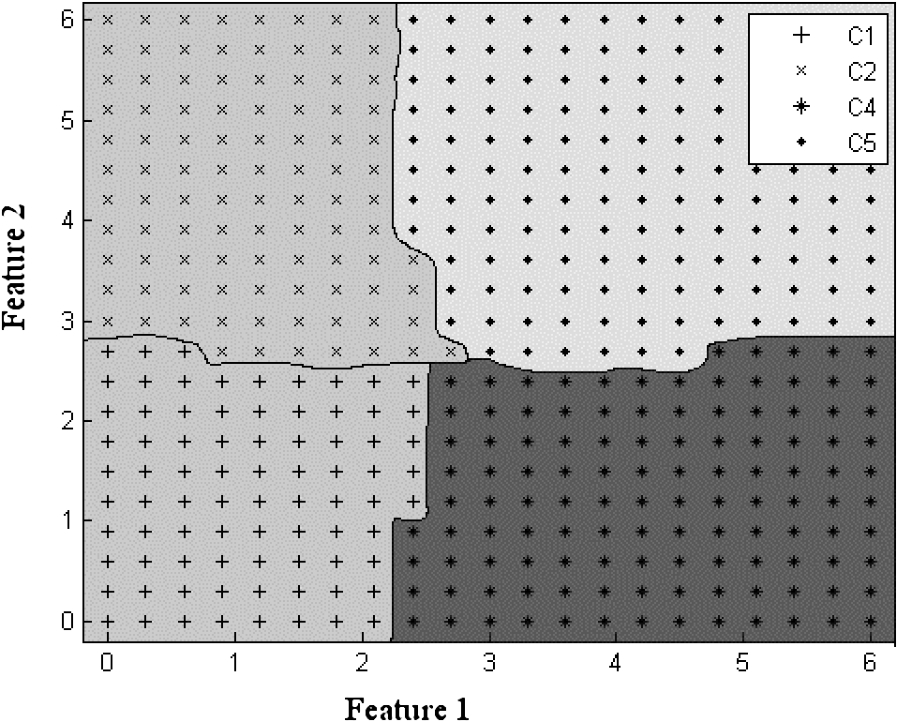
Class boundaries for four classes (C1, C2, C4, C5).
There are two ways of adding new information into a network. The first process is that whenever we get a new class data, we add that data directly to the network [21]. The second method is that we wait for some time and create a batch of new class/classes data and add the batch/batches [30]. This method is called the mini-batch technique [19]. When we are training a new MLP then batch mode algorithm works well because if the number of samples is very low (for new class data), then the resulting decision regions may have large errors. Thus, in case the number of instances of a new class is very small then we wait for more instances to arrive before re-training the network to avoid inaccurate predictions.
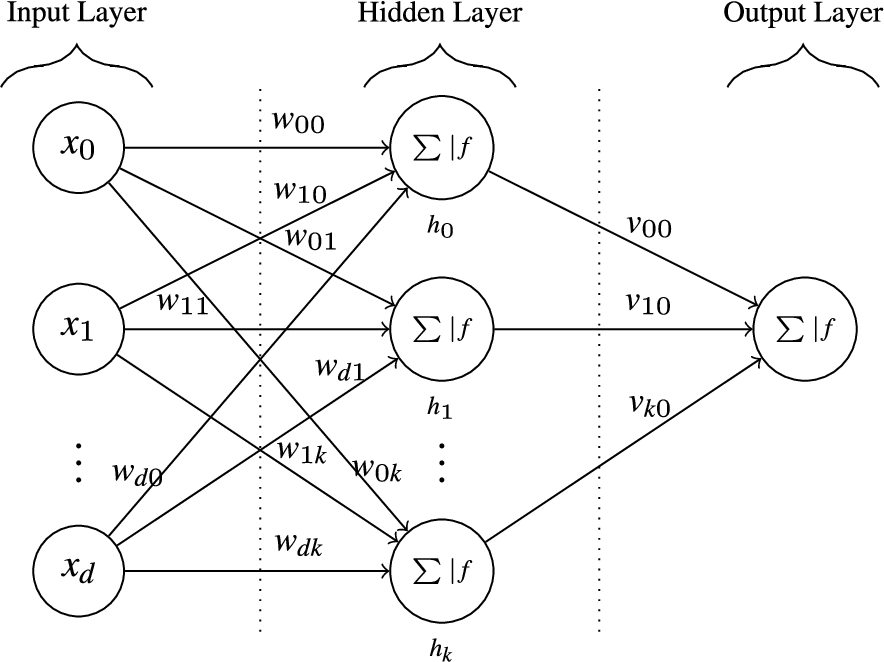
Figure 4 shows the basic structure of Incremental Artificial Neural Network (INNAMP) proposed in the present work. It consists of four layers i.e. input layer, network layer, decision layer and output layer. The decision layer contains the monitor perceptron which plays a pivotal role in the proposed architecture. We assume that each input data consists of ‘d’ features i.e. the sample is represented as a vector of length ‘d’. We also assume that the system has learnt M number of distinct classes. We now describe each of the layers in detail.

Architecture of Incremental Artificial Neural Network where x represents a d-dimensional input data and
The Input layer consists of d neurons corresponding to d-dimensional inputs. This layer simply fans the input to each of the MLPs in the next layer i.e. the network layer. Thus, each MLP in the network layer receives the complete feature vector of a sample. Moreover, each MLP acts independently of all other MLPs and they act in parallel.
The Network layer consists of M number of multilayer perceptron networks corresponding to the M number of classes that the system has already learnt. There is a dedicated MLP for each class. The purpose of each MLP is to decide whether a given sample belongs to the class to which the MLP is dedicated. As will be shown later, the training of these MLPs require some care. In the present work we have used standard MLPs with a single hidden layer and a single neuron in the output. The detailed design of each MLP is given in Fig. 5. These MLPs are designed such that each of them can take a d-dimensional input from the input layer and produce one output. In case the ith MLP decides that the particular sample belongs to the ith class then it will output ‘1’ else it will output ‘0’. It may be noted that one can design other architectures for these MLPs. In fact, we could replace the MLPs with other classifiers as long as these classifiers serve the same purpose as these MLPs i.e. the ith MLP (or any other classifier) will decide whether a particular sample belongs to the ith class.
Multilayer Perceptron with d input neurons and one output neuron.
In the present work the individual MLPs in the network layer are trained using one vs. all training. Effectively, the training of the ith MLP is such that the single neuron in the output layer of the MLP is activated only if the MLP recognizes the sample as belonging to the ith class. In other words, the output from the ith MLP is one if the sample belongs to the ith class and is zero otherwise. In a way, these MLPs are binary classifiers because either they know the pattern or they do not know the pattern. It may be noted that the one vs. all training strategy allows us to train each MLP independently of the others. The ith MLP effectively learns a decision boundary that encloses the samples of the ith class seen so far. However, as will be shown later, the actual decision boundaries learnt by the MLPs may not be the ideal one and some MLPs may learn open decision boundaries.
The Monitor perceptron accepts the input from the output layer neuron of each MLP. As noted earlier, each MLP can output only 1 (if it recognizes the sample) or 0 (if it does not recognize the sample). As mentioned in Section 1, the role of the monitor perceptron is to decide whether the sample belongs to one of the known classes or whether it belongs to a new class. In order to make this decision the monitor perceptron first computes a summation of all its inputs. The following conditions hold for the summation:
The summation will be equal to zero if no MLP in the network layer recognizes the sample.
The summation will be equal to one if exactly one MLP in the network layer recognizes it.
Lastly, the summation will be greater than one if more than one MLP in the network layer recognizes the sample.
Thus, a summation value of one indicates that the sample belongs to one of the known classes and other values indicate that the sample belongs to a new class. Thus, based on the value of the summation, the monitor perceptron is able to take its decision. The above logic can be encapsulated by the activation function given by Eqn. (2). The actual decision region can be visualized in Fig. 6.
Where ϵ is nearly equal to zero and s is the sum of all inputs. It simply states that the monitor perceptron gets activated if the sum is near to one. Otherwise it does not get activated. In order to understand the rationale of the activation function of the monitor perceptron we observe that the sum, ‘s’, in the above equation can be 0, 1 or
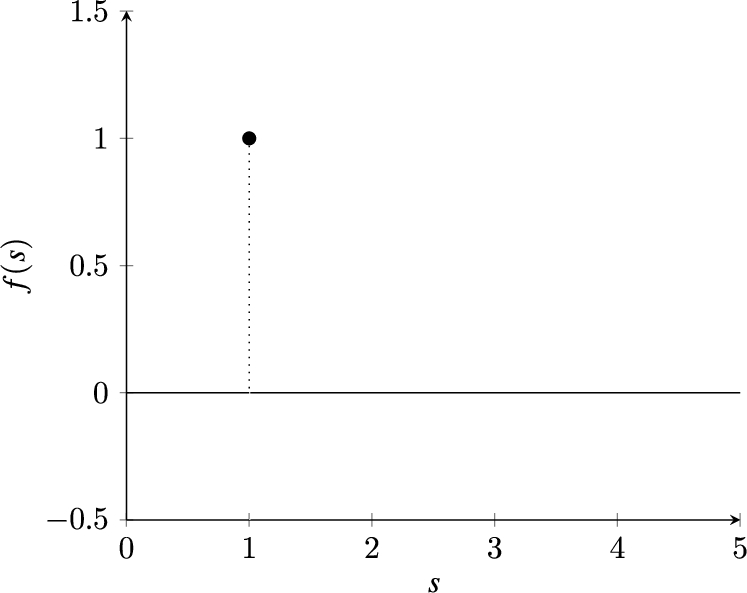
Decision region given by equation (2).
The first condition (i.e.
The logic of the activation function for the monitor perceptron (Eqn. (2)) is that this special perceptron will get activated only if INNAMP sees a sample of a class that it has not learnt yet. In other words, it is a perceptron that will say “I don’t know” when INNAMP is presented with a sample of a class that it has not learnt. Otherwise this special perceptron will not get activated i.e. it will remain silent. An important point to be noted at this stage is that the logic of the monitor perceptron is independent of the number of classes learnt by INNAMP. Thus, we can add any number of classes but we do not have to retrain the monitor perceptron. In fact, since the logic of the monitor perceptron is fixed, we may “hardwire” it from the beginning. This is crucial because it gives scalability to the architecture and helps resolve the stability-plasticity dilemma.
The Output layer contains
The rationale for the above activation function is that the ith output layer neuron is activated if the ith MLP is activated and no other MLP is activated.
Apart from the first M neurons corresponding to the M classes that have been learnt by INNAMP, the output layer consists of one additional neuron that will get activated for samples belonging to new classes i.e. classes that have not been learnt yet by INNAMP. This takes a single input from the monitor perceptron and works as a NOT gate. It may be recalled that the monitor perceptron gives an output of 0 when it gets a sample of a new class. Thus, the NOT function will convert the 0 into a 1. In other words, the
In effect, only one of the neurons of the output layer can get activated by a particular sample. If one of the first M neurons get activated then we have a sample from a known class. On the other hand, if the last neuron gets activated then we have a sample from a previously unseen class. In such situations we have to extend our network to learn this new class. The flow diagram of INNAMP is presented in Fig. 7.
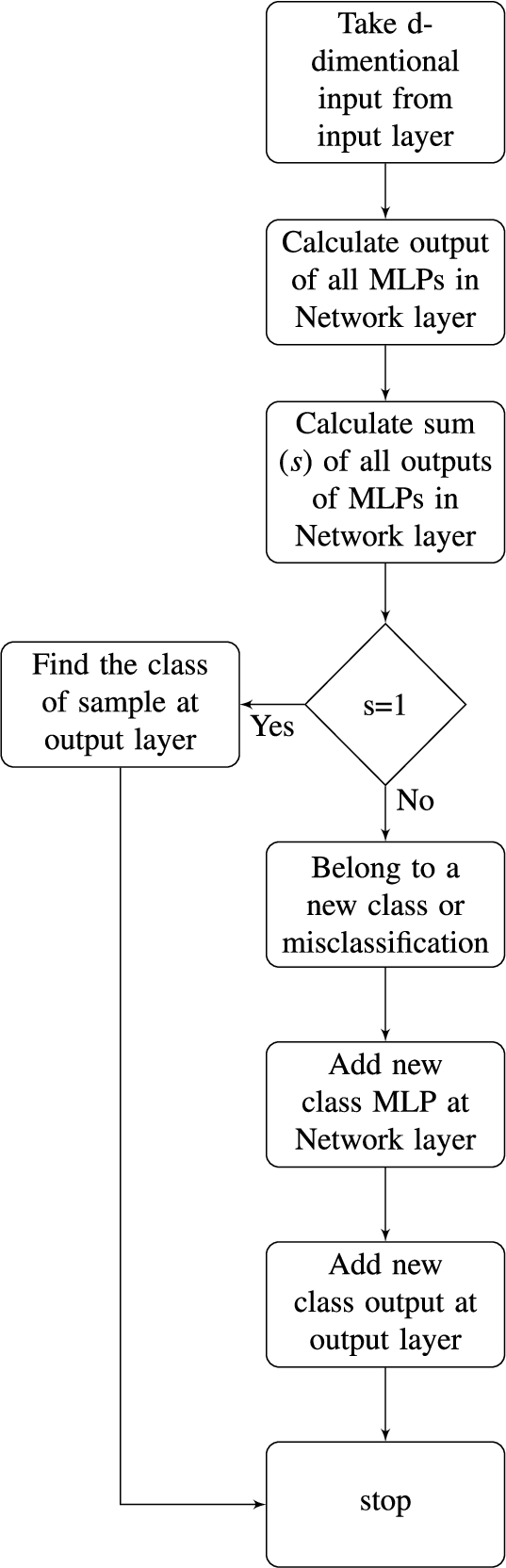
Flow diagram of INNAMP.
We shall now proceed to describe the process of extending the network when INNAMP encounters a sample from a previously unseen class. The first step is to add a new MLP in the network layer, corresponding to the new class. This MLP is again trained using a one vs. all strategy which does not affect the rest of the network. Before training a new MLP we wait for new class samples. Unless these new class samples crosses certain limit we wait. Then we merge these samples to old data set and perform the training of new MLP.
The second step is to add a new neuron in the output layer corresponding to the new class. Since the logic for these neurons is fixed, so no additional training is required for this neuron. No further additions are required in the network. Thus, we see that our architecture allows for a very controlled expansion of the network. In fact, the growth is linear with respect to the number of classes because whenever we add a new class we add a new MLP of fixed size in network layer. Therefore, for every increment in the number of classes we add the same number of neurons in the network.
It is possible that some of the existing MLPs in the network layer may also get activated by the samples from the new class. Therefore, as a third step, we test the MLPs of the existing classes with the new data to check whether they get activated. In case the ith MLP is not activated, then we do not have to perform any retraining of this existing MLP. However, in case the ith MLP is activated, then we have to perform a retraining of this MLP and this is the point where we have to tackle the stability-plasticity dilemma. The retraining will have to be performed using the new and old data. This problem occurs primarily due to poor training of the existing MLPs and can be solved by fine tuning the decision regions learnt by those MLPs.
At this stage we should note that each MLP had learnt a decision boundary that enclosed the samples of its class. It is intuitively clear that even after retraining we will not get a significant shift in the decision boundary i.e. the decision boundary will shift only marginally. Based on this hypothesis we retrain these networks such that the initial estimates of the weights, for the purpose of retraining, are the same as the weights that the MLP has already learnt. In practice, we find that only a few epochs of retraining are required to complete the process of adaptation. After the retraining we update these MLPs with the new weights and add the MLP corresponding to the new class in the architecture along with a corresponding neuron in the output layer. In Algorithm 1 below we have summarized the process to be followed when we extend INNAMP for accommodating samples from a new class.

Add New Class
It is pertinent to note that this architecture also allows removal of classes. Removal of an old class can be done by simply removing the corresponding MLP from the network layer and the corresponding neuron from output layer, leaving the rest of the architecture unchanged.
As can be seen from the above discussion, the proposed architecture allows for expansion of the network in a controlled manner and can be expanded for any number of classes. It is easy to add a new class and remove or update an existing class without disturbing other classes. Adding a new class implies adding a new MLP in the second layer and a single neuron in the fourth layer. We may also have to make small adaptations in the existing MLPs of the second layer. This would be required only for those existing classes whose decision region encloses samples of the new class.
A series of experiments have been performed to validate the proposed architecture. These experiments were conducted using benchmark data sets taken from UCI machine learning repository [25] and additional data sets, WebKB-41
and chars74k [15]. Table 1 presents a summary of all the data sets together with information about the number of classes, number of attributes and number of instances. It may be noted that these are the same data sets as used in an earlier work [11] except chars74k.Details of data sets used in the experiment
These data sets differ in number of classes (2–62) and number of attributes (4–3000). Thus, the chosen data sets will provide a rigorous test of the proposed architecture. In particular, we will be able to examine whether the proposed architecture works when we have a very high number of attributes and classes. Number of attributes of WebKB-4 data set is reduced from 8565 to 3000 as stated in Ciarelli, Oliveira, Salles, 2012 [11].
In order to verify the efficacy of the proposed method we have compared our results with three existing techniques for incremental learning namely the results from Ciarelli, Oliveira, Salles, 2012 [11], the results obtained with fuzzy ARTMAP [9]2
Results for unseen class data on different data sets
Average performance of the full system on data sets where class count is less than or equal to three (values in percentage)
The results obtained for all the data sets are given in Tables 2, 3, 4 and 5. Moreover, we also perform 10-fold cross validation on each data set to verify the correctness of our architecture. We also perform 10-fold cross validation among the arrival of new class data by changing the set of initial classes and arrival of samples of new classes. This additional test has been performed so that we can test whether the architecture is sensitive to the order of arrival of data.
Average performance of the full system on data sets with more than three classes (values in percentage)
Average performance on Chars74K data set (values in percentage)
The performance of our architecture is presented in terms of average performance across all the folds together with the maximum change in performance from the average. It may be noted that if the class count is smaller than or equal to three then we train all the networks at once because there is no scope for adding new classes incrementally. The results for such cases are presented in Table 3. The results obtained with data sets that have more than three classes are presented in Tables 2, 4 and 5. The incremental learning process described earlier is applied only to these data sets.
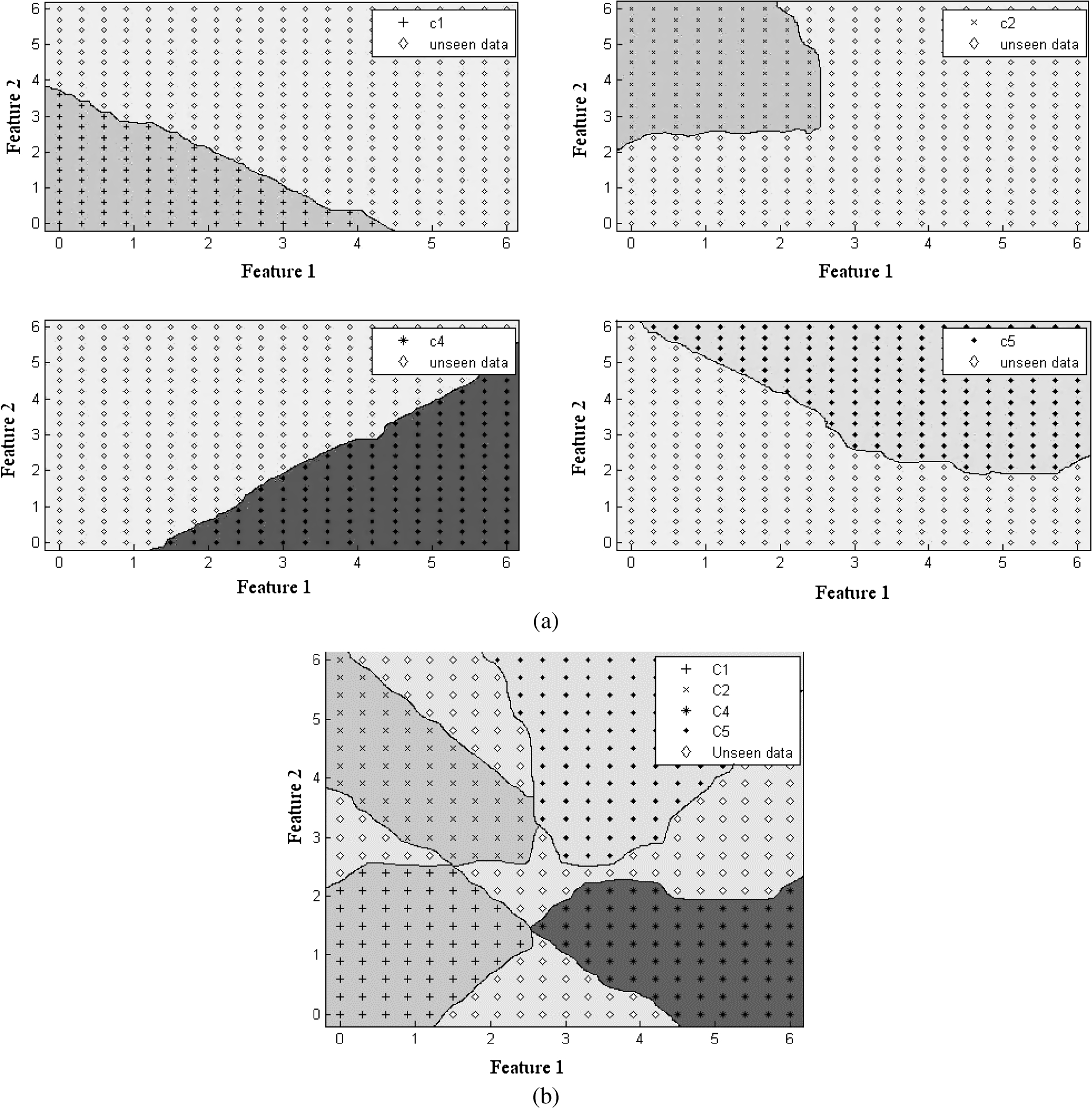
(a) Class boundaries for individual classes C1, C2, C4 and C5; (b) Resultant decision regions for all four classes.
If the class count is larger than three then we first train with half plus one classes initially. Therefore, for Car, WebKB-4 and CNAE-9 we started with 3, 3 and 5 classes initially. In the case of chars74k data set we take 50 classes as the starting point. The remaining classes were added incrementally using the process described in the previous section. After the initial training, we test the system with data from the seen and unseen classes. The performances of the networks for these four data sets are shown in Table 2.
It is clear from Table 2 that classifiers like ARTMAP and Cascade run in two modes i.e. training and testing. Moreover, if they are running on training mode then they can accommodate new data and new class. However, the story is quite different when they are running in testing mode. In the testing mode these networks take a sample and they always classify that sample into one of the existing class. In other words, these techniques can say “I don’t know” only in the training mode and not in the testing mode. In this respect the proposed architecture, INNAMP, works in a different way. In testing mode, when INNAMP sees a sample from an unseen class data it is able to say “I don’t know” and then switch over to the expansion and adaptation as explained in the previous section.
In order to understand the relevance of the numbers we need a few observations. Firstly, we see that our proposed architecture and process does manage to discover the arrival of samples from a class that it has not learnt yet. Moreover, the results are not affected by the ordering of classes i.e. the order of arrival of training data. Moreover, as will be shown subsequently, the overall error rate compares favorably with earlier approaches. However, the error rate for the samples from already learnt classes is significantly lower than that of samples from new classes. This is indicative of poor training. This aspect is analyzed in more detail in the following.
We again consider the example given in the introduction to understand the error rate for unseen data. We train INNAMP with the samples from classes C1, C2, C4 and C5 of Fig. 1. The class boundaries for network layer of INNAMP for different classes are shown in Fig. 8(a), where the dark region denotes the seen data region and light region is for the unseen data region for that particular class.
Now when we combine all these classifiers for output layer of INNAMP, the final decision regions are shown in Fig. 8(b). The first point to be noted is that certain portions of the feature space remain available for unseen data which, in this example, is the data from C3. This result is in stark contrast to the case where we train an MLP using the samples from C1, C2, C4 and C5 which was shown in Fig. 3 which did not have any region for unseen data. Thus, while our architecture and approach does create a decision region for the as yet un-learnt class, we can see that the already learnt classes are occupying decision regions in excess of what they actually require leading to misclassifications of samples from C3.
Now when we test the above architecture with samples of class C3, then some of samples are correctly recognized as unseen data while other samples of C3 are wrongly classified into one of the existing classes. This is depicted in Fig. 9 where the diamond sign represents the samples of C3 that are correctly classified as belonging to an unseen class. This situation is better than training a single MLP for all the four classes (C1, C2, C4 and C5) because such an MLP would have misclassified all samples of C3.
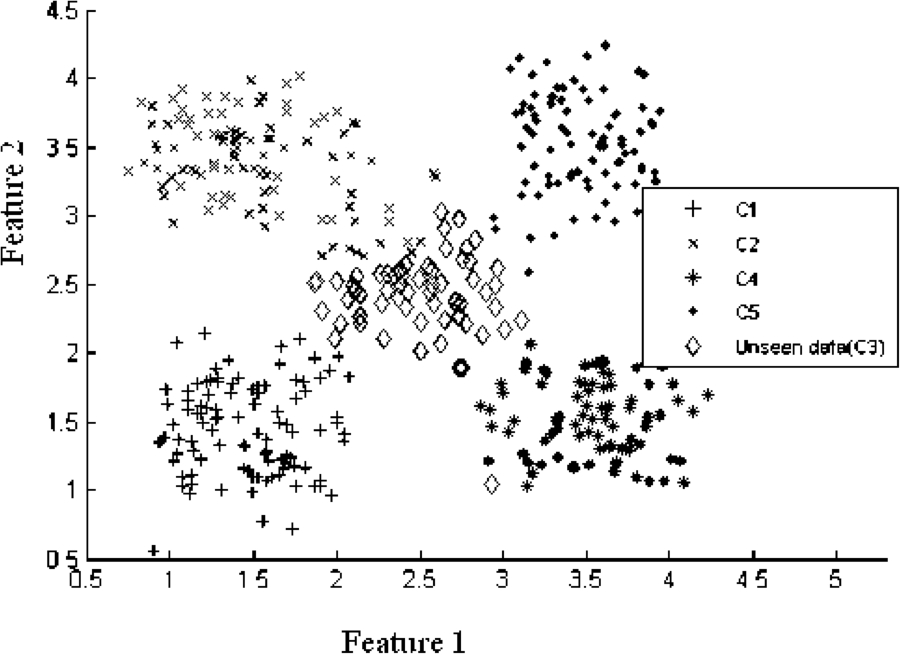
Results of architecture with unseen and seen data.
Once we get sufficient number of samples declared as belonging to a new class, we run through the procedure described above for adding a new class. The number of samples may be decided as the minimum number of samples of a previously trained class or some other heuristic. The final decision boundaries of separate MLPs and decision regions are shown in Fig. 10(a) and Fig. 10(b) respectively. The latter figure clearly shows that a new decision region has been created for the samples of the newly arrived class.
The final results obtained using our method is given in Table 4 for Car, WebKB-4 and CNAE-9 benchmark data sets. We have also included the results by Ciarelli, Oliveira, and Salles on the same data sets [11] for the purpose of comparison. We have also included the results obtained using other methods like Evolving Probabilistic Neural Network (ePNN), Incremental Probabilistic Neural Network (IPNN), Evolving Fuzzy Neural Network (EFuNN), Multilayer Perceptron (MLP) Gaussian Mixture Model (GMM), ARTMAP and Cascade network. As can be observed from this table, our method is comparable to or outperforms all these methods.
Table 5 shows the performance of INNAMP on Chars74K data set. We simply take all the 74k (computer fonts, handwritten and natural scenes). We first binarize the natural scenes images, then crop all the images from all the sides so that only the character remains in the image. Cropped images are then resized to
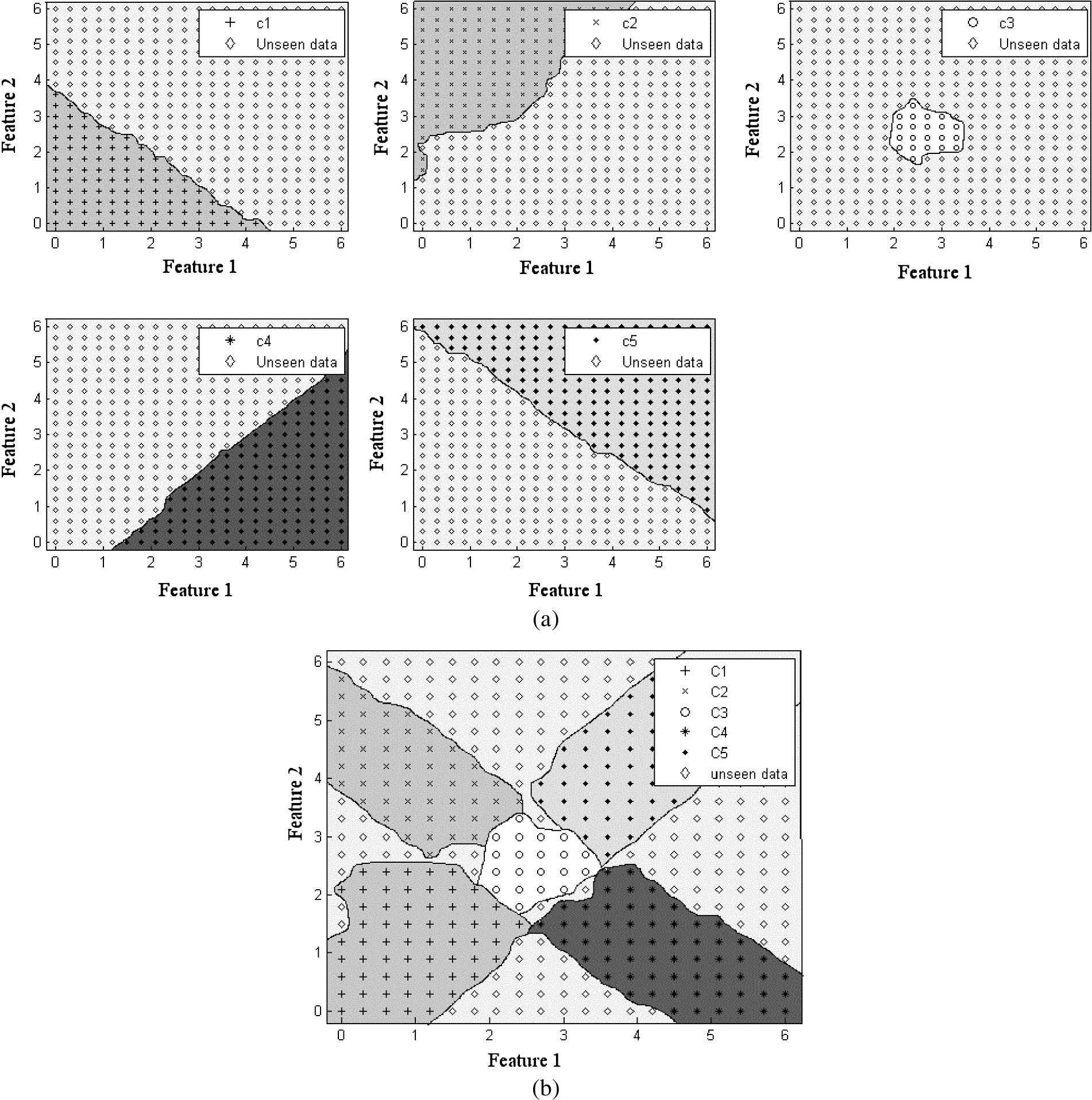
(a) Separate regions of all MLP’s using all 5 classes, (b) Final decision boundaries using INNAMP.
Figure 11(a) and 11(b) shows the performance of INNAMP with respect to class increment for CNAE-9 and Chars74K during training and testing phases. It is very clear from the figure that if the number of classes increase there is slight decrement in the performance of INNAMP. This is due to the overlap in the class boundaries due to training of separate MLPs as shown in the above example. It is clear from these results that if we get tighter boundaries while training the individual networks then we can improve the performance of INNAMP. Ideal decision boundary for a class would be that boundary which encloses the outermost data points of that class. This would leave more regions for accommodating samples of a new class and thus increase the accuracy.
In case of fuzzy ARTMAP we have to initially define the number of classes for which we are going to train our network. If the class count goes above that then we have to create a new network and retrain it. In other words, we need to have an estimate of the total number of classes that the network will ultimately recognize. ARTMAP does not have a mechanism to keep adding new classes. On the other hand, there is no need to define the number of classes in case of INNAMP because we can add any number of classes by simply adding one more MLP for a new class.
In terms of growth of network ARTMAP has a fixed size and there is no necessity of adding new neurons because the maximum number of classes is available a priori. On the other hand, Cascade Correlation Network and Evolving Fuzzy Neural Network (EFuNN) allows the network to grow but the growth is uncontrolled. In the cases of Probabilistic Neural Network (ePNN) and Incremental Probabilistic Neural Network (IPNN) the growth of network depends on the number of training samples because there is a neuron for each training data. For example if your data set contains 10000 training samples then there is 10000 neurons along with one neuron for each class and one output neuron. Thus, for these latter cases, when we add a sample from a new class then we also have to add a neuron into the network. This leads to very large networks and high computational complexity.
In contrast to other models of incremental learning, the growth of network in INNAMP is linear in the number of classes. As explained in the previous section, for each class we need to add one MLP in the second layer and a single neuron in the fourth layer. Thus, the rate of growth depends upon the size of MLP in network layer. If an MLP has one hidden layer with, say, 10 neurons and there is 1 neuron in the output layer of the MLP, then the total number of neurons in each MLP is 11. Moreover, there is one neuron in the output layer of INNAMP for every MLP. Thus, for adding one class we require 12 neurons in the network. We have performed all our experiments using the above architecture. However, the size of the MLPs can change with the data set but we will still require only one MLP per class. The above shows that while our architecture can accommodate an arbitrary number of classes (unlike ARTMAP), the corresponding growth in the network is very controlled.
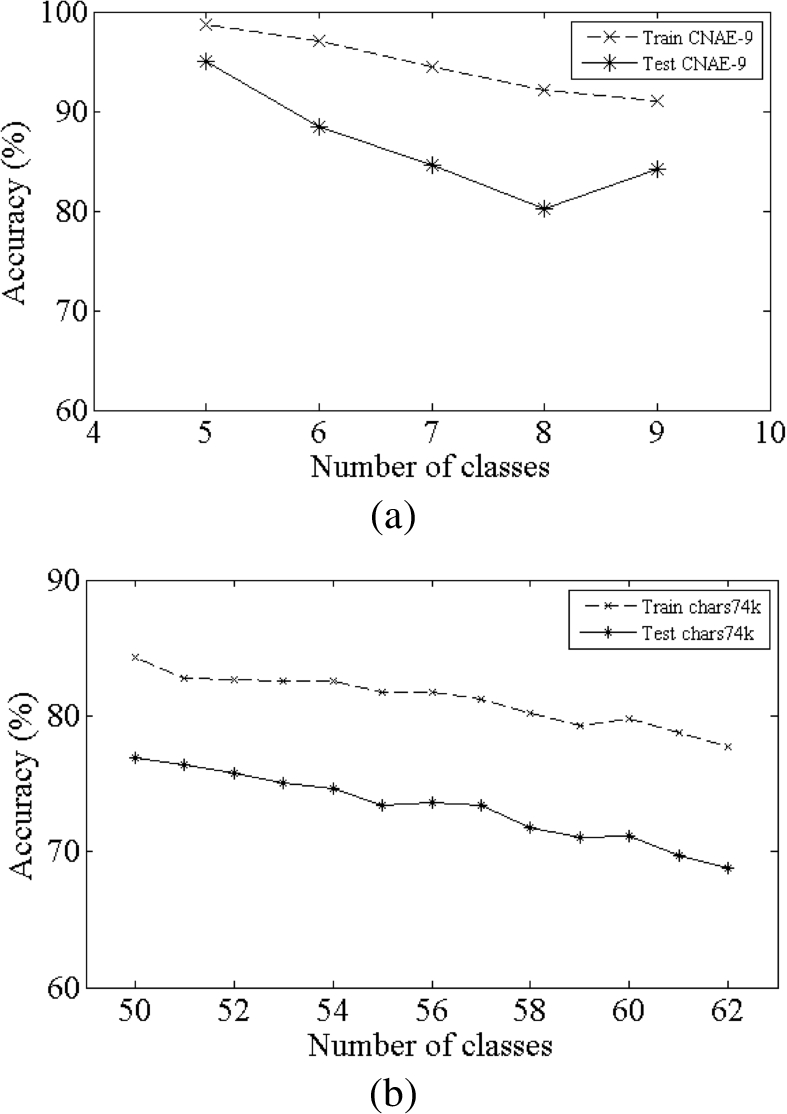
(a) Change in accuracy as number of classes increases for CNAE-9 data set (b) Change in accuracy as number of classes increases for Char74K.
This paper presents INNAMP, which is an incremental neural network architecture, with monitor perceptron, using parallel multilayer perceptron networks. The main advantage of this architecture is that the monitor perceptron is able to differentiate between samples from seen (i.e. already learnt) and unseen (i.e. not-yet learnt) classes. The system grows as the number of classes increase but it is a controlled growth. The network grows linearly with the increase in number of classes. Moreover, the retraining required when a sample of an unknown class is presented represents a nice balance between stability and plasticity. A major difference between the proposed approach and earlier approaches like ARTMAP is that we do not have to adjust or fine tune any parameter. As explained in the previous section, the network is able to recognize the arrival of samples from a new class. In case samples from new classes arrive then the system expands and adapts to the changes in a controlled fashion.
A series of experiments have been performed on public domain data sets with INNAMP and results are comparable with other techniques that include both incremental and non-incremental methods. Therefore, it appears that IANNMP is an effective alternative to the existing incremental neural architectures.
A matter of concern with the present architecture is that while it will work well for classes that are well separated in the feature space, the monitor perceptron may not be able to take correct decisions if there is a strong overlap between the new (unseen) class and one of the existing (known) classes. This is a possible scenario when the number of classes becomes very large. A possible solution to this problem is that we can replace the single monitor perceptron with a full-fledged network that can learn more complex decision boundaries instead of the simple decision boundary learnt by the single perceptron. We can allow each MLP in the network layer to output a probability of a particular sample for belonging to a certain class. These probabilities are then given to the decision layer for determining whether the sample belongs to one of the known classes or whether the sample belongs to a new class.
The other problem with this architecture is open decision regions of some classes. If a sample from a new class lies in one of these regions, then the system classifies this sample wrongly. To overcome this problem we have to create alternative methods of training that can lead to closed decision boundaries that encloses the samples of known classes more tightly. If we succeed in creating closed boundaries that are tight then we do not have to retrain the network while adding the new classes.
Footnotes
Acknowledgement
The authors gratefully acknowledge the infrastructural support provided by Indian Institute of Information Technology, Allahabad (IIIT-A). One of the authors (SG) also acknowledges the financial support from IIIT-A.