
Abstract
Several efficient SAT-based methods for computing the preferred extensions in (abstract) argumentation frameworks (AF) are proposed lately. However, only complete SAT solvers have been exploited so far. It is a natural question that how the appealing stochastic local search (SLS) approach could advance the performance. In this paper, we developed two SLS algorithms for computing the preferred extensions in AF, and a complete one which combines the strength of the better one with complete SAT solvers. Our first SLS algorithm Ite-CCAEP works by calling an SLS SAT solver Swcca in an iterative manner with adaptive heuristics. Our second SLS algorithm Inc-CCAEP realized an incremental version of Swcca, specially designed for computing the preferred extensions in AF. Though Ite-CCAEP and Inc-CCAEP do not guarantee completeness, they notably outperform a state-of-the-art solver consistently on most benchmarks with non-empty preferred extensions. Experimental results also show that Inc-CCAEP is more efficient than Ite-CCAEP, which inspired the design of a novel complete algorithm called CCASATEP that uses Inc-CCAEP as an efficient preprocessor. Further experiments show that CCASATEP is competitive to the state-of-the-art methods.
Introduction
Dung’s theory of (abstract) argumentation frameworks (AF) provides a general model for computational argumentation [18]. AF takes only the inter-relations of arguments into account on an abstract level. An AF consists of a set of arguments and the directed attack relations between them.
Charwat et al. present a selection of evaluation methods for AF, and they group these methods into two categories: the reduction approaches and the direct approaches [16]. In the reduction approaches, SAT-based argumentation systems show good efficiency on solving the reasoning problems in AF. For preferred semantics, CEGARTIX system [19] and ArgSemSAT system [13–15] are two representative SAT-based argumentation systems, which both rely on iteratively calling complete SAT solvers. Each of the above two systems is ranked 1st or 2nd in the SE-PR (determining some extension under preferred semantics), DS-PR (deciding whether the given argument is skeptical inferred under preferred semantics) and EE-PR (determining all extensions under preferred semantics) tracks of the first International Competition on Computational Models of Argumentation (ICCMA’15) [33].1
There are two popular kinds of algorithms for SAT: conflict driven clause learning (CDCL), and stochastic locals search (SLS). CDCL approaches evolved from famous DPLL, and many techniques have been integrated, such as clause-learning and backjumping [9,22,32], restart [1,31], as well as efficient branching heuristics [34]. SLS algorithms are typically incomplete i.e., they cannot determine with certainty that an input formula is unsatisfiable. However, SLS algorithms have surprising efficiency on finding solutions for satisfiable random instances. The efficiency of SLS algorithms mostly depend on the heuristic methods selected by them. An efficient heuristic method named configuration checking (CC) [12] has been proposed to handle the cycling problem, i.e., local search returns to a candidate solution that has been visited recently. Afterwards, the CC heuristics has been successfully applied to solving SAT [11,25] and Max-SAT [10,26]. The SLS algorithm Swcca (smoothed weighting and configuration with aspiration) [11] is designed based on the heuristics named configuration checking with aspiration (CCA), which is an improvement of CC heuristics, to solve SAT problems. It has the advantages of stable, easy modification and high efficiency. CCA heuristics enhances the CC heuristics with an aspiration mechanism, and allows a variable with a great score to be flipped even if its configuration is not changed. Compared to other SLS algorithms, Swcca has a high efficiency based on CCA heuristics. For example, in literature [11], the experiments on random 3-SAT instances show that Swcca2
A preliminary version of this paper has been published in ECAI 2016 with short paper [28]. In literature [28], Inc-CCAEP is introduced, but many details are omitted.
This paper contributes to compute Dung’s preferred extensions based on the SLS algorithm for SAT. Two novel approaches Ite-CCAEP and Inc-CCAEP are proposed, and we compare them with other state-of-the-art systems for random AF instances with non-empty preferred extensions. Because Ite-CCAEP and Inc-CCAEP do not know whether they have found all preferred extension or not, they cannot automatically terminate. That property is similar to SLS algorithms’ in Max-SAT [10,26], which cannot automatically terminate too. For those SLS algorithms, they are terminated manually, i.e. the cutoff time has to be determined.
Because of the high efficiency of SLS algorithms, integrating them to complete algorithms can improve the efficiency of complete algorithms. For example, CCAnr+glucose is ranked 2nd in “sequential, Hard-combinatorial SAT” track of SAT Competition 20143
This paper is organized as follows. Section 2 recalls the basic concepts of argumentation frameworks and preferred semantics. Section 3 recalls the CCA heuristics and Swcca algorithm. Section 4 introduces the two proposed approaches while Section 5 describes the test setting and comments the experimental results. Section 6 concludes the paper.
In this section, we introduce (abstract) argumentation frameworks [18] and recall the preferred semantics we study in this paper.
An argumentation framework (AF) is a pair
Given an AF a set an argument a set an admissible set
An argumentation framework semantics is defined as a function σ which maps each AF
Here we need to recall the function definitions of admissible, complete and preferred semantics only.
Let
Dung has also proved that: 1) each complete extension is an admissible extension, but not vice versa; 2) each preferred extension is a complete extension, but not vice versa [18]. The scale of each conjunctive normal form (CNF) formula encoded from complete semantics function is usually bigger than the scale of corresponding CNF formula encoded from admissible semantics function, and more variables will be created in the encoding of complete semantics function. SLS methods usually select variables to flip according to all heuristic values of all variables. So, more variables and clauses will reduce the efficiency of heuristic selections, and we attempt to compute all complete extensions based on computing admissible extensions firstly, and then compute preferred extensions based on complete extensions.
A CNF formula is a conjunction of clauses, normally expressed as a set. For a CNF formula Φ, a model is a complete assignment which satisfies all clauses in Φ. Given a CNF formula, the SAT problem consists in determining whether there is any model for it or not.
In this paper, we use
Obviously, the right-hand side of formula (1) is a CNF formula. Given a model P, let
In formula (1), if every variable is assigned to 0,
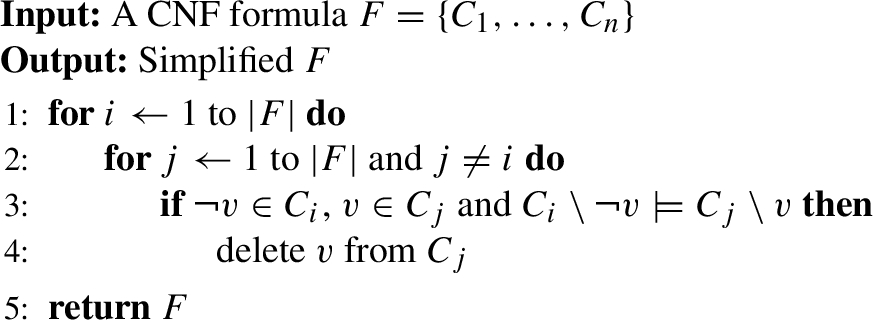
Simplification
Based on formula (2), we can compute admissible extensions which are non-empty. Obviously,
Given two clauses
In formula (1), there are only two kinds of clauses: one kind of clauses contains exactly two negative literals, the other kind of clauses contains one negative literal and some other positive literals (the number of positive literals can be 0). If we add some new clause in which all literals are positive to
Original clauses can also be simplified based on Lemma 1. So we design a simplifying process based on Lemma 1, which is described in Algorithm 1.
The basic concept of CC is configuration which establishes a connection between a variable with truth values of all its neighboring variables. We use
([11]).
Given a CNF formula Φ and s the current assignment to
Given a CNF formula Φ, the CC heuristics can be described as follows [11]: When selecting a variable to flip, for a variable
In the implementation of CC, each clause
The basic process of Swcca is as follows: Beginning with a random complete assignment of truth values to variables; initializing heuristic information; in each subsequent search step, a variable is chosen and flipped based on CCA heuristics, and updating heuristic information. For more details, please refer to the literature [11].
Enumerating preferred extensions based on CCA heuristics
We are now in a position to introduce our first proposed procedure, called Ite-CCAEP and listed in Algorithm 2, to enumerate the preferred extensions of an AF

Ite-CCAEP
In subsequent algorithms,
In order to improve the efficiency of searching process, we use Strategy 1 to further simplify
Unit propagation is executed in Line 3 (in Algorithm 2). Some arguments may attack themselves, and these arguments will not appear in any conflict-free extension. So those arguments will not appear in any admissible extension or preferred extension. The formal description of creating unit clauses in encoding process is that: Given an AF
unit-propagation
After Ite-CCAEP searches a model T which is in correspondence with an admissible extension S, if T is still a model after flipping any negative literal in it, we flip that negative literal and can get a superset of S. Strategy 2 is completed in Lines 10–11 (in Algorithm 2). After executing Strategy 2, we can get a model
After executing Strategy 2 in Lines 10–11 (in Algorithm 2 ), the model is in correspondence with a complete extension.
Let S be the admissible extension corresponding to the model T after executing Strategy 2. Then, for each argument
In Algorithm 2, the heuristic information appeared in Ite-CCAEP mainly contains the scores of all variables, the weights of all clauses and the time stamps of all flipping variables [11]. All possible extensions will be saved as
After adding

Inc-CCAEP
In Algorithm 4, we also add Strategy 1 and Strategy 2 to Inc-CCAEP. The differences between Inc-CCAEP and Ite-CCAEP are that the former updates heuristic information after flipping a variable in Strategy 2 in Lines 12–13, and adds heuristic information of new clause after adds this clause to Φ in Lines 16–17. In Inc-CCAEP, heuristic information is initialized only once, and it conserves all heuristic information after finding a model.
If the CNF formula Φ in Algorithm 4 (resp. Algorithm 2 ) is unsatisfiable after executing Inc-CCA EP (resp. Ite-CCA EP ), Inc-CCA EP (resp. Ite-CCA EP ) finds all preferred extensions of the input AF.
After executing Inc-CCAEP, that Φ in Algorithm 2 or Algorithm 4 is unsatisfiable means there are no more admissible extensions. If there are no more admissible extensions, Strategy 2 can guarantee that any admissible extension of input AF is a subset of some extension in
Now, we introduce the complete CCASATEP algorithm which is listed in Algorithm 5.
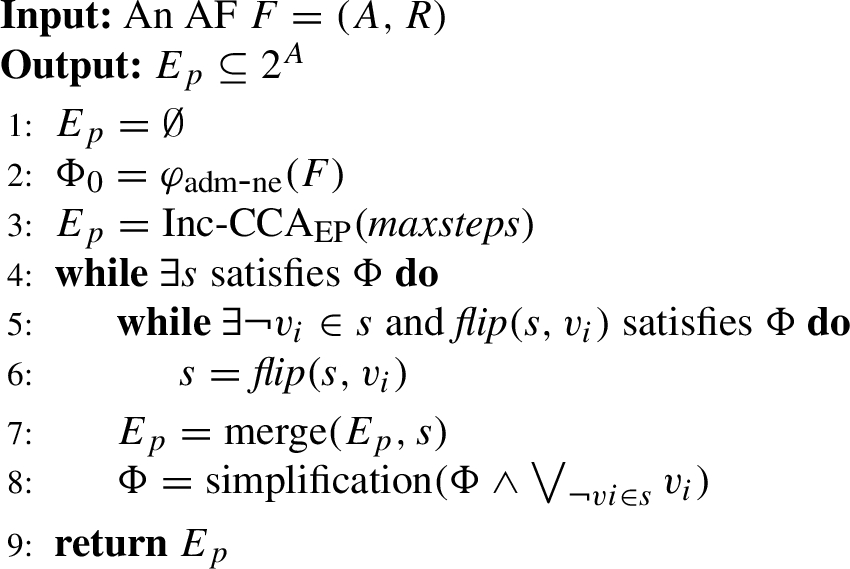
CCASATEP
In Algorithm 5, CCASATEP use Inc-CCAEP to search for complete extensions firstly, and the result is saved as
CCASAT EP is a complete algorithm for enumerating preferred extensions.
First we show that termination is guaranteed. CCASATEP adds
Inc-CCAEP and Ite-CCAEP are two incomplete algorithms for enumerating preferred extensions, so it is not clear whether the found preferred extensions are really preferred extensions. Accuracy rate is an important parameter to measure incomplete algorithms, which is the proportion of instances which are correctly solved in all instances. Swcca has high efficiency and accuracy rate. For example, Swcca has 100% of accuracy rate on the random large 3-SAT instances with 35000 variables from the SAT Competition 2011 [11].
CEGARTIX5
A comparison between Inc-CCAEP with the state of the art
A comparison between Inc-CCAEP with the state of the art
In order to test the effect of computing preferred extensions based on admissible semantics and Strategy 2, with respect to computing preferred extensions based on complete semantics, we simply implement the algorithm Com-CCAEP which is an alternative of the algorithm with the encoding of complete semantics instead of encoding of admissible semantics and Strategy 2. Com-CCAEP also adopts incremental searching process. Our experiments are conducted on the PC with a quad-core Intel(R) Core(TM) i7-3700, 4 GByte RAM and Ubuntu 14.04 operating system. Because Inc-CCAEP, Ite-CCAEP and Com-CCAEP cannot finish their search processes automatically even if they have found all preferred extensions, we use actual search time to measure their efficiencies.
The comparing results on benchmarks in ICCMA’15 are shown in Table 1. In Table 1, the numbers in brackets in first column represent the size of corresponding kind of instances, and the numbers in brackets in second column, fourth column and fifth column represent the numbers of instances which are correctly solved by Inc-CCAEP, Ite-CCAEP and Com-CCAEP respectively. Whether the found preferred extensions by Inc-CCAEP or Ite-CCAEP are really preferred extensions or not can be judged based on Theorem 2, this method is also applicable for Com-CCAEP. In Table 1, the solving time of SLS algorithms begins from start to end of last solution searched by it. The SLS algorithms do not terminate from themselves. If the time since the last solution searched by some SLS algorithm exceeds 100 s, we terminate this SLS algorithm. Then we can record the time in which last solution is searched by Inc-CCAEP, when we use Inc-CCAEP to solve some instance. The above method is also applicable for Ite-CCAEP and Com-CCAEP. The sat-time of Inc-CCAEP is used to compute remainder admissible extensions based on CDCL approach, this process is executed as Lines 4–9 in Algorithm 5. We list the sum time of solving all instances in each row for every solver, since the instances with same kind are greatly different. The unit of time is second.
From Table 1, we can see that Inc-CCAEP and Ite-CCAEP have similar accuracy rate, but the solving time of Inc-CCAEP is evidently shorter than Ite-CCAEP’s. Both Inc-CCAEP and Ite-CCAEP can not completely solve instances in st-small and st-medium, the reason is that methods of local search are incomplete, and they are not appropriate to solve instances with some special structures. Comparing Inc-CCAEP with Com-CCAEP, we can see that Inc-CCAEP is evidently better than Com-CCAEP. So, computing preferred extensions based on admissible semantics and Strategy 2 is more suitable for SLS algorithms.
Based on the comprehensive consideration on searching time and sat-time of Inc-CCAEP, we can see that, Inc-CCAEP has the best efficiency for solving the instances in scc-small and scc-medium. The efficiency of Inc-CCAEP is better than ArgSemSAT’s for the instances in st-small and st-medium, and worse than CEGARTIX’s for these instances. Overall, ArgSemSAT has best efficiency for the instances with gr kind, and the efficiency of Inc-CCAEP is worst for these instances.
The capacity of benchmarks in ICCMA’15 is too small, and the distribution of these benchmarks is not regular, which causes that we can not set appropriate maxsteps for CCASATEP on these instances. So in order to get appropriate maxsteps for CCASATEP, we further test Inc-CCAEP on benchmarks, which are regularly generated with different graph-models, in literature [8]. Because Ite-CCAEP and Com-CCAEP is far slower than Inc-CCAEP, so we do not test the ability of Ite-CCAEP in remaining experiments.
In literature [8], benchmarks are generated with three different graph-models which include Erdős–Rényi, Kleinberg and Barabasi–Albert. The above graph-models are also used to compare other reasoning-tools in AF [5–7].
In the Erdős–Rényi model [20], a graph is constructed by randomly connecting n nodes. Each edge is included in the graph with probability p independent from every other edge. Clearly, as p increases from 0 to 1, the model becomes more likely to include graphs with more edges. In [8], Bistarelli et al. set
The Kleinberg [27] (small-world) graph-model adds a number of directed long-range random links to an
During the generation of Barabasi–Albert (scale-free) graphs, at each time step a new vertex is created and connected to existing vertices according to the principle of “preferential attachment” [3], whereby vertices with higher degree have a higher probability of being selected for attachment. At a given step, the probability p of creating an edge between an existing vertex v and the newly added vertex is
In order to set appropriate maxsteps for CCASATEP, we need to know the solving ability of Inc-CCAEP on different graph-models. In our experiments, maxsteps used in CCASATEP is replaced by cutoff time which is relatively stable and easily observed in experiments. Cutoff time used in CCASATEP means that the executing time of Inc-CCAEP in CCASATEP is fixed as cutoff time.
We are fortunate to get all experimental instances in [8]. In those instances, we omit some easy instances which can be solved in less than 0.01 s by CEGARTIX, and also omit some hard instances which cannot be solved by any of the solvers. Inc-CCAEP can not solve instances with empty preferred extension, so we test it on instances with non-empty preferred extensions in this part. The result is shown as Table 2. In Table 2, we use ER, Kle and BA to indicate Erdős–Rényi, Kleinberg and Barabasi–Albert respectively. The data in the second column of Table 2 contains the argument number of corresponding instances, and the instance numbers which are listed in brackets. The unit of time is second.
Searching time of Inc-CCAEP on instances with different graph-models
Searching time of Inc-CCAEP on instances with different graph-models
In Table 2, max-sr-time and avg-sr-time represent the maximum searching time and average searching time of Inc-CCAEP for corresponding kind of instances. From Table 2, we can get the accuracy rate, maximum searching time and average searching time of Inc-CCAEP for different graph-models.
For Erdős–Rényi graph-models, Inc-CCAEP can not solve all instances, and the solving time is not stable, which means that differences of solving time for instances of same kind are great. For example, for the instances with 500 arguments, the maximum searching time of Inc-CCAEP is 190.05 s, but the average searching time is 31.93 s. The running time of CCASATEP consists of the cutoff time for Inc-CCAEP and the time of calling complete SAT solver. The solving time of Inc-CCAEP is greatly different on instances of Erdős–Rényi graph-models. If we set a long cutoff time for Inc-CCAEP, much time is wasted for easy instances. If we set a short cutoff time for Inc-CCAEP, the performance of Inc-CCAEP for solving hard instances is suppressed, and the time of calling complete SAT solver is long for most hard instances. The instable searching time leads the situation that we can not set cutoff as maximum searching time or average searching time. So, we should set cutoff time of Inc-CCAEP in CCASATEP less than the average searching time for Erdős–Rényi graph-models.
For Kleinberg graph-model, Inc-CCAEP solves all instances, and the solving time is relatively stable. The maximum searching time is twice of average searching time. In order to reduce wasted searching time of Inc-CCAEP and the time of calling CDCL approach, we should set the cutoff time of CCASATEP a little bigger than average searching time of Inc-CCAEP for Kleinberg graph-model.
For Barabasi–Albert graph-model, Inc-CCAEP solves all instances, and the solving time is stable. The maximum searching time is close to average searching time. So, we should set the cutoff time of CCASATEP as maximum searching time of Inc-CCAEP for Kleinberg graph-model. Then the performance of Inc-CCAEP can be sufficiently employed.
In order to show the impact of cutoff time on the performance of CCASATEP and identify the value of cutoff time for different graph-models, we test the efficiency of CCASATEP with different cutoff time for three graph-models. There are many instances with different scales in each graph-models, so we select one kind of instances for each graph-models. The results are shown as Figs 1–3.
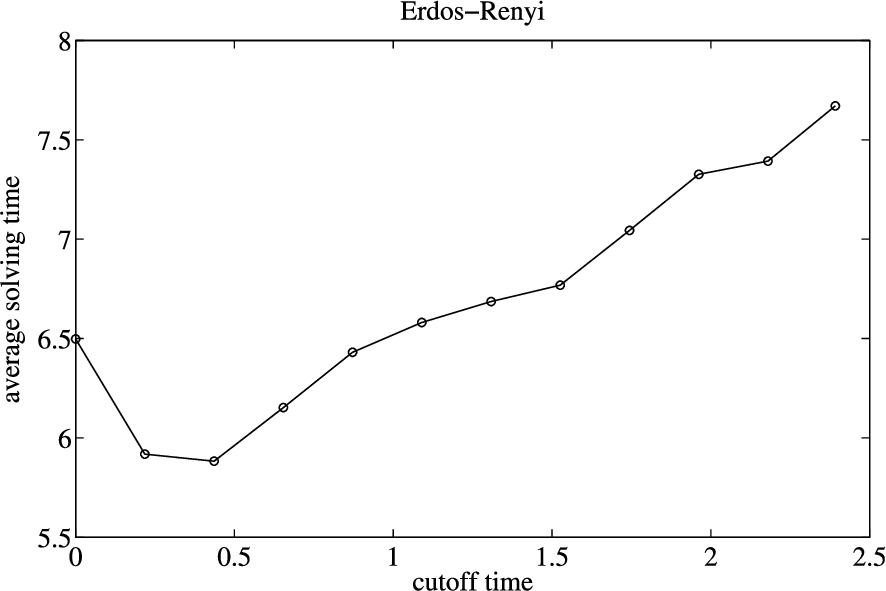
The impact of cutoff time on the performance of CCASATEP for instances with 400 arguments in Erdős–Rényi graph-model.
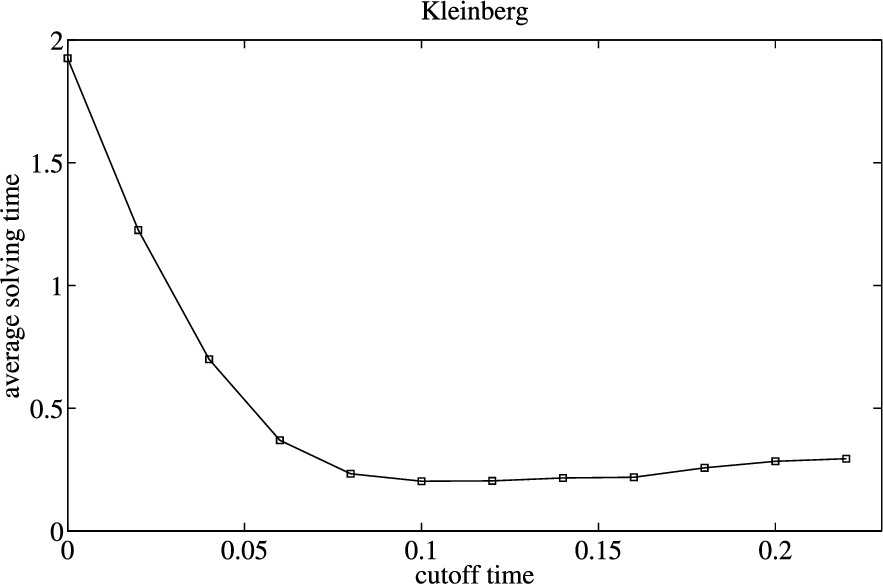
The impact of cutoff time on the performance of CCASATEP for instances with 36 arguments in Kleinberg graph-model.
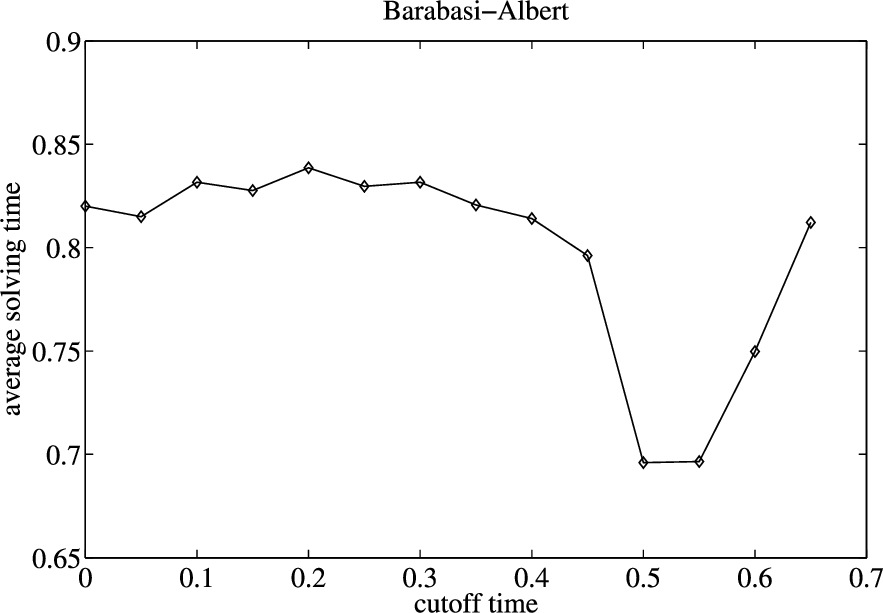
The impact of cutoff time on the performance of CCASATEP for instances with 10000 arguments in Barabasi–Albert graph-model.
In Figs 1–3, when the cutoff time is 0, CCASATEP solves instances without preprocessing of Inc-CCAEP. We can see that, for all kinds of graph-models, the preprocessing of Inc-CCAEP can improve the efficiency of CCASATEP, if the value of cutoff time is appropriate.
For Erdős–Rényi graph-models, the solving time of CCASATEP is least when the value of cutoff time is approximately equal to 0.436 s which is one fifth of average searching time of Inc-CCAEP for this kind of instances. For Kleinberg graph-model, the solving time of CCASATEP is least when the value of cutoff time is approximately equal to 0.15 s which is 1.5 times of average searching time of Inc-CCAEP for this kind of instances. For Barabasi–Albert graph-model, the solving time of CCASATEP is least when the value of cutoff time is approximately equal to 0.55 s which is the maximum searching time of Inc-CCAEP for this kind of instances.
A comparison between CCASATEP with the state of the art
We get all appropriate cutoff time of CCASATEP for different graph-models through experimentally evaluating. Then we test the efficiency of CCASATEP on three graph-models. The results are shown as Table 3, and the solving time of the state of the art is also listed. The best cutoff time of CCASATEP for different graph-models is listed in third column. The data in second column of Table 3 contains the argument number of corresponding instances, and the instance numbers which are listed in brackets. The runtime in Table 3 is average solving time of each solver in each row. The unit of time is second.
From Table 3, we can see that, CCASATEP has the best efficiency for most instances. Overall, CCASATEP is the best algorithms for enumerating preferred extensions of three graph-models. CEGARTIX ranks second, and ArgSemSAT ranks third.
For Erdős–Rényi graph-models, the efficiency of CCASATEP is close to CEGARTIX’s and evidently better than ArgSemSAT’s. Though we set cutoff time for CCASATEP as one third of average searching time of Inc-CCAEP, it still wasted much time for useless searching for some easy instances and some instances with empty preferred extension. For some hard instances and unsolved instances of Inc-CCAEP, the cutoff time is relative small, so CCASATEP calls many times of CDCL approach. So, the solving time of CCASATEP is a little longer than CEGARTIX’s for Erdős–Rényi graph-models. We set cutoff time according to the number of arguments in this paper. There are many parameters, such as the frequency of attacks among arguments, density, treewidth etc., which effect the difficulties of AF instances. Existing benchmarks cannot support us to set cutoff time for Inc-CCAEP according to above parameters, and we will solve this problem in next works. ArgSemSAT exploits encoding method based on labelling, in which every argument has three values. ArgSemSAT integrates two alternative SAT solvers: PrecoSAT and Glucose, which are different from minisat used in CEGARTIX and CCASATEP. The encoding method and SAT solver used in CEGARTIX and CCASATEP are more efficient for instances with Erdős–Rényi graph-models with respect to ArgSemSAT, so ArgSemSAT is weaker than CEGARTIX and CCASATEP.
For Kleinberg graph-model and Barabasi–Albert graph-model, the searching time of Inc-CCAEP is stable, and Inc-CCAEP efficiently solves all instances. So, CCASATEP efficiently solves those instances with our cutoff time. We can see that, CCASATEP always has the best efficiency for instances with above two graph-models.
We further give the computing functions of cutoff time for different graph-models. Because Kleinberg graph-model only has two appropriate kinds of instances which are listed in Table 3, we don’t need to give the computing function of cutoff time for this graph-model. We get the computing functions of cutoff time for Erdős–Rényi and Barabasi–Albert graph-models through curve fitting, and the curve fitting results are shown as Fig. 4 and Fig. 5. In Fig. 4 and Fig. 5, the scatters are the cutoff time listed in Table 3, and the curves are in correspondence with computing functions of cutoff time.
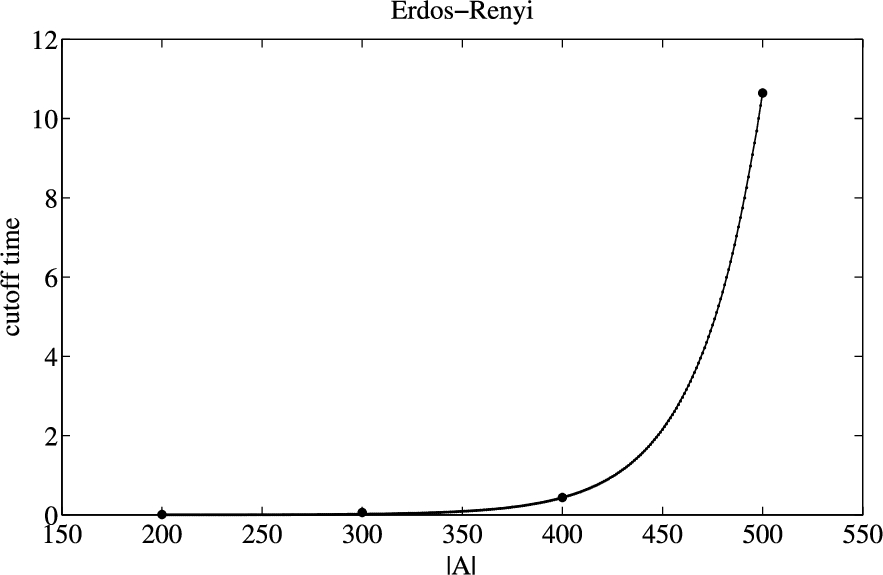
The curve fitting result of cutoff time for Erdős–Rényi.
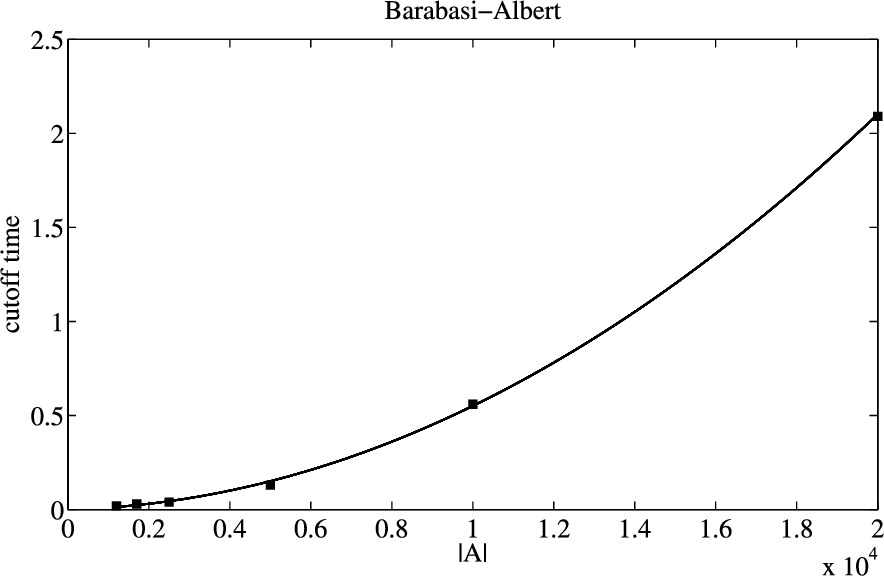
The curve fitting result of cutoff time for Barabasi–Albert graph-models.
The computing function of cutoff time for Erdős–Rényi graph-model is shown as follows:
The computing function of cutoff time for Barabasi–Albert graph-model is shown as follows:
Though we have given the computing functions of cutoff time, and CCASATEP is the best algorithms for enumerating preferred extensions of three graph-models, the cutoff time is not unified, which means that the cutoff time cannot be set if the graph-model of input instances is unknown. That is the weakness of CCASATEP. This weakness also belongs to other similar algorithms for solving SAT or Max-SAT. In SAT Competition and Max-SAT Evaluation, the instances are usually hard for all solvers, and the solving ability (the number of instances solved in fixed time) is the unique standard to compare different solvers. So, both CCLS_to_akmaxsat and CCEHC_to_akmaxsat (which rank 2nd and 3th in many tracks of Max-SAT Evaluation respectively) set the cutoff time of preprocessing as 10 s directly. The existing AF benchmarks are relatively simple for all solvers, and we focus on the comparison of efficiency of different solvers, so we must set appropriate cutoff time in CCASATEP for instances with different graph-models. We believe that more and more hard AF instances will be found, then we can fix cutoff time for CCASATEP (just like CCLS_to_akmaxsat and CCEHC_to_akmaxsat) to compare its solving ability with other solvers’.
In this paper, we innovatively exploit stochastic local search for enumerating preferred extensions in abstract argumentation. Two algorithms: Ite-CCAEP and Inc-CCAEP are proposed based on Swcca for enumerating preferred extensions in abstract argumentation. Ite-CCAEP is realized based on iterative calling of Swcca, so much useful heuristic information calculated in the iterative process is neglected. Inc-CCAEP is an improvement of Ite-CCAEP, which adopts incremental idea to call Swcca. Experimental results show that Inc-CCAEP is better than Ite-CCAEP.
Because Ite-CCAEP and Inc-CCAEP are designed based on stochastic local search, they cannot automatically terminate. Experimental results show that Inc-CCAEP significantly outperform Ite-CCAEP, and is better than the state-of-the-art systems on most AF instances with non-empty preferred extensions.
Learning from the success of CCAnr+glucose and CCLS_to_akmaxsat, we integrate Inc-CCAEP as a preprocessor into complete algorithm, and CCASATEP is proposed. Through setting appropriate cutoff time, CCASATEP outperforms CEGARTIX and ArgSemSAT which are two best systems for enumerating preferred in abstract argumentation.
Lately, ICCMA 2017 has been conducted. In ICCMA 2017, more benchmarks with different graph-models are used. Based on the experiments in this paper, our methods will be also efficient for the benchmarks in ICCMA 2017 after appropriate cutoff time is set.
Next, we will attempt to further improve the ability of Inc-CCAEP. The heuristic methods used in Inc-CCAEP do not consider the special form in the CNF formulae converted by AF instances. So we intend to design better heuristic functions which make Inc-CCAEP be more efficient for abstract argumentation. On the other hand, we intend to design new heuristic functions which consider some hard problems.
Footnotes
Acknowledgements
This work was supported by the National Natural Science Foundation of China under Grant Nos. 61300049, 61502197, 61503044 and 61763003; and the Natural Science Research Foundation of Jilin Province of China under Grant No. 20180101053JC.