
Abstract
The problem of Multi-Agent Path Finding (MAPF) is to find paths for a fixed set of agents from their current locations to some desired locations in such a way that the agents do not collide with each other. This problem has been extensively theoretically studied, frequently using an abstract model, that expects uniform durations of moving primitives and perfect synchronization of agents/robots. In this paper we study the question of how the abstract plans generated by existing MAPF algorithms perform in practice when executed on real robots, namely Ozobots. In particular, we use several abstract models of MAPF, including a robust version and a version that assumes turning of a robot, we translate the abstract plans to sequences of motion primitives executable on Ozobots, and we empirically compare the quality of plan execution (real makespan, the number of collisions).
Introduction
Multi-agent path finding (MAPF) recently attracted a lot of attention of AI research community. It is a hard problem with practical applicability in areas such as warehousing and games. Frequently, an abstract version of the problem is solved, where a graph defines possible locations (vertices) and movements (edges) of agents and agents move synchronously. At any time, no two agents can stay in the same vertex to prevent collisions so the obtained plans are collision free and hence blindly executable. The plan of each agent consists of move (to a neighboring vertex) and wait (in the same vertex) actions. Makespan and sum-of-cost (plan lengths) are two frequently studied objectives.
In this paper, we focus on answering two questions: how to execute abstract plans obtained from existing MAPF algorithms and models on real robots and how the quality of abstract plans is reflected in the quality of executed plans. The goal is to verify if the abstract plans are practically relevant and, if the answer is no (as expected), to provide feedback to improve abstract models to be closer to reality. We use a fleet of Ozobot Evo robots to perform the plans. These robots provide motion primitives, for example, they can turn left/right, follow a line, and recognize line junction, so it is not necessary to solve classical robotics tasks such as localization. Though the robots have proximity sensors, the plans are executed blindly based on the MAPF setting as the plans should already be collision free.
Specifically, we explore the very classical MAPF setting as described above, the k-robust setting [1], where a gap is required between the robots to compensate possible delays during execution, and finally a model that directly encodes turning operations (the classical setting does not assume direction of movement). The abstract plans are then translated to motion primitives, which consist of forward movement, turning left/right, and waiting. We explore different durations of these primitives to see their effect on robot synchronization. As far as we know this is the first study of practical quality of plans obtained from abstract MAPF models. This paper extends the paper [2] by more systematic evaluation of models using a larger set of maps.
The paper is organized as follows. We will first introduce the abstract MAPF problem formally and survey approaches for its solving. Then we will give more details on why it is important to look at the execution of abstract plans on real robots. After that, we will describe all the models used in this study and how they are translated to executable primitives of Ozobot Evo robots. Finally, we will describe our experimental setting and give results of an empirical evaluation.
The MAPF problem
Formally, the MAPF problem is defined by a graph
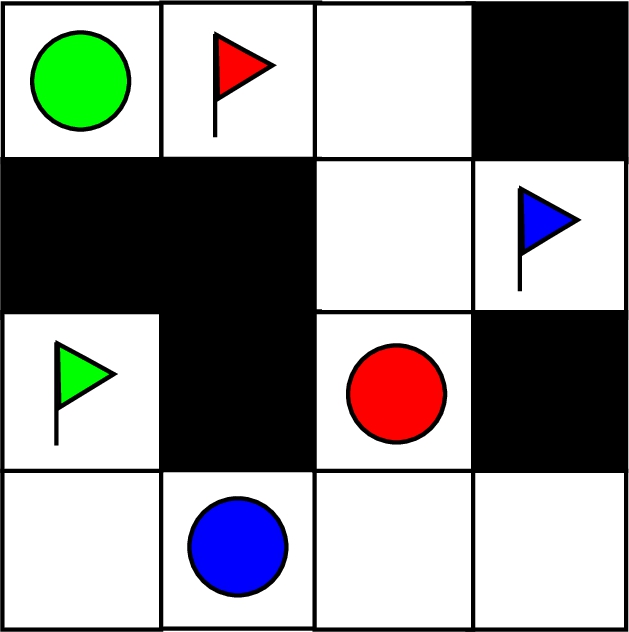
Example of a MAPF instance. Coloured circles represent agents, while flags represent desired goals.
Let
Note that these constraints allow agents to move on a fully occupied cycle in the graph, as long as the cycle consists of at least three vertices. There are other settings in regards to the allowed movements that are used. The first one requires the vertex an agent wants to enter to be empty before entering (sometimes called pebble motion) [9]. The other allows agent to move into an occupied vertex, provided that the vertex will be empty by the time the agent arrives (this part is the same as the conditions for valid solution we are using in this paper), but forbidding movement on closed cycles [17]. All algorithms presented in this paper can be easily modified to work on either of those settings.
We denote
Both makespan [19] and sum of cost (SoC) [16] are well known and studied in the literature. It can be shown that when we require the solution to be optimal for either of those functions, the problem is NP-hard [11,20]. In this paper, we focus only on makespan-optimal plans.
To solve MAPF optimally, one can generally use algorithms from one of the following categories:
Though the plans obtained by different MAPF solvers might be different, the optimal plans are frequently similar and tight (no superfluous steps are used). As solving MAPF is not the topic of this paper (we focus on evaluating the practical relevance of obtained plans), any optimal MAPF solver can be used. We decided for the reduction-based solver implemented in the Picat programming language [4] that uses translation to SAT. This solver has performance comparable to state-of-the-art solvers and has the advantage of easy modification and extension of the core model, for example adding further constraints or using numerical constraints.
The Picat solver (like other reduction-based solvers) follows the planning-as-satisfiability framework [8], where a layered graph is used to encode the plans of a given length. Each layer describes positions of all agents in a given time step. As the plan length is unknown, the number of layers is incrementally increased until a solvable model is obtained. A Boolean variable
Each agent starts and ends in desired location.
Each agent occupies exactly one vertex at each time.
No two agents occupy the same vertex at any time.
If agent a occupies vertex v at time t, then a occupies a neighboring vertex at time
The model consists of

A program in Picat for MAPF.
The abstract plan outputted by MAPF solvers is, as defined, a sequence of locations that the agents visit. However, a physical agent has to translate these locations to a series of actions that the agent can perform. We assume that the agent can turn left and right and move forward. By concatenating these actions, the agent can perform all the required steps from the abstract plan (recall, that we are working with grid worlds). This translates to five possible actions at each time step – (1) wait, (2) move forward, (3, 4) turn left/right and move, and (5) turn back and move. As the mobile robot cannot move backward directly, turning back is implemented as two turns right (or left). For example, an agent with starting location in
Example of graph where an agent has to perform turning actions.
As the abstract steps may have duration different from the physical steps, the abstract plans, which are perfectly synchronized, may desynchronize when being executed, which may further lead to collisions. This is even more probable in dense and optimal plans, where agents often move close to each other.
The intuition says that such desynchronization will indeed happen. In the paper, we will empirically verify this hypothesis and we will explore several abstract models for MAPF and output transformations to robot actions. These models not only try to keep the agents synchronous during the execution of the plan but also to avoid collisions caused by some small unforeseen flaw in the execution. We then compare and evaluate these models on an example grid using real robots. Note that the real robots only blindly follow the computed plan and cannot intervene if, for example, an obstacle is detected.
In this section, we describe several variants of abstract MAPF models and possible transformations of abstract plans to executable sequences of physical actions. Let
Classic model
The first and most straightforward model is a direct translation of the abstract plan to the action sequence. We shall call this a classic model. At the end of each timestep, an agent is facing in a direction. Based on the next location, the agent picks one of the five actions described above and performs it. This means that all move actions consist of possible turning and then going forward. There are no independent turning moves.
The waiting time
Note that this abstract model is the same as the typical definition of MAPF, and the solution (sequence of vertices for each agent) is translated into physical actions. Furthermore, we let the agents perform the actions without any delay (each moving action is performed as fast as possible).
Classic model with padding
One can easily see that the classic model can be prone to desynchronization, as turning adds time over agents that just move forward (different move actions have different durations depending on if turning is needed). Recall Fig. 3 and suppose there is another agent with the same number of steps, but all of the actions are moving forward. This agent will reach its goal
To fix this synchronization issue, we introduce a classic + wait model. The basic idea is that each abstract action takes the same time, which is realized by adding some wait time to “fast” actions as a padding. The longest action is (5), therefore each action now takes
The abstract model for classic and classic + wait models are the same, only the durations of the obtained physical actions differ.
Split actions model
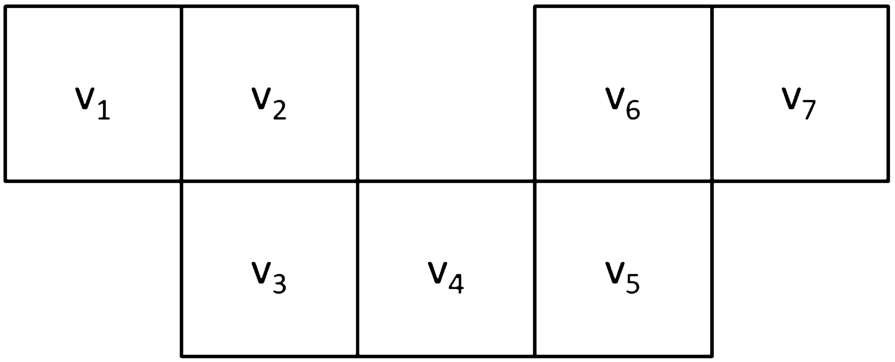
One may desire to represent the executable actions directly in the abstract model. In particular, the need to turn can be represented by an abstract turning action. In the reduction-based solvers, this can be done by splitting each vertex
Example of how two horizontally connected vertices (top) are split into new vertices (bottom) describing possible agent’s orientations. The dotted edges correspond to turning actions.
A synchronization issue is still present in the split model, if the times
This creates a split + wait model, where all physical actions take the same time. Specifically we set all actions to take
Weighted-edges model
Another way to solve the possible synchronization issue in the split model is to use a weighted MAPF [3]. Each edge in the graph is assigned an integer value that denotes its length. The weighted MAPF solver finds a plan that takes these lengths into account. Formally this can cause gaps in the plan of an agent as the agent may not be present in any vertex in the next step because the agent is still moving over an edge. This indeed does not break our definitions and the time is still discrete, only more finely divided. Also, note that it is needed to use a modified solver that can work with edges with non-unit length. Simply splitting the longer edges into several unit edges would allow the agents to turn or wait in the middle of the original edge, which is not allowed.
The lengths of turning edges are assigned a length of
Example of a plan for two agents computed by w-split that do not arrive to some nodes at the same time. The red agent has planned a sequence of actions {move forward, move forward}, while the green agent has planned {turn right, move forward, wait}.
Overview of all of the defined models
Note that for the previous models (classic + wait, split + wait, and their robust variants), synchronization means that all agents leave and enter nodes in the original graph at the same time. This is not necessarily true for the w-split model. Let us assume, for example, that there are agents with
While it was possible and useful in the two previous models to pad actions with waiting time so that they take the same time, it is not meaningful to do so with the w-split model. In this case there are still actions that take a different amount of time, however, these different times are incorporated in the theoretical model itself. For this reason, there is no need to create a new model with padding actions for w-split model.
Robustness
Some of the previously described models and translation to physical actions (theoretically) guarantee a perfect synchronization of the physical agents when performing the plan. However, as the agents are real robots moving in the imperfect real world, there still might be some desynchronization introduced during the execution. This desynchronization is not caused by the plan itself, but rather by some attributes of the environment. This may include imprecise speed of one of the robots, a wheel slipping, a roughness of the terrain, desynchronized start, and many more.
To minimize these effects, we may require the abstract plan to keep some space between the moving agents. We will use the notation from k-robust MAPF [1]. The k-robust plan is a valid MAPF plan that in addition requires for each vertex of the graph to be unoccupied for at least k time steps before another agent can enter it. Note that this is a change to the abstract model itself and needs to be performed by the solver, and it is not added during the translation of the abstract plan to the real actions. This enhancement can be added to all of the previously described models and can be combined with the padding translation to real actions. All that is left to do is to choose a proper k for each model.
For the classic type models, we choose k to be 1. We presume that this is a good balance between keeping the agents from colliding with each other while not prolonging the plan too much. For the split type models, however, it is not enough to use 1-robustness, as the plan is split into more time steps. Instead, we use
Overview of models
In this section, we defined several models that can be seen in Table 1 for a quick overview. We defined three different approaches how to encode the MAPF problem (Classic, Split, Weighted-Edges) with a possible enhancement to the desired plan (Robustness). This creates six abstract models. The abstract models can then be translated to the real actions performed by the physical agents (these actions depend on the model). The translation can then be done by one of two ways – performing the action as fast as possible one after another with no padding, and adding padding to actions that take a shorter amount of time, so all actions take the same time. Note that for the w-split model this padding is equivalent with no padding, therefore we omit these two models. Together we defined ten models that can be experimentally tested.
Experiments
The proposed models for MAPF were empirically evaluated on real robots and in this chapter we will present the obtained results. We shall first give some details on robots, that we used, on the problem instances, and on a system, that was used to create these instances.
Ozobots
The robots used were Ozobot Evo from the company Evollve [10]. These are small robots (about 3 cm in diameter) shown in Fig. 6. We have chosen them because their built-in actions are close to actions needed in the MAPF problems so there is no need to do low-level robotic programming. The robots are programmable through a programming language Ozoblockly [7], which is primarily meant as a teaching tool for children. This can be seen in the simplicity of the drag-and-drop design of the language, see Fig. 7. The program is uploaded to the robot and then the robot executes it. Most importantly, the robots have sensors underneath that allow the robot to follow a line and to detect intersection. An intersection is defined as at least two lines crossing each other. The robots also have forward and backward facing proximity sensors allowing them to detect obstacles. We used them to synchronize the start of robots (see further), but we did not exploit sensors further during plan execution. In addition, the robots have LED diodes and speakers that act as the robots output. We use them to indicate some states of the robot such as a finished plan. The moving speed and turning speed can be adjusted up to a speed limit of the robot.

Ozobot Evo from Evollve used for the experiments. Picture is taken from [10].
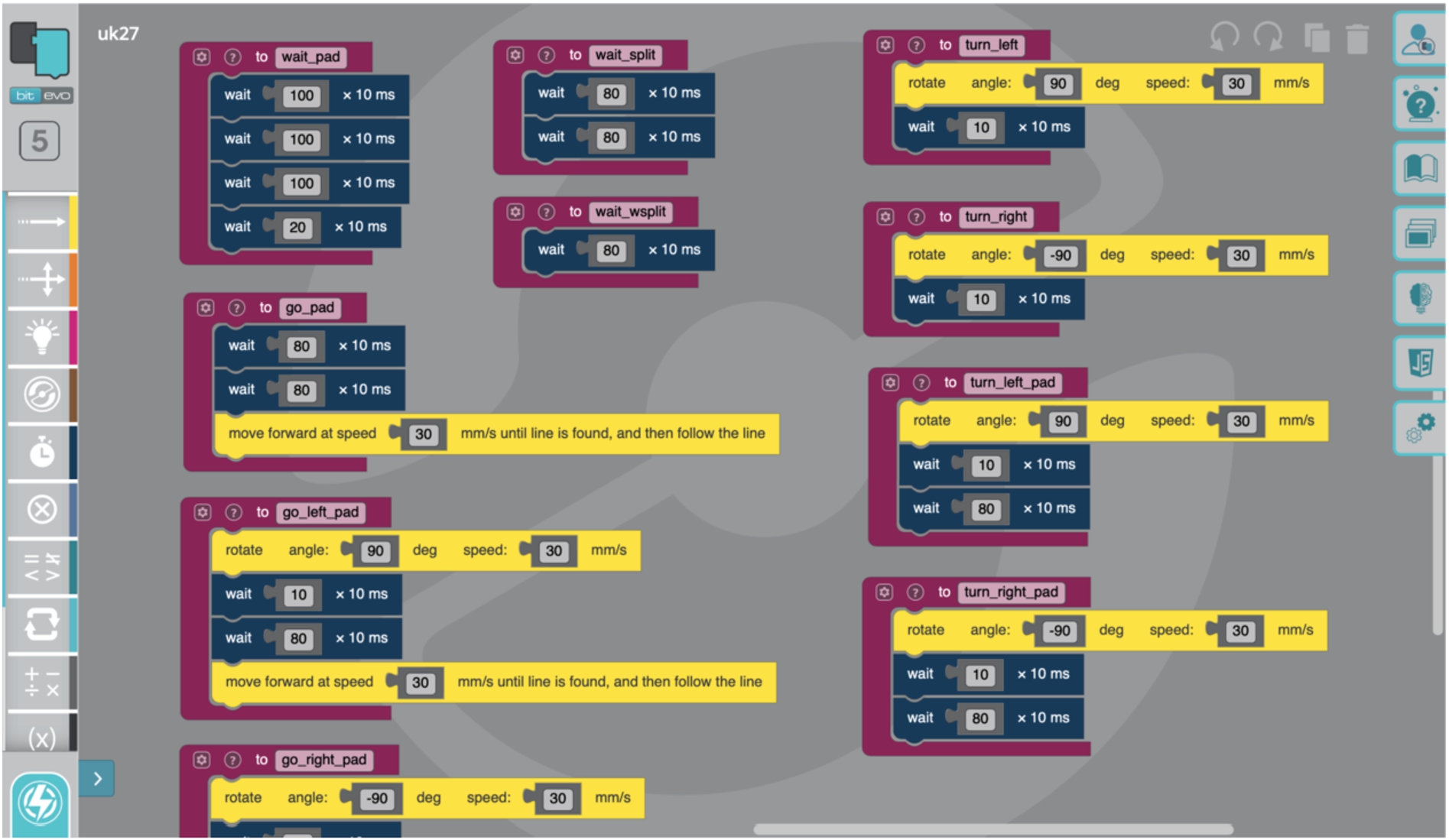
Example program coded in Ozoblockly language. The displayed procedures encode actions used by Ozobots for execution of MAPF plans.
There are some drawbacks in the simplicity of the robots. The main one is that there is currently no communication between multiple robots and therefore starting an instance of MAPF for all of the present robots at the same time is difficult. To solve this problem, we used the proximity sensors and forbid the agents to start performing the computed plan if an obstacle is present in front of them. An obstacle was placed in front of all of the agents and once all of them were ready to start executing the plan, all of the obstacles were removed. This ensured that the start time was identical and any desynchronization at the end of the plan was caused during the execution and not at the start.

User interface of a system that lets user define and solve MAPF instances. The picture shows instance on a 4 by 4 grid map with obstacles and two agents (red and blue). The solution shown was computed by the model classic + wait.
To simplify the process of creating and solving MAPF instances, we designed a software MAPF Scenario that lets its user define grid maps, place agents and solve this instance with any of the models described above. We will describe some of the features of the system now. The user interface can be seen in Fig. 8.
First, a user needs to define a grid map over which the instance will be built or to load a previously created map. The user can define the dimensions of the grid, then obstacles can be introduced into the map by removing some of the vertices and edges of the graph. This map can be also printed on a paper, in which case, the user will be asked to define the length of the edges. A set of agents can be created on this map. For each agent, the user will be asked to specify its color, starting position, and goal position. The map and all agents specify the MAPF instance, which is displayed in the middle part of the user interface.
To solve the defined instance, the user can choose from ten different solvers, which correspond to the defined models in the previous section. Once a solution is found, the actions for each agent are displayed at the bottom part of the user interface. Note that each action has a defined duration it takes to perform it. This let us observe the total time of the plan on the timeline and the synchronization of the plan.
For even better visualization, it is possible to simulate the found plan on the displayed map. In such a case, circles representing the agents will appear and move in the map based on the actions shown in the bottom part.
Lastly, the user can choose to export the found plan to the Ozoblockly language that can be uploaded to the Ozobot robots. Running the plan on real robots rather than in simulation can show some further flaws in the plan caused by the dimensions of the robots and imperfections of the real world.
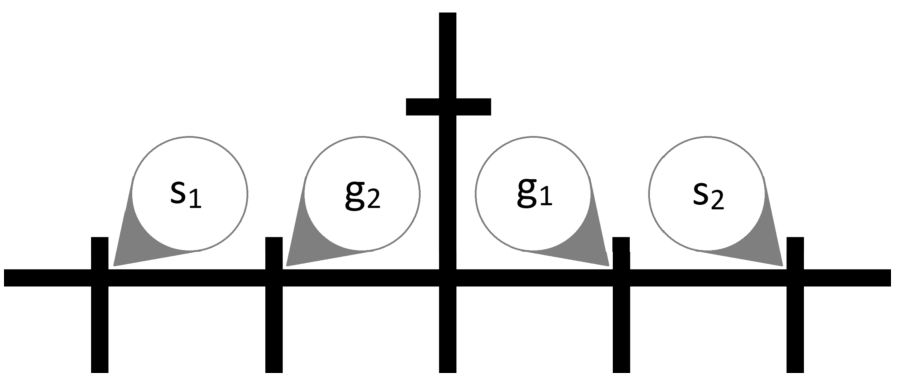
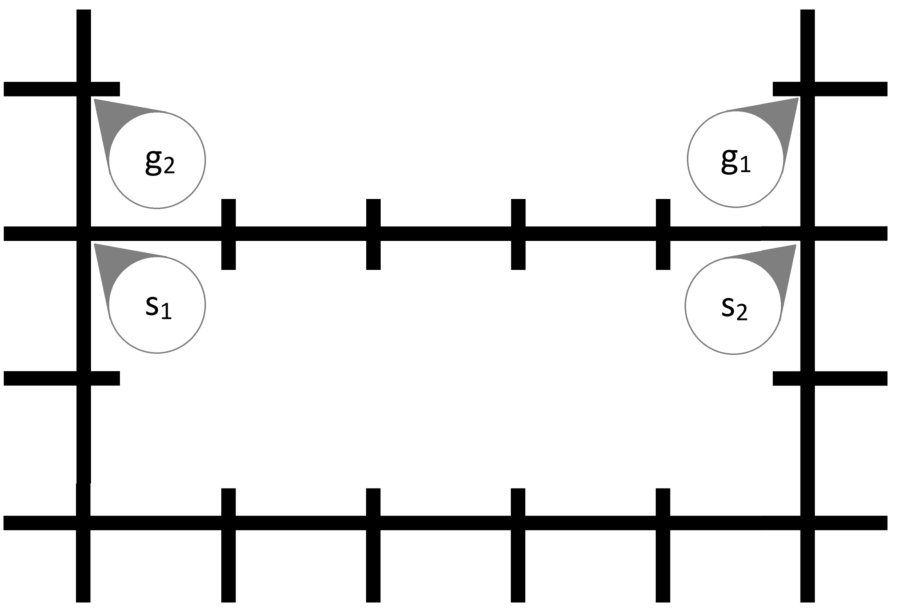
Using the MAPF system described above, several instances were crafted to test the defined models. These instances are shown in Figs 9–13.
As opposed to the usual representation, where agents reside in the cells in between lines, here the agents follow the line and the vertex is represented as the crossing of two lines. These maps were printed on a paper in two scales. In the first scale, each edge is 5 cm long and the line is 5 mm thick as per Ozobots recommended specification. The edge length was chosen to allow two robots to safely stay in neighboring vertices and to observe even minor desynchronization due to turning. For the second scale, we doubled the length of the edges to 10 cm while keeping the thickness at 5 mm. This second scale was chosen to observe the behavior when robots are not as close to each other and thus allowing for bigger slack in the synchronization. We shall further refer to these sets of maps as smaller and larger maps.
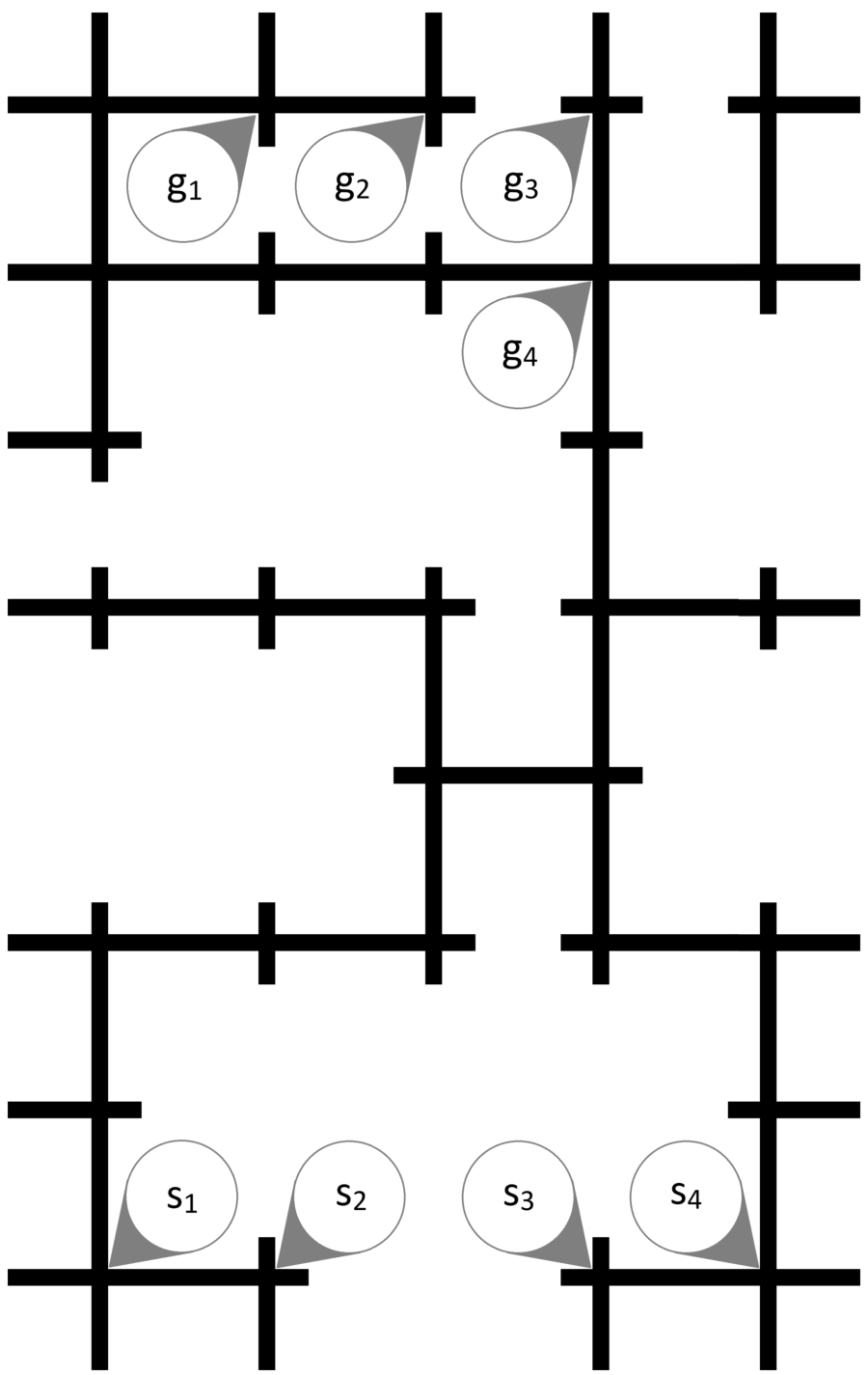
Instance map for Ozobots called Bottleneck.
Instance map for Ozobots called Switch.
Instance map for Ozobots called Basket.
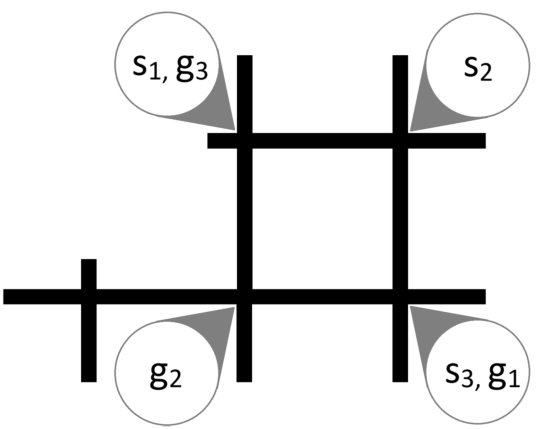
Instance map for Ozobots called Riddle.
In the Figs 9–13, the initial (
The speed of the robots was set in such a way that moving along 5 cm of a line takes 1600 ms (3200 ms for 10 cm lane) and turning takes 800 ms. This means that
Each instance was designed to test some property of the theoretical models. Instance Bottleneck (Fig. 9) is the largest map, that forces four agents to pass through a narrow pass at roughly the same time, thus creating a bottleneck, where agents need to wait for others.
Instance Switch (Fig. 10) requires two agents to switch places. This map is very small and any desynchronization and close proximity can cause the agents to hit each other.
In instance Basket (Fig. 11) the two agents do not interact with each other, however, each agent has to travel a different distance. One will use the bottom path, while the other will use the top path.
In instance Riddle (Fig. 12), three agents need to move along a cycle. This is again a very small map with big interaction between the agents.
Lastly, instance Spiral (Fig. 13) requires three agents to follow the spiral structure of the map. This requires the agents to turn many times, however, each agent turns a different number of times.
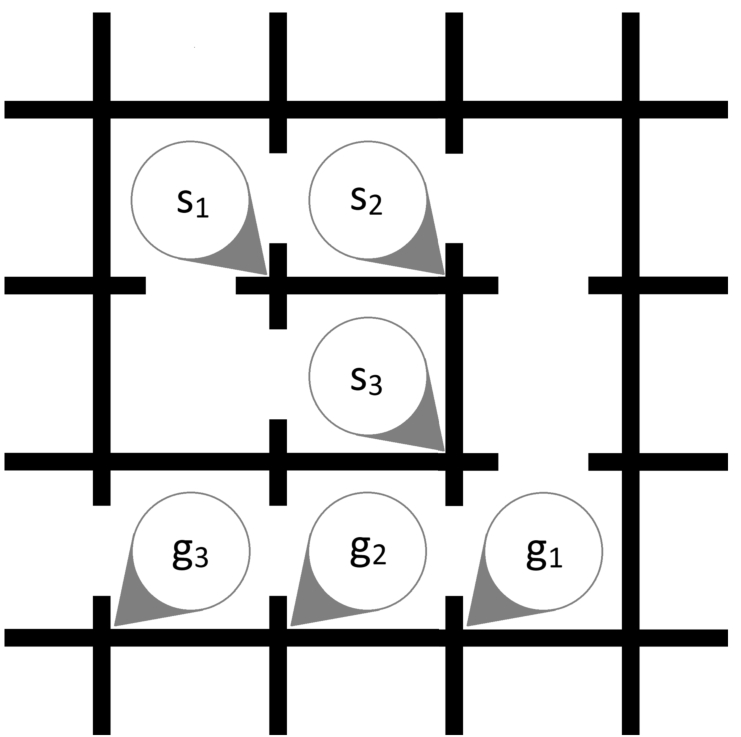
Instance map for Ozobots called Spiral.
We generated plans using each MAPF model for all of the problem instances described above and then we executed the plans five times in total for each model. Several properties were measured with results shown in Tables 2–6. The tables show results for both smaller maps (left columns) and larger maps (right columns).
Computed makespan is the makespan of the plan returned by the MAPF solver. It is measured by the (weighted) number of abstract actions. Note that the split models have larger makespan than the rest because the split models use a finer resolution of actions, namely turning actions are included in the makespan calculation. This is even more noticeable with w-split and w-split + robustness, where the moving-forward action has a duration (weight) of two for smaller maps, respectively four for larger maps. Also note that for all models with the exception to w-split and w-split + robustness, the makespan for smaller and larger maps are identical. This is because there are no changes to the theoretical model if longer edges are used. Only the translation of the robot actions is different. On the other hand, w-split and w-split + robustness compute the solution using the length of the edges.
The number of failed runs is also shown. A model that had most often problems finishing the run is the classic model while the rest (with the exception of split and split + robustness in Bottleneck shown in Table 2) managed to finish all of the runs. A run fails if there is a collision that throws any of the robots off the track so the plan cannot be finished. One such collision can be seen in Fig. 14. The average number of collisions per run shows how many collisions that did not ruin the plan occurred. These collisions can range from small one, where the robots only touched each other (such as in Fig. 15) and did not affect the execution of the plan, to big collisions, where the agent was slightly delayed in its individual plan, but still managed to finish the plan. In the case that the execution fails, we present the number of collisions occurring before the major collision that stopped the plan.
Measured performance of Ozobots on map Bottleneck (Figure 9) using each proposed model. The left columns are for 5 cm edges, the right columns are for 10 cm edges
Measured performance of Ozobots on map Bottleneck (Figure 9) using each proposed model. The left columns are for 5 cm edges, the right columns are for 10 cm edges
Measured performance of Ozobots on map Switch (Figure 10) using each proposed model. The left columns are for 5 cm edges, the right columns are for 10 cm edges
Measured performance of Ozobots on map Basket (Figure 11) using each proposed model. The left columns are for 5 cm edges, the right columns are for 10 cm edges
Measured performance of Ozobots on map Riddle (Figure 12) using each proposed model. The left columns are for 5 cm edges, the right columns are for 10 cm edges
Measured performance of Ozobots on map Spiral (Figure 13) using each proposed model. The left columns are for 5 cm edges, the right columns are for 10 cm edges
Since we are using the makespan objective function, all of the plans can have their length equal to the longest plan without worsening the objective function. Even if the agents reached their destination sooner, their plan was prolonged by waiting actions to match the length of the longest plan. To visually observe this, we used the LEDs on the robots. The LEDs were turned on during the whole plan (including wait actions) and turned off once the plan was finished. This helped us to measure the overall time of the plan execution as the time from start to the last robot turning LEDs off. For the models that did not finish any of the five runs, there is no total time to show.
Summary performance of Ozobots using each proposed model (quality indexes, larger value is better). The left columns are for 5 cm edges, the right columns are for 10 cm edges
Each individual agent was let to execute the plan without interference with other agents to measure the difference between the fastest and slowest agent as Max Δ time. If the agents are perfectly synchronized then this Δ should be zero. All of the times are rounded to one-tenths of a second because the measurements were conducted by hand.
From the number of collisions, the total times, and the Max Δ times, we can conclude some properties of the models. Indeed, models that have added + wait and w-split models keep the agents synchronous, while the other models do not (there is a gap between finishing the plans by different agents). From all models, the classic + wait + robustness model is the slowest one to perform the plan. This is expected as this model uses the longest durations of actions and furthermore, the robustness may add some extra steps to perform. We can see that by just splitting the actions in split models, we save some time even when we use the padding in models split + wait and split + wait + robustness.
Further, we can see that even if the agents are synchronous, some collisions may appear, since the agents have a nonzero diameter and if they are moving close to each other. This issue is solved by making a k-robust plan, however, if the agents are not synchronous, the agents can still collide.

Example of collision that caused the plan to fail on instance Riddle solved by the model Classic. After the collision, the middle robot was unable to follow the line anymore.

Example of collision that did not cause the plan to fail on instance Riddle solved by the model Classic + wait.
Also note that on the larger maps, where the edges are longer and thus the agents are not moving close to each other, there are fewer collisions. This type of maps makes the robustness less useful, since even the non-robust plans do not usually collide. On the other hand, adding the padding in + wait models is counterproductive, because it prolongs the plans too much.
Desynchronization is still an issue even in the larger maps, even though it is not as much visible on any map with the exception of Bottleneck shown in Table 2. On the other maps, the plans are too short for the desynchronization to cause any collision, however, with longer plan we can see that the difference in individual plan lengths is large for split and split + robustness models.
Recall that adding + wait is just a change in translation of the plan to the actions, while adding + robustness requires to find a different plan. This can create a phenomenon seen in the results for instance Basket shown in Table 4. Here the plans for classic and split have the same makespan as classic + robustness and split + robustness respectively, while the Max Δ times are different. This is caused by the solver finding a different plan with the same length for each model. By a chance, the robustness models found a plan that was synchronous (each agent performed the same amount of turning and moving actions), while the classic and split models found a plan where the agents performed different actions.
To compare various models across different maps, we use a quality index (a similar index is used, for example, in International Planning Competitions). This index equals one for the best value of a given parameter and progressively decreases to zero for worse values. Formally, let
In general, we can see that simply translating the sequence of nodes to actions of robots is not enough to create a good executable plan. This can be solved by padding all of the movements with some waiting time so that the agents remain synchronous. However, this costs extra time during the execution. Splitting the actions to turning actions and moving actions provides us with finer granularity and thus a faster plan. This plan is still not synchronous, so padding is required to ensure the agents stay synchronous. The overall best solution is to take the action lengths into account while creating the plan. This allows the agents to stay synchronous without any extra waiting time, thus having the fastest execution time. Adding robustness furthermore betters the plan if the agents are moving close to each other. Table 7 confirms that robust plans are without collisions, but their execution takes more time.
In this paper, we studied the behavior of MAPF plans when executed on real robots. We defined several models that either take the classical plan and translate it into a sequence of robot actions or create a plan that already consists of the robot actions. This mainly included the need for turning of the robot. We discussed ways to keep the agents synchronized during the execution of the plan. This leads to either force the agents to wait for the other agents or to take the various lengths of the physical actions to account during the planning process.
The empirical evaluation confirmed the initial hypothesis that the classic model may have problems when executed on real robots. A bit surprising result was how many times it was not possible to complete the plan for the classic model. A straightforward translation to executable actions with identical duration resolved the issue of desynchronization but for the cost of a significant increase of the real makespan. The closer the model was to reality, i.e., assuming turning actions and weighted arcs to describe durations of actions, the better real makespan was obtained, which is somehow expected as the makespan of the abstract model, that is being optimized, is closer to the actual makespan. When we prolonged the edges to 10 cm, so the agents were more distant, then the classic model achieved surprisingly good results in terms of real makespan. However, this model still has the worst desynchronization, so when the plans become longer, one may expect an increased number of collisions there. Robustness generally helps to decrease the number of collisions, but one can observe that robustness itself does not prevent desynchronization.
The results provide some guidelines which model to select based on the environment. If the duration of turning is a significant portion of the duration of moving then the classic model is not applicable. The split model is particularly useful if these durations are close to each other, but the split model can be actually worse than the classic model if turning time is much smaller than moving time. The models with weighted arcs describing actual durations of actions provide the best actual makespan during executions, as expected, but the classic model is comparable with them if turning time is much smaller than moving time. In some sense, it justifies that the classic model is a viable abstract model. Still, one must be careful about synchronization issues for the classic model.
In the paper, we applied the MAPF plans on real robots, but we still used some assumptions such as that the robot moves with a constant speed. Exploring other ways of translating the abstract model to an executable model, for example, assuming kinematic constraints such as acceleration and deceleration, might be an interesting next step to improve further the quality of executable plans. Finally, the executed plans were static in the sense that robots just blindly executed them. By using information from sensors, the robot may prevent collisions by accommodating the plan to the current situation. For example, the robot may slow down (or even stop) to prevent collision with an unexpected obstacle and then the robot may speed up to catch up with the plan. For such dynamic execution of plans, it would be useful to have some flexibility in the plan that the control procedure can exploit.
Footnotes
Acknowledgements
This research is supported by the Czech Science Foundation under the project 19-02183S, by SVV project number 260 453 and by the Charles University Grant Agency under the project 90119.