
Abstract
Multiple instance learning is a modification in supervised learning that handles the classification of collection instances, which called bags. Each bag contains a number of instances whose features are extracted. In multiple instance learning, the standard assumption is that a positive bag contains at least one positive instance, whereas a negative bag is only comprised of negative instances. The complexity of multiple instance learning relies heavily on the number of instances in the training datasets. Since we are usually confronted with a large instance space, it is important to design efficient instance selection techniques to speed up the training process, without compromising the performance. Firstly, a multiple instance learning model of support vector machine based on grey relational analysis is proposed in this paper. The data size can be reduced, and the importance of instances in the bag can be preliminarily judged. Secondly, this paper introduces an algorithm with the bag-representative selector that trains the support vector machine based on bag-level information. Finally, this paper shows how to generalize the algorithm for binary multiple instance learning to multiple class tasks. The experimental study evaluates and compares the performance of our method against 8 state-of-the-art multiple instance methods over 10 datasets, and then demonstrates that the proposed approach is competitive with the state-of-art multiple instance learning methods.
Keywords
Introduction
Since the mid-to-late 1990s, researchers have proposed the concept of multiple instance learning (MIL) in the study of drug activity prediction. Because of the applicability to many real-world problems recently, MIL, which is a modification of supervised learning, has been gaining interest, such as drug activity prediction [11,26], stock market prediction [25], data mining applications [28], image retrieval [37,40], natural scene classification [27], text categorization [1], and image categorization [8]. MIL provides a framework for the classification of collections of instances called bags rather than individual instances. In a typical binary MIL problem, the training data is presented in the form of bags and their associated binary label. Introduced by Dietterich et al. in the context of drug activity prediction, the standard assumption in MIL is that one positive bag contains at least one positive instance, whereas a negative bag is only comprised of negative instances, although the size of bags may vary [11]. The uniqueness of not requiring labels for individual instances makes MIL very suitable for applications without label information for individual instances [36]. In many cases, however, the negative instances may play a leading role in positive bag. As a result, the main reason for the performance degradation of classifiers is that the traditional supervised classification methods are directly used to deal with MIL problems. Hence, some specialized methods should be devised to use the structure information of MIL. Many methods have been proposed to solve the MIL problems, which can be separated into the following three categories:
Instance-based modeling, which finds the most positive and least negative instances from bags to derive MIL models;
Bag-based modeling, which directly builds classification models at the bag level;
Hybrid approaches, which use both instances and bags to confine the learning space to build classification models.
One of the major complexities associated with MIL is the ambiguity of the relationship between the bag label and the instances within this bag [38]. Since the genuine positive instance inside each positive bag is unknown, the main challenge of MIL is to leverage the bag label and constraints to derive an accurate classification model. Many previous algorithms assigned the label of a bag directly to the containing instances [11,25,28], that is, the instances’ labels in the positive bag are all positive, which simplifies the training process of the classifier. However, the irrationality of this approach also makes the prediction results of the label for unknown bag deviate from the real label to some extent. Selecting a method that is robust for MIL can be difficult when little is known about the nature of the data, especially considering the unknown distribution of the instances within bags [6,24].
Therefore, the challenging problem for MIL still is how to efficiently and effectively prune the unrelated instances and preserve the valid instances. In this paper, we propose the grey-based multiple instance learning with multiple bag-representative (MIMBR) method. The results from experiments indicate that the proposed algorithm is efficient in training and has the following characteristics:
Broad adaptability: It provides a learning framework for transforming multiple instance (MI) problems into supervised learning problems. In our experimental study on benchmark datasets, it shows highly competitive classification accuracy.
Low complexity: It uses gray relational analysis to integrate similar instances in each bag, greatly reducing the number of data to be calculated in the experiment. Although the computational complexity, selecting at least one representative instance for each bag, is slightly higher than previous method, the classification accuracy is effectively improved. This is mainly due to the use of chosen subset of instances for classifier training rather than the use of all instances. In order to ensure convergence, the classifier is then optimized by intertwining instance selection with classifier learning in an alternating optimization framework.
Prediction capability: In some MI problems, the classification of instances is at least as important as the classification of bags. The proposed approach supports predicting instance labels. Moreover, it also has a key feature of being able to identify instances that have significant impact on modeling.
The remainder of the paper is organized as follows: Section 2 reviews the relevant MIL literature and examines the limitations of the existing approaches. In Section 3, the proposed algorithm MIMBR is described in detail, and then extend it to multi-class settings. The efficiency and effectiveness of proposed approach is illustrated in Section 4. The conclusions of the paper and further work on this topic are discussed in Section 5.
MIL approaches
One of the earliest algorithms for learning from MI problems was developed by Dietterich et al. for drug activity prediction [11]. Their algorithms, the axis-parallel rectangle methods, search for appropriate axis-parallel graphs by shrinking or expanding their attribute values, making the graph contain the maximum number of positive bags and the minimum number of negative bags [3,4,23]. And then Readt has demonstrated the connection between MIL and inductive logic programming [10].
After the work of Dietterich et al., many researchers began to design practical MIL algorithms. In 1998, Maron and Lozano-Peréz proposed the diversity density (DD) algorithm, called MIDD [26]. It has great impact on later research, and a lot of work is directly based on this algorithm. For example, Zhang and Goldman put forward EM-DD algorithm by combining DD algorithm with EM algorithm in 2002 [39].
In 2000, Wang and Zucker extended the k nearest neighbor (KNN) algorithm to handle MIL problems [35]. Instead of the usual Euclidean distance, they used the modified Hausdorff distance, which calculates the distance between different bags effectively. On this basis, Bayesian-KNN and Citation-KNN, were proposed. In addition, these extended KNN algorithms need to save the entire training set to calculate the distance when testing, so although it hardly needs training time, its storage and test time is very expensive. Some methods in literature [30,34] converted multiple instance (MI) datasets into traditional instance-level datasets, such as Simple-MI [12], and Bunescu and Mooney mapped each bag to a maximum-minimum vector [5]. The downside of these methods is that they assume instances within a positive bag are all labeled as positive, which may not be the case.
Zhou et al. proposed miGraph, which uses graph cores to construct implicit graphs by deriving affinity matrices [41]. It assumed that these instances are not independent and equally distributed due to the nature of MI data, and the relations among instances may convey important information.
Chen et al. raised MILES which mapped each bag into a feature space defined by instances in all the training bags via an instance similarity measure [7]. On this basis, Fu et al. proposed MILIS, a novel MIL algorithm based on adaptive instance selection which by intertwining the steps of instance selection and classifier learning in an iterative manner [13].
Yang et al. proposed an instance-based support vector machine (SVM), which uses an asymmetric loss function [37]. A false negative instance in positive bag may not cause an error on the bag label, but a false positive instance in negative bag may generate a classification error. Andrews et al. represented MIL as a mixed integer quadratic program. Integer variables are selector variables which selecting a positive instance from each positive bag [2]. The main idea of this method, which is called MI-SVM, transforms the MI data into single-instance data. Andrews et al. also proposed another mixed-integer instance-level approach, named mi-SVM, which tries to identify the instances within positive bags that are negative and utilize them in the construction of the negative margin [1]. The main disadvantage of this approaches is that they create an imbalanced class problem that favors the negative class, resulting in a biased classifier.
Veronika et al. proposed to represent each bag by a vector of its dissimilarities to other bags in the training set, and treat these dissimilarities as a feature representation, called MInD (Multiple Instance Dissimilarity) [33]. Melki et al. proposed a novel SVM multi-instance formulation and presented an algorithm with a bag-representative selector that trains the SVM based on bag-level information, named MIRSVM [28]. The main disadvantage of this approach stems from selecting only unique instance for each bag as representative instances, and each instance is treated as a potential target concept.
Grey-based multiple instance learning with multiple bag-representative
Notation
To describe MIMBR, we give the formal description of MIL problem. Given a training set

The single instance learning.
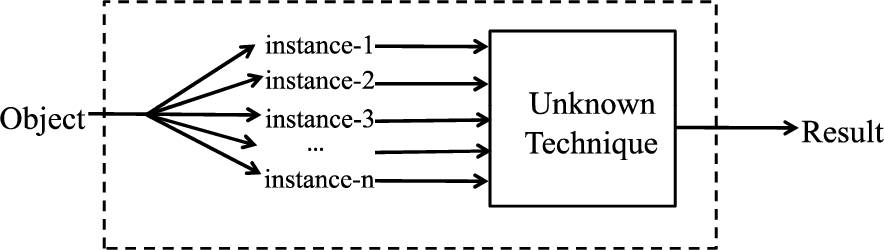
The multiple instance learning.
Each bag
Grey system theory has been proposed for uncertain systems with partially known and partially unknown information [21], and can extract valuable information from partial information. In this paper, we used grey relational analysis (GRA) for measuring the similarity of two random instances in each bag, which involves the grey relational coefficient (GRC) and the grey relational grade (GRG). GRA offers some advantages rather than other measure metrics, such as Minkowski distance. At first, the idea of GRA is clear, which can reduce the loss caused by information asymmetry to a great extent. Besides, GRA gives a normalized measuring function due to its normality, i.e., measuring the similarities or differences among instances for analyzing the relational structure. Furthermore, GRA gives whole relational orders due to its wholeness over the entire relational space [21].

This figure represents a summary of the steps performed by GRA.
As shown in the Fig. 3, if we assume the reference sequence is
In this paper, we use min−max normalization, which is expressed as follows:
As mentioned above, the GRA based on MIL can be employed to measure the similarity between two instances in a bag. Then, instances whose similarity is greater than a certain threshold are integrated, in other words, the “center” of these instances is taken as the representative instance of these instances.
Most classical learning techniques require knowledge of the data distribution to build accurate models, which is a serious restriction because, in most cases, the distribution is unknown [17]. SVM was first proposed by Corinna Cortes and Vapnik in 1995, and quickly applied in various fields [9,21,22]. It represents learning techniques that have been introduced under the structural risk minimization framework and Vapnik–Chervonenkis theory [15,32]. Except for linear classification, SVM can used so-called kernel tricks which implicitly map the input vector into the high-dimensional feature space to perform nonlinear classification effectively. Obviously, the key to SVM is the kernel function. Vector sets in low-dimensional spaces are often difficult to partition, and the solution is map them to higher-dimensional spaces.
But the difficulty with this approach is the increase in computational complexity, and the kernel neatly solves this problem. In other words, as long as the proper kernel function is selected, the classification function of the high-dimensional space can be obtained. After determining the kernel function, two parameters, namely the relaxation coefficient and the penalty coefficient, are introduced to correct the errors in the known data. In this paper, generalization and linear separability can be enhanced by mapping the original input space to a higher dimensional dot-product space by using a kernel function shown in Eq. (4):
MIMBR
With the above ingredients, we can now describe the MIMBR framework. We first focus on the binary classification case, where the label value
Like MIRSVM, our method aims to find bag labels and the representative instances for each bag. Note that MIRSVM only selects unique instances from each bag as representative instances, and each instance is treated as a potential target concept. However, if an instance is labeled as positive, the bag in which the instance reside is labeled as positive, that is, there may be more than one instance are marked positive in a positive bag. In this paper, we have taken into account this point which was ignored by MIRSVM. Moreover, to achieve comparable performance to MIRSVM with almost the same computational complexity, explicit instance pruning and selection is necessary. Therefore, an effective approach is needed to reduce the complexity of processes that are not clustered or quantified. This is an important observation because clustering and quantization do not take bag-level structure or discriminant information into account and may discard the small clusters in the feature space. Hence, we adopt a novel data preprocessing method, which had already been mentioned, and at the same time, the importance of instance pruning for efficient MIL is highlighted. Next, the problems of feature learning and instance updating are addressed. Finally, we summarize the algorithm and provide some theoretical study on its property and computational complexity.
In some MI problems, classification of instances is at least as important as the classification of bags. For example, an object detection algorithm needs not only to identify whether the image contains a certain object, but also to locate the object (or part of the object) from the image if it contains the object [34]. Under the MI formulation, this requires the classification of the bags as well as the instances in a bag that correspond to the object. The classifier
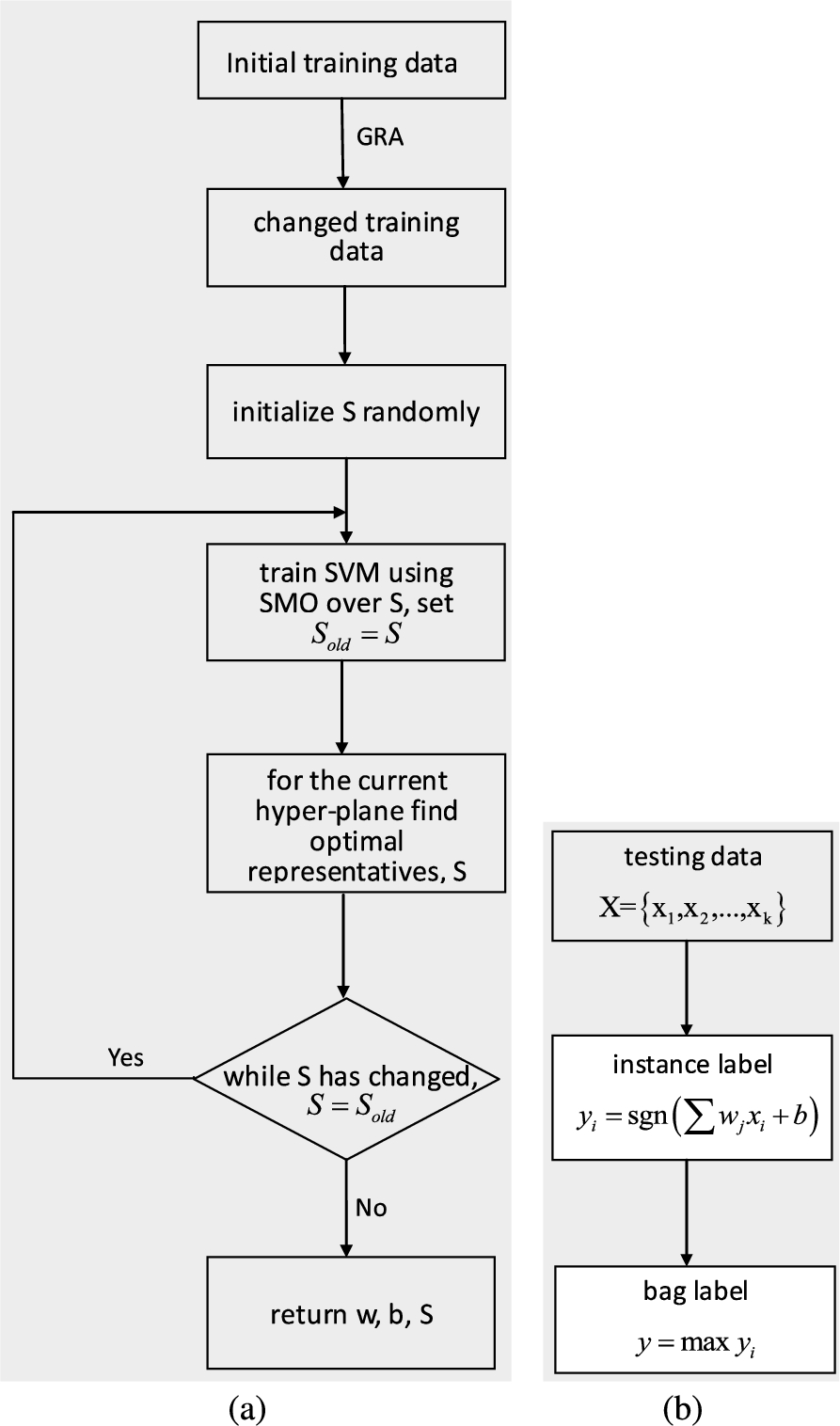
This figure represents a summary of the steps performed by MIMBR. Where (a) is the training process of the algorithm, and the representatives are first randomly initialized, then continuously updated according to the current hyper-plane. And (b) is the testing process of the algorithm, which is given a label for the unknown bag.
MIMBR is based on the idea of selecting representative instances from both positive and negative bags which are used to find an unbiased, optimal separating hyper-plane. Iteratively select at least one representative from each bag and form a new hyper-plane based on those representatives until they converge. According to the standard MI hypothesis, only one instance in a bag is required to be positive for the bag to adopt a positive label. Since the distribution of instances in positive bags is unknown, MIMBR gives priority to negative bags in the training process, because their distribution is known, that is, all instances have negative labels. Figure 4 is a summary of the steps performed by MIMBR.
The previous method of selecting representative instances in a bag was to index the maximum output value within each bag using the following rules:
So this paper fully makes up for the defect, the idea is to divide the training bags into positive and negative parts. For positive bags, all output values are sorted in descending order and then selected from largest to smallest, its termination condition is that at least one instance is selected from each bag as the representative instance. Similarly, for negative bags, all output values are first sorted in ascending order and then selected from smallest to largest until each bag can contain at least one instance as the representative instance. The primal MIMBR optimization problem is presented in Eq. (6):
Note the variables in MIMBR formulation are the similar to those of the classical SVM, except they are now representing each bag as one or more instances. This is one of the benefits of the MIMBR formulation, whereby using bag-representative selector, traditional SVM solvers can be used for new data representations. Solving the optimization problem given in Eq. (6) using quadratic programming solver is a computationally expensive task due to the number of constraints, which scales by the number of bags n, as well as the calculation of the inner product between two d-dimensional vectors. Therefore, in order to solve the optimization problem more efficiently, we take it as the original optimization problem and apply Lagrange duality to obtain the optimal solution of the primal problem by solving the dual problem.
First, the Lagrange function of the primal problem Eq. (6) is constructed as:
It can be noted that in the dual problem above only involve the inner product between the instances. The inner product of the objective function in the dual problem can be replaced by the kernel values

MIMBR
Algorithm 1 shows the procedure for training the MIMBR classifier and obtaining the optimal representative instances from each bag. During the training process, the representatives, S, are first initialized by randomly selecting an instance from each bag. Then the hyperplane is obtained by S, and the new optimal representative is found for the current hyperplane according to the rules given below: for positive bags, all output values are sorted in descending order and then selected from top to bottom until each bag can contain at least one instance. Similarly, for negative bags, all output values are first sorted in ascending order and then selected from bottom to top until each bag can contain at least one instance.
At each step, the previous values in S are sorted in
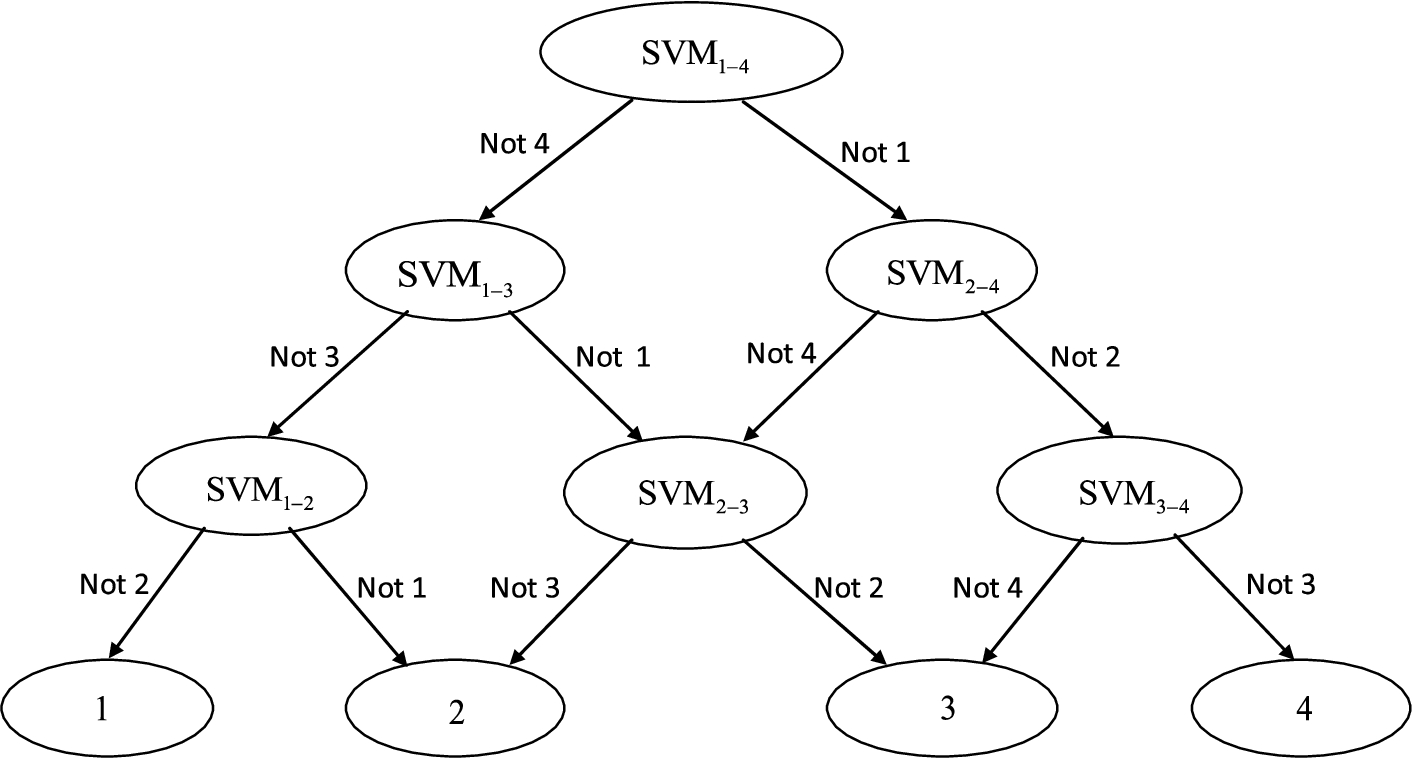
The figure shows that DAG-SVMs is used to illustrate the classification decision process of four samples. It starts from the root node at the top (including two types) and continues to classify with the node at the next layer or right node according to the classification result of the root node until it reaches a certain leaf at the bottom, and the category represented by the leaf is the category of the unknown sample.
Before the training classifier, the relationship between instances in the training datasets is processed by gray correlation analysis is one improvement of MIMBR. The data volume can be reduced on the one hand, and the importance of instances in the bag can be preliminarily judged on the other. Furthermore, unlike MIRSVM, which restricts each bag to one representative instance, MIMBR selects one or more representative instances for each bag based on the hyper-plane output from each iteration. Besides, the initialization process of MIMBR is to randomly select an instance from all the bags. During the initialization process, no wrapper techniques are added with any noise and no assumptions are made for the instance.
In this section, we will show how to generalize the algorithm for binary MIL presented in the previous sections to multi-class MIL tasks. Over here, we adopt a traditional approach that use a variety of classifier fusion framework to decompose the multi-class problem into multiple binary problems, and combines the results of the binary classifiers to carry out multi-class classification.
For multi-class MIL problems, each class is a positive one relative to the other classes. Therefore, for each bag in any class, there exists at least one true positive instance, which carries the discriminant information for the class under consideration, and the rest of the instances may be considered as “background” ones. For some applications, there might be a number of bags that contain background instances alone, akin to the negative class in the binary case.
The SVM method was first proposed for two kinds of classification problems, how to extend the two-category classification method to multi-category classification is one of the important contents of SVM research. Directed Acyclic graph SVMs (DAG-SVMs) is derived from the decision directed cyclic graph proposed by Platt, and it is proposed for the misclassification and rejection of “1-v-1” SVMs [29].
MIL datasets,number of bags,dimensionality,number of instances and the average,minimum and maximum number of instances per bag
MIL datasets,number of bags,dimensionality,number of instances and the average,minimum and maximum number of instances per bag
In the training stage, the algorithm is the same as the “1-v-1” method, and the classification of every 2-type of questions should also be constructed by
Datasets and experimental setup
To validate the effectiveness of the proposed MIMBR, this section describes our contribution to the experimental setup and comparison, as well as 9 other the state-of-art methods on 10 different benchmark datasets. First, the experimental setup is described and the state-of-art methods are listed. Then, the results for each metric are then presented and analyzed. The main purpose of the experiment was to compare our contributions to other MI support vector machines, state-of-the-art multi-instance learners, and ensemble methods.
To investigate the proposed algorithm works in varies scenarios, Table 1 provides a summary of the 10 datasets used throughout the experiment, showing the total number of properties, bags, and instances. The datasets were obtained from the KEEL dataset repositories [16].1
Among the datasets, MUSK1 and MUSK2, are benchmark data sets for MIL. Both data sets are publicly available from the UCI Machine Learning Repository [14]. The datasets consist of descriptions of molecules. Specifically, a bag represents a molecule. Instances in a bag represent low-energy shapes of the molecule. To represent the low-energy shapes of molecules as attribute-value pairs, first fix the molecules in their standard position and orientation, and then 162 rays are emitted fairly uniformly from the origin. The length of each ray cut by the origin and the molecular surface is treated as an attribute. Add four attributes representing fixed oxygen positions, and each instance in the package is described by 166 numerical attributes.
The task of the three datasets, elephant, fox, and tiger, are to estimate whether the images contained elephants, tigers, and foxes. In these three datasets, each image is treated as a bag, and the region of interest of the image is taken as an instance. The experiments were conducted on a 3.40 GHz Intel i7-6700 CPU and 8 GB of memory. MIMBR was implemented in PYTHON while the referenced algorithms are available in the Java implementation of WEKA with the exception of miGraph which was made available by Zhou et al. and tested in MATLAB. To evaluate the performance of our proposed method, we compare it with several representative MIL algorithms, such as miGraph, MIDD, MIOptimalBall [41], MISVM [5] and MIRSVM.
In order to objectively evaluate the performance of the model and optimize the hyper-parameters, the 10-fold cross-validation method is used to carry out the experiment. This process ensures that the model is not optimistically biased towards the complete data set, and that the algorithm is fairly evaluated on the same data in each fold. Optimization in cross validation models includes finding the best penalty parameters, C, and the best shape parameters, the kernel of the Gaussian radial basis function, and σ. Three parameters σ (Gaussian shape parameter), C (error-tolerant rate) and
We fixed
The classification performance was measured using five metrics: Accuracy (8), Precision (9), Recall (10), F0.5-measure (11) and the Area under ROC curve (AUC, 12). On account of accuracy itself can be misleading when categories are unbalanced, the Precision and Recall measures were reported. F0.5-measure and AUC measures are used as complementary measures in order to evaluate the algorithms comprehensively. Although precision and recall are not necessarily related to each other, which can be seen in the above formula. However, in the large-scale data set, these two indicators are mutually restrictive. So F-score is also used as a performance measure, shown in (11), which is based on the definition of harmonic mean of precision and recall. The AUC metric highlights the trade-off between the true positive rate, or recall, and the false positive rate, as shown in (12). The values of the true positive (TP), true negative (TN), false positive (FP), and false negative samples (FN) were first collected for each of the classifiers, then the metrics were computed using the equations shown in (8) on the n bags of the test data:
Accuracy
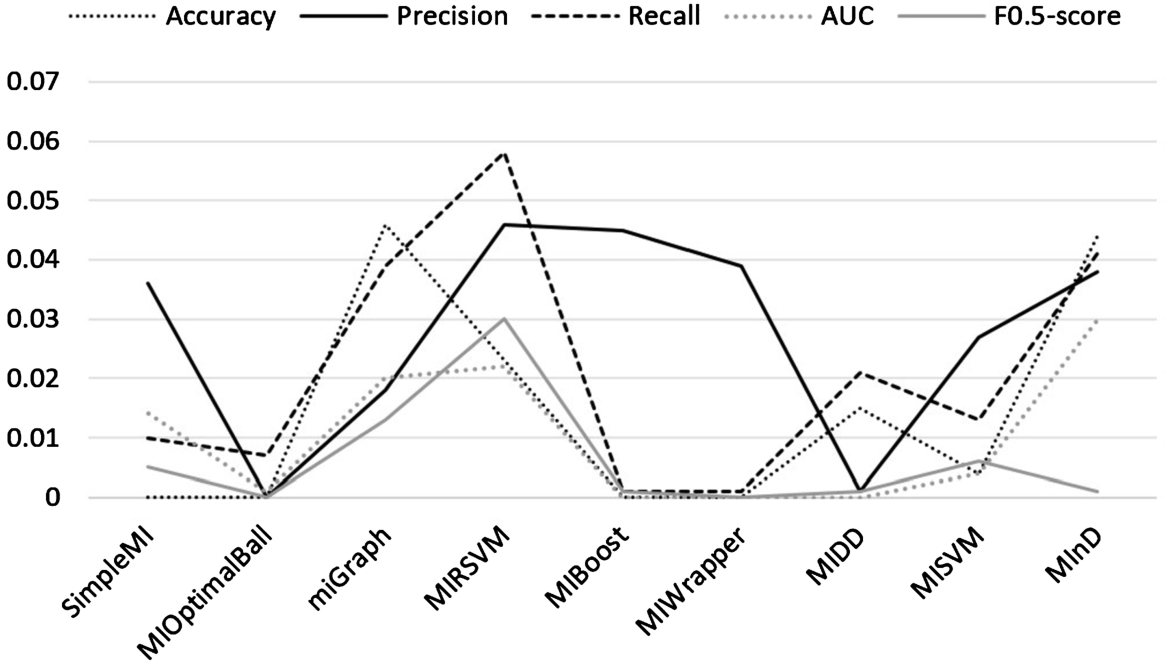
Table 2 shows the accuracy results of 10 algorithms for 10 multi-instance datasets, as well as their average. The results show that the bag-based and ensemble learning performs better than the instance-based and wrapper methods. In particular, MIMBR achieves the highest accuracy in 6 datasets of 10 datasets, while MIRSVM achieves the best results on three datasets. Note that MIMBR performs better than MISVM for all datasets, suggesting that selecting at least one representative instance for each bag by sort can improve classifier performance. The instance-level classifiers and wrapper methods (such as MIBoost, MIWrapper, and SimpleMI) classify the worst. This behavior emphasizes the importance of not assuming a positive bag distribution in advance. The reason why higher accuracy has been obtained by MIMBR is that after selecting at least one representative for each bag MIMBR used, the instance in each bag in dataset are clustered and the difference between positive and negative become clear, which makes easier to classify correctly.
Accuracy on benchmark tasks
Accuracy on benchmark tasks
Precision on benchmark tasks
Recall on benchmark tasks
AUC on benchmark tasks
F0.5-score on benchmark tasks
Precision and recall are contradictory measures in some cases and must be evaluated at the same time to observe their behaviors at the same time, because they are both used to measure correlation. The precision and recall results of each algorithm are given in Table 3 and Table 4. The precision and recall results of MIWrapper and SimpleMI show that they are unstable classifiers and show great differences in the results, making them unsuitable for practical applications. It is also worth noting that when analyzing the performance of mutagenesis datasets, the number of positive bag is greater than the number of negative bag, where MISVM, MIBoost and MIWrapper predict that all bags’ label is negative. Furthermore, although miGraph and MInD achieved unbiased results on these datasets, MIMBR was significantly superior to miGraph in precision and recall, resulting in a better tradeoff. For MIMBR, the experimental results show that it achieves the highest precision in the following datasets: fox, tiger, elephant, while the effect is not very satisfactory in mutagenesis-atoms and mutagenesis-bonds.
AUC and F0.5-score
Table 5 show AUC results obtained by the algorithms, which objectively reflects the comprehensive prediction ability of positive bags and negative bags, and also considers the influence of eliminating sample skew, emphasizing the better performance of bag-based methods. MIMBR achieve the best AUC score on 6 of the 10 datasets, while MIBoost and MIWrapper acquire the worst results. Their AUC values were 0.5 across datasets, indicating that they were random predictors. These results justify the accuracy of the algorithm because the instance-based and wrapper approach performs worse than the bag-based and integrated learning approach. The AUC of the bag-level classifier ranges from 0.75 to 0.85, which is well explained by the precision and recall.
In MIL, due to paying more attention to the classification of positive bags, that is, how many positive bags are correctly labeled after classifier training. So we set
The figure shows that Holm test results of MIMBR versus other 9 datasets.
The figure shows that Wilxocon test results of MIMBR versus other 9 datasets.
The presented classifiers vary significantly in the model assumptions and their complexity. Figure 6 and Fig. 7 show the Holm test and Wilcoxon test, respectively. The MInD and MIRSVM approaches also have reasonably good (but typically worse than miGraph and MIMBR) and consistent performances. On the one hand, the Holm test procedures reflect that MIMBR performs significantly better than SimpleMI, MIOptimalBall, miGraph, MIRSVM, MIDD and MInD. The significance in MIMBR is 0.06, which is lower than the acceptance of the null hypothesis of 0.05 because MISVM, MIBoost and MIWrapper predict that all bags’ label is negative. On the other hand, we can find that except for the recall in MIRSVM, the performance of MIMBR is significantly improved compared to other algorithms. But in other measurement indicators, the results of MIMBR are better than MIRSVM. Therefore, it can be known from the above two types of non-parametric tests that MIMBR’s performance as a competitive classifier.
Conclusion
In this paper, we presented MIMBR, which is an efficient SVM-based MIL approach to classification. This method has universality, and the key lies on the combination of instance selection and classifier learning. An iterative two-step optimization framework to update classifiers is also developed in this paper. This optimization strategy is guaranteed to convergence. Here, initial instance selection is achieved via randomly selected from each bags. And then, for the training set, positive and negative bags are processed respectively according to the classification hyperplane obtained by SVM training, and at least one representative instance is selected for each bag for the next classifier training. This is more efficient and effective than the traditional EM-based instance selection strategies. The proposed approach is proved to be more amenable to improvement than the others. As mentioned in this article, this approach can be applied to a large quantity of classification settings additionally.
Compared with the most advanced multi-instance SVM, experimental results show that traditional MI learners and implicit learning methods, MIMBR has better learning performance. The experimental results are evaluated according to different performance indicators, which further validates the advantages of bag-level classifiers, such as miGraph and MIRSVM, in predicting the accuracy of unknown bag labels in MIL, while instance-level learners perform poorly or are referred to as strongly biased and unstable classifiers.
MIMBR could be further improved by investigating the following approaches. The first research direction is to experiment with different optimal solvers. Iterative Single Data Algorithm [15,18] is a more recent and efficient approach for solving the L2-SVM problem, shown to be faster than the sequential minimal optimization algorithm and equal in terms of accuracy [19,20]. It iteratively updates the objective function by working on one data point at one time, using coordinate descent to find the optimal objective function value. Another area to explore is testing and observing MIMBR performance on highly imbalanced and high-dimensional MI datasets.
In some applications, the training data are given in a one-class setting. For example, the domain-based protein interaction inference problem typically only has positive training samples, namely, pairs of proteins that interact [19]. The mutual effect of two proteins is produced by the interaction of their domains. As a consequence, if a pair of proteins is treated as a bag and the domain-domain pairs are treated as the instances in the bag, an MIL representation is obtained. So MIL of one-class training data is an interesting direction to delve.
Footnotes
Acknowledgements
This work was supported by National Natural Science Foundation of China (No. 61573266).