
Abstract
Financial time-series forecasting, and profit maximization is a challenging task, which has attracted the interest of several researchers and is immensely important for investors. In this paper, we present a deep learning system, which uses a variety of data for a subset of the stocks on the NASDAQ exchange to forecast the stock price. Our framework allows the use of a variational autoencoder (VAE) to remove noise and time-series data engineering to extract higher-level features. A Stacked LSTM Autoencoder is used to perform multi-step-ahead prediction of the stock closing price. This prediction is used by two profit-maximization strategies that include greedy approach and short selling. Besides, we use reinforcement learning as a third profit-enhancement strategy and compare these three strategies to offline strategies that use the actual future prices. Results show that the proposed methods outperform the state-of-the-art time-series forecasting approaches in terms of predictive accuracy and profitability.
Keywords
Introduction
Forecasting stock prices and maximizing profit is one of the most challenging machine learning problems today. The predicted price of a stock allows investors to ensure that they buy and sell the shares of various companies at the most opportune times, and enables them to maximize their profits. The prediction of stock prices is an interesting research area for both researchers and investors. While several forecasting models have been proposed [6,11,13,16,27,32,36,43], the problem of building a prediction model to forecast stock prices accurately is still an open question, and is under research.
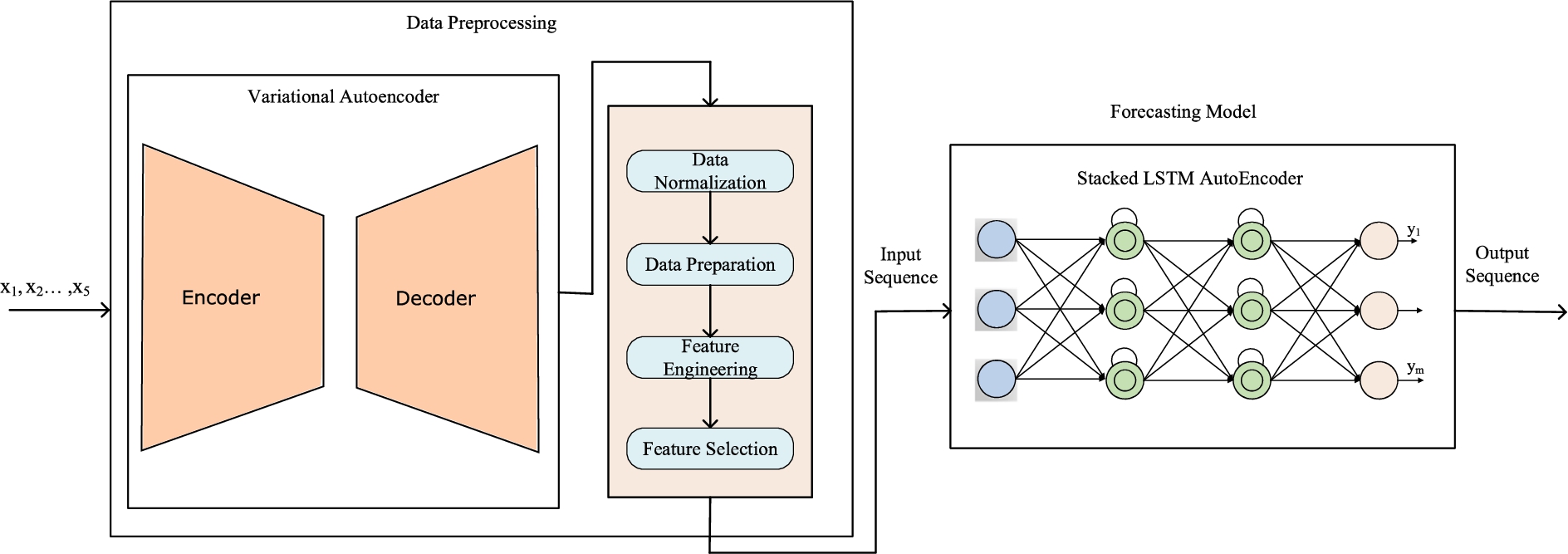
The proposed deep learning framework for financial time series forecasting.
We use historical data to build a deep learning-based framework for the prediction of future stock prices and to enhance profitability. A number of different factors can affect the variation of stock prices. These include political and economic events, annual reports of companies, industry trends, market sentiments, historical prices, pandemics, share issue, and share buybacks [19]. While, it may be possible to build separate systems that predict stock prices from each of these factors and achieve accurate stock price predictions by combining their results, it is challenging to build a system that considers such a vast number of factors. On the other hand, historical patterns of stock prices include the effect of past events, and are the basis for technical analysis [20] of stock prices, which is used by investors and investment companies to predict stock trends. At present, technical analysis is used independently for predicting stock trends and providing advice to investors, and thus, historical stock prices can provide information to perform relatively accurate stock price predictions. While time varying distribution of data, and noise are two major reasons, why the problem of stock price prediction from historical data is challenging [40], a time series forecasting model which achieves high accuracy will be beneficial for the investors.
Profit from stock transactions can be enhanced by using genetic algorithms [38], reinforcement learning [5,48] or algorithms that use stock price predictions [33] to provide advice on when to buy or sell stocks. The efficacy of such algorithms is highly dependent on the accuracy of the stock price predictions. In our case, accurate predictions enable us to effectively use simple, greedy algorithms to provide advice on stock transactions. For our reinforcement learning model, we use per minute current and past price deviations and the current value of the stock owned as the inputs for the reinforcement learning model. Designing a trading strategy for maximizing the profit from stock transactions is challenging since it is difficult to achieve highly accurate predictions or to train reinforcement learning to achieve the maximum possible profit that can be achieved if all future prices are known.
In this paper, considering the complexity of financial time series prediction and the applicability of deep learning in solving such problems [6,13,25], we propose a deep learning framework for stock price prediction and experimentally analyze the applicability and profitability of our framework. Figure 1 shows the proposed deep learning framework for financial time series forecasting. The framework uses an input sequence where each time lag of the input sequence has multivariate features: close, open, high and low prices, and volume. The output of the framework is an output sequence where each time lag of the output sequence corresponds to the stock closing price of the succeeding m time intervals. Therefore, our deep learning framework is designed for multi-step-ahead forecasting with multivariate input data. The output of the prediction framework is used as the input to two profit maximization strategies and the overall profit is analyzed. The strategies used include the use of short selling [3] as well as traditional stock transactions using greedy algorithms. Besides, we use a separate reinforcement learning [26] technique that does not use the predictions and only uses the current and past closing prices.
The proposed stock price prediction framework builds on our previous work in [1] and has two main components, data preprocessing and forecasting. Data preprocessing involves data normalization and data preparation, and may optionally include removal of noise, feature engineering, and feature selection. In data preprocessing, a variational auto-encoder (VAE) [23] is optionally applied on financial time series data with 5 features and is used to remove noise by generating a latent dimension from the original features. In addition, it can help to determine if an anomaly might happen. After applying the variational auto-encoder, the financial time series data has
Using the predicted stock prices, we design two algorithms to help the users to decide when to buy and sell a stock. The first algorithm uses a combination of short selling and traditional stock transactions to enhance profit in a manner similar to [6]. Based on the increase or decrease in price, this strategy decides to perform either short-selling or traditional transactions and the accuracy of the prediction determines actual profit or loss. The second algorithm does not employ short selling and uses a greedy approach to maximize the profit. Based on the predictions at time i, if the predicted closing price for any minute in the next m minutes is greater than the price at time
Besides, we design two offline strategies which give the optimal profits and are used for comparison only. The optimal profits can only be achieved if actual future stock prices are known. For the greedy offline strategy, the actual stock prices for the next m minutes are known and are used to make decisions about stock transactions. On the other hand, the optimal dynamic programming strategy knows the actual future prices for the entire span of the test set. This gives us the maximum possible profit that can be made by multiple stock transactions over the time period spanned by the test set. While it is not realistic for us to know the actual future stock prices, the profit that can be achieved in these cases is larger than the profit from any of our models or from Facebook’s Prophet.1
The novelty of our work lies in the following facts:
We use minutely data to perform multi-step-ahead predictions and make decisions. Since the change in price over milliseconds or seconds is too small, this reduces the profit that can be earned, especially if we consider the transaction fees [42]. On the other hand, the daily price movements are affected by random factors such as news, social behavior and other complex factors, and are thus, more difficult to predict [42].
We design algorithmic as well as reinforcement learning based approaches to decide when to buy or sell a stock in order to enhance profit.
Besides, we design two offline, optimal strategies to provide a measure of the profit that can be achieved if the actual future stock prices are known.
We compare the profits obtained from algorithms designed to use price predictions and reinforcement learning to optimal techniques that use the actual future prices. Thus, we provide a measure of the importance of accurate predictions and the degree of improvement in prediction accuracy that is necessary in order to match the profits from the offline algorithms.
Our prediction framework and the decision strategies can be extended to handle all the tickers in the NASDAQ stock exchange. We perform our experiments on 12 of the top 100 stocks on the NASDAQ exchange. However, since our framework trains a separate model for each stock ticker; if the necessary computational resources are available, it can easily be extended to handle all the tickers on the NASDAQ stock exchange.
The remainder of this paper is organized as follows. We discuss the related work in Section 2. In Section 3, a description of the inputs and the data resources is presented. Data preprocessing is discussed in Section 4 and the proposed deep learning framework for financial stock price prediction is discussed in detail in Section 5. The strategies for profit enhancement are discussed in Section 6. The experiments and results are presented in Section 7 and, finally, we conclude in Section 8.
The analysis of financial market movements and stock market forecasting has been widely studied in the last decade [4,24]. There are two approaches for the prediction and analysis of financial markets. The first approach is related to stock price movement forecasting, which is considered as a classification problem [13]. This approach investigates how to predict future market movements by mining information in textual format. Financial news and financial reports are considered as relevant sources of information for predicting the future market behavior [15,34,45,50]. The other method is to predict the value of the stock price, which is commonly regarded as a regression problem. The regression model used for stock price prediction deals with the problem as a time series prediction [9,22].
For the regression problem, two major classes of work, statistical models and machine learning approaches, have been used to forecast financial time series. Traditional statistical methods assume that financial time series are linear while many machine learning techniques capture non-linear relationships from data. Linear models such as ARIMA and ARMA have been widely used to predict financial time series [12,21]. Besides, various machine learning algorithms have been used in the area of stock prediction. Non-linear models such as Support Vector Regression, Neural Networks, and hybrid mechanisms have been utilized in stock forecasting and have achieved high predictive accuracy [6,11,16,27,32,36,43].
With the advent of deep learning, some researchers [6,13,33] have used deep neural networks to provide more accurate financial market predictions. However, this field remains relatively unexplored. There are related works that apply deep learning on financial data; for example, Ding et al. [13] use a deep convolutional neural network to predict the impact of events on stock price movements. Besides, deep belief networks have been utilized in financial market prediction [25]. Another work [6] proposes a method which uses stacked auto-encoders to predict the stock market. In [33], the authors develop a trading pipeline that uses the predictions from two LSTMs to develop a trading strategy for increasing profit. While one LSTM is used to predict the stock price trend, the second one is used to predict the stock trading price. In case of the second LSTM, the output prediction is corrected by using the error for the previous time step. In addition to the above prediction tools, some pre-processing approaches, such as Principal Component Analysis (PCA) [44], Discrete Fourier Transform [7], and Discrete Wavelet Transform [6], are used to remove noise and reduce the dimensions of raw data.
For the design of trading systems, several techniques have been proposed including ones that use genetic algorithms [38], and reinforcement learning [5,48]. In [38], a genetic algorithm is utilized to decide on the trading strategy. The price predictions used as the inputs to the trading strategy are obtained by using generalized moving averages. In [5,48], the authors use reinforcement learning to design a trading strategy. However, the approaches differ in terms of the information that is fed to the reinforcement learning model. While [5] uses stock trend predictions from sentiment analysis of news headlines as well as moving averages and current stock prices, [48] uses only the daily past and present stock prices without using any future predictions.
While some of the above works use statistical models [12,21] and machine learning techniques [11,16] that do not include deep learning, the use of deep learning [6,13,33] has led to a significant improvement in the accuracy of time series predictions. Our work involves the use of deep learning for stock price prediction and noise removal to ensure higher accuracy. With the advent of high frequency trading, there has been a shift towards autonomous trading involving high frequency predictions and actions performed by trained bots. The future of autonomous trading lies in the use of high-frequency data to perform a large number of hourly transactions. However, the existing works involve the prediction of daily stock prices only and are not suitable for high-frequency trading. In cases where the high-frequency data is used, it may be using data that has a frequency of around 1 second and utilizing a simple MLP model [14], or using Generative Adversarial Networks (GANs) to perform prediction of prices for a single step [49]. We use a dataset that allows us to utilize minutely data to perform multi-step ahead predictions and to provide minutely advice for stock transactions. We utilize an LSTM based autoencoder, which is more suitable than GANs for time-series prediction. To the best of our knowledge, algorithms and datasets that enable stock transactions based on minutely stock prices have not been explored previously. Our framework paves the way for research in the field of high-frequency stock price prediction, which, at present, has not been adequately explored.
Data description
We collect the features, which are depicted in Table 1, for 12 out of the top 100 stocks on the NASDAQ exchange and use this data as the input to our prediction framework. A listing of these stocks is found in Table 2. We collect data for 1-minute time intervals over a period of 5 months plus 1 week and use this historical data to build a model to predict the closing price of the stock.
Iexfinance stock data sample features and their descriptions
Iexfinance stock data sample features and their descriptions
NASDAQ stock listing
The source for our historical data is IEX Cloud,2
which provides data for 5 features for each time interval. The data is retrieved from IEX Cloud using a Python software development kit called iexfinance.3 IEX Cloud provides several features for each stock polled. For our work, we focus on a stock’s open, high, low, and close prices as well as its volume for each time interval. Table 1 clarifies these features in more detail. The data collected for opening and closing prices are not constant for intra-day samples and instead reflect the relative price for the time interval on which the sample is collected. Since the data collected from IEX Cloud has some missing values, we use the backfilling method to deal with these missing values. Historical data from IEX Cloud is collected over a period of more than 5 months from March 01, 2019 until August 7, 2019.Before feeding the data into a forecasting model, we preprocess the data. The data preprocessing component consists of multiple sections: removing noise using variational autoencoder, data normalization, data preparation, feature engineering, and selection. In Section 7, we evaluate whether the use of VAE and feature engineering provides benefits and incorporate the best performing combination of pre-processing methods in our final forecasting model.
Data normalization and preparation
Data normalization
We normalize the data using feature scaling to ensure that the multivariate input and multi-step prediction data that is fed to our model lies in the range
Restructuring of data into input and output windows
Before feeding the normalized data to our forecasting model, we prepare the data by restructuring it into the overlapping sliding window format. Our original, normalized dataset has shape
As mentioned in the conclusion of [1], in this paper, the input and output window sizes are chosen empirically. We use input and output window sizes of 7 because, in most cases, increasing the input or output window sizes does not improve the accuracy of the results and only increases the computational overhead. This means that we look at the stock price at 7 steps before to predict the stock closing price for 7 steps-ahead.
Pre-processing to enable closing price deviation prediction
In [1], we use the above data preparation method and perform experiments on 5 tickers. However, when we attempted to use other tickers, especially INTC, we noticed a divergence in the predicted and actual values for those tickers that have a sharp decrease in price during the time interval that is used for testing. To overcome that issue, for each sample of shape
Feature engineering and variational autoencoder
Here, we discuss the use of VAE and feature engineering. Our model is designed such that it may use one, both, or neither of these two techniques. In Section 7, we empirically choose one of the four possible combinations of these two techniques for our final model.
Variational autoencoder
In order to remove noise, we attempt to utilize a long short-term memory-based variational auto-encoder (LSTM-VAE) which consists of an encoder and a decoder. The encoder maps observations at each time step into a latent space. Then, the decoder estimates the expected distribution of the inputs from the latent space representation. The latent space has Gaussian distribution with

LSTM autoencoder sequence to sequence model.
For feature engineering, the normalized and prepared data are given to a module and is used to extract a new set of features. Our data is time series data, so we need to use time series feature extraction techniques to map the data into a high dimensional feature space. We use
Next, we rank the features according to their importance and then use this rank to perform feature selection. We try to use

The general network architecture used for building the learning model.
Learning model
We use Long Short-Term Memory Networks (LSTMs) [18] for building our learning model. LSTMs are a special kind of Recurrent Neural Networks (RNNs) which solve the gradient vanishing and exploding problem that the standard version of RNNs suffer from. The LSTM structure is well-suited for time series prediction with different number of time lags. For our experiments, we use the Keras framework,6
In our learning model, we use a stacked LSTM Autoencoder as the reference architecture for our neural network. An LSTM Autoencoder built using an Encoder-Decoder LSTM architecture can be utilized for sequence to sequence problems. A sequence to sequence (seq2seq) prediction model takes a sequence as input and predicts an output sequence. It is challenging to use such prediction models in cases where the length of the input and the output sequences are not fixed. However, LSTM Autoencoders have been effectively used for seq2seq prediction problems [39,47], where the encoder reads the input sequences and compresses it to a fixed-length internal representation, while the decoder interprets the internal representation and uses it to predict the output sequence. An LSTM Autoencoder is shown in Fig. 2. LSTM Autoencoders have been used to process video [37] (Image Captioning), text [31] (Machine Translation), audio (speech recognition) [29], and time series sequence data [28,30].
The general structure of LSTM Autoencoder architecture used in our work is presented in Fig. 3. We have an Encoder model that reads the input sequence and outputs an element vector that captures features from the input sequence. The decoder returns the entire output sequence. For example, if we have 10 cells in the last layer of the decoder, each of the 10 cells will generate outputs for each of the timesteps in the output sequence. In the output layer, we use the
Our learning model takes a sequence of stock prices and features of n lags and predicts the output as a sequence with length m. Each lag in the input sequence has multiple features such as opening price, closing price, low price, high price, and volume. Some other features may be added in the feature engineering step discussed in Section 4.2. Each element in the output sequence corresponds to the stock closing price at time step t, where
Since neural networks like LSTM need to utilize hyperparameter optimization for selection of hyperparameters, we attempt to use the Hyperas7
Number of epochs
Batch size
Learning rate
The dropout value for the dropout layer
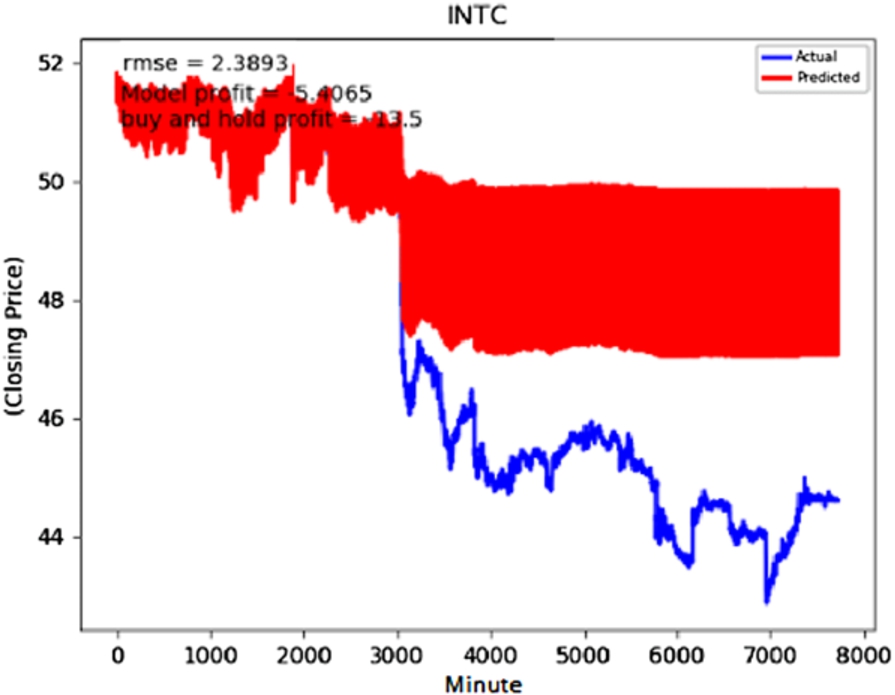
INTC predictions without hyperparameter optimization or the use of the deviation prediction technique.

INTC predictions using hyperparameter optimization without the deviation detection technique.
In models where we do not use the deviation prediction technique, we see significant improvement in the performance especially for tickers for which we do not get suitable performance with the default hyperparameters. An example of one such ticker is INTC. In Figs 4 and 5, we provide the results of INTC ticker before and after using hyperparameter optimization. In Table 3, we provide the root mean square error (RMSE) and the profit as described in [1] before and after hyperparameter optimization. Besides, we tabulate the results for the same quantities after using the deviation prediction technique but without hyperparameter optimization. The RMSE is reduced by using hyperparameter optimization without introducing the deviation prediction method. However, the RMSE shows a more significant decrease when we introduce the deviation prediction method even without performing hyperparameter optimization. In Fig. 6, we provide the plot for INTC after using the average subtraction technique.
Comparison of INTC models with or without use of hyperparameter optimization and deviation prediction
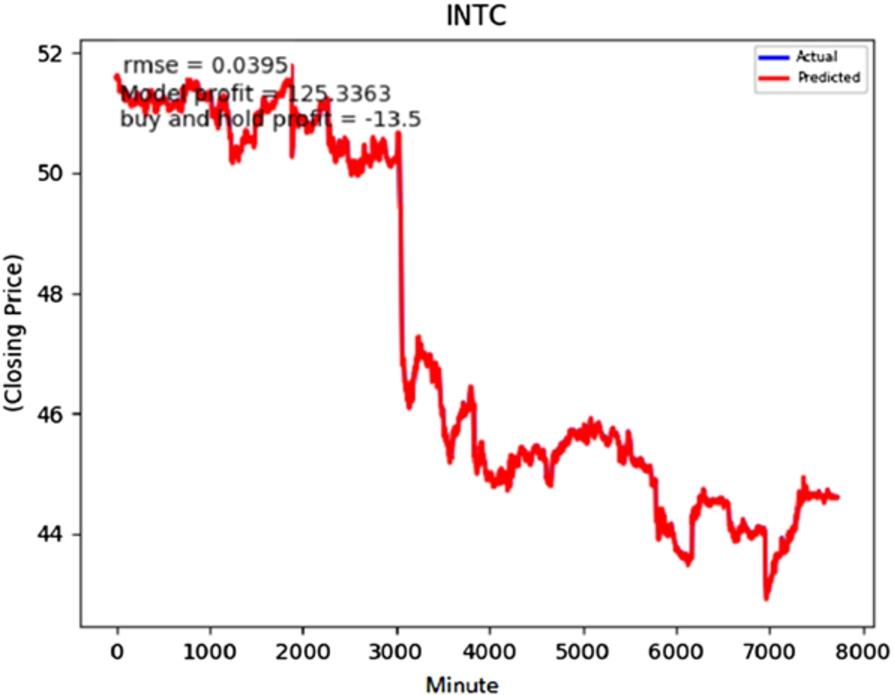
INTC predictions without hyperparameter optimization but using the deviation prediction technique.
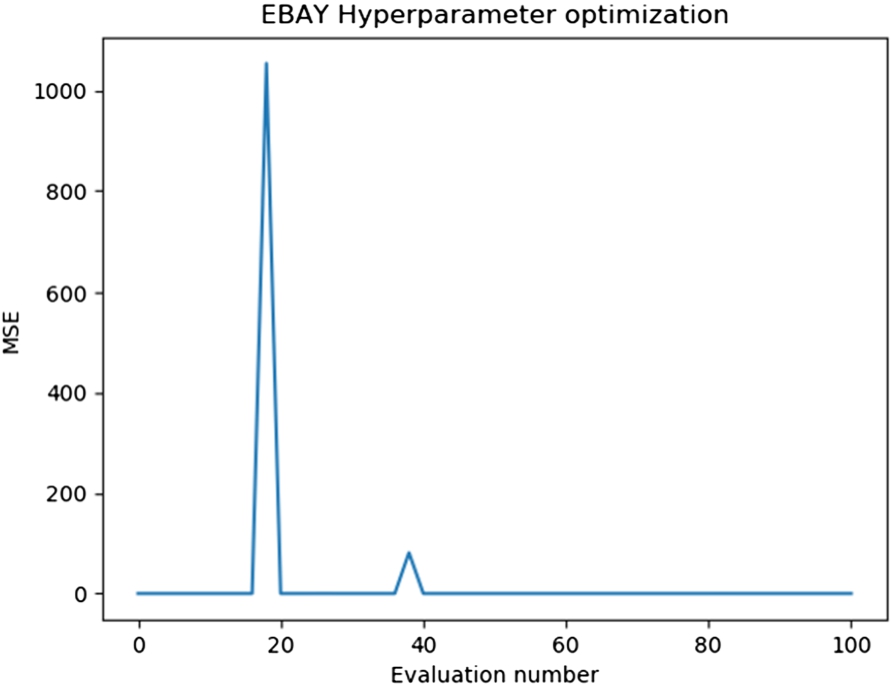
EBAY variation of MSE over hyperparameter optimization evaluations.
Since the stock data for almost all tickers includes a certain amount of randomness, retraining an architecture with the same hyperparameters on the same data can result in models that vary moderately from each other. This causes a challenge in case of hyperparameter optimization especially for the models that use the deviation detection technique because the error in those cases is small. Thus, it is difficult to separate the error due to the use of a model without optimized hyperparameters and error due to the randomness in the data. The effect of randomness can mask or have an equal impact as the improvement due to optimization making it hard for the algorithm that we use to search the hyperparameter space effectively. In Fig. 7, we plot the mean square error (MSE) for EBAY over different evaluations of the hyperparameter optimization algorithm for models that use the subtraction of averages technique. As we see from the figure, there is no significant improvement in accuracy over time. The actual MSE values corresponding to those that are near 0 are in the range of 0.00056 and 0.00037 on the validation set. However, each hyperparameter optimization can take up to 21 hours on a NVIDIA 2080Ti GPU and due to the difference in the distribution of data for each of the tickers the optimization needs to be performed individually for each ticker. Besides, the error is already low without using hyperparameter optimization if we use the deviation detection technique. Thus, we choose not to perform such computationally expensive operations that do not lead to a definite and significant improvement in performance.
Strategy 1: Using short selling and traditional transactions (SS&T)
In [6], a profitability measure is introduced, which uses a buy-and-sell trading strategy. As shown in equation (1), the strategy states that investors should buy if the model predicts that the stock value is going to increase in the next time interval. In accordance with equation (2), if the model predicts a decrease in the stock price, the investors are recommended to sell. The variables
Here, R is the amount gained by using the strategy, while B and S indicate the minutes at which shares are bought for traditional selling or short sold, respectively.
We introduce a greedy strategy that uses the predictions for the next 7 minutes. At a specific minute, say

Strategy 2: Greedy strategy
We use Q-learning [46] to design our third profit enhancement strategy. In Q-learning, an agent attempts to maximize its rewards when it acts in a specific environment. In our case, the environment is the stock market for a specific ticker and the agent attempts to maximize its reward (profit) by buying and selling stocks in this environment. Specifically, we provide the information about the current state,
Computing the Q-value for all the states is computationally intractable due to the large number of possible future states as well as the necessity of computing the rewards for all these states and using the cumulative future reward for computing the Q-value of the current state. As a result, a deep neural network is trained to estimate the Q-value function and then the action with the highest predicted Q-value for state
For our Q-Learning strategy, we design an environment where the agent is allowed to buy one stock for a specific ticker and sell it before it can buy another one. While we can use a situation where we give the agent a certain amount of cash and allow it to buy as many stocks as possible with this amount before it must sell in order to buy more stocks; we choose this environment to ensure compatibility with our other strategies. We use an approach similar to [2]. The state, action, and reward in our case are as follows:
Buy: Buy a stock of the company
Sell: Sell a stock of the company
Hold: Perform no action. The number of stocks owned does not change.
We use 250 epochs and a learning rate of 0.001 to train our Q-learning network. We perform training separately for each ticker. Our network consists of 3 linear layers with the first 2 layers using ReLU activation function.
Offline strategies
For the purpose of comparison, we design two offline strategies, which use the actual future values to decide on the action that is to be taken. These strategies cannot be used in real-life because actual future stock prices are not known to us.
Offline greedy strategy (Greedy-O)
We design an optimal greedy strategy similar to the one described in Section 6.2. However, this offline strategy uses only actual data and does not use any predicted data. Thus, the decisions made are always correct because the actual future data for the next m minutes is known at the time of making the decisions. This is used for comparison to show the benefit of accurately knowing the future.
Offline dynamic programming (DP-O)
The offline dynamic programming strategy gives the maximum amount of profit that can be earned for a specific stock over a period of time. It uses actual (not predicted) future data for the entire future to make decisions. Dynamic programming is used to find the maximal profit if we are allowed to perform at most one transaction per minute. Using the actual future stock prices, we can compute the specific minutes at which to buy and sell a stock in order to maximize the profit. This is an optimal strategy and is used for comparison to show the maximum possible profit.
Experimental results
In order to validate the general forecasting performance of our proposed prediction models, we perform multiple experiments to evaluate the stock closing price prediction for different types of stocks with a variety of different patterns and behaviors. For the experiments, we use historical minutely data from IEX Cloud collected over a period of more than 5 months from March 01, 2019 until August 7, 2019. We choose 12 tickers out of the top 100 stocks on the NASDAQ exchange and evaluate our model. The chosen tickers are listed in Table 2. Besides, we evaluate the profits from our strategies and compare those to baseline and optimal strategies.
We use the first M minutes of training data for training and last L minutes for validation, where
Data splits, baseline and forecasting models
We use almost the first 16 weeks of the data for training and then use the data for the remaining 7 weeks for testing. For the evaluation and experiments, we use historical minutely data for the 12 selected tickers.
We compare our models with:
The profit enhancement strategies compared and the baselines are:
In this study, we use three metrics in order to measure the predictive accuracy: Root Mean Squared Error (
In addition to the predictive accuracy measures applied for evaluating our method, we compare the profits from our two profit enhancement strategies by computing the profit based on the predictions from the LSTM + VAE + AVG model. Our third strategy uses the past and current data to perform reinforcement learning.
Comparison of prediction models for different stocks
Comparison of prediction models for different stocks
By evaluating the metrics for the performance of the models in terms of
Out of our 5 models,

Real and predicted values of GOOG and FAST stocks.
Comparison of profit enhancement strategies
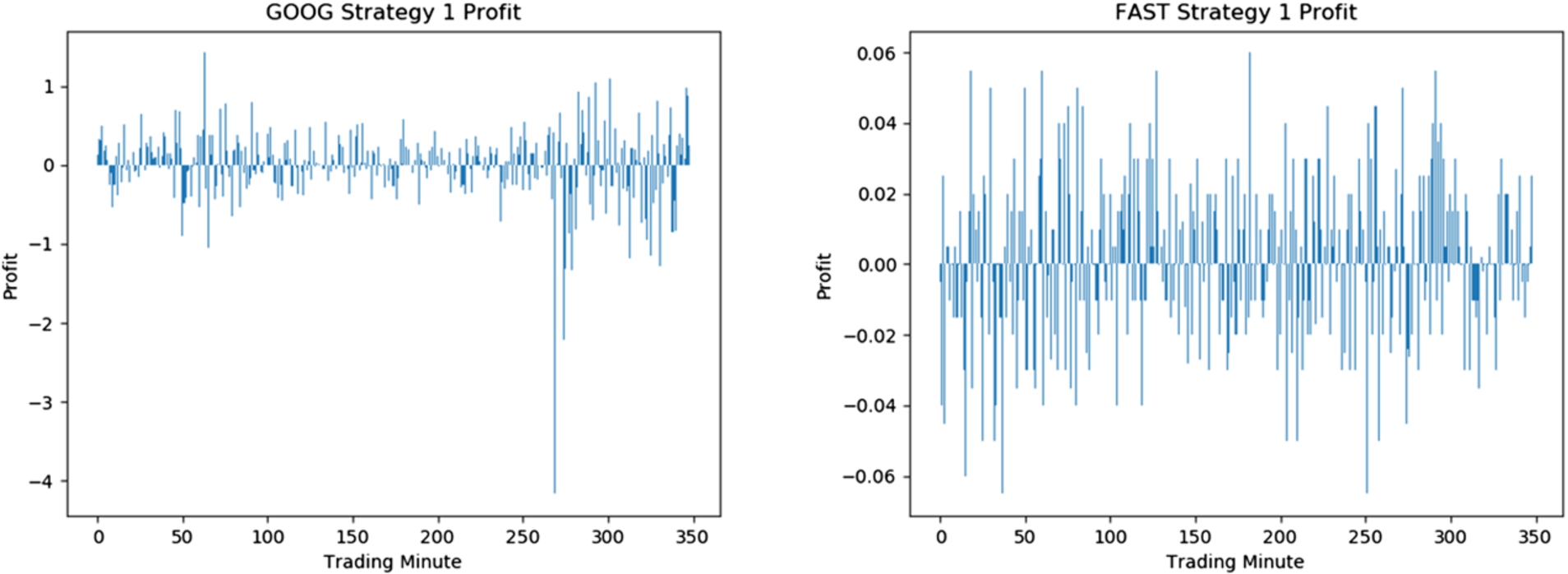
Strategy 1: SS&T profit and loss over time for GOOG and FAST stocks.
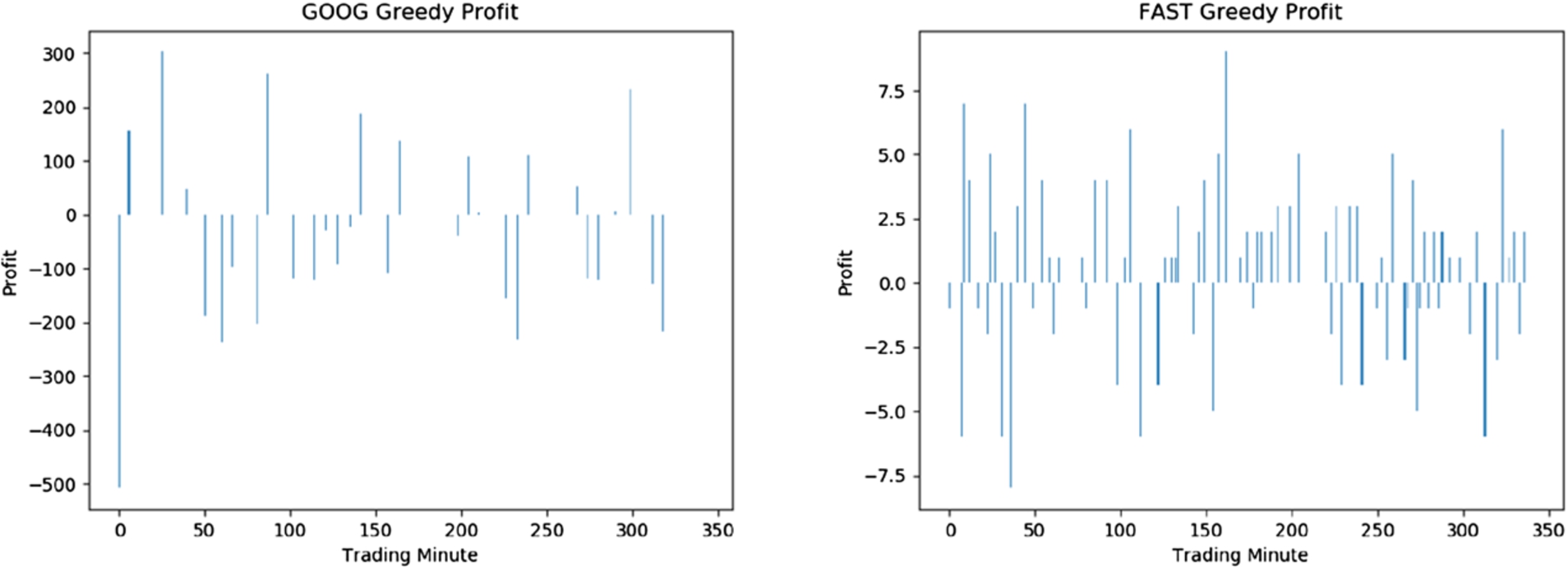
Strategy 2: Greedy strategy profit and loss over time for GOOG and FAST stocks.
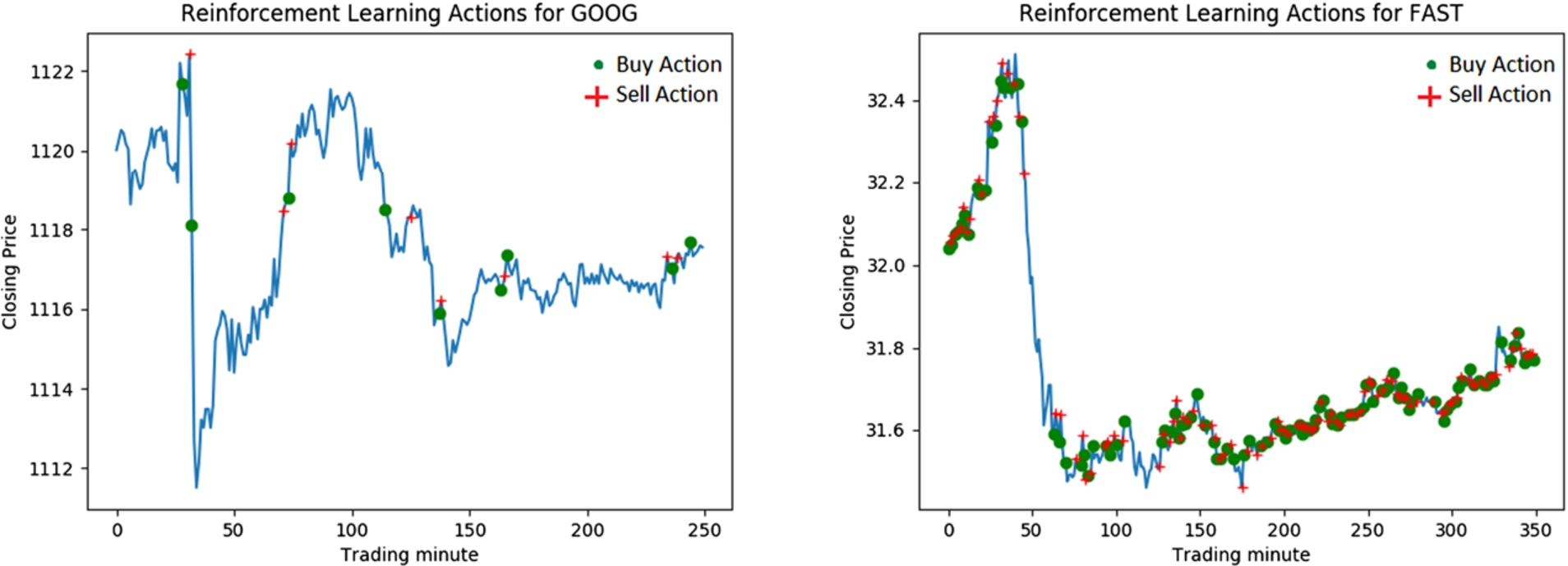
Strategy 3: Reinforcement learning buy and sell operations over time.
In Table 5, we compare the profits from our profit enhancement techniques to two baselines. The prediction model that is used for our two profit computation strategies (SS&T and Greedy) is
By comparing the profits from SS&T and Greedy strategies, we find that in most cases, the SS&T strategy shows better performance. However, it is worthwhile to note that the SS&T strategy involves the use of short selling, which is not traditionally used but provides better opportunities for earning profit. In case we want to only adhere to traditional stock transactions, the Greedy strategy earns positive profit for 11 out of the 12 selected tickers. In Figs 9 and 10, we show the profit and loss achieved by the SS&T and the Greedy strategies over the same interval of 350 minutes.
On comparing the performance of the reinforcement learning strategy (RL) and the Greedy strategy, we see that the Greedy strategy performs slightly better in most cases, even though the profits of the two strategies are comparable. In case of AMZN and COST tickers, the Greedy strategy performs better and this can be attributed to the use of the predicted future prices. While the reinforcement learning algorithm does not use predicted prices, it shows performance that is comparable to the Greedy strategy and achieves higher profit for AAPL. In Fig. 11, we plot the actual prices for a randomly selected 350 minutes in the test set and the minutes during which buy and sell operations are performed for the GOOG and FAST stocks.
Besides, we also provide two ideal strategies: Greedy-A and DP-Optimal to show the profits that can be earned if we know the future closing prices. In Greedy-A, we identify the profit that our Greedy strategy can earn if it knows the actual closing prices for the next 7 minutes. The DP-Optimal strategy assumes that the algorithm knows the entire future closing prices for the whole test set at the very beginning and can decide when to buy and sell stocks on that basis. This is the maximum possible profit that can be earned over the period of time covered by the test set by making at most 1 transaction per minute. These strategies show superior performance to all others but are only provided to emphasize the importance of accurate future predictions, which is difficult in case of stock prices due to the inherent randomness of the data. In reality, we can never use the Greedy-A and the DP-Optimal strategy because the actual future stock prices are always unknown.
The goal of this paper is to address the problem of high frequency stock price predictions from historical prices and to improve upon the state-of-the-art techniques of time-series prediction of stock prices by proposing a deep learning framework. Our framework takes minutely data for 12 different stocks tickers and predicts the stock closing price for 7-minute-ahead. In our framework, before feeding the minute data to a prediction model, we remove noise from the data by using a Variational Autoencoder and explore the use of time series feature extraction techniques to map the data into a high dimensional feature space. The new set of features are fed to a stacked LSTM Autoencoder to predict the deviation of the stock closing price for the next 7 minutes from the average closing price of the last 7 minutes. Two profit enhancement strategies are applied based on this prediction to provide advice to the users about the appropriate time for buying or selling a stock. Besides, we use reinforcement learning to build a third profit enhancement strategies. Our results show that our proposed models beat the state-of-the-art approach in the area of time series forecasting and profitability. The increased profit from our models is due to the higher accuracy of prediction. This fact is corroborated by the much higher profits achieved by the offline models that use the actual future prices. Our framework paves the way for future research in the field of high frequency stock price predictions by providing valuable insights for noise removal, price prediction and profit enhancement as well as by identifying the challenges of performing hyper-parameter optimization on data that involves some randomness.
We will analyze our frameworks on the top 100 NASDAQ stocks in the near future. There are many avenues for improvement in our work. We could incorporate real time sentiment analysis of news. It would be interesting to find out if models that predict seconds, minutes, and hourly data, can be ensembled to produce better models. Optimizing time of model building is another area that needs further research.