
Abstract
In recent years, due to its great economic and social potential, the recognition of facial expressions linked to emotions has become one of the most flourishing applications in the field of artificial intelligence, and has been the subject of many developments. However, despite significant progress, this field is still subject to many theoretical debates and technical challenges. It therefore seems important to make a general inventory of the different lines of research and to present a synthesis of recent results in this field. To this end, we have carried out a systematic review of the literature according to the guidelines of the PRISMA method. A search of 13 documentary databases identified a total of 220 references over the period 2014–2019. After a global presentation of the current systems and their performance, we grouped and analyzed the selected articles in the light of the main problems encountered in the field of automated facial expression recognition. The conclusion of this review highlights the strengths, limitations and main directions for future research in this field.
Introduction
For several decades now, emotional computing has been a flourishing multidisciplinary field of research with broad economic and social applications:
mass emotional analysis (general mood of a population, level of well-being generated by a recreational or tourist structure, etc.);
security (risks of aggression in a stadium or on public transport, detection of drowsy drivers, etc.);
marketing and entertainment (emotional reactions to products, ads or films);
personal assistants;
health (pain detection, support for people with communication disorders, up to assistance with medical and psychopathological diagnosis).
Within this field, the automatic recognition of facial expressions (also called AFER) is the subject of an increasing number of researches.
Indeed, the idea is now widely accepted that facial expressions are a powerful non-verbal means of communication that provides a lot of information on the subjective experience of individuals (mental states, interests, opinions, physiological states, emotions) but also on their social motivations, their representations of the world and their intentions of action [163].
Therefore, they play a vital role in human interactions and are necessary for the progressive humanization of human-machine interactions.
Thanks to the evolution of techniques, in particular with the generalization of convolution networks and other deep learning approaches, progress in this field is constant but much remains to be done.
Indeed, the majority of the systems of AFER are based on a linear model of the emotions: Specific configurations of facial-muscle movements appear as if they summarily broadcast or display a person’s emotions, which is why they are routinely referred to as emotional expressions and facial expressions (Barrett et al., 2019, p. 2 [15]).
Theories postulating a direct link between a finite number of emotions and facial expressions are currently being challenged. There is a consensus that human emotions are ephemeral, subjective and changing processes, the interpretation of which depends on many factors related to individuals as well as to the physical and social environment.
These characteristics make it an infinitely complex phenomenon to model and therefore to decode in all its nuances. Endowing a machine with the ability to recognize human emotional states is a scientific challenge around which researchers from many disciplinary fields (artificial intelligence, computer vision, robotics, psychology, cognitive sciences, neuroscience, sociology, etc.) gather and which still poses many theoretical and technical problems.
In this context, it appears necessary to make a systematic inventory of research in the field of the AFER, in order to update knowledge and critically analyse the theories and techniques that serve as a basis for current systems, as well as the challenges that remain to be taken up.
This article is organized as follows:
After describing our literature search methodology and the article selection process, we will quantitatively analyze the data from these articles. Finally, a thematic and qualitative synthesis will lead us to consider relevant perspectives in the field of automated facial expression recognition.
Methodology
Databases and search items
We searched 13 databases:
Pubmed; Biomed; ScienceDirect; Web of Science; Springerlink; Wiley; IEEExplore; ACM Digital Library; Cochrane; CAIRN; Scopus; Openedition; Open Grey.
The search was conducted using two sets of keywords in combination:
“automatic detection/analysis/automatic recognition/affective” “emotion/facial expression/emotion expression/facial display/action units/computing/emotion context”.
For example, the search terms were:
“automatic detection AND emotion”, “automatic recognition AND facial expression”.
These terms were used in the article metadata (title, keywords and abstract).
Inclusion and exclusion criteria
Because automatic recognition of facial expressions is a rapidly evolving field, we have selected only studies published between 2014 and September 2019 (Table 1).
Inclusion and exclusion criteria
Inclusion and exclusion criteria
As shown in Fig. 1, 890 unique citations were identified, of which 475 were excluded as out of scope, according to the inclusion and exclusion criteria.
The remaining 415 articles were evaluated on the basis of their full text, allowing authors to exclude 195 articles that were not relevant to the topic or contained incomplete data. Finally, 220 articles were included in the review.
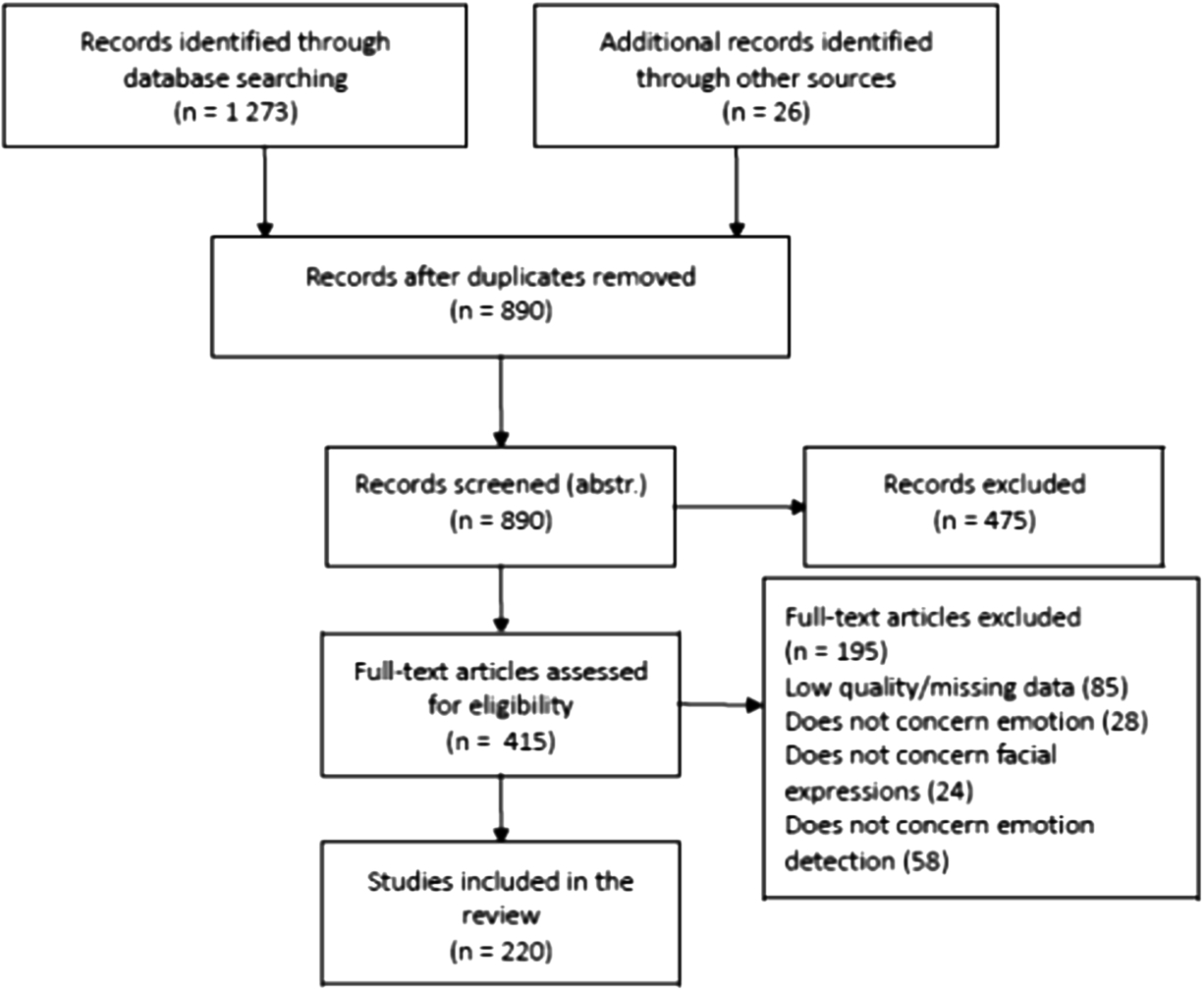
Flow diagram of the documentary search process.
The data extracted from each study included the following:
the full reference and year of publication
the research question or main topic
the technique used (classifier, training and validation datasets)
the number and type of labels (basic, compound emotions, dimensions, Action Units)
performance metrics (accuracy, F1 score)
strengths and limitations of the study
The data were organized in tables to present the basic information for each study. An analysis of variance (ANOVA) was also conducted to compare the performance of the systems according to:
the general type of algorithm (machine learning/deep learning)
the type of label (basic/complex/dimensional emotions)
the type of data used (posed/spontaneous expressions)
Finally, a qualitative and critical analysis was carried out in order to identify the main issues addressed, the strengths and limitations of the studies.
Results and main challenges
Number of publications
First of all, the literature review made it possible to visualize the number of publications year by year (Fig. 2).
Despite a slight decrease in 2016, we can observe a general increase in the number of publications since 2014, showing a growing interest in this field of research.

Number of studies published year by year.
Machine learning techniques are mainly based on statistics in order to model functions and derive predictions that will allow classification of the input data.
There are a wide variety of machine learning algorithms (regressions, k-nearest neighbors, AdaBoost, Naïve Bayes, Decision Tree, Random Forest, SVM,…) which rely on different statistical methods but operate according to the same main steps: extraction of features that are handcrafted by data analysts, model estimation, then classification.
Deep Learning has allowed many technical advances, in particular because algorithms, unlike traditional machine learning ones, require very little or no human intervention before learning. However, they require a very large amount of training data to generalize satisfactorily.
Two main types of deep learning algorithms are currently used:
Convolutional neural networks (CNN), particularly suitable for image processing, consist of a set of interconnected neuron layers which extract the features of the input images (convolutional filtering), transform them and send them to the layers that will operate the classification
Recurrent neural networks (RNN) contain connections by which information can circulate in a recurrent (circular) fashion, and thus make it possible to keep information in memory and therefore to process time sequences or elements of context.
The studies analysed reveal a wide variety of algorithms used, with a preponderance of SVM (Support Vector Machine) and convolution networks (CNN).
For convenience, traditional machine learning techniques (SVM, K-Nearest Neighbors, etc.), as opposed to deep learning algorithms, will be referred to as “machine learning” in the remainder of the text.
Deep learning algorithms (on the right in Fig. 3) account for only 42.7% of the total, but are increasingly used over time, becoming the majority from 2018 onwards (Fig. 4), reflecting a constant evolution of techniques.
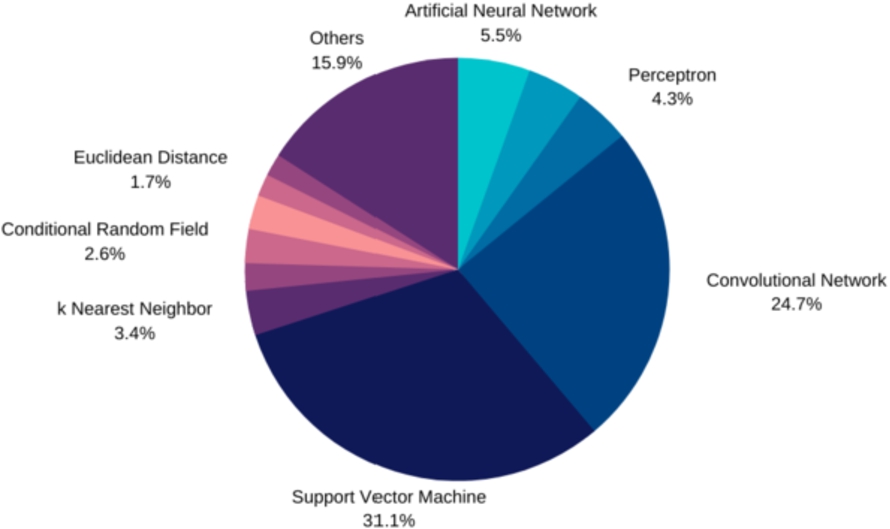
Type of classifiers used in the studies.
Studies using machine learning algorithms report a wide variety of feature extraction techniques, with Gabor filters and local patterns (LBP, LDP) being the most widely used.
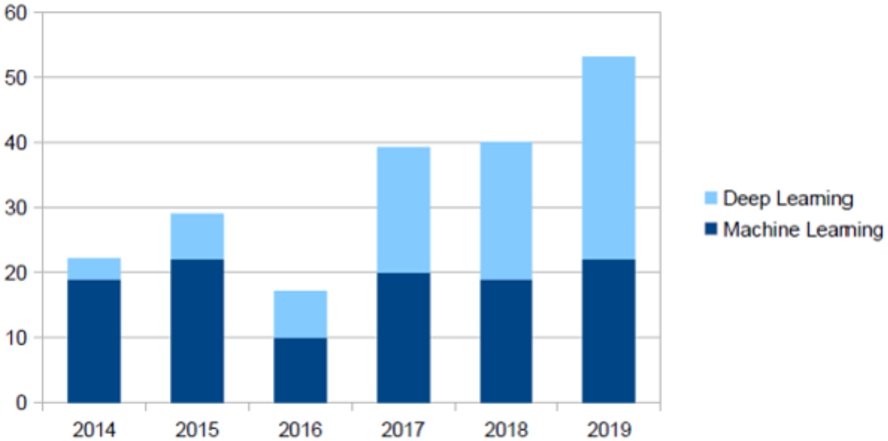
Evolution over time of the type of algorithms.
Most systems operate in real time and deal with most of the problems such as occlusions, different head orientations or differences in brightness. However, some technical challenges remain.
The question of the temporal dynamics of facial expressions. The temporal dimension is an important element of facial expression that has not been fully explored by research, but is attracting the attention of many teams today. Indeed, as modalities of communication and caused by the interactions of the individual with his physical and social environment, emotions and their expressions fluctuate over time.
Since approaches based on convolutional neural networks cannot account for the temporal dynamics of facial expressions, several researchers [19,23,64,84,121,140,181,183,190,201] have used other types of networks, including Recurrent Neural Networks (RNN) and Long-short term memory (LSTM), a special type of RNN capable of learning and linking temporal dependencies between several inputs.
Even if it poses some technical problems (especially the question of segmentation of continuous sequences), temporal dynamics can be rich in information and can greatly increase the performance of facial expression recognition systems [29,53,84].
For example, [1] compared a static approach (ORB and SVM) and a dynamic approach (measurement of facial landmarks and Conditional Random Field) and reported a significant increase in classification performance (average accuracy increases from 74.5% to 80.5%)
Temporal dynamics provides a continuous view of facial expressions, allowing them to be observed in terms of change and to align recognition systems with the natural process of emotional onset [29,84,88,118,190].
According to [118] and [204], the temporal characteristics of facial expressions are also a key factor in distinguishing posed from spontaneous expressions.
Finally, they can also facilitate the detection of micro-expressions, as we will see below.
Recognizing subtle, low-intensity expressions. Micro-expressions are defined as quick, low amplitude facial expressions. They appear when people experience low intensity emotions, begin to feel an emotion (onset), or when emotions are concealed, whether deliberate or unconscious [59,93].
The detection and recognition of subtle expressions, and even more micro-expressions is difficult because of:
their low amplitude, which requires precise movement or appearance descriptors;
their very short duration (1/25 to 1/15 of a second for micro-expressions), which means that they can only be captured by very fast video acquisition systems;
their appearance only in specific high-stakes situations, making them difficult to provoke;
their potentially fragmented character (e.g. a slight tightening of the lips may be a sign of anger)
Because morphological changes in the face are by definition negligible, many researchers use a dynamic approach to facilitate the detection and classification of micro-expressions [66,88,99,116,118,127,190].
Some studies [202,205] use a motion magnification technique that improves the detection of micro-expressions by increasing the amplitude of facial movements. The most commonly used spotting technique is the threshold technique [101,107,134,202] (for a review, see [133]) and peak detection. [26] use a high-speed acquisition system (averaging 170 fps) as well as motion descriptors based on the absolute image difference between the current frame (potentially the apex of the expression) and a previous frame at half the duration (potential onset). In their review, [133] mention the problem of short non-emotional movements (e.g. head movements or eye blinks) which can be detected as peaks of micro-expressions. To deal with this problem, [134] have developed a threshold technique to eliminate head movements, blinks and changes in gaze.
Beyond micro-expressions, the estimation of the intensity of a facial expression provides valuable information, especially in the interpretation of complex or ambiguous behaviours (e.g. an expression that can have several meanings).
For example, the temporal evolution of the intensity of an expression can make it possible to distinguish between a posed smile and a spontaneous smile [118] or even to relate it to the intensity of a person’s emotional experience, or even the level of pain. The structural and temporal dependencies between facial actions and their intensities also make it possible to increase detection performance by “constraining” the detection of one action in relation to another.
[109] and [200] have developed systems for estimating the intensity of Action Units (AU) taking into account the structural dependencies and time dynamics between AUs and their intensities. For example, AU 6 (cheek raiser) and 12 (lip corner puller) are correlated in terms of presence but also in terms of intensity and dynamics of appearance: AU 12 appears and increases in intensity as the intensity of AU 6 increases.
In their study, [152] estimate the intensity using a Conditional Random Field that takes into account several elements that they call contextual: the subject observed (Who), the changes in appearance of facial expressions (How) and the temporal relationships between the different levels of AU intensity (When).
This consideration of spatio-temporal interactions allowed a significant increase in the performance of their systems.
Several studies have explored techniques to provide intensity estimation in discrete levels, mainly through Action Units whose 5-level intensity is provided in several databases (Bosphorus, DISFA, GFT, UNBC). [11] use a local-global ranking technique that compares the differences in Action Unit intensity between two images of the same person, in order to avoid the problem of morphological differences between individuals. [17] trained in a multi-task CNN that simultaneously detects the occurrence and intensity of all Action Units, taking into account different head orientations. [74] propose the detection of the presence and intensity of AUs with a feature extraction system separated into several ROIs, in order to reduce the problem of AU co-occurrences and to avoid errors due to occlusions of certain parts of the face to be reflected in the final output.
For their part, [219] have developed a regression system (SVR) in order to continuously estimate the intensity of the Action Units. They report that this regression model exceeds the performance of classifiers trained to estimate discrete levels.
The term “emotion”, frequently used in literature and in everyday life, is relatively difficult to define from a scientific point of view. Indeed, this multidimensional phenomenon is based on physical, physiological, cognitive and behavioral considerations.
From antiquity to the present day, psychologists, physiologists, anthropologists, philosophers, sociologists, ethologists and neuroscientists have carried out a great deal of work to define and classify human emotions.
Each of them has proposed a different definition.
Stemming from the classical debate between nature and culture, many theoretical controversies currently remain concerning the nature of emotions and their relationship to facial expressions.
In the field of the AFER, these competing theoretical models of emotions lead to choices of measurement and thus of different data.
The large majority of studies postulate a direct link between emotions and facial expressions. The difference lies in the way these emotions are described, in terms of discrete categories or on a continuum of dimensions.
Figure 5 summarizes the type of emotions taken into account in the various studies.
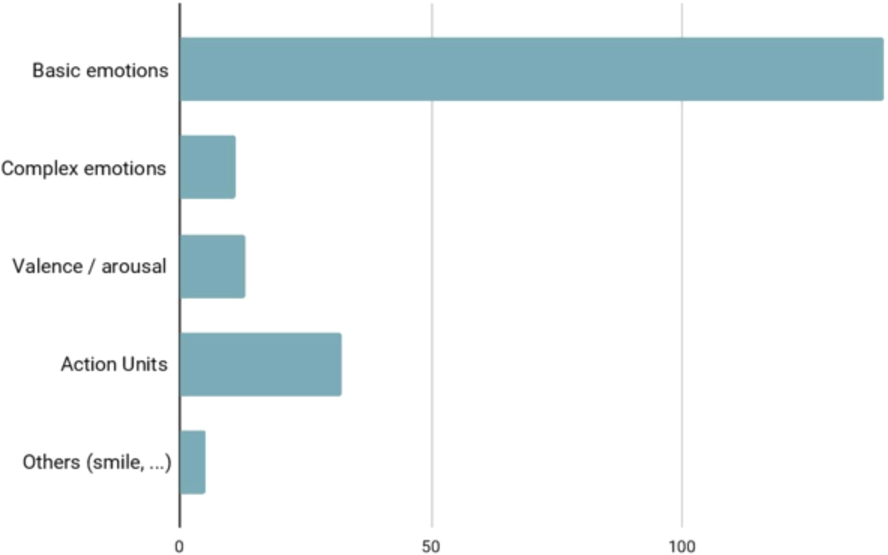
Type of emotions considered in the studies.
Discrete emotions. Drawing on Darwin’s original work, many authors, such as Ekman, Izard, Tomkins and Plutchik, argue that there is a finite number of basic emotions, which are linked to a biologically determined and pre-wired “affect program” to adapt to the demands of the environment, with a dual function of adaptation and social communication.
Each of these basic emotions would be expressed according to a prototypical and specific pattern of facial expression, which would vary little or not at all depending on the culture or context.
Proponents of this theory have proposed different lists of emotions that more or less overlap. Ekman, the most emblematic contemporary representative of this point of view, considers 7 basic emotions: joy, fear, surprise, sadness, anger, disgust and contempt. As can be seen in Fig. 6, a very large majority of studies (94.2%) focus on basic discrete emotions (see for example [1,6,9,10,80,149,167,168,217,226]).
These are inferred from images annotated in terms of emotion labels or from the detection of Action Units [11,73,75,94,129,144,180], see also [224] for a review.
Type of datasets used in the studies.
Based on the assumption that Action Units are very rarely observed in isolation, [63,177] and [219] have taken into account co-occurrences and mutual exclusions (anatomical impossibility, such as opening and closing the mouth) between AUs. They developed a correlation matrix to increase the accuracy of detection, and to model changes in the appearance of some AUs when they occur in combination with another (non-additive effect).
According to the discrete emotion theory, so-called “complex” or “compound” emotions would come from a combination of two or more basic emotions. They can appear either as a juxtaposition of basic emotions (e.g. “happily surprised”, “sadly angry”), or they can be combined, like a mixture of colours, to form new emotions. For example, in the model of 141, the 8 primary emotions can combine to generate second-order emotions (e.g. disgust + anger = contempt).
In this model, there are also other emotions, sometimes called derived emotions, which are represented in the form of discrete labels belonging to the family of basic emotions and differing mainly in terms of intensity, such as rage, fury, irritation, etc. are related to anger. There are still very few studies on complex or compound emotions, mainly due to the lack of theoretical consensus on the existence of specific facial expressions for this type of emotion.
[180] used Plutchik’s theoretical model to develop a system trained to detect Action Units (AU), then implemented AU combinations forming the expressions of the 6 basic emotions, which allows combinations corresponding to secondary emotions (notably awe, a combination of fear and surprise).
In the same vein, [111,112] revisited the databases annotated in basic emotions (notably JAFFE, CK+, DISFA and IMED) by applying a system called “fuzzy inference engine”, giving a multilabel classification in order to represent compound emotions.
[76] compared the recognition performance of their system on 3 databases of spontaneous expressions depicting the 6 basic emotions as well as frustration and fun. With the aim of determining the characteristics allowing the identification of 18 emotions (including the 6 basic emotions and 12 complex emotions, such as interest, pride, disappointment, shame, etc.), [2] created a system allowing the joint detection of facial expressions and head movements.
Dimensions. Sometimes called continuous, the dimensional model suggests that emotions are not discrete entities, but that they are located on a continuum organized according to 2 or 3 dimensions: valence/arousal, approach/avoidance and dominance.
The valence determines the positive or negative aspect of the emotional experience, the arousal describes the degree of excitement (more or less related to the intensity of the emotion).
The notion of dominance makes it possible to distinguish between emotions related to submission (lack of control) and dominance (high potential for control, such as anger). Each emotion can therefore be represented by a point on a two- or three-dimensional space, allowing more nuances than with the categorical model.
[4] have developed a mixed system allowing the detection of Action Units as well as a regression in terms of valence and arousal. The arousal is determined from the degree of intensity of each Action Unit. The authors do not provide information on the model that allowed them to determine the valence.
[85 ,126 ,207] also used regression and valence/arousal labelled databases (RECOLA, Amigos individual and groupDB, AffectNet) to represent 3D facial expressions in two-dimensional space. 162] used Russell’s circumplex model to determine the links between discrete emotions classified from facial expressions (grouped in 4 classes: happy, surprise, neutral and negative) and the dimensional self-reporting of subjects in human-computer interaction situations (task or computer game).
In the same way, some studies [33,43,57,118] are dedicated to smile detection, without interpretation in terms of emotion categories.
The question of context. Psycho-constructionist models (for a review, see [15]), on the other hand, postulate that emotions are changing and dynamic phenomena, and that they depend on many individual factors but also on the environment with which people interact daily.
Indeed, facial expressions always manifest themselves to serve a particular purpose in a given social context, and it is this context that will determine the correct interpretation of an expression.
For example, depending on the situation, a smile may express joy, but also pride, embarrassment, or a polite greeting; a frown may indicate anger in some cases, and in others, strong concentration or confusion.
Anchored in the concrete, these theories help to highlight and explain the intra- and inter-individual variability in the expression of emotions.
Since 2014, only 8 studies have attempted to explore the context in which facial expressions appear.
Context is commonly defined as all the information resulting from the situation in which an event or phenomenon occurs, in this case an emotion.
It is therefore a broad and complex notion, which can be the subject of many definitions according to the authors: cultural origin [40], physical context and events [13,22], purpose of social interaction [157], or context including several parameters.
[89] approaches the notion of context, but as a source of variation to be eliminated. Rather than describing and formalizing context, it seeks to model the specificities of emotional expressions (and their temporal transitions) in order to isolate them from the multiple sources of variation that can be confusing.
[40] explored the effects of culture using 3 databases of subjects from different cultures (CK+, JAFFE and Bosphorus). They performed a cross-database validation to compare recognition performance, and concluded that performance was lower in cases where the training databases involved a different culture (subjects from different ethnies) from the validation database.
[13] have developed a system for interpreting the temporal history of facial expressions in the context of the events that caused the emotion expressed.
In other words, they consider that the temporal dynamic of a facial expression is determined by different types of socially significant events (type of emotion that may be provoked by the event, e.g. funny or sad) and different intensities.
[22] have also used an event-based method. They developed post-processing classifiers to identify the emotional context during a time window. These algorithms allowed them to predict sudden or progressive changes in emotional expressions through event detection.
[157] focused on the link between a virtual agent and a human, in particular on the purpose of the interaction: competition, information, education, collaboration, negotiation, guidance or purely social.
[132] were based on a broad definition of the context. They used formalisms to describe situations in terms of environment, social norms, salient objects and behaviours, and proposed a method for the detection of 8 types of complex social events (interview, wedding, sports event, party, dinner, birthday, class and nightclub) with an accuracy between 37.9 and 51.8%.
On the basis of multimodal data from digital interviews, [182] developed a system for detecting emotions that takes into account the direction of the gaze, prosody, speech, facial expressions and some contextual information: the interaction phase (introduction, negative, positive), the sex of the subject and the content of the previous question.
More recently, [158] developed an emotion recognition system based on contextual information (presence and type of social partners, activities, temperature, physiological state, location and time of day) provided by 32 participants through a mobile application. This information led to individual, general and gender-based models that allowed to weight the prediction of emotions. The authors showed that contextual information is relevant, especially at the individual level, and increases detection performance.
There are currently very many databases of facial expressions used for the training and the validation of the algorithms of AFER.
They differ in their characteristics: number of images or sequences, static or dynamic data (videos), number of categories of emotions, posed or spontaneous expressions, real or controlled conditions, etc.
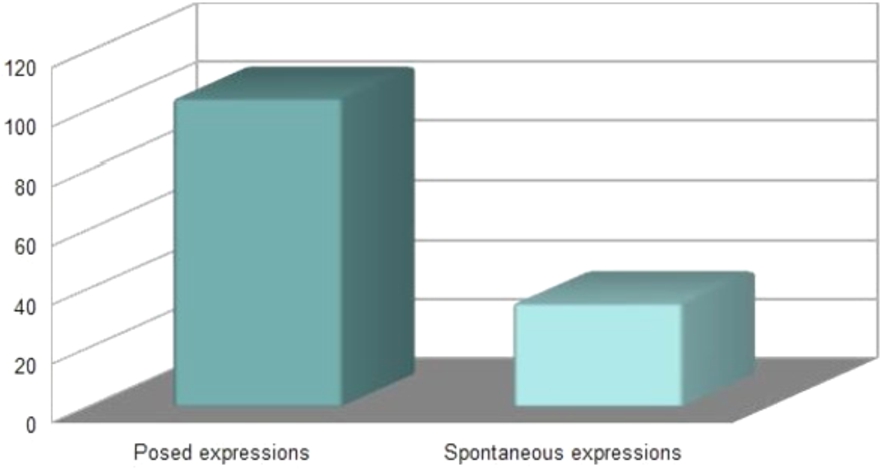
Except certain databases which are composed of images coming from the Internet (e.g. AffectNet, SFEW) or collected in natural situations (Aff-Wild, Fig. 7), the great majority of the databases are constituted in a controlled environment and under controlled conditions of luminosity and background. As can be seen in Fig. 6, more than 74% of the studies use databases with posed expressions, with a clear preference for CK+ (Fig. 8) and JAFFE, which concern 42% and 29% of the studies respectively.

Sample images from Aff-Wild dataset (spontaneous expressions, dimensions).

Sample images from CK+ dataset (posed basic emotion expressions.
Table 2 below provides a brief description of the most used datasets in terms of type of support (video or still image), numer of subjects and frames, type of expression (posed or spontaneous), and labels.
Description of the most used datasets
Most of the studies analysed present their classification performance in terms of accuracy, which corresponds to the rate of correct predictions in relation to the total number of examples:
There has been a general increase in performance over time: the overall accuracy increased from 83.54% in 2014 to 85.38% in 2019.
An ANOVA was performed to determine the effect of system type (machine learning/deep learning), type of emotion (basic/complex/dimension) and type of expression (posed/spontaneous) on accuracy (Fig. 9). The results are shown in Fig. 5.

Average accuracy by type of algorithm, emotion measured and type of data.
Contrary to what is sometimes argued, the ANOVA revealed no significant effect of the type of algorithm. Deep learning systems (
Systems trained to recognize basic emotions (
The nature of the data used also has a significant effect on recognition performance: systems validated on posed expression databases (
Indeed, the 3 datasets that generated the best performances are made up of posed expressions: FABO (average accuracy 95.51), BU-4DFE (90.94) and CK+ (88.06).
On the other hand, the most challenging datasets contain spontaneous expressions: Enterface (average accuracy 66.51), SFEW (67.51) and the two micro-expressions datasets CASME II (63.59) and SMIC (61.03).
However, given the methodological differences between studies, it is difficult to compare performance between systems in a precise manner, and these results, which allow general trends to be identified, should be treated with caution.
In addition, average accuracy is not a sufficient metric to assess an algorithm: it is also important to know the performance of a system according to the categories of emotions.
About half of the studies analyzed in this review have proposed confusion matrix category by category. We analyzed these matrices and noted the categories of emotions that were most often confused.
Overall, it turns out that negative valence emotions (especially fear and anger) are the most difficult to spot and are often confused with each other.
For example, the confusion between anger and sadness is the most frequent in 44% of studies, the one between fear and surprise is the most frequent in 32% of studies. While the confusion between fear and surprise is easily explained by the proximity of these two facial expressions, the one between anger and sadness is more difficult to interpret. It is possible that it is the presence of a frown, present in both expressions, which is confusing for the algorithms.
More unexpectedly, a quarter of studies report frequent confusion between joy and fear. In most databases used with posed expressions, fear is expressed with the lips stretched, which could be mistaken for a smile.
Table 3 provides an overview of the studies included in the review, as well as a description of the classifier and databases used, the type of emotion, and the performance metrics.
Brief description of the studies
Brief description of the studies
(Continued)
(Continued)
(Continued)
(Continued)
A comprehensive review of recent literature was conducted, analyzing a total of 220 original studies.
The automatic recognition of emotional expressions is a rapidly evolving field, and we cannot guarantee that we have taken into account all the articles, especially those written in other languages or published during the writing of this review.
However, this work has made it possible to cover a large part of the research carried out in the field of the AFER. It also proposes a qualitative and thematic approach, which allows a better understanding of this complex field, but also to have an overall view of the issues addressed or to be developed in future research.
Our results suggest a large and steadily increasing number of publications between 2014 and 2019. Automated facial expression recognition is therefore currently attracting a great deal of interest.
The review has also highlighted a wide variety of techniques and models used: while deep learning is widely used, especially in recent studies, conventional machine learning techniques are still in the majority, and involve a wide range of algorithms (SVM, Random Forest, Naive Bayesian network, Decision Tree, etc.).
Despite the generally equivalent performance of conventional techniques and more recent approaches (deep learning), research has made it possible to develop increasingly sophisticated and high-performance models (majority use of deep learning from 2018 onwards, increase in average accuracy over time).
However, the vast majority of these performances are still tested in a very standardised framework, and the data used for validation still concern almost exclusively posed expressions of a limited number of basic emotions, obtained under conditions of luminosity, pose and homogeneous background.
Performance drops significantly when systems are confronted with more natural data, i.e. data obtained in real-life conditions where emotions arise (everyday situations, natural conversations). This is due to the fact that emotion is a multifaceted phenomenon, which is not limited to a few prototypical facial expressions, and which is still subject to many theoretical controversies and therefore remains difficult to model in its complexity. This problem of definition of the concept of emotion leads to several questions, intimately related to each other, which will have to be tackled in the research in the field of the AFER.
Beyond the 6 basic emotions. Current automated systems, despite their increasing performance, use and require a cross-cultural and universal conception of facial expressions, i.e. the ability to translate them into easily interpretable data.
The classical theory of basic emotions, by its simplified and categorized description, makes it possible to give intelligibility to this very heterogeneous phenomenon, but it is now outdated: […] the six categories of emotions have no use for the majority of everyday applications. This simplification of the task, while serving us well in the early days, needs to change significantly. (Gunes et al., 2016, p. 3 [61]).
Recent research has shown that there are many more categories of emotions, and that they are separated by more nuanced boundaries than conventional thinking would suggest, as their emotional characteristics (such as valence or arousal) may in some cases be similar.
It seems therefore necessary, in order to get as close as possible to reality, to develop theoretical models and to train our systems to recognize a wider range of expressions [21,36], relating to complex or compound emotions, as well as to cognitive states [72,117] or even non-emotional facial expressions, which appear more frequently than expressions related to emotions in the context of interactions between individuals.
Taking into account the variability of emotional states and facial expressions. Directly linked to the problem of categories of emotions, the question of the variability of expressions is essential to account for the richness of human emotional life.
In the model of basic emotions, the variability of facial expressions is often put down to methodological errors or secondary factors, such as “display rules”, which lead individuals to inhibit pre-existing and invariable emotional reactions in all situations.
This classical view is now being replaced by theoretical models that seek to take into account the complexity of emotions emerging in the interaction between the individual and his environment (social and non-social) and facial expressions. Indeed, all observations in ecological environments show that facial expressions are highly variable and dependent on multiple factors.
These sources of variation come from the cognitive and psychological state of individuals as well as from other people and the environment. Variability can be observed at all levels of analysis, both within the same person over time and situations, and between individuals and cultures.
First, there may be several patterns of facial expressions or behaviours for the same emotion.
Indeed, depending on many factors such as their personality, their previous experience, their culture, the different social roles they are led to play but also depending on the situation, individuals do not experience or express their emotions in the same way or at the same intensity.
It is therefore necessary, even if exhaustiveness in this field is illusory, to collect a maximum of natural data in order to predict as many variants of facial expressions as possible. Automatic facial expression recognition systems must also, depending on the application, be adapted to the situation and even to each individual in certain cases.
Similarly, the same facial expression can have several meanings. For example, depending on the situation, a frown may mean anger, disgust, sadness, but also more complex mental states such as confusion or intense reflection.
The notion of context then plays an important role in order to disambiguate facial expressions and interpret them correctly.
Since 2015, this field has been the subject of increasing research interest, with numerous studies and workshops (see for example [62]) devoted to the formalization of context in the field of automatic facial expression recognition.
Although most of the studies we have reviewed are devoted to the analysis of elements of the physical context (location, ambient temperature, etc.), it is the notion of social context – in the sense of interactionality – which, for some authors, provides the most relevant information for the interpretation of facial expressions: the presence of other people, their behaviour, the type of relationship one has with them and the type of interaction that is taking place are determining factors in the experience and expression of emotions.
Observing emotions in all their modalities. In their daily interactions with the physical and social environment, humans use many modalities to express and decode their emotional states. For example, it is known that the arousal dimension is more easily perceived through non-visual modalities, such as vocal prosody and physiological signals [61].
It therefore seems natural and necessary for automated systems to be able to use several modalities, such as coupling audio and visual signals to differentiate emotional expressions from speech induced deformations [89], analysing vocal characteristics or emotional discourse, or even merging more than two modalities in order to increase their accuracy [56,78,131,161].
With the multiplication of portable technologies and sensors (touch, microphones, bio-signals, etc.), it is now easy to set up multimodal databases. The difficulty lies rather in the annotation of these data, which requires a deeper understanding of how humans fuse these modalities together to consistently produce or decipher emotional expressions. Moreover, it is often not feasible to apply the full set of sensors to an individual or individuals in the context of everyday life. It is therefore necessary to choose according to the objective.
Collecting and using spontaneous and natural data. As we have seen, most current systems are based on a paradox: while the theoretical model of basic emotions postulates the existence of a direct link between emotion and facial expression, the majority of systems are trained and validated on the basis of stated expressions, which by definition do not reflect an emotion actually felt.
The quality of the data being a paramount condition to train the ARM systems to recognize in a relevant way the facial expressions [50] [97], it is thus necessary to collect and to annotate a great number of spontaneous expressions, collected under natural conditions. However, obtaining the ground-truth is subject to several problems:
data annotation is a time-consuming activity and is often subject to bias [81];
as the research has mainly focused on annotation in terms of 6 basic categories of emotions, there is not yet a way to know what kind of annotation (Action Units, dimensions or discrete categories) is closest to the reality of the expressions;
finally, as we will see below, facial expressions can vary significantly from one person or situation to another. It is thus necessary to constitute data bases presenting a maximum of these variants, in order to confront the AFER systems with a sufficiently broad sample of expressions.
In order to deal with these problems, some research teams have begun to develop the use of non-annotated data, in particular through transfer learning (transfer of learning from one algorithm to another, [73]), semi-supervised [64] or unsupervised learning [206].
Conclusion
The AFER is a field in constant evolution, and the researchers developed these last years more and more elaborate and powerful systems. However, a great majority of these systems have been tested in conditions far from the natural context, and one can advance that Artificial Intelligence is still far from the capacities of the human being as regards decoding emotional states.
One of the main problems is that the algorithms are designed to exploit data and derive stereotyped characteristics from it, which makes them unable to take into account special cases and novel configurations [45]. Emotion, according to the most recent theoretical conceptions, is a highly subtle and changing phenomenon, which varies according to many parameters that theory has not yet been able to formalize in their entirety. Its conceptual precision, reflecting its complexity, is still problematic and remains a “work in progress”.
However, this lack of consensus in the definition and diversity of theoretical models apprehending the concept of emotion and facial expressions should not discourage researchers from studying these phenomena.
It is necessary to pursue research along the four promising avenues highlighted in this review (broadening the range of emotions, taking into account variability and context, tending towards multimodality and generating data from natural conditions), so that artificial intelligence cannot only describe but also apprehend our emotions and all the factors that accompany and determine them in a relevant manner.
All the disciplines concerned with this subject must work in synergy to achieve a more consensual model and to understand the subtle ways in which humans feel, express, decode and exchange their emotions on a daily basis.
Conflicts of interest
There are no known conflict of interest associated with this publication.
Footnotes
Acknowledgements
This research was supported by Two – I SAS. We are grateful to all our colleagues for their useful comments on an earlier version of this paper. We would also like to thank the anonymous reviewers for their helpful and constructive comments and suggestions regarding this manuscript.