
Abstract
Navigation apps have become more and more popular, as they give information about the current traffic state to drivers who then adapt their route choice. In commuting scenarios, where people repeatedly travel between a particular origin and destination, people tend to learn and adapt to different situations. What if the experience gained from such a learning task is shared via an app? In this paper, we analyse the effects that adaptive driver agents cause on the overall network, when those agents share their aggregated experience about route choice in a reinforcement learning setup. In particular, in this investigation, Q-learning is used and drivers share what they have learnt about the system, not just information about their current travel times. Using a classical commuting scenario, we show that experience sharing can improve convergence times that underlie a typical learning task. Further, we analyse individual learning dynamics to get an impression how aggregate and individual dynamics are related to each other. Based on that interesting pattern of individual learning dynamics can be observed that would otherwise be hidden in an only aggregate analysis.
Introduction
Which route to choose for travelling from an origin to a destination is a central question a traffic participant – in our case, a driver – faces. However, the route choice of a driver does dependent on the choices of others, as the cost of a link is determined by the overall load on it. This is the well-known problem of traffic assignment. When repeatedly facing the route choice problem, drivers adapt to their experience and choose a route which they expect to be the best choice – mostly with respect to shortest travel time1
On a side note, we remind that there is a branch of this problem that deals with multi-criteria optimisation, where other factors beyond travel time are considered.
More and more drivers use navigation apps that also show the traffic state collected from real-time speed observations, such as Google Maps or Waze providing dynamic route guidance to drivers. Drivers fuse the information that they receive from those apps with their individual experience to actually make their routing decision. This can also include partially overriding the advice from the route guidance system. One drawback with such schemes is that they seem to be based on recently observed traffic states only.
In this paper, we aim at analysing whether sharing of experience among drivers rather than using recent travel time (or speed, for that matter) information enables the overall system to reach a state that is close to the user (or Nash) equilibrium (UE). Our analysis is inspired by a hypothetical app, with which drivers share what they have learned related to their repeated route choice between some origin and destination in a traffic system – like friends chatting about which route they prefer or avoid, sharing aggregated experiences rather than just the most recent ones.
As discussed later in Section 5, there are some approaches that are based on sharing or transferring knowledge to improve or accelerate the learning process. However, the majority of them deal with cooperative environments. In non-cooperative tasks, such as the route choice, the transfer of a good solution from one agent to others may produce sub-optimal outcomes. Therefore, there is a need for approaches that address transfer of knowledge in other contexts. With the present paper, we provide the first steps in this direction.
The following sections of this paper are organised as follows. First, we introduce some background on route choice, traffic assignment analysis concepts, and on reinforcement learning. Section 3 then describes the proposed approach, while Section 4 discusses experiments performed with a standard scenario and results gained from that. Section 6 then presents the concluding remarks and points to future research.
The traffic assignment problem
The traffic assignment problem (TAP) aims at assigning a route to each driver that wants to travel from its origin to its destination. In traffic analysis and simulation, traffic assignment is the prominent step of connecting the demand (how many drivers want to travel between two nodes in a network?) and the supply (roads in a traffic network with particular capacities, speed, etc.). The TAP can be solved in different ways. Agent-based approaches aim at finding the UE [32], in which every driver perceives that all possible routes between its origin and destination (its OD pair) have similar, minimal costs with the result that an agent has no incentive to change routes. This means that the UE corresponds to each driver selfishly computing a route individually.
A traditional algorithm to solve the TAP, (i.e. to find the UE) is the method of successive averages (MSA). Yet, this method is performed in a centralised way.2
For details see, e.g., Chapter 10 in [22].
In reinforcement learning (RL), an agent’s goal is to learn a mapping between a given state and a given action, by means of a value function. A popular algorithm to compute such value functions is Q-learning (QL) [33]. Value functions take the instantaneous reward received (a numerical signal) and compute the expected, discounted value of the corresponding action. Once such mapping is learned, an agent can decide which action to select in order to maximise its rewards.
We can model RL as a Markov decision process (MDP) composed by a tuple
Q-learning (QL) computes a Q-value
Each agent is a learner that maintains a Q-table that is updated in each
subsequent episode. In order to address the exploration–exploitation dilemma, the
ε-greedy exploration strategy can be used to choose
actions: the action with the highest Q value is selected with a
probability of
Finally, even if agents may be learning independently (as, e.g., in [8]), this is a non-trivial instance of multi-agent RL or MARL.
Sharing experiences
Q-learning in a route choice scenario
Let
Drivers use Q-learning (Eq. (1)) to individually determine which is the best route they can take from their individual origin to their destination. Let S be the particular origin node of the individual driver. S then determines an agent’s state, i.e., this is a stateless formulation of QL, as in [8]. Further, each driver learns independently.
The set of actions A, for each agent, contains all k shortest routes between an agent’s origin and its destination. Therefore the number k needs to be sufficiently large to give enough flexibility in route choice. The reward signal is a function of the experienced travel time on the route (we use the negative of travel time, for maximisation purposes).
It is important to actually understand the multi-agent characteristics of this learning task. Because links have travel times that depend on the number of agents using them, learning is challenging. The desirable, shortest path under free-flow, may end up producing a high travel time, if too many agents want to use it at the same time. Agents need to learn how to distribute themselves in a way that an optimal number of agents use each edge, minimising their individual travel time on the selected routes. Coordination is desirable not just between agents with the same origin-destination pair, but needs to happen between all agents, even if their routes would share only a single link.
Information sharing via app
With the dissemination of various traffic apps, it is no longer realistic to assume that drivers only learn from their own experience when repeatedly travelling from an origin to a destination and by just observing their own travel time. Carrying the idea of traffic apps beyond current traffic state, more information produced by others can be used for decision making. Such a new app could mimic and generalise chatting among friends, neighbours or colleagues their favourite or most disappointing routes choices. The app would make route experiences available for wider social circles and systematic experience exchange.
While there has been a number of works in which the effect of information about current travel times on route or on parts of the route was tested (see Section 5), the question emerged whether explicitly sharing accumulated information about particular routes could improve the learning process. The setup of the suggested app is visualised in Fig. 1.

Setup of the system: drivers decide about sharing their experience via an app with a server. The server processes the collected information and publishes the aggregated experience. Drivers may access this information depending on their information strategy.
The overall decision making happens in three steps:
Agents select an action from their set of possible actions. Each agent experiences the time that it took to perform the travel using the route that corresponds to the selected action. The agent updates its Q-table according to the QL rule (Eq. (1)). At the end of the day, they share an evaluation of a route with the app. The shared information does not need to be about the route they took most recently, it may be their best, their worst, or a random route. The app can be seen as a platform for chatting with “neighbours”, who talk about what their experiences are when travelling to a particular destination. Drivers may also decide to share no information at all. More precisely: sharing their accumulated experience means that they share the Q-value assigned to a particular action.
We assume that agents do not reason about the impact of their information sharing. That means, they do not hide a particular good route in order to prevent others from taking it. This may have the consequence that the travel time on that route increases with the number of agents reacting to this information.
The server that runs the app collects all information from the sharing drivers and determines the shared information that the server then publishes. This information contains, per origin-destination pair, an action and the Q-value that belongs to the action aggregated from all handed-in information.
Driver agents decide whether to access the published information. Accessing has the consequence that they incorporate the published information in their Q-table: they replace the Q-value of the respective action with the published Q-value for the given action. There is no reasoning about the credibility of the published value. The decision of accessing the shared information can be based on a budget acquired by sharing – the more one shares the more one may access the shared value. In the current version, the agents do not reason about whether the investment into acquiring published information may pay off, they rather access the information with a given frequency/probability, provided they have a budget.
This is a multi-agent reinforcement learning setup, in which agents are involved in an anti-coordination game. Sharing happens in groups: only agent within the same group, that means with the same origin and destination pair, share partial information from their Q-tables.
The scenario that we analyse here has some flavour of a rudimentary form of transfer learning. Transfer happens during the learning process, not from one task to another, but rather from one agent to another. These agents are solving the same problem, yet they may be in different learning contexts. Due to the way we modelled actions, transfer between different problems – here different origin-destination pairs – makes no sense since the actions do not belong to the same set.
More details need to be considered to provide full information about the analysed scenarios. Next, we cover the details of the sharing scheme.
Recall that agents select their route before the actual travelling happens. Then, all agents travel through the network. Using cost functions that, given a link’s load, output the travel time on a link, we abstract away from detailed temporal dynamics in which departure time and other issues matter. As we want to focus on the effect of sharing experiences and different aspects related to that, we did not use a microscopic traffic simulation to determine how an individual driver moves through the network. As a consequence, all agents taking the same route face the same travel times. The reward signal from travelling is perceived by the drivers after each has finished its trip. The agents update their Q-tables and can send information to the app. In the next episode, the drivers who want to access the published information, look into the service and again update their Q-tables based on the published value. This way, there are a number of decisions involved. Table 1 summarises these decisions, along various dimensions.
Summary of overall setup options for the sharing scenario
Summary of overall setup options for the sharing scenario
Assuming that a driver needs to pay for the service of getting such information, the decision about whether and when it is best to incorporate information from other agents into ones Q-table may be a strategic one. Here are some alternatives.
Access information in every episode seems to be the simplest strategy;
An agent could collect some budget – e.g., from sharing information – that it could invest into accessing information. This way, whenever an agent has collected enough resources, it accesses the app for getting information. The relation between costs of accessing and gain per sharing is the relevant parameter here, thus linking this dimension to the one described in the next subsection. Unlimited budget then corresponds to access at any time; zero budget corresponds to no episode;
An agent could access the information in the initial episodes, and then with decreasing frequency;
One can imagine more advanced strategies based on the dynamics that an agent observes. For example, if the action with the best Q-value was “disappointing” for a number of times, an agent may invest to access the app for information about better routes;
An alternative could be based on an analysis of the Q-table: an agent could access shared information only when the Q-values are not sufficiently distinct one from another.
We decided to focus on the simpler alternatives and leave the more sophisticated ones to deal with in the future, as they involve a lot of individual parameters, which are necessary to fully specify them. Hence, in this work we follow the second alternative, varying the budget agent has, starting with unlimited budget and then decreasing it, so that agents only access the information in some episodes.
Although we consider that all have the same budget, the access is not synchronous, i.e., not everybody spend their budgets in the same episode (except in the case that budget is unlimited and thus every agent access in every episode).
Whether, when and with whom to share information?
As aforementioned, the agents learn individually about good actions/routes for their origin-destination pairs. In principle, they do not need to share – yet without a sufficiently large population of drivers sharing, the information that the app publishes may not possess any value. This way, it is in the interest of the app providers that as many agents as possible hand-in their experience.
There might be some required consent for basic service usage to send information about an agents’ experience to the app. This has the consequence that basically everybody would share experiences much like GPS traces are collected without full awareness of the traveller.
As an alternative, one can image that there is a small compensation for actively sharing experiences. The aforementioned budget system would need a corresponding side for earning what will be spend later. For every piece of information sent, an agent could increase the budget, and later use it for retrieving information. The compensation for sharing could be also independent from the information usage. It could be financial or in the form of some sort of credits that can be used for other activities.
A further alternative for deciding about to share may be based on whether an agent perceives its experiences to be “special”. For example, an agent shares, if it believes one route is much better than all others, or it is distinct compared to the other routes because the reward on it is improving for a number of times. What exactly “special” means, needs to be further defined.
In the present work, we just analysed situations in which every agent shares its experiences, without further considerations.
Another issue in the whole agenda is related to with whom an agent may share. One possibility is that the app publishes a value that is aggregated from all handed-in experiences; this means that, implicitly, an agent shares with everybody that travel between the same origin and destination. Whether the information that an agent contributes is actually valuable is a decision of the aggregation mechanism used by the app. As a second possibility, one can imagine to restrict the information dissemination to only a group of agents, denoting a group of friends or neighbours. This could bring more heterogeneity into the information transfer. In another, more extreme case, agents could pair and just share information with one other agent, thus thwarting the app idea.
So far we have just tested the alternative without restrictions. In the future work, we plan to test other settings.
What information shall be shared and how the information shall be aggregated?
These are central questions for the setup of the app. The question on what information to share relates to what information the agents do send to the app. This information relates to the costs of the routes; including the route with the highest Q-value. This basically means telling other agents that a given route is the best for everybody in the same origin-destination pair, according to an agent’s experience. Yet, there are situations in which it is better to avoid the same choices made by others. Hence, we foresee that the following alternatives may be relevant:
Share the last chosen action including its Q-value;
Share a randomly selected action with its Q-value;
Share the action with the best Q-value;
Share the action with the worst Q-value.
We did not test the first alternative. However, during the exploitation phase, an agent selects the action with the best Q-value. Thus, in many situations, the action with the best Q-value equals to the last action selected. If an agent explores, it selects a random action. This way, we assume that the outcome of the first alternative will not be different from the second and third alternatives. In Section 4.2.1, the corresponding results are presented.
We now discuss how the information is aggregated, both by the agents consuming such information, as well as by the app, prior to distributing it to agents.
An important point here is that the shared information contains, itself, information that has come from other agents. This is so due to the fact that an agent may not only share but also consume information, sometimes replacing the Q-value of the respective route/action. Hence, consumed information has been integrated into agents’ own individual Q-tables.
The new information may not have immediate effect on an agents’ route choice in the next episode. The case in which an agent actually takes an action corresponding to a consumed information (i.e., information obtained by accessing the app) only happens when an agent is exploiting: in this case, it may greedily select the action with the highest Q-value, where this came from another agent by sharing.
As aforementioned, the app collects and aggregates information from all sharing drivers. Also for this step there are different alternatives:
The app publishes a random value;
The app publishes the overall best Q-value and the corresponding action;
The app publishes the overall lowest Q-value with the corresponding action;
The app averages the Q-values for each possible action and then publishes the action with the best average, including the averaged Q-value;
The app averages the Q-values for each possible action and then publishes the action with the worst of these averages together with the averaged Q-value.
Together with the alternatives for which values to share, this produces a number of interesting alternative combinations. An interesting one is to share randomly selected information that is collected from all the best or all the worst Q-values. We then opted to test these combinations: the app provides a fully randomly selected information, the best of all best, and the worst of all worst Q-values.
While we listed different alternatives separately, clearly combined options can generate interesting strategies. A especially natural line of investigation could focus on the budget perspective. An income budget could be generated from sharing; later, it could be spent for accessing others’ information. This would link different aforementioned dimensions in a coherent way.
Experiments and results
Scenario
We performed a number of experiments to understand how the sharing actually impacts the adaptation and eventually the performance of the drivers using the app.

OW road network (as proposed by Ortuzar and Willumsen) [22].
The OW network (proposed in Chapter 10 in [22])
seen in Fig. 2, represents two residential areas (nodes A
and B) and two major shopping areas (nodes L and M). Hence, there are four OD pairs,
connecting residential areas with shopping areas. The numbers in the edges are their
travel times between two nodes under free flow (in both ways). We assume no additional
delays when passing nodes, e.g., due to traffic lights. We computed
The volume-delay (or cost) function is
For the sake of getting a sense of what would be optimal, the free-flow travel times (FFTT) for each OD pair are shown in Table 2. We note however that these times cannot be achieved because the free-flow condition is not realistic. When each agent tries to use its route with the lowest travel time, traffic jams occur and the times increase. In addition the table shows the number of agents that travel between the four particular origin and destination combinations and the travel time in UE. This is averaged as drivers take different routes between their OD pairs. Also, the fact that 1700 agents learn simultaneously, makes the overall learning complex.
OW network: some characteristics
For the QL, Q-tables are initialised with a random value around −90. This value was selected because it is not as optimistic as the free flow travel times shown in Table 2 (see FFTT column), nor too pessimistic. We recall that rewards are the negative of travel times.
All experiments were conducted with
We measure overall performance of the different approaches with the average travel time over all 1700 agents. We also did some analysis of average travel times for the different OD which are slightly different due to different numbers and different free flow times on the involved links.
Each experiment was repeated 30 times. Standard deviations between runs are not shown to keep the plots cleaner. We remark that they are of the order of 1% of the mean of average travel times. Within some single runs, we observed high oscillations between episodes. We defer this discussion to Section 4.2.3, where we explicitly look at the individual drivers’ results. To be able to dive deeper into these individual performances, we re-implemented the complete setup presented in [5], now using SeSAm3
for a fully agent-based implementation.
OW network: overall average travel time along episodes in the following cases: drivers do not share information, they share the best information, or they share the worst information. Agents access the published information in every step (unlimited budget).
This section discusses experiments that are related to the dimensions what to share and when to access.
The first question that was addressed refers to whether the agents should share their worst or best experience (see Section 4.2.1). After, we look into different setups regarding sharing the best experience, followed by a closer examination of what happens at the individual level (Section 4.2.3).
Which experience to share?
We start by looking at the effects of sharing in general – comparing different sharing settings with a no-sharing. The latter corresponds to the standard QL approach. In the setting where agents do share experiences, every agent shares either the worst, the best, or a random experience.
Once the app collected such experiences, it will pass along to other drivers the worst value collected, the best one, or a random one, respectively.
Upon receiving such information, every driver then integrates it into its Q-table. In the next episode, the driver uses the updated Q-table for determining its next action, provided it is exploiting. On the other hand, if an agent is exploring (which occurs with probability ε), it selects a random action. Due to the individuals’ history of route selections, the shared experiences may be different from the experiences of other agents travelling between the same OD pair on the same route – this is also a difference from scenarios in which agents share only the last reward/travel time information that is the same for agents that selected the same route.
We depict the results in Fig. 3; it shows that sharing and integrating information in every episode is not effective, as it performs worse than the standard QL (no sharing). Note that after 500 episodes standard QL shows convergence towards the UE, which is approximately 67 in the case of the OW network (see Table 2). One must also take into account that, on average, ε percent of the agents explore (due to the ε-greedy action selection strategy. If another scheme for action selection is used, as, e.g., if we would use a decay function on the ε, then the agents would actually find the exact UE. In any case, one also sees that the adaptation process however is somehow slow.
Also worth of notice is what happens when agents share the best experiences (and, similarly, the app distributes this information). In this case, after a sharp drop in average experienced travel time in the first few episodes and some more fluctuations in the beginning, the average travel time stabilises far from the UE.
As discussed in Section 4.2.3 when we analyse the system from an individual driver’s point of view, the overall population of agents overreacts to information about the best action/route. This is not surprising, as the drivers select the action with the best Q-value in 95% of the episodes. If one driver discovers a new best action, it shares it and in the next episode, most drivers select the new best route. The results are clearly worse than when standard QL is used.
We also tested the effect of what happens if agents share their worst experiences, which the app then aggregates in order to distribute. Here we tested two distribution schemes. Either the app informs about the best of these values (i.e., the best of the worst), or the overall worst of the worst.

OW network: overall average travel time along episodes for different sharing
setups. “
We start with the former, while recalling that this information is customised per OD pair, i.e., the app will inform the worst (or the best) value for each pair. In the case the app distributes the best out of the worst route/action for all agents, it seems that this does not give sufficient guidance for the learning agents. The reason is that such a value is unlike to replace a good experience the agents already have. Thus, when exploiting, the agents select the best route, that is unlike to be the one just recommended by the app.
If the app recommends the worst out of the worst action/routes, the learning curve of the agents becomes even worse. As all agents basically agree on what is a really bad route, nobody takes it any more when exploiting and agents distribute themselves among fewer routes. Following this, one of these routes becomes the worst, thus also being eventually avoided, and so on. Hence, updating the Q-tables with the worst out of the worst experiences leads to a kind of downward spiral of negative experiences filling the Q-tables with a lot of very negative Q-values. The way QL updates the values even with good rewards during the rather seldom exploration steps does not compensate for those bad experiences. This leads to learning actually being slowed down massively, despite some learning effect in the beginning.
Figure 3 additionally shows a setting in which agents share a random entry from their Q-table with the sharing app, which then publishes a randomly selected experience from those values handed-in by the agents. If this sharing happens in every episode, with every driver integrating the randomly selected entry into their Q-table, as expected, there is some tendency of improving the overall average travel time, yet with a high level of fluctuations. For improving the learning access with random sharing, some smarter way of integrating the published information needs to be devised. In the current version of our setting, agents simply replace the respective Q-values by the information provided by the app.
In conclusion, sharing has apparently no positive effect no matter scheme was used, if agents do share and get recommendations in each episode. This way, in the following, we focus on cases in which the agents do not access their experiences all the time, but rather, with a given frequency. We keep the setting in which the best experience is shared, as opposed to sharing the worst experience, given that the former has shown a superior performance.
To restrict the frequency of accessing the information provided by the app, we have tested different schemes. The main one is to impose a budget limitation for such access. Thus, agents need to be able to afford looking into what the app publishes.
Figure 4 shows the results of testing scenarios in which
an agent can only afford to access the information twice, 4, 6, or 8 times within 10
episodes. Agents decide individually; specifically, this is implemented as an access
probability. As a consequence, not all agents access the app at the same time, but on
average, with the aforementioned frequency. Henceforth, we denote such frequency by
p, thus we use
As for the cases in which there is sharing of experiences, the following observations can be made: First, no matter how frequently the agents access the shared experience, we see an acceleration in the learning process in the initial episodes. This is clear in Fig. 4, and is due to the fact that agents do not have to try out some actions given that they gain such information from the app, i.e., from others sharing their own experiences. Unfortunately, for higher frequency of access to this shared experience, this could lead to suboptimal learning causing the collective of agents to not converge to the UE.
As aforementioned, if agents access the shared best experience in every episode, then the performance is bad (see green line in Fig. 4). The reason is that too many agents are informed about the best performance in the previous episode and hence try to do the same action. Thus, the supposedly best action is selected by virtually all agents and they then end up using the same route (for each OD pair). This can lead to bad performance, not to mention a lot of oscillations (shown in the plot). This is a well known phenomenon and could be confirmed in our experiments.
When access is limited, so that it allows agents to only integrate shared experiences
in 6 or 8 out of 10 episodes (
When the agents have a lower budget that allows then only to access the shared
experiences from time to time (e.g., 2 or 4 in 10 episodes with
Table 3 compares the average travel times for each of the
OD pairs with the average travel times in the UE. One can see that for some OD pairs,
the 20% frequency (
It is intuitive that when agents have almost found the UE, learning about some other agent’s best action/route is not helpful any more. Even with only a 20% access frequency, there are still in average 340 agents, who potentially integrate published information. Thus, the UE is not fully reached. Therefore, a possible improvement that can be done in the model is that agents reduce the access frequency over time. This would correspond to a situation in which agents spend their budgets when they have less knowledge, reducing access when they already have a lot of experience. It will thus be interesting to analyse more complex access strategies. A strategy in which agents share in the beginning, but then gradually give up sharing over time, may lead to good results combining the fast early learning with actually reaching the UE.
Final average travel times for sharing frequency
and
for each OD pair in relation to UE
Final average travel times for sharing frequency
For confirming our assumptions on which individual adaptation processes had an impact on our aforementioned findings, we look into individual learning histories. Figure 5 shows the dynamics of experienced travel time, for a single agent (OD pair BM), randomly selected from an example run, and for each of the access frequencies p. These individual travel time traces are representative ones.
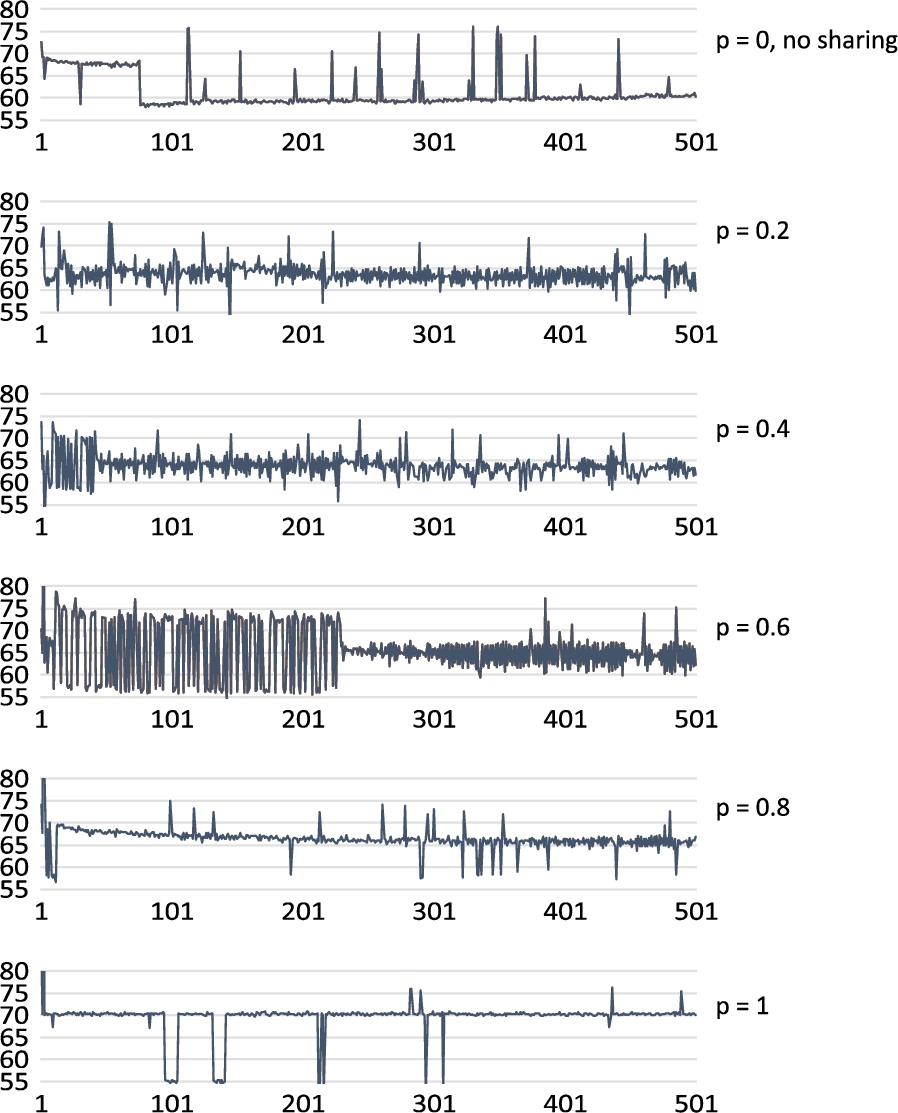
Travel times (y-axis) along episodes (x-axis) for a randomly selected, yet typical individual driver with origin B and destination M, for different values of access frequency p.
Starting with the setting without sharing (standard QL, top curve,
The adaptation history shown in the plot for
In settings with
The travel time history of an agent with
Analysing individual travel time histories as a consequence of the adaptation of the complete population, is quite time and resource consuming, but it is necessary to support statements about the overall learning success. Eventually, the individual agents are the decision makers and only on this level the actual validity and realism of the overall learning model can be evaluated. Also, this analysis confirms that more complex strategies for learning with shared information are necessary.
Besides the classical methods to address the TAP (see, e.g., [22], there are some works – based on other AI paradigms – with the goal of finding the UE. The main motivation for using AI is to solve the TAP from the perspective of the individual agent (driver, driver-vehicle unit), thus relaxing the assumption that a central entity is in charge of assigning routes for those agents. In such decentralised approaches, the agent itself has to collect experiences in order to reach the UE condition. Thus, these approaches are suitable for commuting scenarios, where each agent can collect experiences regarding the same kind of task (in this case, driving from a given origin to a given destination).
One popular approach to tackle such decentralised decision-making is via RL (more specifically MARL). However, other are also mentioned in the literature. We start with these and later discuss those based on RL.
In the work of [10], a neural network is used to predict drivers’ route choices, as well as compliance to such predictions, under the influence of messages containing traffic information. However, the authors focus on the impact of the message on the agents rather than the impact on system-level traffic distribution and travel time.
The work of [11] uses the Inverted Ant Colony Optimisation (IACO). Ants (vehicles) deposit their pheromones in the routes they are using, and the pheromone is used to repel them. Consequently, they avoid congested routes. Also [9] applied ant colony optimisation to the TAP. However, in both cases, the pheromone needs to be centrally stored, thus this approach is not fully suitable for a decentralised modelling.
One game theoretic approach to the route choice problem appears in [13]. This approach uses only past experiences for the route choice. The choice itself is made at each intersection of the network. However, it assumes that historical information is available to all drivers.
The work of [28] uses adaptive tolls to optimise drivers’ routes as tolls change. Differently from our purpose, they are concerned with alignment of choices towards the system optimum, which can only be achieved by imposing costs on drivers (in their case, tolls). In the same line, [6] deal with the problem from a centralised perspective to find an assignment that aligns users and system utilities by imposing tolls in some links. [35] on the other hand, rely on the cooperation of the driver handing in their planned travel details and receiving centrally optimised routing information.
Next we discuss RL-based approaches to compute the UE, as these are becoming increasingly popular. Here, each agent seeks to learn to select routes (these are the actions) based on the rewards obtained in each daily commuting, where the reward is normally based on the experienced travel time.
Two main lines of approaches can be distinguished: One, less popular due to its complexity, follows a traditional RL recipe, where besides a set of actions, there is also a set of states, these being the vertices in which an agent finds itself. Works in this category include [4]. However, the majority of the papers in the literature follow a so-called stateless approach in which there is a single state (the OD pair the agent belongs to), while the agent merely has to select actions, which are normally associated with a set of pre-computed routes that can be recalculated en-route, or not. This literature includes approaches such as [26] that is based on Learning Automata ([20]).
If learning automata is not used, a more popular alternative is to employ QL for the task of route choice. Of particular interest are those approaches that compute the regret associated with the greedy nature of selecting routes in a selfish way ([24,25]), as well as those that combine selfish route choice with some sort of biasing from a centralised entity ([1,7,23]).
There are works which, as we propose in the current paper, also deal with some forms of communication between agents. [3,14,15,17]. Information is here not always truthful, but can be manipulated for driving agents towards overall intended outcome. These works tend to focus on sharing aggregated experiences. Departing from these, in the present paper, only information about the immediate last reward or the actually perceived last travel time and thus the current traffic situation is shared. This intends to mimic the information produced by current route guidance services. Also in those works, it has been shown that if too many agents base their current decision making on the same shared information, one can observe overreactions with negative impact on the overall and individual performance. One idea, specifically analysed in [15], is to predict the traffic state based on the individual route selections that drivers inform a central component about. The central component uses the prediction and manipulates the information given to drive agents, so that these can re-consider their routing, and move the system towards its socially optimum state. This was exemplified in a simply two-route scenario.
Finally, a related line of research is the one dealing with some forms of transfer learning. The idea of sharing either learned policies or Q-values is not new. In fact, as early as in 1993, Tan [29] suggested that communication of some kind of knowledge could help, especially in cooperative environments. In particular, sharing Q-values may reduce the time needed to explore the space-action space.
Some researchers have dealt with aspects such as what and when to share. In an abstract view of sharing, [16] deal with agents that keep a list of states in which they need to coordinate. This idea also appears in the context of traffic management in [21], where traffic signal agents keep joint Q-tables based on coupled states and actions.
Some works – for instance, [30] – deal with more fine grained views of sharing knowledge, as for instance the transfer learning community, in which the quest regarding what and when to transfer gets more precise. Transfer of reward values or policies is also explored in the literature. For instance, [12,31,37] show that the learning can be accelerated if a teacher shares experiences with a student. We remind the reader that virtually all these works deal with cooperative environments, where it makes sense to transfer knowledge. In non-cooperative tasks, such as the route choice, we have seen that transfer of a good solution from one agent to others may produce highly sub-optimal outcomes. Coordination here is actually anti-coordination, appropriately distributing agents between different alternatives.
Conclusion and ideas for the future
The underlying motivation of the present work is to discuss the effects of a possible next type of travel app, in which users intentionally share their experiences, as opposed to conventional navigation apps, which are based on collecting drivers position, in order to be able to display current average speed at a particular segment. The app that we are considering here can be thought as a device that replaces direct interaction between colleagues or neighbours chatting about habits and experiences regarding route choice.
Assuming that humans continuously adapt to what they experience when performing commuting tasks, we analysed the potential effect of such an app in connection with ongoing learning. This way, agents can make decisions not just learn based on their own experience, but also use others’ experience on the same task. In this context, as far as our experiments using a non-trivial traffic network, it makes a difference whether users share bad or good experiences, as well as how often experiences are incorporated into the decision making. As we have shown, integrating other agents’ good experiences only from time to time leads to a speed up of the learning task, thus converging to a situation that approximates the UE. In cases in which sharing experiences happens too often, one can observe overreactions. Among other interesting findings, we can mention the fact that if agents share bad experiences too often, this slows down the convergence to the UE. This happens because integrating a high quantity of bad values, it becomes harder for agents to sort out good choices.
In previous works, drivers were informed about travel times that were collected by a central authority (as, e.g., Waze). This is effective only if some mechanism is introduced, in order to avoid that all agents react at the same time, thus leading to over-reactions. We can observe a similar effect here: the agents who do not excessively integrate others’ experience, learn the best choice for their route. Agents that update their Q-table with additional information from the app in every episode perform worst.
These findings are preliminary. More investigation is necessary to be able to claim general conclusions. Next we discuss some avenues for future work. We need to test other setups such as combining different sharing and aggregation strategies. For example the agents may share their best experience, but instead of aggregating the information, the app publishes a randomly selected value from those sent. As our results indicate that restricted access is advantageous, it might be interesting to restrict access in a different way: We plan to organise the overall population of agents into groups or social circles. Specifically, the app could aggregate experiences not from all agents but from particular groups of agents, such as friends. Similarly, instead of publishing the aggregated information to all agents that have a budget to access it, this could be done only inside a small circle of acquaintances. Issues arise here such as the size of such groups of friends, or to which degree groups could overlap.
Another interesting direction for future extension relates to more complex decision making models involving factors such as individual personality resulting in strategies better grounded in cognitive factors and, thus, more realistic simulations. Simulating drivers with different personalities has been shown to produce more realistic mobility simulations, especially in driving simulators ([27], or [34]). For example, the 5-Factor Model of human personality could be connected to specific strategies: a personality with a high value in “openness” could support more frequent exploration; a high value in “aggreeableness” could lead towards a strategy with which an agent shares its experience in every episode; a high degree of “neuroticism” could result in an overall strategy in which an agent accesses shared information a lot, but does not publish its own experience.
As we have indicated in the previous sections, we also plan to test further dynamic and adaptive strategies: Agents may have a high initial budget and decide to use the budget in different strategies, spending a small share of the budget as a fee to access the published information. A promising strategy could be that an agent uses its budget in the beginning of the learning process, when it needs to explore more than exploit. When their individual reward stabilises, they reduce access and thus less and less incorporate others’ best choices. A second alternative is that agents could spare their budgets and use them when they notice that the Q-value of their best route is decreasing or fluctuating for a given number of episodes. Also, we could let agents forget what they have learned in order to mimic new arising participants in the system.
More innovative, the navigation app – in the case of social circles, we will have more than one app – becomes an agent and actively adjusts the parameters of the budget strategies to improve the overall learning process. The app collects a lot of information from the driver agents, which can be used to drive the system towards a desired state, e.g., by telling agents how to acquire more or less credits. We also plan to run experiments – including the aforementioned new features – using other scenarios, such as the bi-commodity Braess paradox network [19] and the Sioux Falls network [18].
Footnotes
Acknowledgements
Both authors are thankful to the anonymous reviewers. Ana Bazzan was partially supported by CNPq under grant no. 307215/2017-2, and by CAPES (Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – Brazil, Finance Code 001).