Several well known clustering algorithms have their own online counterparts, in order to deal effectively with the big data issue, as well as with the case where the data become available in a streaming fashion. However, very few of them follow the stochastic gradient descent philosophy, despite the fact that the latter enjoys certain practical advantages (such as the possibility of (a) running faster than their batch processing counterparts and (b) escaping from local minima of the associated cost function), while, in addition, strong theoretical convergence results have been established for it. In this paper a novel stochastic gradient descent possibilistic clustering algorithm, called O- is introduced. The algorithm is presented in detail and it is rigorously proved that the gradient of the associated cost function tends to zero in the sense, based on general convergence results established for the family of the stochastic gradient descent algorithms. Furthermore, an additional discussion is provided on the nature of the points where the algorithm may converge. Finally, the performance of the proposed algorithm is tested against other related algorithms, on the basis of both synthetic and real data sets.
Cost function minimization is a task that is met in various fields of applications, including data clustering applications, where the associated cost function is defined in terms of all the available data points. Among the most well established methods/algorithms for tackling this task are the iterative ones, where the algorithm initializes the relative parameter vector at a specific value and updates it iteratively, until convergence is achieved. A celebrated iterative cost function minimization method is the gradient descent (GD) one, where at each iteration, the parameter vector is updated, following the opposite direction of the one defined by the gradient of the cost function, computed at the current parameter estimate. By its rationale, it is clear that the GD algorithms may be trapped to local minima of their associated cost function. Moreover, since all the data points contribute to the formation of the gradient at each iteration, several additional issues may arise, including the inability (a) to handle very large data sets (due to memory limitations that do not allow the storage of all the available data points in the memory) and (b) to deal with cases where the data are available in a streaming fashion. One way to face the above issues is to resort to the stochastic rationale, where the parameter updating takes place after the consideration of a single data point drawn randomly from the available data set. The way to utilize the stochastic rationale in the GD context is to approximate the gradient of the cost function (which requires consideration of all data points) with an “instantaneous” gradient, which is computed taking into account only a single (randomly selected) data point. This gives rise to the celebrated stochastic gradient descent (SGD) method, for which several strong theoretical convergence results have been established (e.g., [4,9,14]).
Clustering is the process of partitioning a set of objects into groups so that “more similar” objects are assigned to the same group, while “less similar” objects are assigned to different groups. The resulting groups of this process are called clusters and the set of these clusters constitute the so-called clustering. In most cases, the representation of the objects under study is carried out via the adoption of a set of d suitably chosen features. More specifically, each object is represented by a d-dimensional vector, called feature vector consisting of the values these features take for (here the case of continuous-valued data is considered). These vectors are called data vectors/points and they constitute the so-called data set. The d-dimensional space, where these vectors live, is called feature space. The degree of similarity between two objects is quantified via a suitably defined proximity measure, computed on their associated feature vectors.
Cost function minimization clustering algorithms is a class of clustering algorithms that has attracted significant attention during the last decades. Here each cluster is modeled by a parameter vector (set of parameters) and an associated cost function is defined, so that its (global) minimum corresponds to values of the parameter vectors that represent the clusters properly. Such algorithms estimate iteratively these parameter vectors through the gradual reduction of the value of their associated cost functions.
The most well studied case is the one where the parameter vectors define points (also called cluster representatives or simply representatives) in the feature space. Assuming that the data points of a cluster are naturally aggregated around a certain data point, its corresponding representative should be located at this point. Several algorithms have been proposed in the above framework, which can be divided into the following general categories, according to the way they define the relation between a data point and a cluster: the hard, the fuzzy and the possibilistic clustering algorithms. The most famous algorithms from the above categories are the k-means [1,6,13], the fuzzy c-means (FCM) [3,7] and the possibilistic c-means (PCMs) [11,12] (algorithms for the case where the clusters are spread around a subspace/affine space of the feature space have also been proposed (subspace clustering, e.g. [16]), but they will not be considered in the present study). In the hard clustering algorithms, each data vector belongs exclusively to a single cluster. In the fuzzy clustering algorithms a certain data vector is shared among all clusters at the same time. The “degree of belongness” of the vector to each cluster is quantified by a number in the interval and these quantities sum up to one. On the other hand, in possibilistic algorithms the relation between a point and a cluster is defined via the notion of “compatibility of the point with the cluster”. That is, for each data vector, although the “degree of compatibility” with each cluster is quantified again by a number in the range , these numbers are not required to sum up to one. Although the sum-to-one constraint is in line with the common intuition, its adoption is not free of problems. Specifically, due to this constraint, both hard and fuzzy clustering (a) require the exact knowledge of the number of clusters (something that, in practice, is rarely known) and (b) they are vulnerable to the presence of noise and outliers. On the other hand, the absence of this constraint from the possibilistic framework abolishes the above problems, at the cost of weaker performance in cases where clusters exhibit significant overlap.
The most well known clustering algorithms of the above general categories perform batch data processing, that is, they update the involved parameters after the processing of the entire data set. However, in order to deal with the case where the data become available in a streaming fashion as well as with the case of large volume data sets, online processing version of the previous algorithms have been developed, e.g., [2] for k-means, [8] for FCM and [18] for PCM. However, only the first one of them follows the stochastic gradient descent philosophy. In the present paper, a stochastic gradient descent possibilistic clustering algorithm, called O-, which has been inspired from the batch possibilistic c-means introduced by Krishnapuram and Keller [12], is proposed. The algorithm enjoys the benefits of both the possibilistic rationale (no need for knowledge of the exact number of clusters, immunity to outliers and noise) and the stochastic gradient descent framework (such as, possibility of faster execution compared to its batch processing counterpart, possibility of escaping from local minima of its associated cost function).
The rest of the paper is organized as follows. Section 2, contains a brief description of the batch possibilistic algorithm [12], as well as a brief presentation of the general stochastic gradient descent scheme. In Section 3, the derivation of the new online possibilistic algorithm O- is carried out. Section 4, contains some mathematical results concerning the convergence behavior of the algorithm. More specifically, it is rigorously proved that the gradient of the cost function associated with O- tends to zero in the sense, while a discussion is provided on the nature of the points where the algorithm may converge. In Section 5, the performance of O- is compared to that of other related algorithms, on the basis of both synthetic and real data sets. Finally, Section 6 concludes the paper.
Related work
Batch processing possibilistic clustering
In this subsection, a brief description of the possibilistic c-means algorithm [12], called , is given (this name is to distinguish this algorithm from the first possibilistic algorithm introduced by Krishnapuram and Keller [11]). As is the case for batch processing algorithms, a parameter updating takes place after the consideration of all the available data points. Let X be a data set consisting of N d-dimensional data vectors. That is
Let , where is the representative of the j-th cluster (which, in the present case, is a point in the space where the data “live”) and c is the number of clusters. Also, let be the degree of compatibility of the data point with the j-th cluster and let be the matrix that accumulates ’s. It is noted that all ’s corresponding to the same vector (which occupy the i-th row of U) are independent from each other and they do not necessarily sum to one. The algorithm proposed in [12] is a parametric one (the parameters are the cluster representatives ’s) and it results from the minimization of the following cost function
where is the j-th column of U, which contains the degrees of compatibility of all data vectors with the j-th cluster. Moreover, each is a measure of the variance of the j-th cluster (usually, ’s are user defined, although an adaptive version of PCM, called APCM [17], has been proposed, where they are adapted, as the algorithm evolves).
Equating to zero the gradient of J with respect to U and Θ, respectively, and solving the resulting equations, it turns out that
Based on the above equations, initializes ’s and then iterates between (2) and (3) until convergence (that is, until no significant difference is observed between the estimates of ’s obtained in two successive iterations).
In order to initialize the representatives close to dense in data regions, it is suggested to execute the FCM algorithm first with an overestimated number of clusters. The final positions of the representatives resulting by FCM are expected to lie within dense-in-data regions. In addition, due to the overestimated number of clusters, it is very likely to have at least one representative in each dense-in-data region. Then, the final estimates of ’s from FCM, will serve to initialize . With a proper choice of ’s, the algorithm will potentially uncover all the physical clusters, with some of the representatives being (potentially) coincident after the termination of the algorithm (this case arises when two or more representatives were initially located within the same dense-in-data region).
Yang et al. [19] proposed the usage of the same γ for all clusters, i.e., . Specifically, the suggested value of γ is given by:
with . The term q is a user-defined parameter, which is set to values greater than 1.
It is noticed that the degree of compatibility decreases exponentially fast as the distance between the data vector and the representative increases. Thus, even though all the data vectors contribute to the computation of the next position of each , as it is indicated by Eq. (3), the closer the data vector is to the corresponding , the greater its influence on the estimation of the next location of . This is the reason why the algorithm eventually moves each representative towards the center of the closer to its initial location dense-in-data region.
(Number of clusters).
From equations (2) and (3), it is clear that, for a given , the ’s for are not interrelated and, as a consequence, the ’s are independent from each other. Thus, the minimization of can be carried out by minimizing every summand , independently from the others. As it was stated by Krishnapuram et al. [12], a consequence of the independence among the ’s is that, for a proper choice of ’s, if some of the representatives ’s are initialized close to the same dense-in-data region, their final positions will coincide (usually) to the center of this region (since they do not compete each other), representing all the same cluster. Such representatives may easily be identified after the termination of the algorithm and the duplicates can be removed, in order to keep one representative for each dense region (cluster). This observation indicates that the a priori knowledge of the exact number of clusters is not necessary, for . In general, given an overestimated number of clusters and provided that at least one representative is initialized close to a dense-in-data region, is able to unravel the correct clusters. It is noted that this is not the case with k-means and FCM algorithms, which both require the exact number of clusters, otherwise they give very poor results. For example, if the data points form four physical clusters (that is, we have four aggregations of data points in the associated feature space) and either k-means or FCM are initialized with five clusters, both of them will return five clusters (probably by splitting a physical cluster to two parts). On the other hand, if these algorithms were initialized with three clusters, they would probably merge two physical clusters to one.
(Immunity to noise and outliers).
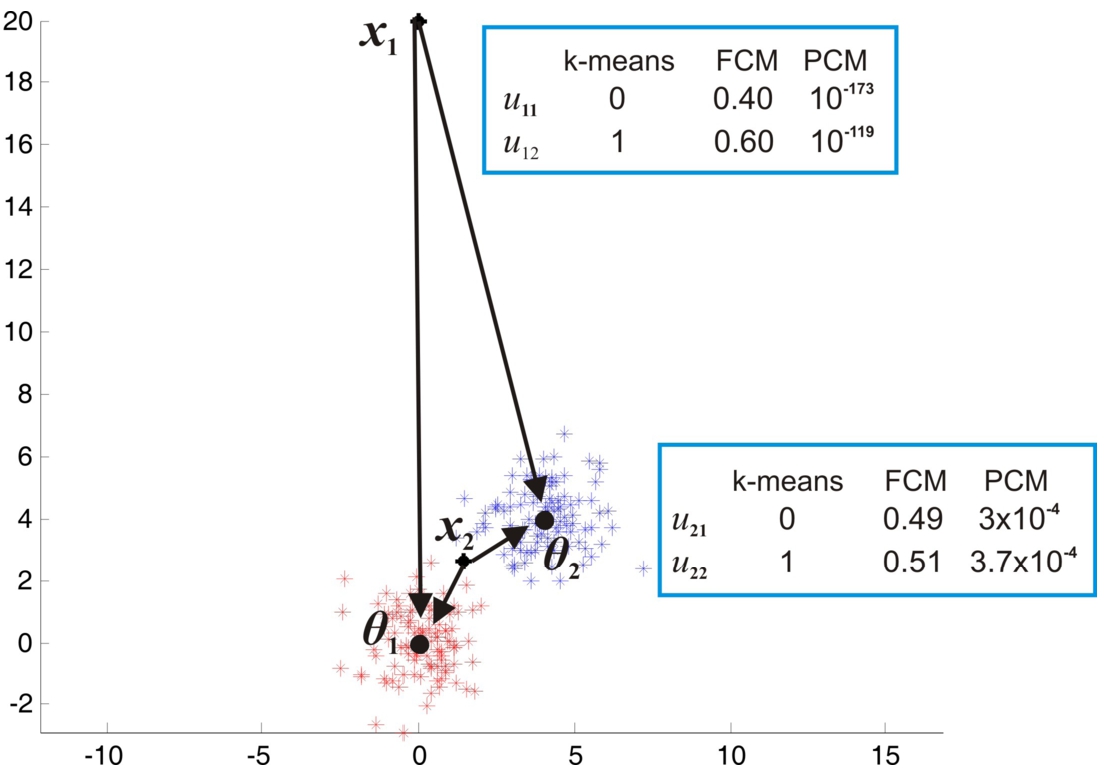
In contrast to k-means and FCM, exhibits high immunity to noise and outliers. This is due to the absence of the sum-to-one constraint. To see this more clearly, consider Fig. 1, where a two-cluster case is shown and a noisy and an outlier points are considered. As it is shown, the coefficients in are substantially lower than those in k-means and FCM, for these points. This implies that these points will have almost no contribution to the estimation of the next values of all ’s (see Eq. (3)), in the context of . On the contrary, they will have a significant contribution to at least one of ’s, in the context of k-means and FCM.
(Limitations).
Due to the fact that , as well as k-means and FCM, use single points as cluster representatives, they are suitable to determine only compact and hyperellipsoidally-shaped clusters, while they are not suitable for the determination of other kinds of clusters, e.g., linear clusters (where the data points are spread around a line/line segment in two-dimensional data spaces) and ring-shaped clusters (where the data points lie around a circle). If, in the context of a certain application, one expects other kinds of clusters (e.g., as the above examples), one can still use the hard, the fuzzy and the possibilistic approach, but he/she should parameterize the clusters properly. For example, in the case of line segment shaped clusters, one can adopt line segments as cluster representatives [10] and in the case of ring-shaped clusters one can adopt circles as cluster representatives (e.g., [5]). Of course, in the case where the shape of the clusters is arbitrary, one can resort to non-parametric clustering techniques/algorithms, such as spectral clustering, DBSCAN (e.g. [15]).
All the above characteristics of are inherited to its descendant O- which is introduced in Section 3.
The effect of the presence/absence of the sum-to-one constraint, for an outlier () and a noisy point ().
The stochastic gradient descent (SGD) scheme
The gradient descent (GD) is an iterative cost function minimization scheme, whose associated cost function is defined taking into account all the available data points. Specifically, GD updates the estimate of the parameter at the t-th iteration, , by following the opposite direction of the gradient of computed at , . The stochastic gradient descent (SGD) can be viewed as an approximating scheme of GD, since is replaced by the “instantaneous” gradient computed at a single data point. Let us be more specific. Each SGD algorithm is associated with a loss function , calculated on a certain data vector and an objective function, which is the mean of the loss function values computed on each data vector. More specifically, the associated objective function can be defined as
Denoting by the gradient of with respect to , computed at , the general SGD scheme is given below
Stochastic Gradient Descent – SGD
Input: X
Initialization: Initialize to
Repeat
Pick at random a sample point from X
Compute
Compute
Update
Until a termination criterion is met
Output:
The sequence , called learning rate sequence, is a deterministic sequence, which tends to 0, as . If, in addition, it fulfills some additional conditions (see below), certain convergence results can be established for SGD scheme .1
In some cases the learning rate can be fixed to a small value. In this case, the algorithm reaches close to the minimum of the cost function and oscillates around it.
Among the advantages of SGD scheme are (a) its ability to deal well with very large data sets, since only a single data point is processed at each iteration, (b) its ability of escaping from local minima of the associated cost function, due to the oscillations introduced by the processing of each individual data point and (c) its ability to converge much faster than the corresponding batch GD scheme in the case of large data sets, where a lot of redundant information is encountered among the data points. On the other hand, the weak points of SGD include (a) the possibility of diverging towards a wrong direction, due to the oscillations introduced by the separate processing of each data point, (b) the larger (in some cases) time needed for convergence, due to oscillation phenomena around the solution and (c) the loss of the ability to take advantage of the performance of vectorized operations. One way to keep the advantages of SGD and to alleviate (to a certain degree) its disadvantages, is the adoption of the mini batch rationale, where a small number of data points is processed simultaneously (e.g., [4]).
The O- algorithm
In contrast to the batch processing framework (see Section 2.1), in the online processing, the values of U are not of significant value anymore, since they are computed based only on the data points processed so far. The only useful information now is about ’s, which identify the location of the clusters in the data space. The assignment of the data points to clusters can take place after the determination of the final locations of the ’s. More specifically, each data vector can be assigned to the cluster associated with the representative that lies closest to . Based on the above observation, the clustering algorithm should be designed so that to determine only the locations of ’s. Thus, it is reasonable to define an objective function, which does not contain the terms ’s. One way to do this is to substitute in the formula of given in Eq. (1), the ’s with their optimal (in the batch case) values given in Eq. (2). Thus, defining , where , , and after some algebra, it follows that
The above expression indicates the following loss function
whose corresponding objective/risk function is
Taking the gradient of the loss function given in Eq. (7) with respect to , it follows that
Hence, in the spirit of the SGD scheme, the following updating rule results, for :
where are the sequences of learning rates, each one corresponding to a cluster, which must satisfy certain conditions to guarantee convergence (they are given in the next section). In order to lighten the notation, the time index will be given as subscript in the absence of any other index.
Having said all the above, it is presented next the proposed online version of algorithm (O- algorithm). The inputs of the algorithm are the dataset X, the number of clusters c (usually, the algorithm is initialized with an overestimated number of clusters) and the parameter γ (in general, one value for each cluster). The algorithm in each iteration selects at random and with replacement a data point from the entire data set X and updates all the representatives ’s, utilizing Eq. (10). The algorithm is terminated, when a certain termination criterion is met. For example when the euclidean norm of the distance between two successive positions of the representatives is less than a (small) user defined parameter, the tolerance. Finally, the final positions of the representatives of the clusters are returned as output of the algorithm (no matrix U is returned). O- can be written as follows:
Online–O-
Input: X, c, ,
Initialization: Initialize
Repeat
Pick at random a sample point from X
For to c
Compute
Compute
Update
Until a termination criterion is met
Output: Θ
Convergence analysis of O-
In this section, the focus is on the convergence of the O- algorithm. More specifically, it will be proved rigorously that the gradient of the objective function F converges (in the sense) to , utilizing some general convergence results for the stochastic gradient descent (SGD) algorithms [4]. Then, a qualitative discussion follows on the nature of the points where O- may converge.
Before the detailed presentation of the above results, the general convergence results on SGD algorithms on which the proof of the convergence of O- is based, are briefly presented.
Convergence result for the SGD scheme
In the following, some convergence results for the general SGD scheme are provided, for the case where is an unbiased estimator of (note that O- exhibits this property). These results can be extracted from more general results given in [4], thus no proofs will be provided for them.
(a) The objective function is continuously differentiable and (b) the gradient of F, namely , is Lipschitz continuous with Lipschitz constant , i.e.
This assumption ensures that the gradient of F does not change arbitrarily quickly with respect to the parameter vector .
In the following, the expectation and variance operators are defined over the distribution of given .
Under Assumption
4.1
, the iterations of the SGD scheme satisfy the following inequality:
Note that is a deterministic quantity (given ), while is of stochastic nature due to the dependence on the randomly selected (see Eq. (10)). In addition, if the (deterministic) quantity on the right hand side of the above inequality is manipulated so that to take negative values (this can be achieved by a proper definition of and if certain conditions are satisfied by ), the above lemma guarantees that, in the mean, the value of the objective function exhibits (asymptotically) sufficient decrease.
The SGD scheme itself and the associated objective function satisfy the following:
(a) the sequence produced by the SGD scheme is contained in an open set over which F is bounded below by a finite value
(b) there exist scalars so that for all t it is
where the variance of , , is defined as
The Assumption 4.2(b) implies that the variance of is restricted above by a quadratic function of the norm of the gradient of F.
Combining Eqs (12) and (13) and taking into account the fact that is an unbiased estimator of , it follows that
The latter combined with Eq. (11), and after some algebra, gives
The bound on the right hand side is now a function of and . More specifically, the first term in the bound is negative (for small ) and proportional to (the deterministic quantity) , while the second term is positive. In order to ensure that the overall bound becomes negative asymptotically, the sequence should be properly chosen. It turns out that if
this aim is achieved.
The combination of all the above ingredients leads to the following general convergence result [4]:
Under Assumptions
4.1
and
4.2
, suppose that the SGD algorithm is run with a stepsize sequence, which satisfies Condition
4.1
. If in addition (a) the objective function F is twice differentiable, and (b) the mappinghas Lipschitz-continuous derivatives, thenwheredenotes the expected value taken with respect to the joint distribution of all the random variables.
Having presented in brief the general theoretical framework that fits to O-, the proof of convergence of O- is provided next.
Convergence proof of O-
Before continuing, recall that the representatives ’s , move independently from each other (as is shown in Eq. (10)). Thus, without loss of generality, the convergence of O- algorithm will be proved for the case of one representative. In this case (), the associated cost function (Eq. (8)) becomes
Note that in the above expression the index j, associated with the clusters, is now useless and has been dropped out.
An important note at this point is that is an unbiased estimator of , since at each iteration one data point is selected randomly (with replacement) with probability from the entire dataset and thus it is
This property allows the use of the theoretical results provided in the previous subsection, in order to establish the convergence results of O-. It is also worth pointing out that the norm of the gradient of the objective function F is bounded above by a quadratic function (of course, this holds also for the loss function ).
Keeping in mind all the above and utilizing Theorem 4.1, it will be proved that for O- it holds that
To this end, it will be proved that O- satisfies the requirements of Theorem 4.1.
Next, an important property of the O- algorithm is stated.
If the stepsize sequencesatisfies Condition
4.1
, then the sequence of iterationsis contained in a bounded set.
The proof follows, if the update rule of O- algorithm is written as:
Since the stepsize sequence satisfies Condition 4.1, it follows that , and thus there is a such that and thus . This means that the sequence of iterations is contained in the convex hull of , which is bounded, since the data set X is bounded, as a finite set. □
The assumptions of Theorem 4.1 require specific regularity conditions for the objective function F over the whole . However, because the iterations of O- algorithm lie in a bounded domain, call it , of diameter D (see Lemma 4.2), it is sufficient to prove that F has the required regularity properties only over the set .
Thus, the regularity properties of F on will be proved.
The objective function F of Eq. (
15
) satisfies Assumption
4.1
.
Clearly, the objective function is continuously differentiable. In order to show that the gradient of F is Lipschitz-continuous, it suffices to show that the gradient of (with respect to ) is Lipschitz-continuous. In turn, due to the Mean Value Theorem, it suffices to prove that the functions , have bounded derivatives.
For , it is
The derivatives of , for , with respect to , are
where if . Thus,
for , since , and D is the diameter of . □
The objective function F of Eq. (
15
) and the sequenceof O-algorithm satisfy Assumption
4.2
.
(a) Based on Lemma 4.2, the sequence of iterations is contained in a bounded set . Moreover, F is bounded below by .
(b) Since , the variance can be written as
In the light of this, it suffices to find such that
Recalling that , it is easy to verify that for and any non negative number, the above inequality is satisfied. □
The objective function F of Eq. (
15
) is twice differentiable and the mappinghas Lipschitz-continuous derivatives.
It is clear that F is twice differentiable. In order to show that the mapping has Lipschitz-continuous derivatives, let us define the function as
Let be the gradient of . Then its jth element is
In order to prove that is Lipschitz-continuous, it suffices to show that its derivatives (elements of the respective Hessian matrix) are bounded (over ).
for . Since and ’s and live in the bounded set , (the absolute values of) all the above quantities are bounded. Thus, the matrix norm of is bounded over this set and this concludes the proof. □
Suppose that the O-algorithm is run with a stepsize sequence, which satisfies Conditions
4.1
. Then
The proof is a direct consequence of Lemmas 4.2, 4.3, 4.4, 4.5 and the Theorem 4.2. □
In words, it has been proved that the gradient of the objective function F converges to , in the sense.
Qualitative discussion about the convergence points of O-
Since the gradient of F over the iterations of O- tends to zero (in the sense), it is essential to comment on the nature of the points where O- may converge.
Of course, these points are expected to belong to the set T of points that satisfy , i.e. . Due to the extreme value theorem, whose prerequisites are fulfilled by O- (see Lemma 4.2), the set T is not likely to be empty (due to the form of the cost function, the extreme points are likely to be in the interior of the compact set ). Thus, T may contain maxima, minima and/or saddle points.
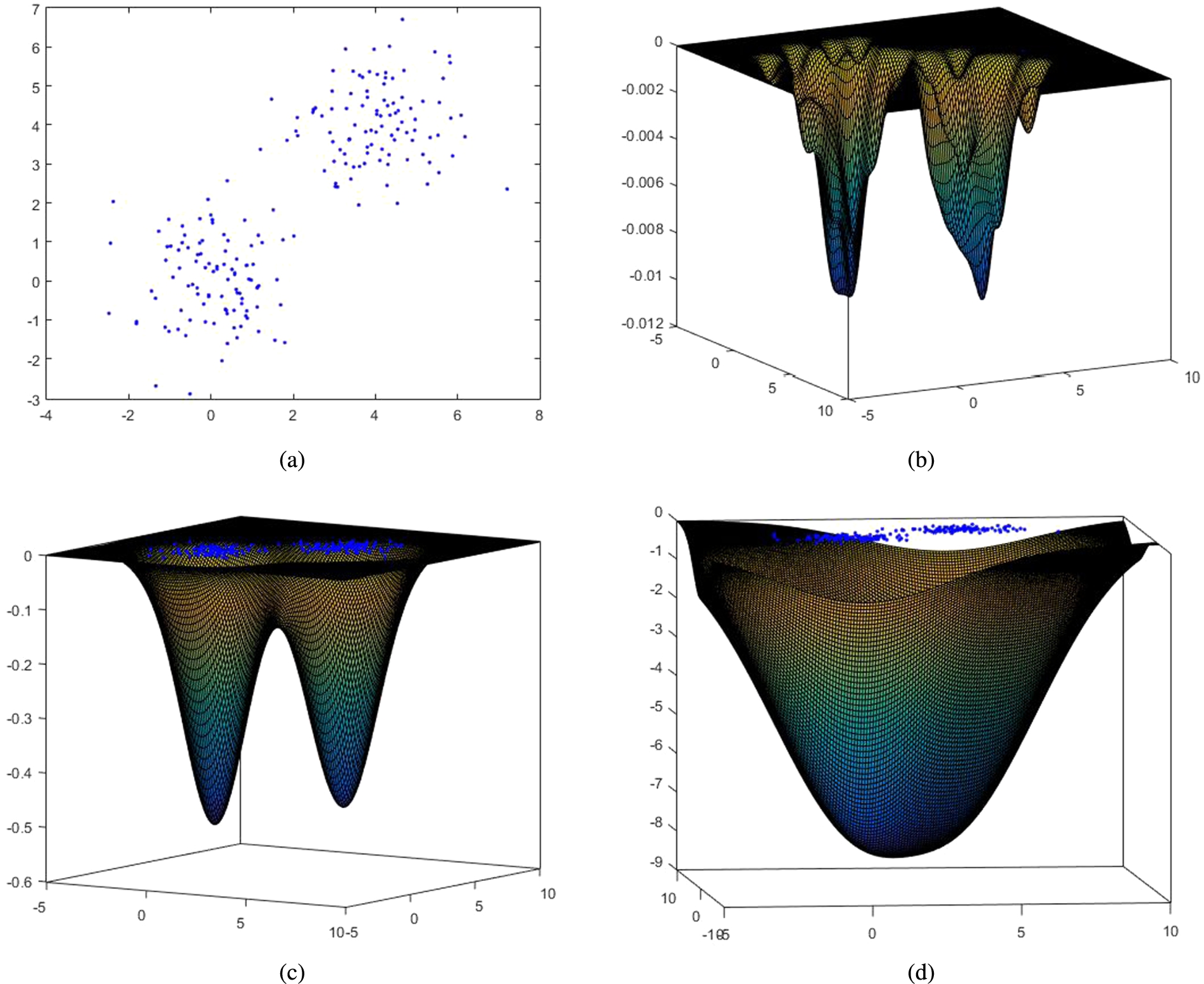
Plot of the cost function F in case of a two-class 2-D dataset. Plot shows (a) the data set and the 3d-plot of function F when (b) , (c) and (d) .
Before proceeding any further, let us open a parenthesis in order to gain some insight on the landscape of , which depends on the choice of γ, via an example. Let us consider a 2-D data set consisting of two clusters of 100 points each, shown on the xy-plane in Fig. 2(a). The clusters are modeled by normal distributions with means and , respectively, while their covariance matrices are both equal to the identity matrix, . As it is illustrated in Fig. 2(b), the function F has more than two local minima, for very small values of the parameter γ. Moreover, as the value of γ increases, the number of local minima decreases, until the function F has only a single (global) minimum (Figs 2(b)–2(d)). It should be noticed that in the cases of Figs 2(b)–2(c), where more than one minima appear, the function F appears to have also saddle points.
Closing the parenthesis, let us now comment on what kind of stationary points of F the O- algorithm can converge. Ineq. (11) (for a proper choice of ) guarantees that the algorithm moves towards positions that (in the mean) decrease the cost function asymptotically. Thus, O- cannot converge to a maximum of F. Let us focus now on the other two possible kinds of points in T, that is, the saddle points and the minima points of F.
Let the weighted covariance matrix, associated with a certain , be defined as
The following Lemma gives a sufficient condition for a to be a local minimum.
Ais a local minima of F ifwhereis the maximum eigenvalue of.
First, the Hessian matrix of F on is computed and then it is examined under which conditions it is positive definite (which implies that is a minimum). It is easy to verify that for any , it is
Combining the above, the Hessian matrix can be expressed as
where is the identity matrix. Focusing on a , since is positive (semi) definite, it can be written as
where contains in its columns the (orthonormal) eigenvectors of and is a diagonal matrix with the eigenvalues of in its diagonal. Note also that .
In the light of the above, becomes
Since is positive (due to the definition of and the fact that lies in a bounded subset of ), is positive definite if
□
The above result is very useful, since it can detect if a stationary point of the cost function, , is a local minimum. Let us gain some more insight on the above result recruiting once more the example in Fig. 2(a). We consider the case where γ (which is a measure of the variance of the clusters) is chosen so that exhibits as many minima as the number of clusters (see e.g. Fig. 2(c)). Let us consider the center of the first cluster . Then, for the points of this cluster, the ’s will have “large” values, in contrast to the points of the second cluster, which are very “far” from and the respective ’s take very “small” values. Thus, up to a good approximation degree, the contribution of the points from the second cluster to the formation of can practically be ignored. Therefore, the eigenvalues of , which measure the spread along the eigenvector directions, will be of the order of γ (since γ is a measure of the variance of the clusters). Of course, similar results hold for points that are close to .
Consider now the case where lies in the middle of the line segment defined by the centers of the two clusters. In this case, the ’s for the points in both clusters are expected to have values of the same order, so all ’s from both clusters contribute to the formation of . Therefore, in this case, is expected to be very large, compared to γ, since the clusters are distant from each other (as an immediate consequence of the fact that they are well-separated) and, thus, the length of the line segment connecting the centers is significantly greater than γ.
As a conclusion, the result of Lemma 4.6 can be used as a criterion to determine if the point where the algorithm converges is a local minimum of , which in the case where γ has been properly chosen, is very likely to correspond to a physical cluster.
Experimental results
Although extensive experimentation has been conducted concerning O-, only a limited amount of results is presented here, due to space limitations. In the following experiments, O- is compared with the online k-means algorithm [2], which is of the stochastic gradient descent philosophy, as well as with its batch processing counterpart . The experiments were conducted on both synthetic and real data sets. At each experiment, the number of the initial clusters () for the two possibilistic algorithms is an overestimation of the number of the true clusters (values of close to the chosen ones lead to very similar results). However, for the online k-means, the true number of clusters has been chosen. It is also noted that the sequences for O- are chosen as , with , a choice that complies with Condition 4.1. Moreover, ’s are initialized through FCM applied (a) over the entire set for and (b) over the first 100 randomly selected data points for the online algorithms. Finally, γ’s are defined via Eq. (4).
The aim of this experiment is to compare the processing time required for the convergence of the three algorithms. Consider the three cluster setup where the clusters stem from three normal distributions with means , and , respectively, while the covariance matrices are all equal to ( is the identity matrix). Four data sets are considered, , , , , of data points, , so that data points are generated from the first distribution (forming the Cluster 1), while data points are generated from each one of the other two distributions (forming Clusters 2 and 3, respectively). Note that clusters and exhibit partial overlap. The obtained results concerning the computational time required are shown in Table 1. As it can be seen, the processing time for increases rapidly, as the size of the data set increases, while this is not the case with O- and online k-means, with the latter being significantly faster, provided that it has been initialized with the correct number of clusters. It is also worth mentioning the increasing standard deviation associated with the processing time for the online k-means and the O-. This is in line with the fact that the SGD algorithms may sometimes take larger times to converge (see Section 2.2).
Results of Experiment 5.1 on the data sets , . The mean execution time along with the standard deviations in parentheses (each experiment run 10 times, except for , which was executed only once due to its batch processing rationale)
Algorithm
Time
Time
Time
Time
10
0.23
1.61
20.23
196.25
O-
10
1.37 (0.68)
1.64 (0.91)
8.31 (4.42)
98.96 (54.72)
Online k-means
3
0.12 (0.05)
0.82 (0.28)
0.83 (0.33)
9.82 (3.25)
The aim of this experiment is to assess the accuracy of the results of the O-, compared to those of the online k-means and on a more demanding setup. Specifically, consider a five cluster set up, where the clusters are modeled by normal distributions as shown in Table 2. Actually, two data sets, and , are formed, that differ on their size. The data set is depicted in Fig. 3(a). In this case, the accuracy of the results obtained by the algorithms is measured. As in the previous case, there is a bias in favor of the online k-means, since it is initialized with the correct number of clusters. Each experiment has been conducted ten times, with different initializations. The accuracy is assessed in two ways: (a) through the number of times where the clusters were correctly identified (i.e. when at least one is located, after the termination of the algorithm, within the region of a physical cluster) and (b) through the accuracy with which the true cluster centers have been estimated (in terms of the Euclidean distance between the true centers, say ’s, and the respective ’s, after the termination of the algorithms). The results are shown in Table 3.
(a) the physical clusters formed by the points of in Experiment 5.2(b) the physical clusters formed by the points of plus the 300 noisy points uniformly distributed over the entire region of the space where the data live. (c) the physical clusters formed by the points of plus 800 additional points uniformly distributed over the entire region where the points of the live.
Results of Experiment 5.2 on the data sets and ( was executed only once due to its batch processing rationale)
Algorithm
Perc. of correct
Accuracy
Perc. of correct
Accuracy
20
1/1
0.0275
1/1
0.0226
O-
20
10/10
0.0944
10/10
0.0897
Online k-means
5
10/10
0.0662
10/10
0.0700
As can be seen from Table 3, all algorithms determine the clusters correctly in all cases, with no significant differences in the accuracy of the estimates of the centers as the volume of the data increases. A similar situation arises, in the presence of uniform noise, as it is shown in the next experiment.
In this experiment, the behavior of the three algorithms under consideration in a noisy environment, is assessed. Specifically, consider the datasets and of Experiment 5.2, where 300 and 800 additional data points, respectively, are now inserted randomly as noise in the region of the feature space where the data live (see Figs 3(b)–3(c)). In this case, the obtained results are shown below in Table 4. It can be seen that O- behaves satisfactorily also in a noisy environment. However, it is noted that the accuracy on is slightly worse in the case of noise, compared to the non-noisy case, for all algorithms. Interestingly enough, this is not the case with the noisy version of , where the and the online k-means perform slightly better performance, compared to the non-noisy version of , while the opposite is true for the O-. This is probably due to the randomness that is inherent in the two SGD algorithms.
Results of Experiment 5.3 on the data sets and in the presence of noise
Algorithm
Perc. of correct
Accuracy
Perc. of correct
Accuracy
20
1/1
0.0360
1/1
0.0182
O-
20
10/10
0.1275
10/10
0.1128
Online k-means
5
9/10
0.0856
10/10
0.0643
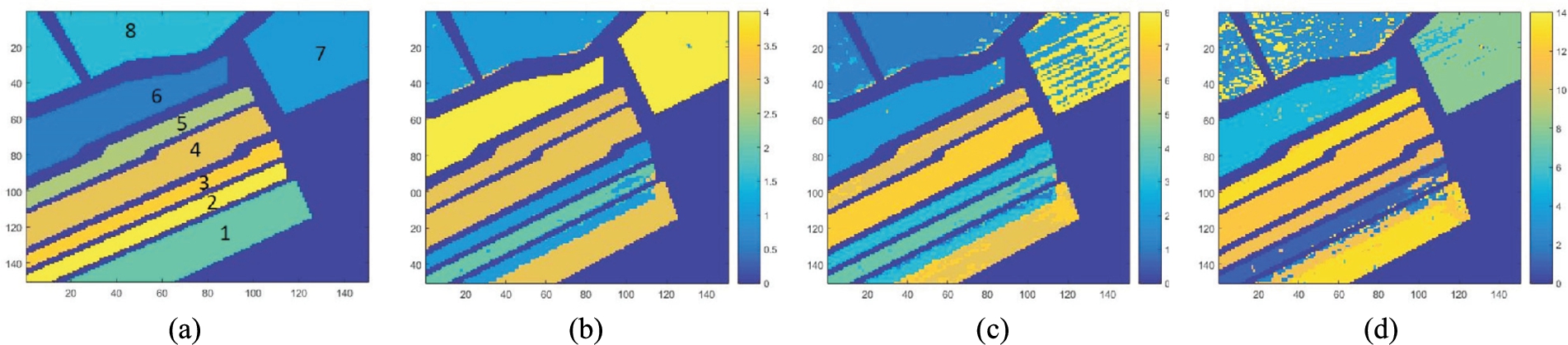
The Salinas experiment. (a) the ground truth information. (b), (c), (d) the results of , online k-means and online , respectively. Note that , recognizes only four distinct clusters.
This experiment deals with a real application and the aim is to assess the performance of all the algorithms in both a low and a high dimensional version of it. Specifically, in this context, a hyperspectral image, depicting a part of the Salinas valley in California is considered2
(Figs 4(a)–4(b)). Each pixel belongs to one out of eight classes corresponding to different cultivations. The size of the image is and the spectral bands are 204. Clustering is performed on the first three principal components of the data set and the agreement of the results with the available ground truth information is measured via the rand measure (RM) (e.g. [15]). The results (Table 5) showed that O- (Fig. 4(c)) gave the best results ( RM), compared to those of () and the online k-means (Fig. 4(d) – ). In addition, it is worth mentioning that the mean execution time for O- with is much smaller than that for the online k-means with (∼ 0.34 secs vs ∼160 secs). Finally, it is noted that O- gave similar results, when it was executed on the original 204-dimensional data, showing that (in principle) it can deal well with high dimensional data.
In this experiment, the potential of the O- to deal with dynamically changing environments, is assessed. Such environments are met in applications like motion tracking, where the aim is to detect movement of various objects along the consecutive images (frames) in a video. More specifically, a simple example of a dynamically changing environment is considered here, which involves three clusters of points that move in time (these may correspond to different moving objects).
Dynamically changing environment: (a)–(c) three snapshots of the clustering results of O-. (d) the entire movement of the clusters and the ’s. The white (black) bullets indicate the final positions of the ’s in the first (last) snapshot and the sequence of crosses shows the consecutive positions of ’s through time.
At each time snapshot, O- is applied on the current data set (consisting of the clusters formed in the previous snapshot, which now are slightly moved). Considering the data set of the first snapshot, the algorithm runs as usual, while considering every next snapshot, the algorithm is initialized by the values of cluster representatives computed in the previous snapshot. The clustering results of O- in three random snapshots of the experiment are illustrated in Figs 5(a)–5(c). Moreover, the total movement of the data set and the representatives is also shown in Fig. 5(d). As it can be seen, the algorithm behaves very well in this simple example of a dynamically changing environment and thus it seems that, in principle, it has the potential to deal efficiently with such environments.
Conclusions
In the present paper, a new online stochastic gradient possibilistic clustering algorithm, called O-, is introduced, which is suitable for uncovering compact and hyperellipsoidally-shaped clusters. The algorithm features the benefits of both its possibilistic background (no need for knowledge of the exact number of clusters, immunity to outliers and noise) and its stochastic gradient descent background (such as, possibility of faster execution, compared to its batch processing counterpart, possibility of escaping from local minima of its associated cost function). It has been proved that the gradient of its respective objective function F converges to , in the sense. The algorithm was extensively tested in various kinds of data sets and gave very encouraging results. More specifically, the capabilities of the algorithm, highlighted by the conducted experiments, are (a) its faster convergence comparing to its batch processing counterpart, when the size of the data becomes very large, (b) its robust behavior in the presence of noise and outliers, (c) its ability to deal well (in principle) with high-dimensional data and (d) its ability to work effectively (in principle) in dynamically changing environments. O- compares well with other relevant algorithms coming from the hard or the fuzzy framework, since the latter require exact knowledge of the number of clusters (something that it is very rare in practice). However, as its ancestor , O- works better when the clusters do not exhibit significant degree of overlap.
Footnotes
Acknowledgement
A. Koutsimpela has been partially supported by the European Regional Development Fund and Greek national funds through the operational program Competitiveness-Entrepreneurship-Innovation, “Retina photonics”, MIS 5031822.
References
1.
G.H.Ball and D.J.Hall, A clustering technique for summarizing multivariate data, Behavioral Science12 (1967), 153–155. doi:10.1002/bs.3830120210.
2.
W.Barbakh and C.Fyfe, Online clustering algorithms, International Journal of Neural Systems18 (2008), 185–194. doi:10.1142/S0129065708001518.
3.
J.C.Bezdek, A convergence theorem for the fuzzy isodata clustering algorithms, IEEE Transactions on Pattern Analysis and Machine Intelligence2(1) (1980), 1–8.
4.
L.Bottou, F.E.Curtis and J.Nocedal, Optimization methods for largescale machine learning, Siam Review60(2) (2018), 223–311. doi:10.1137/16M1080173.
5.
R.N.Dave, Fuzzy-shell clustering and applications to circle detection in digital images, International Journal of General Systems16 (1990), 343–355. doi:10.1080/03081079008935087.
6.
R.O.Duda, P.E.Hart and D.Stork, Pattern Classification, John Wiley & Sons, 2001.
7.
R.J.Hathaway and J.C.Bezdek, Local convergence of the fuzzy c-means algorithms, Pattern Recognition19(6) (1986), 477–480. doi:10.1016/0031-3203(86)90047-6.
8.
P.Hore, L.O.Hall, D.B.Goldgof and W.Cheng, Online fuzzy c-means, NAFIPS2008, 2008.
9.
R.L.Kashyap, C.C.Blaydon and K.S.Fu, Sthochastic approximation, in: A Prelude to Neural Networks: Adaptive and Learning Systems, J.M.Mendel, ed., 1994, pp. 329–355.
10.
K.D.Koutroumbas, Introducing sparsity in possibilistic clustering: A unified framework and a line detection paradigm, IEEE Transactions on Fuzzy Systems26(5) (2018), 2886–2898. doi:10.1109/TFUZZ.2018.2792467.
11.
R.Krishnapuram and J.M.Keller, A possibilistic approach to clustering, IEEE Transactions on Fuzzy Systems1 (1993), 98–110. doi:10.1109/91.227387.
12.
R.Krishnapuram and J.M.Keller, The possibilistic c-means algorithm: Insights and recommendations, IEEE Transactions on Fuzzy Systems4 (1996), 385–393. doi:10.1109/91.531779.
13.
S.P.Lloyd, Least squares quantization in PCM, IEEE Transactions on Information Theory28(2) (1982), 129–137. doi:10.1109/TIT.1982.1056489.
14.
H.Robbins and S.Monro, A stochastic approximation method, Annals of Mathematical Statistics22(1) (1951).
15.
S.Theodoridis and K.D.Koutroumbas, Pattern Recognition, Academic Press, 2008.
16.
R.Vidal, Subspace clustering, IEEE Signal Processing Magazine28(2) (2011), 52–68. doi:10.1109/MSP.2010.939739.
17.
S.D.Xenaki, K.D.Koutroumbas and A.A.Rontogiannis, A novel adaptive possibilistic clustering algorithm, IEEE Transactions on Fuzzy Systems24(4) (2016), 791–810. doi:10.1109/TFUZZ.2015.2486806.
18.
S.D.Xenaki, K.D.Koutroumbas and A.A.Rontogiannis, A novel online generalized possibilistic clustering algorithm for big data processing, in: Proc. of the 26th European Signal Processing Conference (EUSIPCO), Rome, 2018.