
Abstract
We propose a novel pruning method which uses the oscillations around 0, i.e. sign flips, that a weight has undergone during training in order to determine its saliency. Our method can perform pruning before the network has converged, requires little tuning effort due to having good default values for its hyperparameters, and can directly target the level of sparsity desired by the user. Our experiments, performed on a variety of object classification architectures, show that it is competitive with existing methods and achieves state-of-the-art performance for levels of sparsity of
Introduction
The success of deep learning is motivated by competitive results on a wide range of tasks [4,15,42]. However, well-performing neural networks often come with the drawback of a large number of parameters, which increases the computational and memory requirements for training and inference. This poses a challenge for deployment on embedded devices, which are often resource-constrained, as well as for use in time sensitive applications, such as autonomous driving or crowd monitoring. Moreover, costs and carbon dioxide emissions associated with training these large networks have reached alarming rates [38]. To this end, pruning has been proven as an effective way of making neural networks run more efficiently [8,9,23,25,30,43].
Early works [9,23] have focused on using the second-order derivative to detect which weights to remove with minimal impact on performance. However, these methods either require strong assumptions about the properties of the Hessian, which are typically violated in practice, or are intractable to run on modern neural networks due to the computations involved.
One could instead prune the weights whose optimum lies at or close to 0. Building on this idea, the authors of [8] propose training a network until convergence, pruning the weights whose magnitudes are below a set threshold, and allowing the network to re-train, a process which can be repeated iteratively. This method is improved on in [6], whereby the authors additionally reset the remaining weights to their values at initialization after a pruning step. Yet, these methods require re-training the network until convergence multiple times, which can be a time consuming process.
Recent alternatives either rely on methods typically used for regularization [27,30,45] or introduce a learnable threshold, below which all weights are pruned [26]. All these methods, however, require extensive hyperparameter tuning in order to obtain a favorable accuracy-sparsity trade-off. Moreover, the final sparsity of the resulting network cannot be predicted given a particular choice of these hyperparameters. These two issues often translate into the fact that the practitioner has to run these methods multiple times when applying them to novel tasks.
To summarise, we have seen that the pruning methods presented so far suffer from one or more of the following problems:
Computational intractability
Having to train the network to convergence multiple times
Requiring extensive hyperparameter tuning for optimal performance
Inability to target a specific final sparsity
We note that pruning can be performed before the network reaches convergence (unlike the method proposed by the authors of [8]) by determining during training whether a weight has a locally optimal value of low magnitude. To this end, we propose a heuristic, coined the aim test, which determines whether a value represents a local optimum for a weight by monitoring the number of times that weight oscillates around it during training while also taking into account the distance between the two. We then show that this can be used for network pruning by applying this test at the value of 0 for all weights simultaneously, and framing it as a saliency criterion. By design, our method is tractable, allows the user to select a specific level of sparsity and can be applied during training.
Our experiments, conducted on a variety of object classification architectures, indicate that it is competitive with respect to relevant pruning methods from literature, and can outperform them for sparsity levels of
We dedicate this final paragraph of the introduction as a disclaimer. This work represents an extended version of our earlier paper [1]. The final authenticated version is available online at
Method
We are interested in detecting during training whether 0 is a point of local optimum for a weight. Doing so would allow us to simultaneously prune that weight and set it at a point where the loss is minimized, without having to train until convergence multiple times. Additionally, we would like to construct our pruning method such that it avoids the other issues discussed in Section 1, i.e. it is computationally tractable, requires little parameter tuning and allows for an exact level of sparsity to be specified.
In Section 2.1 we present a general method used to determine points of optimality by leveraging the behavior of weights when near such points. In Section 2.2 we show how a specific instance of this test can be applied to pruning, forming the basis of our proposed method.
Motivation
Mini-batch stochastic gradient descent [3] is the most commonly used optimization method in machine learning. Given a mini-batch of B randomly sampled training examples consisting of pairs of features and labels
Indeed, it is also possible that a weight gets updated exactly to a local optimum, i.e. the equality

Over- and under-shooting illustrated. The vertical line splits the x-axis into two regions relative to the (locally-)optimal value
With the behavior of under- and over-shooting, and under the assumption that mini-batches can be used to reliably estimate the empirical gradient, one could construct a heuristic-based test in order to evaluate whether a weight has a local optimum at a specific point without needing the network to have reached convergence:
For a weight Train the model regularly and record the occurrence of under- and over-shooting around If the number of such occurrences exceeds a threshold κ, conclude that
We coin this method the aim test.
Previous works on neural network pruning have demonstrated that neural networks can tolerate high levels of sparsity with negligible deterioration in performance [6,8,26,30]. It is then reasonable to assume that for a large number of weights, there exist local optima at exactly 0, i.e.
However, under-shooting can be problematic; for instance, a weight could be updated to a lower magnitude, while at the same time being far from 0. This can happen when a weight is approaching a non-zero local optimum, an occurrence which should not contribute towards a positive outcome of the aim test. By positive outcome, we refer to determining that
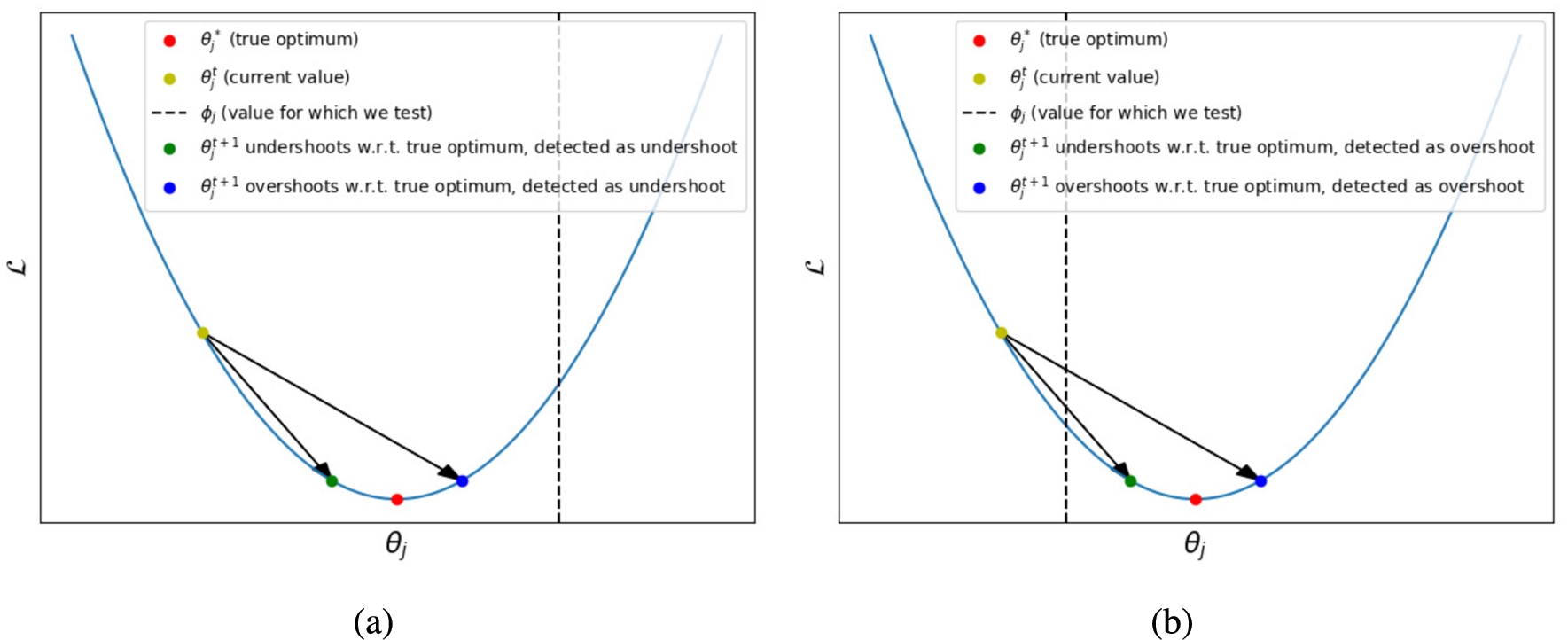
In the plots above, the dotted vertical line represents the value at which the aim test is conducted, i.e. a value we would like to determine as a local optimum or not, while the red dot represents the value of a true local optimum. When testing for a value which is not a locally optimal value
Reducing the impact of deceitful shots. Firstly, one could reduce the impact of deceitful shots by also taking into account the distance of the weight to the hypothesised local optimum, i.e.
Reducing the number of deceitful shots. Our second observation is that by ignoring updates which are not in the vicinity of

(a) All weights that under-shoot but are within ϵ of
We present the two components necessary for applying the aim test for pruning. Specifically, in Section 2.2.1 we propose a saliency criterion that takes into account the number of times over-shooting has occurred as well as the distance of a weight from its hypothesised local optimum, as a result of the previously made observations in Section 2.1 regarding deceitful shots. Finally, in Section 2.2.2 we present a schema of adding perturbation into the weight tensor
Determining which weights to prune
Pruning weights that have local optima at or around 0 can obtain a high level of sparsity with minimal degradation in accuracy. The authors of [8] use the magnitude of the weights once the network is converged as a criterion; that is, the weights with the lowest absolute value, i.e. closest to 0, get pruned. The aim test can be used to detect whether a point represents a local optimum for a weight and can be applied before the network reaches convergence, during training. For pruning, one could then apply the aim test simultaneously for all weights with
When determining the amount of parameters to be pruned, we adopt the strategy from [6], i.e. pruning a percentage of the remaining weights each time, which allows us to target an exact level of sparsity. Given m, the number of times pruning is performed, r the percentage of remaining weights which are removed at each pruning step, k the total number of training steps,
Perturbation through gradient noise
Adding gradient noise has been shown to be effective for optimization [32,44] in that it can help lower the training loss and reduce overfitting by encouraging an exploration in the parameter space, thus effectively acting as a regularizer. While the benefits of this method are helpful, our motivation for its usage stems from allowing the aim test to be performed in a simpler manner; weights that get updated closer to 0 will occasionally pass over the axis due to the injected noise, thus making checking for over-shooting sufficient.
We have seen in Section 2.1 that an update of SGD at time step t will cause a weight
Note that we have also experimented with other recipes for the variance of the Gaussian distribution (Eq. (3c)) which also fulfill the property of automatic annealing, such as the
Pruning periodically throughout training according to the saliency score in Eq. (1) in conjunction with adding gradient noise into the weights using Eq. (3) forms the FlipOut pruning method, which is summarised in Algorithm 1.

FlipOut
Deep-R
In Deep-R [2], the authors split the weights of the neural network into two matrices, the connection parameter
Two similarities with our method can be observed here, namely the fact that the authors also use sign flipping as a signal for pruning a weight, and the addition of Gaussian noise. However, our methods differ in that we do not impose a set level of sparsity throughout training; instead, we use the number of sign flips of a weight in order to determine its saliency, while in Deep-R a single sign flip is required for a weight to be removed. Our method of injecting noise into the gradients also differs in that it does not explicitly encode an annealing scheme, allowing for the pruning process itself to reduce the noise throughout training.
Magnitude and uncertainty pruning
The M&U pruning criterion is proposed in [20]. Given a weight
Our method is similar in that our saliency score also normalizes the weight’s magnitude by a function of its past values. However, this method assumes asymptotic normality. While this is the case when using negative log-likelihood or an equivalent as the loss function, this property does not necessarily hold when using modified variants of the SGD estimator, such as Adam [18] or RMSprop [40]. In contrast, FlipOut is not derived from the Wald test and does not make any assumptions about the weight distribution at convergence.
Zeros, signs and the supermask
[46] conduct a series of ablation studies in order to determine why iterative magnitude pruning with rewinding, introduced by [6], works so well. Among others, they experiment with various rewinding strategies (i.e. the values that the kept weights are re-initialized to after a pruning step). They found that all tested strategies work better when the weights are reset such that their initial sign is kept, even when a single constant is used for all weights, i.e. at time step t a weight
While also emphasizing the importance of signs, we do not use it as a strategy for weight resetting. Instead, we consider a large number of sign flips during training as an indicator that a weight has a local optimum at 0, which makes it an ideal candidate for pruning, since it would then also be set at a point of optimality.
Experiments
We begin this section by detailing our experimental setup and the motivation behind it (Section 4.1). This is followed up by the method we have employed to determine favorable values for the hyperparameters p and λ of our proposed method (Section 4.2). Finally, we present our experiments: a comparison between FlipOut and baseline methods from literature (Section 4.3), an ablation study used to determine whether the performance of our method is simply a result of injecting gradient noise or if, indeed, the weights that have a local optimum at 0 can be reliably selected (Section 4.4), and a study into whether pruning and quantization can be used in conjunction and still maintain an acceptable level of performance (Section 4.5). All experiments have been implemented using the Pytorch deep learning library [34]. For reproducibility, we release our code at
Compression ratios, resulting sparsity levels and prune frequencies (in epochs) used in the experiments, assuming 350 epochs of training and that
of the remaining weights are removed at each step
Compression ratios, resulting sparsity levels and prune frequencies (in epochs) used in the experiments, assuming 350 epochs of training and that
Baselines
As baselines, we consider a slightly modified version of magnitude pruning [8] (Global magnitude), due to the similarity between its saliency criterion and that of our own method, SNIP [24] due to it being an easily applicable method which does not suffer from any of the issues that are commonly found in pruning methods (Section 1) and Hoyer-Square, as introduced in [45], for the state-of-the-art results that it has demonstrated. We also include random pruning (Random) as a control. For FlipOut, Global magnitude and Random, pruning is performed periodically throughout training. We compare these methods at five different compression ratios, chosen at regular log-intervals (Table 1); for Hoyer-square, the performance at those points is estimated by a sparsity-accuracy trade-off curve. Magnitude pruning, in its original formulation, performs pruning only once the network has reached convergence. However, employing this strategy can create a confounding variable: training time. Since we would like to compare all methods at equal training budgets, we have opted to simply perform pruning after a fixed number of epochs for these methods. Note that the training budget that we allocate allows all of the networks that we consider to reach convergence when trained without performing any pruning. We make an exception to this equal budget rule for Hoyer-Square, since it prunes after training and would otherwise not benefit from any SGD updates after sparsification. As such, we have performed an additional 150 epochs of fine-tuning without the regularizer, as per the original method, although we have found that the benefits of this are negligible and the accuracy drop incurred by pruning is relatively low as a consequence of the fact that the weight distribution was already peaked around 0. Following the strategy of [6], the magnitude pruning criterion proposed by [8] is modified to rank weights globally when a pruning decision is made, rather than in a layer-by-layer basis, so as to avoid creating bottleneck layers. For fairness, the same treatment is applied to all other methods that we test, including our own. Bias parameters have not been pruned since they only represent a small fraction of the total parameters in the networks that we test (Table 2). We also do not prune the learnable parameters in the batch normalization layers; an explanation for this is offered in Section 4.1.4. The levels of sparsities that we report going forward do not include the batch normalization and bias parameters.
The models that we test on are ResNet18 [11] and VGG19 [37] trained on the CIFAR-10 dataset [22], and DenseNet121 [15] trained on Imagenette [14]. An overview of the sizes of these models can be found in Table 2.
The number of total parameters and biases for each model. The percentage of biases as compared to the total number of weights in the network is displayed in parenthesis. The last column represents the number of floating point operation required for a forward pass on a single sample, assuming an input size of
for VGG19 and ResNet18, and
for DenseNet121
The number of total parameters and biases for each model. The percentage of biases as compared to the total number of weights in the network is displayed in parenthesis. The last column represents the number of floating point operation required for a forward pass on a single sample, assuming an input size of
The training parameters for all experiments are taken from [41]; specifically, we use a learning rate of 0.1, batch size of 128, 350 epochs of training and a weight decay penalty of
Metric
In order to motivate the choice of the metric used to compare between different pruning methods, we first revisit the practical benefits that can be achieved by pruning, namely the reduction of storage size, memory usage and computational speedup. The way in which these manifest in practice is dependent upon the pruning method used. For element-wise pruning (removing individual weights), a category in which our method and all tested baselines fall into, a dense weight matrix
Firstly, while there exists a strong correlation between sparsity and speedup, one could construct two neural networks of the same architecture with equal levels of sparsity, yet obtain different measurements in terms of inference time depending on how the active weights are distributed throughout the network. This is due to the fact that a weight in a filter from a convolutional layer gets reused multiple times when processing an input volume; as such, pruning a weight from a layer will reduce computation depending on the size of the volume used as input to that layer. In other words, pruning a weight from a layer that receives a larger input volume will generate a higher speedup.
Secondly, sparse networks have traditionally been unable to leverage compute kernels found in GPU accelerators due to the fact that memory reads are data-dependent and thus cannot fully utilize cache memory. This is pointed out by the authors of [29], which propose a more efficient sparse format and a recipe for pruning able to leverage Sparse Tensor Cores found in NVIDIA Ampere GPUs [33]. This format, however, only supports sparsity levels of up to
Batch normalization parameters should not be pruned
Batch normalization [16] is used in many neural network architectures in order to normalize the inputs to a layer, thus preserving gradient flow and allowing for more stable training. Given a mini-batch of m samples, and a layer activation
When comparing between different methods, this can affect the network’s performance in unforeseen ways, depending on the number of batch normalization parameters that get selected for pruning and even the particular dimensions of
Choosing the hyperparameters for FlipOut
We have experimented with different values of the two hyperparameters and found that
Choosing λ
For λ, we have run all networks at 15 different values, ranging from 0.75 to 1.5 in increments of 0.05. The value of
Accuracies when using the best value of λ discovered by grid search and the value of
at two levels of sparsity. The parantheses indicate the gain offered by the optimal parameter
Accuracies when using the best value of λ discovered by grid search and the value of
We perform similar experiments for p on five values,
Table of results for different values of p at two levels of sparsity
Table of results for different values of p at two levels of sparsity

Results of our pruning experiments on the 3 reference networks. Each point is averaged over 3 runs; error bars indicate standard deviation. (a) ResNet18 on CIFAR 10. (b) VGG19 on CIFAR10. (c) DenseNet121 on ImageNette.
The results for the three models tested are found in Fig. 4. FlipOut obtains state-of-the-art performance on ResNet18 and VGG19 for sparsity levels of
Interestingly, the simple criterion of magnitude pruning, when modified to rank the weights globally instead of a layer-by-layer basis, is competitive with other, more recent, baselines, and even obtains state-of-the-art results for moderate levels of sparsity. However, at high levels of sparsity, which correspond to more frequent and implicitly earlier pruning steps (Table 1) there is a performance degradation. This suggests that the magnitude of a weight by itself is not a good measure of saliency when the network is far from reaching convergence. It is also worth noting that SNIP collapses at high levels of sparsity, causing the network to perform no better than random guessing. Upon inspecting these cases (not shown for visibility) we noticed that at least one layer has been entirely pruned, effectively blocking any signal from passing. Interestingly, this does not happen for any of the other baselines (except for Random). We conjecture that this collapse as well as the cases where SNIP performs worse than random pruning (Fig. 4(b)) are a result of pruning at initialization; pruning too early can cause the saliency criterion to be inaccurate, but also impedes training in and of itself.
During our experiments, we empirically observed that Hoyer-Square requires extensive hyperparameter tuning for optimal performance. Our method, however, has strong default values and can also target the final sparsity directly, while also not requiring additional epochs of fine-tuning. Finally, SNIP, the only other baseline which does not suffer from any of the issues commonly found among pruning methods (Section 1) compromises on performance for high levels of sparsity, whereas FlipOut does not.

Results of the ablation study on the noise. Global magnitude without noise addition is also shown for comparison. (a) ResNet18 on CIFAR 10. (b) VGG19 on CIFAR10. (c) DenseNet121 on ImageNette.
The performance of FlipOut could simply be a result of the noise addition, which is known to aid optimization [32,44]. To investigate this, we perform experiments with global magnitude as the pruning criterion in which we add noise into the gradients using the recipe from Equation (3c) and compare it to our own method. Notably, the saliency criterion of these two methods differ only in that FlipOut normalizes the magnitude by the number of sign flips (denominator in Eq. (1a)). The hyperparameters were kept at their default values of
For sparsity levels up to
Since FlipOut with
Additionally, we conjecture that occurrences of under-shooting are indeed converted into over-shooting when adding gradient noise, allowing FlipOut to more accurately compute saliencies. This is evidenced by the fact that gradient noise addition benefits FlipOut more so than it does global magnitude, and implies that our method of dealing with deceitful shots is sound.
Combining pruning and quantization
We study whether quantization can be successfully applied in conjunction with pruning. Through quantization, we refer to the practice of converting a neural network’s weights and activations to 8 bits (whereas typical applications use 32). This technique has the same practical advantages as pruning, namely a reduced memory footprint and model storage size as well as computational speedup (in this case by a factor of up to
We begin by motivating our choice of quantization scheme in Section 4.5.1 and detail our experimental setup in Section 4.5.2. Finally, we analyze our results in Section 4.5.3.
Sparsity preserving quantization
According to the authors of [21], a variable x of range
However, applying this scheme to a sparse network has negative consequences. All previously pruned weights of value
For the activations, there is no need to preserve sparsity. As such, we employ the symmetric quantization scheme with signed integers. The scale and zero-point can then be derived depending on the observed minimum and maximum values
Setup
We first train and prune ResNet18 and VGG19 as per the methodology described in Section 4.1.1 and the same hyperparameters as in Section 4.1.2. As pruning methods, we have tested FlipOut and compared it to Global Magnitude as the baseline, due to the similarity of their saliency criteria. Following this step, we perform post-training quantization, where we calibrate the model on the training set in order to determine the interval bounds
For hyperparameters, we use an averaging constant of 0.01 for the moving average methods and 2048 as the number of bins for the histogram method. Note that MinMax and PC-MinMax do not have any hyperparameters. For calibration, we use the same random seed that was used to generate the trained-and-pruned netoworks and a batch size of 128 in all cases; the random seeds involved in this set of experiments are different than those from Section 4.3 and 4.4. While we have also experimented with using a varying number of epochs for the calibration times, we have found that a single epoch is sufficient and further calibration does not yield any significant improvements. We compare both models (VGG19 and ResNet18) across different levels of sparsity using the five aforementioned calibration schemas. For reference, we also include baseline results, where we simply train the networks without any pruning and apply post-training quantization. As before, 3 runs with different random seeds are used to generate each result. We have also attempted to run these experiments on the DenseNet121 network; however, the results have been unstable, with high degrees of variance and performance losses which would render the network’s predictions unusable in a practical scenario. As such, we defer these experiments to future work, where other quantization methods, such as [17], might be tested.

Table of results for VGG19 when pruning is applied, using either FlipOut or Global Magnitude, with five different quantization schemes applied post-training. Baseline results when only quantization is applied are also included. Each bar chart represents an average over 3 runs using different random seeds.

Table of results for ResNet18 when pruning is applied, using either FlipOut or Global Magnitude, with five different quantization schemes applied post-training. Baseline results when only quantization is applied are also included. Each bar chart represents an average over 3 runs using different random seeds.
We present our results for VGG19 and ResNet18 in Figs 6 and 7, respectively. Notably, it can be seen that the moving average methods obtain equal results to their regular counterparts for all cases we have tested. This suggests that the averaging constant of 0.01 is not large enough to modify the computed bounds with the number of calibration steps that we have used. The behavior of the Histogram method, however, is drastically different depending on the type of network that it is applied to. For VGG19 it has the worst performance of the five when no pruning is performed, while for ResNet18 it is the best in some scenarios, albeit not by a wide margin. A similar pattern can be seen when we apply it to pruned networks, although an additional failure mode appears at the highest pruning frequency for ResNet18 where its relative drop in accuracy is higher than for the other calibration schemes. For VGG19, its performance drop is at levels where it would be considered unacceptable; at the highest level of sparsity for global magnitude it even degenerates to the random prediction case. Overall, the best performing calibration method is MinMax; in the case of VGG19 this is true by a wide margin, while for ResNet18 there are two exception cases where Histogram performs slightly better, namely for FlipOut at a prune frequency of 70 and Global Magnitude at a frequency of 39. Since in a majority of cases the MinMax scheme attains superior performance, all of our comparisons going forward will refer strictly to it.
Comparing the results of pruning and quantization to the baseline case of just quantization, the drop in accuracy for the first 3 levels of sparsity is contained at approximately
A comparison can also be drawn between the two compression methods, pruning and quantization, when applied in isolation; a sparsity of
Table of results for independently pruned, quantized (using the MinMax calibration scheme), jointly pruned and quantized as well as full models, averaged over 3 seeds. Numbers are expressed as accuracy percentages
Table of results for independently pruned, quantized (using the MinMax calibration scheme), jointly pruned and quantized as well as full models, averaged over 3 seeds. Numbers are expressed as accuracy percentages
In this work, we introduce the aim test, a general method for determining whether a point represents a local optimum for a weight. We then show how the impact of observations that lead to a false positive outcome of the aim test (deceitful shots) can be minimized by taking into consideration the distance of the weight from the value tested as a local optimum and by adding gradient noise while ignoring the occurrences of under-shooting entirely. In order to simultaneously prune and set weights to points of local optima, one could then simply conduct the aim test at
This method, coined FlipOut, demonstrates several desirable properties. Firstly, it is computationally tractable, as it only involves the magnitudes of the weights and a count over the number of sign flips, which scales linearly with the dimensionality of
We perform experiments on a variety of commonly used computer vision architectures and demonstrate that there exist values for the hyperparameters p and λ (Eq. (1a), Eq. (3a)) which generate near optimal results in the majority of cases, eliminating the need for extensive hyperparameter search. Moreover, we show that FlipOut has similar performance to other baseline methods from literature, and even achieves state-of-the-art results at the highest levels of sparsity for 2 out of 3 of the tested networks. We also conduct ablation tests in order to determine the cause of its performance. We find that the addition of gradient noise plays an important role in our method, particularly in high sparsity regimes, but cannot by itself explain the performance of FlipOut. This implies that the other component of our algorithm, scaling the magnitude by the number of sign flips in the computation of the saliency score, is also a significant factor. Finally, in Section 4.5 we study whether pruning can be applied conjointly with quantization, a technique which promises the same practical advantages. While we find little difference between using FlipOut and Global Magnitude as the pruning criteria, combining these two methods is feasible in terms of the resulting accuracy of the network when moderate levels of sparsity (up to
As a recommendation for practitioners, the choice of compression techniques used should depend on the target platform to which neural networks are deployed and the desired level of acceleration. With current generation GPU accelerators, one can expect a maximum speedup factor in inferencing of
When deployment is targeted to CPUs, on the other hand, no such restrictions exist and any method could be applied. In this case, both pruning with FlipOut and quantization could be applied separately for a speedup of
Limitations & future work
In this section, we address the shortcomings of our research and discuss potential avenues for future work.
Firstly, we have only conducted tests for convolutional neural networks for the task of object classification. As such, it would be interesting to study whether FlipOut is effective when using architectures that handle sequential data [13,42] or even generative models [7,19]. Moreover, we have used a limited sample size in order to keep our experiments feasible (Sections 4.1.1 and 4.5.3), which means that we could not run statistical significance tests, although our experiments did allow for some degree of informed speculation. Repeating the experiments with a larger sample size could then help to validate our claims in a more principled manner. Also, for the quantization-only experiments from Section 4.5.3 we have used the sparsity preserving schema described in Section 4.5.1. However, when quantization is applied in isolation, there is no need to restrict the zero-point to 0 and use a signed integer interval. Particularly, it has been documented in [21] that for certain networks an asymmetric schema (i.e. the zero-point can take arbitrary values) is preferable. It is therefore possible that the results presented in Table 5 for isolated quantization could be improved by applying a different schema.
At the same time, we believe our method can inspire novel research directions. For instance, FlipOut in its current form performs element-wise pruning and, as such, requires converting the weight matrix
Moreover, our work has potential applications in optimization; the issue of pathological curvature [28] is known to hinder the generalization ability of neural networks and has been traditionally dealt with by using optimization techniques that dampen oscillations across SGD updates [18,40]. The aim test could also serve as one such solution, whereby weights are set to a value they oscillate around, potentially aiding optimization.
Finally, it is our hope that this work can inspire other researchers to develop novel pruning and/or quantization methods of their own. Since a high degree of correlation has been established between computational power and performance of deep learning systems [39], an ever increasing computational demand is to be expected. It is, therefore, not unlikely that model compression techniques will become an ubiquitous component of deep learning pipelines. Methods that are easily applicable and add little additional time cost on the practitioner’s part can help in their widespread adoption.
Footnotes
Acknowledgements
We would like to thank BrainCreators B.V. for the funding of this research. We would also like to thank the University of Amsterdam for the provided guidance and counsel.