
Abstract
Recommendation systems help customers to find interesting and valuable resources in the internet services. Their priority is to create and examine users’ individual profiles, which contain their preferences, and then update their profile content with additional features to finally increase the users’ satisfaction. Specific characteristics or descriptions and reviews of the items to recommend also play a significant part in identifying the preferences. However, inferring the user’s interest from his activities is a challenging task. Hence it is crucial to identify the interests of the user without the intervention of the user. This work elucidates the effectiveness of textual content together with metadata and explicit ratings in boosting collaborative techniques. In order to infer user’s preferences, metadata content information is boosted with user-features and item-features extracted from the text reviews using sentiment analysis by Vader lexicon-based approach. Before doing sentiment analysis, ironic and sarcastic reviews are removed for better performance since those reviews inverse the polarity of sentiments. Amazon product dataset is used for the analysis. From the text reviews, we identified the reasons that would have led the user to the overall rating given by him, referred to as features of interest (FoI). FoI are formulated as multi-criteria and the ratings for multiple criteria are computed from the single rating given by the user. Multi-Criteria-based Content Boosted Hybrid Filtering techniques (MCCBHF) are devised to analyze the user preferences from their review texts and the ratings. This technique is used to enhance various collaborative filtering methods and the enhanced proposed MCKNN, MCEMF, MCTFM, MCFM techniques provide better personalized product recommendations to users. In the proposed MCCBHF algorithms, MCFM yields better results with the least RMSE value of 1.03 when compared to other algorithms.
Keywords
Introduction
Online shopping is ubiquitous; but online stores, while eminently searchable, lack the same browsing options as the brick-and-mortar variety. Visiting a bookstore in person, a customer can wander over to the science fiction section and casually look around without a particular author or title in mind. Online stores often offer a browsing option, and even allow browsing by genre, but usually the number of options available are still overwhelming [1]. Commercial sites try to counteract this overload by showing special deals, new options and favorites, but the best marketing angle would be to recommend items that the user is likely to enjoy or need. Recommendation systems (RS) mainly focus on accuracy, scalability and cold-start problems. Apart from these, explainability and transparency also play essential roles in increasing the user’s trust and satisfaction.
Recently Latent Factor Models (LFM) and deep learning models in collaborative filtering have demonstrated good prediction accuracy. Deep learning models are essentially black boxes, where the developer has no control over the features or aspects extracted from the given input [7]. Most of the LFM models use user-item ratings alone for making the recommendation. Text reviews contain a lot of information that gives us details about user preferences. By analyzing the text reviews, explanations can be provided for recommendations. Using sentiment analysis, features in which the user would be interested while purchasing a product and the features for which a purchased item is rated well are extracted from the text reviews [16].
We aimed to provide a hybrid product recommendation system that infers the preferences of the users from their text reviews in the form of Features of Interest (FoI). Important features of interest are formed as multiple criteria (MC) and the ratings for multi-criteria are inferred from the single user-item rating using Multi-Criteria Decision Making (MCDM) technique. Inferred multi-criteria ratings and metadata are used to find similar users in collaborative filtering techniques. These proposed Multi-Criteria based Content Boosted Hybrid Filtering (MCCBHF) techniques are used to predict the recommendations based on the single ratings, metadata features, user’s features, item’s features and inferred MC ratings. Collaborative Filtering (CF) methods such as Tensor Factorization Model (TFM), Matrix Factorization (MF), Factorization Machine (FM) and K-Nearest Neighbour (KNN) are boosted with metadata and inferred multi-criteria ratings to form multi-criteria based KNN (MCKNN), multi-criteria based TFM (MCTFM), multi-criteria based explicit matrix factorization (MCEMF) and multi-criteria based FM (MCFM). It also provides an explanations for the recommendations (FoI) that automatically increases the user satisfaction on purchasing the products.
This paper is aimed to infer the preferences of the user from the single rating given by the user with the help of the interests extracted from the textual reviews given by the user. The user interests are formulated as the multiple criteria for ratings and the multiple ratings are infered from the single rating given by the user. The rest of the paper is organized as follows. Section 2 describes the work related to the recommendation systems. The concepts of multi-criteria recommendation systems, explainable RS, need for irony detection are discussed in Section 3. Section 4 explains the proposed system for product recommendation. Results are discussed in Section 5. Conclusion in Section 6 has pointers to possible future enhancements
Related work
The importance of textual reviews in recommendation systems is stressed in [33] that contains both user-oriented information (user opinions) and product-oriented information (product features). Zhang attempts to incorporate textual reviews over the yelp dataset to tackle cold-start problems, the explanation of recommendation and automatic generation of user or item profiles. The phrase-level sentiment analysis framework over textual review corpus is proposed in [34] and they have generated a sentiment lexicon for a personalized recommendation. They have designed an Explicit Factor Model to give feature-level explanations for both recommended and non-recommended items with the generated personalized recommendation.
Two novel methods, such as the word-based method and LDA-based method are used for discovering all the contextual information quickly and efficiently across different applications from user-generated reviews [4]. The authors of [14] have introduced a scalable and practical lexicon-based approach, which performs well in terms of speed and accuracy for extracting sentiments using emoticons and hashtags methods.
Topic Matrix Factorization Model is proposed in [2] that combines the idea of Matrix Factorization (MF) for rating prediction and Non-Negative Matrix Factorization Model (NMF) for uncovering latent topic factors in review texts. These two tasks are related by designing the A-T (Addition Transform) or M-T (Multiplication Transform) functions to align the topic distribution parameters with the corresponding latent user and item factors.
Non-linear relationships among users and items are solved using a neural network-based recommendation model (NeuRec) in [32]. It uses a neural network model to untangle the complexity in user-item interaction and its latent factors. Even though the overall I-NeuRec and U-NeuRec models perform well, the NeuRec model with a pairwise learning approach performs poorer in terms of ranking quality. This pairwise learning approach is used to maximize the difference between positive and negative items.
Various features like heuristic terms, classification terms, heuristic aspects and hierarchy aspects are extracted from users reviews and used to find similarity in k-NN algorithm by [8]. The metadata features of the item are not used for making recommendations.
The authors of [19] use LDA method to learn the latent review topics and LFM to learn latent rating dimensions. Sentiment dictionary is used to predict the sentiment score from reviews and Probabilistic Matrix Factorization (PMF) is used to predict the rating by [27]. DeepCoNN model is developed with two parallel Convolutional Neural Networks (CNN) networks to learn user features and item features and used a shared layer to learn the interactions between them [35]. DeepCoNN, reviews are first processed by two CNNs to learn user’s and item’s representations, which are then concatenated and passed into a regression layer for rating prediction. A limitation of DeepCoNN is that it requires reviews in the testing phase, which is not present in most cases.
Aspect-aware LFM and aspect-aware topic model to learn the latent factors and latent topics for making the recommendation is proposed in [6]. The performance of DeepCoNN decreases significantly when reviews are unavailable in the testing phase. TransNet applies neural networks, which has exhibited strong capabilities on representation learning, in reviews to learn users’ preferences and items’ characteristics for rating prediction. However, it may suffer from noisy information in reviews, which would deteriorate the performance; and errors introduced when generating fake reviews for rating prediction, which will also cause bias in the final performance as mentioned in [6].
Neural Attentional Regression model with Review-level Explanations (NARRE) is discussed to predict the ratings and also the usefulness of the reviews in providing a better recommendation in [5]. A method named global and local tensor factorization model is used to jointly learn a global predictive model and multiple local predictive models to capture the overall rating behaviour and also the diverse rating behaviours of users, respectively by [31]. Inorder to perform this, they have used the explicit predefined multi-criteria ratings already obtained from the users in addition to the single overall rating.
While metadata information plays a vital role in identifying user preferences, much of the work surveyed in this section does not take advantage of it. Explicit and implicit feedback along with the metadata can be explored and exploited to infer users’ interests. Recommending items based on user’s interest helps increase user satisfaction and thus increase profit and sales. Also, most of the recommendation systems obtain a single explicit rating from the user, yet we need ratings for various criteria to understand the preferences better. Hence there is a need to infer multi-criteria ratings from the single user-item rating. Different collaborative filtering techniques can be boosted with the content features from text reviews and metadata, and their performance can be analyzed for providing better personalized recommendations.
Methodologies used in the proposed approach
Multi-criteria recommendation system
A user always gives a single rating for each item. Yet, his rating may be based on only some features which are of interest to him. Another user may have assigned the same rating to the item, but the features he is interested in may be different. Therefore, ratings alone or metadata about the items alone are not adequate to know the interest of the user so as to provide a personalized recommendation [31]. However, we can infer the interest of the users from implicit feedback such as pages visited, click rates or time spent on an item’s page. Moreover, the explicit text reviews given by the user are a potential source from where we can infer his interest [12]. Although reviews are sparser than ratings, they provide more detailed and reliable information about the user’s preferences and interests. Personalization can be improved by adding the review text information in addition to ratings and metadata. For example, in a text review of a cellphone, if a user talks about the battery life and charging time, he is more interested in the battery than other qualities of the cell phone such as display, camera, style, and cost. Thus, we identified user preferences from the ratings and text reviews.
Using sentiment analysis on the text reviews given by the user, we identified the Features of Interest (FoI) features of the product the user is interested in. We then form the User-Feature Correlation Matrix (UFCM) that, for each user, assigns a weight to each feature of the item. Similarly, text reviews of each item is analyzed to find out the degree to which each feature is liked or disliked by the overall user community. Item-Feature Correlation Matrix (IFCM) thus formed contains positive or negative sentiment for the features of each item. Ratings for multiple criteria are computed from the single overall rating given by the user. This multi-criteria rating matrix, when used to provide a recommendation, will find similar users of the same interest more effectively than with a single-criterion rating matrix. The user who concentrates more on the battery life will have similar users who consider battery life as important when compared to other features.
Multi-criteria rating matrix
Multi-criteria rating matrix
Table 1 shows the multi-criteria ratings for five items given by 4 users. Features of cellphones such as display resolution, camera quality, battery life and cost are taken into consideration. User 1 and 2 gave rating 5 for item 1. Here user 1 mainly concentrates on battery and cost while user 2 concentrates on display and camera quality. Hence their interests are not matched. Even though both users give same rating, their interests mismatch and they are not considered as similar users or neighbours. Hence item 3 will not be the correct recommendation for user 2. Multi-criteria decision making is used to analyze and split the given single user-item rating among the various criteria that the user likes. These inferred multi-criteria ratings and the product metadata features are used in Multi-Criteria based Content Boosted Hybrid Filtering (MCCBHF) to achieve better personalized explainable recommendations to the user.
A hybrid approach is proposed to give a personalized recommendation with explanation to users. Instead of giving simply recommendations, the user will be given items preferred by him or suggested by similar users. This will increase the satisfaction of the user, and the effectiveness of the system. The text reviews are analyzed for sarcastic and ironic content and those reviews are removed from further processing as they will affect the recommendation adversely. Then the features which are of interest to the user while purchasing a particular product are extracted by analyzing their text reviews. From the text reviews, a sentiment lexicon is constructed using Natural Language Processing (NLP) by analyzing users’ sentiments on the extracted features for a personalized recommendation. The features are extracted as triplets
Ironic and sarcastic content analysis
Humans have a natural ability to identify the sentiment or the irony intent of reviews or comments. This ability starts from childhood and develops as we grow and interact with others. However, for the machine, identifying the intention of a user is a rather difficult task. Sentiment analysis plays a vital role in e-Commerce. In order to increase the accuracy of sentiment analysis, identifying ironic and sarcastic content in the text is necessary [3]. This information plays a vital role in inferring the actual intention of the user.
It is very important to identify the ironic content in the given text since that will inverse the polarity of the sentiment inferred [10,12]. Hence automatic detection of ironic and sarcastic content is necessary. Recently the growth of the Internet and the vast amount of data available in the Internet have made this detection possible. Internet has influenced our daily life events. We rely on the Internet data for buying items, watching movies and searching for any information. Social media comments and reviews plays also a main role in e-commerce. People read the reviews about a particular product before deciding to purchase it. Currently, analyzing the sentiment of reviews is an active area of research.
Ironic content in the text affects the polarity of the sentiment inferred. It gives the opposite meaning of what it actually meant. Therefore it can be called as a polarity reverser [18]. Irony is studied by various disciplines like linguistics, philosophy and psychology. The frequent use of ironic text in social media gains importance in natural language processing tasks but faces difficulty in achieving high-performance [17,30]. The potential applications of irony detection include text mining, author profiling, detecting online harassment and sentiment analysis [29].
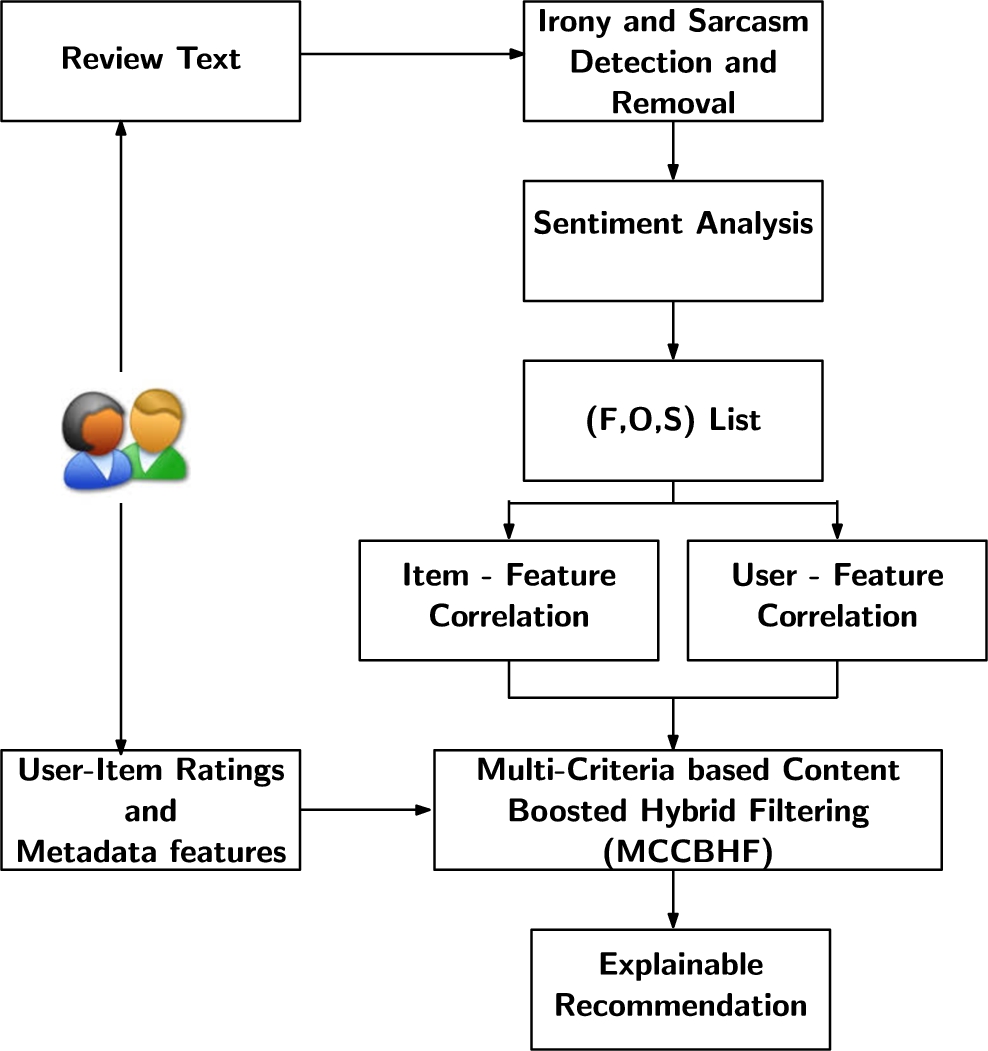
Architecture of explainable product recommendation system.
We have proposed a system that extracts the features of interest (FoI) from text reviews using sentiment analysis and formulate the multi-criteria ratings based on the extracted interesting features. These multi-criteria ratings and metadata are used to provide a personalized recommendation system. Figure 1 shows the architecture of the system. The proposed system consists of the following modules: irony and sarcasm detection and removal, feature extraction using sentiment analysis, item-feature and user-feature correlation matrices generation and recommendation model. User-item ratings and text reviews obtained from the users and the metadata features are the input to the system. The text reviews are supplied to the irony and sarcasm detection and removal module to remove the ironic and sarcastic review contents. This cleaned data is given to the sentiment analysis module to extract the features in the form of triplet (Feature, Opinion, Sentiment) list from which the item-feature and user-feature correlation matrices (IFCM, UFCM) are formed. The newly constructed IFCM and UFCM matrices along with the user ratings and the metadata content features are used to infer the multi-criteria ratings and give personalized recommendations using the proposed MCCBHF algorithms.
Irony and sarcasm detection and removal
We participated in SemEval-2018 for task 3 (irony detection) and developed a system named SSN MLRG1, using machine learning approach with Twitter data [22]. A rule-based approach was used for feature selection and Multilayer Perceptron (MLP) technique was used to build the model for ironic classification subtask. As an extension of that system in addition to Twitter irony dataset, SarcasmCorpus dataset of the product reviews was also used for irony and sarcasm detection purposes. Data was cleaned and processed using the NLTK toolkit functions. The keywords used for irony and sarcasm detection were identified using rule-based feature selection technique. The selected features were formed as a Bag of Words (BoW) dictionary. For each sentence, feature vectors were generated by a one-hot encoding method using the sentence keywords and BoW dictionary. The feature vectors were given to the machine learning and deep learning models to classify the review text as irony or regular. The features in BoW were manually evaluated for correctness. Since the ground truth information about the features were not available we could not use the metrics to evaluate the correctness. Some example words in BoW are humorous, arrogant, mocking, ridiculous, beautiiiifulll, fantasssstic etc.,
Multilayer Perceptron (MLP) and Deep Learning models like Long Short Term Memory networks (LSTM) and Bidirectional Encoder Representations from Transformers (BERT) were used for this classification. Algorithm 1 shows the various steps for irony and sarcasm detection and removal. The system comprises the following modules: data extraction, preprocessing, rule-based feature selection, feature vector generation and machine learning model for classification. The model was built with sarcasm and twitter irony dataset and was used to remove the ironic and sarcastic reviews in Amazon product dataset. The review text and summary of the review were used to identify the ironic or sarcastic content. If the predicted label of the product review is ironic or sarcastic, then that review is removed from the dataset.

Irony and sarcasm detection and removal
Parts of speech categories
After removing the sarcastic text from the dataset, the interesting features of users and items are extracted using sentiment analysis [23]. Feature extraction is described in the form of
Stanford POS tagger is used to parse each phrase which yields the POS tag for each word. Words tagged as a noun are used to represent the product features, whereas words tagged as adjective, verb, or adverb are used for identifying the opinion words from the context. After applying POS-tagging, features and their opinions are extracted using the pattern knowledge. Sentiment is identified using the Vader lexicon-based approach [13]. The resulting patterns are represented by the sentiment lexicon
Table 3 shows the various pattern relations and examples for positive and negative reviews. Algorithm 2 shows the steps for extracting features from review text in the form of
Lexicon construction using POS-tagging
Lexicon construction using POS-tagging

Feature extraction and multi-criteria recommendation
In feature analysis, the user–feature correlation matrix (
User–feature correlation matrix entries are binary, 0 or 1, where 1 denotes that the user is interested about the feature, 0 denotes that the user is not interested in that feature. Item–feature correlation matrix measures the quality of an item for the corresponding product feature. Item–feature correlation matrix entries are ternary,
Multi-criteria based content boosted hybrid filtering (MCCBHF)
Various collaborative filtering techniques like Tensor Factorization Model (TFM) [15], Matrix Factorization (MF) [26], Factorization Machine (FM) [24] and K-Nearest Neighbour (KNN) are boosted with the content information extracted from the text reviews and the multi-criteria ratings imputed from them. User preferences inferred from the text reviews are used to improve the performance of the explainable recommendation system. Multi-criteria based K nearest neighbour (MCKNN) method is used to formulate the neighbourhood with the help of inferred multiple ratings. Traditional KNN finds similar users based on the overall ratings, whereas MCKNN finds similar users based on the multi-criteria ratings. Two users who rated an item with 5 rating may vary in their interest (FoI). Thus MCKNN computes the real interest among the users and identifies the like-minded neighbours for providing better recommendations where simple KNN fails.
Matrix factorization assumes the latent features of interest as two matrices
Multi-criteria based explicit matrix factorization (MCEMF)
In a recommendation system such as Netflix or Amazon, there is a group of users and a set of items. Given that each user has rated some items in the system, the aim of the system is to predict how the users would rate the items that they have not yet rated, such that recommendations can be generated for the users. In this case, all the information about the existing ratings can be represented in the form of the matrix. Ratings are integers ranging from 1 to 5. The problem of predicting the rating for unrated items can be solved by identifying the latent features hidden in the ratings. These hidden features are used to determine how the user rates an item.
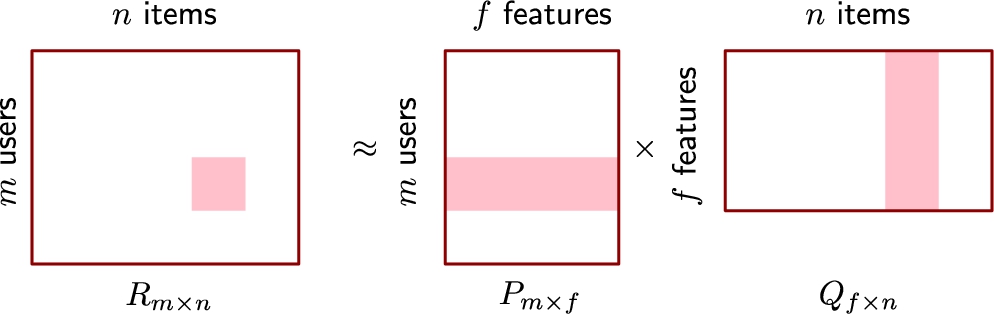
Matrix factorization.
Matrix Factorization (MF) is the process to factorize a given matrix, i.e., to find out two matrices such that multiplying them will give the original matrix. Matrix factorization is a technique that can be used to discover latent features underlying the interactions between two different kinds of entities [26]. The intuition behind using matrix factorization is to solve the problem of recommending items to users who have not rated those items, based on some latent features that determine how a user rates an item. Figure 2 shows the working of matrix factorization.
Equation (1) shows the calculation of rating prediction
The process extracts product features and user opinions explicitly from reviews, incorporates both user-feature and item-feature relations as well as user-item ratings into a new unified explicit matrix factorization framework. UFCM and IFCM replaces the P and Q latent matrices where the latent features are explicitly given in EMF. It mainly focuses on user attention and item qualities from the feature space. The framework combines implicit as well as explicit factors to achieve high accuracy as well as explainability. The explicit feature level explanations help both recommendation and disrecommendation items.
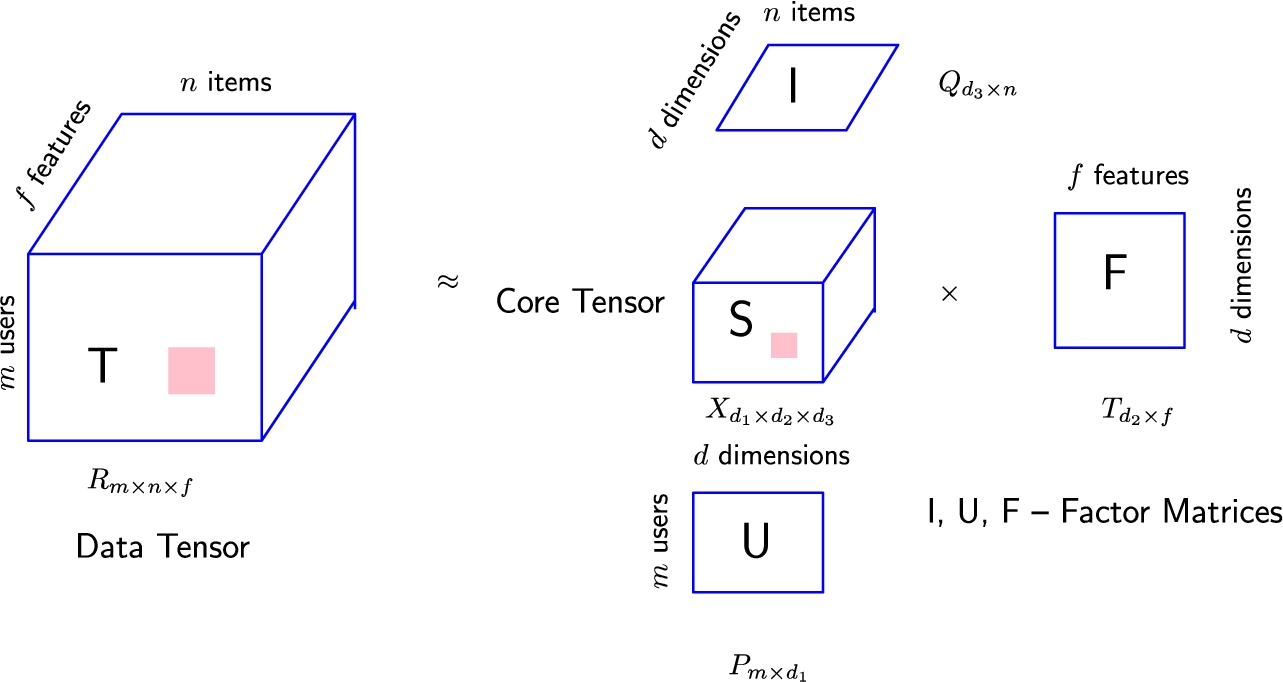
Tensor factorization.
User–Item ratings are used to predict the recommendations about two-dimensional data, and hence latent factor models such as matrix factorization work well. When the features of interest extracted from the review texts using sentiment lexicon are added as a new dimension, it becomes three-dimensional data, and therefore tensor representation is more suitable. Tensor of order N is a high dimensional mathematical notation that represents an object in a multi-linear concept [15]. Figure 3 is a pictorial representation of TF where T is the tensor containing the observations (inferred multi-criteria ratings), S specifies rating observation, U users latent matrix, I items latent matrix and F product features latent matrix. T is a tensor rating matrix
Various decomposition and factorization techniques used are Tucker decomposition [15], Non-Negative tensor factorization (NTF) [15], Exponential family tensor factorization (ETF) [11], Full rank tensor completion (FTC) [21], and so forth. Tensor factorization avoids the sparsity problem and produces more meaningful physical interpretations. In the proposed factorization model, the 3D tensor is decomposed by the Tucker decomposition method with presumed core size in advance. Tucker decomposition is the extension of Multi-linear Principal Component Analysis and Higher-Order Singular Value Decomposition (HOSVD) [15] that are viewed as the generalization of Singular Value Decomposition (SVD). It decomposes the high-order tensor into one core tensor and some set of matrices based on various dimensions. Tucker decomposition has been categorized into various types, namely Tucker1, Tucker2 and Tucker3. The rating data along with extracted features is computed by Higher-Order Orthogonal Iteration (HOOI) [15] under tucker3 decomposition. It undergoes a number of iterations to predict the values that helps us to generate valuable recommendations with explanations for the product.
Multi-criteria based factorization machines (MCFM)
Factorization Machine (FM) is a generic approach that allows to mimic most factorization models by feature engineering. This way, FMs combine the generality of feature engineering with the superiority of factorization models in estimating interactions between the input variables [24]. FMs are not limited to specific types of data – they are general predictors. All nested variable interactions are modeled by the factorizarion machine that can be compared to a polynomial kernel in Support Vector Machines (SVM), but uses a factorized parameterization instead of a dense parameterization like in SVM. Factorization machines can be applied to a variety of prediction tasks like regression, classification and ranking. In regression, utility function
The model Eq. (8) for a factorization machine with degree
Results and discussions
Dataset
The SemEval 2018 dataset used for irony detection and removal consists of 4792 English tweets that are collected from 2676 unique users. The tweets are manually labeled using a fine-grained annotation scheme for irony [28]. The training set contains 1911 ironic tweets and 1923 regular tweets, and the test set includes 958 tweets. We have enhanced this dataset with Sarcasm Product Review Dataset [9] which contains 437 ironic reviews and 817 regular reviews.
The “cellphones and accessories” dataset from Amazon products used for explainable product recommendation contains 194,439 records of review and rating are taken for product recommendation [20]. It comprises of 27,879 unique users and 10,429 unique products. Various features of interest are productID, reviewerID, overall (rating), reviewtext, summary and reviewtime. Metadata features such as title, price, salesrank, brand and category are used as content features. We have carried out 10-fold cross validation for our experiments.
The textual content comprises of a minimum of 18 token of words to maximum of 706 token of words. The distribution of the data ranges from a minimum of 13 sentences with 88 tokens to a maximum of 892 sentences with 556 tokens. The tokens are considered after the stop words removal. Most of the sentences have the tokens in the range of 350 to 600.
Performance comparison
Results of various models used for irony detection are listed in Table 4. Multilayer Perceptron (MLP) and Deep Learning models like Long Short Term Memory networks (LSTM) and Bidirectional Encoder Representations from Transformers (BERT) are used for the detection of ironic and sarcastic content in the review text. BERT model provides better accuracy than other models.
Performance results for irony and sarcasm detection
Performance results for irony and sarcasm detection
Table 5 shows the results of the performance of product recommendation system using traditional techniques with ratings alone. Content-based filtering (CBF) gives larger error when compared to collaborative filtering techniques. In model based CF, Singular Value Decomposition (SVD
Comparison of algorithms with ratings alone
Table 6 shows the comparison of error metrics of traditional algorithms using ratings alone and review text alone. Traditional algorithms such as SVD, SVD
Comparison of traditional algorithms with text alone and rating alone
Figure 4 shows the error metrics for the traditional algorithms with ratings and with the text reviews. From the figure, it is clear that the addition of text features increases the error rate rather than reducing it. This is because all the text features are taken into consideration without any filtration.
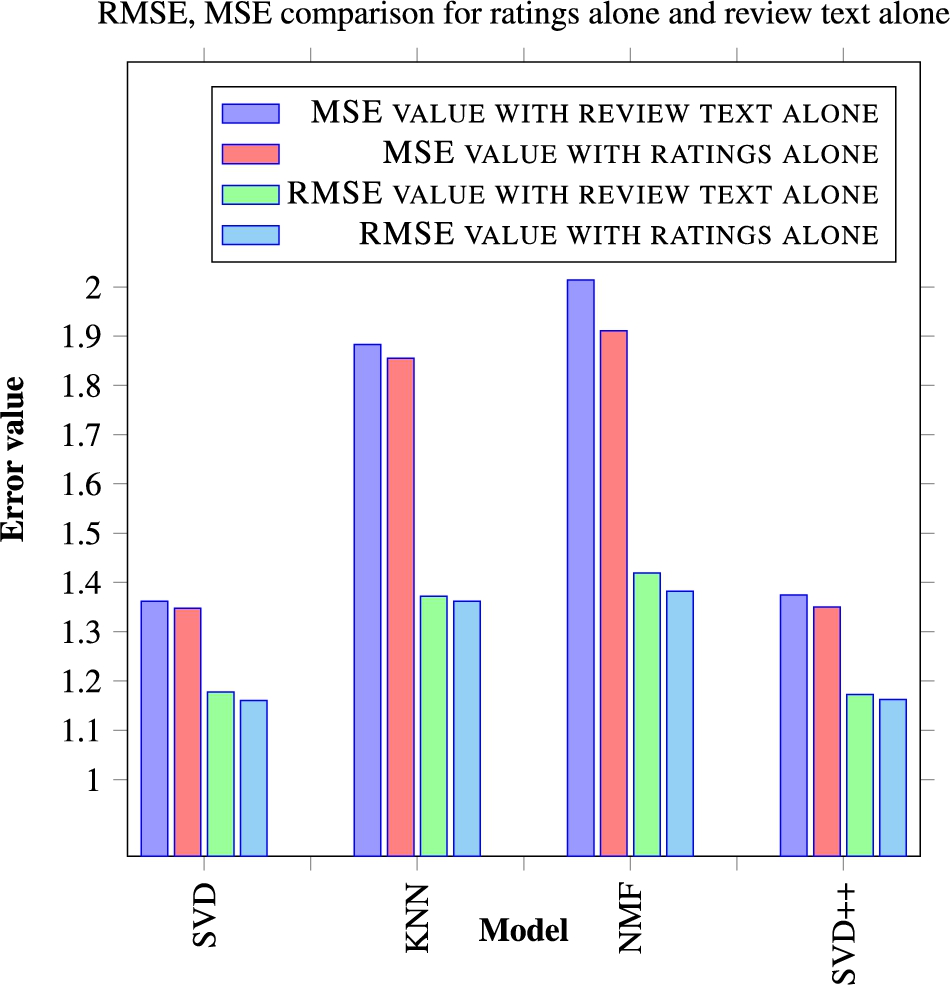
Error metrics comparison for traditional algorithms.
Metrics of reviewtext as regulariser and as features
Table 7 shows the results for using the reviewtext as a regulariser and as features. Error value increases for the algorithms SVD, SVD
Table 8 depicts the performance results for the comparison of algorithms with multi-criteria based hybrid filtering techniques(MCCBHF) like Multi-Criteria based Tensor Factorization Model (MCTFM), Multi-Criteria based K Nearest Neighbors (MCKNN), Multi-Criteria based Factorization Machine (MCFM) and Multi-Criteria based Explicit Matrix Factorization (MCEMF). The comparison is made for the original dataset with all the reviews and the cleaned dataset after removing the ironic and sarcastic reviews. The state of techniques in literature HFT, Deepconn, Narre, Transnet, ALFM are done for the whole dataset. In all the memory-based and model-based collaborative filtering techniques, the content features from metadata and the features of interest extracted from text reviews are added to increase the performance of the personalized recommendation. All the proposed MCCBHF methods performed well, when compared to other CF and CBF algorithms. It is also shown from Table 8 that the proposed MCCBHF algorithms are having less error rate in original dataset itself when compared to other algorithms. The error rate is still reduced on the removal of ironic reviews. This depicts that the minimum error rate is due to the concept of multi-criteria based content boosted hybrid filtering and not because of the ironic content removal.
Comparison of algorithms with ratings and text reviews
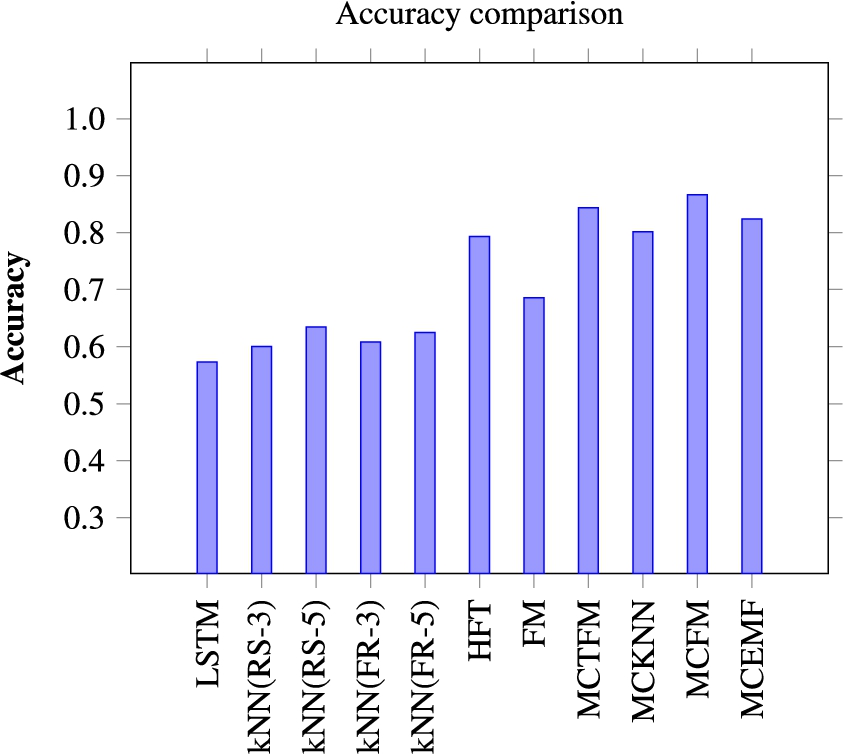
Accuracy for MCCBHF algorithms.
Figure 5 shows the accuracy of different models developed. MCFM provides better accuracy and less error rate than other techniques as factorization machine can deal with different dimensions of the data and the interactions among the data very well.
User satisfaction can be increased by providing recommendations based on the preferences of the user and giving an explanation for recommending the product. User preferences can be identified by their implicit and explicit actions. An easy method to determine the interests of the user is to analyze the user’s reviews. Explanations can also be generated by analyzing the product reviews. For a particular user, features of the user’s interest are extracted from his reviews on various products, and item features are extracted from all the reviews of that particular product. Item contains both positive and negative comments for each feature.
The main challenge lies in verifying the trustworthiness of the text reviews. At a first level, sarcastic reviews are identified and removed from the dataset. Multi-criteria ratings always give better insight into the reason behind the rating of the user, which can also be used to provide explanation for the recommendation. Various collaborative filtering techniques such as KNN, TFM, FM and MF are boosted with the content features and the performance of MCKNN, MCTFM, MCFM and MCEMF are analyzed. With the addition of content features to the basic CF techniques, all MCCBHF algorithms performed better than others. Among the MCCBHF algorithms, MCFM performed the best. This explainable product recommendation system increases the transparency and satisfaction of users in buying the recommended product.
To conclude, we have inferred the user preferences in the form of multi-criteria ratings with the help of the single rating, text reviews and the metadata features of the products. The proposed hybrid filtering methods performed well when compared to the existing techniques as discussed in the results section. There is still scope for reducing the computation time and for extracting features of interest from other explicit and implicit feedback. Further processing of the review text can be done to identify informative reviews and to detect fake reviews for better performance.
Availability of data and material
The datasets used in the experiments are publicly available in the online repository.
Competing interests
The authors declare that they have no conflict of interest.