
Abstract
We are concerned with the construction, formal verification, and safety assurance of dependable multiagent systems. For the case where the system (agents and their environment) can be explicitly modelled, we develop formal verification methods over several logic languages, such as temporal epistemic logic and strategy logic, to reason about the knowledge and strategy of the agents. For the case where the system cannot be explicitly modelled, we study multiagent deep reinforcement learning, aiming to develop efficient and scalable learning methods for cooperative multiagent tasks. In addition to these, we develop (both formal and simulation-based) verification methods for the neural network based perception agent that is trained with supervised learning, considering its safety and robustness against attacks from an adversarial agent, and other approaches (such as explainable AI, reliability assessment, and safety argument) for the analysis and assurance of the learning components. Our ultimate objective is to combine formal methods, machine learning, and reliability engineering to not only develop dependable learning-enabled multiagent systems but also provide rigorous methods for the verification and assurance of such systems.
Keywords
Introduction
A multiagent system consists of a set of interacting agents, each of which performs intelligently and autonomously by continuously receiving information, reasoning about the information, and taking actions. Multiagent systems are pervasive, and many complex real-world systems can be modelled as multiagent systems. In a multiagent system, individual agents have their own goals, and in the meantime a group of agents may have a collective goal. To implement their goals, the agents may need to form coalitions, share information, and find individual and group strategies. The strategies can be obtained through either logic reasoning or machine learning, depending on the available information. If the external interactions of the agent can be correctly modelled, logic reasoning can be conducted to synthesise the strategies. On the other hand, if the interactions cannot be modelled due to the lack of information, but there are positive and negative examples of the interactions, machine learning techniques can be applied to learn a strategy by optimising a learning model’s performance on the example interactions.
The inspection of offshore energy assets [18], such as wind farms and oil platforms, can benefit from having dependable and autonomous multiagent systems, considering that they are in extreme environments which can be dangerous for human inspection. An approach that has been increasingly adopted is to employ an advanced ground control station and a set of unmanned vehicles (drones, surface vehicles, or underwater vehicles). The ground station is to determine mission goals, select key waypoints, and decide on mission characteristics such as risk tolerance and timing constraints. Then, the unmanned vehicles will, either individually or collectively, determine their strategies for the completion of the missions. The strategies may include e.g., a collective route plan that the vehicles may co-operate to complete the mission, the emergency plan to counter the failures of some vehicles, and the vehicles’ individual motion plans to safely move from one waypoint to another without clashing to each other.
In a smart factory, we may consider coordinated multiagent object transportation [3], in which there are multiple robots that aim to move an object to a base station, without clashing into (possibly moving) obstacles. The robot cannot move the object by itself, and only when more than one robot grasps the object simultaneously, can the object be lifted up. Moreover, once lifted up, the object cannot be moved without the robots moving towards the same direction. This task requires the robots to have a collaborative plan on reaching, lifting, and then moving the object. The object can be fragile and of significant value, so in addition to ensure the dependable execution of a robot, the dependability of their collaboration is also valuable.
A complex, intelligent agent itself can also be a multiagent system where perception component, high-level planning component, motion planning component, and low-level control component can all be autonomous agents themselves. Typically, the perception component is implemented with convolutional neural networks, and the motion planning component can be implemented with deep reinforcement learning. However, other components such as the high-level planning component may be more suitably implemented with symbolic methods. The dependability of the intelligent agent will reply on not only the dependability of the component agents but also the interaction between the components. The interaction between components may affect how the failure of a component propagates through the rest of the system.
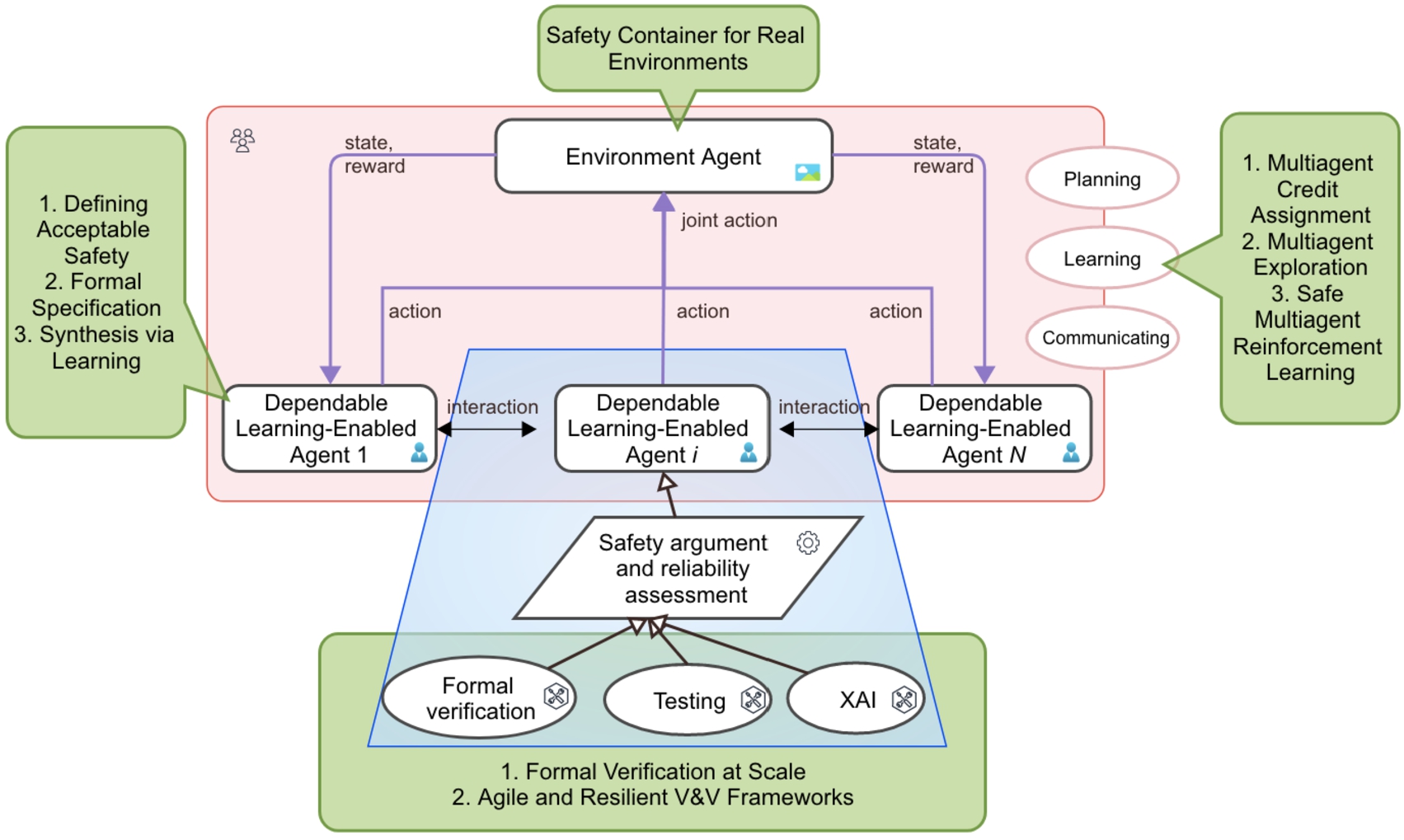
An overview of the research agenda in dependable learning-enabled multiagent systems. Implemented approaches are shown in pink and blue boxes, while open challenges identified are presented in the green boxes associating with implemented topics.
As depicted in Fig. 1, our research revolves around the development of dependable multiagent systems. Various settings of multiagent systems have been studied, including systems with a learned agent and its attacker, systems with a learned agent and several cooperative agents, systems with multiple symbolic agents, and systems with multiple learning agents. The developed techniques – span across the fields of machine learning, verification and validation, and reliability engineering – are to enhance, evaluate, and/or assure the dependability of the systems. A set of dependability properties have been considered, including robustness, safety, security, interpretability, reliability, cognitive trust, and social norm, and we will extend to consider e.g., privacy and fairness in the future.
Our ultimate objective is to provide technical solutions (including theories, algorithms, and tools) for the development of learning-enabled multiagent systems to ensure both performance and dependability with provable guarantees. While many techniques have been developed, the foundations of them are based on either formal methods or machine learning. For example, traditional multiagent systems are mainly based on formal methods, with various specification languages and formal verification methods but without a machine learning component. On the other hand, multiagent reinforcement learning is mainly based on machine learning without rigorous specification and verification methods considered. We believe that a well-founded multiagent system with both performance and dependability achieved at the same time can only be built on three pillars: formal methods (which provides rigorous means for dependability), machine learning (which provides means for performance), and reliability engineering (which provides principled methods for the prediction, prevention, and management of failures). Our technical development for the ultimate objective will base on these three foundations.
We remark that, this is different from the neuro-symbolic computation [15,83], which focuses on various combinations of symbolic methods and machine learning to achieve a good performance. Different from them, we require the consideration of dependability properties and not only the construction of a better performed system but also rigorous techniques to evaluate and to assure the dependability of a system with provable guarantees.
We categorise a research agenda (sketched out at high-level in Fig. 1) in the following according to the settings of the multiagent systems under discussion. It is noted that, when mentioning agents, they can be either software agents or physical agents, because in most systems physical agents are driven by software systems.
Systems with a learned agent and its attacker. The first topic is to investigate the safety, security, and interpretability of a learned agent, or a trained machine learning model. Machine learning has been the de facto technique for the implementation of perception and motion control functionalities of a physical agent. Notable examples of physical agent include e.g., autonomous car, autonomous underwater vehicle, and drug target-controlled infusion. The perception component processes sensory input (such as camera imagery input, LiDAR signal, etc.) to understand the appearance of the objects around the agent (such as pedestrian, obstacles, etc). The motion control component determines the behaviour of actuators according to the knowledge of the agent and its goals.
We concern the potential risks that may appear in any lifecycle stage of a machine learning model. The lifecycle of a machine learning model can be roughly split into three stages: data collection and preparation, model construction and training, and model deployment. Each lifecycle stage may be subject to attacks from either an adversarial agent (which conducts malicious behaviour) or a natural agent (which conducts random, but benign, behaviour). For example, in data collection and preparation stage, it may suffer from data poisoning attack. In model construction and training, it may be subject to backdoor attack. In model deployment stage, there might be robustness attacks, and various privacy attacks such as membership inference, model stealing, and model inversion.
It is of paramount importance to understand the existence of the attack, the extent to which the model is resistant to these attacks, and if a model can be improved against the attacks without compromising its performance. Other than the safety and security risks, it is equally important to understand why the machine learning model performs certain decisions (a.k.a. explainable AI) and whether a machine learning model can be made more interpretable.
Systems with a learned agent and several cooperative agents. As illustrated in Example 3, a complex intelligent system usually includes not only a learning agent (such as a perception component or a motion planning component) but also other cooperative agents. Despite the existence of safety and security risks on a component agent, it is known that the relevance – and severity – of the risks cannot be determined without considering the context, i.e., the whole autonomous system and its environment. To have a comprehensive understanding about this, there can be several perspectives. First of all, formalism and algorithms are required to understand how the failures of certain components may propagate or dissolve, and how they may affect the overall performance of the system. Second, considering that safety evidence (e.g., the probability of failures per demand) can be collected on individual components, it is imperative to estimate – with the support of a theoretical model – the reliability of the whole system based on the evidence.
Systems with multiple symbolic agents. In addition to multiagent systems with a learned agent as suggested above, intense research has been conducted on traditional multiagent systems, i.e., systems composed of multiple symbolic agents. Examples 1 and 2 can both be modelled with such systems. In such systems, agents have partial observation on the underlying system states. Also, agents may take different strategies, which are usually invisible to other agents. The partial observability has led to not only conceptual complexity (e.g., it is hard to comprehend nested reasoning such as “agent
Nevertheless, the main research topics on these systems are to develop various logic languages (or modalities) to enable the reasoning, and based on this, to consider the axiomatisation of the logic and the complexity of model checking or satisfiability. Related to the dependability, fundamental limits may be studied, e.g., given infinite memory and perfect reasoning ability, it is important to determine whether an agent or a group of agents can rightly conclude that the system can still achieve its goal even if other agents act adversarially.
Systems with multiple learning agents. Other than the aforementioned research issues, we focus on the crucial topic of learning in multiagent systems. Specifically, we focus on developing deep reinforcement learning algorithms, which combine reinforcement learning (RL) and deep learning, in multiagent systems. RL is a machine learning paradigm where an agent aims to solve a control problem by directly interacting with an unknown environment. The goal of the RL agent is to learn a sequence of actions or a policy that maximises its long-term expected total reward. In deep RL, deep neural networks are used as a function approximator, representing the policy and/or value function. This enables RL to scale to problems with high-dimensional state and/or action spaces, making it a promising approach to solving complex real-world problems, e.g., enabling a set of unmanned vehicles to automatically learn an optimal coordination strategy to complete the mission in Example 1 illustrated above.
Multiagent RL (MARL) has recently gained significantly more interests due to advances in single-agent deep RL techniques. In a MARL setting, multiple agents learn how to interact optimally in a shared uncertain environment to achieve specified long-term goals. Compared to learning in single-agent settings, learning in multiagent settings is inherently more challenging due to multiagent pathologies, e.g., the non-stationarity problem [22], curse of dimensionality [22], and relative overgeneralisation [74]. It is thus critical to study how to better overcome these issues, when developing deep MARL methods, to enable more efficient and scalable learning among agents within a multiagent system. These deep MARL approaches can potentially be applied to industrial applications such as collaborative robots in manufacturing, autonomous driving, and traffic control systems.
Fully decentralised policies are often used in MARL, due to partial observability, practical communication constraints, or as a way to deal with an intractably large joint action space. However, when training in simulation or under controlled conditions we may have access to additional information, and agents can freely share their observations and internal states. Exploiting these possibilities can greatly improve the efficiency of learning. The paradigm of centralised training with decentralised execution (CTDE) [71] has thus recently attracted considerable attention in the MARL community. However, in this setting, many critical challenges remain open. Our research focuses on addressing challenges surrounding 1) how to fully take advantage of the centralised training phase, 2) how to better extract decentralised policies that are fully consistent with their centralised counterpart, and 3) how to better represent and learn the joint action-value function that most MARL methods learn.
Other than learning in multiagent settings with fixes groups of agents and entities, we also consider the multitask MARL setting where we aim to learn control policies for variable-sized teams of agents. Many real-world multiagent settings contain tasks across which an agent must deal with varying quantities and types of cooperative agents, antagonists, or other entities. This variability in type and quantity of entities results in a combinatorial growth in the number of possible configurations, aggravating the challenge of learning control policies that generalise. We focus on training simultaneously on multiple multiagent tasks and developing training paradigms for improving generalisation and knowledge transfer within and across tasks with varying agent quantities and/or types.
Main approaches
Formal verification for deep learning. We consider a deep learning model as a function
A number of formal verification techniques [36,80,81,93–95] have been developed by the group on the robustness verification of deep learning. This includes methods based on exhaustive search [36], global optimisation [80,81,95], game-based methods [93,94], and symbolic interval analysis [61,62,96]. These methods ensure both the completeness and the soundness of the results. Moreover, in addition to the pixel perturbations measured with norm distances, we are also looking into real-world perturbations such as geometric and spatial perturbations [89].
One of the key features of our verification methods, as compared with others, is that many of them [80,81,89,93–95] are black-box, i.e., they do not rely on the internal architecture of the neural networks. Theoretically, this brings a significant advantage that the computational complexity of the verification problem is NP-complete with respect to the number of input features, while white-box verification methods are NP-complete with respect to the number of hidden neurons. While the complexity class does not change, the number of hidden neurons can be an unlimited number of times more than that of input features, considering the current trend of deep learning on training deeper and larger networks. Also, the black-box verification means that we can work with neural networks of any scale.
Simulation-based verification of deep learning. Unlike formal verification methods which are designed to be exhaustive, simulation-based verification, following software testing methods, generates a set of test cases and uses the generated test cases to improve our confidence in the deep learning model, e.g., the in-existence of counterexamples for
There are three major technical issues. The first is to design test adequacy criteria. Test adequacy criteria determine when the generation of test cases can terminate, and may also be used to guide the test case generation. Towards this, we have designed several test coverage metrics for feedforward neural networks [86] and recurrent neural networks [24], respectively. The second is to design test case generation methods. Some generation methods have been developed and tested on different neural networks, including concolic testing [87], genetic algorithm [24], and importance sampling [99]. The third is to design the test oracle, which automatically determines if a test case fails with respect to a property.
The test cases need to be generated with respect to the data distribution, and in some cases, a sampling from the unknown data distribution is impossible. To deal with this, we consider recent efforts on complexity measure [55], which determines an upper bound of the test performance based on the architecture and weights of the neural network, under the support of some deep learning theory such as the PAC Bayesian theory.
Formal verification for multiagent systems. Components of a complex, autonomous system can be modelled with e.g., reactive modules [2] or knowledge-based program [17], each of which has a set S of states, a set O of observations, a transition relation T to update the states, and an observability function R that maps states to observations. It is not hard to see that a deep learning component can also be modelled in this way, such that
The interactions of components can be modelled through either (synchronous) hand-shaking [68] or (asynchronous) message passing [23]. If the environment is known, the interactions of the system with the environment can also be modelled in this way. This can also be extended to the most general case where multiple agents run in an environment.
This formalism of modelling multiagent systems enables the logic-based formal verification of many properties, including epistemic properties [39,46], probabilistic epistemic properties [40], strategy [26,28,49], diagnosability [27], social norm [43], reconfigurability [29], correlated equilibrium [42], and cognitive trust [35,37]. We also study their computational complexity [30,34,38,45,50,52], the automatic synthesis of programs according to their specifications [48,51], the impact of communications between agents [31], and their applications to e.g., pursuit-evasion games [41,47].
We also consider the verification of practical learning-enabled robotics systems, focusing on the state estimation system [88], vehicle tracking system [25], and deep reinforcement learning enabled mobile robots [16].
Explainable AI (XAI). Deep learning models are highly complex non-linear functions with algorithmically generated (rather than engineered) coefficients. They are effectively “black-box”, so it is difficult to explain their prediction behaviours. The goal of XAI is to create artefacts that provide a rationale for why a deep learning model generates a particular prediction for a given input. This is argued to enable stakeholders to understand and to appropriately trust deep learning models.
XAI methods can be classified by various criteria [69, Chpt. 2.2], such as model-specific vs model-agnostic or local (instance-wise) vs global (entire model). Readers are referred to [1,33] for a comprehensive review. Our previous work [101] focuses on the class of XAI methods using local surrogate models for explaining individual predictions. Specifically, we develop a novel Bayesian extension to the most popular method in this category, Local Interpretable Model-agnostic Explanations [79], called BayLIME. BayLIME shows improved consistency in repeated explanations of a single prediction and robustness to kernel settings. Meanwhile, higher explanation fidelity is also expected in many settings. Arguably, these three properties are among the most desirable ones for any XAI method to have. BayLIME utilises a Bayesian linear regressor as the local surrogate model, which we show analytically is a “Bayesian principled weighted sum” of the prior knowledge and estimates based on new samples. The weights consist of parameters with dedicated meanings that can be either automatically fitted from samples (via Bayesian model selection) or elicited from application-specific prior knowledge (e.g., V&V methods). Our experiments show that BayLIME is superior than several state-of-the-art XAI methods in terms of those 3 desirable properties aforementioned.
Inspired by statistical fault localisation (SFL) methods in traditional software engineering, we also develop a XAI tool called DeepCover [85] that ranks the pixels using four well-known SFL measures (Zoltar, Ochiai, Tarantula and Wong-II) based on the results of running test suites constructed from random mutations of the input image. This ranking is then used by DeepCover to efficiently construct an explanation for the prediction made on the image.
Reliability assessment and safety argument. Two key activities in the assurance of critical systems are: how to rigorously assess the risk and how to convincingly demonstrate the rigour of the assessment. In this regard, our group has been exploring reliability assessment modelling and safety arguments for machine learning components.
Deep learning models are subject to robustness concerns, reliability models without considering robustness evidence are not convincing. Reliability, as a user-centred property, depends on the end-users’ behaviours [63]. The operational profile (OP) information (quantifying how the software will be operated [70]) should therefore be explicitly modelled in the assessment. Prior to our work [99], there is no dedicated reliability assessment model taking into account both the OP and robustness evidence. In [98], we propose a safety case framework tailored for deep learning, in which we describe an initial idea of combining robustness verification and operational testing for reliability claims. In [99], we implement this idea as a reliability assessment model, inspired by partition-based testing [21], operational-profile testing [84,102], and deep learning robustness evaluation [13,92]. It is model-agnostic and designed for pretrained deep learning models, yielding upper bounds on the probability of miss-classifications per input (pmi)1
pmi is similar to the conventional reliability metric of probability of failure per demand (pfd), but retrofitted for deep learning classifiers.
For certification and regulation purposes, it is equally important to demonstrate if the required dependability has been satisfied. As for traditional software-based systems, the emerging consensus within both industry and academia is to use safety cases for this purpose. Typically safety cases support claims of reliability, in support of safety, can be viewed as a structured way of organising arguments and evidence generated from safety analysis and reliability modelling activities. While such assurance activities are traditionally guided by consensus-based standards developed from vast engineering experience, deep learning poses new challenges due to the characteristics of deep learning models. In [100], we first propose an overall assurance framework for learning-enabled systems, presented in Claims-Arguments-Evidence (CAE) assurance cases [6]. While inspired by [7], ours is with greater emphasis on arguing for quantitative safety requirements. This is because the unique characteristics of machine learning increase apparent non-determinism [56] that explicitly requires probabilistic claims to capture the uncertainties in its assurance [9,98]. To demonstrate the overall assurance framework as an end-to-end methodology, we also consider important questions on how to derive and validate (quantitative) safety requirements and how to break them down to functionalities of learning components for a given learning-enabled system. A comprehensive case study based on autonomous underwater vehicles that carry out survey and asset inspection missions (cf. Examples 1 and 3) is conducted, with a video demo at
Multiagent deep reinforcement learning. Regarding learning in multiagent systems, a number of deep MARL algorithms have been developed by the group to enable more sample-efficient [53], robust [20,77], scalable [75,90], and stable [73] learning among agents in cooperative tasks. These methods are evaluated in a variety of cooperative multiagent tasks, including cooperative matrix games, multiagent particle environments [65], and the challenging multiagent StarCraft benchmark tasks [82].
Our work studies and addresses a variety of problems within MARL. For instance, value function factorisation [57] has been widely employed in value-based MARL algorithms, not much work, however, has studied the open question of understanding the representational power of these methods. We illustrate how the representational limitation of existing value function factorisation methods can prevent them from solving cooperative tasks that require significant coordination within a given timestep, and develop new deep value-based MARL algorithms to resolve these limitations in theory and in practice [77]. Our key insight is that, if we ultimately care only about the greedy optimal policy, it is more important to accurately represent the value of the optimal joint action than the sub-optimal ones. We can thus incorporate some weighting schemes into the learning framework to place more importance on representing the value of better joint actions. With the novel weighting scheme, our approach is proved to converge to the optimal policy in an idealised tabular setting, while existing method might fail to recover the optimal policy. It is also shown to be able to scale to more complex deep RL settings, with improved ability to cope with different types of environments and improved robustness to the amount of exploration performed.
Overestimation in Q-learning is a critical problem that has been extensively studied in single-agent reinforcement learning, but has received comparatively little attention in the multiagent setting. We show how overestimation in MARL can be more severe than previously acknowledged and can lead to divergent learning behaviour in practice [73]. To tackle this issue, we propose a novel regularisation-based update scheme that penalises large joint action-values that deviate from a baseline and demonstrate its effectiveness in stabilising learning. Furthermore, we propose to employ a softmax operator, which we efficiently approximate in a novel way in the multiagent setting, to further reduce the potential overestimation bias. We formally prove that our approach can reduce the overestimation bias of existing deep multiagent Q-learning algorithms. We empirically show that our approach, when applied to existing deep multiagent Q-learning algorithms, simultaneously enables stable learning, avoids severe overestimation, and improves learning performance. Our approach is also general and can be applied to any Q-learning based MARL algorithms. This work shed light on how to design better value estimation in MARL.
To enable more efficient and scalable learning on cooperative multiagent tasks, we propose a novel deep multiagent actor-critic method that uses a centralised but factored critic and a new centralised policy gradient [75]. Compared to existing methods that learn a centralised and monolithic critic [19,65], learning a factored critic has two main benefits. First, it can potentially scale better to tasks with a larger number of agents and/or actions. Second, compared to value-based methods [78], factoring the critic allows for a more flexible factorisation as the critic’s design is not constrained. In addition, our approach uses a new centralised gradient estimator that optimises over the entire joint action spaces, rather than optimising over each agent’s action space separately as in existing methods [65]. This can enable learning of more coordinated behaviour among agents, as well as the ability to escape sub-optimal solutions. While Lyu et al. [66] recently show that merely using a centralised critic does not necessarily lead to better coordination between agents, our centralised gradient estimator re-establishes the value of using centralised critics. Our approach is also general and can be readily applied to any multiagent actor-critic algorithms that learn centralised critics.
An alternative approach to achieving more scalable multiagent learning is role-based learning, in which the complex multiagent task is decomposed using roles. Each role in the multiagent task is associated with a certain sub-task and a corresponding policy. Agents taking the same role collectively learn a role policy for solving the sub-task by sharing their learning. The key question to address in role-based learning is how to come up with a set of roles to effectively decompose the task. Previous work typically predefines the task decomposition and roles. However, this requires prior knowledge that might not be available in practice and may prevent the learning methods from transferring to different environments. To solve this problem, we propose a novel framework to automatically learn an appropriate set of roles [90]. Our key insight is that, instead of learning roles from scratch, role discovery is easier if we first decompose joint action spaces into restricted role action spaces by clustering actions according to their effects on the environment and other agents. We can then learn a role selector based on the learned effect-based action representations, which improves generalisability of role policies across actions.
Our research has also tackled some other important problems in multiagent systems such as relative overgeneralisation [74]. Relative overgeneralisation is a game-theoretic pathology that can arise when the optimal joint action’s utility falls below that of a sub-optimal joint action, which prevents agents from learning the optimal joint policy. We show that this problem can be overcome by improving the joint exploration of all agents during training [20]. Specifically, we propose a novel deep MARL algorithm that learns a set of related tasks simultaneously and uses the policies of previously learned related tasks to help improve the joint exploration of all agents. Our approach is based on the key idea that, even when a target task we are interested in solving exhibits relative overgeneralisation, there may be similar tasks that do not. If their optimal actions overlap in some states with the target task, executing these simpler tasks can implicitly weight exploration to overcome relative overgeneralisation. Our empirical results show that our approach significantly outperforms current state-of-the-art deep value-based methods on target tasks that exhibit strong relative overgenralisation and in zero-shot generalisation [10] to other reward functions.
Continuous multiagent learning environments. Although some multiagent benchmark environments for continuous control exist [64,65], few environments specialise in cooperative control and even fewer model partial observability. Moreover, existing benchmarks, like the popular multiagent particle environments [65], are not complex enough to meaningfully compare methods intended for robotic control. Our prior work introduces Multiagent MuJoCo (MAMuJoCo), a new, comprehensive benchmark suite that effectively captures the nature of cooperative robotic manipulation tasks and allows the study of decentralised continuous control [75].
Based on the popular single-agent MuJoCo benchmark [11], MAMuJoCo features a wide variety of novel robotic control tasks in which multiple agents within a single robot have to solve a task cooperatively. This design offers important benefits. It facilitates comparisons to existing literature on both the fully observable single-agent domain [72], as well as settings with low-bandwidth communication [91]. More importantly, it allows for the study of novel MARL algorithms for decentralised coordination in isolation (scenarios with multiple robots may add confounding factors such as spatial exploration), which is currently a gap in the research literature. MAMuJoCo also includes scenarios with a larger and more flexible number of agents, which takes inspiration from modular robotics [58,97]. Compared to traditional robots, modular robots are more versatile, configurable, and scalable. A large number of fundamental continuous MARL research can thus be conducted in MAMuJoCo. We believe the lack of diverse continuous benchmarks is one important factor limiting progress in continuous MARL and MAMuJoCo can potentially stimulate more progress in this research direction.
As natural extensions of the main approaches implemented, we identify key open challenges (shown in the green boxes of Fig. 1) to the dependable learning-enabled multiagent systems as what follows.
Formal methods for deep learning enabled multiagent systems
One of the priorities of the group will be on establishing the foundations for a closer integration of formal methods with the deep learning-enabled multiagent systems. Formal methods and machine learning are two research fields with drastically different foundations and philosophies. Formal methods utilise mathematically rigorous techniques for the specification, development and verification of software and hardware systems. Machine learning is focused on pragmatic approaches to gradually improve a parameterised model by observing a set of training data. While historically the two fields lack communication, this trend has been changed in the past few years – with the group being one of the key players – with an outburst of research interests on the robustness verification of neural networks. Nevertheless, the connection is too narrow, with only one specific property (i.e., robustness) extensively studied. A few aspects of research will be needed to push the research forward.
Formal specification. Existing efforts [4,5] on specifying systems with learning components extend the temporal logics to include constructs for the description of neural network’s external behaviour. These, however, might not be sufficient for the expression of safety and security properties [32] of machine learning models. A more suitable language has to consider not only the interactions of components and agents (i.e., the external behaviour of the neural network) but also the interactions of deep learning components with adversarial attacks and the training process (by considering the training dataset and the posterior distributions of the trained model). The two-player game between deep learning and adversarial attack has led to intensive studies in the past years, and many safety and security risks have been discovered, including data poisoning, backdoor, membership inference, model stealing, and model inversion. See [32] for more discussions. Up to now, these risks are studied in an ad hoc way, without a systematic research to connect them. It will be interesting if we are able to find atomic propositions and operators, based on which a set of properties can be defined for the risks. A coherent specification language, as many other specification languages such as LTL and CTL, will enable the development of a verification algorithm that can work with any properties expressible with the language.
For the consideration of safety risks and the training process, unlike traditional multiagent systems whose specification languages are based on Boolean atomic propositions, a specification language for the deep learning components might require random atomic propositions, i.e., an atomic proposition may represent a (high-dimensional) probabilistic distribution. For example, we may consider either data distribution
Formal verification at scale. The other main technical barrier for the formal verification to be applied to real-world deep learning is the size of the neural network. As discussed earlier, we have suggested the consideration of black-box verification, which can avoid the consideration of internal architecture and therefore deal with large-scale neural networks. Nevertheless, black-box verification algorithms, currently relying on global optimisation techniques, are still hard to deal with problems with thousands of input features. More scalable methods will be needed.
Synthesis via learning. Once we have a set of desirable properties expressed with a specification language, a direct question will be to automatically synthesise a system (or a partial program) that satisfies the properties. Unlike the program synthesis, as we have done in [48,51], for learning-enabled multiagent systems, no prior method has been known. On the other hand, in machine learning, a popular research direction is to design better training schemes (e.g., training objectives, training algorithm) to achieve improved training results. This includes efforts on adversarial training for robust generalisation, such as [54,55] where we consider different definitions of correlation between weights for the improvement of both robustness and generalisation, and on the training enhanced with uncertainty estimation [12]. Nevertheless, these methods can only deal with specific properties, instead of any properties expressible in a specification language. Besides, they may improve the learned model with respect to the properties, but do not provide a guarantee.
Moreover, we may consider methods from control community such as [14] which utilises Lyapunov-based method to remove undesirable actions from a reinforcement learning agent.
Safety assurance on learning enabled multiagent systems
While formal methods provide rigorous foundations for construction and verification of dependable systems, their reliance on the (fidelity of) modelling leads to limitations (including the challenges we identified above). Reliability engineering supplements this with methods for the prediction, prevention and management of failures, and methods for the argumentation of safety and dependability.
Defining acceptable safety. No systems can be claimed as perfectly safe, thus safety cases normally start with a top claim that the system is “acceptably safe”. Since the term “acceptably safe” is abstract and vague, we need first define the acceptable safety for the given system in the target operational environment. For traditional systems, we may argue that all safety requirements are satisfied implies being safe enough, while those safety requirements are derived from well-established safety standards and conventional safety analysis methods (identifying hazards, causes and mitigations, e.g., HAZOP [59,76] and STAMP [60]). Given the lack of validated safety standards/policies and mature safety analysis methods for disruptive technologies of AI/ML [8], it is challenging to derive safety requirements for learning-enabled systems, neither quantitatively nor qualitatively. The interaction dynamics of multi agents only makes the challenge harder, e.g., how to link the safety claims of individual agents to the safety claims of all agents? To this end, we are investigating new safety analysis methods dedicated for learning-enabled multiagent systems, taking into account ML characters while accommodating the inherent complexity of multi-agents.
Safety container for real environments. It is normal that learning-enabled agent cannot achieve an acceptable level of safety. Even if it achieved a certain safety performance in simulation environments (given the availability of a massive amount of synthetic/simulated data), it will be hard to maintain the safety performance in real environments (where the data is sparse and expensive to obtain). A challenge is then on how to increase the safety in the real world to a level where stakeholders can sufficiently rely on to support safety cases. We believe safety containers (e.g., predefined leveraging simulation results) that are monitoring any behaviour outside of the container can help.
Heterogeneous arguments based on agile and resilient V&V. Formal verification and statistical methods (operational/field testing or “proven-in-use”) are two developed areas for the dependability of traditional systems, that fail to talk to each other. Facing the new challenges of assuring learning-enabled multiagent systems, a critical frontier of research for societal and industrial needs is to create agile and resilient V&V frameworks combining both areas to cover their own drawbacks, e.g., the scalability and misuse of abstraction of formal verification, while statistical methods cannot deal with constantly learning agents and evolving environment and become computationally expensive to achieve sufficient confidence in claims. Such new V&V frameworks may then form the evidence required by heterogeneous assurance arguments for safety claims.
Multiagent deep reinforcement learning
Finally, we discuss some important open challenges for MARL the group will focus on for future research. MARL provides well performed solutions to the multiagent system construction, and we will enhance existing research with the consideration of dependability, and moreover seek novel methodologies for the integration of formal methods and reliability engineering into MARL, to achieve not only performance but also rigorous guarantees on dependability.
Multiagent credit assignment. In cooperative settings, joint actions typically generate only global rewards shared by all agents within the system, making it difficult for each agent to estimate its own contribution to the team’s success. This is called the multiagent credit assignment problem. To tackle this, most recent work [19,103] in MARL focuses on developing multiagent actor-critic methods that learn a centralised critic with decentralised actors, using the CTDE paradigm. However, these methods are typically limited to tens of agents. Alternative learning approaches need to be developed to handle large-scale systems with hundreds and thousands of agents. In addition, while learning a centralised critic can help address the non-stationary issue of MARL, it still has some problems. It is recently shown that, compared to learning decentralised critics, learning a centralised critic results in higher variance updates of the decentralised actors, making the policy learning less stable [66]. Furthermore, while the centralised critic has access to the information of the optimal solution available during the centralised training phase, this information is typically not effectively utilised to form a cooperative policy, leading to poor coordination behaviour among agents. How to fully take advantage of the centralised training phase is still an open problem. Therefore, we believe exploring how to reduce variance in policy updates and how to make better use of centralised training can be promising future directions.
Multiagent exploration. In RL, exploration is crucial for gathering sufficient informative data to infer a good control policy. While there has been a lot of work on developing new exploration techniques for single-agent RL, the exploration problem is largely unstudied in MARL. Compared to single-agent settings, exploration in multiagent scenarios is more challenging, as it is more difficult to incentivise the agents to try and visit novel state-action pairs when the state and action spaces grows exponentially with the number of agents. The complex interactions and influences between different agents typically also need to be taken into account to better boost exploration. Most popular MARL methods [19,65,78] use simple noise-based exploration, i.e., the exploration policy is a noisy version of the actor policy. It is recently shown that, these classical exploration techniques are sub-optimal in a MARL setting [67], which can result in slow exploration and sub-optimal solutions in complex environments, especially when rewards are sparse. How to explore effectively in general MARL settings remains an open problem. Our prior work addresses the exploration problem in MARL to some extent, by easing exploration in the joint action space via learning action effect based roles [90], or using the policies of previously solved related tasks in the harder target task to help improve the joint exploration of all agents [20]. For future research, we are interested in developing more exploration methods for MARL that consider interaction and coordination among multiple agents, to better identify states and/or actions that are worth exploring.
Safe MARL. Safety is a critical concern in many real-world multiagent systems, such as air traffic control and autonomous driving. Unfortunately, most existing MARL methods do not have safety guarantees. The convergence process of MARL algorithms is inherently stochastic, making it problematic when applied to safety-critical scenarios. Therefore, to push forward the application of MARL on safety-critical domains, it is of paramount importance to account for the safety constraints during learning and deployment. When developing and deploying MARL algorithms, we need to constrain the agent behaviours such that no unsafe states and/or actions are ever visited. The goal of the learning agents is to maximise the team-average long-term expected return, while subjecting to all safety constraints. To achieve this, we are interested in combining our work on formal verification with MARL algorithms to learn good reliable control policies in safety-critical domains.
Conclusion
In this article, we have reviewed some research activities that were developed in, or brought to, the University of Liverpool in the past few years on the multiagent system research, including formal verification, reliability assessment, multiagent deep reinforcement learning, explainable AI, and others. These research directions nicely form a holistic view towards the dependable learning-enabled multiagent systems, with various settings of multiagent systems considered. Based on them, we have identified that, the ultimate solution for the construction of learning-enabled multiagent systems with both performance and dependability guarantees requires a close communication of three disciplines: formal methods, machine learning, and reliability engineering.