
Abstract
In the field of image classification, the Convolutional Neural Networks (CNNs) are effective. Most of the work focuses on improving and innovating CNN’s network structure. However, using labeled data more effectively for training has also been an essential part of CNN’s research. Combining image disturbance and consistency regularization theory, this paper proposes a model training method (PairTraining) that takes image pairs as input and dynamically modify the training difficulty according to the accuracy of the model in the training set. According to the accuracy of the model in the training set, the training process will be divided into three stages: the qualitative stage, the fine learning stage and the strengthening learning stage. Contrastive learning images are formed using a progressively enhanced image disturbance strategy at different training stages. The input image and contrast learning image are combined into image pairs for model training. The experiments are tested on four public datasets using eleven CNN models. These models have different degrees of improvement in accuracy on the four datasets. PairTraining can adapt to a variety of CNN models for image classification training. This method can better improve the effectiveness of training and improve the degree of generalization of classification models after training. The classification model obtained by PairTraining has better performance in practical application.
Introduction
The convolutional neural network (CNN) is one of the most popular image processing methods, which has excellent performance in image classification, object detection, and semantic segmentation. Numerous excellent network structures have been proposed since CNN was proposed. From LeNet [16], AlexNet [15], VGGNet [20], GoogLeNet [24] to classic ResNet [11], DenseNet [13]. With more effective convolution modules, continuously optimized activation functions [10,14,18] and loss functions [9], the potential of CNN is being continuously tapped. Although the network structure of CNN is the main factor determining the performance of the model, a good training method is the key to give full play to the performance of the model.
Current training methods rely on cyclically bringing data into the model, updating model parameters through gradient descent, and determining the optimal classification boundary in an iterative process. Normal training methods lack correlation with training results, and the entire training process is rigid. Such training method does not well excavate the potential of the classification model. The process of training a model can be seen as a learning process. In a perfect learning process, the difficulty of the knowledge to be learned should also change as the degree of knowledge mastery increases. The normal training method obviously does not meet this requirement. This paper proposes a training method called PairTraining that combines image disturbance techniques with consistency regularization. The method can dynamically modify the degree of image disturbance in response to the feedback from the training results, and trains the disturbed images in pairs with the original images. The whole training process is divided into three stages, and these stages correspond to the three schemes of gradually increasing disturbance:
The qualitative stage: random crop and random horizontal flip.
The fine learning stage: random area mask.
The strengthening learning stage: random area aliasing.
The image disturbance technique used here requires some changes. Conventional image disturbance techniques cannot dynamically change the disturbance strength based on feedback from training. Therefore, the techniques used for random area masking and random area aliasing are D-Mask (Section 3.1.1) and D-Mix (Section 3.1.2). D-Mask and D-Mix can dynamically change the parameters according to the feedback in the training process to achieve the purpose of disturbing the image to varying degrees. As the training accuracy continues to improve, the image disturbance will gradually increase. Dynamic control of training difficulty is achieved by varying disturbance intensity.
In the experiment, PairTraining was used to train a variety of CNN models and test them on multiple datasets. The experimental results show that PairTraining has the following advantages:
Strong adaptability. It can be achieved by simply changing the training code and the loss function of CNN without changing its backbone network structure.
More flexibility. The input data can be changed dynamically according to the training situation, so as to optimize the experimental results.
Improve the effectiveness of training. By using dynamic intensity interference to change the “learning difficulty” in training, the classification model can get better weight parameters. Using PairTraining can train model parameters more effectively and more accurately.
Additionally, the effects of different disturbance schemes on the model were explored through ablation experiments, which provided data for future research.
The main contributions of this work are:
An image disturbance scheme is proposed that can be used during training. The Cutout and Cutmix techniques have been modified. Training feedback can be used to vary the parameters of these two image disturbance techniques. This method is more efficient and effective than the conventional method.
Using the image disturbance technique and the consistency regularization principle, a simple and effective model training scheme is presented. This method can effectively improve the classification accuracy and generalization ability of the model.
The rest of this paper is organized as follows: Section 2 presents the related work. Section 3 describes the design of the method in detail. Section 4 is the experimental part to evaluate the effectiveness of the proposed method through the experimental results. Finally, Section 5 summarizes the work of this paper and gives an outlook on future research directions.
Related works
Typically, image disturbance and consistency regularization are used in Semi-supervised learning (SSL) [3]. They are used in the current mainstream frameworks for SSL. It is possible to solve the problem of how to use unlabeled data more efficiently to improve model performance when only limited labeled data are available using image disturbance and consistency regularization.
Image disturbance
Image disturbance refers to adding elastic deformation and noise to the image without changing the image label to change the pixel information [6]. The most basic ones are random clipping, random color enhancement, random brightness adjustment, random horizontal flipping and random angle rotation, etc. These technologies mainly start with changing the color information and position information of the image. On the basis of these basic technologies, and in order to further enhance the robustness and anti-interference of the model, image random masking is gradually emerging, among which the representative ones are Cutout [8], RandomErasing [30], HideAndSeek [21] and GridMask [4]. It is possible to understand these techniques as a Dropout operation in the image, and the image is partially masked by the algorithm, allowing the network to use more content in the image for classification, as well as simulating the occlusion that may occur in real-world scenes.
Mixup [28] and Cutmix [27] are two methods that are representative of the image aliasing developed with the continuous advancement of image disturbance. Both of these two methods use two images to fuse to generate one image, and the difference is that the aliasing method is different. To a certain extent, these methods continue the advantages of masking, but introduce the interference information of other types of images in the image, making it more difficult to correctly classify the image. The model can be stimulated to perform deeper learning as a result of this strong image disturbance, thereby improving classification accuracy.
In PairTraining, the disturbance scheme is to adjust the existing masking and aliasing technologies in order to use them for model training. Based on Cutout and Cutmix, a masking technique D-Mask and an aliasing technique D-Mix which are suitable for the training process are proposed.
Consistency regularization
In consistency regularization [19], one hopes that even after the image is disturbed, the classifier can still produce the same distribution of classes as the original image. Assuming that X is the input image and
The
Consistency regularization is widely used in the SSL. The Noisy Student model is a classic case. Inspired by knowledge distillation technology, Noisy Student [26] divides the training process into two parts: Teacher and Student. Teacher is responsible for training with labeled data to infer pseudo-labels of unlabeled images. After integrating the data, use RandAugment [7], Dropout [23] As well as image disturbance methods such as Stochastic Depth to train Student. Noisy Student achieves impressive performance on the ImageNet dataset. Since then, various weakly supervised training schemes such as UDA [25], MixMatch [2], ReMixMatch [1], and FixMatch [22] have emerged. These methods all use a weakly-augmented example to generate an artificial label and enforce consistency against strongly-augmented examples. Neither of them used pseudo-labels, but both methods “sharpened” the artificial label to encourage the model to produce high-confidence predictions. The weakly-augmented used in it is the image random flip, random translation and other methods. The strongly-augmented is RandAugment, CTAugment and other technologies. Most of these variables are fixed in these methods, and a few are randomly generated, and there is no direct correlation between the feedback and the training process.
This work argues that consistency regularization can also be applied to conventional supervised learning. In contrast to the soft label of SSL, the hard label of supervised learning will not cause errors due to a wrong classification of the model.
PairTraining method
If an image is mapped to a point in a 2D plane, the classification task can be viewed as finding the best classification boundary in the plane, as shown in Fig. 1. As can be seen from Part A of Fig. 1, the classification boundary obtained by the normal training method is relatively close to the one-class distance. Although accurate classification can be achieved on the training set data, it is prone to wrong judgments on the test data. Therefore, the PairTraining method hopes to offset the mapping points of the original image through the disturbance, so that the classification boundary considers the shifted points, so as to find a more suitable classification boundary. The result is shown in part B of Fig. 1.
The flow chart of PairTraining is shown in Fig. 2. The input data is passed through the decision module to generate the corresponding image pair (image pairs consist of the original image and the disturbed image). The decision module is controlled to make different image disturbance strategies by the classifier in the top-1 of the training dataset. Where the top-1 indicates the category with the highest probability in the model prediction label. If this category is the same as the correct category, it is considered that the prediction is correct. The model then calculates the error of the original image and the disturbed image in turn. In the two calculations, the parameters of the model are the same. Finally, the gradient and update weight are calculated based on the error obtained by the two calculations.
PairTraining will increase training time. Although this method will add additional calculations during the model training phase, this will not change the network structure of the model. After the model training is completed, the infer speed of the model will not be affected. Next, PairTraining is described in detail.

Samples and classes on 2-D feature space. The red and blue dots represent two different categories. The black lines are the classification boundaries. The images on the left side of parts A and B are the performance of the training set, and the images on the right side are the performance of the test set. The light-colored dots in part B are the disturbed mapping points of the original data.
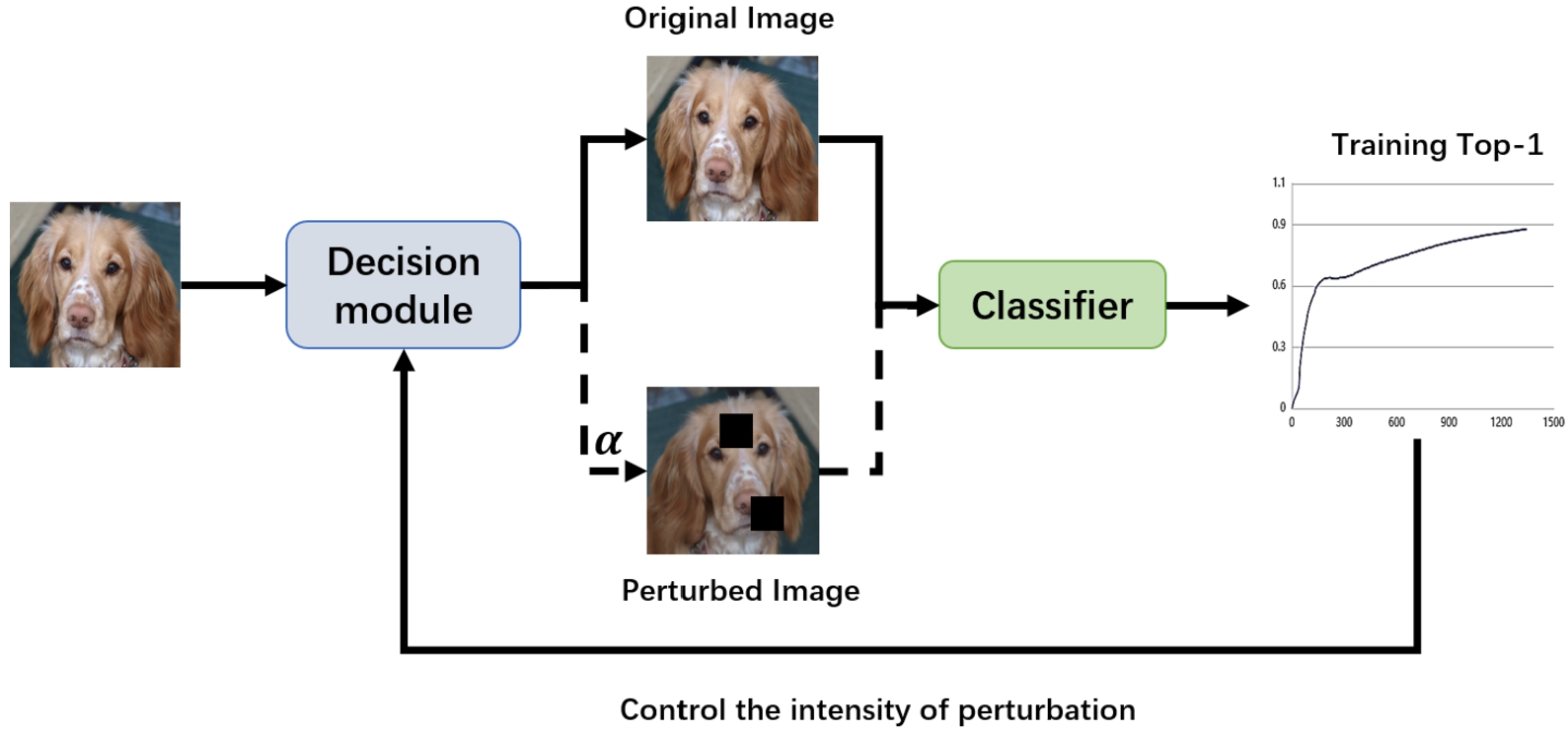
The overall process of PairTraining.
The main role of the decision module is to select the appropriate image disturbance operations to generate disturbance images based on the previous round of training top-1. The decision module is based on the training accuracy top-1 β of the previous round, and the training process is divided into three stages. Different disturbance strategies are employed in each stage. The stages are divided as follows:
The qualitative stage (
The fine learning stage (
The strengthening learning stage (
At the beginning of each stage, a large number of interference operations will actually slow down the training convergence rate. And when the amount of data is large, using image pair training will bring huge computational load. Therefore, α is used to control whether to use the image disturbance technique to generate a contrast image. The calculation formula of α is as follows:
When β is closer to
D-Mask
D-Mask is improved on the basis of Cutout. It can change the strategy of generating mask areas according to the change of training accuracy top-1 β. The D-Mask uses
D-Mix
D-Mix makes adjustments on the basis of Cutmix. D-Mix cuts and aliases the sample images of different labels. The position of the clipping area is randomly generated. The size of the clipping area is related to the training accuracy β, and the image disturbance intensity is adjusted by the increase or decrease of the combination ratio θ. The D-Mix effect is shown in Fig. 4.
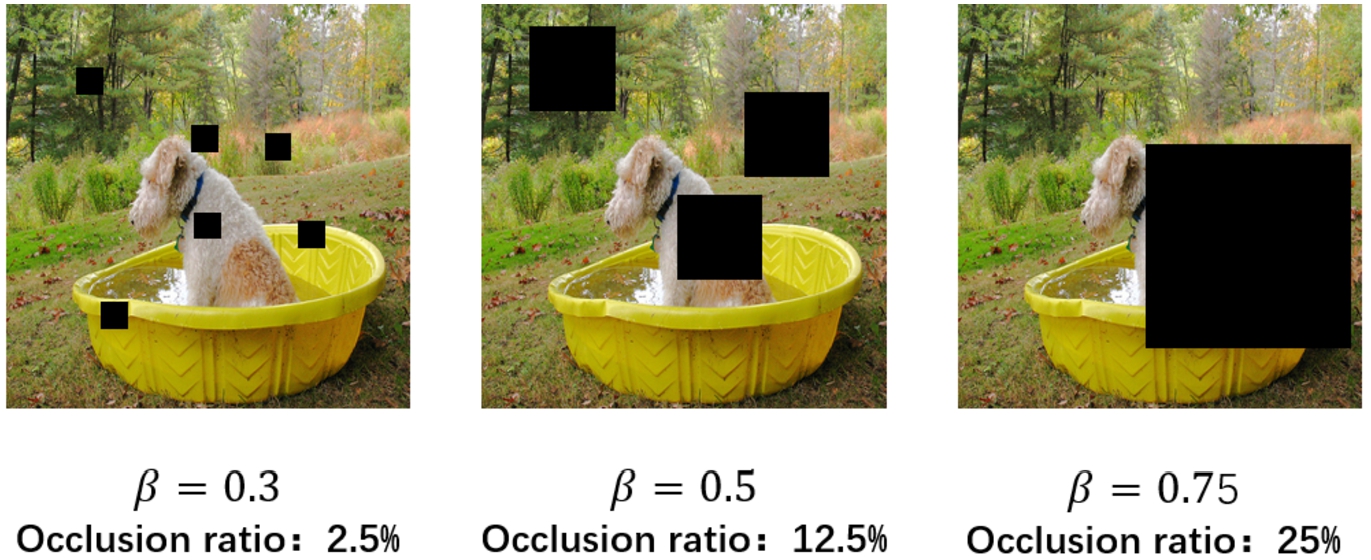
D-Mask effect demonstration.
Comparison between Cutout and D-Mask

D-Mix effect demonstration.
D-Mix’s goal is to generate new training samples
The value range of θ is between 0.3–0.6. The larger the proportion of clipping area, the greater the disturbance to the image, and the more difficult it is for the model to correctly identify the image.
In order to more intuitively reflect what changes have D-Mix made on the basis of Cutmix, the key differences between Cutmix and D-Mix are shown in Table 2.
Comparison between Cutmix and D-Mix
Due to the diversity of CNN network structures, the loss functions used by different network structures may be different. Therefore, in order to increase the portability of PairTraining, only the loss of the input image pair is weighted. Take the cross-entropy loss function [29] as an example. With x representing the predicted value and
In the formula, the subscript z represents the original image of the image pair, and p represents the disturbed image. ω is the weighting coefficient, and ω can be dynamically adjusted with the performance of the model (this article sets
PairTraining overall process
The overall process of PairTraining is shown in Algorithm 1.

PairTraining method for CNN image classification network training
Experimental hardware link GPU: Tesla V100 32GBÕ4. The experimental software environment is paddlepaddle2.0. The pre-training models required for experiments are the official open-source data of paddlepaddle. The datasets used in the experiments include: the Oxford 102 Flowers, the CIFAR10, the CIFAR100 and the ILSVRC2012 (mini). We use multiple CNN network models to train on the above four datasets to verify the effectiveness of PairTraining (Section 4.2). The contribution of each main strategy of PairTraining is investigated using ablation experiments (Section 4.3).
Datasets
This dataset was released in 2008 by the Department of Engineering Sciences, University of Oxford, creating a 102-category dataset containing 102 flower categories. Each class contains 40 to 258 images. The dataset contains 60,000 32Õ32 color images in 10 categories, each containing 6,000 images. 50,000 images are used as the training set and 10,000 images are used as the test set. The dataset is an expanded version of CIFAR10, containing 60,000 32Õ32 color images, 100 categories, and each category contains 6,00 images. 50,000 images are used as the training set and 10,000 images are used as the test set. The dataset is derived from the validation set of ILSVRC2012. The ILSVRC2012 is a subset of the ImageNet dataset. The dataset has a total of 50,000 images, 1000 categories, and 50 images of each type. The data is divided into 40,000 images as training set and 10,000 images as test set.
Experimental result
To test whether PairTraining has general applicability, we conduct experiments using 11 common different series of CNN models. These include AlexNet, VGGNet, DenseNet121, Inception series (GoogLeNet, Xception41 [5]), ResNet series (ResNet50, ResNet101, ResNet50_vd, ResNet101_vd) and mobile series model (MobileNetV3 [12], ShuffleNetV2 [17]). The performances of all models on Oxford 102 Flowers, CIFAR10, CIFAR100 and ILSVRC2012 (mini) datasets are shown in Table 3. (Note: Since ILSVRC2012 (mini) has many categories and few pictures of each category, it is necessary to load the pre-training model for training, otherwise the model will be difficult to converge.)
Model performance comparison using different training methods
Model performance comparison using different training methods
This section sets up three sets of experiments, which are the classification accuracy comparisons of the test set, the training process comparison, and the training cost comparison of the model using different training methods.
The experimental results are shown in Table 3. Details of the model parameters involved in the experiment can be found in the Appendix, where:
top-1 indicates the category with the highest probability in the model prediction label. If this category is the same as the correct category, it is considered that the prediction is correct. Equivalent to classification accuracy.
top-5 indicates that the model predicts the top five categories with the highest probability, and the correct category in these categories is regarded as correct prediction.
Compared with the ordinary training method, the performance of 11 models was improved in the four datasets after training with PairTraining.
In the Oxford 102 Flowers dataset, after using the PairTraining method, the top-1 growth interval of different models is between 0.93% and 2.73%. Among them, the increase of AlexNet and DenseNet121 is very obvious, with an increase of 2.45% and 2.73% respectively. PairTraining has greatly improved the mobile series models. The characteristics of the mobile series models are that some of the accuracy is sacrificed in exchange for the lightweight of the model. The classification accuracy of the mobile series model is low. The top-1 of MobileNetV3 and ShuffleNetV2 increased by 1.92% and 2.16% respectively. These models with larger increases are because these models are prone to fall into the local optimal situation during classification. Their performance has a lot of room for improvement. PairTraining can better tap the potential of the model. The Xception41 model can better complete the classification task of this dataset. Therefore, the improvement of the model by the PairTraining method is relatively small. The model’s top-1 only grew by 0.9%. For the ResNet and ResNet_vd series models, the average accuracy increases around 1.2%.
The classification difficulty of CIFAR10 is lower, and the accuracy of all models can be maintained at a high level, so the performance increase of different models is small. The growth range of top-1 is between 0.33% and 1.57%. For models with poor classification performance, the improvement is more obvious. The models of the mobile series have increased a lot, and the top-1 of MobileNetV3 and ShuffleNetV2 have increased by 1.57% and 1.54% respectively.
The classification of CIFAR100 is difficult, AlexNet and VGG16 are difficult to fit the training data during training, and the top-1 of the training set fluctuates around 75%. This will affect whether the D-mix operation of PairTraining is performed. Their top-1 increased by 1.09% and 1.15% respectively. The growth rate is low compared to other models. All other models in the top-1 of the training set meet the D-mix operation conditions of the third stage. The top-1 growth range of these models is between 1.24% and 2.12%. The Xception41’s top-1 increased by 1.94%. The top-1 of ResNet50_vd increased by 2.12%. It can be seen from the comparison that the use of D-mix can improve the effectiveness of training and increase the classification accuracy of the model.
ILSVRC2012 (mini) has many classification categories, and the top-5 is added for comparative analysis. The limitation of the AlexNet network structure makes it difficult to fit the data to converge, and the D-mix operation cannot be triggered. The top-1 and the top-5 of AlexNet increased by 0.13% and 1.35% respectively. The top-1 of AlexNet basically remained unchanged, but the top-5 was significantly improved. The top-1 of the other 10 models have all been improved to a certain extent, and the growth range is between 0.6% and 1.37%. The growth rate of top-5 is more obvious, and the growth range is between 0.72% and 2.22%.
Multiple experiments can prove the effectiveness of PairTraining. The network structure of different models often determines the performance of the model. PairTraining cannot break through the maximum performance of the model, but it can better tap the potential of the model. In the Oxford 102 Flowers dataset, the top-1 has an average increase of 1.64%. In the CIFAR10 dataset, the top-1 has an average increase of 0.91%. In the CIFAR100 dataset, the top-1 has an average increase of 1.47%. In the ILSVRC2012 (mini) dataset, the top-1 has an average increase of 0.71%, and the top-5 has an average increase of 1.51%.
Training process comparison
The experimental model in this section is ResNet50_vd, and the dataset is Oxford 102 Flowers. Compare the Training loss curve, Training top-1 curve and Test top-1 curve after using the two training methods.
The training process of ResNet50_vd in the Oxford 102 Flowers is shown in Fig. 5. Compared with ordinary training methods, PairTraining will turn around when Training top-1 reaches 0.25 and 0.75. The loss value has a small upward trend, but it only takes a few rounds to resume the downward trend. This is because D-mask and D-mix use variable control methods, which do not instantaneously increase the intensity of violent disturbance at the beginning of each stage. Gradually increasing the disturbance level helps the Training loss to converge smoothly. The loss function of PairTraining has a slower downward trend and requires more steps to converge. But the final Training loss of PairTraining is smaller, and the Training top-1 is higher.
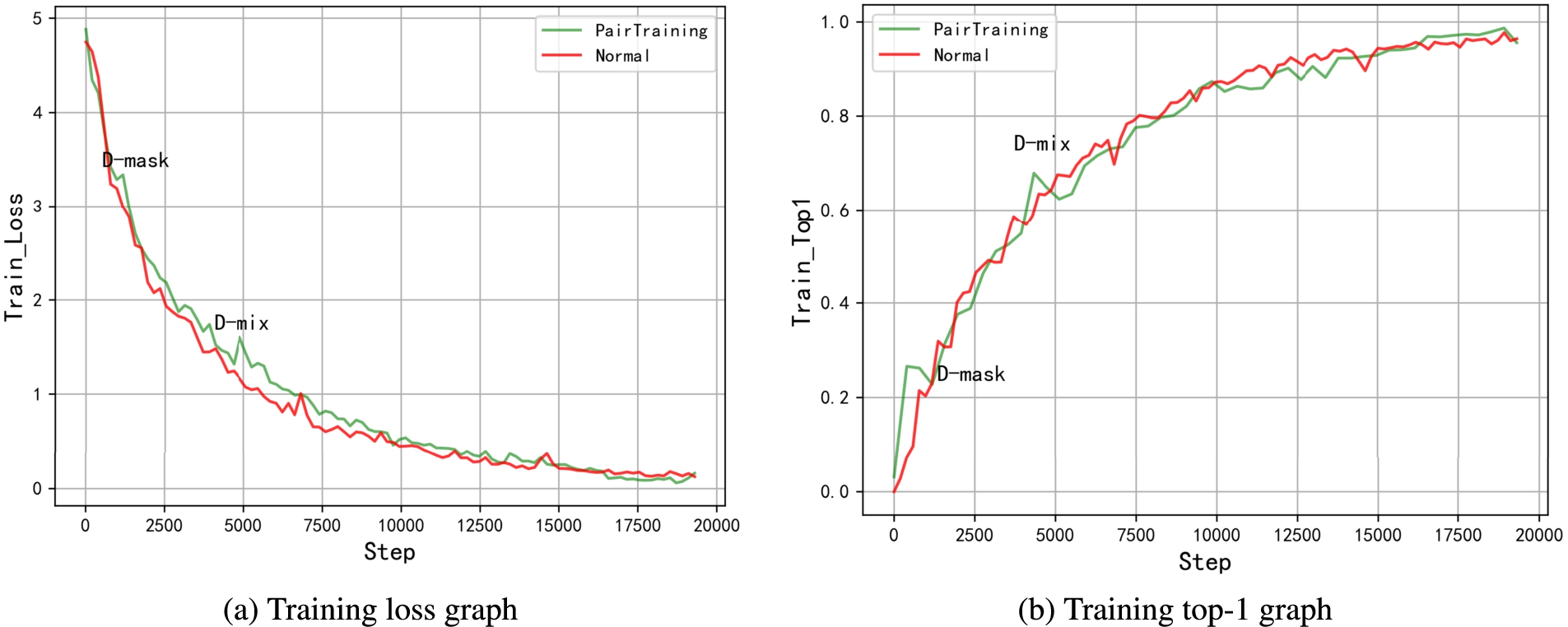
The training process of ResNet50_vd in the Oxford 102 Flowers.
The Test top-1 curve of the model is shown in Fig. 6. Although the loss of the common training method decreases faster, the Test top-1 obtained by the PairTraining method is better. Although the training top-1 of the two methods has a small gap, it can be seen from the test top-1 that after D-mix is used, the test top-1 has been improved rapidly. After using the PairTraining method, Test top-1 rose by 1.33%. The performance of the trained model becomes better.
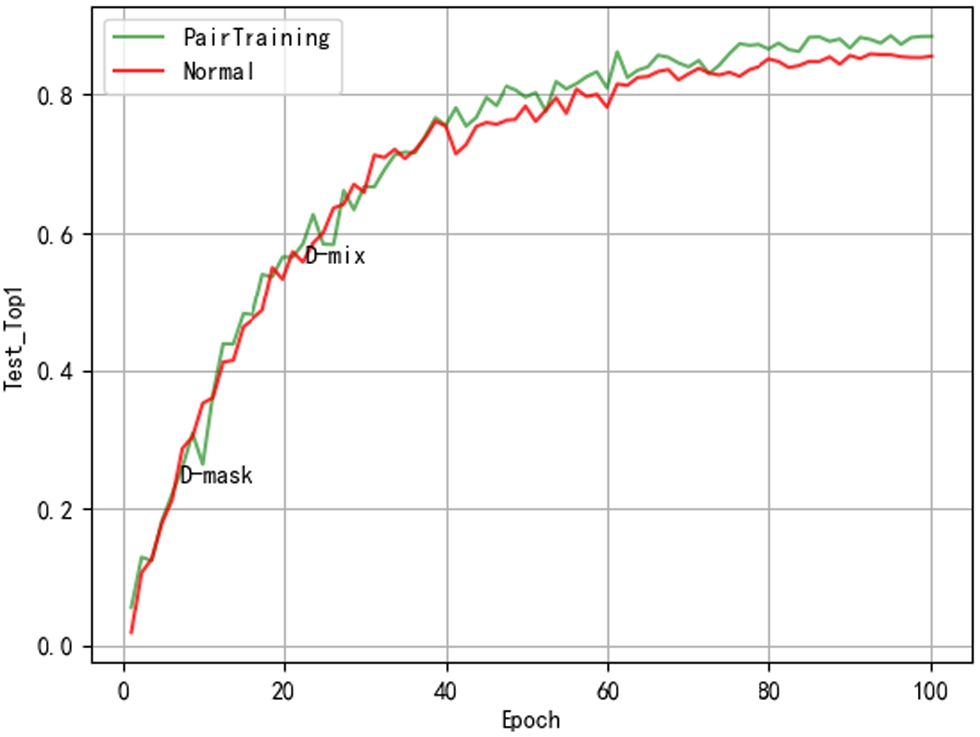
The Test top-1 graph of ResNet50_vd in the Oxford 102 Flowers.
Compared with the ordinary method, PairTraining will increase the extra computation. Each model has a different number of parameters. And the training epoch required for each model to converge is different. So using the average of each training epoch times for each model can compare the computational cost of the two training methods. All models are required to fully trigger the three stages of PairTraining, so CIFAR10 is used as the experimental dataset. The experimental results are shown in Fig. 7. The average training epoch times for all models increased between 15.78% and 28.14%. There is no significant increase in the amount of training computation. The α variable controls the extra computation introduced by training by controlling whether to use the PairTraining method. And in the CNN training process, the back-propagation process bears most of the computation. Since the image pairs share weights in the forward propagation process, the training process of PairTraining still only performs back propagation once. PairTraining only changes the training process and does not affect the inference phase of the model. Does not affect the inference speed of the model.
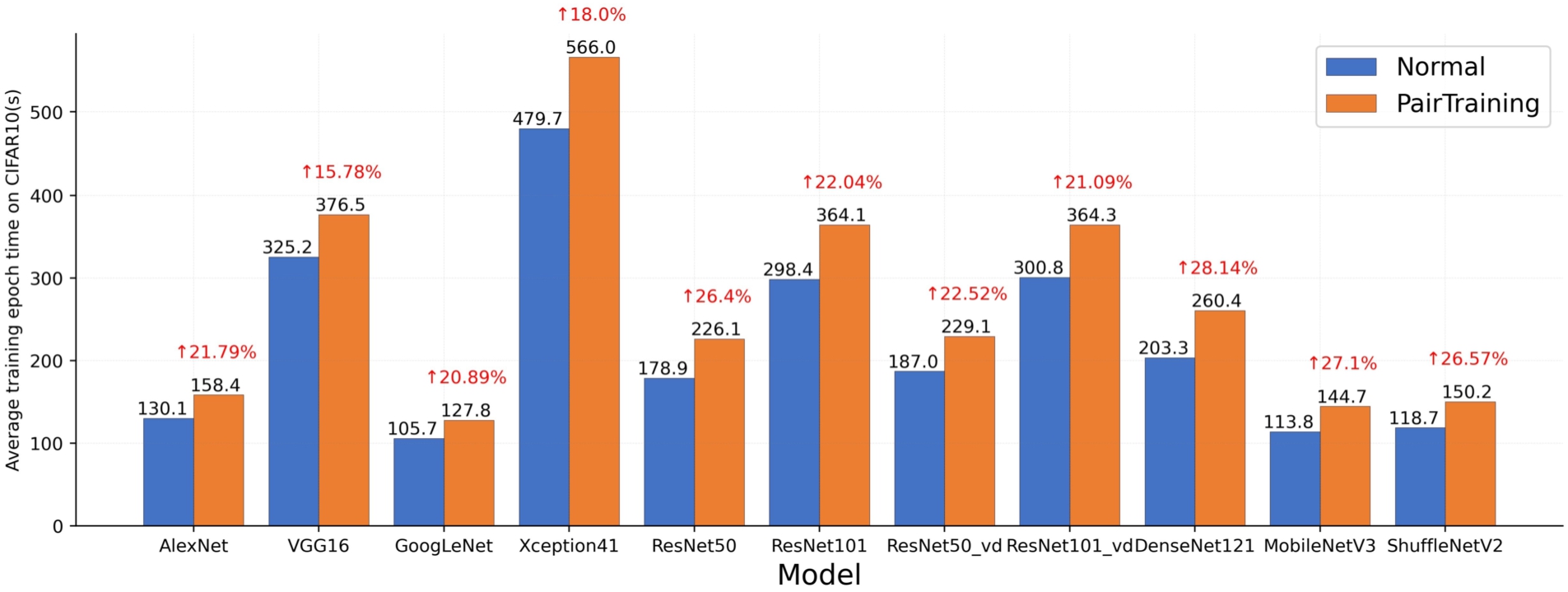
Average training epoch times for different models on CIFAR10.
Combining the data in Table 3 and Fig. 7, it is not difficult to find that PairTraining is more suitable for small and medium-sized data sets. The performance of PairTraining in the ILSVRC2012 (mini) with a large amount of data is relatively ordinary, and the top-1 has increased by about 0.7%on average. And the larger data sets mean higher training costs. At this time, if PairTraining is used, it will increase a lot of training cost. And for small and medium-sized data sets, the classification model with complex network structure is not the best choice. Such as ResNet101, ResNet101_vd and DenseNet121 in small and medium-sized data sets are not prominent. PairTraining does not break through the performance limit of the classification model. Therefore, if the selected classification model is not suitable for the characteristics of the data set, the use of PairTraining will not completely change this situation, it can only play a slight optimization purpose. Blind use of PairTraining will add additional training costs. Before using PairTraining, it is recommended to use normal training methods to find the appropriate classification model. After finding a suitable classification model, PairTraining is used for further tuning.
In order to test whether each component of PairTraining is reasonable and effective, an ablation experiment is designed. The model used in the experiment is ResNet50_vd.
Component testing
The ablation experimental data of each component is shown in Table 4. The stage 1 to 3 in the table correspond respectively to the qualitative stage, the fine learning stage and the strengthening learning stage. The strategy 1 in the table represents the normal training scheme, and the strategy 8 represents the PairTraining scheme. The Strategies 2 to 7 are control experiments. In the table, RF means random crop and random horizontal flip. All the Cutout methods in the table use the same parameter (set
The random crop and random horizontal flip has little effect on training results. Image disturbance that are too small do not improve model performance. The Cutout and Cutmix methods have a small increase in model performance in the Flowers and the Cifar10 with fewer label categories. However, For the Cifar100 and the ILSVRC2012 (mini) with more label categories, the classification accuracy of the model decreases. This is because adding too much disturbance to a dataset with high classification difficulty will lead to difficulty in model training, and the loss value of the model is difficult to converge. Among them, Cutout is less disturbed than Cutmix, so the top-1 of Cifar100 and ILSVRC2012 (mini) has a smaller decrease, with a decrease of 0.29% and 0.38% respectively. Cutmix has poor model training results due to excessive interference with classification. The top-1 in Cifar100 dropped 2.19%. The top-1 in ILSVRC2012 (mini) dropped by 5.53%.
Relatively speaking, D-Mask and D-Mix are stable. There is no situation where the performance of the model is degraded due to excessive disturbance. Compared with Cutout and Cutmix, the improvement effect of model performance is better. Among the single disturbance strategies, D-Mix is the best, and the top-1 of each data set has been significantly increased. In particular, the top-5 of ILSVRC2012 (mini) has been greatly improved by 1.53%. Appropriately sized image disturbance is critical to the success of model training.
Performance comparison of RESNET50_VD using different training methods
Performance comparison of RESNET50_VD using different training methods
Table 5 shows the influence of the weighting coefficient ω of the loss function in PairTraining on the final model performance with different values. Different sizes of ω mean the weight of the classification results of disturbed images during training. The larger the ω, the more emphasis is placed on considering the classification results of disturbed images. When
Influence of weighting coefficient on performance of RESNET50_VD
Influence of weighting coefficient on performance of RESNET50_VD
Aiming at the problems of poor flexibility, low utilization of labeled samples and low generalization degree of common CNN training methods, this paper proposes a training method PairTraining, which uses image disturbance to generate contrast images and train them in pairs with the original images. Furthermore, D-Mask and D-Mix methods are proposed, which can dynamically change the disturbance parameters with the training degree, which can effectively and reasonably combine the image disturbance with the training process. PairTraining effectively improves the training effectiveness of the model by using image disturbance and the idea of consistency regularization. PairTraining greatly improves the accuracy and stability of the model when dealing with image classification at the cost of a small increase in training cost. In the experiments, the performance of the multi-group classification models on different datasets has been improved. PairTraining also puts forward new ideas for the optimization of training methods.
The current experiments of this method are all in the image classification task, and the effectiveness in the fields of object detection and semantic segmentation has not been explored. Future work will be tested in areas such as object detection and semantic segmentation to further improve the training scheme.
Footnotes
Acknowledgement
This work was supported in part by Scientific Research Projects of the Education Department of Liaoning Province (No. LJKZ0537, No. J2020113).