
Abstract
Location-based social networks (LBSNs) have greatly promoted the development of the field of human mobility mining. However, the sparsity, multimodality and heterogeneity nature of the user check-in data remains a great concern for learning high-quality user or other entity representations, especially in the downstream application tasks, such as point-of-interest (POI) recommendation. Most existing methods focus on user preference modeling based on sequential POI tags without exploring the interaction between different modalities (e.g., user-user interactions, user-timestamp interactions, user-POI interactions, etc.). To this end, we introduce a multimodal interaction aware embedding framework to generate reliable entity embeddings on the heterogeneous socio-spatial network. At its core, first, multi-modal interaction sub-graph sampling techniques are designed to capture the heterogeneous contexts; then, a self-supervised contrastive learning technique is leveraged to extract intra-modality and inter-modality interactions in a light way. We conduct experiments on the next-POI recommendation tasks based on three real-world datasets. Experimental results demonstrate the superiority of our model over the state-of-the-art embedding learning algorithms.
Keywords
Introduction
With the rapid development of mobile Internet, numerous location-based social network (LBSN) application services have emerged, such as Yelp, Twitter and Uber. In LBSN, users share digital footprints of daily life with their friends by checking-in at a point of interest (POI), which provides fine-grained user mobility and social network information. Consequently, various location-aware data mining tasks, e.g., next-POI demand modeling [2,31] and friend recommendation [28,32], benefit from such fine-grained information. However, the multimodality (e.g., user, POI and time) and heterogeneity (e.g., user-user interactions, user-POI interactions and user-POI-timestamp interactions) of the data brings challenges for learning good entities’ representation embeddings in data-driven human mobility [31] and social network analysis [28].
Currently, to exploit the complete semantic context information, most existing works [2,3,5,7,15,26,29] regard it as a heterogeneous information network mining problem [25,33]. However, they usually split heterogeneous information networks into bipartite graphs to model multimodal interactions, which drop out part interaction of multimodal information and only focus on the interaction between the user and the item for embedding representation learning.
It is very realistic to consider multimodal interaction modeling in POI recommendation scenarios [34]. For example, Fig. 1 represents the hierarchical relationship of multiple modals of user check-in activities. In the dimension of friends, Emma’s relevance score with Jack is lower than Cora’s with Jack, which holds in the traditional social relationship-based recommendation systems. However, the abovementioned phenomenon is extremely unreasonable because Jack and Emma are similar in their activity schedules (they are all used to activities in the first and third time periods, as shown in Fig. 1’s time period modal). Therefore, it makes sense to recommend Emma’s favorite POIs to Jack. As a result, the interaction between each modality is significant for POI recommendation, and we need to incorporate multimodal information for embedding representation learning as much as possible.
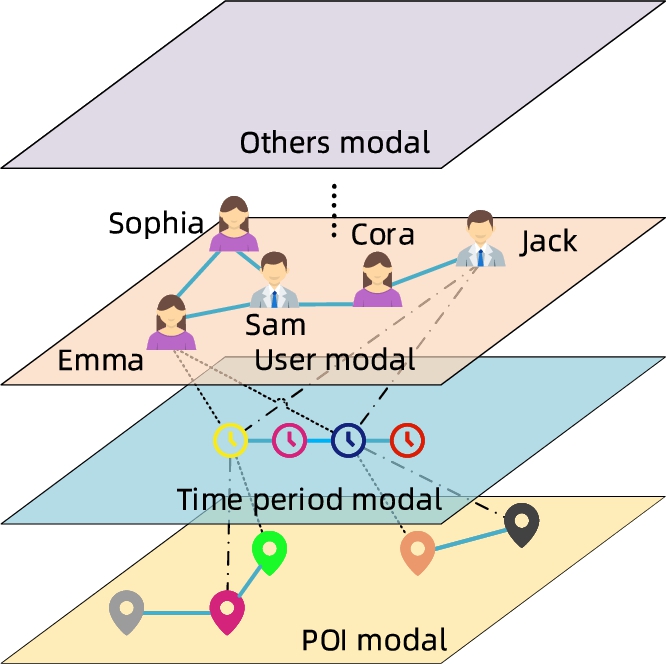
A multi-modal information network contains time period modal, POI modal, user modal, and other modalities. The solid line in the figure indicates the relationship of nodes in the same modal domain, and the dashed line indicates the relationship between different modal domain.
In the process of fusing complex and variable multimodal information into an embedding representation, several key problems remain unsolved. ❶ The relationship between the behavioral relevance of users and the interaction of multiple modals were not sufficiently investigated. ❷ Traditional methods did not consider the interaction effects of multiple modal data, which resulted in the loss of a large volume of multimodal interaction information. ❸ Multiple modal data are independent, and in previous graph convolutional embedding learning models, when the model fuses a large amount of information from neighboring nodes, it leads to over-smoothing of information and inefficient embeddings.
To tackle the aforementioned problems, we develop a sampling-aggregation POI recommendation embedding representation learning framework (SAPRec) based on multi-modal sub-graph sampling and heterogeneous information aggregator. SAPRec aims to capture the interaction between different modalities and generate efficient embedding representations [20,28]. For problem ❶, we explored the relationship between the interactions of different modals and designed SAPRec based on the analysis of the correlations in our paper. For problem ❷, SAPRec focuses on the most characteristic information in the multi-modal interest subgraphs of users, which is exploited to learn the embedding representation for each node in the heterogeneous information network. For problem ❸, SAPRec generates a multi-modal interaction sub-graph of users based on their social connections and recent check-ins. Then, we put the multi-modal interaction subgraphs into the aggregator for feature extraction.
The main contributions of this paper are summarized as follows:
We study the distribution properties of multimodal data on real data sets and analyze the influence of different modal information on each other.
We propose three graph sampling methods based on the interaction features between different modalities, which improve the representation capability of the embeddings generated by the model while reducing the graph learning cost.
We propose a graph information aggregation method named light deep graph infomax network (lightDGI). lightDGI improves the embedding representation’s learning performance while preserving the vital information in the original graph and extracting mutual information from multimodal data.
Extensive experiments were conducted on datasets of three cities to prove our model’s excellent performance on multimodal interaction aware embedding.
Graph neural networks
Graph neural networks have recently become a critical research method in the recommendation system. Li et al. propose a few-shot learning framework, which encodes geographical neighborhood information using graphs and models the dependence relationship among businesses using graph convolutional networks [11]. Wang et al. propose NGCF, which exploits the user-item graph structure by propagating embeddings [22]. NGCF leads to the expressive modeling of high-order connectivity in user-item graph, effectively injecting the collaborative signal into the embedding process in an explicit manner. Ying et al. propose PinSage, which paves the way for a new generation of web-scale recommender systems based on graph convolutional architectures [30]. In this paper, we partition heterogeneous information network (HIN) into subgraphs by three sampling methods in order to better capture the personalized information of users and the attribute features of items. Compared with previous work, SAPRec focuses more on the local features of the HIN, i.e., the personalized information of the user.
Graph neural embedding learning
Most of the current research addresses generic graph embedding. Zeng et al. propose a graph sampling-based inductive learning method named GraphSAINT, which constructs mini-batches by sampling the training graph, rather than the nodes or edges across GCN layers. GraphSAINT demonstrates superior performance in both accuracy and training time on five large graphs. [33]. The ActiveHNE framework [1] contains a novel semi-supervised heterogeneous network embedding method based on GCN. Wang et al. propose a heterogeneous graph neural network based on the hierarchical attention, including node-level and semantic-level attentions [23]. Inspired by Deep Graph Infomax [20] and lightGCN [6], this paper adds lightDGI module compared to the previous work on graph neural embedding learning, which improves the generalization ability of embedding.
POI recommendations embedding learning
Few studies focus on the embedding representations for multi-modal POI recommendations in recent years. LBSN2Vec
Preliminary analysis
In this section, we first describe the different modal data features in the user check-in record. Then we explored the distribution preferences of user check-in records under different modalities. The symbol table of this paper is shown in Table 1.
Symbol definition descriptions
Symbol definition descriptions
In the POI recommendation task scenario, users share their location checking-in at POI with their friends. With the user’s check-in record, we denote U as user set, P as POI set, T as time period set, and
Notably, human movement patterns are very intricate, and various factors have been studied in POI recommendation tasks [21]. In this paper, we only consider mixed interactions of three modalities, i.e., users, POIs, and time periods, which have been shown effective in next-POI recommendation [13].
Data observation
We observed the user’s mobility behavior and the correlation between different modal data on three real-world datasets: New York City, Jakarta, and Tokyo [10].
Figure 2 shows the size of POI intersections between users and their friends in three cities. Figure 2(a) shows the intersection size in New York City is generally less than 5. However, in Jakarta and Tokyo, the intersection size mostly ranges from 1 to 20. The differences in the POI intersection size show that user POI preferences in Jakarta and Tokyo are more likely to be influenced by social relationships compared to New York City.
Figure 3 shows the size of time period intersections between users and their friends in three cities. Users in Tokyo have more similar time periods of activities to their friends, because the intersection size of time periods between the user and their friends in Tokyo is around 1-40. On the contrary, Fig. 3(a) and Fig. 3(b) show that users in New York City and Jakarta have less similar time periods of activities to their friends.
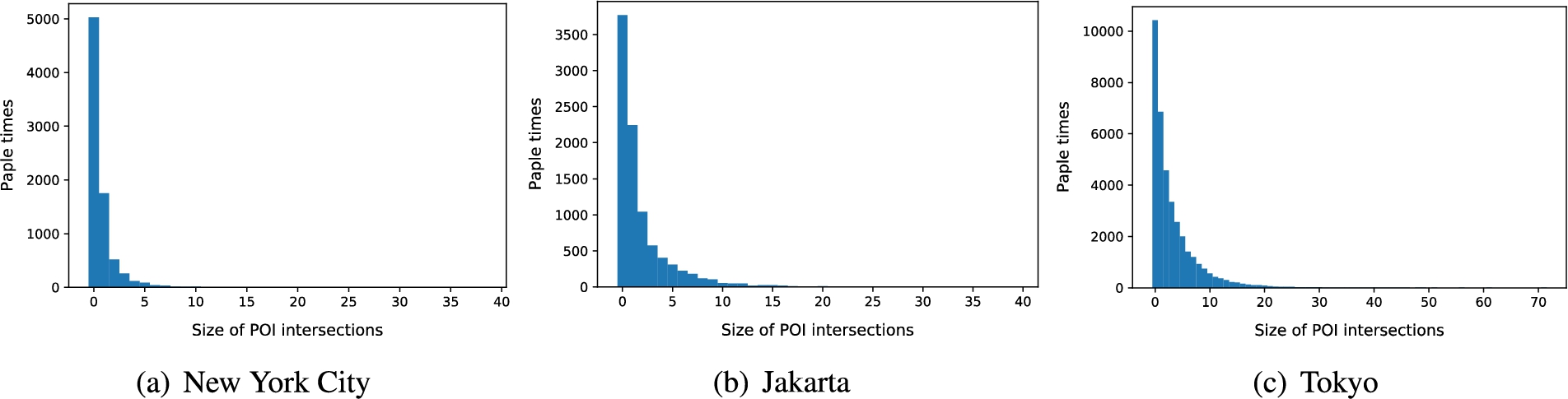
Number of POI intersections between the user’s friends and the user.
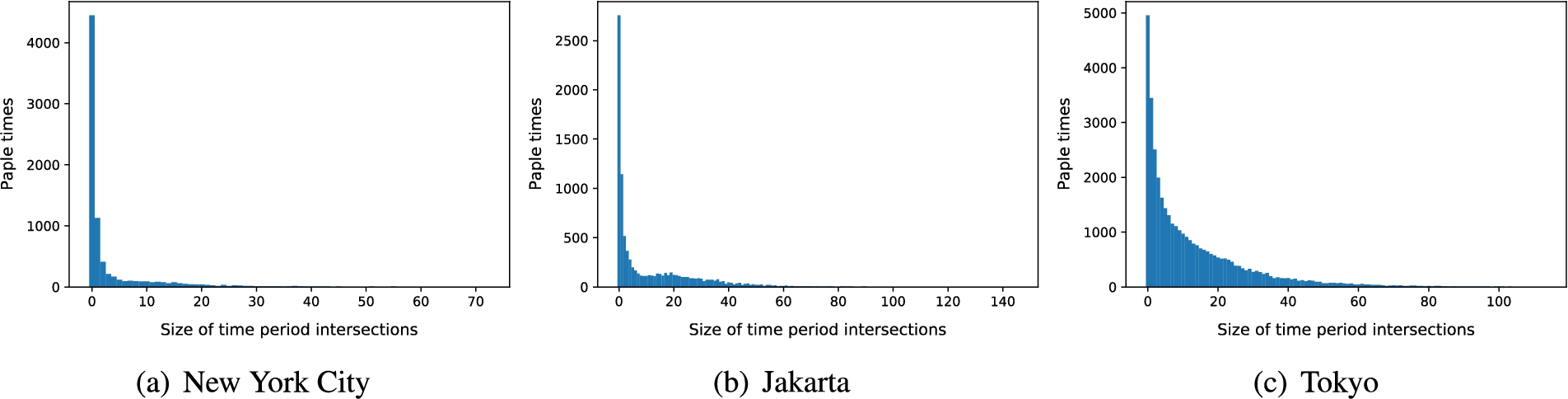
The number of time period intersections between the user’s friends and the user.
Combining the observations in Fig. 2 and Fig. 3, we can infer that New York users’ check-in preferences are less influenced by their friends, while Tokyo users’ check-in preferences are easily influenced by their friends. Although Jakarta users’ check-in location preferences are easily influenced by their friends, the time period of their activities is personalized. Therefore, it is necessary to introduce the influence of different modal factors on users’ check-in preferences.
By analyzing the check-in dataset, we can conclude that implicit affiliations between users’ different modal check-in data exist, and these implicit affiliations often show a power-law distribution. Many studies have also proposed that user check-in data have power-law distribution properties, but these studies only focus on the power-law distribution of check-in frequency and POI transitions [2,16]. Therefore, the study of embedding representation based on multi-modal check-in data is significant.
In this section, we first introduce the proposed multi-modal sub-graph sampling method. Then we present a method named light deep graph infomax to learn the embedding representation for each node in the heterogeneous information network. The model structure is shown in Fig. 4.
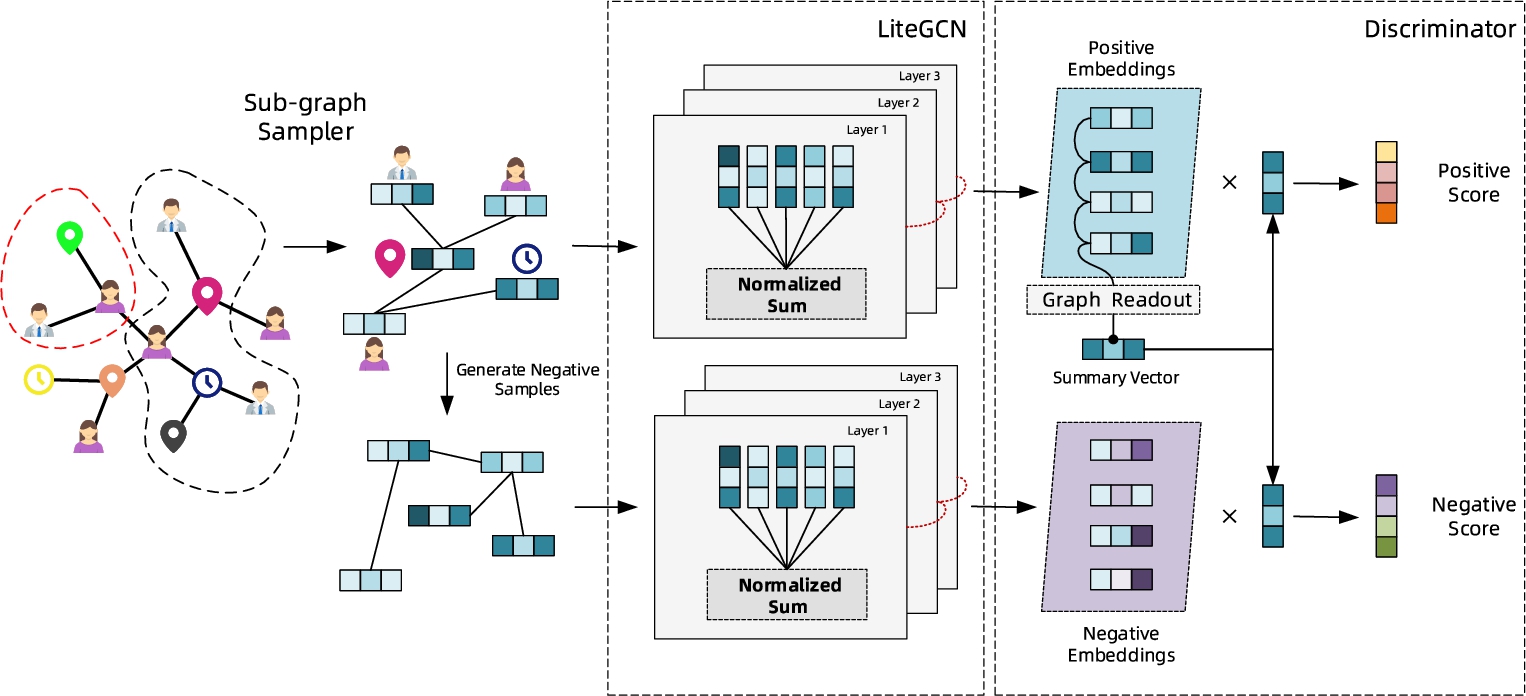
Sampling-aggregated POI recommendation embedding representation learning framework.
Graph sampling-based method is motivated by the challenges in scalability (in terms of model depth and graph size) [33]. When more modalities are considered, the larger the HINPR (the heterogeneous information network for POI recommendation) is constructed. In this context, the solution time and memory requirements of traditional methods, such as GCN, increase exponentially [9]. Therefore, we introduce the graph sampling method into HINPR, which effectively alleviates the model time complexity and space complexity. Based on the features of heterogeneous information networks, we introduce three modality-aware sub-graph sampling techniques.
There is a part of HINPR in which we can apply multi-modal sub-graph sampling. In this paper, we only consider the interaction between three modal data: user, POI, and time period. The HINPR matrix
With Equation (1), we can generate an adjacency matrix for each modal interaction, shown as Equation (2)
In Equation (2),
We propose three sampling strategies to obtain sub-graphs: node-level hop sampler, random walk sampler, and user-based random walk sampler.
Using the Node-level Hop Sampler, the probability of nodes with different modalities being sampled is as follows:

Node-level hop sampler
Using the Random Walk Sampler, the probability of nodes with different modalities being sampled is as follows:

User-based random walk sampler
We construct the edge
After getting the sub-graph set S, we need to deal with the problem of how to generate node embeddings
From the viewpoint of graph convolution, the convolution process already fuses its neighbor information, and after several such patch-level fusions, the neighboring nodes already have similar expression vectors. Thus, in the loss function part, we should pay more attention to the variability among neighboring nodes to generate a more efficient node embedding representation.
Therefore, Velickovic et al. propose the DGI method to maximize mutual information in graph convolutional neural network [20]. GCN was initially designed for graph node classification tasks, and these nodes are rich in attributes to be used as input features. However, each node (user, POI or time period) in HINPR is only described by an ID, which has no concrete semantics besides being an identifier. In such a case, feature transformation will bring no benefits, but negatively increases the difficulty for model training [6]. Therefore, we propose lightDGI to improve model performance and reduce the number of parameters on HINPR.
In each embedding learning batch of lightDGI, we need to maximize local mutual information as much as possible. In Section 4.1, we obtained the sub-graph set S of HINPR. Moreover, for each sub-graph
In order to obtain the sub-graph summary vectors
Since lightDGI is based on an unsupervised graph embedding method, we need to obtain negative sample
For the loss function, we use maximize Jensen–Shannon divergence loss [20] to evaluate mutual information probability scores for positive and negative samples, and it is defined as
Experiments
In this section, we evaluate SAPRec on location/activity prediction tasks. First, we introduce the experimental setup and discuss the advantages of SAPRec over other baseline models. Then we explore the performance of the SAPRec under different samplers. Finally, we analyze the information embedding effect of the SAPRec under different parameter settings.
Experimental setup
We used a large scale and long interval LBSN dataset containing three cities collected by [27]. Due to the cultural differences and social preferences of users in different regions, the three selected cities Tokyo (TKY), New York (NY), and Jakarta (JK). Details of the datasets are shown in Table 2.
Statistics of three city datasets
Statistics of three city datasets
The hardware configuration of our experimental platform is as follows: AMD Ryzen 7 3700X 8-Core Processor, 64GB DDR4 memory and GeForce RTX 2070 (8G). The software configuration of our experimental platform is as follows: Python 3.6.12, Pytorch 1.7.0, Numpy 1.19.2 and Pandas 1.1.3.
We use Xavier uniform to initialize the embedding parameters and set the initial learning rate to 0.001. We set embedding size to 128, sub-graph size to 200, number of sub-graph to 2000, node-hop to 3, number of root node to 32, length of random walk to 16, friend sample number to 8, friend windows size to 2, and check-in sample number to 3. We divided the dataset into training set, validation set and test set by 8:1:1.
To avoid the variability of different model metrics, we metricize all comparison models under cosine space. The metric formula is
We use the precision of Top@K as an evaluation metric, and its formula is defined as
We compare our method to the following state-of-the-art graph information embedding methods:
Precision@K comparison results of different models on 6 cities datasets
Precision@K comparison results of different models on 6 cities datasets
As shown in Table 3, our model achieves state-of-the-art embedding results on the datasets of three cities. Through the previous analysis of the datasets in Fig. 2 and Fig. 3, Tokyo users have the most frequent interactions between different modal data. Hence, our model performs best on the Tokyo dataset, proving that our model can fully explore the interactions between different modal data and generate effective embedding representations. Furthermore, the three sampling strategies we propose have different performances on the three cities’ dataset, and the random walk strategy has the best average performance.
NetMF is a matrix decomposition-based graph embedding representation model that learns the representation of each node in a graph network by converting the network embedding into a matrix decomposition. However, NetMF does not consider the heterogeneous information in the LBSN graph and the correlation of information between different modals; therefore, NetMF achieves a poor performance in this experiment.
DHNE proposes a deep hyper-network embedding model to embed hyper-networks with indecomposable hyper-edges. DHNE does not decompose the connections between nodes into bipartite graphs as in previous graph embedding models but learns the embedding directly on the heterogeneous network, thus preserving the rich structural information retained in the heterogeneous network. However, DHNE is a graph embedding model without a targeted design for LBSN heterogeneous graphs and thus has poor performance on the three city datasets.
LBSN2Vec
IMP-GCN performs high-order graph convolution inside subgraphs to identify users with common interests by exploiting user features and graph structure. IMP-GCN achieves excellent performance in traditional recommendation scenarios by relying on user-item interaction, so IMP-GCN also achieves suboptimal performance on LBSN-based POI recommendations. However, like DHNE, IMP-GCN is not explicitly designed for LBSN heterogeneous graphs, so there is still a tiny gap in LBSN-based POI recommendations compared to SAPRec.
To investigate the effect of three sampling strategies on the performance of the embedding representation of SAPRec, we experiment on the dataset of Tokyo.
In Fig. 5, it shows that the random walk strategy has the best embedding representation performance on the Tokyo dataset. This situation is because the random walk can obtain deeper neighboring nodes than the node-level hop and user-based random walk. Therefore, more mutual information can be learned in lightDGI.
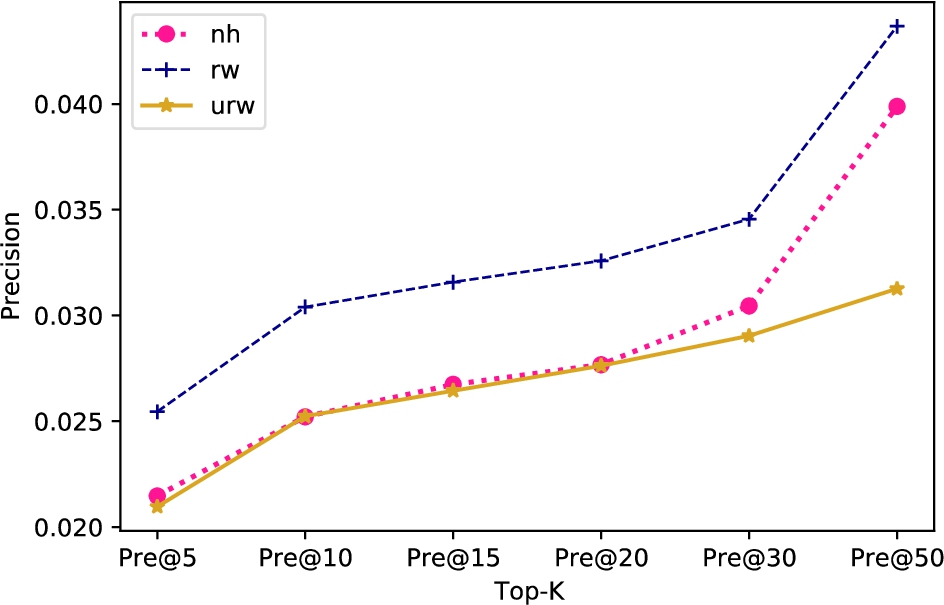
Effect of three sampling strategies on the performance of the embedding representation of SAPRec.
In this section, we verified the effectiveness of lightDGI by ablation experiments and explored the different parameter settings of SAPRec.
Ablation experiments for lightDGI
In Table 4, we compare the embedding representation performance of SAPRec with feature transformation layer (FTL) and SAPRec without feature transformation layer on the Tokyo dataset. As we can see, SAPRec without Dense has achieved an enormous performance boost, an average performance improvement of up to 35%. This result proves the effectiveness of lightDGI.
Light deep graph infomax with dense and without dense on Tokyo dataset
Light deep graph infomax with dense and without dense on Tokyo dataset
To verify the effect of different modal data on the performance of our model, as well as to demonstrate that multimodal data has a positive effect on improving the embedding representation, we conducted ablation experiments on multimodal data. γ indicates that all modalities are considered, α indicates that the effect of time period on POI is not considered, β indicates that the effect of the time period on POI and users is not considered, θ indicates that we only consider social influence and interaction between users and POIs. As shown in Fig. 6, on the Tokyo dataset, the time period has a strong influence on user check-in preferences. And the performance of the embedding representation of the model decreases whenever some of the modal data is removed so that SAPRec can generate effective embedding representations for multimodal information.
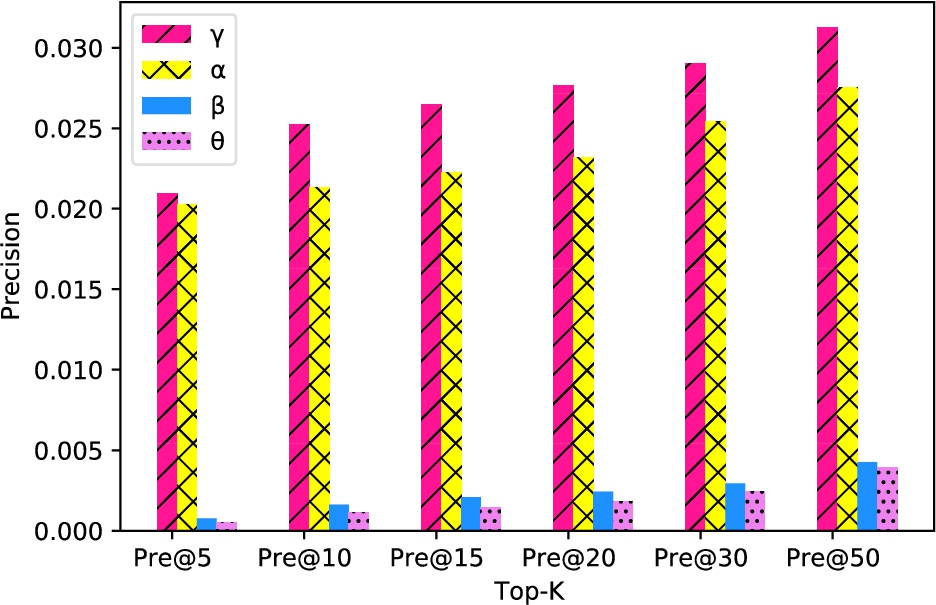
Embedding representation performance of SAPRec with different modalities.
As shown in Fig. 7, through parametric experiments on SAPRec, we can draw a conclusion that the model can obtain the best embedding representation performance at an embedding dimension of 128. When the embedding dimension is too small, it is not conducive to the fusion of multimodal information, which results in information loss. On the other hand, when the embedding dimension is too large, it causes difficulties in model convergence, which leads to the degradation of model performance.
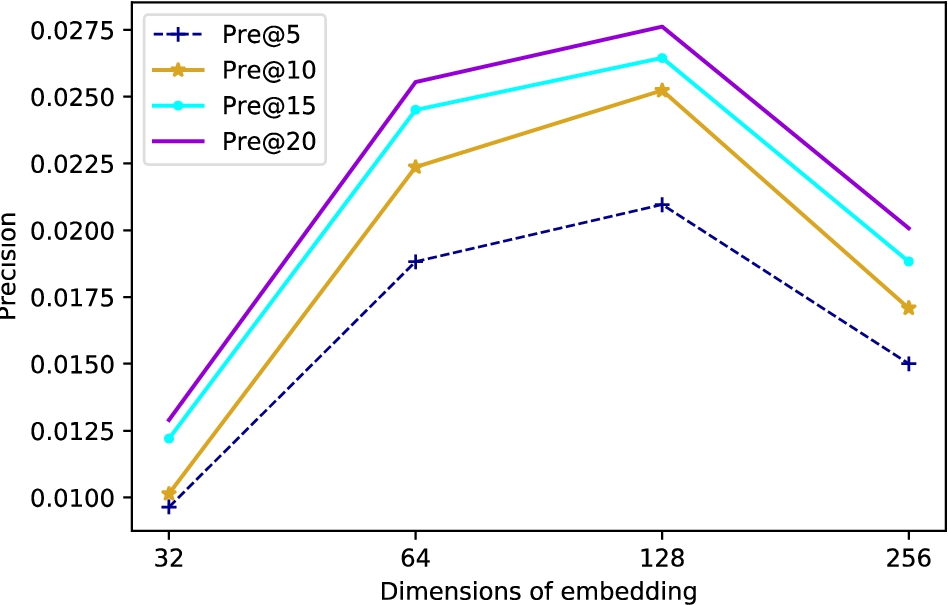
Embedding representation performance of SAPRec with different embedding dimensions.
In this work, we propose a multimodal interaction aware embedding learning framework named sampling-aggregated POI recommendation embedding representation learning framework (SAPRec). SAPRec can generate reliable embeddings on the heterogeneous socio-spatial network by the modality-aware sub-graph sampling and the self-supervised contrastive learning. We conduct experiments to demonstrate the strengths of SAPRec: better information fusion capabilities and more effective embedding representation. In the future, we will further explore the integration of SAPRec with downstream recommender systems and further improve the accuracy and robustness of POI recommendations.
Footnotes
Acknowledgements
This work is supported by the National Natural Science Foundation of China (62072094), the LiaoNing Revitalization Talents Program (XLYC2005001), and the Key Research and Development Project of Liaoning Province (2020JH2/10100046).