In this work we design an information extraction tool text2alm capable of narrative understanding with a focus on action verbs. This tool uses an action language to perform inferences on complex interactions of events described in narratives. The methodology used to implement the text2alm system was originally outlined by Lierler, Inclezan, and Gelfond (In IWCS 2017 – 12th International Conference on Computational Semantics – Short Papers (2017)) via a manual process of converting a narrative to an model. We refine that theoretical methodology and utilize it in design of the text2alm system. This system relies on a conglomeration of resources and techniques from two distinct fields of artificial intelligence, namely, (i) knowledge representation and reasoning and (ii) natural language processing. The effectiveness of system text2alm is measured by its ability to correctly answer questions from the bAbI tasks published by Facebook Research in 2015. This tool matched or exceeded the performance of state-of-the-art machine learning methods in six of the seven tested tasks. We also illustrate that the text2alm approach generalizes to a broader spectrum of narratives. On the path to creating system text2alm, a semantic role labeler text2drs was designed. Its unique feature is the use of the elements of the fine grained linguistic ontology VerbNet as semantic roles/labels in annotating considered text. This paper provides an accurate account on the details behind the text2alm and text2drs systems.
The field of Information Extraction (IE) is concerned with gathering snippets of meaning from text and storing the derived data in structured and machine interpretable form. Consider an example by Bird, Klein, and Loper [3, Chapter 7] starting with a sentence
BBDO South in Atlanta, which handles corporate advertising for Georgia-Pacific, will assume additional duties for brands like Angel Soft toilet tissue and Sparkle paper towels, said Ken Haldin, a spokesman for Georgia-Pacific from Atlanta.
A sample IE system that focuses on identifying organizations and their corporate locations may extract the following predicates from this sentence:
These predicates can then be stored either in a relational database or a logic program, and queried accordingly by well-known methods in computer science. Thus, IE allows us to turn unstructured data present in text into structured data easily accessible for automated querying.
In this paper, we focus on an IE system that is capable of processing simple narratives with action verbs – verbs that express physical acts such as go, give, and put. Take a sample narrative that we refer to as the JS discourse:
The actions travel and journey in the narrative describe changes to the narrative’s environment, and can be coupled with the reader’s commonsense knowledge to form and alter the reader’s mental picture for the narrative. For example, after reading sentence (1), a human knows that John is the subject of the sentence and traveled is an action verb describing an action performed by John. A human also knows that traveled describes the act of motion, and specifically that John’s location changes from an arbitrary initial location to a new destination, the hallway. The JS narrative has a nice property. All entities impacted by any sentence of the narrative are also mentioned within that sentence. Let us now extend the JS discourse by two more utterances:
Note how in the new discourse the location of a suitcase mentioned only in sentence (3) is impacted in sentence (4), where no explicit reference to this object is made. Lierler et al. [19] outline a methodology for constructing a narrative understanding/question answering (QA) framework by utilizing IE techniques, where the complex interactions of events in narratives exemplified by (1)–(4) are accounted for. The key ingredients of that methodology include an action language [14] and an extension of the VerbNet lexicon [17,26]. Language enables us to structure knowledge regarding complex interactions of events and implicit background knowledge in a straight-forward and modularized manner. The represented knowledge is then used to derive inferences about a given text. The proposed methodology assumes the extension of the VerbNet lexicon with interpretable semantic annotations in . The VerbNet lexicon groups English verbs into classes allowing us to infer that such verbs as travel and journey practically refer to the same class of events.
The processes described in [19] are exemplified in that work via two sample narratives that were completed manually. The authors translated those narratives to programs by hand and wrote the supporting modules to capture knowledge as needed. To produce system descriptions for considered narratives, the method by Lierler et al. [19] utilizes resources stemming from the natural language processing (NLP) subfield of AI, such as semantic role labeler lth [15], parser and co-reference resolution tools of coreNLP [21], and lexical resources propbank [27] and SemLink [4]. Here, these resources are used in implementing the text2drs system automating parts of the method. In particular, text2drs extracts entities, events, and their relations from a given action-based narratives. Then, a narrative understanding system called text2alm is developed. It utilizes text2drs and automates the remainder of the method outlined in [19]. When considering the JS discourse as an example, system text2alm produces a set of facts in spirit of the following:
where 0, 1, 2 are time points associated with occurrences of described actions in the JS discourse. Intuitively, time point 0 corresponds to a time prior to the utterance of sentence (1). Time point 1 corresponds to a time upon the completion of the event described in (1). Facts in (5) and (6) allow us to provide grounds for answering questions related to the JS discourse such as in Table 1.
Sample questions and relevant facts
Question:
Ground:
Is John in the hallway at the end of the story (time 2)?
Who is in the hallway at the end of the story?
We note that modern NLP tools and resources prove to be sufficient to extract facts (5) given the JS discourse. Yet, inferring facts such as (6) requires complex reasoning about specific actions present in a given discourse and modeling such common sense knowledge as inertia axiom (stating that things normally stay as they are) [18]. In addition, if we consider the extended JS discourse (1)–(4) then concluding that the suitcase is not in the hallway at the end of the story requires reasoning about indirect effects of actions (or, in other words, addressing a ramification problem [11]). Indeed, John’s action of moving indirectly affects the suitcase that he previously grabbed.
System text2alm combines the advances in NLP and knowledge representation and reasoning (KRR) to tackle the mentioned complexities. As stated earlier, it utilizes KRR action language for encoding content of a considered discourse. Then, it relies on an inference engine to draw additional non explicitly stated information from the discourse. A prominent part of text2alm consists of the CoreAlmLib – an library of generic commonsense knowledge for modeling dynamic domains – developed by Inclezan [13]. The library’s foundation is the Component Library or CLib [2], which is a collection of general, reusable, and interrelated components of knowledge. The important part of the text2alm project was designing a “mapping” extension for the CoreAlmLib that allows us to connect the linguistic VerbNet ontology together with the ontology chosen in CoreAlmLib, and previously in CLib, to encode the knowledge about actions. We call this extension CoreCALMLib in the sequel and describe it in great detail. The effectiveness of system text2alm measured by its capability to answer questions from the bAbI tasks [31] proves the validity of knowledge bases engineered by hand. Overall this work illustrates the ability of general purpose knowledge library, in this case CoreAlmLib, to capture sufficient amount of knowledge for drawing inferences in a third-party application. We find this a remarkable achievement for KRR as knowledge elicitation/engineering is often pointed as a bottleneck for the use of its technique. We view the success of text2alm utilization of and CoreCALMLib as a sign of maturity of the KRR technology.
As mentioned, system text2alm was evaluated on so called bAbI tasks [31]. These tasks were proposed by Facebook Research in 2015 as a benchmark for evaluating basic capabilities of QA systems in twenty categories. Each of the twenty bAbI QA tasks is composed of narratives and questions. We extend the information extraction component of the text2alm by a specialized QA processing module to tackle seven of the bAbI tasks containing narratives with action verbs. The remaining tasks of bAbI go beyond the kind of narratives targeted in this work. Tool text2alm matched or exceeded the performance of modern machine learning methods in six of these tasks. It is due to make a remark on a tool by Mitra and Baral [24] (see more details in Section 6). This tool is a relative to a proposed framework in a sense that it attempts to reconcile the progress in knowledge representation and reasoning with advances in natural language processing. This tool achieved nearly perfect test results on the bAbI tasks. However, its approach is unable to tackle narratives that utilize other action verbs than provided within the training set of bAbI, whereas the proposed method utilized within text2alm has no such limitation.
We start the paper by a review of relevant tools and resources stemming from the NLP community. We then proceed to describe the architecture of the text2drs semantic role labeler implemented in this work. Its unique feature is the use of the VerbNet ontology elements as its labels. Common semantic role labelers focus on far less detailed ontology propbank for this task. Next, we proceed to a review of the language and several resources stemming from the KRR community. The paper culminates in the presentation and detailed discussion of the architecture of the text2alm system designed in this work. We conclude by providing the evaluation data on this tool.
Parts of this paper appeared as technical communications of the 35th International Conference on Logic Programming [25]. It is due to note that this work is an important step towards bringing together the advances in knowledge representation and reasoning and natural language processing subfields of artificial intelligence. The resulting tool provides us with a human readable model written in the language of . With that the solutions can be verified and explained following the reasoning engine inferences and inspecting the knowledge encoded in the model capturing a considered narrative. It is a future work direction to utilize this fact in constructing a system capable of explanations of derived conclusions.
Natural language processing preliminaries for text2drs and text2alm
The text2drs system was designed within this work as a key subcomponent of the text2alm tool. Before we proceed to the description of this subcomponent we have to review various resources required for the design of this system. Such lexical resources as propbank [27], VerbNet [17,29], and SemLink [28] form the important components of text2drs. Also, several natural language processing tools such as lth [15] and coreNLP [21] are parts of the system. This section reviews key features of these NLP resources and tools sufficient to make the presentation of text2drs in the next section comprehensive.
Lexical resource propbank and semantic role labeler lth
propbank [27] is a Verb Lexical Resource that systematizes knowledge about verbs with respect to their predicate-argument or, in another word, event-participant structure. The information about verbs is organized into so called “frames” that we illustrate by an example. Consider a propbank frame for verb grab:
In this frame, Arg0 and Arg1 are called (prototypical) semantic roles, and grabber and entity grabbed are descriptions of these particular semantic roles pertaining the specific verb sense grab.01. Numeric ids such as .01 annotating verbs in propbank are meant to denote different senses of the same verb. The propbank frames are often used within so called semantic role labeling systems to annotate sentences with verb grab (and others) in a systematic fashion. These systems identify event participants and their roles within given sentences. For example, Fig. 1 presents the propbank semantic role labeling for sentences (3) that contains an inflected form of the verb grab.
Sample semantic role labeling.
A software tool lth is an of the shelf semantic role labeler that takes English sentences as input and annotates them using propbank semantic role labels. For instance, for our sample sentences (1), (2), and (3), the lth system produces the following output (letter A in the output is identified with expression Arg):
[A0 John][V (travel.01) travelled][A4 to the hallway] [A0 Sandra][V (journey.01) journeyed][A2 to the hallway] [A0 John][V (grab.01) grabbed ][A1 the suitcase].
While we already presented the propbank frame for the predicate grab.01, we now present these for predicates travel.01, and journey.01:
travel.01: the act of moving to journey.01: the act of moving to Arg0-PPT: traveller Arg0-PAG: traveller Arg1-LOC: location or path Arg2-LOC: location or path Arg2-DIR: start point Arg4-GOL: destination
Note how lexical verb ontology propbank organizes each verb/predicate individually without grouping similar/synonymous verbs or, rather, their senses together. In addition, the semantic roles of the predicates are not always consistent across similar verbs. Indeed, note how synonymous verb senses travel.01 and journey.01 assign different labels Arg1 and Arg2, respectively, to an argument that plays the same role of location or path. Lexical verb ontology VerbNet that we review next addresses these shortcomings and provides us with a more fine-grained resource for systematic annotation of sentences with respect to the predicate-argument structure.
Verb lexicon VerbNet
VerbNet is a domain-independent English verb lexicon organized into a hierarchical set of verb classes [17,26]. The verb classes aim to achieve syntactic and semantic coherence between members of a class. Each class is characterized by a set of verbs and their thematic roles. The term thematic role has the same meaning as the term semantic role in the propbank, but the VerbNet frames adopt a richer system of thematic roles than the prototypical system of propbank. Importantly, VerbNet groups relevant verbs into verb classes. For example, the verb run is a member of the VerbNet class run-51.3.2. This class is characterized by
96 members including verbs such as bolt, frolic, scamper, and weave,
four thematic roles, namely, theme, initial location, trajectory and destination,
two subbranches: run-51.3.2-1 and run-51.3.2-2. For instance, run-51.3.2-2 has members gallop, skip, and strut, and has additional thematic roles agent, result, and source.
Consider verb travel from the JS discourse. It evokes (is a member of) VerbNet class:
As we see, verbs travel and journey are members of run-class. They have close/synonymous meaning and share three thematic roles: Agent; Theme; Location. Let us revisit semantic role labeling by considering VerbNet lexicon as a supplier of the semantic labels in place of propbank. For instance, for our sample sentences (1), (2), and (3) Tables 2, 3, and 4, respectively, present their VerbNet and propbank semantic role labelings (SRLs).
Semantic role labelings for sentence John travelled to the hallway using propbank and VerbNet
John
travelled
to the hallway
propbank SRL
Arg0
travel.01
Arg4
VerbNet SRL
Theme
run-51.3.2
Location
Semantic role labelings for sentence Sandra journeyed to the hallway using propbank and VerbNet
Sandra
journeyed
to the hallway
propbank SRL
Arg0
journey.01
Arg2
VerbNet SRL
Theme
run-51.3.2
Location
Semantic role labelings for sentence John grabbed the suitcase using propbank and VerbNet
John
grabbed
the suitcase
propbank SRL
Arg0
grab.01
Arg1
VerbNet SRL
Agent
steal-10.5-1
Theme
The verb grab evokes three VerbNet classes steal-10.5, obtain-13.5.2, and hold-15.1. Without the emotional connotations to their meanings, these three verb classes represent a similar action. In this example, we consider class steal-10.5-1 for the purpose of semantic role labeling.
Let us look closer to the VerbNet SRLs for the case of sentences (1) and (2) and contrast these with their propbank SRLs. We find that distinct propbank predicates travel.01 and journey.01 are converted into a single verb class run-51.3.2. Also, the phrase to the hallway in the two sentences are labeled by the same thematic role of Location, even though they have different semantic roles, namely, Arg4 and Arg2 in their propbank SRLs.
Lexical mappings set SemLink
SemLink [28] is a project from the University of Colorado Boulder whose aim is to link together several lexical resources including propbank and VerbNet. It constitutes a set of mappings. For example, entries in the SemLink resource for verbs travel, journey, and grab are given in Listing 1.
A snippet from SemLink
A mapping for (a single sense of) verb travel is listed in lines 1–6 in Listing 1; a mapping for journey is listed in lines 8–13; three possible mappings for grab are listed in lines 15–28. Consider verb travel. In its mapping, the propbank predicate travel.01 is mapped to VerbNet class 51.3.2-1, which is a subclass of run-51.3.2 – see line 2. The semantic role Arg0 (of propbank) is mapped to thematic role Theme (of VerbNet) – see line 3, and semantic role Arg1 is mapped to the thematic role Location – see line 4.
NLP “one stop shop” tool coreNLP
The Stanford coreNLP system [21] provides a set of NLP tools including an entity recognition and a coreference resolution subsystems. For example, given a discourse consisting of sentences (1)–(3), coreNLP detects four mentioned entities in this discourse, namely, John, suitcase, hallway, and Sandra. The system also recognizes that the entity John in sentence (3) is the same entity that appears in the sentence (1). Similarly, the entity corresponding to the noun phrases the hallway in sentences (1) and (2) is the same. The process of identifying different mentions of the same entity across a considered narrative is called coreference recognition.
Semantic role labeler text2drs
Figure 2 presents a schematic architecture of the text2drs system. It is implemented using a popular pipeline methodology in the design of NLP tools [3, Chapter 1]. While we already introduced sufficient details to explain the inner blocks of the architecture we ought to spend some time speaking of the output of the system (denoted by the letters DRS within Fig. 2). text2drs converts a given narrative into what linguistics often refer to as logic form (in this case, we take discourse representation structures (DRS) [16] as a language for the logic form of our choice). In the terminology of logicians we can draw some parallel to what is called a “normal form” of some considered language. In the logic form that we settled on for this project there is one crucial idea that is essential: the use of VerbNet ontology for “normalizing” all of the distinct ways in which natural language may convey the same information. We start this section by presenting the key ideas of a logic form considered here using our sample discourse composed of sentences (1)–(3). Then, we describe each block – of Fig. 2 to document how the transition from an input narrative to its corresponding logic form is achieved.
Architecture of the text2drs system.
A discourse representation structure (DRS) [16] is a construct in spirit of a first order logic formula used by linguists to encode key information carried by a narrative. A DRS consists of two parts:
a universe that consists of so-called “discourse referents”, which represent the objects/entities/events/participants under discussion
a set of DRS-conditions, which encode the information that has accumulated on these discourse referents: event descriptors and participants’ roles information.
We exemplify this linguistic concept on our running narrative using the VerbNet classes and thematic roles introduced earlier to capture conditions/properties carried by the narrative in a uniform way. Consider the narrative composed of sentences (1)–(3), its respective DRS produced by text2drs is presented in Table 5. The first block displays the entities and events introduced by the narrative. The entities are represented as r1, r2, r3, r4 (“r” stands for a referent), and the events are represented as e1, e2, e3. The second block shows descriptive details about the entities and events of the narrative. The property is a mapping of an entity referent and a key word in the narrative evoking this referent. The events are encoded in Neo-Davidsonian style. The eventType is a relation between an event referent and its corresponding VerbNet class. In this example, both verb travel and journey are mapped to the verb class run-51.3.2-1, and verb grab is mapped to the verb class steal-10.5-1. An eventArgument relation presents information about events. For instance, eventArgument(e2,location,r2) says that entity r2 (that has a property of being a “hallway”) plays a thematic role “location” of event e2 (that belongs to VerbNet class run-51.3.2-1). The eventTime indicates the time order of the occurred events in the narrative. Here, we consider events to begin at time zero and be separated from each other by an increment of 1. The order of the events (i.e., their mentions) in the considered narrative will be reflected in our representation. In other words, if the description of event e immediately precedes the description of event in the input narrative then our representation will reflect that by stating that happens at timepoint that is greater than timepoint of e by 1. Obviously, this is a simplistic model of time (for example, words such as before, after may change the order of events and are not accounted for in our model.) Yet, it is a representative default behavior for simple narratives. Also, we only assume simple conditions of the form presented in our example where we can view these conditions being composed into a complex statement by a logical connective and. Discourse representation structure allow more complex conditions and connectives between them. Once again, we consider this simple and yet representative default here.
In the tool chain of the text2drs implementation, the lth and Stanford coreNLP systems are used as pre-processing components. The lth tool produces semantic role labelings utilizing propbank semantic roles. Block of the architecture depicts this part of the pipeline. The coreNLP tool is used to identify entities in an input text and perform coreference resolution, which is depicted by block in Fig. 2. Block is designed within this project to interpret the output of lth. In particular, it is responsible for converting semantic labels of propbank produced by lth to thematic roles of VerbNet utilizing mappings of SemLink. As such, given this block text2drs can be seen as a semantic role labeler whose semantic annotations correspond to the ontology developed within verb lexicon VerbNet. To the best of our knowledge there is no semantic role labeler of the kind available. Blocks and extract entities and events mentioned in provided narratives based on the output of the earlier components together with their key properties. Block merges all the extracted information to compose an output DRS.
During the text2drs system implementation, there were three main challenges. First, lth typically labels a phrase by a semantic role label rather than a word caring key semantic information of the phrase (linguists refer to such a word of a phrase as head). For example, for sentence (1) lth marks phrase to the hallway with label . As a result, text2drs considers deeper syntactic structure of a sentence to properly assign roles to recognized entities. In case of sentence (1), text2drs will recognize that an entity identified with the word hallway serves the role of an argument .
The second issue that we have to overcome is missing mapping entries in the SemLink. Some predicates have partial mapping data in their entries, while other predicates do not have entries in SemLink. Currently, we address this issue as follows. If an entity is assigned a semantic role by lth, but text2drs cannot find the corresponding thematic role from SemLink, then text2drs marks the semantic role with NONE-THEMEROLE in the output. If text2drs cannot find the verb class for the predicate in SemLink, then a NON-FOUND-IN-SEMLINK will be used as a label in the narrative’s DRS. In the sequel, we document several additions to SemLink, which were made within the design of the text2alm system.
The third challenge concerns generating DRS for complex narratives as some sentences have multiple events (verbs) with multiple associated entities. Consider sentence
I stood up feeling confident and turned it in.
In this sentence, we can find three events as “stood”, “feeling”, and “turned”, and two associated entities “I” and “it”. So, in a corresponding DRS, we have to encode all three events with their respective information. To address this challenge, since we have to include all event properties in the final output, we generate an intermediate representation that adds columns and respective information for all predicates extending the output of lth.
Knowledge representation and reasoning preliminaries for text2alm
The text2drs tool described so far is an important building block of the -based information extraction system text2alm. This section presents the remaining key concepts required in understanding the design of text2alm. We review several projects stemming mainly from the KRR community research and necessary in understanding the overall architecture and inner workings of text2alm. Next section will introduce the system itself.
Dynamic domains, transition diagrams, and action language
Action languages are formal KRR languages that provide convenient syntactic constructs to represent knowledge about dynamic domains. The knowledge is compiled into a transition diagram, where nodes correspond to possible states of a considered dynamic domain and edges correspond to actions/events whose occurrence signal transitions (or, changes) in the dynamic system.
The JS discourse exemplifies a narrative modeling a dynamic domain with three entities John, Sandra, hallway and four actions, specifically:
– John travels into the hallway,
– John travels out of the hallway,
– Sandra travels into the hallway, and
– Sandra travels out of the hallway.
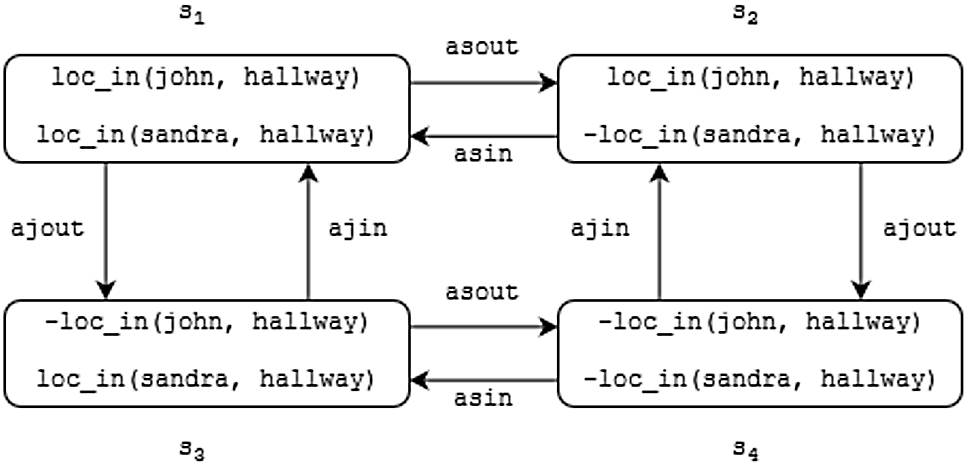
The transition diagram capturing the possible states of this domain is given in Fig. 3. State designates the state where the location of John and Sandra is the hallway. Likewise, state characterizes the state where John’s location is the hallway, but Sandra’s location is not the hallway. Occurrence of action is responsible for the transition from state to state .
Sample transition diagram capturing the JS discourse.
Scenarios of a dynamic domain correspond to trajectories in the domain’s transition diagram. Trajectories are sequences of alternating states and actions. A trajectory captures the sequence of events, starting with the initial state associated with time point 0. Each edge is associated with the time point incrementing by 1. Consider a sample trajectory for the transition diagram in Fig. 3. It captures the following scenario:
John and Sandra are not in the hallway at the initial time point 0,
John travels into the hallway at time point 0, resulting in a new state of the dynamic system to be (John is in the hallway, while Sandra is not) at time point 1,
Sandra travels into the hallway at time point 1, resulting in a new state of the dynamic system to be (John and Sandra are both in the hallway) at time point 2.
It is easy to see how this sample trajectory captures the scenario of the JS discourse.
In this work we utilize an advanced action language [14] to model dynamic domains of given narratives. This language allows us to capture the commonalities of similar actions. We illustrate the syntax and semantics of using the JS discourse dynamic domain by first defining an “system description” and then an “history” for this discourse.
An system description formalizing the JS discourse dynamic domain
In language , a dynamic domain is described via a system description that captures a transition diagram specifying the behavior of a given domain. An system description consists of a theory and a structure. A theory is comprised of a hierarchy of modules, where a module represents a unit of general knowledge. A module contains declarations of sorts, attributes, and properties of the domain, together with axioms describing the behavior of actions and properties. There are four types axioms, namely, (i) dynamic causal laws, (ii) executability conditions, (iii) state constraints, and (iv) function definitions. The properties that can be changed by actions are called fluents and modeled by functions in . The structure declares instances of entities and actions of the domain. Listing 2 illustrates these concepts with the formalization of the JS discourse domain. The resulting formalization depicts the encoding of the transition diagram that we can obtain from the diagram in Fig. 3 by erasing the edges annotated with and .
The JS discourse theory is composed of a single module containing the necessary knowledge associated with the domain. The module starts with the declarations of three sorts agents, points, move (lines 4–10 in Listing 2) and a single fluent loc_in (lines 11–14). Sorts universe and actions are predefined in so that any entity of a domain is considered of universe sort, whereas any declared action/event is considered of actions sort. While declaring actions, the user specifies its attributes, which are roles that entities participating in the action take. For instance, the attributes of move include actor, origin, and destination – see lines 7–10 in Listing 2. Here we would like a reader to draw a parallel between the notions of an attribute and a VerbNet thematic role.
There are two types of axioms in the JS discourse theory: dynamic causal laws and executability conditions. The only dynamic causal law – lines 17–18 in Listing 2 – states that if a move action occurs with a given actor and destination, then the actor’s location becomes that of the destination. The executability conditions, declared in lines 20–23, restrict an action from occurring if the action is an instance of move, where the actor and actor’s location are defined, but either (i) the actor’s location is not equal to the origin of the move event or (ii) the actor’s location is already the destination.
An structure in Listing 2 defines the entities of sorts agents, points, and actions that occurred in the JS discourse – see lines 26–27. For example, it states that john and sandra are agents. Then, the structure declares an action as an instance of move where john is the actor and hallway is the destination – see lines 28–30. Likewise, in concluding lines 31–33 is declared as an instance of move, where sandra is the actor and hallway is the destination.
In , a history is a particular scenario described by observations about the values of fluents and events that occur. In the case of narratives, a history describes the sequence of events by stating occurrences of specific actions at given time points. For instance, the JS discourse history contains the events
John moves to the hallway at the beginning of the story (an action occurs at time 0) and
Sandra moves to the hallway at the next point of the story (an action occurs at time 1).
The following history is appended to the end of the system description in Listing 2 to form an program for the JS discourse. We note that happened is a keyword that captures the occurrence of actions.
history happened(ajin, 0). happened(asin, 1).
An solver calm
System calm is an solver developed at Texas Tech University by Wertz, Chandrasekan, and Zhang [30]. It uses an program to produce a “model” for an encoded dynamic domain. Behind the scene system calm
constructs a logic program under stable model/answer set semantics [7,12], whose answer sets/solutions are in one-to-one correspondence with the models of the program, and
uses an answer set solver sparc [1] for finding these models.
The program in Listing 2 extended with the history follows the calm syntax. However, system calm requires two additional components for this program to be executable. The user must specify (i) the computational task and (ii) the max time point considered.
System calm can solve temporal projection and planning computational tasks. Our work utilizes temporal projection, which is the process of determining the effects of a given sequence of actions executed from a given initial situation (which may be not fully determined). In the case of a narrative, the initial situation is often unknown, whereas the sequence of actions are provided by the discourse. Inferring the effects of actions allows us to properly answer questions about the domain. To perform temporal projection, we insert the following statement in the program prior to the history:
temporal projection
Additionally, calm requires the max number of time points/steps to be stated. Intuitively, we see this number as an upper bound on the “length” of considered trajectories. In temporal projection problems, this information denotes the final state’s time point. To define the max step for the JS discourse program, we insert the following line in the program:
max steps 3
The number 3 coincides with the number of actions/sentences within a considered discourse. In this sense, the current system is rather simplistic as far as handling the time/action-line of the stories conveyed by the considered discourses. (This line is inserted automatically by the designed system text2alm detailed in the next section.)
For the case of the temporal projection task, a model of an program is a trajectory in the transition system captured by the program that is “compatible” with the provided history. For example, a trajectory is the only model for the JS discourse program. For the JS discourse program, the calm computes a model that includes the following expressions:
No other expressions including loc_in property occurs in the found model.
knowledge base CoreAlmLib
The CoreAlmLib is an library of generic commonsense knowledge for modeling dynamic domains developed by Inclezan [13]. The library’s foundation is the Component Library or CLib [2], which is a collection of general, reusable, and interrelated components of knowledge. CLib was populated with knowledge stemming from linguistic and ontological resources, such as VerbNet, WordNet, FrameNet, a thesaurus, and an English dictionary. CLib was successfully used in a challenge problem for DARPA’s Rapid Knowledge Formation project, where the goal was to provide a software environment in which a biologist can build a knowledge base from information in a Cell Biology textbook. The CoreAlmLib was formed by translating CLib into to obtain descriptions of 123 action classes grouped into 43 reusable modules. The modules are organized into a hierarchical structure and contain action classes.
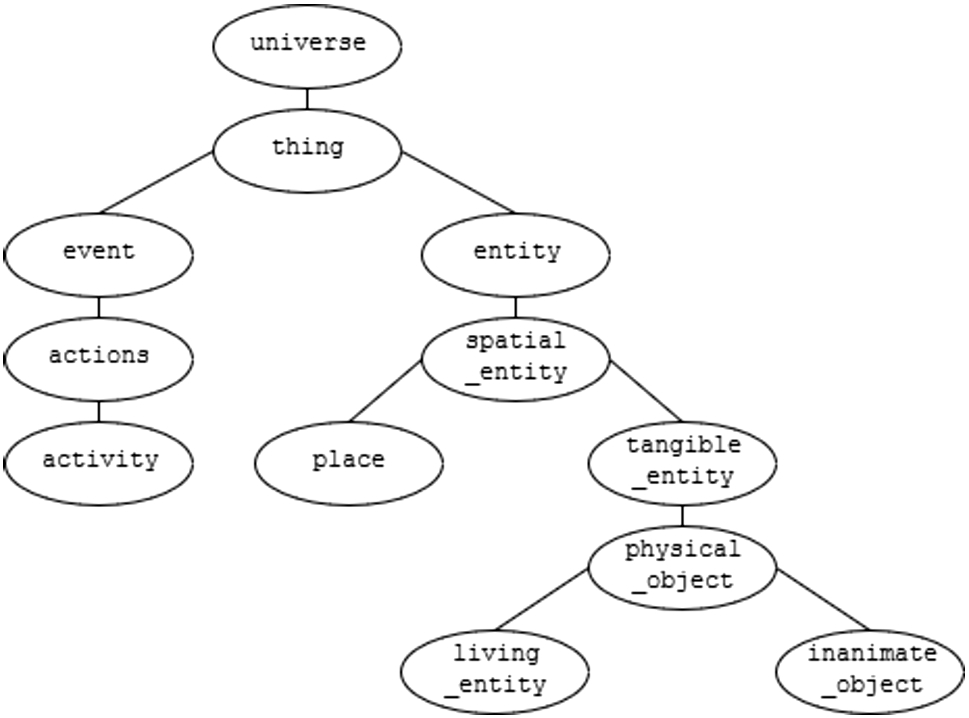
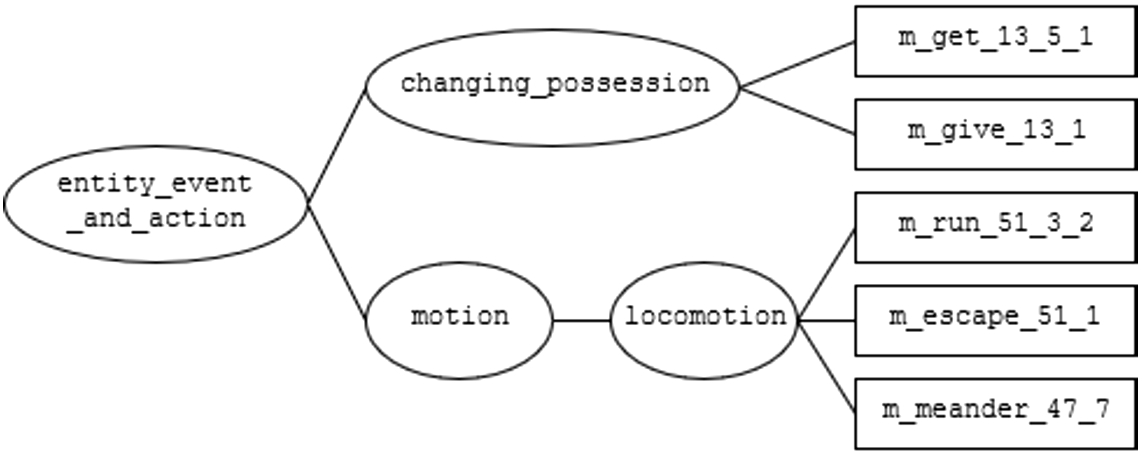
The sort hierarchy of module entity_event_and_action.
The root of the module hierarchy is the entity_event_and_action module. This module declares the sort hierarchy of basic entities and events. Figure 4 presents the sort hierarchy declared in this module. The event sort, unlike other sorts declared in the module, also declares attributes associated with it and sorts inheriting from event. The attributes support mapping between defined sorts and roles associated with events. For example, agent, object, and destination are three attributes associated with event. The CoreAlmLib code containing sort declarations for event, with some of event’s attributes, actions, and activity from the entity_event_and_action module are presented in Listing 3.
The entity_event_and_action module sort hierarchy
The CoreAlmLiblocomotion module
The entity_event_and_action module has thirteen branches inheriting from it (the root), each for a different category of action classes. For example, one branch begins with the motion module. The container_motion and locomotion modules inherit from the motion branch to represent knowledge on specific aspects of movement. Here we review the details of module locomotion whose CoreAlmLib code is presented in Listing 4. The module contains commonsense axioms about events related to an agent’s movement. The locomotion module inherits from the motion module, and implements more specific classes of movement, such as carry, go_to, leave, and walk. Import statements, like the statement in line 2 in Listing 4, denotes the dependence on knowledge in external modules. Line 2 suggests that we inherit module motion encoded within the theory of the same name. The locomotion module declares a new event sort named locomotion extending from the move sort in line 6. The move sort is declared in the motion module as a subsort of actions. Therefore, the locomotion event sort inherits all the attributes associated with events. Additionally, the locomotion module contains a single fluent, held_by, to define the objects held by an agent. This fluent is stated in lines 11–14. Lines 15–26 list state constraints, dynamic causal laws, and executability conditions for the actions. Let us consider the intuitive reading of the only executability condition encoded in lines 25–26: an action of carrying an object by an agent cannot occur unless this agent holds this object.
The bAbI project
The bAbI project is a Facebook AI Research project whose goal is the advancement of automatic text understanding and reasoning [31]. The bAbI project contributes to the field of question answering and KRR by providing data sets to evaluate progress in various reasoning tasks. The project includes so called QA bAbI tasks. They provide benchmarking abilities for QA systems in twenty reasoning tasks. Each task focuses on unique aspects of text and reasoning. The tasks contain simple narratives and ask questions during the narrative. The questions were developed so a human could potentially achieve 100% accuracy when answering the questions. Each task contains 2000 questions split into a training set of 1000 questions and a testing set of 1000 questions.
For instance, consider the following narrative/question pair
John picked up the apple. John went to the office. John went to the kitchen. John dropped the apple. Where was the apple before the kitchen? A: office
stemming from the Three Supporting Facts QA bAbI task. In this task a question is given whose answer requires information from three sentences in a preceding narrative. In the sample narrative above a reasoner must combine the information about John and the apple from sentences 1, 2, and 3 to answer the listed question. In this work we consider tasks 1, 2, 3, 5, 6, 7, and 8 from the QA bAbI dataset. These tasks are selected because they contain action-based narratives that the system text2alm is designed for. The presented sample narrative/question pair and its respective Three Supporting Facts task falls into this category. To illustrate the task of bAbI that is outside of the focus of this work consider the narrative/question pair stemming from the Agent’s Motivations QA bAbI task:
John is hungry. John goes to the kitchen. John grabbed the apple there. Daniel is hungry. Where does Daniel go? A: kitchen Why did John go to the kitchen? A: hungry
This task is geared at testing a reasoner’s ability to answer questions about motivation and intentions of an agent in performing a specific action. This kind of reasoning is outside of the scope of the presented work.
We use the bAbI datasets for tasks 1, 2, 3, 5, 6, 7, and 8 for two purposes. First, a portion of training sets of these tasks is utilized to steer the development of the text2alm system. We describe that process in detail in Section 5.2.1. Second, testing sets of these tasks are used to evaluate the text2alm performance and put it into perspective with its peer systems. Once more, the details on that are to come.
-based information extraction system text2alm
Lierler, Inclezan, and Gelfond [19] outline a methodology for designing IE/QA systems to make inferences based on complex interactions of events in narratives. This methodology is exemplified with two sample narratives that were completed manually by the authors. The proposed method utilizes:
The action language ;
The VerbNet lexicon annotated with information on relevant modules encoding commonsense knowledge about verb classes of the VerbNet.
The represented knowledge is then used to derive inferences about the text. System text2alm automates the process outlined in [19]. It proves the validity of the efforts by Lierler et al. [19]. It enables us to identify successes, challenges, and limitations of the approach. For example, the knowledge base CoreAlmLib plays a prominent role in creating the text2alm tool. It is used to provide the required annotations for verb classes of the VerbNet lexicon. It is important to remember that the CoreAlmLib was developed independently of this project and yet it was practically sufficient for populating the required knowledge base of the system to be able to perform reasoning about relevant verbs. This is a remarkable and an important achievement! It points at the possibility to escape so called knowledge elicitation bottleneck well known in knowledge representation community.
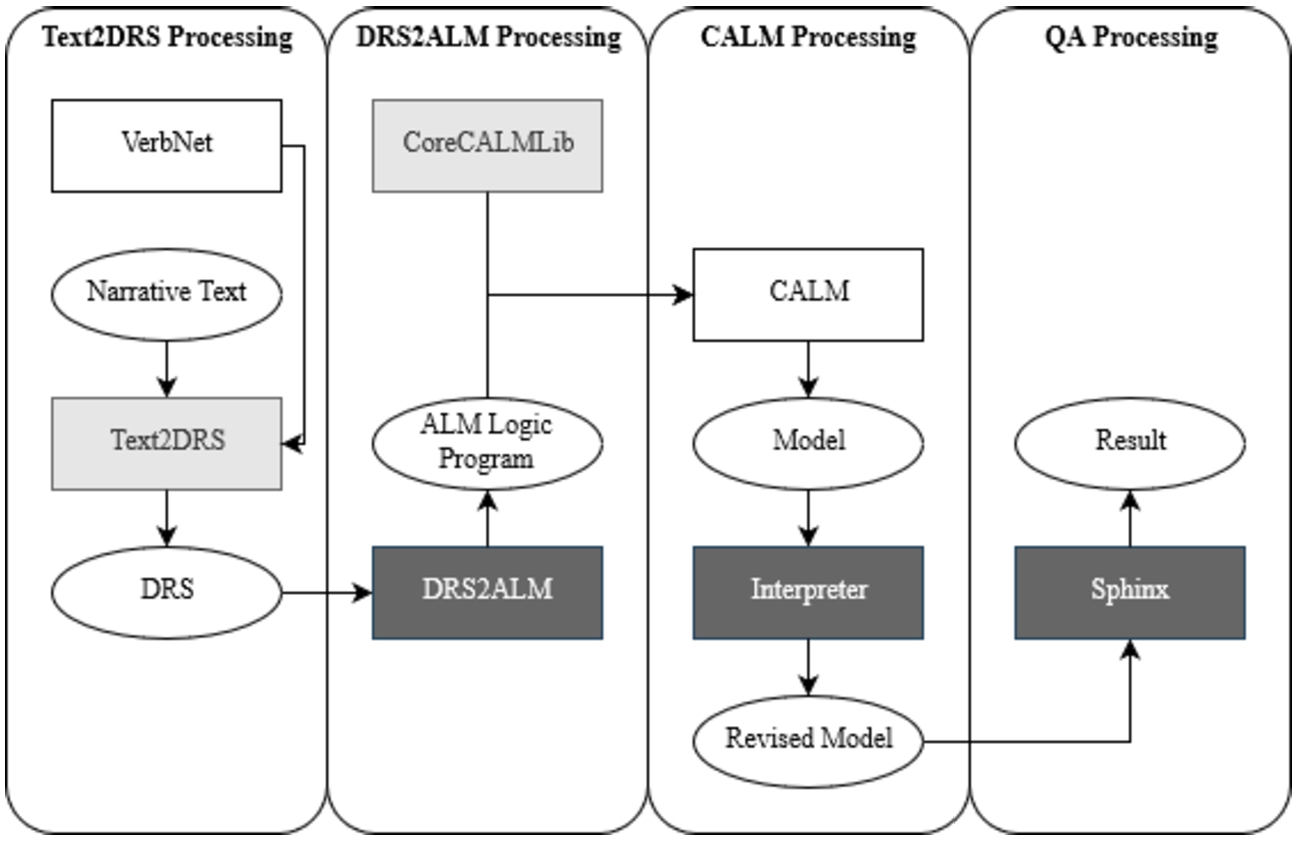
Figure 5 presents the architecture of the text2alm system. It implements four main tasks/processes:
text2drs Processing – Entity, Event, and Relation Extraction
drs2alm Processing – Creation of Program
calm Processing – Model Generation and Interpretation
QA Processing
In Fig. 5, each process is denoted by its own column. Ovals identify inputs and outputs. Systems or resources are represented with white, grey, and black rectangles. White rectangles denote existing, unmodified resources. Grey rectangles are used for existing, but modified resources. Black rectangles signify newly developed subsystems. The first three processes form the core of text2alm, seen as an IE system. The QA Processing component is specific to the bAbI QA benchmark that we use for illustrating the validity of the approach advocated by text2alm. The system is available at https://github.com/cdolson19/Text2ALM.
System text2alm architecture.
We now explain how each process accomplishes its task. We rely on two examples to outline the tasks: the JS discourse presented in the introduction and an augmented version of the JS narrative titled the JSB discourse. The JSB discourse adds one more sentence to the sentences of JS, namely:
text2drs processing
Section 2 provided the details of the text2drsProcessing part of the architecture. We note that the VerbNet v 3.3 lexicon was used within this project to provide respective annotations for the verbs and thematic roles. Also, the work on text2alm lead to several additions to the SemLink resource. For instance, in the working of the semantic role labeler lth the verbs hand.02 and pass.01 often annotated events for a transfer of possession. However, SemLink lacks mappings for either of these to the respective VerbNet class. Therefore, new entries were inserted into the SemLink library to allow the text2drs system to translate propbank annotations to VerbNet annotations for these verbs. As a result, the SemLink used within text2alm contains several additional entries.
drs2alm processing
The drs2alm subsystem is concerned with combining commonsense knowledge related to events in a discourse with the information from the DRS generated by text2drs. The goal of this process is to produce an program consisting of a system description and a history pertaining to the scenario described by the narrative. The system description is composed of a theory containing relevant commonsense knowledge, and a structure that is unique for a given narrative. One of the key components of the drs2alm Processing is the CoreAlmLib knowledge base, which was modified to form CoreCALMLib to suit the needs of the text2alm system. We organize this section by first presenting the details on how CoreCALMLib was obtained. Second, we provide the details on how the program is generated by combining the information stemming from a narrative’s DRS and the CoreCALMLib library.
Library CoreCALMLib
To obtain the CoreCALMLib knowledge base, the following modifications to the CoreAlmLib were made:
Syntactic changes,
Fluent extractions,
VerbNet extensions, and
Axiom changes.
Syntactic changes. Syntactic changes were implemented to make the library compatible with the calm syntax. The calm system requires the user to specifically split axioms into types and label the types as state constraints, function definitions, executability conditions, and dynamic causal laws. We went through each module and manually grouped the axioms under their corresponding label. As a byproduct, we translated a substantial knowledge base into a format that can be used in other calm systems. Figure 6 displays the differences between a set of axioms in the CoreAlmLib module called changing_possession and the same module in the CoreCALMLib.
System text2alm architecture.
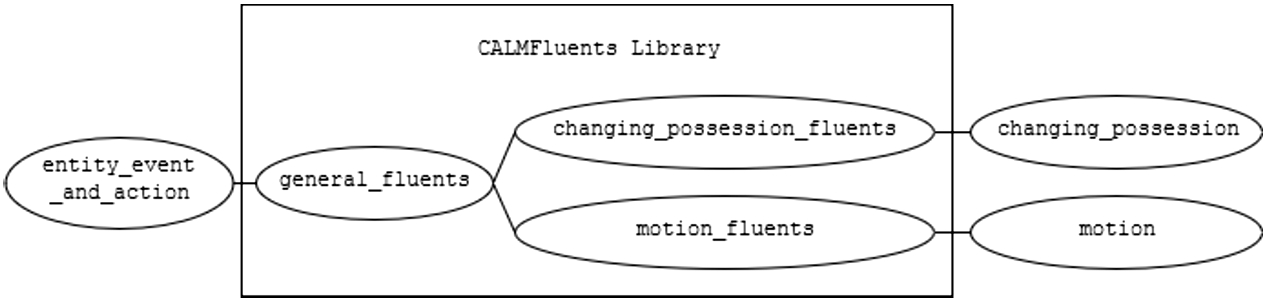
Fluent extractions. The CoreAlmLib library defines fluents to describe properties relevant to the action classes in a module. As a result, this library contains instances where fluents with the same name are declared in multiple modules. Yet semantically, since the fluents have the same name, they are assumed to be the same fluents across all the modules. We find that this approach is counterintuitive from the point of view of knowledge base design. Therefore, we extract all fluent declarations from the CoreAlmLib modules and create new modules, whose purpose are to declare fluents. We organize all fluents based on the properties they capture. For example, the location_fluents module encapsulates the related fluents location and is_at. The code of this module follows.
These fluent modules are contained in a newly created sub-library, titled CALMFluents. The modifications of CoreAlmLib into CoreCALMLib include the following. At each branch from the entity_event_and_action root we add a corresponding fluent module, which imports the fluents necessary for that branch from CALMFluents. As a result, the CALMFluents library consists of 14 distinct collections of modules, where:
One of the collections contains fluent declarations that are used across the CoreCALMLib. For example, module location_fluents presented above is a part of this collection.
The remainder correspond to collections of all fluent declarations per each existing branch.
For instance, fluents related to the motion branch are contained in the module called motion_fluents that we partially reproduce below:
theory motion_fluents import entity_event_and_action.entity_event_and_action from CoreALMLib import fluents.abuts_fluents from CALMFluents ... import fluents.location_fluents from CALMFluents ... module motion_fluents depends on entity_event_and_action, abuts_fluents, ... location_fluents, possession_fluents, restrained_fluents, shut_out_fluents function declarations fluents basic is_above : spatial_entity * spatial_entity -> booleans is_along : spatial_entity * spatial_entity -> booleans ... is_under : spatial_entity * spatial_entity -> booleans
We depict the introduced changes in the following visualizations presented in Figs 7 and 8. Figure 7 displays a subset of the original CoreAlmLib hierarchy containing the branches utilized in the JSB discourse; Fig. 8 displays the CoreCALMLib fluent hierarchy for the corresponding subset. The rectangle in Fig. 8 denotes the difference.
CoreAlmLib fluent hierarchy.
CoreCALMLib fluent hierarchy.
This method of declaring fluents has two key benefits. First, fluents are modularized and can therefore easily be imported into other modules if the need arises. Second, the modules are clearer now that a knowledge engineer must no longer consider whether fluents defined in separate branches are instances of the same global fluent or if they should be considered distinct.
VerbNetextensions. Regarding VerbNet extensions, CoreAlmLib was modified by adding a module for every VerbNet class we observed in the part of the bAbI QA task training sets. In particular, twenty VerbNet-based modules were added. Each VerbNet module defines a sort for that verb class that inherits from one of the 123 action classes stemming from CoreAlmLib. Thematic roles from the VerbNet lexicon are then mapped via state constraints to the attributes associated with actions already used by the CoreAlmLib library. These VerbNet modules are stored in a CoreCALMLib sub-library that we call vn_class_library. Lastly, we modified and added axioms into some CoreAlmLib modules, by identifying pieces of knowledge that were not represented within the original library. When not considering fluent extractions, fluents were altered or added to only four modules from the original CoreAlmLib. This supports the hypothesis that CoreAlmLib provides an effective baseline for commonsense reasoning about actions. We now detail the changes.
In Section 4.4, we reviewed the QA bAbI dataset. In the sequel by training set (training data) we understand 700 questions and respective narratives formed by extracting 100 questions and their respective narratives from each training set provided with the bAbI tasks 1, 2, 3, 5, 6, 7, and 8 (recall that each one of these sets includes 1000 questions). For instance, if we concatenate the two sample bAbI narrative/question sequences presented in Section 4.4, we obtain a training set that contains eight declarative sentences and three questions. The training set obtained from the enumerated seven tasks contains a total of 3580 declarative sentences. This training set was used to compile the set of VerbNet classes for which we introduced the described modifications to the CoreAlmLib dataset. In particular, we identified 20 first-level VerbNet classes out of its 274, whose verbs were mentioned within our training set. It is a direction of future work to extend CoreCALMLib to cover all action verb classes of the VerbNet lexicon. As such the compiled CoreCALMLib can be seen as the knowledge base containing the semantic annotations for these 20 first-level classes (and its sub-classes) of VerbNet. As a side-remark these semantic annotations are formal entities as they are written in a formal language whose semantics is defined. This distinguishes these annotations from the ones present in original VerbNet and marked with the word “semantics”, where these can be considered only on an intuitive level. This can be seen as an additional by product of this project that supplies some of the VerbNet classes with their formal semantics.
To reiterate, knowledge bases CoreAlmLib and CoreCALMLib differ in the fact that CoreCALMLib is compatible with the VerbNet lexicon. We organize CoreCALMLib so that every VerbNet class has a corresponding module. For that we add VerbNet modules, which link information from VerbNet classes to the CoreAlmLib knowledge base. Each VerbNet class module defines a sort for that verb class inheriting from an existing action sort in the CoreAlmLib. The thematic roles from the VerbNet lexicon are connected to the general semantic roles already used in the CoreAlmLib modules through state constraints. The new VerbNet theories are stored within the sub-library vn_class_library.
We design vn_class_library to mirror the class hierarchy in VerbNet. Subclasses in VerbNet also have their own modules which inherit from its VerbNet parent class. For example, the VerbNet class run-51.3.2 has the subclasses run-51.3.2-1, run-51.3.2-2, and run-51-3.2-2-1. Therefore, the corresponding theory is structured in the following manner:
theory t_run_51_3_2 module m_run_51_3_2 <implement module> module m_run_51_3_2_1 depends on run_51_3_2 <implement module> module m_run_51_3_2_2 depends on run_51_3_2 <implement module> module m_run_51_3_2_2_1 depends on run_51_3_2_2 <implement module>
We are now ready to explain the methodology of creating the modules in vn_class_library. First, we extract all VerbNet classes used in the training set. Then, we extend the CoreAlmLib hierarchy to include new VerbNet modules. For every VerbNet class, we identify the components of CoreAlmLib associated with this VerbNet class. Our primary resource to identify the associated CoreAlmLib modules was CoreAlmLib’s searching capabilities. CoreAlmLib provides searching over the library by linking WordNet senses to CoreAlmLib actions classes and fluents. WordNet [22,32] is a large English lexical database, where nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. We identify the WordNet senses associated with the VerbNet classes and link the VerbNet modules to the action class recommended by CoreAlmLib.
To exemplify the process of creating an module for a VerbNet class, consider the VerbNet class run-51.3.2-1. The VerbNet class run_51.3.2-1 is a subclass of the VerbNet class run-51.3.2, so we define a theory named after the root class, t_run_51_3_2, to contain all modules inheriting from the root. Listing 5 presents this theory. The explanations of the intuitions behind this code follow. Line 1 contains the theory declaration. In line 2, we import the CoreAlmLib action class associated with the root VerbNet class run-51.3.2. We now describe the process of identifying this association. Searching CoreAlmLib for a WordNet sense matching “run” returns no matches. In addition to verb “run”, class run-51.3.2 contains verb “go”. The WordNet sense go_1 is defined as “change location; move, travel, or proceed, also metaphorically” and this definition captures this VerbNet class. CoreAlmLib states that go_1 corresponds to the locomotion action class in the locomotion module. Therefore, we import this module into the t_run_51_3_2 theory.
The CoreCALMLibt_run_51_3_2 theory
In lines 4–17, we define the module for the base VerbNet class run-51.3.2, named m_run_51_3_2. The module depends on the locomotionCoreAlmLib module. We declare a new action sort for class run-51.3.2 extending from the locomotion action sort. A module for a VerbNet subclass inherits from its superclass’s module in the same manner that a VerbNet subclass inherits information, such as thematic roles, from their parent class. To illustrate this hierarchy, consider the run-51.3.2-1 class. It is a subclass of run-51.3.2 so we declare a new module named m_run_51_3_2_1 in theory t_run_51_3_2. The module depends on the module of its VerbNet parent, m_run_51_3_2, and declares a new action sort run_51_3_2_1 inheriting from its parent’s sort. Lines 19–32 present the m_run_51_3_2_1 module.
Finally, we define the axioms in the VerbNet modules. We use state constraints to map VerbNet thematic roles to the attributes associated with the respective actions from the CoreAlmLib. The state constraints were created manually by identifying the CoreAlmLib attribute most similarly representing the thematic role through trial and error. For example, the VerbNet class run-51.3.2 has the thematic roles theme, initial_location, destination, and trajectory. We identified the CoreAlmLib action attributes agent, origin, destination, and path to convey similar information as these thematic roles, respectively. Lines 8–17 present the resulting state constraints for the m_run_51_3_2 module. The axioms of the m_run_51_3_2_1 module are given in lines 23–32. The t_run_51_3_2 theory contains the code for two more modules, namely, m_run_51_3_2_2 and m_run_51_3_2_2_1. Their creation followed already outlined principles and we leave their code outside of the paper.
The described process is repeated to expand vn_class_library to all VerbNet classes identified in the training set. Figure 9 presents a snippet of the module hierarchy obtained within vn_class_library. The module m_run_51_3_2 relies on knowledge represented in the locomotionCoreAlmLib module. The oval nodes in the figure represent original CoreAlmLib modules. Figure 10 presents another snippet of the hierarchy with modules for the VerbNet classes escape-51.1, meander-47.7, get-13.5.1, and give-13.1. Like Fig. 9, the oval nodes represent original CoreAlmLib modules.
Example module hierarchy.
Extended example module hierarchy.
Related to the new VerbNet modules, we define additional attributes to the actions sort defined in CoreAlmLib’s root module, entity_event_and_action. The attributes match the names of the VerbNet thematic roles, with vn_ prepended to the thematic role name. For example, below we list a portion of the new attributes of actions that replace line 8 of the code presented in Listing 3.
Axiom changes. A final category of modifications made to CoreAlmLib were changes to axioms about actions. We found gaps in the CoreAlmLib knowledge base and we made axiom adjustments to represent the missing knowledge. The mentioned process of identifying gaps brings the training test of 3580 sentences stemming from bAbI into the picture once more. The use of text2alm on this training test and its inability to draw necessary conclusions suggested to us the gaps in the knowledge base. To illustrate the case of missing knowledge in the CoreAlmLib, consider the JSB discourse. When John gets the ball, it is important to know that the location of the ball is the same location as John after he picks up the ball. The verb get is defined by an action declared in the changing_possession module of CoreAlmLib. We extend this module with the following axiom that encodes the desired knowledge in terms of fluents of CoreAlmLib.
state constraints location(A, Q) if held_by(A, B), location(B, Q), instance(A, tangible_entity).
There were only handful adjustments of the kind. Appendix A lists all axiom adjustments made to the CoreAlmLib to form the CoreCALMLib. The few number of axiom adjustments had significant effects to improve training results. This shows that the CoreAlmLib provides a solid foundation of knowledge that can be adapted for a system’s domain.
program generation
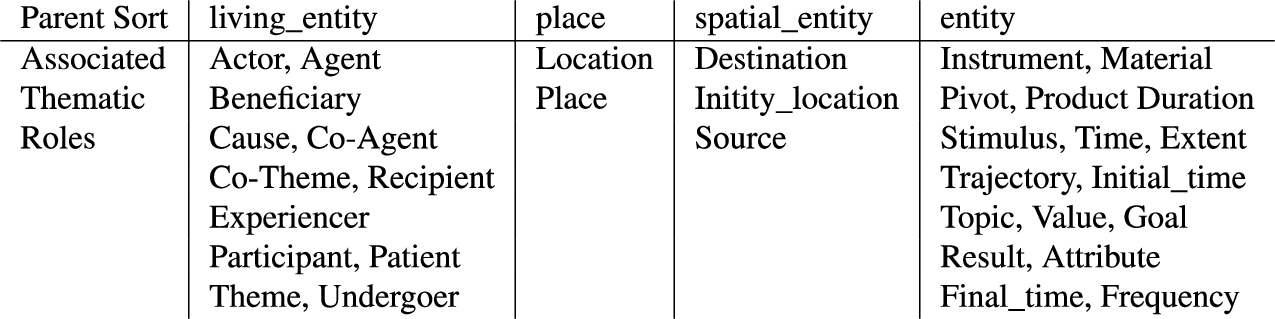
The drs2alm processing step generates an program for a given discourse. We first examine the generation of the theory in the program’s system description. We start by identifying general knowledge associated with a narrative’s domain by importing the VerbNet modules from the CoreCALMLib for all VerbNet classes associated with a narrative. These provide commonsense knowledge connected to the actions in the narrative. Then, we define a new module unique to the narrative. This module declares entities from the narrative as new sorts inheriting from base CoreCALMLib sorts. We chose to declare the narrative’s entities as new sorts so that we have more flexibility to define additional, unique attributes associated with the entities if the need arises. However, to declare these new sorts we must identify the CoreCALMLib parent sort to inherit from. We rely on the VerbNet thematic roles an entity plays to make this selection. We grouped VerbNet thematic roles into four parent sorts of CoreCALMLib: These groupings were made by reviewing the thematic roles associated with the VerbNet classes in the training sets, and attempting to map these to the most similar sorts defined by the original CoreAlmLib. Figure 11 presents the groupings. If an entity is associated with roles from different categories, we use a prioritized sort order defined as follows
where ≫ is transitive and states that the left argument has a higher priority than the right one.
VerbNet thematic roles to CoreAlmLib sorts.
DRS for the JS discourse.
An system description automatically created by the drs2alm processing.
We now turn our attention to the process of generating the structure and history for the program. This structure declares the specific entities and events from the narrative. Entity IDs from a given narrative’s DRS are defined as instances of corresponding entity sorts from the theory. Events are also declared as instances of their associated VerbNet class sort, and the entities related to events are listed as attributes of these events. The history states the order in which narrative’s events happened and when they happened. We extract this information from the arguments expressed in DRS such as, for instance, DRS for the JS discourse given in Fig. 12. To exemplify the described process, Fig. 13 presents the output of the drs2alm Processing applied towards the JS discourse (or, in other words, towards its DRS).
Note that the theory in Fig. 13 imports the VerbNet module for run-51.3.2-1 from the vn_class_library. The two events in the JS discourse were identified as members of the VerbNet class run-51.3.2-1. Thus, the module associated with this class is imported to retrieve knowledge relevant to events in the JS discourse domain.
calm and QA processing
In the calm Processing performed by text2alm, the calm system is invoked on a given program stemming from a narrative in question; then, the calm system computes a model. We then perform post-processing on this model to make its content more readable for a human by replacing all entities IDs with their names from the narrative. For instance, given the program in Fig. 13, the output of the calm Processing will include expressions:
We note that no other loc_in fluents will be present in the output. A model derived by the calm system contains facts about the entities and events from the narrative supplemented with basic commonsense knowledge associated with the events.
We use the bAbI QA tasks to test the text2alm system’s IE effectiveness. These test results are detailed in the next section. To support the bAbI tasks we implement special purpose QA capabilities within the sphinx subsystem (see Fig. 5). The questions in the bAbI QA tasks use a set of specific syntactic formats. The sphinx component utilizes regular expressions to identify a kind of question that is being asked in the bAbI tasks and then query the model for relevant information to derive an answer. The sphinx system is not a general purpose question answering component. Appendix B provides sufficient details on which kind of questions sphinx supports and how the system derives an answer for all considered question formats.
Related work
We start by mentioning a system named Boxer [6]. This system can be viewed as the most relevant system to the text2drs semantic role labeler described in Section 3. System Boxer is an open-domain NLP tool for semantic analysis that produces a DRS for a given narrative. text2drs provides additional information in comparison to Boxer due to its connection to VerbNet. Yet, Boxer is capable of dealing with richer natural language input by allowing more complex forms of conditions.
Many modern QA systems predominately rely on machine learning techniques. Past year, ChatGPT1
https://chat.openai.com/
– a chatbot developed by OpenAI, 2022 – has captured the attention not only of the scientific community but also the general public. It is probably safe to say that at the moment it is the most well known QA system. One of the system’s main subcomponents is a large language model GPT-3 [8] (or, GPT-4, depending on the version of ChatGPT). A language model is a tool, which typically given a running text completes this text with the next most probable word based on the (presumably statistical) information captured by this language model. Upon the inception of a language model, it is trained on multitude of textual entries to solicit information on language used within these entries. The term large language models is used when a particular class of neuron-network based architectures utilized for creating such tools also relying on vast number of parameters. In creation of chatbot or QA capabilities another stage called fine-tuning is necessary. This process is closer in spirit to supervised machine learning techniques. During fine-tuning, a large language model is utilized within a training process geared towards a specialized task that goes beyond a single word prediction. For more details on large language models and fine-tuning process we refer an interested reader to a survey article [20]. In many ways, ChatGPT and its relatives are superb systems capable of multitude of generic language processing tasks including summarizing, story telling, some question answering. The system text2alm that we present here is by far less versatile focusing only on (action-verb based) story comprehension task. In other ways, ChatGPT and its relatives have serious shortcomings (see, for instance, [5]). Their results are not reliable and are not explainable. Provided the same input ChatGPT may produce different responses, sometimes correct and sometimes incorrect and, to the best of our understanding, there is no way to trace all of its subcomponents to explain the produced results. In this regard, the system we devised is superior. It is guaranteed to repeat the same line of reasoning while prompted by the same input. In addition, it is possible to interpret every reasoning step of its processing.
Recently, there has been more work related to the design of QA systems combining advances of natural language processing and knowledge representation anad reasoning. The text2alm system belongs to this group of approaches. Other approaches include the work by Clark, Dalvi, and Tandon [9] and Mitra and Baral [24]. Mitra and Baral [24] use a provided training dataset of narratives, questions, and answers to learn the knowledge needed to answer similar questions. The authors of this approach reported nearly perfect test results on the bAbI tasks. However, this approach doesn’t scale to narratives that utilize other action verbs, which are not present in the training set, including synonymous verbs. For example, if their system is trained on bAbI training data that contains verb travel it will process the JS discourse correctly. Yet, if we alter the JS discourse by exchanging travel with a synonymous word stroll, their system will fail to perform inferences on this altered narrative (note that stroll does not occur in the bAbI training set). In case of the text2alm system, if the verbs occurring in narratives belong to VerbNet classes whose semantics have been captured within CoreCALMLib then text2alm is normally able to process them properly.
Another relevant QA approach is the work by Clark, Dalvi, and Tandon [9]. This approach uses VerbNet to build a knowledge base containing rules of preconditions and effects of actions inspired by the semantic annotations that VerbNet provides for its classes. As mentioned earlier, in our work we can view modules associated with VerbNet classes as machine interpretable alternatives to these annotations. Clark et al. [9] use the first and most basic action language strips [10] for inference. The strips language allows more limited capabilities than the language in modeling complex interactions between events.
text2alm evaluation
We use Facebook AI Research’s bAbI dataset [31] to evaluate system text2alm. We reviewed this dataset in Section 4.4. We evaluate the text2alm system with all 1000 questions in the testing sets for tasks 1, 2, 3, 5, 6, 7, and 8. As mentioned earlier, these tasks are selected because they contain action-based narratives that are of focus in this work.
System evaluation and training set sizes.
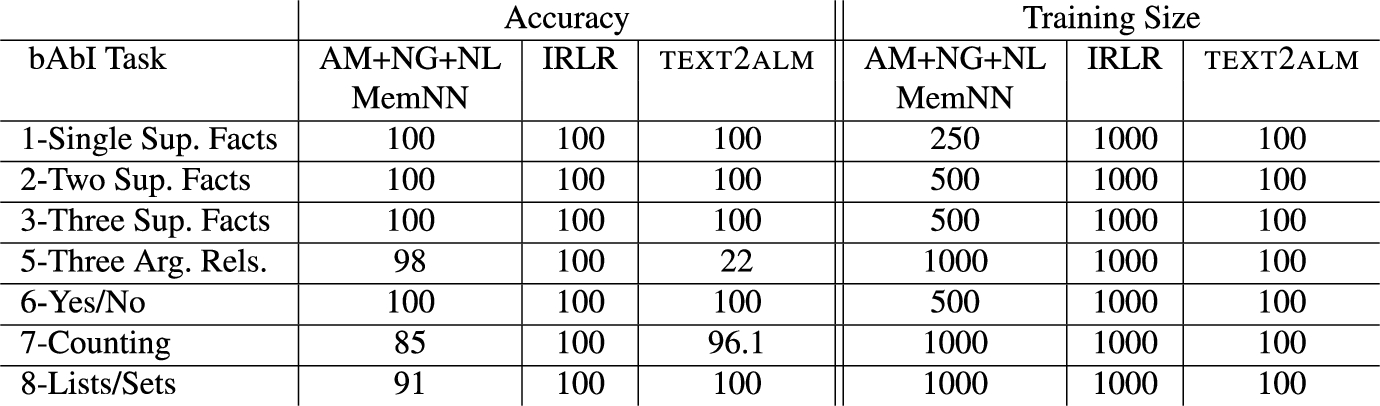
The bAbI dataset enables us to compare text2alm’s IE/QA ability with other modern approaches designed for this task. The left hand side of Fig. 14 compares the accuracy of the text2alm system with the machine learning approach AM + NG + NL MemNN described by Weston et al. [31] (the numbers presented in this table for the AM + NG + NL MemNN columns are the ones reported by Weston et al. [31]). In that work, the authors compared results from 8 machine learning approaches on bAbI tasks and the AM + NG + NL MemNN (Memory Network) method performed best almost across the board. There were two exceptions among the seven tasks that we consider. For the Task 7-Counting the AM + N-GRAMS MemNN algorithm was reported to obtain a higher accuracy of 86%. Similarly, for the Task 8-Lists/Sets the AM + NONLINEAR MemNN algorithm was reported to obtain accuracy of 94%. Figure 14 also presents the details on the Inductive Rule Learning and Reasoning (IRLR) approach by Mitra and Baral [24] reviewed earlier. We cannot compare text2alm performance with the methodology by Clark et al. [9] because their system is not available and it has not been evaluated using the bAbI tasks.
System text2alm matches the Memory Network approach by Weston et al. [31] at 100% accuracy in tasks 1, 2, 3, and 6 and performs better on tasks 7 and 8. When compared to the methodology by Mitra and Baral [24], the text2alm system matches the results for tasks 1, 2, 3, 6, and 8, but is outperformed in tasks 5 and 7.
The right hand side of Fig. 14 presents the number of questions in training sets used by each of the reported approaches in considered tasks. The AM + NG + NL MemNN method uses training sets of varying sizes [31]. To the best of our knowledge, Mitra and Baral [24] use all 1000 training questions per task in the design of IRLR. The text2alm system uses a smaller training size to achieve its results. Our training set comprised of 100 questions per QA bAbI task, for a total of 700 questions. These training questions and their associated narratives were used to develop the CoreCALMLib knowledge base (see LibraryCoreCALMLib subsection in Section 5.2). As a result of this process, the CoreCALMLib covers 20 first-level VerbNet classes out of its 274.
Overall, the results of the text2alm system were comparable to the industry-leading results with one outlier, namely, task 5. We investigated the reason. It turns out that the testing set frequently contained a phrase of the form:
Entity1handed theObjecttoEntity2.
e.g., Fred handed the football to Bill.
The text2alm system failed to properly process such phrases because the semantic role labeler lth, a subcomponent of the text2drs system, incorrectly annotated the sentence. In particular, lth consistently considered a reading in spirit of the following: Fred handed Bill’s football away. This annotation error prevents text2drs from adding crucial event argument to the DRS stating that Entity2 plays the thematic role of destination in the phrase. Consequently, the text2alm system does not realize that possession of the object was passed from Entity1 to Entity2.
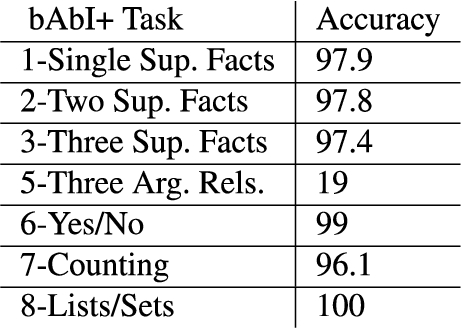
To illustrate that the approach by system text2alm generalizes well, we create a variant of the bAbI task, which we call bAbI+. We obtain bAbI+ by changing of action verbs occurring in testing set narratives with their synonymous counterparts. For example, of instances of travelled and grabbed were replaced with sprinted and seized, respectively. In total, 13 synonymous verbs were introduced. To ensure that text2alm system handles the bAbI+ tasks, two extensions were made to its resources. First, the CoreCALMLib knowledge base was augmented with appropriate mappings for two more VerbNet classes. Second, two new entries in SemLink were introduced for verbs lacking the mappings and four modifications to existing SemLink entries were required (where SemLink is a key resource of the text2drs system). Figure 15 presents the accuracy of the text2alm system on the bAbI+ tasks. As mentioned earlier, the approach by Mitra and Baral [24] is unable to generalize to the verbs it has not seen in training phase. The best performing method reported by Wetson et al. [31] does not account for unseen words either (although, the authors mention that the method they generally rely on can be extended to unseen words; yet, we do not have an access to an implementation to asses that modification of the method).
text2alm evaluation on bAbI+ tasks.
Conclusion and future work
Lierler, Inclezan, and Gelfond [19] outline a methodology for designing IE/QA systems to make inferences based on complex interactions of events in narratives. To explore the feasibility of this methodology, we built the text2alm system to take an action-based narrative as input and output a model encoding facts about the given narrative. We tested the system over tasks 1, 2, 3, 5, 6, 7, and 8 from the bAbI QA dataset [31]. System text2alm matched or outperformed the results of modern approaches on all but one of these tasks. However, our approach adjusts well to narratives with a more diverse lexicon. Additionally, the ability of the CoreCALMLib to represent the interactions of events in the bAbI narratives serves as a proof of usefulness of the original CoreAlmLib endeavor.
We conclude our work by listing future research directions in some areas, (i) Expanding narrative processing capabilities, (ii) Expanding QA ability, (iii) Exploring additional reasoning tasks, (iv) Providing explanations for system’s reasoning.
The bAbI QA tasks provided basic narratives to evaluate the effectiveness of information extraction by system text2alm. However, these are basic narratives with simple sentence structures. Future work includes expanding the narrative processing capabilities of system text2alm as well as reducing the impact of semantic role labeling errors. Also so far we provided annotations via the CoreCALMLib library for twenty two classes of VerbNet. In the future we intend to cover all action-verbs VerbNet classes.
Questions in the bAbI QA tasks follow pre-specified formats. Therefore, system text2alm’s QA ability relies on simple regular expression matching. Further research is required on representing generic questions and answers before using the system’s IE abilities in other applications. Additionally, our approach should be tested on more advanced QA datasets, such as ProPara [23]. Conducting tests on the ProPara dataset would enable us to compare the results of text2alm to the approach by Clark et al. [9].
We will build on text2alm’s reasoning abilities. For example, the calm model may sometimes not contain atoms that could be argued as reasonable. For example, given a narrative The monkey is in the tree. The monkey grabs the banana., the calm model will contain fluents stating that the monkey’s location is the tree at time point 1, the monkey is holding the banana at time point 2, and the banana’s location is the tree at time point 2. However, it is also natural to infer that the banana’s location is the tree when the monkey grabs it (time point 1). Yet, that requires reasoning that goes beyond temporal projection.
Finally, we will explore possibilities to benefit from the fact that text2alm relies on a human readable model of its knowledge and encoded narrative written in the language of . With that the solutions can be verified and explained following the reasoning engine inferences and inspecting the knowledge encoded in the model capturing a considered narrative.
Footnotes
Acknowledgements
We would like to thank Nicholas Hippen, Daniela Inclezan, Michael Gelfond, Jorge Fandinno, Edward Wertz, and Yuanlin Zhang for the valuable discussions pertaining this work as well as answering questions on their prior work. We are also grateful to anonymous reviewers who helped to streamline the presentation of this work. The work was partially supported by NSF grant 1707371.
CoreCALMLib axiom adjustments
New Axioms
Module: location_fluents
Axiom(s):
Module: changing_possession
Axiom(s):
Module: letting_go_and_taking_hold
Axiom(s):
Module: motion
Axiom(s): Convert uses of place to spatial_entity.
Altered Axioms
Module: changing_possession
Original Axiom(s):
New Axiom(s):
bAbI question to text2alm answer process
We note that the questionTimePoint is already known and can be at any point in the narrative.
Question Format: Where is ?
Atom(s) to Query: location(, , ).
Answer: The variable that matches to .
Question Format: Where is the ?
Atom(s) to Query: location(, , ).
Answer: The variable that matches to .
Question Format: Where was the before the ?
Atom(s) to Query: location(, , *) and location(, , *).
Answer: Extract all atoms that match. Sort the atoms descending by time point. Find the first instance that matches location(, , *) and traverse the list of matches until the location no longer matches . This must be the location of the entity before .
Question Format: What did give to ?
Atom(s) to Query: event_object(, ), event_agent(*, ), and event_recipient(*, ).
Answer: Find all matches to atoms 2 and 3. Sort them in descending order by event number. Then find the first match where the desired event_agent and event_recipient are associated with the same event. This gives us the event number we want. Then find the most recent match for atom 1 using the event number in the field. The answer is the variable that matches to .
Question Format: Who the ?
If Received:
Atom(s) to Query: event_object(*, ), event_recipient(, ).
Answer: Find all matches to atom 1. Sort them in descending order by event number. Then plug the event numbers in to the field in the second atom and continue through all event numbers until a match is found. The answer is the first variable that matches to .
If Gave:
Atom(s) to Query: event_object(*, ), event_agent(, ).
Answer: Find all matches to atom 1. Sort them in descending order by event number. Then plug the event numbers in to the field in the second atom and continue through all event numbers until a match is found. The answer is the first variable that matches to .
Question Format: Who did give the to?
Atom(s) to Query: event_object(*, ), event_agent(*, ), and event_recipient(, ).
Answer: Find all matches to atoms 1 and 2. Sort them in descending order by event number. Then find the first match where the desired event_object and event_agent are associated with the same event. This gives us the event number we want. Then find the most recent match for atom 3 using the event number in the field. The answer is the variable that matches to .
Question Format: Is in the ?
Atom(s) to Query: location(, , ).
Answer: Yes if there is a match. No if there is no match.
Question Format: How many objects is ?
Atom(s) to Query: held_by(, , ).
Answer: Count the number of matches.
Question Format: What is ?
Atom(s) to Query: held_by(, , ).
Answer: List the matches to .
Question Format: Who gave the to ?
Atom(s) to Query: event_object(*, ), event_agent(, ), and event_recipient(*, ).
Answer: Find all matches to atoms 1 and 3. Sort them in descending order by event number. Then find the first match where the desired event_object and event_recipient are associated with the same event. This gives us the event number we want. Then find the most recent match for atom 3 using the event number in the field. The answer is the variable that matches to .
References
1.
E.Balai, M.Gelfond and Y.Zhang, Towards answer set programming with sorts, in: Logic Programming and Nonmonotonic Reasoning, P.Cabalar and T.C.Son, eds, Springer Berlin Heidelberg, Berlin, Heidelberg, 2013, pp. 135–147. ISBN 978-3-642-40564-8. doi:10.1007/978-3-642-40564-8_14.
2.
K.Barker, B.Porter and P.Clark, A library of generic concepts for composing knowledge bases, in: Proceedings of the 1st International Conference on Knowledge Capture – K-CAP, 2001, pp. 14–21, http://portal.acm.org/citation.cfm?doid=500737.500744, http://www.cs.utexas.edu/users/mfkb/papers/kcap01.pdf. doi:10.1145/500737.500744.
3.
S.Bird, E.Klein and E.Loper, Natural Language Processing with Python, 1st edn, O’Reilly Media, Inc., 2009, ISBN 0596516495, 9780596516499.
4.
C.Bonial, K.Stowe and M.Palmer, SemLink, 2013, https://verbs.colorado.edu/semlink/.
5.
A.Borji, A categorical archive of chatgpt failures, 2023.
6.
J.Bos, Wide-coverage semantic analysis with boxer, in: Proceedings of the 2008 Conference on Semantics in Text Processing, STEP ’08, Association for Computational Linguistics, Stroudsburg, PA, USA, 2008, pp. 277–286, http://dl.acm.org/citation.cfm?id=1626481.1626503.
7.
G.Brewka, T.Eiter and M.Truszczyński, Answer set programming at a glance, Communications of the ACM54(12) (2011), 92–103. doi:10.1145/2043174.2043195.
8.
T.B.Brown, B.Mann, N.Ryder, M.Subbiah, J.Kaplan, P.Dhariwal, A.Neelakantan, P.Shyam, G.Sastry, A.Askell, S.Agarwal, A.Herbert-Voss, G.Krueger, T.Henighan, R.Child, A.Ramesh, D.M.Ziegler, J.Wu, C.Winter, C.Hesse, M.Chen, E.Sigler, M.Litwin, S.Gray, B.Chess, J.Clark, C.Berner, S.McCandlish, A.Radford, I.Sutskever and D.Amodei, Language models are few-shot learners, in: Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Curran Associates Inc., Red Hook, NY, USA, 2020. ISBN 9781713829546.
9.
P.Clark, B.Dalvi and N.Tandon, What happened? Leveraging VerbNet to predict the effects of actions in procedural text, CoRR, 2018. arXiv:1804.05435.
10.
R.E.Fikes and N.J.Nilsson, Strips: A new approach to the application of theorem proving to problem solving, Artificial Intelligence2(3–4) (1971), 189–208, ISSN 00043702. doi:10.1016/0004-3702(71)90010-5.
M.Gelfond and V.Lifschitz, The stable model semantics for logic programming, in: Proceedings of International Logic Programming Conference and Symposium, R.Kowalski and K.Bowen, eds, MIT Press, 1988, pp. 1070–1080.
13.
D.Inclezan, CoreALMlib: An ALM library translated from the component library, Theory and Practice of Logic Programming16(5–6) (2016), 800–816, ISSN 14753081. doi:10.1017/S1471068416000363.
14.
D.Inclezan and M.Gelfond, Modular action language ALM, TPLP16(2) (2016), 189–235. doi:10.1017/S1471068415000095.
15.
R.Johansson and P.Nugues, Lth: Semantic structure extraction using nonprojective dependency trees, in: Proceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007), Association for Computational Linguistics, Prague, Czech Republic, 2007, pp. 227–230, http://www.aclweb.org/anthology/S/S07/S07-1048. doi:10.3115/1621474.1621522.
16.
H.Kamp and U.Reyle, From Discourse to Logic, Vol. 1,2, Kluwer, 1993.
17.
K.Kipper-Schuler, VerbNet: A broad-coverage, comprehensive verb lexicon, PhD thesis, University of Pennsylvania, 2005.
Y.Lierler, D.Inclezan and M.Gelfond, Action languages and question answering, in: IWCS 2017 – 12th International Conference on Computational Semantics – Short Papers, 2017.
20.
P.Liu, W.Yuan, J.Fu, Z.Jiang, H.Hayashi and G.Neubig, Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing, ACM Comput. Surv.55(9) (2023), ISSN 0360-0300. doi:10.1145/3560815.
21.
C.D.Manning, M.Surdeanu, J.Bauer, J.Finkel, S.Bethard and D.McClosky, The Stanford CoreNLP natural language processing toolkit, in: Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 2014, pp. 55–60, ISSN 1098-6596, http://aclweb.org/anthology/P14-5010. doi:10.3115/v1/P14-5010.
22.
G.A.Miller, R.Beckwith, C.Fellbaum, D.Gross and K.M.Wordnet, An on-line lexical database, International Journal of Lexicography3 (1990), 235–244. doi:10.1093/ijl/3.4.235.
23.
B.D.Mishra, L.Huang, N.Tandon, W.Yih and P.Clark, Tracking state changes in procedural text: A challenge dataset and models for process paragraph comprehension, CoRR, 2018. arXiv:1805.06975.
24.
A.Mitra and C.Baral, Addressing a question answering challenge by combining statistical methods with inductive rule learning and reasoning, pp. 2779–2785, 2016.
25.
C.Olson and Y.Lierler, Information extraction tool text2alm: From narratives to action language system descriptions, Electronic Proceedings in Theoretical Computer Science306 (2019), 87–100. doi:10.4204/EPTCS.306.16.
M.Palmer, D.Gildea and P.Kingsbury, The proposition bank: An annotated corpus of semantic roles, Computational Linguistics31(1) (2005), 71–106, ISSN 0891-2017. doi:10.1162/0891201053630264.