
Abstract
Discovering the business process model from an organisation’s records of its operational processes is an active area of research in process mining. The discovered model may be used either during a new system rollout or to improve an existing system. In this paper, we present a process model discovery approach based on the recently proposed bio-inspired Manta Ray Foraging Optimization algorithm (MRFO). Since MRFO is designed to solve real-valued optimization problems, we adapted a binary version of MRFO to suit the domain of process mining. The proposed approach is compared with state-of-the-art process discovery algorithms on several synthetic and real-life event logs. The results show that compared to other algorithms, the proposed approach exhibits faster convergence and yields superior quality process models.
Keywords
Introduction
Organizations generate large volumes of data related to their business processes. A wide variety of tools are available nowadays that support automation of the business process (also known as workflow) in different application domains such as healthcare, medicine, industry, manufacturing, finance, logistics, education, information, and communication technology. However, organisations still face the challenge of mining the business data and developing a refined understanding of their processes to improve their work. Process mining generates process models that accurately describe processes by considering only an organisation’s records of its operational processes.
In the context of process mining, a process is understood as a collection of tasks requiring of coordination amongst them [36]. These tasks are carried out by a set of actors. For example, in a hospital universe, patients are the actors who participate in the process of treatment of a patient, comprising of a sequence of activities such as registration, admission, patient care (assignment of an available doctor, patient medical history, diagnosis, medical tests, treatment, nursing care, counseling, management of patient medical records), and patient discharge. However, there may be deviations from the expected process behaviour. For instance, in the hospital domain, the patient registration process may not be followed for a patient who requires emergency treatment. While many deviations may be acceptable to the system, such as non-availability of the X-ray machine, causing a delay in the patient’s treatment, may be unacceptable. Identifying the reasons for delays in patient treatment can help the hospital provide better medical care to the patients.
For the domain of process mining, data generated by an organisation is presented as an event log, and the organisation’s process flow is termed as a process model. The discovery of a process model for a given organisation is a key aspect of process mining [21,26]. Process models generated from process mining algorithms are evaluated on four quality dimensions, namely, completeness, preciseness, generalization, and simplicity [3,31,35,36]. A “good” model is expected to enact the minimal behaviour encoded in the log (simplicity) [35,36], echo all the traces in the log (completeness) [3], avoid any spurious behaviour (preciseness) [35,36], and fit well on unseen behaviour (generalization) [31].
In this paper, we are proposing a process discovery algorithm based on the Manta Ray optimisation technique. Manta Ray Foraging Optimization (MRFO) algorithm [42] imitates the following foraging strategies of manta rays— chain foraging, cyclone foraging, and somersault foraging. While chain and somersault foraging strategies aid the local search ability, the cyclone foraging strategy enhances the global search ability.
That is, the proposed algorithm benefits from the global as well as the local search ability of the Manta ray foraging optimization approach [42].
The main contributions of this proposal are:
A novel metaheuristic algorithm, Manta ray foraging process miner (MantaRay-ProM), to address the problem of process discovery is proposed.
The proposed approach is based on Manta ray foraging optimization for process model discovery and benefits from the strength of the MRFO approach.
Since the formulation of the problem of process discovery is binary, and MRFO is proposed for real-valued problems, we adapted a binary version of MRFO to suit the domain of process mining.
The proposed algorithm (MantaRay-ProM) is evaluated on ten synthetic and three real-life event logs.
The proposed approach (MantaRay-ProM) is compared with both evolutionary and traditional state-of-the-art algorithms.
This study is organised as follows. Section 2 begins with the process mining terminology used in the paper and discusses the related work in the context of the proposed work. Section 3 describes the Manta ray foraging optimization (MRFO) algorithm. Section 4 describes the proposed Manta ray foraging process mining (MantaRay-ProM) algorithm. Section 5 describes the experimentation and results. Section 6 discusses the conclusion and offers future research directions.
Related work
In the literature, various meta-heuristic strategies, such as Particle Swarm Optimization (PSO), Differential Evolution (DE), and Genetic algorithms (GA) have been applied for process discovery in the domain of process mining [3,9].
Basic constructs of process mining
The data for a business process, stored in the form of an event log, can be represented as a two-dimensional table. A row represents the data corresponding to an event (also called activity). The columns represent the characteristics of an event. Table 1 depicts an example event log for a transportation company involving the activities ‘Customer request’ (
An example event log
An example event log
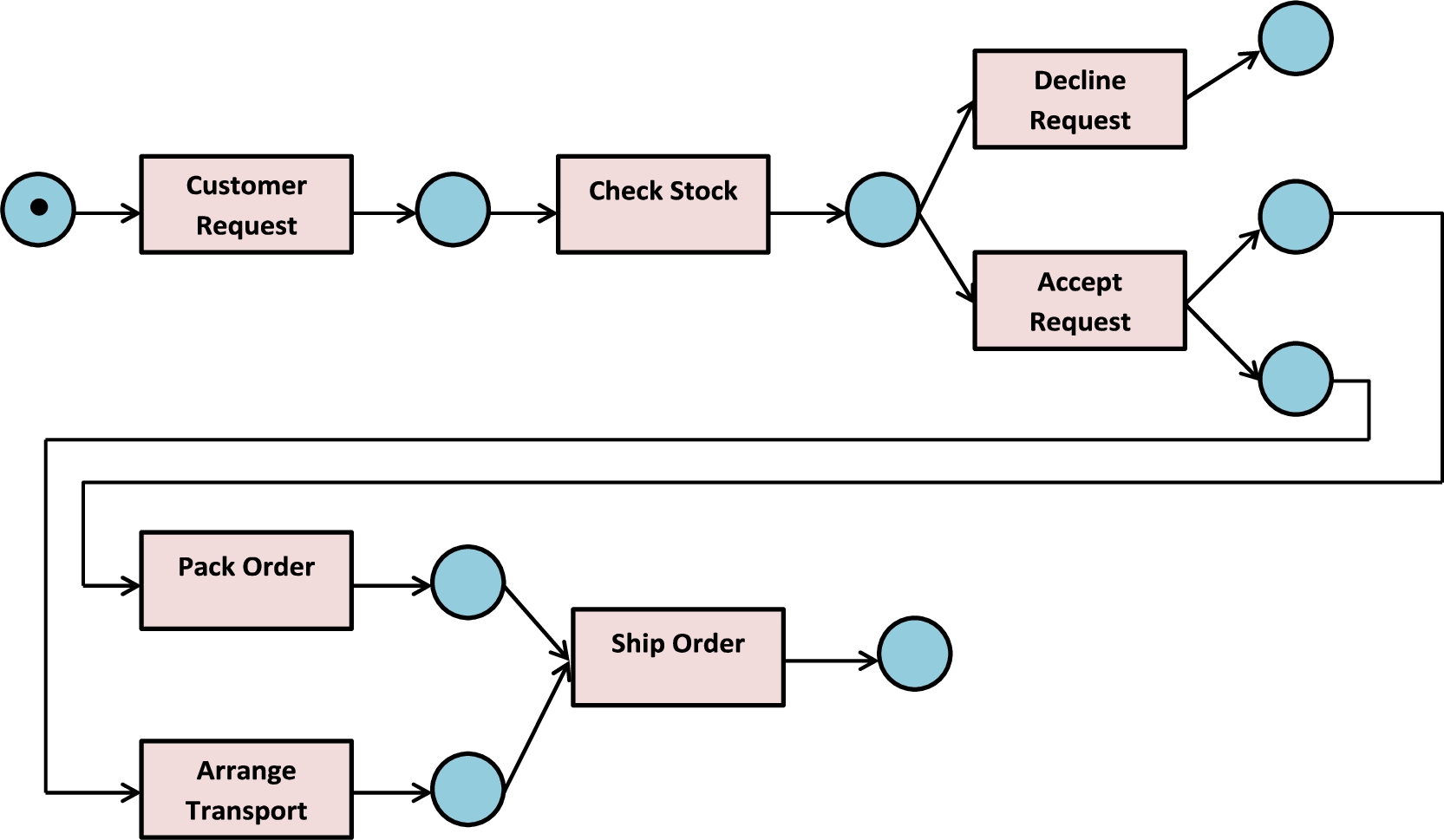
Petri net for the example event log of Table 1.
For any two activities, say
(Direct succession relation (succeeds or follows)).
For any two activities, say
(Exclusive relation (unrelated)).
For any two activities, say
(Parallel relation).
For any two activities, say
(Short loops (loops of length one and length two)).
For any two activities, say
(Input set).
In the given log L, the set S of all activities
(Non-free choice constructs).
The transformation from the input sets,
To illustrate, consider a process model with five tasks
Traditional algorithms in process mining
In the domain of process mining α algorithm [25] is one of the earliest techniques. It analyses the event log and identifies the relationship for every pair of activity. Subsequently, many extensions of the α algorithm were proposed [2,18,38–40]. Alves de Medeiros et al. [2] proposed the
Evolutionary algorithms in the literature
Alves de Medeiros [3] proposed the genetic process miner (GPM), a genetic algorithm for process discovery. GPM is based on random initialization of the population. This technique deals with non-free choices, noise, non-local relationships, and non-trivial constructs in the event log. The authors defined a fitness function to guide the global search for mining a process model that is complete and precise. Buijs et al. [7] proposed an extension of the ETM algorithm [8] that uses NSGA-II algorithm [22] to generate process models. Cheng et al. [9] introduced a hybrid process mining methodology that integrates GPM, particle swarm optimization (PSO), and discrete differential evolution (DE) techniques to extract process models from event logs. Deshmukh et al. [12] proposed a process mining approach based on binary differential evolution.
State-of-the-art algorithms for discovering process models
State-of-the-art algorithms for discovering process models
Manta rays are marine creatures that consume large amount of plankton each day. Manta rays have unique foraging behaviour with which they effectively search the dispersed plankton in the ocean. Based on this rare behaviour of Manta Rays, Zhao et al. [42] proposed a meta-heuristic algorithm, Manta Ray Foraging Optimization algorithm (MRFO) that imitates three foraging strategies of Manta Rays, namely, chain foraging, cyclone foraging and somersault foraging. The chain foraging and somersault foraging behaviours are used to enhance local search ability (exploitation), whereas the cyclone foraging activity contributes to global search ability (exploration). This technique has proven to be effective in a variety of disciplines including energy allocation, geophysics, electric power, and image processing [19].
MRFO algorithm [42] begins by initializing the population randomly. Subsequently, the population evolves by emulating the foraging behaviour. According to the chain foraging behaviour, Manta Rays form a linear foraging chain moving forward according to a linear function of the position of maximum concentration of plankton found so far and position of the Manta Ray in front of it. The mathematical model is as follows:
When encountering a dense plankton patch in deep waters, Manta Rays exhibit a foraging chain formation, moving towards the food in a spiral pattern, demonstrating cyclone foraging behavior. The mathematical representation of this phenomenon is as follows:
In the somersault strategy, the position of the food acts as the pivot. Manta Rays oscillate around this pivot, adjusting their position in response to the best plankton position discovered thus far. The mathematical model is outlined as follows:
Proposed manta ray foraging process miner (MantaRay-ProM) algorithm
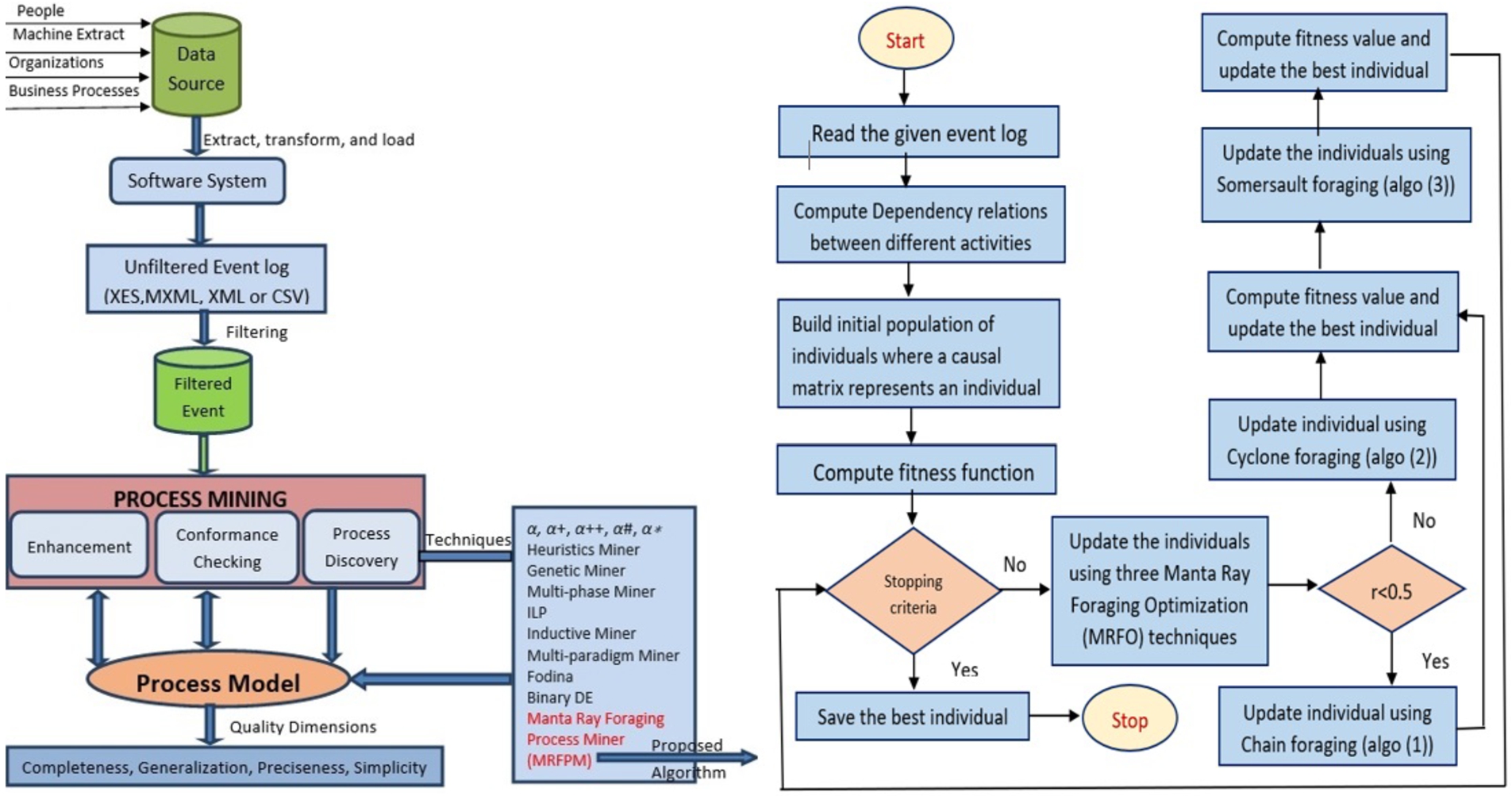
Whereas the original proposal of the MRFO algorithm is for continuous search space problems [42], the proposed MantaRay-ProM algorithm (Algorithm 1, flowchart in Fig. 2) is a meta-heuristic algorithm that applies a binary adaptation of the MRFO algorithm for the problem of process mining.
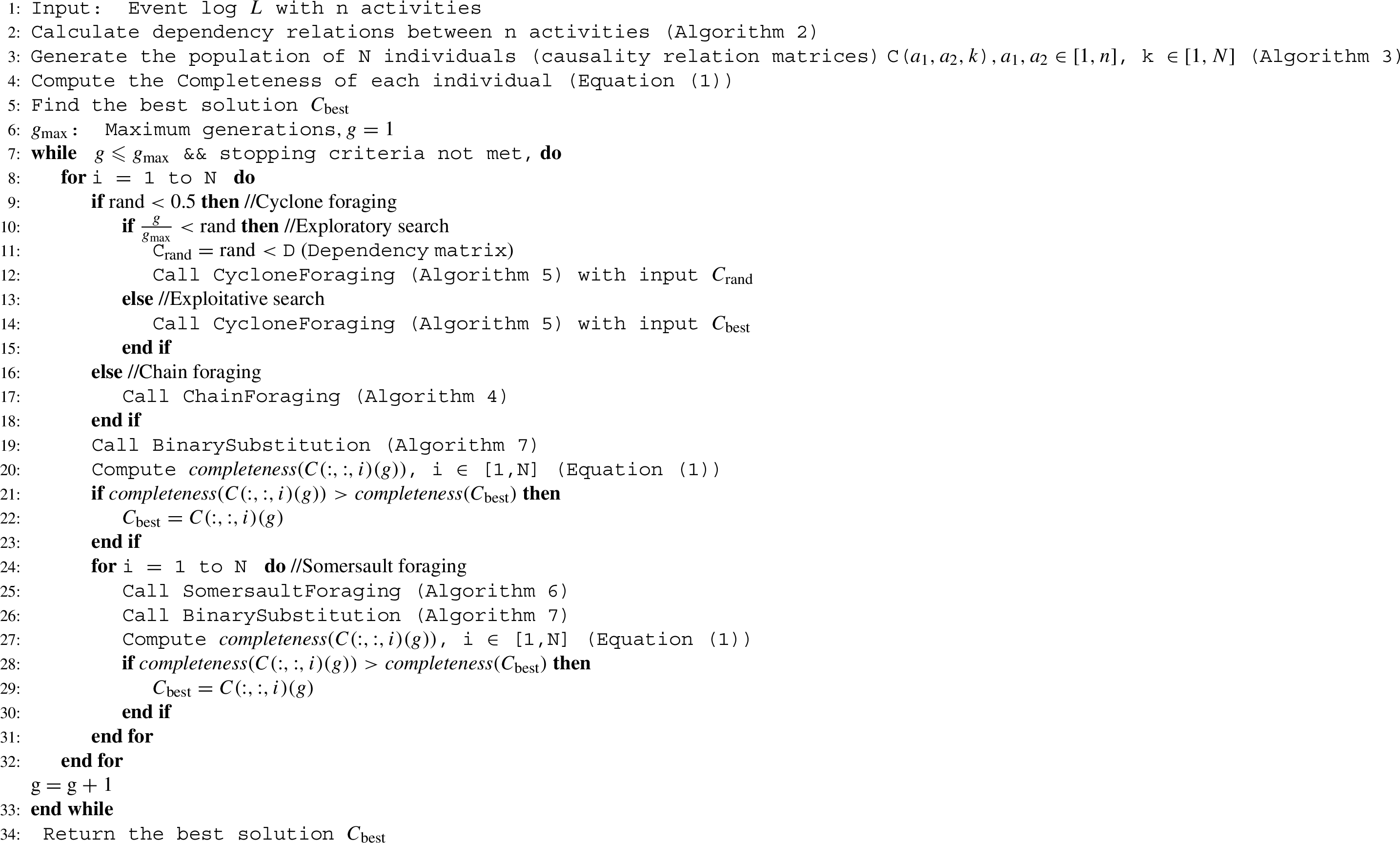
The proposed manta-ray foraging process miner (MantaRay-ProM) algorithm
A metaheuristic algorithm begins by initializing a population. From the given event log, say, L comprising n activities, the knowledge contained in the event log is first summarized in the form of a dependency measure matrix D that specifies the strength of dependencies between activities (Algorithm 2) [3]. A dependency exists between activities
The proposed MantaRay-ProM algorithm for process model discovery.

Computation of dependency measure matrix D for the event log L
In the proposed approach, each individual space in the population is a two-dimensional matrix of order n, representing the causal relations between the n tasks, and is known as the causality relation matrix. The population of N causality relation matrices, denoted by C(:, :, k), k

Generation of initial population. Each individual is called a causality relation
In the present work, process models are evaluated based on four quality dimensions, namely, completeness, preciseness, generalization, and simplicity [3,11,24,31,35,36]. It is to be noted that we represent a process model using the causality matrix notation which instructs the definition of the quality dimensions.
The proposed MantaRay-ProM algorithm optimizes the completeness value of the individuals as the fitness function using the following equation [3]:
Completeness is a measure that involves the computation of all the parsed activities while replaying the traces of the log in the model. The tokens that are missing in a trace and the extra tokens that were left behind (unconsumed tokens) during parsing contribute to the punishment value. The completeness value of a process model is an essential aspect of its quality because it indicates how well a model captures the behaviour in the event log i.e., for the discovered process model, other quality dimensions will make sense only when completeness is acceptable [14,15].
Additional metrics for evaluating the quality of a process model encompass Precision, Simplicity, and Generalization. Preciseness [35,36] quantifies the additional behavior produced by a model not observed in the event log. It is calculated as shown in Equation (2).
Generalization, as described in [31], evaluates how effectively the mined model can reproduce future unseen behavior. It is quantified based on the frequency of execution of each node, as denoted in Equation (4). A higher frequency suggests that the path is utilized more often, indicating that the model is more generic.
Updation
The three foraging approaches, namely, chain foraging (Algorithm 4), cyclone foraging (Algorithm 5), and somersault foraging (Algorithm 6), are used to update the population. The process of chain foraging begins by computing the value of the control parameter (α) that dictates the impact of distance of an individual from the best individual found so far. Except for the first individual, each individual is updated concerning its distance from the best individual found so far and the individual in front. The process of cyclone foraging occurs in a spiral fashion. Following a two-pronged approach, the cyclone foraging strategy promotes exploration by selecting a random individual

Chain foraging approach to update the population C (generation g) of N individuals, each of order n

Cyclone foraging approach to update the population C (generation g) of N individuals, each of order n

Somersault foraging approach to update the population C (generation g) of N individuals, each of order n

Binary substitution function
Details of the datasets
For the proposed MantaRay-ProM algorithm, the hyperparameters are set as suggested in the original MRFO algorithm [42] with population size = 30, maximum iterations = 100, number of runs = 30. It was observed that the proposed algorithm converges before 100 iterations for most of the datasets. The experimental outcomes are determined by the average performance over all the runs.
The proposed algorithm is run on both real-life and synthetic datasets. Over the last decade, BPI challenge event logs have become important benchmarks in the data-driven research area of process mining [1] (Table 3). The proposed algorithm is tested for three BPI event logs, namely, BPI 2012 [28], BPI 2013 [23], and BPI 2017 [27], varying in terms of the number of activities, traces, and their respective domains. BPI 2012 is one of the extensively studied datasets in process mining. It comprises 13,087 traces, and 23 activities, and is derived from a structured real-life loan application procedure released to the community by a Dutch financial institute. The BPI 2013 dataset is sourced from the IT incident management system of Volvo Belgium, consisting of 7554 traces and 13 activities. The BPI 2017 dataset represents a loan application process of another Dutch financial institute, encompassing 21,861 traces and 41 activities. Additionally, the proposed algorithm is evaluated on a real-life medical event log featuring events related to sepsis cases from a hospital [20]. Sepsis, a severe medical condition typically triggered by an infection, is addressed in this dataset, which includes 1,050 traces and 16 tasks.
We also experimented on ten synthetic logs, namely, ETM, and g2-g10 [3,36]. First proposed by Alves de Medeiros [3], they are among the most popular unbalanced logs used in the literature. These logs are unbalanced regarding the frequencies with which the traces occur.
Under the constraints of availability of the code/ datasets, the results of the proposed MantaRay-ProM algorithm for synthetic datasets are compared with those of state-of-the-art algorithms, namely,
The values of completeness, preciseness, and simplicity for the state-of-the-art algorithms, namely,
Analysis of the results
The quality dimensions for the process models discovered by the proposed MantaRay-ProM algorithm, the state-of-the-art methods, and the binary differential evolution (DE) algorithm for process mining are shown in Tables 4 and 5. “−” indicates that a certain accuracy or complexity measurement could not be reliably acquired because the discovered model has syntactical or behavioral problems that could be because of a disconnected model or an unsound model. Completeness is used as the fitness function for the binary DE algorithm and the proposed MantaRay-ProM algorithm. With respect to the completeness value, the proposed MantaRay-ProM algorithm achieves the highest possible value of completeness for most of the datasets. That is, MantaRay-ProM is capable of exploiting the search space competitively. For BPI 2012 and BPI 2013 datasets, the value of completeness obtained by Binary DE is marginally better compared to MantaRay-ProM. In order to analyze the other qualities of the discovered process model, we also compute the value of quality dimensions, namely, preciseness, simplicity, and generalization [3,31,35,36]. The results show that the process models generated by the proposed strategy have a higher quality in terms of Generalization, Simplicity, and Preciseness in all the cases. In order to rank the proposed approach and the traditional algorithms, a composite fitness value function of the quality metrics is computed as follows [8]:
Tables 8 and 9 show that, in terms of the F-score, the proposed MantaRay-ProM algorithm outperforms the state-of-the-art algorithms and is better than or at least as good as the binary DE algorithm.
Wilcoxon signed-rank test is used to estimate the statistical significance of these results. Table 10 reveals that in the context of process mining, the suggested MantaRay-ProM method produces results that are superior or on par with the compared algorithms. The results show that MantaRay-ProM is efficient in tackling real-life as well as synthetic datasets.
We also compare the convergence rates of the proposed MantaRay-ProM algorithm and the binary differential evolution algorithm. Figures 3 and 4 show that MantaRay-ProM converges faster in all cases, demonstrating its superior exploration. In 13 out of 14 datasets, the proposed algorithm converges atleast 45% faster than the binary differential evolution algorithm.
Quality dimensions for the process models obtained using the state-of-the-art algorithms, binary DE algorithms, and the proposed MantaRay-ProM algorithm for synthetic datasets (C: completeness, P: preciseness, S: simplicity, G: generalization)
Quality dimensions for the process models obtained using the state-of-the-art algorithms, binary DE algorithms, and the proposed MantaRay-ProM algorithm for synthetic datasets (C: completeness, P: preciseness, S: simplicity, G: generalization)
Quality dimensions for the process models obtained using the state-of-the-art algorithms, binary DE algorithm, and the proposed MantaRay-ProM algorithm for real-world datasets (C: completeness, P: preciseness, S: simplicity, G: generalization)
Weighted average of the quality dimensions for synthetic datasets for the state-of-the-art algorithms, binary DE algorithm and the proposed MantaRay-ProM algorithm
Weighted average of the quality dimensions for real-world datasets for the state-of-the-art algorithms, binary DE algorithm, and the proposed MantaRay-ProM algorithm. “-” where all the quality metrics are not available
F-score obtained for synthetic datasets for the state-of-the-art algorithms, binary DE algorithm and the proposed MantaRay-ProM algorithm
F-score obtained for real-world datasets for the state-of-the-art algorithms, binary DE algorithm and the proposed MantaRay-ProM algorithm
Wilcoxon signed-rank test for MantaRay-ProM vs. Binary DE. The symbol ‘+’ (‘−’) shows that the first (second) algorithm displays better performance at 95 % significance level. ‘=’ denotes no substantial difference between the ranks of the algorithms
The discipline of process mining is focused on extracting process models from databases comprising time-stamped business process data. An accurate process model allows a better understanding of the business workflow and can assist in redesigning and improving the processes. In the present work, the problem of process discovery is formulated as the problem in the binary domain. In the present research, we have proposed a bio-inspired optimization algorithm, Manta Ray foraging process miner (MantaRay-ProM), for discovering the process models based on timestamped workflow data in the form of an event log. The proposed approach searches the solution space by mimicking the foraging strategies of Manta Rays. As we deal with binary data in process mining, we adapted the original MRFO algorithm [42] designed to work for the floating point data for process mining.
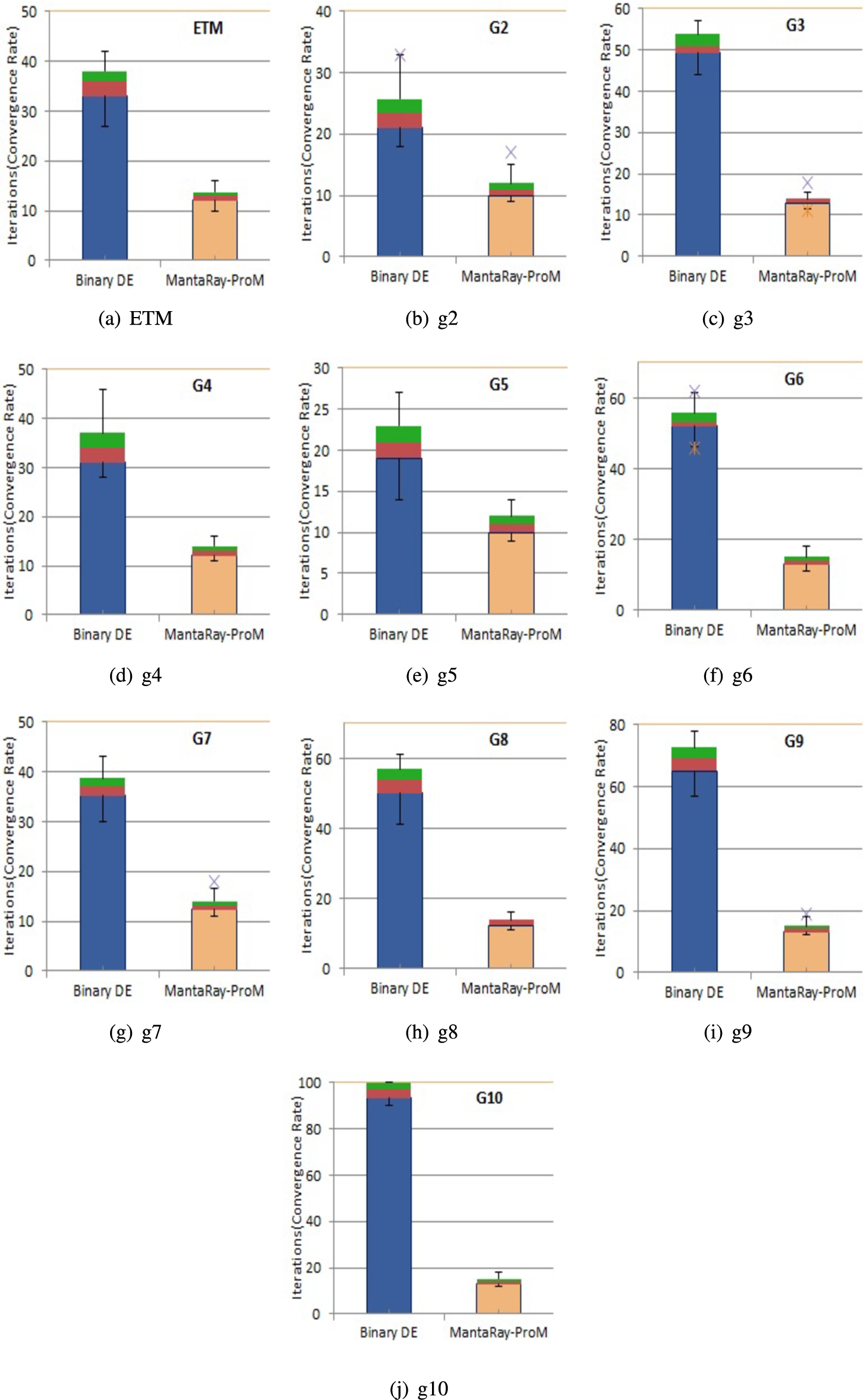
Convergence rate for the binary DE algorithm for process mining and for the proposed MantaRay-ProM algorithm when run on synthetic datasets (ETM, g2-g10).
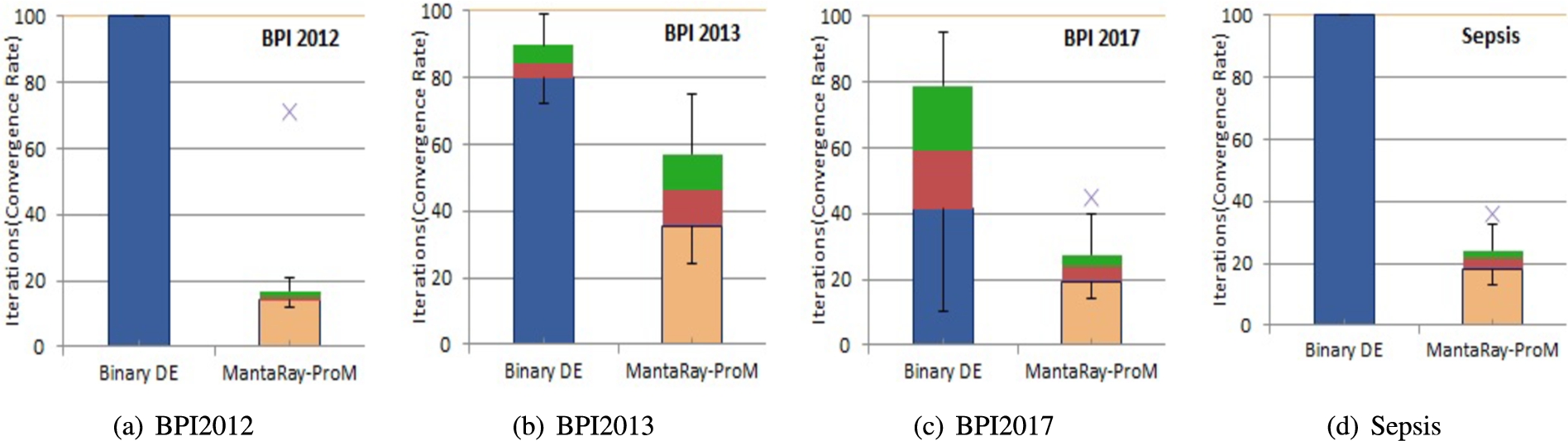
Convergence rate for the binary DE algorithm for process mining and for the proposed MantaRay-ProM algorithm when run on real-world datasets.
The quality of the process model discovered for the given event log can be measured in terms of completeness, preciseness, simplicity, and generalization of the model. However, completeness is the most important of these as the other quality dimensions become meaningful for models with a high completeness value. The proposed Manta Ray Foraging Process Miner (MantaRay-ProM) algorithm optimizes the completeness of the process models. The proposed Manta ray foraging process miner (MantaRay-ProM) algorithm is tested for synthetic as well as real-life event logs. The results of applying the proposed MantaRay-ProM algorithm are compared with those of other state-of-the-art algorithms, namely,
The experimental results show that the proposed Manta ray foraging process miner (MantaRay-ProM) algorithm exhibits a faster convergence rate than the Binary DE algorithm for process mining. The proposed algorithm surpasses the compared algorithms in the quality of the extracted process models with better completeness and composite fitness value.
For future work, we aim to explore a parallelized MantaRay-ProM for a trade-off between different quality dimensions.
This research did not receive any grant from funding agencies in the public, commercial, or not-for-profit sectors.