
Abstract
This paper presents a multi-objective optimization approach for developing efficient and environmentally friendly Machine Learning models. The proposed approach uses Genetic Algorithms to simultaneously optimize the accuracy, time-to-solution, and energy consumption simultaneously. This solution proposed to be part of an Automated Machine Learning pipeline and focuses on architecture and hyperparameter search. A customized Genetic Algorithm scheme and operators were developed, and its feasibility was evaluated using the XGBoost ML algorithm for classification and regression tasks. The results demonstrate the effectiveness of the Genetic Algorithm for multi-objective optimization, indicating that it is possible to reduce energy consumption while minimizing predictive performance losses.
Introduction
Artificial intelligence (AI) has become an integral part of our lives, with subfield machine learning (ML) finding applications in various domains. Although the benefits of AI are widely recognized, concerns have been raised about its negative impact on ethical and environmental issues. This is mainly due to data-driven approaches, such as ML, which has been trained using increasingly large datasets and significant computation times, leading to high energy consumption and carbon emissions [6,7,39,45].
A more pressing concern about how modern AI directly creates
In this context, Automated Machine Learning (AutoML) has emerged as a promising approach for reducing the costs associated with ML. AutoML [17] seeks to automate the development of parts or the entire pipeline of an ML model; several frameworks and tools are available for this purpose. However, most existing approaches focus only on maximizing predictive performance without considering energy efficiency.
Based on this gap in efficient environmentally ML solutions and this potential of AutoML, the main research question of this study is how to develop more efficient and environmentally friendly ML models by optimizing their accuracy, time to reach a solution and energy consumption, thereby solving a multi-objective optimization problem. Our proposed approach uses Genetic Algorithms (GA) to generate the ML model, focusing on architecture and hyperparameter search as part of an AutoML solution. We implemented a customized GA scheme and operators to work on two ML models: XGBoost (XGB) for classification and regression and Convolutional Neural Network for image classification. In this work, we present the GA scheme for XGB and evaluate its feasibility.
GA is the optimization technique in the formulation of our AutoML approach, as it has shown good results in optimizing different ML models [14,16,22,23,28,46,50]. Furthermore, GA is considered one of the most efficient techniques for multi-objective optimization [25] and with the potential to create stable pipelines [37]. XGB is one of the most widely used algorithms by data scientists and has been widely recognized in several ML challenges, such as the Kaggle competitions [3]. In addition, XGB can deal with missing examples, outliers, handle large numbers of features, and examples; it is memory efficient, allowing more experiments to be performed in less time, which are desirable properties to be incorporated into an AutoML system, and it is very useful for the early development and prof-of concept of the proposed GA.
The main contribution of this work is the development and evaluation of this specialized GA scheme and operators. In addition, our scheme enables the objectives of optimization to be defined according to the user’s requirements. It is possible to set priorities for time, energy, and predictive performance. Our results demonstrate the effectiveness of the GA for multi-objective optimization, indicating that it is possible to reduce energy consumption while minimizing predictive performance losses. According to our review of the literature (detailed in Section 2), this is the first multi-objective optimization approach to consider the efficiency of ML models by simultaneously considering accuracy, time to solution, and energy consumption, which still allows them to be chosen. Moreover, this approach represents an important and inspiring step towards the development of efficient and environmentally friendly ML. We believe that our work not only presents a novel approach, but also stimulates a crucial conversation about the importance of developing greener and more inclusive artificial intelligence.
This paper builds on our previous work [47] by incorporating new related work, improving the introduction, the background on evolutionary algorithms, and providing a detailed description of our GA scheme and operators. Furthermore, we conducted additional experiments, presenting new results and discussions.
The remainder of this paper is organized as follows. Section 2 provides background information on Green AI and AutoML concepts and related work. In Section 3, our proposal for multi-objective optimization is presented along with the details of the GA implementation. Section 4 presents the experimental methodology, and Section 5 discusses the results. Finally, in Section 6, we discuss the contributions and limitations of this work, as well as future research directions.
Background and related works
This section briefly introduces the domain of Automated Machine Learning and Green AI with some background information and the main work related to our proposal. We conducted a literature search using the Rapid Literature Review (RLR) methodology [42]. To find publications, searches were performed on the CAPES Portal ,1
Schwartz et al. [40] introduced the concept of “Green AI”, AI research that is more environmentally friendly and inclusive. On the contrary, Red AI refers to AI research that seeks to improve accuracy through massive computational power, while being both environmentally unfriendly and prohibitively expensive, raising barriers to participation. The costs of actual state-of-the-art AI research limit the ability of many researchers to study it and practitioners to adopt it. The use of massive data and large amounts of computation in tuning hyperparameters of computationally intensive models creates barriers for many researchers to reproduce the results of these models and train their models on the same setup [29]. Research on red AI has yielded valuable scientific contributions to the field; however, it is time to increase the prevalence of green AI. Creating efficiency in AI research will decrease its carbon footprint and increase its inclusivity, as AI studies should not require large budgets or computational power. Green AI refers to research that yields novel results while considering computational cost [12]. In the aforementioned references [1,35,40,43,44], we highlight the need to develop a more efficient and environmentally friendly ML.
AutoML is an approach that has shown great promise and has been among the AI trends in the coming years 2
Gartner
The works found in the literature are distinguished mainly by the optimization technique used in their formulation, the most common being Bayesian [13], Reinforcement Learning [18], Grid and Random Search [27] and Evolutionary Algorithms (EA) [37], such as GA and swarm intelligence [49]; by the type of input data being tabular, text, images, and time series; and by the pipeline processes that are involved [11]. However, most of them have in common that the formulation of the optimization process is single-objective, mainly involving maximizing the predictive performance (Red AI approach), without considering the energy consumption as our proposal, which is Green AI centric.
Among the optimization techniques used in the formulation of AutoML approaches, EA-based methods, more specifically Genetic Algorithms [19], have shown good results to optimize different ML models [14,16,22,23,28,46,50]. GA is considered one of the most efficient techniques for multi-objective optimization [25] and, according to [37], one of the potential choices for AutoML to create stable pipelines and is easier to implement, being adopted by FEDOT [33]. GAs, especially with co-evolutionary approaches [30] (more than one evolutionary process occurs simultaneously), are also considered the best options by Amazon, which according to [9], allows the result of more general-purpose approaches.
Several works with AutoML are for DL models and use GA as an optimizer [8,16,28,38,41,46,48]. This is justified by the fact that, as previously mentioned, these algorithms have achieved surprising results for unstructured data. Furthermore, these models require adjustment of a large number of hyperparameters. Moreover, eXtreme Gradient Boosting (XGB [4]) is very effective for structured data. It is among the most used ML algorithms for all types of data science problems and is responsible for solving and winning most of Kaggle’s challenges [24]. The work [11] presents a benchmark of supervised AutoML, performing a comparison study with hundreds of computational experiments based on three scenarios: General Machine Learning (GML), DL, and XGB.
There is a growing number of tools for AutoML: Auto-Weka, Auto-sklearn [13], TPOT [34], Autokeras, Auto PyTorch, H2O [27], rminer 3
Multi-objective optimization is implemented in some existing AutoML solutions, and various criteria can be involved in its design. AutoxgboostMC [36] proposed a Bayesian approach to optimize the predictive performance, fairness, and interpretability of the HPO process for XGB. [37] proposes an EA as a model design to be implemented as part of the FEDOT AutoML framework. Two optimization objectives were used: solution quality and chain complexity. Hong et al. [20] proposed the use of a multi-objective evolutionary algorithm for pruning neural networks that considers the accuracy of the pruned network and the available computational resources of the environment where the network will run. The proposed hardware-aware multi-objective evolutionary network pruning method evaluates the accuracy, latency, and amount of used memory, but not energy consumption. Karl et al. [26] presented a survey of multi-objective hyperparameter optimization. Despite the number of studies discussed in this paper, when energy consumption is considered as the optimization objective, it is heavily based on the topic of hardware NAS for efficient neural accelerator design. According to our review of the literature, work [21] is the only one considering energy in the NAS for software. They proposed a framework for Multi-Objective Neural Architectural Search (MONAS) that employs reward functions considering the predictive accuracy and energy consumption when searching for neural network architectures in a CNN for image classification. However, MONAS adopts a two-stage framework: a Reinforcement Neural Network (RNN) is used in the generation stage to generate a hyperparameter sequence for the CNN. In the evaluation stage, an existing CNN model is trained as a target network with hyperparameter output by the RNN. Accuracy and energy consumption of the target network are rewards.
Comparing our work with the literature review, we see that most of the works are single-objective and existing multi-objective optimization approaches, with the exception of [21], do not consider the energy consumption of HPO and NAS. In contrast, our multi-objective proposal using GA considers predictive performance, time to solution, and energy consumption, and allows the priorities to be chosen for each of them. In addition, in our design, the strategy is a joint hyperparameter optimization and architecture optimization. Most NAS methods fix the same setting of training-related hyperparameters throughout the search stage. After the search, the hyperparameters of the best-performing architecture are further optimized. However, this paradigm may result in suboptimal results because different architectures tend to fit different hyperparameters [17].
Among the optimization techniques used in AutoML formulation, including hyperparameter and architecture optimization, Evolutionary Algorithms [37], such as GA [15] and swarm intelligence [49] have shown good results to optimize different ML models. There is no consensus accepted in the evolutionary computation community that differentiates the definition of Genetic Algorithms from other evolutionary computation methods. However, in this work we follow the elements in common finding in the definitions of the works [5,19,31]. Under these definitions, we developed our proposed multi-objective GA, as detailed in Section 3.2.
Basic elements of genetic algorithms
Genetic Algorithms is a meta-heuristic widely used in search or optimization problems, which is inspired by the process of evolution of a population of individuals through reproduction and natural selection [19]. Mathematically, GA mimic the mechanisms of natural evolution of species, comprising the processes of genetic evolution of populations, survival, and adaptation of individuals [5]. The methods called GA have the following elements in common: populations of chromosomes, selection according to fitness, crossover to produce new offspring and random mutation of new offspring [31].
In GA, the reproductive process involves the recombination of genetic material (chromosomes) from two “parent individuals”, known as crossover, as well as genetic mutations that may occur during the formation of offspring chromosomes. Natural selection determines the individuals who will reproduce and be part of a new population. Chromosomes in a GA population are typically represented as bit strings, with each locus having two possible alleles: 0 or 1. Each chromosome is considered a point in the search space of candidate solutions, and the GA processes the populations of chromosomes, replacing one population with another. A fitness function assigns a score to each chromosome based on its ability to solve the problem [31].
First, a population of solutions is initialized and evaluated. In each generation (iteration), better solutions are probabilistically selected as parents to generate new offspring solutions through crossover and mutation. The resulting offspring solutions are evaluated and inserted into the population, while some solutions are removed through survival selection to maintain a constant population size. If the stopping criterion is met, the best solution is returned; otherwise, the process repeats with the next iteration [26].
These algorithms have a lower probability of getting stuck in a local optimum than most optimization algorithms because they perform a global search in the solution space, they are also very robust and stable, and have a straightforward parallelization capability since they are population based, allowing multiple solutions to be tested simultaneously (limited by the hardware available). To apply GA, we must define specially designed genetic operators (crossover, mutation and selection) and fitness functions. These special operators are important for processing individuals, as described by a GA. They also offer the possibility of considering single or multiple-objective functions.
When applying GAs to a multi-objective problem, the only component that requires change is the selection step (selecting parents and selecting survivors to the next generation). In single-objective optimization, the objective function can be used to rank individuals and select the better ones. In multi-objective optimization, many solutions have different trade-offs between the objectives, and we are interested in finding a good approximation [26].
The next section presents the GA design choices for a multi-objective approach centered on Green AI.
GA design
The solution proposed in this work will be part of our AutoML framework developed in the future in the project where this work is inserted, which aims to automate the model construction process by focusing on HPO and AO/NAS optimization. The GA design was developed to work on two ML models: XGB for classification and regression (tabular data) and CNN for image classification. This section presents the GA scheme for XGB (HPO + AO). The general GA workflow is shown in Fig. 1 and is detailed below. Hyperparameter and architecture model tuning are treated as optimization problems. The multi-objective functions we want to optimize are the predictive performance (accuracy or MSE), the energy, and time to solution (fitness function). The GA method (Fig. 1) and operators (in bold) are designed as follows:
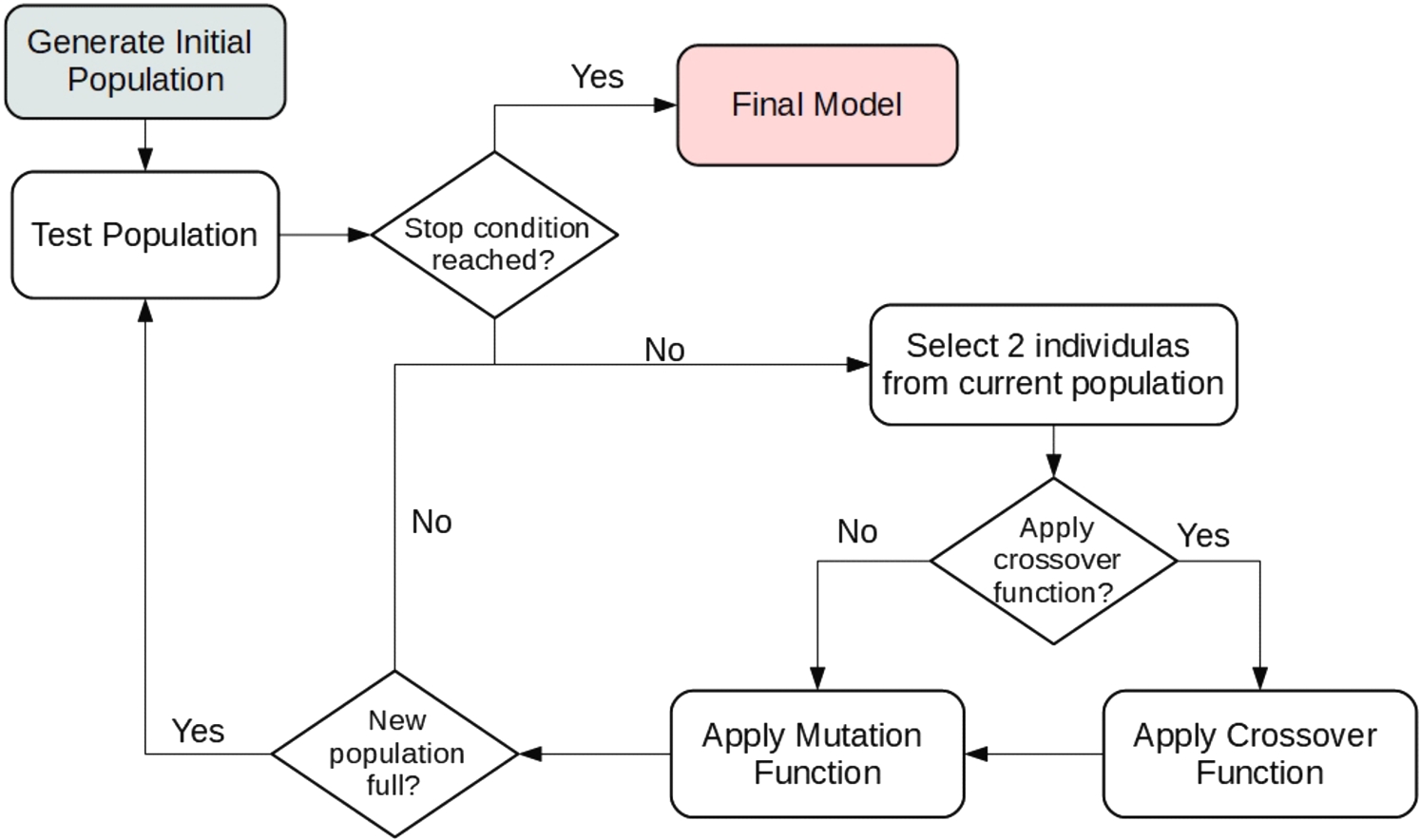
Flowchart for the GA method workflow implemented in this work.
Genetic evolution starts with the creation of an initial population of randomly generated solutions using functions
After creating the population, each individual was tested and assigned a fitness score. This is the most time- and energy-consuming part of the evolutionary process. Fitness scores are given by Equations (1) (for the XGB classification) and (2) (XGB regression) as follows (developed by the authors):
A
The two new offspring are then added to the latest population pool along with the best n solutions of the current population, where n is given by the elitism parameter. This is due to the preservation of the best solution found up to that generation.
The generation of new individuals is repeated until the new population pool is full; once the new population is full, it is evaluated. This process is repeated until the stop condition is not reached.
The details of the GA scheme presented in this section are for XGB (HPO + AO) for the classification and regression tasks for structured data (tabular). However, as mentioned, the GA method was also designed for CNN (HPO + NAS) for image classification. For this, the selection, mutation, and generation of the population presented above do not change. However, they must be applied to larger chromosomes, and the functions responsible for decoding the chromosome and testing individuals of the population are specific to XGB. The main change is in the fitness function. Furthermore, this GA can be extended for use in other ML models with minimal additions to the code, preserving the main operators, that is, selection, mutation, and crossover functions as they are; for tasks similar to those presented in this work (classification and regression), even the fitness evaluation can be used as is. In addition, in our design, the strategy is a joint hyperparameter and architecture optimization. Most NAS methods fix the same setting of training-related hyperparameters throughout the search stage. After the search, the hyperparameters of the best-performing architecture are further optimized. However, this paradigm may result in suboptimal results because different architectures tend to fit different hyperparameters [17].
In order to evaluate the feasibility of the multiobjective optimization using the proposed GA method, experiments with the XGB algorithm were performed using two datasets and seven experimental configurations.
XGB [4] is an implementation of the gradient-boosted tree algorithm. This technique, known as boosting, is an ensemble learning technique that uses a set of base learners to improve the stability and effectiveness of an ML model. This is called gradient boosting, because it uses a gradient descent algorithm to minimize loss when adding new models. The central idea of boosting is the sequential implementation of homogeneous ML algorithms, where each of these algorithms attempts to improve the stability of the model by focusing on the errors made by the previous algorithm. XGB is one of the most widely used algorithms by data scientists, mainly in forecasting problems involving structured data, and has been widely recognized in several ML and data mining challenges, such as Kaggle competitions [3]. In addition, it has desirable properties to be incorporated into an AutoML system, as it can deal with missing observations and outliers and can handle a large number of features and examples in a very optimized manner. Additionally, it is numerically stable and memory efficient, allowing more experiments to be performed in less time, which is very useful for the early development and proof-of-concept of the proposed GA. Despite this, the HPO is helpful for XGB because it is highly configurable with a large number of hyperparameters for regularization and optimization.
The dataset utilized for the classification task is Boson Higgs ,4
GA tunes a combination of four parameters of the XGB, looking for the best multi-objective optimization. The HPO (N_jobs, ETA) and AO (N_estimators, max_depth) parameters are optimized jointly. The parameter N_jobs defines the number of cores in parallel that the processor will execute the algorithm. When N_jobs = −1, all cores are used, and for N_jobs = 1, only one core. The ETA parameter is the learning rate and defines the correction made at each boosting step. The N_estimators is the number of gradients boosted trees and the maximum tree depth for base learners is defined by max_depth. XGB splits up to the max_depth specified and then starts pruning the tree backward and removing splits beyond which there is no positive gain.
For the tests, the total length of the chromosome was fixed in 22 alleles, where the first six represent the ETA (ranging from 0.01 to 0.64); the next four are used for the N_jobs, (1 to 16), followed by 9 alleles for N_estimators (9 to 520), and the last three are used for the max_depth (3 to 10). The GA parameters were set as follows: population size = 20; number of generations = 30 (for the classification) and 20 (for the regression); elitism = 4; probability of crossover = 80; probability of mutation = 10.
The developed scheme enables the multi-objective optimization to be defined according to the user requirements. It is possible to set priorities for time, energy, and predictive performance. This defines the configuration of the GA fitness function (a combination of maximizing accuracy or minimizing the MSE, minimizing time, and minimizing the energy). These possibilities define the methodology for the experiments, resulting in 11 different experimental configurations, as listed in Tables 1 and 2.
Table 1 shows the combinations of relevance, in percent, attributed to model accuracy, training time, and energy consumed when training XGB for the classification task (XGBC). Table 2 shows the combinations of XGB for regression (XGBR). For example, the combination 1,0,0 in configuration 1 indicates that only the metrics with value 1 is to be considered (having 100% of relevance), which in this case is the MSE, which is equivalent to a red AI approach, where only the predictive accuracy matters.
Configurations of the relevance for the experiments performed with XGB for classification
Configurations of the relevance for the experiments performed with XGB for regression
Test environment was a computer with an Intel Core i7-8700 CPU with 6 cores e 12 threads, frequency 3.20 GHz, memory 64 GB DDR4 (16 GB X4), 1 HD SATA Seagate de 2TB e 1 SSD Corsair MP510 de 240 GB of storage, and a GPU Nvidia GeForce RTX 2080Ti with a base clock of 1350 MHz, boosted clock of 1545 MHz, and 11 GB of memory GDDR6 with ECC off, and OS Ubuntu 20.04.
XGB was implemented and executed with Python 3.8. The time and energy were measured with Perf Tool. The GA is implemented in C++. As a reproducibility compromise, all the codes and configurations are available at:
Figure 2 shows the fitness of each individual (bars) and the average population (line) for a sample test with a population of 10 individuals over nine generations for XGBC. Generation 0 is the initial randomly generated population. For this test, we used an elitism of 1, where only the best solution of the generation is passed on to the next due to the small size of the population. The graph shows the evolution, and as new generations are created, it is possible to observe the improvement in the fitness function (the higher, the better). This can be seen for the best individual (blue bar) and the general population (AVG line). This shows that you can improve the population, even with this small example with 10 individuals (for visualization purposes only).
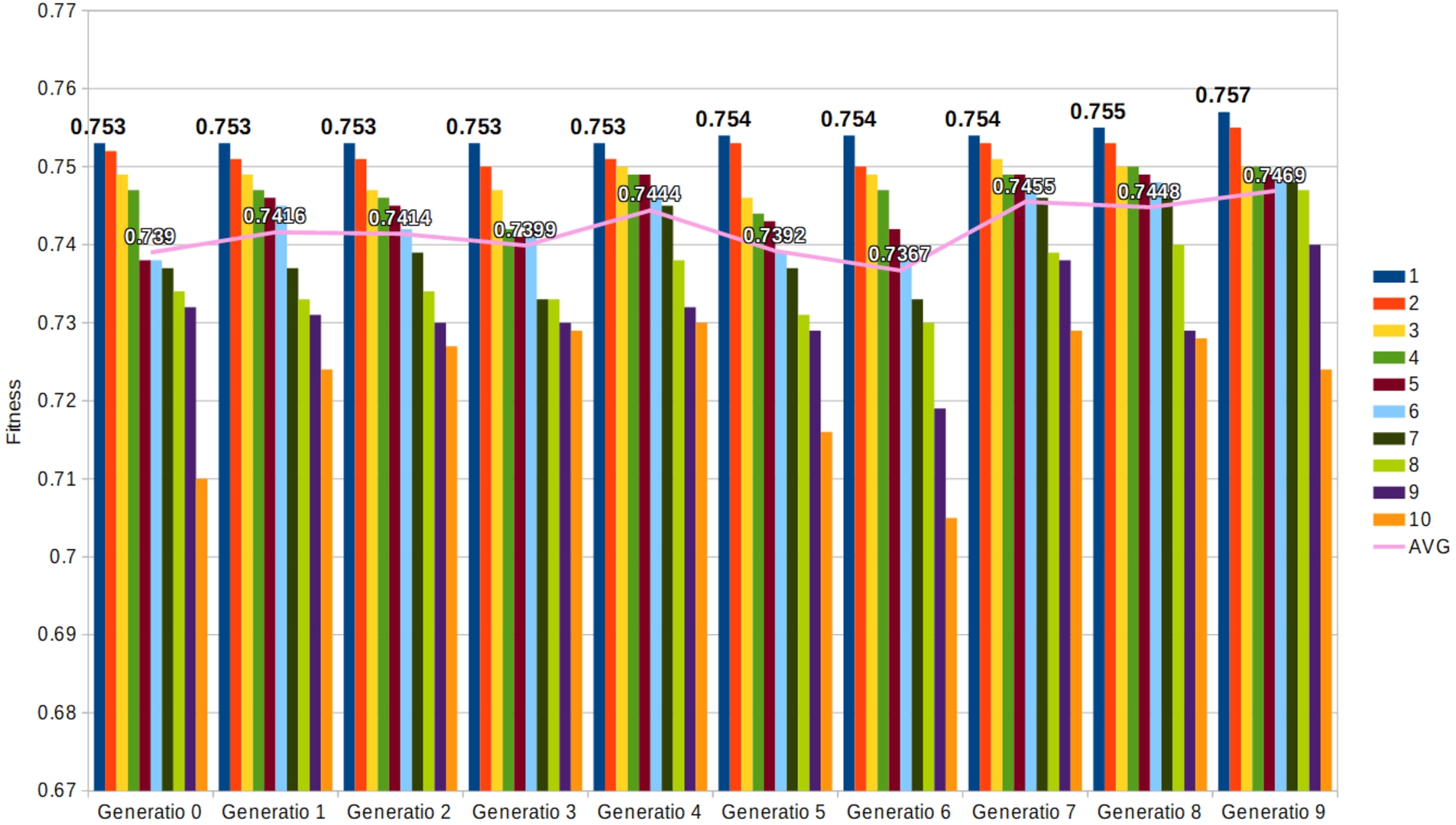
Example of the evolution process with a population of 10 individuals.
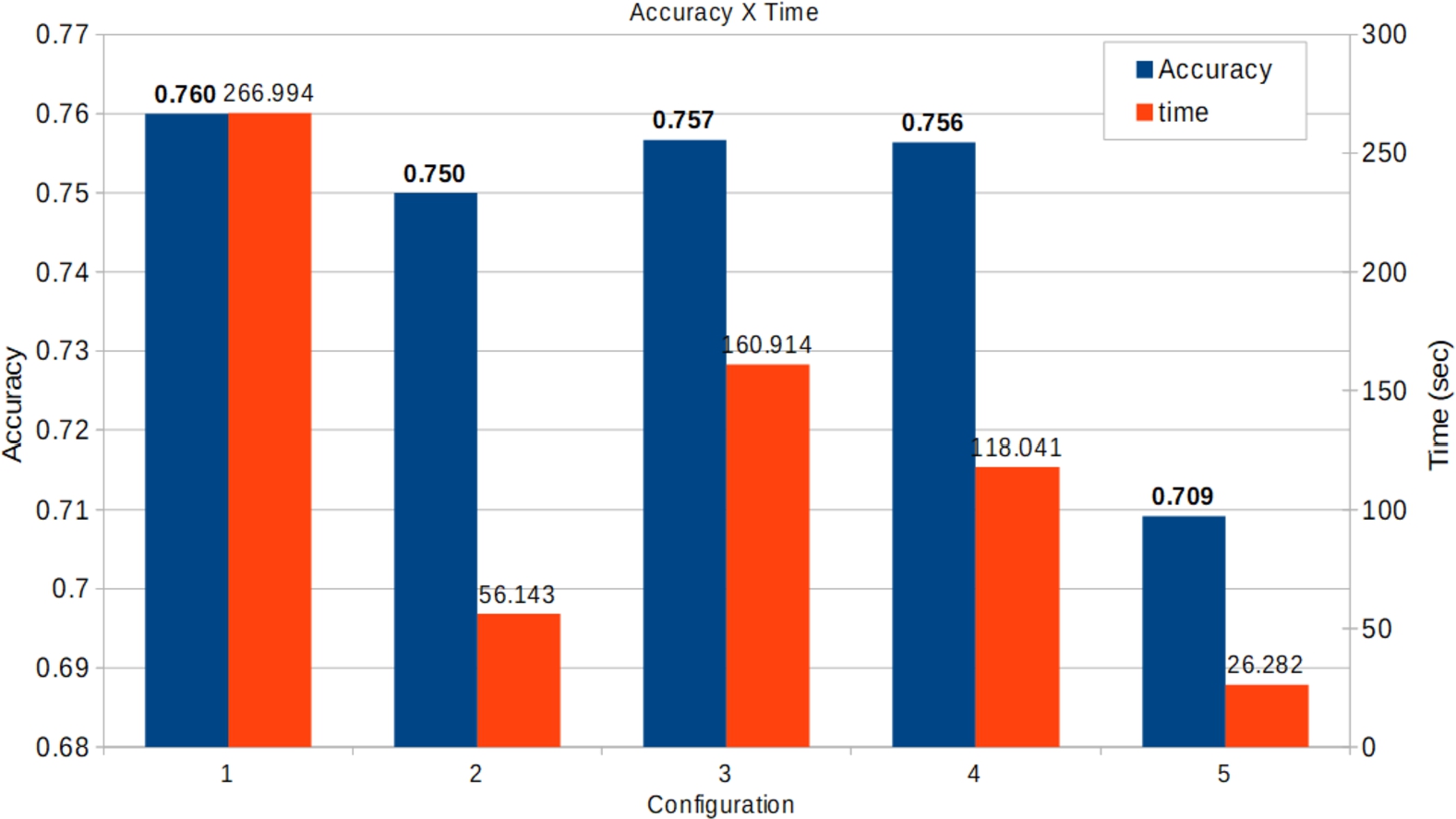
Comparison of the accuracy and time for the XGB for classification.
Figures 3, 4, 5 and 6 show the accuracy/MSE, time and energy, for the best solution for each configuration (Tables 1 and 2).
Figure 3 compares the accuracy and time of the XGBC, where configuration 1 focuses mainly on accuracy (Table 1). As expected, it had the best accuracy (76%), but the worst time at 266.99 seconds. For Configuration 2, both the time and the energy relevance increased slightly. The results showed a significant decrease in time and a reduction of only one percentage point in accuracy. Configurations 3 and 4 also show time reductions, although not as much as configuration 2, but had a smaller loss in accuracy. Configuration 5, which is highly relevant to time, had the worst accuracy (70. 9%) and the best time (26.28 s), which is less than 10% of the time spent by Configuration 1. These results show the ability of GA to perform multi-objective optimization, even allowing for defining priorities. Furthermore, it can be seen that the GA manages well to optimize the defined criteria.
In Fig. 4 it can seem that the energy had the same behavior as the time.
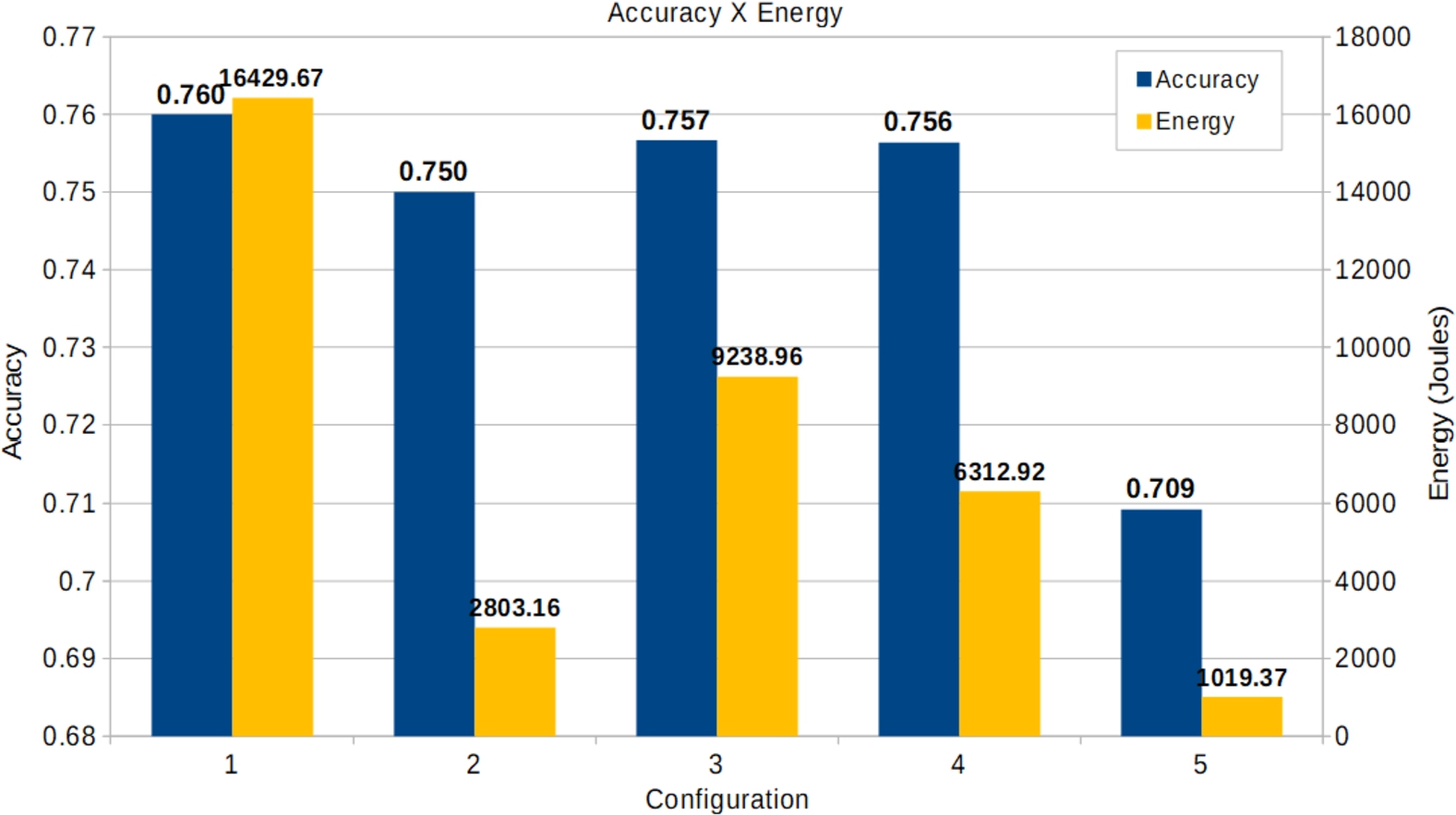
Comparison of the accuracy and energy for the XGB for classification.
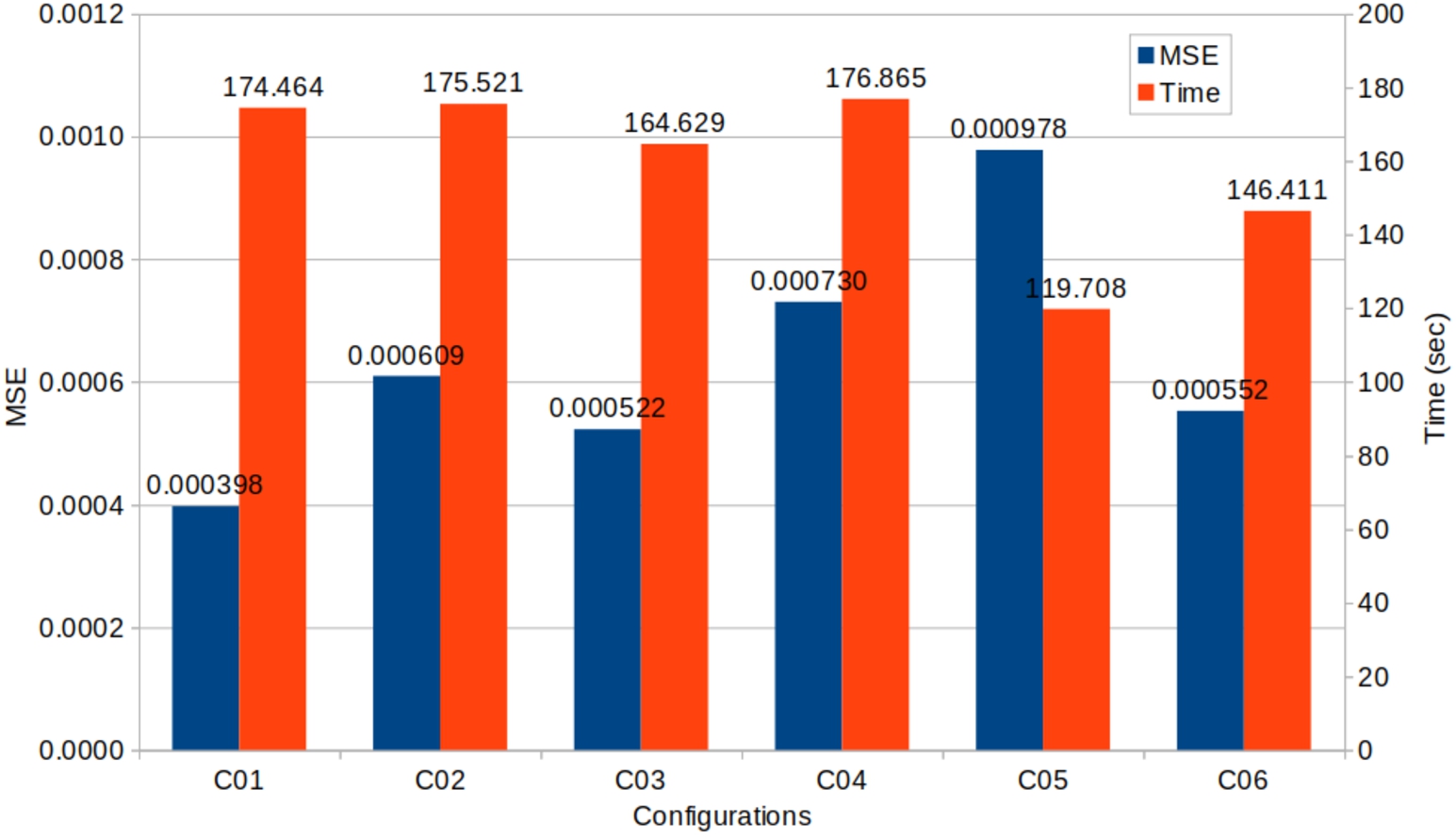
Comparison of the accuracy and time for the XGBR.
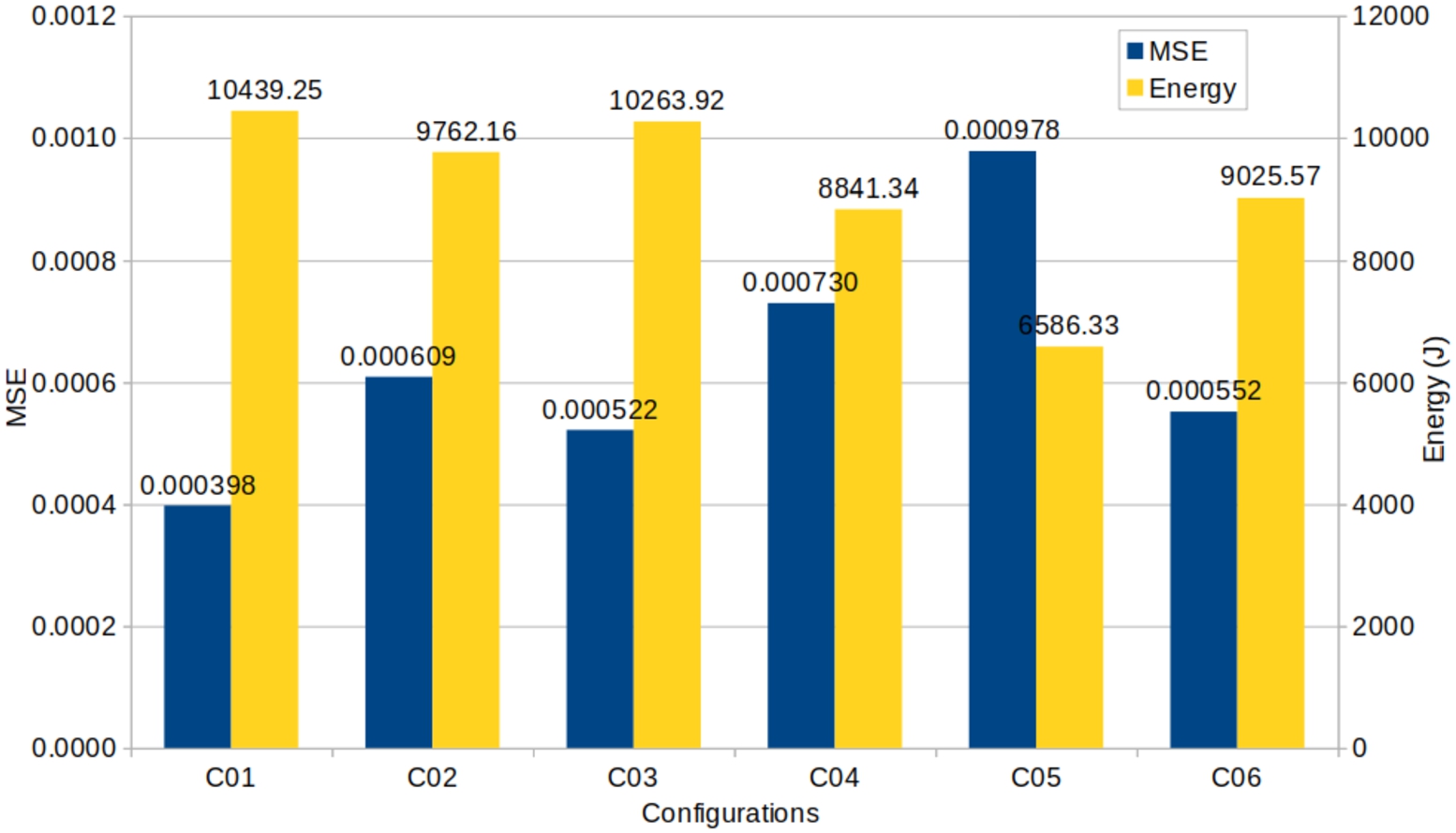
Comparison of the accuracy and energy for the XGBR.
Figure 5 compares the MSE and the time for the XGBR, and Fig. 6 shows the MSE and energy. The lower these values, the better. Configuration 1 has 100% relevance to MSE (red approach), and obtained the lowest MSE but the third highest time (174.46 seconds) and the highest energy consumption. The two highest times were performed by configurations 2 and 4 (175.52 and 176.86 seconds, respectively); this was expected since they focused on the energy but not on time. However, the most significant difference compared to configuration 1 was less than 2.5 seconds. These configurations had a lower energy consumption than configuration 1, with the lowest overall, obtained by configuration 4, which had a [50/50] split between MSE and energy. However, this reduction came at the cost of increasing the MSE.
Configurations 3 and 5, which focused on reducing time without considering energy, achieved a reduction in time, with the lowest obtained by configuration 5 (119.71 sec). This is more than 54 seconds lower than in configuration 1. However, it had the highest MSE, almost 2.5 times the MSE of configuration 1. This is mainly due to the XGB algorithm, which is highly optimized. As configurations 1, 3, and 5 used all available CPU cores, there was little or no room to reduce the time by increasing the parallelism, and the solution of the algorithm was to minimize the number of estimators. For configuration 1, the number of estimators was between 450 and 500, while in configuration 5, it was between 200 and 250, allowing the models to train faster but increasing the MSE.
In comparison, configurations 2 and 4 reduced the energy by reducing the number of cores used from 12 to 4. Interestingly, configuration 5 had the lowest energy consumption, resulting from the significant time reduction.
Configuration 6 showed an interesting result, having the third best MSE, very close to Configuration 3 with the second best MSE, but with lower energy and time than Configuration 3, having the third best energy and second best time overall.
These results were compared with a previous study, co-authored by some of the authors of this work [2], training XGB with the same Higgs dataset with 11 million examples searching for energy savings when tuning, empirically and manually, the hyperparameters of the algorithm. The comparison here is with the results of [2] obtained with the default parameters of XGB and with one who got the best accuracy. The configuration with the best accuracy achieved the same precision as our configuration 1. However, their result was obtained in a shorter time (223.86 seconds compared to the 266.994 of ours and energy consumption of 13095.18 J to 16429.67 J). For the default configuration, the accuracy of [2] was 74% with a time of 108.36 seconds and an energy of 5647.08 J. Compared to our configuration 2, it had the closest accuracy (75%), but the total time was 56.143 seconds and the energy 2803.16 J. It is about half of the time and energy consumption.
The results were not compared with other AutoML frameworks or GA approaches, since finding other works that implement multi-objective optimization evaluating energy and time in addition to predictive performance was impossible.
In this work, a multi-objective optimization centered on Green AI was designed, implemented, and evaluated, searching for an AI that is more environmentally friendly. It was implemented through GA using a workflow and operators specially designed for this problem to be part of an AutoML solution. A set of experiments was performed for the joint optimization of the XGB algorithm with HPO + AO for classification and regression tasks. Although GA was evaluated using XGB, the workflow and some operators were designed to be used for ML models in general with minimal additions to the code, preserving the main operators as they are. For classification and regression tasks similar to those presented in this study, even fitness evaluation can be used without modifications.
The initial results show the effectiveness of the proposed solution for multi-objective optimization using XGB. In addition, some experiments enabled significant energy savings compared to manual hyperparameter tuning when searching for the same objectives, indicating that it is possible to reduce energy consumption while minimizing predictive performance losses. To the best of our knowledge, this is the first multi-objective optimization approach to consider the efficiency of ML models by simultaneously considering accuracy, time-to-solution, and energy consumption, which still allows them to be chosen.
The limitation of this work is that only the XGBoots were evaluated, which is not a power-hungry model like the Deep Neural networks mentioned in the works related to green AI. However, this first model had a proof-of-concept objective, conducting experiments more quickly. To demonstrate the usefulness of this approach using a GA, a large number of experiments must be performed to evaluate mutation and crossover and to verify if the population is evolving. There were many implementations and tests until the final result was obtained. Even so, a single test with 20 generations took approximately 20 to 30 h for each experiment. This time could easily be up to four times higher if we tested it using a neural network according to our initial tests with a CNN. However, the fitness implemented and tested for XGB shows the possibility of this multi-objective optimization. Therefore, time tests with CNN will be greatly reduced. Recall that the purpose of this study is to reduce the impact of training ML models.
However, despite this limitation, this work makes contributions by presenting a specialized GA scheme and operators. Moreover, this approach represents an important and inspiring step towards the development of more environmentally friendly ML. We believe that our work not only presents a novel approach, but also stimulates a crucial conversation about the importance of developing greener and more inclusive artificial intelligence. Furthermore, even with the actual version of the GA model developed, this multi-objective optimization is already a contribution in itself, as although predictive measures of performance are still decisive in most cases, models that also have other measures of efficiency become increasingly important. For example, in many IoT applications, an ML model is deployed on edge devices, such as smartphones, watches, and embedded systems, and power consumption can be a limiting factor when deploying models in such settings. Therefore, trade-offs between energy consumption and predictive performance are essential factors in which our multi-objective approach can be directly applied to XGB because current state-of-the-art models in computer vision and LLMs with NN processing with millions or billions of weights are not applicable in such settings.
In future work, the GA is evolving to include HPO + NAS for the CNN model. Additionally, more tests are being performed with different configurations for GA parameters, such as the number of individuals and generations. In addition, A new crossover function for HPO + AO for XGB is under development. Finally, the multi-objective AutoML framework will be developed to incorporate the GAs designed initially for the mentioned tasks and algorithms.