
Abstract
Under the foggy environment, lane line images are obscured by haze, which leads to lower detection accuracy, higher false detection of lane lines. To address the above problems, a multi-layer feature fusion dehazing network based on CycleGAN architecture is proposed. Firstly, the foggy image is enhanced to remove the fog in the image, and then the lane line detection network is used for detection. For the dehazing network, a multi-layer feature fusion module is used in the generator to fuse the features of different coding layers of U-Net to enhance the network’s recovery of information such as details and edges, and a frequency domain channel attention mechanism is added at the key nodes of the network to enhance the network’s attention to different fog concentrations. At the same time, to improve the discriminant effect of the discriminator, the discriminator is extended to a global and local discriminator. The experimental results show that the dehaze effect on Reside and other test data sets is better than the comparison method. The peak signal-to-noise ratio is improved by 2.26 dB compared to the highest GCA-Net algorithm. According to the lane detection of fog images, it is found that the proposed network improves the accuracy of lane detection on foggy days.
Keywords
Introduction
Driverless technology is one of the current high-profile technologies in the field of artificial intelligence. With the continuous development of deep learning technology and computer hardware, driverless technology has made significant progress. [28,32] Lane line detection plays a crucial role in driverless technology by helping to ensure that vehicles remain safely within their lanes, preventing accidental collisions, and ensuring the safety of passengers. The accuracy, real-time performance, and stability of lane line detection directly affect the overall performance of the autonomous driving system. Lane line detection is one of the important components of advanced driver assistance systems (ADAS), which is mainly used in lane departure warning systems (LDWS) to provide an important safety function by alerting the driver when he or she leaves the lane without paying attention. [31,36] There have been many studies to solve the lane line detection problem, including the use of traditional lane line fitting methods and deep learning-based lane line detection algorithms, but most of these algorithms apply to lane line detection in normal environments, and very few researches have been conducted on lane line detection in adverse environmental conditions. It is very difficult to perform lane line detection under adverse weather conditions because unfavorable environmental conditions may lead to blurring of the images captured by the unmanned vision sensors and degradation of the image quality of the lane lines, which leads to a decrease in the accuracy of lane line detection. Therefore, further research is needed to address methods and techniques for lane line detection under adverse environmental conditions to ensure the normal operation of the autonomous driving system and the safety of passengers. [37] Foggy days are one of the more common weather phenomena in inclement weather. The probability of having a road accident in foggy conditions is much greater than in normal weather. Foggy lane lines are covered by mist due to the floating of water vapour in the air, which causes the lane lines to become blurred. In dense foggy weather, lane lines may disappear completely. These factors can cause the lane line detection accuracy to drop a lot and the false detection rate can become higher. [17] At present, there have been studies on fog lane detection from the perspective of deep learning. Xu et al. [35] dehaze by expanding the foggy data set, generating fog lane images of different concentrations according to the atmospheric scattering model, and then using the expanded data set to train the spatial convolution neural network (SCNN) to improve the accuracy of fog lane detection, although this method performs well on the composite data set. However, the generalization ability of the network in the real foggy environment is weak. Therefore, this paper first enhances the foggy image and then carries on the lane detection.
In this paper, because of the above problems, a multilayer feature fusion dehazing network is designed, firstly using CycleGAN network [39] as the main framework, in which the generator adopts U-Net as the base network.In order to make full use of the different layers of encoder features, a multilayer feature fusion module is designed to fuse the different layers of encoder features with the decoding layer. Meanwhile, in order to better improve the network’s dehazing ability, affected by the dark channel prior, the dehazing effect is closely related to the channel of the foggy image. Therefore, the FCA-Net attention mechanism proposed by Qin et al [23]is added to the important part of the generator to assign different weights to different channels.
In order to better judge the effect of the image generated by the generator and to prevent the generated image from overly deviating from the original input image, the discriminator of the initial CycleGAN is extended to two, the global discriminator and the local discriminator. The global discriminator is a global level judgement of whether the generated image was generated by the generator or not. The local discriminator randomly crops the input foggy image into four parts, and then discriminates each part, and calculates the average of all the blocks when calculating the loss function of the local discriminator, which can greatly improve the discriminative ability of the discriminator. To solve the problems of pattern collapse and convergence difficulties encountered in training CycleGAN, soft likelihood estimation is introduced into the discriminator, which improves the stability of the network training, and also the soft likelihood estimation improves the overall dehazing quality. Finally, the lane line detection network ENet-SAD is used for lane line detection on the enhanced foggy images.
The structure of this paper is as follows. In the first section, the development of dehazing methods is introduced. The second section introduces the overall idea and network architecture of the dehaze network in this paper. In the third section, the experimental results of the network on the real fog test set and the synthetic fog test set are given, and the effect of the network on lane detection before and after dehaze is tested. Finally, the conclusion is given in the fourth section.
Related work
Methods based on prior knowledge
Most of the dehazing methods based on prior knowledge mainly rely on the atmospheric scattering model [33], which is shown in Eq. (1):
The dehazing results were obtained by calculating the transmission map and atmospheric light in the atmospheric scattering model and then inputting them into Equation (1). [10,21] The classical algorithm is the dark channel prior theory proposed by He et al. [12] which suggests that out of the three RGB color channels for each pixel in a fog-free image, there is always one channel with a low grey value, from which the transmission map can be derived. For atmospheric light, the approximation is obtained by taking the first 10% of the brightest pixels of the image, but this leads to the failure of the dehazing algorithm when dealing with scenes similar to atmospheric light values. Zhu et al. [40] proposed a priori of color attenuation, which holds that the brightness and saturation of pixels in the image change sharply with the change of fog concentration, and the haze concentration is estimated by the difference between brightness and saturation. Berman et al. [3] proposed the fog line theory for dehazing. The theory suggests that each color cluster in the fog-free image is a line in the fogged image, and using these fog lines can restore the transmittance and the fog-free image. When the density of fog is high, the dehazing effect of the method will be reduced. Gao et al. [11] proposed to remove fog by combining bright channel with dark channel. Dehazing algorithms based on prior knowledge are simpler to implement, but these algorithms generally have serious time-consuming and high requirements for fogged images, which can lead to serious degradation of dehazing effect if the required dehazed image conflicts with the prior knowledge.
Methods based on deep learning
With the development of deep learning, many researchers have adopted deep learning to dehaze from the data and network level. [18,30] The initial neural network dehazing was used in conjunction with the atmospheric scattering model. Many algorithms calculated the transmission map of the foggy image by designing the network and then used Formula (1) to restore the fog-free image. For example, Cai et al. [4] designed an end-to-end network to estimate the transmittance of foggy images and then used an atmospheric scattering model to recover fog-free images. Ren et al. [25] used a multi-scale convolutional neural network for the calculation of transmittance. The rough structure of each image transmission map is obtained from a coarse-scale network and then refined by a fine-scale network. However, when the transmission map is not calculated accurately, the dehazing result will be seriously affected. Li et al. [15] redesigned the atmospheric scattering model to generate end-to-end dehaze results by supervised learning. The above algorithms perform dehazing by calculating intermediate parameters, which will produce large errors without constraints, which will cause color distortion in the haze-free image output by the network. Chen et al. [6] designed an end-to-end gated context aggregation network that introduces smooth dilation convolution to remove meshing artifacts and fuses different levels of features with a gated network. Qin et al. [22] proposed an end-to-end feature fusion attention network, which uses a feature attention module repeatedly, combines it with skip connection into block structure, and invokes block structure and group structure for dehaze many times. This method has achieved considerable results in end-to-end dehaze.
Because the above algorithms all require foggy images and fog-free images of the same scene, but the data pairs are difficult to acquire and have no generalization ability to real-world foggy days, an unsupervised dehazing method based on GAN emerges spontaneously. Engin [9] designed the Cycle-Dehaze network based on CycleGAN, which mainly optimizes the loss function, introduces the cyclic perception loss into the loss function, and improves the Laplace pyramid to get a high-resolution dehaze image. Sun [27] embeds the iterative dehaze model into the generator of CycleGAN to obtain detailed information from the physical model, while designing consistency loss to remove haze. Zhang et al. [38] decompose the output projection rate and dehaze image by dark channel a priori, and then use the discriminator to process and judge the output, to obtain the dehaze result. Dan [8] proposed a multi-channel attentional dehazing algorithm based on dual discriminator heterogeneous CycleGAN. By introducing first-order and second-order feature statistics, a multi-order channel attention module was proposed to improve the visual quality of the dehaze image. Chaitanya et al. [5] embedded an all-in-one dehazing network (AOD-Net) in the middle of the encoder and decoder and added the SSIM loss to the loss function to improve the dehazing quality.
Proposed method
Multi-layer feature fusion module
The network designed in this paper is an unsupervised learning model that can be trained using unpaired images to enhance the generalization ability of the network in real foggy environments. The overall architecture of the network is based on CycleGAN and consists of two generators and four discriminators. As shown in Fig. 1, the function of
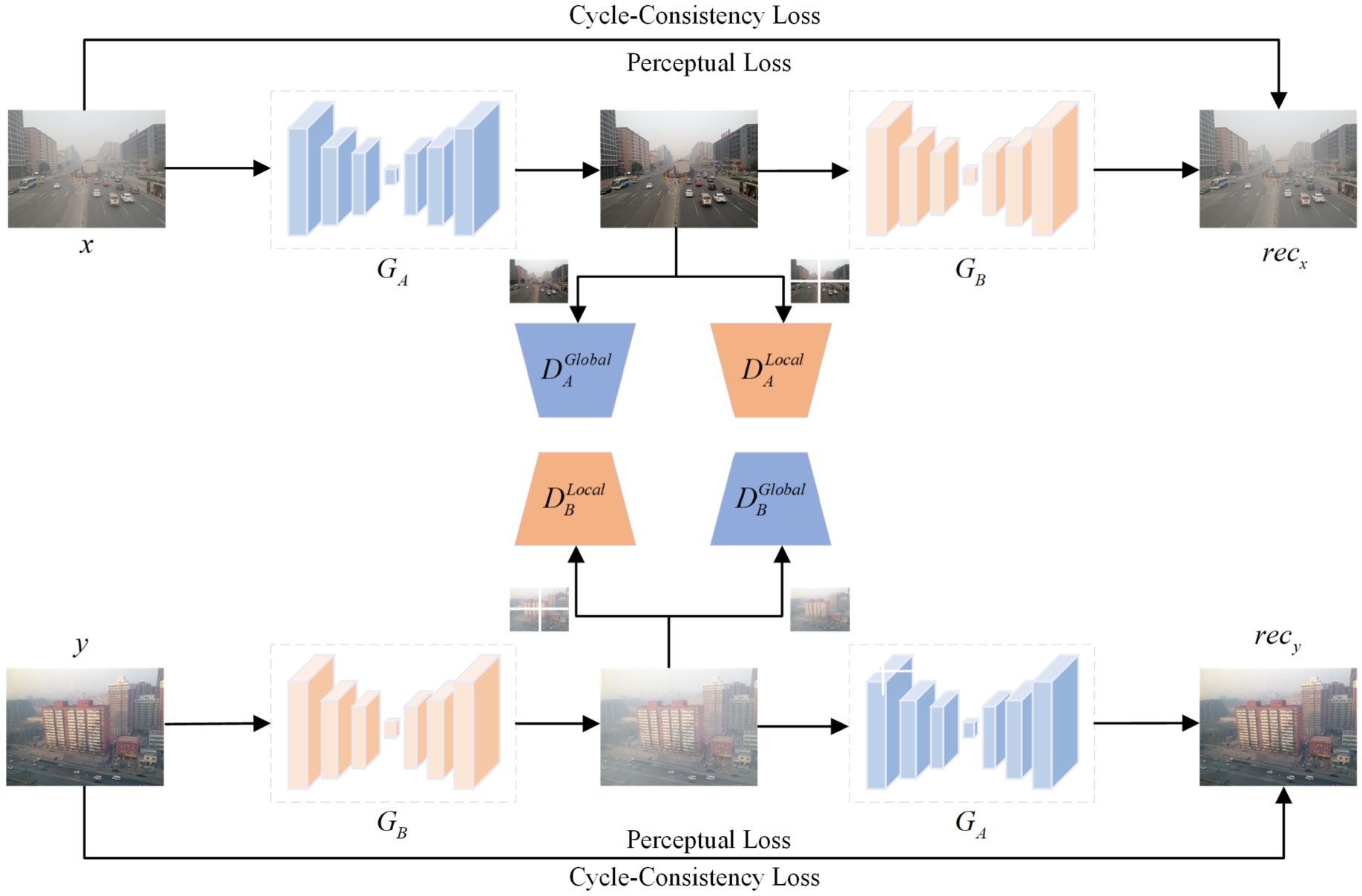
Network entity architecture diagram.
The generator of the network uses U-Net as the basic network, which is a U-Net network that connects the features of the corresponding scales of the coding and decoding layers, so that although the feature information of the coding layer can be introduced, the information contained in the coding layer at different scales is ignored. In the U-Net network, the features extracted by the shallow coding layer contain more color, texture, and edge information because they are close to the input. The receptive field of the shallow network is smaller and the overlap area of the receptive field is smaller, so it can ensure that the network can get more details. The receptive field of the deep coding layer increases and the overlapping area between the receptive fields will also increase, and some information about the whole image, such as semantics and brightness, will be obtained. The decoding layer connects the deep coding layer and the shallow decoding layer when restoring the image. The shallow decoding layer and the deep coding layer are the same, and both lack detailed information such as texture and edges. With the upsampling process, the semantic and brightness information will also gradually decrease, resulting in poorer final recovery results. To solve the above problems, a multi-layer feature fusion module is added to the network, so that the decoding layer can fuse the feature information of the encoding layer at different levels. As shown in Fig. 2, the encoding layer has two downsampling layers, and each downsampling layer consists of a convolutional layer, an instance normalization layer, a ReLU activation function, and an FCA-Net, through which the two downsampling layers extract features of different layers. The decoding layer consists of two upsampling layers and an output layer. The upsampling layer consists of a transposed convolution, an instance normalization layer, a ReLU activation function, and an FCA-Net. The output feature maps of the encoding layer are F1, F2, and F3. At this time, the size of the three feature maps is not the same, and the content information they contain is not the same, then F1 will be kept the same size as F1 by a 1 × 1 convolution kernel, F2 will be adjusted to the same resolution as F1 by a 3 × 3 transposed convolution, F3 will be adjusted to the same resolution as F1 by a 5 × 5 transposed convolution. The LeakyReLU activation function is added after the feature maps output from each convolution and transposed convolution layer as a way to improve the nonlinearity of the network. The feature maps of the convolution kernel transposed convolution outputs are summed and fed into the FCA-Net network. The network assigns weights to each channel and fuses the above features to obtain CF1. Then fuses CF1 with the feature DF1 of the corresponding scale of the decoding layer. Finally, the dehazed image is recovered by upsampling. The remaining CF2 and CF3 differ only in the convolution and transposed convolution of the different feature maps, otherwise, they are the same as above. In this way, the decoding layer can then fuse the features of the different coding layers so that the image recovery can contain more details and edge information.
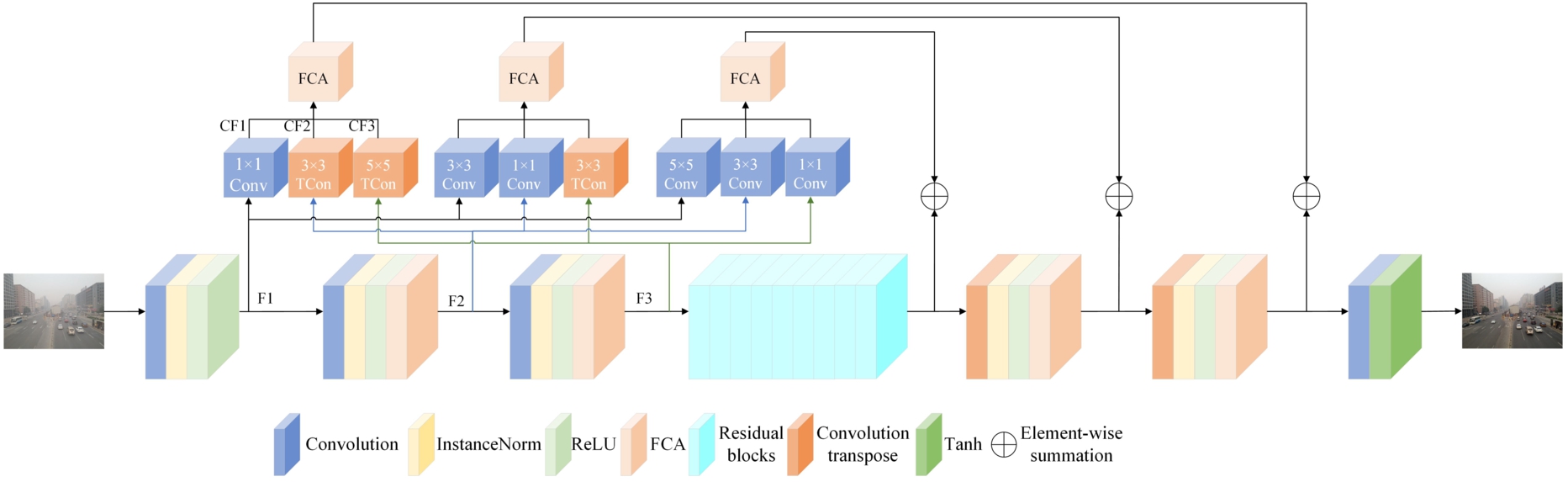
Generator network structure diagram.
The dark channel prior theory proposed by He et al. illustrates the importance of channel processing in the dehazing process. In addition, the real foggy environment will not be the same as the synthetic foggy image, and the fog in the real foggy day is unevenly distributed. Therefore, it is necessary to perform dehazing processing on foggy areas and assign lower weights to fog-free areas or areas with thinner haze, to enhance the dehazing effect of the network. Most of the current research has used the attention mechanism to enhance the dehazing effect. They all use the global average pooling to calculate the weight. Direct pooling with global averaging loses a lot of information and does not allow full access to a wide range of information for each channel, leading to a more limited actual dehazing capability, hence the introduction of FCA-Net into the network. FCA-Net cuts in from the frequency domain perspective, which will fill in the lack of feature information in the existing channel attention methods, introducing more frequency domain components with the discrete cosine transform. FCA-Net enables the network to adaptively learn the weights from the feature maps, improving the network’s handling of different fog concentrations. FCA-Net is added to both the downsampling and upsampling layers of the network, and FCA-Net is used to fuse multilayer features in the multilayer feature fusion module.
The residual network in the middle of the encoding and decoding layers is used to extract features in depth. The residual network consists of 9 residual blocks to extract more complex features. The residual block usually used in the dehazing network is relatively simple and the number of parameters becomes larger after stacking many times, so the residual block is redesigned and the structure of the residual block is shown in Fig. 3. The convolution in the residual network is divided into three parts. First, 1 × 1 convolution is used to reduce the number of channels in the input image. Then use two 3 × 3 ordinary convolutions to extract features. This will significantly reduce the number of parameters in the network model. Adding FCA-Net to the tail of the residual block, the features extracted at the tail end of the residual network are all deep features, adding FCA-Net to the back end allows the network to focus on the parts that need to be enhanced.

Residual network structure diagram.
Traditional CycleGAN uses a single discriminator to judge the image generated by the generator, which judges the image from a global point of view and has a weak ability to deal with the changes in local information, such as the image with high fog concentration or the image with uneven fog distribution, so two discriminators are used to judge the image generated by the generator. Both the global and local discriminators use PatchGAN [14] as the underlying network architecture. PatchGAN is a model based on Generative Adversarial Networks used for image authenticity detection and generation. Unlike traditional GANs, PatchGAN generates more detailed and realistic images by evaluating the authenticity of various local regions within the images. It contains five 4 × 4 convolution, the output channel is from 64 to 512, and the output channel of the last convolution is 1. For the global discriminator, the image generated by the generator is directly input into the global discriminator. The global discriminator is used to ensure the overall semantic accuracy and coherence of the generated dehaze image so that the reconstructed image information is consistent with the context. For the local discriminator, firstly, the input image is randomly cut into four parts, that is, four 128 × 128 blocks, and then the local discriminator judges. The local discriminator acts in areas with different fog concentration distributions, which can judge whether the restoration of local texture, color, and other features is reasonable.
Directly calculating the average value of all blocks at the output of the local discriminator will affect the final discriminant effect. Inspired by Wang et al. [29], soft likelihood estimation is used to calculate the output of the local discriminator. The use of soft likelihood estimation can enhance the discriminator’s attention to the detailed information of the image, thus improving the quality of image dehazing. Firstly, the similarity of each block and the probabilistic minimum block likelihood is calculated to obtain the weight matrix. The maximum objective function and the minimum objective function of the weight matrix are smoothly solved by using SoftMax and SoftMin functions. Then the weight matrix of each block is multiplied by the corresponding likelihood, and finally added to get the final output. After this processing the discriminator will pay more attention to the changes in the low probability region, and the generator will produce a more detailed and more realistic image. The calculation formula is shown in Eq. (2):
Loss functions
Adversarial loss
Adversarial loss is mainly used to optimize the generator and the discriminator to make the discriminator more and more discriminative while making the data generated by the generator more realistic, and letting the generator and discriminator learn the game. Similar to the ordinary GAN loss, the least square loss is used to match the distribution between the generated image and the target fog-free image. The formula against loss is shown in Eq. (3):
Identity loss
The identity loss is mainly used to keep the color composition of the image generated by the generator and the image initially fed into the network identical. If the loss is not added, the generator will independently modify the hue of the image and change the overall color of the image. The identity loss simultaneously enhances some detailed information of the dehaze image, so that the output image of the network is structurally consistent with the input image. This loss function is defined as shown in Eq. (4):
Cycle consistency loss
The reason why the CycleGAN network does not need pairs of fog images and fog-free images is because of the loss of cycle consistency, which can make the image generated by the generator retain the information of the original image and prevent the mode from collapsing, so that the generator can always generate the same image that can deceive the discriminator. The cycle consistency loss is defined as shown in Eq. (5):
Perceptual loss
Perceptual loss is very important for style conversion networks such as CycleGAN. In the experimental process, it is found that the loss will directly affect the quality of the output image of the network. The perceptual loss can recover texture information from the foggy image, and can maintain the overall structure of the input image and some fine details. Compared with the traditional mean square error function, the perceptual loss pays more attention to the perceptual quality of the image, which is more in line with people’s subjective feelings. The perceptual loss is calculated by a pretrained neural network to calculate the difference between two images. The formula for perceptual loss is shown in Eq. (6):
Color loss
The style conversion class of the network changes the color of some regions of the image while converting the style of the image, in order to make the dehazed image brighter, colour loss is used to compare the colour difference between the de-fogged image and the real input fog free image. Since the contrast of a fogged image is usually lower than that of a fog-free image, both the dehazed image and the real fog-free image are first made blurred using a Gaussian filter so that only the change in color information is considered, and then the difference is calculated using the mean square error. The formula for color loss is shown in Eq. (7):
SSIM loss
In order to make the generated images consistent in terms of structural similarity and contrast similarity, the SSIM loss function is added, the SSIM loss compares the two images in three aspects, namely brightness, contrast and structure, compared to the pixel-by-pixel comparison of the MSE loss, the SSIM loss takes into account more aspects, which improves the SSIM metrics of the generated images. The equations for SSIM losses are shown in Eq. (8):
Total variation loss
In order to promote the spatial smoothness of the network output results and to reduce the noise of the generated images, the total variation loss is added to the loss function. The total variance loss is defined as shown in Eq. (9):
The total loss function is shown in formula (10):
Experiment
In this section, the method of this paper is compared with several other dehazing algorithms, which are tested on synthetic foggy day dataset and real foggy day dataset respectively. Since the full-reference evaluation metrics require paired image data for computation, the full-reference image quality evaluation metrics and the no-reference image quality evaluation metrics are used to quantitatively evaluate the fog removal results. Among the full reference image quality evaluation metrics, peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) are selected for evaluating the performance of the dehazing method on the synthetic dataset. The referenceless evaluation metrics were selected from natural image quality evaluator (NIQE) [20], fog aware density evaluator (FADE) [7] and blind/ referenceless image spatial quality evaluator (BRISQUE) [19] for evaluating the dehazing effect in real foggy environments.
Datasets
The network in this paper is designed based on CycleGAN and does not need to be trained in pairs of foggy data. At the same time, to enhance the generalization ability of the network to the real foggy environment, the images in the real foggy environment are selected for training. Currently, the larger and more commonly used foggy day dataset is the realistic single image dehazing dataset (RESIDE) [16]. The RESIDE training set contains 13990 synthetic foggy day images, which are composed of indoor training set (ITS), outdoor training set (OTS), synthetic objective testing set (SOTS), unannotated real-world hazy images (URHI), real-world task-driven testing set (real-world task-driven testing set (RTTS) and hybrid subjective testing set (HSTS). 6000 foggy images from RTTS and URHI are selected as foggy images in the training set, while 40 pairs of images from DenseHaze [1] are selected for training to improve the network’s ability to process non-uniform foggy images. For the fog-free images in the training set, 6000 fog-free images are randomly selected from OTS for training because pairs of data are not required. For the test set for network evaluation, some images from SOTS, HSTS and URHI are selected as the test set.SOTS contains both indoor and outdoor images, and since fog often exists outdoors, 500 outdoor images from SOTS were chosen as the test set.The HSTS contains only 20 images, all of which are used as the test set.Since 3000 images from URHI were used during network training, the remaining 1000 fogged images were selected as the test set.
Implementation details
The network in this paper is tested on a device with Intel (R) Xeon (R) Platinum 8255C CPU and NVIDIA RTX3090 GPU, in which the framework uses PyTorch architecture. Because of the size mismatch between the foggy image data and the fog-free image data, the image is cut to 256 × 256 at the data input port, and the clipping mode is random. The network uses an adaptive momentum stochastic optimizer (ADAM) to train the generator and discriminator, where the momentum parameters
Experimental results and analysis
The network dehazing effect of this paper is compared with several other more classical and better dehazing methods from both quantitative and qualitative points of view. The methods of comparison can be divided into three categories, which are based on a priori, supervised learning and unsupervised learning. A priori dehaze method based on a priori selection of dark channels (DCP) [12]. Supervised learning-based use of dehazing methods such as AOD-Net [15], gated context aggregation network (GCA-Net) [6], and Enhanced Pix2pix Dehazing Network (EPDN) [24]. Unsupervised learning based using methods such as CycleGAN [39], Cycle-Dehaze [9]. For supervised learning methods, since this network cannot share the same training set as the network in this paper, we choose the best model provided by the authors for testing, and for unsupervised learning methods, the network is trained using the same dataset as our training set. In the next section, the dehazing results will be analyzed separately for synthetic datasets and real foggy weather conditions.

Experimental results of various algorithms on the SOTS dataset.

Experimental results of various algorithms on the HSTS dataset.
Firstly, the dehaze methods are compared on the synthetic outdoor test set SOTS. The dark channel prior dehazing method often results in incomplete dehazing, as can be seen from the image where its dehazing effect is poor. It especially shows weak performance in handling fog in the sky area, leading to color distortion. This is because the image dehazing based on prior knowledge is influenced by constraints, causing errors in unconstrained areas and affecting the dehazing results. As shown in Fig. 4(c) and Fig. 5(d). the color of the sky area has deviated from the color in the real image. Similarly, methods like AOD-Net and Feature Fusion Attention Network (FFA-Net) have improved the overall dehazing effect of the image and addressed the issue of color distortion. However, they still fail to completely remove the fog in certain regions of the image. EPDN uses a multi-scale generator and discriminator for dehazing to achieve good dehazing results, but color distortion occurs for both sky regions, and the overall darkness of the defogged image is not conducive to subsequent image processing tasks. GCA-Net achieves a good dehazing effect by utilizing multi-modal features and a global contextual attention mechanism to detect differences between global and local information. However, it also darkens the dazed image, as shown in Fig. 4(d). The edges of buildings exhibit significant color variations, resulting in less smooth image processing. Additionally, the sky area has high color saturation, leading to a noticeable decrease in image quality. Although the CycleGAN network does not require paired data, it tends to distort the fine details of the image and does not yield satisfactory dehazing results. As shown in Fig. 4(c), the textual information on the wall and the details of tree branches are distorted in the network output. Additionally, the fog in deeper parts of the image remains uncleared. In comparison, the network proposed in this paper can effectively remove fog from images and restore the original colors and other object information. It performs better in detail recovery compared to other methods, as it integrates information from different scales of images.
The chosen algorithm in this paper utilizes the optimal model provided by the authors. For networks that do not have a pre-trained model provided, training is conducted on the RESIDE dataset to obtain the model. From a quantitative perspective, all methods are evaluated on outdoor test sets by calculating PSNR and SSIM values. Through comparison, it can be observed that the proposed method outperforms other methods on both the HSTS dataset and the SOTS dataset. Table 1 shows the quantitative comparison of the various algorithms on the synthetic datasets SOTS and HSTS. Compared with methods such as AOD-Net, FFA-Net, and EPDN, the proposed method achieves an improvement of 2.74 dB, 2.11 dB, and 0.53 dB in terms of PSNR values, respectively. Many of the other selected algorithms are designed based on U-Net, but these methods do not fully use the characteristics of different layers of downsampling, which makes the image output of the network recover poorly in structure and detail. The proposed network in this paper takes into account features at different scales and incorporates an SSIM loss function in the training process. Therefore, the SSIM values of the network in this paper are higher compared to other algorithms.Compared with methods such as AOD-Net, FFA-Net, and EPDN, the proposed method achieves an improvement of 0.077, 0.046, and 0.03 in terms of SSIM values, respectively.Meanwhile, two novel networks, MFINEA [26] and HFDMN [34], are introduced in this paper for quantitative comparison, and it can be found that the algorithms in this paper are better than the compared networks by analysing the data in Tables 1.
Quantitative comparison (PSNR/SSIM) of different algorithms on SOTS and HSTS datasets
Quantitative comparison (PSNR/SSIM) of different algorithms on SOTS and HSTS datasets
In addition to using full-reference image quality evaluation metrics, this paper also employs no-reference image quality evaluation metrics. Table 2 presents the results of the no-reference comparison among various algorithms on the synthetic datasets SOTS and HSTS. A comparison shows that the NIQE and BRISQUE values of the network in this paper are lower than the other methods, and the value of FADE is only 0.007 higher than Cycle-Dehaze. (Note: Higher values of PSNR and SSIM indicate better image quality, which aligns with subjective human perception. Conversely, lower values of NIQE, FADE, and BRISQUE correspond to superior image dehazing effects.)
Quantitative comparison (NIQE/FADE/BRISQUE) of different algorithms on SOTS and HSTS datasets

Experimental results of various algorithms on the URHI dataset.
The network of this paper is an unsupervised learning model, that uses the data in the real foggy environment, so this method has a strong ability to generalize the real world. The testing of this paper also included a dataset from real-world environments. The testing dataset used was unlabeled real haze images, and all the testing images were different from the ones used for training. Figure 6 depicts the experimental results of the selected algorithms and the algorithm proposed in this paper on a real-world foggy weather dataset. From the Fig. 6, it can be observed that although the DCP algorithm can remove some of the fog in the image, the color distortion in the sky area is severe, and most of the images exhibit checkerboard artifacts, as shown in Fig. 6 (a). The sky area exhibits red and purple patches, and the edge features near the buildings are badly broken. AOD-Net can remove the fog in the near-view part of the image, for the deeper parts of the image, the ability to remove the fog is weaker, as shown in Fig. 6 (a) and (d), the driveway part of the near-view and the building architecture are clearer, but the sky and the buildings in the far-view part of the image are shrouded by the fog, and the effect of removing the fog is very poor, this is because the AOD-Net is a light-weighted network, and it uses synthetic data pairs to be trained, but the Fog is not uniform in the real environment, which causes AOD-Net to process different regions of the image differently. From Fig. 6, it can be observed that FFA-Net performs poorly in handling real-world foggy weather conditions. Similar to AOD-Net, FFA-Net is also trained on synthetic datasets, which leads to a limited generalization capability of the network in real-world foggy environments. As shown in Fig. 6 (c), neither the bridge structure nor the fog in the sky area has been removed. Although EPDN and GCA-Net demonstrate relatively good dehazing performance in some images, their color restoration capability is poor, similar to the results obtained on synthetic datasets. As shown in Fig. 6 (d), after the restoration process, the details of buildings that were heavily obscured by fog are severely lost, and there is color distortion and color blocks in the sky area. Although the CycleGAN network is an unsupervised learning method, it cannot control the degree of style transfer. As shown in Fig. 6 (c), in areas near the bridge with high fog density, the network incorrectly performs style transfer, converting the foggy region into buildings. In comparison, the network in this paper has a strong generalization ability for the real foggy environment, the recovery of details and color is also better than other selected methods, and the treatment of dense fog areas is also better.
In this paper, experiments are also conducted on the non-uniform real environment dataset NH-haze [2], and Fig. 7 shows the experimental results of each algorithm on NH-haze. Similar to the above treatment in a real foggy environment, DCP, AOD-Net, and FFA-Net have removed some of the haze, but on the whole, there is still a lot of fog not removed. Although some images of EPDN and GCA-Net have a better effect of removing fog, the color of the image is offset and the restored image is darker as a whole. CycleGAN still shows style migration errors. The images processed using the method proposed in this paper are generally clear, with a higher degree of object restoration. Although some images still retain some haze, the remaining haze is thin enough to reveal the details.

Experimental results of various algorithms on the NH-haze dataset.
Using each algorithm to make a quantitative comparison in the real foggy environment, Table 3 shows the average values of NIQE, FADE, and BRISQUE of each algorithm on URHI. By comparing the index values of each algorithm, it can be found that this paper’s method has achieved the best results on NIQE and BRISQUE. The FADE metrics are also only 0.029 higher than Cycle-Dehaze, and these metrics reflect that the method in this paper is well adapted to real environment dehazing.
Quantitative comparison (NIQE/FADE/BRISQUE) of different algorithms on URHI datasets
This section confirms the role of each part of the network through ablation experiments. The network of this paper is divided into the following parts, the first part is the base network V1, which is the original CycleGAN network, the second part V2 is based on the first part plus the loss functions such as perceptual loss and SSIM loss. The third part V3 is based on the second part plus the FCA attention mechanism and finally V4 plus the multilayer feature fusion module. Since this paper focuses on dehazing outdoor environments, it is tested on the outdoor dataset of SOTS.The quantitative analysis of the ablation experiments is presented in Table 4, from which it can be seen that each part of the added structure acts positively on the network. Figure 8 shows the results of the ablation experiment, from which it can be seen that each of the proposed parts contributes to the dehazing effect, with the addition of perceptual loss, the parts damaged by CycleGAN style migration can be repaired, and the addition of the feature fusion module improves the network’s restoration of detailed information.
Quantitative analysis of ablation experiments
Quantitative analysis of ablation experiments

Results of ablation studies.
Quantitative comparison of calculation amount, parameter amount and running time of each algorithm
In some scenarios, the dehazing time is an important indicator for evaluating the effectiveness of a method for dehazing, such as dehazing roads in an unmanned environment or monitoring violation information in foggy environments, all of which require fast dehazing. Table 5 shows the amount of calculation, the number of parameters, and the running time of this method and other comparison methods. These indicators are calculated on the input image of 256 × 256, and all the methods are tested on the NVIDIA RTX 3090 system. The number of parameters reflects the amount of memory occupied by the network model, and the amount of calculation directly affects the time of network execution.Although FFA-Net has a small number of parameters, the network structure of the algorithm contains three group structures, each of which consists of 19 block structures, which leads to a significant increase in the computational effort of the network. By observing Table 5, we can find that the amount of calculation in this paper is slightly higher than that of CycleGAN, because 1 × 1 convolution is used in the residual module of the network generator, which greatly reduces the amount of calculation of the network. Although the reasoning speed of this method is not as fast as that of lightweight network AOD-Net, the reasoning time of this method is not different from that of other complex network algorithms.
Lane line detection
In foggy environments, some advanced vision tasks will be affected by fog, such as detecting lane lines in unmanned driving, fog will obscure the lane lines, leading to a decrease in the accuracy of lane line detection and an increase in the false detection rate, which will directly affect the assisted driving of the car. In this paper, the trained ENet-SAD [13] is used to detect the lane lines of different methods, and the detection results are shown in Fig. 9. As can be seen from the picture, the image of DCP and EPDN darkens after removing fog, resulting in only one lane line detected, while CycleGAN destroys the lane information of the image, resulting in a decline in detection accuracy. In this paper, the detection accuracy of lane image after defog is improved, and the rate of missed detection is also reduced. compared with other methods, this paper detects the third lane, that is, the blue lane on the left.

Lane detection results after fog removal using different methods.
Aiming at driverless lane line detection which is easily affected by the foggy environment, resulting in lower detection accuracy and higher false detection rate, this paper designs a multi-layer feature fusion dehazing framework based on the CycleGAN network, which is an unsupervised learning model that does not require pairs of foggy data, and improves the network’s ability to generalize the processing of real foggy environments. To enhance the utilization of the feature information of each layer of the encoder, a multi-layer feature fusion module is designed to enhance the network’s use of details and edge information, prevent features from being diluted during up-sampling, and use the FCA attention mechanism to improve the network’s attention to different channels and optimize the network’s handling of non-uniform fog. Experiments on various datasets prove that this paper’s network is better than other algorithms for image haze, and the NIQE value in real foggy environments is improved by about 0.26 compared with other unsupervised methods. The color and detail information of this paper’s network is maintained better after haze removal, which plays an auxiliary role in advanced vision tasks after haze removal, and the lane line detection accuracy of this paper’s network is improved after haze removal.
Footnotes
Acknowledgements
This work is supported partially by National Natural Science Foundation of China (NSFC) (No. U21A20146). This work was supported by the Open Foundation Project of State Key Laboratory of Power System and Generation Equipment (No. SKLD21KM09), Collaborative Innovation Project of Anhui Universities (No. GXXT-2020-070), and Scientific Research Projects for Academic and Technical Leaders and Candidates of Anhui Province (No. 2020H225).