
Abstract
In this paper we introduce a novel assistant for autonomous navigation of partially sighted people. The system, called ALICE, offers information about the location and possible directions a visual impaired user must follow in order to reach the desired destinations. The navigation is completed with a novel computer vision method that is able to detect and classify, in real-time, both static and dynamic obstacles without any a priori information about the obstacle type, size, position or location. The GPS localization is enriched with a visual landmark recognition technique. Finally, through audio feedback a set of warnings is launched so that the user is alerted of potential hazards. For the feedback, audio bone conduction headphones are employed in order to allow the visually impaired to hear the systems warnings, but also other sounds from the environment. At the hardware level, the system is totally integrated on a smartphone which makes it easy to wear, non-invasive and low-cost.
Keywords
Introduction
According to the World Health Organization the total number of visually impaired people worldwide is 285 million while 39 million are completely blind [31]. In this context, the elaboration of assistive devices for autonomous navigation dedicated to blind and visual impaired people is a challenge.
Nowadays, the white cane and the walking dogs still represent the most popular tools used to increase the mobility of visually impaired and to avoid collision with outdoor obstacles. The cane is also the cheapest, the simplest and most reliable element used as navigation aid. However, it is not able to provide additional information elements such as: the speed and type of object the user is encountering, the static or dynamic nature of the obstacle, the distance and time to collision or information about the path the user has to follow in order to reach the desired destination. This information is gathered for normal users by their eyes and it is absolutely necessary to have it in order to percept and control the locomotion during the navigation [3].
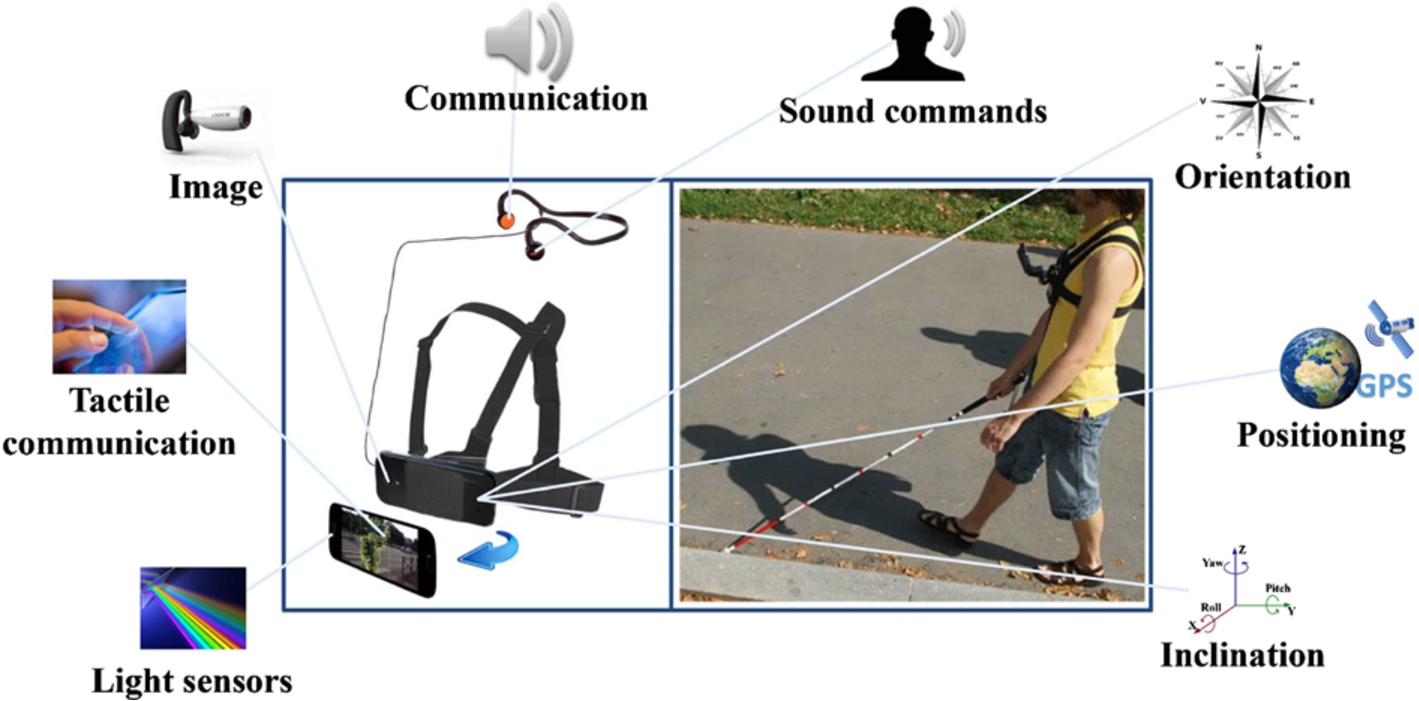
ALICE device.
In its absence the visual impaired (VI) user struggle to memorize all locations they have to traverse, in order to recognize them afterwards. In unknown settings, they feel insecure and depend on other humans to guide them and reach the desired destination [37].
Since 1960s, evolving technologies are selected by researchers in order to develop electronic assistive devices used for navigation. Many sensors were designed to detect and locate objects and to provide users with information that allows them to determine the dimension and height of the object, its position and direction of movement. The sensors allow the partially sighted users to receive directional information about the environment in which they travel (e.g., the physical structure, detection and identification of objects, time to collision based on acoustic feedback
The task of route planning in an unforeseen obstacle environment can severely affect their willingness to travel, despite of having access to white canes or walking dogs [14].
In this context, in order to improve cognition and assist the navigation of VI users, it is absolutely necessary to develop a real-time system that is able to provide guidance (e.g., offer information about the directions and distance through a waypoint) and is able to recognize static and moving objects, in highly dynamic urban scenes. This technology will not replace the cane, but should complement it by alerting the user of obstacles in a few meters or will provide directions. Only one major constraint is imposed on the system: it should not interfere with the other senses as: acoustic or haptic.
Motivated by the above considerations, the European AAL (Ambient Assisted Living) ALICE project (www.alice-project.eu) recently developed a novel navigation assistant, called ALICE. The system, illustrated in Fig. 1, includes a smartphone attached at the level of the user’s chest with the help of a dedicated harness. The principle consists of exploiting the sensorial information (visual, GPS, accelerometer, pedometer
Our contributions presented in this paper notably concern the computer vision-based techniques integrated in the system, which include:
real-time detection and classification of objectsobstacles encountered in outdoor environments for semantic scene analysis and understanding, and
enhanced landmark-based localization within the framework of a joint GPS/inertial navigation methodology that exploits annotated itineraries.
In addition, the device offers an acoustic feedback that warns the user of the presence of any type of obstacle situated in his near surrounding.
At the system level the novelty concerns a real-time, standalone application, working on a regular smartphone. In this context, the ALICE device provides a low-cost, non-intrusive and simple device for VI/blind navigation.

The rest of the paper is organized as follows. Section 2 presents a state of the art review in the field. In Section 3 we introduce and describe in detail the ALICE mobility assistant. The device is composed of an outdoor navigation module (Section 3.1), an obstacle detection and classification module (Section 3.2) and an audio feedback system (Section 3.3). Section 4 presents the experimental results obtained in challenging environments, with various arbitrary moving objects and real blind/VI users. Finally, Section 5 concludes the paper and opens some perspectives of future work.
In the last couple of years various assistive technologies for blind and visually impaired people were introduced. Most of them are based on ultrasonic, infrared or laser sensors.
Various commercial approaches exploit the Global Positioning System (GPS) in order to provide guidance and to localize a VI person. However, in the context of people with special needs such systems prove to be sensitive to signal loss and have a reduced accuracy rate in estimating the user position [34]. This limitation notably appears in the case of urban environments, where the density of buildings is high. Here, the GPS sensors can offer an accuracy error of only 15 meters [34], which in the context of VI is unsatisfactory. On the other hand, the GPS cannot provide information about the type of obstacle the user is encountering or of its position (e.g., front, at the head or foot level, near surrounding) [8].
A different axis of research was directed on ETAs (Electronic Travel Aids) devices designed to replace the traditional vision system. Most ETAs are based on sensors to acquire environmental information. Even though ETAs have been widely used [33,35,36] they have had limited success because of inadequate interfaces and usability issues. Such interfaces (e.g., acoustic, haptic) aim at providing a sensorial substitution to vision. However, the information captured by the eyes cannot be entirely substituted by audition or touch. In addition, the overall hardware architecture of any existent ETA system should be embedded, lightweight and comfortable to wear [13].
In an outdoor navigation scenario normal humans acquire all information for safe displacement through the vision system. Based on this observation, we propose using artificial vision in the context of partially sighted users.
Due mostly to the high limitations related to the required computational power and to the lack of robustness of the vision algorithms, this axis of research has been poorly exploited for the VI assistant purposes.
Nevertheless, in the last years, significant advances in computers and vision techniques have been achieved. Today, it becomes possible to perform reliable real-time algorithms on embedded computers and even on smartphones that run on powerful multi-core processors. The computer vision systems, unlike ultrasonic, infrared or laser technologies offer superior level of reality reproduction in exchange of processing complexity.
In the following part, we will briefly present the most important systems existent in the literature. We will study them and give comparative evaluation that answers questions of how advanced, useful and desirable each system is. The focus is put on the feedback sent to a VI user.
The vOICe system (Fig. 2a) is composed of a video camera and a processing unit. The video frames are sent to a computer, designed to convert the visual information into sound maps of the environment [27]. The system has a simple architecture, is easy to ware, light weighted and is able to augment the human hearing capabilities. However, the authors propose using regular headphones that block the user ears. Also, in order to become familiar with the sound patterns the VI user requires an intensive training phase which is time and money consuming.
In [16], authors propose a system compose of a sensor module with detachable cane and a computer that tries to develop a 3D map of the environment (Fig. 2b). The framework can be used in indoor scenarios and is able to assists the VI to orient themselves. However, the entire system performance depends of the sensor robustness. Even so, the prototype can identify only a reduced number of objects, needs to be hand-hold and all the testing are performed in simulated environments.
Figure 2c illustrates the virtual acoustic space [15] designed to help VI users to orient themselves by using a sound map of the environments and receiving spatial information at the neuronal level. By using eyeglasses (equipped with video cameras) and headphones, the system is considered easy to wear and small. The major drawbacks are given by the violation of the ear-free constraint. In addition, it has never been tested with real VI user in outdoor environments.
The University of Guelph project [40] proposes using the tactile stimulation in order to transmit information to VI user. The system is composed of low price video cameras and develops a depth map of the environment by using the stereoscopic vision. The system is simple with a reduce power and cost (Fig. 2d).
In spite of that, the system is sensitive even to slight modifications in the light intensity and returns inaccurate depth maps. Also, the hands-free constraint imposed by the VI users is violated.
By using electro-tactile stimulation, GPS and visual sensors, in [26] is introduced the electronic neural vision system (ENVS).
ENVS is designed as a real-time system that facilitates the navigation of VI and also alerts users of potential hazards in their way. The warning messages are transmitted to VI by electrical nerve stimulation gloves. In this case, the user hands are always occupied (Fig. 2e). Moreover, the ground and overhead objects are not detected, while the walking path needs to be flat (i.e. no stairs).
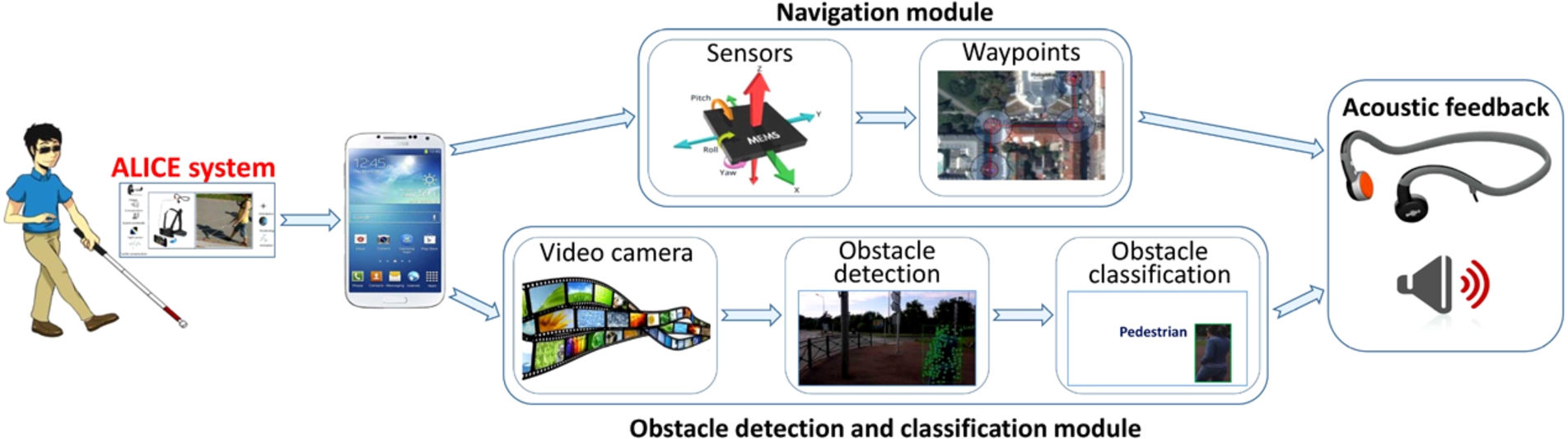
The proposed navigation and obstacle detection framework.
In [17], authors introduce the electronic aid device CyARM that helps VI users to localize and orient themselves by providing guiding information. By using an ultrasonic sensor, the system is able to detect various types of obstacles that are present in the scene and also compute an estimative distance between the VI user and the object (Fig. 2f). CyARM returns a high detection rate for static obstacles and has an intuitive interface. On the other hand, in the case of dynamic objects the detection performance decreases with more than 25%. Furthermore, the user needs to hold the device when scanning the environment. Furthermore, experiments with real VI users were never been performed.
The tactile vision system (TVS) introduced in [18] is designed as a compact, wearable device able to detect in real-time obstacles and provide directional information during navigation. The alerting messages are sent to the user with the help of 14 vibrating motors attached to a flexible belt (Fig. 2g). In this way the hands and ears-free conditions are always satisfied. However, the system is not able to differentiate between ground and overhead. Also, the experimental evaluation was never performed with real visually impaired users.
The EPFL system proposed in [4] uses stereoscopic sonar to detect obstacle situated at the head and shoulder level (Fig. 2h). The prototype can estimate the distance to the nearest obstacle and translate it into vibration information. From the experimental evaluation, performed solely in indoor scenarios, it can be observed that users can orient themselves, manage to walk through corridors and distinguish between obstacles. Still, the use of sonar for the 3D environment estimation is unreliable. Even so, the system returns a high number of false alarms given mostly by the user own hands motion.
The navigation assistant Tyflos, first introduced in [6] and extended in [7] uses at the hardware level two video cameras for depth image estimation, a microphone, an ear headphones, a processing unit and a 2D vibration vest (Fig. 2i). The architecture satisfies the hands-free constraints and the VI can be alerted about obstacles situated at various levels of height. However, the necessity of wearing a vibration vest situated near the skin makes the entire framework invasive. Also, experiments on real VI users need to be conducted.
By using a Kinect camera combined with a depth sensor and acoustic feedback, in the KinDetect system proposed in [19] is designed to recognize objects and other humans. The system can identify obstacles situated at head or foot level by processing the depth information on a backpack computer (Fig. 2j).
As expected, by using a Kinect sensor the KinDetect applicability is limited to indoor scenarios. Also, by using regular headphones to transmit acoustic warnings the user ears are always occupied. Also, the system has never been tested on actual VI users. To our very best knowledge the only systems designed to incorporate a navigation assistant on a regular smartphone (Fig. 2k) is proposed in [32]. By using the computer vision techniques, the prototype is able to detect with high confidence objects situated at arbitrary height levels. However, the evaluation was performed only in indoor spaces and only by regular people. In addition, the hands-free condition [25] imposed by the VI user is violated because the smartphone needs to be hand-hold.
After intensive discussions with several groups of VI users and researchers the following conclusion can be highlighted: no system incorporates all required features (i.e. works in real-time without any connection to a processing unit, is wearable, portable, reliable and robust at a reduced cost) in a satisfactory degree. Every system presents its own advantages and limitations but cannot meet all the features and functionalities needed. The difficulty is not developing a system that has all the “bells and whistles” but to conceive the technology that can last in time and be useful. For the moment, the VI users cannot be completely confident about the robustness, reliability or overall performance of the existing prototypes. Any new technology should be designed not to replace the cane or the walking dog, but complement them by alerting the user of obstacles in a few meters, and provide guidance.
Let us now detail the ALICE approach, which aims at fulfilling such constraints and requirements.
The ALICE framework consists of two major parts (Fig. 3): a computer vision module which enables the system to perceive the environment and a navigation module which helps the VI to travel along the chosen path.
Navigation system
For navigational purposes, we have adopted and extended the ALICE navigation framework, proposed by the ALICE project (www.alice-project.eu). Let us first summarize the main functionalities proposed by the baseline ALICE navigational framework.
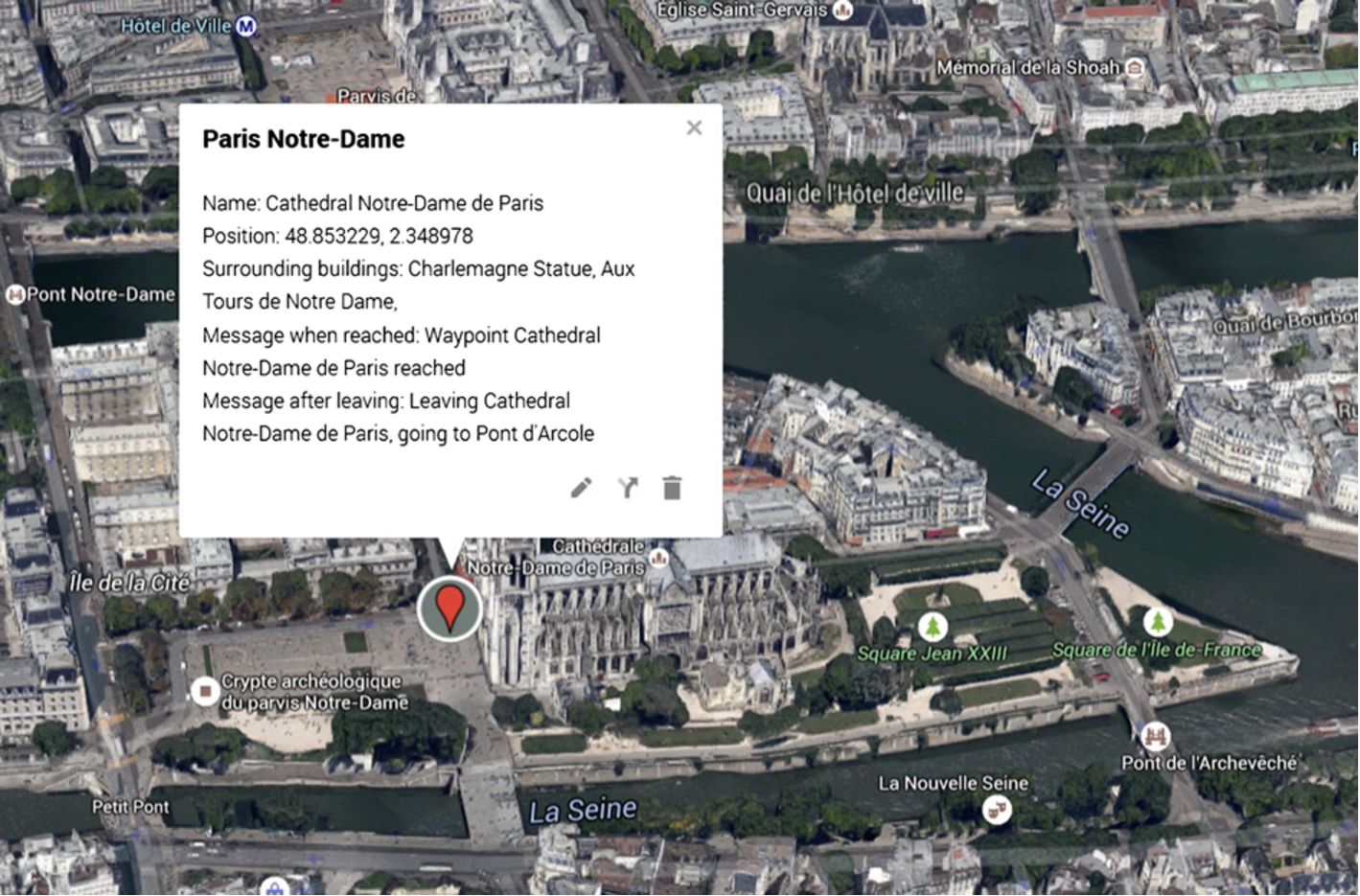
Waypoint annotation.
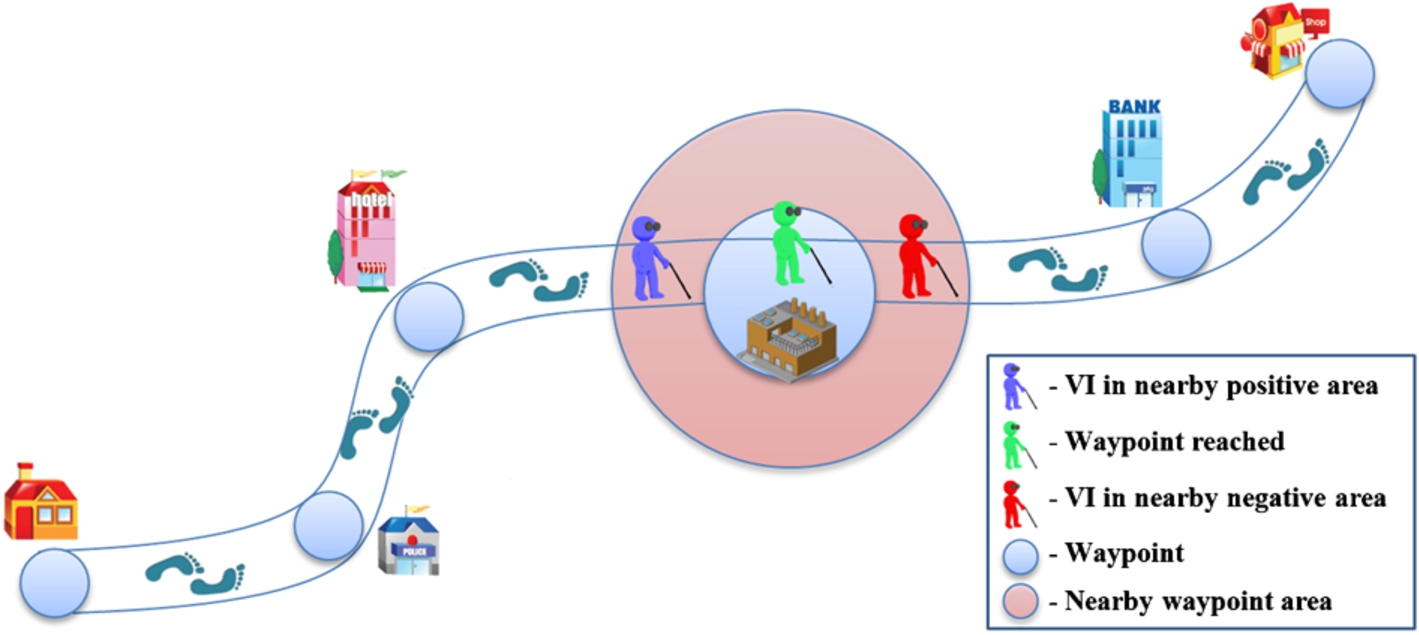
Three types of proximity areas associated to a waypoint: near positive, reached, and near negative.
The user’s position is estimated using the GPS signal. Such an approach provides relatively accurate localization in open spaces. However, in the case of urban canyons, the position can be lost due to sensor dropout/failure. To address such limitations, various improvements have been considered.
A first solution retained concerns the so-called inertial navigation [20] method. The relative principle consists of using the measurements provided by accelerometers, gyroscopes and pedometers to track the position and orientation of a user relatively to a known starting point. In this manner, it is possible to determine the user’s velocity, direction and elapsed time from a given waypoint. Also, by counting the number of steps an estimation of the traveled distance can be obtained and thus of the novel user location, even when the GPS signal power is reduced or lost.
The inertial capabilities are further combined with an enhanced navigation mode, based on annotated maps, which makes it possible to reinforce the positioning system with map-based priors [30].
The principle consists of creating annotated itineraries, which include a set of waypoints to be detected [28]. With the help of a dedicated user interface, the caretaker or a relative can establish a path for the VI user and also specify some waypoints. This is performed interactively, by using available web maps (such as OpenStreetMap, Google maps
The resulting information is stored in a KML file and saved on the VI smartphone.
In run-time mode, the user first selects one of the annotated itineraries available. We consider as base-point for navigation the current location of the VI user and as target the following waypoint on the path. Once a waypoint is reached, it becomes the new base point. The process is conducted iteratively until user reaches the final destination.
In the context of ALICE three areas of proximity are defined (Fig. 5). They are denoted by:
nearby positive (i.e. the distance to the waypoint becomes inferior to 10 meters),
reached (i.e. the user is situated at a distance of maximum 5 meters from the waypoint), and
nearby negative (i.e. the distance to the waypoint becomes superior to 10 meters).
When the user enters in one of these areas, the system informs him and offers directional information in order to reach the waypoint. When the user enters in a nearby negative area the system informs the VI user that he is leaving the current waypoint and offers guidance to reach the following waypoint in the itinerary.
Experiments with blind/visual impaired users in various scenarios (traveling alone and/or accompanied by a friend) showed that the relative accuracy of the inertial navigation is about 5–10% of the total distance between target and source waypoints (e.g., 2,5–5 meters for a distance of 50 meters). Such an error is fairly acceptable, since the distances to be covered solely on the base of inertial navigation (e.g., in the absence of the GPS signal) are rarely greater than 50 meters. When combined with GPS and when also taking into account the user’s own abilities of identifying a waypoint by himself (e.g., based on previous experiences), this globally leads to satisfactory positioning performances, validated by the end-users involved in the ALICE project that intensively evaluated the system.
When the GPS signal is lost, due to any extrinsic limitation, the system will inform the visual impaired user about this situation (e.g., GPS signal lost). Because we complement the GPS localization with sensors and computer vision (i.e. landmark detection) the lost of localization can rarely occur (as long as user does not willingly leaves the annotated path). However, when this situation happens the user is informed and he knows to has to rely only on the cane and on the obstacle detection/classification module. When the connection is reestablished the VI is informed and he can continue the navigation normally.
Additionally, we propose an extension to the ALICE navigational framework, which concerns a landmark annotation system used to further enhance the localization capabilities.
Landmark-based localization
The principle consists of enriching each waypoint with a set of landmarks, defined as images associated to the considered waypoint. The challenge here consists of achieving the image recognition approach exclusively by using the smartphone computational capacities. To this purpose, an adapted, dedicated learning and recognition process is proposed.
The core of the proposed method is notably based on the concept of vocabulary tree, introduced in the following. Here, instead of matching a query descriptor to its nearest visual word, we perform the matching with respect to a reduced list of interest points extracted from an image in the dataset.
Each landmark image in the dataset is described by a set of interest points, detected with the help of the Difference of Gaussians (DoG) [22] method and described by SIFT descriptors [23]. By applying a k-means clustering algorithm, a visual vocabulary is constructed. In our case, the size of the vocabulary was set to 4000 elements which represent the visual words.

An example from the Zurich Building dataset. (a) the five labeled images used for the training phase. (b) two test samples that were successfully matched to the correct class of buildings with correctly (in blue) and wrong (in red) interest point assignment. (Color figure online)
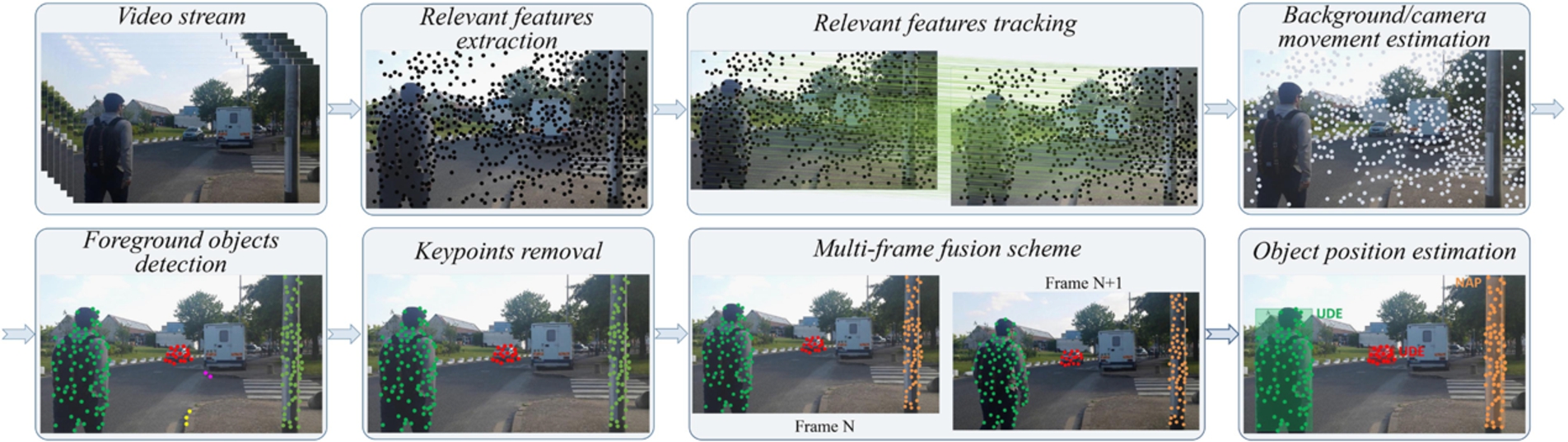
Static/dynamic obstacle detection.
Each interest point in the dataset is then assigned to the three nearest visual words in the vocabulary, with the help of the FLANN matcher [29]. Such a soft assignment makes it possible to reduce the influence of the relative quantization errors.
At run-time phase, images are automatically acquired at a relatively slow user-defined rate (typical settings: 5–10 seconds) and used as a query to be compared with the landmarks in the database.
For each query image, we extract DoG interest points and their corresponding SIFT descriptors. We train a kd-tree from the list of visual words in the vocabulary using the FLANN approach as an initialization step. The trained kd-tree is used as a first step to find the corresponding visual word for each interest point. Then, a BruteForce matcher, based on the Euclidean distance between SIFT descriptors is applied. This makes it possible to determine the most similar elements from the cluster of descriptors corresponding to the same visual word.
This two phase matching method allows us to benefit from both FLANN matcher’s speed search and the BruteForce matcher’s consistency. In fact, the BruteForce search becomes computationally expensive only if the number of comparisons is too high. In our case, the average number of descriptors in a given cluster is around 250 which ensures a relatively low computational cost. As a final step, a class histogram collecting the different scores obtained is constructed. Assuming that an image can only be labeled to one class or none, we require that the confidence measure of the top-ranked class to be greater than a predefined threshold. This measure is defined as the ratio between the best score and the number of interest points in the image. If the top ranked class has a confidence measure less than the fixed threshold, we assume that none of the known classes exists in the query image. A negative label is then returned. Otherwise, the label of the class with the best score is returned. In our experiments, we have considered threshold values between 5% and 15% which yield relatively stable results.
The proposed approach has been totally implemented on an Android smartphone without the need of any server-client communication. It is an offline application that the user can run even without an internet connection. In this case, we have to limit the number of possible building categories to about 5–10 landmarks. This is however sufficient to deal with a given itinerary.
Concerning the relative performances, we have conducted an objective evaluation, carried out on the publically available Zurich [38] dataset. The global mean recognition rate obtained is superior to 90%. A recognition example is illustrated in Fig. 6.
Let us note that the great majority of interest points is correctly assigned, which makes it possible to determine the correct class.
This concludes the description of the ALICE navigational capabilities. Let us now detail the scene interpretation functionalities proposed and integrated within the ALICE device.
Static and dynamic object detection
Figure 7 illustrates the main steps involved in our static and dynamic obstacle detection framework, which are detailed in the following.
From our experiments we have observed that the frame background has a significantly higher number of interest points than the one corresponding to the obstacle. Furthermore, in the case of low resolution videos or for less textured regions SIFT or SURF detectors extract a reduced number of interest points or even none. In the case of important camera or background motion, which translates into an abrupt variation in the background characteristics the interest points and their neighbors can be substantially different between adjacent images.
Another aspect that needs to be considered is the computational complexity of traditional interest points descriptors which in the case of real-time application becomes an important constraint.
Based on the above considerations, in this paper we have selected to use the regular grid sampling strategy. In our case, an important parameter is the grid step that is defined as:
In the literature there are various methods such as [2] that are able to increase the estimation accuracy and are robust to abrupt changes in the illumination.
However, in our case, where the computational burden is an important constraint, we cannot adopt this strategy because the main goal of this step is to provide a relative good estimation of the motion vectors, rather than a highly accurate one but with an increase processing time. So, in order to initialize the LKA tracking algorithm we used on the first frame of the video sequence the interest point extraction algorithm using the regular grid (presented in Step 1).
The same process can be locally applied to reinitialize the tracker when such action is required (e.g., when obstacles disappear or other/new objects appear).
If we denote with
Then, for every interest point we compute the difference between the estimated position and the tracked position of that interest point determined using the LKA:
Ideally, if the transformation matrix is perfectly estimated then the difference between
In our experiments we set the background/foreground separation threshold
Obstacles relevance establishment based on their position and relative direction.
The basic principle of the method is to consider each interest point as a cluster and then to try to reduce the number of groups by merging adjacent clustering based on a similarity criterion. The operation stops when no point is able to satisfy the similarity constraint [5]. The sensitivity of the method is given by the proximity computation of interest points assigned to different clusters. We propose the following strategy:
Phase I – Sort the interest points motion vectors in descending order of the number of occurrences of the corresponding angular value. Then, the first interest point in the ordered list will determine a new cluster (
Phase II – For all the interest points not yet assigned to any cluster we compute the angular deviation by taking as reference the centroid:
If
Based on this observation we propose reinforcing the object detection process with a multi-frame fusion scheme.
By saving the object location and its average velocity within a temporal sliding window of size N, we can predict its novel position (Fig. 7) using the following equation:
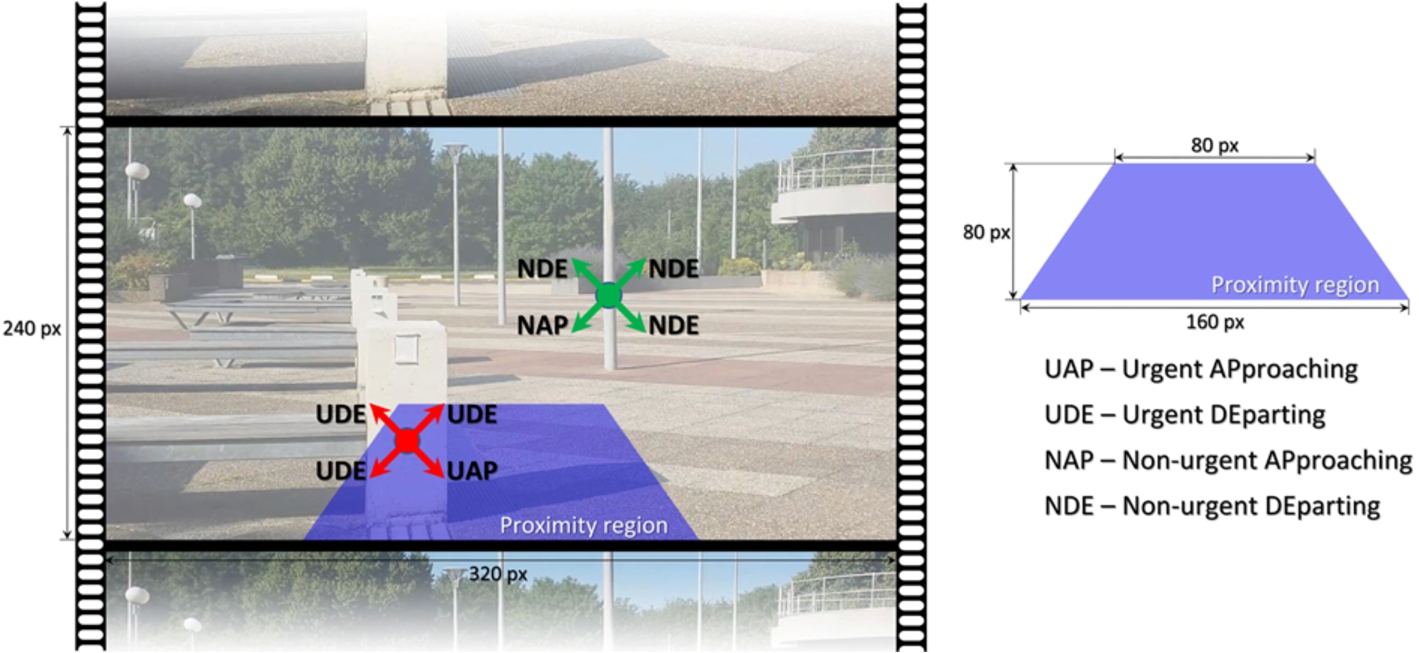
We propose to use a trapezium region projected onto the image in order to define the user’s proximity area. In Fig. 8 we give also the trapezium dimensions (in pixels).
We used for video acquisition the camera embedded on regular smartphone with a field of view
For the trapezium the height is equal with a third of the total image height and we can establish its associated Euclidian distance as:
Nevertheless, the size of the trapezium can be adjusted in a pre-calibration step by the user. The camera proximity distance is computed as:
An obstacle is marked as urgent (U) if it is situated in the proximity of the blind/visual impaired person (1.5 meters). Otherwise, if located outside the trapezium, the obstacle is categorized as non-urgent or normal (N).
However, by employing two areas of proximity we can prevent the system to continuously warn the subject about any object existent in the scene. A warning can be launched just for objects situated in the urgent region (Fig. 8).
The downside of this assumption is given by the rejection of warnings for dynamic objects (e.g., vehicles) approaching the user very fast or for obstacles situated high at the head level, such as tree branches, arcades or small banners. To avoid these situations in the following part of the paper (Section 3.2.2) we introduced a novel classification method designed to help us differentiate between various types of obstacles. Using this information we can generate warning outside the trapezium, when such an action is required.
Each frame of the video stream can be considered as a hierarchical structure with increasingly higher levels of abstraction. The objective is to capture the semantic meaning of the objects in the scene. In this framework, we have considered a training dataset divided into the following four major categories depending on their relevance to a VI person: vehicles, bicycles, pedestrians and static obstacles.
The considered categories were selected according to the most important obstacles encountered in an outdoor navigation scenario by VI users. Let us note that the class of static obstacles is characterized by a high variability of instances: fences, pylons, trees, garbage cans, traffic signs, overhanging branches, edge of pavements, ramps, bumps, steps
The proposed obstacle classification framework can be summarized in the following five steps:
In the context of ALICE framework the extraction of traditional HOG implies constraining the size of the image patch (extracted using the obstacle detection method described in Section 3.2.1 and representing the object’s bounding box) to a fixed resolution. Such a constraint may penalize the entire system that will return high recall rates only for the pedestrians’ classification. A fixed resolution of the analysis window will alter significant the aspect ratio of the patch and the descriptor will have reduced discriminative power.
In the literature, different authors [10] propose overcoming such limitations by modifying the size of the patch to a pre-established value appropriate for each category (e.g., for bicycles 120 × 80 pixels, for cars 104 × 56 pixels
Even so, in our case the class of static obstacles is characterized by a high variability of instances and it is impossible to find a specific resolution adequate for each element (e.g., garbage cans or traffic signs). On the other hand, because our system is designed to assist the VI on navigation, it should also work as a real-time application. So, a multiple window size decision approach would be intractable.
In order to avoid this limitation, we introduce a novel version of HOG descriptor denoted adapted HOG (A-HOG) that dynamically modifies the patch resolution while preserving its original aspect ratio. In this case, the image resolution is not distorted to match the requirements of a specific class. Our system limits the maximum number of cells for which the descriptor is extracted. In order to satisfy this constraint we propose reducing the size of the patch in such a way to meet both requirements: conserving the initial aspect ratio and matching the fixed number of cells imposed. This approach makes it possible to extract the descriptor only once, regardless of the object’s type.
Figures 9 and 10 present a visual comparison of the classical HOG descriptor and the proposed A-HOG (when fixing the maximum number of cell to 128).
It can be observed that in our case the patches are no longer distorted and the extracted descriptor is able to capture the informational content of the image.
In our experiments, we have considered the cell dimension of 8 × 8 pixels with 18 orientation bins and a number of cells fixed to 128.

The associated HOG descriptors at a fixed resolution (64 × 128 pixels) of the image patch.

A-HOG descriptors at dynamic modified resolution of the image patch.
If we consider a training dataset of images
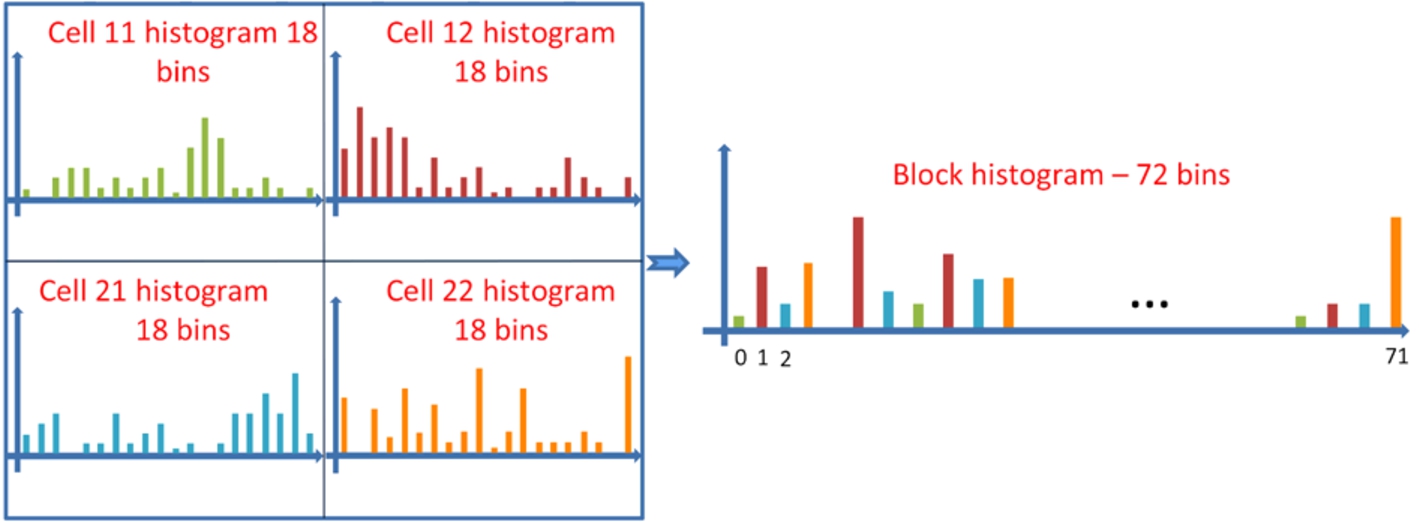
A-HOG descriptor associated to block of 4 cells.
However, developing visual words only by using cells of 18 bins is insufficient to capture the contextual information. In order to avoid this limitation, we propose creating an off-line vocabulary
We used for clustering the k-means algorithm [12].
Now, each image in the dataset is represented as a histogram of visual words. The total number of bins that compose the histogram is equal to the number of words M included in the vocabulary. If each bin
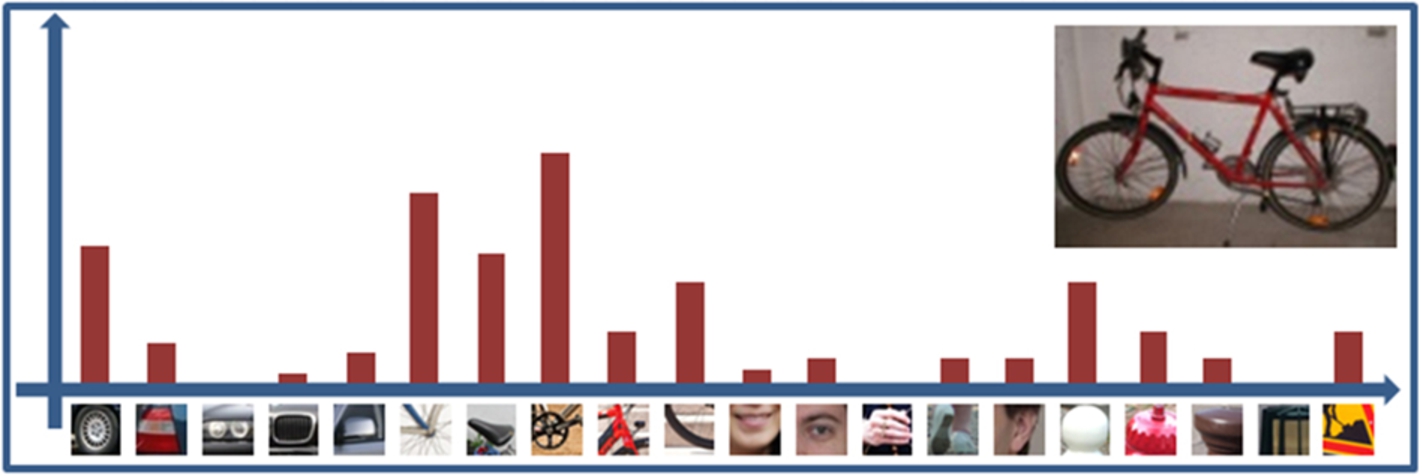
Histogram of visual words.
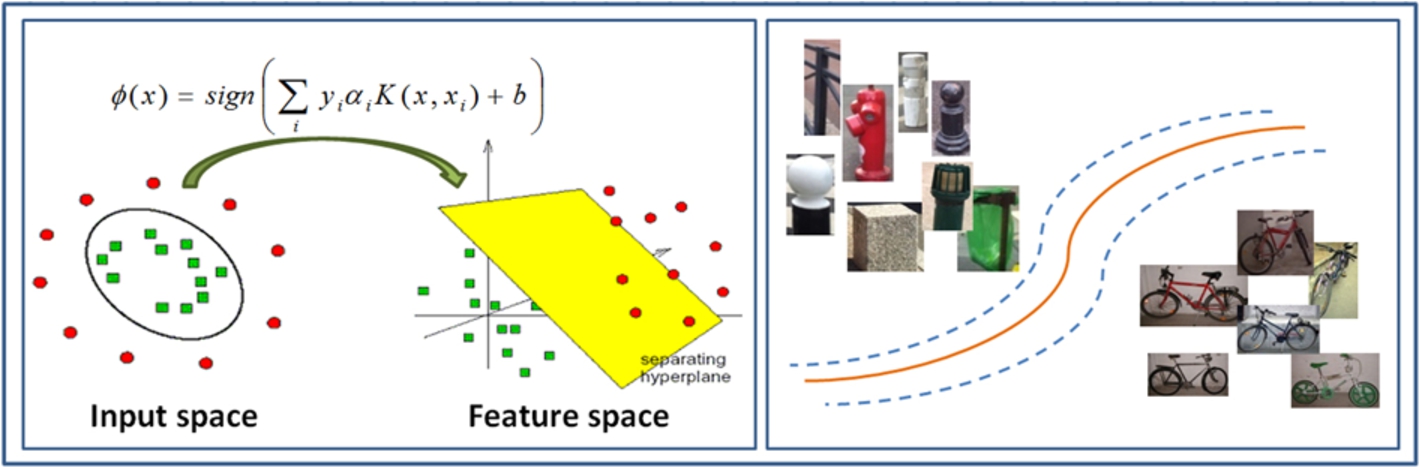
Feature classification using SVM.
The SVM training phase completes the offline process of our object classification framework.
Our technique requires a reduced computational power because there is no need to perform an exhaustive sliding window search within the current frame in order to determine objects and their associated positions. In our case, the obstacle classification already receives as input the location and size of the object we want to label.
The acoustic feedback is responsible of informing the VI user about the presence of potential static/dynamic obstacles in his way and of the navigation messages which guide the user along the predefined path.
The audio interface need to satisfy one major requirement: “not to block the user’s ears” [34] In our work, we have considered the recommendations of two end-user blind people associations involved in the European AAL ALICE project (www.alice-project.eu) in order to design the human-machine interface (HMI) and the acoustic feedback.
In order to determine the path to destination or insight potential dangerous situations, the VI people use the sounds from their surroundings to infer information. For example, they use the sounds coming from vehicles to understand the orientation of the streets so they can avoid drifting or follow a straight trajectory.
Warning Messages Generated by the system
Warning Messages Generated by the system
Within the navigation framework, the user is informed about the starting or ending point of the journey, getting near, reaching or leaving a waypoint, leaving the path or getting back on it.
In the case where various objects are presented in the scene, in order to not confuse the user, only one warning at a time is generated by the system. Table 1 presents the set of alarms retained in our framework, in descending order of priority (relevance).
Functional and structural requirements imposed on a navigation assistant
After the analysis of the navigation systems presented in Section 2 and after a set of discussions with several groups of VI users involved in the ALICE project, software developers and researchers, we determined the most representative features an ETA should have (Table 2).

ALICE device.
The system architecture adopts the recommendations specified by the ALICE project consortium. It is simply composed of a regular smartphone attached to a chest mounted harness and bone conduction headphones.
The harness has two major roles: it makes it possible to satisfy the hands-free requirement imposed by the VI and improves the video acquisition process, by reducing the instabilities related to cyclic pan and tilt oscillation.
The system can be described as a wearable and friendly device, ready to use by the VI without any training. The proposed solution is low-cost, since it does not require any expensive, dedicated hardware architecture, but solely general public components available at affordable prices on the market.
In addition, the system is also non-intrusive, satisfying the hands-free and ears-free requirements imposed by VI users (Fig. 14).
Also, by using only a regular smartphone the system is portable and does not require any connection to a processing unit.
We tested the system in multiple complex outdoor urban environments acquired within the framework of the ALICE project and used as objective evaluation corpus with the help of visual impaired users.
The image sequences are very challenging because they contain in the same scene multiple static and dynamic obstacles, including vehicles, pedestrians or bicycles. Also, because the recording process is done by VI users, the videos are trembled, noisy, include dark, clutter and dynamic scenes. In addition, different types of camera and background motions are present.

Experimental results of the obstacle detection and classification framework using ALICE device.
The annotation of each video was executed frame by frame by a set of human observers. We used a group of five persons to annotate the videos in order to reduce the accidental errors like: missing events or false labeled objects due to the annotator concentration loss. Other well-known errors made by humans are bias and observer drift (observation influenced by context). Furthermore, human annotators are subjective in their interpretation regarding the precise timing of the events (e.g., the moment an obstacle becomes dangerous for a subject, the moment an obstacle leave the user field of interest
When a ground truth test data set was available the detection errors were globally described with the help of two error parameters, denoted
Based on these entities, the most often popular evaluation metrics encountered in the technical literature are the recall (R) and precision (P) rates, respectively defined as described in Eqs (13) and (14).
The recall and precision rates can be combined within a unique evaluation metric, denoted by F1 norm and defined as follows:
Warning Messages Generated by Our System
Obstacle classification module performance evaluation
Notes: GT – Ground Truth, MD – Missed Detected, FA – False Alarms

Precision, recall and F1 score variation with the increase of the codebook size.
From Videos 1–4 we can observe that our system can correctly detect static obstacles (e.g., pillars, road signs and bushes) situated either at the head level or down on the foot area at around two meters distance from the user. In all cases, the recording camera has important motion caused mostly by the subject own displacement.
Regarding the dynamic obstacles (e.g., pedestrian, bikes or vehicles) they are detected at larger distances from subjects (about ten meters). However, because in some cases, only parts of the obstacle are detected, the classification phase can be penalized by this behavior. In the case of Video 2 the pedestrian in the second frame (colored with magenta) is labeled as obstacle because only the body of the subject is given as input to the classification method.
In the following part we present a comprehensive evaluation of the obstacle classification module when modifying the various parameters involved.
We conducted multiple tests on a set of 2432 image patches that were extracted from the video database using our obstacle detection method introduced in Section 3.2.2.
In Table 4 we give, for a vocabulary size of 4000 words, the system performance for each considered category and the associated confusion matrix. As it can be observed from Table 4 we have extended the number of categories with one extra class called Outliers.
We adopted this approach to make sure that our system classifies a patch to a class due to its high resemblance with a word in the vocabulary and not just because it is required to make a decision. For all the objects included in the Outlier class a beep signal will be generated in order to alert the user about its presence.
We also studied the impact the vocabulary size has on the overall system performance. Figure 16 presents the experimental results obtained in terms of precision, recall and F1 score. As it can be noticed, a vocabulary with 4000 words returns the best results.
However, we have to consider that our framework is designed to work as a real-time application for which the classification speed is a crucial parameter. With the increase of the vocabulary size, the computational complexity will significantly increase. So, due to this constraint we selected for the vocabulary a size of 1000 words.
The system can be optimally integrated on any mobile device running Android as operating system, with a processor superior to 1.3 GHz and 2 GB of RAM in order to ensure a frame rate superior to 7 fps. Regarding the computational complexity, the average processing time of the entire framework (obstacle detection and classification) running on a Samsung S4 smartphone is around 140 ms per frame which leads to a processing speed around 7 frames per second.
Discussion: We proposed to use a trapezium region projected onto the image in order to define the user’s proximity area. By employing two areas of proximity (i.e. the surface bounded by the trapezium and the outside area) we can prevent the system to continuously warn the subject about any object existent in the scene. A warning can be launched just for objects situated in the urgent region.
However, the area the trapezium of interest is directly influenced by the camera viewing angle. In Fig. 17 we present an example of a correct way of filming and two different wrong examples that are influenced by the tilt angle of the smartphone.
So, by using the sensor existent on the smartphone (i.e. accelerometer) we can also inform the user about possible problems generated by the device position.
All the experimental results were obtained when the smartphone tilt angle varies between 60 and 90 degrees.
In order to determine the VI satisfaction level after using ALICE system we defined a list of basic objectives we want to achieve during tests. The main goal of testing was to get information if users are able to: start the application, navigate between annotated waypoints one the route, avoid obstacles and reach the final destination.
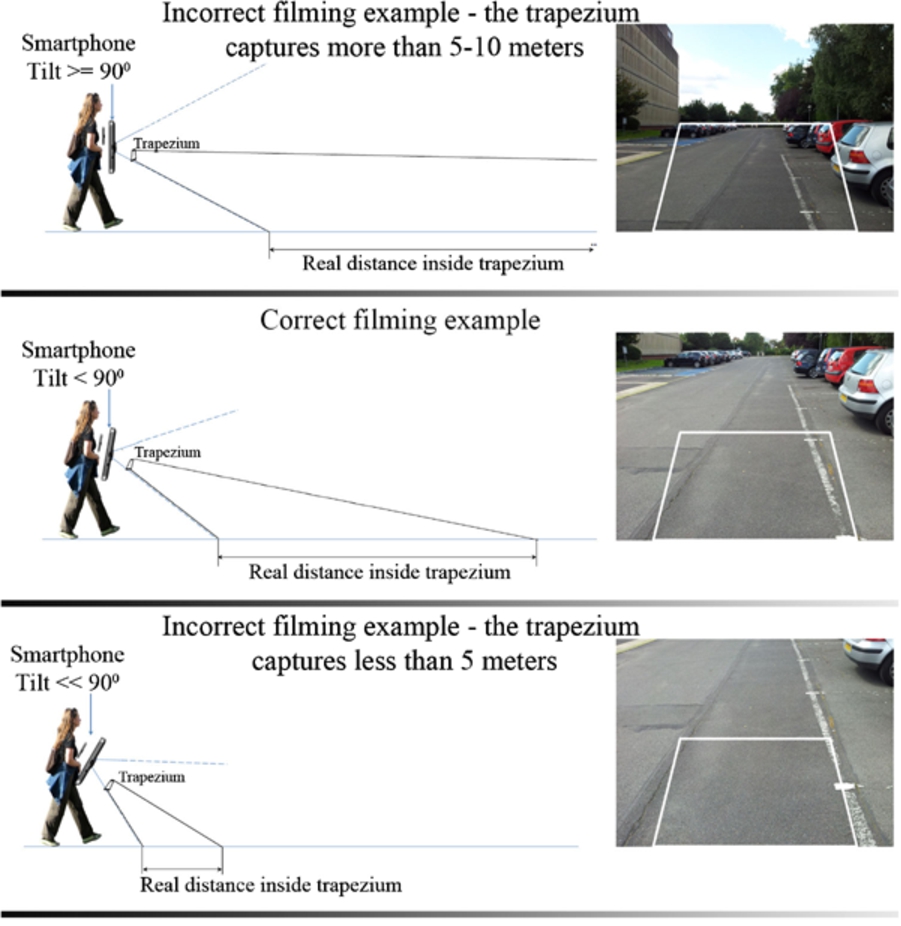
Smartphone filmining examples.
After a participant completed the task, an observer conducted a post-test debrief interview with users about the behaviors they observed during the testing. A number of 20 VI and blind end-users from the two end-users associations involved in the ALICE project participated to the experiments.
Results reveal that the overall satisfaction with ALICE is relatively good. At the beginning of the testing because of consequently mistrust innovations and lack self-esteem some users preferred to rely on their remaining sight or other senses, rather than on technical solutions. This was due to inadequate knowledge about the working of the ALICE system.
At the end users expressed that the system is useful and easy to learn if they receive appropriate introductory training and support from the technicians or carriers. VI without sufficient abilities for handling software equipment independently expressed strong interest for such kind of training in the future.
Most users are willing to wear headphones. In fact, the discovery of bone-conduction headphones delivered very acceptable speech feedback without impeding the ambient sound cues and clues so vital to visually impaired travelers.
In addition, users reported that ALICE delivers reasonably accurate navigation on pre-set routes which have been properly annotated, and also delivers useful and reasonably accurate landmark information. Regarding the obstacle detection and classification module VI concluded that the alerts were accurately delivered at the right moment. There were no delays in informing of the user and no alert was missing.
In this paper we have described a novel assistive device simple and portable satisfying both the hands and ears-free constraints, able to facilitate the partially sighted person navigation in outdoor scenarios. Without any a priori information about the obstacle type, size, position or location, the proposed framework is able to detect and classify in real-time both static and dynamic obstacles. In addition, a visual landmark recognition approach makes it possible to enhance the localization capabilities of the device. Then, through an audio feedback a set of warning is launched to the VI. The method is embedded on a regular smartphone that is attached to the user with the help of a chest mounted harness.
We tested our method on different outdoor scenarios with visually impaired participants. The system shows robustness and consistency even for important camera and background movement or for crowded scenes with multiple obstacles.
Our further work mainly concerns the elaboration and development of more advanced detectors/classifiers that can take into account different floor models, including stairs. In addition, the recognition of specific urban signalization elements would also enhance the navigational capabilities proposed. Finally, a more precise estimation of distances/time to collision with respect to the various objects detected would be beneficial.
On the other hand, a much more elaborated study on VI users behavior and requirements will offer us some further guidelines.
Footnotes
Acknowledgements
This work has been partially supported by the AAL (Ambient Assisted Living) ALICE project (AAL-2011-4-099), co-financed by ANR (Agence Nationale de la Recherche) and CNSA (Conseil National pour la Solidarité et l’Autonomie).