Abstract
In this paper, a novel variational method is introduced for multi-object tracking in a network of cameras. In a camera network, objects are tracked by each camera using any of conventional algorithms and their tracks are extracted. Each extracted track is called a tracklet. The extracted tracklets are the inputs to our proposed method. Our objective in this paper is to associate the corresponding tracklets of an object and present the persistent trace of all objects. The association is formulated and solved using a variational energy function, which is based on appearance and motion model of objects. The optimization is realized by, first converting the variational energy function into an Ordinary Differential Equation (ODE) employing the Euler-Lagrange equation; then, the ODE is solved by numerical methods. The proposed method is evaluated on three well known real datasets and one synthetic dataset. The performance of our method is compared with the state of the art methods, employing the conventional metrics and under less restrictive assumption, and superiority of our method is demonstrated.
Introduction
In recent years, demands for monitoring wide geographic area, for different applications, is increased. The visual monitoring is realized by utilizing a network of cameras. In order to take advantage of these systems more efficiently, autonomous tools are required [15,22]. An important component of this autonomous system is an algorithm that tracks objects in different cameras persistently. The persistent tracking of objects includes of two steps: 1-Tracking objects in each camera and extracting the tracklets, 2-associating the tracklets for each object.
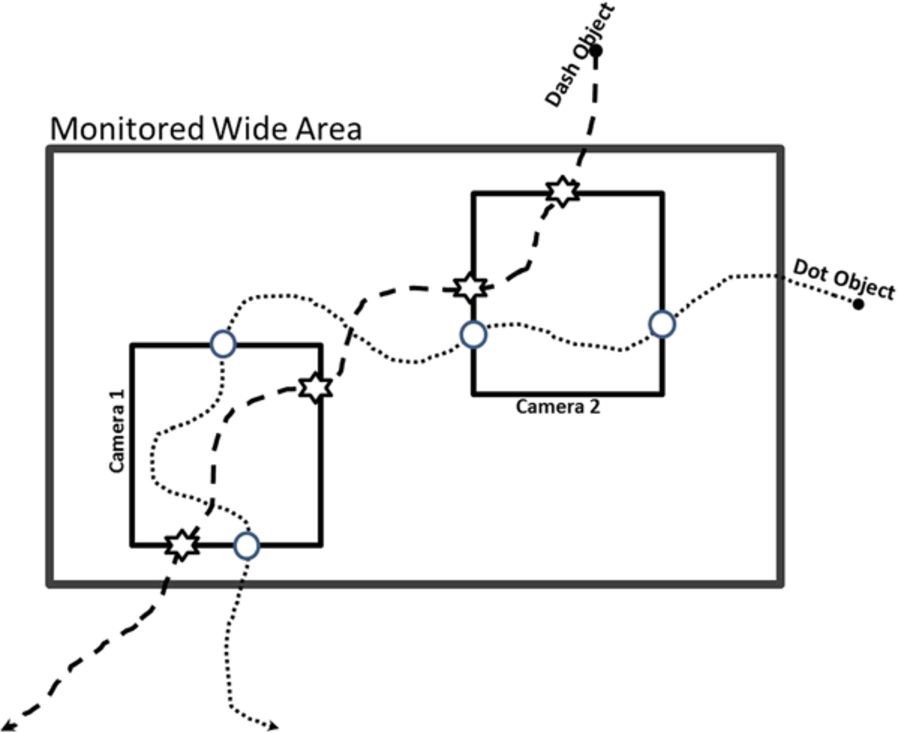
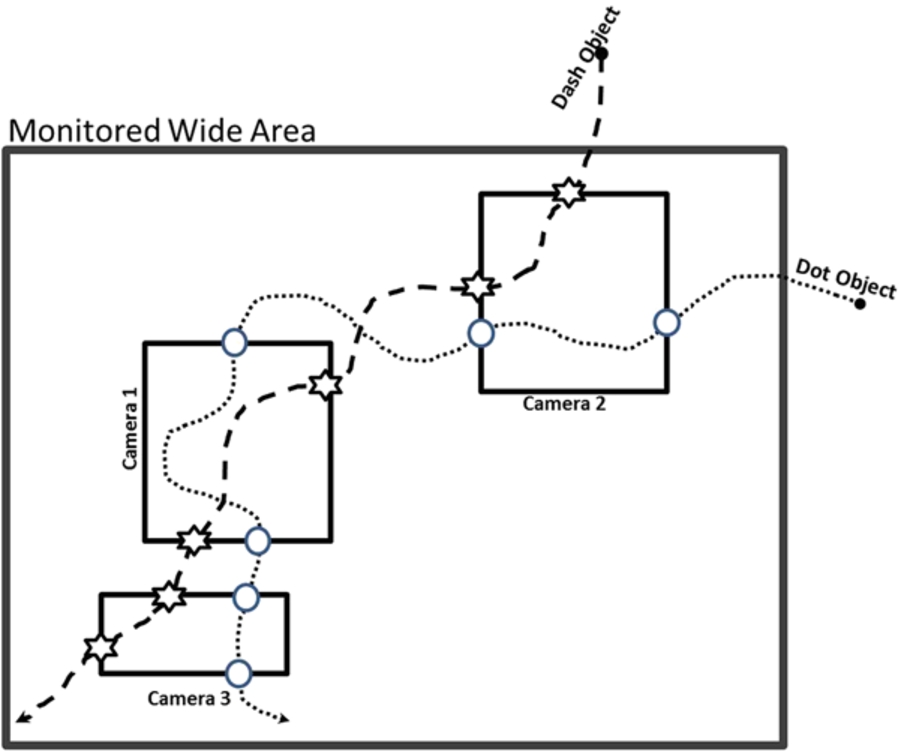
Various algorithms have been proposed for the implementation of the first step and remarkable progresses have been introduced in this area of research [32]. However, for the subject of second step, which is a new area of research, less research has been conducted [21]. In this paper, it is assumed that the tracklets are obtained accurately in the first step using any preferred methods [32]. The persistent tracking of objects within a camera of network are dealt in [1,12,14,20,21,24–26,30,31]. In [21,24,25] by combining short term feature correspondences across the cameras and using the long-term feature dependency models, a novel multi-objective optimization framework has been proposed. In this method, the similarities between features observed at different cameras are adapted based on the long-term models then a stochastically optimal path for each person is extracted. In [20], a new representation model has been proposed to extract tracklets followed by a statistical method for associating the tracklets. In [12], a statistical model has been proposed based on appearance and motion of the objects and the maximum a posterior (MAP) is used to solve the correspondence. In [26] a planar tracking correspondence model (TCM) is presented for addressing the association problem. In this work, the first fully automatic methods for estimating the planar TCM in large camera networks is introduced. The planar TCM is estimated only based on the overlapping camera’s correspondence. In [14] the authors have presented a method for learning the model of the camera network topology and using this model for tracking targets across blind regions. These blind regions are exist due to either large occlusions or separation of the camera views. In this work, it is assumed that the topology of cameras in camera network and transition model of objects between cameras are trainable. In [1] the camera networks are categorized into three groups. Then, the statistical methods are presented for associating based on the appearance and motion model of objects. In [30] a Petri Net based model is presented which associate the tracklets based on the color and gray histogram, local binary bitmap features and some estimated motion models. In [31], the appearance model of objects is extracted in different poses, different lighting situations and different cameras, then, the objects are tracked based on these extracted models. The common approach for associating the tracklets is performed by, first establishing all possible hypothesizes and then each hypothesis is evaluated based on different models in order to determine the best ones. The complexity of data association hypothesizes grows exponentially [6] with time and the number of the cameras and objects. Most of the related works, which are proposed to deal with this problem, use two restricted assumptions in order to relax this challenge. The first restriction assumes the topology of the cameras in the camera network is known. For example in [12,21,24] it is assumed that the camera network has known or trainable topology and movement trend of objects between each pair of cameras are also known. However, this assumption is not applied globally. The second restriction is to assume that the correspondences obey the Markovian model as a conditional dependency [12,20,21,24]. In other works, this assumption is addressed by introducing a second objective to the model. Considering this restrictive assumption when pruning the solution space, in some cases, it may converge to a false solution. To substantiate this claim, we use the scenario presented in Fig. 1. In this scenario, assume there are two objects that are appeared in the view point of camera 3 following their exiting from the view of camera 1. If the first order Markovian model be used for extracting the persistent trace of two objects in this scenario, the error which is shown in Fig. 2 will affect the final results. This phenomenon happens because in first order Markovian model, the next state of the model is related to only the first previous state of the model. While, if all state of the model, which in our problem means all tracklets of the persistent trace, be used in association process, extracting the true solution is possible. In this paper, a novel model is proposed for solving the problem of tracklet association problem without imposing the mentioned restrictive assumptions.
A sample of the persistent tracking problem.

Incorrect solution of persistent tracking of the objects.
This problem is an illustration of ill-posed inverse problem [2] where the tracklets are the observation and assumed to be known and the persistent trace is the ideal output and unknown (more details are presented in Appendix B). On the other hand, the variational model is an effective solution for solving the ill-posed inverse problem [28,29]. This model is commonly used for solving the ill-posed inverse problem in the scope of image processing and computer vision [8,19,27]. Motivated by the above mentioned discussions, this paper proposes a novel variational method for solving the problem without introducing the restrictive assumptions. In the proposed method, we have assumed that for each camera a tracking algorithm is used and the tracklets of objects are extracted. The collected tracklets of all cameras are considered as input to our problem. Then, our objective is to use these tracklets in order to extract persistent trace of the objects based on the appearance and motion model.
The rest of this paper is organized as follows. In Section 2 the problem is formulated. In Section 2.1 the proposed variational method is presented. In Section 2.3 the numerical solution for solving the variational method is considered. The experimental results, which are achieved using real and synthetic video sequence, are considered in Section 3 and finally, a brief summary of the proposed method and achieved results are presented in Section 4.
Problem notations
Problem notations
The persistent trace of an object, i.e.
The smoothness part of the energy function is minimized when the assigned tracklets to the object ith have lower variation with respect to the mean appearance and motion model of this object. The smoothness part involves with two different variations. In the first variation which is denoted by
Level set representation
The level set representation is applied in our formulation by representing
The symbols used in this equation,
Our objective is to solve the optimization equation, which is presented compactly below, and its optimal solution for each object is denoted by
In order to solve this optimization, we deduce the associated Euler-Lagrange equation for
Numerical solution
The final equation that is presented in Eq. (16) is an autonomous Ordinary Differential Equation (ODE). In our experiments, the Runge Kutta [17] method is used for solving the numerical discretized equation. Also, the color histogram (RGB) is used as the appearance model, and the orientation and the speed change rate are selected as the motion model. The Hellinger [16] distance is used as the appearance distance measure and the norm-one is used for the motion distance measure. In addition,
The principal steps of the algorithm are presented in Algorithm 1. This algorithm includes five main steps. First, the tracklets of the tracklets set T are sorted (line 2 of the Algorithm 1). Second, an initial value is created for persistent tracking ith object (lines 3 and 4 of the Algorithm 1). Third, the best

The tracklets association algorithm
Definition of the used metrics
The information of the used datasets
To demonstrate the performance of our proposed variational multi-object camera network tracking algorithm, we performed several experiments on synthetic sequences as well as real dataset and the results are presented. In our experiments, the tracklets set T is generated based on the ground truth annotation of the datasets. Then, the persistent trace of the objects are determined by our proposed model. Our objective in this paper is to present a method for tracking objects in a wide area within a network of cameras with disjoint views for a surveillance system. So, in the proposed method, we could not benefit from additional information provided by overlapping cameras. Therefore, in our experiments, before employing the association algorithm, the extracted tracklets are examined and all tracklets which are covered with at least one other tracklets thorough, are removed from extracted tracklets list. The experiments are performed on the desktop system with Dual Core 3 GHZ CPU and 2 Gigabyte RAM. The performance of our algorithm is quantitatively evaluated using the well known metrics of tracking algorithms which are introduced as following.
Evaluation metrics
For evaluating the proposed model quantitatively, 10 well known metrics which are commonly used in scope of the proposed model are selected and the quality of the proposed model is measured using these metrics. The definition and some information about these metrics are given in Table 2. The first two metrics, TCF and TF, are introduced in [20]. TCF is presented in percentage and provides the quantitative measure of the completeness tracking of the persistent trace of the objects and TF is presented in numerical measure of the fragmentation in tracking results. The POIF, PT, ST and FS are four common metrics in INRIA Laboratory which are defined in [23]. The PT, ST and FS are presented in percentage and provide the accuracy and recall of the proposed model in object tracking and POIF is a numerical measure for expressing the fragmentation rate of the tracking results. The metrics IDS, FG, ML and MT are the most common metrics in tracking scope which are defined in [13]. The ML presents the number of objects in percentage which lower than twenty percent of their persistent trace is tracked and MT provides the number of objects in percentage which higher than eighty percent of their persistent trace is tracked. The IDS and FG provide a numerical measure for presenting fragmentation rate of the tracked objects.
Real datasets
Our variational multi-object tracking algorithm is validated on three public datasets: the NGISIM Peachtree dataset [18], the PETS2009 S2.L1 Walking dataset [10] and CAVIAR dataset [7]. For adapting these dataset with our problem, some modifications on the dataset are required. The information of the used dataset is shown in Table 3. The NGSIM dataset [18] is created by capturing video sequence from Peachtree street located in Atlanta, Georgia by using eight synchronized cameras. The aerial image of the wide area which is monitored by several cameras is given and all annotation information of the dataset is presented in NAD83 coordinate. This dataset is presented in two 15 minutes video segments which are collected from 12:45 p.m. to 1:00 p.m. and 4:00 p.m. to 4:15 p.m. This dataset is used in this paper as presented in [20]. In our experiments, for expanding our algorithm to the blind area with no camera coverage, only five cameras are used. The world ground plane images of this dataset with camera coverage, persistent trace and extracted tracklets are shown in Fig. 3.
The world ground plane image of the NGSIM dataset based on the ground truth annotation: (a) Camera coverage (coverage area of each camera is shown by particular color); (b) Persistent trace (persistent trace of each object is shown by a particular color); and, (c) Extracted tracklets (each tracklet is shown by particular color).
Also, the image plane of the cameras of this dataset are presented in Fig. 4 and the images of two objects in three different poses of dataset NGSIM are shown in Fig. 5.
The image plane of the NGSIM dataset: (a) Camera one; (b) Camera two; (c) Camera three; (d) Camera four; and, (e) Camera five. Examples of objects of the NGSIM dataset in different poses: (a) Pose one of object one; (b) Pose two of object one; (c) Pose three of object one; (d) Pose one of object two; (e) Pose two of object two; and, (f) Pose three of object two.

The PETS2009 S2.L1 Walking was captured using eight cameras which is set up to monitor a road corner of a university campus and involves about 10 people. Since the cameras of this dataset have a large amount of overlapping in their coverage only four cameras are used in this paper to reduce the amount of overlapping. The images of two objects in three pose of this dataset are presented in Fig. 8. The world ground plane images of this dataset are presented in Fig. 6 and the image plane of cameras of this dataset are shown in Fig. 7.
The world ground plane image of the PETS2009 S2.L1 Walking dataset based on the ground truth annotation: (a) Camera coverage (coverage area of each camera is shown by particular color); (b) Persistent trace (persistent trace of each object is shown by particular color); and, (c) Extracted tracklets (each tracklet is shown by particular color). The image plane of the PETS2009 S2.L1 Walking dataset: (a) Camera one; (b) Camera two; (c) Camera three; and, (d) Camera four. Some examples of objects of the PETS2009 S2.L1 Walking dataset in different poses: (a) Pose one of object one; (b) Pose two of object one; (c) Pose three of object one; (d) Pose one of object two; (e) Pose two of object two; and, (f) Pose three of object two.


The CAVIAR dataset [7] is collected in a shopping mall corridor with heavy inter-object occlusions. The image size of this dataset are 384 × 288 pixels. The dataset contains two different views of the shopping corridor, the frontal view and the corridor view. But, in our experiment, as has been done in [25], only the corridor view is used. To use the single view of this dataset in our proposed model, at first, tracks of all objects from the ground truth of the corridor view are broken down into the small pieces and the resulted pieces are used as the tracklets in the proposed model. Then, the proposed model is used to associate the small pieces of tracks of objects and determining the overall tracks of each object. In [25] 7 challenging part of the dataset have been used which contains TwoEnterShop3, TwoEnterShop2, ThreePastShop2, ThreePastShop1, TwoEnterShop1, OneShopOneWait1 and OneStopMoveEnter1. The world ground plane images of this dataset are given in Fig. 9. Some examples images of objects of this dataset are presented in Fig. 12. Also, the image plane images of this dataset is shown in Fig. 11. The obtained results of these real datasets are presented in Table 5.
The world ground plane top view of the OneStopMoveEnter1 that is part of the CAVIAR dataset based on the ground truth annotation: (a) Camera coverage (coverage area of each camera is shown by particular color); (b) Persistent trace (persistent trace of each object is shown by particular color); and, (c) Extracted tracklets (each tracklet is shown by particular color). The world ground plane image of the synthetic dataset based on the ground truth annotation: (a) Camera coverage (coverage area of each camera is shown by particular color); (b) Persistent trace (persistent trace of each object is shown by particular color); and, (c) Extracted tracklets (each tracklet is shown by particular color). The image plane of the CAVIAR dataset. Some examples of objects from ThreePastShop1 part of the CAVIAR dataset: (a) Pose one of object one; (b) Pose two of object one; (c) Pose three of object one; (d) Pose one of object two; (e) Pose two of object two; and, (f) Pose three of object two.



Producing camera network datasets with complicated scenario which embodies the complete annotation are rarely available. Hence, synthesizing the dataset is an alternative for validating our proposed method. A tool has been developed that can generate through annotated dataset according to every complicated surveillance scenario based on the given information [11]. The information includes characteristics of the observed area, parameters and topology of the cameras and the motion and appearance model of the objects. A dataset has been created by this tool. The characteristic of synthetic dataset are presented in Table 3. Also, the world ground plane images of this dataset are shown in Fig. 10. In this tool, the appearance model of the objects can be allotted with real image of the objects. So, in synthetic dataset of this paper, the images of the people in various poses of 3DPeS [3–5] are used as the appearance model of the objects. Some examples of these appearance model are given in Fig. 13. The results of our experiments with this dataset are presented in Table 5.
Some examples of objects of the synthetic dataset in different poses: (a) Pose one of object one; (b) Pose two of object one; (c) Pose three of object one; (d) Pose one of object two; (e) Pose two of object two; and, (f) Pose three of object two.
The time complexity and the number of steps required for optimization of the experiments
The time complexity and the number of steps required for optimization of the experiments
The results
In this paper, a novel variational method is introduced for tracking multi-objects in camera networks which imposes less limitative assumptions compare to the previous method in more realistic scenario. The quality and accuracy of the proposed method was evaluated by common metric through experimenting the method on the common real datasets. Also, in order to evaluate the proposed method on a more challenging problem, experiments are performed on the synthetic datasets; tracking problem while requiring less high level information. In order to improve the proposed method, various aspect can be considered. As an alternative, the formulation can be represented such that the persistent trace of all objects can be extracted simultaneously. Further improvement can be achieved by combining our algorithm with high level features, such as human gait recognition.
Footnotes
The appearance and motion formulation
In this appendix the proposed representation for appearance and motion model and distance measure of these models are given. The mean appearance model of object i which is used as a candidate appearance model of this object is defined as,
Ill-posed problem
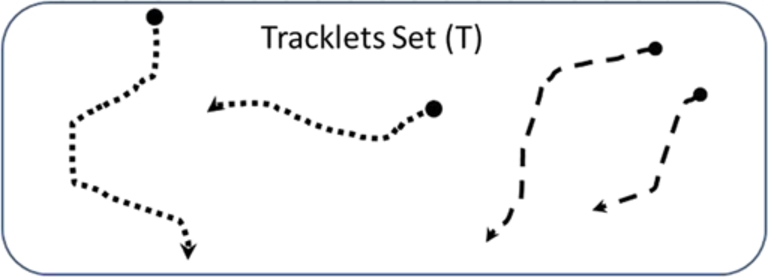
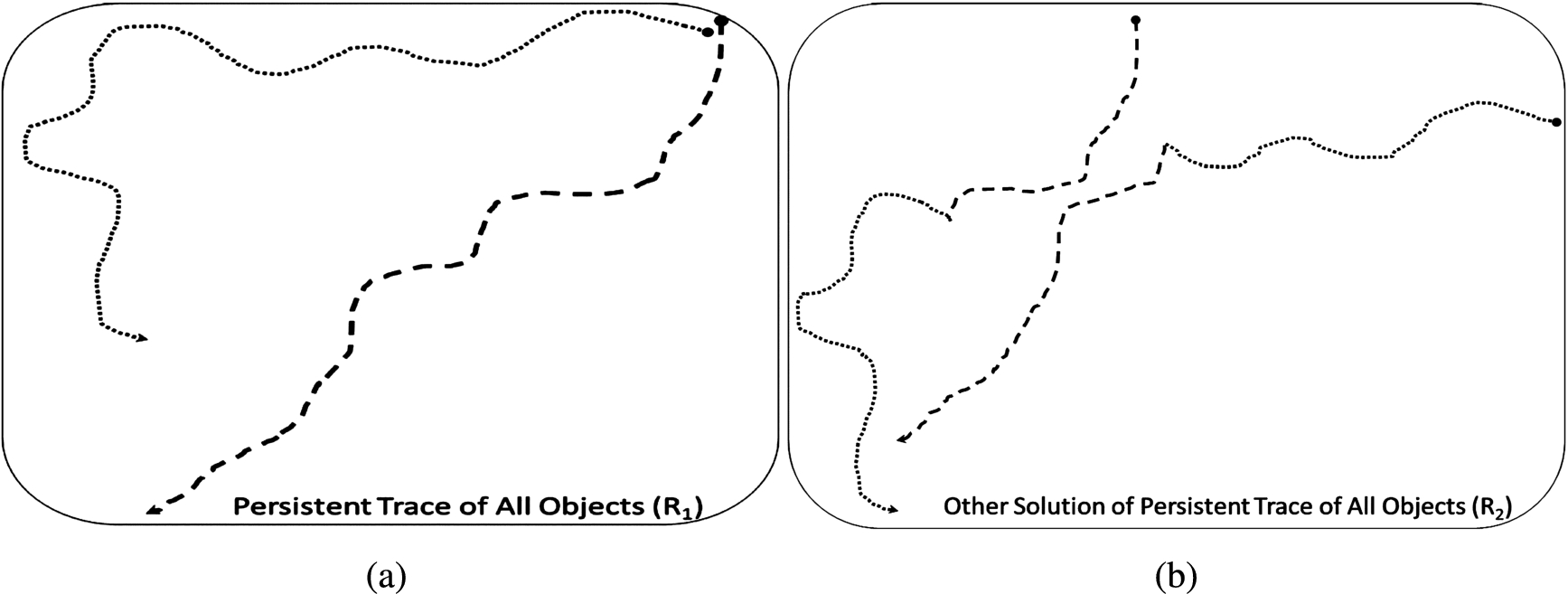
Based on definition of ill-posed problem which is presented in [2] extracting the persistent trace is an ill-posed problem. To prove this claim, we present and analyze a sample of persistent tracking in Fig. 14, the traces of two objects which shown by dots and dash lines representing the movements of these two objects within the wide are ( A sample of the persistent tracking problem. The tracklets set T of the sample presented in Fig. 14. The persistent trace set R of the sample presented in Fig. 14: (a) The first persistent trace set R of the sample, (b) The second persistent trace set R of the sample.