
Abstract
In this paper, qualitative descriptors of images (
Keywords
Introduction
Imagine the following scenarios. You are an 80-year-old modern ageing person who lives alone in your smart home. One morning during breakfast you cannot find your vitamins and you ask to your smart home: Where are my pills? Your smart home scans the house and finds them on your desk. It answers: Your pills are on your desk, next to your laptop, on the right (Scenario I). Moreover, you have also a service robot at home which helps you with the daily routine activities. It is the one getting your pills from your desk and giving them to you. It asks you: How can I further help you? And you provide the following instruction: Please, tidy the living room. To clarify, your robot asks back: Should the new stool go in front of the armchair or down the table? (Scenario II). And you answer: Just move it a bit towards your left and that’s it (Scenario III).
In Scenario I, the location of a target object is described using qualitative descriptors. In Scenario II, the location of a piece of furniture is described using the orientation of another piece of furniture. And in Scenario III, a movement is described also using qualitative descriptors. These scenarios illustrate the need of spatial intelligence and the usability of qualitative descriptors in human-machine communication contexts.
Ambient Assisted Living (AAL) applications need Ambient Intelligence (AmI) for: (i) scene understanding (i.e. to ‘know’ what is happening in a building); (ii) reasoning, to identify the consequences of what is happening and provide assistance if needed; and (iii) learning, to identify routine activities and ‘predict’ events by analogy with the past, and also identify uncommon or ‘new’ activities. Moreover, systems that must carry out a task in environments where people live or work need cognitive capabilities for enhancing human-machine communication. As Vernon [58] pointed out: ‘Cognition implies an ability to understand how the world around us might possibly be (…) and being able to interpret a visual scene without having complete data’. Therefore, a cognitive system should be able to describe and identify scenes without having complete information about them (i.e., it should be able to describe objects that have not seen before and identify them by the context).
A key issue in the study of Ambient Intelligence is reasoning about context to deduce new knowledge. The main challenges of this effort derive from the imperfect context information, and the dynamic and heterogeneous nature of the ambient environments [6]. Henricksen and Indulska [31] characterise four types of imperfect context information: unknown, ambiguous, imprecise, and erroneous. Sensor or connectivity failures result in situations where not all context data is available at any time. When the data about a context property comes from multiple sources, the context information may become ambiguous. Imprecision is common in sensor-derived information, while erroneous context information arises as a result of human or hardware errors. The role of reasoning in these cases is to detect possible errors, make predictions about missing values, and decide about the quality and the validity of the sensed data. The raw context data needs, then, to be transformed into meaningful information so that it can later be used in the application layer.
Qualitative Reasoning (QR) [28,33,59] is a field in AI. Instead of using precise numerical representations, qualitative models focus on representing relevant aspects in the domain, by discretising quantity spaces, and as a consequence, they deal with imprecise numerical values. Therefore, they can reason with non-exact data, ambiguous or incomplete. Qualitative Spatial and Temporal Representations and Reasoning (QSTR) [12,29,37] models and reasons about time (i.e. coincidence, order, concurrency, overlap, granularity) and also about properties of space (i.e. topology, location, direction, proximity, geometry, intersection, etc.) and their evolution in time between continuous neighbouring situations. Maintaining the consistency and constraints in space and time are the basics in qualitative reasoning when solving spatial problems. QSTR also reflects cognitive aspects about reasoning and talking about space, that is, they reflect human spatial cognition [48]. As a result, well-defined qualitative models and reasoning techniques have appeared in the literature and applied to many domains: robotics [20,35], computer vision [11,18,34], ambient intelligence [4,24], architecture and design [3], geographic information systems [1,27], education [7,14,16] etc.
In this paper, qualitative spatial representations have been used to built three qualitative descriptors: (i) a Qualitative Image Logic Descriptor (
The Qualitative Image Descriptor (QID) [22] has been able to extract qualitative knowledge from real images: location of objects in the image, their topological situation, their shape and colour. Logics have also been provided for the qualitative image descriptor (QIDL) [24]. This paper extends QIDL approach by including qualitative sizes of the objects as a new feature. None of the previous works in the literature integrate all these shape, colour, size, topology and location qualitative descriptors when producing first order logic predicates in Prolog for reasoning about images/scenes.
Cognitive studies can be found in the literature, which investigates how people describe object arrangements in the real space [55,56]. Some of the results obtained were applied to improve human-robot interaction [43,44], which used a robot incorporating a range laser sensor to extract information from the environment. Taking into account these previous works, the Qualitative descriptor of 3D Scenes (
The Qualitative Descriptor of Movement (
The rest of the paper is organised as follows. Section 2 introduces the qualitative descriptors for ambient intelligent systems proposed in this paper: the qualitative descriptor of images (
Qualitative descriptors for ambient intelligent systems: QIDL+, QSn3D, QMD

Qualitative Descriptors for Ambient Intelligent Systems.
In the previous section, several scenarios have been introduced. The qualitative descriptor which can provide the ground for your smart home to answer ‘where are your pills’ (Scenario I) is the Qualitative Image Logic Descriptor,
The qualitative 3D scene descriptor (
The qualitative movement descriptor (
As Fig. 1 illustrates, the main aims of all these qualitative descriptors (
The
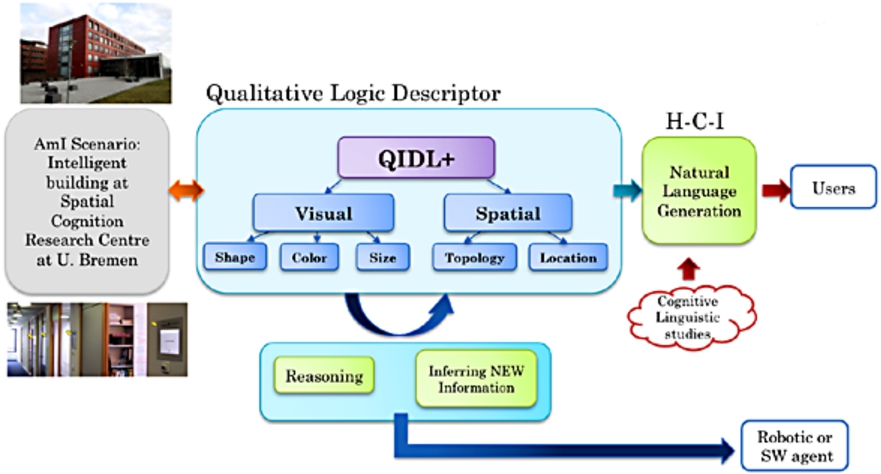
The extended Qualitative Image Logic Descriptor (
The
The rest of this section is organised as follows. The qualitative descriptors of shape (QSD), colour (QCD), size (QSize), topology and location are described next. The following sections show logic definitions for inferencing new information about the context and how they are useful in a real office top desk scenario.
Each of the relevant points of a shape (
Edge Connection (EC) occurring at P, described as: {line_line, line_curve, curve_line, curve_curve, curvature_point};
Angle (A) at the relevant point P (which is a not a curvature_point) described by the qualitative tags: {very_acute, acute, right, obtuse, very_obtuse};
Type of Curvature (TC) at the relevant point P (which is a curvature_point) described qualitatively by the tags: {very_acute, acute, semicircular, plane, very_plane};
Compared Length (L) of the two edges connected by P, described qualitatively by: {much_shorter (msh), half_length (hl), a_bit_shorter (absh), similar_length (sl), a_bit_longer (abl), double_length (dl), much_longer (ml)};
Convexity (C) at the relevant point P, described as: {convex, concave}.
The corresponding reference systems (
Thus, by using these descriptors, the complete shape of an object can be categorised as: {triangle, quadrilateral, square, pentagon, …, polygon}. Figure 3 presents an example of a QSD.

Example of shape described by QSD.
The Red, Green and Blue (RGB) colour channels of object pixels are translated into Hue, Saturation and Lightness (HSL) coordinates, and a reference system for colour naming is defined as:
The

Reference System for the Qualitative Colour Descriptor (QCD). The vertical axis contains the colours in the grey scale (
The topological situation in space (invariant under translation, rotation and scaling) of an object A with respect to (wrt) another object B (A wrt B) is described as:
The
Location description
For obtaining the location of an object A wrt its container or the location of an object A wrt an object B, neighbour of A, the following Location relations are identified which divide the space into nine regions as shown in Fig. 6:
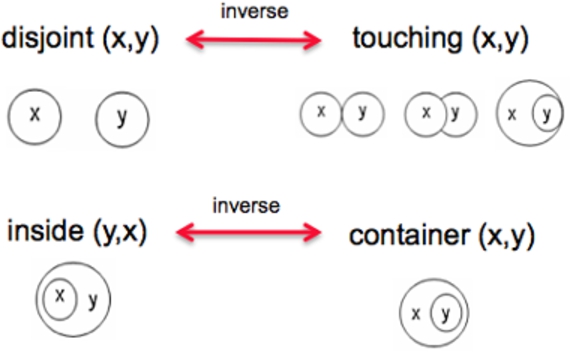
Topological situations distinguished by the
The location of an object is determined by the union of all the locations obtained for each of the relevant points of the shape of the object (

Locations described by the
In this paper, a qualitative size descriptor is proposed for
The chosen
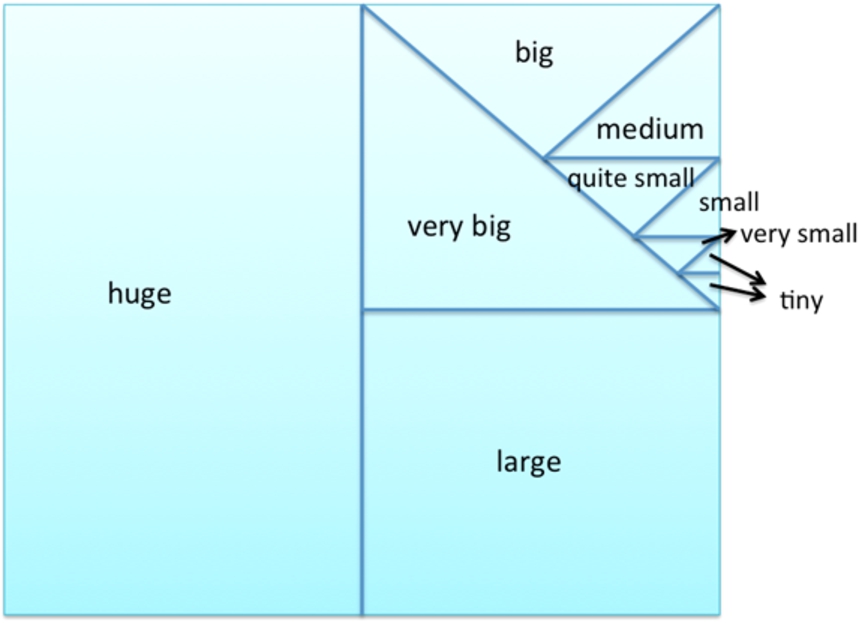
Reference system for the size descriptor used in
The 
where n is the number of objects. In order to describe a digital image using the
Formulas are recursively built from atomic formulas using logical connectives and quantifiers. A formula is satisfiable if and only if there exists at least one world in which it is true. First-order KB are usually built using Horn clauses, which contains at most one positive literal. The Prolog programming language is based on Horn clause logic [38].
The
Logics facts extracted for the objects in the images based on the qualitative descriptors
Logics facts extracted for the objects in the images based on the qualitative descriptors
By using the previous Prolog predicates, the 
where the variables 
which retrieves objects which are small
The context is reflected by the domain knowledge introduced in the
Logic definitions to categorise objects based on their qualitative descriptors. For example, a wall can be defined as:
And a postit can be defined using
Images of target objects already ‘known’ by the system which are used to detect the reference objects in the scene. The properties of QSD, QCD, QSize, Topology and Location are inherited by these target objects after a matching of their features to a region identified by the
The category inferred can also be included in the query logic in order to retrieve information from the KB. Thus, queries as the following can be formulated: 
where the variables 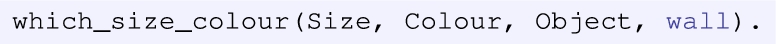
In the same way, the following query can retrieve locations of any object: 
For example, objects categorised as posits and located up can be retrieved by the following query: 
Moreover, any location of any object can be retrieved by its name or by its object identifier (i.e. where is the postit?) by the following query: 
Testing
Cartesium building at Universität Bremen incorporates intelligent door tags (computers) installed in the walls next to every office (see Fig. 8). This is a scenario suitable to obtain pictures of a daily living environment and to study different situations in ambient intelligence.

An office floor in the Cartesium building: arrows indicate intelligent door tags.
In this context, let us consider a picture taken at the Cartesium building, which may be obtained by the cameras incorporated at the door tags or by a robot incorporating a camera as a visual sensor. As Fig. 9 shows, the
Target objects are provided to the system according to the task to do and they are detected by the Speeded-Up Robust Features (SURF) invariant descriptor [2] and the Fast Library for Approximate Nearest Neighbours (FLANN) detector [45]. In this scenario, the target objects are a laptop, a notebook, a mouse and some pills.

Outlook of the
As Fig. 9 shows, the target object pills is detected in the image by feature detectors and matched to the segmented object-57 which inherits all the qualitative characteristics of shape, colour, size, topology and location. According to the scene, the Prolog predicates obtained are the following: 
Moreover, using the Prolog logic predicates in the KB and the testing platform Swi-Prolog1
SWI-Prolog:
a) the following query finds out the location of the mouse as down_right: 
b) the following query finds out all the objects categorised as postit’s and indicates also their size, colour, and location in the scene: 
c) the following query indicates the size and colour of an object not categorised, such as the screen or object-16: 
A context-free grammar,
Thus, these narratives can be used by Cartesium smart building to answer questions in natural language asked by users, such as, the question ‘where are my pills?’ – described in Scenario I. Moreover, the logics generated provide also AmI system with spatial understanding of the real situation for further reasoning.
A first step for describing a 3D scene involves identifying objects and then describing their locations (Fig. 10). In this paper, the

A Qualitative 3D Scene Descriptor (
The
the floor in the scene is extracted by applying a RANSAC-based segmentation (RANdom Sample And Consensus) [26];
an Euclidean Cluster Extraction is carried out in order to distinguish different objects. For each extracted cluster, two geometrical 3D-features are calculated:
the Viewpoint Feature Histogram (VFH) [49] which is scale invariant but viewpoint variant. The main idea of this feature is to obtain three distinct angles between two points, using the normal vectors and the viewpoint direction;
the Global Radius-based Surface Descriptor (GRSD) [39]. The basic idea of GRSD is to approximate 3D-objects by searching for best-fitting circles at each point.
For each type of object, a bunch of point clouds is obtained, recorded and labeled with the name of the object. These point clouds contain different orientations and scales of the objects. With these labeled feature vectors a SVM-model is trained, which is later used to classify extracted clusters using LIBSVM [10]. The result of this step is the identification and recognition of some target 3D objects categorised by a name.
Spatial references in natural language
In spatial expressions, projective terms refer to the idea that a spatial relationship is projected from an origin (position anchoring the view direction) to a relatum (a known object nearby) in order to specify the location of the intended object, called also the locatum [56]. This is done using lexical items such as front, back, left, right.

Two spatial configurations which can be described using the same natural language sentence using a relative reference system located at the office chair.
The employment of projective terms presupposes underlying conceptual reference systems, which are systematically categorised by [36] as relative versus intrinsic. In relative reference, a viewer specifies the location of an object relative to a relatum, as in The chair is in front of the table. Here, the relatum does not necessarily possess intrinsic sides, and the reference system consists of three different positions. In intrinsic reference systems, the role of the relatum coincides with the role of origin, which therefore needs to possess intrinsic sides, which then serve as basis for reference. In The table is in front of me, the speaker serves both as relatum and as origin, and her/his view direction determines the direction of front. For example, in the scene in Fig. 11, the following narrative might be used independently of the point of view of the observer: The rubbish bin is in front of the office chair. This is a particular case since the office chair is an oriented object which has a front and a back which can be used as our relative reference system for locating objects.
The
an deictic reference system located at the RGB-Depth camera from which the objects in the scene are described; and
a intrinsic or relative reference system between objects in the scene that have clear orientations, as for example, chairs, sofas, armchairs, etc.
To generate these kind of natural language descriptions, the coordinates from the 3D-data obtained from the point clouds are used. As Fig. 12 shows, the scene is divided into different regions to distinguish between the depth information or distance to the observer (i.e. foreground and background) and the locations of the objects in the horizontal plane. These descriptors are formalised as follows.
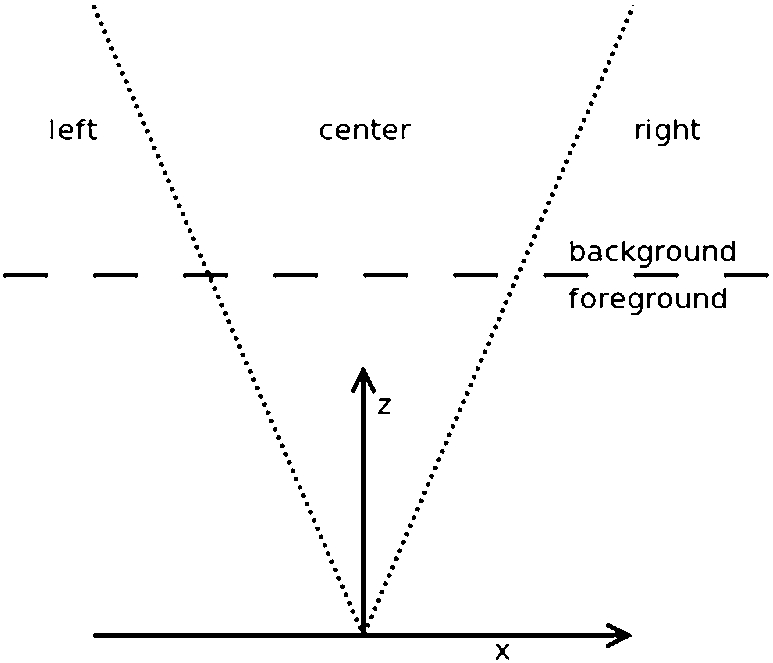
Model for dividing the space observed from a RGB-Depth camera.
The closeness of the observer to an object can be described using a Distance Reference System or
The location of an object can be obtained using a Horizontal Location Reference System or
The HLoRS and the DRS can be combined as follows:
Computationally, the space division depicted in Fig. 12 is used in
Both reference systems used in
Note that for spatial relations between two objects, the reference frame is located on the oriented object so that its front corresponds to the front of the reference system. For both configurations in Fig. 11, although the objects are on different positions considering the deictic reference frame, the intrinsic reference system will produce the same description because the chair has an oriented front side, which is taken as reference.
The
Experimental results [32] showed that the random error of depth measurement increases with increasing distance to the sensor, and ranges from a few millimetres up to about 4 cm at the maximum range of the sensor. Others [50] have modified this sensor to work at a much high accuracy retrieving depth fields of objects at an accuracy in the sub-millimetre range. However, in the work presented, the original depth accuracy provided by our Kinect sensor was enough, since the information extracted here is qualitative and it does not require exact accurate values and it can also deal with range of depth measurements.

Scenario with furniture (oriented and non-oriented objects) where QSn3D descriptor is applied.
The system presented is written in C++ and built upon the Robot Operating System (ROS) framework.2
Figure 13(a) shows our scenario and Fig. 13(b) shows the result of the object recognition process. Note that the orientation of each object is also obtained and represented.
An excerpt of the 
The object0c is identified as the armchair, which is a kind of chair. The location of object0c with respect to the observer (from where the picture is taken) is left and background. Moreover the object0c is oriented to the right. There are 2 close objects: object1c which is an office chair located on the left wrt the armchair, and object3c, a stool located to the right wrt the armchair.
Regarding the non-oriented objects, the 
The object2c is identified as the rubbish bin, which has no orientation. It is located in the foreground on the right. And it is close to objects object1c (an office chair) and object3c (the armchair).
The qualitative descriptors obtained by
Starting the narrative by the biggest object as the most salient object. In our current example, the biggest object is the armchair, then
In the background there are two chairs. One of them is an armchair (oriented to the right). The armchair has an office chair on the left, a stool and a rubbish bin on right.
Starting the narrative by the object closest to the observer as the most salient object. In our current example, the closest object to the observes is the rubbish bin, then
In the foreground, there is a rubbish bin on the right. There is a stool on the left. In the background there are two chairs. One of them is an office chair (oriented to the left). The office chair has an armchair in the front.
These logics and narratives provide AmI systems and service robots with the grounds to produce and understand natural language instructions such us ‘the new stool goes in front of the armchair’ where oriented objects (i.e. armchair) are involved as described in Scenario II in the Introduction.
A video can be defined as a set of digital images or frames (I) such as,

A Qualitative Movement Descriptor (
For the representation of location information, the reference system shown in Fig. 15 is used for obtaining the location of an object with respect to (wrt) the current frame. This Location of Movement Reference System
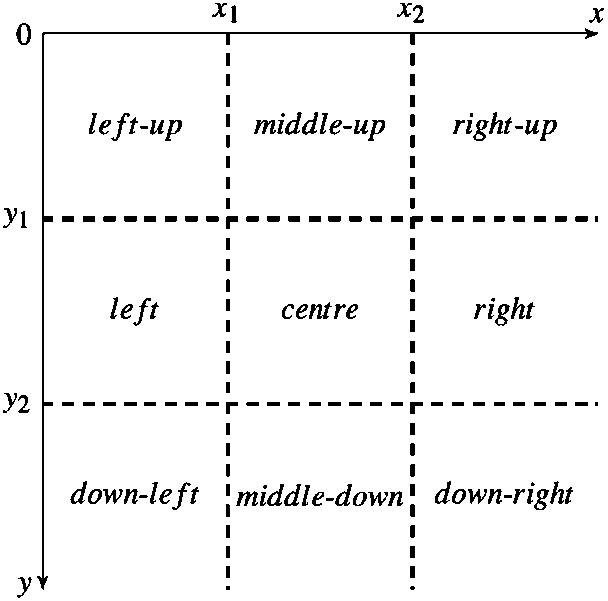
Location movement Reference System (
In order to obtain the location of an object wrt the current image frame, the coordinates of the boundary of the object are extracted and its qualitative location is obtained according to
In order to obtain the direction of the movement of an object wrt the previous and current frame, the coordinates of the boundary of the object are obtained and the increasing or decreasing slopes of coordinate locations are calculated according to the Direction of Movement Reference System (
Logics for a Qualitative Movement Descriptor (QMD) for one moving object

Direction movement Reference System (
The movement of an object in a video can be described qualitatively by the QMD defined in the previous section as:
In order to describe a video using spatial logics, a first-order knowledge base (KB) can be built as a set of formulas in first order logic [30] constructed using Prolog predicates as explained in previous sections. The 
Other first-order Prolog predicates can be defined to ask about semantics of movement, such as:
(i) where is an object at a time, 
(ii) towards which direction is an object moving at a time, 
and (iii) if an object is placed in a broader location which involves more than one region defined by the





Moreover, some domain knowledge can be added to the AmI system using Prolog predicates which are built using the features extracted by 
In order to track any moving object in any video, the Background Subtraction5
Tutorial on Background detection by Stankiewicz:
OpenCV:
A proof-of-concept has been implemented taken as input the video showing a moving ball.7
Download data from:

Frames obtained from a video showing a racquetball play. The red circle indicates the tracked ball.
An excerpt of the QMD predicates produced corresponding to the frames showed in Fig. 17 are the following: 
The predicates obtained indicate that: from 4–5, the ball is moving from the wall towards the left (from middle-down to left-down), and from 6–7, the ball is falling back from the wall towards the left (from the right to the left-down).
These logics provide AmI systems and service robots with the grounds to understand instructions such us ‘move it a bit towards your left’ as described in Scenario III in the Introduction.
This section discusses how AmI systems can have a more cognitive interaction with people (Section 6.1), and the usability of qualitative descriptors, in particular of the
From digital AmI systems to cognitive human-interactive AmI systems
In computer vision, images of scenes are digitalised, that is, divided into pixels or points corresponding to 3 colour coordinates (i.e. RGB). In order to recognise objects inside digital images, these pixels can be: (i) split by a boundary (i.e. transforming the image into grey scale and analysing intensity transitions between the pixels [9]); (ii) brought together using a similarity measure (i.e. based on colour closeness or other features) [25]; (iii) matched to predefined pixels corresponding to objects know a priori (i.e. feature detectors such as SIFT, SURF, etc. see the work by Mikolajczyk et al. [42] for an overview). In 3D object recognition the problem is similar: a scene is represented as a set of points floating in the air, called point clouds. In order to recognise objects there, these points must be put together again by learning different views of the object using machine learning methods [19].
Because digital images represent visual data numerically, most image processing has been successfully carried out by applying mathematical techniques to obtain and describe image content. All these approaches succeeded in their tasks, but they need to produce and store in memory huge numerical descriptions that cannot be interpreted or given a meaning if a successful match is not found. A disadvantage of these methods is their requirement of a repository of all possible images of objects existing in a scenario for identification, because they lack the ability to describe any feature of an object that they have not seen before. Those methods try to recompose the continuity of the space lost in the digitalisation, since this continuity is important in order to detect/recognise objects to give them a name/meaning to communicate with humans.
An AmI system that can interact with a human using concepts/names of objects and their features (shape, colour, location, etc.) may learn which objects belongs to their house and their usual location. Similarly to how we teach children the name of things and their usual location, so that they are able to store them correctly. To achieve this goal, qualitative descriptions of scenes might be obtained and correctly used in a dialog with a human. Numerical descriptions are not useful in this task, since most humans might not understand location coordinates inside their kitchen or colour coordinates of a banana, for example. The work presented in this paper is a step towards achieving such a goal.
The usability of the
The Qualitative Image Description (
In this paper, the feature size was added to get an extended Qualitative Image Description Logic (
Context information is introduced when providing images of a-priori-known objects or target objects, which can be detected using the SURF and FLANN feature object detectors. If object recognition is successful, then it contributes to the
From qualitative descriptors to logics
Qualitative spatial descriptors can be expressed in any logic form. This has been showed by previous works in which the QID was expressed using description logics [18] and used to infer knowledge from the camera of a mobile robot which moves through the corridors of a building. The QID has also been expressed using first order logics [24] to infer further knowledge in a closed indoor scenario in the Cartesium building at University of Bremen. Therefore, this generality of QID is extensible to other qualitative spatial descriptors. And the kind of logics used depend on if the environment is considered as a closed or open world, as it is discussed next.
Description logics are based on an open world assumption (OWA), that is, they assume they do not know all the objects belonging to a category, for example, in our smart home we can have different kinds of chairs, but these are not all the existing chairs in the world. The disadvantage of the OWA approach comes when counting operations are needed [18], such as: A chair has at least 3 legs. In order to reason, operations to close the world are needed which results in longer reasoning times. The OWA approach involves that an AmI system needs to know what is typically happening in all houses in the world and then learn what is particular for the house it is controlling. For intelligent systems, the OWA approach is suitable when dealing with affordances of objects, since a system may find out a new creative use of an object depending on its features [47], that is, the uses of things have endless possibilities.
In contrast, first order logics are based on a closed world assumption (CWA). Therefore, in order to reason, they assume that what is known is true, and what it is not known is false, what makes reasoning procedures quicker. For example, an AmI system may need only to know the rules applied for the house that is controlling, which are the ones that matter in its task. The total set of rules that can be applied in different houses all over the world (OWA) will not be considered important for monitoring a particular house (CWA). Thus, this involves that any AmI system is preferred to be able to customise its configuration to fulfil the particular needs of their users, rather than having a general or universal configuration. And this configuration must be done via human-machine interaction where dialogs using qualitative concepts will be used.
Some approaches which use Semantic Web-based representations to describe context and reasoning have been proposed in the literature [6]. They retrieve information from the context knowledge base, check if the available context data is consistent or derive implicit ontological knowledge, but they have some drawbacks in reasoning: they cannot deal with missing or ambiguous information (which is a common case in ambient environments) and they are not able to provide support for decision making. Some of these reasoning issues are due to the fact that ontology-based models are based on open world assumption (OWA) for reasoning and there is a need to close the world for solving inferences (i.e. regarding counting individuals) [18].
Qualitative descriptors can also be expressed in fuzzy logic (CWA) or fuzzy description logic (OWA) to represent concepts which lack well defined boundaries. The reference systems of the qualitative descriptors can be defined in terms of fuzzy sets, instead of interval sets, and thus a degree of uncertainty for the concepts can be calculated. This has been showed by the vague colour descriptor used in [40] which was inspired in the QCD used by the
Integrating QIDL+, QSn3D and QMD
By integrating all the proposed qualitative descriptors, for each object in a scene, the following features may be retrieved:
its shape (QSD), its colour (QCD), its size (Qsize) and its static location and topology;
its distance with respect to the point of view of the observer (i.e. background or foreground) and its orientation (if it is an oriented object);
its direction and its location in a snapshot, if it is a moving object. If it is not a moving object, then it can be categorised as static object.
The integration of these qualitative descriptors can be done in two ways:
involves an integration at a logic level, that is, adding all the logic facts obtained from the qualitative descriptors to the AmI agent knowledge base. Then checking the consistency of the descriptors and, after that, reason with them to infer new knowledge;
involves an integration at a sensory level, that is, using the RGB image taken by the Kinect and getting the
Method-A has the advantage of extracting the object features more easily and quickly, since the integration part is left for the knowledge base (KB) in the consistency checking process. The disadvantage is that some inconsistencies in the KB might need to come back to the sensory level for discarding errors.
Method-B has the advantage of solving the conflicting facts at a sensory level. For that, the same reference systems must be used for the location of objects in videos and images, for example. This will create less conflicting facts in the AmI agent’s KB. However, if a conflicting sensory situation is produced, then no fact might be written in the KB, and this is a disadvantage.
The integration of all these descriptors may enhance the AmI agent’s ability to differentiate moving objects from static objects and also to detect 3D topological situations, as for example, partially overlapping objects. However, note that sometimes, having too much information about the environment, may decrease the agent’s effectivity, since the task/activity to carry out can be delayed while extracting not needed descriptors. Therefore, the integration challenge is interesting, but it must be also defined when the descriptors must be integrated and when it is sufficient to use them in a separate manner.
Note also that both Method-A and Method-B are theoretical and they are intended as future work.
Combining QIDL+, QSn3D and QMD with qualitative activity descriptors
In order to provide the right information to the users at the right time and in the right place, an ambient intelligent system must ‘understand’ its environment, users’ needs/preferences and the tasks and activities that are being undertaken.
In this paper, the
Finally, the qualitative descriptors presented in this paper can also be combined logically with qualitative activity descriptors [5] in order to know the context of operation (i.e. task/activity which is carried out by the user) and then to select a proper descriptor or the integration of all of them. This is a challenge intended as future work.
Conclusions and future work
In this paper, qualitative spatial representations have been used to built three qualitative descriptors: (i) a Qualitative Image Logic Descriptor (
The main aim of those qualitative descriptors (
It is important to notice that none of the previous works in the literature integrate all the shape, colour, size, topology and location qualitative descriptors as
The experimentations presented showed the usefulness of the 3 descriptors presented:
As future work, we intend to: (i) integrate the
Footnotes
Acknowledgements
This work was conducted on the scope of 2 projects: (i) COGNITIVE-AMI8
Cognitive-AmI:
CogQDA: