
Abstract
This paper’s main objective is to consolidate the knowledge on context in the realm of intelligent systems, systems that are aware of their context and can adapt their behavior accordingly. We provide an overview and analysis of 36 context models that are heterogeneous and scattered throughout multiple fields of research. In our analysis, we identify five shared context categories: social context, location, time, physical context, and user context. In addition, we compare the context models with the context elements considered in the discourse on intelligent systems and find that the models do not properly represent the identified set of 3,741 unique context elements. As a result, we propose a consolidation of the findings from the 36 context models and the 3,741 unique context elements. The analysis reveals that there is a long tail of context categories that are considered only sporadically in context models. However, particularly these context elements in the long tail may be necessary for improving intelligent systems’ context awareness.
Introduction
In 1991, Mark Weiser [81] introduced a vision of intelligent environments in which systems are aware of their context and adapt their behavior accordingly. While such sophisticated systems are frequently referred to by different names (e.g., “intelligent,” “context aware,” “adaptive,” “situated,” “ambient,” etc.), this paper will hereafter refer to them by the term “intelligent systems.” Context is pivotal for making this vision reality.
“In order to use context effectively, we must understand what context is,” Dey [20] claimed in 2001. However, since the 1990s [64], there has been an ongoing debate over what constitutes context [15,23,32,75].
Early attempts to define “context” for the realm of context-aware computing are based on synonyms for context [12] or are built on enumerations of examples [19,65]. Some researchers have taken a dynamic viewpoint, considering context as an “open concept” [76] or a “process” [9] through which context is “dynamically constructed” [23]. Some consider context from the user’s perspective [12], from the system’s view [61] or abstract from both, by referring to context as aspects of the current situation [38]. Dey and Abowd [21] define context as “any information that can be used to characterize the situation of an entity.” Still, such characterization of a situation is no easy task [3].
In addition to such attempts to conceptualize context through definition, another common approach is to divide context into different categories and subcategories [32]. Such structured context conceptualizations are known as “context models.” A context model is a simplified representation of context intended to describe and/or structure context elements. Furthermore, a context element is defined as a subset of context that describes one contextual aspect, such as the location of a user.
Context models have been proposed by researchers in various fields, including human-computer interaction (HCI) (e.g., [44]), ubiquitous computing (e.g., [58]), context awareness (CA) (e.g., [14]), and com puter-supported collaborative work (CSCW) (e.g., [82]). Throughout these fields of research, the models are scattered and heterogeneous. So far, these “puzzle pieces” have not been put together.
Against this background, this paper’s main objective is to consolidate and organize the dispersed knowledge about context. To achieve this goal, this paper will first present and analyze a set of 36 context models in the realm of intelligent systems. Second, it will investigate whether these models reflect the context elements that are considered in the discourse on intelligent systems. Third, it will consolidate the findings that reflect previous knowledge about context from context models as well as from the discourse on intelligent systems. The paper closes with a discussion and conclusions.
Analysis of context models
To gain an understanding of how context is conceptualized and categorized by researchers in the field of intelligent systems, we conducted an analysis of the context models that other researchers have employed.
Frequently, context models were set up as “working models” on which its authors could develop and build their own systems (e.g., [68]). Note that some authors use the term “context model” to describe the data structure representing the context for a specific intelligent system (e.g., [4,6,11]). This paper, however, only refers to conceptual context models independent of any particular system.
Literature search and acquisition
As suggested in the literature [8,28], we performed a multistep procedure to identify relevant context models in existing research. First, we performed a literature search in three electronic databases: ACM Digital Library, IEEE Xplore Digital Library, and Web of Science. Second, we acquired literature by searching backwards in time, scanning reference lists of identified publications for relevant sources (snowball search). Third, we searched forward in time for relevant publications in which the already-identified publications were cited. Finally, further publications were gathered with the help of other researchers in the intelligent systems community as well as serendipitous encounters with relevant publications while browsing the literature.
Following this multistep approach, we retrieved a total of 47 publications (18 journal articles, 17 conference publications, two monographs, five book sections, three standards, and one working paper) containing potentially relevant models. After in-depth examination, 11 publications had to be excluded because their models were not designed to cover the entirety of context [4,5,13,63,70]; described systems that only use context [7,30,34,35]; were exclusively concerned with user experience, made no reference to intelligent systems [33]; or did not relate to systems at all [16]. An overview of the remaining 36 context models we analyzed is presented in the Tables 1–4.
Coding from publications
For each publication, we obtained the following information: (1) meta-information on the publication (citation information); (2) meta-information on the publication that the respective model builds upon (if available); (3) research field of the publication, including HCI, CA, and CSCW; and (4) context elements for all hierarchy levels of the model.
Overview of context models with a high level of detail, part 1
Overview of context models with a high level of detail, part 1
CA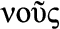 , French for “us”): ability to reason with care for the community and people, i.e., the ability to consider social context; t
, French for “us”): ability to reason with care for the community and people, i.e., the ability to consider social context; t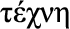 , “craft, skill of hand”): ability to act and adapt based on the installed technology base, and deployed techniques, methods and IT landscape, i.e., the ability to adapt to the technology context; e
, “craft, skill of hand”): ability to act and adapt based on the installed technology base, and deployed techniques, methods and IT landscape, i.e., the ability to adapt to the technology context; e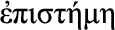 , “knowledge”): ability to reason based on the sensible knowledge of the world and the environment, predominantly in the physical surroundings of a system, i.e., physical context.
, “knowledge”): ability to reason based on the sensible knowledge of the world and the environment, predominantly in the physical surroundings of a system, i.e., physical context.
We assume that a context model follows a tree structure with “context” as the root element.
The detail index D of each model has been calculated by taking the reciprocal value of the product of the number of context nodes on the root + 1 level N and the total number of hierarchical layers (number of levels) H as:
A detail index greater than or equal to 0.2 indicates low detail, including a small number of generic context categories. Models having a detail index smaller than or equal to 0.1 exhibit high detail, with a considerable number of both generic and specific context categories enriched by explicit examples. Models with medium detail have an index value greater than 0.1, but smaller than 0.2.
Overview of context models with a high level of detail, part 2
CA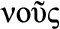 , French for “us”): ability to reason with care for the community and people, i.e., the ability to consider social context; t
, French for “us”): ability to reason with care for the community and people, i.e., the ability to consider social context; t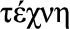 , “craft, skill of hand”): ability to act and adapt based on the installed technology base, and deployed techniques, methods and IT landscape, i.e., the ability to adapt to the technology context; e
, “craft, skill of hand”): ability to act and adapt based on the installed technology base, and deployed techniques, methods and IT landscape, i.e., the ability to adapt to the technology context; e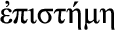 , “knowledge”): ability to reason based on the sensible knowledge of the world and the environment, predominantly in the physical surroundings of a system, i.e., physical context.
, “knowledge”): ability to reason based on the sensible knowledge of the world and the environment, predominantly in the physical surroundings of a system, i.e., physical context.
We assume that a context model follows a tree structure with “context” as the root element.
The detail index D of each model has been calculated by taking the reciprocal value of the product of the number of context nodes on the root
A detail index greater than or equal to 0.2 indicates low detail, including a small number of generic context categories. Models having a detail index smaller than or equal to 0.1 exhibit high detail, with a considerable number of both generic and specific context categories enriched by explicit examples. Models with medium detail have an index value greater than 0.1, but smaller than 0.2.
Overview of context models with a medium level of detail
CA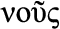 , French for “us”): ability to reason with care for the community and people, i.e., the ability to consider social context; t
, French for “us”): ability to reason with care for the community and people, i.e., the ability to consider social context; t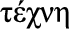 , “craft, skill of hand”): ability to act and adapt based on the installed technology base, and deployed techniques, methods and IT landscape, i.e., the ability to adapt to the technology context; e
, “craft, skill of hand”): ability to act and adapt based on the installed technology base, and deployed techniques, methods and IT landscape, i.e., the ability to adapt to the technology context; e , “knowledge”): ability to reason based on the sensible knowledge of the world and the environment, predominantly in the physical surroundings of a system, i.e., physical context.
, “knowledge”): ability to reason based on the sensible knowledge of the world and the environment, predominantly in the physical surroundings of a system, i.e., physical context.
We assume that a context model follows a tree structure with “context” as the root element.
The detail index D of each model has been calculated by taking the reciprocal value of the product of the number of context nodes on the root + 1 level N and the total number of hierarchical layers (number of levels) H as:
A detail index greater than or equal to 0.2 indicates low detail, including a small number of generic context categories. Models having a detail index smaller than or equal to 0.1 exhibit high detail, with a considerable number of both generic and specific context categories enriched by explicit examples. Models with medium detail have an index value greater than 0.1, but smaller than 0.2.
Overview of context models with a low level of detail
CA , French for “us”): ability to reason with care for the community and people, i.e., the ability to consider social context; t
, French for “us”): ability to reason with care for the community and people, i.e., the ability to consider social context; t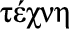 , “craft, skill of hand”): ability to act and adapt based on the installed technology base, and deployed techniques, methods and IT landscape, i.e., the ability to adapt to the technology context; e
, “craft, skill of hand”): ability to act and adapt based on the installed technology base, and deployed techniques, methods and IT landscape, i.e., the ability to adapt to the technology context; e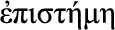 , “knowledge”): ability to reason based on the sensible knowledge of the world and the environment, predominantly in the physical surroundings of a system, i.e., physical context.
, “knowledge”): ability to reason based on the sensible knowledge of the world and the environment, predominantly in the physical surroundings of a system, i.e., physical context.
We assume that a context model follows a tree structure with “context” as the root element.
The detail index D of each model has been calculated by taking the reciprocal value of the product of the number of context nodes on the root + 1 level N and the total number of hierarchical layers (number of levels) H.
A detail index greater than or equal to 0.2 indicates low detail, including a small number of generic context categories. Models having a detail index smaller than or equal to 0.1 exhibit high detail, with a considerable number of both generic and specific context categories enriched by explicit examples. Models with medium detail have an index value greater than 0.1, but smaller than 0.2.
We compared the models by identifying mapping and differences between them based on their defined properties and levels [52]. We compared the models with respect to (1) their provenience (i.e., research field) and the ways they build upon each other, (2) the variety of context covered by the models, (3) the context categories that the context models share, (4) their relation to Nicomachean ontological thinking, (5) their independence from technical implementation, and (6) their consideration of multiple domains. Our analysis of the 36 context models is structured according to the following six aspects.
(1) Context model provenience: We analyzed in which fields of research the context models were built and the ways the models build upon on each other.
(2) Variety of context covered: A context model should embrace the variety of context that may be used to characterize a situation. To reflect this variety, context models need to have breadth and depth. To allow for a quantified comparison of the context models, we assumed that a context model follows a tree structure with “context” as the root element. We defined H as the number of hierarchy levels and N as number of nodes on the level root + 1. The “level of detail” index D of each model is calculated by taking the reciprocal value of the product of the number of context nodes on the level root + 1 (N) and the total number of hierarchical layers (number of levels) H (Eq. (1)).
A value of D greater than or equal to 0.2 indicates a low level of detail, including a small number of generic context categories. Models with D smaller than or equal to 0.1 exhibit high detail with a considerable number of both generic and specific context categories enriched by explicit examples. Models with medium detail have a D value greater than 0.1, but smaller than 0.2.
(3) Shared context categories: To identify the most frequently used context categories and elements among the context models, we considered all hierarchy levels. First, we identified the context categories in the top level of the context models that were named identically in several models and grouped them accordingly (e.g., “physical context”). Other context categories had different labels; these were grouped based on their semantics, which we inferred based on content analysis. This approach allowed us to merge categories and elements that were labeled differently, but represented the same concept (e.g., “physical condition” and “physical characteristics”). Two independent researchers judged the categories to determine which categories or elements should be grouped together.
(4) Relation to Nicomachean ontological thinking: Nicomachean ontological thinking considers three types of dianoetic virtues that intelligent actors, such as intelligent systems, should consider when reasoning on context:
Nous (Greek 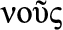 , French for “us”): the ability to reason with care for the community and people; the ability to consider social context.
, French for “us”): the ability to reason with care for the community and people; the ability to consider social context.
Techne (Greek  , “craft, skill of hand”): the ability to act and adapt based on the installed technology base and deployed techniques, methods, and information technology (IT) landscape; the ability to adapt to the technology context.
, “craft, skill of hand”): the ability to act and adapt based on the installed technology base and deployed techniques, methods, and information technology (IT) landscape; the ability to adapt to the technology context.
Episteme (Greek 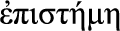 , “knowledge”): ability to reason based on sensible knowledge of the world and the environment, predominantly in the physical surroundings of a system – that is, physical context.
, “knowledge”): ability to reason based on sensible knowledge of the world and the environment, predominantly in the physical surroundings of a system – that is, physical context.
(5) Independence from technical implementation: Our work aims at consolidating context that is independent from a technical implementation representing what may be used to characterize a situation and not the means to do so.
(6) Consideration of multiple domains: Context exists in various domains, which may – but need not – overlap [10]. For example, in order to design an intelligent system that can be worn by a firefighter, the system designer must consider not only generic context elements such as location, movement, and time, but also domain-specific context elements such as the distance to the closest exit and hidden debris [24]. Therefore, our consolidation of context models aims at considering a multitude of different domains.
Context model provenience
Out of our 36 models, fifteen categorize context in the field of HCI. Eighteen explicitly recognize systems that intelligently adapt their behavior to the considered context (marked as CA in the Tables 1–4). Two models consider both HCI and CA, and one focuses on HCI and CSCW.
Although some context elements, such as location, appear in many context models, the context models largely do not build on each other. Only a few context models build on earlier models. For instance, the models of Schmidt et al. [67], Gwizdka [31], and Truillet [78] enhance the model of Schmidt et al. [68]. Schmidt et al. [68] proposed a working model for context in the field of mobile systems. They divided context information into two categories: human factors and the physical environment. The human factors were categorized as information about users themselves, their social environment, and their tasks. The physical environment was similarly defined through location, infrastructure, and physical conditions. Although building upon Schmidt et al.’s model [68], Gwizdka [31] followed a rather different approach; his model distinguishes between internal (e.g., user goals and tasks) and external (e.g., location and time) context.
Variety of context covered
The context models also differ considerably in the variety of context elements they include. Nine models structure context into only a few categories and hierarchy levels (see Tables 1–4); for example, Lucas [53] distinguished between physical, device, and information context. In contrast, however, 14 of the context models provided a wider array of context elements and examples; for example, categories in the context model presented by Sigg et al. [72] include location (geographical, relative), time (period, relative), activity (action, task), constitution (biological, mood), environment (physical, technological, equipment), and identity (user, social, organizational). The remaining models reflect a medium level of detail.
Shared context categories
Among the 36 context models, we identified five shared context categories: social context, location, time, physical context, and user context. Social aspects, which go beyond isolated conceptions of the user, are recognized by 78 percent of the models (28 models). User context is also part of many context models, although the models consider this category at different levels within their hierarchies. Further, the models use various terms to describe user context including “user,” “identity,” “self,” “internal dimension,” “consequences for user,” “personal context,” “participants,” “personal properties,” “human factors,” and “intrinsic context.” Location and time are featured in almost all the context models. All models except the one described by Prekop and Burnett [58] include aspects of physical context (e.g., “physical context,” “physical environment,” “physical,” “environmental conditions,” “environment including the physical aspect,” “physical conditions,” and “physical characteristics”). In a few models [44,68,69,78], location context, time context, and physical context together determine the physical environment in which a system operates. Furthermore, many models include technological aspects of context, such as the “computing environment,” “hard-/software platform,” “network characteristics,” and “factors of the technological infrastructure” [44,82].
Relation to Nicomachean ontological thinking
Sixteen of the evaluated 36 models relate to all three dianoetic virtues. Sixteen context models relate to two virtues only, and two models relate to only one virtue. Interestingly, most of the models that consider two virtues relate to “nous” and “episteme,” while “techne” is rarely considered in combination with “nous” or “episteme.”
Independence from technical implementation
Most of the models are built independently from technical implementations and can thus also be leveraged with novel technologies. For instance, the model of Sigg et al. [72] refrains from defining the user’s location in terms of specific technologies, such as global positioning systems’ (GPS) raw coordinates or indoor location systems’ vector data. This independence from a specific technical implementation allows the model to be used with both current and future technologies.
Consideration of multiple domains
None of the evaluated 36 models consider generic and domain-specific aspects. Models that contain only generic context (e.g., [69,83]) provide little support for understanding the context in a particular system’s domain [4] (e.g., healthcare, automotive, advertising, or accounting). Models that focus on only one domain (e.g., [46,61]), in contrast, can rarely be reused in other domains.
Content analysis of context in pervasive computing articles
Having analyzed this heterogeneous set of context models (see Section 2), we explored whether these models reflect the context elements that are considered in the discourse on intelligent systems.
Our approach is based on the assumption that context models should cover the context elements included in research on intelligent systems. To gain an understanding of context in this discourse, we sampled context elements that were mentioned in the IEEE Pervasive Computing magazine over a six-year period. We chose this magazine for two reasons. First, a literature review [37] identified that this magazine is a prominent source for practitioner articles on intelligent systems. Second, both practitioners and academics frequently use this magazine to obtain knowledge and spread their findings. Including the perspective of practitioners was particularly interesting for our analysis as the context models already represented the academic perspective on context for our consolidation.
Data acquisition
The sample’s scope included all articles from issue 4(1) to issue 10(2) of the IEEE Pervasive Computing magazine. We included the following article categories in the sample: Applications, News, Smart Phones, Spotlight, Standards & Emerging Technologies, Wearable Computing, and Works in Progress. The following categories of articles were excluded from the sample because they are not concerned with the subject matter: Conferences, Education & Training, New Products, From the Editor in Chief, and Guest Editor’s Introduction. Out of 414 articles in the reviewed issues, 297 met our inclusion criteria.
Coding of implicitly stated context elements (type b)
Coding of implicitly stated context elements (type b)
Our data acquisition (i.e., coding procedure) of the context elements in the articles involved two steps. In the first step, we identified context elements in the articles. Two reviewers inductively coded the raw data (i.e., the articles) and obtained explicitly stated context elements (type a) and implicitly stated context elements (type b). A context element is considered to be explicitly stated when a word or any form of the word (e.g., its plural form) of a context element is explicitly mentioned in the article (e.g., “atmospherics,” “color”). We considered two types of implicitly stated context elements in our consolidation: (i) a context element may be circumscribed in the article (e.g., “rate of the vehicle’s speed change” is coded as “acceleration and deceleration”) and (ii) a value of a context element is stated in the article (e.g., “loud” is coded as “noise level”). For examples, see Table 5. In some instances, the authors initially disagreed on the coding of an element. More precisely, one of the authors considered a stated term an explicitly stated context element for the consolidation (type a). The other author considered the term one of the various values of a corresponding context element that had to be included in the consolidation (instead of including the value itself); (type b(ii); see Table 5). For example, “efficiency” may be an explicitly stated context element because an intelligent system may change the transmission channel based on the spectral efficiency of the available transmission channels. In another system, “efficient” could be one of the various values of the context element “cost.” When such disagreement emerged, the authors carefully examined the original text in the articles and discussed its respective elements until they reached a consensus. A total of 10,498 elements (9,867 explicit, 631 implicit) were coded, including duplicates from different articles, but excluding duplicate occurrences within one article.
In the second step, for the purpose of grouping, we applied a “word stemming” procedure for explicitly and implicitly stated context elements. This procedure eliminates redundancy by combining different terms that have the same base form. For example, “locations” was coded as “location.” This procedure resulted in 3,741 distinct context elements (without duplicates).
Informed by the results of the analysis of existing context models (Section 2.3.3), we jointly built a classification scheme from the raw data. When we disagreed about a categorization, we discussed the respective context element until we reached consensus. Several iterations were necessary to assign the 3,741 distinct context elements to categories. (The reasoning underlying our assignment of the identified context elements to categories is presented together with our consolidated framework of context in Section 4).
The final consolidation presented in Fig. 1 integrates all context categories and elements identified in the context models as well as in the content analysis.
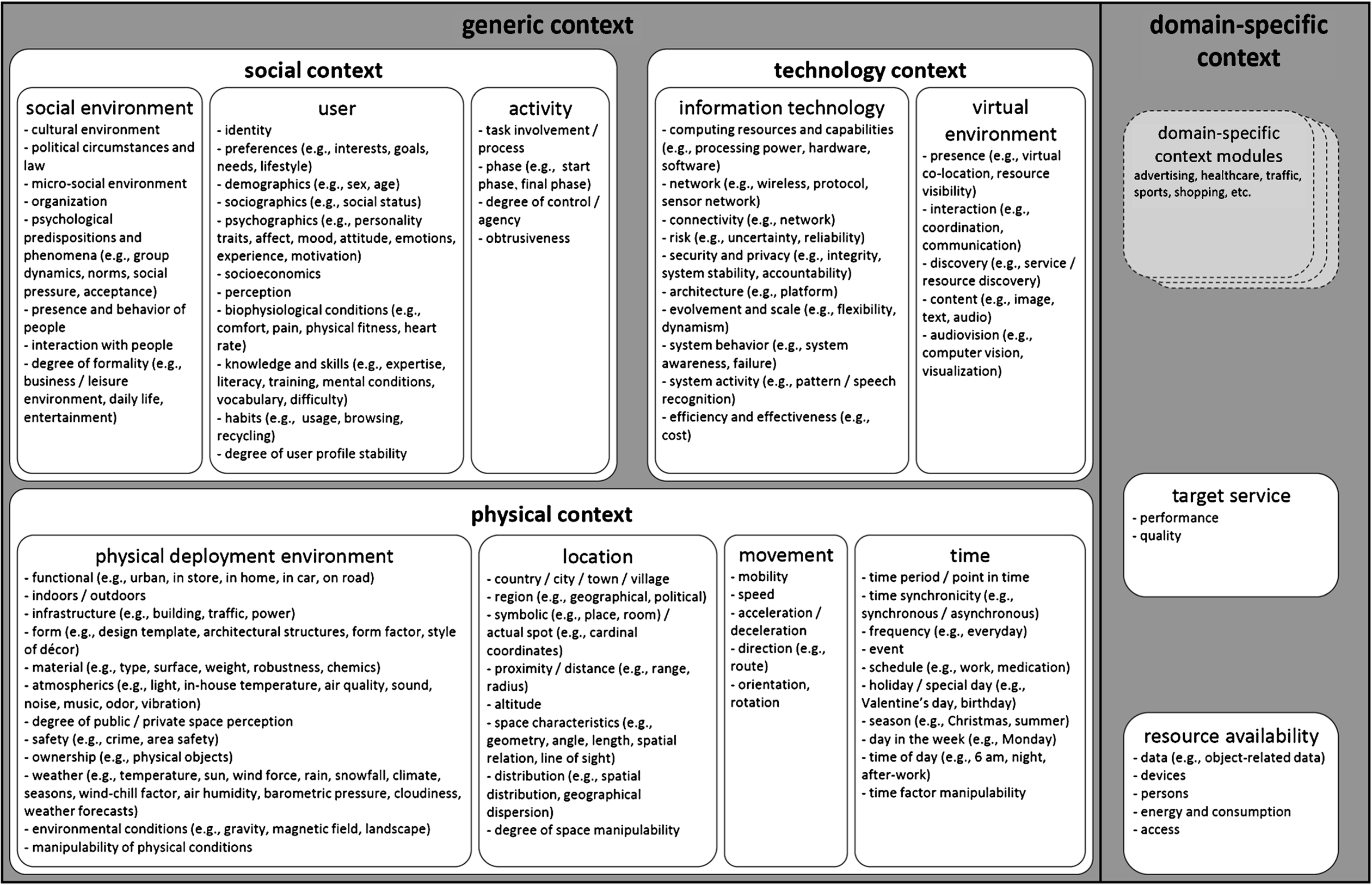
Graphical representation of the consolidated findings on context.
Our process of assigning the context elements that were identified in the content analysis was informed by the results of the analysis of existing context models (see Section 2.3.3). Two reviewers assigned each element to a respective category or decided to leave it unassigned, if no corresponding category existed. Then, the reviewers discussed the elements for which disagreement emerged until they reached a consensus about the appropriate context element (see Table 6). Of the 3,741 unique context elements identified in the content analysis, 1,973 could be directly assigned to existing categories, whereas the other elements could not be assigned, as they did not match any of these categories.
Analysis of the unassigned context elements suggested that coherent element clusters existed, with each being relevant only to a specific application domain. The content analysis helped identify clusters, each targeting one domain and showing no overlap with generic context elements. Overall, 715 context elements could be attributed to domain-specific context element clusters (see Section 4.2).
The remaining 592 context elements were assigned to newly introduced categories. For example, we added the context elements “ownership,” “distribution,” “degree of space manipulability,” “user habits,” “socioeconomics,” and “obtrusiveness,” among others. Based on the content analysis, we extended the categorization of existing context models by introducing new categories and new elements. The resulting categorization of context elements is presented in Section 4.
A consolidation of context for intelligent systems
Based on our analysis of existing context models (Section 2) and our content analysis of context in the IEEE Pervasive Computing magazine (Section 3), we present the following consolidated findings, which reflect the variety of contexts in which intelligent systems are embedded. The consolidation distinguishes between (1) generic and (2) domain-specific context elements. We deduced the structure and concepts of the consolidation from the analysis of the 36 context models identified in Section 2. Unlike earlier context models, the consolidation’s domain-specific context category explicitly considers the context specificities of a system’s domain, as called for by Brézillon and Abu-Hakima [10]. Domain-specific context comprises the categories of “target service” and “resource availability.” This dyadic split into system-specific output (i.e., “target service”) and input (i.e., “resource availability”) was adopted by Bauer and Spiekermann [4] for a domain- and system-specific context model in the field of advertising.
Selective examples for category assignments
Selective examples for category assignments
The structure of the generic context reflects 2,300 years of Nicomachean ontological thinking that we already used for analyzing existing context models. We structured generic context based of the three types of dianoetic virtues that intelligent actors should consider when reasoning on context: nous (i.e., social reasoning), techne (i.e., reasoning in adaption to technology), and episteme (i.e., reasoning based on knowledge of the world and the environment). Thus, in our consolidation, generic context is divided into three categories: social context, technology context, and physical context. Figure 1 provides an in-depth visualization of our consolidation. The figure is to be read top-down as it reflects the hierarchical structure of the context categories. Generic context is subdivided by the categories social context, technology context, and physical context, which are illustrated by white boxes. Each of these categories has several subcategories, which are illustrated by black-framed boxes. Social context contains the subcategories “social environment,” “user,” and “activity.” In our structure, we list the context elements for each subcategory. Illustrative examples for context elements are provided in brackets. We want to stress that a single context element is never exclusively generic, domain-specific, social, technological, or physical. For example, consider the context element “birthday.” The date of a person’s birthday (e.g., May 5, 1994) has a physical temporal meaning marking its calendar date. It also has a social meaning because the birthday represents a special day for the person in the course of the year, distinguishing it from the other “unbirthdays”:1
The term “unbirthday” inverts the special social meaning of the term “birthday” and was coined by the fairytale Alice in Wonderland.
We structure the generic part of the consolidation into the three categories of context that we derived from the analysis of existing context models (see Section 2): social context, technology context, and physical context. The social context includes all elements that are concerned with the user’s social environment and the user him- or herself. The technology context includes all elements that relate to IT and the virtual world, such as the presence of devices in networks and their respective connectivity. The physical context comprises all elements that are part of a system’s surroundings but are not specific to a domain; these elements may be useful for a variety of systems across several domains.
Social context
Social context is context that results from human behavior, which includes the actions and interactions of social actors. This context includes the behavior of the people surrounding the user of an intelligent system. The German philosopher Georg Wilhelm Friedrich Hegel (1770–1831) postulated that an individual is always bound to a social context, which is external to him or her.
Cultural environment and political circumstances are part of the social environment because they are created by the interactions of social actors. The micro-social environment includes small scale time- and space-regulated social situations [29]. Social systems are influenced by psychological predispositions and phenomena, such as group dynamics and social surroundings, which include the presence and behavior of other people and their interactions [47,68]. While building the consolidation of context, we considered that psychological predispositions could also be assigned to the user category because predispositions stem from within the user. Psychological predispositions affect the interactions between people, resulting in peer pressure, for example. Therefore, this context element has been assigned to the social environment. Moreover, assigning social context to environment helps to distinguish formal (e.g., business environment) and informal (e.g., leisure environment) social settings [11].
Social context also involves the user of an intelligent system. A user’s identity includes both a stable profile – with elements that evolve very slowly over time, and a situational or dynamic profile – with elements, which may vary more frequently [50]. Stable elements include a user’s social security number, demographics [68], sociographics [79], and socioeconomics whereas dynamic elements include psychographics, such as a user’s affect, mood, and emotions [59], preferences [11], biophysiological conditions [68], knowledge, and habits. These context elements are part of the “user” category because they build a one-to-one relationship with the user. Moreover, a user’s perception refers to the user’s own perspective, view, and impression.
Activity theory [54,58] suggests that context is dynamically co-constructed by the activities of social actors [23]. Activity refers to the process that users are involved in when they are using a system [68]. For contextual advertising in retail, for instance, the buying process engages the user. Thereby, the user is in a certain stage within this process (for instance, the user might need recognition while engaged in that process) [59]. Because a task is an activity that a user may perform [58], we assigned involvement in a task process to the activity category. Degree of control refers to the extent that a system allows its users to determine its actions [26]. In contrast, obtrusiveness is the amount of distraction (e.g., noise) that a user is exposed to while performing a task [74]. Where being “in control” or “distracted” are always connected to and dependent on an activity (making a case against these context elements to the “user” category), degree of control and obtrusiveness are characteristics of the activity that a user performs.
Technology context
Technology context is the pervasive network of technologies that surrounds people and intelligent systems within smart environments. Systems never operate in technological isolation; but rather, they interact with diverse information systems. For instance, many systems adapt their behavior based on available speed of network connection. We therefore distinguish between the context of IT and the virtual environment. IT comprises the context elements that are internal to the technological solution that the system runs on. IT context not only refers to computing resources but also to issues such as connectivity to a network [17], platform characteristics, security, and privacy concepts (e.g., integrity, system stability) [11]. Privacy is a technical design feature of intelligent systems [39], leading to its assignment to technology context. Behavior, which is also assigned to technology context, refers to a system’s actions and reactions. Such actions or reactions could include failure. Risk, which also falls under the same category, concerns the probability that a system-related event or behavior will occur (e.g., system outage) [36]. Additional contextual determinants of system use are the system’s performance (i.e., effectiveness) and its operating costs (i.e., efficiency) [18]. Effectiveness and efficiency relate to the economic aspects of technology, which are inherent to the characteristics of the technology itself [71].
Technology context extends into the real world by enhancing it with elements from the virtual environment. Virtual environment encompasses the cyberspace surrounding a system, which includes other services, as well as interactions with those services. Virtual presence connotes co-location in a virtual space. For instance, a network-capable printer that is “visible” in the network environment is “present.” Additionally, the virtual environment considers interaction with technological components and includes coordination of networks, wireless communication, and service and resource discovery (e.g., [17]). The “content” element refers to information artifacts such as images, text files, audio, etc. (e.g., [25]), and their audiovisual representations. Because of their manifested representation in virtual information structures such as files, we assigned this context element to the virtual environment instead of to another category, such as available resources.
Physical context
Physical context is the sum of observable elements in the “real world.” In a narrow sense, the physical context involves the conditions of the local environment in which an intelligent system operates – namely, the physical deployment environment. Such operative environments include, for example, a store or a car. Since such operative environments represent a functional type of environment rather than a specific location, this context element has been assigned to the physical deployment environment category [44]. Indoor and outdoor environments are two possibilities for deploying systems within the physical environment. Elements of the built environment, including form, material, architectural structures and the presence of distinct physical objects [56], influence a system’s physical surroundings. A significant part of the physical deployment environment consists of infrastructure, such as traffic infrastructure [11]. Light, sound, and air quality also contribute to atmospherics, which are part of the physical environment. This physical deployment environment may also be divided into objective states based on an individual’s perceptions. For instance, a space can be perceived as public or private. In this regard, Paay [55] calls space perceptions “locatedness,” which refers to the physical-environmental characteristics that space perceptions imply. Safety refers to the crime rate in a physical environment [1]. Ownership defines the property rights related to a physical object, such as “this house is owned by company X.” Typically only relevant to outdoor settings, weather includes temperature and wind-chill factor. These environmental conditions, as well as other objects in nature cannot be easily manipulated.
Elements of the physical deployment environment frequently depend on location (e.g., weather). As reflected by the importance of location-based services [68], the location of entities is a widely used category of context. Although many existing context models consider physical context and location as two distinct categories, location is part of the physical context within the consolidation. The notion of “location” as understood in the consolidation refers to physical location – a tangible point or area. Location corresponds to the intelligent system’s place of use, or its absolute and relative location, as well as the position of other entities that are relevant to the service [56,68]. Location may be considered from a broad perspective such as considering households in a particular region, or on a narrowly defined basis such as the proximity to a fridge. Furthermore, location can be symbolic (e.g., “room 2.23”) or geometric (e.g., real space representations, such as distance or altitude) [14]. Location also comprises aspects deeply anchored in physics, such as space characteristics – geometry, angle, spatial relation, line of sight – and distribution – spatial distribution, geographical dispersion. Arminen [2] argues that space-related characteristics relating to the entities’ activities and interactions provide more meaningful location information to a system than geographical location. Some of these characteristics can be manipulated (e.g., where to install a system), whereas others cannot (e.g., mobile devices).
Movement describes changes in location. It considers the “mobility” of life showcased by myriad intelligent mobile services [11,57,82]. The movement element includes parameters like speed, acceleration, and deceleration [44]. Moreover, it considers whether an object is mobile at all and indicates movement variations, such as orientation, rotation, and directions (e.g., for routes).
Finally, location and movement are interrelated through the aspect of time, which is among the most mentioned context elements identified in the content analysis (601 assigned elements, see Section 3). Time context can refer to particular points in time (e.g., 6:00 a.m.) or to periods of time (e.g., summer, Christmas). Although “special” time periods, such as Valentine’s Day or a birthday, also have social meaning, we assigned them to a category based on their temporal aspect. An event is an incident in time [77]. In synchronous time, events are perceived to occur simultaneously. Time also includes the day in a week (e.g., Monday) and time of day (e.g., after work) [12]. While an intelligent system may be triggered by a time event, which the operator can manipulate, other systems may be used at the user’s convenience and are thus out of the operator’s control.
The domain-specific context
The domain-specific context is any context that is particular to the intelligent system’s field of operation. In the consolidation, this context comprises the categories of “target service” and “resource availability.” While the target service category considers the “output view,” the resource availability category considers the “input view.”
The target service category uses domain-specific factors to make a service work. It refers to the purpose and action of the target service, rather than to the deployed technologies or resources. For instance, for intelligent context-adaptive advertising, the target service would be advertising or, more specifically, the advertising campaign. For an intelligent alarm clock, the range of clock types and features (e.g., sounds, lights, movements) would make up the target service.
The resource availability category includes the range of data, objects, devices, persons, energy, and access to these resources that are necessary to fulfill the intelligent system’s purpose. A navigation system, for example, would fall under resource availability, because it requires spatial information and data on the user’s current position.

Domain-specific context cluster for the traffic domain.
The graphical representation of the consolidation (Fig. 1) also contains the domain-specific context clusters category. These domain-specific element sets, or clusters, can be interchangeably plugged into the consolidation representation depending on the domain of the envisaged intelligent system.
In total, we could identify 50 different domain-specific clusters. The context elements contained in these clusters go beyond the generic context of an intelligent system. They are particularly relevant for intelligent systems within a specific domain, such as healthcare, advertising, or agriculture.
Figure 2 shows an example of a domain-specific context cluster consisting of 30 particular context elements for the traffic domain. This domain-specific context cluster is not intended to be an exhaustive representation of the context in the domain but represents the context elements for the domain as identified in our content analysis of context in pervasive computing articles. The “traffic cluster” might be a relevant example when designing an intelligent system in the traffic domain. Specific examples of intelligent system instances within the traffic domain are intelligent automotive applications or a context-adaptive alternative routing system. For example, a car navigation system could recalculate a route (including estimated arrival time and refueling stops) based on traffic and the driver’s behavior could cause a car navigation system to reschedule the route.
In pervasive, context-aware, and mobile computing, context is an essential source of information for intelligent systems: context influences the system’s behavior. The environments in which systems operate are potentially complex and comprise a wide variety of context elements. Dividing context into different categories is a common approach to conceptualize context. The many context models that exist are heterogeneous and scattered throughout the research fields of CA, CSCW, and HCI. Putting these “puzzle pieces” together was the prime objective of this work.
When discussing our work, several caveats and limitations should be considered. First, our content analysis of context considered in research on intelligent systems is based on data from a single journal. For analyzing the context of a particular intelligent system within a specific domain, further methods – in addition to the context considered in our consolidation – are required to comprehensively understand context within the respective domains. In the current state, the domain-specific context clusters that we have identified do not represent context within the respective domains exhaustively; they constitute just excerpts of the domains as discussed in the analyzed papers. Second, despite being careful about establishing intersubjective validity when consolidating the context elements (see Section 3.3), different approaches of consolidating could lead to a different categorization. Still, as the high-level context categories (generic and domain-specific context as well as social, technology and physical context) remained stable throughout our analysis, we do not expect that different approaches to consolidation on lower context levels would considerably change our results.
These caveats notwithstanding, our work offers three key contributions. First, this article provides an overview of 36 context models. In these models, we identified shared context categories: social context, location, time, physical context, and user context. Research on context for intelligent systems in CA, CSCW and HCI has predominantly put these five categories into spotlight. However, the analysis also revealed that there is a long tail of context categories that are considered only sporadically in the context models. Context elements represented in the long tail, though, may be important for intelligent systems operating in specific domains because they may enable them to gain richer insight into their environment beyond the shared context categories. If intelligent systems considered the long tail of context, they would possibly be capable of providing even more innovative, adaptable, and intelligent services to users.
Second, motivated by the results of our context model analysis, we analyzed the models against the context elements that were considered in the discourse on intelligent systems. This content analysis – considering a total of 10,498 context elements – revealed that about half of the identified unique context elements did not match any of the context models’ categories. On the one hand, this finding called for the introduction of new categories. On the other, the analysis helped identify domain-specific context element clusters, indicating the importance of considering domain-specific context. Intelligent systems in specific domains often need to adapt to particular types of conditions that do not occur in other domains. We claim that context is a rich concept that has different facets within different application domains and thus cannot be represented in models that represent context purely generically.
Third, based on these findings, we have presented a consolidation of findings of context that reflects the variety of context that intelligent systems are embedded in. The consolidation considers generic and domain-specific context elements, which is a novel perspective, as existing approaches to context categorization have not considered domain-specific aspects of context.
Still, our consolidation is a snapshot at the time of analysis. We emphasize that the consolidation covers as much of context as is reflected by the reported context elements in the analyzed literature; it needs to evolve in line with the amount of information known about context (in the “real world”).