
Abstract
The numerical value discretization is a process that is performed in the data preprocessing phase of intelligent data analysis. Preprocessing phase is very relevant because the quality of the models obtained in data mining step depends on this phase. Value discretization is an important task in data preprocessing because not all data mining techniques can handle continuous values. In this paper an unsupervised technique to discretize continuous data values using fuzzy partitions is proposed. Specifically a clustering technique that gets fuzzy partitions is presented. In addition, to evaluate the behavior of the proposed technique a series of experiments have been proposed using a Extreme Learning Machine classifier and a committee of Extreme Learning Machine. Beside comparing with the K-means discretization technique. These experiments have been validated statistically obtaining the best results the approach proposed.
Introduction
The discretization is a relevant task of data preprocessing within Intelligent Data Analysis. This task has as objective to transform the attributes with continuous values into discrete values, either through intervals or through fuzzy partitions. This discretization process is essential because there are data mining techniques that can not manage continuous values, these techniques can only handle categorical/discretized values some of these are: association rules, induction rules, Bayesian networks, some techniques of decision trees, random forest, etc. There are even data mining techniques, that being able to work with continuous values, obtain more satisfactory models working with discrete values. Between the advantages of dicretization it can be highlighted the capability to reduce the number of store data, to improve the interpretability both initial data and results obtained and the effectiveness and efficiency that will be established later in the application of data mining techniques. The effectiveness and efficiency caused by discretization favors to a certain extent the reduction of the computational cost [4,8].
In literature several taxonomies to classify the different discretization techniques can be found [22,35]. Without being exhaustive some of these classifications are analyzed taking into account the characteristics of them:
Static versus Dynamic: A static discretizer performs the learning task independent from the learning algorithm. A dynamic technique performs the discretization during the learning phase of the data mining technique.
Global or Local: Global discretization is performed when all the information is used to discretize. Local discretization technique only uses part of the information to perform the discretization process.
Supervised or Unsupervised: Unsupervised techniques do not consider the label class to perform the discretization. Supervised techniques need to evaluate the label class to perform the partition.
Univariate or Multivariate: Multivariate techniques create the initial cut point with all attributes simultaneously. The univariate techniques only consider an attribute each time.
Direct or Incremental: Direct techniques divide the range into k intervals simultaneously, requiring a criterion to determine the k value. By contrast, incremental discretizers begin with a simple discretization, and perform improvement process until a stop criterion is fulfill.
Splitting or Merging: Splitting discretizers create new intervals dividing the domain of the continuous values. Merging techniques create a number of intervals which are removing and merging to obtain the final partitions. Some techniques can be considered hybrid because they can alternate splits with merges in running time [8].
Evaluation measure: Discretizers can also classify considering the measure used to assess the partitions. Thus, some measure used are: information measure such as entropy and Gini Index, rough set measure, statistical measures, error in classification or binning that is the absence of measure.
Fuzzy or crisp: This type of discretization depends on the logic used (classical or fuzzy logic). The difference between a fuzzy discretization or a crisp discretization is the result of the intervals. When the discretization is fuzzy, the intervals overlap and a value may belong to more than one interval. On the contrary in a crisp discretization, the intervals are disjoint and a value can only belong to an interval.
Parametric or Nonparametric: A parametric discretizers need that users fix a maximum number of intervals. However, a nonparametric discretizer determines automatically the number of intervals to discretize a continuous attribute.
Top-Down or Bottom Up: This characteristic is usual in incremental discretizers, [8]. Top-down techniques start with an empty discretization and add new cut point during the discretization process. On the contrary, bottom up techniques start with all possible intervals, and during the discretization process, they are removing cut point, that means, merging intervals.
Stopping criteria: This characteristic is referred to the stop conditions of the discretization process, some of this conditions are confidence thresholds [17], inconsistency ratios [5] or the Minimum Description Length measure [6].
Disjoint or Non-disjoint: Disjoint techniques divide the domain in crisp partitions, that means, in intervals. Non-disjoin techniques allow the overlapping between partitions. Usually, fuzzy discretization techniques are non-disjoin.
Nominal or Ordinal: Nominal discretizers divide the domain in nominal qualitative values. On the contrary, ordinal discretizers transform the domain in ordinal qualitative values. This last type of discretization is not very common.
The assessment of the partitions can be performed using different method such as number of intervals, inconsistency, predictive classification rate or time requirements. The most commonly used method is usually the classification predictive classification rate, therefore, we use them for our experiments. In this paper, a modification of the Fuzzy C-Means (FCM) technique [34] is used to develop a fuzzy and unsupervised discretization algorithm. This proposal is based on Cauchy distribution to discretize numerical values. To assess the approach datasets from UCI repository, [20] are used. The results obtained after comparing with the classical discretization technique based on K-means (KM) algorithm [12] are satisfactory. The paper is organized as follow. In Section 2 a brief review of some work on discretization is carried out. Then, in Section 3 the discretization technique proposed is explained. Next, Section 4, the classifier used to assess the quality of discretization is exposed. Finally, in Section 5 and 6 the experiments, conclusion and future works are presented, respectively.
Background
Different discretization techniques can be found in literature due to the fact that there are not an universal technique to obtain categorical values that works properly with any data mining method. Thus, in [25], several discretization techniques are evaluated to use the most suitable for clinic data. The discretization performed by these authors is crisp and the techniques used are both supervised and unsupervised. In their conclusions, the authors affirm that supervised discretization is more particular and unsupervised is more general and it can be applied in more domains.
In [21], a fuzzy and unsupervised discretization is presented. In this work the discretization process is performed by means of clustering technique, selecting initial clustering centers by large density area and using density function as samples’ weights to reduce effectively noise interference. Then, the compatibility of decision table in rough set theory is used as criteria to adjust dynamically the parameters of the algorithm to achieve optimal discretization effect. Another clustering technique is exposed in [1]. In this case, the authors develop a clustering technique as a discretization technique to recognize solar images, extracting texture features of these images. In [23] a non-parametric discretization technique for continuous values with missing data is presented. This technique uses the statistical technique z-score with an index measure to impute the missing data values for numeric or continuous attributes. In [39] an iterative and novel scheme to dicretize is presented. This method dynamically discretizes the continuous random variables in intervals at each iteration. The interactive method is focused on estimating the likelihood of low-probability failure events instance of focusing on getting the overall shape of the distribution correct. The method is assessed using a dynamic Bayesian Networks.
The authors of [15] present a supervised and multivariate discretization algorithm called SMDNS based on rough sets, which is derived from the traditional algorithm naive scaler. This method simultaneously considers all attributes, that is, takes into account the interdependence among various attributes. The method iteratively merges adjacent intervals of continuous values according to a given criterion. A hybrid discretization method for naïve Bayesian classifiers is presented in [36]. The propose discretizer uses a nonparametric measure to assess the dependence level between a continuous attribute and the class.
In [37] other algorithm to perform fuzzy partition is developed. Specifically authors expose a two-step method to create membership function. In the first step the method divides domain of continuous attributes in intervals and then in the second step the different membership functions are created. For creating the membership functions they use four different measures, particularly partition width, standard deviation of examples, coverage rate of neighbor partitions and Entropy Based Fuzzy Partitioning. Another discretization technique that uses different measures to perform the discretization process is presented in [16]. In this case, the authors propose a weighted hybrid discretization technique based on entropy and contingency coefficient.
In [3], a method to discretize continuous attribute is proposed. This method performs the discretization during the learning phase of a decision tree. Specifically to perform the discretization the authors propose an extension of the method Ant Colony Decision Tree. In [19] a self-adaptive discretization method is proposed to discretize continuous values for association rule. The self-adaptive method proposed creates partitions which can give a high confidence to the calculated association rule while guaranteeing the relatively high support.
Discretization technique
This section describes the proposed discretization technique based on clustering analysis. This technique can be categorized according to the above categorization as a global, unsupervised and fuzzy discretization technique.
Clustering analysis consists of dividing a data into several clusters where data in same cluster have high similarity while data in different clusters are distinct each other. KM algorithm is one of the most popular clustering methods, [12]. This algorithm starts by guessing k cluster centers and then iterates the following steps until convergence is achieved. Each cluster is built by assigning each instance to the closest cluster center and each cluster center is replaced by the mean of the elements belonging to that cluster. Traditional clustering methods, such as KM, each instance is assigned to one cluster in an unequivocal way. As opposed to this, in fuzzy clustering an instance x may belong to different clusters at the same time, and the degree to which it belongs to the kth cluster is expressed in terms of a membership degree. Consequently, the boundary of single clusters and the transition between different clusters are usually soft rather than abrupt. An example of fuzzy clustering would be FCM. The k-means algorithm has been extended to the fuzzy c-means algorithm by Bezdek in the early eighties [2] and is one of the most widely used fuzzy clustering methods. The cluster analysis FCM aims to find the patterns in data by processing a range of clusters by the calculation of distances of registers to clusters centers through the FCM algorithm.
Consider the dataset X to a set of n instances
Clustering a dataset requires finding the center of each cluster and deciding to which cluster each point belongs to. In FCM to find the center of a cluster, the sum of the distance between points in the cluster and its center is used as criterion. The criteria is represented by an objective function, J, which needs to be minimized with respect to P, a fuzzy c-partition of the dataset, and V, a set of c prototypes for cluster centers
The formula incorporates the fuzzy membership function
The function J is minimized by using the following equations for updating the membership degrees and V iteratively until
The μFCM algorithm is derived from FCM algorithm, and μFCM is explained in [34]. This algorithm is the approach proposed in this paper to be applied as discretization technique instead of classifier technique. Between others differences, the membership function of μFCM (
The fuzzy covariance matrix at cluster k is defined, in [10], as:
The membership of all samples to all clusters defines a partition matrix as
So that, the objective function (1) is rewritten here as:
The μFCM algorithm computes interactively the clusters centers coordinates from a previous estimate of the partition matrix as:
Algorithm 1 shows the μFCM process. It is an iterative process where one standard value is included in the computation, ϵ. The algorithm is composed of the following steps:

Algorithm μFCM
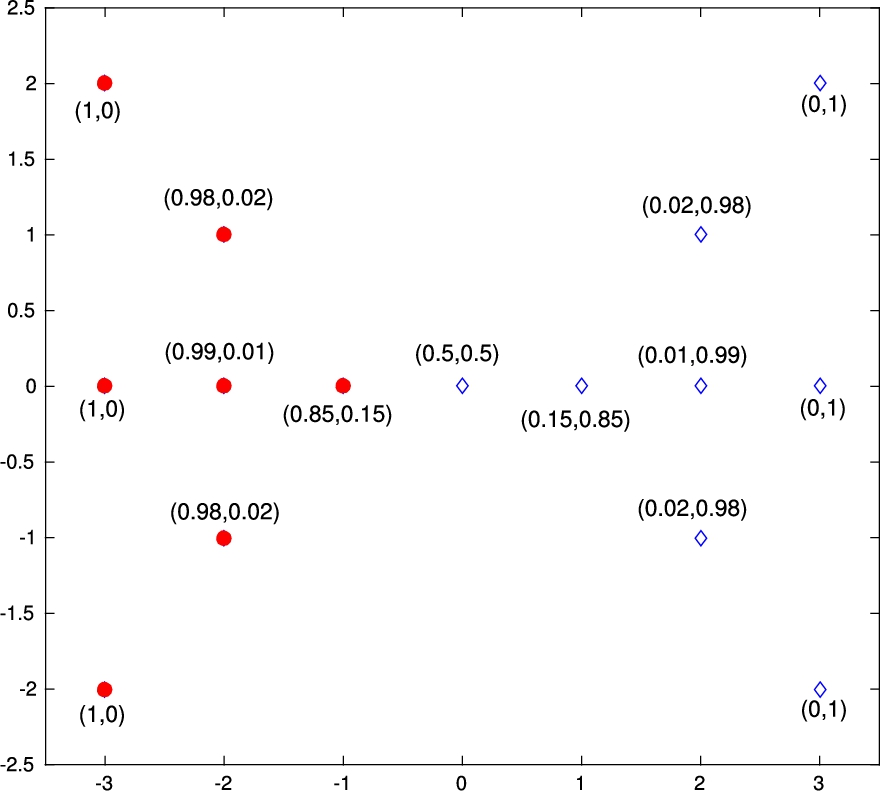
Illustration for the sample of Butterfly dataset. The point and diamond differentiate the two groups classified with K-means algorithm, while the pairs in brackets indicate the probabilities of diffuse belonging of each point to each of the two groups in which the set has been segmented.
The μFCM algorithm is used as a discretization technique by applying it to each attribute separately. In this way, the values are classified in three clusters (good-regular-bad). From this performance, a “weight” is assigned to every value of the attribute selected, which corresponds with the μ-values. This process avoids the possibility of correlation, to avoid problems with the classifier.
Let’s exemplify the difference between KM and μFCM. Figure 1 shows the two groups that the KM algorithm obtains. These groups are represented by points and diamonds. The algorithm places the point
μ-function and KM Classification for the sample of Butterfly dataset
Table 1 shows the values obtain for μ-function for each of the centers
In order to illustrate the process, the example of Iris Data has been considered. The attributes sepal length, sepal width, petal length and petal width are discretized independently, and the interpolation of μ-functions are represented in Figs 2, 4, 5 and 6 respectively.
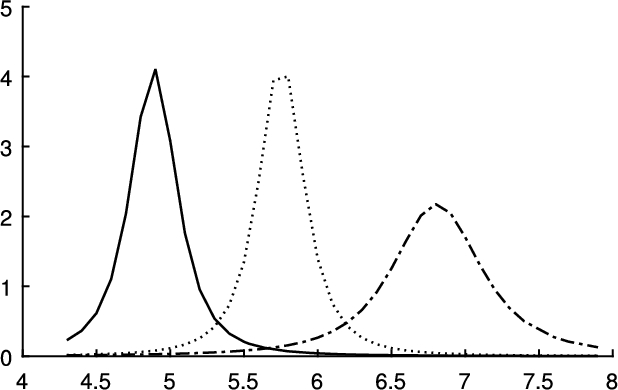
A linear interpolation of the μ-function for the sepal length attribute in cm.
The μ-function for each cluster created by the μFCM algorithm for the sepal length attribute is represented in Fig. 2. The graphic depicts three clusters represented by the prototypes in the maxims of the function. The μFCM algorithm uses the showed probabilities values of the μ-function in Fig. 2. In this way, for a 6.5 cm sepal length, the membership probability value is 98.17%,
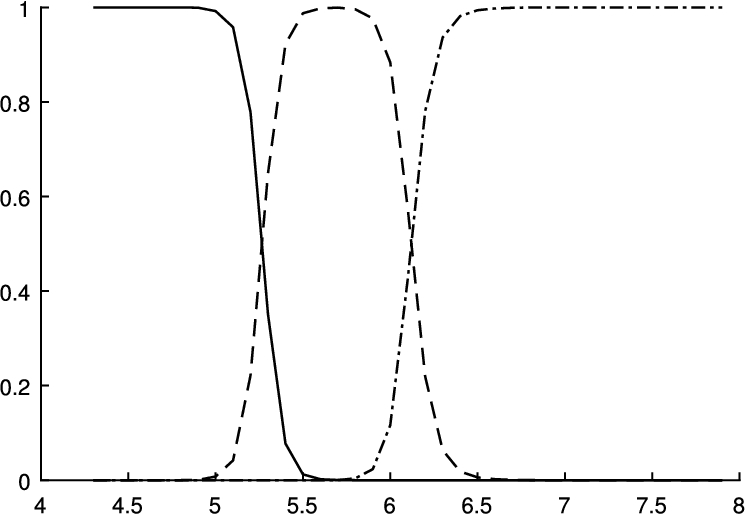
The membership probability for the sepal length attribute.
Usually, fuzzy clustering algorithms return the membership probabilities using graphics as Fig. 3. The values obtained through the μ-function of the μFCM algorithm are used and represented in Fig. 2.
In the following Figs 4, 5, 6, the μ-functions for the rest of attributes are represented. Each cluster is represented by a different line types and each prototype is identified by the maximum of the function.
Using the same notation employed to explain Fig. 2, Fig. 4 shows for a 2.4 cm sepal width the μ-function values obtained are

A linear interpolation of the μ-function for the sepal width attribute in cm.
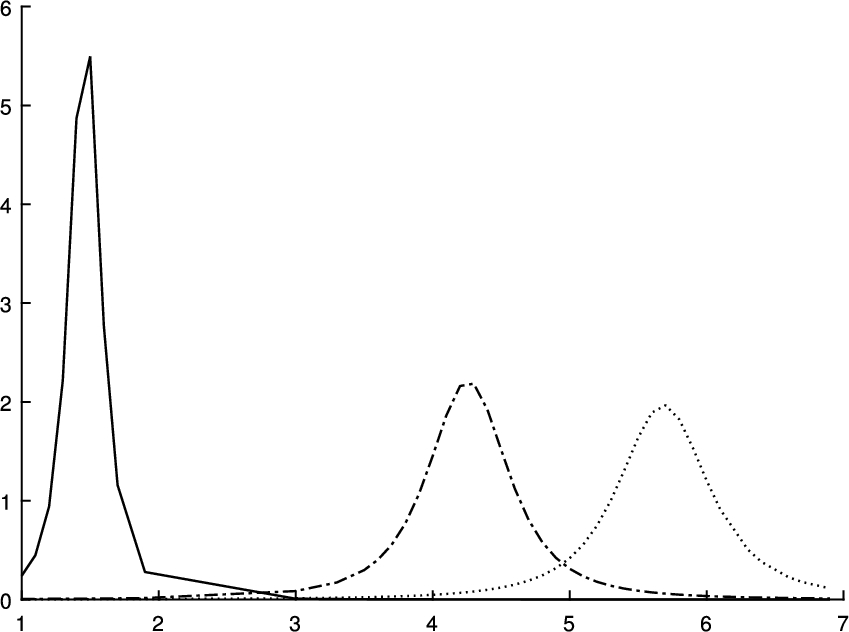
A linear interpolation of the μ-function for the petal length attribute in cm.
In Fig. 4, it is shown for example that for a 4 cm petal length the following μ-function values are obtained:

A linear interpolation of the μ function for the petal width attribute cm.
Finally, Fig. 6 shows for example that for a 1.6 cm petal width the following μ-function values are obtained:
Once the proposed μFCM discretization technique is detailed, the following section presents the classifier used to evaluate the quality and suitability of this technique. In addition, this evaluator is also used in the comparison with the KM technique. The classifier used as evaluator is the Extreme Learning Machine.
For Multilayer Perceptron (MLP), Extreme Learning Machine (ELM) provides a fast and efficient training [14]. Formalized by Huang [9,13], it is demonstrated that the ELM is an universal approximation for a wide range of random computational nodes. The MLP input weights are fixed to random values, so, the output weights can be easily obtained using the pseudo-inverse of the hidden neurons outputs matrix
The previous N equations can be expressed by:

Extreme Learning Machine (ELM)
A problem that presents the ELM is to obtain the number of neurons for the MLP. This requires a pruning method for the ELM. Although there are several pruning methods [26–31], the most commonly used, to avoid the exhaustive search for the optimal value of M, is the ELM Optimally Pruned (OP-ELM) [29]. The OP-ELM sorts the hidden neurons (previously has been initialized to a very high initial number) according to their importance to solve the problem [33]. The pruning of neurons is done by choosing that combination of neurons that provides lower Leave-One-Out error [29]. For more detail, OP-ELM is summarized in Algorithm 3.

Optimally Pruned-ELM (OP-ELM)
Each input characteristic provides a membership function. The union of all of them is trained with the OP-ELM (Fig. 7). This paper also discusses the use of a combination of MLPs (trained width OP-ELM). The use of multiple models may often improve the performance with respect to an individual model [11,38]. Such combination of networks are called committees. A combination of MLPs is presented where each network has been trained with a single input characteristic, because μFCM works individually with each input feature by generating a membership function for each of the partitions created. This allows to create a network committee formed by many networks as the input features have the database, and where each feature has been transformed into its membership function, thus forming the network input. Once trained each network, this provides us with an output that will be the input for a new network, newly trained with OP-ELM, that provides the classification accuracy (Fig. 8). It should be noted that once each network has been trained, the importance of that input for the new network is verified. In this way, networks that do not generate good performance are discarded, which may be due to the fact that this input characteristic is not relevant to learning the model. This transformation of each input characteristic to its membership function provided by the μFCM could be used to make a selection of relevant input characteristics because it is done individually for each input.
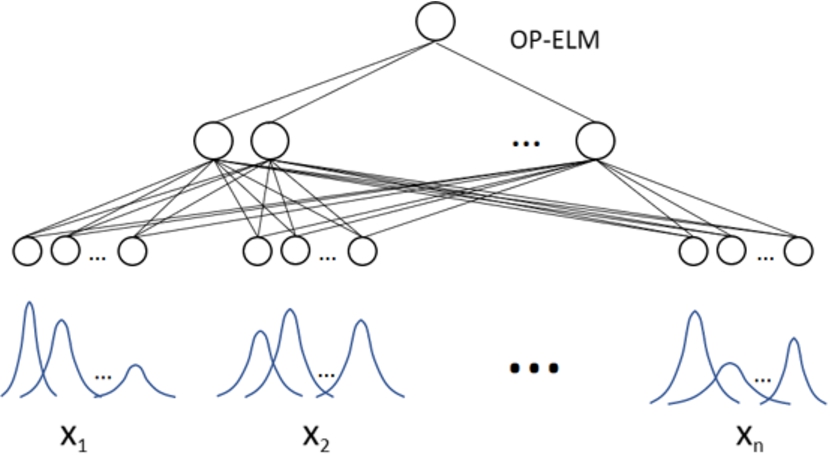
Single classifier model. Each input is transformed with the membership function, thus forming the input of the network to be trained with the OP-ELM algorithm.
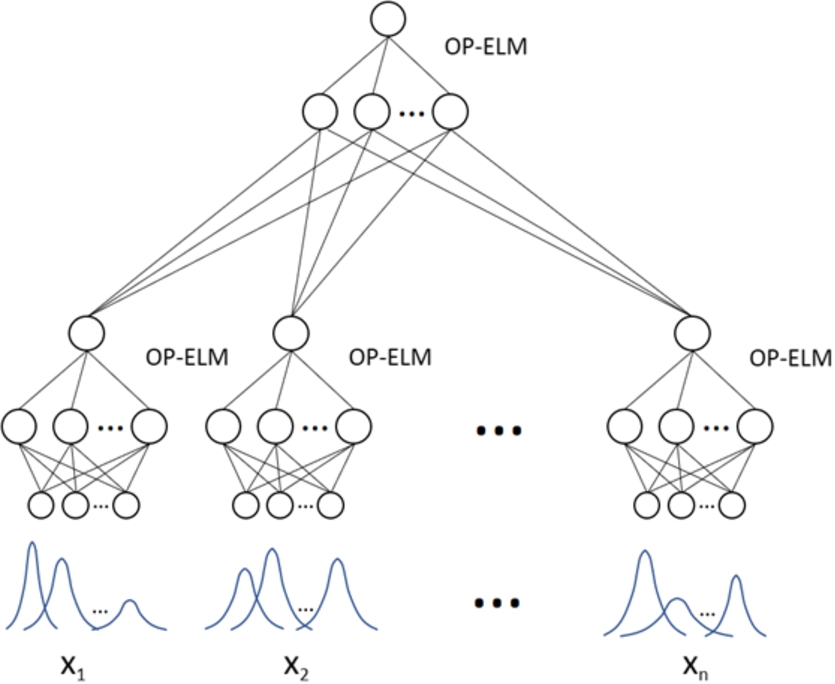
Network committee used to train the model. Each input characteristic is trained by one network and its output is the input of the final network. All are trained with the OP-ELM algorithm.
The proposed discretization technique is evaluated using the ELM explained in Section 4. Table 2 shows the number of input features and number of classes for each dataset, these datasets are obtained from UCI repository [20].
Dataset Description
Dataset Description
The proposed technique (μFCM) is compared with the classic technique K-means (KM). On the one hand, the goodness of the techniques is assessed by a Leave-One-Out Cross-Validation repeated 30 times. On the other hand, a series of tests have been carried out in order to validate the best number of partitions to divide each one of the numerical attributes of the datasets. In this way, in this study it is taken into account not only the accuracy obtained in classification but also the interpretability of the results obtained.
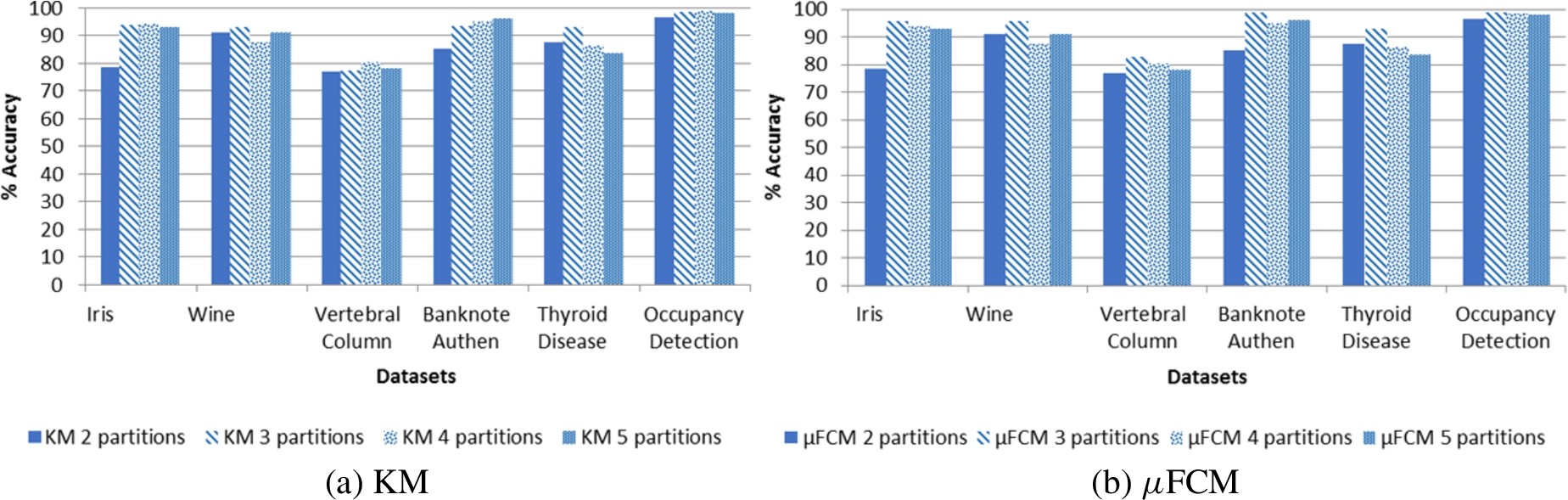
Comparative for the KM and μFCM technique with different granularity in partitions.
Figure 9 shows the results obtained by KM (Fig. 9(a)) and μFCM (Fig. 9(b)) techniques using different granularity in partitions. Specifically, a division of 2, 3, 4 and 5 partitions have been used for each attribute. In general, this figure shows how the division into 3 partitions achieves the best results.
Experimental results with three partitions
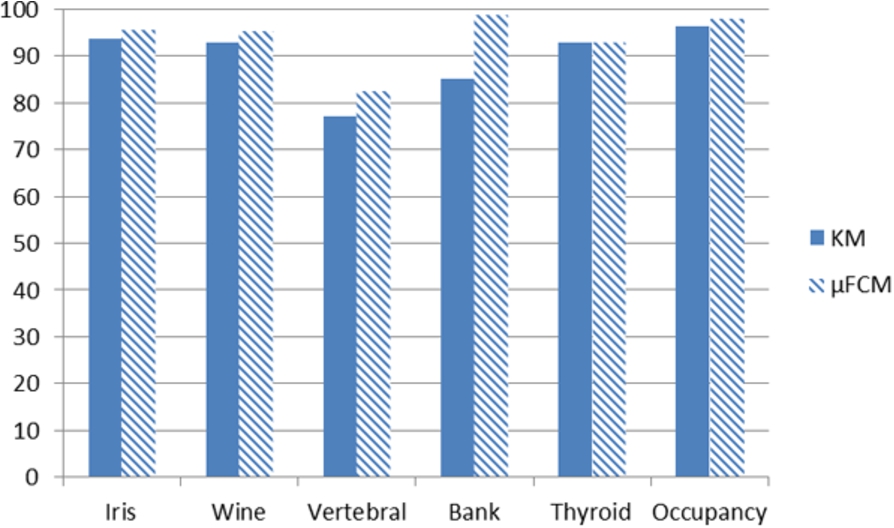
Graphical comparison of the validation of the techniques KM and μFCM.
The best results obtained with three partitions are shown in Table 3, where it can be seen the classification accuracy with its associated standard deviation. It can be clearly seen that μFCM gets better results. More graphically, the results are shown in Fig. 10.
To validate this assertion, a non parametric statistical test has been performed. Specifically, the Wilcoxons Signed Ranks Test is used [18]. This test compares two paired groups and can be used to test where the null hypothesis indicate that two populations have the same continuous distribution.
Table 4 shows the p-value and the negative and positive rank and the statistical Z that is based on negative rank. As it is shown in this table, the technique μFCM is compared statistically with KM technique, obtaining a p-value of 0.028, that means the null hypothesis (the result means of both technique are similar) is rejected with 97% of confidence level. According to the statistical Z, the technique with more satisfactory results is μFCM. In addition to the quantitative results, it must be also highlighted the qualitative part of them. Considering that these results are achieved with three partitions for numerical attributes, it can be indicated that the results obtained are satisfactory and interpretable, since for each attribute all the continuous values are reduced to 3 values.
Statistical test result
In addition to the results obtained, a committee system to validate the results has been used. The use of a committee system has been tested with Iris and Vertebral datasets. Figures 11 and 12 show the classification of each individual network for each input features. It can be seen that features number 3 and 4 are the most relevant for Iris data, Fig. 13 shows the accuracy classification (in %) for iris data, where it has trained with the KM, μFCM and two different committees: where only the input feature number 2 has been removed, and another where the features 1 and 2 have been removed. It can be observed as improving the learning by eliminating the less relevant input features. Nevertheless, all features are similar for accuracy classification in the vertebral dataset (see Fig. 12), so, Fig. 14 shows the KM, μFCM and several different committees: with all features and removing each feature separately. It can be observed that improves learning by eliminating the fourth input characteristic.
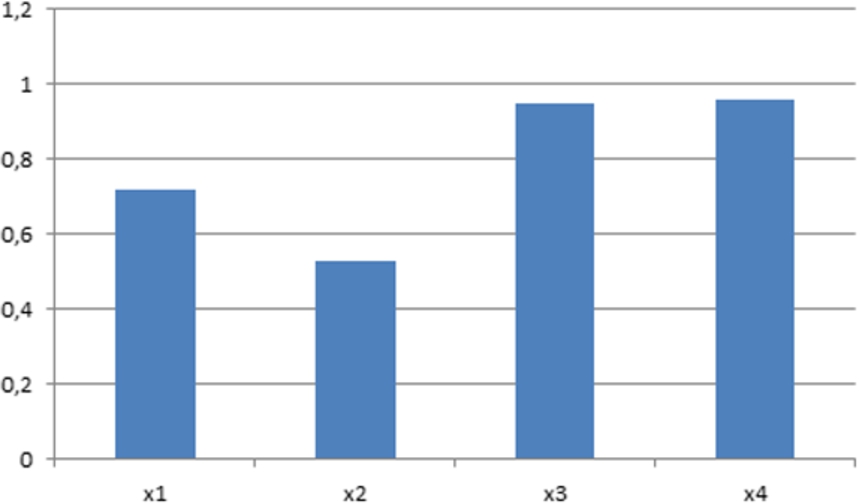
Iris data. Detail of the learning of each input characteristic for the network committee. It can be seen that the best classification accuracy is for x3 and x4.
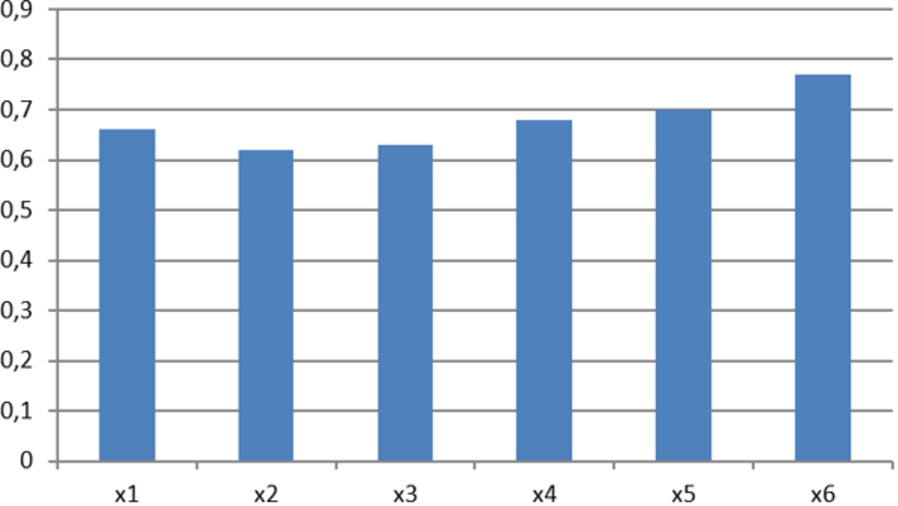
Vertebral Column dataset. Detail of the learning (accuracy in %) of each input characteristic for the network committee.
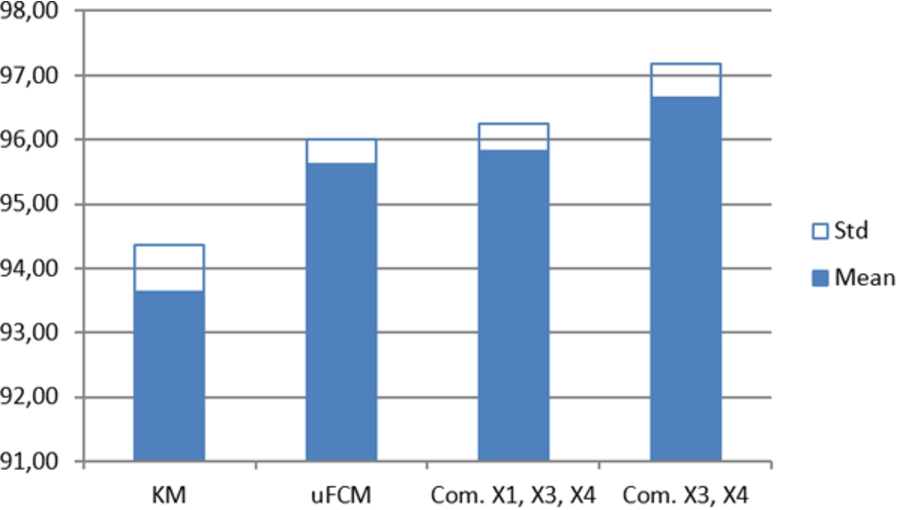
Iris data. Classification accuracy (mean and standard deviation) with KM algorithms, μFCM and μFCM committee with all inputs features and removing each feature.
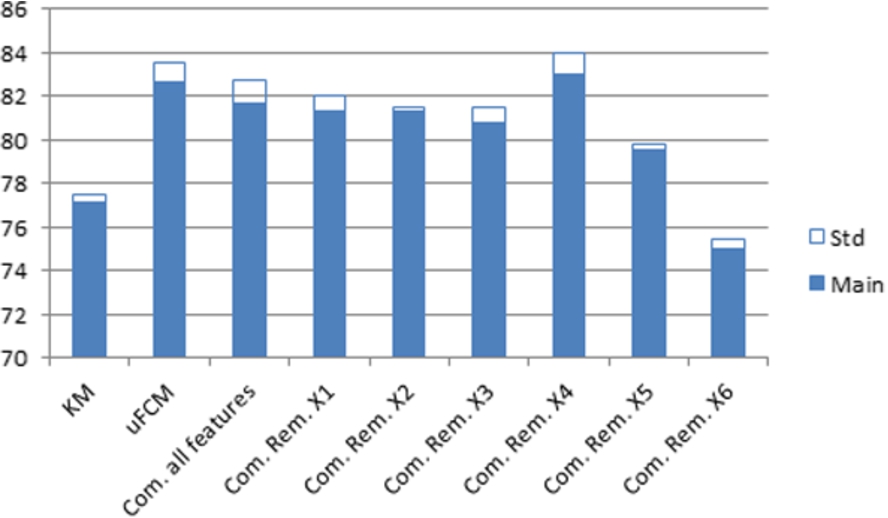
Vertebral Column dataset. Classification accuracy (mean and standard deviation) with KM algorithms, μFCM and μFCM committee.
In this paper, a discretization technique based on fuzzy clustering is proposed. This technique is based on the μFCM algorithm to perform a numerical discretization using Cauchy distribution. In order to assess the discretization technique a ELM classifier and a committee of ELM classifiers are applied. The classifiers are also applied to asses the discretization obtained for the KM technique. In addition, from a qualitative point of view, the best granularity has also been evaluated to carry out discretization. For this purpose, different granularities have been evaluated regarding the number of partitions for each numerical attribute. This evaluation has made it possible to verify that in general terms satisfactory results are obtained with 3 partitions in each attribute. This gives us a great interpretability of the results, since the technique allows to transform continuous values for each attribute into discrete values through 3 partitions. Therefore, from a qualitative point of view, the results are quite interesting. Besides, the results of the comparison between μFCM and KM techniques have been statistically validated, where the proposed technique (μFCM) obtaining the best results with 97% of confidence level.
As future work, the new objective functions of the discretization clustering technique will be implemented. Also, the option to discretize using probabilistic functions for the clustering technique instead of the membership function used in this study can be explored and analyzed.
Footnotes
Acknowledgement
This work is supported by the Spanish MINECO under grant TIN2016-78799-P (AEI/FEDER, UE).