
Abstract
Low-cost robots are usually specialized systems that cannot solve complex tasks, e.g., doing the laundry or tidying up. These tasks are usually solved by more complex and expensive general-purpose systems. The most common problems are the lack of sensors and actuators or computing power to perform multiple functions in parallel. The integration of robots into intelligent environments can help to solve more complex tasks by utilizing the components of the intelligent environment. Such an approach is used in the system to detect pointing gestures from a user and locating objects that a low-priced robot then collects and carries away. This approach is performed by cameras and supported by lights of the intelligent environment. The experimental results show that the cooperation of robots and smart environment increases the success rate of complex tasks in situations where the robot or components of the intelligent environment would underperform.
Introduction
Robots become more and more applicable in everyday life to relieve people of various tasks or to collaborate with them. They are a great support, especially for people who are unable to perform tasks independently or who are unable to do them at all. A problem for robotics is the range and complexity of tasks. Simple tasks, such as opening doors [14], vacuuming [30] or handing over objects [21], can be performed by simple and specialized robots that have been designed and developed for this purpose. So far, more complex tasks have only been solved in research with expensive general-purpose robot systems. These systems have in most cases an extended and cost-intensive sensor and actuator technology compared to practice-oriented simple robot systems. An alternative is the extension of simple robots by connecting several heterogeneous devices, sensors and actuators of a smart environment and use them to sense and change the state of the environment. Smart environments aim to increase comfort, economy, security and other daily human life factors [3] and can also be a supportive pillar for robot systems. This leads to a powerful system, which is able to solve more complex tasks efficiently.

Illustration of the laboratory environment used for both evaluations. The three humans represent the three locations from where the user points at the different object locations. The three colored areas represent the fields of view of the ceiling-mounted smart cameras. Smart lights are used to illuminate the scene and give visual feedback to the user. The different points of view of the same environment were chosen to visualize the various components of the system.
In order to demonstrate the effectiveness of this approach, a use case with a highly practical relevance for users was implemented, namely the instruction of a mobile service robot to tidy up a room. The application consists of several capabilities: (1) an intuitive interaction method based on pointing gestures, (2) cooperative task execution mechanisms for working in different rooms and (3) a situation-aware feedback system.
Thus, a cooperative system consisting of a robot and an intelligent environment to make the system more effective are proposed. In the scenario, which is shown in Fig. 1, different cameras perform the object detection and localization as well as the recognition of human gestures. Smart lamps in the ceiling support the cameras by illuminating a suitable area. Colored lamps serve as a feedback mechanism revealing the status of the system to the user. In addition, a mobile robot performs the physical manipulation of the environment.
The system described here is founded on the results of the previous work [25] as shown in Fig. 1(a). This was only comprised of different smart cameras. In this work, the system is extended by several additional components, which are described below. The contribution of this paper is the integration and evaluation of these additional components to expand the original idea and enable novel use cases. The new composition of the entire system is illustrated in Fig. 1(b). Therefore, the original system is extended by a
This paper is structured as follows: first, an overview of related works concerning tidying-up systems, ubiquitous robots, pointing gesture detection and its applications is given. Afterwards, a cooperative smart environment is introduced that is evaluated in the following section in terms of the accuracy and success rate of the approach. At the end, the work and present future work are concluded.

Overview of the cooperative behavior of the tidying-up system.
While the general idea of tidying-up robots is attractive for users [4], the applied research on this topic is limited. Abdo et al. [1] present a general purpose robot that put away different types of objects based on the prediction of user preferences. Yamazaki et al. [31,32] present a tidying-up robot system based on the cost-intensive PR2.1
PR2 (Personal Robot 2) is a robotic platform developed by Willow Garage –
Integrating robots into intelligent environments is a cost-effective alternative to the previously mentioned expensive general-purpose robot systems. There is no unified term for this integration but some terms that are closely related to each other. Kim et al. [12] introduce the notion of ubiquitous robots that deals with the embedding of robots into a ubiquitous space. This space features a high degree of connectivity between several heterogeneous components classified as software components, embedded components and mobile components like mobile robots. The term physically embedded intelligent systems (PEIS) coined by Saffiotti et al. [22] summarizes the vision of integrating different devices, e.g., smart cameras and mobile robots, into a joint space opening the opportunity for more advanced robot applications. Nor and Mizukawa [16] propose a similar system called Kukanchi that is an intelligent space for home-based robotic services. Another term is used by Pyo et al. [20] who developed an architecture for an informationally structured environment. The environment consists of sensors embedded into the environment, which continuously monitor and provide information, such as the position of objects, to other agents in the environment, e.g., mobile robots.
None of these approaches, except of a preliminary work in the Kukanchi project [17], allows the non-verbal interaction with the system employing human pointing gestures. However, since the interaction is intuitive, natural and does not require additional devices, human pointing gestures are extensively applied in human-robot interaction systems. For example, Tölgyessy et al. [26] use human pointing gestures to control an autonomous mobile robot equipped with a RGB-D sensor. Furthermore, they evaluated different pointing vectors and found out that the pointing vector described by the elbow-wrist line is more accurate than the shoulder-wrist and wrist-palm lines. Van den Bergh et al. [28] developed a real-time hand pointing gesture detection system for interaction with a robot. The pointing direction indicates a navigation goal for the mobile robot. They use a RGB-D sensor mounted on the mobile robot for the hand posture recognition. A similar approach is proposed by Droeschel et al. [6] who present a method for pointing gesture recognition using a Time-of-Flight camera mounted on a domestic service robot. Additionally, they use a laser scanner to keep track of the interacting person by detecting the person’s legs. Thus, a person does not need to be at a predefined position for interacting with the mobile robot. Yan et al. [33] use a pointing gesture together with verbal interaction to deal with situations where ambiguities about the execution of task exist, e.g., which object should be grasped. Pateraki et al. [18] use pointing gestures in combination with face poses and a priori information about object positions to estimate pointed targets. Other works in this field of research comprise the visual interpretation of pointing gestures in 3D space [13], the probabilistic detection of pointing gestures [23], the probabilistic optimization of robot pointing gestures [9] and the visual pointing gesture recognition for human-robot interaction [15]. The mentioned works have in common that the gesture-based interaction is directly performed between human and robot. They do not consider any other sensors of an intelligent environment. Thus, they are limited to the field of view of the robot’s on-board camera. Various interfaces are being developed for human interaction with smart environments. Some approaches use verbal methods to query the system or get feedback from the system [10,27]. Other approaches are based on visual data to interact through motion. Varkonyi-Koczy and Tusor [29] use hand-postures to interact with the building, and Abid et al. [2] use dynamic sign language for interactive applications in smart homes. Zhang et al. [34] present an alternative sensor. Their approach uses conductive paint to create a smart wall that can detect gestures and touches as well as the use of electronic devices.
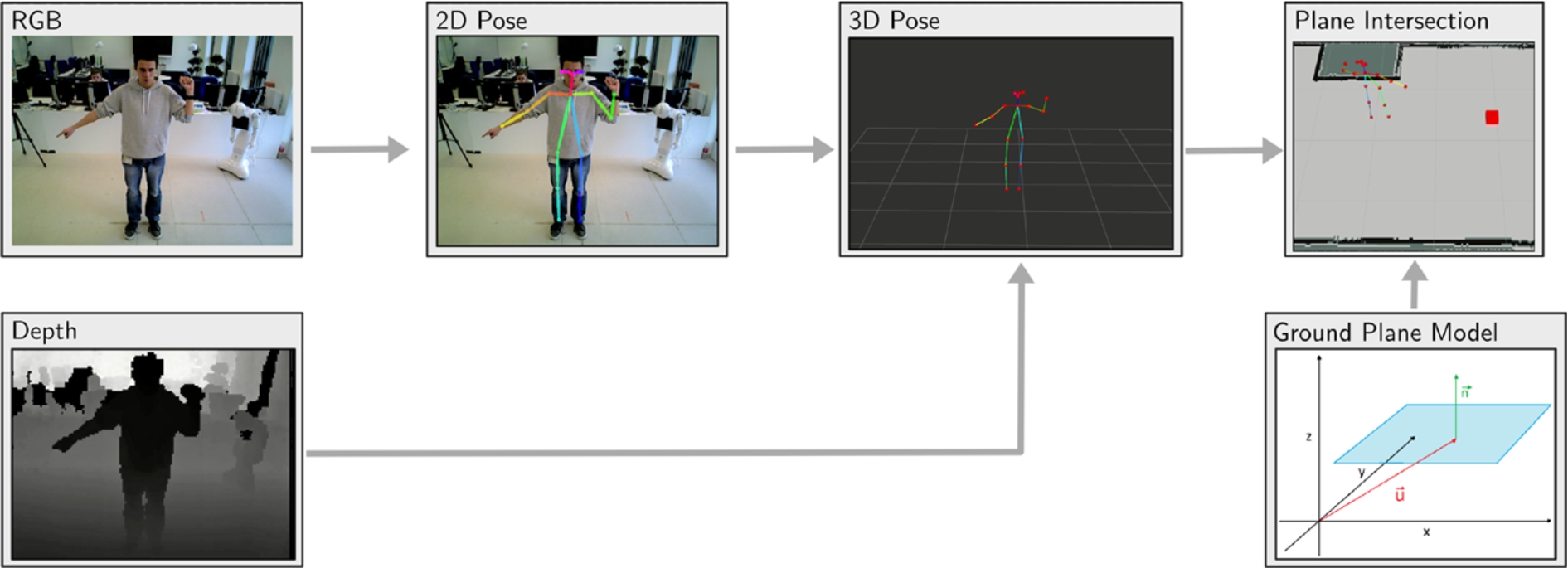
Processing pipeline for the human pointing gesture detection task.
In order to address the limitations of simple robots, a cooperative smart environment with the focus on a tidying-up application is proposed. The user interaction is based on human pointing gestures to determine objects to be picked up by a mobile robot and carried away. The gesture-based interaction method for the localization of objects considers the whole intelligent environment as interaction partner instead of a single camera mounted on a mobile robot or in the environment. The tidying-up system consists of multiple stages as depicted in Fig. 2. Human pointing gesture detection is performed on RGB-D images obtained by RGB-D cameras mounted in the environment. This first step yields a pointing position in 3D space as well as certain human pose characteristics that are used for the calculation of a probabilistic region of interest (ROI) in the next step. The ROI assigns a probability to each position in the environment to be the position pointed at by the user. See Section 3.2 for more details. Based on this information, RGB cameras in the environment are asked to search for and localize objects in their fields of view, where the selection of the cameras depends on the spatial overlap between their fields of view and the probabilistic ROI. Therefore, only cameras that are likely to see the object pointed at by the user are activated. The same applies for the selection of controllable lights to illuminate the area around the pointing position and support the detection process. Afterwards, the position of the object with the highest global probability is determined. Thus, this step refines the initial pointing position. This object position is finally sent to a mobile robot to pick up the object and carry it to its correct location, e.g., a shoe belongs into a shoe rack. An exemplary video of the whole system can be found online at
Pointing gesture detection
The detection of human pointing gestures is realized using a RGB-D camera as part of the intelligent environment. The purpose of the approach is to allow users to point at certain locations in the environment and to determine the corresponding pointing position on the ground plane. Therefore, several image processing and geometry transformation steps need to be performed as depicted in Fig. 3. At first, humans and their body parts are detected using the RGB image of the camera. To this end, the OpenPose library [5] is employed, which is a real-time multi-person detection system. The library operates on single RGB images and outputs the estimated locations of humans and their body parts including face and fingers in 2D image space. In case of detecting a pointing gesture, especially, the elbow
The index
The definition of the ROI for object localization and the selection of controllable lights is obtained using a probabilistic approach to deal with the uncertainty of the pointing gesture. The approach is based on a Gaussian function where the parameters are calculated based on the pointing position and human pose characteristics. The basis of the Gaussian function in the two-dimensional domain is defined as:
From now on, the direction vector of the pointing forearm is denoted independent of the body side.
An example of the approach is depicted in Fig. 4. The black rectangle illustrates the forearm and the red line shows the virtual pointing line in extension to the forearm. The upper graph illustrates the three-dimensional representation of the gesture and its corresponding probability distribution in the two-dimensional domain. The higher the probability value of a position, the more likely the position is the location pointed at by the user. The illustration assumes an exemplary position of the elbow at
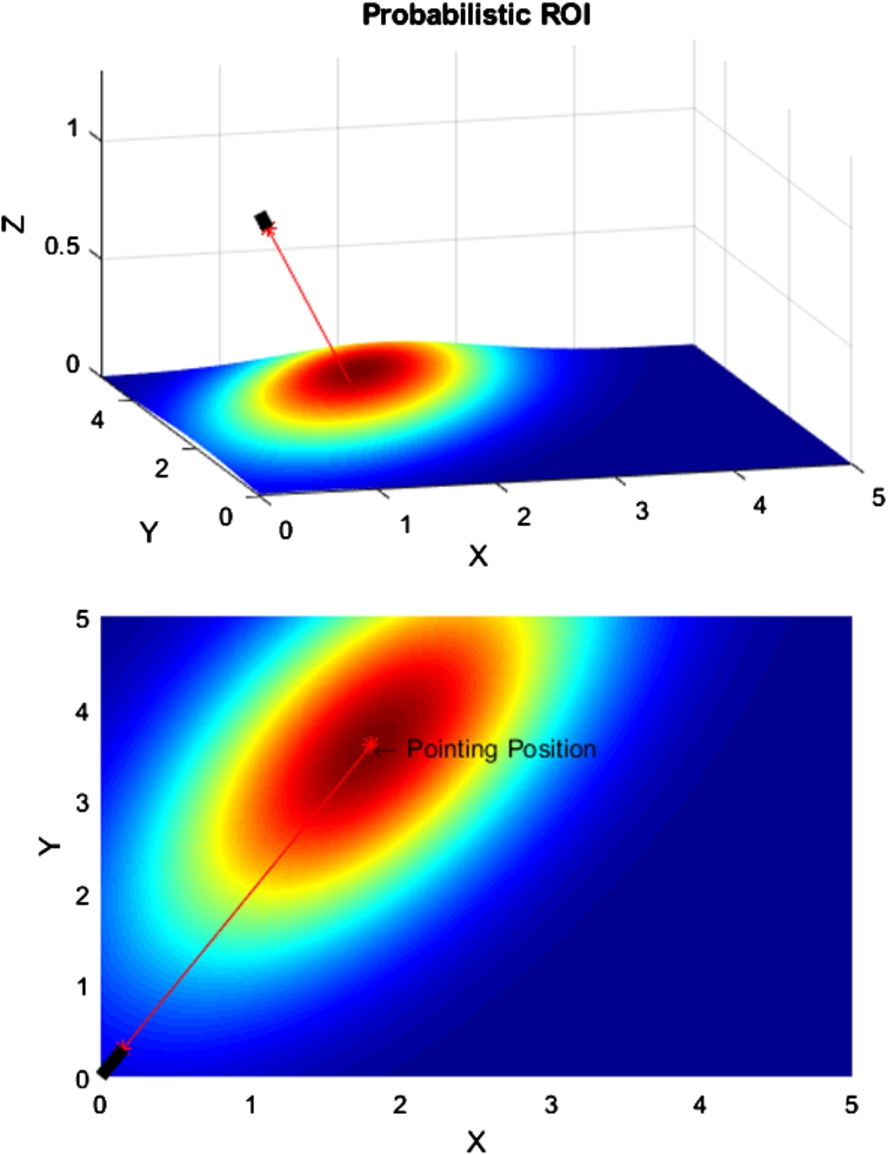
Colored probabilistic region of interest based on the pointing gesture (red) of the forearm (black). The width of the Gaussian “bell” is different for the axis along the pointing direction resulting in an ellipsoid shape. The center of the Gaussian is the calculated pointing position.
In order to determine the responsibility of a camera or a controllable light for a given ROI, the volume
In case of an activation of a camera, the camera calculates a likelihood for each object o in its field of view. An object o was modeled as a polygon describing the object’s contour similar to a contour of a camera’s field of view. In order to consider the size of an object and prevent unequal treatment in favor of large objects, the mean probability of an object o is calculated as follows:
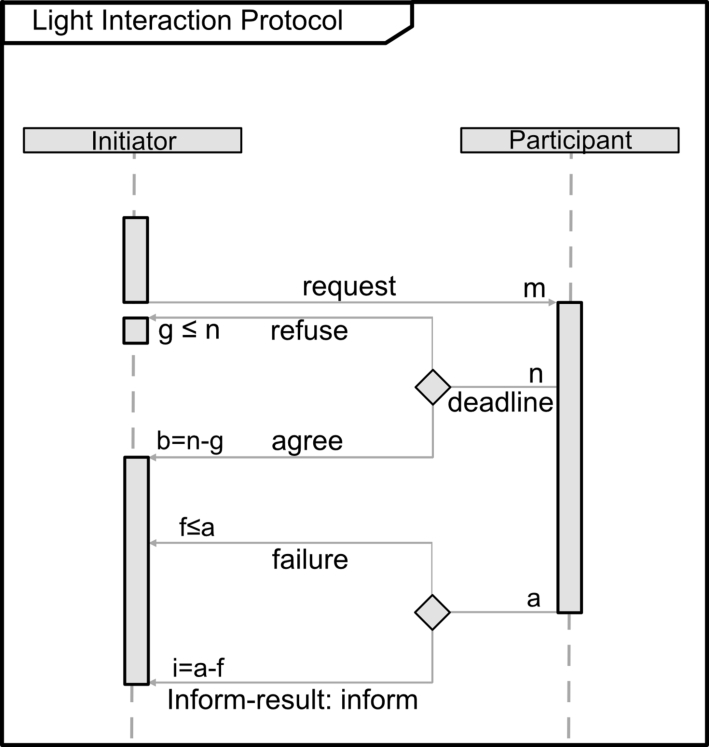
Light interaction protocol for the light activation.
Because the environmental parameters, e.g., brightness, temperature, etc., are oftentimes not adequate to carry out a specified task, a situation-aware approach is shown that reacts to difficult conditions using the example of brightness and lighting. The approach is founded on an agent-oriented approach and uses the Agent Communication Language (ACL) [7] to guarantee the common representation of message contents as well as a mutual understanding of interaction protocols across the different agents. The network of light agents is a set of homogeneous controllable lights
Distributed object localization
In order to refine the gesture-based object localization, the system relies on a distributed object localization mechanism that is also founded on an agent-oriented approach as introduced in Section 3.3. The network of smart camera agents is a set of heterogeneous cameras

Camera interaction protocol for the distributed object localization.
In this work, the detection of visual markers as objects is replaced with a more enhanced object detection module. Therefore, the system can currently detect two different object types: (1) a shoe and (2) a cup. These types of objects was chosen because they are small enough to be carried by a low-cost mobile robot and they are realistic objects for a tidying-up scenario. The detection of the objects is performed in two stages. Each RGB camera integrated into the environment searches for objects in its field of view whenever the camera is requested to detect objects (see Section 3.4). This detection is based on local color changes in the image and morphological properties of detected segments. In order to determine the 3D position in world space for each detected object, the contour of the object in image space is projected onto the ground plane. This is possible because the objects are assumed to be on the ground plane. The probability for a detected object is calculated according to Equation (12).
The second stage comprises the local detection and recognition of objects on the mobile robot when the robot approaches an object. Therefore, the mobile robot’s on-board RGB-D camera is used. Additional to the color information used to recognize an object, the depth image is employed to accurately determine the position of the object for grasping.
Object grasping robot
The approach involves cooperation between robots and an intelligent environment. In the example application, a mobile robot with a gripping system is used to pick up the found objects. Similar to the previous approach [24], the robot first uses map-based navigation to reach the target position determined by the camera agents. Once the object has been detected by the robot’s on-board camera, the navigation switches to a visual-servoing approach. This is used to position the robot appropriately in front of the object. Based on optical and geometric data from an RGB-D camera, the object is identified and a grasping variant is selected. The robot then approaches the object until it is within reach of the manipulator. Due to the short range of the robot arm, the object is outside the robot’s field of vision during the grasp. The robot lifts the object and centers the arm in front of the camera to check whether it has successfully picked up the object. If it fails, the robot performs a recovery behavior by moving back, relocalizing the object again and performing another gripping attempt. This behavior is performed three times before the robot aborts the task. Once the robot has successfully gripped the object, it moves its arm into a transport pose where the object is not hanging in front of the camera, as this is required for localization. Finally, the object is transported to a user-defined position depending on the object type and deposited. The positioning is negligible for the evaluation.
Evaluation of the multi-stage object localization
The multi-stage object localization system based on human gestures was evaluated concerning four criteria to prove the appropriateness of the approach. The first criterion is the drift of the pointing gesture indicating how accurate the system can detect pointing gestures with respect to a given target position. Afterwards, the success rate of the object selection based on the probabilistic ROI was assessed. As third criterion, the drift of the object position determined by the last step of the multi-stage object localization where RGB cameras mounted in the environment localize the selected object was evaluated. Finally, the pointing gesture detection time was measured.
Experimental setup
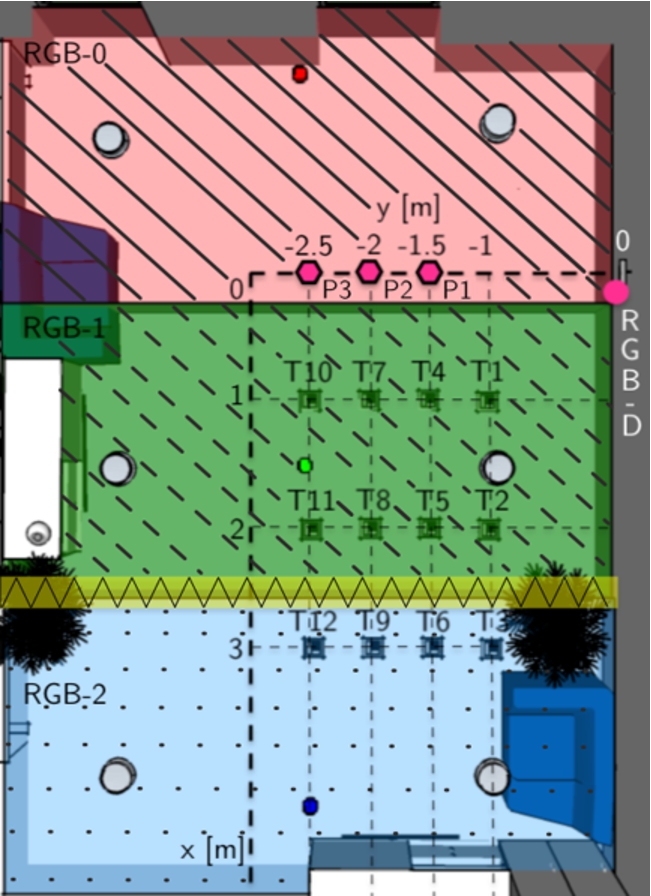
Experimental setup describing camera, person and target positions.
The experimental setup used for the evaluation is depicted in Fig. 7 as a top view of the environment. At the origin of the coordinate system, a RGB-D camera is mounted in a height of 1.79 m and a pitch angle of

Drift of the pointing gesture depending on the person position (from left to right:
A participant performed pointing gestures from three different person positions (
Person position: This is the position of the human, and in the experimental setup there are three person positions with different distances to the RGB-D camera denoted as
Target position: This is the position to be pointed at by a participant, and in the experimental setup there are twelve target positions denoted as
Pointing position: This is the actual position pointed at by a participant. If pointing and target position are close to each other, this results in a small pointing gesture drift.
Object position: This is the position of the object pointed at by the user calculated in the distributed object localization step. If object and target position are close to each other, this results in a small object localization drift.

Discrepancy between elbow-wrist and wrist-palm vector.

Success rate of the object selection depending on the person position (from left to right:
In order to assess the pointing gesture drift, the Euclidean distance between the pointing and target positions is considered. Figure 8 visualizes the drift of the pointing gesture depending on the three person positions. The smallest drift is reached from person position
Object selection success rate
This subsection aims to evaluate the success of the object selection based on the probabilistic ROI. For example, if the participant points at target position
Distributed object localization drift
The final step of the multi-stage object localization system calculates the position of the object pointed at by the user to refine the initial pointing position. Therefore, the Euclidean distance between object and target position was considered to assess the drift of the distributed object localization step. Since this step is independent of the person position, the mean results for all three person positions is visualized in Fig. 11. This data also contains the 35.3% incorrectly selected objects. The drift ranges between 0.02 m for target position

Drift of the distributed object localization. Note that a different color scaling compared to the pointing gesture drift results shown in Fig. 8 was used.
During this experiment, the time between the start of a pointing gesture (raising one forearm) and the detection of the gesture by the system was measured. This time highly depends on the hardware configuration running the pointing gesture detection. The pointing gesture detection time for the hardware configuration as described in Section 4.1 is visualized in Fig. 12. The boxplots reveal that there are no significant differences of the detection times for the different person positions. Thus, the detection time is independent of the distance between a human and the RGB-D camera. The mean detection time for all person positions is 4.0 seconds. Another characteristic is that the interquartile range is 0.7 seconds on average (

Pointing gesture detection time depending on the person position.
The experimental results show that the system can successfully detect pointing gestures with a mean drift of
Evaluation of the tidying-up system
In a second experiment, the success rate of the tidying-up system was determined. The first criterion here was the performance of the overall system, how often the application run successfully, and which errors occurred. The second criterion was the influence of the support of the lighting agents on the success rate of the system.
Experimental setup

Setup showing cameras, lights, robot and objects.
In this evaluation, the experimental setup was extended by further actuators, which are shown in Fig. 13 as a top view of the environment. In addition to the ceiling cameras, six ceiling lamps (
In this part of the experiment, the interaction with the user through pointing gestures was omitted because the recorded pointing positions from the first part were used again. The pointing positions which led to incorrectly selected objects in the previous evaluation (see Section 4.4) were also part of this experiment. One real object, i.e., shoe and cup, was placed at a time on each target position (
Object Detection Error: The ceiling camera agents could not detect any objects on the surface.
Robot Navigation Error: The robot could not reach a target pose, e.g., the position of the object, or was unable to find an object at the target coordinates.
Robot Object Error: The robot failed three times in a row to grasp the object.
Wrong Object Error: The robot misidentified the object and put it in the wrong cupboard.
The evaluation took place in two different lighting situations. In both situations, bright and dark environment, the experiment was carried out once with the light agent switched on and off. This resulted in a total of 192 experiments.
Results

Final status of all tries per scenario and per failure category.
The results of the performance evaluation depending on the scenarios and failure categories are visualized in Fig. 14. They reveal that the success rate in a bright environment is higher (with light system: 79.2%; without light system: 72.9%) than in a dark environment (with light system: 58.3%; without light system: 4.2%). The influence of the light system is small in case of the bright environment (difference: 6.3%), but has a significant impact on the success rate under bad lighting conditions (difference: 54.1%). This indicates that situational use of additional actuators of an intelligent environment can help support robotic tasks. In detail, the most significant error under good lighting conditions is the Robot Object Error which can be attributed to errornous sensor data occurring in the grasping process. In contrast to this, the Object Detection Error and the Robot Navigation Error play a major role in dark environments. The reasons for this is that the object detection of the ceiling cameras is strongly influenced by noise resulting in the detection of no objects. This noise is caused by darkness and a weak light output of the smart lights. Furthermore, the Robot Navigation Error is the result of the detection of incorrect or non-existing objects leading to wrong robot navigation goals.
In summary, the results show an improvement of the success rate under poor lighting conditions when using a cooperative and situation-aware smart environment.
A cooperative multi-agent system for service tasks in smart environments was proposed. As an example, a tidying-up system was implemented due to its highly practical relevance. It consists of a mobile robot, several distributed cameras and smart lights. Human pointing gestures were used to select objects and a multi-stage object localization approach was used to accurately determine the location of these objects. Unlike other approaches in the area of human-robot interaction, that only allow gesture-based interaction with single robots, the entire intelligent environment was used as interaction partner. Hence, the system is no more limited to the field of view of a single robot by taking advantage of multiple smart cameras mounted in the intelligent environment. Additionally, smart lights are employed to support the camera-based object detection, e.g., if an area is too dark, and to act as feedback channel revealing the system’s state through colored light. The evaluation of the system examines different scenarios and shows that the approach can significantly increase the success rate of the tidying-up system under bad lighting conditions.
Future work should focus on the reduction of the pointing gesture drift for object distances more than 3 m away from the user and the recognition of different kinds of objects. The latter requires an advanced recognition module based on semantic segmentation and the integration of further grasping approaches. Additionally, the limitation that the gesture recognition is error-prone to crowded environments will be addressed. Furthermore, the integration of a speech recognition system could avoid ambiguities concerning the object selection when multiple different objects are located close to each other. Additional actuators and sensors in the environment could help with further applications, e.g., presence detectors to locate the user within an environment or smart cupboards that open themselves when the robot approaches. In order to improve the performance of the system, an optimized recover behaviour is planned in case the robot cannot see the object or cannot grasp it correctly. Finally, the system can be adopted to other service tasks, such as fetching and delivering medicine or food, as well as pointing to areas for vacuum spot cleaning. Due to the agent-based architecture, this can easily be achieved by integrating new skills, agents and task routines.
Footnotes
Acknowledgements
This work is financially supported by the German Federal Ministry of Education and Research (BMBF, Funding number: 03FH006PX5).