
Abstract
Creating domain ontologies is usually performed by teams of knowledge engineers and domain experts, and is considered to be a time-consuming and difficult task. As a result, scientists have started to develop automatic approaches to ontology learning and population. For the proposed research, we focus on the central subtask of ontology learning, being the hypernym detection task, where the system has to detect hierarchical semantic relationships, i.e. hypernym–hyponym relationships, between domain-specific terms, resulting in a domain-specific taxonomy.
We propose in this paper a hybrid approach to automatic taxonomy learning, which combines a data-driven and a knowledge-based component. The data-driven component is composed of a lexico-syntactic pattern-based module, a morpho-syntactic analyzer and a distributional model, whereas the knowledge-based component extracts structured semantic information from the Linked Open Data cloud (DBpedia) and WordNet. The proposed methodology has been applied to three different knowledge domains: viz. food, equipment and science. A thorough quantitative and qualitative evaluation has shown promising results for all considered test domains. In addition, the results show a clear contribution of all different modules to the automatic taxonomy learning task. Although there is still room for improvement for all different modules, our approach outperforms state-of-the-art systems that participated in the SemEval “Taxonomy Extraction Evaluation” task when it comes to comparing the automatically constructed taxonomy against a manually verified gold standard taxonomy. As all modules are run automatically, the system provides a flexible and domain-independent approach to automatic taxonomy learning and could be an important step in solving the knowledge acquisition bottleneck in ontology learning.
Introduction
Ontologies have shown to be indispensable to enrich text with semantic information or “meaning” as they have been successfully applied to various natural language processing (NLP) tasks such as word sense disambiguation (e.g. to distinguish between stone (mass of hard consolidated mineral matter) and the Rolling Stones (music band)) (Alexopoulou et al., 2009) or coreference resolution (e.g. to link UN with United Nations) (Prokofyev et al., 2015) as well as for different language technology applications such as efficient information retrieval (Liang et al., 2006) or advanced online question answering services (by expanding on the queries) (Ray et al., 2009).
Also from a business perspective, ontologies and user-specific taxonomies appear to be very useful (Azevedo et al., 2015). Companies often desire to build their own mono- or multilingual enterprise semantic resources containing all relevant sector- and company-specific terminology, which allows them to standardize the company’s language use and fastens the translation processes. In addition, these resources also help shorten the learning curve for new employees by self-teaching in a new domain and improve the effectiveness of definitions and explanations in technical writing (e.g. by grouping products in product types or hierarchically structured families) (Wright and Budin, 2001). Whereas automatic terminology extraction from domain-specific data is a well-researched NLP task (Bernhard, 2006; Zhang et al., 2012; Lefever et al., 2009), organizing the resulting terminology into a hierarchically structured taxonomy remains a very challenging task.
As opposed to the recognized value of ontologies, globalization and rapid technological evolution have made it virtually impossible to manually create and manage ontologies for a large variety of scientific and technological (sub)domains (Cross and Bathijaa, 2010). Because manual ontology creation is such a cumbersome and expensive task, researchers have started to investigate how terminological and semantically structured resources such as ontologies or taxonomies can be automatically constructed from text (Biemann, 2005).
Biemann (2005) defines ontologies as “specifications of shared conceptualizations of a domain of interest” that build upon a hierarchical backbone, a definition that goes back to Gruber (1993). Sowa (2000) further states that a formal ontology is “specified by a collection of names for concept and relation types organized in a partial ordering by the type-subtype relation”. Ontologies can then be further distinguished by the way the subtypes are distinguished from their supertypes:
A well-known example of a terminological ontology is WordNet (Fellbaum, 1998), whose categories are specified by relations such as hypernymy or part-whole relations, which determine the relative positions of the concepts with respect to one another without completely defining them. The advantage of using terminological ontologies is that they enable a connection between the formal representation of the domain and the language used to refer to domain concepts within text (Velardi et al., 2013). As stated by Peters (2013), terminological and formal ontologies maintain a rather uneasy relationship; both models partially overlap and complement each other, which results in linguistic confusion. This viewpoint is shared by Grabar et al. (2012), who believe that the increasing interest for ontologies has made the distinction between ontologies and other semantic resources such as taxonomies and terminologies somewhat fuzzy.
As a result, a lot of ongoing work is now focusing on representing lexical knowledge within formal ontologies. Examples are OpenMinTeD (Peters, 2016), the Open Mining Infrastructure for Text and Data, which aims at enabling interoperability between linguistic and ontological knowledge by adhering to existing Linked Data standards (e.g. populated RDF or OWL models), and the Lemon framework (McCrae et al., 2012), a model for sharing lexical information on the semantic web. In contrast with this work, the aim of our research is to hierarchically organize a domain-specific term list in a fully automated way, without specifying the categories of the taxonomy by axioms and definitions.
To avoid confusion, we briefly review the most important notions and their definitions as adopted in this research. Terms are considered as lexical units or “the words that are assigned to concepts used in the special languages that occur in subject-field or domain-related texts” (Wright, 1997). Terminologies are then defined as a set of terms, which represent the system of concepts for a specific domain, whereas ontologies describe a system of concepts and its associated properties for a specific area, built upon formal specifications and constraints. Taxonomies, finally, are collections of terms that are arranged hierarchically. In the proposed research, these hierarchical relations cover both the ontological IS-A relations (e.g. a “dog” is an “animal”) as well as the Instance-of relations (e.g. “China” is an instance of the general concept “country”). As there is only one type of relationship between these terms, namely the hypernym–hyponym relation, and we do not specify the categories of our taxonomy by axioms and definitions, our notion of taxonomy is most related to the definition of terminological ontologies as specified by Sowa (2000). An important difference, however, is that we build hierarchies of terms, which at their turn denote concepts, whereas Sowa considers terminological ontologies as hierarchies of types. A limitation of our term-driven approach is that we do not resolve cases of polysemy, where the same term denotes different concepts (e.g. bank as a “financial institution” or “sloping land”). Given the “one sense per discourse” theory (Gale et al., 1992), however, we believe that terms occurring in the same context or specialized domain are nearly always used with the same sense. As a result, the impact of polysemy is expected to be limited, but not negligible, for domain-specific taxonomies.
This paper presents a multi-modular domain-independent taxonomy learning system to detect hypernym–hyponym relations between terms. Therefore we build upon prior research (Lefever, 2015), and combine a previously developed pattern-based module, morpho-syntactic analyzer and WordNet module, with a newly developed DBpedia and neural networks module. The contribution of this research is twofold. Firstly, the implementation of different approaches to automatic taxonomy learning allows us to perform a thorough analysis and comparison of the different methodologies. In addition, the evaluation of all modules against the same gold standard for different test domains provides solid insights in their weaknesses and strengths. Secondly, by combining the separate modules in a hybrid system, we can overcome shortcomings of individual modules and obtain very promising results when comparing the hybrid system with other state-of-the-art systems for different test domains.
The remainder of the paper is organized as follows: in Section 2 we give an overview of related research. Section 3 explains in great detail the different modules of our taxonomy learning system, while Section 4 describes the experimental setup and results on different data sets from the SemEval-2015 “Taxonomy Extraction Evaluation” competition. These results consist of both an evaluation of our system against a gold standard taxonomy for three test domains (viz. food, equipment and science) and a comparison of its performance with state-of-the-art taxonomy learning systems. In Section 5, we summarize our main findings and suggest directions for future work.
Related research
The task of automatic taxonomy learning consists in finding hypernym–hyponym relations between terms of a given domain of interest. Different approaches have been proposed to automatically detect hierarchical relationships between (domain-specific) terms.
Hearst’s
The lexico-syntactic approach has been applied and further extended for English (Pantel and Ravichandran, 2004) and various other languages such as Romanian (Mititelu, 2008) and French (Malaisé et al., 2004). In addition, Hearst’s method has also been applied to technical texts. Oakes (2005) implemented lexico-syntactic patterns to automatically detect hypernym relations in a pharmaceutical corpus. While some researchers have defined these lexico-syntactic patterns manually (Kozareva et al., 2008), statistical and machine learning techniques have also been deployed to automatically extract and extend the list of patterns and to train hypernym classifiers (Ritter et al., 2009). Kozareva and Hovy (2010), for instance, have proposed a weakly supervised bootstrapping algorithm that starts from a seed hypernym–hyponym pair in a doubly anchored hyponym pattern to learn new hyponym and hypernym terms. Their method looks for the seed hypernym and hyponym term in conjunction with another noun, which is then identified as an additional hyponym for the seed hypernym. For example, given the input pair (bruises, injuries), the method looks for occurrences of patterns like injuries like bruises and other NP, where the nouns instantiating NP can be considered as additional hyponyms of injuries. In contrast to Hearst (1992), who also proposes a simple algorithm to learn new patterns by bootstrapping from patterns found by hand, or by bootstrapping from an existing lexicon or knowledge base, Kozareva and Hovy (2010) introduce recursive patterns that use only one seed to harvest the arguments and supertypes of a wide variety of relations with little supervision.
The pattern-based approach has two well-known weaknesses. Because of the strict syntactic (and sometimes lexicalized) constraints imposed by the predefined patterns, the coverage of this approach is assumed to be rather low. In addition, some patterns tend to overgenerate and introduce noise in the output. We have tried to address this issue by only implementing patterns with high precision in our pattern-based module.
Other researchers have applied a
More recently, also the potential of word embedding spaces has been investigated to predict hypernyms. Word embeddings are word representations computed using neural networks, resulting in word vectors that are representing the distribution of the context in which the target word appears. Fu et al. (2014) construct semantic hierarchies based on word embeddings, which can be used to measure the semantic relationship between words. They report F-scores of 73.74% for a manually labeled set of hypernym–hyponym relations. Rei and Briscoe (2014) evaluate how well different vector space models and similarity measures perform on the task of hyponym generation. They conclude that simple window-based vectors perform just as well as the ones trained with neural networks, but the dependency-based vectors outperform all other vector types.
Lately, focus has shifted towards supervised distributional methods, where candidate hypernym–hyponym pairs
As distributional methods are able to find implicit hypernym relations in text, they obtain a higher coverage for hypernym detection than pattern-based approaches. On the other hand, they suffer from lower precision scores, since they often have problems to determine the exact nature of the semantic relationship (synonymy, part-whole, hypernymy, antonymy, etc.) between the terms appearing in the same cluster of distributional space. The more recent supervised approaches, however, claim to be able to distinguish between the different types of semantic relations (Roller et al., 2014). Moreover, Shwartz et al. (2016) propose a hybrid system, where dependency paths (i.e. extension of Hearts’s patterns) are encoded using a recurrent neural network, and show that the combination of lexico-syntactic paths and distributional information obtains state-of-the-art results on the task of hypernym detection.
The morphological structure of terms has also been used to extract hypernym–hyponym pairs from compound terms (Tjong Kim Sang et al., 2011). These
In addition to the emergence of data-driven approaches to taxonomy construction, other approaches use heuristics to extract hypernym relations from
The
The great interest in automatic taxonomy learning is also reflected in the set-up and success of the
We present a hybrid system combining data-driven and knowledge-based approaches to detect hypernym relations between domain-specific terms. The system combines four main components: a lexico-syntactic pattern-based approach, a morpho-syntactic analyzer, a distributional model and a module retrieving hypernym relations from structured semantic resources, being WordNet and DBpedia more specifically. Each module takes as input a domain specific term list and outputs a list of hypernym–hyponym pairs from this list. The domain-specific term lists were provided in the framework of the SemEval-2015 “Taxonomy Extraction Evaluation” competition, and will be discussed in more detail in Section 4.1.
Pattern-based approach
The first module that automatically detects hypernym relations is a lexico-syntactic pattern-based approach, based on the work of Hearst (1992). These patterns are implemented as a list of regular expressions containing lexicalized expressions (e.g. like), as well as isolated Part-of-Speech tags (e.g. noun) and chunk tags, which group different Part-of-Speech sequences (e.g. noun phrase (NP) = determiner + adjective + noun, adjective + noun, noun + noun, etc.). An example of these manually defined patterns is “NP {, NP} ∗ {,} or/and other NP”,7
Curly brackets indicate optional parts of the pattern.
As the pattern-based module is a purely data-driven module, which applies lexico-syntactic patterns that are indicative of hypernym relations on linguistically preprocessed text, we first needed to compile corpora for all considered domains. Corpora for three different domains (science, equipment, food) were compiled by means of the BootCaT toolkit (Baroni and Bernardini, 2004), which can be used to build a specialized web-based corpus starting from a list of seed terms. Whereas the BootCat tool only requires a small set of seed terms, and iteratively extracts new seed terms from the retrieved pages, we decided to use all items of our entire domain-specific term list as seed terms. This way, the corpus compilation process was guided in order to look for pages containing all our domain-specific terms. We ran BootCat allowing 10 queries per seed term and did not use the option to construct multi-word terms by combining the seed terms. As a post-processing step, sentences containing (1) only URL links or (2) no domain specific term were removed. Table 1 gives an overview of the number of seed terms and resulting number of tokens (words, punctuation marks, symbols, etc.) in the three domain-specific corpora (before and after post-processing).
Number of seed terms and tokens in the domain-specific web corpora
Number of seed terms and tokens in the domain-specific web corpora
As our pattern-based approach takes as input a linguistically enriched text, we first performed a number of linguistic preprocessing steps on the original web-based corpus. The following preprocessing tasks were performed by means of the LeTs Preprocess Toolkit (Van de Kauter et al., 2013):
Lexico-syntactic pattern matching
We optimized the pattern-based model presented by (Lefever et al., 2014) in different ways. As the original list of lexico-syntactic patterns was designed for clean company-specific text, a major drop in precision was noticed when applying the approach to our noisy web corpus. Therefore we decided to only consider patterns that proved to obtain high precision in previous research (Lefever et al., 2014). Table 2 lists the lexico-syntactic patterns that were implemented for this research, together with examples of matched sentences in the corpus and the resulting hypernym–hyponym pairs.
List of lexico-syntactic patterns that were used for hypernym detection and resulting examples from the domain corpora
List of lexico-syntactic patterns that were used for hypernym detection and resulting examples from the domain corpora
The efficiency of the pattern-based module was further improved by only considering noun phrases containing a maximum of 6 consecutive nouns and by ignoring Named Entities. This appeared to be necessary as the web-based corpus contains a lot of lists and enumerations, causing problems for the recursive way the regular expressions are built. Manual analysis of the output showed that patterns containing Named Entities did not perform well on the web corpus either. For the other hypernym modules (e.g. word embeddings module), however, we did consider Named Entities for the extraction of the hypernym–hyponym pairs. Precision, on the other hand, was improved by ignoring pairs containing terms appearing both as hypernym and hyponym (e.g. (hand truck, truck) and (truck, hand truck)). Finally, the output of the pattern-based module was filtered by only considering pairs where both terms (either lemma or full form) occurred in the term list of the considered domain.
Our second hypernym detection module applies a morpho-syntactic approach where the morphological structure of compound terms is used to extract a hypernym-hyponym relation from this term. As already mentioned in Section 2, this approach is inspired by the head-modifier principle (Sparck Jones, 1979). We can indeed observe that the head of the compound refers to a more general semantic category, whereas the modifying part narrows the meaning of the compound term. Following this reasoning, the complete compound term can be considered as a hyponym of the head term (or hypernym).
Rules were implemented for three different syntactic hypernym–hyponym relations in compounds:
food: (torte, sachertorte)
food: (fruit, dragonfruit)
equipment: (pin, candlepin)
science: (linguistics, psycholinguistics)
quoc fish sauce is not a valid hypernym of phi quoc fish sauce. This is resolved by our system by only considering terms included in the domain-specific term list as valid hypernym/hyponym terms.
food: (sauce, béarnaise sauce)
equipment: (microscope, scanning hall probe microscope)
science: (physics, quantum physics)
food: (soup, soup all’imperatrice)
science: (immunology, immunology of infectious disease)
science: (sociology, sociology of culture)
In addition, restrictions were added to these general rules in order to improve the precision of the morpho-syntactic module. In order to prevent noise by detecting very short suffix terms occurring in the term list, we set a threshold of minimum three characters for the detection of valid hypernyms. An example of invalid hypernyms filtered out this way is tu that could be detected as a hypernym of pesarattu, as both terms occurred in the food term list.
Manual inspection of the system output made it clear that food terms (e.g. names of dishes) are often loan words from other languages. Therefore we added a list of foreign adjectival affixes (e.g. french affix al/ale) that should not be considered as a hypernym of the compound term. This way we prevent for instance ale to be detected as the hypernym of chicken provencale or café royale.
Our third module is based on the distributional approach, which represents all words in a corpus through the contexts in which they have been observed. As a result, words are represented as a vector in a high-dimensional space, in which each dimension is a context word and the coordinates of the vector reflect the association degree of the term with this context word. To build our distributional model, the word2vec algorithm of Mikolov et al. (2013) was used, which implements recurrent neural networks to learn the word vector representations. The following steps were taken to generate hypernym pairs based on distributional semantic information:
The fourth module we implemented is a knowledge-based module, which extracts hypernym relations from (1) structured Linked Open Data resources, being DBpedia more specifically, and (2) WordNet.
DBpedia
In order to extract hierarchical information from DBpedia, we used DBpedia Spotlight (Mendes et al., 2011), a system that automatically annotates text documents with DBpedia URLs. The whole process of hierarchical relation extraction is performed in the RapidMiner Linked Open Data Extension (Paulheim et al., 2014). Figure 1 shows a screenshot of the RapidMiner process, which consists of the following steps:
Import Data: domain-specific term list in csv format (“Read CSV”).
Select the Linked Open Data extension (“DBpedia Spotlight Linker”).
Select the SPARQL DBpedia connection to extract Hierarchy Relations (“Specific Relation Generator”).
Write the output to a CSV file, which contains (1) the term of interest, (2) retrieved Wikipedia URLs containing the respective concept and (3) detected hypernyms of the term in the DBpedia Hierarchy (“Write CSV”).
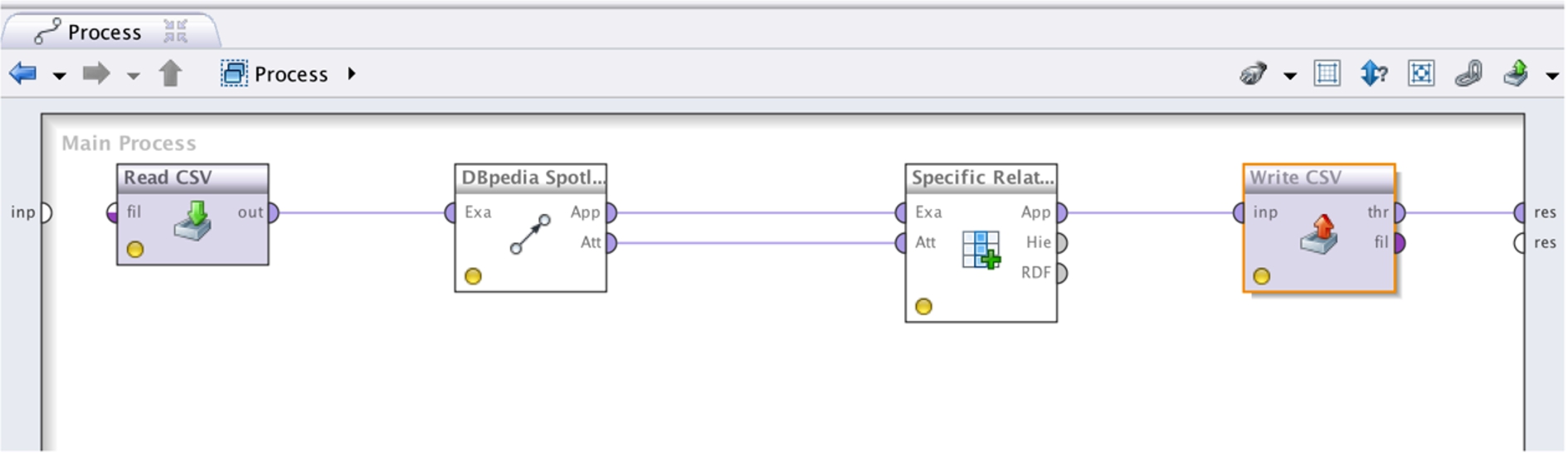
RapidMiner.
In a final step, we selected from the resulting CSV file the terms and their associated hypernym terms in case both occurred in the domain specific term list. As we noticed that the DBpedia terms and hypernyms often contained plural forms, we also performed the lookup in the domain specific term list after stripping off the plural morpheme -s. Examples of hypernym pairs retrieved from the DBpedia ontology are listed in Example 4:
equipment: (equipment, headgear)
equipment: (telescope, schmidt camera)
food: (vegetable, artichoke)
food: (soup, borscht)
science: (natural science, aeronautics)
science: (medical science, cardiology)
The second hierarchically structured lexical resource we exploited is WordNet (Fellbaum, 1998). WordNet is a lexical database where content words (nouns, verbs, adjectives and adverbs) are grouped into synsets, which are sets of synonyms that express a specific concept. Synsets are interlinked by means of, amongst others, hierarchical semantic relations (hypernyms–hyponyms). The WordNet module looks up these synsets in WordNet for all domain-specific terms and retrieves all hypernyms appearing in the full hierarchical path of the synsets. Hypernym pairs containing identical terms were removed. Examples of hypernym–hyponym pairs retrieved from WordNet are listed in Example 5:
science: (science, semantics) science: (linguistics, semantics) science: (computer science, artificial intelligence) science: (science, computational linguistics) equipment: (scientific instrument, refracting telescope) equipment: (equipment, batting helmet) food: (vegetable, artichoke) food: (vegetable, beetroot)
Combined system
For the combined system, all hierarchical relations resulting from the different hypernym detection modules are aggregated into a single hypernym–hyponym pairs list. As opposed to Shwartz et al. (2016), who combine different hypernym detection approaches by integrating lexico-syntactic patterns into the distributional system itself, we rather combine the results of the different approaches in an aggregation step. By doing so, error percolation between the different hypernym detection modules is avoided.
We implemented three different versions of our hybrid taxonomy learning system:
terms appearing in reflexive hypernym relations (e.g. (truck, truck)), terms appearing in symmetric hypernym relations (e.g. (hand truck, truck) and (truck, hand truck)).
In a post processing step, only one hypernym–hyponym pair was kept in the case of identical pairs (e.g. (handtruck, truck) and (handtruck, truck)) and the following term pairs were removed from the final hypernym–hyponym list:
Experiments
This section describes the experimental set-up and the results from a detailed evaluation of our taxonomy learning system. A detailed analysis is provided for all individual modules as well as for the different flavors of the combined system. In addition, we benchmark our results by comparing them with state-of-the-art systems that took part in the SemEval-2015 “Taxonomy Extraction Evaluation” competition (Bordea et al., 2015).
Data sets
All experiments were carried out on the data sets provided within the framework of the SemEval-2015 “Taxonomy Extraction Evaluation” competition (Bordea et al., 2015). We participated for three domains, namely food, equipment and science. For all domains, two different types of data sets were provided. The first type of data sets was extracted from WordNet (Fellbaum, 1998), a structured lexical database containing more general vocabulary, whereas the other data sets were composed from more technical domain taxonomies:
The
The
The
As our system contains a knowledge-based module retrieving semantic information from WordNet, we do not show results for the WordNet data sets because this would give a misleading picture of the actual system performance. Table 3 gives an overview of the number of domain-specific terms and hierarchical relations for all different data sets.
Number of domain-specific terms and hierarchical relations for all different data sets
The use of these data sets was twofold: they were used (1) to create the domain-specific term list, which is the input for the taxonomy learning system, and (2) to create the gold standard taxonomy, which was used to evaluate the system taxonomy for that particular term list.
As stated by Velardi et al. (2013), ontology evaluation is not a trivial task – even for humans – as there is always more than one valid solution to model the domain of interest. To evaluate our domain taxonomies, we applied automatic evaluation of the taxonomy considering all hypernym relations output by the system against the respective gold standard taxonomy. We are well aware of the fact that this evaluation is incomplete, as hypernym relations between terms produced by the system that are not in the gold standard taxonomy can be either wrong or correct.
To evaluate the performance of the separate modules as well as the different flavors of combined systems, we calculated
Let S be the number of hypernym relations output by the system, and
Results
The results section gives a detailed overview of the performance of the separate modules (Section 4.3.1) and of the combined taxonomy learning systems (Section 4.3.2). This section concludes with a comparison of the system results with the performance of other state-of-the-art systems (Section 4.3.3).
Detailed performance of the separate modules for the food domain (total of 1587 gold standard relations)
Detailed performance of the separate modules for the
Detailed performance of the separate modules for the
Detailed performance of the separate modules for the
This section presents an extensive analysis of all hypernym detection modules: the pattern-based approach (referred to as Patterns in the results), the morpho-syntactic analyzer (Morpho-synt), the two knowledge-based modules (WordNet and Rapid Miner), and three flavors of the word embeddings module, using a similarity threshold of 0.50 (Word2Vec_50), 0.60 (Word2Vec_60) and 0.70 (Word2Vec_70). Table 4 lists the precision, recall and F-scores per module for the food domain, while Tables 5 and 6 list the scores per module for the science and equipment domains respectively. In addition, we also provide the number of generated hypernym relations and correct (viz. belonging to the gold standard) hypernym relations per module.
A number of observations can be made based on the presented results. When it comes to recall, we see that the morpho-syntactic approach performs consistently well, whereas the pattern-based module only results in few hypernym pairs, especially for the equipment domain. This can be explained by the very strict constrains imposed by the lexico-syntactic patterns. This recall could be improved by compiling larger domain specific corpora for the pattern based approach, as the current corpora are rather small. We could also perform more focussed querying, by only retrieving high informative web pages, such as for instance Wikipedia pages, as we noticed that the retrieved web pages often contain a lot of noise. The knowledge-based and distributional (especially the Word2Vec_50 flavor) modules show a more varied picture, with reasonable recall figures for the food and science domains, but more modest scores for the equipment domain. This can be explained by the fact that the equipment data set contains a lot of very specialized vocabulary (e.g. kugelrohr, uppsala southern schmidt telescope, claas axion, allis-chalmers d series, hook gauge evaporimeter, etc.) which are not contained by neither the structured lexical resources nor by the news corpus that was used to train the distributional model.
A qualitative error analysis revealed that there is still room for improvement for all different modules. The morpho-syntactic analyzer achieves good recall results, but the downside is that the module outputs a considerable number of invalid hypernym pairs as well. Examples of wrong output are listed in Example 6:
(sour soup, hot and sour soup)
(apple, pineapple)
(cream, ice cream)
(cake, david eyre’s pancake)
(rice, soup all’imperatrice)
A number of improvements could be implemented to augment the precision of this module. Although it is often the case that a substring of the final noun results in a valid hypernym of that word (e.g. (fruit, dragonfruit)), we noticed that this rule often over generates for multi-word terms (e.g. (rice, soup all’imperatrice)). Another restriction should be added to prevent that hypernyms are generated from multiword terms containing conjunctions, as it is the case for (sour soup, hot and sour soup). In these cases, only the last noun of the compound can be considered as a valid hypernym of the full compound term.
Even for the knowledge-based module, which extracts information from manually verified and collaborative knowledge resources, we detected some invalid results,13
Although one might argue about the correctness of pairs such as (music, communication), these are no valid hypernym–hyponym pairs given the respective domain of interest, being science in this case.
(apple juice, pineapple juice)
(cheese, macaroni and cheese)
(hand truck, truck)
(physics, phonetics)
(food, alcohol)
(communication, music)
(game, baseball bat)
(game, baseball equipment)
(game, baseball glove)
(herb, artichoke)
As expected, the distributional model generates a lot of invalid hypernym pairs, as terms with high distributional similarity scores are not always characterized by hypernym relations but also by other types of semantic relationships (e.g. synonymy, antonymy). Therefore, the output of the distributional model should preferably be used as additional evidence to validate hypernym relations also generated by other approaches. When considering the different flavors of the word embeddings module, each applying different similarity thresholds, our experimental results show the best precision–recall balance for the flavor incorporating the 0.50 similarity threshold.
In a next step, we measured the performance of the three flavors of hybrid taxonomy learning systems:
Table 7 shows all hybrid system results for the equipment domain (on a total of 615 Gold Standard relations), whereas Table 8 lists the results for the food domain (total of 1587 Gold Standard relations). Finally, Table 9 gives an overview of the results obtained for the science domain (total of 465 Gold Standard relations).
Performance of the various combined systems for the Equipment domain
Performance of the various combined systems for the
Performance of the various combined systems for the
As shown by the experimental results, the Relaxed voting system obtains the best precision scores, with moderate losses on the recall side. As a result, the latter system also achieves the best overall F-scores. Although one could expect that stricter constrains result in better precision, the overall good performance of the morpho-syntactic analyzer highly impacts the results of the Relaxed voting system. The scores also confirm the word embeddings module applying the 0.50 similarity threshold to be the best flavor of the distributional module for integration in the hybrid taxonomy learning system.
Another important insight is that the aggregation of different approaches contributes to the correct detection of hierarchical semantic relations between terms. If we compare the results of the best individual module with the best hybrid system, being the relaxed voting system integrating the word2vec model applying a similarity threshold of 0.50, we can observe that the combined system consistently outperforms the best individual module with F-scores of 0.448 versus 0.443 for the equipment domain, 0.321 versus 0.273 for the food domain and 0.408 versus 0.386 for the science domain.
Performance of the various combined systems for the
To further analyse the contribution of the different modules in a combined framework, we generated some additional statistics per module. Table 10 lists the number of correct hypernym relations that were only detected by one specific module, whereas Table 11 shows the overlap between the output of the different modules. To measure the overlap, a label “found” (detected hypernym relation) or “not found” (missed hypernym relation) was assigned per entry of the GS for each module. The percentage of overlap was then calculated by dividing the number of shared labels by the total number of GS relations. As the results of the combined systems confirmed the Word2Vec module applying the 0.50 similarity threshold to be the best distributional model, we focused on this flavor for the analysis.
Number of GS hypernym relations only detected by one particular module
Overlap in hypernym relations between the different system modules, measured on the total number of GS relations
Table 10 further motivates the setup of the Relaxed voting system. As the morpho-syntactic analyzer outputs a high number of correct hypernym relations that are not detected by any of the other modules, it is an obvious choice to always include the output of this module in the combined system output. In addition, Table 11 shows the least overlap between the output of the morpho-syntactic analyzer and the other modules. It is also interesting to notice that both structured knowledge bases, being WordNet and DBpedia, contain different hypernym relations for all considered test domains. In contrast, the distributional module does not extract any correct hypernym relation that is not detected by one of the other modules.
To conclude, depending on the envisaged application of the automatically constructed taxonomy, one might consider to use the Combined or Relaxed voting system. In the case where the taxonomy will be manually verified, it is more interesting to start from the combined taxonomy, which has a higher recall. If the taxonomy will be applied as such, it is preferable to opt for a system with higher precision, which is the Relaxed voting system with the word2vec model applying a similarity threshold of 0.70 in this case.
Performance of all systems participating to the SemEval-2015 Taxonomy Extraction task (TExEval)
Performance of all systems participating to the SemEval-2015 Taxonomy Extraction task (TExEval)
As a last step, we also compared our results with all systems participating in the SemEval “Taxonomy Extraction Evaluation” task (Bordea et al., 2015). As can be noticed in Table 12, our new system (LT3) obtains state-of-the-art performances and ranks first when considering precision and F-score for all three test domains. The INRIASAC system (Grefenstette, 2015), which also uses morpho-syntactic information and co-occurrence statistics, obtains higher recall but suffers from low precision scores. For the official competition, the organizers also performed a manual evaluation of the system output in order to measure the precision of the hypernym pairs that were not present in the gold standard taxonomy. There as well, the LT3 system, which aggregated a pattern-based, morpho-syntactic and WordNet module as presented in (Lefever, 2015), achieved with an average precision of 0.60 the highest score for the precision of the novel hypernym pairs not present in the gold standard.
We presented a taxonomy learning system combining four components: a lexico-syntactic pattern-based approach, a morpho-syntactic analyzer, a word embeddings module and a knowledge-based module retrieving hierarchical relations from the Linked Open Data cloud (DBpedia in this case) and WordNet. A comparison with state-of-the-art systems that participated in the SemEval “Taxonomy Extraction Evaluation” competition shows very competitive results for our system when it comes to quantitative analysis against a gold standard taxonomy. As our system starts from the domain-specific corpora at hand, this data-driven approach could be a valid solution to the knowledge acquisition bottleneck for automatic hypernym detection in specialized domains and low-resourced languages, which do not dispose of large lexico-semantic resources.
With respect to the individual modules, the experimental results reveal a very good performance of the morpho-syntactic analyzer, both for recall and precision. To detect hypernym relations between terms that do not share morphological features, the WordNet and DBpedia, and to a lesser extent, the pattern-based and distributional models, were successfully applied. The latter two modules, which are both trained on web corpora, complement each other to some degree: the pattern-based module operates under very strict constrains, resulting in low recall figures, while the word embeddings module over-generates, resulting in more modest precision scores. Experiments with the similarity threshold for the word embeddings module demonstrated that a similarity score of 0.50 gives the overall best F-score.
For our final hybrid taxonomy learning system, we experimented with different ways of aggregating the various hypernym detection modules. The system simply combining all different modules’ output achieved the highest recall figures. The best precision and overall F-scores were obtained, however, by a relaxed voting system combining the output of the morpho-syntactic analyzer and hypernym relations generated by at least two different modules.
A qualitative analysis indicated that there is certainly room for improvement. In future research, we would like to improve the recall of the taxonomy learning system by crawling larger dedicated web corpora for the different test domains and adding additional structured lexical resources. In addition, we will also experiment with other distributional techniques and explore the use of multilingual information for automatic taxonomy learning. Another line for future work consists in combining TExSIS (Macken et al., 2013), our in-house term extraction system, with the presented relation detection system. TExSIS is a hybrid system combining linguistic and statistical information to automatically extract a list of domain-specific terms from a text collection without using external knowledge resources. In a first step, candidate terms are generated based on a list of predefined Part-of-Speech sequences such as “noun noun” (e.g. beef [Noun] stew [Noun]), “adjective noun” (e.g. white [adjective] pepper [noun]) or “named entity” (e.g. IPod). In a second step, statistical filters are applied to check the domain-specificity (termhood) of terms as well as the degree of cohesiveness inside multi-word terms (unithood). In contrast with the current research, where the different modules take as input a predefined domain-specific term list, the system would then (1) start from a list of automatically extracted terms and named entities and (2) automatically identify semantic relationships between these terms and named entities. Taking the automatically extracted terms as the input for the hypernym relation finder would enable to generate full-fledged taxonomies from scratch for any given domain- and user-specific text collection.