
Abstract
This paper considers how to frame different kinds of ontology, in the broader concept of the different dimensions of models in general. A key motivating factor has been to cut across conversations about what may be called an “ontology”, by setting out the features and uses of different kinds of artifacts that are characterized as ontologies. As such this work aims to integrate various well-established perspectives on ontology development and usage, in such a way that practitioners in industry can work from this directly. This is further extended to consider the relationship between the different kinds of ontology and data. The framework described here is intended as the precursor to a more extensive methodology and is based on considerations of semiotics and ontological commitment. The goal is not to define new artifacts or perspectives, but to organize them and create a guideline for ontology development and re-use.
Introduction
This paper describes work carried out by the author in collaboration with an informal community of ontology modelers and information science specialists. At present this work is characterized as a “framework”. Later work is intended to extend this into a formal methodology.
We consider how to analyze models in general, in order to situate various types of ontologies within this framework. The framework identifies distinct dimensions of models and the languages that support those. It focuses on addressing questions about ontological commitment and the semiotics of model artifacts. The framework starts by identifying three separate dimensions of any kind of model. This part of the framework starts with a general description of the ontology modeling space and ties that to Ullman’s Triangle (Ullmann, 1972), a diagram that relates signs, concepts and things in the world. We extend this triangle into a rhombus by refining the notion of concept to address intensions and extensions.
Exploration of the dimensions of the rhombus is intended to provide a simple, accessible way of thinking about issues of representation, semiotics and model semantics such that practitioners can carry out useful ontology work in an industry setting, as well as understand how various kinds of ontology may be deployed in those settings.
Further development of the framework includes the treatment of ontology based data within this framework but certainly could be extended to more general data types. We also consider aspects of the model formalisms of ontologies, including an outline of classification theory and a look at how different types of ontology may be understood in terms of distinct approaches to meaning. Future development of the framework includes considerations about the use and re-use of foundational and upper ontologies but these are not included in this paper.
Motivations
The perceived need for a methodology arose out of participants’ experiences in the development of industry ontologies and standards in general, including the Financial Industry Business Ontology (“Financial Industry Business Ontology”, n.d.) from the Enterprise Data Management Council (EDM COUNCIL: EDM Council – Enterprise Data Management, n.d.).
The primary motivation of this work was to come up with a simple formal framework in which various kinds of ontologies can be understood and used, and in which the requirements for developing any ontology can be formally specified.
A secondary motivation has been to take the literature in this area and set it out in a simple but rigorous framework that can be used and understood by ontology practitioners or by suitably cross-trained business analysts. This was approached by setting out most of the concepts in the literature as simple geometrical constructions, building on Ullman’s Triangle. Where there are alternative approaches given in the literature, the geometry identifies the choices taken.
The framework can therefore be considered and communicated as a geometry of semantics.
Model dimensions
The semantics of models may be considered in relation to the expressivity of the language used. For example, Obrst (2006) gives a linear graph that is widely referenced in the ontology community, describing the progression of models from simple taxonomies of words, through thesauri that organize words, to models of concepts and ending with concepts defined and refined by first order logic.
This graph clearly shows a correlation between the expressive power of the language and the ability to express semantics. In order to consider this correlation it should be clear that the two things that are correlated, the expressive power and what it is that is expressed, are dimensionally distinct.
Many ontologists choose to limit the expressive power of the full Web Ontology Language (OWL), described in McGuinness and Van Harmelen (2009), to a more restrictive, Description Logic subset, OWL-DL (McGuinness et al., 2009), in order to ensure tractable and decidable models. As such, OWL-DL limits the range of things that may be expressed semantically in its language or dialect.
Similarly, other formalisms, most notably XML may be more expressive than OWL-DL, for example by supporting the representation of ordered sequences, but not the same as what is expressed in that language.
Meanwhile different modeling communities make different distinctions between conceptual, logical and physical models, such that for example the term ‘conceptual model’ may be interpreted by different audiences as being highly abstract models of some solution, or concrete models of the problem space.
The intended usage of a model is something else that needs to be documented for any model, and is distinct from both the model formalism and the relationship between model elements and what they represent.
We therefore propose a dimensional view of any model, in which the formalism of the language used, the referents of the model elements (what is expressed), and the purpose of the model, are given as three orthogonal dimensions (Fig. 1).
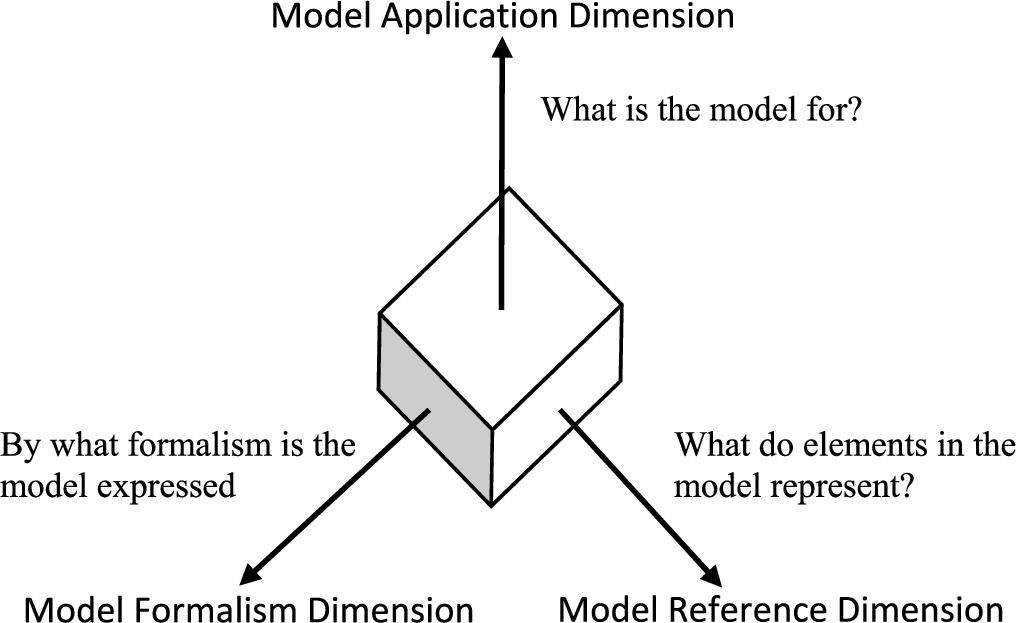
Dimensions of a model.
A model formalism may lend itself to a particular use, for example object oriented formalisms for logical data model design, while others may be used to represent more than one kind of subject matter. For example state machine models may represent real interactions in the world or they may represent some aspect of a designed solution.
Clearly some combinations go well together. For example, UML is widely used to model things in some real or imagined world in the form of conceptual ontologies. However, the model formalism of UML is largely object orientated and may be less appropriate than using formal first order logic or some syntax that supports it, such as OWL, the proposed Semantic Modeling for Information Federation standard (“Architecture Ecosystem SIG Wiki”, n.d.), or OntoUML (n.d.).
The
The
The
These dimensions are described in more detail in the sections that follow.
The model reference dimension
This part of the framework adds more detail to the “Model Reference Dimension”. This deals with the question, “What do the elements of the model represent?” Typical answers being that they represent features of some technical design or that they represent features of some real or imagined world.
Here we look more closely at the latter case, as it applied to ontologies: what is the nature of the relationship between elements of an ontology, and what those elements are meant to represent?
Semiotic Triangle
We take as our starting point the well-known “Semiotic Triangle”, often attributed to Charles Sanders Peirce (1904) but here attributed to Ullmann (1972), building on the work of Ogden and Richards (1923) and the semiotics of de Saussure (1916), as related in Guizzardi (2007).
This sets out the relationships between symbols, concepts and things in the world. Figure 2 shows a representation of this with some commonly used labels for the three corners.
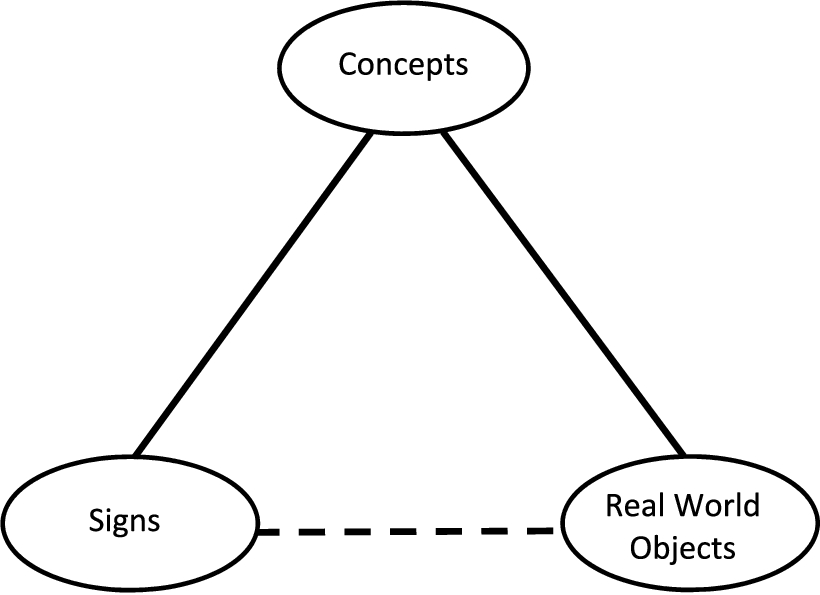
The Semiotic Triangle (Ullmann, 1972).
Separately, an account of the notion of “concept” is given in Odell (2011, Chapter 2). This is illustrated in Fig. 3.
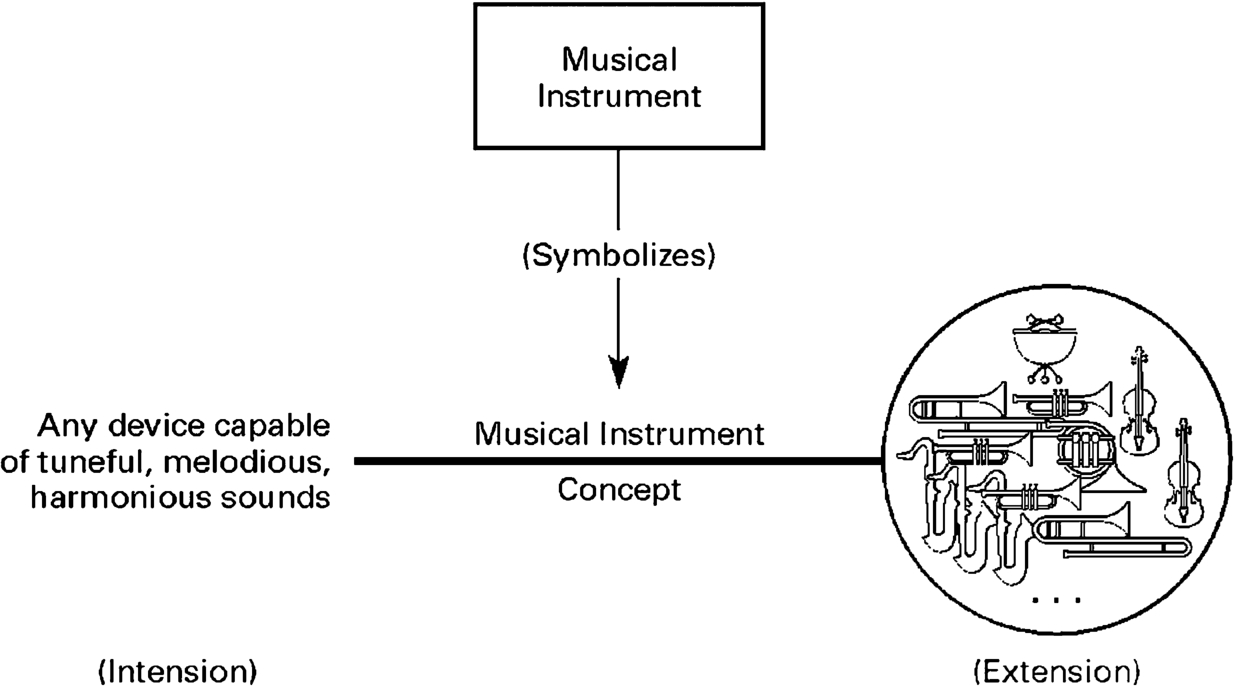
A view of concept from Odell (2011).
In this framework, we will use the term “concept” in the same way as is given in Odell. On this account, a concept is capable of having an intension and an extension, and may have a symbol representing that concept.
Considering the relationship between intension and extension, we can regard the extension of some intension as being something that may occur once or many times in different contexts, or no times at all. Instead of framing the intension as being something that has extensions in some “possible world” we tweak the language slightly to consider extension as an act, and the possible world as the world, or context, in which the intension is so extended. This could for example be in the creation of some application that makes reference to the intensions in the conceptual ontology.
Figure 4 sets out this separation of concept concerns.
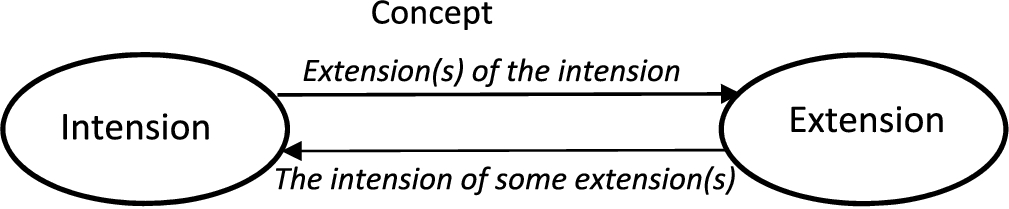
Intensions and extensions.
Unpacking the notion of concept in this way divides the top node of the Semiotic Triangle to two separate concepts, thus giving rise to the “Semiotic Rhombus” in Fig. 5. This is the core geometric construction in the framework described in this paper. This was introduced by the author at a workshop co-located with the 2016 FOIS conference (Bennett, 2016).
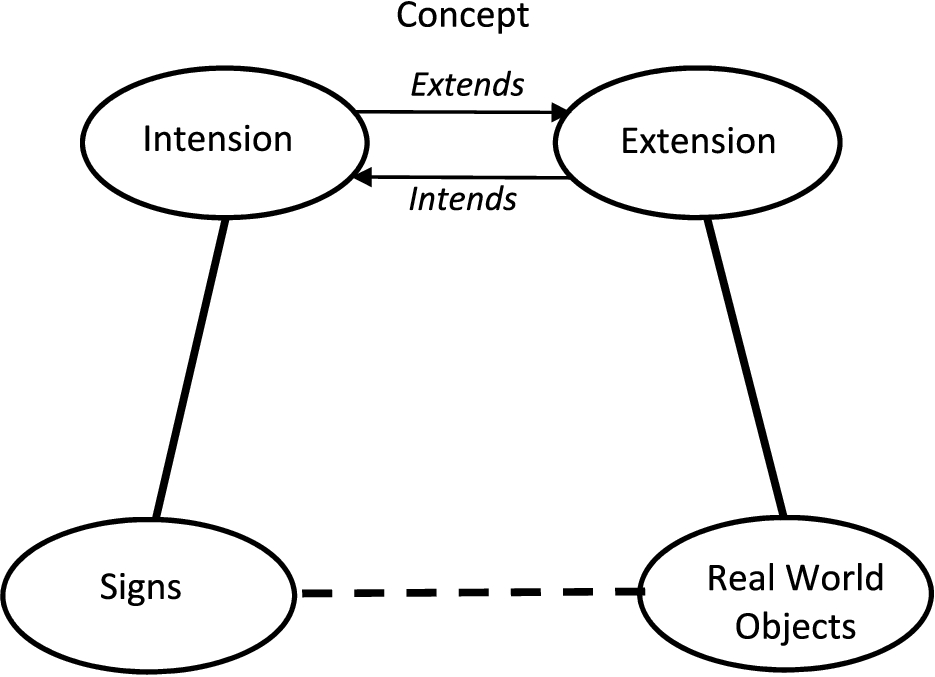
A Semiotic Rhombus.
The distinction between intensions and extensions can be considered in a kind of dualist language. Real things in the world are on the “extensions” side of the diagram, while our understanding of them consists of intensional descriptions. Considering these intensions in the context of human cognition for a moment rather than model artifacts, these distinctions are well understood in modern cognitive psychology.
This is the view that, while the “real” world most certainly does exist (it is a reliable true belief that there is a real world there and that it contains or consists of such and such things), it is also the case that the only things we know about this real world are the results of our sensory inputs and the intensional representations that are built up from those through our continuing experience of that real world via those senses. The real world is no less real, but it is the un-knowable, while what we know directly is only in our mental intensions. This is a reversal of the older, neo-Platonic view where there is a spiritual world that is unknowable and we experience the real world, and this reversal is best expressed in the language of Kant, for example in Kant (1998).
We will label the distinctions between intension and extension using the language of Kant, in terms of a world of real things (extensions) on the right hand side, characterized as the noumenal world, and the world of intensional representations of those things on the left hand side, characterized as the phenomenal world.
We are not committed to a literal reading of Kant, but are using Kant’s language to sum up a view of the world that is quite prevalent in cognitive psychology. While some readings of Kant seem to call into question how “real” the noumenal world is, we generally assume that it is. However, in terms of the framework itself, any one or more extensions of some intensional model, while these may usually be things in the real world, could just as easily be something in an imagined world, or a set of falsehoods about the world as we know it.
The reader will note that this is a description framed in terms of phenomenology rather than ontology. The thing we have been calling an “ontology” could perhaps better be considered as a phenomenology, in this sense.
Having characterized this thinking in terms of how minds form intensions, we apply the same approach to the kinds of models we have been considering. We treat a certain kind of model (our ontology or phenomenology) as being for an organization what the mental intensions of things are for a living organism. Just as a creature such as a human has sensory inputs like sight, sound and touch, and forms intensions based on those, such as notions of people, lamp posts, fish and so on; so a business organization has its own sensory inputs (accounting, law, logistics, contracts and so on), and builds up its own intensional representations of the things that matter to it. These intensions are to be found in corporate documents, in reports, in the minds of members of the organization and, finally, in the data assets held by the organization. Whether or to what extent the latter correspond to any of the former is one of the reasons we believe this methodology is needed.
Interpreting the Semiotic Rhombus
In terms of the language adopted above, the right hand side of the Semiotic Rhombus represents the noumenal world, with undifferentiated world-stuff at bottom right and discretely carved up parts of the real world at top right, corresponding to (being extensions of) intensional definitions of that world by some entity – typically a business. The principles are applicable to humans as well as to institutions but this framework focuses on the intensional representations owned by organizations.
Ontology in terms of the Rhombus
We can now frame a typical conceptual ontology with reference to the rhombus. The ontology so called is in effect a set of intensional representations of concepts, without reference to how those intensions are extended. Questions of the commitment of the “ontology” to things in the world are not questions that may be addressed to the “ontology”, but are questions that apply to each use of the “ontology”.
We refer to “ontology” here in scare quotes because what we call an ontology is really a set of intensional models. Perhaps these kinds of resource should have been called a “phenomenology”? We will continue to use the word “ontology” in this paper and drop the quotes from here on, but it should be understood as referring to a model of a set of mutually coherent intensions, to be used or adapted as needed for different sets of extensions in different application contexts.
This is true of a range of types of ontology, but in different ways. An ontology that is intended as a conceptual model represents how the entity forms concepts of the real world. Other ontologies exist which are really focused on data-available representations of things in the world and how those are intended, and are sometimes referred to as data ontologies. The distinctions between these kinds of ontology are described later in this paper.
As with the model dimensions, we are teasing out two matters that usually travel together but are not the same thing: the intension of a data model or a set of program variables (or an OWL file), and how the data in these applications relates to things in any real or possible world. Data introduces a separate issue in that it represents claims about truths in some world.
Extensions as ontology usages
The possible extensions of an intensional model correspond to the ways in which a conceptual ontology may be put to use. By virtue of its role and nature, a conceptual model is never used directly as part of an application, though in rare cases something identical to it might be. The uses of the conceptual ontology are applications derived from it, such as logical data models, operational ontologies for reasoning, semantic querying applications (with or without interfaces into conventional databases), common message busses and so on.
The notion of extension as an act can be compared to the use case for an application. Whereas applications are built as solutions against a specific application requirement or use case, a conceptual model cannot be an application and cannot have an application-specific requirement. Instead, there is a context or set of contexts in which concepts represented by the intensions are extended to things in the world.
Extensions may involve non ontology artifacts, such as when the conceptual ontology is used as a conceptual model in the model driven development of conventional database artifacts, messages or programs. Every data model and every application’s set of variables has an ontology whether or not this is documented, and the conceptual type of ontology is tool with which to formalize that.
There may also be several separate reasoning or querying ontology applications derived from the same conceptual ontology. These each have a relationship to some data, and that data has a relationship to the things it represents, whether that relationship already existed (in a legacy database for example), or whether decisions are made about the intended relationship between the data and the things in the world for that application. This affects for example considerations like the temporality of the data – is it current, past, bi-temporal and so on. These matters of ontological commitment become matters about the data in a specific application, and not about the ontology, which is itself simply used and applied in these different use cases, providing intensional definitions for different extensions in different applications.
Phenomenal extensions
The OWL language provides for the representation of concepts both intensionally and extensionally, the latter being by means of lists of individuals that make up a class extension. So far we have considered only the intensional use of OWL.
The thing we have been calling an ontology lives entirely on the phenomenal side of the Semiotic Rhombus. This means that in general there should be no role for extensions as a model construct. However, there are cases where there is a concept that may only easily be represented by listing its members. These include for example days of the week, kinds of code for identification or classification of things as occur very commonly in industry standards, and so on. It would not include more open-ended application extensions such as the set of all trains or the set of all ducks.
For this framework, the principle is to model a concept by way of extension only when there is available proof that the concept is capable of being represented intensionally. Extensions may be used in this way when doing otherwise would clutter the model for no good reason. For example, days of the week represent periods in which the Earth turns during any given phase of the Moon. This is the available intensional definition. Since we are working exclusively on Earth, the ontology doesn’t need to “know” that the earth rotates on an approximately 24 hour cycle, it just needs the categories within which to bin “things”. Representing this in the conceptual ontology would require the addition of a considerable amount of astronomical concept material that has no other purpose.
The framework therefore allows for the use of what for want of a better word we might call “phenomenal extensions”, these being extensionally defined sets of things that exist only in the phenomenal domain, and can be proved to be so by indicating the existence of some available intensional representation.
This principle anticipates another aspect of the framework that is developed later, namely the segregation of conceptualization and formalization.
The correct versus the appropriate
It is important to note that the aim of these intensions is not to come up with an ideal model of how the world “is”, but to identify and formalize whatever conceptualization some target organization uses when interacting with its world, including conceptualizations implicit in data, in reports, in management communications and so on. One might be tempted to model a “correct” notion of time as being one in which there are no instants, only intervals. However, given a database of loans in which each loan has a maturity date, that date is effectively an instant. Such instants have granularity (days in this example) but they are conceptualized as instants not as intervals. The intensional, conceptual resource we call a conceptual ontology needs to reflect and formalize those conceptualizations. This cuts out a lot of unproductive conversations about the “right” way to represent some concept. Instead, the thing to do is to discover how it is already thought of by the organization for which the ontology is created, and formalize that.
Exploring the dimensions of the rhombus
A detailed exploration of each of the vertices of the rhombus gives rise to further detailed material that forms part of the current framework. Some of this is ongoing work and is too much detail for the current paper. To give an initial sense of this we would note as follows:
The left hand side of the rhombus represents the phenomenal while the right hand side represents the noumenal.
Up and down the left hand side, we go from discrete symbols such as letters, words or their IT equivalents such as terms and field names at the bottom left, through to complex intensional representations of subject matter (intensional “ontologies”) at the top left. The bottom left effectively represents what de Saussure (1916) refers to as symbols.
Up and down the right hand side we have the things in the world, carved up by the perceptual apparatus of the thing whose perceptions and intensions are represented on the left.
Consider forests and trees. If there is an intension that represents a forest, then on the top right there is the extension that is that forest. The world less carved up is a world of vegetation, of trees and of wood. The world of course does not care how it is carved up, but as the entity we are working for considers and forms intensional representations of its world, it carves that world at its joints, and these carvings up can be considered as what is at top right in the Rhombus.
At bottom right there is whatever in the world the symbols at bottom left refer to via their intensions and extensions (i.e. via their concepts). If an extension at top right is the set of all ducks, then the referent at bottom right of the symbol “duck” is any duck.
The model application dimension
This dimension describes the ways that a given model is intended to be used. We follow the terminological distinctions given in Zachman (2000) for physical, logical and conceptual models.
Conceptual models
At least two notions of something called a “conceptual model” are widely attested. In one view, prevalent in Information Technology, a conceptual model is a more abstract view of a logical model, usually for presentation to a business audience. The other view, widely used in formal semantics, is that a conceptual model is a model of the conceptualization of things in some problem domain. In this reading, a conceptual model is not a more abstract model of a solution but a fully concrete model of the problem domain. The latter reading is intended throughout this paper. In dealing with models that are already in place within a business, it is important to be aware that either one of these readings may be intended when someone presents or describes what they call a conceptual model.
This reading of what it means to be a conceptual model is based on the Zachman Framework (Zachman, 2008) and the descriptive material in Zachman (2000). As noted in that article, any kind of conceptual model provides some view of the problem space as seen by the “owner” of the problem itself. On this basis anything that provides an owner’s view of a problem to be solved, is a kind of conceptual model. This includes requirements catalogs where the requirements are framed from the owner’s perspective, use case models and anything else that describes the problem domain.
Something called an “ontology” may turn out to be a conceptual model or a logical or physical model. One use for ontologies is to fully describe the problem domain, in terms of conceptualizations of things in the world, as a means for defining the intended semantics of subsequently-developed data models, messages, reports or other information artifacts. There are other uses of ontologies whereby they are developed for use in specific applications or in a set of applications. Such ontologies also take account of performance constraints imposed by reasoners. The fact that a given ontology is written in OWL, for example, does not automatically answer the question of whether it is a physical or a conceptual model.
Kinds of ontologies
For the model application dimension we can consider different types of ontology that are encountered in the wild.
These distinctions are considered in Guarino (1998), which describes a number of kinds of ontologies and their uses in applications or as models of concepts in the problem domain.
Guizzardi (2007) provides a detailed treatment of the types and uses of ontologies in a range of settings.
Another good analysis of these questions that was analyzed in the creation of this framework is that given in a paper by McCusker, Luciano & McGuinness (2011). This paper sets out to build on Smith, Kusnierczyk, Schober & Ceusters (2006), which describes three kinds of ontology, representing objects in reality, cognitive representations of those objects and concretizations of those representations in graphical or textual representational artifacts.
Introducing design ontologies
At first glance the work cited from Smith, Kusnierczyk, Schober & Ceusters (2006) appears to call for one kind of ontology for each vertex of the Semiotic Triangle but a closer reading suggests otherwise. The collaborators on the current framework considered this idea but backed away from the notion of three kinds of ontologies representing these concerns. However, we did find the notion in McCusker, Luciano and McGuinness of a distinction between conceptual and what they call “logical ontologies” compelling. This provides an explanatory framework and language for the kinds of ontology that were starting to emerge from recent work on FIBO, as well as being evidenced in work seen elsewhere.
The term “logical ontology” is not one that is in use among ontology developers. In this framework we refer to this as a “design ontology”. Some practitioners may refer to these, or something similar, as being an “operational ontology”, though that term more typically reflects an ontology focused on one specific application and is more in line with a physical model. The design ontology may have been developed to support a wide range of applications, but within the technical constraints of reasoners, and so it has more in common with logical data models in conventional data modeling paradigms.
The key distinction here is between conceptual and design ontologies. Considering the word “ontology” in a broad enough sense to embrace OWL or other first order logic based technology artifacts (such as those in SMIF and OntoUML), we can frame some of these artifacts as being computationally independent representations of some business problem space, and others as being designed artifacts intended to provide reasoning or querying applications across some specific area of interest or use case.
In the model application dimension a conceptual model is any kind of computationally independent model of some aspect of the problem domain. As soon as someone says “you can’t do that in this ontology because it will slow down the reasoner”, they are not describing a computationally independent model, since “slowing down the reasoner” is a computational consideration.
The art of conceptual ontology is the art of not designing something.
It is clear that many of the modeling choices made by OWL ontology designers are appropriate for what we call a design ontology, that is an ontology at the logical design level, and by definition are not necessarily appropriate for what we call a conceptual ontology.
Some developers of OWL based technology may not have considered the use of OWL for conceptual modeling, while many developers of conceptual models avoid using OWL on the perception that OWL files are frequently encountered as being for some kind of application. For this framework we take the view that OWL is a suitable language for both kinds of ontology, providing as it does a means to express first order logic, but that the usage and model representation dimensions may differ from one OWL model to another. Other languages such as SMIF and OntoUML may also be used for a conceptual ontology and their use would overcome such confusion since they are explicitly developed for conceptual model creation; however that should not be the primary reason to select one language over another. Meanwhile many upper ontologies and cross-domain ontologies are now being expressed in OWL, whether or not that was their original or primary means of expression.
Namespaces
In the work of McCusker, Luciano and McGuinness it is recommended that these separate kinds of ontology exist in separate namespaces. This requirement is incorporated in the current framework.
Some commentators (in informal conversations) have suggested that it should be possible to have one set of namespaces for everything. In our view this is at best simplistic and most likely unsupportable. As we show in the section on model semiotics, there is no one “real” world that is being modeled, but a set of intensions that is more or less suited to the conceptualization of some aspect of the real world for the purposes of some entity or organization. Not every conceptualization will be logically compatible with every other.
Further, a good logical design, as with design in any technology, must be able to support simplifications, non-semantic re-use of common material and other techniques that satisfy the technical constraints for that application, without reference to semantics. One of the benefits of having a separate conceptual ontology is that people can create application ontologies that are robust and future proof precisely because they are derived from the conceptual ontology, without those design artifacts having to carry with them all of the detailed conceptual nuances that reflect the formal semantics of the problem domain. In this sense, OWL is just another deployment language like SQL, Java, RDB or XML. That OWL can also be used to model the conceptual intensions from which that application was derived, is a separate matter, reflected in the separate model dimensions, and should be in a separate namespace.
OWL files that are not ontologies at all but are extensional lists of data elements (such as lists of codes used in Linked Data), can be in the same namespace as design ontologies. These cannot be conceptual ontologies, although there is a role for a kind of enumeration in conceptual ontologies, as described earlier.
The model formalism dimension
Approaches to model semantics
There is an aspect of the Semantic Web style of ontology that was seemingly at odds with conceptual ontology modeling. This is the question of what approach to semantics is taken within an ontology, specifically the use or non-use of foundational concepts.
This difference is most clearly indicated by the presence or absence in an ontology of properties that have no domain or range.
In many Semantic Web applications, you might see an ontology with a number of object properties with no domain or range. The classes in the ontology are then defined in terms of restrictions on those properties.
If the ontology is intended to provide a conceptual representation of the problem domain, then these kinds of properties would appear to be under-defined. A typical response to this is that the semantics comes into play when the properties are referenced by restrictions on classes. In these accounts, the semantics of the model arises when reasoning is applied over the deductive closure of the overall graph that is the ontology.
If this is the case then, to paraphrase Searle, “Where does the meaning get in?” Do the properties retrospectively have some semantics because of the way they are used in restrictions? Does each restriction have to be taken into account in order to understand the intended referents (semantics) of the property? Or does the semantics inhere in the graph as a whole? Whatever the answers to these questions, this approach seems to represent a different approach to semantics to that used in many ontologies such as FIBO that use highly abstract semantic primitives to define industry concepts.
An explanation of the thinking behind Semantic Web OWL ontology semantics was given by Fabian Neuhaus in a conversation with the author in 2014. Any misrepresentation of this is the author’s own.
According to this account, the “semantics” of an OWL ontology or set of ontologies is considered in terms of the deductive closure of the graph at the point where it is fed into a reasoner. That is, at that point you “close the world” of that graph and reason over the graph as a whole to ensure that it is internally coherent and therefore potentially meaningful. Semantics inheres in the graph as a whole.
In this account, the graph can be considered as being analogous to a map: if there is enough detail in a map or a graph that it can only correspond to one set of things in the world, then there is a correlation between the graph and the world. It is possible to draw inferences about the world based on logical operations on the graph since these correspond.
This is similar to a correspondence theory of truth, but applied to semantics (referent of a symbol) rather than to truth as such. We therefore refer to this approach as “correspondence” semantics.
The contrasting approach could be characterized as a “foundational” approach, by analogy with foundational epistemology. In this approach the “meaning” (the semantics or intended referent) of some concept, is based on the elaboration of semantically primitive concepts. For example securities are a kind of contract. There is a semantically primitive notion of contract that has all the properties that are common to all contracts, and no additional properties. Concepts in the domain of discourse are built up from refinements of these primitive concepts, these generally being sub-classes of each primitive kind of thing with additional properties providing the differentiae in a taxonomic hierarchy.
This approach was taken in the early parts of the FIBO initiative, and is one that is instinctively recognized by business domain experts when asked to review ontologies.
Faceted classification
It is a common misunderstanding among some modelers, that to be a taxonomy or classification scheme, is to be a mono-hierarchical taxonomy. This is sometimes a requirement for a physical application data model but the world is not like that. Happily the OWL language and other expressions of first order logic do not impose this restriction.
Each facet is a set of sub classes of a thing, based on the addition or variation in some specific property.
Ontologies that are developed under this framework and are intended to be styled as “Conceptual Ontologies” (as described in the Model Application section) are expected to apply faceted classification. This is explained in more detail in Loehrlein, Lemieux & Bennett (2014).
It is also recommended that where facets are identified, the ontology should have metadata added that named and identifies these. There is no standard way of doing this in for example the OWL language, however it is trivially possible to add logical unions of the sub classes in a facet and add an equivalent class relationship to a class that has the name of the facet. Ideally this information would be in a separate file, for example a separate OWL file, since it adds no information to reasoning or other applications. This information would also not be carried forward to an application ontology.
The use of facets also raises the question of “when to stop” in the creation of named, identifiable and defined classes of thing. At one extreme, it is possible to have a facet for every property of every kind of thing, and a set of sub classes of each thing based on every possible variation in those properties. This is clearly unnecessary. At the other extreme one would have a class of some broad concepts like “trade” or “contract” and have lots of optional properties, without defining known and named categories of that thing.
As rule of thumb, categories of thing should be defined for every concept that the enterprise or industry needs to deal with as an entity. For example things for which there are specific regulatory or reporting requirements, things for which specific policies exist, or against which performance measures are made and so on. This is the set of intensions by which the organization carves up its world.
Conceptual ontology modelers should also beware of so called “fuzzy” categories. For example, if a chair and a rock can both be sat on, are they both kinds of chair? The answer in most of these cases is to split the ontology into independent and relative things, such that there are contextually defined concepts like ‘seat’ (where in this case the context is a function), that are distinct from kinds of independent thing.
Another ‘fuzzy’ scenario arises when things are to be classified according to values of some property that is analog in nature, for example the maturity duration of a loan. Here the members of the facet would need to be distinguished against threshold values of that variable.
Similarly, there are facets in whose categories the membership varies from day to day, such as the ‘remaining maturity’ of a loan or other debt.
A more detailed treatment of these and other aspects of classification theory is beyond the scope fo this paper, but forms an important component of the framework.
The data dimension
So far, everything we have said about ontologies has been about how we relate to the real world that is the problem domain and how we form intensional representations of carved-up pieces of the real world. Nothing in any of this has been about data.
Data presents two separate challenges that need to be articulated in this framework. The first of these, as noted in Section 4.3 on design ontologies, is the use of datatypes in something that is called an ontology. The second is that data constructs may themselves be considered as being things in the world.
Data in ontologies
An ontology language such as OWL comes equipped with datatype properties, these being properties of something that are expressed with reference to some computational datatype, specifically one of a limited set of the datatypes provided in the XML language (XML, 1999). Datatypes represent a technical data modeling choice, for example whether elements of a given kind are to be sorted alphabetically, to have arithmetic operations applied to them, and so on.
Most things in the world are defined in terms of real world concepts such as social constructs rather than by data itself. This calls into question whether an ontology with datatype properties can be used as a purely conceptual model, in the sense used here. That is, there may be models written in OWL that belong to different places on the model application dimension.
In Table 1 Logan (2017) sets out some distinctions between types of things in the world and information about those things at three levels of specificity: the overall type, sets of things of that type, and members of those sets, being individual things or data records in some data schema.
Things and information in sets and their members (Logan, 2017)
Things and information in sets and their members (Logan, 2017)
Consider the distinctions given in Table 1 for the notion of a tower. The intensional specification of what it is to be a tower (shown as ‘Type’ in the ‘Things’ column) corresponds to sets of things in the world that are towers, the members of which are individuals such as the Eiffel Tower. Separately, the set specification for data about towers corresponds to a set of things that are record structures for various towers, with instance data for specific individual towers, such as the Eiffel Tower, being data records that stand in a relation of “represents” to the actual structures in the world that are those towers.
It is not uncommon to speak entirely of the data about things in a way that sounds very similar to a conversation about the things. In discussing the contents of ontologies, particularly ones that use a language like OWL that is optimized for carrying out machine processing of facts about real things, it becomes very easy to make this elision.
As the saying goes, it is not your personnel record that goes to jail.
A conceptual ontology is a formal logical representation of (the intensions of) the ‘Things’ in the column labeled Thing, not of records about those things. However there is clearly a role for ontologies that represent data.
In the language of ABox and TBox, we would say that the ABox contains instance data while the TBox represents the representations (theory, hence T) of the concepts that such data represents. In which case we can ask, is an ABox individual a member of the set of things that are for example a tower, or a member of the set of things that are data representations of such a tower?
Let’s flip the Semiotic Rhombus on its edge and add a place for A Box and T Box ontology content (Fig. 6).
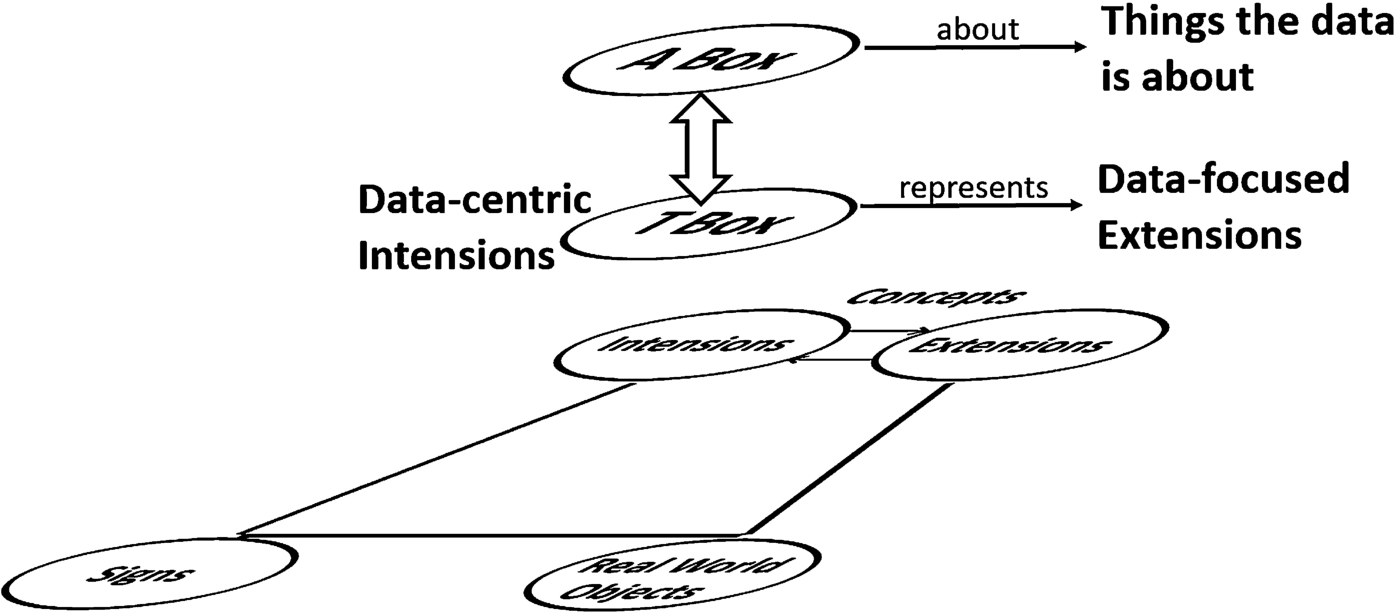
Semiotic Rhombus with ABox and TBox.
To this we can add details of what is represented by what. The ABox clearly contains representations of individual things in the world, and is data about those things. The TBox then represents intensional representations of data sets that correspond to things in the world. These are distinct from the intensional representations of things themselves as defined in the Semiotic Rhombus. The TBox is a data-centric set of intensions, representing sets of data individuals (for example OWL individuals) in the ABox, which themselves are data that represent things in the domain of discourse.
The kind of ontology we have identified in this framework as a conceptual ontology is not this TBox. It is not an ontology for which there would ever be instance data (e.g. OWL individuals). The kind of ontology we are more used to seeing in OWL and comparable languages is the TBox above, and it contains representations of intensional data structures that represent things in the world. This is what we have characterized as a kind of design ontology. It defines sets of potential data individuals that correspond as closely as possible to the things in the world, but may have datatype properties that make reference to data literals.
For example, while my place of birth may be a given as a string, I was not born in a string.
The TBox is the design ontology. This frames concepts (theory) with reference to data in ways that are amenable to data representation, with reference to computational datatypes. The extensions of the TBox intensions are sets of things in the world, carved up according to ways in which that world can be represented in data.
This design ontology is a very important technology artifact. It can be used to reason over information about the world and it can be queried semantically. It is not, however, a conceptual ontology.
When developing a design ontology it makes sense to look for data that is available in data assets and which reflects the presence of some real world matter.
Consider what it “means” to be a bank, or more accurately, what is the intensional representation of real things that are understood to be banks? Or in plain English, “What is a bank?”
A bank is some kind of entity that has certain legal capacities conferred upon it, such that it is legally and institutionally capable of taking in funds from other parties, investing those funds, and disbursing funds to various parties.
These are not kinds of data. In many cases, especially in finance and commerce, many of the real things that give something its meaning (the ‘truth-makers’ of those things) will be social constructs as described by Searle (2010). Social Constructs include things like commitments, rights, the value of money, contracts, legal capacities, capabilities and many others.
Application developers tend to regard these kinds of things as being abstract. In fact these are as real as it gets, for defining the semantics of concepts like the value of money or the legal capacity to enter into contracts; it is the data that is abstract.
Other real-world things include physical and geophysical concepts, geopolitical concepts (which again are social constructs), amounts and quantities of things, mathematical operators and so on.
For each of these real world things, whether they are physical, social, mathematical or of whatever nature, there are often things in data that correspond to those real-world things. These are what we might call data surrogates. In other cases, the data may not contain a direct surrogate for a thing in the world, but rather there would be things that appear in data, such as various kinds of licenses, that are a kind of signature: when that kind of data is present, it is indicative that a given, different kind of real world thing, is also present.
Design ontologies would therefore be expected to have a combination of direct data surrogates (like the measure of temperature in a vessel) and data signatures, such as licenses that correspond to some legal capacity or capability.
As an example of direct correlation (data surrogates), terms in a contract have a direct descriptive relationship to the real thing that is the commitment described by those terms, this being a social construct.
As an example of data signatures, consider the problem of formally defining what a bank is, in a design ontology. The capacities and capabilities of taking in and disbursing funds may not be represented directly in any data. However, a bank may have a license by which some government allows it to exercise those capabilities in its jurisdiction.
A data signature may be semantically further removed from the thing of which it indicates the existence. For example a bank in the US may be required to have insurance provided by the Federal Deposit Insurance Corporation (“Federal Deposit Insurance Corporation”, n.d.), and this may be selected as a suitable data signature with which to define that some kind of organization is a bank. However not all entities that have FDIC insurance are banks, as some are clearing houses. Using FDIC insurance to define that something is a bank would turn out to be a mistake. Banks were briefly modeled this way in FIBO before this non-correspondence was realized. FIBO developers were instinctively looking for data signatures rather than defining the real meaning of the concept by seeking out its truth-makers. Similarly, the concept of Organization is defined in FIBO as being a group of autonomous agents with some goal, whereas the truth-maker for Organization as a concept is that it includes some common organizing principle, as the name would suggest. An informal cartel of investors may pursue a common goal but not be an organization.
Data signatures need to be carefully chosen and this should only be done with reference to a conceptual ontology that has already been constructed. In this way, the design decisions about what data signatures are used for what social constructs or other real-world matter, can be inspected, reviewed and validated. This is the same discipline that is applied to the development of any kind of designed artifact in any branch of engineering, so this should be no surprise.
Other examples
For a design ontology there would need to be data that indicates the presence of these things, for example data about shareholdings would indicate de jure controlling interest in the issuing entity on the part of the holders. The presence of a deed of sale would indicate that the holder and beneficiary of that deed has the capacities conferred on someone by ownership.
A conceptual model of
Many of these temporal concepts are of limited value in an application, and very few if any applications would need them all. Many semantic processing applications would instead be able to rely on the data-centric semantics of the available XML date and time datatypes, along with some simple relationships.
Including non data elements in design ontology
While a design ontology may need to be closely aligned with available data and datatypes, there are often good reasons to represent real world things like social constructs that are not in existing data. This makes it possible to reason over available data to draw inferences about real things that are not primarily found in the source data. For example, one may reason over the terms of a contract to draw inferences about contractual commitments or exposures. The latter are social constructs and are not usually found in the available data. However, by reasoning over things that are in that data it becomes possible to draw inferences about these real-world things, providing data representations for them that may be results from a reasoner, running over the design ontology.
For this reason, design ontologies may include notions that are not represented in available data, just as concepts of real world things may be represented as data.
Data as real things
With the above framework in place, it is possible to consider the problem of real things in the world that are themselves data. We look at two particular cases of this (there may or may not be others):
Things in the business domain that exist only as computer data e.g. identifiers, dematerialized securities Information systems and their data as part of the problem space for a new application
Data as things in the business domain
Some of the real things in the domain of discourse exist only electronically. These include things like published identifiers for securities or business entities, as well as more complex things such as dematerialized securities.
These are kinds of information construct.
It is important to distinguish between a thing itself as an information construct, and data about a thing.
In the case of FIBO as a public standard, the approach taken was to rule as being in scope any data code or scheme that has a publisher, as this puts the matter in a public space. Local identifiers and codes are also real things but they are a feature of some application not a feature of the world.
There are other kinds of information construct that are not data related, for example names, languages, messages, social constructs (since these arise from speech acts or linguistic acts), and so on. Information in its most general sense may be framed as an upper ontology partition or as a high level abstraction representing information in the sense given in Shannon (1948).
Information systems in the problem space
Any analysis of the problem space for a new application necessarily includes an ‘old world’ versus ‘new world’ set of representations, setting out the environment as it is now and the environment as it will be when the intended application has been delivered into production. Most applications are not deployed in a ‘green field’ setting where there are no existing applications in the problem space. The ‘old world’ therefore includes existing computer systems, existing data sources, message feeds and so on.
The data in these existing resources are part of the real world, since they are part of the problem space in which the application is to be delivered. Meanwhile the information requirements for a to-be-delivered system form part of the analysis. These are distinctions that may be described in the Model Application dimension. The precise nature of a model in the Model Application dimension (whether it is a conceptual model or represents some aspect of the solution design) will help to determine what kinds of information constructs it would be appropriate to include in that model.
As with published identifiers or classification code standards, these kinds of thing are also kinds of “information” in the world and would be part of the taxonomy of kinds of information construct.
Summary: Applying the framework to ontologies
The framework presented in this paper allows us to frame different types of models in the enterprise, including many that are called ontologies. These include conceptual ontologies; ontologies that don’t use first order logic; OWL-based models that are not ontologies; things we might call conceptual data models and so on.
The role of a conceptual ontology, as with any conceptual model, is to formally define the whole conceptual space so that developers of applications, including design (logical) or physical ontologies for use in semantic technology applications, can identify and select only what is needed for that specific application use case, in other words what competency questions are to be answered by that ontology application.
In general, developers of ontologies for applications (design ontologies) would be expected to look for signatures in data that imply the presence of real world, identifying matter defined in the conceptual ontology. Meanwhile the real meaning of most things in the world is by its nature defined without reference to data.
The two approaches to semantics
Another difference between design ontologies and conceptual ontologies that often shows up is in different ways in which semantics are intended to be determined from the model, as described in Section 5 on Model Formalism.
These two approaches to semantics are not necessary determinants of one or other type of ontology. In terms of the language introduced in Section 5, the foundational approach is best suited to conceptual ontologies while the correspondence approach should only be used in design ontologies. The use of the correspondence approach is widespread in Semantic Web ontologies, the main reasons being that it leads to more parsimonious models since the higher level abstractions are not needed, and thus to better performance in reasoning and potentially in semantic querying applications.
Conceptual ontology
Using the axes of the model dimensions as a point of reference it is possible to formally define a kind of conceptual ontology as being a model that has the formalism of first order logic (or other orders of logic), the model semiotics whereby each thing in the model represents something in the world, and in so being, provides a conceptual model in terms of the model application dimension.
Design ontology
The design ontology reflects design decisions about what kind of data is available to the application and what kinds of information are to be extracted from that data, as well as decisions about computational requirements that would determine what datatypes to use. It would draw upon the conceptual ontology for definitions about the real things, and would add further assertions based on data that is available to the application and that has some identifiable relationship to those things as data surrogates or less direct data signatures.
In some cases, the design ontology may simply be a copy of all or part of the conceptual ontology. This makes it harder to tell from inspection whether an existing ontology is intended to be a conceptual ontology or a design ontology, except in the case where there are datatype properties. The important determining feature is the process through which the ontology was created and its positioning within the Model Application dimension (conceptual, logical etc.).
Identifying ontology types
One area that needs more work is precisely how to identify when an existing OWL or other artifact should be characterized as a design ontology in the sense given here (an artifact at the logical model level), and when it is truly conceptual.
Some aspects of the use of OWL can be considered quite simply: if there are datatype properties then the model represents some logical design in which decisions have been made about how best to capture and store information about things in computers.
There are legitimate uses of datatypes in a conceptual ontology, where the “real thing” that is being intensionally represented is itself made of data, such as a textual identifier. For the rest, there are not datatypes but there should be a range of “information kinds”. These include names, measurements and so on.
A detailed treatment of information kinds is beyond the scope of this paper, but it should be noted that there are treatments in the “ISO/TC 37 Terminology and other language and content resources” (2016) that may provide a set of information kinds that are suitably semantic and intensional.
Similarly, if an ontology contains properties that have no domain or range (a feature in the Model Formalism dimension), this indicates that it is most likely a design or physical application ontology.
Conclusions
The motivation of this work was to set out a coherent and navigable means of navigating the various kinds of ontology and features of ontologies that are defined in the Applied Ontology literature and elsewhere. What we hope to have achieved here is to provide one of several possible views in which different kinds of ontology can be created, designed, recognized and re-used in a range of real world application contexts.
This framework needs to be communicated to business stakeholders in terms of the need to bring in a seemingly new discipline, describable as semantic engineering or in existing terms like information engineering or knowledge engineering, library science, or in some cases “taxonomy”.
It must be made clear to business stakeholders that this is not primarily a computational discipline. Many IT personnel seem to struggle with classification and concept formation. There are people who can work with IT as well as with conceptual semantics, but there are also developers who can play a musical instrument; the two skill-sets are not related even when some people can do both. This will present a recruitment challenge for industry as companies start to realize the potential of semantics.
The framework includes a number of areas that need further development or are the topic of ongoing development. These include identification of common conceptualizations and their range of possible formalizations (referred to informally as concept families), guidelines for the use and re-use of established upper ontology and foundational ontology material, metadata for mapping between kinds of ontology, metadata for specific features such as classification facets, and the open ended task of communicating an appreciation of conceptual semantics, classification theory, terminology and other aspects of information science in a world that has largely been dominated by technological considerations.
It is to be hoped that end users gain an appreciation of semantic engineering as a discipline in its own right and not simply something to be handed to IT to get on with. This framework aims to apply a level of engineering discipline, particularly as reflected in the Zachman Framework (Zachman, 2008), into the still relatively immature world of ontology development and deployment.
Footnotes
Acknowledgements
The author would like to thank Fran Alexander, Geoff Campbell, Cory Casanave, Donald Chapin, Marcel Fröhlich, John Gemski, Maxwell Gillmore, Christof Hasse, Jim Logan, Joanne Luciano, Robert Nehmer, Fabian Neuhaus, Terry Roach, Daniela Rosu, Marina Severinovskaya, Rebecca Tauber, Bobbin Teegarden and Andrea Westerinen for conversations, presentations and participation in sessions that provided valuable input to the issues and ideas in this article.