
Abstract
The purpose of this study was to evaluate, revise, and extend the Informed Consent Ontology (ICO) for expressing clinical permissions, including reuse of residual clinical biospecimens and health data. This study followed a formative evaluation design and used a bottom-up modeling approach. Data were collected from the literature on US federal regulations and a study of clinical consent forms. Eleven federal regulations and fifteen permission-sentences from clinical consent forms were iteratively modeled to identify entities and their relationships, followed by community reflection and negotiation based on a series of predetermined evaluation questions. ICO included fifty-two classes and twelve object properties necessary when modeling, demonstrating appropriateness of extending ICO for the clinical domain. Twenty-six additional classes were imported into ICO from other ontologies, and twelve new classes were recommended for development. This work addresses a critical gap in formally representing permissions clinical permissions, including reuse of residual clinical biospecimens and health data. It makes missing content available to the OBO Foundry, enabling use alongside other widely-adopted biomedical ontologies. ICO serves as a machine-interpretable and interoperable tool for responsible reuse of residual clinical biospecimens and health data at scale.
Introduction
Informed consent is a foundational requirement in both clinical care and research studies. Informed consent forms serve as the primary source of evidence that an informed consent process occurred, and that the consenter has received enough information to make an informed decision regarding the permissions they are being asked to either grant or deny (The Joint Commission, Division of Healthcare Improvement, 2016). While efforts are underway for tracing such permissions for biospecimens collected during research studies, significantly less attention has been given to clinical consent forms and permissions to reuse residual clinical biospecimens. Residual clinical biospecimens are the portions or derivatives of blood or tissue collected during clinical care process that remain after their clinical indications are fulfilled. These specimens are increasingly recognized as a valuable resource.
There is a need for information systems to facilitate discovery, access, and responsible reuse of stored biospecimens and data, and to facilitate data integration and knowledge discovery within a contemporary connected research environment. This vision requires development of technology which supports expectations around FAIR (Findable, Accessible, Interoperable, Reusable) Principles and includes metadata to support discovery of biospecimens and data according to their permitted and restricted uses (Wilkinson et al., 2016). Semantic web technologies such as ontologies hold great promise as infrastructure solution for scalable, interoperable approaches in health care and research (Kock-Schoppenhauer et al., 2017). Ontologies structurally enable integration of heterogeneous data sources by semantically representing core entities and relationships of a given domain and have been widely successful in biomedical data sciences (Smith et al., 2007).
The Basic Formal Ontology (BFO) is a realism-based, upper level ontology comprised of terms that represent objects (i.e., continuants) and processes (i.e., occurrents) (Arp et al., 2015). This common structure is the basis for enforcing logical rules across all ontologies which import or refer to BFO, including those of the Open Biomedical Ontologies (OBO) Foundry. All OBO Foundry ontologies share core principles, including (1) use of a shared logical structure (i.e., BFO) as the source for common classes and relationships, (2) open access and use, (3) community-based collaborative development, (4) and non-overlapping, strictly scoped content. The OBO Foundry enforces these design principles to achieve scientific accuracy and semantic interoperability through a formal logical basis (Smith et al., 2007).
The Informed Consent Ontology (ICO) is part of the OBO Foundry and serves as a reference ontology for representing informed consent (He, 2015/2020; Lin et al., 2014). ICO was designed to represent documents and processes specifically relevant to biomedical and health research. ICO contains representations of processes such as signing an informed consent form and Institutional Review Board (IRB) approval of the consent form, as well as for the investigator and participant roles. Although ICO was not developed to represent the nuanced information specific to informed consent in health care processes, ICO offers the ability to model individuals’ decisions during a process of informed consent. While some of the existing classes may be transferable to this new domain, ICO must be formally evaluated for reuse in clinical consent processes and extended or revised as necessary.
Objectives
The purpose of this study was to evaluate ICO for its completeness in expressing clinical permissions, including the reuse of residual clinical biospecimens and health data. ICO was subsequently revised and extended to broaden the reference terminology artifact and to make interoperable representations of clinical permissions available.
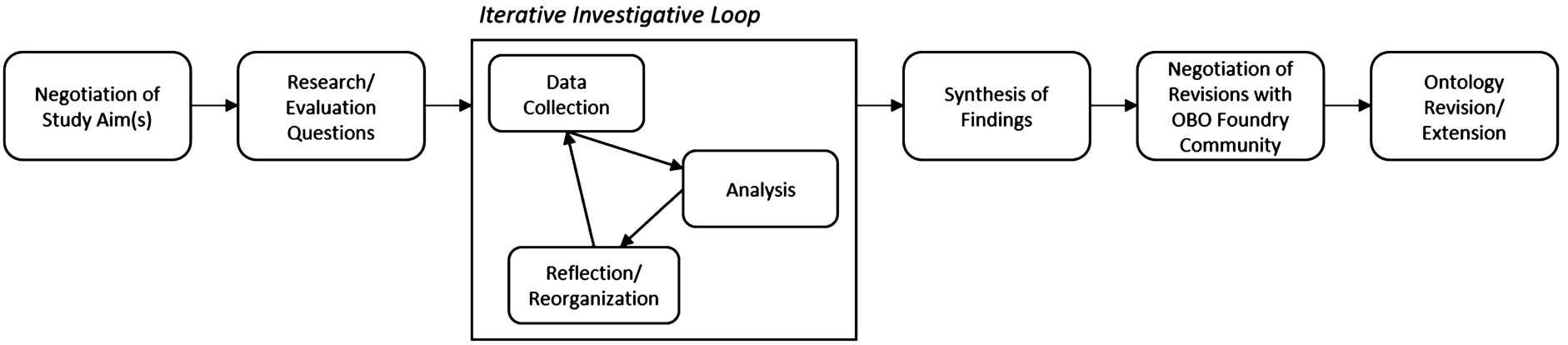
Multistep, iterative ontology evaluation process.
This study follows a formative evaluation design in which we examined an information resource (ICO) under development (Friedman and Wyatt, 2006). Figure 1 depicts our multistep evaluation process which includes: identification of study aim(s), development of research or evaluation questions, the iterative investigative loop – comprised of data collection, data analysis, and reflection and reorganization – synthesis of findings, community negotiation of revisions, and ontology revision and extension. Our analysis was also guided by evaluation methods and questions abstracted from the literature, including the National Institute of Standards and Technology’s (NIST) Ontology Summit’s guidance for evaluating ontologies across ontology life cycles (Neuhaus et al., 2014). Stakeholder involvement, including ICO developers and the OBO foundry community members, was solicited throughout the evaluation process.
Identify life cycle phase
Our evaluation focuses on adaptation of ICO to include a new domain. This aligns with Neuhaus et al.’s (2014) Ontology Development & Reuse Phase. Four evaluation tasks are recommended at this phase: informal modeling, formalization of competency questions, formal modeling, and operational adaptation (Neuhaus et al., 2014). Our analysis focuses on graphically modelling classes and relationships of content identified from relevant regulations and clinical consent forms through concept maps (i.e., informal modeling), followed by formal modeling within Web Ontology Language (OWL).
Determine evaluation aims and questions
Evaluation largely depends on contribution and feedback from domain experts (Gelernter and Jha, 2016; Neuhaus et al., 2014). We developed evaluation aims and questions together with a community of ICO developers and OBO Foundry stakeholders. The questions guiding this evaluation were:
Does ICO contain the necessary classes and relationships to represent permissions from clinical consent forms? Does ICO contain the necessary classes and relationships to represent permissions to reuse residual clinical biospecimens and health data, both from US federal regulations and clinical consent forms?
Iterative investigative loop
The Iterative Investigative Loop was comprised of three steps: data collection, analysis and modeling, and reflection and negotiation (Friedman and Wyatt, 2006). These steps were performed both iteratively and in tandem, enabling continuous revisiting of the data, revision of the models, and collaboration with stakeholders.
Data collection
Data collected and analyzed for this evaluation study included permissions for clinical processes generally and reuse of residual clinical biospecimens and health data specifically. These permissions were abstracted from US federal regulations and clinical consent forms. First, permissions to reuse residual clinical biospecimens within US federal regulations were identified through a review of biomedical, legal, and health policy literature. The full methods and results of this review are described elsewhere (Umberfield et al., 2021b). By identifying these permissions through the literature, we reduced introducing our own biases into ICO by instead extracting the interpretations of what is legally permissible by experts in their respective fields and incorporating a range of perspectives. The included regulations were:
21st Century Cures Act, 2016
Americans with Disabilities Act of 1990
Clinical Laboratory Improvement Act, 1992
Food and Drug Administration Amendments Act of 2007
Genetic Information Nondiscrimination Act of 2008
Health Insurance Portability and Accountability Act, 1996
Patient Protection and Affordable Care Act, 2010
Protection of Human Subjects (i.e., Common Rule), 2019
Rehabilitation Act of 1973
Research and Investigations Generally (2011) (as cited in Public Health Services Act, 2019)
Second, an annotation study of clinical consent forms was conducted to identify permission-sentences. Permission-sentences are statements within the consent form that, when the form was signed by the patient or their legally authorized representative, permitted the health care facility or its clinicians to do some action or activity. Clinical consent forms were collected via direct contribution by health care facilities and systematic web searching, the methods of which are described elsewhere (Umberfield et al., 2021a).
List of permission-sentences from clinical consent forms which were included in this evaluation. Note: by agreement with recruited facilities, we obscured facility names whose consent forms were not publicly available using “XXX”. For all facilities whose consent forms were publicly available, we did not remove identifiers
List of permission-sentences from clinical consent forms which were included in this evaluation. Note: by agreement with recruited facilities, we obscured facility names whose consent forms were not publicly available using “XXX”. For all facilities whose consent forms were publicly available, we did not remove identifiers

Context for a permission directive (permission-sentence).
Permission-sentences were eligible for inclusion if they were positively identified by all three annotators of the consent forms. A sample of 15 permission-sentences were included in this evaluation (Table 1). Four sentences were selected to for the heterogeneity of the activities they permitted (e.g. videotaping, surgery, anesthesia). Six permission-sentences were purposively selected because they explicitly permitted sharing or reuse of residual clinical biospecimens or health data. Five additional permission-sentences were randomly selected to reduce bias potentially introduced through purposive sampling. The sample was not further extended as the design pattern for permission-sentences (Fig. 2) remained stable when modeling the five randomly selected sentences.1
While these sentences pointed to a range of processes (e.g., telemedicine, induction of labor), all processes fit under the umbrella class of ‘health care process’ (OGMS:0000096) or its parent, ‘planned process’ (OBI:0000011). Similarly, although a new role, ‘Pathologist role’ (OBI:0000145) further specified who might also bear the ‘permission role’ (ICO:0000199). The list of all permitted processes and all roles of those granted permission in all instances of consent forms is innumerable. Inclusion of these processes and roles is more apt in application ontology, rather than in ICO or other reference ontology. All permission-sentences included in this analysis are listed in Table 1.
The goal of informal modeling is to identify all relevant ontological entities (i.e., classes and relationships), the entities’ important attributes, and appropriate terminology for the new domain. By informally modelling in concept maps, the models’ content is made understandable to both ontologists and domain experts (Neuhaus et al., 2014).
First, we identified all entities and their relationships within each permission from the source data. We then referenced key parent classes modeled in ICO – including information content entity, material entity, process, and role – and began sorting the identified entities into these categories without defining them or their hierarchies. At the same time, we graphically modeled the loosely defined classes from the consent forms using Mindjet MindManager and PowerPoint.2
For regulations, we focused just on identifying classes rather than graphically modeling their relationships, as there is not yet a legal ontology in the OBO Foundry. While important, a formal legal ontology is out of scope for the present work and is beyond the domain scope of ICO.
Ontology evaluation methods are not yet standardized. Therefore, we abstracted evaluation questions from the literature to guide verification (i.e., did we build it right?) and validation (i.e., did we build the right thing?) of ICO revisions and extensions. These reflection questions were used to guide negotiation during regular meetings with ICO team members and biweekly calls with members of the Ontology for Biobanking (OBIB) community. The list of evaluation questions includes:
Verification.
Are the revisions adherent to OBO Foundry principles (OBO Foundry, 2020)?
Are classes consistent across the ontology’s hierarchy (Zhu et al., 2009)?
Are classes non-redundant (Zhu et al., 2009)?
Does the model capture only entities within the specified scope of the ontology (Neuhaus et al., 2014)?
Is the documentation sufficiently unambiguous to enable a consistent use of the terminology (Neuhaus et al., 2014)?
Validation.
Does the ontology contain the necessary and sufficient information (identified through the source data) to make it fit for our particular purpose? Are all entities within the scope of the ontology captured (Neuhaus et al., 2014; Zhu et al., 2009)? Do the domain experts agree with the ontological analysis (Neuhaus et al., 2014)?
Ontology revision and extension
ICO was revised and extended following all evaluation steps, synthesis of findings, and negotiations of proposed revisions with members of the OBO Foundry community. We categorize these revisions into three categories: (1) classes or relations within ICO that needed modification (2) classes or relations required for modeling clinical permissions, but whose content more appropriately belonged to the domains of other OBO Foundry ontologies, and (3) classes required for modeling clinical permissions that were not available in ICO or another OBO Foundry ontology. For the first category, we worked with ICO developers to revise the semantic labels, definitions, and the logical position of the entity within the ontology. Once completed, we performed automated artifact evaluation including lightweight reasoning using ROBOT, an open-source ontology tool (Jackson et al., 2019), to ensure structural consistency with OBO Foundry design principals. For the second category, we submitted requests to other OBO Foundry ontologies or worked directly with the developers to implement updates necessary to cover clinical permissions. Finally, for the third category, we added these classes to ICO’s import specification before running automated evaluation using ROBOT.
Results
Prior to this evaluation, ICO contained 893 classes and 95 object properties (relations). Table 2 provides summary counts of all classes used in the modeling process, including those ICO classes that were transferable to this new domain and those that should either be imported or added to ICO or the OBO Foundry suite of ontologies for representing clinical permissions.
Summary counts and sources for terms used in modelling
Summary counts and sources for terms used in modelling
Modeling permissions abstracted from US federal regulations and clinical consent forms used 52 classes and 12 object properties already within ICO, demonstrating the appropriateness of extending ICO for the clinical domain rather than developing a new ontology. Five of these classes from ICO were flagged for revision. Revisions were regarding either the classes’ formal definitions (i.e., position within the hierarchy) or human-readable definitions, which were ambiguous or inaccurate.
Evaluation also revealed that extension of ICO is necessary to represent permissions from the source data. Twenty-six classes were recommended for import into ICO from other OBO Foundry ontologies. Additionally, we recommended twelve new classes to either be added to ICO or another OBO Foundry ontology in order to express all content within the included source data. These changes are summarized in Appendix A, which is available in Umberfield et al. (2021c). Appendix A includes tables summarizing:
Terms used that were already present in ICO,
Terms used that were not present in ICO but were identified in another OBO Foundry ontology (recommended for import), and
New terms which were not identified in ICO or another OBO Foundry Ontology.
Following these changes, ICO contains 20 new classes or relations via import and 9 de novo ICO classes. Remaining classes not imported required further discussion and are documented as requests. In total ICO contains 1000 classes and 93 relations. Table 3 provides the ontology abbreviations used throughout this paper as well as the full PURL for that ontology. Appendix B contains supplementary tables reporting the respective classes and relationships used for each of the fifteen permission-sentences from clinical consent forms and mapping classes to sentence content (Umberfield et al., 2021c).
Summary of source ontologies of classes in ICO, their abbreviations, PURLs, and citations. Abbreviations are compact URIs (CURIE) that shorten the full resource identifier for terms in a given ontology. For example, ‘ICO:’ refers to the prefix ‘
Early in the modeling process, a design pattern for the context of permission-sentences emerged. Figure 2 is the informal model of this base design pattern: The individual who is granting permission (‘homo sapiens’ (NCBITaxon:9606); ‘consenter role’ (ICO:0000086)) participates in a process of consenting (‘informed consent process’ (OBI:0000810)) by using a consent form (‘informed consent form’ (ICO:0000001)) which contains a permission-sentence (‘permission directive’ (ICO:0000244)) that prescribes some process (‘planned process’ (OBI:0000011)). It should be noted that this is the most simplified version of this design pattern, and there is significant heterogeneity and added complexity as each permission-sentence was modeled. As an example, the real-world person (i.e., instance) who is the consenter may also have a range of other important roles including being the patient (‘patient role’ (OBI:0000093)) or the patient’s legally authorized representative (‘legal guardian role’ (OMRSE:00000038)). Likewise, the processes that are prescribed by permission-sentences also varied widely, but most often included a ‘health care process’ (OGMS:0000096) like surgery or blood product administration, a ‘specimen collection process’ (OBI:0000659), or an ‘act of data sharing’ (ICO:0000228).

Graphic model for the following permission sentence: “…I give permission for GeneDx to retain any remaining sample longer than 60 days after completion of testing and use my de-identified data for scientific and medical research purposes.”.
As the permission-sentences became more complex, so too did their graphic models. Figure 3 demonstrates this complexity. In this example, not only was some process prescribed, but also specifications on how the data that emerged from that process may be used (‘data use limitation’ (DUO:0000001)) and the timeline by which these processes may occur (‘temporal restriction directive’ (new class, ICO:0000363)). Additionally, the flow of a given biospecimen becoming a residual clinical biospecimen which bears an ‘excess material role’ (ICO:0000313) was fleshed out to ensure that all necessary classes were modeled.
As the source data were modeled and reviewed with team members, we asked the following evaluation questions to evaluate the revisions and extensions of ICO in terms of verification and validation:
Are the revisions adherent to OBO Foundry principles (OBO Foundry, 2020 )?
OBO Foundry principles are centered on openness and reusability to a range of users and applications, and facilitating reuse through shared best practices such as common formats, clear definitions, community collaborations, and regular maintenance of the ontologies (OBO Foundry, 2020). ICO is released under a Creative Commons 3.0 license and written in OWL. The revisions from this evaluation do not affect ICO’s adherence to OBO Foundry principles, and any added classes will follow naming, defining, and documentation requirements.
Are classes consistent across the ontology’s hierarchy (Zhu et al., 2009 )?
We aimed to appropriately map new classes at the same level of granularity as existing classes across the ontology. Three of the five revisions to existing ICO classes revolved around editing the location within the class hierarchy.
Are classes non-redundant (Zhu et al., 2009 )?
During the informal modeling phase, we attempted to use existing ICO classes prior to suggesting extension of the ontology by adding classes. We also searched Ontobee (Ong et al., 2017) and Ontology Lookup Service (Côté et al., 2006) to identify classes and their definitions (formal and textual) that could be imported into ICO. The shared logical structure and hierarchy of classes in the OBO Foundry facilitates interoperability and ease of importing individual classes or entire branches of the ontologies’ trees.
Does the model capture only entities within the specified scope of the ontology (Neuhaus et al., 2014 )?
Permissions from the source data and their relevant entities largely included terms specific to consent processes, their forms, and the individuals involved in the consent process; however, they also included entities relevant outside of consent processes, including health care processes such as surgeries, organizations such hospitals, and processes like the act of selling or owning some material. For this reason, negotiation with representatives from a range of OBO Foundry ontologies is ongoing to determine where this content fits best. As an example, efforts have already been completed to add and define the term ‘owner role’ in The Document Acts Ontology (D-Acts; Ceusters, 2012). Even though ownership was identified as a necessary concept, ownership extends beyond the context of informed consent (e.g., deeds and land ownership) which merits modeling in a broader reference ontology that provides content inherited by ‘downstream’ ontologies, including but not limited to ICO.
Is the documentation sufficiently unambiguous to enable a consistent use of the terminology (Neuhaus et al., 2014 )?
Text definitions for all newly added terms were proposed based on existing and credible sources. Additionally, these text definitions have been double-checked to ensure that they match the terms’ formal definitions.
Validation
Does the ontology contain the necessary and sufficient info (identified through the source data) to make it fit for our particular purpose? Are all entities within the scope of the ontology captured (Neuhaus et al., 2014 ; Zhu et al., 2009 )?
Our purpose was to represent permissions relevant to clinical contexts, including reuse of residual clinical biospecimens and health data for secondary purposes. By systematically extracting entities from all relevant US federal regulations and a sample of permission-sentences from clinical consent forms, we aimed to represent all necessary and sufficient classes for our purposes in ICO. After modeling a few permission-sentences, a distinct and consistent design pattern emerged for representing the context of permission-sentences (see Fig. 2). By following our progression of modeling permission-sentences – from those purposively sampled for our most narrow use case, then purposively selected for heterogenous clinical permissions, and lastly a random sample of permission-sentences – we achieved saturation when identifying new classes, which demonstrates that a sufficient and representative sample of permission-sentences were modeled to capture most relevant classes.
Do the domain experts agree with the ontological analysis (Neuhaus et al., 2014 )?
We presented our questions about modeling decisions and tentative models to the ICO development team and OBIB community during their weekly and biweekly meetings respectively. Graphic models were iteratively refined and presented back to these communities until members agreed that further changes were not needed. Likewise, we brought lists of new and revised classes to these meetings. We adopted their suggestions for class labels, formal definitions, textual definitions, and which OBO Foundry ontology each class should be placed in.
Discussion
This evaluation revealed substantial overlap and therefore appropriateness of using ICO to represent permissions expressed in clinical consent forms. It further identified gaps and inconsistencies for representing such permissions and summarizes necessary extensions and revisions of ICO and other OBO Foundry ontologies. In their study to identify the minimum metadata necessary for biobank information systems to share their samples and data, Norlin et al. (2012) recognized the need for ontologies which represent the “ethical standards under which the samples are collected, any restrictions on research use, and access requirements to the samples” (p. 344). This work addresses a critical gap in formally representing how residual clinical biospecimens and health data can be responsibly reused, which is of increasing value in data-intensive health sciences (e.g., population health, translational science, precision health, etc.) which require access to such information. This work produces a machine-readable semantic resource, grounded in real-world sources included regulations and clinical consent forms. It further demonstrates the importance of continued development of reference terminologies to solve real-world problems.
One important feature of this work is demonstration of a bottom-up modeling approach to evaluate and extend an existing information resource using real-world source data. Such an approach has historically been used to map out the structure of a domain as a step towards developing information infrastructure (Harris et al., 2015; Schleyer et al., 2007). It enables discovery of the information needs of users (Shang et al., 2018) and – by fitting such modeling within an existing top-level structure – builds out content that is interoperable with existing, in-use classes and promotes infrastructure reuse (Freimuth et al., 2012). By using real world source data (regulations and consent forms), we were able to identify content coverage gaps in ICO and other OBO Foundry ontologies that may not have been otherwise identifiable. It also adds this missing content to the suite of ontologies, enabling use alongside widely adopted biomedical ontologies and acting as a valuable contribution for biobank information management.
It is our hope that ICO will serve as a reference terminology to facilitate responsible reuse of residual clinical biospecimens and health data, by both increasing their discoverability by entities that will advance scientific knowledge related to health and also protecting the agency and rights of patients, whose expressed choices regarding the disposition of their biospecimens and health data should be respected. Revising and extending ICO to include representation of this new domain enables future system interoperability of permissions and obligations for sharing and use which can be adopted by a range of systems and applications. As examples, ICO may also be used for assessing informed consent tools such as eConsent forms and as a resource for mapping and annotating text in future natural language processing tasks. It may also be used to build query tools or decision support systems to support covered entities, biorepositories, federated research networks, institutional review boards, and other individuals in identifying eligible biospecimen and data resources that meet their needs or deciding if and when certain biospecimen and data resources should be shared.
Ontology evaluation is a well-recognized challenge. Despite more than a decade of publication on the issue, there remains no standard methodology for ontology evaluation (Burton-Jones et al., 2005; Gelernter and Jha, 2016). Among the criteria by which ontologies are evaluated are “its coverage of a particular domain and the richness, complexity, and granularity of that coverage; the specific use cases, scenarios, requirements, applications, and data sources it was developed to address; and formal properties such as the consistency and completeness of the ontology and the representation language in which it is modeled” (Obrst et al., 2007). Ontology evaluation is underutilized, leading to the release of poor ontologies and ultimately hindering “the successful deployment of ontologies as a technology” (Neuhaus et al., 2014). Currently, systematic evaluation of ontologies requires that evaluators assemble methods from across various evaluation schemas. One strength of this study is its systematic evaluation of ICO, including both verification and validation.
Importantly, our evaluation and modeling process provides a roadmap for improving and expanding domain knowledge within ontologies, and addressing knowledge-representation gaps that hinder their successful uptake (Harris et al., 2015). This role is particularly well-suited to clinical research informaticists, an emerging and recognized specialty that leverages informatics to discover and manage new knowledge relating to health and disease and their use in research (American Medical Informatics Association, 2020). We also wish to amplify the need for collaboration and transparency in ontology development. There are hundreds to thousands of ontologies across repositories, but these ontologies are not necessarily interoperable. It is only with a shared semantic structure and collaborative negotiation of ontology structures that dynamic and changing knowledge can successfully be modeled in interoperable families of ontologies. This work must occur in open and collaborative communities to achieve transparency in knowledge representation.
Several limitations of this evaluation are recognized. First, deliberation with other OBO Foundry ontology communities is ongoing to determine the most appropriate home for some of the new terms which may be out of scope for ICO. Citations for correspondences regarding proposed and actual changes to ICO and other OBO Foundry ontologies are listed in Appendix C (Umberfield et al., 2021c). Second, while we have worked with ontologists and clinical research informaticists, we have not yet presented our models to domain experts from the legal and compliance, health information management, or biobanking domains. However, the extensive literature review and systematic collection and analysis of clinical consent forms mitigates this limitation; the literature and approved consent forms are a form of the collective voice of domain experts. Future refinements will include further checking with experts to ensure we have correctly interpreted the literature and the permissions.
Conclusion
Representing permissions to reuse residual clinical biospecimens and health data in an information resource that is interoperable within a family of recognized biomedical ontologies is valuable for facilitating the responsible reuse of these resources at scale. By evaluating and extending ICO, we make a meaningful step in this direction. Our methods demonstrate the use of a bottom-up approach to modeling content from their respective domains’ perspectives. We propose such methods as a valuable way for clinical research informaticists and domain experts to engage in the development and revision of semantic information resources.
Footnotes
Acknowledgements
The authors would like to thank members of the Ontology for Biobanking (OBIB) community for their support and feedback throughout the evaluation process, including but not limited to Chris Stoeckert, Jihad Obeid, Frank Manion, and Mathias Brochhausen, and Sarah Bost.
Competing interests
The authors declare that they have no competing interests in the research.
Funding statement
EU was supported in part by the Robert Wood Johnson Foundation Future of Nursing Scholar’s Program predoctoral training program. The study was further supported by the National Human Genome Research Institute of the National Institutes of Health under award number U01HG009454, the Rackham Graduate Student Research Grant, and the University of Michigan Institute for Data Science. EU is presently funded as a Postdoctoral Research Fellow in Public & Population Health Informatics at Fairbanks School of Public Health and Regenstrief Institute, supported by the National Library of Medicine of the National Institutes of Health under award number T15LM012502. The content of this publication is solely the responsibility of the authors and does not necessarily represent the official views of the Robert Wood Johnson Foundation, the National Institutes of Health, the University of Michigan, Indiana University, or Regenstrief Institute.