
Abstract
Recently, there has been growing interest in the use of ontology as a fundamental tool for representing domain-specific conceptual models to improve the semantics, accuracy, and relevance of domain users’ query results. Although the amount of data has grown steadily over the past decade, much data shares similar characteristics that can be captured by a foundational ontology. In this paper, we show how queries based on a foundational ontology can be evaluated and their performance measured. We also present a Foundational Patterns benchmark to help select the most efficient triple memory and its layout. We evaluate the foundational benchmark with both generated and real datasets for state-of-the-art triple stores.
Keywords
Introduction
Recently, there has been growing interest in the use of ontology as a fundamental tool for representing domain-specific conceptual models to improve the semantics, accuracy, and relevance of domain users’ query results. Although the amount of data has grown steadily over the past decade, much data shares similar characteristics that can be captured by shared conceptualization. Thus, for describing real-world phenomena and answering user queries in computer science, conceptual modeling has become widely used in the context of cognitive science (Guizzardi, 2005; Mylopoulos, 1992). Conceptual modeling is defined as the activity of formally describing some aspects of the physical and social world around us for the purposes of understanding and communication (Mylopoulos, 1992). While the descriptions that arise from conceptual modeling activities were originally intended to be used by humans, not machines, recent works show how to create computable conceptual models, e.g. Kremen and Necaský (2019), that can be published as linked data and used as a source of truth for data modelling tasks.
While the goal of a conceptual model is to express the meaning of concepts used in a specific domain to discuss the problem and find appropriate relationships between different concepts, the Web Ontology Language (OWL 2) (W3C Consoritum, 2012) is too low-level to capture key modeling decisions like concept rigidity (Student vs. Person). This can result in semantically incorrect representation (yet consistent in OWL 2 sense) ending up in irrelevant query results. For example, events, objects, or their properties are modeled in each domain ontology differently. Foundational ontologies aim to tackle this problem by extending the basic conceptual schema (i.e. the conceptual model that doesn’t have foundational concepts that we can use with any domain) with additional constructs.
In this paper, we show how existing triple-stores perform for data compliant with foundational ontologies. In particular, we focus on existing main-stream triple stores and compare them in terms of efficiency of evaluating typical queries. Typical queries reflect the structure of a top-level ontology and which is recurrently repeating in existing domain and task ontologies. We selected the Unified Foundational Ontology (UFO) (Guizzardi and Wagner, 2005a) among other foundational ontologies because (i) it is one of the most widely used foundational ontologies (Verdonck and Gailly, 2016) in applications, (ii) our experience with using UFO in various domains (Kostov et al., 2017; Křemen et al., 2017) (iii) maturity of UFO for conceptual modeling (Guizzardi, 2005) using OntoUML, a formal UFO-based modeling language based on UML.

(a) querying scenario (b) UFO-based querying scenario (c) UFO-based querying of generated data.
Scenarios. We extend our previous work (Ahmad et al., 2018) on a new Resource Description Framework (RDF) (Klyne and Carroll, 2004) indexing approach based on UFO. The different querying scenarios are depicted in Fig. 1. The leftmost diagram shows standard querying scenario – a knowledge base (data) compliant with a domain ontology is queried by users. Typically, large knowledge bases are stored in triple stores and the user queries are formulated in SPARQL (Harris and Seaborne, 2013). The middle diagram shows one of the benefits of using foundational ontologies – it unifies the types of queries to be executed on data. Here, the types of queries are expressed by UFO query patterns, which are then instantiated as user queries in terms of domain ontologies.
The rightmost diagram shows the scenario we use in this paper – we define a benchmark consisting of a set of UFO Query Patterns and of a UFO-based data generator. Based on the created foundational-based domain ontology, the generator provides instances of the ontology, stores the generated data in triple stores, indexes the stored data with a foundational index and evaluates this data on generated foundational patterns. This benchmark can be reused not only for our foundational generated data but also for all datasets compliant with the unified foundational ontology such as INBAS,1
Thus the main research questions this paper contributes to are:
The paper is organized as follows. Section 2 presents related work. Section 3 reviews the necessary background on querying RDF and OWL. In Section 3.2 we introduce the Unified Foundational Ontology. The data generator is explained in Section 4 including the UFO model and UFO indexing technique. Foundational patterns benchmark is presented in Section 5. The evaluation of benchmark query results is given in Section 6, with the description of our use-case. The discussion of the experimental results is present in Section 7. Finally, we conclude the paper in Section 8.
Recently, several benchmarks have been proposed to compare query execution performance for triple stores. These benchmarks focus on different aspects of SPARQL query evaluation. A comprehensive overview of the main features of the benchmarks can be found, for example, in Saleem et al. (2019). The authors describe a benchmark as a combination of a dataset, a set of queries, and a set of performance metrics, and evaluate existing SPARQL benchmarks accordingly. We select here only some of the representative SPARQL benchmarks along with their main features.
FEASIBLE (Saleem et al., 2015) is a cluster-based SPARQL benchmark generator able to synthesize customized benchmarks from the query logs of SPARQL endpoints. The Berlin SPARQL Benchmark (BSBM) (Bizer and Schultz, 2009) is designed to compare the query performance of native RDF stores with the performance of SPARQL-to-SQL rewriters in different architectures. It is applied to several triple stores, such as Sesame (now RDF4J), Virtuoso, and Jena-TDB. The BSBM benchmark is settled in an e-commerce use case where a set of products are offered by different vendors and consumers who have posted reviews about these products on different review sites. The Lehigh University Benchmark (LUBM) (Guo et al., 2005) is a widely used benchmark for comparing the performance, completeness, and soundness of OWL reasoning engines. It is based on a customizable deterministic generator of synthetic OWL data based on the Univ-Bench ontology – an ontology of the university domain that includes universities, their departments, their professors, employees, courses, publications, and their relationships in the OWL language, and provides the features necessary for evaluation purposes. The data generated is random and repeatable and can be scaled to any size, and it uses plain SPARQL queries. The University Ontology Benchmark (UOBM)4
Relation to our approach. The benchmarks mentioned above focus on various features and performance of the SPARQL evaluation scenario (size of the data, expressiveness of the ontology, variety of queries). However, no attention is paid to the shape of data. For example, although most top-level ontologies distinguish between objects and events, these benchmarks are agnostic to this distinction and do not reflect the top-level semantics of data and queries. For example, although a triple store with UFO index might perform poorly on star-shaped graph patterns (i.e., a tree-like pattern with a root node and depth 1) in general, particular graph patterns with specific ontological types of nodes (e.g.,
We claim that a top-level ontology gives a common and recurring shape to both data and queries. In our approach, the distinction between ontological categories is made explicit. For example, queries that search for objects involved in an event are covered by a foundational pattern, which can then be optimized using the UFO indexing technique presented in our previous work. Thus, our benchmark can be used to measure what is the efficiency of evaluating a class of queries corresponding to the given foundational pattern. In particular, our benchmark shows how an index based on a OWL representation of UFO5
First, we present a fragment of OWL 2-DL (W3C Consoritum, 2012) in a simplified manner, as a knowledge representation language, along with simple conjunctive queries over this fragment. Next, we give an overview of UFO, one of the foundational ontologies. Then we show an example of RDF representation of the OWL-based UFO fragment and queries.
OWL 2-DL
An OWL 2-DL ontology a class assertion an object property assertion a terminological axiom of the form each atomic class boolean operators ( existential restriction universal restriction qualified cardinality restrictions
where
Full OWL 2-DL syntax as well as its formal semantics can be found in W3C Consoritum (2012).
Having an OWL 2-DL ontology Having an OWL 2-DL ontology
UFO is a top-level ontology that has been developed based on a number of theories from Formal Ontology, Philosophical Logic, Philosophy of Language, Linguistics and Cognitive Psychology (Guizzardi and Wagner, 2005a).
Based on Description Logic formalization of basic UFO concepts introduced in Benevides et al. (2017) we publish Unified Foundational Ontology with dereferencable identifiers in OWL.6
Moreover, UFO defines Dispositions which are Intrinsic Tropes (moments) (
Additionally, UFO introduces the notion of agents (
Representation language: UFO-A is expressed in a quantified modal logic (QML) that allows the expression of the alethic modalities of truth (viz., necessity and contingency), and UFO-B is defined in first-order logic (FOL) with the Method of Temporal Arguments (MTA) (Vila and Reichgelt, 1996). But Benevides et al. (2019) defines a method for rewriting UFO-A in FOL, with no loss of content, and consistently with a revisited UFO-B. Also, to represent UFO using Description Logic (DL), authors in Benevides et al. (2017) proposed a number of alternative translations from UFO-B’s original axiomatization in first-order logic to the description logic SROIQ, which is the formal underpinning of OWL 2 DL. UFO is used in domains such Geology, Biodiversity Management, Petroleum Reservoir Modeling, Disaster Management, Datawarehousing, Telecommunications, Petroleum and Gas, Logistics, among many others (Guizzardi et al., 2015).

Main concepts of UFO.
To use a wide-spread technology for UFO index representation, we will consider RDF triple stores. Indexing techniques over RDF are discussed in Section 2. At this point, we show how to represent common OWL axioms, representing an OWL ontology in RDF and a distinguished conjunctive query over the ontology as basic graph patterns of SPARQL (Harris and Seaborne, 2013), a query language for RDF.
Consider a triple pattern, an ordered tuple
For the purpose of this paper, we consider constant to be IRIs only.
Having an OWL ontology
Example:Having an OWL 2-DL ontology
We use the prefix “ufo:” to denote the namespace
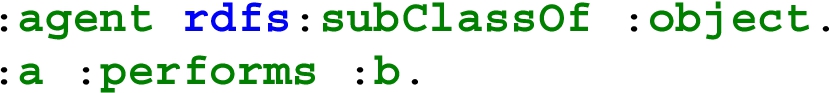
and the SPARQL representation of the query Q would be a SPARQL basic graph pattern 
UFO-based Data Generator (UDG)10

UFO model entities.
Once the model based on UFO is designed, the task is to generate the data. For this we use JOPA, a persistence library for programmatic access to OWL ontologies (Ledvinka and Kremen, 2015). It is used here to create instances of the model entities, i.e., to generate an object graph and then persist it in a repository.
The structure of the generated data is depicted in Fig. 3. A predefined amount of Persons, Actions and Tropes (or moments) is generated as follows.
generate and persist Persons (OWL instances) together with their tropes; generate and persist an initial set of Actions (OWL instance). For each action generate a random Person (OWL instance) that participated in this event and persist them; also generate and persist parts of the actions. These parts have the form of a balanced binary tree.
Validator
The previous sections have shown how to generate the synthetic UFO-compliant RDF data. In order to use our benchmark for existing real-world datasets, we provide a validator based on SHACL (W3C, 2017) rules. The validator checks for cardinality and domain/range constraints of RDF data on the input to determine if it is usable for the benchmark queries presented in Section 5.
For example, the RDF graph in Listing 1 will not pass validation because it lacks a

RDF graph that not pass the validation

RDF graph that passes the validation
Once having the generated data in the repository, the task now is to index the generated data using the UFO-index script. In Ahmad et al. (2018), we have presented our novel approach to improve the efficiency of SPARQL12
Common SPARQL prefixes are
UFO Triple Tables that store triples physically into two tables instead of one triple table as in general design (Faye et al., 2012; Abadi et al., 2007); one for Perdurant category and the other for Endurant.
UFO Property Table that builds a UFO property table for endurants and another table for perdurants, that will reduce Null values in each property table (Faye et al., 2012; Abadi et al., 2007), but we will still have them.
UFO Vertical Partitioning that applies vertical partitioning approach where each triple table includes n-two column tables where n is the number of unique properties in the data. In each of these tables, the first column contains the subjects that match the property, and the second column contains the object values for those subjects (Abadi et al., 2007,2009; Harris and Shadbolt, 2005).
Perdurant table, depicted from Ahmad et al. (2018)
Endurant table, depicted from Ahmad et al. (2018)
After indexing the data, the task now is to create a benchmark of queries that interest the user, i.e., queries that correspond to people’s thoughts and languages. Users are interested in asking queries about physical objects (e.g., man, woman, car, animal, etc.), properties (e.g., weight, height, color, etc.) and events (e.g., accident, party, flight, war, sale, etc.), i.e., immaterial entities that exist only in the mind of the user or a community of users of a language (Guizzardi and Wagner, 2010). For example, people look for people who perform or participate in a particular action, the characteristics or dispositions of those people, etc.
The meanings of a variety of words such as: red, John, Jana, marriage, accident, ball, process, participate, happen, party, hot, warm, play, situation, tasks reflect the essential differences between things that happen and who performs those things, i.e., the distinction between behavioral elements and structural elements. UFO distinguishes between these two categories, where behavioral elements (events) and structural elements (objects). The question word (“how” versus “what”) is often invoked to verify the different nature of these elements (Guizzardi et al., 2016). Moreover, UFO-B proposes a discrete linear ordering of time points in order to answer question word (“when”) (Benevides et al., 2019).
Thus, for a more comprehensive representation of an ontological domain, it is important to focus on the representation of endurants (e.g., objects, their parts, their properties, etc.) and perdurants (e.g., events, their parts, etc.). This representation is exactly what we consider when creating our benchmark.
The benchmark can be used in several ways. First, to test the suitability of a novel triple store towards real-world UFO-based queries. Second, to identify usability of novel UFO-based queries in existing triple stores. Both use cases help to ensure that the UFO-backed data can be reasonably exploited in real-world applications.
How this benchmark is created. Conceptually, we have created a benchmark of all possible foundational queries, i.e., patterns based on UFO concepts and entities that could be created between Perdurant–Endurant, Perdurant–Perdurant or Endurant–Endurant, i.e., foundational patterns between structural (objects, tropes, agents, situations, etc.) and dynamic aspects (events, actions, etc.) of reality, so that it must be able to characterize ontological aspects of endurants, perdurants, as well as their interplay. Table 3 shows examples of foundational patterns of the generated benchmark.13
See
Foundational query patterns and their formal representations

SPARQL query for endurant
Query 4 retrieves all relations that have event as a domain, i,e, the dynamic aspects of reality. Then, the user can have answers to questions such as, when did the second world war start? What are the parts of Jana’s wedding party? etc.
However, the generic generated patterns in Table 3 are simple and represent only single triple patterns generated based on UFO predicates. We therefore generate more complex patterns with multiple triples. We selected these patterns from our previous experience with UFO-based systems such as INBAS,14

SPARQL query for perdurant
Extended foundational query patterns and their formal representations
In this section, we describe the created foundational patterns. As we mentioned in Section 3.2, UFO mainly distinguishes between events and objects. Thus, the foundational benchmark consists of all the patterns between UFO categories, i.e., the interplay between endurants and the dynamic aspects of reality (e.g., events, processes, causation, dispositions, situations, moments). Given the objective of characterizing this interplay between endurants and perdurants, these two ontologies are meant to form an integral whole. Thus, let us discuss some examples or queries of benchmark patterns from Table 3.
Events are ontologically dependent entities in the sense that they existentially depend on their participants (things and people participate and play certain tasks) in order to exist. (
Endurants are entities that, whenever they exist, they exist with all their parts, while maintaining their identity, i.e., we can refer to Jana’s arm, leg and head as the same entity (
This pattern describes how events relate to their parts. According to UFO, every complex event consists of parts (
An event occurs in a certain
A situation triggers an event if and only if (iff) there is a disposition (e.g skills, abilities, disabilities, weak points, etc.) that is activated by the situation (
In UFO, events existentially depend on the objects that participate in them and an event is a manifestation of a disposition of an object, then an event occurs due to the dispositions of its participants (
Agent has its own beliefs, intentions, and goals that are sets of intended states of affairs of an agent. He performs actions to achieve their goals
Table 5 contains the SPARQL representations of the benchmark queries.
SPARQL representations of the foundational queries
SPARQL representations of the foundational queries
For evaluation, we tested the foundational patterns in two different use cases, generated data using UDG and existing real world data by instantiating our foundational patterns, i.e., we instantiate the general patterns in real data (individuals), the instance components structure (Subject, predicate, and objects) meets the pattern structures. The comparison is done in different triple stores. We run the Foundational SPARQL Benchmark against four popular RDF stores (Sesame (or RDF4J19
Version 2.5.2+0dedb9c with Tomcat Version 8.0.48, Operating System Windows 10 10.0 (amd64), Java Runtime Oracle Corporation Java HotSpot(TM) 64-Bit Server VM (1.8.0-151). It is physically designed bases on B-Tree indexing triple tables with context. It allows the user to choose between three storage engines (in-memory, native, DBMS-backend).
Version 3.13.1 with Tomcat Version 8.0.48, Operating System Windows10 10.0 (amd64). It provides the SPARQL 1.1 protocols for query and update as well as the SPARQL Graph Store protocol. Fuseki is tightly integrated with TDB to provide a robust, transactional persistent storage layer, and incorporates Jena text query. It can be used to provide the protocol engine for other RDF query and storage systems.
Version 9.1 with Tomcat Version 8.0.48, Operating System Windows10 10.0 (amd64). It is the free standalone edition of GraphDB. It is implemented in Java and packaged as a Storage and Inference Layer (SAIL) for the RDF4J RDF framework. GraphDB Free is a native RDF rule-entailment and storage engine. The supported semantics can be configured through rule-set definition and selection. Included are rule-sets for OWL-Horst, unconstrained RDFS with OWL Lite and the OWL2 profiles RL and QL. Custom rule-sets allow tuning for optimal performance and expressiveness.
Open-Source Edition v7.02 with Tomcat Version 8.0.48, Operating System Windows10 10.0 (amd64).
Version 2.1.5, open-source and commercial license), Operating System Windows10 10.0 (amd64) with Java version 8. It is an ultra-scalable, high-performance graph database with support for the RDF/SPARQL APIs.
We run the queries against different datasets to compare their execution time (performance), number of results and correctness w.r.t. each triple store (they implement different level of reasoning for OWL ontologies). To check whether the results are correct, the domain expert checks that they do not contain wrong result items and that they are complete w.r.t the input data. This check has been done for real data only. Each query will be executed 10 times either on the Perdurant table (named graph) or on the Endurant table after indexing the data by running UFO indexing script on a triple’s repository. As we proposed in Ahmad et al. (2018), this script automatically group all Perdurant statements together through a single group identifier (Named Graph), i.e., in one Perdurant table. And all Endurant triples in another Endurant table.
To use the foundational benchmark on different datasets by running multiple queries against triple stores, we select a number of frequently executed queries based on domain experts in real data and on our previous experience of developing UFO based systems. We selected queries that cover most SPARQL features that allow us to assess the performance of foundational queries with SPARQL features. Note, all the executed queries are instances of our foundational patterns. The SPARQL features we consider are:
the overall number of triple patterns
SPARQL pattern constructors (UNION or OPTIONAL)
the solution sequences and modifiers (DISTINCT)
filter conditions and operators (FILTER, LANG, REGEX and STR)
aggregates such as (COUNT, HAVING and GROUP BY).
We used the methodology proposed in Saleem et al. (2019) to analyse the characteristics of the proposed benchmark. The diversity score of our benchmark queries is approx 1.6, which is rather a low value, similarly to synthetic benchmarks presented in the comparison. This is not surprising as our benchmark focuses on studying evaluation of rather simple foundational queries.
Generated data experiments
We instantiated the foundational patterns w.r.t. the generated data benchmark and w.r.t. SPARQL features; we tested the instances of UFO pattern for different generated data-set sizes (200000, 500000, million and 10 million triples). We create instances of foundational patterns, i.e., the individuals in triple stores. The instances meet the UFO relations.
Following are samples of the foundational patterns instances with their SPARQL queries.
Q1: Select all agents with their properties(first name, last name, etc.) instance of
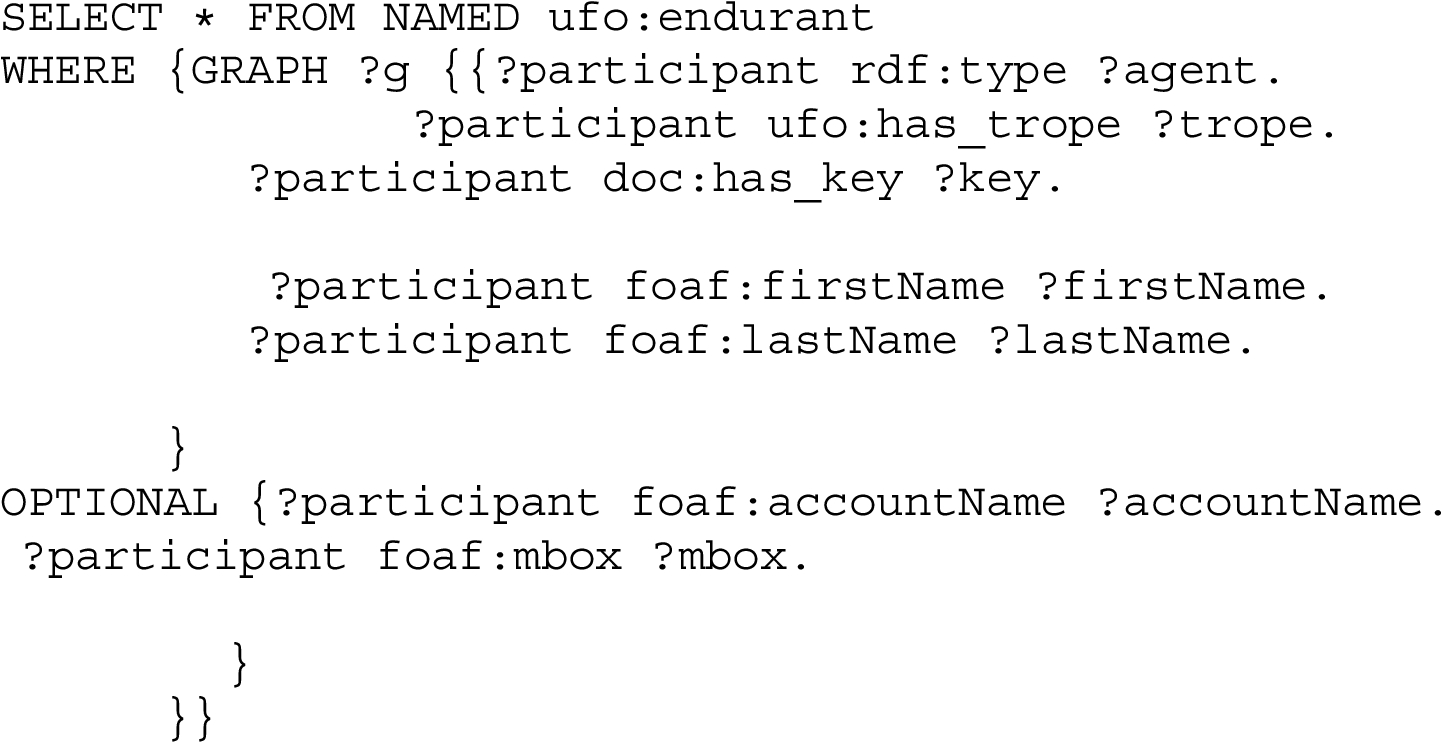
Q2: Select participants of all events.
(Instance of P2)

Q3: return all events with their parts, properties (e.g., start and end time) and their participants. Instance of

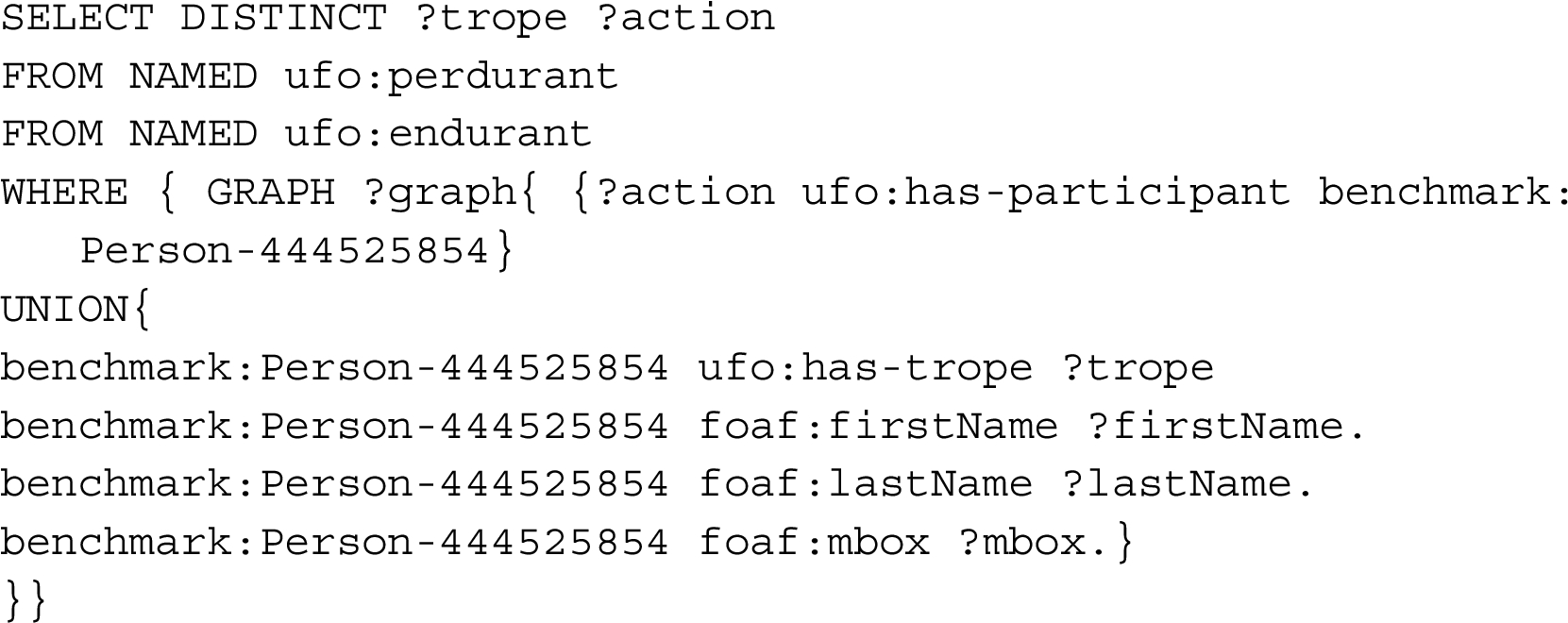
Q4: Select all actions with their start and end times that have (Person-444525854) as a participant with all properties of this person instance of

Mean value and standard deviation of execution query time for generated data.
Figure 4 shows the box plot of the results of running execution time of the instantiated queries on the different triple stores. Figure 5 shows how the query (Q1) execution time is affected by different dataset sizes on the selected triple stores. Moreover, we run query (Q1) with and without UFO. The results in Fig. 6 shows how the UFO index improves the performance by around 50%.

Mean value ϕ of execution query time for Q1 on different dataset size.

Mean value ϕ of execution query time for Q1 with and without UFO.
The ontology that we used to evaluate the benchmark is the Aviation Safety ontology. We designed the Aviation Safety Ontology24

Aviation safety ontology.
CQ1: What are the properties or qualifications of the safety agents (e.g., the air traffic control agents) (maps P1)
CQ2: Which people do necessarily participate in a particular event (e.g., specific damage event, a runway incursion)? (maps P2)
CQ3: Which safety events happen during a particular flight phase (e.g. take-off)? (maps P4)
CQ4: Who is responsible for a particular safety operation (e.g., ground handling)? (maps P8)
CQ5 What are the parts of an Aircraft? (maps P6)
CQ6 Which safety events have air traffic controller/pilot/ground service personnel as their participant? (maps P2)
CQ7 What are the conditions/properties of an aerodrome surface area? (maps P1)
CQ8 What are the factors/ dispositions that are manifested in particular events? (maps P5)

Mean value and standard deviation of execution query time for real data.
For evaluation, we answer the domain user competency questions by using foundational patterns. We ran the following queries against selected triple stores. The dataset consists of approximately 25000 triples. Figure 8 shows the mean values and standard deviation of execution time of running the following queries.
RQ1: What are the tropes (properties) that inhere in the air traffic control agent? (instance of P1 and CQ1)

RQ2: What are the participants of a damage event? (instance of P2 and CQ2)

RQ3: What are the event parts of a specific Flight which has Aircraft-i as a participant? (instance of P4 and CQ3)

RQ4: Who performs ground handling operation-i? (instance of P8 and CQ4)

RQ5: Select everyone that performs actions in aviation domain and filter all participating relation? (instance of P8,P2 and CQ2,CQ4)

RQ6: What are the parts of aircraft-i and in which event this object participates? (instance of P’6 and CQ5)

In order to compare the performance of triple stores with and without using UFO index, we ran the previous queries (RQ1, RQ2, RQ3, RQ4) on the aviation ontology without applying UFO index. The results in Fig. 9 indicates that using UFO-indexing approach makes the search process easier and faster, as we demonstrated in Ahmad et al. (2018).

Mean value of execution query time with and without UFO index.
In this section, we optimize the foundational patterns by running the same following foundational queries on the same size of both generated and real data, i.e., safety data (around 26000 triples). Our goal is to compare triple stores performance in the same size with different UFO-based data and show how these foundational patterns are applicable for any dataset based on a unified foundational ontology, i.e., we can run these fondational patterns on different UFO based datasets.
Q’1: Who are the participants in all event in each dataset?

Q’2: What are all properties in each dataset?

Q’3: What are all actions that happened in both datasets with their parts?

Q’4: Who are the participants in all events in each dataset and what are the properties of every participant?

Figure 10 presents the mean values and standard deviations of the execution queries time on both datasets, i.e., real and generated data sets, where the box represents the standard deviation and the points represents the data labels. The figure indicates that Fuseki Jena is the worst and Virtuoso is the best.

Mean value of execution query time on generated vs real data.
In this section, we discuss the performance of triple stores after running the above different foundational SPARQL queries and the SPARQL features we used in those queries against them. The results of the execution time experiments we performed on different triple stores with different datasets sizes and types (i.e., generated data and existing real data) show that the performance of Fuseki Jena-TDB is the lowest among all triple stores and for all dataset sizes, and Virtuoso is better than RDF4J, Blazegraph, and GraphDB with respect to various features of SPARQL queries.
The mean values have the largest values in Q1 and Q3 in the generated dataset, as they are more complex queries with multi joins and also OPTIONAL blocks are evaluated before the parent block. However, Virtuoso has better space utilization compared to Blazegraph and other stores, and with its well-engineered query optimization engine, it is likely to be faster than others at processing optional join queries, especially for low-selective optional join queries. RDF4J (Sesame) and Fuseki perform worse on complex queries that contain many triple patterns and joins, as well as complex SPARQL clauses. Also for UNION and FILTER because of its optimization engine. For subject-object joins (e.g., Q6 in real data), Blazegraph performed best, perhaps due to its use of a B+ tree-based index nested loop join, which is more read-optimal compared to the bitmap index-based of both row- and column- store in Virtuoso. Virtuoso and Blazegraph typically use a hash join algorithm for executing subject-subject joins over the intermediary results. Subject-subject Joins (e.g., Q3 in real data) all triple-store typically use a hash join algorithm for executing subject-subject joins over the intermediary results. However, using UFO index improves the performance of all triple stores by 65% comparing without UFO index. Most interesting is the comparison of triple stores with and without UFO index which is the most interesting thing. The results show that using UFO-indexing approaches speeds up result retrieval by 68% for RDF4J, 72% for Jena, 70% for GraphDB, 67% for Virtuoso, and 65% for Blazegraph, see Fig. 9. The results also show that the performance of Fuseki Jena-TDB is the lowest and Virtuoso is the best. Figure 11 shows how the differences of triple stores performances by using UFO is lower than the differences without UFO. The results indicate that, even if Virtuoso is better than other triples stores, the performance’s difference between triple stores is lower than using UFO.
Blazegraph is better than RDF4J (Sesame) and GraphDB, taking into the consideration that in many cases, RDF4J is almost equal to GraphDB performance in simple queries; that is because GraphDB is built on top of RDF4j.
Moreover, in our experiment, we have shown a significant performance increase on a relatively small data sample for all foundational queries, i.e., the size of dataset plays an important role in a triple store performance.
Regarding the number of results, all of the selected triple stores return the same number of results. But, the result set size plays an important role on triple stores performance. Also, Fig. 5 shows that the dataset size affects the performance of triple stores. The results of the real dataset validation were checked by a domain expert, who confirmed their correctness and the usability of foundational ontologies in developing safety domain ontologies.
It is interesting to note that based on foundational patterns, we were able to run the same queries on different datasets, as we showed in Section 6.4. However, based on the results, we note that the performance of the triples was somehow better on real word data than on generated data, even though they have the same size, which could be due to the size of the result set.
In summary, the differences of performance of the benchmark on major triple stores are not huge, yet visible. This also shows that foundational queries are generic and structurally simple enough to align well with their existing indexing mechanisms. Moreover, it provides a basis for a substantial evaluation of the approach on real-world datasets that will show the applicability on larger diversity of foundational ontology-compliant data.

The differences of triple stores w.r.t mean value of execution query with and without UFO index.
In this paper, we proposed a foundational benchmark that evaluates performance of UFO-based SPARQL queries on domain ontologies. We used this benchmark for evaluating the performance of different triple stores on both real world and generated data. For this purpose, we created a foundational data generator that generates data based on the UFO model. The benchmark is applicable for any ontology based on UFO.
Furthermore, we indexed all datasets using our foundational indexing technique and evaluated selected triples stores using the designed benchmark. The performance gains are significant and are mostly comparable among the triple stores (with Jena being the winner).
Several improvements are planned for the future work to cover more SPARQL features with OWL entailment regimes. Also, we will do more evaluation for our UFO indexing approach by generating larger and more heterogeneous data and we will compare more triple stores with bigger sizes of UFO-based indexed datasets.