
Abstract
In this paper, we showcase our research on the use of ontologies and information extraction for the purpose of modeling damages incurred on car bodies. With the increasing use of technology in the automotive industry, it is important to have a standardized and efficient way of documenting and analyzing car damage reports. Most existing reports are unstructured, and there is a lack of standardization in describing the damage. To address this issue, we have developed a domain ontology for car damage modeling (OCD),1
,2 and proposed an end-to-end system to extract information from French automotive reports. The information extraction process involves using named entity recognition (NER) and relationship extraction (RE) techniques to identify and extract relevant information from the reports. Then, the extracted information is used to populate theIntroduction
Information modeling and ontologies have become increasingly crucial in today’s data-driven world (Munir and Anjum, 2018), where the effective sharing, structuring and processing of knowledge across different domains, including healthcare (Kim and Chung, 2014), finance (Benjamin et al., 2022), and transportation (Ahaggach et al., 2023a) can be a significant challenge. The use of structured data and standardized models allows for seamless communication and exchange of information across different systems and stakeholders, which reduces ambiguity and ensures accuracy in data representation. The automotive industry can benefit from the application of information modeling and ontology, where vehicle transportation can be a delicate process. Cars are often subject to various forms of damage during transit, requiring a detailed quality control process to ensure their safe arrival. However, damage reports that lack a consistent structure and standard for describing the damage result in a manual data entry process that is time-consuming and error-prone.
To this end, we have developed
The rest of this article is organized as follows: In Section 2, we discuss related work in the fields of ontology and information extraction, including the use of these techniques in the automotive field. Section 3 presents our approach, which comprises two primary steps: ontology construction and information extraction for the ontology population. In the ontology construction step, we identify the relevant concepts and relationships in the domain of car damage assessment and construct a structured representation of this knowledge. In the information extraction step, we extract information from the text and map it to the relevant concepts and relationships in the ontology. Section 4 presents the results of our experimentation, including the evaluation of each step of our approach. We also demonstrate the scalability of our approach by applying it to a large dataset of car damage reports. Finally, in Section 5, we conclude our article by summarizing our approach and discussing its potential impact on the automotive field. We also provide perspectives on how to further extend this work.
Related work
In this section, we present an overview of the existing literature on ontology-based approaches in damage modeling and information extraction, including the use of these techniques in the automotive sector.
Ontology
In recent years, ontologies have become more popular to express machine-readable semantic knowledge. We can consider the ontology
Ontology construction
Numerous studies (Browarnik and Maimon, 2015; Wong et al., 2012) have delved into ontology construction, aiming to create structured representations of knowledge for diverse applications. The process of ontology construction involves several key tasks, such as specifying the domain, identifying relevant terms and concepts, establishing rules and axioms, encoding the ontology using representation languages like Resource Description Framework (RDF), RDF Schema (RDFS), or Web Ontology Language (OWL), incorporating existing ontologies, and evaluating the constructed ontologies.
Researchers (Buitelaar et al., 2005; Mishra and Jain, 2015; Browarnik and Maimon, 2015) have explored three primary approaches to ontology construction: manual construction, cooperative construction, and (semi-) automatic construction. Manual construction involves domain experts manually creating the ontology, while in cooperative construction, experts oversee most or all tasks in the construction process. On the other hand, (semi-) automatic construction involves reducing human intervention, aiming for more automated processes while acknowledging the difficulty of achieving full automation.
Addressing challenges (Zhou, 2007; Albukhitan et al., 2017) in automatic ontology construction remains a priority. Among these challenges are achieving fully automatic construction, handling noise terms to improve pre-processing, enhancing the discovery of relations between concepts, and refining the learning of ontology axioms. Furthermore, ontology construction systems need to accommodate data from various sources, including static text collections and heterogeneous data on the World Wide Web. Additionally, there is a need to establish standardized evaluation platforms for assessing ontology construction systems.
Ontology-based damage modeling
The application of ontologies is widespread in various domains, serving as valuable tools for representing and organizing knowledge. In particular, ontologies have found utility in modeling damages across diverse areas, including buildings, production plants, and electrical systems. For instance, Everett et al. (2002) built an ontology to model copier damage, in order to analyze textual documents containing repair information and identify similar documents. Rachman and Chandima Ratnayake (2018) used ontologies to model damages to processing plant equipment, while Hamdan et al. (2019) introduced an ontology to represent building damages as well as relationships with building elements and affected spatial zones. In the automotive domain, ontologies have been used to model traffic accidents by describing the circumstances, location, causes, and effects of the accident, as evidenced by the previous works of Barrachina et al. (2012) and Dardailler (2012). Despite this, not enough attention has been given to modeling the damage sustained by the vehicle, creating a void in the existing literature. To the best of our knowledge, no existing ontology describes the various car damage types in the automotive domain. Although some existing ontologies focus on car information and parts, they serve different purposes and use cases. Vehicle signal specification ontology (Klotz et al., 2018) and the automotive ontology (Feld and Müller, 2011), focus on car-related information and aspects of intelligent in-car systems. Other work on the vehicle sales ontology (Hepp, 2010) primarily addresses e-commerce scenarios, facilitating the description of cars, boats, bikes, and other vehicles for commercial activities.
Table 1 offers a comprehensive comparison of various automotive ontologies mentioned in this section. It is clear that these ontologies lack a specific emphasis on detailed car damage modeling. Consequently, their underlying structures do not align with the specific requirements for a comprehensive car damage ontology. Additionally, some of these ontologies are not available online, lack multilingual support, and do not cater to our specific needs, as our ontology supports French, Arabic, and English languages. This multilingual support facilitates the modeling of car damage and populating it using diverse car damage reports.
Furthermore, it’s worth noting that these existing ontologies lack inference reasoning capabilities. In contrast, our developed ontology, as described in Section 3.2.3, incorporates reasoning, enabling it to perform inference to enhance information extracted from car damage reports and deduce new information.
Comparison of automotive ontologies
Comparison of automotive ontologies
By addressing the limitations of existing ontologies, our work is centered on developing a domain-specific ontology explicitly tailored to the car damage assessment, with a specific focus on capturing the various types and severity levels of car damages, as well as modeling the car and its parts. Our aim is to create a robust ontology that substantially enhances the understanding and management of car damage assessment.
Information extraction refers to the process of automatically extracting relevant information from various sources, including but not limited to text documents, websites, and social media. This is typically accomplished through the application of NLP and machine learning (ML) techniques. The extracted information can range from simple and straightforward facts such as names, dates, and locations, to more complex information such as events, relationships, and sentiments. Information extraction is included in several domains, such healthcare (Ayadi et al., 2020; Chandra et al., 2023) where the physician’s report are often unstructured, making it challenging to extract and process information effectively. By applying NLP techniques to extract information from these reports to deduce valuable knowledge about the patient’s sickness, potential treatments, and other relevant medical insights.
In the construction industry, several works (Nepal et al., 2013; Zhou and El-Gohary, 2017; Nundloll et al., 2022) propose information extraction systems to extract relevant information from unstructured reports. These systems are designed with the objective of automating the extraction of requirements, thereby assisting construction users in expeditiously extracting the requisite information and organizing it within their database.
In the automotive field, Information extraction has received significant attention from researchers and practitioners because of its potential to improve various processes in the industry. There have been many studies exploring different NLP and ML techniques for information extraction, including NER, part-of-speech (POS) tagging, rule-based methods, and machine learning algorithms.
One of the earliest attempts was made by Rubens and Agarwal (2002). The authors proposed a combination of NLP and ML classification algorithms to extract attributes from online automotive classifieds. The paper was designed to facilitate structured searches over unstructured data. The extracted attributes, such as brand, model, year, price, and condition of the vehicle, can help automate searching and sorting through large amounts of vehicle-related information available online, saving time and effort compared to manual data entry.
Another study by Bhatia et al. (2008) developed a system to extract structured information using natural language processing techniques. The system relied on maximum entropy classifiers for named entity recognition, and manually crafted rule-based approaches. The extracted information was used to perform structured searches for certain attributes of interest, enabling a more efficient search experience for potential buyers.
More recently, Jalal (2020) discussed the use of regular expressions, a type of pattern matching used in computer programming, to extract structured information from online automobile advertisements. The author explored how this information could improve the search experience for online automobile buyers. By using regular expressions, the author was able to extract relevant information, such as the brand and model of the car, and present it in a structured form to users.
Entity recognition approaches
Named-entity recognition is a subtask of information extraction that involves identifying named entities in unstructured text and placing them into predefined categories. Let T be a text (sentence) with length n and E a set of named entity types. The goal of NER is to find all named entities
NER based on dictionaries. One approach to NER is based on using dictionaries or knowledge bases to map text phrases to synonyms for concepts. This dictionary-based NER approach, as described by Zhou et al. (2006), has the advantage of updating the dictionary with new concepts and synonyms. However, the downside of this approach is that it can only recognize entities that are already in the resource. Also, creating a well-constructed and inclusive terminology resource can be an expensive task.
NER based on rules. Another approach to NER is rule-based, which uses regular expressions to combine information from dictionaries and entity features. Petasis et al. (2001) describe this approach, which also involves updating the dictionary with new concepts and synonyms. The downside of this approach is that creating the rules manually can be a tedious process.
NER based on the corpus. This approach involves using corpora annotated by domain experts and machine learning algorithms to predict entity labels. Alnazzawi et al. (2015) and Leaman et al. (2015) describe this corpus-based approach that does not rely on dictionaries or manually created rules. However, this approach requires the existence of an annotated corpus.
NER based on active learning. NER based on active learning is a type of semi-supervised learning that uses unlabeled data in the training process. Chen et al. (2015) and Tran et al. (2017) describe this approach, which requires fewer learning examples compared to supervised learning. However, it also requires constant user intervention.
NER based on deep neural networks. NER based on deep neural networks, as described by Huang et al. (2015) and Lopez and Kalita (2017), is a type of corpus-based approach that does not depend on dictionaries or manually created rules. This approach has shown better results compared to other NER methods.
Besides these approaches, there are also hybrid approaches that combine multiple techniques. Thomas and Sangeetha (2019) present a NER method that combines deep learning, clustering, and rule-based algorithms to extract clinical entities from medical reports.
Relation extraction approaches
Relation extraction is a subdomain of information extraction that identifies semantic relations between text entities. Let S be a sentence with n words, represented as a sequence of word embeddings:
There are several methods for relation extraction, and these methods can broadly be classified into four categories: rule-based, supervised, semi-supervised (bootstrap learning), and unsupervised approaches.
Rule-based approaches. These approaches rely on manually crafted rules or patterns that define the relationship between entities. These patterns are based on syntactic and semantic features. One of the major disadvantages of rule-based approaches is that creating and updating these patterns can be time-consuming and challenging, especially for complex relationships. According to Nadeau and Sekine (2007), rule-based methods have the advantage of being interpretable and explainable, but their effectiveness depends on the availability of high-quality rules.
Supervised approaches. These approaches treat relation extraction as a classification problem and train a machine learning model to predict the relationship between two entities. The model learns to identify the relationships between entities based on features such as part-of-speech tags, dependency parsing, and word embeddings. The most commonly used algorithms for this approach are support vector machines (SVM) and neural networks. According to Zeng et al. (2014), supervised learning approaches are effective in identifying a wide range of relationships but require large annotated datasets for training.
Semi-supervised approaches. These approaches also known as bootstrapping, start with a small set of seed pairs and use them to automatically learn additional relationships from annotated data (Brin, 1999; Agichtein and Gravano, 2000). These methods combine labelled and unlabeled data to iteratively expand the seed set and improve the model’s accuracy. Bootstrapping can be computationally efficient and does not require a large amount of labelled data, but it can be susceptible to errors in the initial seed set and generate noisy patterns.
Unsupervised approaches. These approaches involve recognizing pairs of entities that appear together frequently within the same sentence or document. When two entities occur together with enough frequency, it is assumed that there exists some sort of relationship between them (Yates et al., 2007; Davidov and Rappoport, 2008). Additionally, some studies use large amounts of text to extract relations between entities by analyzing strings of words that appear between them. These strings of words are then clustered and simplified to generate relation-strings, as seen in works such as Shinyama and Sekine (2006) and Etzioni et al. (2008).
Discussion
The existing literature has given limited attention to modeling the vehicle damage. Additionally, the existing works in information extraction in the automotive field mostly rely on online automobile advertisements to extract simple entities such as car brands and models. However, these works use traditional rule-based methods that have limitations, such as their inability to handle variations in natural language and context, leading to reduced accuracy and reliability of the extracted information. Furthermore, they are not designed to extract relations between entities, which is crucial to understanding the underlying semantics of the data.
In our study, we used deep learning approaches for NER since they produce promising results, especially when dealing with large datasets of car damage reports where patterns cannot be easily captured by traditional methods. Deep learning models leverage machine learning algorithms and statistical techniques to learn patterns and associations from labeled data, enabling them to generalize well to new, previously unobserved car damage reports. We compared various deep learning-based NER models and chose the one that yielded the most accurate performance on our data. For relation extraction, we employed ML approaches and tested different algorithms and features to determine the most effective combination for our task. We also used ontology reasoning to further improve the accuracy of our relation extraction. In the next section, we will provide more detail about our approach to constructing
Approach
Our approach comprises two main steps: ontology construction and information extraction. In the ontology construction step, we identify the relevant concepts and relationships in the domain of car damage assessment and construct a structured representation of this knowledge. In the information extraction step, we extract information from the text and map it to the relevant concepts and relationships to populate our ontology.
Ontology construction
In this section, we provide a detailed account of the ontology construction process, focusing on the various steps (Fig. 1) involved in creating the ontology for car damage (

Steps in the creation of the ontology for car damage (
The main objective of constructing the
The structured data resulting from this information extraction process is instrumental in training regression models to predict the approximate cost of repairing reported damages, providing valuable insights for the automotive industry.
Competency questions
The OCD (Ontology for Car Damage) addresses several competency questions within the domain of car damages. Some of the key questions that the ontology helps to answer include:
This question addresses the fundamental classification of car damages. The ontology would define various types of damages such as dents, scratches, collisions, etc., providing a structured framework for understanding and categorizing different damage scenarios.
This question delves into the specific components of a car that could be damaged. The ontology would list and define various parts like bumpers, doors, windows, etc. It helps in understanding the granularity of damage, aiding in precise identification and assessment.
This question seeks to establish a severity scale for different types of damages. The ontology should incorporate severity levels (e.g., minor, moderate, severe) associated with each damage type, allowing users to assess the impact of the damage.
This question explores the relationships between different types of damages and the car parts they affect. The ontology defines these relationships, outlining which damages commonly impact specific parts. This information is crucial for insurers and repair shops.
This question addresses the practical application of the ontology. It involves extracting relevant information from unstructured sources like accident reports and linking this information to the defined concepts within the ontology. This linkage enhances data organization and retrieval.
This question focuses on the ontology’s role in improving the accuracy and relevance of extracted information from automotive reports.
This question deals with the ontology’s structure. It requires defining a clear hierarchy and structure for car components and damage types. For example, organizing parts hierarchically (e.g. CarBody > Trunk > TrunkLid) and categorizing damage types under appropriate categories (e.g. Damage > BodyDamage > Scratches) creates a structured ontology, aiding in efficient data management and knowledge retrieval.
These questions were formulated after a careful examination of the requirements within the car damages domain. The corresponding SPARQL queries for these questions are highlighted in Table 3.
Collection of terms
To construct the ontology and gather terms and concepts describing the domain of car damages, we relied upon the expertise of insurance professionals. We analyzed their detailed description reports and consulted repair shop records, ensuring comprehensive coverage of all types of damages and car models. The
Concepts
In our
The concept of damage can be further categorized into three main subclasses: body damage, mechanical damage and missing damage.
Within the subclass of mechanical damage, we can identify different types of damage, such as electrical damage (faulty wiring or malfunctioning sensors), transmission damage (slipping gears or leaks), and engine damage (overheating or broken components). Repairing missing damage typically involves replacing the missing components or parts with new ones, or in some cases, with used or refurbished ones.
The concept
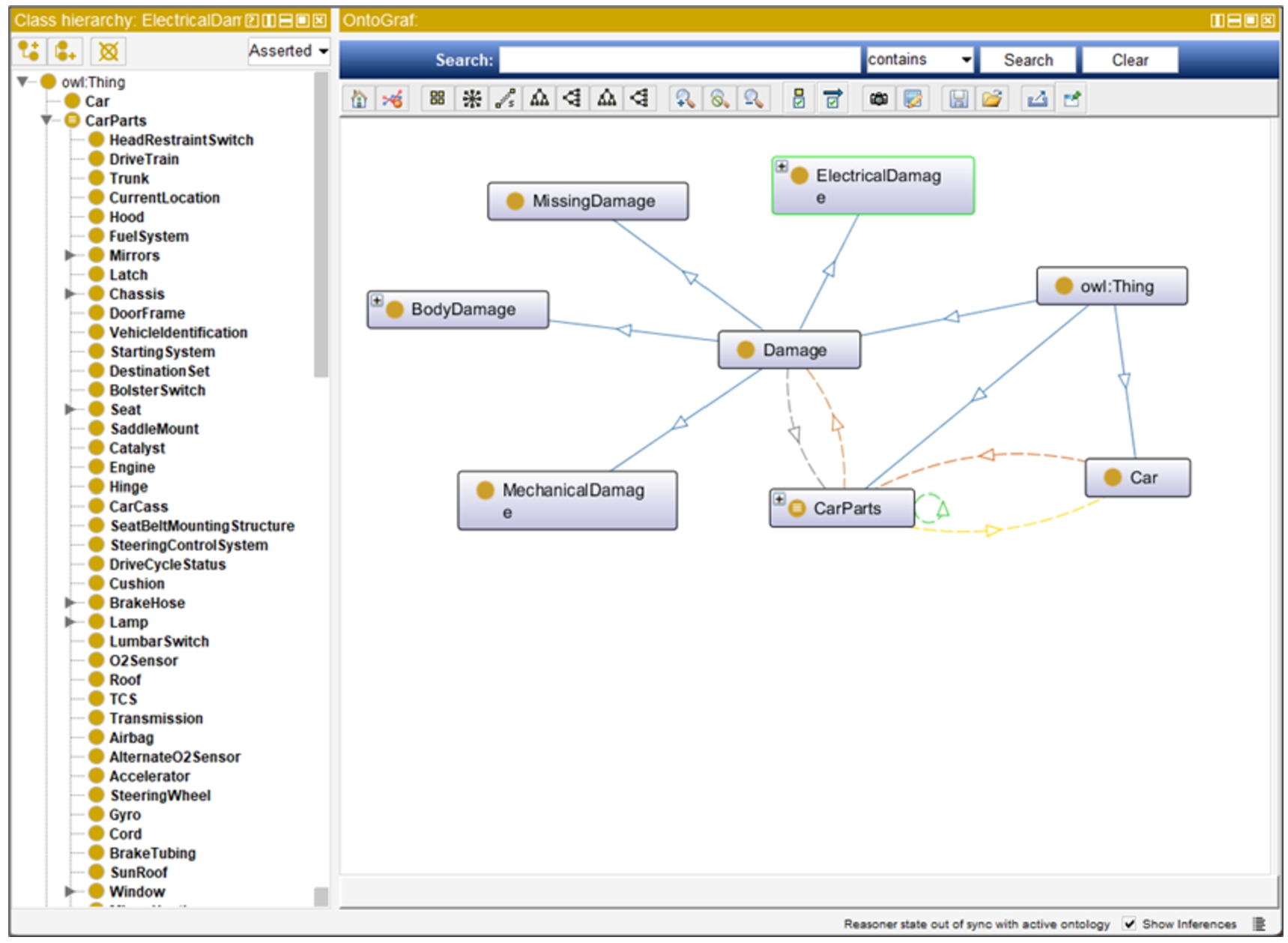
A snapshot of the classes present in the
The
Data properties for the
ontology
Data properties for the
The
Ontology evaluation
Ontology evaluation is the process of assessing the quality of an ontology by measuring it against a set of established criteria, including accuracy, completeness, conciseness, adaptability, clarity, computational ability, and consistency. This helps to ensure that the ontology is reliable and can effectively support its intended applications (Raad and Cruz, 2015).
There are four common techniques used for evaluating ontologies (Hazman et al., 2011; Asim et al., 2018). The first technique, golden standard-based evaluation, compares the learned ontology to a standard one, representing the ideal knowledge representation for a specific domain. The second one is application-based evaluation, which focuses on assessing the ontology’s performance in a particular task-specific application. The third one, data-driven or corpus-based evaluation, measures the ontology’s coverage of a domain using domain-specific knowledge sources. Lastly, the expert-based evaluation usually involves evaluating the ontology through the experiences of users by defining indicators and assessing the ontology against each of them.
In our case, we check the consistency of the ontology and ensuring that the reasoner does not produce any errors using the reasoners
The
Competency questions and SPARQL queries

Competency questions and SPARQL queries
To populate our ontology, we propose an information extraction system that comprises four critical modules (Fig. 3): the pre-processing module, the information extraction module, the ontology population module, and the ontology reasoning module. These modules work in concert to provide a complete solution for extracting relevant information from unstructured automotive reports.
Pre-processing module
The text describing the car damage is extracted from
There are several approaches to correcting spelling errors, such as dictionary-based, rule-based, statistical-based, and neural network-based methods. In this module, we use a dictionary-based approach due to its simplicity, but it has the limitation that it cannot correct composed words, which are common in the automotive domain.
Hence, we propose an algorithm based on the
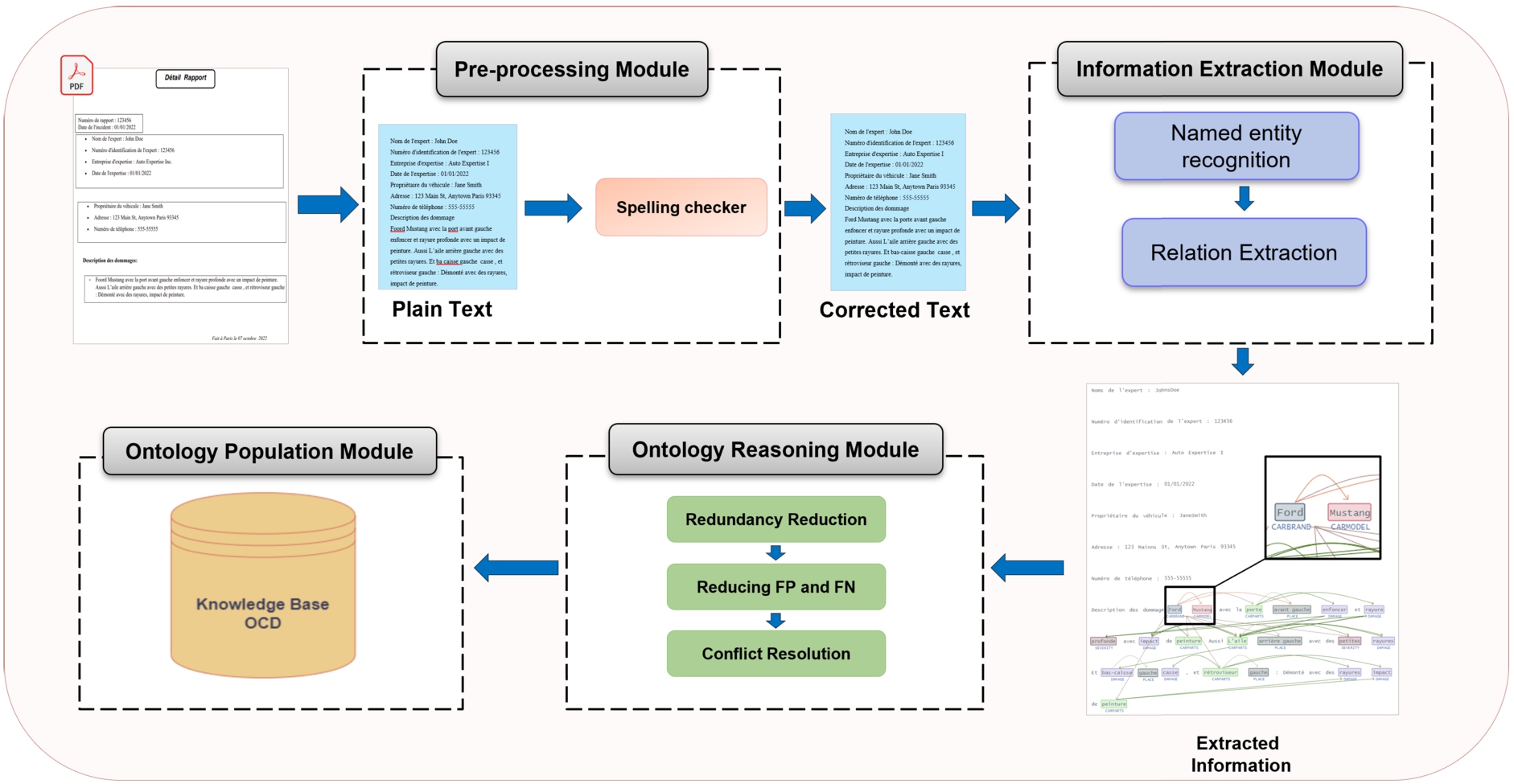
The overall architecture of our methodology.
The
Input: “
Output: “

Spelling checker algorithm with
The information extraction module aims to extract the car information (brand, model, color …), the damaged component entities, the damage type and the damage characteristics (severity, location…). For example, in this sentence: “Ford B-MAX with a severe dent on the back-left door and small scratches on the bumper, and a broken rearview mirror”, the extracted information would be: “Ford” as the brand of the car, “B-MAX” as the model of the car, “door”, “bumper”, and “rearview mirror” as components of the car, “dent”, “scratches”, and “broken” as damages, and “severe”, “small” are the severity of these damages. And “back-left” is the place. All of these concepts are defined in the proposed ontology
Data labeling. To train our models of NER and RE, we first needed to label our car damage reports. We used the
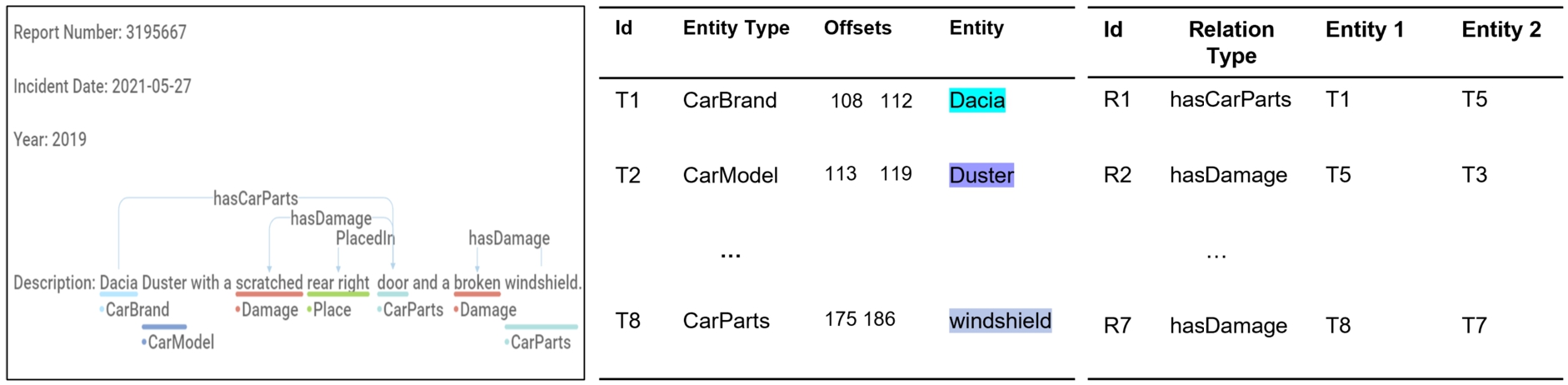
Example of entities and relations annotation in
Named entities recognition. We used the labeled data generated by the
In this study, we conducted a comparison of five different NER algorithms, each using a distinct approach to NER, namely transformer-based models, probabilistic models, and sequence models, with the addition of fine-tuning to improve performance. Specifically, we compared the performance of Conditional Random Fields (
This model is available at:
The
The
Section 4 presents a detailed description of the experimentation process and results of each NER algorithm. Finally, we select the best model to predict and extract entities from newly arrived car damage reports.
Relation extraction. The next phase in our information extraction module is relation extraction, which involves identifying relationships between different entities extracted with the NER model from a report.
To train RE models, we use the process describe in Fig. 5. First, we use the annotated reports to extract three categories of features: distance features, word features, and embedding features. We describe each type of feature below:
Distance features: Rely on measurements between entities.
Word distance (word dist): the number of words between two entities.
Character distance (char dist): the number of characters between two entities.
Sentence distance (sent dist): the number of sentences between two entities.
Orientation: indicates whether entity 1 appears before or after entity 2.
Word features: Take into account various properties of context and entity words.
Bag of entities: the frequency counts of all annotation types between the entities.
Entity types: indicate the types of entities.
Embedding features: Generated from pre-trained word embedding models for each entity, here we used two models Word2Vec and
Word2Vec embeddings: Word2Vec (Mikolov et al. (2013)), uses a neural network to generate vector representations of words based on their co-occurrence patterns in a large corpus of text data.

Extracting relationships: a visual representation of relation extraction process.
The extracted features are then put through a feature selection using the Recursive Feature Elimination (RFE) method. This method aims to identify only the relevant features, reduce data dimensionality, and eliminate irrelevant or redundant features, leading to improved model performance, reduced overfitting, and faster training times.
To create our relation extraction models, we use four commonly used classification algorithms for relation extraction: support vector machines (SVM), K-nearest neighbors (KNN), decision trees (DT), and random forest (RF), as illustrated in Fig. 5. To determine the optimal hyperparameters for each model, we apply the grid search method, which is further elaborated on in Section 4. Ultimately, we choose the model with the highest score for predicting relations. In the process of predicting relationships between entities in a new car damage report, we first extract entities from the reports. Next, we extract the same features from these entities that were used during the model training phase. These extracted features are then employed to predict the relationships between the entities accurately.
Once our relation extraction model has processed the reports and identified relevant relationships between entities, we take our analysis one step further by incorporating
Type-based reasoning: Ontology provides a hierarchy of entity types and their properties, which can be used to guide the extraction of relations between entities of a certain type. For instance, the ontology assists in defining the possible relationships between
Validation-based reasoning: Ontologies also provide rules and inference engines that can be used to infer additional relations between entities. For example, if the relation extraction model detects multiple relationships between a
Implicit inference-based reasoning: Inferring implicit relationships involves identifying relationships that may not be explicitly recognized by the relation extraction model. By using the semantic relationships between entities in our ontology, we can infer additional relationships between entities. For instance, in a car damage report, all
The ontology reasoning process occurs in two steps. Initially, the raw extracted entities and relationships are populated into the ontology without applying reasoning. This step allows for the identification of incomplete or inaccurate data.
In the second step, the ontology reasoning engine applies logical inferences and deductions based on the ontology’s axioms, relationships, and rules. This enhances the information extraction process and improves the accuracy of the extracted entities and relationships.
Ontology population module
This module takes the output of the information extraction and ontology reasoning modules to populate our
In this section, we present the experiments conducted in the second phase of our study, which focuses on information extraction from automotive reports describing damages to cars. Additionally, we provide a comprehensive description of the dataset used in the study and the steps taken to preprocess and label the data. Furthermore, we detail the evaluation of the spelling checker algorithm and its impact on the overall performance of our named entity recognition and relation extraction models.
Dataset description:
The dataset used in our study was obtained from the reputable company
The car damage reports encompass a wide range of entities and relationships relevant to the automobile domain. The distribution of entities and relations in the labeled dataset is depicted in Fig. 6.
Before conducting the experiments, the raw dataset underwent thorough preprocessing to ensure data quality and uniformity, with special attention given to the implementation of the spelling checker algorithm (Algorithm 1).
During the labeling process, we conducted a comprehensive evaluation of the spelling checker algorithm to assess its ability to identify and correct spelling errors in the labeled data. To ensure accurate and effective performance, the algorithm was thoughtfully configured with two specific thresholds, denoted as
The dataset was then labeled using the
The application of the spelling checker algorithm significantly improved the accuracy of the labeled data, providing greater confidence in the overall performance of our information extraction models. However, it is crucial to emphasize that the spelling checker was not the sole determinant of the final corrected word. After the algorithm performed its correction, a secondary verification step was carried out by human agents responsible for reviewing and validating the corrected words. This manual validation ensured that the final corrected words aligned contextually with the intended meaning in the car damage reports, adding an extra layer of scrutiny to guarantee accuracy and reliability.
Experimental setup:
For evaluating the effectiveness of our information extraction approach, we divided the labeled dataset into training and testing sets for both NER and RE tasks. The training set constituted 80% of the dataset, while the testing set accounted for the remaining 20%. The experiments were conducted on a machine equipped with 16 GB RAM and an Intel Core i7-12700H processor, ensuring sufficient computational resources for training and testing our models.

Distribution of entities and relations in the labeled dataset.
Our aim is to extract entities from automotive damage reports. Specifically, we focused on extracting six types of entities:
As discussed in Section 3, we used word context as our feature, which comprises a window of two words on either side of the current word and the current word itself. In addition to this, we also extracted the part-of-speech (POS) context feature, which includes a window of two POS tags on either side of the current word and the current tag itself. The relevance of these features was determined through a RFE method. The extracted features were subsequently organized into a list of dictionaries, with each dictionary representing the features of a specific entity. To ensure consistency and fairness in our experimentation, we kept the same features for all models.
NER model hyperparameters
Hyperparameters are crucial settings that influence the behavior and performance of NER models. All of these hyperparameters were fine-tuned through experimentation to achieve optimal performance on our NER task.
In the
NER model evaluation
After training our models with the aforementioned hyperparameters, we evaluated their performance on a separate test set. We used
We calculated these evaluation metrics as follows:
Comparative results of NER models. The highest precision
ner
(P
ner
), recall
ner
(R
ner
) and F1-score
ner
(F1
ner
) are in bold
Comparative results of NER models. The highest precision ner (P ner ), recall ner (R ner ) and F1-score ner (F1 ner ) are in bold
Table 4 shows how different models performed when they were tested on various entity types such as
Overall, the table suggests that the
Once we had extracted the entities, we used ML algorithms to identify the relations between them. Specifically, we aimed to extract four types of relation:
The
The
The
The
RE model hyperparameters
The hyperparameters for ML models for RE were carefully selected through a grid search approach. We experimented with different combinations of hyperparameters for each model to determine the optimal values that yield the best performance on our dataset. After evaluating various options, we found the following hyperparameters to be optimal for each model: For SVM, we selected the radial basis kernel function (
RE model evaluation
In relation extraction, the performance of the model is also evaluated using precision
re
(P
re
), recall
re
(R
re
), and the F1-score
re
(F1
re
). The formulas for calculating precision
re
, recall
re
, and F1-score
re
are as follows:
Table 5 presents the results of four models, SVM, KNN, DT, and RF, for relation extraction using baseline features that include all distances and word features. The results show that the performance of the models varies based on the type of relationship.
The DT and RF models exhibit consistently good performance across all relation types, achieving the highest F1-score for all relations.
The SVM model shows good performance in terms of precision for the
The KNN model shows a consistent, average performance across all relation types, with F1-score of 0.75 for the
However, incorporating additional features can potentially improve the performance of the models, as demonstrated in Table 6.
Comparative results of models for relation extraction using baseline features (all distances & word features). The highest precision
re
(P
re
), recall
re
(R
re
) and F1-score
re
(F1
re
) are in bold
Comparative results of models for relation extraction using baseline features (all distances & word features). The highest precision re (P re ), recall re (R re ) and F1-score re (F1 re ) are in bold
Table 6 presents the results of a comparative analysis of the performance of different feature sets in relation extraction using the random forest algorithm. The table is divided into three main parts. The first part illustrates the performance of the baseline features, which include all distances and word features. The second part shows the performance of the baseline features along with Nous avons soulevé plsueirs, specifically
In terms of the baseline features, the table shows that the best results were obtained using the features that included all word distance features.
The second part of the table shows that adding embedding features
Finally, the third part of the table shows that the best performance was achieved when using the baseline features and ontology reasoning described in Section 3.2.3, as it achieved the highest F1-score for three out of the four relation types, indicating its superiority in enhancing the quality of the extracted relations. By leveraging the capabilities of the ontology, we were able to reduce redundancy, resolve conflicts, and minimize false positives and false negatives in the extracted relations.
Comparative results of the best features for relation extraction using random forest algorithm. The highest precision (P re ), recall (R re ) and F1-score re (F1 re ) are in bold

FP re and FN re relation extraction with and without ontology-reasoning.
The plot (Fig. 7) illustrates the number of false positives, indicating the count of incorrectly extracted relations, and false negatives, representing the number of relations that should have been extracted but were missed by the model. This analysis was conducted for different relations, with and without the use of ontology reasoning. The right subplot, which uses ontology reasoning, exhibits a substantial decrease in both FP
re
and FN
re
when compared to the left subplot, which does not employ ontology reasoning. These findings suggest that integrating ontology reasoning into the model can significantly enhance its capacity to identify the correct relations, as demonstrated in Fig. 8. This figure in question contains text written in French. Here is the English translation of the text: “Rear door heavily scratched, and the front right door dented”. The NER model successfully extracts all the entities correctly.
Despite the significant improvement brought about by incorporating ontology reasoning, some false positives and false negatives still exist, representing less than

Comparison of entity recognition and relation extraction with and without ontology reasoning.
The experiment results demonstrate the effectiveness of our information extraction approach for automotive damage reports. We used the
We created the

Information extraction: entity recognition and relation extraction in complex scenarios.
In this section, we present an illustrative example that demonstrates the step-by-step process of each module. The example covers the entire workflow, from the preprocessing of car damage reports to the final population of the
Consider the following car damage report (French report in Fig. 10): “Volvo XC60 damage found are:
front and rear bumpers broken and perforated
right front and right rear door with deep scratches
right front and right rear wing with deep scratches and impact to paintwork
front right fog lights broken
right-hand door mirror broken.”
The first step is

Spelling checker.
The second step, in
The relationships between these entities are also extracted. For instance, the
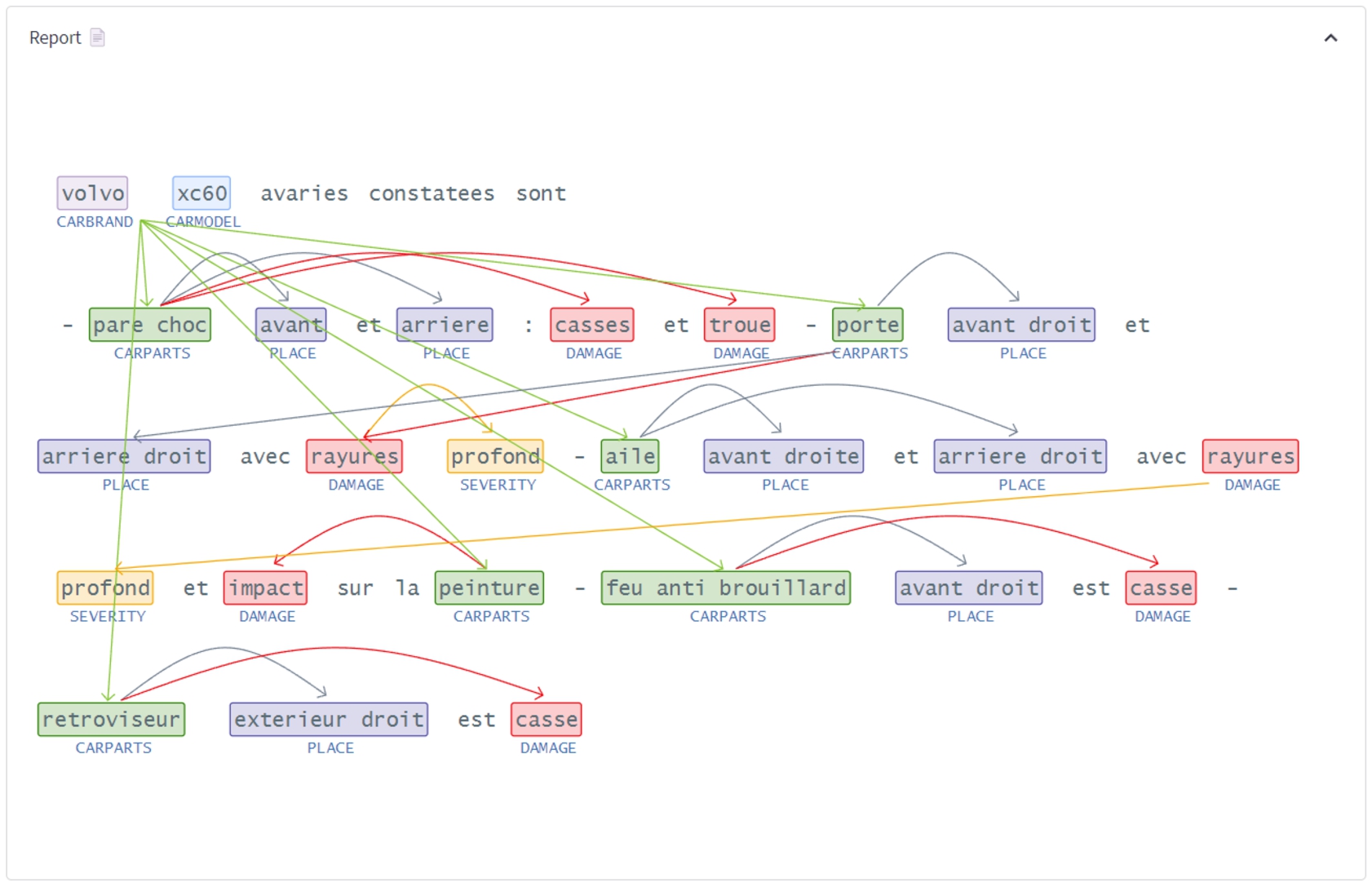
Extraction of entities and relations.
The next step is,
Regarding the linking of entities and handling possible ambiguities, the population process ensures that entities with the same name or meaning are linked to the same resource in the ontology. For example,
In scenarios where a single “
For n-Ary relationships, we decompose these complex relationships into multiple binary relationships. As illustrated in the provided example, let’s consider the entities
The relation “
In cases where various possible candidates can be linked to the same entity, we prioritize the entities with a higher probability of belonging to the entity based on the NER model score. Additionally, the ontology reasoning module plays a crucial role in making accurate decisions. By applying logical inferences and considering the ontology’s structure, the reasoning process ensures that the correct entities and relationships are linked together.
After the initial population of the ontology, we then leverage the power of ontology reasoning techniques in the second step. The ontology reasoning engine applies logical inferences and deductions based on the ontology’s axioms, relationships, and rules. This reasoning step helps to enhance the information extraction process and improve the accuracy of the extracted entities and relationships.
In

Instantiation of extracted information from car damage report into the
In conclusion, the development of the
Future research can focus on the expansion and refinement of the
Footnotes
Acknowledgements
This work is supported by both the company
Online resources
The supplementary online material supports the comprehension and reproduction of this study. It includes: an OWL file representing the ontology (