A famous result due to Ko and Friedman (Theoretical Computer Science20 (1982) 323–352) asserts that the problems of integration and maximisation of a univariate real function are computationally hard in a well-defined sense. Yet, both functionals are routinely computed at great speed in practice.
We aim to resolve this apparent paradox by studying classes of functions which can be feasibly integrated and maximised, together with representations for these classes of functions which encode the information which is necessary to uniformly compute integral and maximum in polynomial time. The theoretical framework for this is the second-order complexity theory for operators in analysis which was introduced by Kawamura and Cook (ACM Transactions on Computation Theory4(2) (2012) 5).
The representations we study are based on approximation by polynomials, piecewise polynomials, and rational functions. We compare these representations with respect to polytime reducibility.
We show that the representation based on approximation by piecewise polynomials is polytime equivalent to the representation based on approximation by rational functions.
With this representation, all terms in a certain language, which is expressive enough to contain the maximum and integral of most functions of practical interest, can be evaluated in polynomial time. By contrast, both the representation based on polynomial approximation and the standard representation based on function evaluation, which implicitly underlies the Ko-Friedman result, require exponential time to evaluate certain terms in this language.
We confirm our theoretical results by an implementation in Haskell, which provides some evidence that second-order polynomial time computability is similarly closely tied with practical feasibility as its first-order counterpart.
Consider the integration and maximisation functionals on the space of univariate continuous functions over the compact interval :
Both functionals constitute fundamental basic operations in numerical mathematics. They are considered to be easy to compute for functions that occur in practice. It was hence surprising that when Ko and Friedman [10] introduced a rigorous formalisation of computational complexity in real analysis and analysed the computational complexity of these functionals within this model, they found that both problems are computationally hard in a well-defined sense. They constructed an infinitely differentiable polytime computable function such that the function is again polytime computable if and only if and an infinitely differentiable polytime computable function such that the function is again polytime computable if and only if . Moreover, the real number is polytime computable if and only if , and the number is again polytime computable if and only if .
This obvious discrepancy between practical observations and theoretical predictions deserves further discussion. We will focus on two possible explanations for this observation:
Accuracy of results. Hardness in the theoretical results refers to how hard it is to compute the values of the function to an arbitrary accuracy. An algorithm for computing a real number takes as input a natural number n, encoded in unary, and outputs an approximation to x to n bits of accuracy. An algorithm for computing a real function f takes as input a real number x, encoded as an oracle which maps accuracy requirements to approximations, and a natural number n, encoded in unary, and is required to output an approximation to to n bits of accuracy. The running time of the algorithm is a function of n which measures the number of steps the algorithm takes. By contrast, practitioners usually work at a fixed floating-point precision, which implies a fixed maximum accuracy. It hence may not be justified to measure the complexity in the output accuracy, and other complexity parameters should be considered more important. In fact, if one relaxes the definition of polytime computability such that in both the definition of real number computation and real function computation the requirement that the approximation be correct to n bits of accuracy is relaxed to the requirement that the approximation be close to the true value, then the range and integral of every polytime computable function are polytime computable. So maybe the theoretical infeasibility of these functionals is an artefact of poorly chosen normalisation.
Representation of functions. Theoreticians use a simple representation (which we call Fun) that treats all continuous functions equally, in the sense that a function is polynomial time computable if and only if it has a polynomial time computable Fun-name. Practitioners, on the other hand, tend to work on a much more restricted class of functions. They tend to work with functions which are given symbolically or which can be approximated well by certain kinds of (piece-wise) polynomial or rational functions. As not every polynomial time computable function can be approximated by polynomials or rational functions in polynomial time, the implicit underlying representations favour a certain class of functions, for which it is easier to compute integral and range.
The aim of this paper is to discuss these different explanations both from a theoretical and a practical perspective and to resolve the apparent contradiction between the theoretical hardness results and practical observations. To this end we study the computational complexity of the maximisation and integration functionals with respect to various representations of continuous real functions within the uniform framework of second-order complexity theory, introduced by Kawamura and Cook [6,7], and compare the practical performance of algorithms which use these representations on a small family of benchmark problems.
Classes of feasibly approximable functions. The complexity of integration and maximisation of univariate real-valued functions has been studied by various authors: Müller [15] showed that if f is a polytime analytic function, then the function is again polytime (and analytic), and the function is again polytime (but not differentiable in general). This result was generalised by Labhalla, Lombardi, and Moutai [12] to the strictly larger class of polytime functions in Gevrey’s hierarchy, a class of infinitely differentiable functions whose derivatives satisfy certain growth conditions. These functions are characterised in [12] as those functions which can be approximated by a polynomial time computable fast converging Cauchy sequence of polynomials with dyadic rational coefficients. It is also shown that integral and maximum of a function are uniformly polytime computable from such a sequence. These results were strengthened and refined in various ways by Kawamura, Müller, Rösnick, and Ziegler [8] who studied the uniform complexity of maximisation and integration for analytic functions and functions in Gevrey’s hierarchy in dependence on certain parameters which control the growth of the derivatives or the proximity of singularities in the complex plane.
While these results already show that maximisation and integration are polytime computable for a large class of practically relevant functions, there are many practically relevant functions which are not contained in the class of infinitely differentiable functions with well-behaved derivatives:
For applications in control theory it is often necessary to work with functions which are constructed from smooth functions by means of pointwise minimisation or maximisation, and thus differentiability is usually lost.
It is not difficult to show that the class of polytime computable functions in Gevrey’s hierarchy is not uniformly polytime computably closed (with respect to the representation introduced in [8]) under division by functions which are uniformly bounded by 1 from below (see the Appendix for a proof).
Also, while for any polytime computable f in Gevrey’s hierarchy, the function is again polytime computable, it is in general no longer smooth. Thus, assuming , the question arises whether is easy to maximise and, more generally, whether every function which is obtained from a polytime computable function in Gevrey’s hierarchy by repeatedly applying the parametric maximisation operator is polytime computable.
One of our main contributions is to identify a larger class of feasibly approximable functions which supports polytime integration and maximisation and is closed under a larger set of operations, including division and pairwise and parametric maximisation.
Compositional evaluation strategies. In practice, functions of interest are usually constructed from a small set of (typically analytic) basic functions by means of certain algebraic operations, such as arithmetic operations, taking primitives, or taking pointwise maxima. In other words, most functions of practical interest can be expressed symbolically as terms in a certain language. Our main observation is that there is such a language which is rich enough to arguably contain the majority of functions of practical interest, yet restrictive enough to ensure that all functions which are expressible in this language admit uniformly polytime computable integral, maximum, and evaluation.
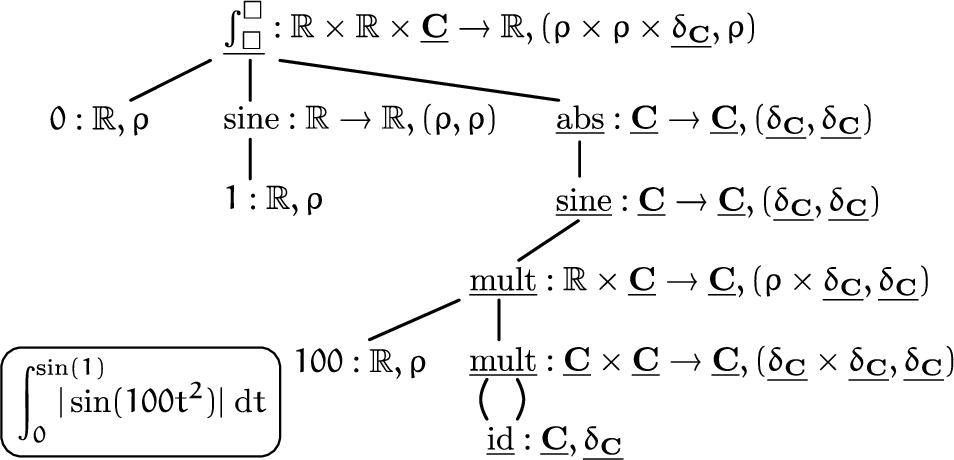
To make this claim precise, we introduce the notion of “compositional evaluation strategy” for a structure Σ. To motivate this notion, consider how a user might specify a computational problem involving real numbers and functions (see also Fig. 1). We assume that the user specifies the problem symbolically as a term in a certain language and that the end result will be a real number which is expected to be produced to a certain accuracy. A library for exact real computation will translate the symbolic representation of the inputs into some internal representation, the details of which will be irrelevant to the user. It will operate on the internal representations — usually in a modular, compositional manner — to eventually produce a name of a real number in the standard representation, which can be queried for approximations to an arbitrary accuracy. Thus, there are certain types, such as real numbers in this example, whose representation is relevant to the user, as the user is interested in querying information about them according to a certain protocol, and other types, such as real functions in this example, which are only used internally and whose internal representation can be freely chosen by the library.
Evaluating the term as a real number. The output is represented in the standard representation ρ of real numbers. The underlined type of real functions is used for internal computations only and its representation can be freely chosen by the library.
The structures Σ we consider consist of:
Fixed spaces: A class of topological spaces with a given representation. These kinds of spaces correspond to the kinds of objects which are to be used, among other things, as inputs and outputs, so that the kind of information we can obtain on them is fixed.
Free spaces: A class of topological spaces without any given representation. These kinds of spaces correspond to the types of intermediate results, whose internal representation is irrelevant to the user.
A set of constants and operations on these spaces.
A compositional evaluation strategy provides representations for the free spaces in Σ and algorithms, in terms of these representations, for all constants and operations in Σ. It allows us to evaluate a term in the signature of Σ by applying the algorithms in a compositional manner. Compositional evaluation can be contrasted with evaluation that involves processing whole terms, for example, symbolic differentiation.
We say that a compositional evaluation strategy is polytime if it evaluates every term of fixed space type whose free variables are all of fixed space type in polynomial time. Hence the resource usage of a strategy is measured only in terms of those representations that are relevant to the user.
Any representation of a space X offers a trade-off between the ability to construct names efficiently and the ability to extract information from names efficiently. If α and β are representations of some space X with α reducing to β in polynomial time, then any function that is polytime when X is represented by β is also polytime when X is represented by α. Dually, any function that is polytime when X is represented by α is also polytime when X is represented by β. In other words: the higher a representation sits in the reducibility lattice, the fewer functionals and the more points become polytime computable with respect to this representation. However, the task of evaluating symbolic expressions in a modular manner will usually involve functions of “symmetric” type or , such as algebraic operations or closure operations on X. In general, if α reduces in polynomial time to β but not vice versa, then neither does polytime computability of a function with respect to α imply polytime computability with respect to β nor vice versa. Thus, polytime reducibility does not allow us to measure how well a given representation trades off the ability to construct names with the ability to extract information from names. On the other hand, the study of compositional evaluation strategies will allow us to compare the trade-offs that are offered by different representations.
Results. We study various representations of the space based on polynomial and rational approximations and their relationships in terms of polytime reducibility. We show that the representation based on rational approximations is polytime equivalent to the representation based on piecewise polynomial approximations (Corollary 22). This result helps us prove that the class of functions which are representable by polynomial time computable fast converging Cauchy sequences of piecewise polynomials is uniformly closed under a set of operations which are typically used in computing to construct more complicated functions from simpler ones.
In particular, we give a compositional evaluation strategy that uses the representation based on approximation by piecewise polynomials which evaluates in polynomial time all terms of a structure whose constants are the polytime computable functions in Gevrey’s hierarchy and whose operations include evaluation, range computation, integration, arithmetic operations (including division), pointwise and parametric maximisation, anti-differentiation, composition, and square roots.
We observe that no compositional evaluation strategy that uses the representations based on polynomial approximation, piecewise affine approximation, or black-box function evaluation can evaluate this structure in polynomial time. This suggests that when it comes to computing with certain functions of practical interest, the representation based on piecewise polynomial approximations offers a better trade-off between the ability to construct names efficiently and the ability to extract information from names efficiently than other commonly considered representations.
Implementation. Whilst in the discrete setting the link between polytime computability and practical feasibility is – up to the usual caveats – well established and confirmed by countless examples of practical implementations, to our knowledge, little to no work has been done to link the somewhat more controversial model of second order complexity in analysis with practical implementation. Thus, in order to demonstrate the relevance of our theoretical results to practical computation, we have implemented compositional evaluation strategies based on the aforementioned representations for a small fragment of the aforementioned structure within AERN2, a Haskell library for exact real number computation. We observed that for the most part the benchmark results fit our theoretical predictions quite well. Our separation results translate to big differences in practical performance, which can be observed even for moderate accuracies.
This suggests that the latter of the two explanations offered on page 2 is more applicable: The infeasibility of maximisation and integration with respect to the “standard representation” of real functions is not a mere accuracy normalisation issue, and the differences between theoretical predictions and practical observations are really due to the choice of representation. The proofs which establish polytime computability translate to algorithms which seem to be practically feasible, at least up to some common sense optimisations.
The computational model
Here we briefly review the basic aspects of the theory of computation with continuous data in the tradition of computable analysis, as well as the basics of second-order complexity theory. For background on computability in analysis see e.g., [17–19,21]. Second-order computational complexity for computable analysis was developed in [7], building on ideas from [9,10].
Let . Let denote the set of all finite binary strings. Let denote Baire space.1
In computable analysis it is more common to use the computably isomorphic space of functions on the natural numbers, but this choice is of course inconsequential.
A partial function is called computable if there exists an oracle Turing machine M which on input with oracle computes . Sometimes, to emphasize the distinction, we will refer to u as the “input string” and to p as the “input oracle” to M.
A represented space consists of a set X together with a partial surjection called the representation. We will usually write X for if is clear from the context. A partial multi-valued function between represented spaces and is just a relation on the underlying sets. We write and . If and are partial multi-valued functions, then their composition is the partial multi-valued function with and . If and are represented spaces, and is a partial multi-valued function, we call a realiser of f if and for all . The map f is called computable if it has a computable realiser. The composition of computable partial multi-valued functions is again computable. If X carries a topology τ then is called admissible for τ if is continuous and every continuous map factors through δ via some continuous , i.e., . One can show that if X and Y are represented spaces and their respective representations are admissible for topologies on X and Y, then a partial function is sequentially continuous with respect to these representations if and only if it is computable relative to some oracle. It was shown by Matthias Schröder [19,20] that the class of represented spaces which admit an admissible representation are precisely the -spaces: quotients of countably based spaces. The spaces with (sequentially) continuous total functions form a Cartesian closed category. For further details see [19].
Let us now turn to computational complexity, following the ideas of Kawamura and Cook [7]. A string function is called length-monotone if
for all . If φ is a length-monotone function, we define its size via
Note that length-monotonicity implies that whenever , which justifies the seemingly arbitrary choice of the string in the definition of the size. Let denote the set of length-monotone string functions. Note that there is a computable retraction of onto , so that computability theory remains unaffected by replacing with . Thus, a mapping is computable if there is an oracle Turing machine which on input oracle , and input string outputs . The mapping f is computable in time, if there is such a machine which outputs within time .
We now introduce the class of “feasibly computable functions” within this setting. The set of second-order polynomials is defined inductively as follows:
The “free variable” X and the “constant” 1 are second-order polynomials.
If P and Q are second-order polynomials then so are their sum , their product , and the term .
A second-order polynomial P defines a map which is inductively defined as follows:
.
.
We will from now on just write P both for the second-order polynomial P and the induced map .
A partial mapping is called polytime computable if is computable in time for some second-order polynomial P. The class of total second-order polytime computable functions coincides with the class of basic feasible functionals [5,13,14].
These notions translate to represented spaces in the usual way: A point x in a represented space is polytime computable if and only if it has a polytime computable name. A partial multi-valued function is polytime computable if and only if it has a polytime computable -realiser. It is often convenient to express the assertion that a function is polytime computable by saying that the value is uniformly polytime computable in x. The composition of polytime computable functions is again a polytime computable function. If X is a represented space with representations and we say that reduces to in polynomial time and write if the identity on X is polytime -computable. If and then we say that and are polytime equivalent and write .
We will need to introduce canonical representations of finite products. Let be a finite family of representations where . Our goal is to define the product representation Encode the numbers in binary with a fixed number of digits () and denote the resulting strings by . Let be length-monotone functions for . Let
Define the length-monotone function
Extend this function to all of by letting , where ε denotes the empty string, if and , if and was not previously defined. Now define the representation as follows:
Finally, let us give some concrete examples of represented spaces that we will use in the rest of the paper. Countable discrete spaces such as the space of natural numbers , the space of dyadic rationals , or the space of rationals are represented via standard numberings, e.g., . By identifying with , we can view such numberings as maps , which allows us to introduce representations such as , where . As a more interesting example, consider the space of real numbers. Let with and . Using the canonical product construction, we obtain a representation of .
When working with a compact space, one can restrict its representation to a compact subset of , removing the need for second-order complexity bounds. Let us illustrate this in the case of the compact unit interval . Using a suitable encoding of dyadic numbers we can find for every real number x a dyadic approximation of x to error which uses at most bits. Hence, the interval admits a representation with .
It is worth noting that we can restrict ρ in a similar way to obtain a representation of all of , where every name of is bounded by , so that we can bound the running time of an algorithm in terms of the output accuracy and the single number alone, without having to resort to general second-order bounds.
In contrast, the use of genuine second-order bounds cannot be avoided with spaces that are not σ-compact, such as , the focus of this work.
Representations of
In this section we introduce a number of commonly used representations of the space of continuous functions over the interval and study their relation in the polytime-reducibility lattice. Most of these representations and their relationships have been studied already by Labhalla, Lombardi, and Moutai [12], albeit in a slightly different framework. Nevertheless, many proofs from [12] carry over easily to our chosen framework. The main new result is the equivalence of rational- and piecewise-polynomial approximations, which is left as an open question in [12].
Most of the representations we study are so-called Cauchy representations, where an element of a metric space is represented by a fast converging Cauchy sequence of elements from a countable dense subset. To spell it out explicitly:
Let X be a separable metric space. Let be a countable dense subset of X. Let be a numbering of A. Then the Cauchy representation of X induced by is the representation of X where a length-monotone string function is a name of if and only if for all we have .
We define representations Poly, PPoly, Frac, PFrac, PAff, and Fun of the space of continuous functions over the interval as follows:
A Fun-name of a function is a length-monotone string function such that encodes a sampling of f on dyadic rational points and encodes a modulus of uniform continuity of f. More explicitly, we require
where denotes a standard pairing function on binary strings, and for all :
A Poly-name of a function is a fast converging Cauchy sequence of polynomials in the monomial basis with dyadic rational coefficients. More formally, fix a standard numbering of the polynomials with dyadic rational coefficients. The representation Poly is the Cauchy representation induced by .
A piecewise polynomial with dyadic rational breakpoints and coefficients is a continuous function such that there exist dyadic rational numbers such that is a polynomial with dyadic rational coefficients. A PPoly-name of a function is a fast converging Cauchy sequence of piecewise polynomials in the monomial basis with dyadic rational breakpoints and coefficients. More formally, fix a standard numbering of the piecewise polynomials with dyadic breakpoints and coefficients and let PPoly be the Cauchy representation of induced by this numbering.
A PAff-name of a function is a fast converging Cauchy sequence of piecewise affine functions with dyadic breakpoints and coefficients. Piecewise affine functions are defined analogously to piecewise polynomials. More formally, fix a standard numbering of the piecewise affine functions with dyadic breakpoints and coefficients and let PAff be the Cauchy representation of induced by this numbering.
A Frac-name of a function is a fast converging Cauchy sequence of rational functions with dyadic coefficients. A rational function is a quotient of two polynomials whose denominator has no zeroes in . We choose our notation such that every such rational function is given as a quotient of two polynomials which is normalised such that for all . More formally, fix a standard numbering of the rational functions with dyadic coefficients and let Frac be the Cauchy representation of induced by this numbering.
A PFrac-name of a function is a fast converging Cauchy sequence of piecewise rational functions with dyadic breakpoints and coefficients. Piecewise rational functions are defined analogously to piecewise polynomials and piecewise affine functions. We again require that the denominator of every rational function be bounded from below by 1. More formally, fix a standard numbering of the piecewise rational functions with dyadic breakpoints and coefficients and let PFrac be the Cauchy representation of induced by this numbering.
The representation Fun is the most efficient representation which renders evaluation computable, in the sense that it satisfies the following universal property:
The following are equivalent for a representation of continuous functions:
Evaluationis polynomial-time-computable.
.
It is easy to see that evaluation is polytime computable with respect to Fun. Hence, if , then evaluation is polytime computable with respect to δ. Conversely, assume that δ renders evaluation polytime computable. Given a δ-name of a function f we can clearly evaluate f on dyadic rational points in polynomial time, which yields “half” a Fun-name of f. It remains to show that a modulus of continuity of f can be uniformly computed in polynomial time. Since δ renders evaluation polytime computable there exists a second-order polynomial P which bounds the running time of some algorithm which computes eval. Since is compact, we can assume that the running time of the algorithm on input , where , , is bounded by the function (since the size of ξ can be bounded independently of ξ, cf. Remark 1). Since this function bounds the running time of a -algorithm which computes , it follows that is a modulus of continuity of f. As φ is length-monotone we have , so that this modulus of continuity is uniformly polytime computable in the name φ. □
Letbe a continuous function. Then f has a polytime computable realiser if and only if it has a polytime computable Fun-name.
On the other hand, the representation PPoly is interesting since it allows for maximisation and integration in polynomial time. The following result is folklore, see e.g., [1, Algorithm 10.4]:
There exists a polytime algorithm which takes as input a non-constant dyadic polynomial, a rational number, and an accuracy requirementand outputs a list of disjoint intervalssuch that
Every interval contains a solution to the equation.
Every solution to the equationis contained in some interval.
Every interval has diameter.
The operatorsandwhere, are uniformly polytime computable with respect to PPoly.
The proof is very elementary but requires a fair amount of easy but cumbersome quantitative estimates of the size of the objects involved in the construction. We will therefore only sketch the main ideas behind the proof.
All three claims easily reduce to the claim that the respective operation is computable in polynomial time when the input is a dyadic polynomial and the output is a fast converging Cauchy sequence of dyadic piecewise polynomials.
To compute paramax for a given polynomial f on an interval , first use Theorem 6 to compute a sufficiently good approximation of the set of critical points of f in . Use this to find a list of points meeting the following three conditions: Every is close to either a critical point or a boundary point, we have the inequalities , and satisfies .
On the open interval the equation has either no solution, e.g., if is a saddle point, or exactly one solution, e.g., if is a local minimum. We can use Theorem 6 to find out in polynomial time which is the case, and in case there is a solution, compute this solution in polynomial time to arbitrary accuracy. Put if there is no solution, and if there is a solution, let be a sufficiently good approximation to this solution. We then have an ascending sequence of points
On the intervals of the form a good approximation of is given by the constant function . On the intervals of the form a good approximation of is given by f.
The computation of the pointwise maximum of two polynomials reduces to the problem of solving the equation to sufficient accuracy.
To avoid case distinctions involving boundary points, it is easiest to compute a piecewise polynomial approximation to on all of . Given two dyadic polynomials P and Q, use Theorem 6 to compute intervals that enclose the solutions to the equation on to sufficient accuracy.
Then, by construction, on all intervals of the form either P is strictly larger than Q or Q is strictly larger than P. We can decide which of these is the case by comparing and . This yields a polynomial approximation to on all intervals of the form . An analogous argument yields a polynomial approximation on the intervals and .
It remains to compute an approximation on intervals of the form . We have already computed a polynomial approximation f to on and another polynomial approximation g to on . On , let the approximation be the linear interpolation of the values in and in . If is sufficiently small, then P and Q will be very close on , so that this yields a good approximation.
The polytime computability of join is established using similar ideas. □
Our goal is to fully understand the relationship between the representations we have just introduced with respect to polytime reducibility.
There exists a polytime algorithm which takes as input a piecewise rational function f (given by our standard numbering) and returns as output a Lipschitz constant of f.
If is a rational function with for all , then by the mean value theorem, a Lipschitz constant of f is given by a bound on over . Since it suffices to compute a bound on the absolute value of the polynomial . If then for all . This is clearly computable in polynomial time. If f is a piecewise rational function with pieces then a Lipschitz constant for f is given by the maximum of the Lipschitz constants of the ’s. □
We have,, and.
The reductions , , and are immediate. It hence suffices to show . We will use the universal property of Fun (Proposition 4) to do so, i.e., it suffices to prove that a piecewise rational function can be evaluated in a point in polynomial time.
Suppose we are given a piecewise rational function f with dyadic breakpoints and coefficients, a point encoded as a ρ-name and an accuracy requirement . By Proposition 8 we can compute a Lipschitz constant L of f in polynomial time. Query the ρ-name of x for a dyadic rational approximation to error . We can determine an interval with and with in polynomial time. Now, a dyadic rational approximation to error of is computable in polynomial time. We have
□
The proof of Theorem 10 given in [12] relies mainly on Newman’s theorem [16] on the rational approximability of the absolute value function. To establish lower bounds in the reducibility lattice we need to employ Markov’s inequality. For a proof of Markov’s inequality see e.g., [3].
(Markov’s inequality).
Let P be a polynomial of degreeon the interval. ThenOn the intervalwe hence have
We haveand.
The absolute value function is trivially polytime PAff-computable. By Markov’s inequality, it is not polytime Poly-computable: Assume that is a sequence of polynomials such that for all . Then on the interval we have and on the interval we have . Let denote the degree of . Applying Markov’s inequality to the polynomial on the interval yields:
Applying the inequality to on yields:
If then this implies that converges to 1 and at the same time, which is absurd. It follows that the size of grows exponentially in n. In particular, cannot be polytime computable.
For the converse direction we show that the polynomial does not have a polynomial size PAff-name. Consider a piecewise linear approximation L to to error with breakpoints and values . We have , and hence for all :
We may hence assume without loss of generality that . Consider a segment . We have
Now, there exists a segment with . It follows that . □
Together with a result which is proved in the next section (Corollary 22), we arrive at a complete overview of the reducibility lattice:
The following diagram shows all reductions between the representations introduced, up to taking the transitive closure:
No arrow reverses unless indicated.
Proposition 9 establishes the more obvious reductions. Proposition 12 implies that PPoly does not reduce to either PAff or Poly, for any such reduction would establish a reduction from Poly to PAff or vice versa. The reduction follows immediately from . The converse is Corollary 22 in Section 4. To see that , consider the family of functions . It is clearly uniformly polytime Fun-computable in n, but not uniformly polytime Frac-computable: Any approximation to the function on to error has at least zeroes, so that any rational approximation to this error has a numerator of degree at least . □
The class of polytime computable points with respect to the representation Poly has a useful analytic characterisation which was proved by Labhalla, Lombardi, and Moutai [12] and strengthened by Kawamura, Müller, Rösnick, and Ziegler [8]. For , , and let
denote the set of Gevrey’s [4] functions of level γ with growth parameters B and ℓ. Note that corresponds to the class of analytic functions. The results in [8,12] imply in particular that the above hierarchy collapses on for all fixed B, ℓ, and γ:
([8,12]).
Let B, ℓ, and γ be fixed. Onwe have
It suffices to show that . Given a Fun-name of a function , compute a polynomial approximation via Chebyshev interpolation. Since the Chebyshev interpolation is a near-best approximation and f can be approximated efficiently by polynomials, the number of nodes we need in order to compute a polynomial approximation to error is bounded polynomially in n. Since we know the constants B, ℓ, and γ, we can choose the right number of nodes in advance. See [8, Proposition 21 (e), Theorem 23 (b)] for details. Also note that the proof in [8] establishes a much stronger uniform result, where B, ℓ, γ are not fixed but given as part of the input. □
Letfor some positive constants B, ℓ, γ. Then f is polytime computable if and only if it has a polytime computable Poly-name.
Bounded division for piecewise polynomials
We now establish the reduction by giving a polytime division algorithm for piecewise polynomials. The algorithm will first compute a linear interpolation of the divisor and then employ an iteration to improve the approximation. As we cannot evaluate the divisor to infinite precision, we have to use the following notion: Let be a continuous function. Let . A linear ε-interpolation of f at is a piecewise linear function L with breakpoints which satisfies .
(Bounded division).
Input: A non-constant polynomial with on . An accuracy requirement .
Output: A piecewise polynomial approximation to on to error .
Procedure:
Compute a Lipschitz constant ℓ of P using Proposition 8 and use it to compute an upper bound on the range of P of the form for some .
Use Theorem 6 to compute interval upper bounds on the solutions to the equations
to error . By this we mean a list of intervals such that each interval contains a solution, each solution is contained in an interval, and each interval has diameter at most .
Sort the intervals together with the boundary points (viewed as degenerate intervals) in ascending order to get a list
If two intervals should overlap, refine them such that they are either disjoint or their union has diameter smaller than . In the latter case replace them with their union.
Compute a linear -interpolation of at the centres of the intervals.
Let .
For :
Put .
Output .
The iteration employed in Algorithm 16 is the well-known Newton-Raphson division method.
While, by Lemma 20 below, Algorithm 16 already runs in polynomial time, its practical performance can be improved significantly by employing, within the iteration, size-reduction techniques such as degree reduction and sweeping, maintaining rigorous error bounds.
The resource usage of Algorithm 16 is mainly dominated by the multiplication of polynomials with potentially large degree within the Newton-Raphson iteration. While the degrees can sometimes be kept small by the aforementioned size-reduction techniques, there are practical instances of the problem where the degrees grow quite large, resulting in poor practical performance, despite the algorithm being polytime. For more details, see Section 7.
If is any non-constant polynomial with on , we can apply Algorithm 16 to and use it to compute an approximation to . If we know that , without knowing a bound, we can use Corollary 7 to find a lower bound , but since we need to witness that b is above 0, the complexity depends additionally on .
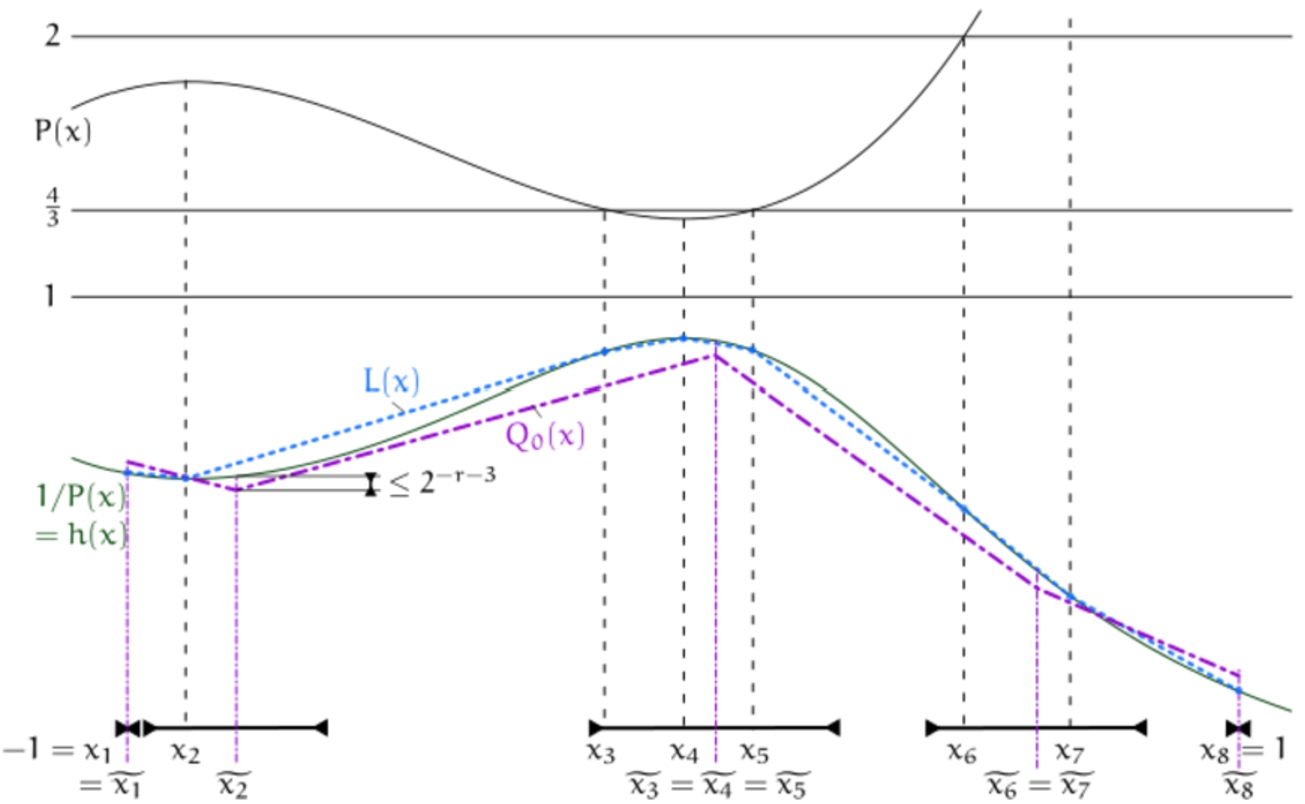
Overview of the notation used in the correctness proof of Algorithm 16 (Lemma 18).
Let be the union of the boundary points and the zeroes of , sorted in an increasing order, so that is monotone on each interval . On , let
be the solutions of the equations and , where , together with the boundary points. Let
denote the ’s, sorted in an increasing order. Let L be the linear interpolation of in the ’s. See Fig. 2 for a graphical overview of the notation used in this proof.
The proof relies on the following two inequalities:
Claim 1: for all .
Claim 2: for all .
We prove by induction on k the inequality for all . The base case is established by combining the above claims using the triangle inequality. The induction step is given below:
Using the definition we obtain which finishes the proof.
Proof of Claim 1. We claim that for all . Consider an interval of the form . Since is monotone on the interval, we have
If and are inner points of the interval then there are four cases:
, . We have:
Since P is monotonically increasing, we have:
, . We have:
Since P is monotonically decreasing, we have:
, . We have:
Since P is monotonically increasing, we have:
, . We have:
Since P is monotonically decreasing, we have:
The cases where or is a boundary point are treated similarly.
Proof of Claim 2. We claim that for all . By construction every is contained in some interval which is computed by Algorithm 16. Conversely every interval contains some . Let denote the centre of the interval which contains . Note that different ’s could yield equal ’s.
As both L and are piecewise linear, the distance attains its maximum in one of the ’s or one of the ’s.
Let us introduce some notation to improve the readability of the following estimates. Write . Write for the distance between and . Write for the distance between and .
We find:
The last line uses that r is by definition an upper bound on . The estimate of the second factor in the third-to-last line uses the fact that any Lipschitz constant for h is also a Lipschitz constant for L. Note that since P is bounded by 1 from below, any Lipschitz constant for P on is also a Lipschitz constant for on .
To estimate we need to find a bound on the Lipschitz constant of . As is piecewise linear, it suffices to compute a number satisfying
for all i.
If then any non-negative will do. Hence let us assume that . Then by construction . We calculate:
We now obtain:
□
Let us now show that Algorithm 16 runs in polynomial time. The following lemma ensures that the initial approximation can be computed in polynomial time:
There exists a polytime algorithm which takes as input a Fun-name of a function, a list of points, and an error bound, and returns as output a linear ε-interpolation of f at.
The size of the Lipschitz constant ℓ of P is bounded polynomially in the degree and the size of its coefficients. The bound on the range can be given as . Hence there are only polynomially many equations to solve, and since the algorithm in Theorem 6 runs in polynomial time, the overall complexity of the construction of the initial approximation is polynomial. In particular, the number of segments of is polynomial in the size of P. The degree of the approximation is , so the degree of the approximation is in , which is polynomial in the size of P and n. The number of segments does not change during the iteration.
It remains to estimate the size of the coefficients. For a polynomial A, encoded as a list of dyadic rational numbers in standard notation, let denote the number of terms of A, i.e., , and let (by abuse of notation) denote the bit-size of the coefficients of the given encoding of A. Let and . We have . If A and B are polynomials then , so that
and hence
it follows by induction that
Hence we have:
which is polynomial in and n. □
By applying Algorithm 16 piece-by-piece we obtain:
Suppose we are given a fast converging sequence of rational functions which converge to , normalised such that on . Apply Algorithm 16 to obtain a piecewise polynomial approximation to to error . Then the sequence is a fast converging sequence of piecewise polynomials with limit f, in other words, a PPoly-name of f. □
We also obtain a corollary on the complexity of integrating rationally approximable functions, which is not immediately obvious:
The integration functionalis uniformly-polytime computable.
Compositional evaluation strategies
In this section we introduce the notion of compositional evaluation strategy over an algebraic structure Σ. This will allow us to state our main result on the existence of a modular polytime algorithm for evaluating all sufficiently simple symbolic expressions which involve maximisation or integration.
For a class of spaces C, let denote the class of all finite and countable products of members of C, i.e., a space A belongs to if and only if it is of the form or with being members of C.
Consider structures of the form
where
Fix is a set of represented spaces , containing at least the space of natural numbers with the standard representation induced by the binary notation.
Free is a set of represented spaces.
Op is a set of partial multi-valued operations of the form where .
Const is a subset of the disjoint union of all spaces in .
The set Fix is called the set of fixed spaces, the set Free is called the set of free spaces, the set Op is called the set of operations and the set Const is called the set of constants. An operation of the type will be called an -ary operation. An -ary operation will also be called an n-ary operation for short.
A constant where will be called a constant of type X and we write . For every we introduce a countable set of free variables of type X. A term over the signature of Σ is defined inductively as follows:
Every free variable of type X is a term of type X.
Every constant of type X is a term of type X.
If and are terms, then is a term of type .
If is a term of type X with a free variable n of type then is a term of type .
If is a term and is an operation, then is a term of type Y.
A term is called closed if it contains no free variables. We denote the set of closed terms of Σ by . If is a closed term we denote by the set of elements of X which it represents under the obvious semantics.2
The application of a partial operation could lead to the semantics of a term to be undefined. It is however straightforward to define (inductively) what it means for a term to be well-defined, and we will henceforth assume that all terms are well-defined.
A term is called semi-closed if it contains no free variables of free space type. We denote the set of semi-closed terms of Σ by . If are the free variables in t, then on the semantic side t defines a partial operation
Suppose we are given a structure Σ. A compositional evaluation strategy for Σ consists of:
For every free space X of Σ a representation .
For each operation of Σ an algorithm which computes a -realiser of f.
For each constant of Σ an algorithm which computes a -name of x.
A compositional evaluation strategy S defines a map
which sends a closed term of type X to a point with . We define the running time of S on t
as the time it takes to compute using the compositional evaluation strategy. The map extends to a map
which sends a semi-closed term to a realiser of the operation . The running time of S on – if it exists – is then the smallest second-order function
such that is a bound on the time it takes to compute using S. We say that a strategy S is polytime if it evaluates every semi-closed term of Σ of fixed space type in polynomial time.
It should be noted that a strategy being polytime does not imply that the running time of the strategy grows polynomially in the size of the term it is evaluating. For example, consider the structure , where is the squaring operation. This structure can be evaluated in polynomial time. However, when evaluating the term
to an accuracy of 1 bit, the running time of any compositional evaluation strategy for this structure grows super-exponentially in n.
On the complexity of integration and maximisation for common functions
Consider the structure
where Const is the disjoint union of all polytime computable real numbers and all polytime computable functions in Gevrey’s hierarchy and Op consists of the following operations:
, .
, .
, .
, .
, , where
, .
, , where
, .
, .
where .
, .
, .
Note in particular that Σ allows us to express the integral as
and the maximum as
The structure Σ arguably contains most univariate functions on a compact interval that are used in practical computing, as it contains the polytime analytic functions and all commonly available closure operations.
There exists a compositional evaluation strategy for Σ, using PPoly to represent the space, that runs in polynomial time.
Let f be a polytime computable function in Gevrey’s hierarchy. Then f has a polytime computable Fun-name by Proposition 4. It follows from Theorem 14 that f has a polytime computable PPoly-name.
It remains to show that the operations listed above are polytime computable with respect to PPoly. Polytime computability of the first four operations is obvious. Polytime computability of div is proved in Theorem 21. Polytime computability of composition is easily established for Frac, which is polytime equivalent to PPoly by Corollary 22. The polytime computability of , follows from Newman’s Theorem [16] on the rational approximability of the square root (see [12] for details) in conjunction with the polytime computability of division and the polytime computability of composition. The polytime computability of max, paramax, and join is established in Corollary 7. The polytime computability of primit is elementary. The polytime computability of eval is established in Proposition 9. □
Theorem 24 can be taken as evidence that there are no “natural” functions whose integral and maximum are difficult to compute.
There is no evaluation strategy which uses the representations Poly, PAff, or Fun which evaluates Σ in polynomial time.
Consider the problem of computing the integral which can be expressed by the term of Σ.
Any correct algorithm that sends a Fun name of a function f to a Cauchy name of the real number has to query its input function at least times, where is the modulus of continuity provided by the Fun name of f, to produce an approximation to error . A fortiori any compositional evaluation strategy using Fun requires running time at least when evaluating the term to error . This shows that no compositional evaluation strategy using Fun evaluates Σ in polynomial time.
Any correct algorithm that sends a Poly name of a function f to a Cauchy name of the real number has to query its input for a polynomial approximation to f to error at least in order to compute an approximation to the output to error . But it was shown in the proof of Proposition 12 that the size of any sequence of polynomial approximations to grows exponentially in the accuracy of the approximation. This shows that no compositional evaluation strategy using Poly evaluates Σ in polynomial time.
To show the analogous claim for the representation PAff consider the term which represents the number and use that, by the proof of Proposition 12, any PAff name of grows exponentially. □
Compare Theorems 24 and 25 with Theorem 13. By Theorem 13 there is a strict linear chain of polytime reductions
Intuitively this says that among the three representations Poly contains the greatest amount of information about a function while Fun contains the least, with PPoly being somewhere in the middle. By Theorem 25 and its proof, the representation Poly contains too much information to evaluate all terms of the structure Σ in polynomial time, as it does not render sufficiently many points of polytime computable. By contrast, the representation Fun contains too little information to evaluate all terms of Σ in polynomial time, as it does not render sufficiently many functionals on polytime computable.
By Theorem 24 and its proof, the representation PPoly does evaluate all terms of Σ in polynomial time, which can be intuitively interpreted as saying that PPoly contains just the right amount of information to evaluate Σ efficiently.
Experiments
We describe a set of experiments we conducted to gauge the practical efficiency of the representations Fun, Poly, PPoly, Frac as well as some more efficient variants:
BFun represents a function by , where is the discrete space of intervals with dyadic rational endpoints, such that for each .
DBFun represents a continuously differentiable function f by a pair F, where F is a BFun name of f and is a BFun name of .
“Local” representation LPoly that represents f by a dependent-type function F that maps each to a Poly-name of . Representations LPPoly and LFrac are defined analogously.
The representation BFun is the standard representation of continuous functions in interval analysis. Our benchmarks confirm that it is much more efficient than Fun from a practical perspective. The main reason why we use Fun instead of BFun in our theoretical considerations is that BFun is not a well-behaved representation from the point of view of second-order complexity, as the size function of a name does not provide sufficient information on the “complexity” of that name. In fact, it is easy to show that every computable function has a polytime computable BFun-name. On the other hand, the use of Fun is justified by Proposition 4. We consider DBFun, although it is not a representation of continuous functions, because it alleviates one of the disadvantages that Fun and BFun have compared to polynomial-based representations, namely the in-ability to utilise the potential smoothness of f. The “local” representations are polytime equivalent to their “global” counterparts, so that we did not have to consider them in the theoretical part of this paper. However, it is obvious that they offer a great practical advantage, as it would be wasteful to compute an approximation over the whole interval when only a local approximation over a small interval is needed.
For each representation, we implemented a calculator for the following task:
Input:
A real function given as a symbolic expression over a signature with the functions , and pointwise sine, cosine, maximum, and field operations
Output:
or encoded as a fast converging Cauchy sequence
Note that the input and output are independent of the chosen function representation. Thus all the calculators have the same “user interface”.
The input expressions are evaluated bottom-up using an evaluation strategy based on the chosen representation. E.g., on input the Poly-calculator constructs a polynomial approximation of and feeds this approximation again to the same implementation of sine that produces a polynomial approximation of . The calculators do not attempt to simplify, differentiate or otherwise symbolically manipulate the given expression.
In other words, we implement compositional evaluation strategies for the structure
based on the different representations. Theorems 24 and 25 suggest that representations based on PPoly will perform best in our benchmarks. In particular, they should perform better than representations based on Fun for almost any function. They should also perform better than representations based on Poly for non-smooth functions. Our experimental findings confirm this for the majority of functions we have considered.
Implementation
Due to space constraints we describe only the most significant aspects of our implementation. We describe it in more detail in the technical paper [11]. The source code3
is available online. It should be emphasized that our implementation is not designed to outperform practical algorithms for integration and range computation, but to provide a common framework to offer a fair comparison of different algorithmic approaches. Our implementation framework is not optimised for speed, and, with the exception of DBFun, we do not exploit any information about the derivatives of our functions, which in practice makes an enormous difference.
Fun representations. Most operations over Fun, BFun and DBFun are implemented in a straightforward manner ball/point-wise. Range maximum and integration are implemented using bisection. The target accuracy of integration is raised by 1 bit with each domain bisection. Integration bisection ends when the area of the “box” enclosing the function over the segment is below the target accuracy. The maximisation algorithm employs a simple branch and bound method to prune away intervals where the maximum is not attained. The derivative available in DBFun is used solely to improve the interval extension of f using the formula .
Polynomial representations. Polynomials are represented primarily sparsely in the Chebyshev basis over with dyadic coefficients. Any terms that are smaller than the current accuracy target are sweeped away, i.e., removed and their size added to the error radius. The choice of the Chebyshev basis is motivated by the fact that this sweeping procedure works well in the Chebyshev basis, but not in the monomial basis. While our theoretical results are formulated with respect to the monomial basis, it is straightforward to verify that the translations between the Chebyshev basis and the monomial basis are computable in polynomial time. The range maximisation algorithm combines the root counting techniques described in Chapter 10 of [1] with a branch and bound method similar to the one employed in the maximisation algorithm for BFun. It temporarily translates the polynomials to a dense representation in the monomial basis with integer coefficients.
Poly division, pointwise maximisation, and for very large polynomials also multiplication, is computed using an interval version of Chebyshev interpolation for analytic functions via the encoding of discrete cosine transform (DCT) from [2].
PPoly division is described in Section 4. PPoly, Frac, and local representations use essentially the same algorithm as Poly for range maximisation. Frac integration is computed via a translation to PPoly.
The local representations delegate integration to their non-local counterparts over the equidistant partition of the domain into n segments where n is the target accuracy.4
i.e., the required error bound is .
Benchmarks and results
The benchmarks have been compiled using ghc-7.10.3 with -O2 and executed on a Lenovo T440p laptop with 16 GB RAM, Intel(R) Core(TM) i7-4710MQ CPU @ 2.50 GHz running Ubuntu 14.04.
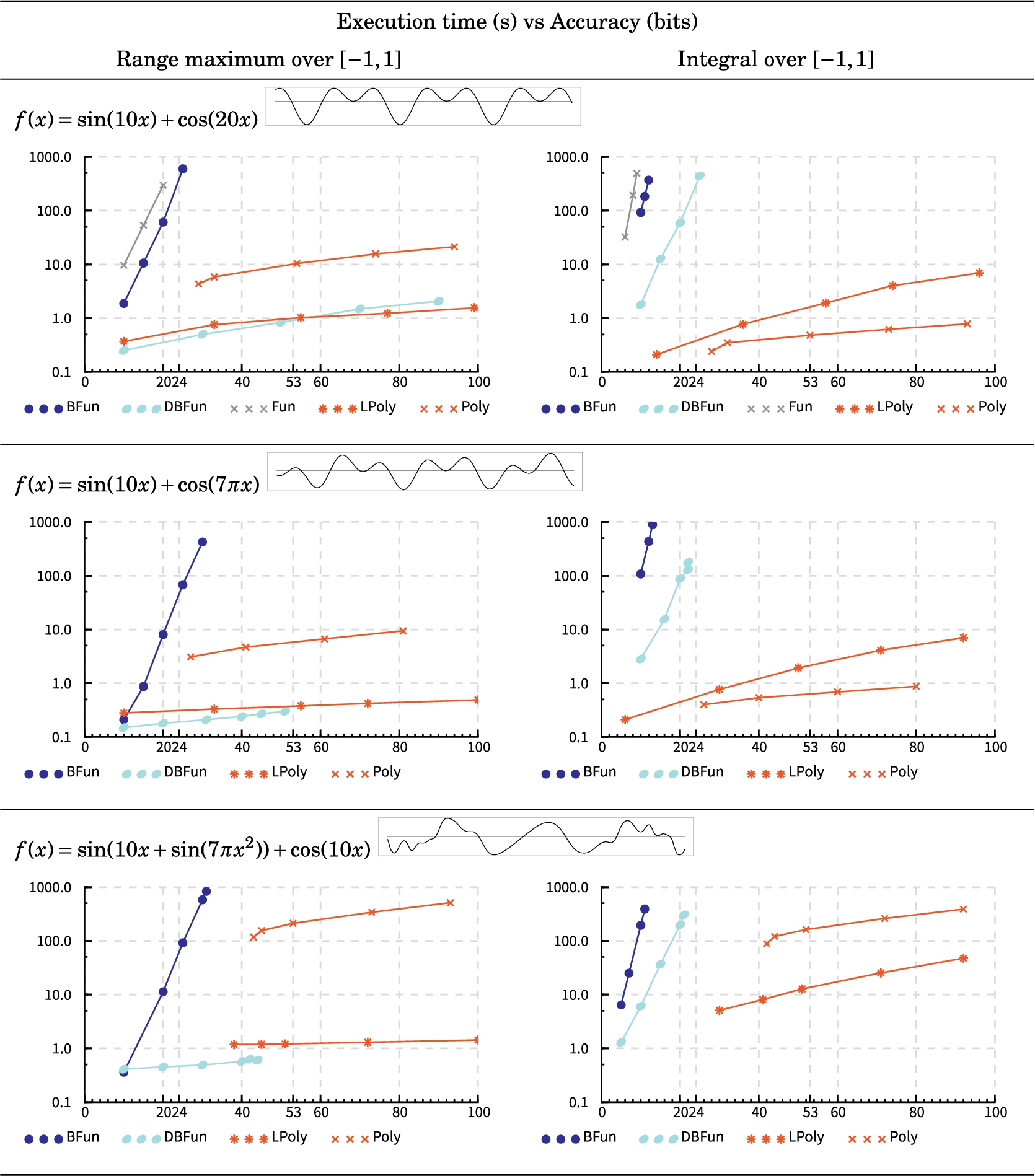
Well-behaved analytic functions. First, consider the functions in Fig. 3 that are analytic on the whole complex plane. As the charts are linear-logarithmic, exponential maps show as straight lines and a polynomial maps show as logarithmic curves.
We have not included timings for representations PPoly, Frac, LPPoly and LFrac in Fig. 3 because for these expressions our implementations of PPoly and Frac compute identical approximations as our implementation of Poly.
Measurements for analytic functions without nearby singularities.
Fun performed so poorly that we struggled to get any points within the constraints of our charts. Therefore we applied it on the first and simplest function only.
DBFun has computed the range of much more efficiently than the range of . This indicates that DBFun maximisation is very sensitive to the quality of the interval extension of f. We expect that BFun is also sometimes similarly sensitive although we have not observed it in our benchmarks.
These examples confirm our prediction that range and integral for these kinds of functions are much more efficient to compute via polynomial approximations than simply via Fun representations. Moreover, localisation seems to help when functions are defined by a nested application of elementary functions.
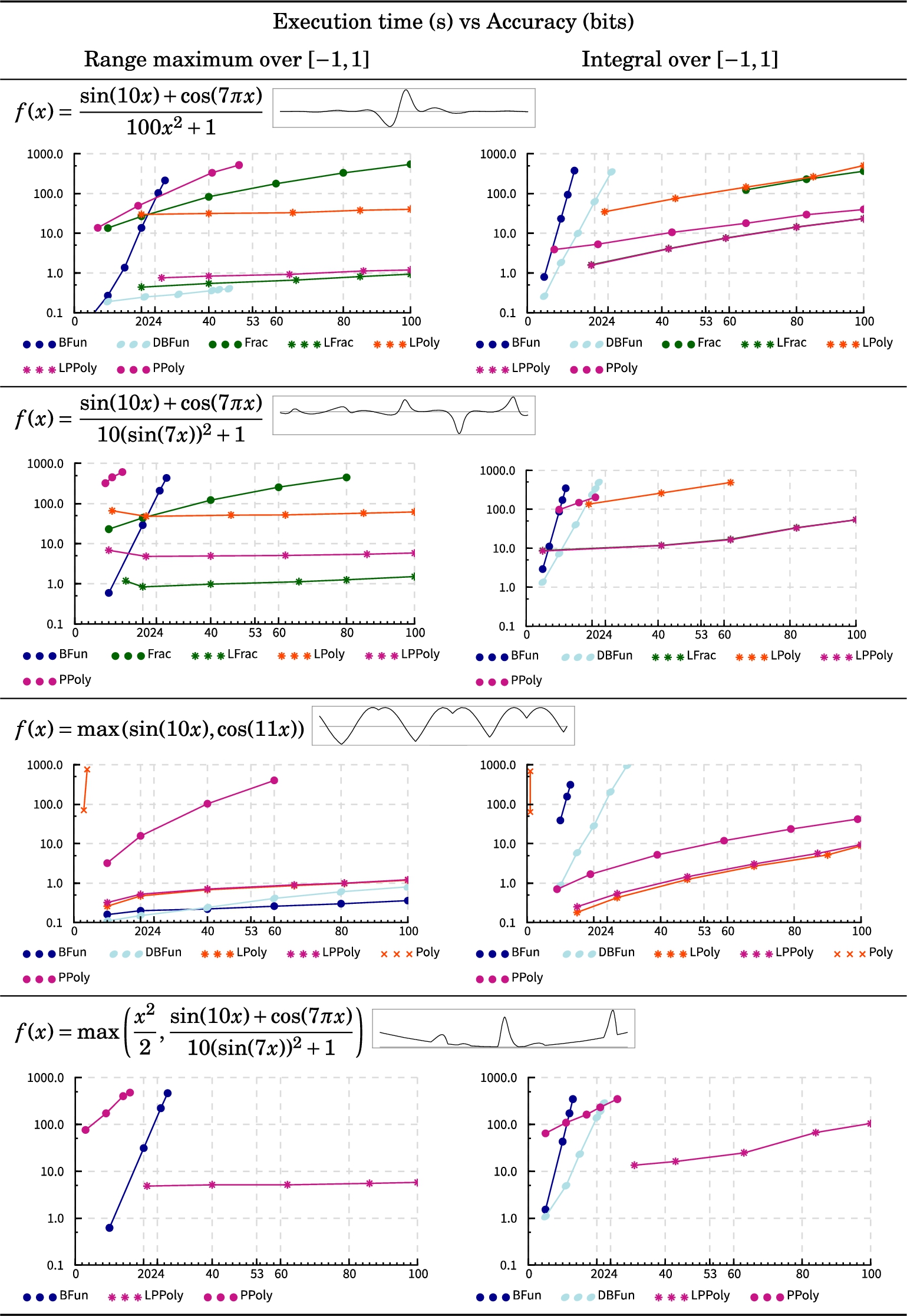
Functions with division and pointwise maximum.
Measurements for functions with division and max.
The first two functions in Fig. 4 are variants of the Runge family of functions, which have singularities in the complex plane near our domain . It is shown in the proof of Theorem 27 that the degree of any polynomial approximation to the function to error is polynomial in n but exponential in . Thus, these functions are expected to be difficult to approximate by polynomials even for moderately large values of a. This turns out to be the case in our implementation, separating the performance of Poly from that of PPoly and Frac. Still, PPoly performs quite poorly for both functions, which suggests that while our division algorithm runs in polynomial time, it cannot be considered practically feasible. However, the local version LPPoly performs very well on both examples. The Fun representations seem to perform with an exponential or worse time complexity, which is in line with our complexity results.
The last two functions in Fig. 4 are non-smooth and thus cannot be efficiently approximated by polynomials. The simpler of these two function is easily handled by the Fun representations because there is no dependency error, as x appears in the expression effectively only once over each point in the domain. As predicted, Poly cannot cope with these functions but its local version performs acceptably for the simpler function. In theory, Frac should be able to approximate non-smooth functions as well as PPoly, but we have not yet found an efficient algorithm for this.
Note that DBFun does better for the last function in Fig. 4 than for the very similar function without max. This again points to an element of luck due to a high sensitivity of the Fun representations to the quality of the interval extension of f. The local representations have consistently outperformed their global counterparts, and while the representation PPoly did quite poorly on some inputs, its local version performed reasonably well overall.
Footnotes
Acknowledgements
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 731143.
On the uniform complexity of division for functions in Gevrey’s hierarchy
In this appendix we prove the claim made in the introduction that bounded division is not polytime computable with respect to the representation for functions in Gevrey’s hierarchy that is implicit in [8].
An infinitely differentiable function belongs to Gevrey’s hierarchy if and only if there exist positive constants B, ℓ and γ such that for all and all we have:
The following definition is essentially due to Kawamura, Müller, Rösnick, and Ziegler [8]. While the use of explicit representations is avoided throughout [8], the following is implicit in [8, Definition 22 (a)].
The encodings for the integer constants in Definition 26 are chosen such that a polytime algorithm on the space of Gevrey functions is required to run in polylogarithmic time in B, in polynomial time in ℓ, and in exponential time in γ. This convention ensures that [8, Theorem 23] translates to a result on second-order polytime computability on the represented space of Gevrey functions. One should note that a different representation of the space of Gevrey functions is implicitly given in [8, Definition 22 (b)], but it is polytime equivalent to the above by virtue of [8, Theorem 23 (a) and (b)].
References
1.
S.Basu, R.Pollack and M.-F.Roy, Algorithms in Real Algebraic Geometry, Springer-Verlag, New York, 2006.
2.
G.Baszenski and M.Tasche, Fast polynomial multiplication and convolutions related to the discrete cosine transform, Linear Algebra and its Applications252(1–3) (1997), 1–25. doi:10.1016/0024-3795(95)00696-6.
3.
E.W.Cheney, Introduction to Approximation Theory, AMS Chelsea, 1966.
4.
M.Gevrey, Sur la nature analytique des solutions des équations aux dérivées partielles. Premier mémoire, Annales scientifiques de l’École Normale Supérieure35(3) (1918), 129–190. doi:10.24033/asens.706.
5.
B.M.Kapron and S.A.Cook, A new characterization of type-2 feasibility, SIAM J. Comput.25(1) (1996), 117–132. doi:10.1137/S0097539794263452.
6.
A.Kawamura and S.A.Cook, Complexity theory for operators in analysis, in: Proceedings of the 42nd ACM Symposium on Theory of Computing (STOC 2010), 2010, pp. 495–502.
7.
A.Kawamura and S.A.Cook, Complexity theory for operators in analysis, ACM Transactions on Computation Theory4(2) (2012), 5. doi:10.1145/2189778.2189780.
8.
A.Kawamura, N.Müller, C.Rösnick and M.Ziegler, Computational benefit of smoothness: Parameterized bit-complexity of numerical operators on analytic functions and Gevrey’s hierarchy, Journal of Complexity31(5) (2015), 689–714. doi:10.1016/j.jco.2015.05.001.
9.
K.-I.Ko, Complexity Theory of Real Functions, Birkhäuser, 1991.
10.
K.-I.Ko and H.Friedman, Computational complexity of real functions, Theoretical Computer Science20 (1982), 323–352. doi:10.1016/S0304-3975(82)80003-0.
11.
M.Konečný and E.Neumann, Implementing evaluation strategies for continuous real functions, 2019, CoRR abs/1910.04891.
12.
S.Labhalla, H.Lombardi and E.Moutai, Espaces métriques rationnellement présentés et complexité, le cas de l’espace des fonctions réelles uniformément continues sur un intervalle compact, Theoretical Computer Science250 (2001), 265–332. doi:10.1016/S0304-3975(99)00139-5.
13.
B.Lambov, The basic feasible functionals in computable analysis, Journal of Complexity22(6) (2006), 909–917. doi:10.1016/j.jco.2006.06.005.
14.
K.Mehlhorn, Polynomial and abstract subrecursive classes, in: Proceedings of the Sixth Annual ACM Symposium on Theory of Computing, STOC’74, ACM, New York, NY, USA, 1974, pp. 96–109. doi:10.1145/800119.803890.
15.
N.T.Müller, Uniform computational complexity of Taylor series, in: Automata, Languages and Programming, Lecture Notes in Computer Science, Vol. 267, Springer, 1987, pp. 435–444. doi:10.1007/3-540-18088-5_37.