
Abstract
The current article statistically analyzes several PRNG for well-known high-speed stream ciphers. The study focuses on frequency detection, uniformity distribution alongside with randomization in the generated sequence. The purpose of this work is to show if there is a signature left by these PRNG in theirs produced sequence. In addition, the work compares these PRNG to indicate which is the safest against statistical cryptanalysis.
Keywords
Introduction
The common symmetric ciphers used today are in fact block ciphers which uses iterations of a deterministic algorithm that operates on plaintext bits of fixed length – known as block – at a time. Each iteration is called round and uses a different subkey created from the primary key of encryption. There have been numerous operating modes developed for block cipher in order to allow authenticity and confidentiality while some modes also provides the padding for the plaintext block. Padding the plaintext block is simply adding bits to the plaintext block in cases where plaintext bits are shorter than the block size. It should be noted that block ciphers have also been used in Pseudo-Random Number Generators “PRNG” and universal hash functions. Today’s most Famous Block Ciphers can be found gathered in [1].
On the other hand, a stream cipher, takes plaintext characters (1 bit or byte) at a time and XOR them with the pseudo-random bits to get the output. The infinite pseudo-random bits actually refer to the key that is known as the keystream. The keystream is normally created using the initial encryption key – called the seed – by the PRNGs. To remain secure, PRNGs should be unpredictable in stream cipher. In addition, stream ciphers should not use the same keystream twice, otherwise the cipher may be broken. The aim of designing stream cipher was to approach the idealistic cipher, known as the One-Time Pad.
The One-Time Pad, which is supposed to use a purely random key that is longer than plaintext, can potentially reach “the perfect secret”, that is, the total safe against brute force attacks. Nevertheless, such a cipher would be too impractical to use, because if someone likes to encrypt and send a one-minute full HD video file to another, he would need a key of at least 144 megabytes in size (this size is calculated), that is to say, a key with 1,125 Gigabits of length.
General model of a synchronous stream cipher.
As appears the impractical use of a key that is longer than the plaintext, stream ciphers are far from the perfect secret. However, the key change per use makes them difficult to break. In fact, if the keystream sequence is at least as long as the plaintext being encrypted, i.e. the keystream is used once when encrypting the plaintext, before the seed is changed, then the block cipher in counter mode cannot be any more secure than the stream cipher. The vulnerabilities of the two is then the same, according to Albert Manfredi-Principal Engineer at Boeing Defense Systems.
Statistical cryptanalysis is an important tool in a cryptanalysis study. Even if a stream or bloc cipher is protected against today’s cryptanalysis attacks [2], the enormous amount of encrypted data can be seriously dangerous for any cipher if statistical bias has occurred.
In today’s communication, stream ciphers are widely used. Each human language contains a signature. The signature is actually the occurrence number of letter and the occurrence number of word used in the language. This signature can be easily computed due to quantization [3], i.e. the binary vector representing the analog signal for human voice is not infinite. Hence, the huge importance of a statistical analysis for stream ciphers.
Consequently, this paper investigates the behavior of several stream ciphers on statistical cryptanalysis attacks such as frequency analysis, the goodness-of-fit, the serial test, the runs test, the poker test and the autocorrelation test. Each stream cipher is directly related to the behavior of their pseudorandom number generator. The latter can easily be studied by encrypting a constant plaintext. Henceforth, the stream cipher studies are equivalent to pseudorandom generator studies. Moreover, this work do contain statistically comparison between stream ciphers based on some experiment and result discussions, so as to deduct the presence or the absence of weakness and safety level obtainable thru each cipher.
Stream ciphers create successive characters of key- streams based on their internal state. They are two types of stream ciphers.
–
If synchronization is lost during the process, some approaches are applied to resynchronize the two machines. Among these approaches, we have: the systematic use of various offsets until achieving the synchronization, or tagging the ciphertext with markers at set points.
In this schema, if synchronization is lost, i.e. there is a corrupted bit in the data stream transmitted between Bob and Alice, then a single bit will be corrupted in the recovered plaintext and the error does not affect the rest of the data stream. Consequently, this mode is very useful in case of high error rate in a communication. However, this scheme can be very susceptible to active attacks if a malicious attacker has access to the stream.
General model of a self-synchronizing stream cipher.
The encryption process of a synchronous stream cipher can be described by the Eq. (1):
where
–
The CTR mode of operation.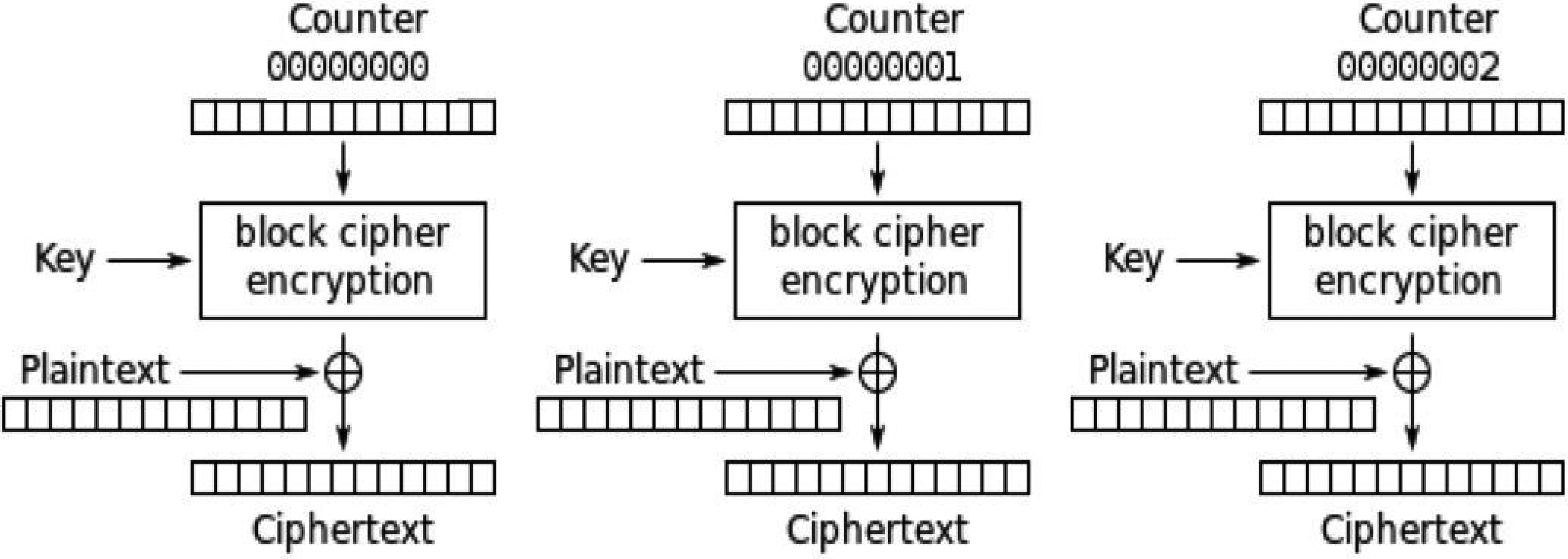
As example of self-synchronizing stream cipher, we have RC4 [6] or a block cipher that operates in CFB mode [7] (cipher feedback). Other ciphers that use this technique are A5/1 [8], A5/2 [9], Helix [10], ISAAC [11], MUGI [12], Phelix [13] …
The encryption function of a self-synchronizing stream cipher can be described by the Eq. (2):
where
Stream cipher differs from the block cipher design. This causes a difference in use. For instance, Block ciphers require more memory to save the master key, subkeys, plaintext block and often more data from previous blocks depending on the encryption mode [7], which can also associate confidentiality to the key integrity check. Whereas stream ciphers only work on a few bits at a time, they have relatively low memory requirements, i.e. more suitable to embedded devices, firmware …
Block ciphers are more susceptible to transmission noise, that is, if a bit is corrupted in the ciphertext, the rest of the block is probably unrecoverable. While stream ciphers encrypt bytes independently without connection to each other.
Stream ciphers are usually faster than block ciphers, but they are often less secure and subject to weaknesses based on usage, because of the very strict requirements for the keystream.
Stream ciphers do not provide integrity nor authentication, whereas some block ciphers can provide integrity in addition to confidentiality (depending on encryption mode). Because of all the above, stream ciphers are typically best for cases where the amount of data is either unknown, or continuous, such as network streams, radio mobile communication …While Block ciphers are more suitable when the amount of data is known or high secret, such as a file sharing, top-secret communication …
In this work, several high-speed stream ciphers are examined to observe the presence or absence of potential vulnerabilities to statistical analysis. The studied stream ciphers are ChaCha8/12/20 [14], HC128/ 256 [15, 16], Panama [17], Rabbit [18], RC4, Sosemanuk [19], Salsa20/XSalsa20 [20], SEAL [21] and WAKE [22]. Despite that RC4, SEAL and WAKE have been broken and are no longer secure, they are still used (e.g. RC4 is widely used in web encryption).
The OFB mode of operation.
It is still possible to create a PRNG using block cipher in a particular mode such as the output counter (CTR) and the FeedBack (OFB) [23].
In CTR mode, the output of the ith block is parameterized by the secret key K added (by XOR) to a counter ci (which usually takes the value i) (see Fig. 3).
In OFB mode, the block parameterized by the secret key K is assigned to an initial value (IV). The output corresponding to the block is added to the plaintext for encryption. Also, this output is used to provide the initial value (IV) of the next block (see Fig. 4).
These modes have been standardized for many years and make it possible to generate a keystream from a secret key and an initial value. The OFB mode was initially defined in FIPS 81 [24]; CTR mode has been added to the usual procedures in NIST’s special publication, NIST SP 800-38A [25]. Their specifications are included in the recent ISO/IEC10116 [26].
Normally, a PRNG constructs by a block cipher that resists to cryptanalysis attacks is often considered reasonably secure. However, theoretically, these block ciphers are not very strong because they are vulnerable to Distinguished Attack with a chosen initial value [23]. In CTR mode, the ith block of the sequence generated from the initial value IV is always equal to the ith block of the sequence generated from the initial value
Obviously, these properties facilitate the distinction of the keystream produced by each of these modes. This weakness has recently led to modifying each of these modes to provide a keystream that cannot be distinguished from a random sequence if the underlying block cipher has a similar property. The classification of the different types of PRNG is a delicate task. However, we can distinguish three major families [27] according to the type of function used by the PRNG:
Linear transition function: The use of a linear transition function is indeed a preferred choice because of the simplicity of its implementation. Among the linear transition functions, we have those that have been implemented using the linear feedback shift registers (LFSR) [28]. These are favored for the low cost of their hardware implementation in addition to the statistical properties alongside with the large period of their sequences produced. Among the stream ciphers using PRNGs based on LFSR, we have E0 deployed in the Bluetooth standard [29], A5/1 used to encrypt mobile communications in the GSM or SNOW 2.0 standard [30], which targets software applications.
Nonlinear transition function: To avoid weaknesses that may result from the linearity of the transition function, some designs favor a nonlinear function. However, the transition function must ensure that the internal states of the PRNG do not process a sequence of short periods, regardless of the value of their initial state. Unlike linear functions, it is relatively difficult to obtain such theoretical results for nonlinear functions. This difficulty can be circumvented if the size of the internal state of the generator is not limited by implementation constraints (unfortunately this is not the case), because it is very unlikely that an initial state generates a small period sequence if the internal state is large enough. The typical example of this is RC4. However, in hardware applications, size constraints dictate that the internal state of the generator is not too large, that is, the size should not exceed twice the length of the key. At present, we can mention some nonlinear LFSRs with holdbacks [31, 32] and LFSR with T-functions [33, 34].
Hybrid designs: In some PRNGs, the internal state is divided into two parts, one being updated by a linear function and the other by a nonlinear function. When the linearly advancing part is much larger, the PRNG is often classified as a linear transition generator with memory. This is the case of SNOW 2.0 and E0 for instance. However, there is an internal state for PRNG with a similar size of its linear and nonlinear parts, this category includes the MUGI generator designed by Hitachi as well as SNOW 2.0.
To resist a distinguish attack [35] the PRNG used by stream cipher must have good statistical properties. A classic criterion of security is that the output of the PRNG cannot be distinguished from a random sequence of cipher with cost less than 2
In strong PRNG, consecutive bits shall not easily help to predict the value of the next bit with a probability substantially distinct from 1/2 [36]. Note that a bias in the keystream sequence causes typically an information leaking on the plaintext. For instance, let denote
We know that
Knuth [39] and Golomb [40] have described the first statistical properties required for a pseudo-random sequence in the general context of a periodical series
In each period T, the numbers of 0 and 1 differ by no more than 1 (see Eq. (3)):
If we define a “run” by a group of identical values in the sequence (e.g. 111, 0000), a “block” by group of ones (e.g. 111, 11111) and a “Gap” by group of zeroes (e.g. 00, 0000). Then, half the runs have length 1, one-fourth have length 2, one-eight has length 3, etc., as long as the number of runs indicated exceeds 1. Moreover, for each of these lengths, there are equally many gaps and blocks. The out-of-phase autocorrelation
Many statistical tests has been established since Knuth and Golomb works. Today, we usually use the so-called statistical-test libraries. The most used libraries is NIST test-suites 800-22 [41], DIEHARD [42] and Crypt-XS [43].
Studying cryptanalysis cannot go past over statistical analysis [44, 45], because even if there is no connection between plaintext and ciphertext, statistical analysis and more specific frequency analysis can show to attacker important information. In this section, we examine our tested stream ciphers to observe the presence or the absence of a signature into theirs ciphertext that can lead to some useful data in plaintext. In this test, we analyze the frequency of character (letter) in English as language. Then, we evaluate each stream cipher PRNG from a statistical point of view and finally, we study the distribution of the encrypted characters based on the Chi-square statistical test, in order to have a global idea about the statistical resistance of each stream cipher.
Frequency analysis
With a long enough plaintext, each character occurs with a characteristic frequency. The most frequently used character in English is the letter E with a frequency of 12.7% followed by the letter T with a frequency of 9.1% [46] (see Table 1).
The frequency of letters in English (L denote the letter and F denote the frequency in%)
The frequency of letters in English (L denote the letter and F denote the frequency in%)
The percentage of each character in the plaintext.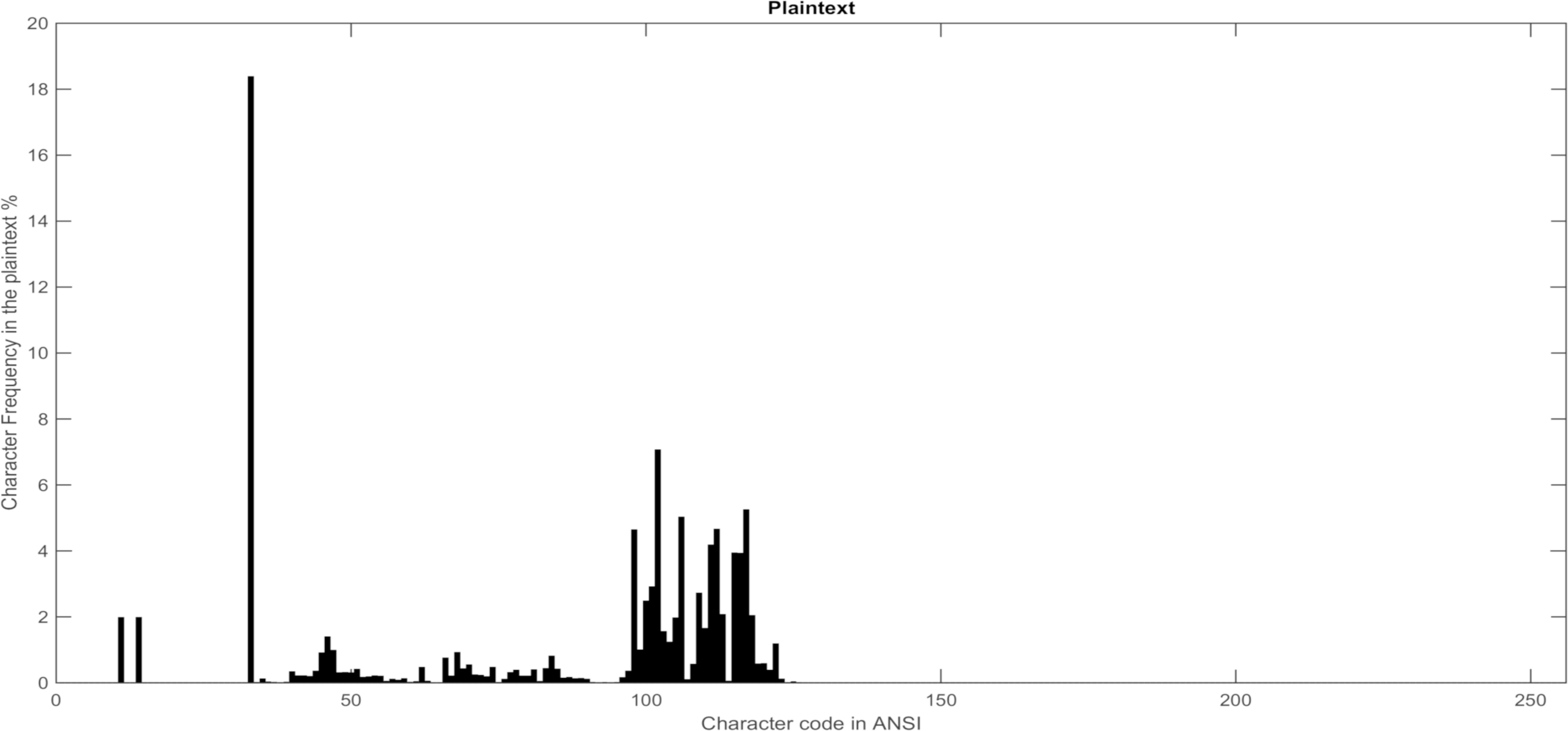
The percentage of each character in the ciphertext.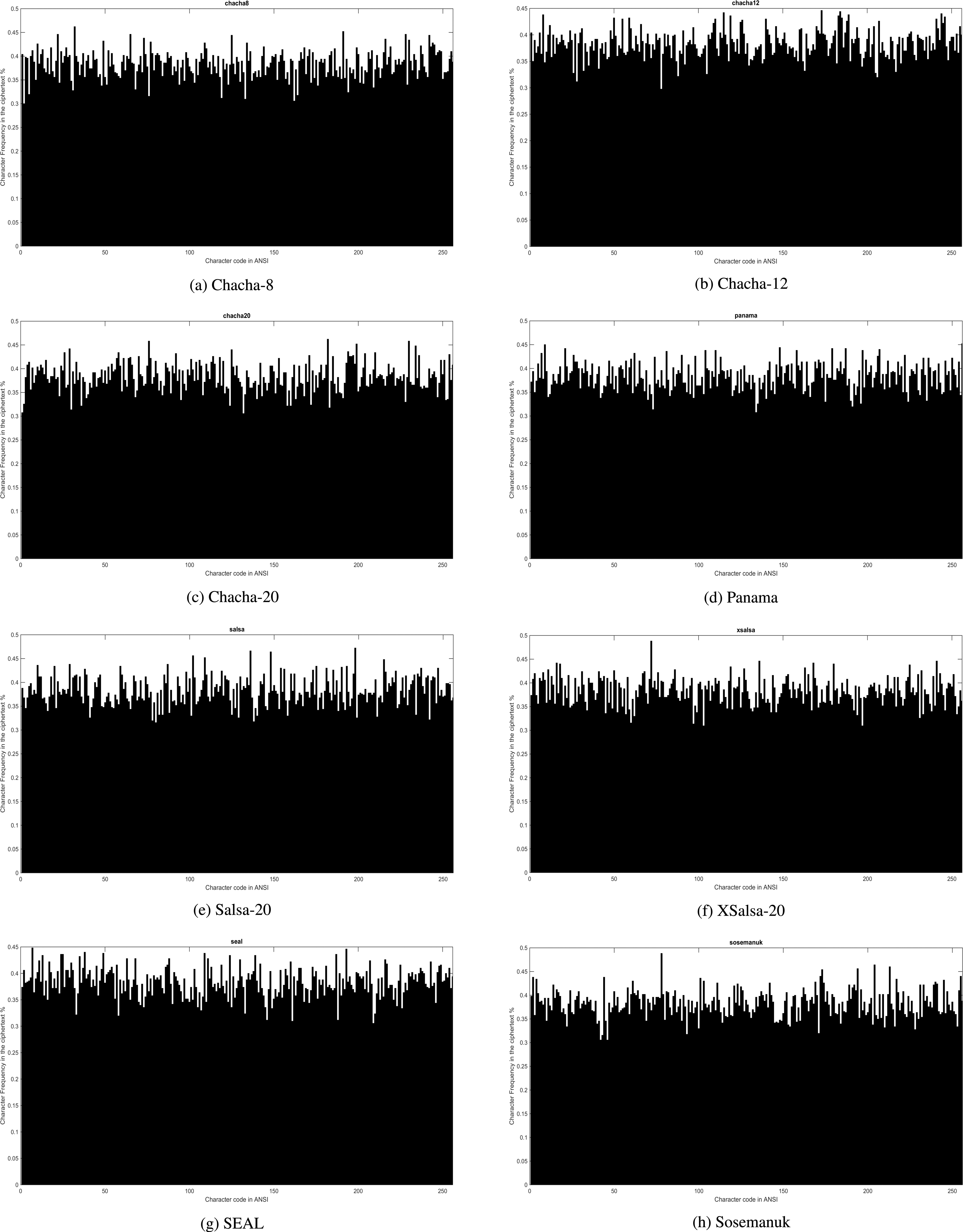
continued.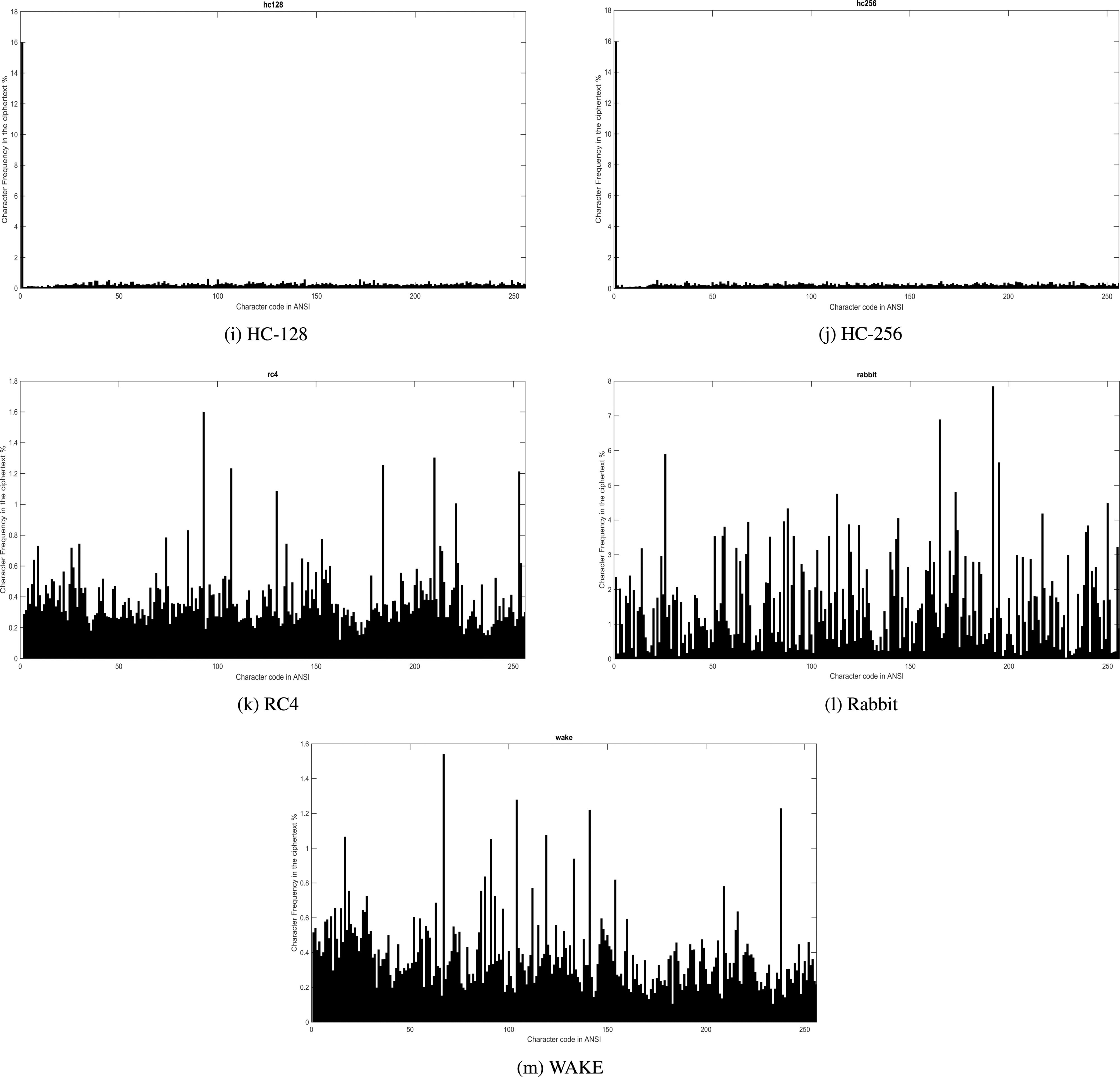
The frequency study will lead to apply a guess attack because it is normal to suggest that the character with a higher frequency in the ciphertext has more probabilities of being the character with a higher frequency in the plaintext. As a result, we define the probability of success of guessing attacks for each stream cipher as the ratio equal to the number of good guessed character divided by the total number of characters. This ratio will help to compare the resistance of stream ciphers to these types of attacks. It should also be mentioned that the probabilities of the guessing attack is also related to the number of obtained ciphertext. The higher the number of obtained ciphertext the higher the guessing attack success probability.
Typically, stream ciphers are mono-alphabetic ciphers, but the continuous changes of keystream allows them to act as polyalphabetic [47]. This complicate the frequency cryptanalysis study because the search of the possible mono-decrypted character become a search of the possible poly-decrypted character.
Furthermore, the probability of success of the guessing attack is also related to the probability of searching for the character in the ciphertext from the plaintext. We call this, the mission candidate, i.e. we define the group of poly-decrypted character as the possible candidate for each plaintext character. The candidate assignment is based on a binomial distribution, in this way, every candidate of the encrypted character has a probability of being the corresponding character [48] (see Eq. (5)):
where
The percentage of each character in the ciphertext.
continued.
The first observation taken from Fig. 6 is that some ciphertext has a near pseudo-uniform distribution and the character frequency seem bounded between zero and 0.47%. This pseudo-uniform distribution of information into ciphertext attests the huge difficulty of extracting information from ciphertext to determine the plaintext even with clear character frequency (see Fig. 5). Moreover, Fig. 6i and j showed that one character appeared 16% in the ciphertext while the rest of characters has a frequency seem bounded between zero and 0.746%. For HC128 and HC256, our guessing attacks has showed 0.037934% and 0.048203% as probability of success for guessing one character. However, it is still difficult to apply frequency analysis further because the rest of encrypted data with HC128/256 has a near pseudo-uniform distribution. As for RC4, Rabbit and WAKE in Fig. 6k–m respectively, the frequency analysis showed a big bad character distribution into ciphertext, which gives attractive information to break the cipher. In this work, our attempt in guessing attacks showed 0.081989%, 0.10249% and 0.10044% as probability of success for guessing one character for Rabbit, RC4 and WAKE respectively. Of note, our work here is not trying to break those ciphers, but to show that with only few attempt, the guessing attacks succeed in guessing one character with a probability of success near to 0.1%. Therefore, we deduce that RC4, Rabbit and Wake are potentially vulnerable to frequency analysis.
In general, the strength of a stream cipher is based on the unpredictability of its PRNG used. Statistically, a good PRNG is linked to the uniform distribution of the character from the set domain to the codomain. For instance, if Bob sends a message to Alice and this message contains only a duplicate of a character, then it will be bad if the encrypted message contains a bias. It is not necessary that all the characters encrypted have the same frequency of appearance, what is bad for a cipher is to find an encrypted character with a frequency of appearance higher than the others.
For that reason, we test the PRNGs of our studied stream ciphers by applying a frequency analysis for a duplication of a random character in the plaintext. The result is illustrated in the following Fig. 7.
Figure 7 shows the probability of occurrence of each ciphertext character for one plaintext character. We notice that Chacha8/12/20, Panama, Rabbit, Wake and XSalsa showed a good distribution of encrypted characters, which leads to good diffusion and confusion by their PRNGs. On the other hand, HC128/256, RC4, Salsa, SEAL, and Sosemanuk had a bad statistical distribution (e.g., an encrypted character with Salsa has a probability of occurrence equal to 2.4%, which is approximately seven times bigger than it should be). Therefore, we deduce that their PRNGs are not statistically strong, hence their produced keystream has a good probability of bias appearance.
The Chi-squared statistic [49] is a measure of similar degree for two categorical probability distributions. If the two distributions are matching, the Chi-squared statistic is zero, if the distributions are very different, some higher numbers will result. The Chi-square test is a general case of the statistical test of normality. The formula for the Chi-squared statistic is presented in Eq. (6):
where
To resist the test
Pearson’s chi-square test
The chi-square test value for the same ciphertext used in the frequency analysis is listed in Table 2. It is found that for Chacha8/20, Panama and Salsa the real
Statistical test for a keystream sequence is used to test a null hypothesis (H0). In this paper, the null hypothesis H0 indicates that the sequence tested is random and the alternative hypothesis H1 indicates that the sequence tested is not random [51].
The significance level
Actually, the probability of a Type II error may be completely independent of
The NIST test mentioned in previous section can only applied for a sequence of
This Beker and Piper tests suite consists of five tests [36, 38]: the frequency test or the mono-bit test, the serial test or the two-bits test, the poker test, the runs test, and the autocorrelation test. Note that if a sequence fails the mono-bit test, it is not necessary to apply the remaining four tests.
Mono-bit test
This test checked whether the number of 0 or 1 is equal or not as would be expected for a random sequence. If we denote A, B and C as the number of 0, 1 and bits in a sequence, respectively, the frequency test is computed as Eq. (7):
which approximately follows a
The purpose of this test is to determine whether the number of occurrences of 00, 01, 10, and 11 as subsequences of keystream are approximately the same, as would be expected for a random sequence. Let A, B denote the number of 0 and 1 in the keystream, respectively, and let C, D, E, F denote the number of occurrences of 00, 01, 10, 11 in the keystream, respectively. For a keystream length equal to n, we have
which approximately follows a
This test checked whether the behavior of changes in a sequence meet the criterion of random sequence. The expected number of gaps (or blocks) of length m in a random sequence of length n is
which approximately follows a
This test checked whether the number of times the p-bits block appears in the entire sequence is the same. Let’s denote by n the length of a sequence and m be a positive integer such that
which approximately follows a
This test checked the degree of dependence between a sequence and its shifted sequence. Let’s denote by n the length of a sequence, bi the bits number i and m be a positive integer such that
which approximately follows an
The required interval for passing the Runs test according to length of blocks and gaps
The required interval for passing the Runs test according to length of blocks and gaps
Instead of making the user select appropriate significance levels for the Beker-Piper test, explicit bounds are provided by FIPS 140-2 [54] for several computed value that must be respected in order to succeed four tests. These bounds presents the FIPS passing criteria condition. A single keystream of length 20000 bits is subjected to each of the following tests. If any of the tests fail, then the stream cipher fails the test. The FIPS 140-2 randomization tests are:
Mono-bit test: The number of 1 in the keystream sequence should belong to the interval
Poker test: The Eq. (10) is computed for
Runs test: The number blocks and gaps of length
Long runs test: The test is passed if there are no long runs. A long run is defined to be a run of length 26 or more (of either zeros or ones).
In this work, we use the FIPS 140-2 bounds as a required condition to pass the following three tests: the mono-bit test, the poker test and the runs test. For the remaining two tests: the two-bits test and the autocorrelation test, we denote our significance level
The Mono-bit test respectively the Two-bits test in Table 4 for all the studied streams cipher are above 94%. This confirms the good balance of 0 and 1 respectively of 00, 01, 10 and 11 in the generated sequence. As for the Poker test, the results satisfy the defined passing criteria to all the studied streams cipher except HC128/256 and RC4.
The Autocorrelation test of HC128/256, Panama, RC4, Sosemanuk and XSalsa proves the correlation between the sequences and their shifted versions. Also the failed result for Chacha20, HC256, Panama, RC4, Salsa, WAKE and XSalsa in Runs tests indicates the dependency and correlation among the generated keystream of HC256, Panama, RC4 and XSalsa.
However, since the total passing ratio failed for HC128/256, Panama and RC4, it is then concluded that the H0 is rejected and H1 is true. Therefore, a statistical analysis for keystream generated by HC128/256, Panama or RC4 is applicable with high probability.
As conclusion, Table 4 shows that Rabbit has the best keystream randomization among all the studied streams cipher followed by Chacha12/Chacha8, Sosemanuk then WAKE, Chacha20, SEAL, Salsa/XSalsa, Panama then RC4. While it seems that HC128/256 has the worst keystream randomization.
This article contains a statistical cryptanalysis study for several high-speed stream ciphers that are Chacha8/
The aim of this work is to show either the presence or the absence of any statistical signature in the ciphertext by the ciphers studied. It has been found that RC4, Rabbit and WAKE have a lot of attractive information in the ciphertext, which provides a frequency statistic that can be used in order to reduce the brute-force attack against them. Our guessing attack applied in this paper managed to link a character of plaintext to some characters to the ciphertext with a probability of success equal to 0.1%. This number means that, starting from n characters in the ciphertext, the attack succeeds in cracking an encrypted character
According to these tests, we deduce from our statistical analysis that Chacha8/12/20 are the best stream ciphers among those studied in this paper in terms of hidden statistical information in the ciphertext, followed by Rabbit, Salsa and SEAL while it seems that RC4 is the worst of them.