In this paper, a new hybrid binary version of Genetic algorithm (GA) and enhanced particle swarm optimization (PSO) algorithm is presented in order to solve feature selection (FS) problem. The proposed algorithm is called Hybrid Binary Genetic Enhanced PSO Algorithm (HBGEPSO). In the proposed HBGEPSO algorithm, the GA is combined with its capacity for exploration of the data through crossover and mutation and enhanced version of the PSO with its ability to converge to the best global solution in the search space. In order to investigate the general performance of the proposed HBGEPSO algorithm, the proposed algorithm is compared with the original optimizers and other optimizers that have been used for FS in the past. A set of assessment indicators are used to evaluate and compare the different optimizers over 20 standard data sets obtained from the UCI repository. Results prove the ability of the proposed HBGEPSO algorithm to search the feature space for optimal feature combinations.
Feature selection (FS) is a way of recognizing the independent features and removing expendable ones from the dataset [7]. In the real world, data representation often uses too many features with some repeated ones, which means certain important features can fill in for others and the redundant features can be removed. Furthermore, the output is influenced by the pertinent features because they contain salient information about the data and the results will be uncertain if any of them is excluded [5]. The objectives of FS are dimensionality reduction of the data, improving the accuracy of prediction, and apprehending data for different machine learning applications [6]. The traditional optimization techniques have some shortcomings in solving the FS problems [23], and hence evolutionary computation(EC) algorithms are the substitute for solving these limitations and searching for the ideal solution [36]. Evolutionary computation(EC) algorithms are inspired by biological exchange, group dynamics and social behavior of species in a group. ECs algorithms are strong tools to solve continuous global optimization problems, see e.g., [13, 2, 3, 30, 31, 32, 33]. Therefore, there is a need and desire to develop discrete and binary version of ECs in order to deal with various complex problems. The binary version of these algorithms permits us to explore topics like FS and arrive at superior results.
Many heuristic algorithms have been used with an aim to solve the FS problem. A survey on evolutionary computation outlooks to FS is expounded in [36]. A binary bat based FS technique is delineated in [27]. [16] introduces a feature subset selection model by grey wolf optimization. [4] describes a firefly-based FS perspective. Hybrid algorithms have also been used to address FS problems. [16] elucidates a hybrid flower pollination algorithms for FS. A hybrid genetic algorithm on mutual information is explained in [20]. [34] introduces hybrid binary bat enhanced PSO algorithm to solve for FS problem and [35] suggests hybrid binary dragonfly enhanced PSO algorithm to solve FS problem.
GAs were developed by Holland to understand the evolutionary process of natural systems [19]. The GA is a stochastic search inspired by natural selection and biological evolution and is generally implemented in the binary form. The GA has been applied to many machine learning and optimization problems [14, 18]. GA simulates the natural process by mimicking the mechanism of evolution such as selection, crossover, and mutation. There has been much work going on for implementing different types of crossovers and mutations in GA to enhance it further [21]. Nowadays the term GA is used interchangeably with the evolutionary algorithms (EAs).
PSO is a populace based stochastic optimization method developed by Eberhart and Kennedy in 1995 [15], inspired by social interaction such as fish schooling and bird flocking. In the past, although PSO has been satisfactorily applied in many research and application areas like the ideal design of combinational logic circuits [10], extant hydraulic issues [24] and the constrained non-linear optimization problems [9], but the domain of FS remains unexplored [1]. One reason that PSO is captivating is that there are less parameters to tweak. A single version, with little variations, works well in a plethora of real-world scenarios. It is exhibited that PSO gets superior results in a faster, computationally economical way compared to other algorithms. Here an enhanced version of the traditional PSO is used [26] to address the FS issue.
Hybridization of different algorithms is a technique to acquire superior performing systems and is concluded to gain from synergy, i.e., usually it utilizes and combines perks of the individual pure methods. It is mostly due to the no free lunch theorems [37], that the universal perspective of metaheuristics altered and people identified that there cannot exist an inclusive optimization technique which is globally superior to others. To address a particular issue most prudently, it almost always needs a specialized method that requires to be compiled of sufficient parts. Hybridization is categorized into many classes [11, 29]. Hybridization of one metaheuristic with another is a favored method to enhance the performance of both the algorithms.
This work aims to propose a new hybrid binary version of Genetic and enhanced PSO algorithm in order to solve FS problems efficaciously. The Hybridization permits us to unite the best attributes of both these techniques and obtain superior performance. In this paper, a new hybrid algorithm is proposed, which is called HBGEPSO Algorithm by combining the GA with the Enhanced PSO algorithm in order to obtain better results when compared to the respective individual algorithms. The binary HBGEPSO algorithm is tested on 20 standard data sets obtained from the UCI repository [17]. The algorithm is also compared with the HBEPSOG, where the PSO is carried out first and then given to the GA. A set of assessment indicators are used to evaluate and compare the different optimizers. The experimental results show the potential of the proposed HBGEPSO algorithm to search the feature space for ideal feature combinations.
The reminder of this paper is organized as follows. In Section 2, the definition of the FS problem is introduced. The main concepts of the GA are summarized in Section 3. The main ideas of the enhanced PSO algorithm are summarized in Section 4. The structure of the proposed HBGEPSO algorithm is presented in Section 5. The Section 6 gives details about the FS problem, evaluation criteria and an understanding regarding the classifier used. In Section 7, the experimental results are given and finally, the conclusion makes up Section 8.
Definition of the feature selection problem
In this section, the definition of the FS problem is described as follows. The FS problem can be defined as choosing certain number of features out of the total number of features present, such that the classification performance is maximum and the number of selected features is minimum.
Where is the classification quality of set R relative to decision D, is the length of the chosen feature subset, is the total number of available features, and are two parameters corresponding to the significance of classification quality and subset length, and . The fitness function maximizes the classification quality; , and the ratio of the unselected features to the total number of features; . The above equation can be easily transformed into a minimization problem by using error rate rather than classification quality and using selected features ratio rather than using unselected feature size. The minimization problem can be formulated as in Eq. (2).
where is the error rate of the classifier, is the length of the chosen feature subset, and is the total number of available features. and are parameters used to control the weights of classification accuracy and feature reduction.
Overview of binary genetic algorithm
In the following subsection, an overview of the main concepts and structure of the binary GA will be given as follows.
Main concepts and inspiration
The GA is a stochastic search algorithm that mimics natural evolutionary process employing defined operators that are applied to the population [25]. There are two main operators used in the GA algorithm. The Crossover operator is responsible for mating the individuals in the parent population, and the Mutation operator randomly changes the characteristics of individuals resulting in diverse offspring. In this algorithm, a systematic replacement of the parents by the offspring occurs as and when they are generated. The crossover is single point symmetric in nature, and the mutation is achieved through bit flipping.
Definition of concepts
Selection: This is the process by which a portion of the population is selected to breed the next generation. The selection is made based on the measured fitness values using the fitness Eq. (2). The scheme for selections is described in Eq. (3)
where sorted_Solutions is the list consisting of sorted fitness values and respective solutions in ascending order.
Crossover: From the previously selected pool of candidates, two parents are selected randomly for further breeding. The new solution shares many of the characteristics of its parents and this process is continued until the appropriate population size is reached. The crossover takes place at only one point, and that is at the mid-point of both the parent solutions. The parameter Crossover Probability(), controls the frequency of crossovers that occur. Crossover is illustrated here,
Mutation: Random solutions from the selected candidates for breeding are chosen and bit flipping is carried out on these. This gives rise to a diverse group of solutions that retain many of the characteristics of their parents. The parameter Mutation Probability(), controls the frequency of mutations. The result of mutation at 2 is shown below,
The relationship between the Crossover and Mutation probabilities are given in Eq. (4)
Binary genetic algorithm
In this section, the main steps of the binary GA are presented in details as shown in Algorithm 3.3.
Binary GA[1] Set the initial value of swarm size , , , and . Randomly initialize the population as , for each solution. Evaluate fitness of each solution using Eq. (2). Set . Counter initializationEvaluate fitness and Evaluate the fitness function for each of the new solutions using . select nsite number of random sites to mutate using Evaluate the fitness of the new solution. X=combination of X_sel and X_newIteration counter increasing untilTermination criteria are satisfied. Produce the best solution Best_sol.
Step 1. Initialize the values of swarm size SS(N), nsite, , and .
Step 2. Randomly initialize the population as for each solution.
Step 3. The following steps are repeated until the terminating criteria is met.
Step 1. The fitness value of each solution is calculated using .
Step 2. The population for breeding is selected as .
Step 3. A random value is taken, if which is greater than , crossover of random samples from X_sel is carried out.
Step 4. If the new solutions are better than old ones, they are updated.
Step 5. A random value is taken, if which is greater than , mutation of random sample from X_sel is carried out.
Step 6. If the new solution is better than the old one, its updated.
Step 4. The new population is a combination of X_sel and X_new
Step 4. Produce the global best as the best found solution.
Overview of binary enhanced particle swarm optimization
In the following section, a summary of the important concepts and structure of the Binary Enhanced PSO algorithm will be given as follows.
Main concepts and inspiration
The PSO is a populace based search technique derived from the information exchange of birds [22]. In PSO, initially a random population of particles is initialized, and these particles move with certain velocity based on their interchange with other particles in the population. At each iteration, the personal best achieved by each particle and the global best of all the particles is followed, and the velocity of all the particles is updated based on this information. Certain variables are used to give weights to the global and personal best. In the Enhanced version of the binary PSO [26], a particular type of S-shaped transfer functions is used to transform a continuous value to a binary value alternative to a simple hyperbolic tangent function.
Movement of particles
Each of the particles is represented by D dimensional vectors and they are randomly initialized with each individual value being binary.
where is the available search space.
The velocity is represented by a D dimensional vector and is initialized to zero.
The best personal position recorded by each particle is retained as
At each iteration each particle updates its position according to its personal best(Pbest) and the global best(gbest) as follows
where and are acceleration constants called cognitive and social parameters respectively. and are random values . is called as the inertia weight. It determines how the previous velocity of the particle effects the velocity in the next iteration. The value of is determined by the following expression
where and are constants. Max_iteration is the maximum number of iterations to be run.
The continuous to binary map
The position of each particle is decided by the S shaped transfer function that maps the continuous velocity value to the position of the particle. This is a unique sigmoid function that enhances the PSO.
Enhanced particle swarm optimization algorithm
In this section, the main steps of the binary enhanced PSO algorithm will be delineated as shown in Algorithm 4.4.
Enhanced PSO algorithm[1] Set the initial value of swarm size SS(N), acceleration constants and , , , and . Randomly initialize the population as using Eq. (5) for each solution and the velocity vectors as D dimensional zero vectors as in Eq. (6). Set . Counter initializationEvaluate the fitness function for each of the solutions using Eq. (2) and Assign the values for Pbest and gbest. Update the velocities of Particles Iteration counter increasing untilTermination criteria are satisfied. Produce the best solution gbest.
Step 1. Initialize the values of swarm size SS(N), acceleration constants and , , , and .
Step 2. The population is randomly initialized as in Eq. (5) and the velocity vectors are initialized to zeros as in Eq. (6).
Step 3. The following steps are repeated until the terminating criteria is met.
Step 1. Update the value of inertia weight according to Eq. (9)
Step 2. The fitness value of each solution is updated using .
Step 3. The personal best solution Pbest and the global best solution gbest are assigned.
Step 4. At each iteration , the velocity of each particle is calculated according to Eq. (8).
Step 5. The continuous values are mapped to binary values using the S shaped transfer function mentioned in Eq. (10) and new solutions are created.
Step 4. Produce the global best as the best found solution.
The main steps of the proposed HBGEPSO algorithm for FS are shown in Algorithm 5 and summarized as follows.
Hybrid binary genetic enhanced PSO algorithm[1] Split the given data set into three equal sizes of training, validation and testing sets. Set the initial value of swarm size SS(N) and make the dimension equal to the number of features in the data set. Set Acceleration constants and , , nsite, , , , and . Randomly initialize the population as using Eq. (5) for each solution and the velocity vectors as D dimensional zero vectors as in Eq. (6). Set . Counter initializationEvaluate the fitness function for each of the solutions using the Eq. (2) and Assign the values for Pbest and gbest. The fitness function for FS Run BGA algorithm as given in Algorithm 3.3Update the values of Pbest and gbest. Update the velocities of Particles Iteration counter increasing untilTermination criteria are satisfied. Produce the best solution gbest.
Step 1. Split the given data set into three equal sizes of training, validation and testing sets.
Step 2. Set the initial value of swarm size SS(N), Acceleration constants and , , nsite, , , , and and make the dimension D equal to the number of features in the data set.
Step 3. Randomly initialize the population as using Eq. (5) for each solution. Initialize the velocity vectors as D dimensional zero vectors as in Eq. (6).
Step 4. The following steps are repeated until the terminating criteria is met.
Step 1. Evaluate the fitness function for each of the solutions using the Eq. (2) and Assign the values for Pbest and gbest.
Step 2. Run the BGA algorithm.
Step 3. Update the values of Pbest and gbest.
Step 4. Run the EPSO algorithm as mentioned in Algorithm 4.4 with the new population, Pbest and gbest.
Step 4. Here the New velocity information is generated from the previous EPSO velocity and the new velocity generated from the solutions generated by GA which are better than the previous iteration.
Step 5. Produce the global best as the best found solution.
Datasets
Dataset
No. Attributes
No. Instances
Zoo
16
101
WineEW
13
178
IonosphereEW
34
351
WaveformEW
40
5000
BreastEW
30
569
Breastcancer
9
699
Congress
16
435
Exactly
13
1000
Exactly2
13
1000
HeartEW
13
270
KrvskpEW
36
3196
M-of-n
13
1000
SonarEW
60
208
SpectEW
60
208
Tic-tac-toe
9
958
Lymphography
18
148
Dermatology
34
366
Echocardiogram
12
132
hepatitis
19
155
LungCancer
56
32
Parameter setting
Parameter
Value
No of iterations ()
70
No of search agents ()
5
Dimension ()
No. of features in the data
Search domain
[0 1]
No of runs ()
10
nsite
2
0.95
0.05
0.9
0.4
2
2
6
in fitness function
0.01
in fitness function
0.99
Feature selection
The FS problem is as defined in Section 2. For a feature vector of size , the number of different feature combinations would be , which is a huge space to search exhaustively. So the proposed Hybrid metaheuristic Algorithm is used to adaptively search the feature space and produce the best feature combination. The fitness function used is the one given in Eq. (2)
where is the error rate of the classifier, is the length of the selected feature subset, and is the total number of features. and are constants used to control the weights of classification accuracy and feature reduction.
Mean fitness function obtained from the different algorithms
Dataset
HBGESPO
BGA
EPSO
BBA
BDA
BGWO2
HBEPSOG
Zoo
0.042
0.124
0.031
0.094
0.067
0.119
0.059
Wine EW
0.030
0.065
0.042
0.128
0.050
0.092
0.031
IonosphereEW
0.100
0.143
0.137
0.146
0.130
0.172
0.130
WaveformEW
0.174
0.186
0.175
0.193
0.183
0.185
0.174
BreastEW
0.045
0.106
0.050
0.070
0.057
0.080
0.058
Breastcancer
0.028
0.036
0.032
0.035
0.032
0.042
0.029
Congress
0.032
0.059
0.033
0.053
0.042
0.073
0.037
Exactly
0.075
0.269
0.104
0.303
0.178
0.316
0.083
Exactly2
0.223
0.243
0.234
0.243
0.240
0.263
0.235
HeartEW
0.140
0.250
0.153
0.240
0.153
0.268
0.145
KrvskpEW
0.041
0.089
0.043
0.108
0.041
0.080
0.041
M-of-n
0.046
0.108
0.024
0.167
0.048
0.154
0.024
SonarEW
0.150
0.262
0.192
0.277
0.194
0.290
0.191
SpectEW
0.150
0.168
0.160
0.167
0.133
0.205
0.148
Tic-tac-toe
0.222
0.241
0.222
0.270
0.223
0.262
0.223
Lymphography
0.454
0.466
0.392
0.487
0.412
0.531
0.402
Dermatology
0.015
0.031
0.016
0.081
0.017
0.099
0.019
Echocardiogram
0.054
0.072
0.083
0.112
0.058
0.200
0.058
Hepatitis
0.110
0.152
0.123
0.175
0.101
0.192
0.147
LungCancer
0.219
0.318
0.220
0.427
0.255
0.455
0.175
Average
0.118
0.169
0.123
0.189
0.131
0.204
0.120
Best fitness function obtained from the different algorithms
Dataset
HBGESPO
BGA
EPSO
BBA
BDA
BGWO2
HBEPSOG
Zoo
0.003
0.032
0.001
0.005
0.000
0.035
0.000
Wine EW
0.003
0.035
0.019
0.021
0.003
0.003
0.003
IonosphereEW
0.063
0.114
0.113
0.079
0.108
0.089
0.089
WaveformEW
0.166
0.174
0.165
0.176
0.181
0.167
0.160
BreastEW
0.024
0.060
0.027
0.045
0.055
0.056
0.045
Breastcancer
0.017
0.029
0.018
0.024
0.024
0.027
0.021
Congress
0.015
0.038
0.022
0.029
0.019
0.045
0.029
Exactly
0.013
0.058
0.025
0.270
0.040
0.298
0.022
Exactly2
0.208
0.216
0.219
0.212
0.235
0.241
0.214
HeartEW
0.113
0.147
0.104
0.168
0.082
0.147
0.113
KrvskpEW
0.031
0.041
0.033
0.060
0.034
0.059
0.0323
M-of-n
0.004
0.067
0.004
0.113
0.004
0.128
0.004
SonarEW
0.118
0.220
0.118
0.205
0.156
0.234
0.134
SpectEW
0.160
0.125
0.125
0.127
0.093
0.161
0.115
Tic-tac-toe
0.185
0.217
0.185
0.236
0.206
0.242
0.216
Lymphography
0.367
0.388
0.307
0.427
0.344
0.450
0.326
Dermatology
0.003
0.012
0.004
0.029
0.003
0.046
0.003
Echocardiogram
0.024
0.045
0.047
0.049
0.025
0.093
0.024
Hepatitis
0.058
0.078
0.080
0.117
0.058
0.097
0.098
LungCancer
0.093
0.093
0.058
0.093
0.003
0.28
0.003
Average
0.083
0.109
0.084
0.129
0.084
0.145
0.083
Worst fitness function obtained from the different algorithms
Dataset
HBGESPO
BGA
EPSO
BBA
BDA
BGWO2
HBEPSOG
Zoo
0.089
0.208
0.089
0.208
0.208
0.208
0.179
Wine EW
0.053
0.122
0.070
0.122
0.119
0.157
0.053
IonosphereEW
0.121
0.189
0.171
0.191
0.155
0.309
0.163
WaveformEW
0.181
0.197
0.186
0.215
0.192
0.195
0.178
BreastEW
0.065
0.315
0.081
0.103
0.065
0.115
0.072
Breastcancer
0.038
0.049
0.041
0.049
0.039
0.052
0.038
Congress
0.045
0.085
0.049
0.092
0.063
0.089
0.063
Exactly
0.207
0.349
0.251
0.326
0.308
0.342
0.231
Exactly2
0.235
0.268
0.248
0.276
0.263
0.286
0.261
HeartEW
0.191
0.322
0.289
0.334
0.334
0.201
0.200
KrvskpEW
0.051
0.177
0.054
0.191
0.052
0.101
0.052
M-of-n
0.102
0.157
0.073
0.232
0.136
0.170
0.083
SonarEW
0.191
0.306
0.219
0.391
0.234
0.349
0.306
SpectEW
0.182
0.205
0.204
0.216
0.170
0.238
0.192
Tic-tac-toe
0.243
0.275
0.244
0.313
0.239
0.298
0.232
Lymphography
0.528
0.588
0.469
0.569
0.491
0.581
0.508
Dermatology
0.029
0.061
0.029
0.290
0.053
0.222
0.036
Echocardiogram
0.091
0.114
0.160
0.230
0.092
0.840
0.115
Hepatitis
0.173
0.212
0.174
0.234
0.138
0.253
0.213
LungCancer
0.363
0.723
0.543
0.813
0.454
0.545
0.452
Average
0.159
0.246
0.182
0.277
0.184
0.285
0.181
Classifier
K-nearest neighbor (KNN) [8] is a favored elementary technique used for classification. KNN is a supervised learning algorithm that classifies an unknown instance based on the majority vote of its K-nearest neighbors. Here, a wrapper approach to FS is used which uses the KNN classifier as a guide for the same. Classifiers do not use any model for K-nearest neighbors and are decided solely based on the minimum distance from the current query sample to the neighboring training instances. In this proposed system, the KNN is used as a classifier to ensure robustness to noisy training data and obtain optimal feature combinations. A single dimension in the search space represents an individual feature, and hence the position of a particle represents a single feature combination or solution.
Experimental results
The proposed binary HBGEPSO algorithm is tested against 20 data sets in Table 1 taken from the UCI machine learning repository [17] and is compared with other algorithms like binary versions of dragonfly, Enhanced PSO, GA, bat, and greywolf2. The algorithm is also compared with HBEPSOG, where the order of implementation of the two algorithms is reversed. The datasets are chosen to have variety in a number of instances and features to test for various data. The datasets are divided into three sets: training, validation, and testing. The value of K is selected as five based on the trial and error. The training set is used to evaluate the KNN on the validation set through this algorithm to steer the FS process. The test data is only utilized for the final evaluation of the ideal selected feature combination. The global and optimizer-specific parameter setting is given in Table 2. The parameters are set according to either domain-specific information or trial and error. The evaluation criteria are expounded in Subsection 7.1.
Standard deviation of the fitness function obtained from the different algorithms
Dataset
HBGESPO
BGA
EPSO
BBA
BDA
BGWO2
HBEPSOG
Zoo
0.027
0.066
0.033
0.070
0.075
0.067
0.055
Wine EW
0.016
0.026
0.018
0.080
0.030
0.057
0.019
IonosphereEW
0.019
0.025
0.016
0.040
0.018
0.057
0.024
WaveformEW
0.004
0.008
0.008
0.012
0.006
0.007
0.005
BreastEW
0.012
0.755
0.019
0.017
0.007
0.018
0.008
Breastcancer
0.007
0.007
0.007
0.009
0.005
0.008
0.004
Congress
0.008
0.013
0.008
0.019
0.016
0.015
0.010
Exactly
0.069
0.078
0.082
0.020
0.119
0.016
0.070
Exactly2
0.009
0.019
0.009
0.017
0.015
0.018
0.014
HeartEW
0.025
0.062
0.055
0.064
0.036
0.069
0.027
KrvskpEW
0.004
0.051
0.007
0.044
0.007
0.012
0.006
M-of-n
0.034
0.032
0.022
0.036
0.051
0.019
0.026
SonarEW
0.026
0.030
0.029
0.059
0.033
0.043
0.046
SpectEW
0.015
0.029
0.027
0.028
0.022
0.024
0.032
Tic-tac-toe
0.007
0.021
0.020
0.025
0.012
0.017
0.008
Lymphography
0.041
0.062
0.048
0.047
0.049
0.044
0.051
Dermatology
0.007
0.014
0.008
0.075
0.014
0.050
0.010
Echocardiogram
0.024
0.024
0.030
0.055
0.026
0.228
0.032
Hepatitis
0.024
0.038
0.028
0.043
0.025
0.052
0.038
LungCancer
0.113
0.233
0.180
0.194
0.151
0.093
0.149
Average
0.024
0.080
0.033
0.048
0.036
0.046
0.032
Average performance of the selected features by different algorithms
Dataset
HBGESPO
BGA
EPSO
BBA
BDA
BGWO2
HBEPSOG
Zoo
0.888
0.863
0.791
0.799
0.788
0.851
0.805
Wine EW
0.890
0.886
0.881
0.726
0.923
0.896
0.9
IonosphereEW
0.831
0.828
0.829
0.817
0.799
0.824
0.825
WaveformEW
0.819
0.806
0.809
0.779
0.807
0.819
0.815
BreastEW
0.936
0.892
0.931
0.842
0.944
0.908
0.933
Breastcancer
0.958
0.957
0.956
0.957
0.956
0.957
0.957
Congress
0.944
0.915
0.943
0.893
0.931
0.928
0.940
Exactly
0.891
0.687
0.884
0.647
0.798
0.680
0.879
Exactly2
0.743
0.734
0.738
0.711
0.739
0.732
0.730
HeartEW
0.796
0.711
0.776
0.648
0.810
0.702
0.801
KrvskpEW
0.959
0.906
0.958
0.772
0.954
0.917
0.958
M-of-n
0.954
0.892
0.975
0.719
0.949
0.843
0.973
SonarEW
0.704
0.694
0.682
0.678
0.658
0.682
0.695
SpectEW
0.765
0.750
0.757
0.755
0.752
0.777
0.755
Tic-tac-toe
0.750
0.734
0.740
0.647
0.745
0.713
0.738
Lymphography
0.440
0.416
0.354
0.422
0.417
0.379
0.418
Dermatology
0.957
0.95
0.952
0.802
0.940
0.908
0.945
Echocardiogram
0.870
0.852
0.906
0.861
0.893
0.877
0.852
Hepatitis
0.742
0.798
0.813
0.788
0.788
0.788
0.786
LungCancer
0.481
0.409
0.390
0.343
0.427
0.345
0.398
Average
0.816
0.784
0.803
0.730
0.801
0.776
0.805
Average selected feature ratio by different algorithms
Dataset
HBGESPO
BGA
EPSO
BBA
BDA
BGWO2
HBEPSOG
Zoo
0.330
0.412
0.356
0.512
0.331
0.473
0.356
Wine EW
0.3
0.315
0.4
0.538
0.338
0.516
0.323
IonosphereEW
0.378
0.402
0.388
0.526
0.397
0.541
0.411
WaveformEW
0.666
0.676
0.709
0.634
0.666
1
0.714
BreastEW
0.322
0.290
0.241
0.480
0.283
0.470
0.335
Breastcancer
0.477
0.566
0.511
0.511
0.422
0.644
0.511
Congress
0.312
0.412
0.325
0.493
0.337
0.575
0.350
Exactly
0.481
0.561
0.507
0.538
0.538
0.576
0.481
Exactly2
0.353
0.4
0.492
0.546
0.392
0.8
0.376
HeartEW
0.392
0.415
0.407
0.492
0.407
0.430
0.392
KrvskpEW
0.470
0.530
0.502
0.513
0.475
0.633
0.511
M-of-n
0.515
0.576
0.476
0.446
0.530
0.923
0.476
SonarEW
0.411
0.42
0.463
0.521
0.413
0.533
0.473
SpectEW
0.452
0.395
0.463
0.481
0.454
0.529
0.4
Tic-tac-toe
0.511
0.511
0.666
0.577
0.555
0.866
0.666
Lymphography
0.338
0.4
0.416
0.461
0.438
0.535
0.416
Dermatology
0.488
0.479
0.511
0.494
0.411
0.544
0.5
Echocardiogram
0.231
0.283
0.266
0.508
0.233
0.483
0.233
Hepatitis
0.231
0.231
0.321
0.515
0.273
0.431
0.331
LungCancer
0.346
0.380
0.423
0.498
0.498
0.526
0.410
Average
0.400
0.434
0.442
0.514
0.411
0.601
0.433
Average Fischer index of the selected features by different algorithms
Dataset
HBGESPO
BGA
EPSO
BBA
BDA
BGWO2
HBEPSOG
Zoo
163
156
143
112
105
130
115
Wine EW
1355.5
540.52
648.48
11784.7
374.67
20939.7
673.40
IonosphereEW
5.094
4.769
3.870
4.154
3.986
5.042
4.793
WaveformEW
2.575
2.165
2.314
2.029
2.314
3.456
2.396
BreastEW
7.0E+13
1.4E+13
3.3E+13
5.7E+12
2.5E+11
6.9E+13
1E+13
Breastcancer
1.184
0.923
1.070
0.942
0.748
1.105
0.730
Congress
68.072
13.045
13.996
11.003
31.797
18.317
36.857
Exactly
0.381
0.378
0.131
0.350
0.259
0.282
0.085
Exactly2
0.355
0.287
0.267
0.200
0.259
0.237
0.320
HeartEW
3.022
140.64
3.357
161.62
3.424
430.07
2.651
KrvskpEW
1332.5
1023.2
940.24
639.91
544.21
1187.5
704.20
M-of-n
1.819
1.786
1.735
1.652
1.711
1.373
1.727
SonarEW
8.7E+6
5.5E+6
8.2E+6
8.2E+6
7.3E+6
1.2E+7
7.1E+6
SpectEW
0.008
0.004
0.005
0.006
0.006
0.006
0.004
Tic-tac-toe
0.164
0.119
0.161
0.136
0.090
0.117
0.127
Lymphography
9.35
2.43
9.18
4.41
3.13
2.73
4.87
Dermatology
352
148
343
210
269
174
193
Echocardiogram
568.97
62931
1376
130939
579.06
53037
1671
Hepatitis
2.422
14.420
51.80
132.03
3.491
53037
7.634
LungCancer
46.965
29.405
40.203
30.810
31.148
33.615
37.911
Average
3.5E+12
6.9E+11
1.6E+12
2.8E+11
1.3E+10
3.4E+11
5.2E+11
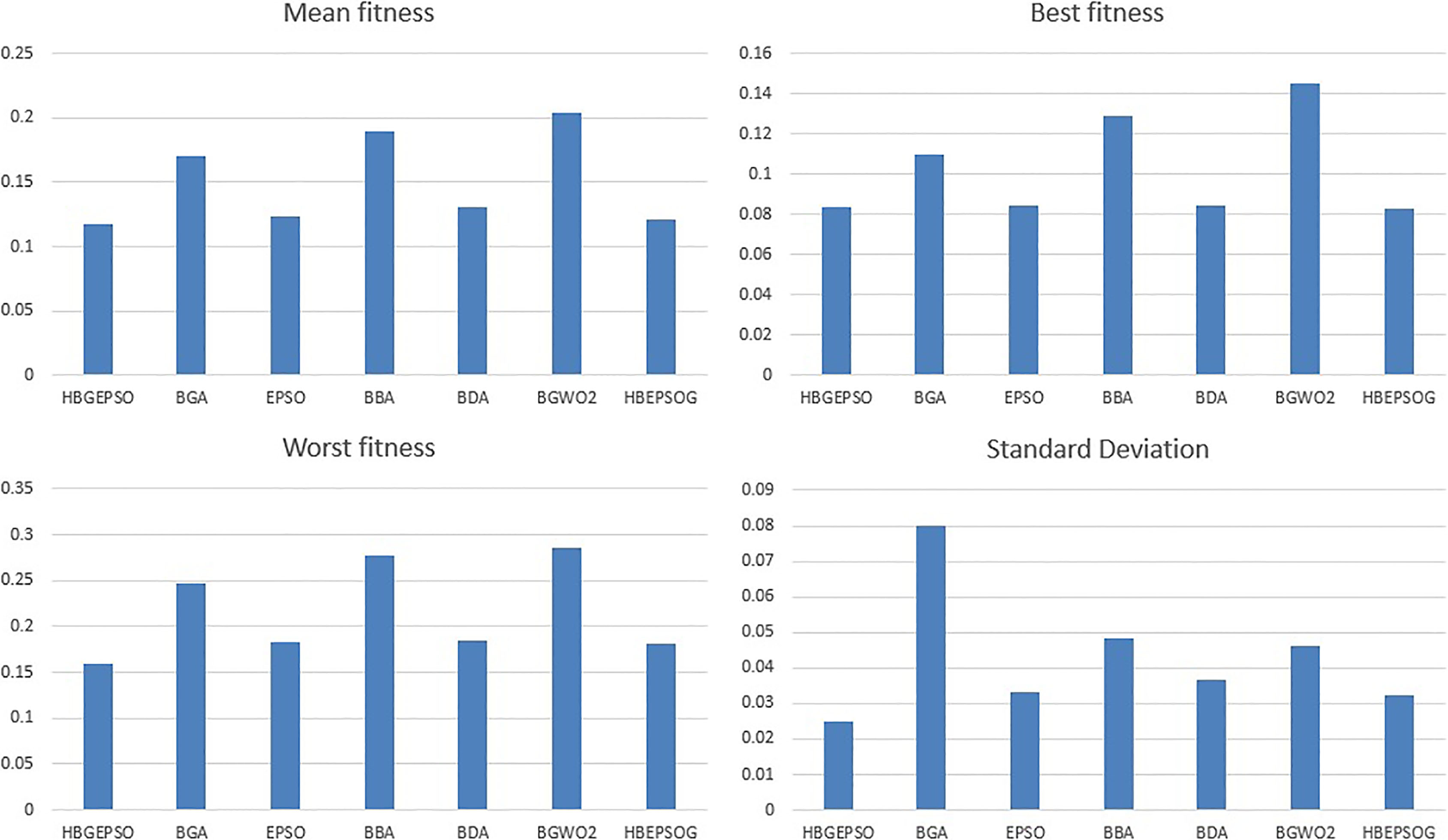
The Comparison of performance the HBGEPSO algorithm with other optimizers through main objectives of FS. The values are averaged over all the datasets.
The Comparison of performance the HBGEPSO algorithm with other optimizers through few assessment indicators. The values are averaged over all the datasets.
Evaluation criteria
The datasets are divided into 3 sets of training, validation and testing. The algorithm is run repeatedly for 10 times for statistical significance of the results. The following measures [16] are recorded from the validation data:
Mean fitness function is the average of the fitness function value obtained from running the algorithm times. The Mean fitness function is calculated as shown in Eq. (12).
where is the best fitness value obtained at run .
Best fitness function is the minimum of the fitness function value obtained from running the algorithm times. The Best fitness function is calculated as shown in Eq. (13).
where is the best fitness value obtained at run .
Worst fitness function is the maximum of the fitness function value obtained from running the algorithm times. The Worst fitness function is calculated as shown in Eq. (14).
where is the best fitness value obtained at run .
Standard deviation gives the variation of the fitness function value obtained from running the algorithm times. It is an indicator of the stability and robustness of the algorithm. Larger values of standard deviation would suggest wandering results where as smaller value suggests the algorithm converges to the same value most of the times. The Standard deviation is calculated as shown in Eq. (15).
where is the best fitness value obtained at run .
Average Performance(CA) is the mean of the of the classification accuracy values when an algorithm is run times. The Average Performance is calculated as shown in Eq. (16).
where is the Accuracy value obtained at run
Mean FS ratio(FSR) is the mean of the ratio of the number of selected features to the total number of features when an algorithm is run times. The Mean FS ratio is calculated as shown in Eq. (17).
where is the best fitness value obtained at run , gives the number of features selected and is the total number of features.
Average F-score is a measure that evaluates the performance of a chosen feature subset. It requires that in the data spanned by the feature combination the distance between data points in different classes be large and of those in the same class be as small as possible. The Fischer index for a given feature is calculated as in Eq. (18) [28].
where is the fischer index for , is the mean of the entire data for feature , is defined as in Eq. (19), is the size of class , is the mean of class for feature , is the variance of class for feature . The Average F-score is calculated by taking the average of values obtained from runs for only the selected features.
Results
The proposed binary version of the HBGEPSO algorithm is compared with the binary GA, the Enhanced PSO, and other optimizers. The results are tabulated as follows.
Table 3 outlines the performance of the algorithms using the fitness function mentioned in Eq. (2) in the minimization mode. The table shows the average fitness obtained over runs and is calculated using Eq. (12). The best performance is achieved by the proposed binary version of the HBGEPSO algorithm proving its ability to search the feature space effectively.
Similar results are seen in Tables 4 and 5 that outline the best and the worst fitness function obtained over runs and is calculated using Eqs (13) and (14) respectively.
For testing the stability, robustness and the repeatability of convergence of these stochastic algorithms the standard deviation of the fitness values over runs is recorded as per Eq. (15) in Table 6. The table shows that the HBGEPSO algorithm can converge repeatedly irrespective of the random initialization.
The Best selected feature combinations by the algorithms are also allowed to run on the test data, and the average classification accuracy and the average FS ratio over runs is recorded using Eqs (16) and (17) respectively as shown in Eqs (7) and (8). As can be seen from these tables, the HBGEPSO algorithm can select the minimum number of features and yet maintain the classification accuracy. This shows the capability of the HBGEPSO algorithm to satisfy both the objectives of optimization.
To analyze the separability and closeness of the selected features Fischer score of these features is calculated as shown in Eq. (18). The average over runs is recorded in Table 9. As shown in the table, HBGEPSO algorithm achieves superior data compactness in comparison with the other algorithms.
These tables show that the HBGEPSO algorithm outperforms the other algorithms concerning all of the assessment indicators. It can also be seen that it performs much better when compared to its switched version HBEPSOG algorithm. This leads us to believe that the GA is powerful in exploring the search space and the enhanced PSO algorithm aids in exploiting the reduced feature space.
Conclusion
In this paper, a new hybrid binary metaheuristic algorithm with GA and Enhanced PSO algorithm is proposed in order to solve FS problems. The proposed algorithm is called Hybrid Binary Genetic Enhanced PSO(HBGEPSO) algorithm. The two algorithms come together to give better solutions that each of them individually. In order to verify the ruggedness and the effectiveness of the proposed algorithm, the proposed algorithm is applied on 20 FS problems. The evaluation is performed using a set of evaluation criteria to assess different aspects of the proposed technique. The experimental results show that the proposed method is promising with its ability to search the feature space effectively. The given algorithm was also run on test data, and observations show the higher performance of the selected features when compared to the other optimizers. The Fischer index table reveals better separability. It is also noted from the values of standard deviation that the algorithm has the robustness to repeatedly converge to similar solutions, therefore, a powerful ability to solve FS problems better than other algorithms in most cases.
Footnotes
Acknowledgments
This research was supported partially by Mitacs Canada. The research of the 1st author is supported in part by the Natural Sciences and Engineering Research Council of Canada (NSERC).
References
1.
AgrafiotisD.K. and CedenoW., Feature selection for structure-activity correlation using binary particle swarms, Journal of Medicinal Chemistry45(5) (2002), 1098–1107.
2.
AliA.F and TawhidM.A., Hybrid bat algorithm and direct search methods for solving minimax problems, International Journal of Hybrid Intelligent Systems14(4) (2018), 209–223.
3.
AliA.F and TawhidM.A., Hybrid particle swarm optimization with a modified arithmetical crossover for solving unconstrained optimization problems, INFOR: Information Systems and Operational Research53(3) (2015), 125–141.
4.
BanatiH. and BajajM., Fire fly based feature selection approach, IJCSI International Journal of Computer Science Issues8(4) (2011), 473–480.
5.
BellD.A. and WangH., A formalism for relevance and its application in feature subset selection, Machine Earning41(2) (2000), 175–195.
6.
ChandrashekarG. and SahinF., A survey on feature selection methods, Computers & Electrical Engineering40(1) (2014), 16–28.
7.
ChiziB.RokachL. and MaimonO., A survey of feature selection techniques. Encyclopedia of Data Warehousing and Mining, seconded, IGI Global, 2009, pp. 1888–1895.
8.
ChuangL.Y.ChangH.W.TuC.J. and YangC.H., Improved binary PSO for feature selection using gene expression data, Comput Biol Chem32 (2008), 29–38.
9.
CoathG. and HalgamugeS.K., A comparison of constraint-handling methods for the application of particle swarm optimization to constrained nonlinear optimization problems, Proceedings of IEEE Congress on Evolutionary Computation 2003 (CEC 2003), Canbella, Australia, 2003, pp. 2419–2425.
10.
Coello CoelloC.A.LunaE.H. and AguirreA.H., Use of particle swarm optimization to design combinational logic circuits, Lecture Notes in Computer Science (LNCS), No. 2606, 2003, pp. 398–409.
11.
CottaC., A study of hybridisation techniques and their application to the design of evolutionary algorithms, AI Communications11(3–4) (1998), 223–224.
12.
EberhartR.C. and KennedyJ., A new optimizer using particle swarm theory, Proceedings of the Sixth International Symposium on Micromachine and Human Science, Nagoya, Japan, 1995, pp. 39–43.
13.
DasA.K. and PratiharD.K., Performance improvement of a genetic algorithm using a novel restart strategy with elitism principle, International Journal of Hybrid Intelligent Systems (2018), 1–15.
14.
De JongK.A, Genetic algorithms: A 10 year perspective, In International Conference on Genetic Algorithms, 1985, pp. 169–177.
15.
EberhartR.C. and KennedyJ., A new optimizer using particle swarm theory, Proceedings of the Sixth International Symposium on Micromachine and Human Science, Nagoya, Japan. 1995, pp. 39–43.
16.
EmaryE.ZawbaaH.M.GrosanC. and HassanienA.E., Binary grey wolf optimization approaches for feature selection, Neurocomputing172 (2016), 371–381.
17.
FrankA. and AsuncionA., UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of School of Information and Computer Science, 2010.
18.
GoldbergD.E., Genetic Algorithms in Search, Optimization, and Machine Learning, Addison-Wesley, 1989.
19.
HollandJ.H., Adaptation in Natural and Artificial Systems, University of Michigan Press, Ann Arbor, MI, 1975.
20.
HuangJ.CaiY. and XuX., A hybrid genetic algorithm for feature selection wrapper based on mutual information, Pattern Recognition Letters28(13) (2007), 1825–1844.
21.
KayaM., The effects of two new crossover operators on genetic algorithm performance, Applied Soft Computing11(1) (2011), 881–890.
22.
EberhartR.C.ShiY. and KennedyJ., Swarm Intelligence (The Morgan Kaufmann Series in Evolutionary Computation), 2001.
23.
KhalidS., A survey of feature selection and feature extraction techniques in machine learning,Science and Information Conference (SAI), 2014.
24.
KrohlingR.A.KnidelH. and ShiY., Solving numerical equations of hydraulic problems using particle swarm optimization, Proceedings of the IEEE Congress on Evolutionary Computation (CEC 2002), Honolulu, Hawaii USA, 2002.
25.
ManK.F.TangK. and KwongS., Genetic algorithms: concepts and applications (in engineering design), IEEE Transactions on Industrial Electronics43(5) (1996), 519–534.
26.
MirjaliliS. and LewisA., S-shaped versus V-shaped transfer functions for binary particle swarm optimization, Swarm and Evolutionary Computation9 (2013), 1–14.
27.
NakamuraR.Y.PereiraL.A.CostaK.A.RodriguesD.PapaJ.P. and YangX.S, BBA: a binary bat algorithm for feature selection. In 2012 25th SIBGRAPI Conference on Graphics, Patterns and Images, IEEE, 2012, pp. 291–297.
28.
GuQ.LiZ. and HanJ., Generalized fisher score for feature selection, In Proc. of the 27th Conference on Uncertainty in Artificial Intelligence (UAI), Barcelona, Spain, 2012, arXiv preprint arXiv:12023725.
29.
TalbiE.G., A taxonomy of hybrid metaheuristics, Journal of Heuristics8(5) (2002), 541–565.
30.
TawhidM.A. and AliA.F., A Hybrid grey wolf optimizer and genetic algorithm for minimizing potential energy function, Memetic Computing9(4) (2017), 347–59.
31.
TawhidM.A. and AliA.F., A hybrid social spider optimization and genetic algorithm for minimizing molecular potential energy function, Soft Computing21(21) (2017), 6499–514.
32.
TawhidM.A. and AliA.F., A simplex grey wolf optimizer for solving integer programming and minimax problems, Numerical Algebra, Control & Optimization7(3) (2017), 301–23.
33.
TawhidM.A. and AliA.F., Direct search firefly algorithm for solving global optimization problems, Applied Mathematics & Information Sciences10(3) (2016), 841–860.
34.
TawhidM.A. and DsouzaK.B., Hybrid binary bat enhanced particle swarm optimization algorithm for solving feature selection problems, Applied Computing and Informatics (2018 Apr 11). https://doi.org/10.1016/j.aci.2018.04.001
35.
TawhidM.A. and DsouzaK.B., Hybrid binary dragonfly enhanced particle swarm optimization algorithm for solving feature selection problems, Mathematical Foundations of Computing1(2) (2018), 181–200.
36.
XueB.ZhangM.BrowneW.N. and YaoX., A Survey on Evolutionary Computation Approaches to Feature Selection, IEEE Transaction on Evolutionary Computation20(4) (2015), 606–626.
37.
WolpertD.H. and MacreadyW.G., No free lunch theorems for optimization, IEEE Transactions on Evolutionary Computation1(1) (1997), 67–82.