
Abstract
Statistical uncertainties are rarely incorporated into machine learning algorithms, especially for anomaly detection. Here we present the Bayesian Anomaly Detection And Classification (BADAC) formalism, which provides a unified statistical approach to classification and anomaly detection within a hierarchical Bayesian framework. BADAC deals with uncertainties by marginalising over the unknown, true, value of the data. Using simulated data with Gaussian noise as an example, BADAC is shown to be superior to standard algorithms in both classification and anomaly detection performance in the presence of uncertainties. Additionally, BADAC provides well-calibrated classification probabilities, valuable for use in scientific pipelines. We show that BADAC can work in online mode and is fairly robust to model errors, which can be diagnosed through model-selection methods. In addition it can perform unsupervised new class detection and can naturally be extended to search for anomalous subsets of data. BADAC is therefore ideal where computational cost is not a limiting factor and statistical rigour is important. We discuss approximations to speed up BADAC, such as the use of Gaussian processes, and finally introduce a new metric, the Rank-Weighted Score (RWS), that is particularly suited to evaluating an algorithm’s ability to detect anomalies.
Introduction
In any fully rigorous or scientific analysis, uncertainties must be quantified and propagated through the full analysis pipeline.1 This is difficult to do with traditional machine learning algorithms that do not explicitly take into account uncertainties on the data or features. As machine learning is increasingly given authority for making more important and high-risk decisions, (e.g. in self-driving cars), and with the potential for adversarial attacks [1], there is an increasing need for interpretable models and rigorous statistical uncertainties on machine learning predictions.
In classification problems class labels are typically inferred through the use of a separation boundary that is learned from training data [9] and is based on a score combined with a threshold. This threshold is often arbitrary or learned as a hyperparameter to minimise some chosen loss function [19]. Any resulting class “probabilities” are systematically distorted in ways unique to the classification algorithm used and are not true probabilities, though in some cases these can be calibrated in a frequentist sense with more training data using isotonic regression or Platt scaling for example [20].
However, particularly in the physical sciences, we desire an algorithm that automatically outputs unbiased, accurate probabilities, since knowing the probabilities of an object belonging to various classes is typically more useful than the class label alone. The classification process is often just one step in a multi-stage pipeline, and it is important to propagate class uncertainties through the additional steps. This need is especially true in cases where the true class labels of the training data are noisy or subjective, or the training data are not representative of the test set. An example in astronomy is provided by the photometric classification of type Ia supernovae which are subsequently used for studies of dark energy. Hard label classification leads to contamination from non-Ia supernovae that leads to biases in dark energy properties while fully propagating class probabilities instead allows for unbiased results at the end of the pipeline [15, 11].
In this context Bayesian methods are ideal [7], as they have been proven optimal for classification for certain loss metrics, e.g. [8], and allow the option of both supervised or unsupervised classification [4]. In the context of astronomy, Bayesian techniques have been applied to classification of transient objects such as supernovae [5]. A common limitation in the classification of noisy data however, is that the classes in the training data are typically represented by a single template with zero variability (e.g. [24]). This allows straightforward Bayesian methods to be applied but does not apply if there is significant intraclass variability. Ignoring this intraclass variability also makes principled anomaly detection challenging: how unlikely is an example if one doesn’t know the underlying distribution within a class? Examples of recent work in this area include [26, 12, 28].
Here we address these limitations, constructing what we will argue is a natural, statistically robust supervised Bayesian method that can simultaneously be used for both anomaly detection and classification in the presence of measurement uncertainties on all data. Our method works directly with raw data, requiring no feature extraction, and requires minimal assumptions about the nature of the anomalies or classes.
We begin by describing the formalism in Section 2. We introduce a new metric optimised for anomaly detection, namely the Rank-Weighted Score (RWS) in Section 3 (the other metrics we also use to assess algorithm performance are discussed in Appendix B). Finally, we compare algorithm performance against various benchmark algorithms on simulated data in Section 4.
Formalism
Bayesian Anomaly Detection and Classification (BADAC) is a hierarchical formalism for both classification and anomaly detection in the presence of measurement uncertainty on all data. We make use of language common to machine learning by referring to training data (data for which we have a class label) and test data (unlabelled data we wish to classify). Additionally, we refer to features for the data for a specific instance of a class.
We start by assuming we have a training dataset consisting of multiple classes,
where
Let us now assume the data of each class can be modelled by
where
Since we won’t know
where
In general, the likelihood term
If we assume
The likelihood for a new test instance
Here
Schematic representation of BADAC as a classifier. Left: a single test example consisting of just two data points (black triangles with error bars). The training data comes from two classes shown schematically as the blue (
The posterior can be analytically evaluated in the special case of uncorrelated Gaussian distributed test and training data, and for (improper) flat priors on
and
where
where
In order to simultaneously perform anomaly detection and to normalise the posterior probabilities in Eq. (6), we compute the Bayesian evidence for
where the likelihood is given by Eq. (6). We use the evidence in Eq. (7) as our anomaly score: lower evidence values imply a data instance is more anomalous than test instances with higher evidence for one of the known classes.
If one has some prior knowledge of the anomalies, then a better alternative is to create a
In this section we introduce a new anomaly-sensitive metric that we call the Rank-Weighted Score (RWS). In addition to being insensitive to class imbalance, this metric is sensitive to the relative ranking of anomalous objects. In many cases there is a clear hierarchy of how interesting anomalous objects are (a new class is generally more interesting than a new subclass for example), and hence we prefer algorithms that correctly rank more anomalous objects more highly.4 This is natural because following up and investigating potential anomalies typically consumes resources (whether human or instrumental) and false positives, at any anomaly threshold, must be minimised.
The RWS is defined by ranking the
where:
Note that this gives (linearly) more weight to correctly identifying anomalies at the top of the ranks (with low values of
To illustrate and test the performance of BADAC, we simulate a number of one-dimensional datasets and compare results with multiple metrics including the Rank-Weighted Score (RWS) introduced in Section 3, that is optimised for anomaly detection.
Simulations
We simulate data from arbitrary mathematical functions. We use two mathematical functions to build two “normal” classes and use three other functions as anomalies. Each function has parameters which, when generating the data, are randomly drawn from a Gaussian distribution. The class functions and their corresponding parameter distributions are given in Table 1.
Description of the functions used to create the simulated data. 99% of the test objects in the dataset are of the type “inlier” and 1% are “outliers”. Each class has the corresponding functional form with parameters drawn randomly for each instance from Gaussian distributions with hyperparameters specified in the table
Description of the functions used to create the simulated data. 99% of the test objects in the dataset are of the type “inlier” and 1% are “outliers”. Each class has the corresponding functional form with parameters drawn randomly for each instance from Gaussian distributions with hyperparameters specified in the table
For each experiment, we generate 15000 curves of roughly equal number of objects from class 0 and 1 as training data. In the test data, we add 1% outliers from classes 2, 3 and 4. Figure 2 illustrates some randomly drawn objects from the training and test sets (equal numbers from each class).
Illustrations of example objects from the simulated data. The plotted error bars correspond to 1
We use the framework of Section 4.1 to create a variety of experiments to test our anomaly detection and classification algorithm. Here we simulate the data as described in Section 4.1 with uncorrelated Gaussian errors on all data points. The standard deviation of the underlying noise distribution depends on the class, and is given by:
Experiment 2: Compact anomalies
In this experiment, we test BADAC’s ability to detect curves with a compact anomaly embedded somewhere in them. We use one of the base inlier classes described in Experiment 1, the sine curve (class 0), and place on top of it a narrow Gaussian. We randomly draw the parameters of the sine curve from the distribution described in Table 1 and draw the parameters of the compact anomalies as described in Table 2. An example of a compact anomaly is shown in Fig. 3.
Description of the functions used to create the compact anomaly simulated data. 99% of the test objects in the dataset are of the type “inlier” which are the same as class 0 and 1 in Table 1. The remaining 1% are drawn from one of two compact anomaly classes. These are narrow Gaussians added to a randomly generated function of class 0. The parameters of the Gaussian are drawn randomly for each object from a distribution with hyperparameters as specified in the table
Description of the functions used to create the compact anomaly simulated data. 99% of the test objects in the dataset are of the type “inlier” which are the same as class 0 and 1 in Table 1. The remaining 1% are drawn from one of two compact anomaly classes. These are narrow Gaussians added to a randomly generated function of class 0. The parameters of the Gaussian are drawn randomly for each object from a distribution with hyperparameters as specified in the table
Example of the compact anomaly simulations. The underlying function from which the data were generated is shown as an orange solid line. The underlying function with the compact anomaly superposed is shown as the light blue solid line. The final data with noise are shown by the dark indigo scatter where the errorbars represent the 1
We assess the performance of our algorithm on the simulated data discussed in Section 4.1. We then compare our algorithm to a series of benchmark algorithms, namely IsolationForest [16] and Local Outlier Factor (LOF) [3] for anomaly detection, and random forests [2] for classification.
We use sklearn [21] implementations for all of the benchmark algorithms we compare against BADAC. For anomaly detection, all algorithms receive only the input training data, and the percentage of outliers of 1%. For classification with random forests, we set the input parameter n_estimators
Gaussian noise
Here we illustrate the performance of BADAC, as well as the benchmark algorithms, on the data discussed in Section 4.1 with Gaussian measurement error. We use the formalism shown in Section 2 to provide two probabilities,
Scatter plot showing the computed log-probabilities for the test data discussed in Section 4.1. Each point corresponds to a test object, which is shown in the log(
Probability calibration curve for the Gaussian case for BADAC and random forests (for classification only). Perfectly calibrated probabilities would lie on the line 
Anomaly detection challenge results for the Gaussian noise simulations and Gaussian noise compact anomalies for the three metrics (MCC, AUC and RWS) discussed in Section B. Metrics for algorithm evaluation. The best performer is shown in bold. Note the particularly poor performance of IsolationForest in the MCC and RWS metrics. BADAC significantly outperforms the other algorithms in the Gaussian case
Plotting the unnormalised probabilities is useful for visualising the decision boundary that separates both the known classes and anomalies. It also does not require us to make any assumptions about the nature of the anomalies we expect to see. However, to make use of these probabilities in an analysis pipeline, they must be normalised. In order to normalise the probabilities, we compute the Bayesian evidence. The evidence in the case where one is interested in classification only would be
If we bin the normalised probabilities for a single class, we can measure whether or not they are calibrated. It is a well known problem that many machine learning algorithms give uncalibrated probabilities that do not correspond to the true probability of an object belonging to a certain class. The reliability of probabilities can be investigated by plotting a probability calibration curve: the output probabilities from the algorithm for a selected class only are binned and compared with the actual fraction of objects in that bin belonging to the class. We show this result for classification only for type 1 objects in Fig. 5, and compare the results of BADAC with those of random forests.
ROC curves for BADAC, LOF and IsolationForest on the dataset with uncorrelated Gaussian error, for anomaly detection. BADAC performs best under the AUC metric shown in each legend. The best classification algorithms have a ROC curve that reaches close to the top left hand corner, with perfect performance corresponding to an AUC of one.
We show the ROC curves (see Appendix B for a description of ROC curves) for BADAC as well as LOF and IsolationForest in Fig. 6 in order to compare algorithm performance in anomaly detection. A summary of algorithm performance from all algorithms on all the datasets we consider in both anomaly detection and classification is shown in Tables 3 and 4.
Comparison of BADAC’s classification performance to that of random forests using average accuracy across both inlier classes
In this section we illustrate the performance of BADAC as well as the benchmark algorithms we consider on the compact anomaly data discussed in Section 4.1. It should be noted that the compact anomaly data is generated with Gaussian noise, which is the type of noise we assume in this implementation of our formalism, and is also the same kind of noise as the data described in Section 4.1. This means we would expect the algorithms to have similar performance in classification only in this section as in Section 4.2. For this reason, we don’t discuss classification performance of any of the algorithms on the compact anomaly dataset. We proceed in the exact same manner as we did in Section 4.2, except here we test how robust the algorithms are to different types of anomalies (compact ones).
The importance of an algorithm being able to detect compact anomalies is twofold. Firstly, compact anomalies are often interesting in science when one wishes to measure or detect aberrant behaviour of known sources. Secondly, an algorithm’s ability to detect compact anomalies demonstrates its overall sensitivity in measuring small variations within data.
The probabilities,
Scatter plot showing the computed log-probabilities for the test data discussed in Section 4.1. Each point corresponds to a test object, which is shown in the log(
As we can see from Fig. 7, the outlier data has significant overlap with type 0 data. This is because we create compact anomalies on top of type 0 data only. The varying scale/amplitude to the anomaly is responsible for where the outlier data is positioned on the log(
ROC curves for anomaly detection with BADAC, LOF and IsolationForest on the dataset with compact anomalies. BADAC performs best under the AUC metric, whose values in each case are shown in the legend.
We show the ROC curves for BADAC as well as LOF and IsolationForest in Fig. 8 in order to compare algorithm performance in anomaly detection. Under the AUC metric, BADAC performs the best in this case. LOF is almost as good, and actually performs better under the MCC and RWS metrics. A summary of algorithm performance from all algorithms on all the datasets we consider in both anomaly detection and classification is shown in Tables 3 and 4.
It is difficult to give a “fair” comparison of computational performance between BADAC, random forests, LOF and IsolationForest, since unlike the benchmark algorithms we compare it with, our algorithm has no distinct training and testing phases. This means that these algorithms scale very differently (depending on amount of training and test data available). For example, for a dataset with
For an even comparison of computational performance, we have compared the same number of training and testing samples as were used in Section 4.2 (15000 training samples and 15000 test samples). We quote the total time (training time
Comparison of the computational performance between the three algorithms we compare in Section 4. All measurements were made on the dataset used in experiment 1 (Gaussian noise) with 15000 training and 15000 test curves. There are no values shown for testing and training times for BADAC, since there are no distinct training and testing phases. Measurements were made on a 2.9 GHz processor, where each algorithm was limited to use a single core
Comparison of the computational performance between the three algorithms we compare in Section 4. All measurements were made on the dataset used in experiment 1 (Gaussian noise) with 15000 training and 15000 test curves. There are no values shown for testing and training times for BADAC, since there are no distinct training and testing phases. Measurements were made on a 2.9 GHz processor, where each algorithm was limited to use a single core
As is evident in Table 5, BADAC has a computational cost of around an order of magnitude more than any of the competing algorithms we considered. We discuss ways of mitigating this in Section 6.3.
So far, i.e. in the case of Gaussian errors, BADAC has outperformed random forests, LOF and IsolationForest under most metrics we consider. This is perhaps not surprising since BADAC was designed to use the extra information available, namely that there are uncorrelated errors on the data that are Gaussian distributed. Here we try a series of more challenging tests where we use the uncorrelated Gaussian BADAC formalism, but test it on data that do not obey this model.
Experiment 3: Non-Gaussian errors
Here we simulate the data exactly as in Experiment 1, however we use non-Gaussian errors instead of the Gaussian errors of Experiment 1. For 80% of the y values (randomly selected) of any given simulated object, the noise is drawn from a Gaussian distribution with standard deviation as described in Section 4.1, meaning the scatter matches the error bar. However, for the remaining 20% of the values, the noise is drawn from a Gaussian distribution of five times the width, resulting in scatter dramatically underestimated by the reported error bar.
Experiment 4: Correlated Gaussian noise
To test the sensitivity of our algorithm to the uncorrelated noise assumption, we generate correlated Gaussian data. We choose to only correlate class 0, according to a “wedding cake” covariance matrix (based on [13, 14]):
where
where
Here we present the results for both classification and anomaly detection for the data discussed in Sections 5.1 and 5.2 with both non-Gaussian and correlated Gaussian noise. It should be noted that we still use Eq. (6) to determine classification/anomaly detection probabilities, despite the fact that the data does not have Gaussian uncorrelated noise as Eq. (6) assumes. Thus we must expect BADAC performance to decrease; the question is how much?
The covariance matrix used for correlating the class 0 data for Experiment 3. This is a “wedding cake” covariance matrix, the form of which is shown in Eq. (10). The data are ordered by 
Probability scatter plot for the dataset with non-Gaussian noise (left panel), and the dataset with correlated Gaussian noise (right panel). Each point corresponds to a test curve, which is shown in the log(P0)-log(P1) space. The line 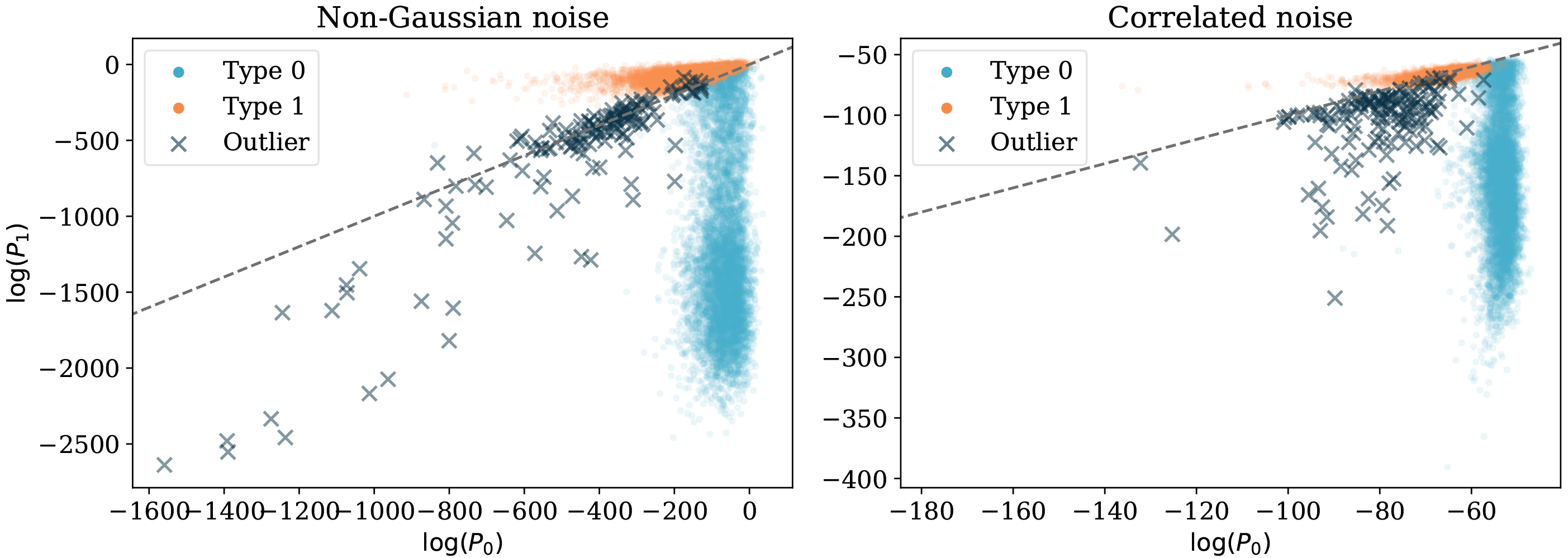
In order to normalise the probabilities shown in Fig. 10, we compute the evidence,
Probability calibration curves showing the degree to which the probabilities returned by each algorithm (in classification only) are calibrated for the non-Gaussian case we consider (left panel) and the correlated Gaussian case (right panel) respectively. Perfectly calibrated probabilities would lie on the line 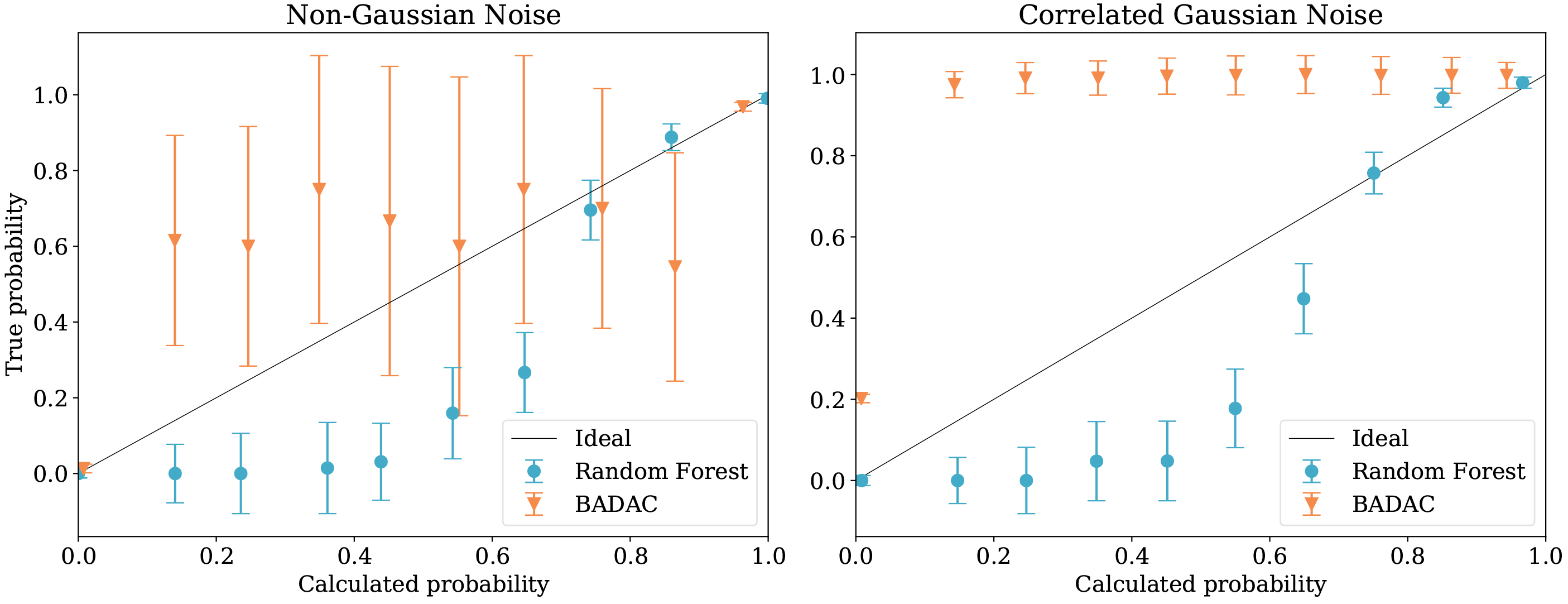
As we can see from the scatter of classification probabilities shown in Fig. 10, there is more overlap of different object types present than in the uncorrelated Gaussian noise case we considered. Additionally, in the correlated case, there is a significant bias introduced due to the noise from only one of the classes being correlated. Since the model does not favour fitting this class, the classification probabilities are not reliable. This is illustrated both by Fig. 10, where the diagonal dashed line shows where type 0 and type 1 clusters should be separated, and Fig. 11, where we can see that the classification probabilities are far from calibrated. This is due to the fact that we use a uncorrelated Gaussian model for the noise, despite the fact this model is wrong.
ROC curves for anomaly detection with BADAC, LOF and IsolationForest on the dataset with non-Gaussian error (left pane), and the dataset with correlated Gaussian error (right pane). BADAC performs best in both cases under the AUC metric (values shown in the legend).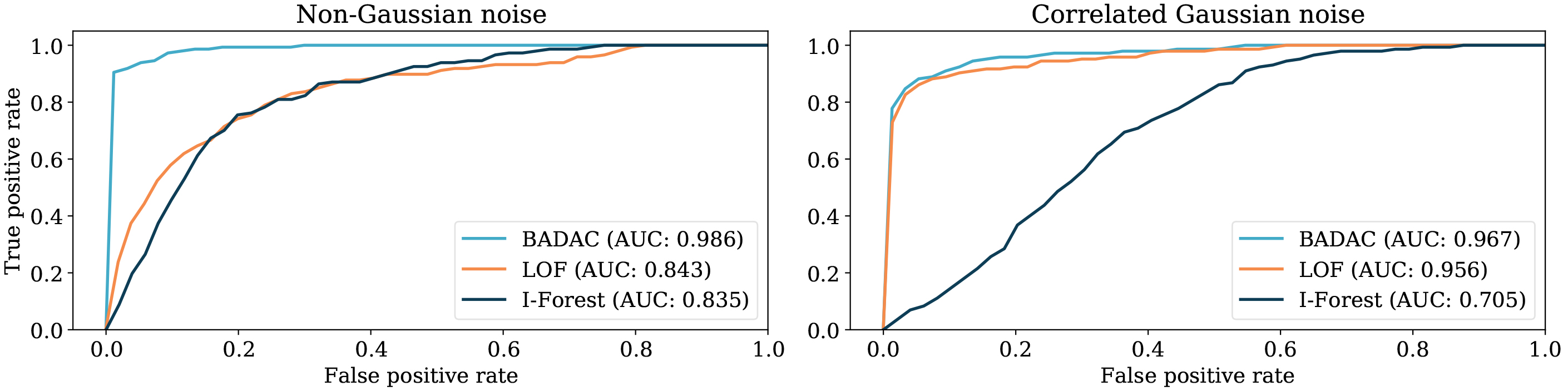
Results for anomaly detection only: Non-Gaussian and correlated Gaussian noise. BADAC shows the best performance in both experiments, showing some robustness to incorrectly choosing the model of the noise. In the non-Gaussian case both IsolationForest and LOF perform poorly in terms of MCC and RWS due to the wide tails allowing for large noise fluctuations
We show the ROC curves for BADAC as well as LOF and IsolationForest in Fig. 12 in order to gauge performance in anomaly detection. In these two cases, it is surprising BADAC performs best, since we don’t correctly model the noise. Random forests however achieves a higher accuracy in classification in these two cases. A summary of algorithm performance from all algorithms on all the datasets we consider in both anomaly detection and classification is shown in Tables 3 and 4.
We compare BADAC average accuracy for classification of all classes to that of random forests. BADAC performs reasonably in the case of non-Gaussian noise but fairly poorly on the correlated noise case, due to the incorrect model assumption in BADAC, while random forests is more robust as it can learn a model from the training data, while BADAC insists on interpreting the fluctuations as coming from an uncorrelated Gaussian distribution. This relatively poor performance of BADAC can be rectified by using, or learning, the right noise model
Learning subclasses
The BADAC algorithm we have presented can classify and identify anomalies. It can also add new classes as needed when run in online learning mode, as discussed in Section 6.7. The following example illustrates how BADAC can potentially identify subclasses of existing classes. But first, what do we mean by a subclass? Here a subclass corresponds to a large intrinsic variation in a class inconsistent with measurement errors.
In Eq. (6) we explicitly allowed each instance of a class
Let us define a hierarchy of models,
Dealing with missing data
In our discussion so far we have assumed the idealised case that we have data at the same points for all training and test data. This is clearly unrealistic and an important limitation. How do we deal with missing data?
There are two approaches. The first, more conservative, approach is to sample from the prior distribution with the error given by the prior distribution for that class. If the data is missing from test data, the missing data can be sampled as above, but in each case we use the prior for the class that it is being compared against.
The second approach is to use some form of interpolation. A natural approach is to use Gaussian processes, since these give both an expected value and Gaussian error at the missing data. Gaussian processes need a covariance function which encodes how rapidly the underlying class varies. As a result each class will have their own Gaussian process and covariance function which should be learned from the training data. Test data should then be compared to training classes using the appropriate Gaussian process for each of the training classes.
Template construction
As shown in Table 5 the full BADAC calculation is much slower than other classification or anomaly detection algorithms. This stems from the pairwise comparison of all data in the test dataset with all data in the training set, something which becomes computationally infeasible for very large amounts of training data.
Fortunately in the limit of large training data we can expect to sample the class distribution well and therefore we can instead create a single template for each class (or as an intermediate step, each sub-class), which will dramatically speed up BADAC, though at the cost of having a non-Gaussian spread in general.
How should we compute class or sub-class templates? An elegant solution is to fit a single Gaussian process to the data of each class [27]. This has the advantage of automatically dealing with any missing data, but will not deal with non-Gaussian or multi-model intra-class variability. To get around this limitation one could use a Kernel Density Estimate summed over the training data in each class at each value of the independent variable (or in bins). However, since this is a still a sum over all the training data examples it will be slow. To speed it up we need some approximation to the KDE sum.
Probably the simplest approximation – which also preserves the Gaussian distribution – is to use the inverse-variance estimator
If the intraclass variability is highly non-Gaussian then it would be better to fit a more appropriate low-dimensional distribution to describe this to create the template.
In the formulation presented earlier we assumed that the variability in the observed data for a given class was given by the measurement errors on the observed data, i.e. that the intraclass variability was small. If this is not the case one can build more complex models for the intra-class variability. The simplest is to fit for a global standard deviation,
Calibration and zero-point issues
In applying BADAC to real examples there may be systematic differences in the data between test and training. This could, for example, be because the data comes from different instruments or is taken under different conditions. As an example, consider applying BADAC to images where there may be large-scale calibration differences across the images. How can one deal with such effects which will invalidate the use of the simple versions of the BADAC formalism presented earlier, along with most anomaly and classification algorithms?
In the spirit of the Bayesian approach, one way to deal with such large-scale artefacts is to model their effects and introduce nuisance parameters
A related problem is the issue of zero-points, which occurs if the examples in training and test data are not all aligned on the
Depending on the exact nature of the data these translation parameters may be well-constrained. For example, one may be able to align all examples approximately, in which case one can put priors on the translation parameters. However, the zero-point issue does raise significant complications. For each pair in the training and test sets one should in principle allow a translation parameter. This leads to
A cheaper alternative is to pre-align all the training data by class. Now there is only one translation nuisance parameter per class and per instance in the test set. However, the alignment of the training data will not be perfect in general. This can be handled by adding an
Non-Gaussian data
Often, the standard deviation is used as a proxy for the error distribution on an observation, even when the distribution is non-Gaussian. In Section 5.1 we test how the algorithm developed in Section 2 performs while assuming a Gaussian error distribution, even when the error distribution is non-Gaussian. However, if the error distribution is known, the forms of the likelihood can be replaced with the known non-Gaussian distribution. These could be the binomial distribution in the case of count data, or the Poisson distribution in the case of certain time series. Any appropriate distribution that can be modelled can be used in this formalism. In the case of the binomial distribution, one would do a summation rather than an integration over the latent variables. For any distribution that doesn’t yield an analytically integrable form for
Online learning of new classes
Once we have confirmed that an anomaly represents a new class (i.e., if the Bayesian evidence for the anomaly class is higher than that of any of the existing classes) it can automatically be added to the training data as a new class (with a single example) to be compared with. This provides an online-learning version of the BADAC algorithm. Any future data belonging to the new anomaly class will be automatically assigned the new anomaly class label.
This process in no way limits us to a single new anomaly class. The BADAC formalism allows for the automatic addition of new classes as demanded by the data. If a new kind of anomaly is different from any previously identified anomalies it will automatically be assigned to a new class.
Conclusions
We have presented a novel statistically robust joint anomaly detection and classification method, Bayesian Anomaly Detection And Classification (BADAC), that is designed to take advantage of any knowledge of the underlying noise distribution in the training and test data. Although we perform tests for the case of Gaussian distributed data, our formalism is general.
Using simulated one-dimensional data, we test the classification and anomaly detection capabilities of BADAC. We make use of several metrics, including our novel Rank-Weighted Score that rewards algorithms for ranking more anomalous objects above those that have been commonly seen. We find that in the case where the correct noise model is known BADAC outperforms random forests at classification and both IsolationForest and local outlier factor (LOF) at anomaly detection, due to its ability to correctly exploit uncertainty information. In the case of compact anomalies, which could emulate noisy spikes in data, we find that BADAC’s performance is comparable to LOF and superior to IsolationForest. We demonstrate how BADAC produces calibrated classification probabilities, which is crucial if a machine learning algorithm is to be incorporated into a precise, scientific analysis pipeline.
We performed tests to investigate the degradation of performance if the assumptions of BADAC are violated. Interestingly, we find BADAC still outperforms the other anomaly detection algorithms in the presence of non-Gaussian and correlated noise. However we find its classification performance degrades, especially in the correlated case. We also note that with an incorrect noise model, the probabilities of BADAC are no longer guaranteed to be calibrated. However, if the structure of the noise is known, the correct noise model can be incorporated into the BADAC likelihood.
While BADAC provides excellent performance by exploiting the extra information about the underlying noise distributions, the computational limitations discussed in Section 4.3 mean that it does not scale well to large training datasets. In this case one must either use prototype templates to represent the classes (e.g. through Gaussian processes) or parametrise the data, to speed up classification and anomaly detection with BADAC.
We find ourselves in an era of exponentially increasing data volume, driving the need for machine learning algorithms. However in the physical sciences there is equal need for accurate propagation of uncertainties from all parts of an analysis pipeline, including any machine learning algorithms. With its statistically principled approach to both classification and anomaly detection, BADAC is able to provide believable and interpretable probabilities in the presence of measurement uncertainties, as required by high precision scientific analysis.
Footnotes
It is worth noting that this method of modelling the uncertainty fails when the measurement errors are zero, since the probability of classifying data
Strictly speaking we should write
Acknowledgments
We thank Alireza Vafaei Sadr, Martin Kunz and Boris Leistedt for discussions and comments. We acknowledge the financial assistance of the National Research Foundation (NRF). Opinions expressed and conclusions arrived at, are those of the authors and are not necessarily to be attributed to the NRF. This work is partially supported by the European Research Council under the European Community’s Seventh Framework Programme (FP7/2007-2013)/ERC grant agreement no 306478-CosmicDawn.
Appendix
A. Correlated data
It is possible to take correlated data into account in the formalism we’ve developed, if it is known how the data are correlated. Taking into account correlated data allows for better classification accuracy. Here we will talk about two types of correlation. Firstly, correlations may exist between different features in the same instance. Here we’ll refer to this as intra-instance correlation. Then we have correlations between different instances, which we refer to as inter-instance correlation. The following sections show where accounting for these correlations would enter the formalism we developed in Section 2.
B. Metrics for algorithm evaluation
In this section we outline the metrics we use in Section 4.2 to quantify algorithm performance for both classification and anomaly detection. The choice of a metric is important since inappropriate metrics can give very misleading results. In our case we want metrics that are insensitive to class imbalance (since anomalies are assumed to be rare).
While one of the metrics considered, the AUC (Section B.1. Area Under the Curve), uses the probability of belonging to a particular class, the other metrics discussed require a strict classification. In all cases, we take the class with the highest probability to be the algorithm’s classification.