
Abstract
The present paper aims to propose a new information-theoretic method to minimize and maximize selective information repeatedly. In particular, we try to solve the incomplete information control problem, where information cannot be fully controlled due to the existence of many contradictory factors inside. For this problem, the cost in terms of the sum of absolute connection weights is introduced for neural networks to increase and decrease information against contradictory forces in learning, such as error minimization. Thus, this method is called a “cost-forced” approach to control information. The method is contrary to the conventional regularization approach, where the cost has been used passively or negatively. The present method tries to use the cost positively, meaning that the cost can be augmented if necessary. The method was applied to an artificial and symmetric data set. In the symmetric data set, we tried to show that the symmetric property of the data set could be obtained by appropriately controlling information. In the second data set, that of residents in a nursing home, obtained by the complicated procedures of natural language processing, the experimental results confirmed that the present method could control selective information to extract non-linear relations as well as linear ones in increasing interpretation and generalization performance.
Introduction
Interpretation and information control
Though much attention has been paid to improved generalization performance of neural networks, the interpretation of their core inference mechanism has been considered more important than the mere improving of generalization performance for the deeper understanding of learning as well as their application from the beginning of research on neural learning, in particular, in the connectionism approach to cognition [48, 49, 50]. Naturally, many different types of interpretation methods have been developed, in particular, recently in the rapidly developing fields of convolutional neural networks (CNN) [41, 39, 43, 57, 58, 35, 3, 25], due to the urgent need for the interpretation. In spite of those studies, it seems that the interpretation methods so far developed have not been so successful as had been expected.
In this context, the present paper aims to extract the core inference mechanism of a neural network for interpretation by an information-theoretic method. For successfully reaching the core mechanism behind a great number of actual and complicated representations, we certainly need to maximize information on the core and important properties related to the learning of neural networks. However, because it is impossible to separate the core from peripheral information in learning, the information maximization methods cannot necessarily produce the expected results. One of the possible solutions for this problem is not to separate the supposed core from peripheral information, but ironically, to eliminate differences between them as much as possible for the subsequent procedures to distinguish between them easily and impartially. This corresponds to minimizing information in input patterns for the subsequent information maximization processes to select and augment more appropriate information. We need to minimize information to a point where learning becomes almost impossible, and then information maximization should begin to restore important information for learning.
Information minimization and maximization
The necessity of both information maximization and minimization in learning has been well clarified in the recent discussion on the necessity of selectivity. One of the main objectives of neural networks is to obtain selective information by which neural components can respond selectively to the other components as well as incoming input patterns. The selectivity has been studied for a long time in the neurosciences, including neural networks, and the necessity of selectivity has been considered one to be naturally accepted [19, 5, 65, 7, 47, 4, 64, 21, 44, 27, 6]. However, there have recently been some important reports on the necessity of selectivity in neural networks, stating that the selectivity is of no use in improving generalization or is sometimes harmful to it [37, 26, 27]. Naturally, immediate counter responses to this statement have been made public to stress the importance of selectivity [62].
As mentioned above, those opposite statements toward or against the selectivity are mainly due to the properties or characteristics of input patterns and the types of target neural networks. This means that the necessity of selectivity can be justified only within several conditions. For example, in the convolutional neural networks (CNN), dealing with image data sets and represented by many pixels, the input variables naturally do not have any meaning. Then, we need to extract information in input patterns as much as possible, meaning that the components in the CNN should respond very selectivity to non-informative inputs to obtain necessary information in input patterns for learning.
On the contrary, in other data sets, such as business data sets, dealt with in this paper, input variables have a very specific meaning, because they are artificially created to encode information in input patterns according to the so-called “human bias” [52, 54]. This encoding of information may not be necessarily useful to all types of learning, due to the human bias against information inside input patterns. In particular, it should be noted that the human bias can be seen in the contrary meaning in the discussion of adversarial examples [24, 8, 17, 20]. The majority of the discussions on this subject have focused on how to eliminate these adversarial ones as much as possible. Then, they have tried to force learning to have more humanly biased representations. The adversarial examples, from our viewpoint, can be considered the important parts of the input data by which we can reach the true inference mechanism of neural networks, supposed to be different completely from our inference [20]. It should be stressed that our objective in neural learning lies not in make learning more humanly acceptable, but in extracting how neural networks process information in their own ways. The humanly acceptable learning can be one of the most important efforts, in particular, for neural networks to be applied to real data sets. However, we suppose that the neural network, one of the main extensions of the human being, does not necessarily follow human inference logic, but possibly it tries to create its own inference procedures, different from ours. Thus, the humanly biased and acceptable information in the encoding process, including the biases against the adversarial examples, should be eliminated. We can say that artificially created input variables do not necessarily represent real and necessary information in input patterns due to some biases toward or against the input patterns. In this case, it is necessary to reduce the selectivity of components as much as possible. The selectivity can be of some use, only depending on the conditions of learning.
Concerning the data and the problem to be discussed in this paper, we deal here not with huge image data sets with impartial inputs but with a small but complicated data set in a natural language, whose input variables may not be encoded to represent well the information of input patterns due to the fact that, in the process of obtaining a data set, much ambiguous processing inherent to a natural language should be taken. Thus, before the selectivity is actually dealt with, it is better to decrease the selectivity arising from the humanly biased input variables. Then, after excluding the biased factors from the input variable, we should try to increase the selectivity of components. This shows the necessity of selective information minimization and at the same time maximization. When we can successfully reduce complicated information encoded through the artificially created input variables, it can be easier to obtain the main and important information.
In the conventional information-theoretic methods, there have been serious efforts in introducing both information maximization and minimization, though sometimes implicitly. In addition, we have used more complicated information measures, such as mutual information in which information maximization and minimization are implicitly built in. We should note that the information concept is ambiguous in its meaning, and we suppose here that information is dealt with from not its transmission but its storage viewpoint [16]. Since the introduction of information-theoretic methods in neural networks, there have been several attempts to include both information minimization and maximization in one framework or in a unified way. One of the well-known and classical information-theoretic methods of this type is “the maximum information preservation” by Linsker [30, 31, 32, 33], where information is represented in terms of mutual information. This mutual information has been extensively used in the information-theoretic methods [60, 61, 28, 63, 46, 45, 34], following Linsker’s methods. In maximizing mutual information, implicitly, information minimization and maximization are included. This means that, on average, information should be decreased, but also, conditionally, information should be increased. More concretely, each component should have specific or conditional information, and those informative components should be activated as equally as possible on average with the least information. However, the majority of methods were realized not by directly computing mutual information but by indirectly replacing it with some bounds to be computed [2, 10]. Furthermore, the recent information-theoretic approach can be directed to the unification of information maximization and minimization to obtain the simplest representations, in which multiple operations of mutual information should be simultaneously performed [22, 9, 59, 55, 1, 53]. This unified approach, quite similar to Linsker’s approach, has faced the same but more serious problem of computing the complicated information measures and of how to compute the relevant and residual information. Even simple information minimization and maximization cannot be easily compromised, much less mutual information.
Incomplete information control
In addition, this problem can be related to the incomplete information control, which can be summarized by three points, namely, contradiction within the information control, simultaneous operation, and contradiction outside the information control. First, incomplete information control can be found within the information control. As mentioned above, mutual information methods have not been successfully applied, because information minimization and maximization are contradictory to each other, and in addition, conditional information (conditional entropy) could not be easily computed compared with unconditional information (entropy). Information is maximized and minimized with much difficulty even though these processes are performed in different levels due to the interactions between different levels. Thus, as mentioned above, many information-theoretic methods have used not the full mutual information but partial mutual information, focusing on either information maximization or minimization, as was done in the classical studies by Linsker [30, 31, 32, 33].
This incomplete information control can be observed more explicitly in information minimization. Dating back to Deco’s well-known papers on information minimization to improve generalization [11, 12, 13], information minimization methods have received due attention. By replacing the information for the selectivity, this statement shows the same point, that the information or selectivity is of no use in improving generalization. As mentioned above, one of the main reasons for these statements on the non-necessity of selectivity or information is that there is an expectation that, by decreasing the selectivity and information, some absolutely necessary ones should survive in the end. Thus, behind this selectivity and information minimization, there are implicit attempts to detect informative components, meaning that those methods try to increase selectivity and information in those surviving components. This implicit meaning of information minimization can be applied to the well-known regularization methods such as the weight decay in improving generalization [36, 23, 18, 66, 15]. By reducing the strength of connection weights, they actually try to detect important weights. Eventually, they try to detect a small number of sparse informative weights and try to increase the information. Thus, information minimization processes can be said to be incomplete, because they suppose a process of implicit information maximization inside information minimization.
Second, a contradiction can be observed in the simultaneous operation. Usually, information maximization and minimization are simultaneously applied, making it harder to compromise between them. We think that incomplete information (mutual information) minimization and maximization can be due to the difficulty in this simultaneous information maximization and minimization. Thus, we need to develop a method to weaken the simultaneous information minimization and maximization. Third, there is the incomplete information control due to the contradiction between information control and error minimization. Learning by neural networks lies in reducing errors between outputs and their targets. This error minimization can be contradictory to the information control. For example, information minimization on input patterns is contrary to the error minimization, because it tries to increase information on input patterns as much as possible. Thus, in addition to the contradiction within the information control, there is the other contradiction between information control and error minimization. Thus, we need to compromise between those contradictory operations as much as possible.
Cost-forced learning
The present paper aims to extract the core inference mechanism behind complicated information, and for realizing this, we need to control information content, where we must decrease unnecessary information, and then core information should be increased as much as possible. However, as mentioned above, the information control tends to be incomplete, and we have had much difficulty in controlling the information, in particular, information minimization. For this problem, we try to minimize information even at the expense of the necessary cost in learning. After this minimization, information is again maximized to enhance the features of components. In addition, this process of information minimization followed by information maximization should be repeated many times, and gradually information maximization should be realized.
In living systems, naturally, the cost control to process information plays an important role [42, 29]. We have so far mainly focused on how to reduce the cost to process information content in living systems. However, we can imagine that there exist naturally some cases where the necessity of cost augmentation is needed. In this case, to reduce information content, we must augment the corresponding cost, meaning that information control needs the corresponding cost control. In the conventional approach, the cost for learning has been considered one to be decreased as much as possible. For example, if the strength of weights is supposed to be the cost, there are many different types of regularization methods in which the strength of weights is decreased as much as possible [18, 23, 66]. We suppose here that, to minimize information against error minimization, we need to force information to decrease at any cost. The cost augmentation may be accompanied by an increase in the strength of all weights, which is contrary to the conventional approach of regularization. We stress here that we need to augment the cost in terms of the strength of connection weights to reduce unnecessary information, but at any time this cost augmentation should be accompanied by the cost reduction in the subsequent phase of learning. Monotonic increase or decrease in information or cost is not effective in compromising between error minimization and appropriate information acquisition in learning. Information and cost should be minimized and maximized repeatedly to gradually reach a final state where important information is appropriately obtained.
The purpose of the present study
From the above discussion, we can now clarify the objectives of the present paper. We propose a new type of information learning method, called “cost-forced selective information learning,” to extract the core inference mechanism of neural networks. The new method has two characteristics, namely, repeating information maximization and minimization, and cost-forced information control. First, we try to develop a method to control learning processes, realized by changing information content inside neural networks. The basic technique lies in repeating information minimization and maximization many times and gradually reaching the final states with clear, stable, and core representations for interpretation. Second, to deal with the incomplete information control problem, information is forced to decrease and to increase by augmenting and reducing the cost in terms of weight strength. Thus, contrary to the concept of the regularization approach, the new method tries to “de-regularize” networks to reach a state where networks’ possibilities can be fully utilized even at the expense of larger cost.
Concept of cyclic information minimization and maximization.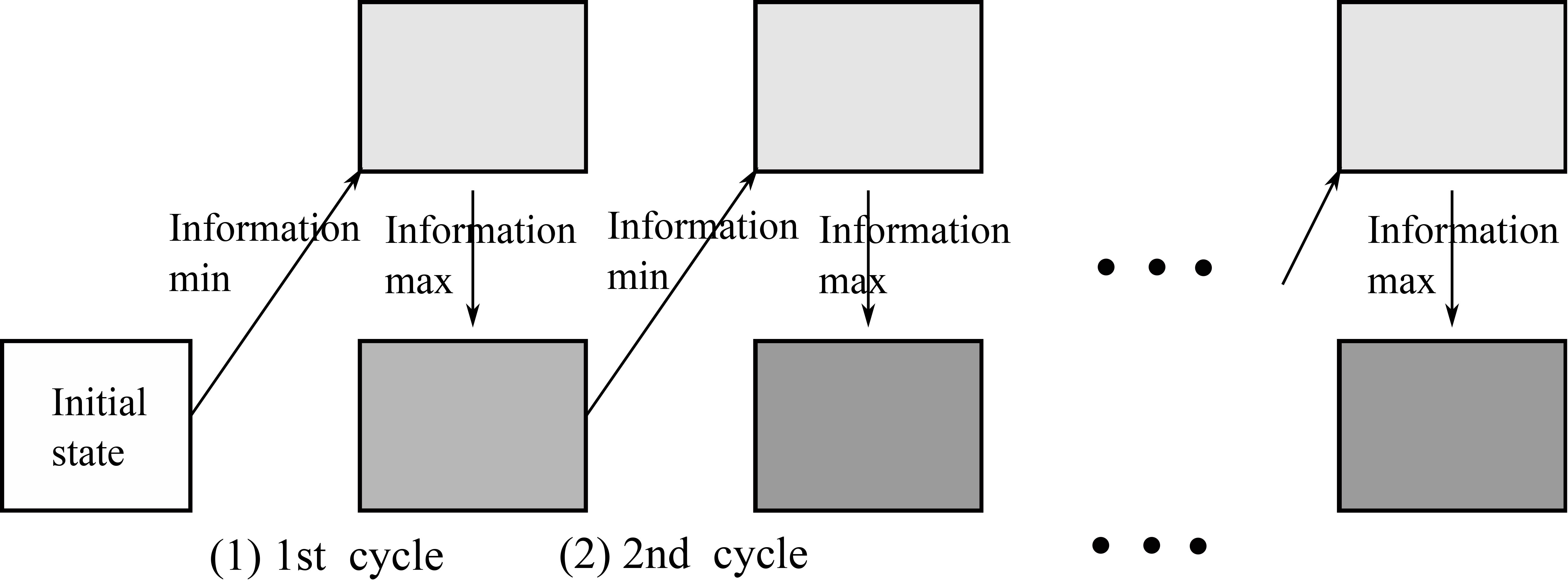
This paper is organized as follows. In Section 2, after briefly explaining the concept of repeated information minimization and maximization, we introduce the basic information-theoretic terms, such as potentiality and selective information. Then, we try to explain how to decrease and increase selective information by controlling the cost in terms of the sum of all absolute weights. In addition, we try to explain a new approach to the interpretation called “open” interpretation for compressing and condensing information in multi-layered neural networks. In Section 3, we apply the method to two data sets, namely, an artificially created symmetric data set and a nursing home data set, obtained by the natural language processing. In the symmetric data set, we try to show that, even with very redundant ten hidden layers, by controlling the information inside, the original symmetric property could be restored. In the second data set, by controlling the cost, we could produce networks having collective and compressed weights with higher correlation coefficients between inputs and targets as well as better generalization. By examining collective weights obtained by averaging all compressed weights at any learning step, we could see on which inputs the networks tried to focus.
Theory and computational methods
Cost-forced information control
Information minimization and maximization
We suppose here that a neural network tries to minimize and maximize information repeatedly, as shown in Fig. 1. As discussed above, input patterns are not necessarily encoded appropriately and given to the target neural networks. In those cases, we need to reduce information from inputs as much as possible, which makes it possible to increase necessary information. In addition, when information minimization cannot be performed sufficiently and information maximization cannot produce appropriate results, we need to repeat this process of information minimization and maximization several times.
Figure 1 shows a concept of this repeated information minimization and maximization. In the first cycle, information coming from inputs is reduced as much as possible, and then information is increased. This cycle of information minimization and maximization can be repeated many times for neural networks to reach the final informative states. In this paper, we restricted the number of cycles to two due to the stability of learning in the actual experiments, and in future studies, we will try to extend the number of cycles as much as possible.
Potentiality and information
Information in this paper can be called “selective information,” showing how selectively neurons respond to other neurons. The selective information is computed in terms of connection weights. Usually, the selectivity has been computed by using the input patterns, implying to which input patterns the corresponding neurons respond. We restrict the computation of selective information within connection weights, because we try to focus on the inner inference mechanism as independently as possible of any input patterns.
For simplicity, we focus here on connection weights between the second and third layer (2, 3), as shown in Fig. 2. Naturally, the following formulation can be applied to any connection weights in all hidden layers. First, we take the absolute values of connection weights.
Selective information minimization (potentiality maximization) (a) and selective information maximization (potentiality minimization) (b).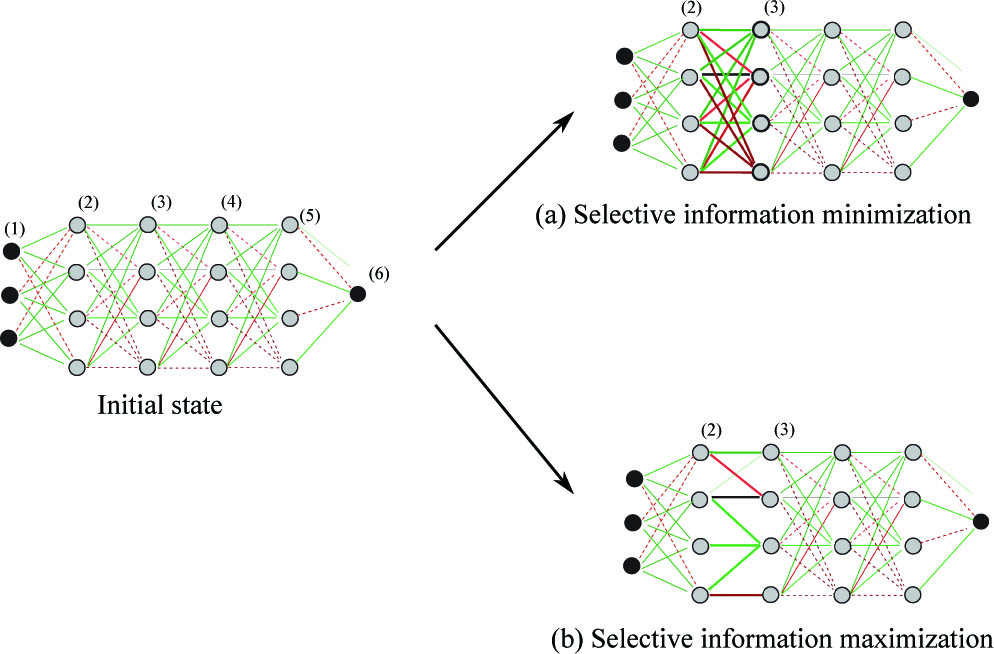
Then, normalized absolute weights are defined by
where the maximum operation is over all connection weights from the second to the third layer. We call this importance “potentiality,” because it has some power to increase or decrease the selectivity. By using this potentiality, selective potentiality can be computed by
When all connection weights have equal potentiality, this selective potentiality becomes maximum in Fig. 2(a). On the contrary, when a connection weight has some strength, while all the others are zero, this selective potentiality becomes minimum. In other words, when the number of strong connection weights becomes smaller, the potentiality becomes smaller in Fig. 2(b). For simplicity and practical reasons, at least one weight should be larger than zero.
In addition, we define the complementary potentiality by
By using the complementary potentiality, selective information can be computed by
This selective information is exactly the inverse of the selective potentiality. When the selective potentiality becomes smaller, the selective information is larger in Fig. 2(b). Then, when the selective potentiality is larger, the selective information becomes smaller in Fig. 2(a). This process of selective potentiality and information corresponds to the entropy and information in the conventional information theory. However, the selective potentiality and information can be more easily computed and interpreted.
Then, we should compute the cost associated with this selective information. In this paper, the cost is computed simply by the sum of all absolute weights
When the strength of potentialities becomes larger, this cost simply becomes larger.
Concept of cyclic cost-forced information maximization and minimization.
As shown in Fig. 3, the present paper restricts the number of information cycles to two for the stability of learning, and for the first approximation to more general learning cycles. Thus, the process of information minimization and maximization is repeated only twice.
First, to reduce the selective information, we can use the complementary potentiality, and the weights in the
When the complemental potentiality becomes larger, larger weights are forced to be smaller. However, some instability has been observed by this direct method, and we introduce a modified one with three parameters.
The parameter
Second, the selective information can be increased by using the usual and individual potentiality with two parameters.
Then, we use the same type of potentiality assimilation process.
One of the main characteristics of this method is that information minimization and maximization can be controlled by the primary parameter
Figure 3(a) shows connection weights for the first cycle. For an easy explanation of the cost, suppose that the parameter
Finally, we should note an assimilation method to incorporate the potentiality into connection weights. The potentiality is not simultaneously assimilated with error minimization. Once the potentiality is applied to weights, the connection weights are updated as usual for several learning epochs. Thus, in one learning step, there should be several sub-steps or learning epochs for assimilation.
Open and closed interpretation
We use here a new type of interpretation method called “open interpretation.” For an easy explanation of the method, we need to introduce two types of interpretation, namely, open and closed interpretation. The open interpretation aims to clarify the inner working mechanism, considering all possible representations generated by neural learning, which is connected with the interpretation of neural models as they are. The closed one tries to interpret an instance or a component among many possibilities, which is naturally dependent on specific input patterns as well as specific learning conditions. From our viewpoint, the majority of interpretation methods seem to be classified as closed ones, because they have eventually tried to interpret only an instance or a component for a specific condition among many interpretation possibilities. They cannot consider many different kinds of interpretation for the same data sets, depending on different initial conditions, different subsets of input patterns, different learning methods, and so on. For example, the visualization by optimization [14, 56, 41] has shown better performance in understanding the meaning of neurons or to what inputs they try to respond to maximally. However, neurons can have sometimes completely different roles and functions by different initial conditions [40]. In this case, the sum of any full interpretation by this kind of optimization cannot lead us to find the true meaning of the component. Those individual, local, and closed interpretation methods can be very useful to specific application fields, because many application studies naturally need a specific interpretation for a specific objective of the corresponding application field. Those closed methods have been considered the most important and typical interpretation approach, in particular, for the CNN. This is easily understood, because the CNN must process input patterns in various information filters, such as convolutional and pooling layers. Thus, we can easily see or visualize a process of information transformation in many hidden layers in terms of extracted features, leading us to find a specific interpretation for a specific input pattern. Though more general features can be extracted sometimes, they seem to be changed, depending on initial conditions and the other many conditions introduced in learning.
On the contrary, the open interpretation proposed here aims to consider as many instances, components, and representations as possible, obtained and generated in the course of learning. This means that it aims to interpret the main mechanism, as independently as possible of outer conditions. The main objective is to find more universal and deeper types of inference mechanisms behind complicated ones. In the open interpretation, the explanation should be focused on the mechanism behind a great number of different types of interpretations. This approach aims to see a more general principle, and each interpretation instance should be transformed from the core one. In multi-layered neural networks, the method aims not to explain specific responses of neurons but to explain how multiple layers cooperate with each other to unify individual representations and to produce the core ones in the end.
We think that the interpretation of the inference mechanism of neural networks should be the open interpretation, in which we should try to take into account all possible representations obtained by different initial conditions, different subsets of input patterns, different parameter values, and so on. For this purpose, we train multi-layered neural networks with a number of different conditions. For each condition, we compress the multi-layered networks into the simplest ones without hidden layers. Then, all the compressed weights are averaged to get the final compressed weights or collective weights. We introduce here the full compression to produce the collective weights for the open interpretation. In addition, we propose methods to examine the states of hidden layers by partial compression.
Full compression
In the first place, we need to compress all connection weights in all layers into connection weights of two layers, namely, an input and an output layer for the easy interpretation. As mentioned above, we use the open interpretation, in which we do not deal with an individual case of compression, but we try to deal with all instances of all connection weights. Thus, the compression is over all networks obtained in a process of learning, and we try to average the compressed weights to obtain “collective” weights, computed collectively over all possible representations.
As shown in Fig. 4, in the first learning step, all connection weights from the input to the output layer are compressed, and we have the final compressed network in Fig. 4(a5). In the second learning step in Fig. 4(b), compression is applied in the same way to get the second final compressed network in Fig. 4(b5). This compression process continues until the final learning step is reached in Fig. 4(c). This process of compression is applied for all cases with different initial conditions and different subsets of the original data set in Fig. 4(d). Finally, all these networks are averaged to obtain the final collective network with collective weights in Fig. 4(e).
Let us show how to compress a network. We use connection weights from the second layer represented by (2) to the third layer (3) in the first step (a). As shown in Fig. 4(a1), weights from the first layer to the second layer
where (1, 3) represents a route from the first to the third layer, and
In the same way, we can get the compressed weight from the first layer to the fifth layer
The compression step is repeated from the first step (a) to the final step (c). Then, combining the compressed weights obtained by different conditions (d), the final collective weights are obtained in Fig. 4(e).
The compression of the first learning step (a), the second learning step (b), and final learning step (c). Compression weights by other conditions (d) and the final collective weights averaged over all compressed weights (e).
Full compression (a), cumulative compression (b) up to the fourth layer, and individual compression (c) only with the fourth layer.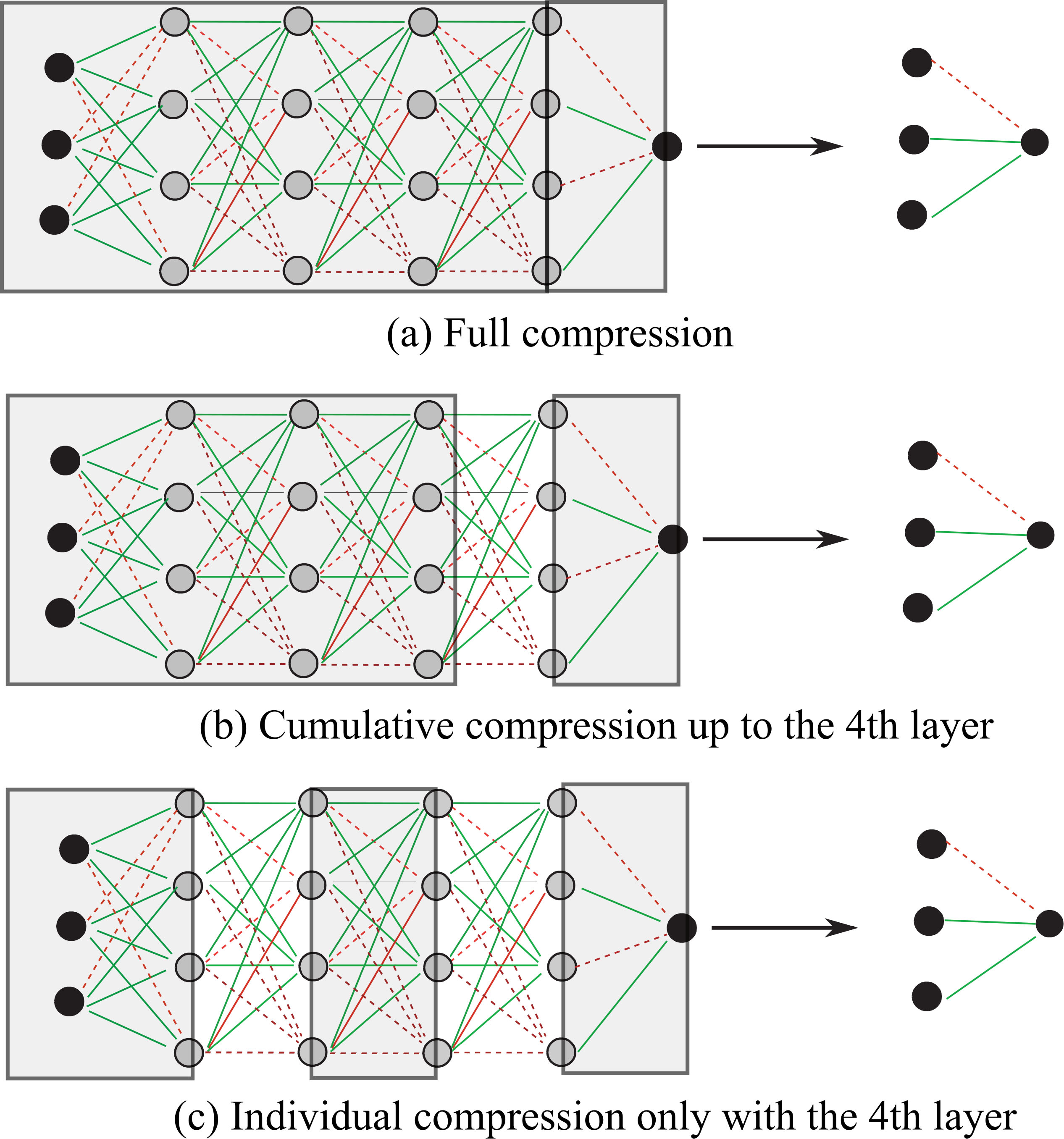
In addition to the full compression for collective weights, we introduce partial compression with individual and cumulative compression applied to an instance of connection weights. The individual compression aims to examine what features a specific hidden layer tries to extract, while the cumulative compression tries to compress weights up to a specific hidden layer and tries to examine what features compressed weights compressed up to a specific hidden layer try to detect. Figure 5 shows the full compression (a), cumulative compression (b), and individual compression (c). As explained above, in the full compression in Fig. 5(a), all connection weights are compressed into the simplest compressed weights between the input and output layers. In the cumulative compression in Fig. 5(b), we compress connection weighs up to a specific layer. In the figure, we compress connection weights up to the fourth layer. The cumulative compressed weights up to the fourth layer, represented by (1, 4, 6), can be computed by
where
On the other hand, in the individual compression in Fig. 5(c), we focus on connection weights for a specific layer and compress them. In the figure, we compress only the connection weights between the third and fourth layers and input and output layers to produce the final compressed weights. The individual compression with the fourth layer, denoted by (1, (4), 6), is computed by
where
Symmetric data set
Experimental outline
The first experiment was designed to demonstrate the power of our information-theoretic method by showing to what extent information maximization and minimization could be effective in controlling final representations. Figure 6 shows the network architecture and the process of repeated information minimization and maximization used in this experiment. The number of inputs was 20, corresponding to the symmetric input pattern. The network should determine whether an input was located on the left-hand side or on the right-hand side. As shown in Fig. 6, there were two cycles, in which information in each cycle was forced to decrease in the first place and the information was increased as much as possible. As shown in the figure, for the first 25 learning steps (a1), information was minimized, and for the following 25 steps up to the 50th learning step (a2), information was maximized. This process was repeated in the second cycle (b1) and (b2). The information could be controlled by changing only the parameter
A network architecture for the symmetric data set with two learning cycles, where the number of inputs and hidden neurons were 20 and 10. Only the first 20 input patterns are plotted on the left-hand side.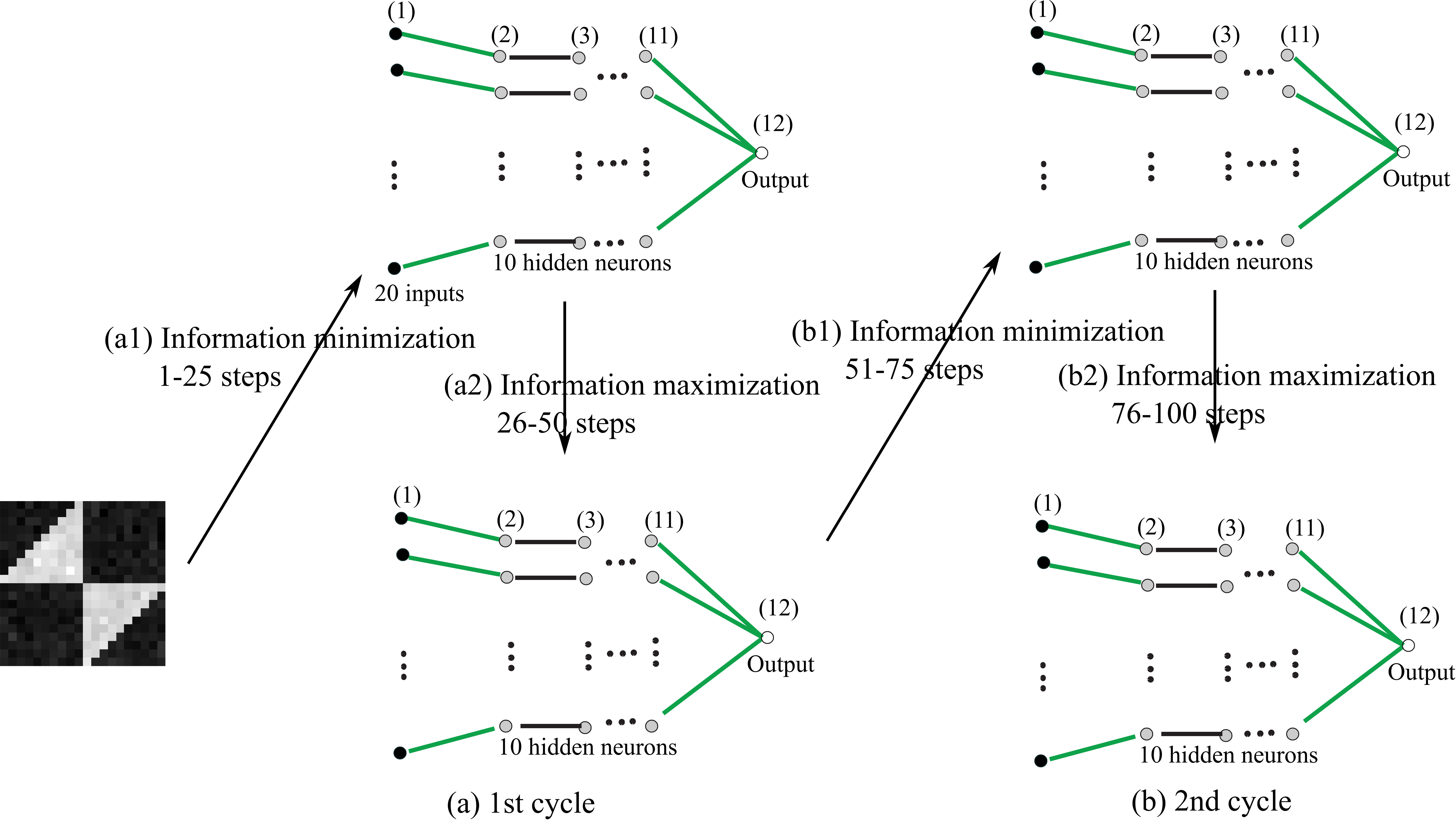
The results show that the parameter
Figure 7 shows the results of selective information (left), cost (middle), and ratio of information to its cost (right) by the conventional method without selective information, and when the parameter
Selective information (left), cost (middle), and the ratio of information to its cost (right) as a function of the number of learning steps by the conventional method (a) and by the new method, when the parameter 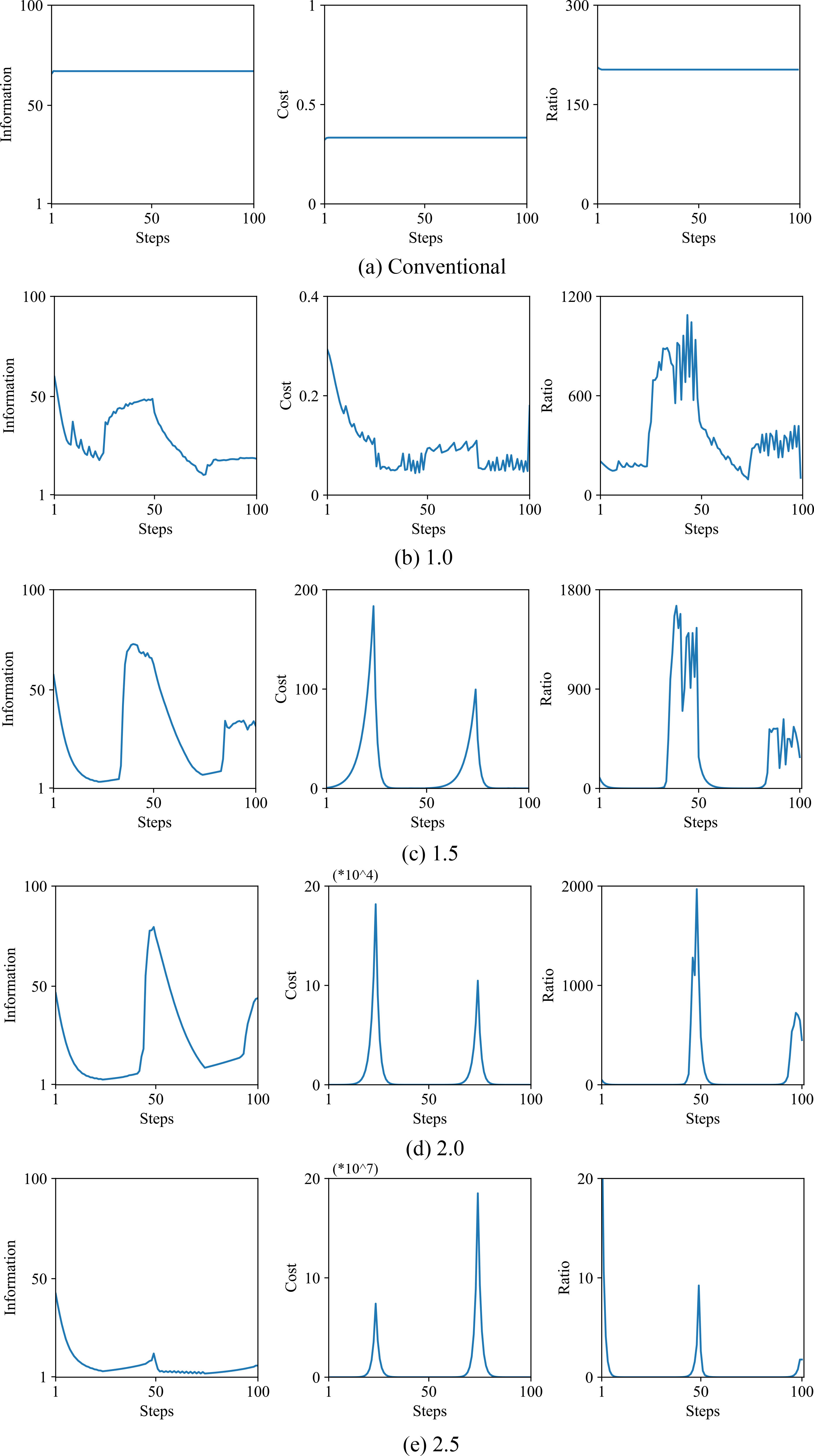
The results show that the appropriate increase in the parameter
Figure 8 shows connection weights (1) and potentialities (2) by the conventional method (a) when the parameter
Weights (1) and potentialities (2) for all hidden layers by the conventional method (a) and by the selective information method when the parameter 
This shows that, when the parameter
Weights (1) and potentialities (2) for all hidden layers by the selective information, when the parameter 
The results show that when the parameter
The correlation coefficients between inputs and targets computed for the original data set (a), and collective weights (left) and relative collective weights to the original correlation (right) by the conventional method (b), and by the information method when the parameter 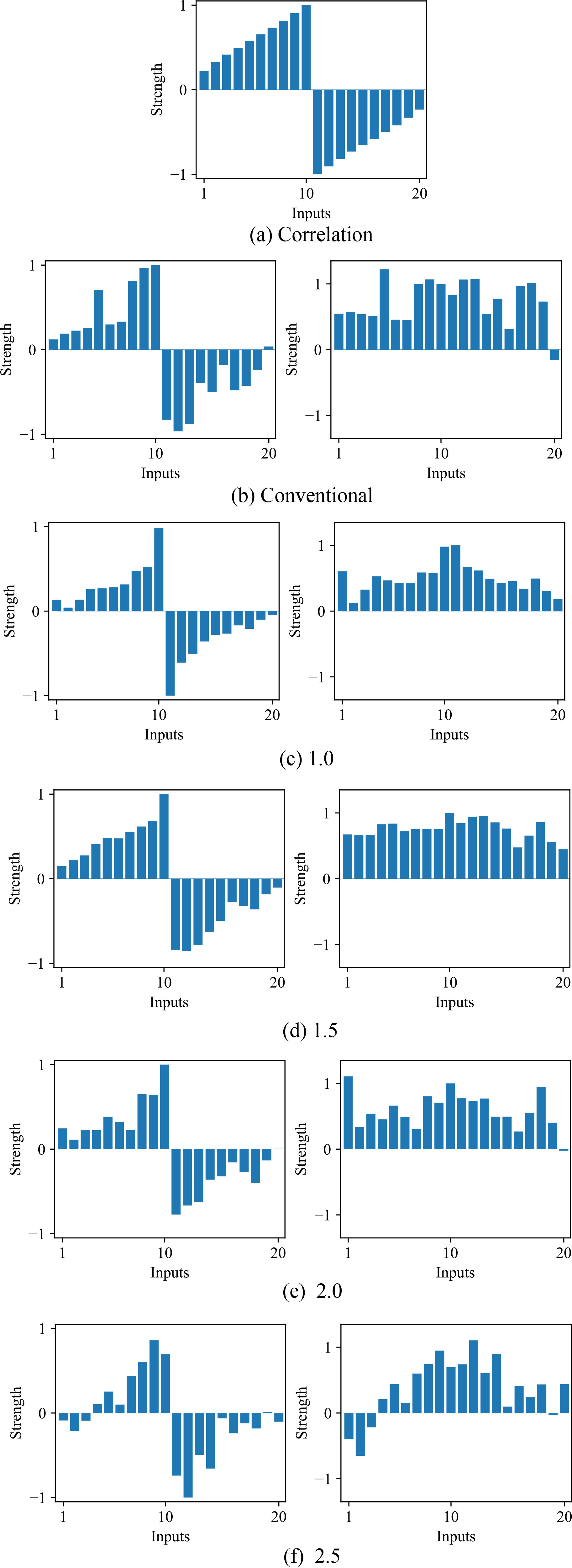
Figure 10(a) shows the correlation coefficients between inputs and targets of the original data set. When the conventional method was used in Fig. 10(b), collective weights were activated rather randomly. When the parameter
The results confirmed that the appropriate control of the parameter
Figure 11 shows compressed weights computed individually for connection weights for each hidden layer. As can be seen in Fig. 11(a), the conventional method seemed to try to capture the original correlations for each hidden layer. On the contrary, the selective information methods in Fig. 11(b) to (e) seemed to respond not collectively but individually to inputs. However, when the parameter
Individually compressed weights by the conventional method (a) and by the information method when the parameter 
Figure 12 shows cumulatively compressed weights. One of the main characteristics is that, with all the methods except the one with the parameter
Cumulatively compressed weights by the conventional method (a) and by the information method when the parameter 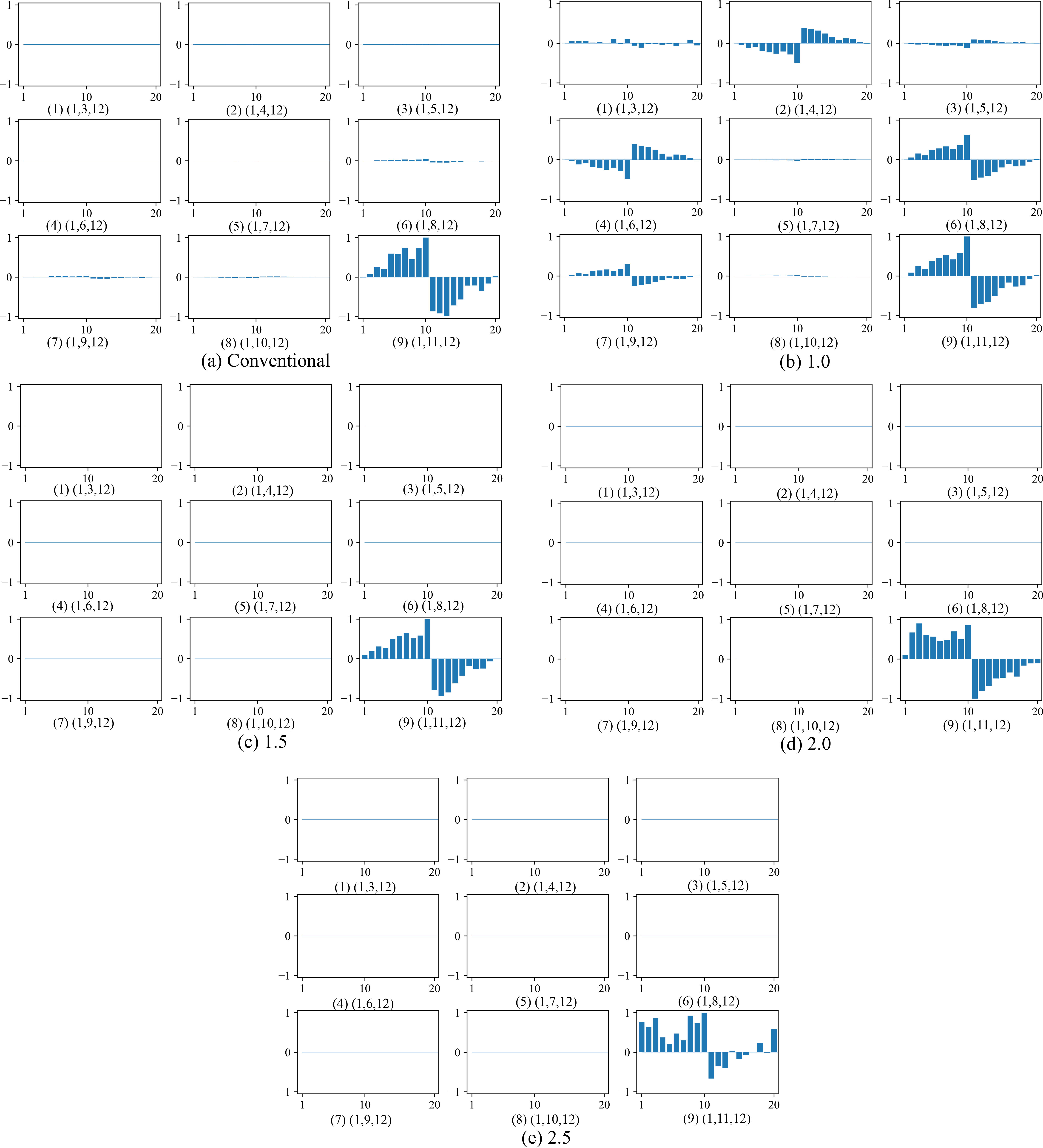
A network architecture for the nursing home data set, where the number of inputs and hidden neurons were 7 and 10.
The results confirmed that the appropriate increase in the parameter
The correlation coefficients increased gradually when the parameter
Summary of experimental results on correlation coefficients, averaged over 20 different initial conditions and different training data subsets for the symmetric data set
Summary of experimental results on correlation coefficients, averaged over 20 different initial conditions and different training data subsets for the symmetric data set
Experimental outline
The second experiment aimed to examine gender differences in a nursing home [38]. The analysis of the data set was complicated with difficulties, though they were relatively small ones. In this type of data set, the interpretation was much more important than improving generalization.
The data set was obtained by processing real natural languages with many irregular sentences. Naturally, the conventional methods such as the logistic regression and random forest could not produce a reasonably good generalization performance. Thus, the problem was whether a too-redundant multi-layered neural network with ten hidden layers for this seemingly simple data set could deal with this kind of data set. Our hypothesis was that the redundant multi-neural networks were necessary in processing the seemingly simple data set, because they could flexibly control the information content to be stored due to its very redundancy, and it might have been possible to obtain the necessary and important information if we could control the process of information acquisition in terms of information maximization and minimization. The data set was obtained by processing the real data in natural languages, and the total number of input patterns was 600, with seven input variables. As shown in Fig. 13, the data set was represented in terms of seven features: “daily support,” “watching service,” “cultural exchange,” “job and social activity,” “aged care,” “hobby support,” and “financial support.” The neural networks should distinguish between elderly men and women in the nursing home. We should try to see which features play important roles in distinguishing between them.
We should state again that the final results were obtained by processing the real and sometimes very ambiguous natural languages. If it were possible to obtain some important information from those complicated data sets by using redundant neural networks, the neural networks could be more extensively applied to smaller but ill-formed data sets, in which the interpretation of data sets is always much important than improving generalization performance.
Selective information control
The results show that, by increasing and decreasing the cost, selective information could be decreased and increased. This means that, when the parameter
Figure 14 shows selective information (left), cost (middle), and the ratio of information to its cost (right) by the conventional method (a), and the information method when the parameter
Selective information (left), cost (middle), and ratio of information to its cost (right) as a function of the number of steps by the conventional method (a) and the information method when the parameter 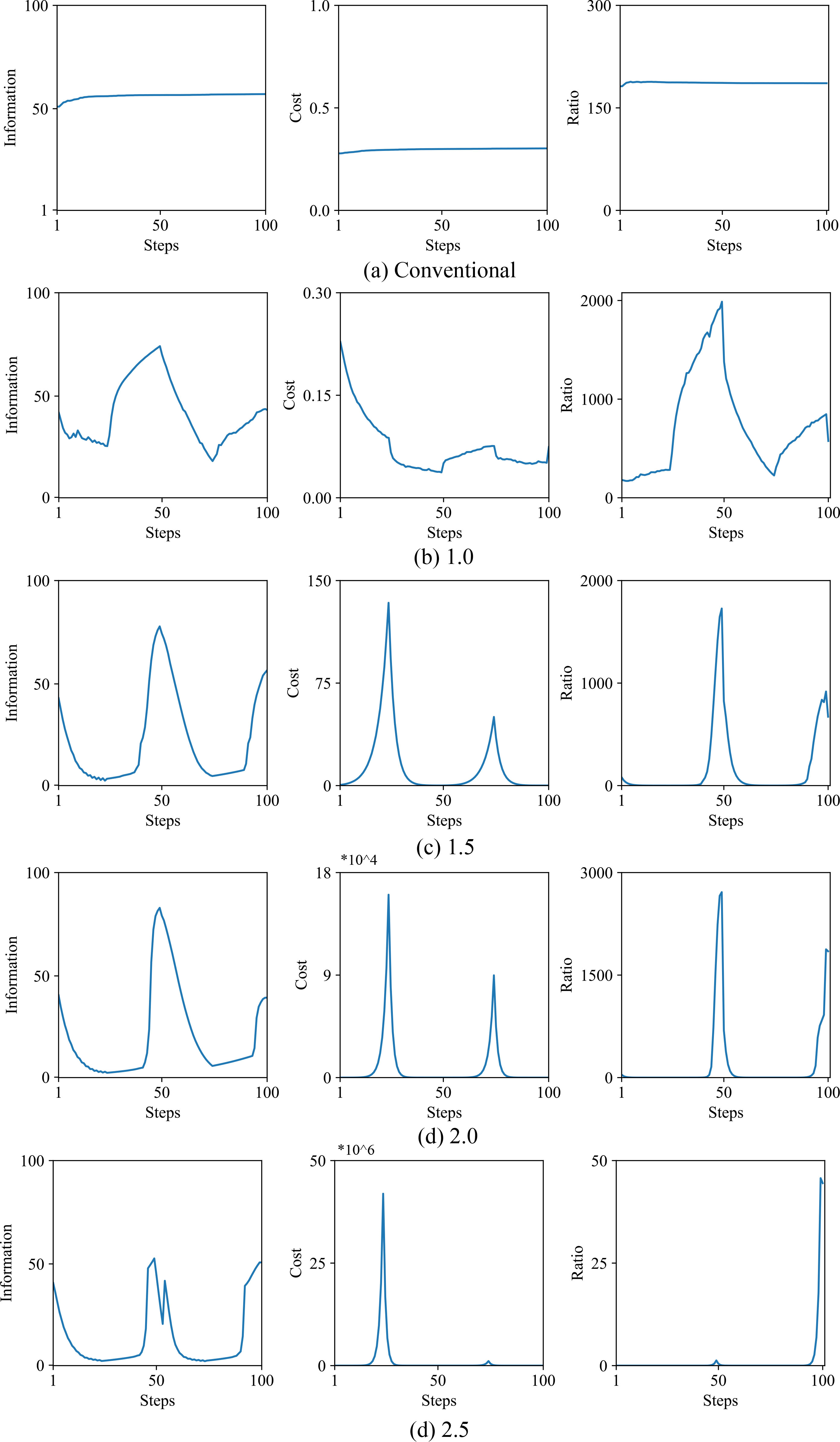
Weights (1) and potentialities (2) for all hidden layers by the conventional method (a) and the information method when the parameter 
Weights (1) and potentilities (2) for all hidden layers by the information method when the parameter 
The results confirmed that by decreasing and increasing selective information, the regularity of connection weights and the number of stronger weights could be flexibly controlled, which could be related to higher correlation coefficients and higher generalization accuracy.
Figure 15(a) shows connection weights for all hidden layers by the conventional method. As can be seen in the figure, connection weights were almost random, and we could not see any regularity inside. When the parameter
Figure 16 shows weights when the parameter
Collective weights
The results show that we could control compressed and collective weights flexibly by changing the parameter
The original correlation coefficients between inputs and targets (a) and collective weights by the conventional method (b), and by the information method when the parameter 
Figure 17(a) shows the correlation coefficients between inputs and targets of the original data set, and we could see that the first three inputs had larger strength. This means that the input variables of “daily support,” “watching service,” and “cultural exchange” had larger importance in discriminating between elderly men and women. The men needed the watching services, while the women needed the daily supports and cultural exchanges. When the conventional method (a) was used and when the parameter
Figure 18 shows individually compressed weights by the conventional method (a), and by the information method when the parameter
Compressed weights for all individual layers by the conventional method (a), and by the information method when the parameter 
Compressed weights for all individual layers by the conventional method (a), and by the information method when the parameter 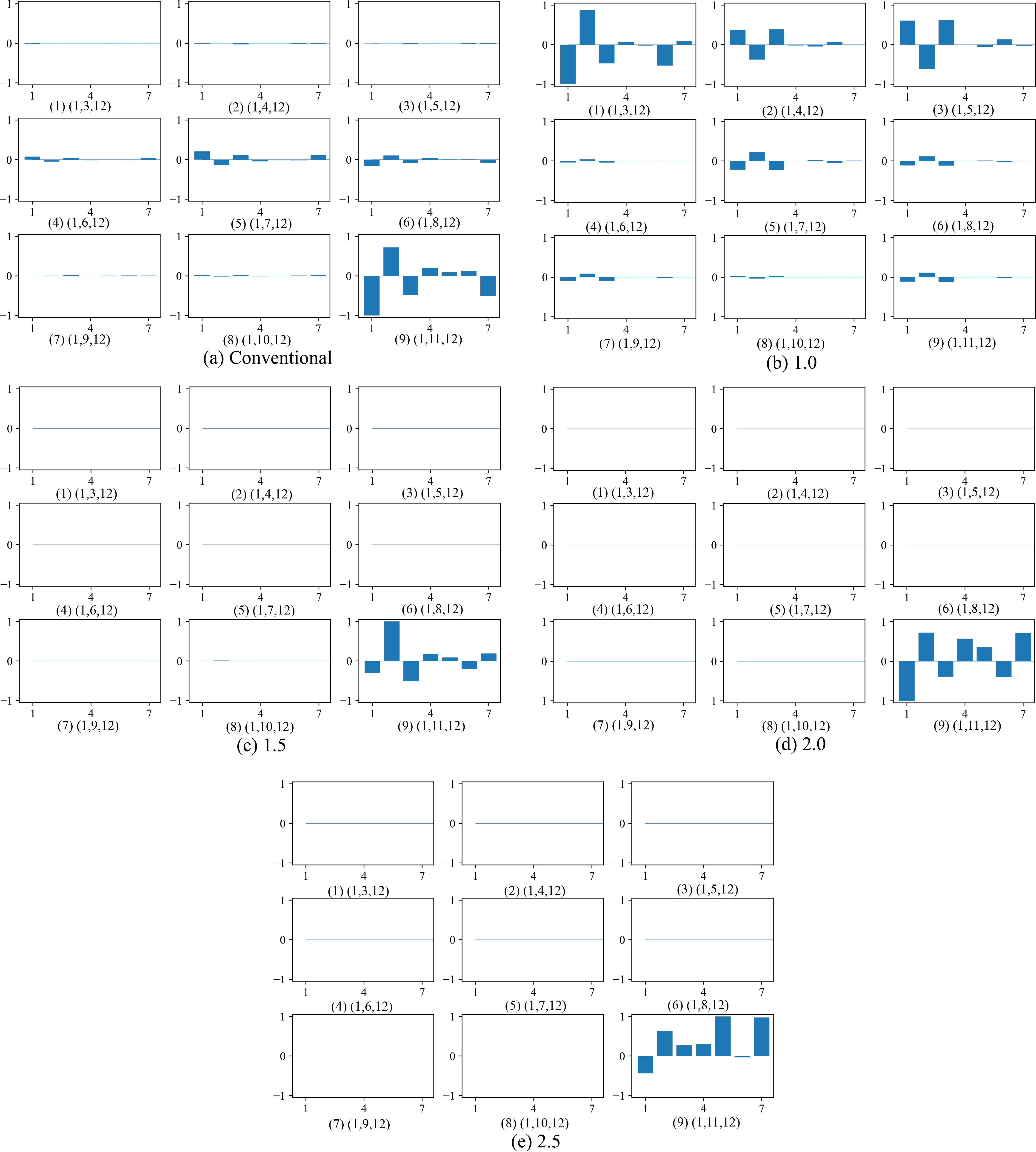
Figure 19 shows cumulatively compressed weights by the conventional method (a) and by the information method when the parameter
The summary of experimental results show that the information method could produce higher generalization accuracy, keeping higher correlation coefficients than the original ones. In addition, we could see that, by slightly reducing the correlation, we could obtain higher accuracy by the information method.
Table 2 shows the summary of experimental results. The highest correlation coefficient of 0.985 was obtained by the logistic regression analysis, and almost the same coefficient of 0.984 was obtained when the parameter
The summary results confirmed that the information method could control selective information by changing its cost to produce the higher correlation and the highest accuracy, compared with the conventional methods.
Summary of experimental results on correlation coefficients and generalization accuracy, averaged over 20 different initial conditions and different training data subsets for the nursing home data set
Summary of experimental results on correlation coefficients and generalization accuracy, averaged over 20 different initial conditions and different training data subsets for the nursing home data set
The present paper tried to propose a method to efficiently extract information on the main properties of neural networks by minimizing and maximizing information repeatedly. The process of information minimization is usually preformed with much difficulty, because the process of error minimization is contradictory to information minimization, where the error minimization tries to obtain some information in inputs as much as possible. Thus, we developed a method to minimize information at any cost, and even by increasing the cost, information should be minimized. The information minimization is forced to be realized by a new “ cost-forced” approach for information control. We applied the method to two data sets: an artificial symmetric data set and a nursing home data set obtained by the natural processing for natural languages with many ill-formed sentences. The symmetric data set could show that the present method could capture the symmetric property by changing the parameter
We restricted the number of repeated applications of information minimization and maximization only to two for the stability of learning. However, it may be possible to repeat many times this process of information minimization and maximization. If it is possible to control those processes, we can more flexibly obtain information in neural networks to get more explicit and open interpretation.