
Abstract
The identification and severity assessment of plant leaf diseases is crucial to food security and sustainable agriculture. This study shows an innovative way to improve plant leaf disease detection. The recommended method uses Optuna for parameter optimization and the Genetic Algorithm for feature selection to improve plant leaf disease identification. We do this to improve diagnosis accuracy. This method improves classification accuracy and is called ECPLDD-OGA. Modern hyper parameter optimization framework Optuna is employed. This allows classification model parameters to be fine-tuned. A systematic feature selection method is the Genetic Algorithm. It finds the most useful characteristics in the input dataset. By applying the algorithm on the data. By facilitation, the iterative process helps create a simplified and meaningful subset of features. Contrary to parameter tinkering and feature selection, empirical data suggests that utilizing Optuna and the Genetic Algorithm simultaneously improves disease identification. The updated model recognizes sick plants more accurately and generalizes better. Optimization enabled both gains. The usage of this technology can improve agricultural operations and reduce crop losses by increasing productivity. The present ECPLDD-OGA technique helps integrate hyper parameter tweaking and feature selection into machine learning-based agricultural applications.
Keywords
Introduction
To guarantee enough food for everyone and promote sustainable agriculture, plant leaf diseases should be detected and assessed early. The study emphasises crop disease detection accuracy and earlyness. It has significant potential to reduce crop losses, boost output, and encourage efficient farming. Early and accurate wheat disease diagnosis is stressed in the study [1]. Accurate and timely identification of agricultural diseases may minimise the transmission of the disease to other crops. This paper proposes a new way for recognising natural plant leaf diseases. The major purpose is to enhance disease categorization and give crop management system information. Some suggest combining the Genetic Algorithm for feature selection with Optuna for parameter optimisation using ECPLDD-OGA. Proposed application of this idea. This was done using ECPLDD-OGA. Use the classification model and extract the most important properties from the input dataset to maximum accuracy [2]. Optuna is a sophisticated framework for optimising hyperparameters; using it to improve classification model parameters is highly recommended. This step is considered essential to the process. Optuna reliably detects diseases affecting plant leaves by meticulously examining hyperparameter space. Because of this achievement, you can find the best combinations for maximum performance. This is now within reach, thanks to Optuna’s hyperparameter space travel capabilities. When choosing features, a genetic algorithm is used [3]. This computational tool was based on the idea of natural selection. One of the several processes that propel evolution is natural selection.
Several studies were conducted in a thorough manner using a large number of plant leaf photos [4]. We did this so that the test results would be easier to understand. The assortment included both healthy foliage and a range of diseases. The plan is put to the test using evaluation methodologies that are widely recognised as industry standards. These results show that Optuna and Genetic Algorithm both make illness detection more effective [5]. This improvement transcends traditional setup and attribute selection. Sick plant identification accuracy and generality improved in the new model. The optimising method enabled these improvements [6].
The suggested strategy can improve crop management efficiency, minimise crop losses, and boost food security, which has major implications for agriculture. This study examines whether advanced optimisation methods work for machine learning-based agricultural applications. This study seeks new and improved solutions to agricultural issues [7]. The technique provides a robust foundation for hyperparameter tweaking and feature selection-based plant disease detection applications. The above technique might revolutionise agricultural disease diagnosis. It encourages research and development of ecologically friendly agricultural technologies and the reduction of global food production barriers. This study presents an innovative method for early plant leaf disease detection. The approach was invented by the authors. The current ECPLDD-OGA approach [8] combines Optima’s hyperparameter optimisation with the Genetic Algorithm’s feature selection. Because of this, the procedure yields excellent results. This combination may improve classification accuracy [9]. Optuna, a complicated hyper parameter optimisation framework, is utilised to fine-tune classification model parameters [10]. To achieve accuracy, we do this. This method improves illness diagnosis over time by finding model configurations that optimum performance.
Genetic Algorithms are used by feature selection researchers to carefully extract the most important qualities from a dataset [11]. We aim to learn about feature selection this way [12]. The approach iteratively refines a compact and meaningful property list. One option is to create a subset of characteristics. This strategy increases the model’s plant leaf disease pattern recognition. The approach is evaluated using a huge collection of plant leaf photos [13]. Besides sick leaves, the collection includes healthy leaves. Comparing Optuna with Genetic Algorithm to conventional parameter tuning and feature selection approaches, illness detection accuracy is dramatically improved. This conclusion comes from empirical investigations. An improved ill plant identification accuracy is another way the optimised model displays its greater generalizability [14]. The above technical advances may improve agricultural efficiency and reduce crop losses. The suggested ECPLDD-OGA technique provides a flexible framework for optimising hyperparameter tuning and feature selection in machine learning-based agricultural applications.
Related works
Veerendra et al. [5]. This study investigates various digital image processing approaches used to identify and categorize plant diseases. Nevertheless, the essay fails to provide a thorough analysis of the practical application of the Optuna approach. The utilization of digital image processing techniques to diagnose and classify agricultural illnesses. The study comprises three independent components: severity quantification, detection, and categorization.
Shishira [6]. This study investigates the utilization of image processing and deep learning methodologies for the purpose of detecting and categorizing plant illnesses. The suggested methodology employs textural qualities obtained from statistical analysis.. The offered material contains the confusion matrix for the plant classification phase, which differentiates between damaged and healthy plants. A comprehensive examination of image processing techniques utilized in the diagnosis of diseases. The evolution of image-based methodologies for the management and evaluation of diseases throughout history.
The publication was written by Jayme, Garcia, Arnal, and Barbedo in 2016. The recently developed algorithm has shown a significant decrease in both the rates of false positive (FP) and false negative (FN) for most diseases. Channel H revealed remarkable precision in capturing strong vein patterns and overall variations in leaf color. However, channel A demonstrated superior accuracy in detecting both bright and dark symptoms, particularly in low-contrast settings. The aim of this study is to present a new method for distinguishing disease markers from normal tissue by segmentation. The current study is to evaluate the accuracy and robustness of the innovative algorithm in a diverse range of plant species and diseases.
Eimad, Abdu, and Abusham (2021). The aim of this work is to employ image processing techniques to identify and classify plant illnesses that especially affect the leaves of al-berseem plants. A variety of image processing approaches have been used to detect anomalies in al-berseem. Various diseases can be categorized into several subgroups, such as fungal infections, insect infestations, mild leaf tissue damage, and nutritional deficiencies. The identification and assessment of illnesses by employing diverse image processing methodologies. The primary aim of this study is to ascertain and categorize diseases that cause damage to al-berseem leaves.
In 2017, Bhawana, Moon, Nigkhat, Sheikh, and their coauthors conducted and published a study. The diagnostic accuracy demonstrates a notable level of uncertainty, varying between 83% and 94%. The current strategy exhibits a 20% enhancement in speed in comparison to the old approach. A sophisticated technique for automatically detecting and categorizing diseases that have the potential to impact the leaves of plants. Due to the implementation of enhanced detection techniques, there has been a significant enhancement in both the velocity and precision, along with a substantial 20% increase in processing efficacy.
In 2021, an article was published by Darah, Aqel, Shadi, AlZu’bi, and their colleagues. This work presents an automated methodology that seeks to detect and classify plant leaf diseases that cause harm. The gathered data demonstrated promising results in terms of categorization metrics. A accuracy of 94% has been established. The research revealed a worldwide margin of error of 6%.
S., Ashwinkumar., S., Rajagopal., and colleagues [21]. This study suggests utilizing the Emperor Penguin Optimizer (EPO) method to improve the hyperparameters for classifying plant leaf diseases in image processing. The EPO algorithm was devised by Emperor Penguin. The researchers conducted a study that introduces a novel approach to identify and classify diseases that impact plant leaves. The proposed methodology employs a highly efficient CNN that functions on a mobile network to automate the procedure. To accurately determine the affected regions, the leaf image underwent preprocessing using the bilateral filtering (BF) technique and image segmentation based on Kapur’s thresholding methodology.
Yashwant Kurmi and Suchi Gangwar (2021). The objective of this study was to enhance the precision of image categorization and the recognition of distinct regions on foliage for the purpose of detecting diseases that impact plant leaves. The findings indicate an average accuracy of 0.932. The curve integration yields a value of 0.9033. The objective of the provided strategy is to enhance the results by optimizing the obtained information. Prior to commencing the categorizing process, the methodology employed in this experiment involved ascertaining the exact geographic position of the leaf area.
Yogeshwari and Thailambal [23]. The framework demonstrates exceptional classification performance in comparison to alternative classifiers. The methodology provided in this study exhibits exceptional performance in terms of categorization results. The abstract lacks precise quantitative findings. This study presents a novel methodology for identifying illnesses in plant foliage. The objective of categorization was achieved by utilizing convolutional neural networks (CNNs) with many layers.
Proposed methodology
For sustainable agriculture to thrive and food security to persist across the world, the rapid detection and accurate diagnosis of leaf diseases affecting plants is crucial. We provide a new approach to improve the detection of leaf diseases as part of this study. The combination of Optuna hyperparameter tuning abilities with the Genetic Algorithm’s feature selection capabilities in our method improves classification accuracy.
Image preprocessing
Any computer vision or image analysis project must include the preprocessing of photos. The term “image preprocessing” describes the steps used to improve the quality of raw images, decrease noise, and prepare them for subsequent processing methods like object recognition, classification, and segmentation. The purpose of image preprocessing is to ensure that machine learning algorithms are fed high-quality, problem-specific data, which will enhance the algorithms’ accuracy and performance. For consistency’s sake and to make calculation easier, images are often shrunk or scaled to a consistent size. Cropping a photograph could highlight its most important features by eliminating distracting backgrounds or other items. Consistent images and quicker convergence during training are outcomes of normalisation, which involves modifying pixel values to correspond to a given range. The process of denoising involves applying filters to images, like the Gaussian or Median, to reduce noise and enhance clarity. We are using this approach to enhance clarity. Increasing the brightness and contrast of a picture to make people and things stand out more clearly. The term “colour space conversion” describes the process of changing an image’s colour space from RGB to grayscale or HSV with the purpose of improving feature extraction.
The distribution of the norms A method called equalisation is used to balance out the intensity levels of a picture. Its objective is to increase contrast and bring out finer details. The term “edge detection” describes a technique for locating and emphasising the boundaries of visual objects. Separating foreground items from backgrounds in grayscale images is as simple as applying a threshold value. The method of augmentation may be used to create a more diverse dataset by adding extra training samples using transformations like flipping and rotation. Image registration, as it pertains to a common analysis, is the act of bringing together photographs from many sources or time periods and aligning them. The features of the dataset and the needs of the present computer vision task dictate the choice of image preprocessing methods, which can be grouped according to their intended use. Proper preprocessing is essential for the success of image analysis and machine learning methods.
Image segmentation
Many in the computer vision community consider picture segmentation to be among the most important tasks that can be undertaken. Deconstructing a picture into its constituent parts, each of which stands for a distinct facet of the overall image, is an integral part of the process. Correctly separating foreground objects from their surrounding backgrounds is the main goal of photo segmentation. We may do this by breaking the image down into its constituent parts, each of which is significant in its own right. Using this strategy, studying the image becomes considerably easier. Thresholding is a commonly used technique in image processing to enhance the transformation of grayscale pictures into binary ones. In this area, a wide variety of approaches are used. The technique consists of many steps, one of which is setting a threshold value. The outcome of this process is a binary image, as the name implies. The intensity levels of the pixels used for the picture’s foreground and background are decided by this value. To put it simply, pixels in the foreground are those that are higher than the threshold, while pixels in the background are those that are lower. You may think of the background pixels as the backdrop right now.
Regional considerations Segmentation is a step in image processing that involves clustering pixels with similar attributes, such as texture, intensity, or colour. It’s likely that this will take a lot of time. For the most part, this method relies on iterative procedures that merge or divide areas according to predefined criteria. The application of picture segmentation is widespread across several fields. Just a few examples of these areas of study include autonomous cars, medical imaging, object recognition, and scene comprehension. Instance segmentation, which entails defining specific instances of objects inside the image, and object recognition and tracking are both dependent on this step. In other words, this step helps identify whether parts of the image include certain objects or people.
Tune the parameters with the help of Optuna
Optuna, a free and open-source framework, automates machine learning model hyperparameter optimisation. The software makes hyperparameter field exploration easy and effective. This approach integrates many optimising strategies.
The Optuna algorithm exposes a number of significant characteristics and qualities all at once.
Bayesian optimisation, a stringent global optimisation strategy, helps Optuna search the hyperparameter space. Bayesian optimisation requires a probabilistic model, or surrogate or response surface. This model examines hyperparameters and objective function performance. After this, the model suggests suitable hyperparameter combinations. Optuna uses Successive Halving and Asynchronous Successive Halving to avoid assessing low-potential hyperparameter settings. By ending attempts that are unlikely to outperform the ideal configuration, pruning conserves computing resources. Optuna offers the Tree-structured Parzen Estimator (TPE) and Covariance Matrix Adaptation Evolution Strategy (CMA-ES) as optimisation techniques. These algorithms offer various hyperparameter space sampling and exploration methods. Users can choose the method that best suits their optimisation goal. Optuna supports distributed and parallel computing, letting consumers employ many processors. This method efficiently explores hyperparameter space by assessing several configurations. The Optuna framework includes visualisation tools for optimising analysis and comprehension. People can use these technologies. Framework tools are available. This programme displays hyperparameter distributions, convergence graphs, and parameter significance charts. This helps clients gain search progress information and make informed decisions.
Optuna works well with several machine learning library frameworks. Scikit-learn, PyTorch, TensorFlow. Optuna integrates well with other frameworks due to this interoperability. The application lets users specify and tune hyperparameters in numerous models and frameworks using a single interface. Optimising hyperparameters might be difficult, but Optuna automates the process. Bayesian optimisation, pruning, parallelization, and visualisation make it a potent tool for identifying machine learning model settings and quickly exploring hyperparameter space. Because of these properties, the tool can visualise.

Selection of features using a genetic algorithm
A “Genetic Algorithm” is a prominent search and optimisation approach. This strategy draws on evolution and natural selection. One of the most common uses of this method is solving complex problems that standard algorithms cannot. This strategy relies on it. Genetic algorithms replicate evolution by refining a population of solutions over many generations, like animals. Each answer is generally described as a set of binary or real-valued numbers called “individual” or “chromosome”. These folks may be examined using a fitness function. This function shows how difficult it is for them to overcome the present one.
The genetic algorithm consists of several key stages, which include: Randomly create a population for the first generation. Population estimates take into account current demands.We may assess fitness by comparing an object or person’s efficiency to the fitness function. This objective is usually metric optimisation, such as greatest accuracy or lowest possible error. Either increasing accuracy or lowering inaccuracy, the function’s principal purpose is to summarise the ultimate goal.The most basic component of selection is selecting a population subset for future generations. According to “survival of the fittest,” probability should determine selection, hence the fittest should be chosen. One of the most important genetic recombination simulations is “crossover” (sometimes “recombination”). By matching selected people, a future generation can inherit qualities from both sets of parents. This approach allows efficient examination of possible choices. Mutation is caused by random, minor genetic changes. One of a population’s most important roles is genetic variety, which this system preserves. This method carefully selects unstudied places in the search zone.Children and a smaller number of their parents’ relatives make up the next generation. Because of generational balance, the population stays the same size. When it finds a decent solution, reaches a certain number of generations, or fulfils other criteria, an algorithm ends.
The genetic algorithm’s iterative nature facilitates the continuous improvement of the population over multiple generations, ultimately resulting in the convergence towards superior solutions. This methodology is especially well-suited for tackling the difficulties related to vast and complex search spaces, landscapes featuring multiple peaks, and objective functions that do not possess differentiability.

Optuna-GA: CNN-based feature selection and classification
Optuna is an open-source framework and hyperparameter optimizer that aims to automate the process of finding the best hyperparameters for deep learning machine learning models. An efficient exploration of the hyperparameter search space is achieved by the application of Bayesian optimisation techniques. Because of this, finding the optimal set of hyperparameters that boosts the model’s performance becomes much simpler. Optuna may be used to tune hyperparameters for CNN classification workloads. The learning rate, batch size, number of layers, dropout rates, and other hyperparameters are among the most important choices that determine the CNN’s operational efficiency. More quicker convergence and improved model accuracy are the end outcomes of using Optuna to automate and optimise the process of changing the model’s parameters. Using Optuna makes this possible.
Genetic algorithms are a popular and successful method that is currently being used to carry out feature selection. Ideas exhibited by natural selection have been a source of inspiration and motivation throughout the process of building these algorithms. What is commonly done is a technique called “feature selection,” which involves picking out important traits from a list of potential ones. The process is described by the term “feature selection,” from whence the word “feature selection” is derived. Our goal in implementing this technique is to enhance the models’ overall performance and reduce the negative effects of the overfitting problem. Genetic algorithms use a series of steps, such as mutation, selection, and crossover, to painstakingly build a population of possible feature subsets. This is carried out continuously while the algorithm runs. To get the desired result, this is being done. To find the most useful and discriminative features in the input data, the genetic algorithm may be used in the context of convolutional neural network (CNN) classification. Finding and choosing the characteristics will allow you to achieve this. To achieve this goal, it is necessary to analyse the data in order to determine which attributes have this dual property. The method then uses the training and validation datasets linked to the CNN model to evaluate the performance of the people representing reasonable subsets of characteristics within the population. This step is conducted to ensure that our clients receive the highest quality outcomes that our capabilities allow. In order to keep building the population, the genetic algorithm uses a selection technique that favours the most suitable individuals, called feature subsets, and then uses genetic operations to create new generations of potential feature subsets. The overall health and fitness of the population will continue to improve with this method. Since this is the case, the populace can get closer to the state of enhanced complexity it seeks.
There is a two-step process that may be used to get better CNN classification using Optuna and a genetic algorithm. This method incorporates both Optuna, which optimises parameters, and a genetic algorithm, which selects features. Achieving the overall goal is made possible by the combined use of both of these components. Using a Genetic Algorithm to identify important traits is the initial stage of the procedure and an integral part of the whole approach. A possible way to reduce the data’s dimensionality is to apply feature selection to the initial feature set using the evolutionary method. The evolutionary algorithm will be used to achieve this. Before deciding if a feature subset is suitable for use, its fitness is evaluated. A fitness function is utilised for this evaluation, which considers the performance of the CNN model trained with the selected features. The second necessary step is to optimise the hyperparameters using the Optuna framework. Hyperparameter optimisation is carried out using the Optuna framework. The goal of this approach is to find the best hyperparameters that maximise the performance metric, such accuracy, on both the training and validation datasets. At the end of this exhaustive procedure, you will get a CNN model that has been optimised using certain hyperparameters. Also, given the provided classification goal, the model will include a selection of important attributes that give the highest potential accuracy.
Result and discussion
According to Table 1, the dataset has 4030 samples divided into four classes.
Details of dataset
Details of dataset
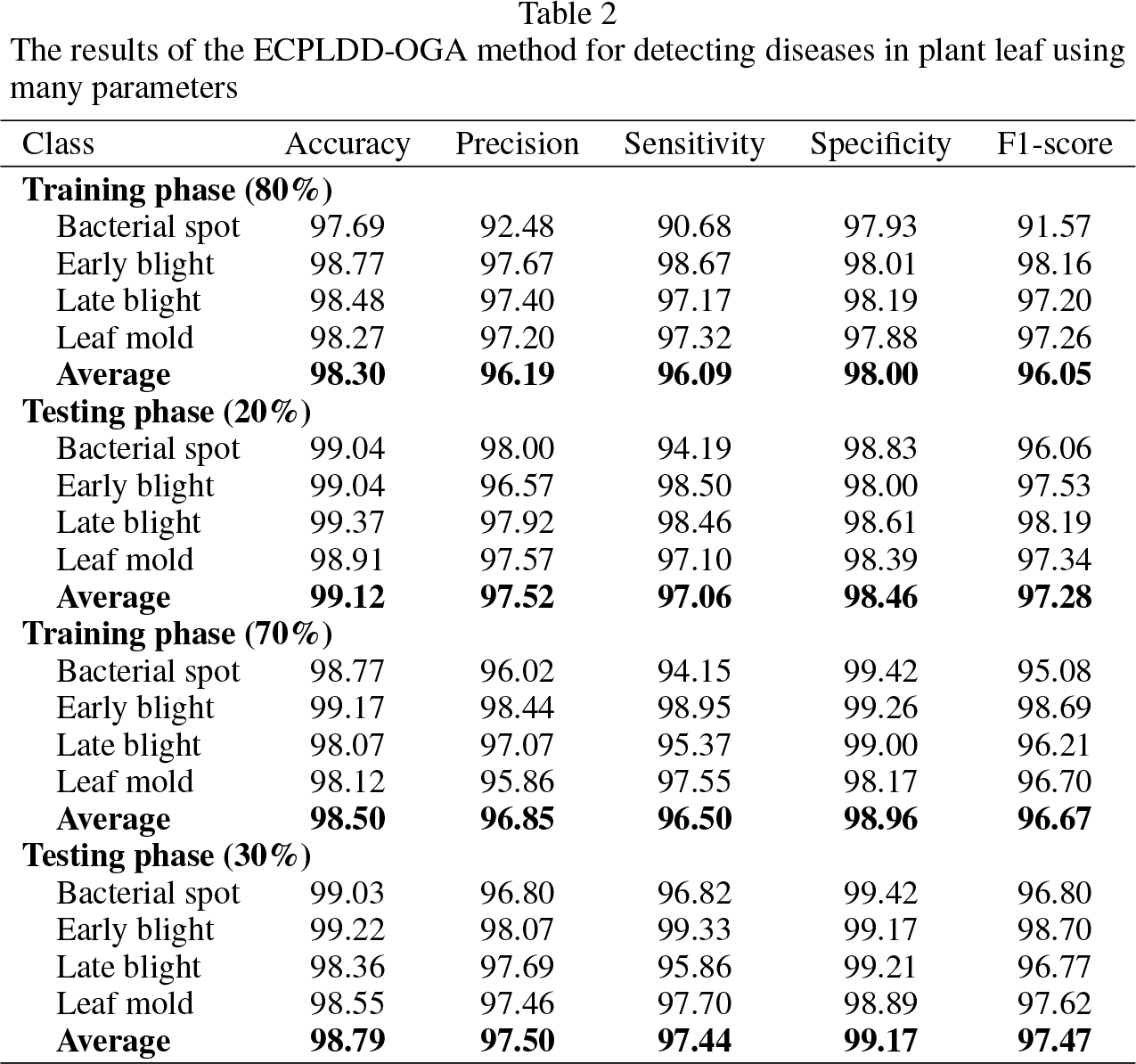
The proposed ECPLDD-OGA architectural process is depicted in Fig. 1.
The ECPLDD-OGA technique provides a comprehensive demonstration of plant leaf disease detection, as shown in Table 2 and Fig. 2.
The results of the ECPLDD-OGA method for detecting diseases in plant leaf using many parameters
Proposed ECPLDD-OGA architectural workflow.
Results of the ECPLDD-OGA method compared to state-of-the-art systems
Typical outcome of the ECPLDD-OGA method with separate measures.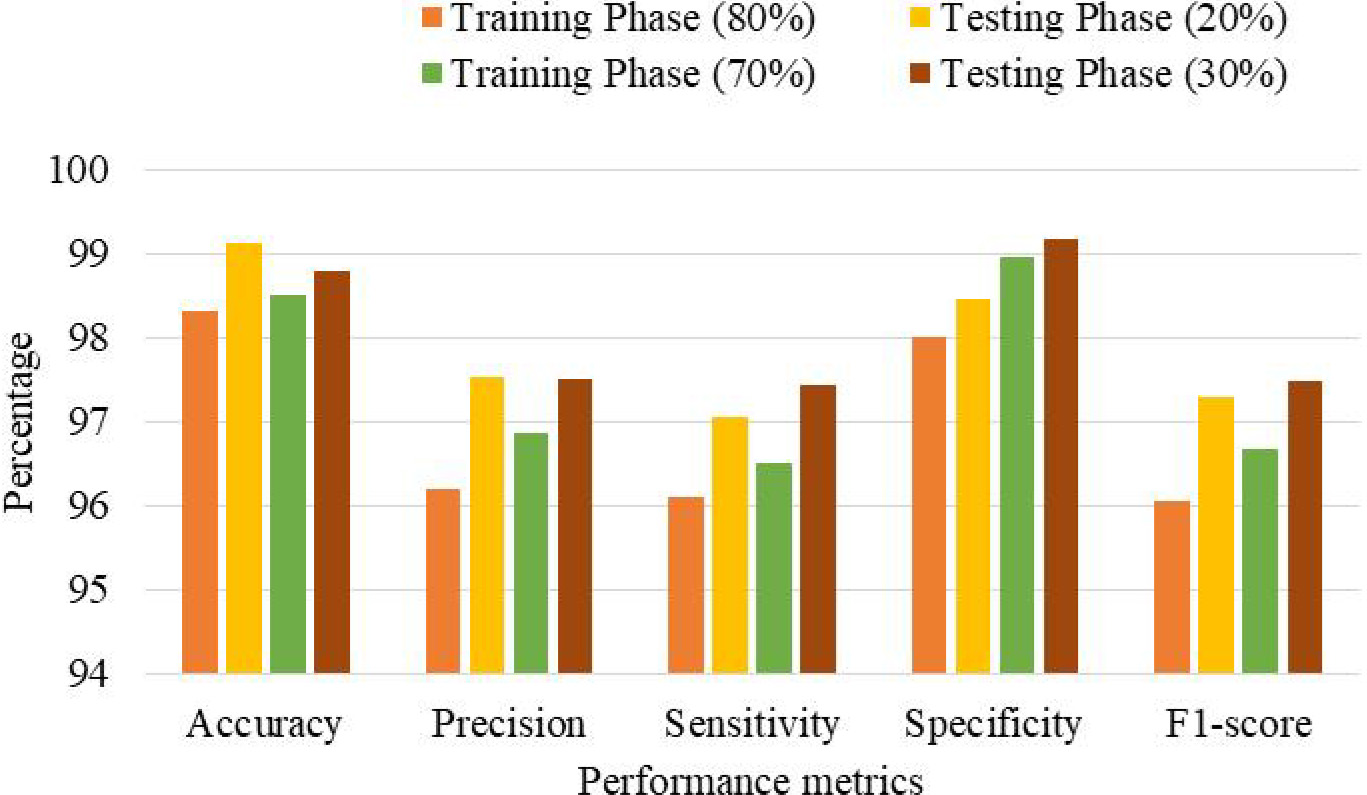
Figure 3 examines the precision of the ECPLDD-OGA methodology in both the training and validation models using the test database.
Curve of accuracy for the ECPLDD-OGA method.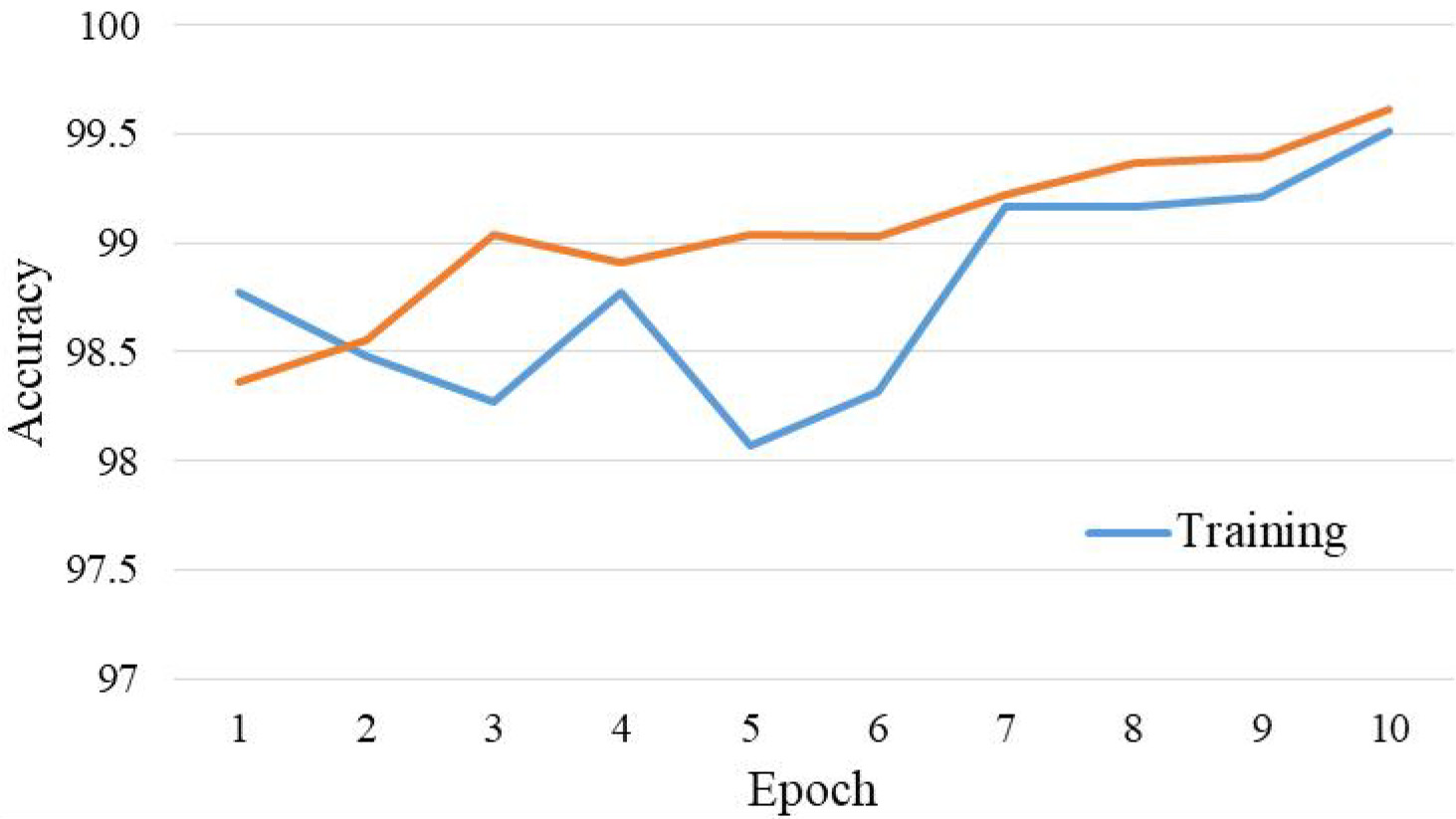
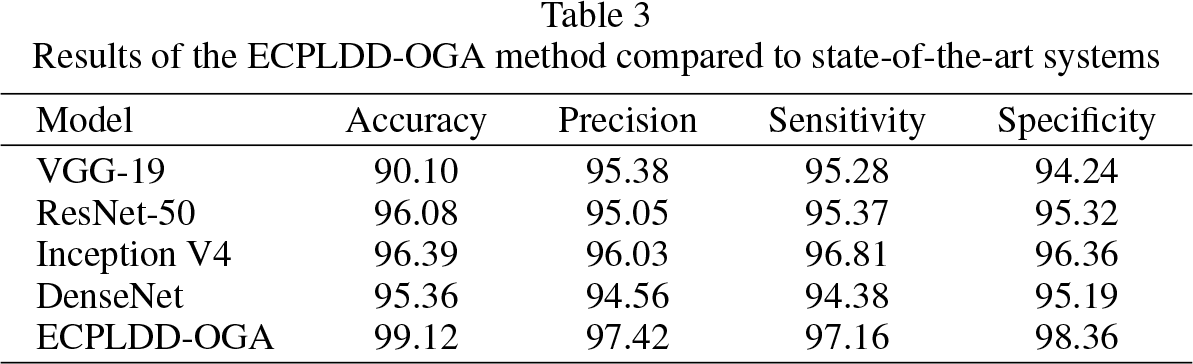
Table 3 and Fig. 4 present a comprehensive comparative analysis of the ECPLDD-OGA technique.
Results of the ECPLDD-OGA method compared to state-of-the-art systems.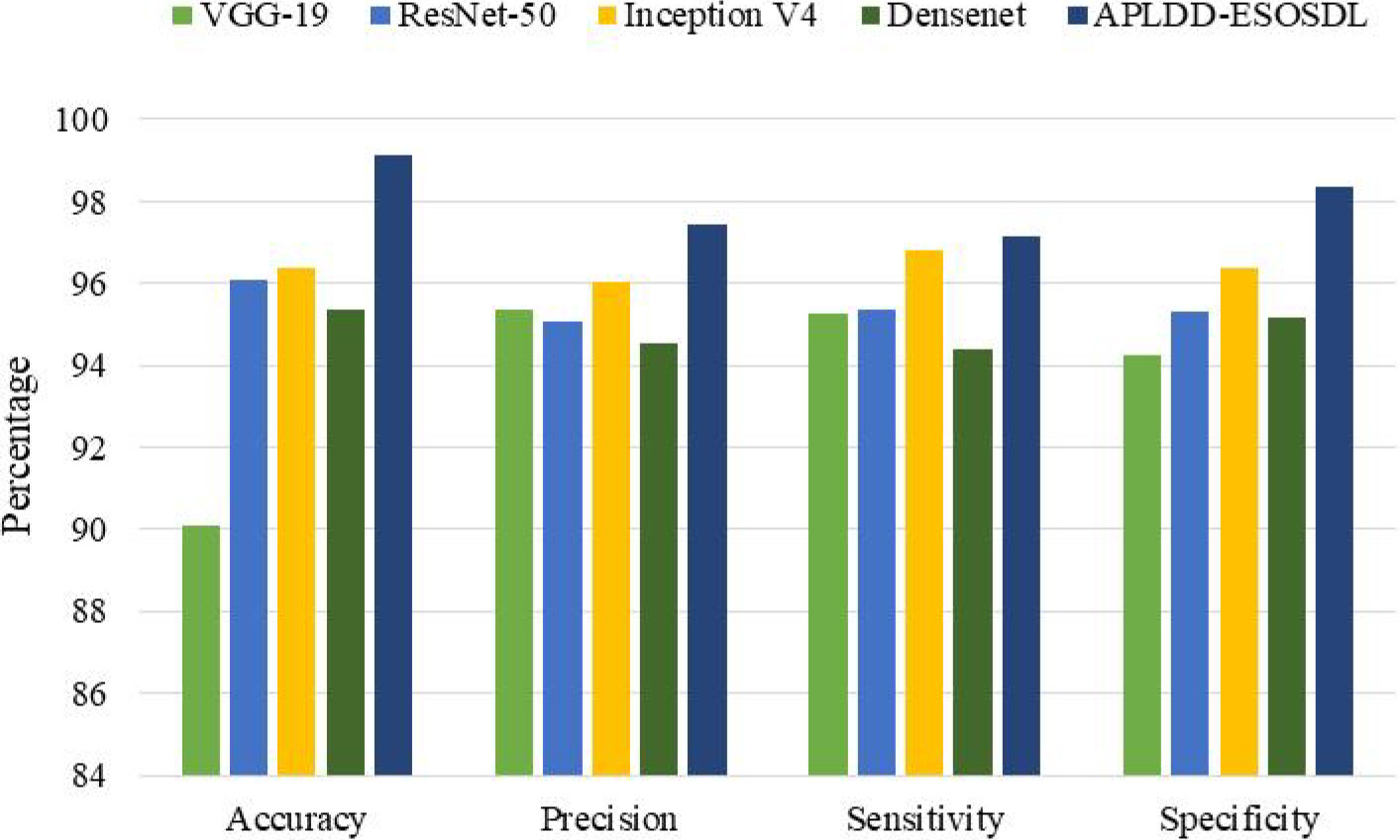
The ECPLDD-OGA system’s results for detecting plant leaf diseases are examined in this section using a plant disease dataset.
The experimental results demonstrated that the ECPLDD-OGA approach achieved favorable outcomes in all four categories. The ECPLDD-OGA technique demonstrates an average accuracy, precision, sensitivity, specificity, and F1-score of 98.30%, 96.19%, 96.09%, 98.00%, and 96.05%, respectively, with an 80% rate. The ECPLDD-OGA technique demonstrates significant enhancements in accuracy, precision, sensitivity, specificity, and F1-scores, with average improvements of 99.12%, 97.52%, 97.06%, 98.46%, and 97.28%, respectively, while utilizing a 20% sample size. Using the ECPLDD-OGA method, one may attain high F1-scores as well as sensitivity, specificity, accuracy, and precision. Its exact output is as follows: an F1-score of 96.67%, an average accuracy of 98.50%, a precision of 96.85%, a sensitivity of 96.50%, and a specificity of 98.96%. It was determined that 70% of the dataset was utilised to reach these findings. With a 30% success rate, the ECPLDD-OGA system achieves an average of 98.79% accuracy, 97.50% precision, 97.44% specificity, 99.17% accuracy, and 97.47% specificity.
The findings indicate that the ECPLDD-OGA algorithm achieves the highest levels of accuracy across multiple epochs. Additionally, it is worth noting that the ECPLDD-OGA algorithm demonstrates superior performance on the test database, as evidenced by its maximal validation accuracy surpassing the training accuracy.
The findings indicate that the VGG-19 model exhibits inferior performance, while the ResNet-50, Inception V4, and DenseNet models achieve slightly improved results. Nevertheless, the ECPLDD-OGA technique exhibited exceptional outcomes, achieving a maximum accuracy rate of 99.12%, precision rate of 97.42%, sensitivity rate of 97.16%, and specificity rate of 98.36%. The findings of this study provide further evidence supporting the superior performance of the ECPLDD-OGA technique in comparison to alternative models.
The ability to detect and assess plant leaf diseases is crucial for ensuring food safety and maintaining agricultural sustainability. In order to enhance plant leaf disease identification, this study combines Optuna for hyperparameter optimization and Genetic Algorithm for feature selection. The effectiveness of classifications is enhanced. Modern hyperparameter optimization software like Optuna facilitates fine-tuning of classification model parameters for peak performance. In order to construct a small but meaningful subset, the Genetic Algorithm chooses the most informative features from the input dataset. The discussed method is assessed by comparing photos of diseased and healthy plant leaves. Empirical evidence demonstrates superiority over parameter tuning and feature selection for disease diagnosis. The improved approach has greater accuracy in identifying ill plants and is more generalizable. If implemented, the plan might lessen agricultural waste and save more food. The accurate diagnosis and treatment of plant leaf diseases protects crops and promotes sustainable agriculture and food production. This technique improves hyperparameter tuning and feature selection for a wide range of agricultural applications utilizing machine learning. The ability to detect plant diseases with this method paves the way for sustainable crop management and precision farming. It advocates for high-level agricultural optimization to help with food security around the world and to further the cause of sustainable agriculture. This comparison illuminates the best ways to optimize methods for different uses. Given these results, academics and practitioners will have a better idea of whether to use Optuna or GAs for optimization tasks. They need to tailor their option to the specifics of the problem and their needs. In order to develop optimization strategies in a wide range of real-world contexts, this study highlights the need of recognizing the synergistic interplay among different optimization methodologies.