
Abstract
In this paper, we propose a framework based on Hierarchical Reinforcement Learning for dialogue management in a Conversational Recommender System scenario. The framework splits the dialogue into more manageable tasks whose achievement corresponds to goals of the dialogue with the user. The framework consists of a meta-controller, which receives the user utterance and understands which goal should pursue, and a controller, which exploits a goal-specific representation to generate an answer composed by a sequence of tokens. The modules are trained using a two-stage strategy based on a preliminary Supervised Learning stage and a successive Reinforcement Learning stage.
Keywords
Introduction
Humans can solve tasks of varying complexity which require to satisfy different types of information needs, ranging from simple questions about common facts (whose answers can be found in encyclopedias) to more sophisticated ones in which they need to know what movie to watch during a romantic evening or what is the recipe for a good lasagne. These tasks can be solved by an intelligent agent able to answer questions formulated in a proper way, eventually considering user context and preferences. Conversational Recommender Systems (CRS) assist online users in their information-seeking and decision making tasks by supporting an interactive process [20] which could be goal oriented. The goal to reach consists in starting general and, through a series of interaction cycles, narrowing down the user interests until the desired item is obtained [31].
Generally speaking, a dialogue can be defined as a sequence of turns, each one consisting of an action performed by a speaker or by a hearer. A CRS can be considered a goal-driven dialogue system whose main goal, due to its complexity, can be solved effectively by dividing it in simpler goals. Indeed, a dialogue with this kind of system can include different phases, such as chatting, answering questions about specific facts and providing suggestions enriched by explanations, with the aim of satisfying the user information needs during the whole dialogue. The Hierarchical Reinforcement Learning (HRL) literature has consistently shown that, given the right decomposition, problems can be learned and solved more efficiently, that is to say in less time and with less resources [22]. The most popular HRL framework, called the Options framework [37], explicitly uses subgoals to build temporal abstractions, which allow faster learning and planning. An option can be conceptualized as a sort of macro-action which includes a list of starting conditions, a policy and a termination condition. An hierarchy is defined between the options to be solved and the primitive actions executed for each option.
Deep Learning (DL) architectures are widely used in dialogue systems [30, 38] and are able to achieve good performance in generating meaningful dialogue. However, in this paper we are interested in CRS where the dialogue should support the user in a decision making task. The system should be able to produce both meaningful dialogue and relevant suggestions to the users. In order to integrate these two aspects in our DL model, we design an end-to-end architecture, called Converse-Et-Impera (CEI), in which the dialogue generation and recommendations are learnt using an unified model. The HRL is used to model the different goals required by the decision making task. Moreover, in order to enrich the descriptions of items suggested to users we leverage information coming from the Linked Open Data (LOD) cloud.
The main contributions of our paper are the following: a framework based on HRL in which each CRS goal is modeled as a goal-specific representation module which learns a useful representation for the given goal; an answer generation module leveraging the learned goal-specific representations and the user preferences to generate appropriate answers.
The goal of our research is to prove that an end-to-end architecture is able to both generate dialogue and provide relevant recommendations to the user.
The paper is structured as follows: Section 2 contains details about our methodology and summarizes the DL architecture. The evaluation is described in Section 3, while Section 4 provides related work. Final remarks are reported in Section 5.
Methodology
Overview
A dialogue can be considered as a temporal process because the assessment of how “good” an action is depends on the options and opportunities available while the dialogue progresses further. For this reason, action choice requires foresight and long-term planning to complete a satisfying dialogue for the user. We employ the mathematical framework of Markov Decision Processes (MDP) [2] represented by states s ∈ S, actions a ∈ A and a transition function T : (s, a) → s′. An agent operating in this framework receives a state s from the environment and can take an action a, which results in a new state s′. We define the reward function as
A CRS can be considered a goal-driven dialogue system whose main goal, due to its complexity, can be solved effectively by dividing it in simpler goals. Indeed, a dialogue with this kind of system can include different phases, such as chatting, answering questions about specific facts and providing suggestions. In all these phases, the agent should use the words of the language to generate appropriate responses for the user conditioned on the goal to be solved. Our model, whose architecture is depicted in Fig. 1, takes inspiration from [15] to design a framework able to manage the different phases of a goal-driven dialogue by learning a stochastic policy π
g
which defines a probability distribution over a finite set of agent goals g ∈ G given a state s ∈ S. The agent goals can be considered as high-level actions, thus they can be consistently modeled by the Options Framework [37]. In fact, the completion of a goal g can be achieved by a temporally extended course of actions, starting from a given timestep t and ending after some number of steps k. A module of the framework called meta-controller is responsible of selecting a goal g
t
in a given state s
t
. Moreover, an additional module called controller selects an action a
t
given the state s
t
and the current goal g
t
following a goal-specific policy π
g
t
, which defines a probability distribution over the actions that the agent is able to execute to satisfy the goal g
t
. Given the two modules, an external critic evaluates the reward signal f
t
which the environment generates for the meta-controller, while an internal critic is responsible for evaluating whether a goal is reached and providing an appropriate reward r
t
(g) to the controller. So, the objective function for the meta-controller is to maximize the cumulative external reward
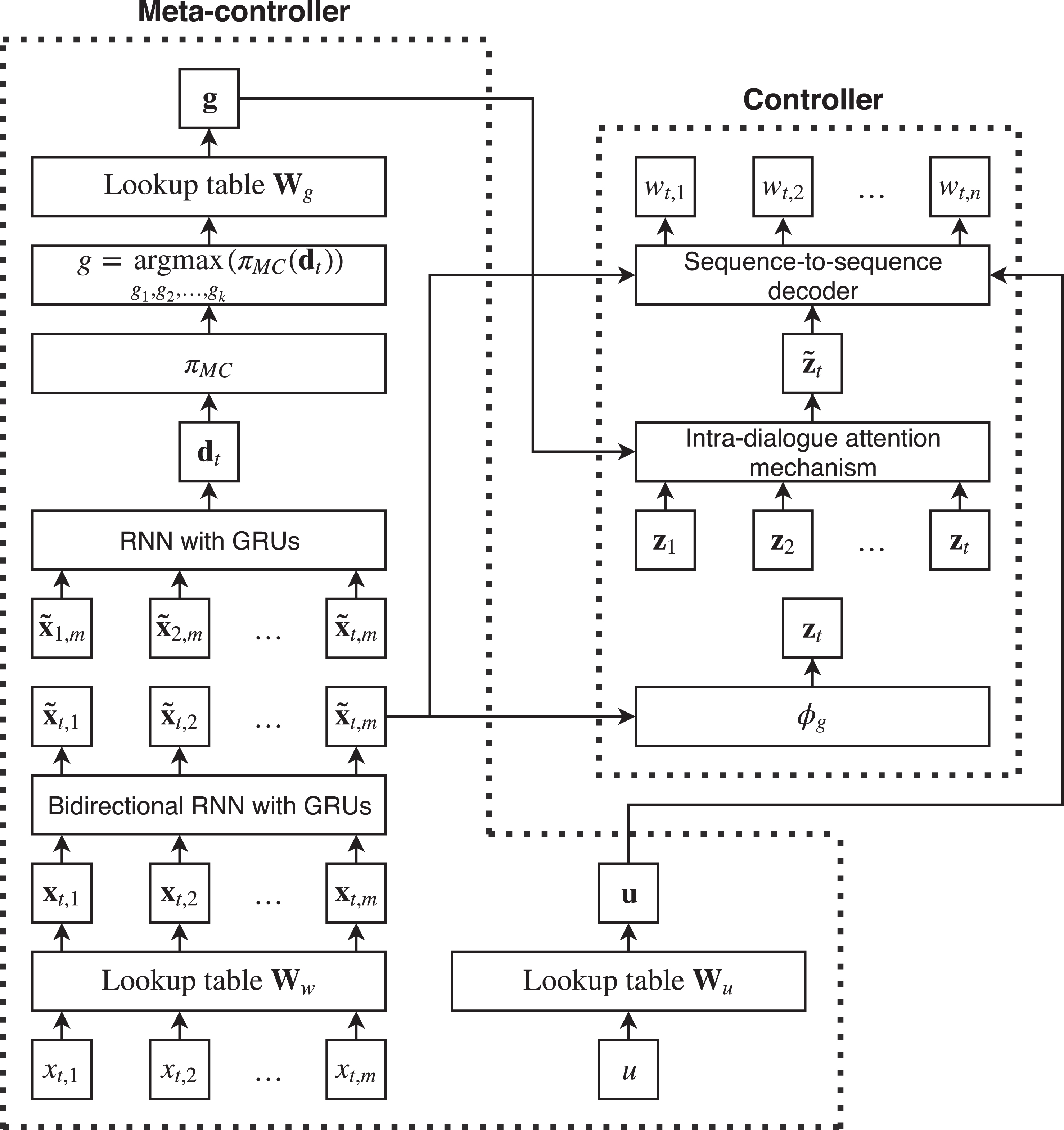
CEI architecture: A bidirectional RNN generates a representation for the input utterance x. The learned representation is first exploited by the meta-controller, which learns to predict the goal g associated to a specific turn. The controller learns to condition its responses on the goal representation for the goal
During a dialogue, in a given timestep t, the system receives a user utterance x = 〈x1, x2, …, x
m
〉 and the user identifier u ∈ U. Each word x
i
is encoded in a vector representation (embedding)
Meta-controller module
We define the meta-controller policy π
MC
as a feedforward neural network which receives in input the dialogue state
Due to the various requirements of each goal, differently from [15], we design a goal-specific representation module which represents relevant aspects of the current state exploited by the agent to complete the current goal. Given the current goal g, the system encodes it in g by using a lookup operation on the goal embedding matrix
Intra-dialogue attention mechanism
In order to fully support the user during the conversation, the system should be able to exploit information gathered during previous turns that can be useful in subsequent turns. For instance, during a given turn an agent may know the preferred movie director by the user and in a successive turn needs to leverage it in order to suggest relevant items to him. For this reason, the system applies an intra-dialogue attention mechanism to refine the score vector
Controller module
The controller exploits the refined score vector
Inspired by [33, 43], we develop a two-stage training strategy for our conversational agent composed by a preliminary Supervised Learning (SL) stage and a successive Reinforcement Learning (RL) stage. The motivation behind the adoption of the above-mentioned training strategy is to take into account historical data collected from previous interactions between a user and a system, which can be used to learn an initial effective policy for the meta-controller and the controller which can be further improved by the successive RL stage.
SL training procedure
In the SL stage, the agent learns to replicate the conversations which belong to a given dataset D which consists of N dialogs, each of them composed by T turns (xi,j, u
i
, gi,j, (ai,j,1, …, ai,j,n)) by minimizing a loss function which takes into account both the meta-controller and the controller errors with regard to the training data. Given a subset D
MC
consisting of the N dialogs belonging to D, each of them composed by T turns (xi,j, u
i
, gi,j), we define the supervised loss function for the meta-controller policy π
MC
as follows:
where CE is the cross-entropy loss function and ω (yi,k,j) is a function which defines a weight associated to a token ai,j,k equal to 2 if the position j refers to the last utterance in position T - 1 and ai,j,k ∈ E, where E is the set of entities defined in the dataset (e.g. movies, actors,...), 1 otherwise. The function ω weights more errors done on generated suggestions. The meta-controller and the controller are jointly trained by minimizing a loss function L
a
which linearly combines the two loss functions and applies L2-regularization on it as follows:
Given a set of experiences D
MC
which consists of N dialogs, each of them composed by T turns (xi,j, u
i
, gi,j, Ri,j), we define a loss function based on REINFORCE [41] for the meta-controller policy π
MC
as follows:
The experimental evaluation aim is to evaluate the performance of the developed agent in the generation of accurate suggestions and appropriate response to the user utterances. In order to achieve our objective, we defined a general procedure that can be used on classical recommender system datasets to generate a goal-oriented dialogue exploiting user preferences.
We applied the dialogue generation procedure (see Sub-section 3.1) on two well-known Recommender System (RS) datasets such as Movielens 1M [12] and Movie Tweetings [9]. For Movielens we leveraged the available demographic information associated to the user in order to extend the generated conversation with useful contextual questions about the user name, age and occupation. For each dataset, we retrieved information associated to the properties director (wdt:P57), cast member (wdt:P161) and genre (wdt:P136) associated to the items coming from the Wikidata knowledge base. The procedure generates two datasets: ML1 generated from Movielens is composed of 157, 135 dialogues containing 19, 039 tokens whose mean length is 14.78, while MT is generated from Movie Tweetings and contains 48, 933 dialogs whose mean length is 6.64 for a total of 53, 988 tokens.
In order to assess the effectiveness of the two-stage training strategy, we designed an evaluation procedure in which we first evaluated the CEI model after the SL training and then we evaluated the trained model after the successive RL training to demonstrate the improvement of the model performance.
Dialogue dataset generation procedure
Starting from a large scale dataset typically used in RS, we designed an automatic procedure [35] to generate a set of dialogues for a given user, paying attention to the fact that the procedure should introduce different linguistic variants of the user utterances and the dialogue flow should not be completely predefined. In this way we avoid the possibility that the agent “memorizes” the applied dialogue generation procedure. In particular, the idea behind our strategy is similar to the one proposed in [28]: For understanding which is the “best” set of questions that will lead to a given set of suggestions for the current user, the authors decide to apply this procedure to user preference data automatically generated by an NLP pipeline able to extract from item reviews the relevant factors that are interesting for the user. Our datasets have not item reviews, but we have access to users feedbacks. For this reason, we decide to exploit data from large knowledge bases for describing items using a set of attributes extracted from the Linked Open Data (LOD) cloud [13].
The defined dialogue generation procedure is general enough to be applied on any RS dataset which contains binary preferences for each user. In addition, each item of the dataset should have a unique identifier in a knowledge base of the LOD cloud. This is absolutely not a strict requirement because it is something that we can easily find available on the Web thanks to previous authors that have defined those mappings [24] or by using manual procedure or automatic algorithms to find the correct identifier associated to a given item.
Given a classical RS dataset composed by triples (u, i, r) which represents a binary preference r ∈ {0, 1} that the user u ∈ U has expressed for the item i ∈ I and suppose that each item has an URI which allows to reference a specific entity of the LOD cloud, it is possible to build a dataset R (u), for each user u, which consists of LOD-based feature vectors associated to each item i rated by the user u and a class value which is equal to r. Given a set of properties P associated to the type of item to be suggested (i.e., film, music band, etc.), where each p has a set of associated values equal to O (p), a LOD-based feature vector can be intended as a feature vector generated considering all the dummy variables [10] that can be generated from the set of properties P. For example, suppose that we want to represent the entity Pulp Fiction 1 as a LOD-based feature vector using the set of properties P = {p136, p57} and suppose that each property can assume 2 values. We need to create 4 binary features that represent the fact that the item has a specific value for a defined property or not.
Given a dataset R (u) for each user u built using the above-mentioned procedure, Decision Trees [27] 2 are used in order to learn a model for the preferences of the user. As shown in Fig. 3, the learned model can be considered as a specification of possible decision steps that the user can do to choose the item that he/she likes or does not like. In fact, a path from the root to a given leaf node represents the set of properties and their values that are considered by the model to classify the item. For this reason, a decision tree is a suitable choice in order to derive all the alternative paths that can be considered to get to specific items rated by the user and can be exploited to generate questions with regard to the attributes found in the selected paths.
The dialogue generation procedure is based on a random dialogue state graph which represents different states of the dialogue as nodes and its edges represent the possible state transitions that can be done according to a given probability distribution over them. In particular, the dialogue generation procedure starts from an initial state and traverses the graph following edges sampled according to a predefined probability distribution. The random traversal continues until a final state is reached which determines the end of the dialogue generation procedure. The procedure is applied multiple times for each user in the dataset until all the user preferences have been considered in order to generate multiple conversations for him/her. As stated before, the random nature of the graph allows to visit nodes in a random fashion which is something that is required if we want to generate a realistic dataset for an in-vitro evaluation of a conversational agent.

Dialogue state graph used in the dialogue generation procedure. For each user, the dialogue state graph is exploited in order to generate plausible conversations between the user and the system based on the user preferences present in the dataset. Starting from the user_starts state, a random walk procedure allow to visit each state and add specific information to the conversation.

Decision tree generated from the preferences of a specific user included in a recommender system dataset. Each branch in the tree represents a binary LOD feature (e.g., genre, director, etc.). By traversing the tree from the root to one of the leaf node, it is possible to obtain a set of decisions that can be exploited to generate questions regarding the user preferences. The leaf node will represent the item satisfying the binary features traversed during the tree visit.
The designed dialogue state graph, depicted in Fig. 2, contains nodes related to demographic information and nodes related to the elicitation of the user preferences, mainly preferences about specific values of the selected items properties or preferences of the user towards specific items. By doing a graph traversal, it is possible to generate a dialogue which resembles a plausible use case for a CRS. Usually, in a goal-oriented conversation, the user says to the agent his/her demographic information (i.e., name, age, occupation), after that, the agent may ask for some preferences related to items or properties which are fundamental for the suggestion step. Finally, a recommendation state is reached in which the elicited user preferences are exploited to generate a list of suggestions for the user. Given the user profile, a reference list of recommendations for the current dialogue is generated. The list is composed of a randomly selected percentage of positive items while the remaining are randomly sampled from the negative items. A description of the possible states contained in the dialogue state graph is reported as follows:
The designed dialogue generation procedure, as previously stated, is general because starting from a classical recommender system datasets typically used in well-known challenges augmented with supplementary information retrieved from the LOD cloud, it is possible to generate coherent and meaningful conversations from which a conversational agent can be trained. Due to the hierarchical nature of the developed model, we annotate each step of the dialogue with a specific goal which should allow the system to understand which goal-specific module should be used to complete a given task. In particular, the states associated to the goal chitchat are: user starts, ask name, ask age, ask occupation, user ends. On the other hand, the states associated to the goal recommendation are recommend, refine, ask preferences and ask liked items. An example of a conversation generated by the designed automatic procedure related to the movie domain is reported in Table 1. The whole dataset is freely available on Github 3 . We associated to each entity in the dataset a compact representation generated from its Wikidata URI in order to associate a specific token to each entity in the dataset and that will be considered in the vocabulary V.
Conversation between the bot and the user generated from the decision tree trained using user preferences
Conversation between the bot and the user containing a refine step
In the SL stage the CEI model was trained on a dataset obtained by removing the utterances corresponding to the “refine” step from the generated dialogues because it should replicate the dialogues ignoring the additional “refine” steps. Intuitively, we want that the model avoids to learn from incorrect dialogue turns.
The effectiveness of the model was evaluated against some baselines such as
As regards the CEI model parameters, we fixed the embedding size d w , d u e d g to 50. In addition, due to the complexity of the model, we applied dropout of 0.5 on all the GRU cell input and output connections, a dropout of 0.2 on the IMNAMAP search gates and a dropout of 0.5 on all the hidden layers in fully connected neural networks employed in the architecture. The batch size was fixed to 32 and we applied the same early stopping procedure employed in the seq2seq model. The training procedure exploited the Adam optimizer with a learning rate of 0.0001 and we decided, due to the different datasets sizes, to apply a lower L2 regularization weight α equal to 0.0001 on the ML1M dataset whereas we fixed α to 0.0001 on MT. To stabilize the training procedure and avoid that the model converges to poor local minima, we applied gradient clipping considering as the maximum L2 norm value 5. We exploited the same procedure used in [11] to manage all the facts related to the given user query. In particular, the search engine returns at most the top 20 relevant facts for the user query. All the tokens which compose the knowledge base facts are stored in the vocabulary V as well as all the other tokens which belong to the dataset. The conversations which belong to the dataset were tokenized using the NLTK default tokenizer 6 . The model was implemented using the TensorFlow framework [1].
Firstly, we evaluated different configurations of the CEI model in order to find the best configuration on a specific dataset. In the evaluation, we have tried different values for a limited set of parameters while all the others are fixed to the above-mentioned values. In particular, the GRU output size can assume a value in the set {128, 256}, the inference GRU output size s in the IMNAMAP model can assume a value in the set {128, 256}, the output representation of the dialogue state RNN q can assume a value in the set {256, 512} and the hidden layer size r in the controller RNN decoder can assume a value in the set {1024, 2048}.
Thanks to the preliminary comparisons, we have selected the best configuration of the CEI model on the two datasets, which is the one that has the higher average score between all the evaluated measures (in the tables of results the best configurations are highlighted in bold). After that, we compared the best CEI model with the proposed baselines. Table 3 shows the experimental comparison between the best-performing configuration and the other baselines according to the evaluation measures. An NA value in the table is associated to a configuration for which, due to its implementation constraints, it is not possible to evaluate the measure (i.e., the seq2seq model it is not equipped with a meta-controller so it is not possible to evaluate its effectiveness). Table 4 shows a real conversation between the CEI agent and a simulated user whose preferences are taken from the test set.
Evaluation between the best performing CEI model and all the baselines on MT and ML1M
Evaluation between the best performing CEI model and all the baselines on MT and ML1M
Real conversation between the CEI agent and a simulated user whose preferences are taken from the test set. The user greets the bot and the bot asks some demographic information like the name and the age. After that, the agent is correctly able to generate questions regarding some relevant preferences that can be required to propose appealing suggestions to the user. Finally, exploiting the collected information about the user preferences, generates a list of suggestions which contains “The Shawshank Redemption” (wd_q172241) and “Dead Calm” (wd_q845077) which are both movies which have “film adaptation” as genre (see the corresponding Wikidata page for more information). An interesting thing is that the preferred cast member “Kathleen Turner” it is not present in the cast members of the suggested movies. We expect that the model learned a latent relationships between the current user preferences and the similarity between the cast members of the suggested movies and the actress liked by the user
In the final experimental evaluation we can observe that all the values associated to the measures related to the effectiveness of the suggestions are pretty satisfying compared to the one obtained by Random and Seq2seq. In particular, on both the MT and the ML1M dataset, there is a marked difference in terms of per-userF1 and F1 measure between CEI and the baselines which is justified by the ability of the intra-dialogue attention mechanism to propagate the attention scores collected during the conversation to the controller which exploits them in the response generation procedure. It is worth noting that on the MT dataset the BLEU measure evaluated for the Seq2seq model is higher than the one for our model. A justification for this result can be found in the fact that the baseline focuses on the generation of language and it ignores completely the generation of suggestions, as demonstrated by the lower F1 measure. In addition, it is clear that an RNN easily overfits on the simple templates adopted in the generated system responses. Results prove that our architecture is able to provide the best recommendations with respect to the baselines and it is able to produce meaningful dialogues comparable to the state of the art approach based on Seq2seq.
In this section we discuss the evaluation of the Reinforcement Learning (RL) stage.
For each dataset, we selected only the best configuration in the SL training phase for the successive RL training stage. In this way, we expect to assess, thanks to a quantitative evaluation, if the system is able to improve its performance by learning from its own experiences with users. We exploited the REINFORCE algorithm for the meta-controller and the controller in order to fine-tune their policies directly from the experiences collected by the agent. The model trained using the SL training procedure is used in the RL training procedure during which it interacts with the environment by exploiting the meta-controller and the controller policy to collect experiences from which it can learn from.
The adopted training procedure starts by loading the pre-trained model obtained from the SL stage and uses it in a RL scenario so it selects actions according to a state given by the environment and observes a reward according to their goodness. The model parameters are the same as the ones used in the SL training procedure so the parameters are used as they are in the RL setting. The only difference relies in the optimization method employed and in the loss function exploited to optimize the model parameters. We run the training process in the RL scenario for a fixed number of experiences e and we used mini-batches of them to update the model parameters. The advantages of this strategy are twofold: first we are able to obtain more accurate gradient approximation and second we are able to exploit the power of the GPU leveraged in our experiments to compute simultaneously multiple matrix operations. The batch size is fixed to 8 on the MT dataset and to 32 on the ML1M dataset. The entropy regularization weights ɛ MC and ɛ C are fixed to 0.01, the number of experiences is fixed to 10, 000 for each dataset and we apply a discount factor on the meta-controller rewards equal to 0.99. In the RL scenario we do not design a joint training procedure because the loss functions of the meta-controller and the controller are updated in different moments, as described in [15]. Moreover, they represents different behaviour strategies that cannot be easily mixed together as they are. We also changed our optimization algorithm from Adam to the vanilla SGD because we observed during our experiments with Adam catastrophic effects on the effectiveness of the policies due to the aggressive behaviour of the algorithm in the early stages of the training. Indeed, according to our experience, it upsets the learned policies making them completely useless for our tasks.

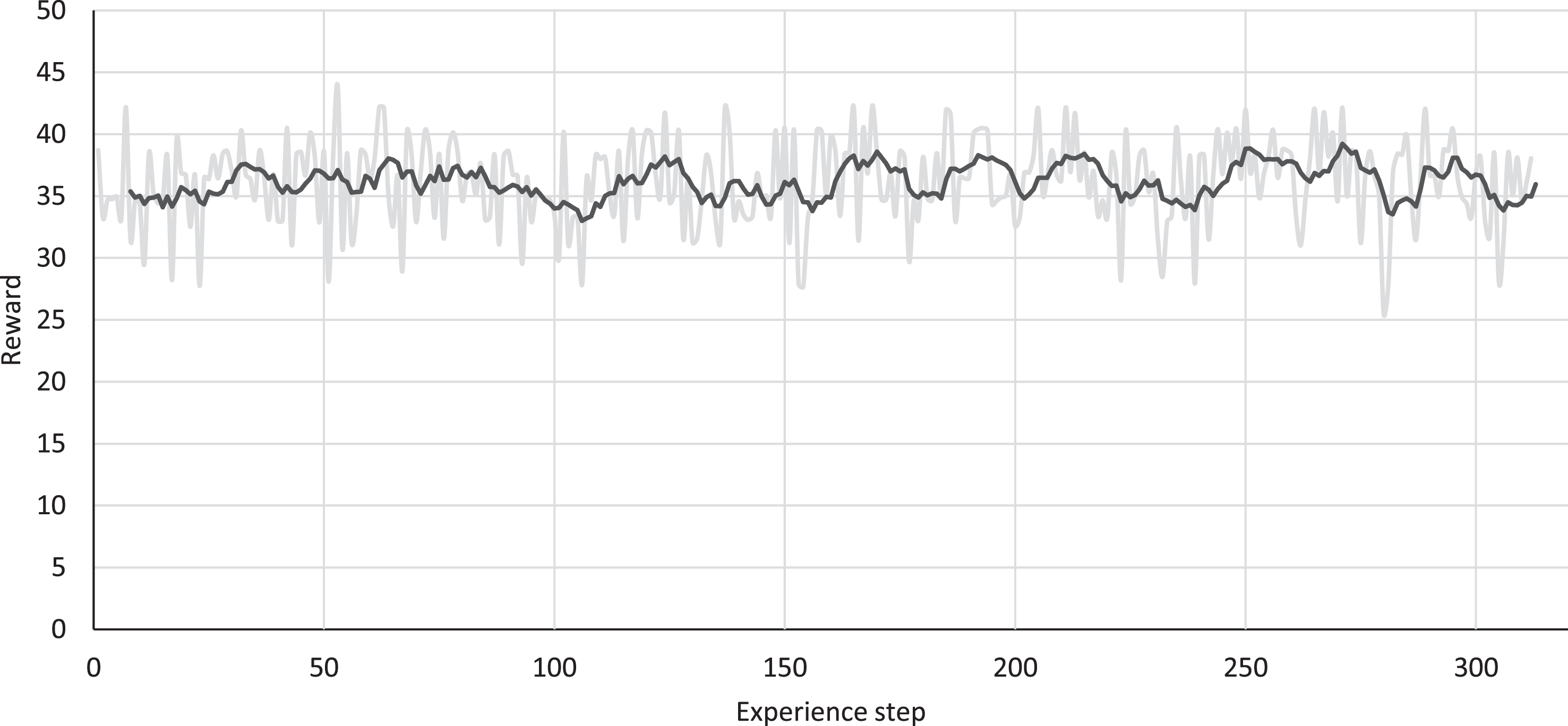
MC reward on MT test set: each data point represents the average reward for the MC among a given set of experiences that the agent is exposed to during test time in the RL training phase.
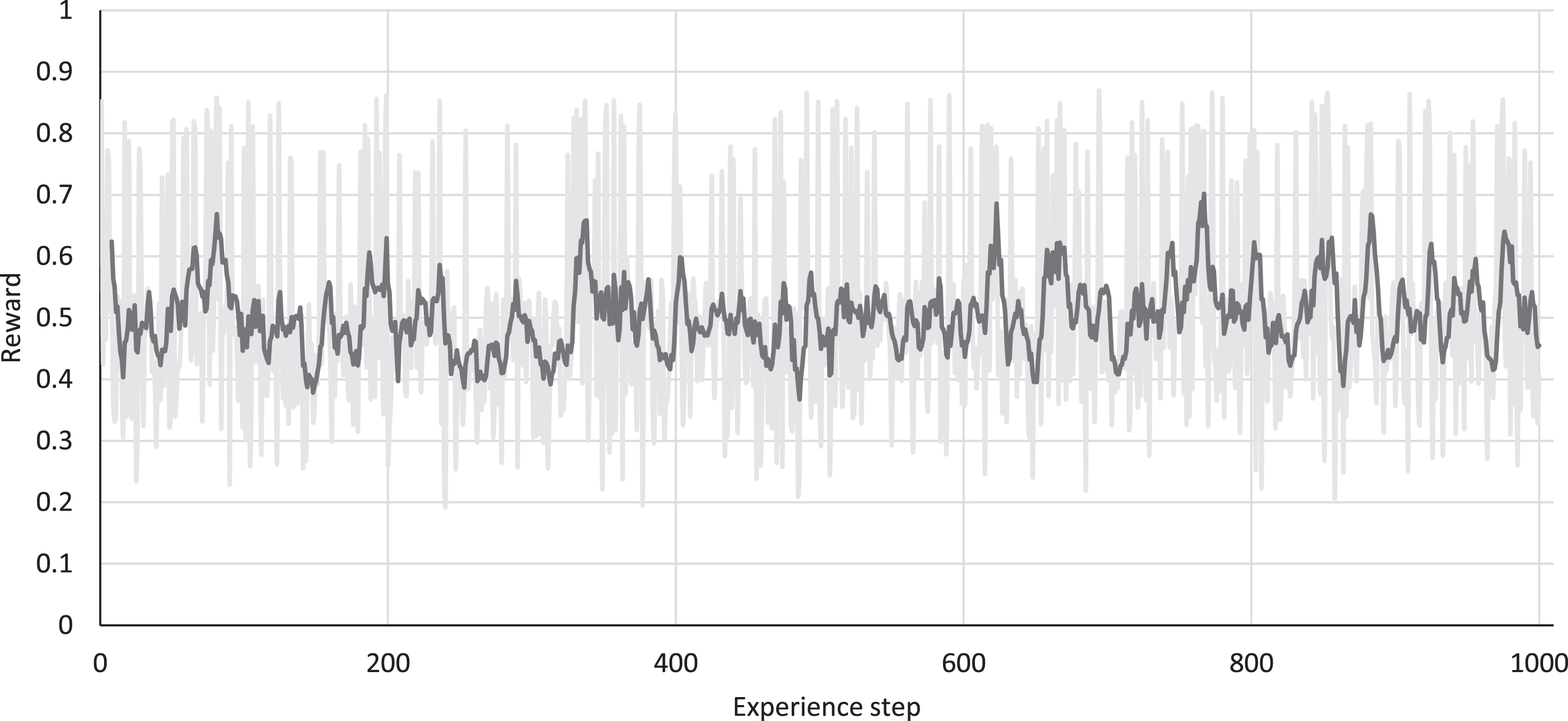
MC reward on ML1M test set: each data point represents the average reward for the MC among a given set of experiences that the agent is exposed to during test time in the RL training phase.
C reward on MT test set: each data point represents the average reward for the C among a given set of experiences that the agent is exposed to during test time in the RL training phase.
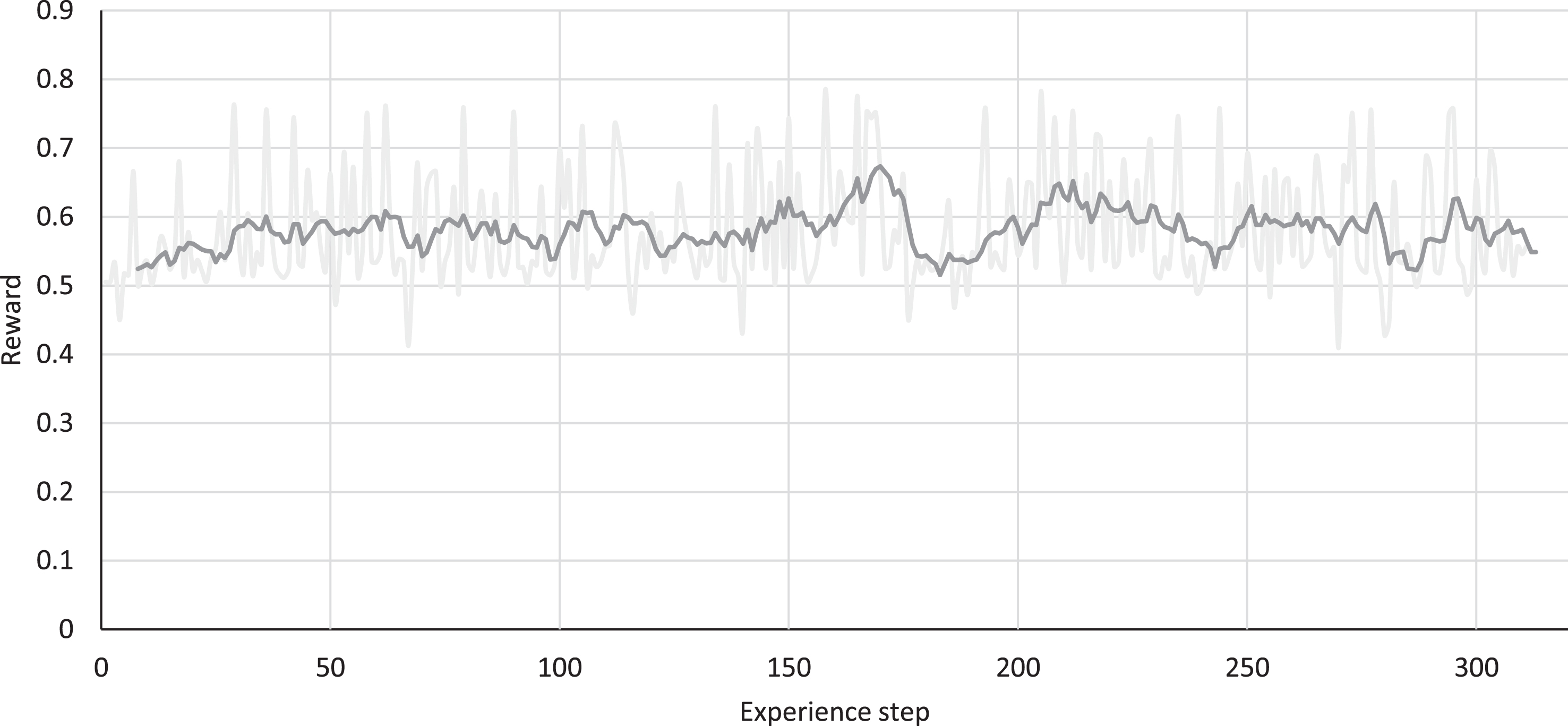
C reward on ML1M test set: each data point represents the average reward for the C among a given set of experiences that the agent is exposed to during test time in the RL training phase.
DL models have been applied in different modules of a dialogue system [30]. First of all, as feature extractors in order to learn a representation of the user utterance which is effective for the final task. In the work presented in [32], Convolutional Neural Networks are exploited in order to generate a representation for the user utterance which is obtained as a composition of multiple low-level representations for the words – word embedding – for each language supported. This represents a way to incorporate prior knowledge learned from huge textual corpora so as to grasp meaningful representations for the words and then fine-tune them for the task at hand. An interesting hybrid dialogue systems that combines DL models with rule-based component is described in the work presented in [39]. Their architecture is composed of four main components: 1) RNN, 2) domain-specific software, 3) domain-specific action templates, and 4) entity extraction module. The RNN is used as a method to extract a representation for the user utterance. The entity extraction module is responsible for extracting mentions to entities using string matching with database keys. An entity tracker returns entities specific information hand-crafted by the user. Action templates are scored using a NN and the resulting probability score vector is multiplied by an action mask that prevents the execution of specific actions. If the selected action contains placeholders they are replaced by an entity output module or if it is an API call it is directly invoked. The action taken is given in input to the next step because it may be considered a relevant feature for the dialogue. Its training procedure it is composed by two SL stages and one final RL phase in which the REINFORCE algorithm [41] is used to optimise the return of the given dialogue. Its effectiveness has been validated in a real-world scenario and an interesting interactive tool has been developed for it [40]. Dialogue response generation can be intended as a Structured Prediction problem in which, given the user input utterance (source), the system learns to generate a response (target). However, as argued by [38], by considering a dialogue as a simple input/output mapping, as is done in Machine Translation, is considered a limitation because it completely disregards the dialogue structure.
In the literature CRSs have been classified under different names according to the strategy adopted in order to extract relevant information about the user and provide recommendation to him/her. Case-based Critique systems finds cases similar to the user profile and elicits a critique for refining the user’s interests [23, 29] throughout an iterative process in which the system generates recommendations in a ranked list and allows the user to critique them. The critique will force the system to re-evaluate its recommendations according to the specified constraints.
A limitation of classical CRSs is that their strategy is typically hard-coded in advance; at each stage, the system executes a fixed, pre-determined action, notwithstanding the fact that other actions could also be available for execution. This design choice negatively effects the flexibility of the system to support conversation scenarios which are not expected by the designer. In fact, despite the effectiveness of these systems in different complex scenarios, as reported in [23], they always follow a predefined sequence of actions without adapting to the user requirements. Moreover, typically they uses a representation for the items that is hand-crafted which is incredibly labour-intensive for complex domains like music, movies and travels. For instance, in the work presented in [4] is exploited a first-order logic representation of the items by an attribute closure operator able to refine the attribute set of the items considered in the current conversation.
To overcome these limitations the work first presented in [18] and then extended in [19–21], proposes a new type of CRS that by interacting with users is able to autonomously improve an initial default strategy in order to eventually learn and employ a better one applying RL techniques. It was first validated in off-line experiments to understand which were the state variables required by the system and then it was evaluated in an online setting in which the system had the task to support travellers. Another relevant work is the one presented in [8], which exploits a probabilistic latent factor model where the observed likes/dislikes of users on items are generated on the basis of latent variables. The model variables are learned so that the model can explain the observed training data. In this way, the model is able to provide suggestions to the user by asking each question with the goal of eliminating or confirming strong candidates.
Conclusions and Future Work
CEI represents a framework for a goal-oriented conversational agent whose objective is to provide a list of suggestions according to the user preferences. Our intuition is that a dialogue can be subdivided in fine-grained goals whose achievement allows the agent to successfully complete the conversation with the user. The framework exploits a combination of Deep Learning and Hierarchical Reinforcement Learning techniques and it is trained by using a two-stage procedure. Moreover, we enrich the items description leveraging on information coming from the LOD cloud. Experimental results prove that our approach is able to both provide relevant recommendations and produce meaningful dialogues.
With regards to the answer generation module we plan to understand if the current implementation is well suited to take into account the score vector weights generated by the intra-dialogue attention mechanism in order to effectively exploit them in the recommendation phase. In addition, we think that allowing the model to leverage multiple information sources can enable it to grasp different views of the items that can be used to provide more accurate suggestions according to the user preferences.