Probabilistic Bipolar Abstract Argumentation Frameworks (prBAFs), combining the possibility of specifying supports between arguments with a probabilistic modeling of the uncertainty, have been recently considered [34, 35] and the complexity of the problem of computing extensions’ probabilities has been characterized [22]. In this paper we deal with the problem of computing extensions’ probabilities over prBAFs where the probabilistic events that arguments, supports and defeats occur in the real scenario are assumed to be independent probabilistic events (prBAFS of type ind). Specifically an algorithm for efficiently computing extensions’ probabilities under the stable and admissible semantics has been devised and its efficiency has been experimentally validated w.r.t. the exhaustive approach, i.e. the approach consisting in the generation of all the possible scenarios, showing that the proposed algorithm outperforms the exhaustive approach.
An abstract argumentation framework (AAF) represents a dispute as an argumentation graph 〈A, D〉, where A is the set of nodes (called arguments) and D is the set of edges (called defeats or attacks). Herein, an argument is an abstract entity that may attack and/or be attacked by other arguments, where “aattacksb” means that argument a rebuts/weakens b. Reasoning on the possible strategies for winning the dispute typically requires looking into the extensions of the AAF. An extension S is a set of arguments that satisfies some properties certifying its “strength”, so that a party using the arguments in S has reasonable chances to win the dispute. Different semantics for AAFs (i.e., sets of properties assessing whether a set of arguments is an extension) have proven reasonable, such as admissible (ad), stable (st), preferred (pr), complete (co), grounded (gr), ideal (id) [2, 16], and the complexity of the fundamental problem ext of verifying whether a set is an extension has been studied under each of these semantics [17, 19].
Since the introduction of AAFs in [16], many variants have been proposed, with the aim of modeling disputes more accurately. Among these, Bipolar Abstract Argumentation Frameworks (BAFs) allow supports, besides attacks, to be specified between arguments. Specifically, two alternative formal semantics of support have been introduced: in [6], the support is a generic “inverse” of the notion of attack (“abstract semantics”: “a supports b” means that a strengthens the validity of a), while, in [4], it is viewed as a “deductive” correlation between arguments (“deductive semantics”: if a supports b, the acceptance of a implies the acceptance of b). The various extensions’ semantics defined for AAFs have been shown to have a natural counterpart over BAFs, after noticing that combining attacks with supports (of any semantics) generates “implicit” attacks (see Example 1).
Example 1. The graph in Fig. 1 is a BAF with six arguments a, b, c, d, e, f. The dashed and the standard arrows denote supports and attacks, respectively. The co-existence of supports and attacks entails the existence of implicit attacks. For instance, under both the abstract and deductive semantics, the fact that a strengthens b and b attacks c implicitly says that a attacks c. This kind of implicit attack is often called “supported attack”. If the deductive semantics is adopted, there are other forms of implicit attacks. For instance, since a supports b and e attacks b, there is an implicit attack from e to a. Otherwise, a would be acceptable while b would be not, thus contradicting the deductive support from a to b.
A bipolar abstract argumentation framework.
Other variants of AAFs that, owing to their practical impact, have gained interest from the research community are those addressing the representation of uncertainty. In this regard, probabilistic AAFs (prAAFs) are a popular paradigm, and in particular those following the constellation approach. Here, the dispute is modeled as a set of possible scenarios, each consisting of a standard AAF (called possible AAF) associated with a probability of representing all and only the arguments and attacks actually occurring in the dispute. In particular, two main paradigms have been adopted for specifying the probability distribution function (pdf), called ex and ind. In the general case, the extensive form ex is used, where the composition of each possible AAF must be explicitly specified along with its probability. Otherwise, when independence between arguments/attacks is assumed, the form ind can be used, where the possible scenarios and their probabilities are represented compactly and implicitly by specifying the marginal probabilities of the arguments and attacks.
Recently, for both ex and ind, the complexity of the probabilistic counterpart p-Ext of Ext (asking for the probability that a set of arguments is an extension) has been characterized for ind in [23] for prAFFs and in [22] for prBAFs. Interestingly, when considering ind and the stable or the admissible semantics, moving from prAAfs to prBAFs makes p-Ext intractable (FP#P-complete).
In this paper, we consider the probabilistic Bipolar Argumentation Framework (prBAF), where the bipolarity of BAFs is combined with the probabilistic modeling of the uncertainty of prAAFs under the paradigm ind, and provide an efficient algorithm for solving p-Ext in the cases that the stable or the admissible semantics are considered. We provided the soundness proof of the algorithm and performed an extensive experimental validation comparing it wtih the naive computation of the extensions’ probabilities.
Related Work. [6] first introduced BAFs, where supports have the general “abstract” semantics of positive interactions between arguments. Later, three more specific interpretations for supports have been proposed: [4], [32] and [33] introduced the deductive, necessary, and evidential semantics for the support relation, respectively. In this paper, we focus on the abstract and deductive semantics, but our results also hold for necessary supports (as shown in [8], they are dual to deductive ones). 8] reviews the four different semantics for supports, and discusses the similarities and differences among these interpretations. [9] introduces a more general framework that incorporates attacks, supports and a preference relation to decide between conflicting arguments. In [30], subarguments in AAF have been introduced, that in [10] have been shown to be closely related with the necessary support. Other related works are [5, 38] where, although supports are not mentioned, similar dependencies have been considered. A detailed survey over BAFs can be found in [10].
Regarding uncertainty in AAFs, the approaches based on probability theory can be classified in two categories: those adopting the classical constellations approach [12, 36] and those adopting the recent epistemic one [24, 37]. The former category has the two sub-categories ex [13, 36] and ind [12, 29], described in the paper. The interested reader can find a more detailed comparative description of the two categories in [27]. Furthermore, many proposals have been made where uncertainty is represented by exploiting weights or preferences on arguments and/or defeats [1, 31]. Although the approaches based on weights, preferences, or probabilities to model uncertainty have proved effective in different contexts, there is no common agreement on what kind of approach should be used in general. In this regard, [26, 27] observed that the probability-based approaches may take advantage from relying on a well-established and well-founded theory, whereas the approaches based on weights or preferences do not.
As regards probabilistic Bipolar Argumentation Framework (prBAF) they have been recently introduced [34, 35] and the computational complexity of the problem of computing extensions’ probabilities has been characterized [22].
Preliminaries
We assume that the reader is familiar with the notions of Abstract Argumentation Framework (AAF), extension, and acceptability of arguments. We now review Bipolar Abstract Argumentation Frameworks (BAFs) and the concepts of support, attack and defense, along with the most popular extensions’ semantics over BAFs [6].
Bipolar abstract argumentation frameworks
Definition 1.[BAF] A bipolar abstract argumentation framework (BAF) is a tuple , where is a set of arguments, is a defeat/attack relation and is a support relation.
In the first proposal of BAF [6], supports are given an abstract semantics, that is the opposite of the traditional semantics of attack, inherited from classical AAFs. This was shown to make the combination of supports and attacks imply the so-called supported attacks
1
.
Definition 2.[Supported attack] Let be a BAF, and . There is a supported attack from a to b iff there is a sequence , with n ≥ 2, where a1 = a, an = b, ∀i ∈ [1 . . n-2] , and .
Example 2. In the BAF in Fig. 1, there is a supported attack from a to c. Also the three direct attacks (e, b), (b, c) and (f, d) are special cases of supportedattack.
Besides the abstract, other semantics have been proposed for supports (see Related Work). In particular, we consider the well-established deductive semantics, first proposed in [4]. Here, “asupportsb” is interpreted as a strong correlation between a and b, meaning that if a is acceptable, then b is acceptable too. As observed in [8], under this semantics, a new form of implicit attack, called d-attack, must be considered.
Definition 3.[d-attack] Given a BAF and , there is a d-attack from a to b iff
, or
there is an argument a′ such that there is a path from a to a′ consisting of only support edges, and a′ attacks b, or
there is an argument a′ such that there is a path from b to a′ consisting of only support edges, and a attacks a′.
Example below shows that d-attacks include supported attacks, but can be also of the form of supermediated attacks (described by the last point in Definition 3).
Example 3. Under the deductive semantics for supports, in the BAF of Fig. 1, it is easy to see that the supported attacks reported in Example 2 are d-attacks. Further d-attacks are the supermediated attacks from e to a, and from f to c, that are not supported attacks.
In order to analyze what changes when moving from one semantics of supports to the other (or, equivalently, from one form of implicit attacks to the other), we partition BAFs into two classes: s-BAFs and d-BAFs, where only supported attacks and d-attacks are considered, respectively. From now on, we assume the presence of a BAF , and, when needed, we will specify whether is an s- or a d- BAF.
The concepts of support, attack and defense from sets of arguments are mandatory to define the extensions over BAFs.
Definition 4.[Set-support] A set set-supports an argument iff there is an argument a′ ∈ S such that there is a path from a′ to a consisting of only support edges.
Definition 5.[Set-attack] Let be an s-BAF (resp., d-BAF). A set set-attacks iff there is a supported attack (resp., d-attack) from some b ∈ S to a.
Definition 6.[Set-defense] A set set-defends an argument iff, , if {b} set-attacks a then ∃c ∈ S such that {c} set-attacks b.
Example 4. Consider the BAF in Fig. 1. Independently from supports’ semantics, {a, e} both set-supports and set-attacks b, and also set-attacks c. If is an s-BAF, then {a, e} does not set-defend c, since there is a supported attack from a to c, and no attack from e to a. Observe that {a, e} does not set-defend c if is a d-BAF either, since, although e d-attacks a, no argument in {a, e} d-attacks f, that in turn d-attacks c.
Semantics
We first recall the notions of conflict-freeness and safety.
Definition 7.[Conflict-free and safe sets of arguments] A set of arguments is:
conflict-free iff ∄ a, b ∈ S such that {a} set-attacks b;
safe iff such that S set-attacks b and either S set-supports b or b ∈ S.
Example 5. If the BAF in Fig. 1 is an s-BAF, both {a, e}, and {f, c} are conflict-free but not safe, while both {a, b, f} and {a, b, d} are conflict-free and safe. If is a d-BAF, both {a, e}, and {f, c} are not conflict-free, while both {a, b, f} and {a, b, d} are still conflict-free and safe.
All the most popular semantics of extensions of “standard” AAFs have been extended to the case of BAFs [6]. We start with the stable semantics.
Definition 8.[Stable extension] A set of arguments is a stable extension iff S is conflict-free and it holds that S set-attacks a.
The presence of supports and the fact that, in BAFs, conflict-freeness and safety do not coincide (while they do in AAFs) is at the basis of the fact that, for some AAF’s semantics, different variants are considered when moving to BAFs. This is the case of the admissible semantics.
Definition 9.[Admissible extension] A set is
a d-admissible extension iff S is conflict-free and set-defends all of its arguments;
an s-admissible extension iff S is safe and set-defends all of its arguments;
a c-admissible extension iff S is conflict-free, closed for and set-defends all of its arguments.
In turn, the other semantics subsuming the admissible one are defined as follows. A set is said to be:
a d-complete (resp. s-complete, c-complete) extension iff S is d-admissible (resp., s-admissible, c-admissible) and S contains all the arguments set-defended by S;
a d-grounded (resp. s-grounded, c-grounded) extension iff S is a minimal (w.r.t. ⊆) d-complete (resp. s-complete, c-complete) extension;
a d-preferred (resp. s-preferred, c-preferred) extension iff S is a maximal (w.r.t. ⊆) d-complete (resp. s-complete, c-complete) extension;
a d-ideal (resp. s-ideal, c-ideal) extension iff S is a maximal (w.r.t. ⊆) d-admissible (resp. s-admissible, c-admissible) extension and S is contained in every d-preferred (resp. s-preferred, c-preferred) extension.
We denote the set {d-ad, s-ad, c-ad, st, d-co, s-co, c-co, d-gr,c-gr, c-gr, d-pr, s-pr,c-pr, d-id,s-id, c-id} consisting of the above semantics as SEM (herein, st means stable, d-ad d-admissible, s-ad s-admissible, and so on).
Example 6. Consider the BAF in Fig. 1. Both {a, b, f} and {a, b, d}, although conflict-free and safe, are not d-ad extensions in both the cases of s-BAF and d-BAF (since b is not set-defended). Furthermore, for the s-BAF case, we have: both {a, f} and {e, f} are s-ad, s-gr and s-pr extensions, {a, e, f} is a st, d-ad, d-gr, d-pr, and d-id extension, {f} is an s-id extension, {e, f} is a c-pr, c-gr and c-id extension.
For the d-BAF case we have: {e, f} is the unique stable extension, that is also c-preferred, c-grounded and c-ideal.
The fundamental problem of verifying whether a set S of arguments is an extension over a given BAF under a semantics sem ∈ SEM will be denoted as Extsem (S). Basically, solving an instance of Extsem (S) means checking whether a set of arguments is a reasonable strategy in the dispute, where the meaning of “reasonable” is encoded in the semantics.
Given a BAF , a set S ⊆ A, and a semantics sem ∈SEM, we define the boolean function ext(α, sem, S) returning true iff S is an extension under sem.
Probabilistic BAFs (prBAFs)
We now consider the extension of BAFs where uncertainty is addressed and modeled probabilistically as in “traditional” probabilistic Abstract Argumentation Frameworks - prAAFs (in particular, we refer to prAAFs employing the constellation approach recalled in the introduction and adopting the ind approach for specifying pdfs).
A probabilistic BAF (prBAF) of type ind is a tuple where A = {a1, …, am}, and are the sets of arguments, attacks and supports, respectively, and , {P (δ1) , …, P (δn) , P (σ1) , …, P (σk)} are their marginal probabilities.
A prBAF is used to represent a set of possible BAFs, that is the alternative cases of dispute that may occur, and their probabilities. More in detail is the set of possible BAFs represented by and the pdf P over the possible scenarios that is implied by the independence assumption and the marginal probabilities is as follows. For each possible BAF , the probability P (α′) is:
The size of a prBAF of type ind is .
Example 7. Consider a prBAF of form ind, where and are those of Fig. 1, and and are the following: P (a) = P (b) = P (c) = P (d) = P (f) =1, P (e) =0.5, P (e, b) =0.5 and the probabilities of the other supports and attacks are equal to 1. We have three possible scenarios: , , , whose probabilities are: P (α1) =0.25, P (α2) =0.25, P (α3) =0.5.
In what follows, given a prBAF , we denote as the possible BAFs that are assigned non-zero probability by , and as their probabilities.
The probabilistic versions of the two sub-classes s-BAF and d-BAF will be called s-prBAF and d-prBAF, respectively.
When switching to the probabilistic setting, the decision problem Extsem (S) makes no sense, since a number of different scenarios are possible, and a set of arguments can be an extension in a some scenarios, but not in others. Thus, the most natural “translation" of the problem of examining the “reasonability” of a set of arguments S becomes the functional problem P-Extsem (S) of evaluating the probability that S is an extension, according to the following definition.
Definition 10. [P-Extsem (S) and Psem (S)] Given a prBAF , a set S of arguments, and a semantics sem ∈SEM, P-Extsem (S) is the problem of computing the probability that S is an extension under sem, i.e.
Example 8. Continuing examples 6 and 7, we now compute the probability that S = {a, e} is d-admissible in both the s-and d- prBAF cases.
Case s-prBAF: S is d-admissible in both α1 and α2 (as e is missing in α3), thus Pd-ad (S) = P (α1) + P (α2) =0.5.
Case d-prBAF: S is d-admissible only in α2, as in α1e d-attacks a and in α3e is missing, thus we have Pd-ad (S) = P (α2) =0.25.
An algorithm for computing
We now provide our main contribution, that is the definition of an algorithm for efficiently computing the probability that a set of arguments is an extension according to a semantics sem ∈ {st, d-ad, s-ad, c-ad}.
The algorithm is based on the following results, provided in [21], that hold for traditional prAAF of type ind. A PrAAf of type ind correspond to a prBAF of type ind where the support relation is empty.
Fact 1. [21] Given a prAAF and a set of arguments, the probability that S is an admissible extension in is equal to P1 (S) · P2 (S) · P3 (S), where
2
:
,
, and
, where:
,
((d, b))),
Fact 2. [21] Given a prAAF and a set of arguments, the probability that S is a stable extension in is equal to P1 (S) · P2 (S) · P3 (S), where P1 (S) and P2 (S) are defined as in Fact 1 and
where:
, and
((a, d))))
Before defining the algorithm we introduce some preliminary notations used in its definition. Formally, given a prBAF , we consider the sets:
(called set of supp-arguments, as they are those involved in supports), and
(called set of supp- attacks and supports, as they are attacks/supports incident to supp-arguments).
The algorithm evaluation strategy is based on the notions of contraction and completion. A contraction for a prBAF is a prBAF where:
and ;
and ;
;
if and otherwise;
if , and otherwise.
Basically, ’s supports are a subset of ’s, and arguments (resp., attacks) are a subset of ’s containing at least the non supp-arguments (resp., the non supp-attacks). Then, the probabilities are copied from those specified in , except for those over supp- arguments and attacks, that are overwritten with 1.
will denote the set of possible contractions of . For , we define the probability of given as:
where:
if , ; else, ;
if , ; else, .
As regards completions, their definition uses the function cert, returning the BAF consisting of all and only the arguments in plus the arguments in involved in the attacks/supports in and the attacks/supports of that appear in . More formally, given a prBAF , cert is the BAF suchthat:
,
,
.
Thus, the completion of is the prBAF compl where:
and ;
, where R′ consists of the s- or the d- attacks of cert, depending on whether is an s- or a d- prBAF;
, ;
, if then , else .
, .
We now define Algorithm 1 that computes the probability that a set of arguments S is an extension for according to the semantics sem ∈ {st, d-ad, s-ad, c-ad} for both s- and d-prBAFs by iterating over .
Algorithm 1 Computing by enumerating contractions
Require: A prBAF
A set S ⊆ A
A semantics sem ∈ {st, d-ad, s-ad, c-ad}
Ensure:
1: Pr = 0.0
2: compute
3: compute
4: fordo
5: fordo
6: contract
7:
8: complete
9: ifsem = s-adthen
10: if not safethen
11: Pr′ = 0.0
12: end if
13: else ifsem = c-adthen
14: if not supclosedthen
15: Pr′ = 0.0
16: end if
17: else
18: Pr′ = 1.0
19: end if
20: toPrAAF
21: ifsem = stthen
22: aafsem = st
23: else
24: aafsem = ad
25: end if
26: computePrAAF
27:
28: end for
29: end for
30: returnPr
Algorithm 1 first computes the sets and of supp-arguments and supp-attacks and supports of (Lines 2-3) and it initializes Pr to 0. Then it iterates over the possible contractions of by iterating over the subsets of (Line 4) and then for each subset of iterating over the subsets of (Line 5).
The contraction o f corresponding to the sets and is generated by calling function contract (Line 6) and its probability is computed using Equation 3 (Line 7). Then the completion of is computed as by calling function complete (Line 8).
Then the variable Pr′ is computed according to the following definition (Lines 9- 19):
Pr′ = 0.0 if sem = s-ad and S is not safe in cert,
Pr′ = 0.0 if sem = s-ad and S is not closed for supports over cert,
Pr′ = 1.0, otherwise.
Next, the probability that S is an admissible/stable extension in the prAAF obtained removing supports by () is computed according to the formulas reported in Facts 1 and 2 (Lines 20- 26). Specifically function computePrAAF is responsible for computing the probability that S is an admissible/stable extension in and is added to the probability Pr. Finally Pr is returned.
Correctness of Algorithm 1
In this section we show that Algorithm 1 is sound and characterize its computational complexity. First we introduce a lemma (which straightforwardly follows from the definition of ) that allows for decomposing the evaluation of into evaluating over each contraction .
Lemma 1.Let be a prBAF and S a set of its arguments. For sem ∈ {d-ad, s-ad, c-ad, st}, it holds that .
Proof. It straightforwardly follows from the definition of . □
The following lemma state that the method for computing for each used in Algorithm 1 is correct. Indeed, it states that can be computed by taking the prAAF obtained by removing the supports from the completion of , and then using over any state-of-the-art algorithm for computing the extensions’ probabilities over “traditional” prAAFs (e.g. using the formulas reported in Facts 1 and 2).
Lemma 2.Let be a prBAF, a contraction for , the prAAF obtained from compl by removing the supports, and S a set of arguments of . Then:
For sem ∈ {d-ad, st} , where sem′ ∈ {ad, st} respectively;
if S is not safe over cert(compl; otherwise, ;
if S is not closed for over cert(compl; otherwise, .
Proof. The first statement trivially holds from the definition of d-ad and st. We prove the second and third statements by showing that S is safe over cert(compl (resp. S is closed for over cert(compl) iff for each possible BAF S is is safe over α (resp. S is closed for over α).
The only if part straightforwardly follows from the fact that supp- arguments and attacks in contractions are certain, as this and the fact that S is safe over cert(compl (resp. S is closed for over cert(compl) makes it impossible that a possible BAF exists such that S is is not safe over α (resp. S is not closed for over α).
We prove the if part reasoning by contradiction. That is we assume that S is not safe over cert(compl (resp. S is not closed for over cert(compl) and for each possible BAF S is is safe over α (resp. S is closed for over α). Consider the possible BAF which contains all the argument, attacks and supports in . Since any support in compl is also implied in α and any attack in compl is implied in α then the fact that S is not safe over cert(compl (resp. S is not closed for over cert(compl) implies that S is not safe over α (resp. S is not closed for over α) thus yielding a contradiction. □
Theorem 1.For sem ∈ {d-ad, s-ad, c-ad, st}, Algorithm 1 computes for both s- and d- prBAFs in time , F is a polynomial function.
Proof. The fact that Algorithm 1 computes followos form the fact that it computes . Specifically, Lemma 1 ensures that can be computed as , where for each . Moreover, for each Algorithm 1 computes as specified byLemma 2.
Finally, it is straightforward to see that computing as done by Algorithm 1 (i.e., following Lemma 2 and applying the formulas reported in Facts 1 and 2) is feasible in time , where F is a polynomial function. Hence, since , it follows that Algorithm 1 runs in time , which completes the proof. □
Experimental validation
In this section we report an extensive experimental assessment of the efficiency of Algorithm 1. To this end we compared running times of Algorithm 1 (denoted as contract in what follows) with a naive algorithm that computes by directly applying Equation 2 of Definition 10 (denoted as naive in what follows). We performed experiments over 500 prBAFs with a number of arguments ranging over {8, 10, 12, 14, 16}. Specifically we randomly generate 100 prBAFs for every number of arguments in {8, 10, 12, 14, 16} and run several experiments on the generated prBAFs by randomly generating, for each n ∈ {2, 3, 4, 5, 6}, 4 subset S of their arguments of cardinality n and running both algorithms twice for each combination, the first one considering the generated prBAFs as an s-prBAF and the second one considering it as a d-prBAF. The probability of each argument, attack and support was randomly chosen in the interval [0, 1]. Hence, on the overall we run 20000 experiments. All the experiments were run on a workstation equipped with an Intel Core i7-8700k 3.70 GHz with 32 GB of ram.
We compared the efficiency of contract and naive from several standpoints. That is we considered the running times of both algorithms w.r.t the number of arguments in the argumentation framework (), the size of the prBAF (), the “probabilistic” size of the prBAF, that is the number of arguments, attacks and support with probability less than 1, and the ratio of number of supp-arguments, supp-attacks and supports w.r.t the prBAF size (named Ratio of the prBAF in what follows). Moreover for clarity of presentation of the results in addition to the running times of the two algorithms in the following figures we report the gain of contract vs naive, defined as:
that is the percentange of running time that is saved (in the case that gain is less than 1) or wasted (in the case that gain is greater than 1) using contract instead of naive.
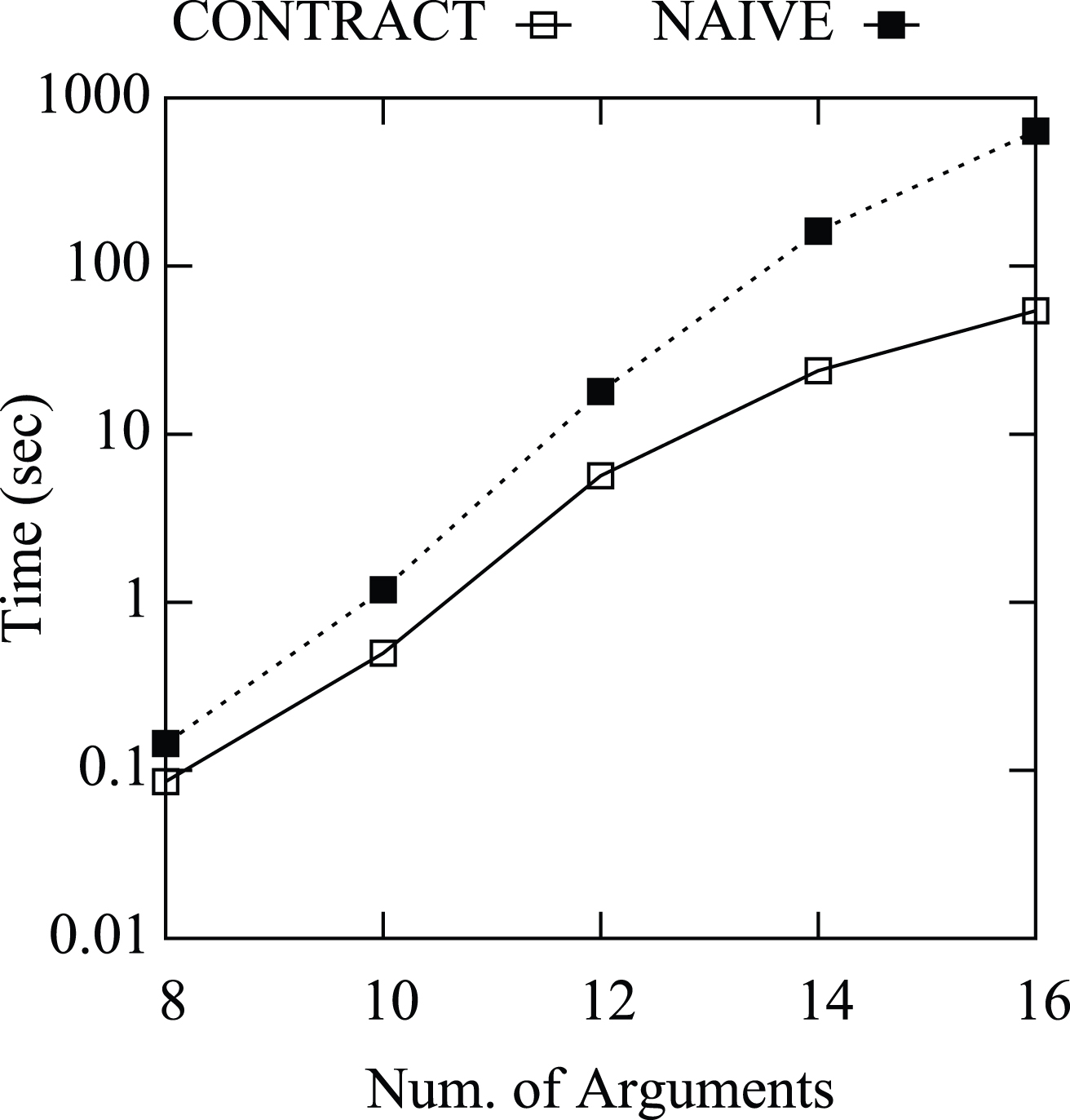
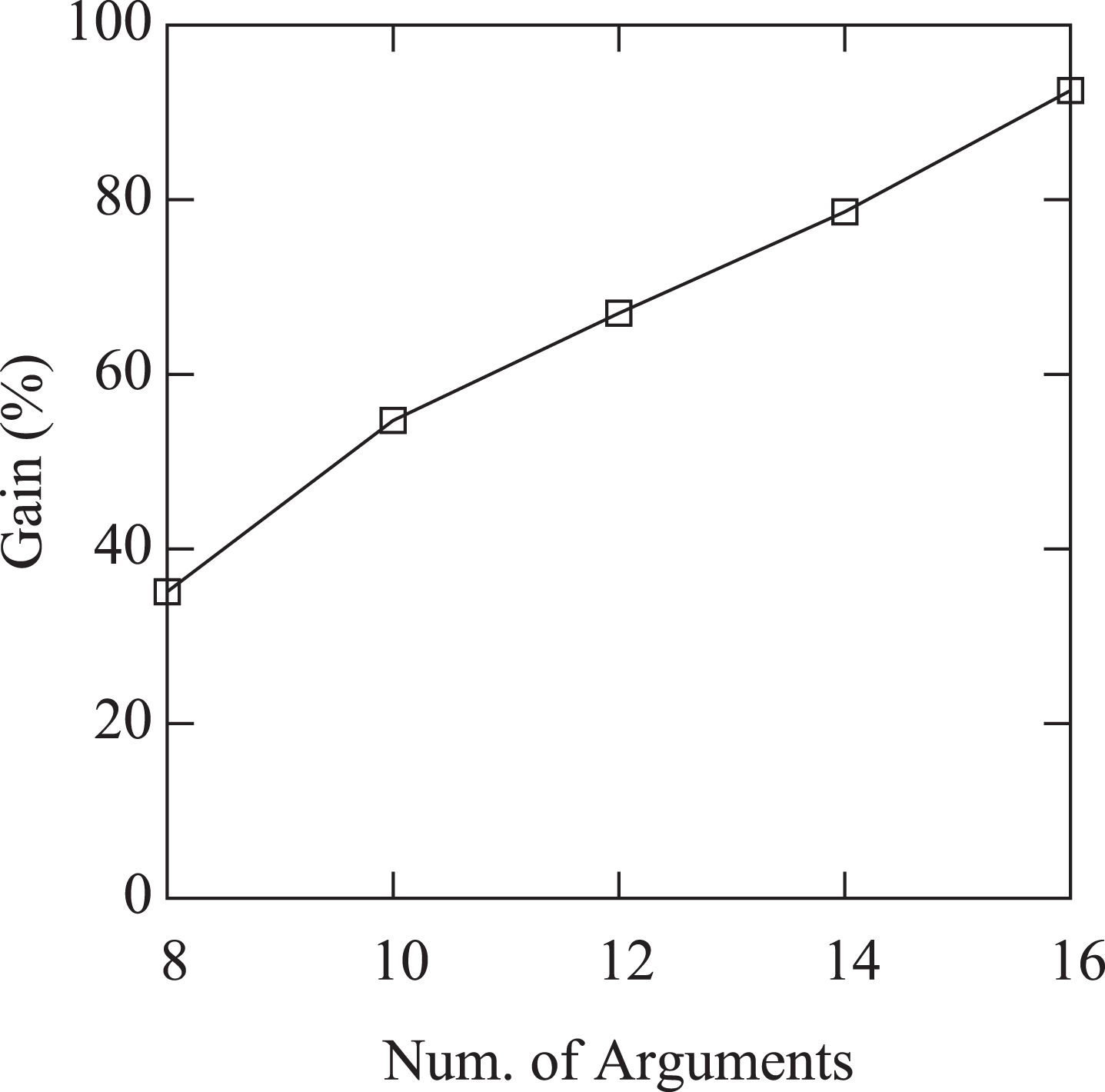
Figures 2 and 3 report the average running times of contract and naive (Fig. 2) and the gain of contract vs naive (Fig. 3) w.r.t the numebr of arguments. The drawings show that the running times of both contract and naive grows exponentially with the number of arguments while the gain grows linearly with the number of arguments.
Average running times of contract and naive (sec) vs number of arguments in the prBAF.
Average gain of contract vs naive (%) vs number of arguments in the prBAF.
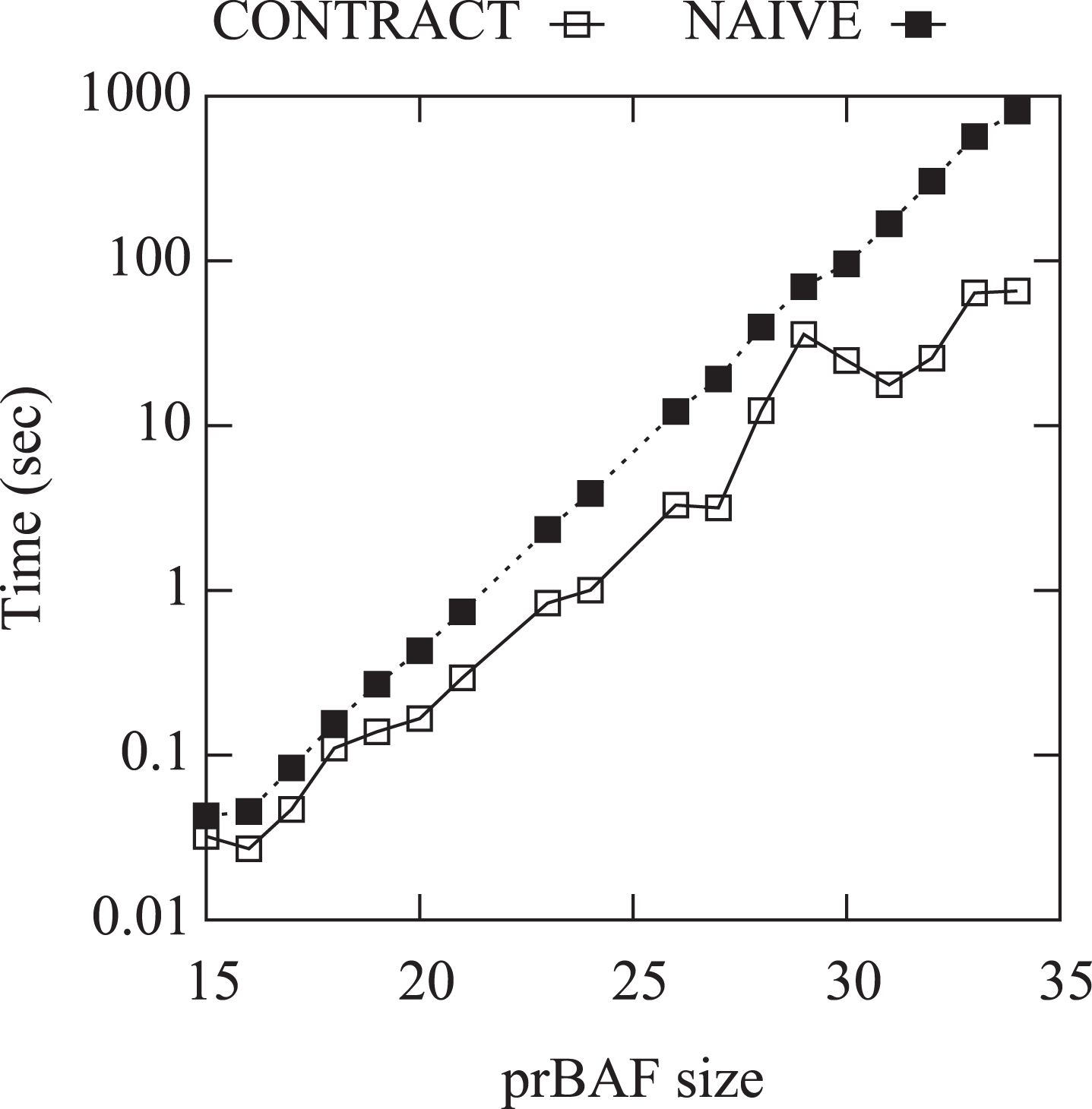
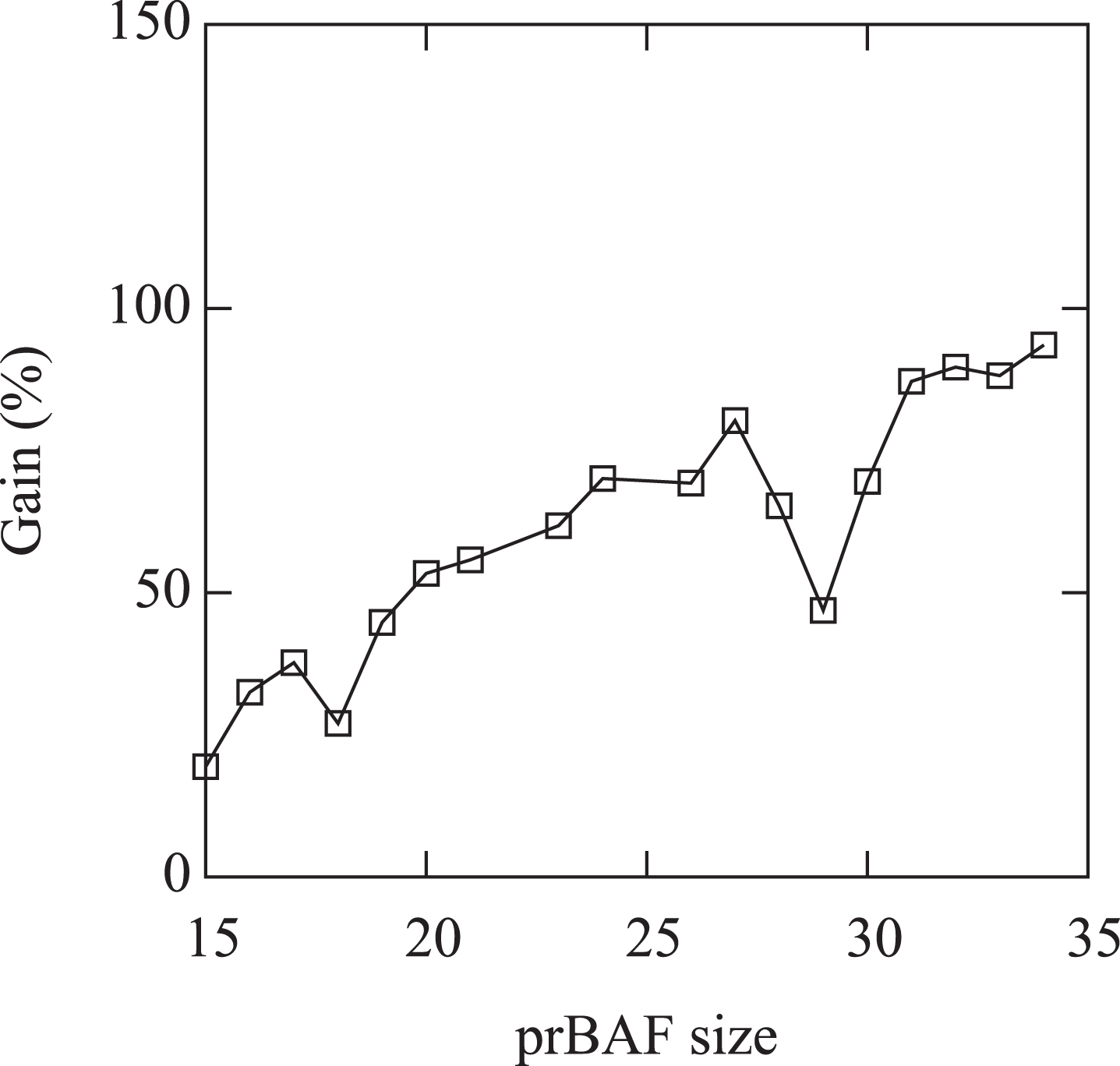
Figures 4 and 5 report the average running times of contract and naive (Fig. 4) and the gain of contract vs naive (Fig. 5) w.r.t the prBAF size. The drawings show that, as in the case that the number of argument is considered, the running times of both contract and naive grows exponentially with the prBAF size while the gain grows linearly with the prBAF size.
Average running times of contract and naive (sec) vs the size of the prBAF.
Average gain of contract vs naive (%) vs the size of the prBAF.
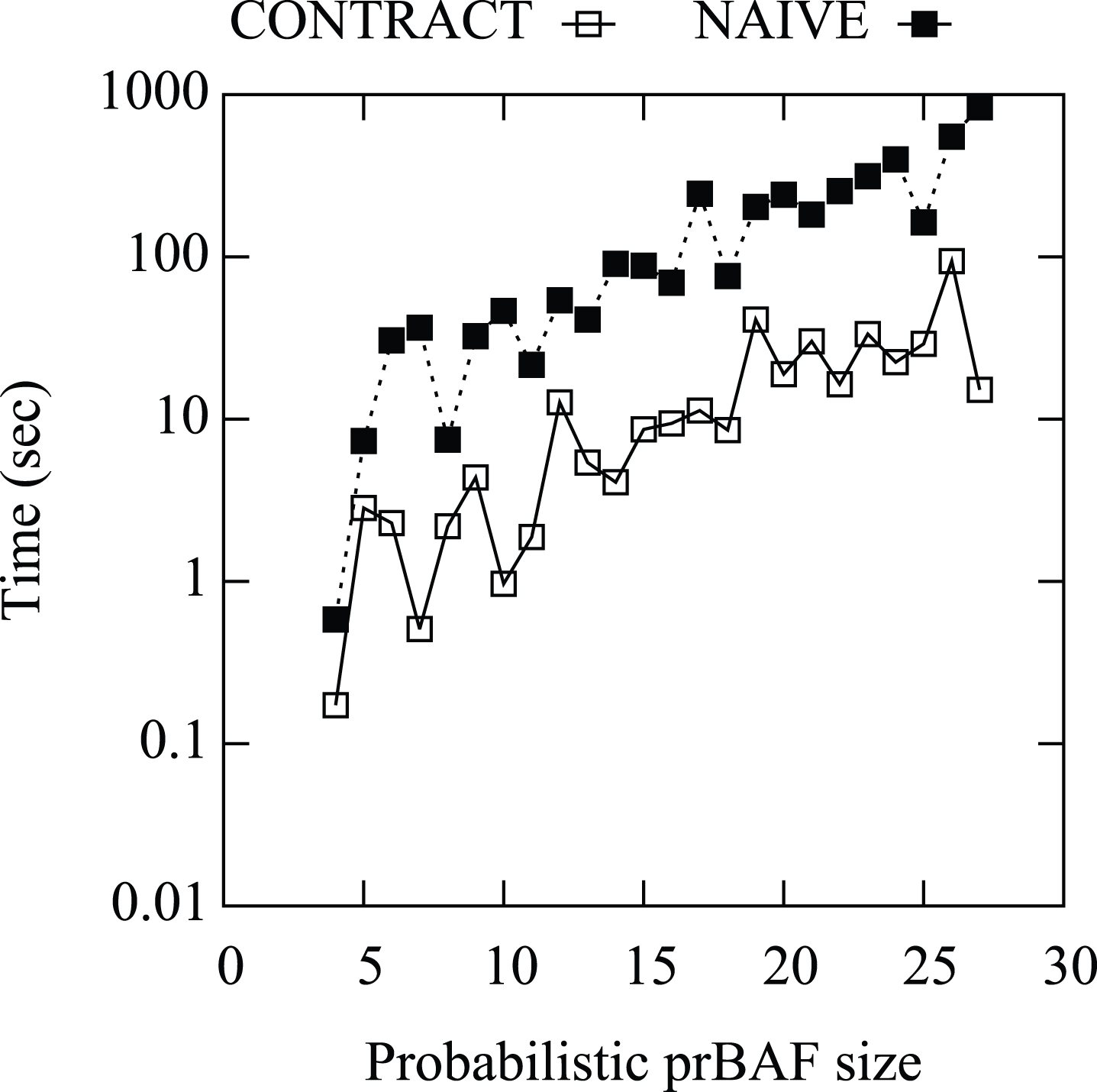
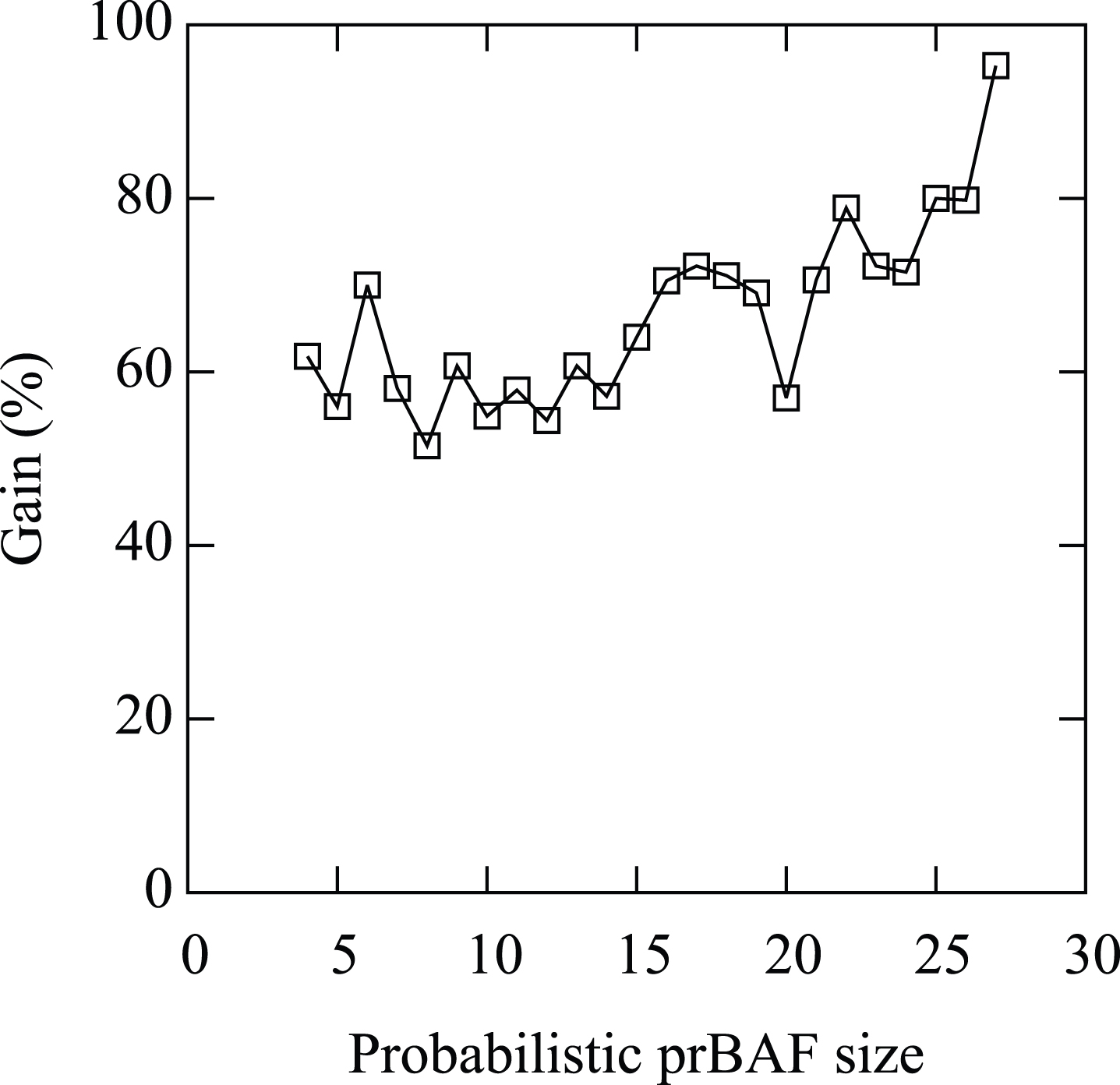
Figures 6 and 7 report the average running times of contract and naive (Fig. 6) and the gain of contract vs naive (Fig. 7) w.r.t the probabilistic size of the prBAF. The drawings show that the running times of both contract and naive grows exponentially with the probabilistic size of the prBAF while the gain grows linearly with the probabilistic size of the prBAF. However the correlation between running times and gain with the probabilistic size of the prBAF is less tight than those with the number of arguments or the prBAf size and the liner growth of the gain is slower than in the cases that the number of argument or the size of the prBAF areconsidered.
Average running times of contract and naive (sec) vs the probabilistic size of the prBAF.
Average gain of contract vs naive (%) vs the probabilistic size of the prBAF.
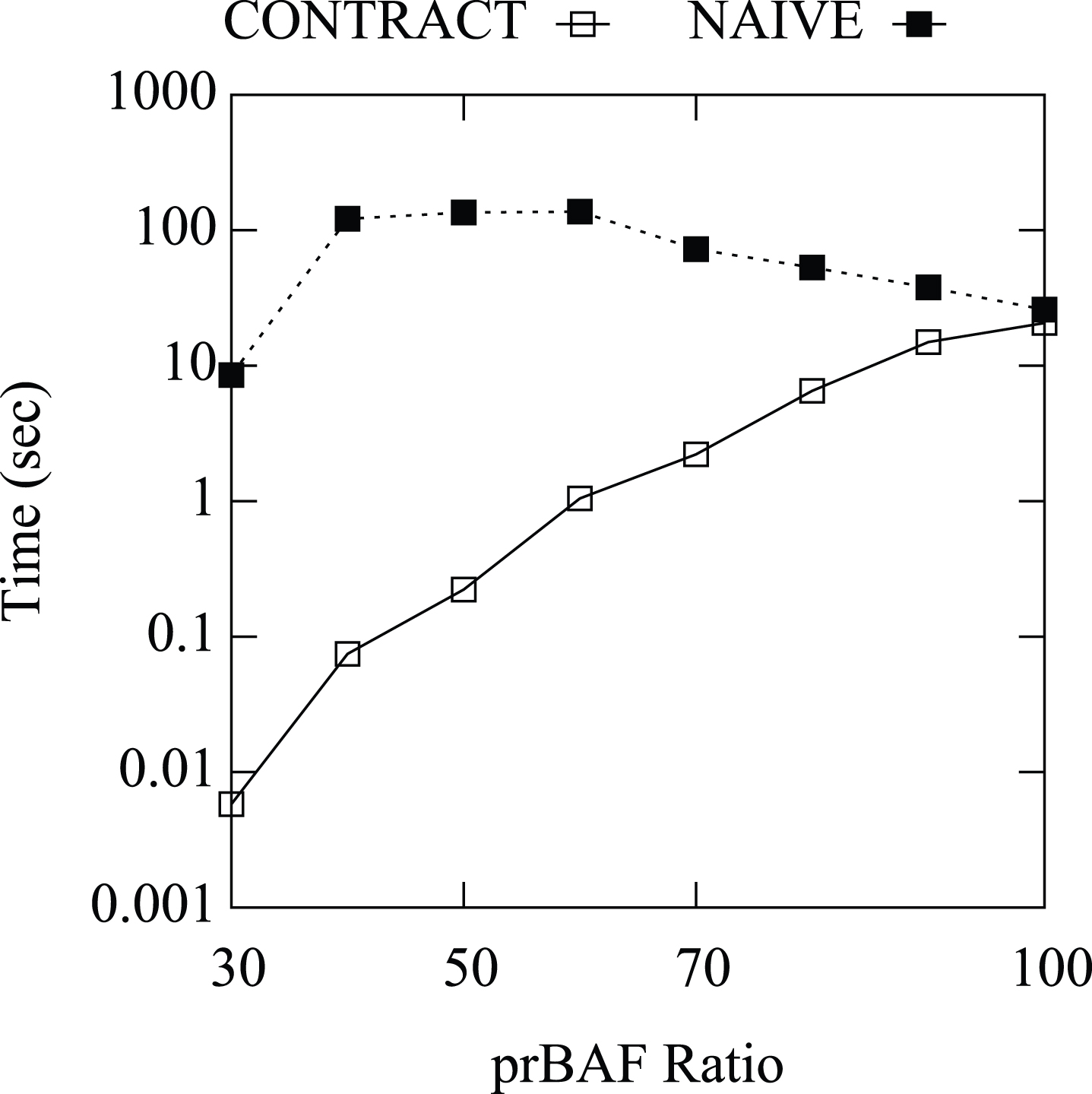
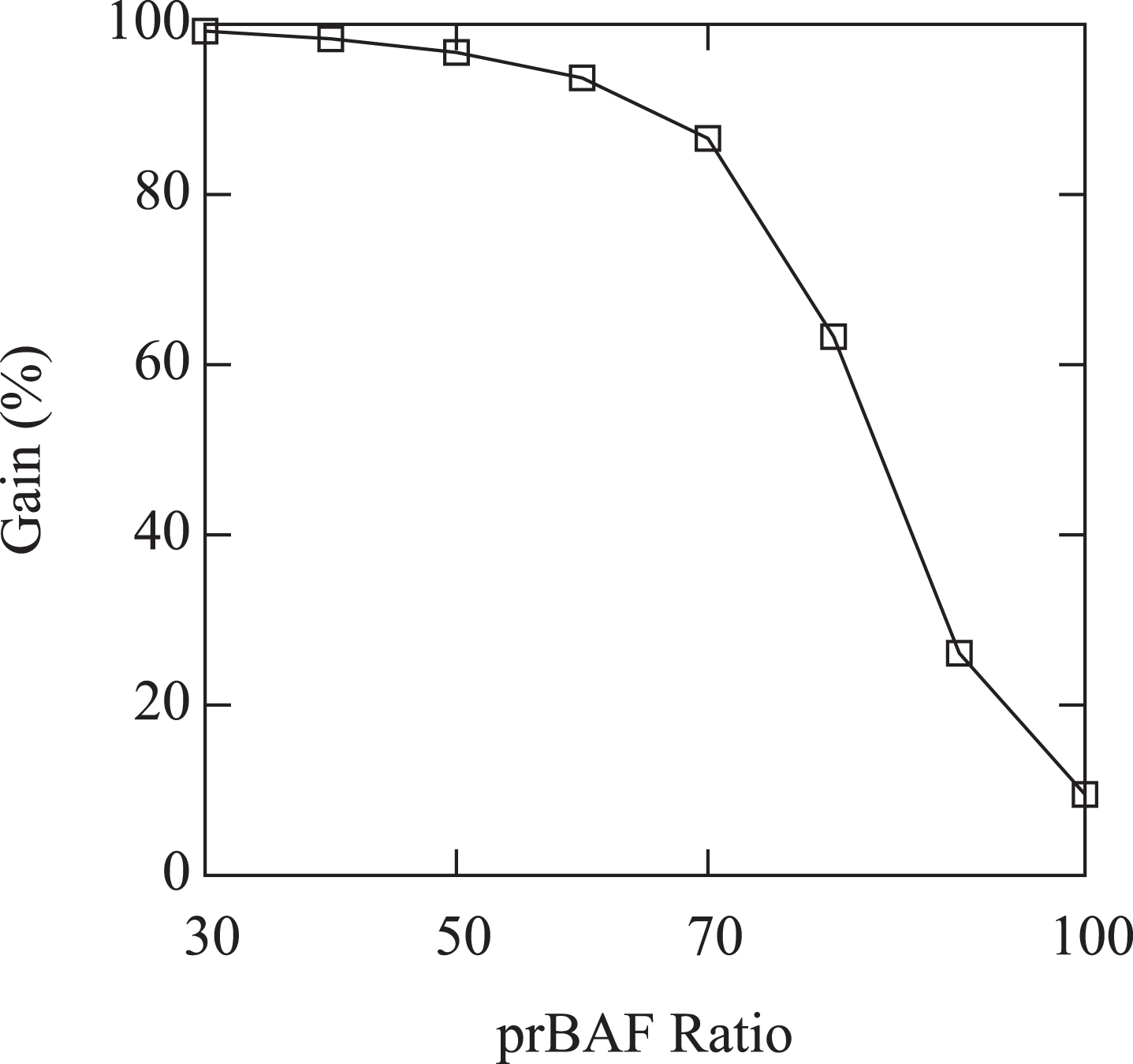
Figures 8 and 9 report the average running times of contract and naive (Fig. 8) and the gain of contract vs naive (Fig. 9) w.r.t the probabilistic size of the prBAF. The drawings show that the running time of contract grows exponentially with the ratio of the prBAF while, as expected the running time of naive does not depend on the ratio of the prBAF. Moreover, the gain decrease as the ratio of the prBAF increases.
Average running times of contract and naive (sec) vs the Ratio of the prBAF.
Average gain of contract vs naive (%) vs the Ratio of the prBAF.
From the experiments it follows that contract outperforms naive in any of the considered cases, even if there are single experiments where the ratio is very large (close to 1), where the running time of contract is larger than that of naive. However, it is worth noting that even using contract computing requires a large amount of time (the algorithm was halted after 20 minutes) on prBAFs with more than 18 arguments.
Conclusions
In this paper we devised an algorithm for computing extensions’ probabilities over prBAFs of type ind when the stable, d-admissible, s-admissible or c-admissible semantics are considered. The correctness of the algorithm has been formally proved and its efficiency experimentally validated w.r.t. the naive computation based on the enumeration of possible BAFs. The gain in efficiency of the proposed algorithm is due to the fact that it enumerates contractions rather than possible BAFs and in most cases the number of possible contractions is much smaller than the number of possible BAFs. However, from the experiments it turns out that the algorithm is not able to deal with large prBAFs in reasonable time. Hence, for large prBAFs resorting to estimating extensions’ probabilities is reasonable. An interesting research direction for future work is that of finding properties that might improve the efficiency of estimation algorithms.
Footnotes
[6] discussed also indirect implicit attacks. W.l.o.g., as in [], we disregard them, as their presence would not affect our results.
Note that an empty product evaluates to 1.
References
1.
AmgoudL., VesicS., A new approach for preference-based argumentation frameworks, A Math Artif Intell63(2) (2011), 149–183.
2.
BaroniP., GiacominM., Semantics of abstract argument systems. In Argum in Artif Intell (2009), pp. 25–44.
3.
Bench-CaponT.J.M., Persuasion in practical argument using value-based argumentation frameworks, J Log Comput13(3) (2003), 429–448.
4.
BoellaG., GabbayD.M., van der TorreL.W.N. and VillataS.Support in abstract argumentationIn Proc of COMMA 2010 (2010), pp. 111–122.
5.
BrewkaG., WoltranS., Abstract dialectical frameworks. In Proc of KR, 2010.
6.
CayrolC., Lagasquie-SchiexM.-C., On the acceptability of arguments in bipolar argumentation frameworks. In Proc of ECSQARU (2005), pp. 378–389.
7.
CayrolC., Lagasquie-SchiexM.C., Bipolar abstract argumentation systems. In Argum. in Artif Intell (2009), pp. 65–84.
8.
CayrolC., Lagasquie-SchiexM.-C., Bipolarity in argumentation graphs: Towards a better understanding, Int J Approx Reasoning54(7) (2013), 876–899.
9.
CohenA., GarcíaA.J., SimariG.R., Backing and undercutting in abstract argumentation frameworks. In Proc of FoIKS (2012), pp. 107–123.
10.
CohenA., GottifrediS., GarcíaA.J., SimariG.R., A survey of different approaches to support in argumentation systems, Know Eng Review29(5) (2014), 513–550.
11.
Coste-MarquisS., Koniec-znyS., MarquisP., OualiM.A., Weighted attacks in argumentation frameworks, In Proc of KR, 2012.
12.
DoderD., WoltranS., Probabilistic argumentation frameworks - A logical approach. In Proc of SUM (2014), pp. 134–147.
13.
DondioP., Toward a computational analysis of probabilistic argumentation frameworks, Cybernetics and Systems45(3) (2014), 254–278.
14.
DungP.M., ThangP.M., Towards (probabilistic) argumentation for jury-based dispute resolution. In Proc of COMMA (2010), pp. 171–182.
DungP.M., On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming and n-person games, Artif Intell77(2) (1995), 321–358.
17.
DunneP.E., WooldridgeM., Complexity of abstract argumentation. In Argum. in Artif Intell (2009), pp. 85–104.
DunneP.E., The computational complexity of ideal semantics, Artif Intell173(18) (2009).
20.
FazzingaB., FlescaS., ParisiF., On the complexity of probabilistic abstract argumentation. In Proc of IJCAI2013.
21.
FazzingaB., FlescaS., ParisiF., On the complexity of probabilistic abstract argumentation frameworks, ACM Trans ComputLog16(3) (2015), 22.
22.
FazzingaB., FlescaS., FurfaroF., Probabilistic bipolar abstract argumentation frameworks: Complexity results. In Proceedings of IJCAI 2018 (2018), pp. 1803–1809.
23.
FazzingaB., FlescaS., FurfaroF., Complexity of fundamental problems in probabilistic abstract argumentation: Beyond independence, Artificial Intelligence (2019), 268:1–29.
24.
HunterA., ThimmM., Probabilistic argumentation with epistemic extensions. In Proc of DARe@ECAI2014.
25.
HunterA., ThimmM., Probabilistic argumentation with incomplete information. In Proc of ECAI (2014), pp. 1033–1034.
26.
HunterA., Some foundations for probabilistic abstract argumentation. In Proc of COMMA (2012), pp. 117–128.
27.
HunterA., A probabilistic approach to modelling uncertain logical arguments, Int J Approx Reasoning54(1) (2013), 47–81.
28.
HunterA., Probabilistic qualification of attack in abstract argumentation, Int J Approx Reasoning55(2) (2014), 607–638.
29.
LiH., OrenN., NormanT.J., Probabilistic argumentation frameworks. In Proc of TAFA2011.
30.
MartínezD.C., GarcíaA.J., SimariG.R., On acceptability in abstract argumentation frameworks with an extended defeat relation. In Proc of COMMA (2006), pp. 273–278.
31.
ModgilS., Reasoning about preferences in argumentation frameworks, Artif Intell173(9–10) (2009), 901–934.
32.
NouiouaF., RischV., Bipolar argumentation frameworks with specialized supports. In Proc of ICTAI (2010), pp. 215–218.
33.
OrenN., NormanT.J., Semantics for evidence-based argumentation. In Proc. of COMMA, pages 276–284, 2008.
34.
PolbergS., HunterA., Empirical evaluation of abstract argumentation: Supporting the need for bipolar and probabilistic approaches, Int J Approx Reasoning93:487–543, 2018.
35.
ProiettiC., Polarization and bipolar probabilistic argumentation frameworks. In Proc of Work AI3 (2017), pp. 22–27.
36.
RienstraT., Towards a probabilistic dung-style argumentation system. In Proc of AT (2012), pp. 138–152.
37.
ThimmM., A probabilistic semantics for abstract argumentation. In Proc of ECAI (2012), pp. 750–755.
38.
VerheijB., The toulmin argument model in artificial intelligence. In Argum in Artif Intell (2009), pp. 219–238.